
Efficient FPGA Implementation of an ANN-Based Demapper Using Cross-Layer Analysis

 , ,
, ,
Abstract
:1. Introduction
1.1. From Communication System Layer to Artificial Neural Network Layer
- (1)
- Partitioning of the processing blocks at the transmitter and receiver into different subcomponents, e.g., source coding, channel coding, and modulation;
- (2)
- Optimizing each subcomponent individually for a channel model while considering the application requirements.
1.2. From Neural Networks Layer to Hardware Layer
- Low-latency, which is essential for delay-sensitive applications;
- Low-power, which is mandatory to meet the constraints of embedded devices;
- Adaptability, which is of high relevance due to the varying channel conditions.
1.3. Our Work as Cross-Layer Approach
- A cross-layer approach that relates the application requirements (SNR, bit error rate (BER)) to the ANN architecture (time of convergence for training the ANN) and to the hardware implementation capabilities (DOP, utilization of the FPGA resources);
- The evaluation of the hardware performance of a trainable demapper in the context of AE-based communication systems that enables online fine-tuning to the latest noise conditions in wireless channels. To the best of our knowledge, such an FPGA implementation is unprecedented;
- A parameterizable framework that enables the adjustment of the DOPs to satisfy the application requirements, to ensure environmental adaptation and optimize latency or power;
- A benchmark of the highly efficient FPGA design by comparing the performance to a PyTorch implementation on a high-performance GPU, an embedded GPU, and an embedded CPU.
2. Related Work
2.1. AE for Communication
2.2. FPGA-Based Neural Network Training Accelerators
3. System Model
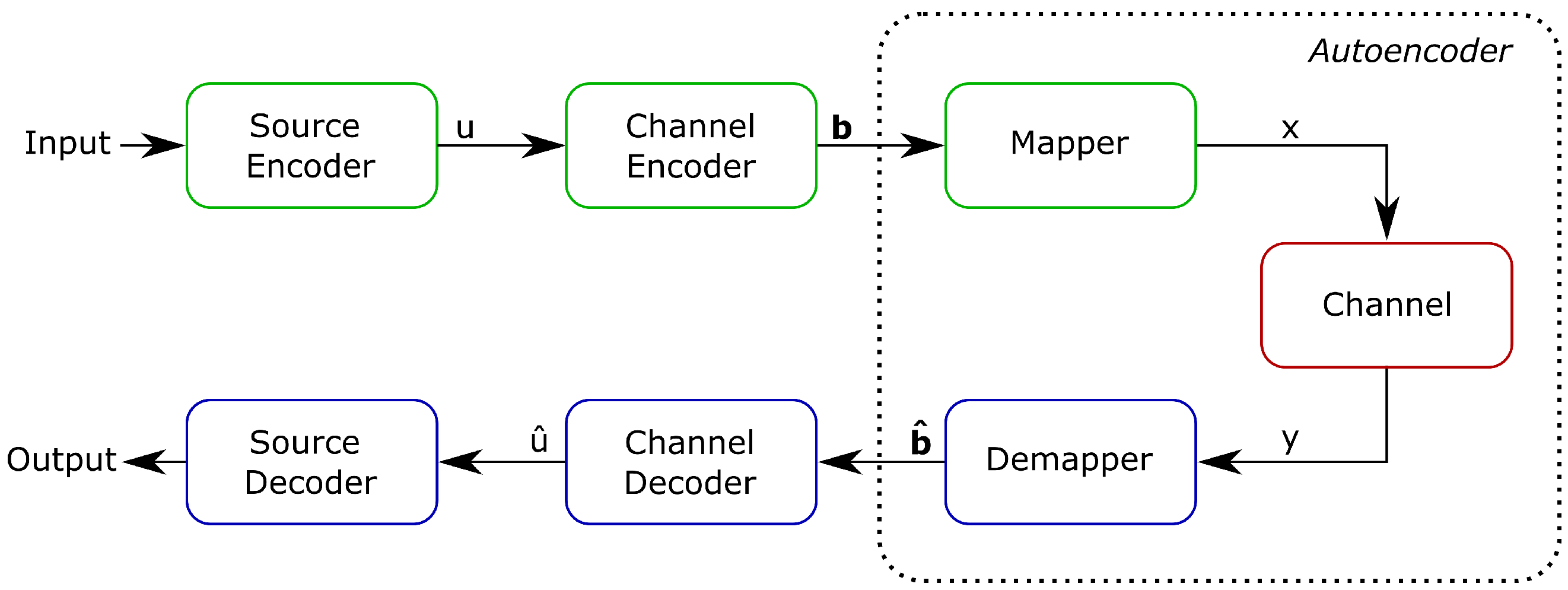
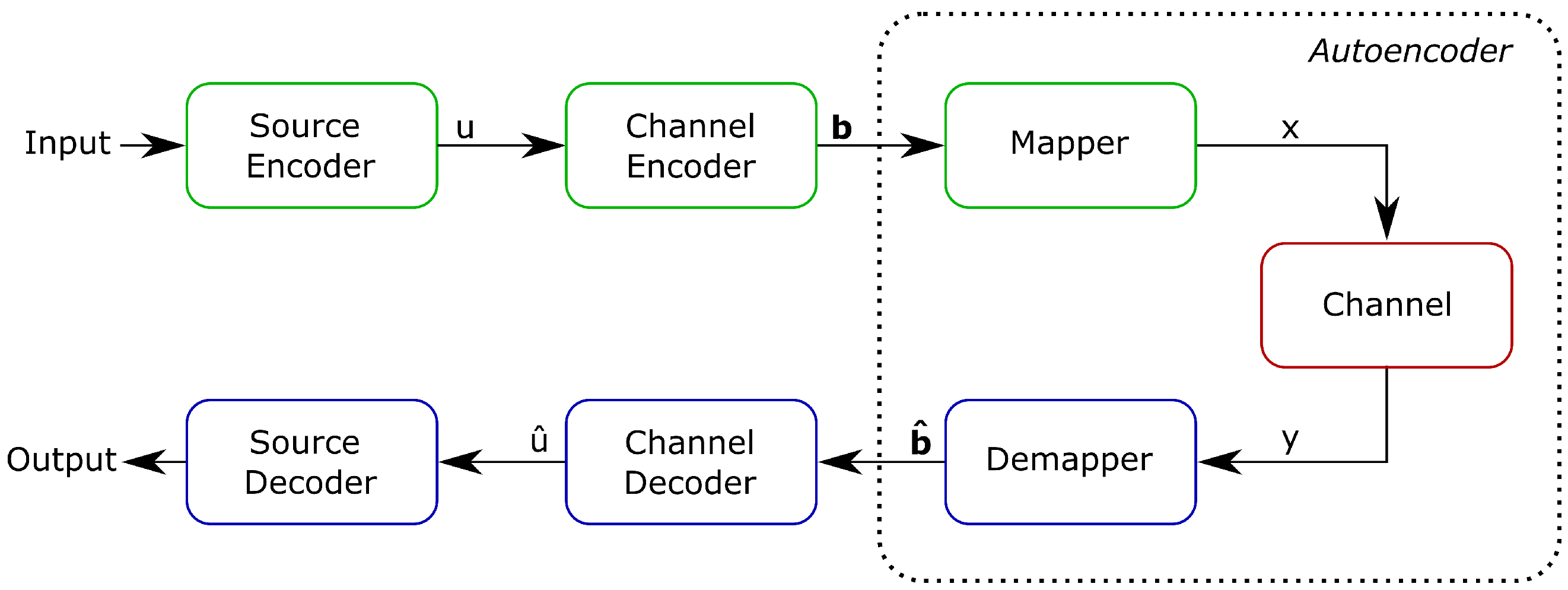
3.1. Communication System
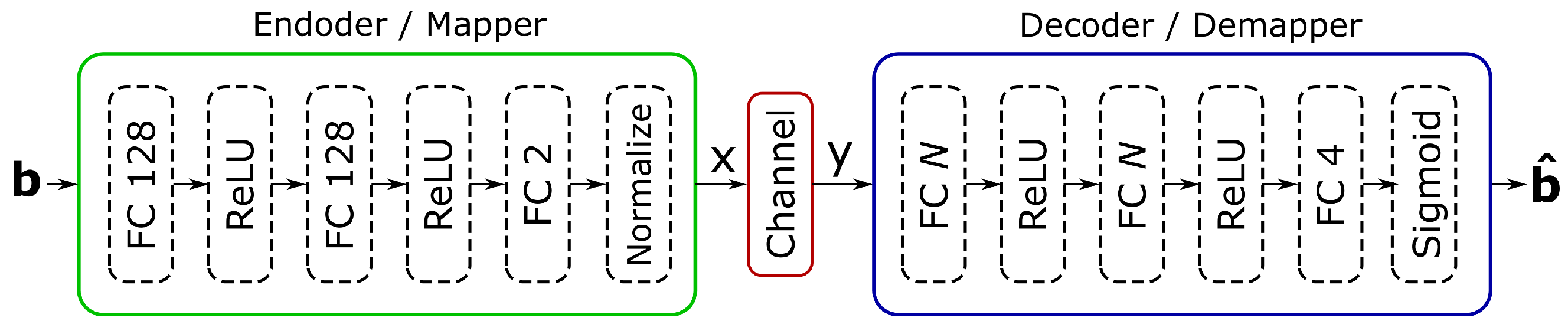
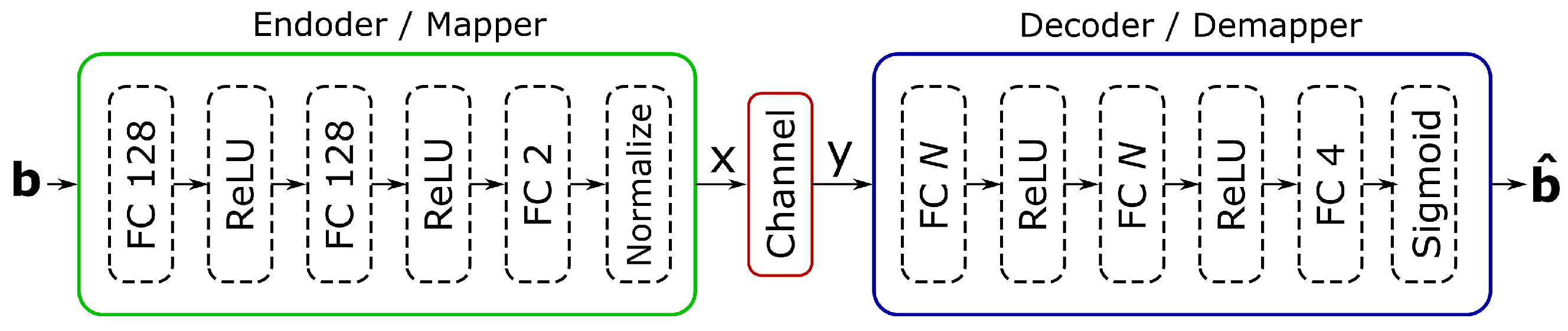
3.2. Autoencoder
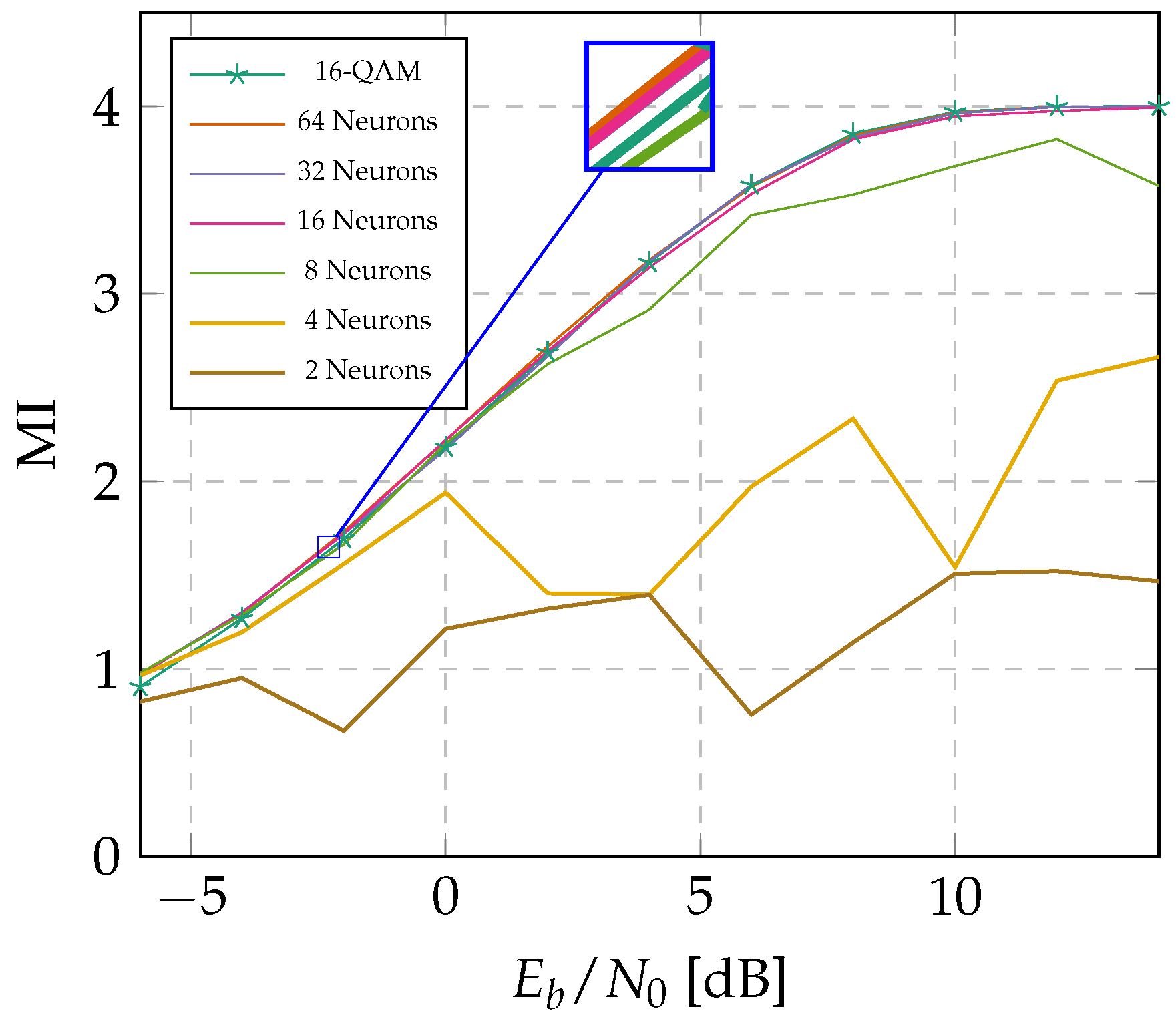
3.3. Topology Optimization Using Cross-Layered Analysis
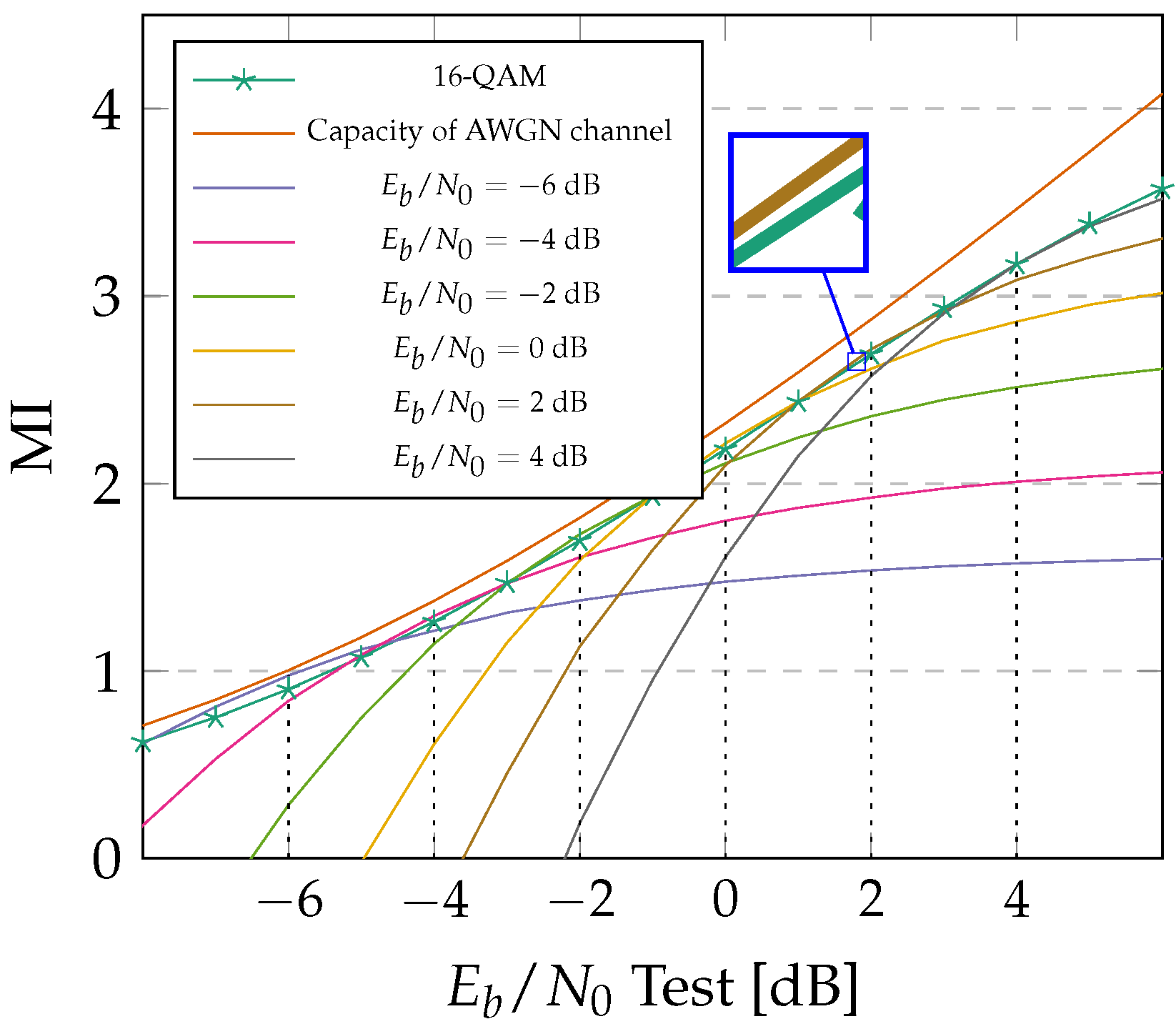
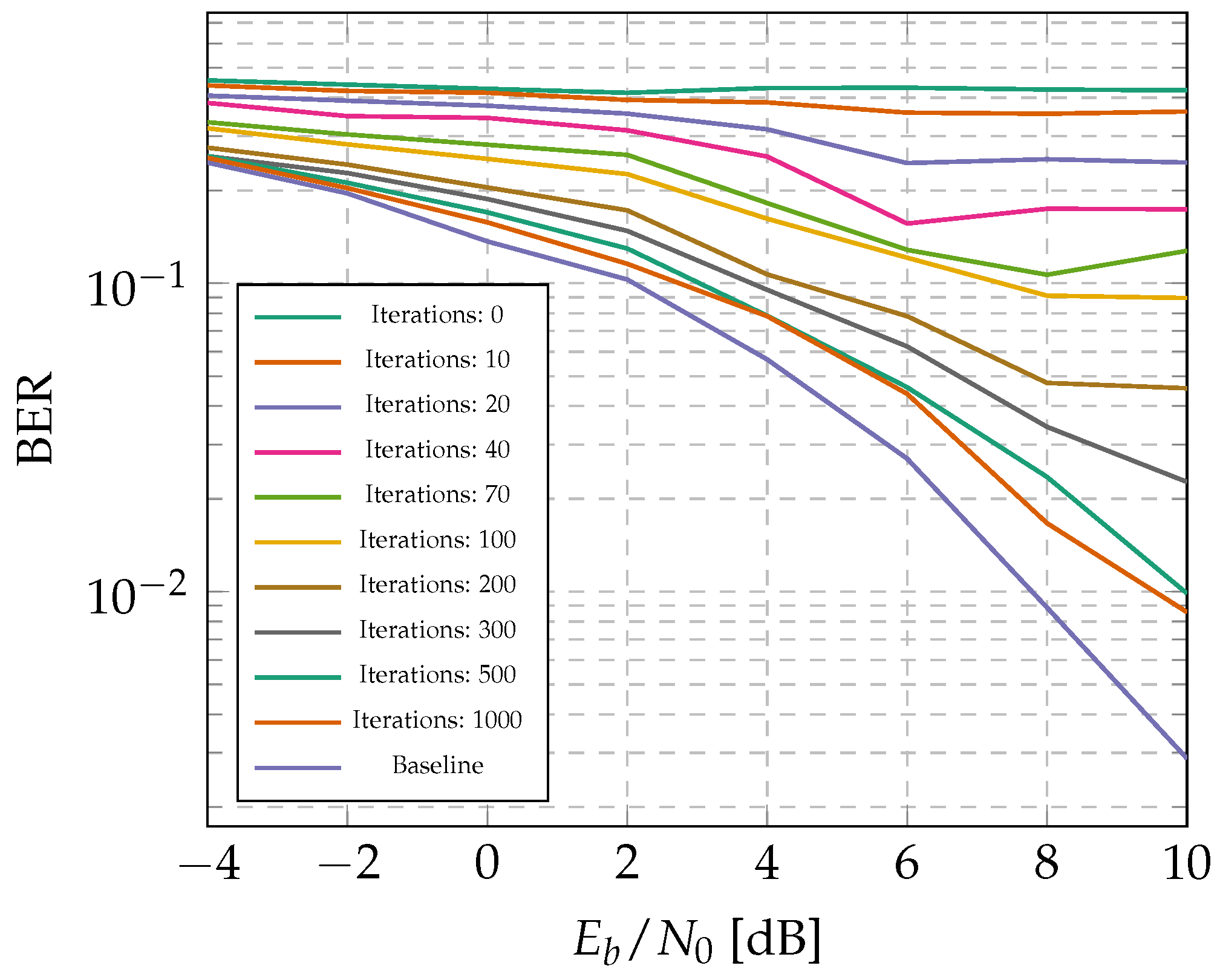
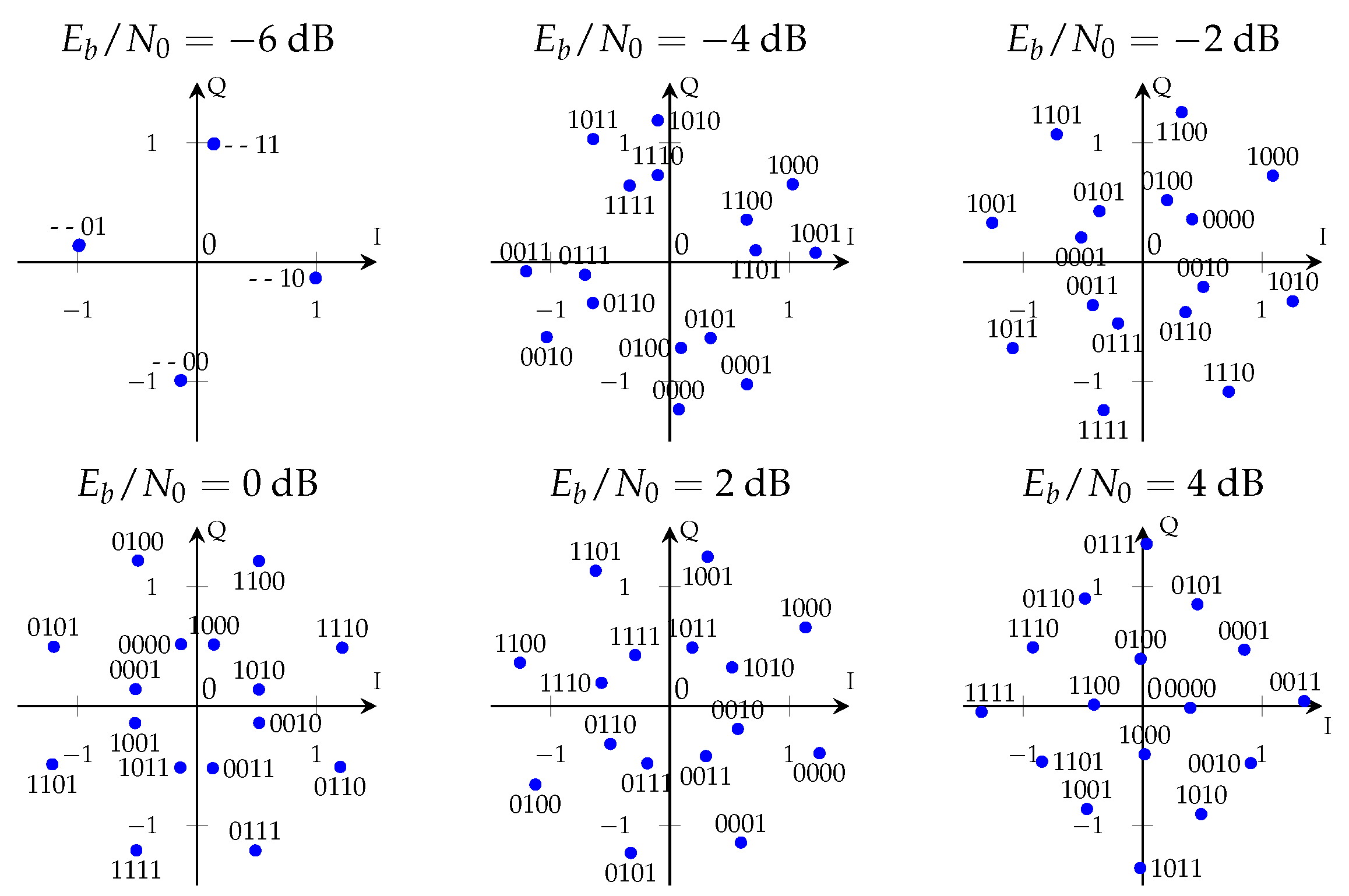
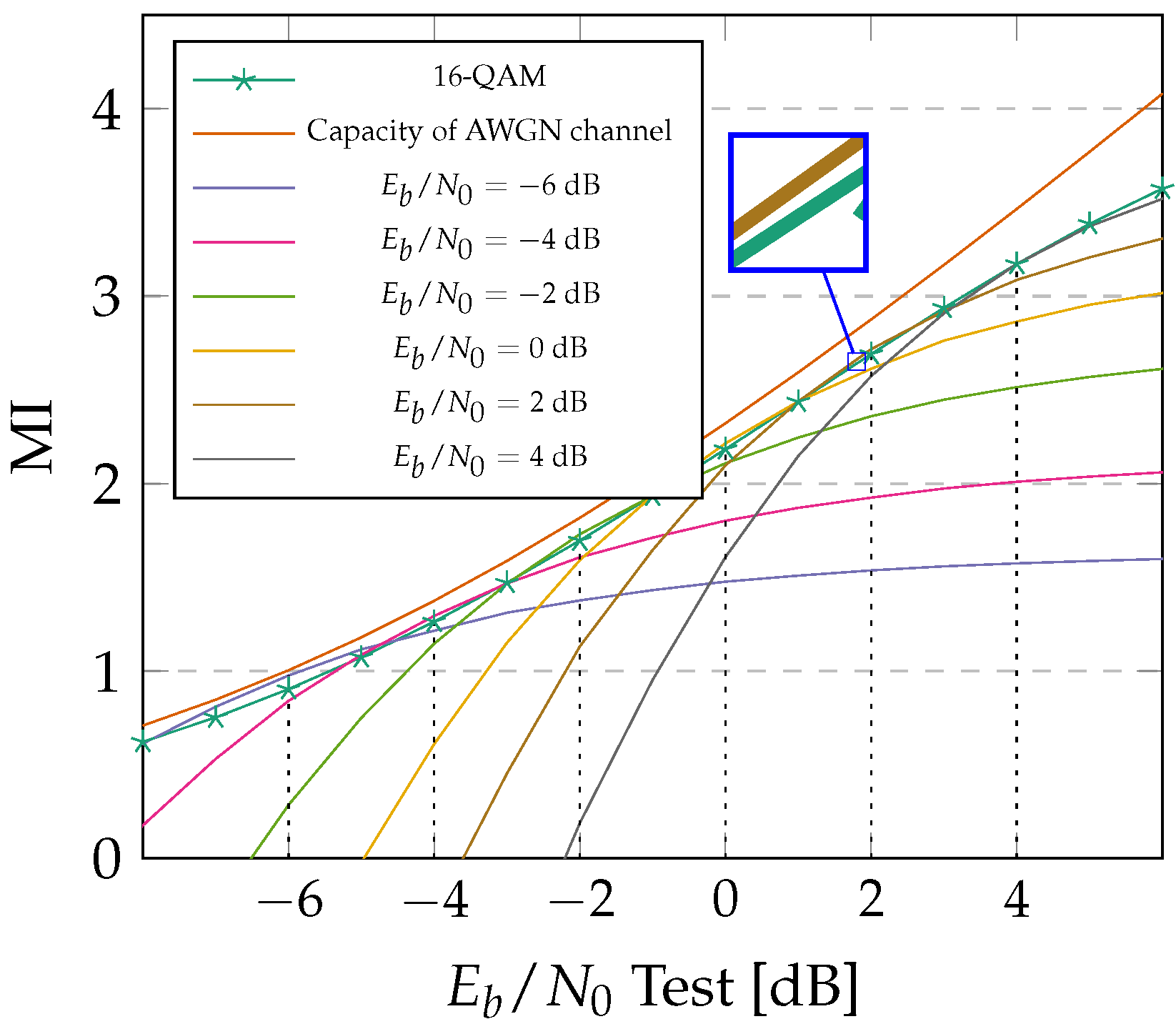
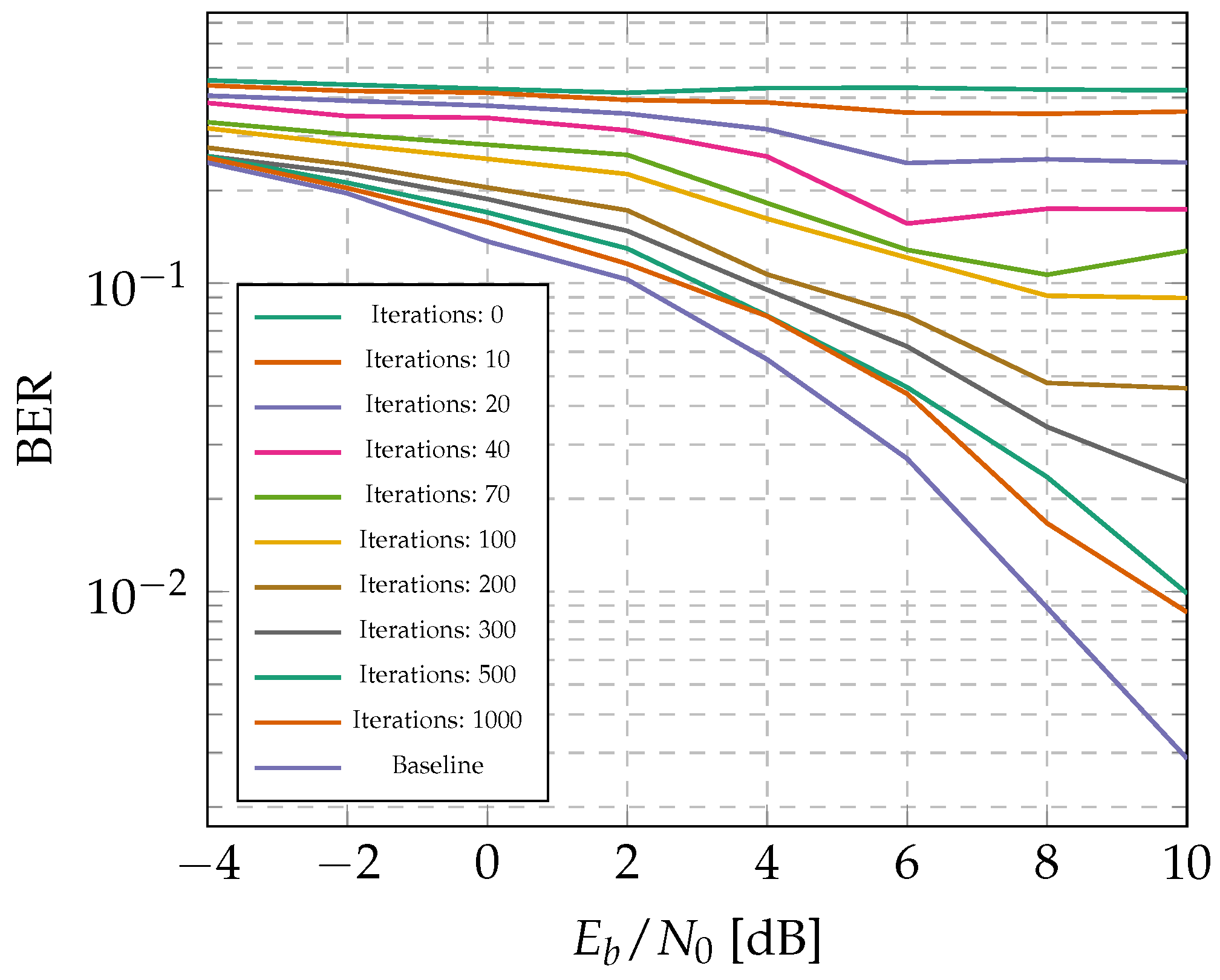
3.4. Training Results
4. Hardware Implementation
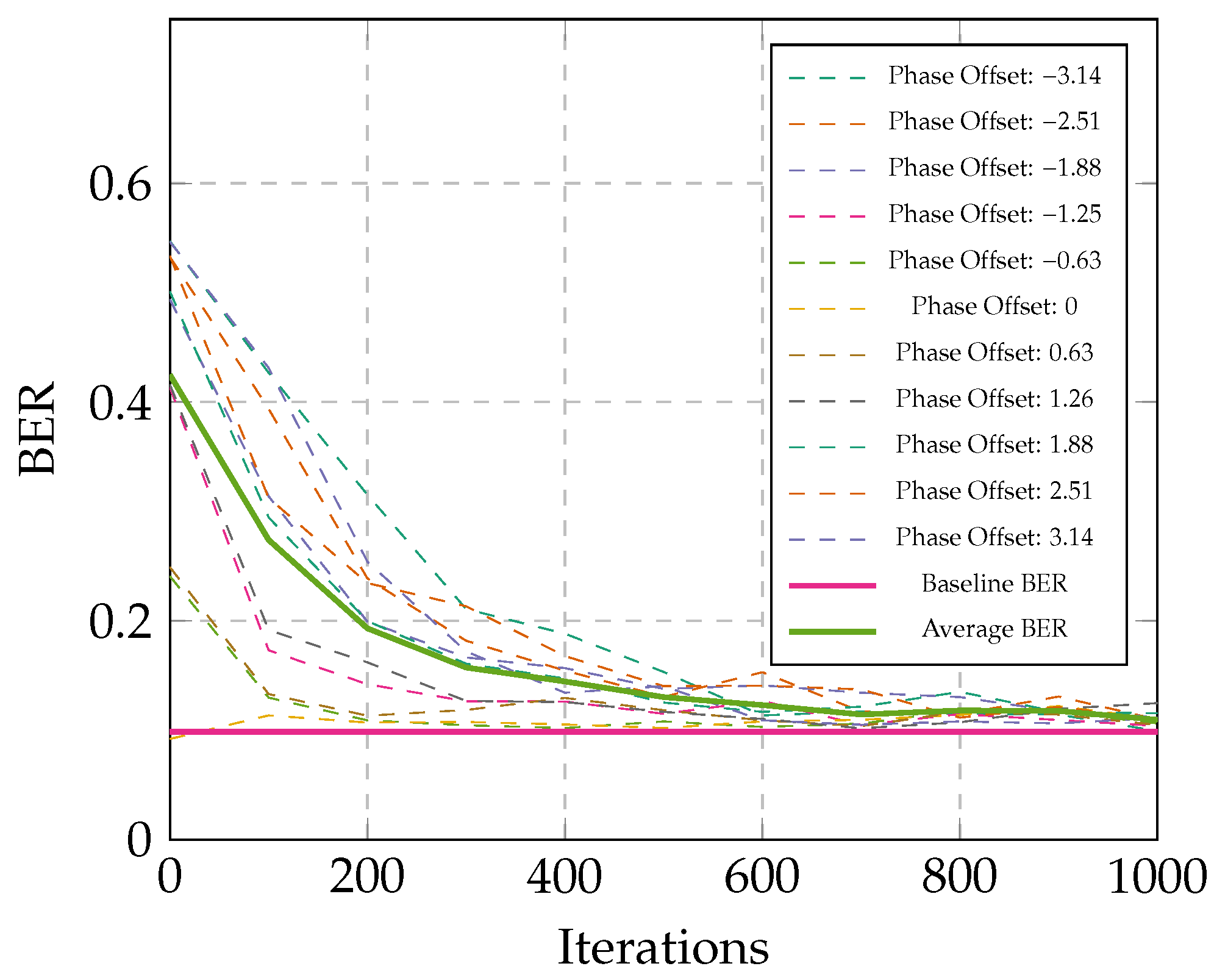
4.1. Reasonability of Demapper Fine-Tuning
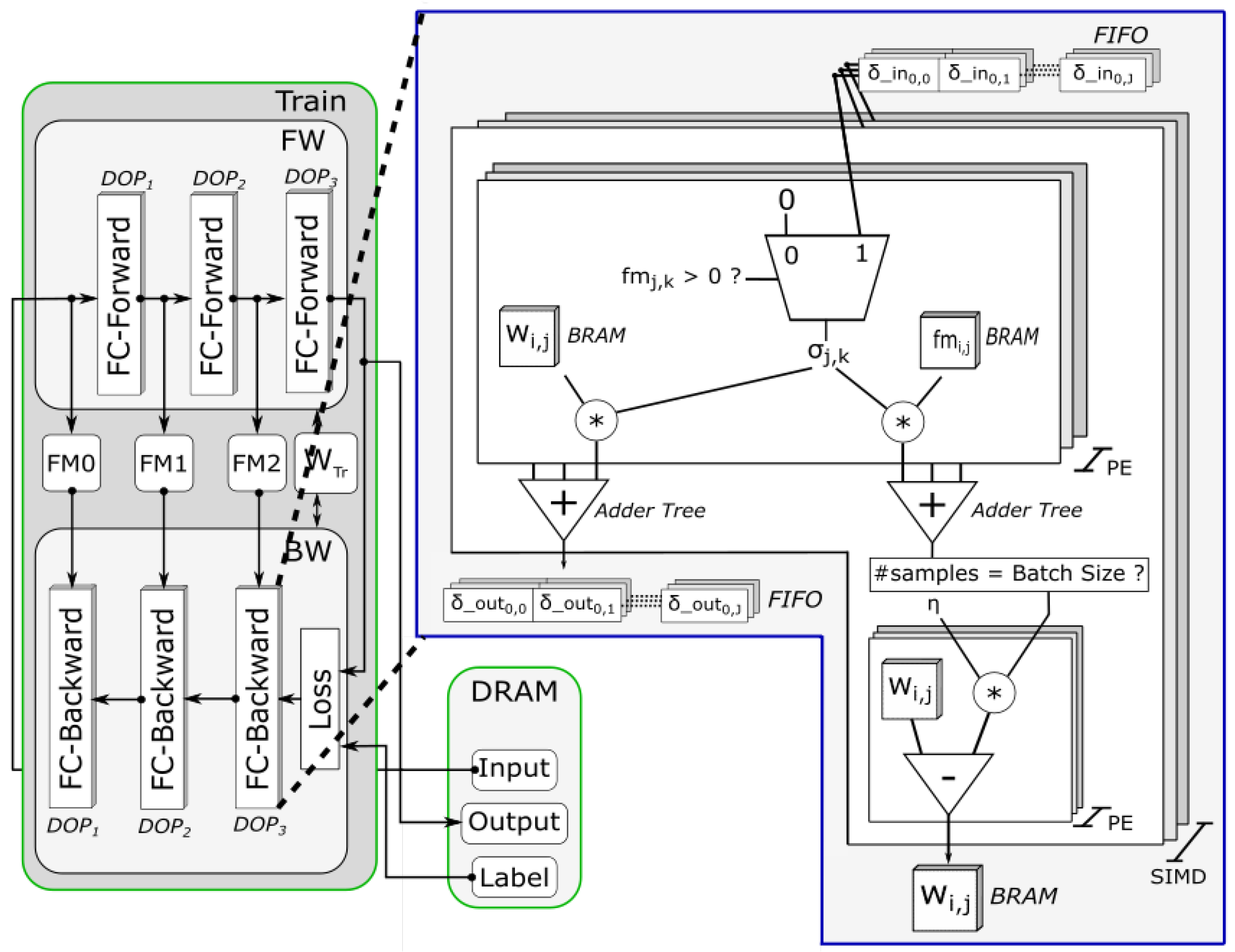
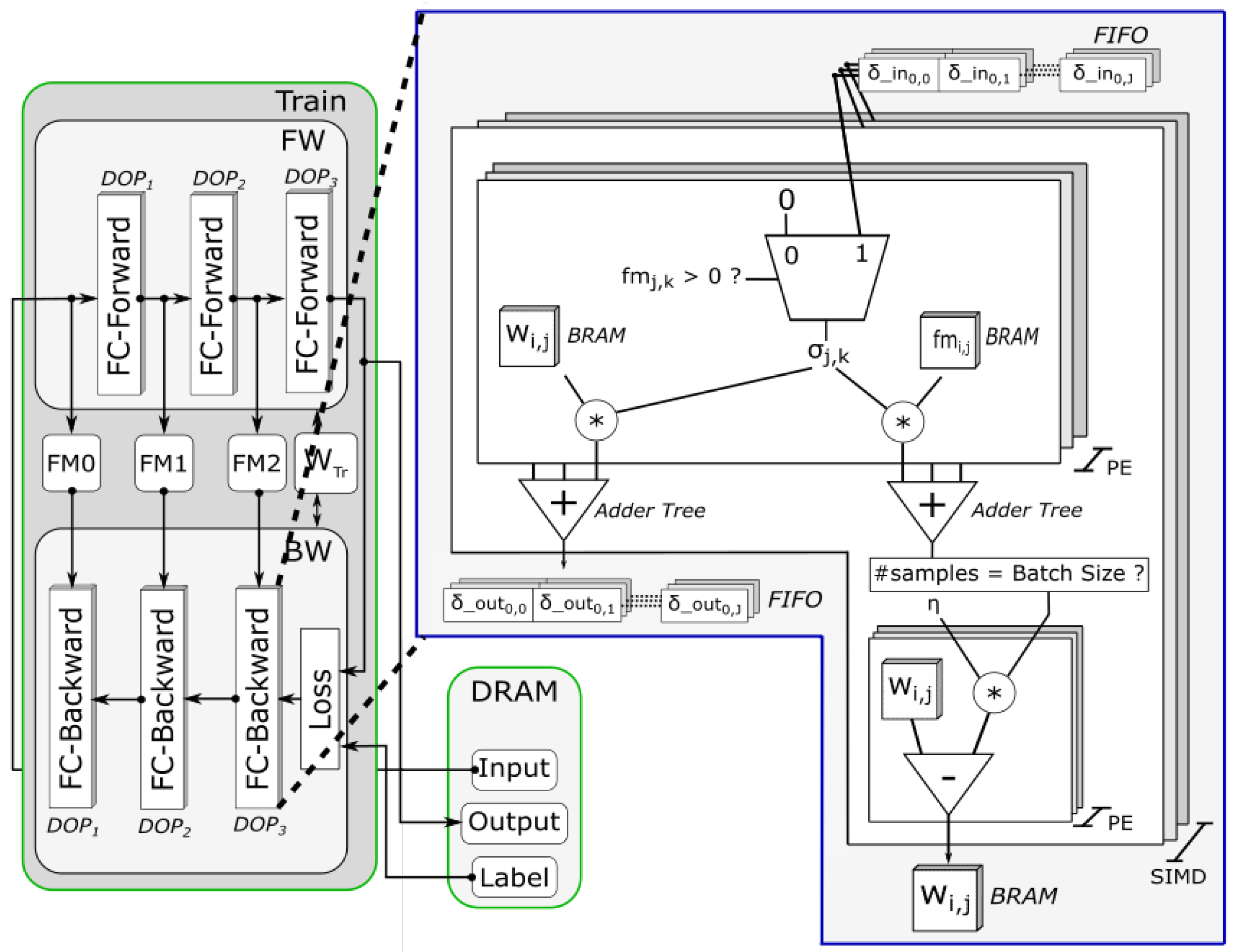
4.2. Hardware Architecture
4.2.1. Architecture Overview
- It allows us to set the DOP separately for inference and training module to partition the resources according to the requirements as described in Section 4.3;
- We are able to operate on a reduced bit-width during inference as compared to training, to save power and energy during inference while keeping high precision during training.
4.2.2. Training Module
- Separately adjustable DOPs for inference and train module allow to adapt to application requirements and objectives, which is exploited by our framework as described in Section 4.3;
- Fully pipelined, on-chip architecture achieves low-latency and high-throughput even for applications that rely on small batch size;
- Different weight-width for inference and training enables training with higher precision while minimizing resources for inference.
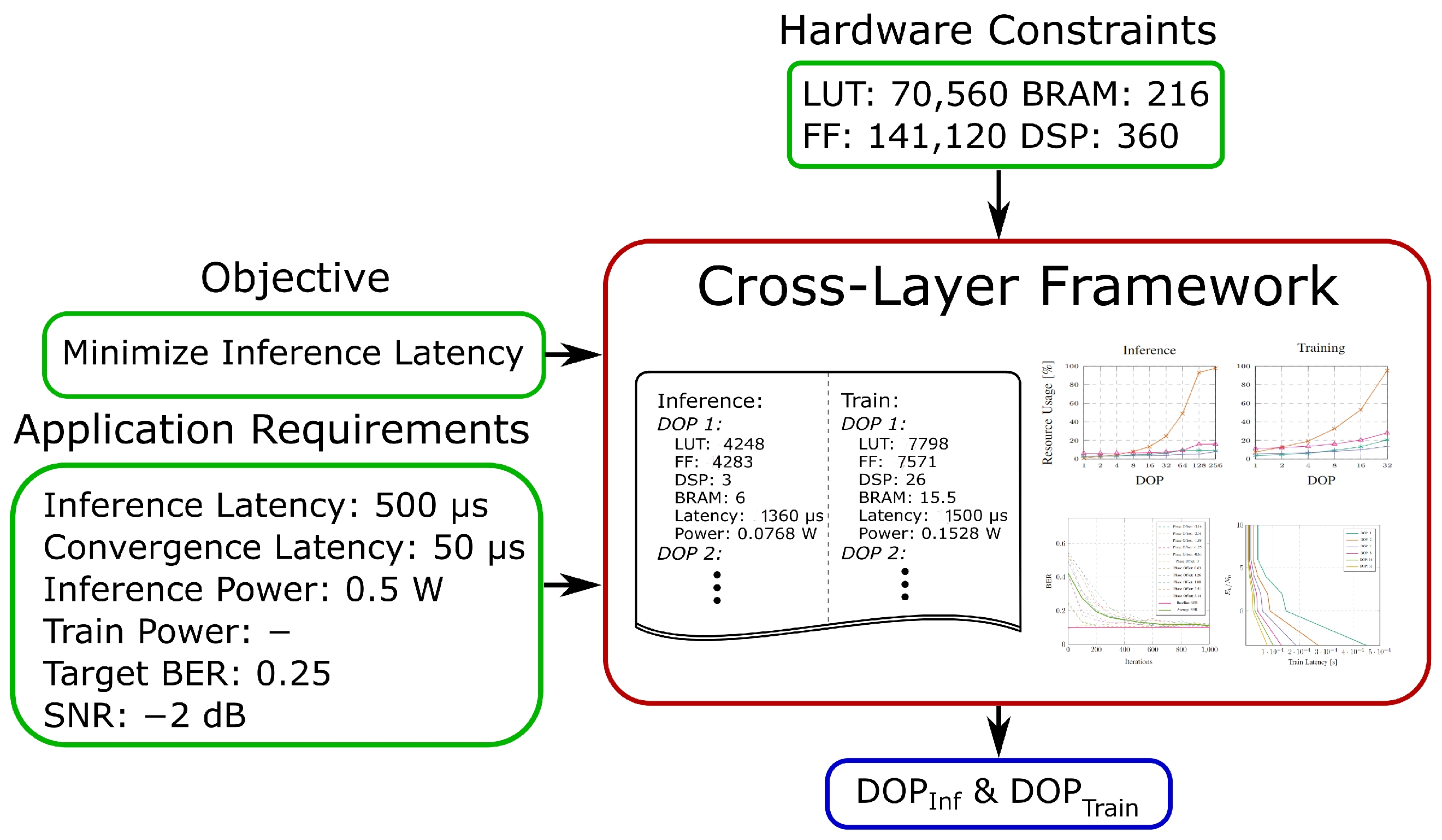
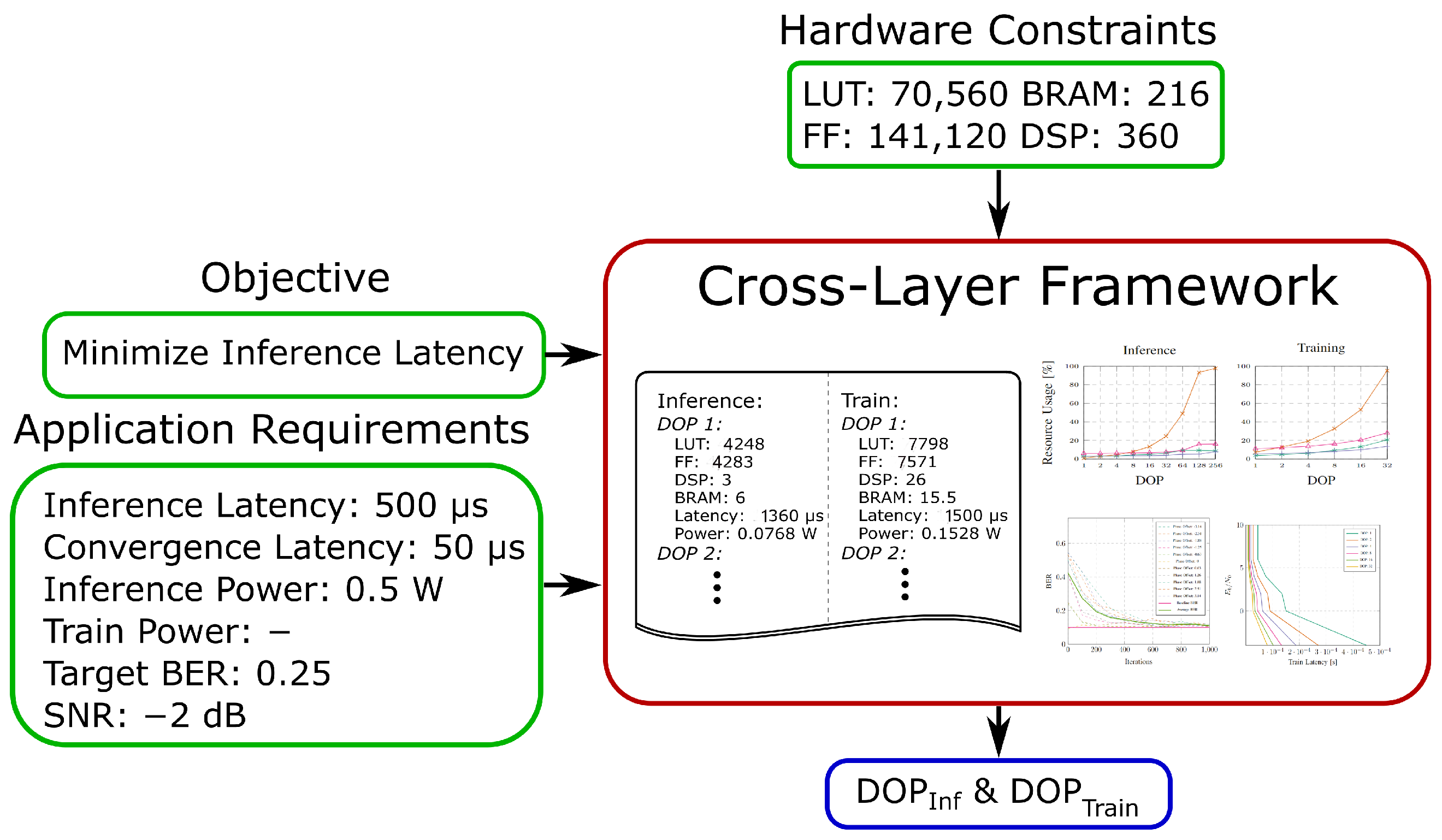
4.3. Cross-Layer Exploration Framework
- Initial configuration: initial inference module, initial training module;
- Temporal configuration: initial inference module, new inference module;
- New configuration: initial training module, new inference module.
- The objective, e.g., min. inference latency, min. convergence latency, min. inference power or min. training power;
- Application requirements in form of latency and power demands and, optionally, a target BER for an estimated SNR;
- Hardware constraints based on the available resources of the target platform.
| Algorithm 1: DOP Calculation. |
 |
- (1)
- Environmental Adaption: The receiver can be fine-tuned to compensate variations of the communication channel by retraining the ANN;
- (2)
- Requirement Adaption: The FPGA can be reconfigured to satisfy changing application requirements by adapting the DOP of inference and training module.
5. Results and Discussion
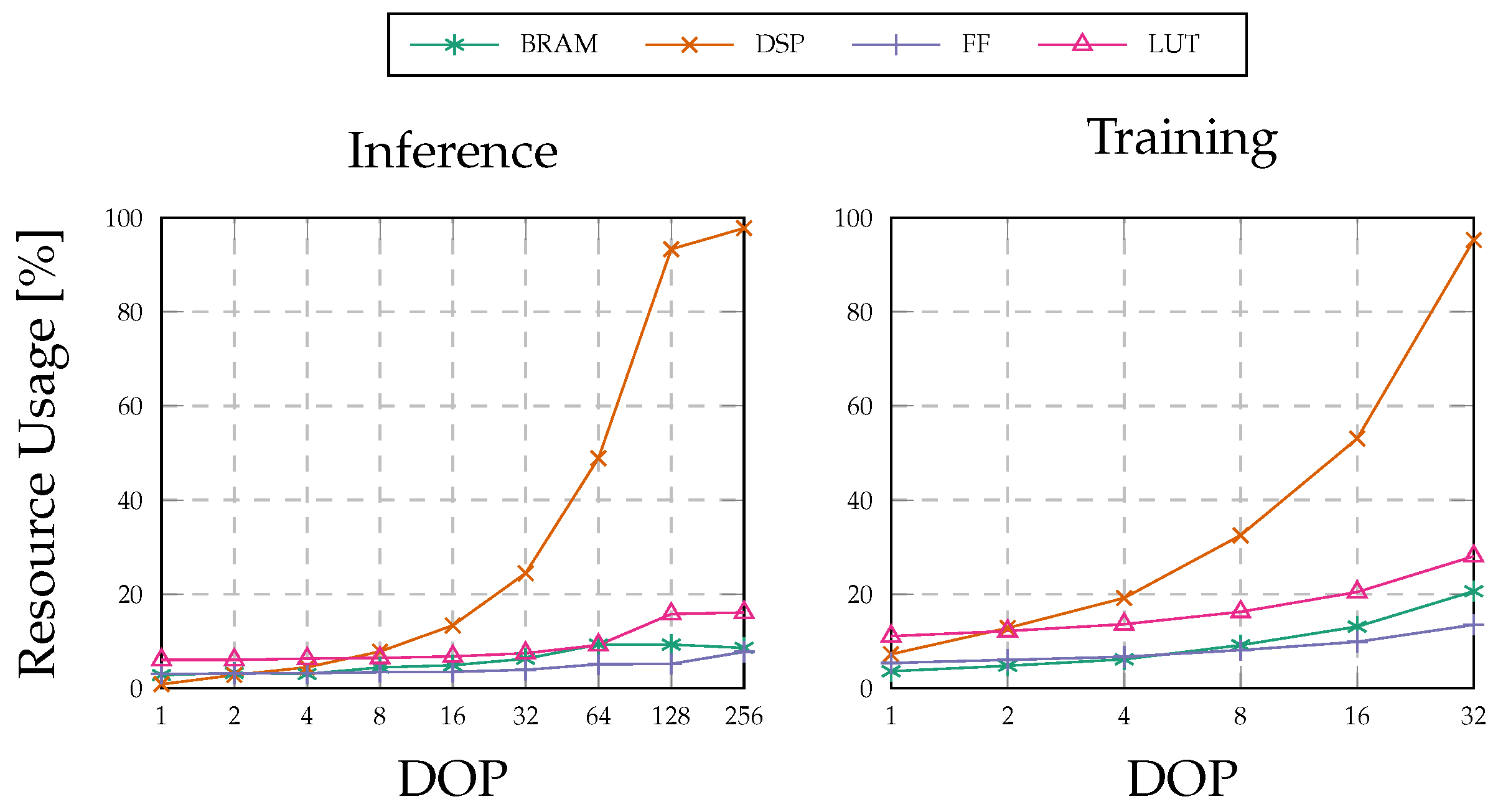
5.1. Resource Utilization
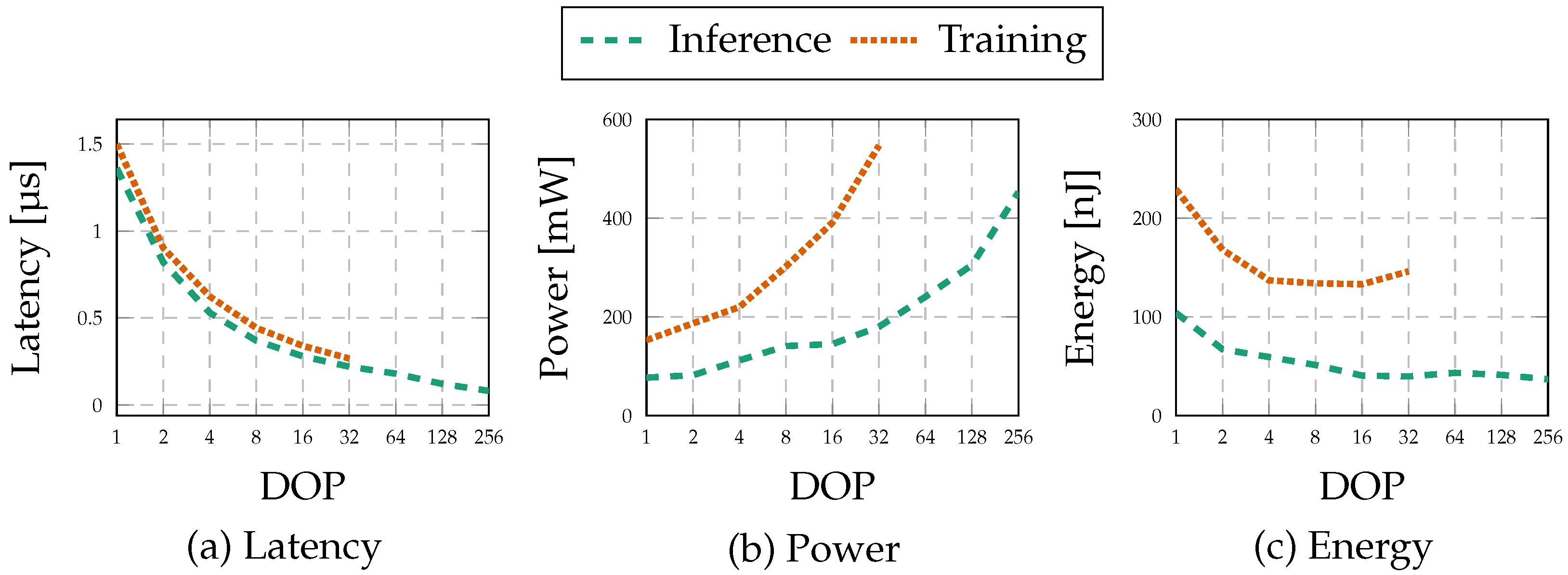
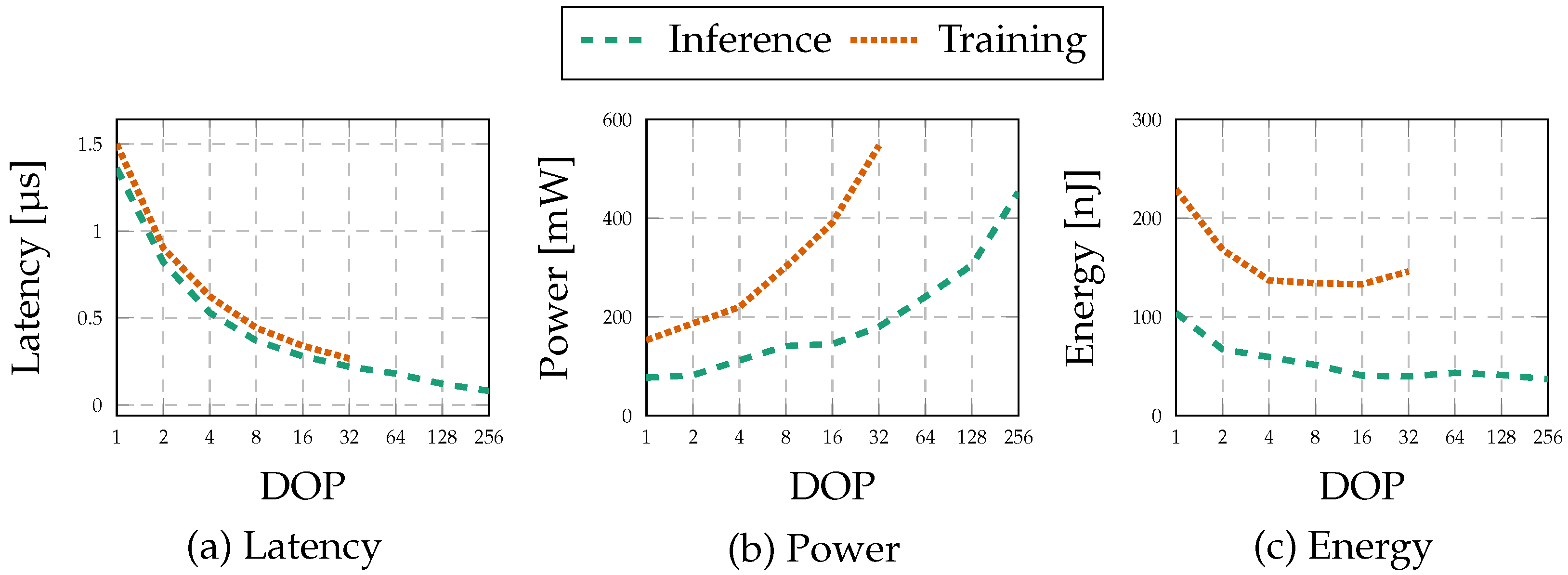
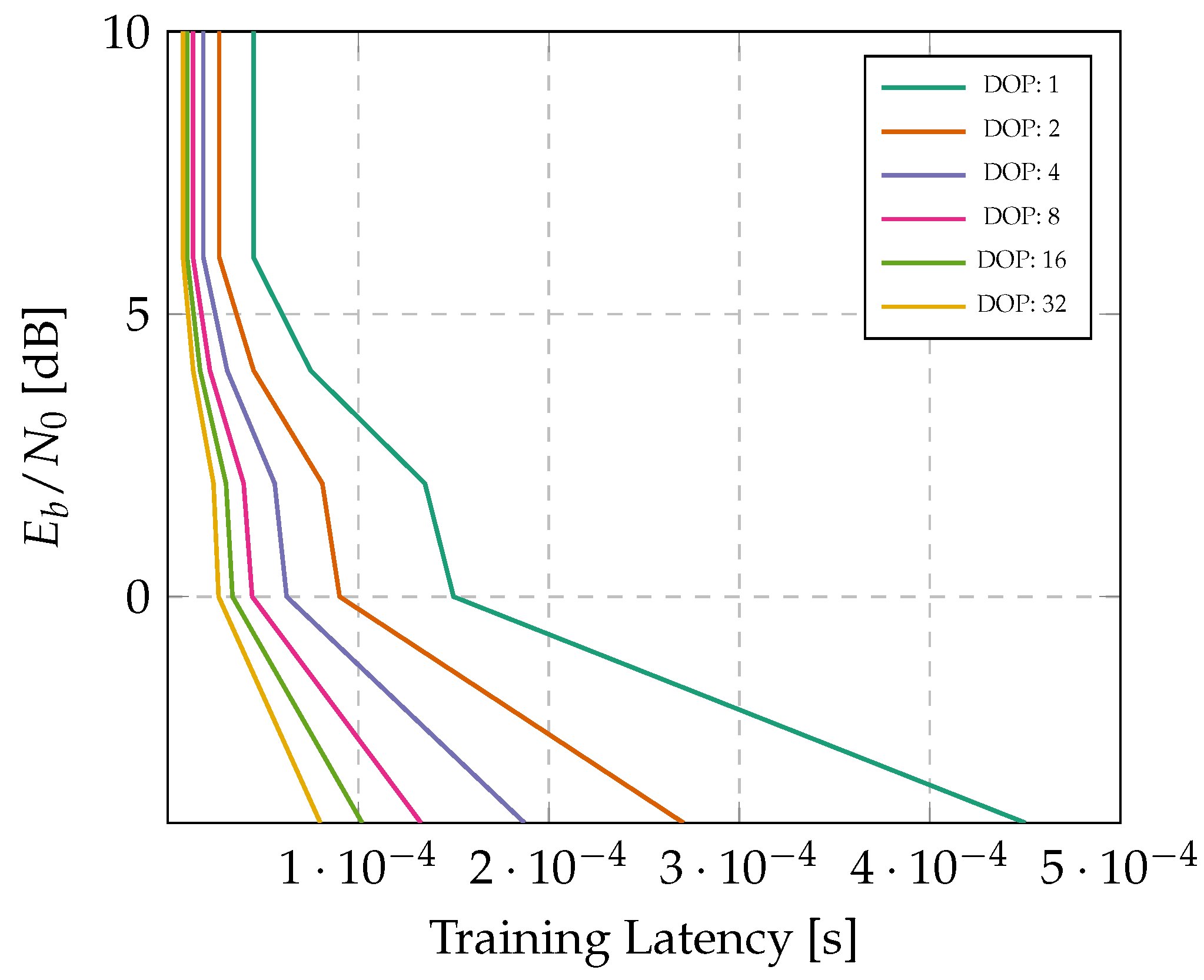
5.2. Latency
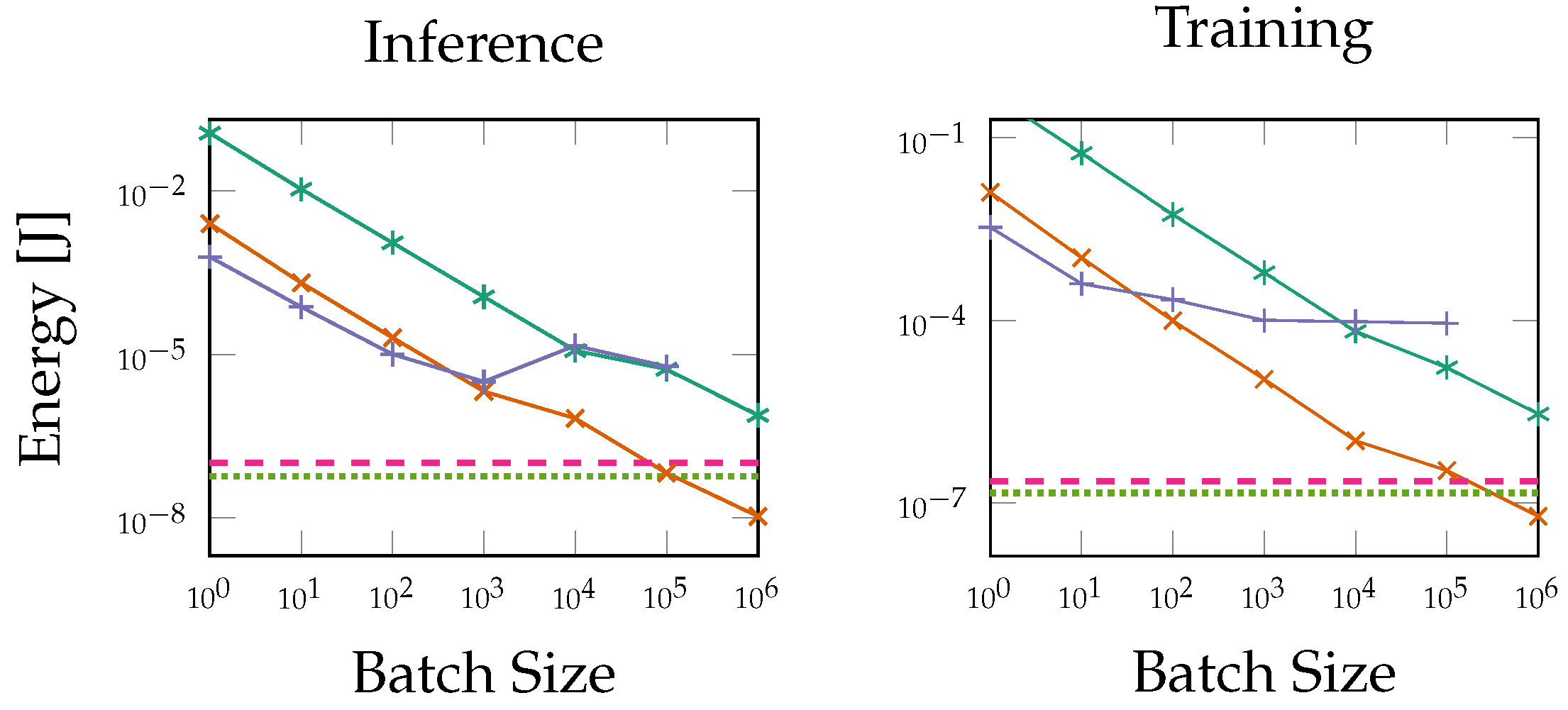
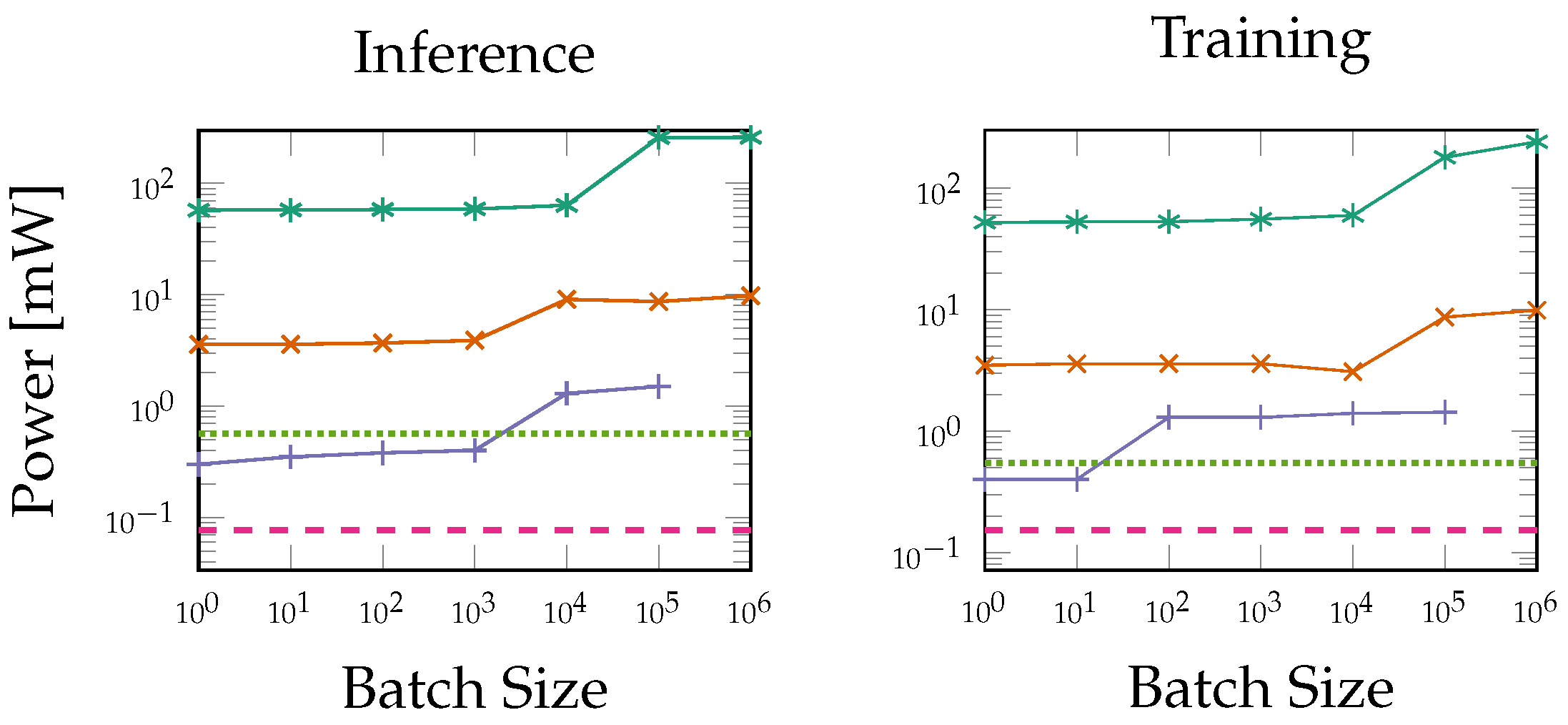
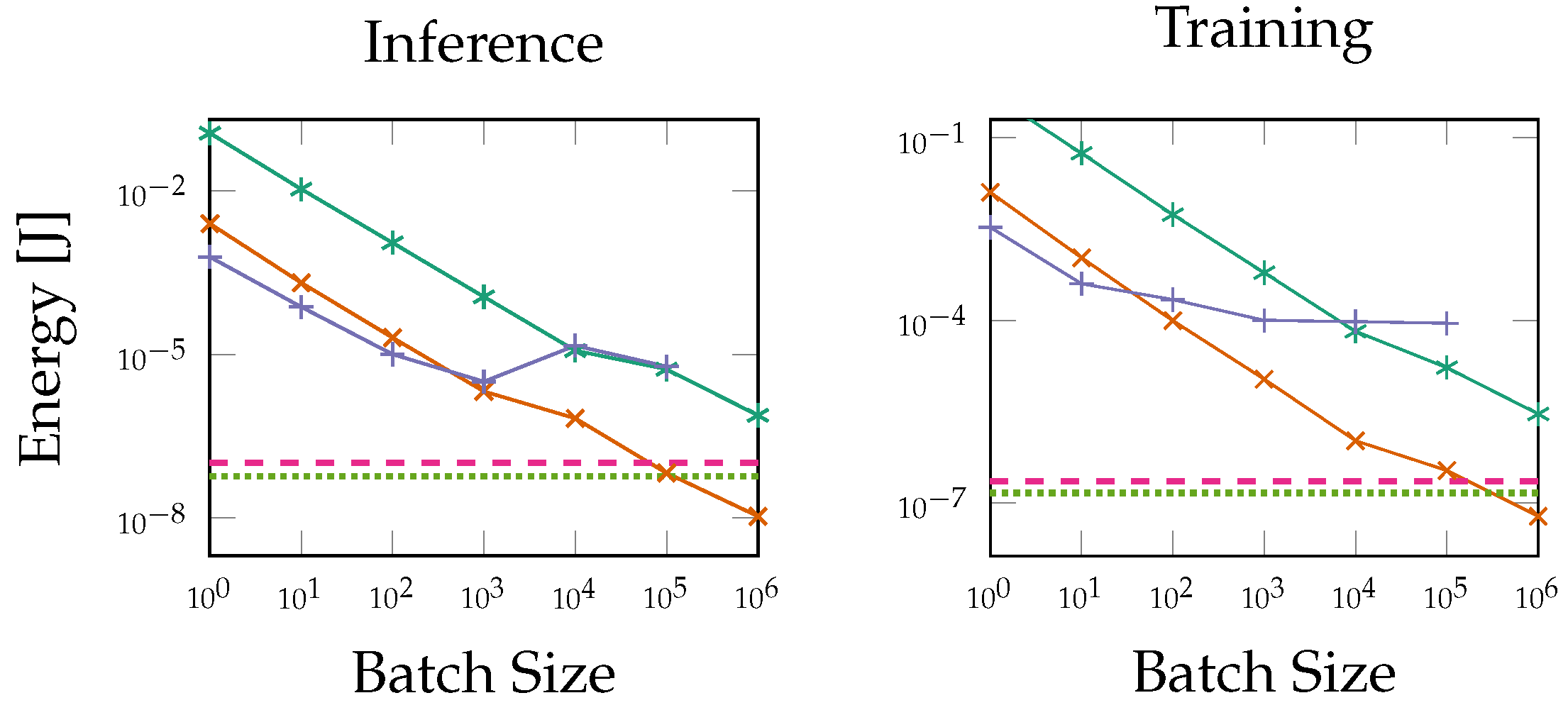
5.3. Power and Energy
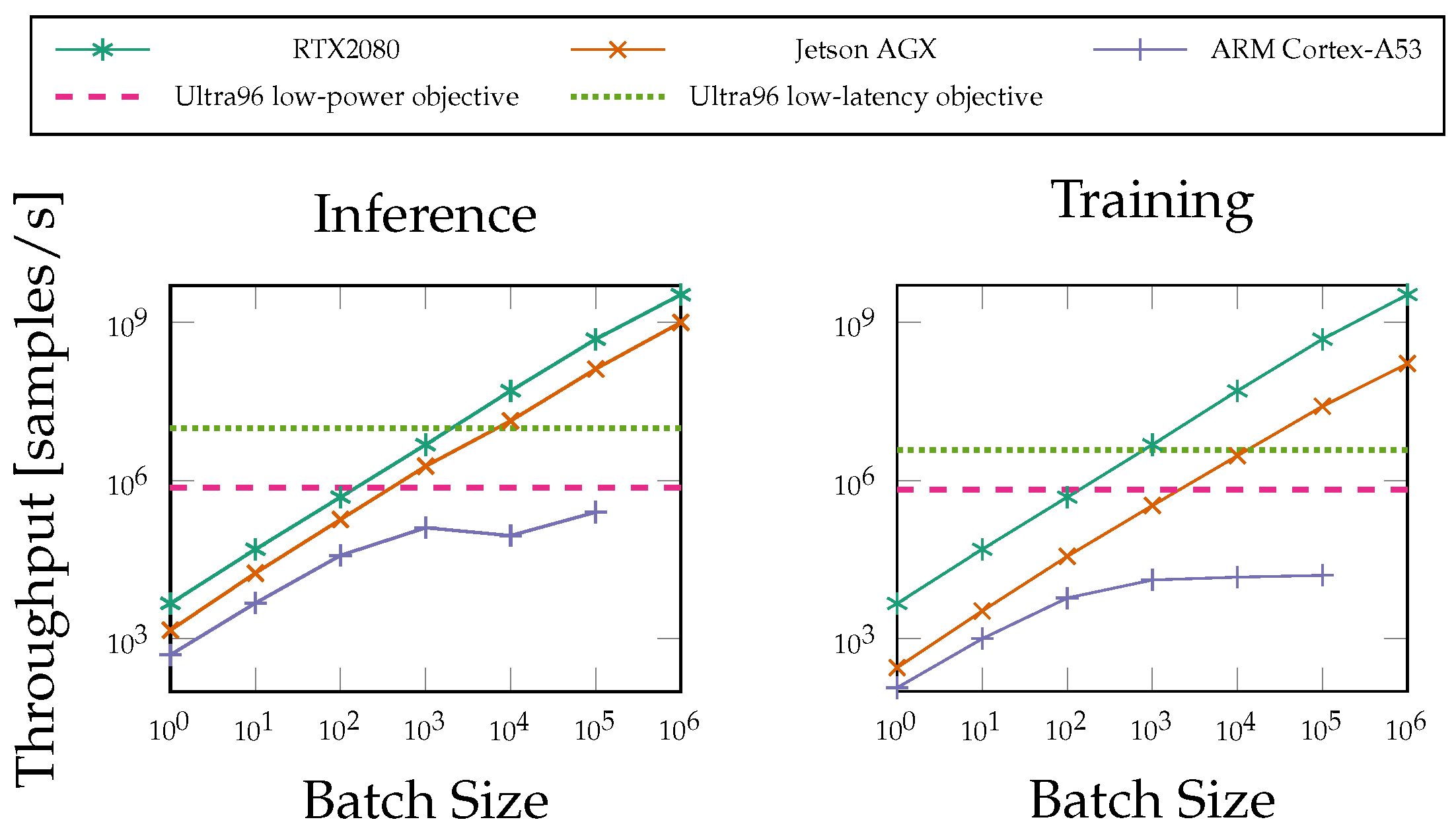
5.4. Performance Demonstration
5.5. Interaction of Design Layers
6. Comparison
6.1. Comparison to State of the Art FPGA-Based Training
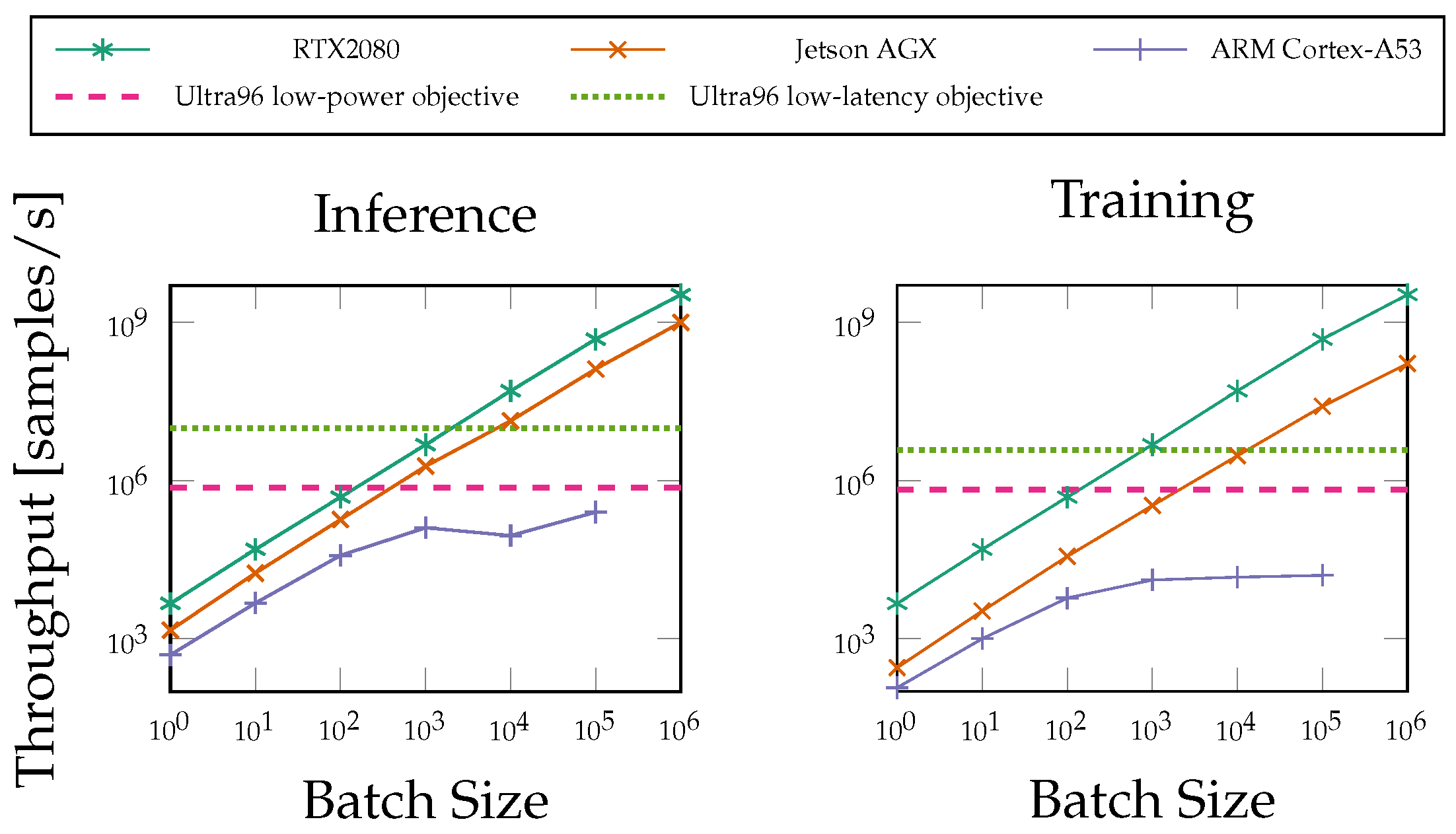
6.2. FPGA Performance Compared to General-Purpose Processors
6.3. ANN Solution vs. Conventional Systems
7. Conclusions
8. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Zehavi, E. 8-PSK trellis codes for a Rayleigh channel. IEEE Trans. Commun. 1992, 40, 873–884. [Google Scholar] [CrossRef]
- Sethuraman, T.; Elias, S.; Ashok, A. A Machine Learning based M-ary Amplitude Modulated Visible Light Communication System. In Proceedings of the 2020 International Conference on COMmunication Systems & NETworkS (COMSNETS), Bengaluru, India, 7–11 January 2020; pp. 694–695. [Google Scholar]
- Gao, B.; Bu, B.; Zhang, W.; Li, X. An Intrusion Detection Method Based on Machine Learning and State Observer for Train-Ground Communication Systems. IEEE Trans. Intell. Transp. Syst. 2021, 1–13. [Google Scholar] [CrossRef]
- Mahmood, M.R.; Matin, M.A. A Design of Extreme Learning Machine Based Receiver for 2 × 2 MIMO-OFDM System. In Proceedings of the 2021 IEEE International Conference on Communication, Networks and Satellite (COMNETSAT), Purwokerto, Indonesia, 17–18 July 2021; pp. 367–370. [Google Scholar]
- Kim, H.; Moon, S.; Hwang, I. Machine Learning-based Channel Tracking for Next-Generation 5G Communication System. In Proceedings of the 2021 Twelfth International Conference on Ubiquitous and Future Networks (ICUFN), Jeju Island, Korea, 17–20 August 2021; pp. 267–269. [Google Scholar]
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- Karanov, B.; Chagnon, M.; Thouin, F.; Eriksson, T.A.; Bulow, H.; Lavery, D.; Bayvel, P.; Schmalen, L. End-to-End Deep Learning of Optical Fiber Communications. J. Light. Technol. 2018, 36, 4843–4855. [Google Scholar] [CrossRef]
- Zhu, Z.R.; Zhang, J.; Chen, R.H.; Yu, H.Y. Autoencoder-Based Transceiver Design for OWC Systems in Log-Normal Fading Channel. IEEE Photonics J. 2019, 11, 1–12. [Google Scholar] [CrossRef]
- Mohamed, S.; Dong, J.; Junejo, A.R.; Zuo, D.C. Model-Based: End-to-End Molecular Communication System Through Deep Reinforcement Learning Auto Encoder. IEEE Access 2019, 7, 70279–70286. [Google Scholar] [CrossRef]
- Cammerer, S.; Aoudia, F.A.; Dörner, S.; Stark, M.; Hoydis, J.; ten Brink, S. Trainable Communication Systems: Concepts and Prototype. IEEE Trans. Commun. 2020, 68, 5489–5503. [Google Scholar] [CrossRef]
- Ibnkahla, M. Applications of neural networks to digital communications—A survey. Signal Process. 2000, 80, 1185–1215. [Google Scholar] [CrossRef]
- Bkassiny, M.; Li, Y.; Jayaweera, S.K. A survey on machine-learning techniques in cognitive radios. IEEE Commun. Surv. Tutor. 2012, 15, 1136–1159. [Google Scholar] [CrossRef]
- Zorzi, M.; Zanella, A.; Testolin, A.; De Grazia, M.D.F.; Zorzi, M. Cognition-based networks: A new perspective on network optimization using learning and distributed intelligence. IEEE Access 2015, 3, 1512–1530. [Google Scholar] [CrossRef]
- Kim, M.; Kim, N.I.; Lee, W.; Cho, D.H. Deep learning-aided SCMA. IEEE Commun. Lett. 2018, 22, 720–723. [Google Scholar] [CrossRef]
- Karanov, B.; Liga, G.; Aref, V.; Lavery, D.; Bayvel, P.; Schmalen, L. Deep learning for communication over dispersive nonlinear channels: Performance and comparison with classical digital signal processing. In Proceedings of the 2019 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 24–27 September 2019; pp. 192–199. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 65–74. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Wang, J.; Zhu, C.; Lin, Y.; Xiong, J.; Hwu, W.m.; Chen, D. DNNBuilder: An Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Fahim, F.; Hawks, B.; Herwig, C.; Hirschauer, J.; Jindariani, S.; Tran, N.; Carloni, L.P.; Guglielmo, G.D.; Harris, P.C.; Krupa, J.D.; et al. hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices. arXiv 2021, arXiv:2103.05579. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 23 February 2022).
- Alberge, F. Deep Learning Constellation Design for the AWGN Channel with Additive Radar Interference. IEEE Trans. Commun. 2019, 67, 1413–1423. [Google Scholar] [CrossRef] [Green Version]
- Dörner, S.; Cammerer, S.; Hoydis, J.; ten Brink, S. Deep Learning Based Communication Over the Air. IEEE J. Sel. Top. Signal Process. 2018, 12, 132–143. [Google Scholar] [CrossRef] [Green Version]
- Geng, T.; Wang, T.; Sanaullah, A.; Yang, C.; Xu, R.; Patel, R.; Herbordt, M. FPDeep: Acceleration and Load Balancing of CNN Training on FPGA Clusters. In Proceedings of the 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; pp. 81–84. [Google Scholar] [CrossRef]
- Luo, C.; Sit, M.K.; Fan, H.; Liu, S.; Luk, W.; Guo, C. Towards efficient deep neural network training by FPGA-based batch-level parallelism. J. Semicond. 2020, 41, 022403. [Google Scholar] [CrossRef]
- Nakahara, H.; Sada, Y.; Shimoda, M.; Sayama, K.; Jinguji, A.; Sato, S. FPGA-based Training Accelerator Utilizing Sparseness of Convolutional Neural Network. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 180–186. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks; Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Di Cecco, R.; Sun, L.; Chow, P. FPGA-based training of convolutional neural networks with a reduced precision floating-point library. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, Australia, 11–13 December 2017; pp. 239–242. [Google Scholar] [CrossRef]
- Liu, Z.; Dou, Y.; Jiang, J.; Wang, Q.; Chow, P. An FPGA-based processor for training convolutional neural networks. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, Australia, 11–13 December 2017; pp. 207–210. [Google Scholar] [CrossRef]
- Venkataramanaiah, S.K.; Ma, Y.; Yin, S.; Nurvitadhi, E.; Dasu, A.; Cao, Y.; Seo, J. Automatic Compiler Based FPGA Accelerator for CNN Training. arXiv 2019, arXiv:1908.06724. [Google Scholar]
- Hong, J.; Arslan, S.; Lee, T.; Kim, H. Design of Power-Efficient Training Accelerator for Convolution Neural Networks. Electronics 2021, 10, 787. [Google Scholar] [CrossRef]
- Böcherer, G. Achievable Rates for Probabilistic Shaping. arXiv 2017, arXiv:1707.01134. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of Adam and Beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Dörner, S.; Henninger, M.; Cammerer, S.; ten Brink, S. WGAN-based Autoencoder Training Over-the-air. arXiv 2020, arXiv:2003.02744. [Google Scholar]
- Schibisch, S.; Cammerer, S.; Dörner, S.; Hoydis, J.; ten Brink, S. Online Label Recovery for Deep Learning-based Communication through Error Correcting Codes. arXiv 2018, arXiv:1807.00747. [Google Scholar]
- Labs, X.R. FINN HLS Library. Available online: https://github.com/Xilinx/finn-hlslib (accessed on 22 January 2022).
- Robertson, P.; Villebrun, E.; Hoeher, P. A comparison of optimal and sub-optimal MAP decoding algorithms operating in the log domain. In Proceedings of the IEEE International Conference on Communications ICC ’95, Seattle, WA, USA, 18–22 June 1995; Volume 2, pp. 1009–1013. [Google Scholar] [CrossRef]
- Caciularu, A.; Burshtein, D. Blind Channel Equalization using Variational Autoencoders. arXiv 2018, arXiv:1803.01526. [Google Scholar]
- Fischer, M.B.; Dörner, S.; Cammerer, S.; Shimizu, T.; Cheng, B.; Lu, H.; ten Brink, S. Wiener Filter versus Recurrent Neural Network-based 2D-Channel Estimation for V2X Communications. arXiv 2021, arXiv:2102.03163. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Batch Size | Power [W] | Throughput [GOPS] | Efficiency [GOPS/W] | |
|---|---|---|---|---|
| [22] | 128 | 24.7 | 1220 | 38.13 |
| [23] | 128 | 12.4 | 276.7 | 22.3 |
| [29] | 16 | 14.24 | 86.12 | 6.05 |
| [30] | 40 | 50.5 | 479 | 9.49 |
| [31] | 1 | 0.67 | 4.39 | 6.55 |
| Ours | 1 | 0.568 | 5.28 | 9.656 |
| BRAM | DSP | FF | LUT | Latency [s] | Throughput [bit/s] | Power [W] | |
|---|---|---|---|---|---|---|---|
| AE low-power objective | 6 | 3 | 4283 | 4248 | 1.36 | 2.94 | 7.68 |
| AE low-latency objective | 18.5 | 352 | 10,895 | 11,343 | 8.10 | 4.92 | 4.53 |
| Conventional demapper | 0 | 1 | 1042 | 1107 | 5.33 | 3.00 | 5.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ney, J.; Hammoud, B.; Dörner, S.; Herrmann, M.; Clausius, J.; ten Brink, S.; Wehn, N. Efficient FPGA Implementation of an ANN-Based Demapper Using Cross-Layer Analysis. Electronics 2022, 11, 1138. https://doi.org/10.3390/electronics11071138
Ney J, Hammoud B, Dörner S, Herrmann M, Clausius J, ten Brink S, Wehn N. Efficient FPGA Implementation of an ANN-Based Demapper Using Cross-Layer Analysis. Electronics. 2022; 11(7):1138. https://doi.org/10.3390/electronics11071138
Chicago/Turabian StyleNey, Jonas, Bilal Hammoud, Sebastian Dörner, Matthias Herrmann, Jannis Clausius, Stephan ten Brink, and Norbert Wehn. 2022. "Efficient FPGA Implementation of an ANN-Based Demapper Using Cross-Layer Analysis" Electronics 11, no. 7: 1138. https://doi.org/10.3390/electronics11071138
APA StyleNey, J., Hammoud, B., Dörner, S., Herrmann, M., Clausius, J., ten Brink, S., & Wehn, N. (2022). Efficient FPGA Implementation of an ANN-Based Demapper Using Cross-Layer Analysis. Electronics, 11(7), 1138. https://doi.org/10.3390/electronics11071138