
Closed-Loop Residual Attention Network for Single Image Super-Resolution


Abstract
:1. Introduction
2. Related Work
2.1. CNN-Based Networks
2.2. Attention-Based Networks
3. Proposed Method
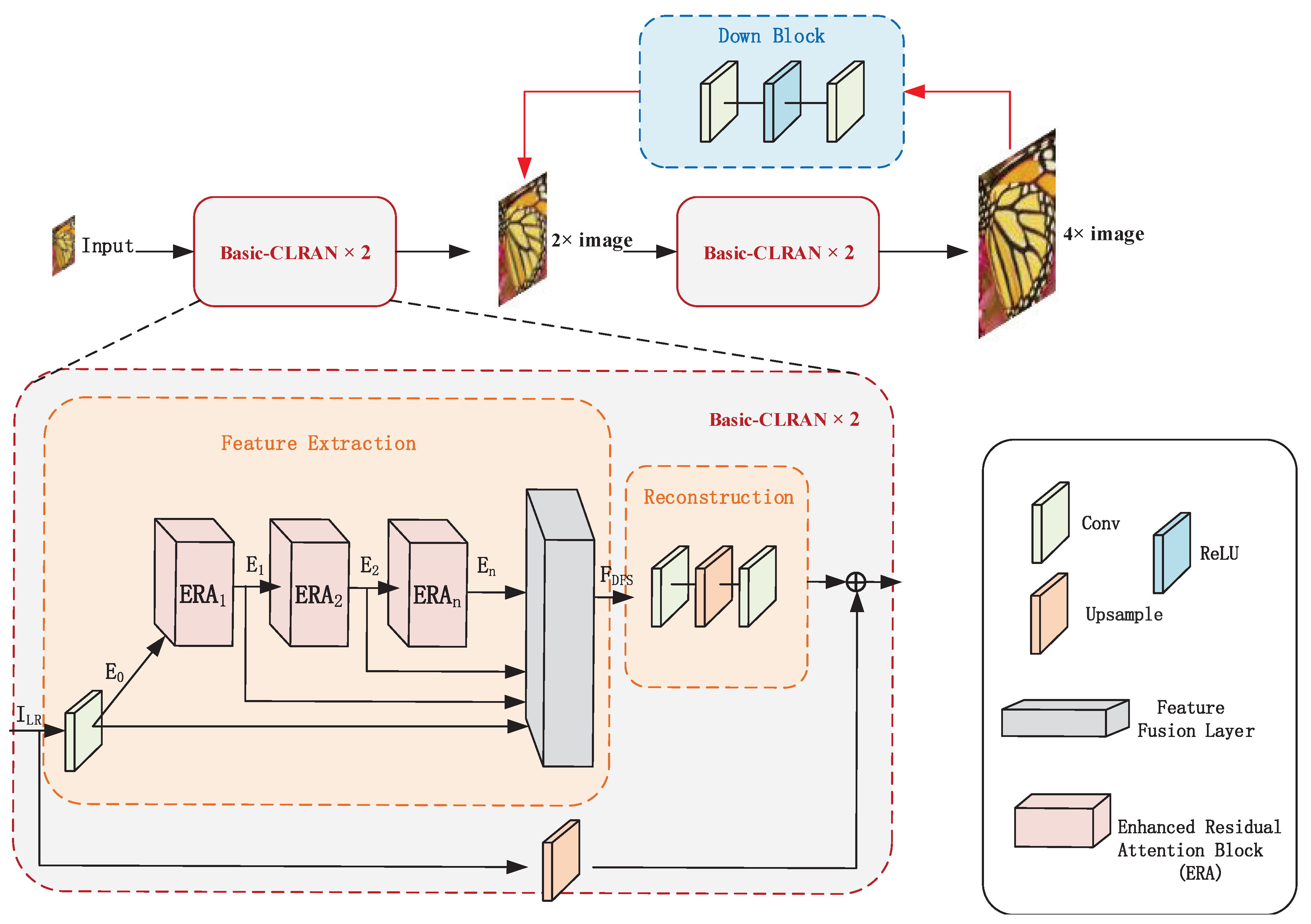
3.1. Network Architecture
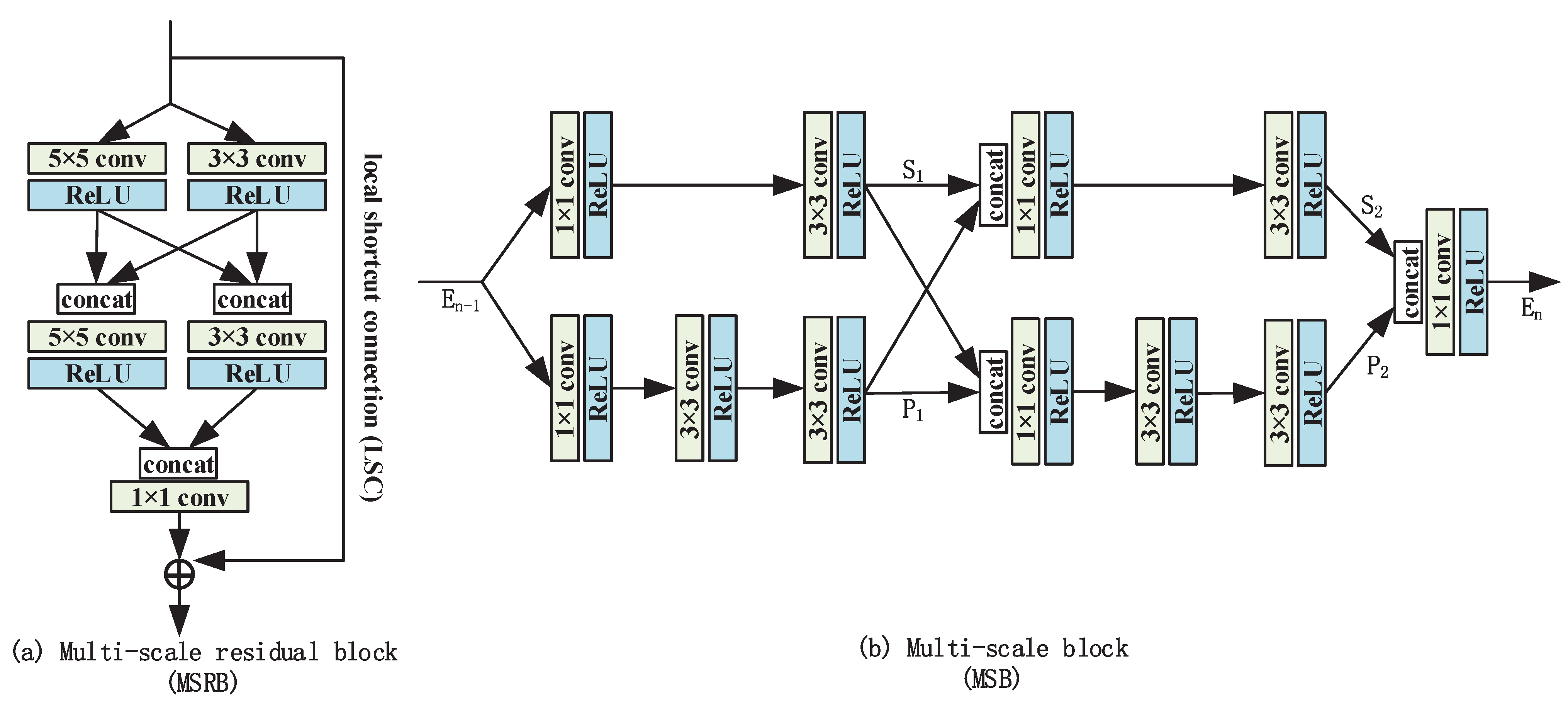
3.2. Enhanced Residual Attention Block (ERA)
3.3. Multi-Scale Block (MSB)
3.4. Enhanced Attention Mechanism
4. Experiments
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Results
4.4. Discussion
4.5. Model Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bevilacqua, M. Algorithms for Super-Resolution of Images and Videos Based On Learning Methods. Ph.D. Thesis, Université Rennes 1, Rennes, France, 2014. [Google Scholar]
- Gao, X.; Zhang, K.; Tao, D.; Li, X. Image super-resolution with sparse neighbor embedding. IEEE Trans. Image Process. 2012, 21, 3194–3205. [Google Scholar] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Computer Vision–ACCV 2014, Proceedings of the 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 111–126. [Google Scholar]
- Dai, S.; Han, M.; Xu, W.; Wu, Y.; Gong, Y. Soft edge smoothness prior for alpha channel super resolution. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Yang, X.; Zhang, Y.; Zhou, D.; Yang, R. An improved iterative back projection algorithm based on ringing artifacts suppression. Neurocomputing 2015, 162, 171–179. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HA, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale residual network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 517–532. [Google Scholar]
- Muqeet, A.; Iqbal, M.T.B.; Bae, S.H. HRAN: Hybrid residual attention network for single image super-resolution. IEEE Access 2019, 7, 137020–137029. [Google Scholar] [CrossRef]
- Behjati, P.; Rodriguez, P.; Mehri, A.; Hupont, I.; Tena, C.F.; Gonzalez, J. Hierarchical Residual Attention Network for Single Image Super-Resolution. arXiv 2020, arXiv:2012.04578. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018 pp. 0–0. [Google Scholar]
- Musunuri, Y.R.; Kwon, O.S. Deep residual dense network for single image super-resolution. Electronics 2021, 10, 555. [Google Scholar] [CrossRef]
- Chen, H.; Gu, J.; Zhang, Z. Attention in Attention Network for Image Super-Resolution. arXiv 2021, arXiv:2104.09497. [Google Scholar]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Xu, Y.; Tan, M. Closed-loop matters: Dual regression networks for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5407–5416. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 783–792. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21-26 July 2016; pp. 1646–1654. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21–26 July 2016; pp. 1874–1883. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Show, A. Tell: Neural Image Caption Generation with Visual Attention Kelvin Xu. Available online: https://kelvinxu.github.io/projects/capgen.html (accessed on 1 March 2022).
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Computer Vision—ECCV 2020, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 492–511. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-local recurrent network for image restoration. arXiv 2018, arXiv:1806.02919. [Google Scholar]
- Hu, Y.; Li, J.; Huang, Y.; Gao, X. Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3911–3927. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2359–2368. [Google Scholar]
- Muqeet, A.; Hwang, J.; Yang, S.; Kang, J.; Kim, Y.; Bae, S.H. Multi-attention based ultra lightweight image super-resolution. In Computer Vision—ECCV 2020 Workshops, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 103–118. [Google Scholar]
- Zhao, H.; Kong, X.; He, J.; Qiao, Y.; Dong, C. Efficient image super-resolution using pixel attention. In Computer Vision—ECCV 2020 Workshops, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 56–72. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhang, Y.; Yu, J.; Zhou, Y.; Liu, D.; Fu, Y.; Huang, T.S.; Shi, H. Pyramid attention networks for image restoration. arXiv 2020, arXiv:2004.13824. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HA, USA, 21–26 July 2016; pp. 126–135. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution Based On Nonnegative Neighbor Embedding; BMVA Press: Swansea, UK, 2012. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada; 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, Z.; Wang, X.; Jung, C. DCSR: Dilated convolutions for single image super-resolution. IEEE Trans. Image Process. 2018, 28, 1625–1635. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Wang, Z.; Liu, D.; Yang, J.; Han, W.; Huang, T. Deep networks for image super-resolution with sparse prior. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 370–378. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input Channel | Output Channel | Kernel Size |
|---|---|---|---|
| Input conv | 64 | 64 × 2 × 2 | 3 × 3 |
| PixelShuffle (×2) | 64 × 2 × 2 | 64 | / |
| Input conv | 64 | 1 | 3 × 3 |
| Upscaling Factor | Number of Basic-CLRANs | Upscaling Factor in PixelShuffle | Number of ERAs |
|---|---|---|---|
| ×4 | 2 | ×2 | 2 |
| ×8 | 3 | ×2 | 2 |
| Algorithms | Scale | Set5 PSNR/SSIM | Set14 PSNR/SSIM | B100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|
| Bicubic | 4 | 28.42/0.810 | 26.10/0.702 | 25.96/0.667 | 23.15/0.657 | 24.92/0.789 |
| SRCNN [7] | 30.48/0.863 | 27.50/0.751 | 26.90/0.710 | 24.52/0.722 | 27.58/0.856 | |
| FSRCNN [27] | 30.72/0.866 | 27.61/0.775 | 26.98/0.715 | 24.62/0.728 | 27.90/0.861 | |
| VDSR [9] | 31.35/0.883 | 28.02/0.768 | 27.29/0.726 | 25.18/0.754 | 28.83/0.887 | |
| SRDenseNet [29] | 32.02/0.893 | 28.50/0.778 | 27.53/0.733 | 26.05/0.781 | 29.49/0.899 | |
| DRCN [25] | 31.56/0.881 | 28.15/0.763 | 27.24/0.715 | 25.15/0.753 | 28.98/0.882 | |
| LapSRN [13] | 31.54/0.881 | 28.19/0.772 | 27.32/0.728 | 25.21/0.756 | 29.09/0.890 | |
| DCSR [49] | 31.58/0.887 | 28.21/0.772 | 27.32/0.726 | 27.24/0.831 | -/- | |
| MemNet [30] | 31.74/0.889 | 28.26/0.772 | 27.40/0.728 | 25.50/0.763 | 29.42/0.894 | |
| SRMDNF [50] | 31.96/0.893 | 28.35/0.779 | 27.49/0.734 | 25.68/0.773 | 30.09/0.902 | |
| MSRN [14] | 32.07/0.890 | 28.60/0.775 | 27.52/0.727 | 26.04/0.790 | 30.17/0.903 | |
| CARN [32] | 32.13/0.894 | 28.60/0.781 | 27.58//0.735 | 26.07/0.784 | -/- | |
| IMDN [51] | 32.21/0.895 | 28.58/0.781 | 27.56/0.735 | 26.04/0.784 | 30.45/0.908 | |
| CLRAN-S(Ours) | 32.24/0.898 | 28.65/0.781 | 27.59/0.735 | 26.05/0.785 | 30.37/0.908 | |
| Bicubic | 8 | 24.39/0.657 | 23.19/0.568 | 23.67/0.547 | 20.74/0.515 | 21.47/0.649 |
| SRCNN [7] | 25.34/0.647 | 23.86/0.544 | 24.14/0.504 | 21.29/0.513 | 22.46/0.661 | |
| FSRCNN [27] | 20.13/0.552 | 19.75/0.482 | 24.21/0.568 | 21.32/0.538 | 22.39/0.673 | |
| SCN [52] | 25.59/0.707 | 24.02/0.603 | 24.30/0.570 | 21.22/0.557 | 22.68/0.696 | |
| VDSR [9] | 25.73/0.674 | 23.20/0.511 | 24.34/0.517 | 21.48/0.529 | 22.73/0.669 | |
| SRDenseNet [29] | 25.99/0.704 | 24.23/0.581 | 24.45/0.530 | 21.67/0.562 | 23.09/0.712 | |
| DRCN [25] | 25.93/0.674 | 24.25/0.551 | 24.49/0.517 | 21.71/0.529 | 23.20/0.669 | |
| LapSRN [13] | 26.14/0.737 | 24.35/0.620 | 24.54/0.585 | 21.81/0.580 | 23.39/0.734 | |
| MemNet [30] | 26.16/0.741 | 24.38/0.620 | 24.58/0.584 | 21.89/0.583 | 23.56/0.739 | |
| MSLapSRN [53] | 26.34/0.756 | 24.57/0.627 | 24.65/0.590 | 22.06/0.596 | 23.90/0.756 | |
| MSRN [14] | 26.59/0.725 | 24.88/0.596 | 24.70/0.541 | 22.37/0.598 | 24.28/0.752 | |
| CLRAN-L(Ours) | 26.97/0.776 | 24.85/0.637 | 24.76/0.593 | 22.35/0.610 | 24.35/0.773 |
| Case Index | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| MSB | × | ✓ | ✓ | ✓ |
| DRM | ✓ | × | ✓ | ✓ |
| ADM | ✓ | ✓ | × | ✓ |
| Parameter (M) | 0.88 | 3.32 | 3.32 | 3.33 |
| PSNR (dB) | 31.92 | 32.20 | 32.12 | 32.24 |
| Case Index | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| SA | × | ✓ | × | × | × |
| CA+SA | × | × | × | ✓ | × |
| MSCA | × | × | ✓ | × | × |
| MSCA+SA | × | × | × | × | ✓ |
| Parameter (M) | 3.15 | 3.32 | 3.32 | 3.32 | 3.33 |
| PSNR (dB) | 32.04 | 32.14 | 32.15 | 32.17 | 32.24 |
| N | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| PSNR | 32.04 | 32.24 | 32.26 | 32.30 | 32.34 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Luo, W. Closed-Loop Residual Attention Network for Single Image Super-Resolution. Electronics 2022, 11, 1112. https://doi.org/10.3390/electronics11071112
Zhu M, Luo W. Closed-Loop Residual Attention Network for Single Image Super-Resolution. Electronics. 2022; 11(7):1112. https://doi.org/10.3390/electronics11071112
Chicago/Turabian StyleZhu, Meng, and Wenjie Luo. 2022. "Closed-Loop Residual Attention Network for Single Image Super-Resolution" Electronics 11, no. 7: 1112. https://doi.org/10.3390/electronics11071112
APA StyleZhu, M., & Luo, W. (2022). Closed-Loop Residual Attention Network for Single Image Super-Resolution. Electronics, 11(7), 1112. https://doi.org/10.3390/electronics11071112