
Tobacco Spatial Data Intelligent Visual Analysis


Abstract
:1. Introduction
- Need 1: Tobacco single-field data visualization. Visualize the information about a single field of tobacco in a geographic space and analyze its overall distribution in space.
- Need 2: Comparative visual analysis of tobacco multi-category information. Analyze the similarity of the distribution of tobacco multi-category information in the geographic space.
- Need 3: Visual analysis of distribution characteristics and similarities of high-dimensional scientific research data of tobacco in the geographic space.
- Need 4: Free mapping of data attribute field and flexible configuration of graphic parameters.
- Designing a set of visual analysis methods for tobacco spatial data, including reduced-dimensional clustering mapping visualization, combined with minimum spanning tree and contour, spatial distribution visualization that overlays multiple graphics on the map, and visual interaction.
- Developing the visual analysis system—TobaccoGeoVis—for scientific research spatial data of tobacco to assist users in the rapid analysis of data.
- Creating a set of interactive configuration methods that can flexibly configure the loading of data and selection of visual graphics.
2. Literature Review
2.1. Simulation Visualization
2.2. GIS-Based Visualization
2.3. Information Visualization
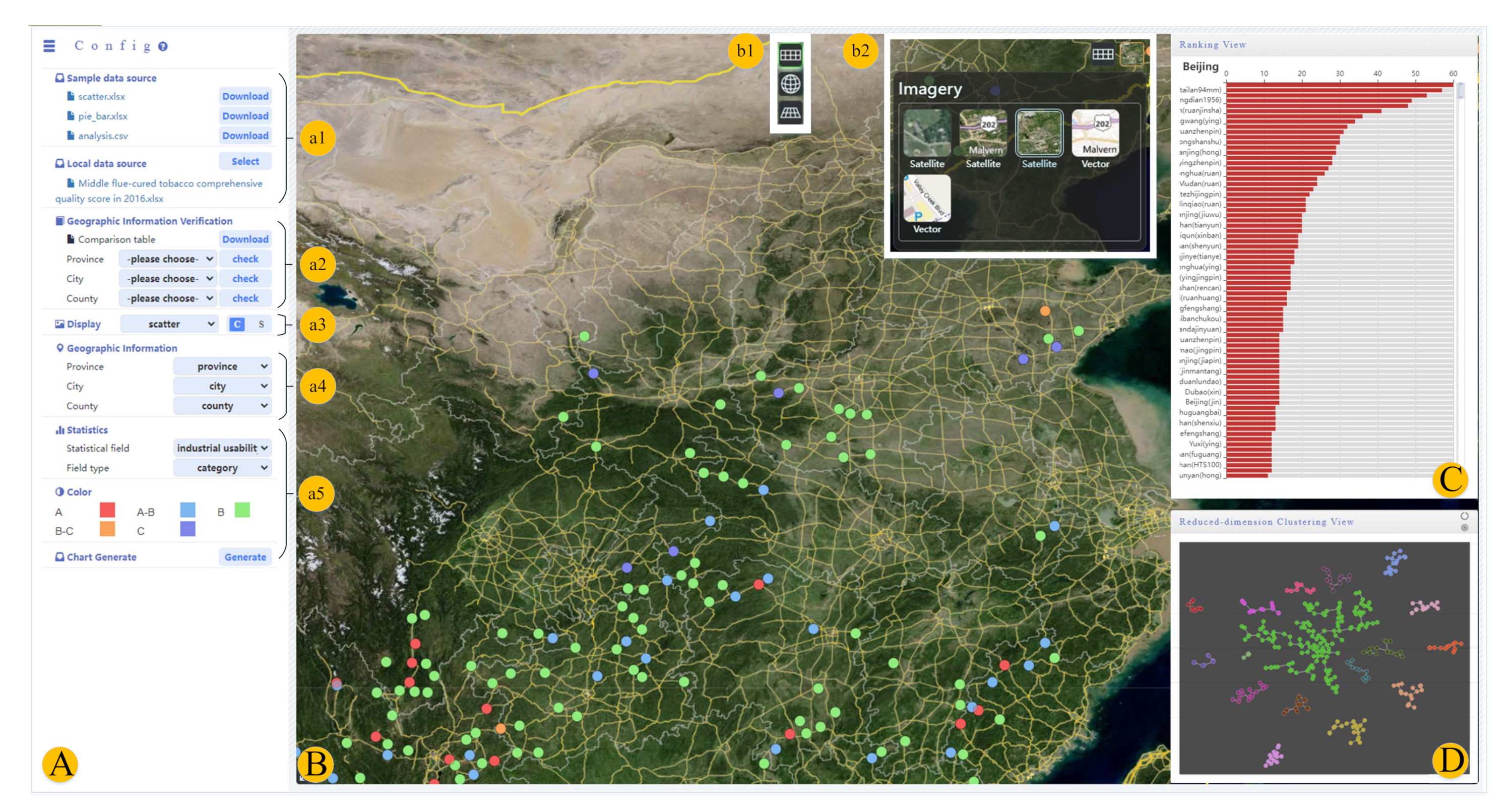
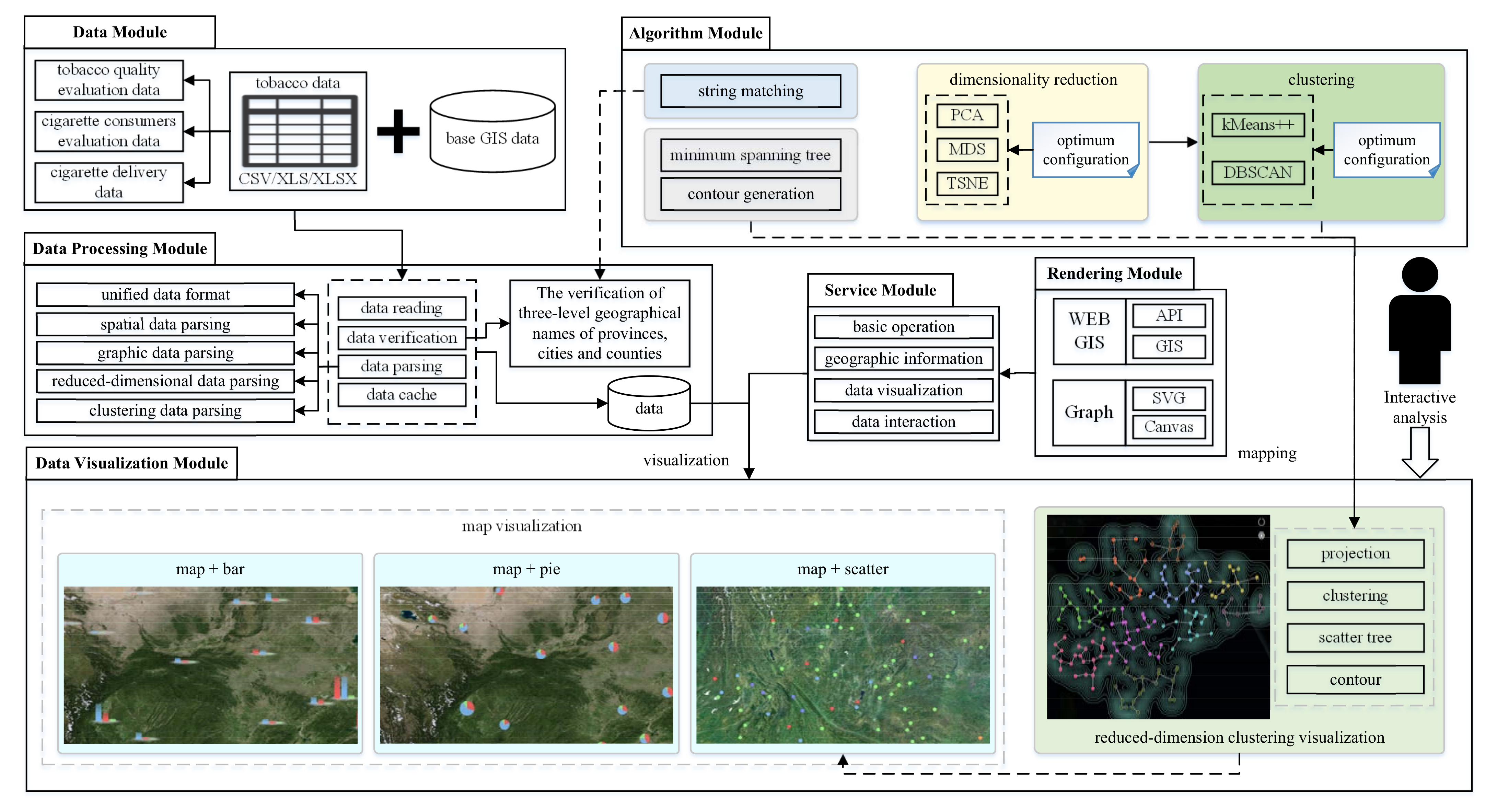
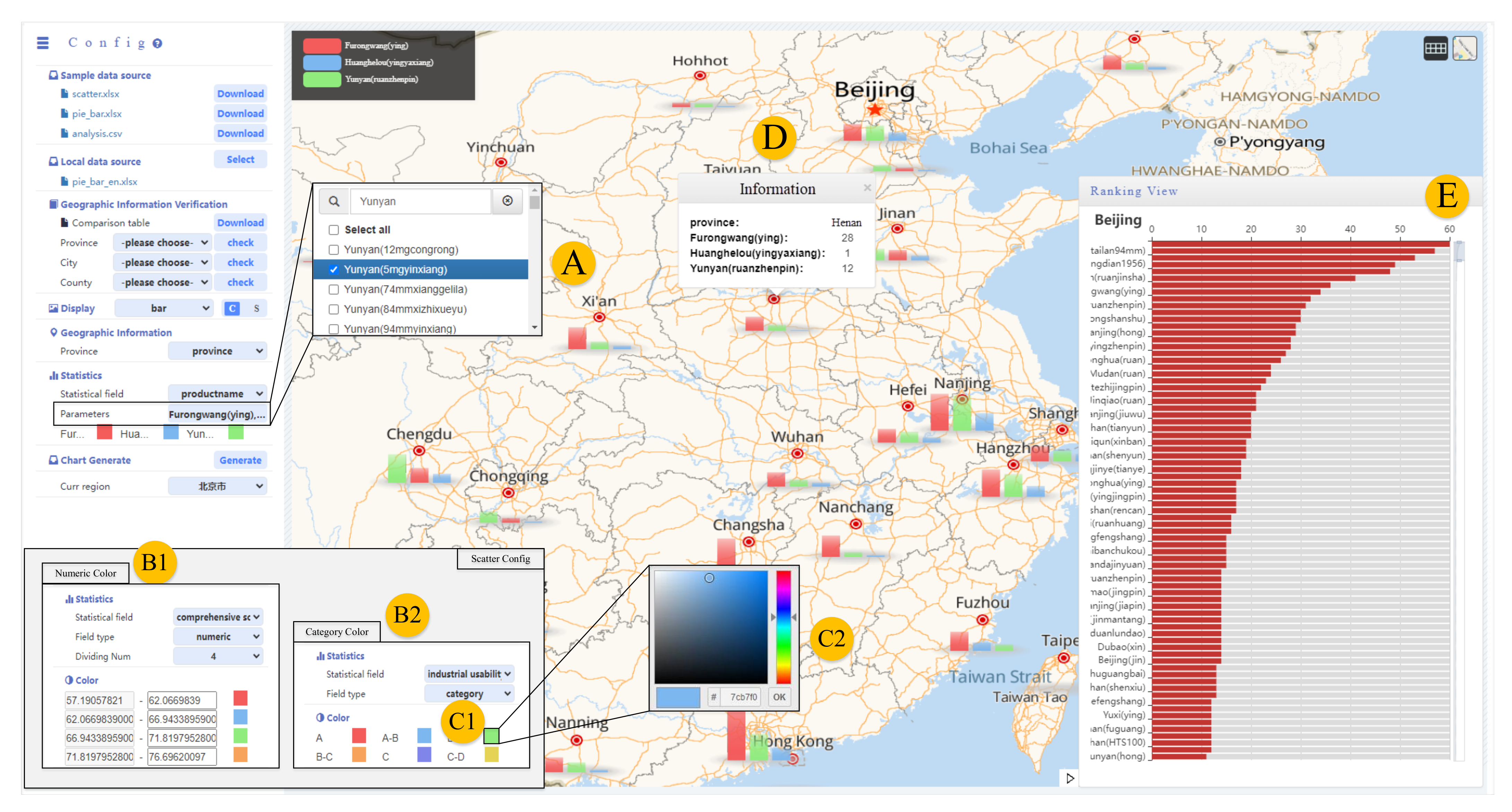
3. System Design
3.1. System Analysis
3.2. Visualization Pipeline
- Data reading: The data processing module provides remote and local data source reading functions and supports common file formats, such as CSV, XLS, and XLSX.
- Data verification: The data processing module judges whether geographical location names and formats in data meet system requirements and provides a correction plan.
- Data parsing: The data processing module parses names of provinces, cities, and counties in the original data into latitude and longitude coordinates in the map and converts original data into the format required by different visualization graphics.
- Data cache: The data processing module caches parsed data to improve the visualization rendering speed.
3.3. System Overview
4. Data Feature Analysis and Processing
4.1. Data Feature
4.2. Data Processing in Administrative Region
5. Visual Design
5.1. Single-Field Data Visualization
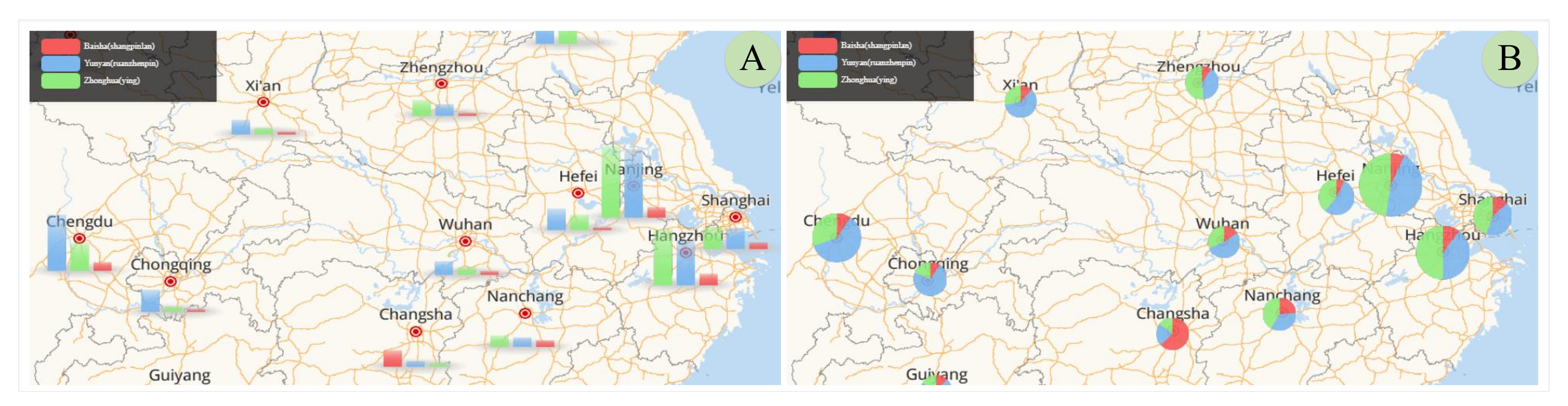
5.2. Multi-Category Information Contrast Visualization
5.3. High-Dimensional Data Space Mapping Visualization
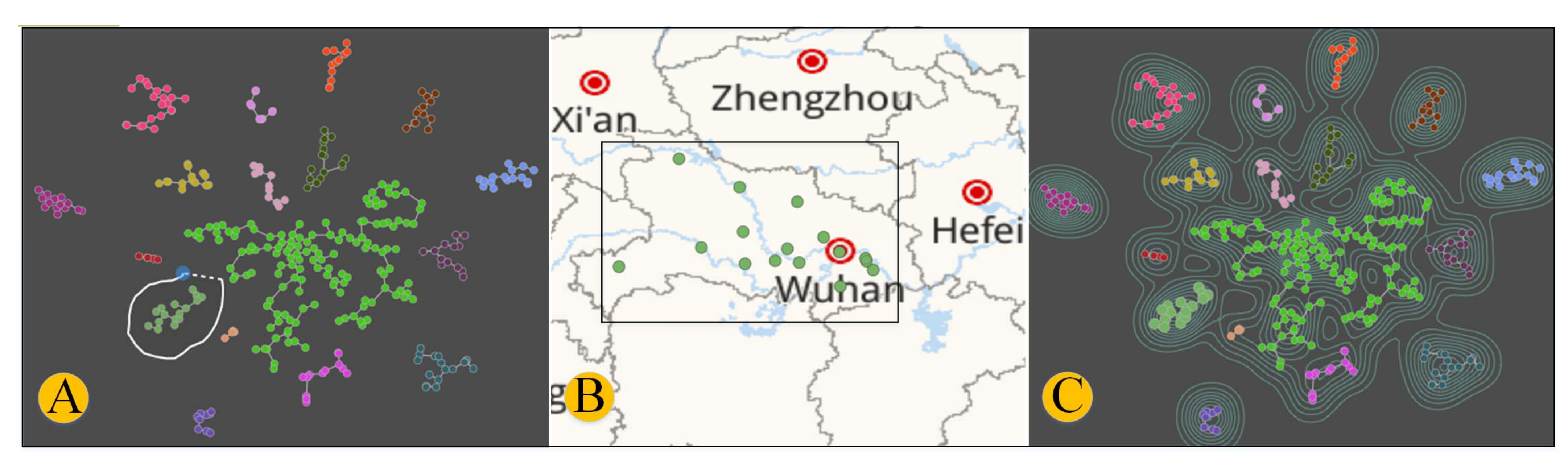
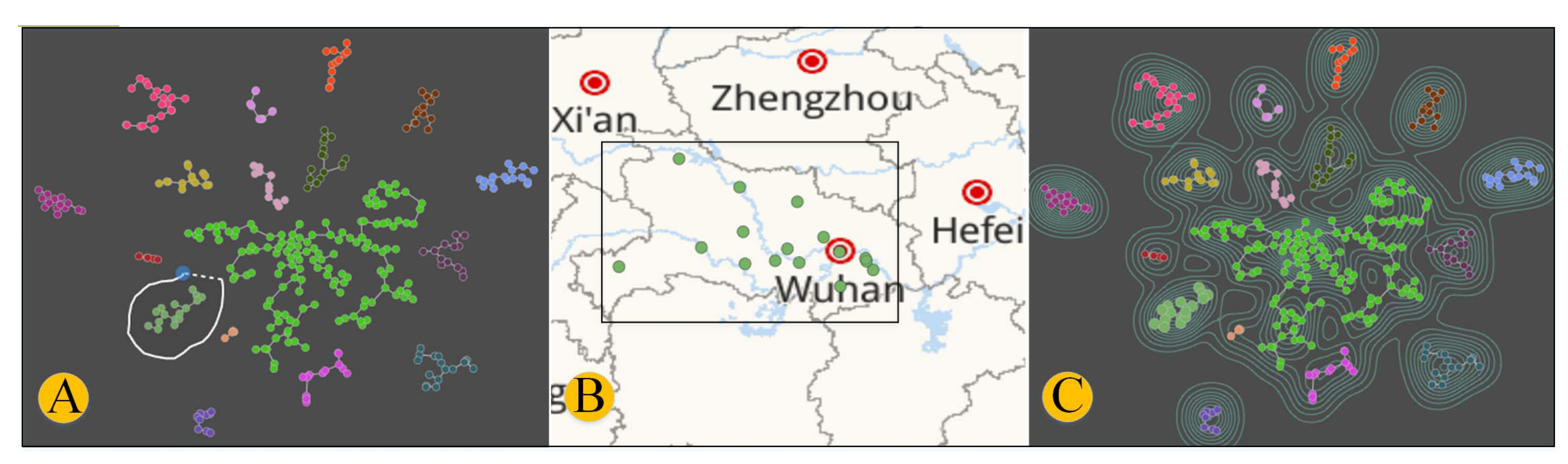
5.3.1. Data Dimension Reduction Analysis
5.3.2. Data Clustering Analysis
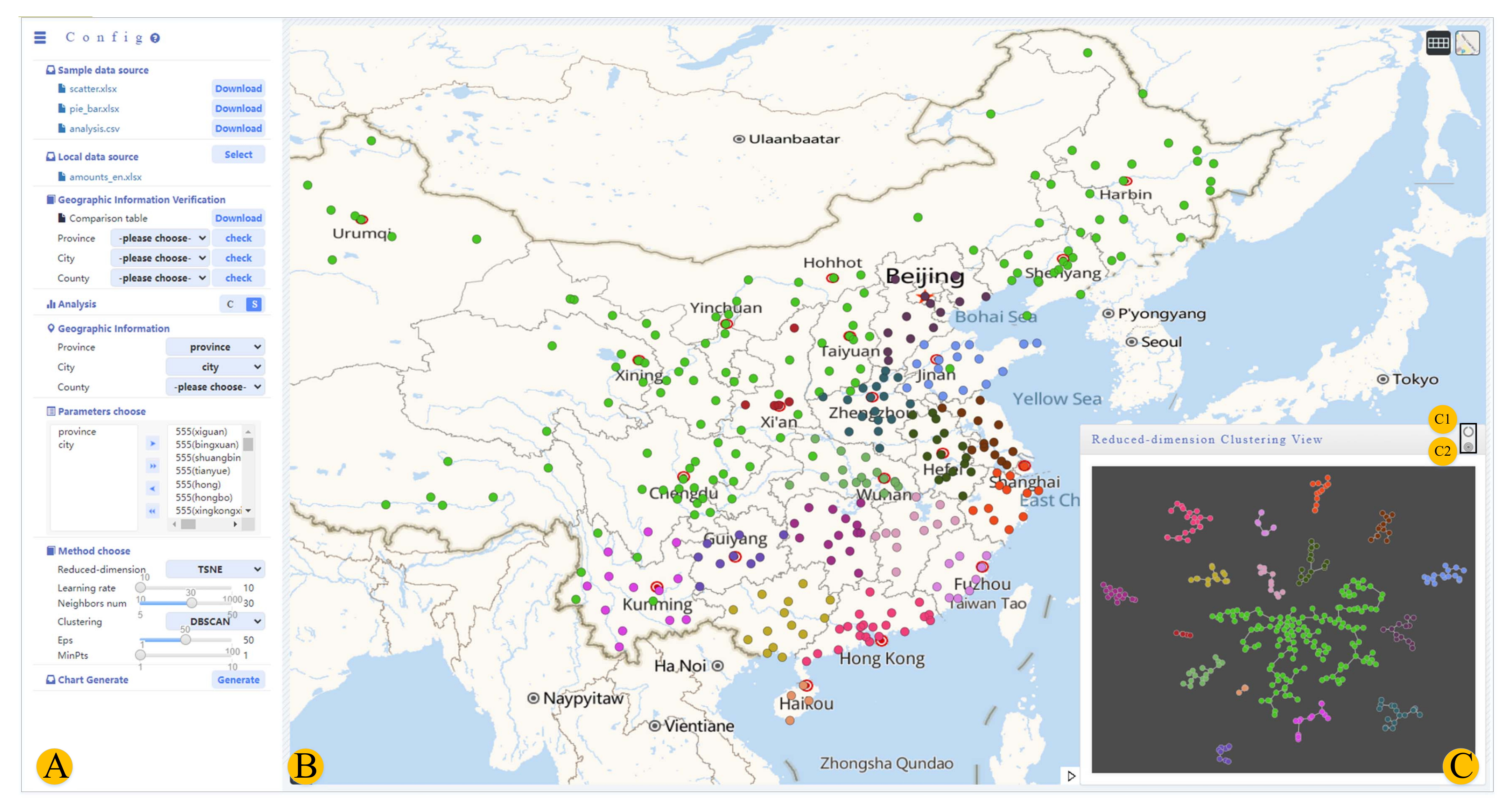
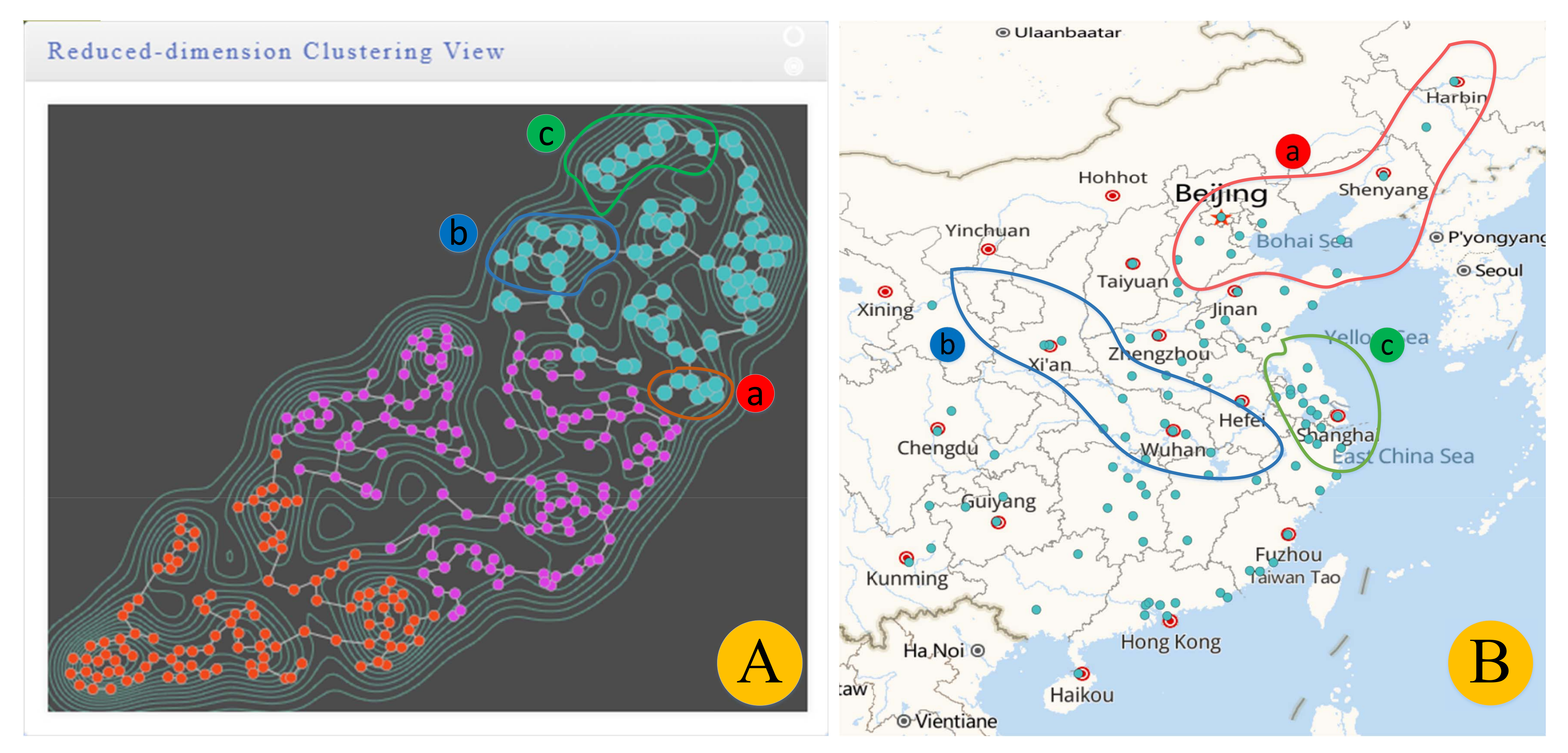
5.3.3. Reduced-Dimensional Clustering Mapping Visualization
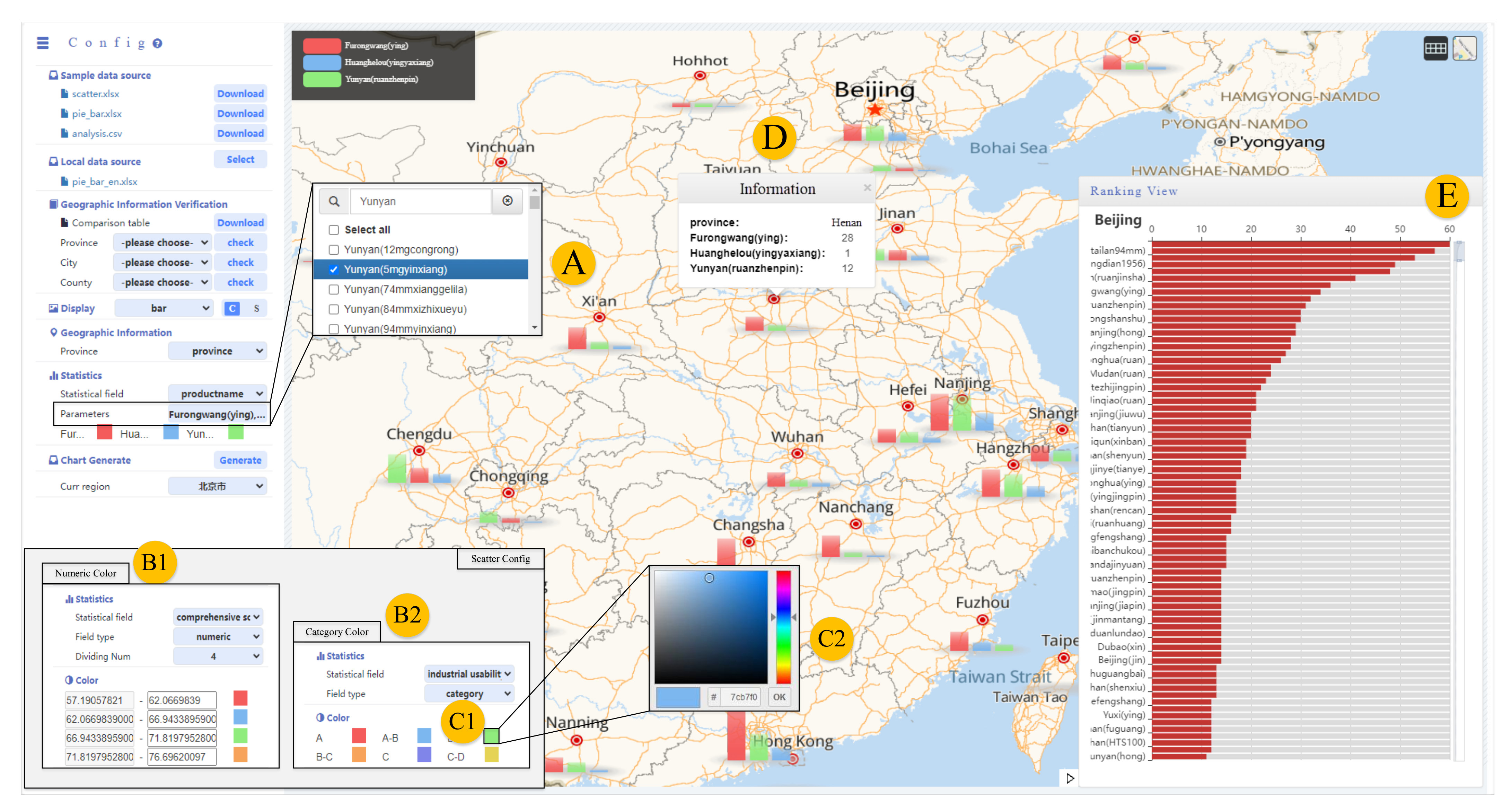
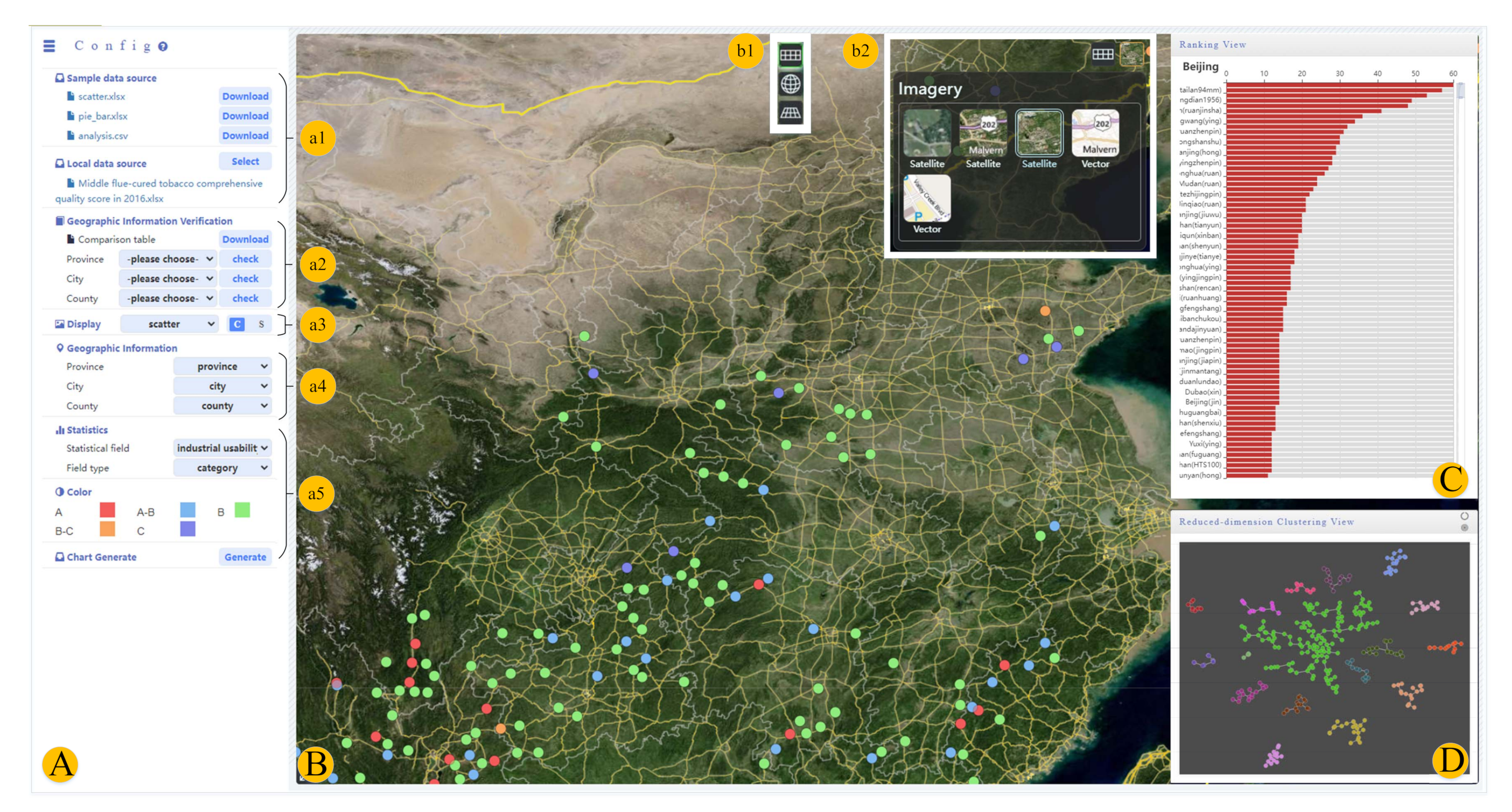
6. Interactive Design
6.1. Spatial Data Visualization Interaction
6.2. Map-Based Data Similarity Interaction
7. Case Study
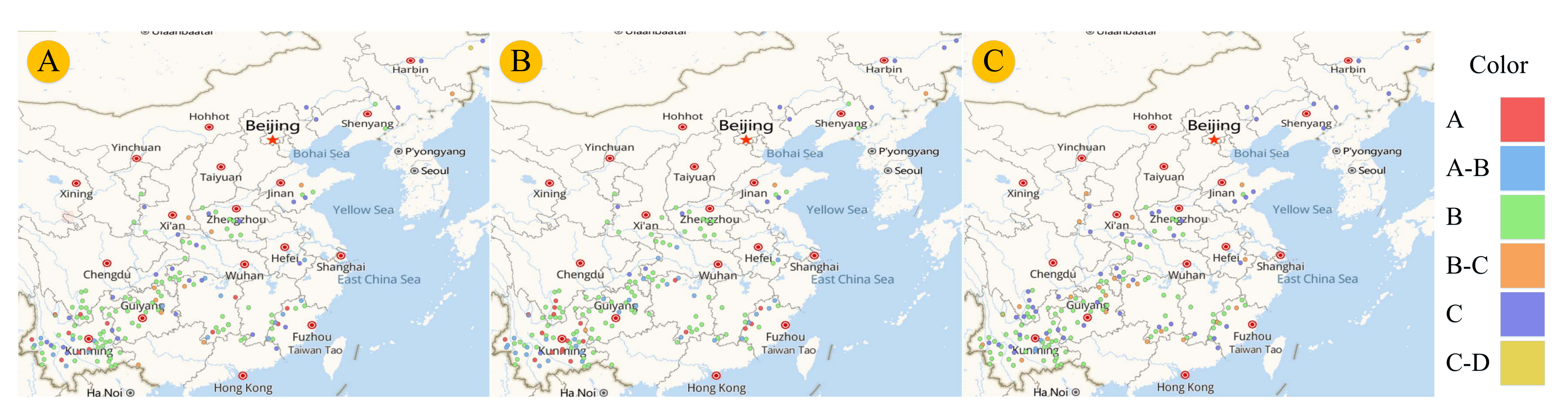
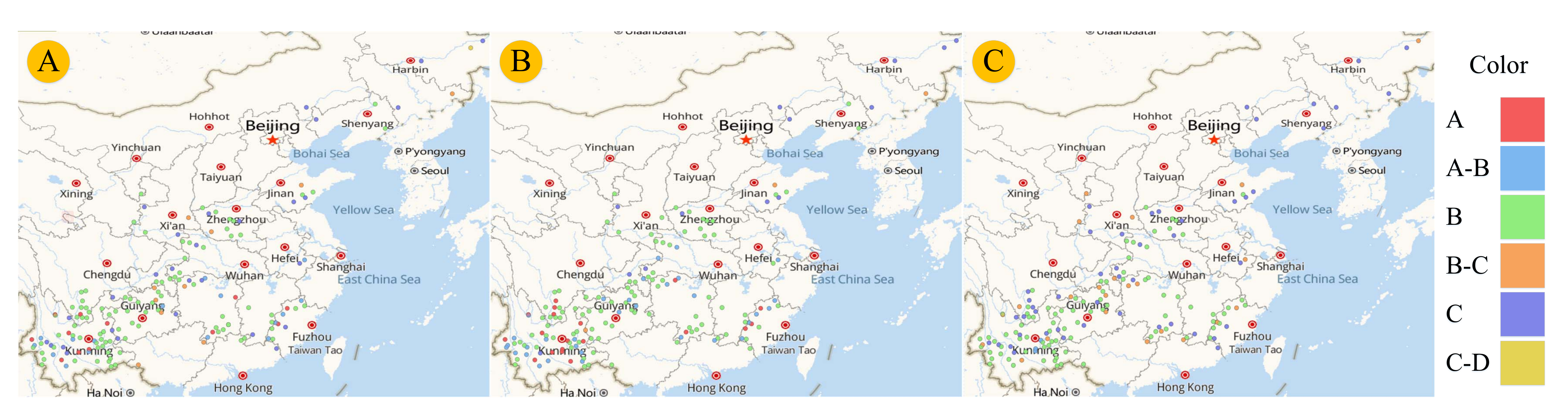
7.1. Spatial Distribution of Industrial Usability of Flue-Cured Tobacco Leaves
7.2. Analysis on Consumer Attention of Cigarette Products
7.3. Visualization Analysis of Cigarette Laying Structure Similarity
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, R.; Qiu, J.; Zheng, X.; Shi, C.; Zhang, C.; Wang, Z.; Wang, J.; Liu, Y.; Jia, N.; Feng, W. Survey on Status of Scientific Research Data in Tobacco Industry. Tob. Sci. Technol. 2020, 53, 107–112. [Google Scholar]
- Ren, L.; Du, Y.; Ma, S.; Zhang, X.; Dai, G. Visual Analytics Towards Big Data. J. Softw. 2014, 25, 1909–1936. [Google Scholar]
- Tian, D.; Shan, G.; Chi, X. Visual Analysis Method of Ecosystem Changes Based on Transfer Matrix. Comput. Syst. Appl. 2020, 29, 66–73. [Google Scholar]
- Yang, H.; Zhang, Z.; Yang, M.; Yang, D.; Jiang, X.; Chen, J. Design and Development of Online Visualization Platform for Meteorological Grid Data. Comput. Eng. Appl. 2019, 55, 207–211. [Google Scholar]
- Huang, D.; Xu, C.; Zheng, X.; Zhao, D.; He, S. Research on Big Data Visualization System for Marine Forecast Missions. Comput. Eng. Appl. 2019, 55, 87–94. [Google Scholar]
- Deng, C.; Sun, R.; Chen, Z.; Guo, X.; Nong, Y.; Qin, Y.; Zhao, K.; Wu, Q.; Li, S. Visual Analysis of Tobacco Market Big Data Based on Spatial-Temporal Grid. Tob. Sci. Technol. 2018, 51, 106–112. [Google Scholar]
- Yang, J. Studies on Creation and Visualization of Dynamic Simulation Model on Root Growth and Development in Tobacco (Nicotiana tabacum L.). Master’s Thesis, Henan Agricultural University, Zhengzhou, China, 2004. [Google Scholar]
- Wang, Y.; Wen, W.; Guo, X.; Zhao, G.; Lu, S.; Xiao, B. Research on Three-Dimensional Reconstruction and Visualization of Above-Ground Tobacco Plant. Sci. Agric. Sin. 2013, 46, 37–44. [Google Scholar]
- Wang, Y.; Wen, W.; Guo, X.; Zhao, G.; Xiao, B.; Lu, S. Research on Visualized Simulation of Tobacco Inflorescence. J. Agric. Mech. Res. 2011, 33, 51–54, 58. [Google Scholar]
- Hu, L.; Liu, M. Design and Realization of Visual Tobacco Management Information Based on 3 - Layer System Structure. Haidian Univ. J. 2005, 65–67, 23. [Google Scholar]
- Fan, X.; Lu, H. Research on Visual Management Platform of Tobacco Monopoly. Sci. Technol. Innov. 2018, 108, 111. [Google Scholar]
- Wang, K. Construction of Geographic Information System for Tobacco Visual Monopoly Management. Fujian Comput. 2015, 31, 113, 96. [Google Scholar]
- Zhang, S. Research on Visual Customer Relationship Management for Tobacco Industry. Master’s Thesis, Shandong University, Qingdao, China, 2006. [Google Scholar]
- Fang, Q.; Zhou, S. Application of Visual Customer Relationship Management in Tobacco Industry. Enterp. Econ. 2009, 123–125. Available online: https://xueshu.baidu.com/usercenter/paper/show?paperid=9aed8ffe85ca7fc0dd95ca3aed98f958amp;sc_from=pingtai4amp;cmd=paper_forwardamp;title (accessed on 20 February 2022).
- Shen, L.; Ma, R.; Li, S.; Zhang, X.; Liu, Z.; Li, F. Application on the Special and High Quality Tobacco Based on 3D Visualization Technology in the Jinshajiang River within Lijiang. J. Yunnan Agric. Univ. 2011, 172–177. [Google Scholar]
- Guo, D.; Fan, H. Analysis and Visualization of Cigarette Sales Data Based on ETL-KETTLE. Comput. Syst. Appl. 2017, 26, 74–80. [Google Scholar]
- Zhuo, H. Analysis of the Application of Heat Map in Tobacco Monopolization Management Based on Information Visualization. In Proceedings of the China Tobacco Society 2016 Annual Excellent Papers Compilation—Monopoly Management Theme, Beijing, China, 1 January 2016; Volume 12, pp. 2–13. [Google Scholar]
- Deng, C.; Song, J.; Sun, R.; Guo, X.; Shi, Y.; Yuan, G.; Sun, C.; Deng, X.; Lu, Y. Visual Analysis System of Cigarette Marketing Data Based on Thermodynamic Diagram. Tob. Sci. Technol. 2016, 49, 91–97. [Google Scholar]
- Meng, K. Research on Equipment Management Data Visualization of X Cigarette Factory Based on Lean Thinking. Master’s Thesis, Shaanxi Normal University, Xi’an, China, 2016. [Google Scholar]
- Yang, J.; Wang, H.; Li, B.; Li, S. Visible Analysis of Tobacco Strands’ Movement in Upright Pipe. Tob. Sci. Technol. 2009, 10–13. [Google Scholar]
- Ouyang, K. Tobacco Near Infrared Analysis Index System Web Visualization. Master’s Thesis, Hunan Normal University, Changsha, China, 2016. [Google Scholar]
- The Importance of Tobacco Control in Mexico. Available online: https://www.healthdata.org/data-visualization/importance-tobacco-control-mexico (accessed on 26 November 2019).
- Guindon, G.; Fatima, T.; Li, D.; Joukova, A.; Sudhir, J.; Mishra, S.; Chaloupka, F.; Jha, P. Visualizing data: Trends in smoking tobacco prices and taxes in India. Gates Open Res. 2019, 3, 8. [Google Scholar] [CrossRef]
- Gueorguieva, R.; Buta, E.; Simon, P.; Krishnan-Sarin, S.; O’Malley, S. Data Visualization Tools of Tobacco Product Use Patterns, Transitions and Sex Differences in the PATH Youth Data. Nicotine Tob. Res. 2020, 22, 1901–1908. [Google Scholar] [CrossRef]
- Tian, D.; Shan, G.; Chi, X.; Zhang, Y.; Feng, W.; Wang, J.; Wang, A.; Wang, R. Visual Analysis Method of Tobacco Quality Data Based on Dimension Reduction. J. Syst. Simul. 2021, 33, 2279–2288. [Google Scholar]
- Wei, C.; Yang, M.; Liu, Y.; Cai, X.; Wang, X.; Song, J.; Yin, Q. Spatial Feature Analysis of Apparent Quality Index in Flue-cured Tobacco at County Level. Acta Tabacaria Sin. 2010, 16, 45–49. [Google Scholar]
- Yang, J.; Zhang, Y.; Wang, J.; Hu, A.; Wang, H. Regional Differences in Smoking Preferences. Tob. Sci. Technol. 2012, 57–59. [Google Scholar]
- Lin, Y.; Yang, G.; Miao, M.; Yang, D.; Chen, X. Analysis on Regional Differences of Smoking Quality Indicators. Hubei Agric. Sci. 2009, 48, 3063–3067. [Google Scholar]
- Yang, B. Research on Visual Analysis Method of the Forest Disease and Pest Data. Ph.D. Thesis, Beijing Forestry University, Beijing, China, 2019. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann: Boston, MA, USA, 2012; pp. 83–124. [Google Scholar]
- Borg, I.; Groenen, P. Modern Multidimensional Scaling: Theory and Applications. J. Educ. Meas. 2010, 40, 277–280. [Google Scholar] [CrossRef]
- Maaten, L.; Hinton, G. Visualizing High-dimensional Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Hinton, G.; Roweis, S. Stochastic Neighbor Embedding. In Proceedings of the 15th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 1 January 2002; pp. 857–864. [Google Scholar]
- Agarwal, P.; Mustafa, N. K-Means Projective Clustering. In Proceedings of the Twenty-Third ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Paris, France, 14–16 June 2004; pp. 155–165. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Ester, M.; Kriegel, H.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96), Portland, Oregon, 2–4 August 1996; pp. 226–231. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Feature | Value | Function |
|---|---|---|---|
| space category | longitude and latitude | numeric | spatial feature |
| high-dimensional | high dimension | numeric, category | feature analysis |
| Province | City | County | Evaluation Score | Industrial Usability |
|---|---|---|---|---|
| Yunnan | Baoshan | Longyang | 73.39 | A |
| Hunan | Changsha | Liuyang | 67.97 | A |
| Fujian | Longyan | Shanghang | 70.45 | B |
| Jilin | Tonghua | Liuhe | 62.14 | C |
| Province | Product | Number of Favorable Comments |
|---|---|---|
| Beijing | Zhonghua | 37 |
| Beijing | Yunyan | 15 |
| Beijing | Furongwang | 10 |
| Yunnan | Zhonghua | 20 |
| Yunnan | Yunyan | 50 |
| Yunnan | Furongwang | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, B.; Tian, D.; Shan, G. Tobacco Spatial Data Intelligent Visual Analysis. Electronics 2022, 11, 995. https://doi.org/10.3390/electronics11070995
Yang B, Tian D, Shan G. Tobacco Spatial Data Intelligent Visual Analysis. Electronics. 2022; 11(7):995. https://doi.org/10.3390/electronics11070995
Chicago/Turabian StyleYang, Bo, Dong Tian, and Guihua Shan. 2022. "Tobacco Spatial Data Intelligent Visual Analysis" Electronics 11, no. 7: 995. https://doi.org/10.3390/electronics11070995
APA StyleYang, B., Tian, D., & Shan, G. (2022). Tobacco Spatial Data Intelligent Visual Analysis. Electronics, 11(7), 995. https://doi.org/10.3390/electronics11070995