
Deep Learning-Based Consensus Control of a Multi-Agents System with Unknown Time-Varying Delay


Abstract
:1. Introduction
2. System Model and Problem Formulation
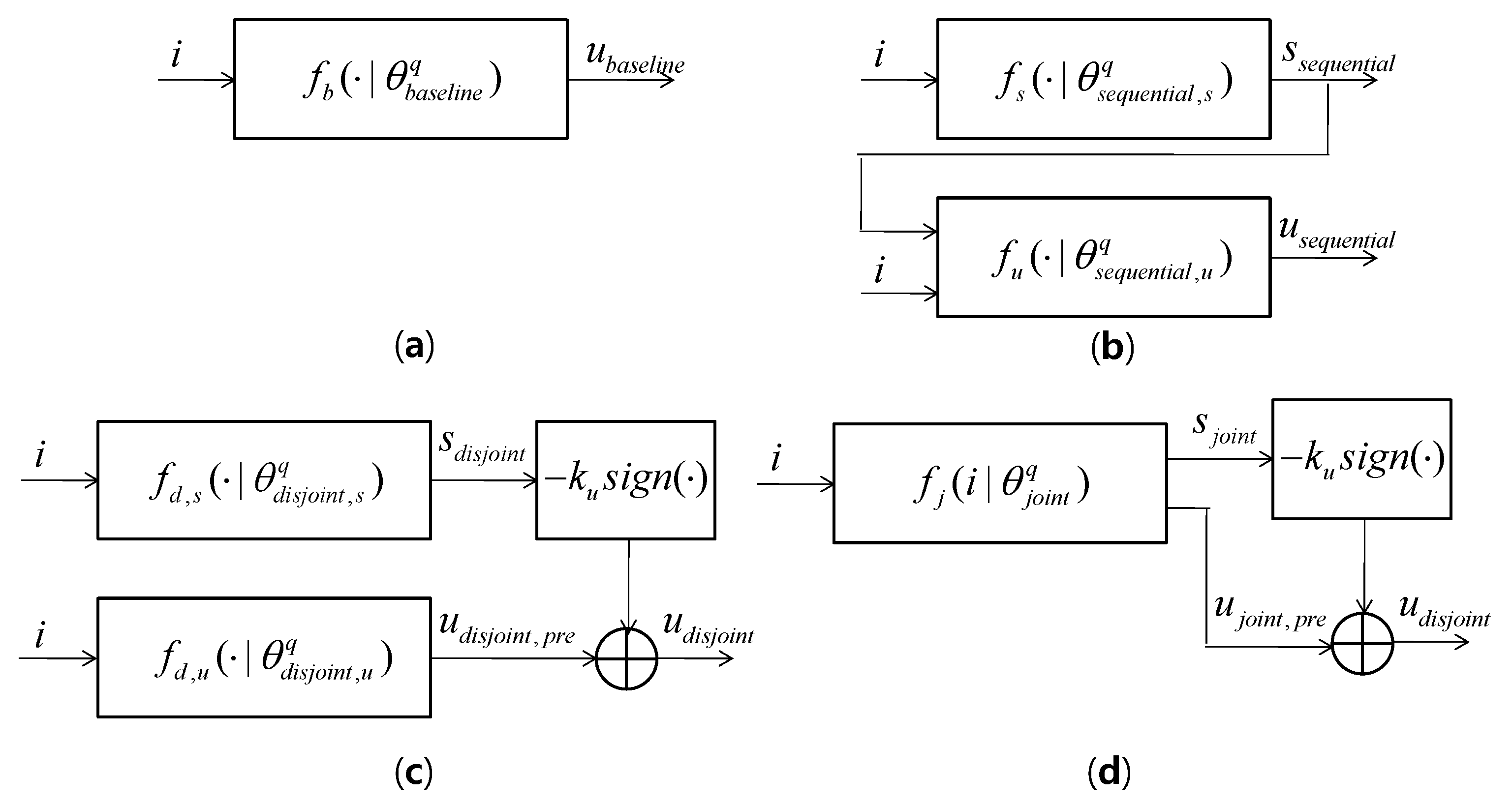
3. Deep Learning-Based Consensus Algorithms
3.1. Baseline DL
3.2. Sequential DL
3.3. Disjoint DL
3.4. Joint DL
3.5. Architecture of the Network
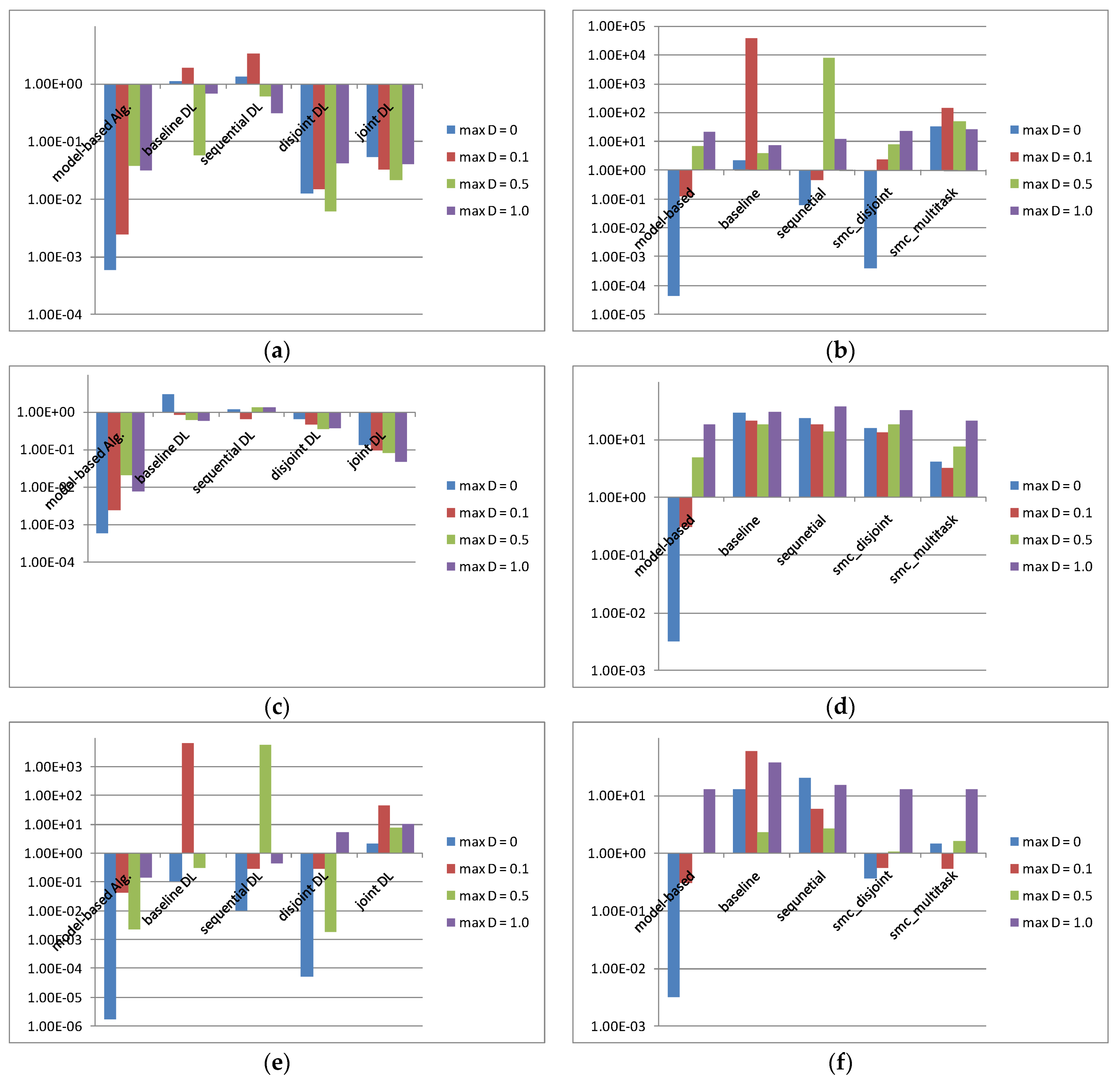
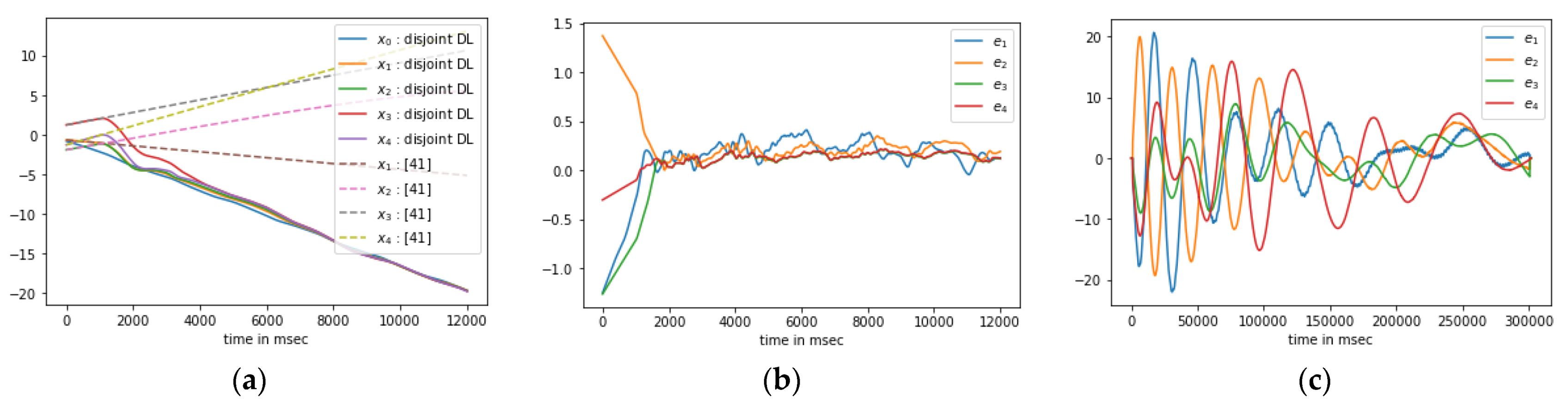
4. Numerical Results and Discussion
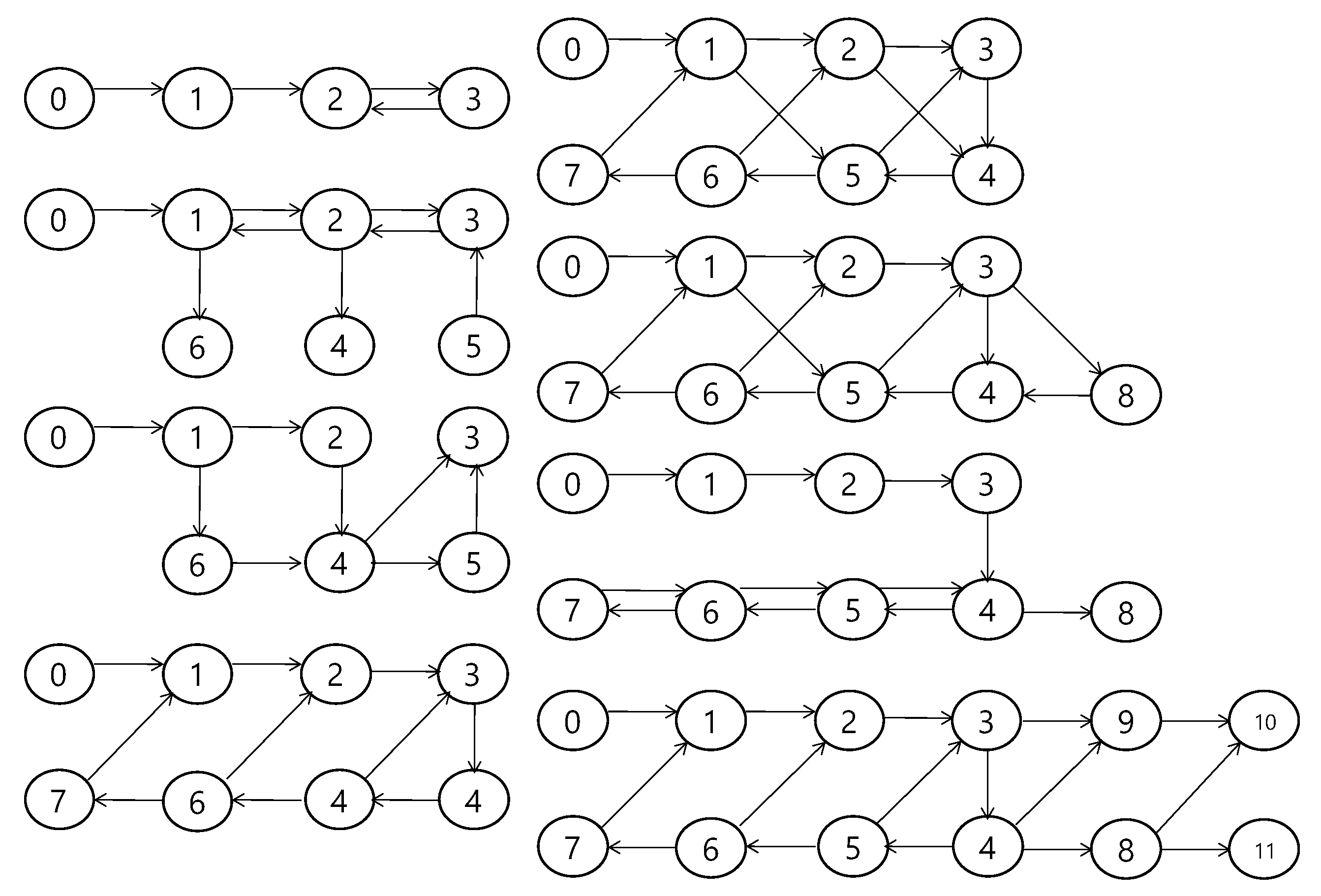
4.1. Train Data Generation
4.2. Training the Proposed DL
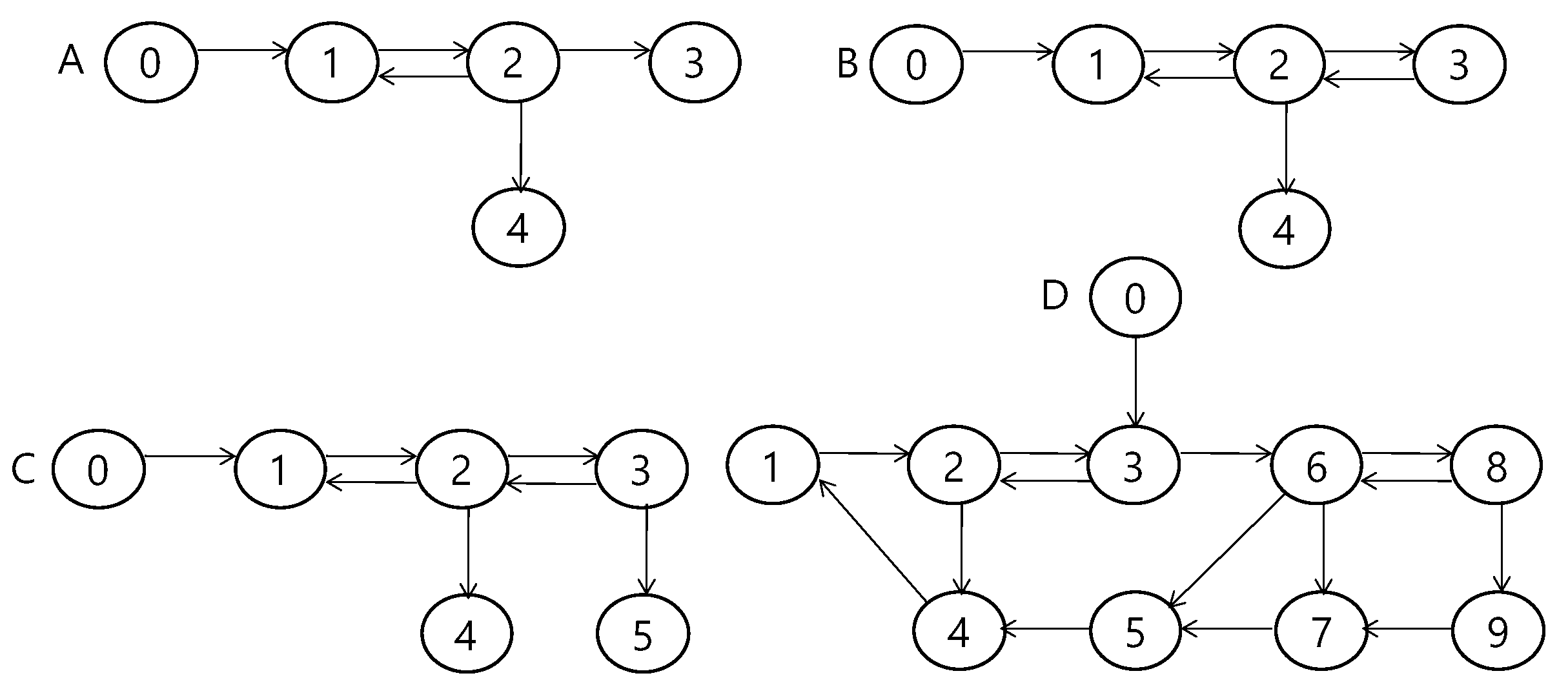
4.3. Simulation Setup
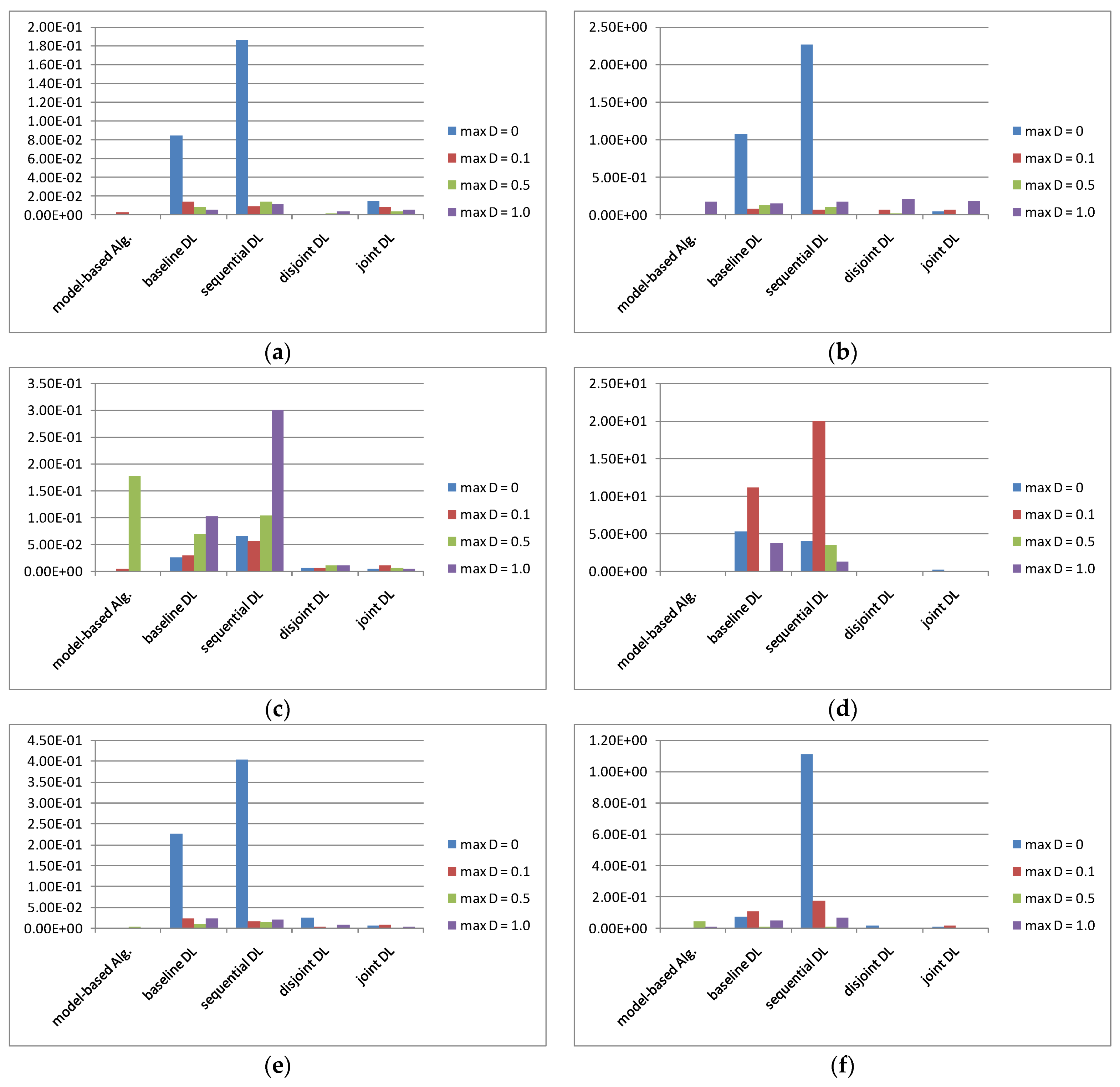
4.4. Simulation Results
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ding, L.; Han, Q.; Ge, X.; Zhang, X. An Overview of Recent Advances in Event-Triggered Consensus of Multiagent Systems. IEEE Trans. Cybern. 2018, 48, 1110–1123. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Duan, Z.; Chen, G.; Huang, L. Consensus of Multiagent Systems and Synchronization of Complex Networks: A Unified Viewpoint. IEEE Trans. Circuits Syst. 2010, 57, 213–224. [Google Scholar] [CrossRef]
- Nguyen, D.H. A sub-optimal consensus design for multi-agent systems based on hierarchical LQR. Automatica 2015, 55, 88–94. [Google Scholar] [CrossRef]
- Oh, K.K.; Park, M.C.; Ahn, H.S. A survey of multi-agent formation control. Automatica 2015, 53, 424–440. [Google Scholar] [CrossRef]
- Li, S.E.; Zheng, Y.; Li, K.; Wang, J. An overview of vehicular platoon control under the four-component framework. In Proceedings of the IEEE Intelligent Vehicles Symposium, Seoul, Korea, 28 June–1 July 2015. [Google Scholar] [CrossRef]
- Kim, B.; Ahn, H. Distributed Coordination and Control for a Freeway Traffic Network Using Consensus Algorithms. IEEE Syst. J. 2016, 10, 162–168. [Google Scholar] [CrossRef]
- Trianni, V.; De Simone, D.; Reina, A.; Baronchelli, A. Emergence of Consensus in a Multi-Robot Network: From Abstract Models to Empirical Validation. IEEE Robot. Autom. Lett. 2016, 1, 348–353. [Google Scholar] [CrossRef] [Green Version]
- Amelina, N.; Fradkov, A.; Jiang, Y.; Vergados, D.J. Approximate Consensus in Stochastic Networks With Application to Load Balancing. IEEE Trans. Inf. Theory 2015, 61, 1739–1752. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, Y.; Li, Z. Consensus reaching for social network group decision making by considering leadership and bounded confidence. Knowl. Based Syst. 2020, 204, 106240. [Google Scholar] [CrossRef]
- Jadbabaie, A.; Lin, J.; Morse, A.S. Coordination of groups of mobile autonomous agents using nearest neighbor rules. IEEE Trans. Autom. Control 2003, 48, 988–1001. [Google Scholar] [CrossRef] [Green Version]
- Moreau, L. Stability of multi-agent systems with time-dependent communication links. IEEE Trans. Autom. Control 2005, 50, 169–182. [Google Scholar] [CrossRef]
- Ren, W.; Beard, R.W. Consensus seeking in multi-agent systems under dynamically changing interaction topologies. IEEE Trans. Autom. Control 2005, 50, 655–661. [Google Scholar] [CrossRef]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and Cooperation in Networked Multi-Agent Systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef] [Green Version]
- Cao, Y.; Ren, W. Optimal Linear-Consensus Algorithms: An LQR Perspective. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 819–830. [Google Scholar] [CrossRef]
- Yang, D.; Ren, W.; Liu, X.; Chen, W. Decentralized event-triggered consensus for linear multi-agent systems under general directed graphs. Automatica 2016, 69, 242–249. [Google Scholar] [CrossRef] [Green Version]
- Lomban, D.A.B.; Bernardo, M. Multiplex PI control for consensus in networks of heterogeneous linear agents. Automatica 2016, 67, 310–320. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Liu, L.; Feng, G. Consensus of Heterogeneous Linear Multiagent Systems Subject to Aperiodic Sampled-Data and DoS Attack. IEEE Trans. Cybern. 2019, 49, 1501–1511. [Google Scholar] [CrossRef]
- Li, X.M.; Zhou, Q.; Li, P.; Li, H.; Lu, R. Event-Triggered Consensus Control for Multi-Agent Systems Against False Data-Injection Attacks. IEEE Trans. Cybern. 2019, 50, 1856–1866. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, J.L.; Wu, H.N.; Huang, T. Consensus and H∞ Consensus of Nonlinear Second-Order Multi-Agent Systems. IEEE Trans. Netw. Sci. Eng. 2020, 7, 1251–1264. [Google Scholar] [CrossRef]
- Zheng, J.; Xu, L.; Xie, L.; You, K. Consensus ability of Discrete-Time Multiagent Systems with Communication Delay and Packet Dropouts. IEEE Trans. Autom. Control 2019, 64, 1185–1192. [Google Scholar] [CrossRef]
- Olfati-Saber, R. Kalman-Consensus Filter: Optimality, Stability, and Performance. In Proceedings of the 48th IEEE Conference on Decision and Control, Shanghai, China, 16–18 December 2009. [Google Scholar] [CrossRef]
- Kamal, A.T.; Ding, C.; Song, B.; Farrell, J.A.; Roy-Chowdhury, A.K. A Generalized Kalman Consensus Filter for Wide-Area Video Network. In Proceedings of the 50th IEEE Conference on Decision and Control and European Control Conference (CDC-ECC), Orlando, FL, USA, 12–15 December 2011. [Google Scholar] [CrossRef]
- Hou, Z.S.; Wang, Z. From model-based control to data-driven control: Survey, classification and perspective. Inf. Sci. 2013, 235, 3–35. [Google Scholar] [CrossRef]
- Barto, A.G. Reinforcement learning control. Curr. Opin. Neurobiol. 1994, 4, 888–893. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. Available online: https://arxiv.org/abs/1312.5602 (accessed on 5 April 2022).
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. Available online: https://arxiv.org/abs/1707.06347 (accessed on 9 February 2022).
- Zhang, H.; Jiang, H.; Luo, Y.; Xiao, G. Data-Driven Optimal Consensus Control for Discrete-Time Multi-Agent Systems with Unknown Dynamics Using Reinforcement Learning Method. IEEE Trans. Ind. Electron. 2017, 64, 4091–4100. [Google Scholar] [CrossRef]
- Peng, Z.; Hu, J.; Shi, K.; Luo, R.; Huang, R.; Ghosh, B.K.; Huang, J. A novel optimal bipartite consensus control scheme for unknown multi-agent systems via model-free reinforcement learning. Appl. Math. Comput. 2020, 369, 124821. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, W.; Yu, N. Consensus Multi-Agent Reinforcement Learning for Volt-VAR Control in Power Distribution Networks. IEEE Trans. Smart Grid 2021, 12, 3594–3604. [Google Scholar] [CrossRef]
- An, N.; Zhao, X.; Wang, Q.; Wang, Q. Model-Free Distributed Optimal Consensus Control of Nonlinear Multi-Agent Systems: A Graphical Game Approach. J. Franklin Inst. 2022, in press. [Google Scholar] [CrossRef]
- Batra, S.; Huang, Z.; Petrenko, A.; Kumar, T.; Molchanov, A.; Sukhatme, G.S. Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement Learning. arXiv 2017, arXiv:2109.07735. Available online: https://arxiv.org/abs/2109.07735 (accessed on 9 February 2022).
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [Green Version]
- Yang, J. A Consensus Control for a Multi-Agent System with Unknown Time-Varying Communication Delays. IEEE Access 2021, 9, 55844–55852. [Google Scholar] [CrossRef]
- Li, Y.; Li, H.; Wang, S. Finite-Time Consensus of Finite Field Networks with Stochastic Time Delays. IEEE Trans. Circuits Syst. II: Express Briefs 2020, 67, 3128–3132. [Google Scholar] [CrossRef]
- Wang, X.; Wang, H.; Li, C.; Huang, T.; Kurths, J. Consensus Seeking in Multiagent Systems with Markovian Switching Topology Under Aperiodic Sampled Data. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 5189–5200. [Google Scholar] [CrossRef]
- Ahmed, S.F.; Raza, Y.; Mahdi, H.F.; Muhamad, W.M.W.; Joyo, M.K.; Shah, A.; Koondhar, M.Y. Review on Sliding Mode Controller and Its Modified Types for Rehabilitation Robots. In Proceedings of the 6th International Conference on Engineering Technologies and Applied Sciences (ICETAS), Kuala Lumpur, Malaysia, 20–21 December 2019. [Google Scholar] [CrossRef]
- Yu, S.; Long, X. Finite-time consensus for second-order multi-agent systems with disturbances by integral sliding mode. Automatica 2015, 54, 158–165. [Google Scholar] [CrossRef]
- Qin, J.; Zhang, G.; Zheng, W.X.; Kang, Y. Adaptive Sliding Mode Consensus Tracking for Second-Order Nonlinear Multiagent Systems with Actuator Faults. IEEE Trans. Cybern. 2019, 49, 1605–1615. [Google Scholar] [CrossRef]
- Zhang, J.; Lyu, M.; Shen, T.; Liu, L.; Bo, Y. Sliding Mode Control for a Class of Nonlinear Multi-agent System with Time Delay and Uncertainties. IEEE Trans. Ind. Electron. 2018, 65, 865–875. [Google Scholar] [CrossRef]
- Li, J.; Ji, L.; Li, H. Optimal consensus control for unknown second-order multi-agent systems: Using model-free reinforcement learning method. Appl. Math. Comput. 2021, 410, 126451. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Acceleration of Leader Agent | Disturbance |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 |
| Case | Acceleration of Leader Agent | Disturbance | Graph | Delay |
|---|---|---|---|---|
| 1 | A | |||
| 2 | A | |||
| 3 | B | |||
| 4 | C | |||
| 5 | D | |||
| 6 | D |
| No Delay Train Data | Small Delay Train Data | Large Delay Train Data | |
|---|---|---|---|
| model-based alg. | 4.62 × 10−2 | 7.64 × 10−3 | 1.82 × 10−2 |
| baseline DL | 1.72 × 103 | 1.28 × 100 | 9.47 × 10−1 |
| sequential DL | 1.49 × 103 | 1.11 × 100 | 1.42 × 100 |
| disjoint DL | 1.42 × 100 | 4.55 × 10−1 | 1.87 × 10−2 |
| joint DL | 1.70 × 101 | 8.68 × 10−2 | 3.70 × 10−2 |
| No Delay Train Data | Small Delay Train Data | Large Delay Train Data | |
|---|---|---|---|
| model-based alg. | 7.03 × 100 | 5.97 × 100 | 3.58 × 100 |
| baseline DL | 9.66 × 103 | 2.53 × 101 | 2.85 × 101 |
| sequential DL | 2.10 × 103 | 2.36 × 101 | 1.11E × 101 |
| disjoint DL | 8.56 × 100 | 2.05 × 101 | 3.81 × 100 |
| joint DL | 6.69 × 101 | 9.07 × 100 | 4.21 × 100 |
| Training (s) | Inference (s) | |
|---|---|---|
| baseline DL | 6.11 × 100 | 1.29 × 101 |
| sequential DL | 1.26 × 101 | 1.27 × 101 |
| disjoint DL | 1.26 × 101 | 2.47 × 101 |
| joint DL | 7.77 × 100 | 1.67 × 101 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J. Deep Learning-Based Consensus Control of a Multi-Agents System with Unknown Time-Varying Delay. Electronics 2022, 11, 1176. https://doi.org/10.3390/electronics11081176
Yang J. Deep Learning-Based Consensus Control of a Multi-Agents System with Unknown Time-Varying Delay. Electronics. 2022; 11(8):1176. https://doi.org/10.3390/electronics11081176
Chicago/Turabian StyleYang, Janghoon. 2022. "Deep Learning-Based Consensus Control of a Multi-Agents System with Unknown Time-Varying Delay" Electronics 11, no. 8: 1176. https://doi.org/10.3390/electronics11081176
APA StyleYang, J. (2022). Deep Learning-Based Consensus Control of a Multi-Agents System with Unknown Time-Varying Delay. Electronics, 11(8), 1176. https://doi.org/10.3390/electronics11081176