
Run-Time Adaptive In-Kernel BPF/XDP Solution for 5G UPF

 and
and 
Abstract
:1. Introduction
2. Background
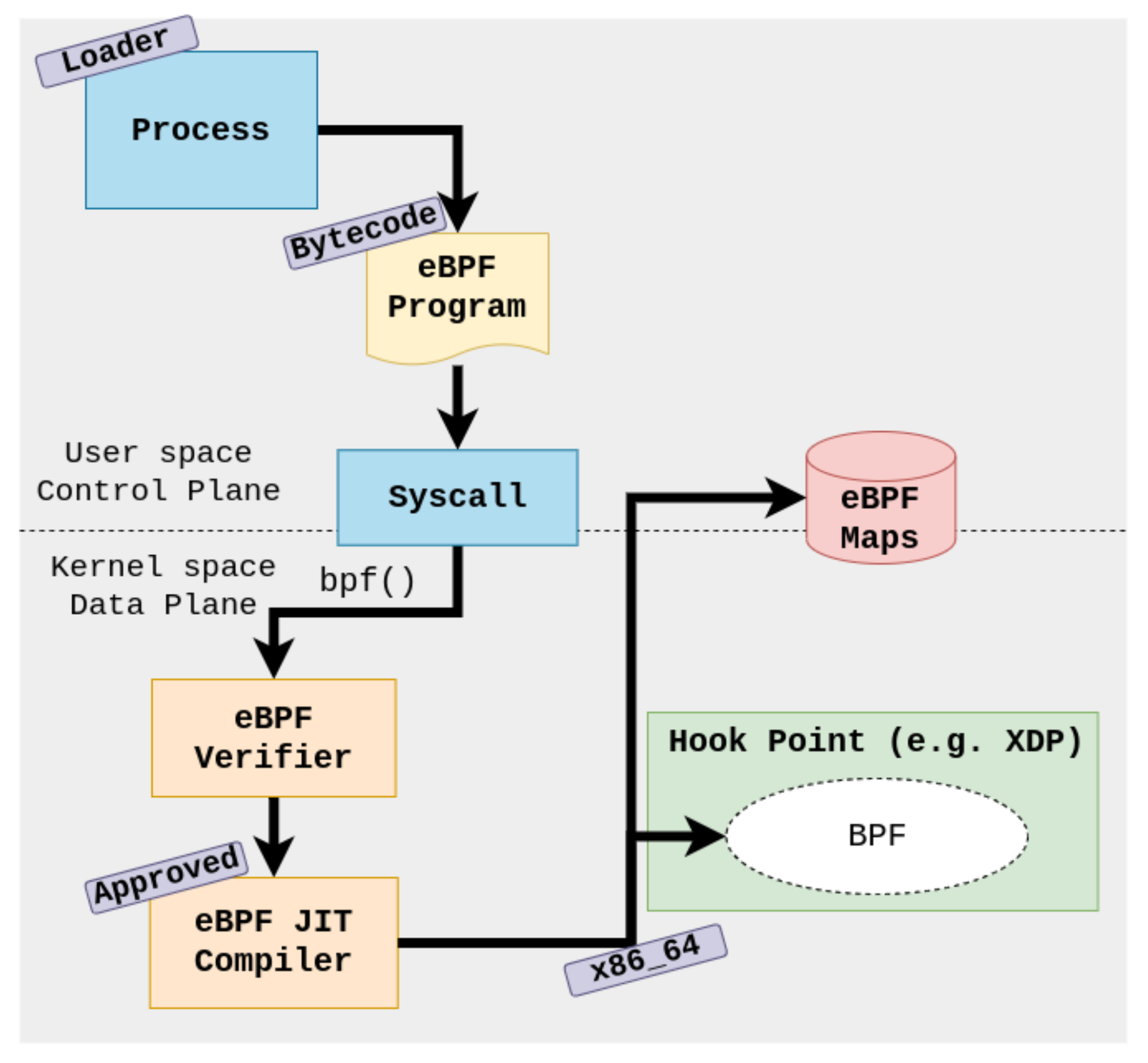
2.1. BPF
- Limit of 5 arguments for a function;
- Limit of 32 nested tail call calls;
- Infinite loops are not allowed;
- Send the same packet to multiple ports;
- Only 30 data structure BPF maps types available (kernel v5.16.10) (https://elixir.bootlin.com/linux/v5.16.10/source/include/uapi/linux/bpf.h#L878 accessed on 18 March 2022);
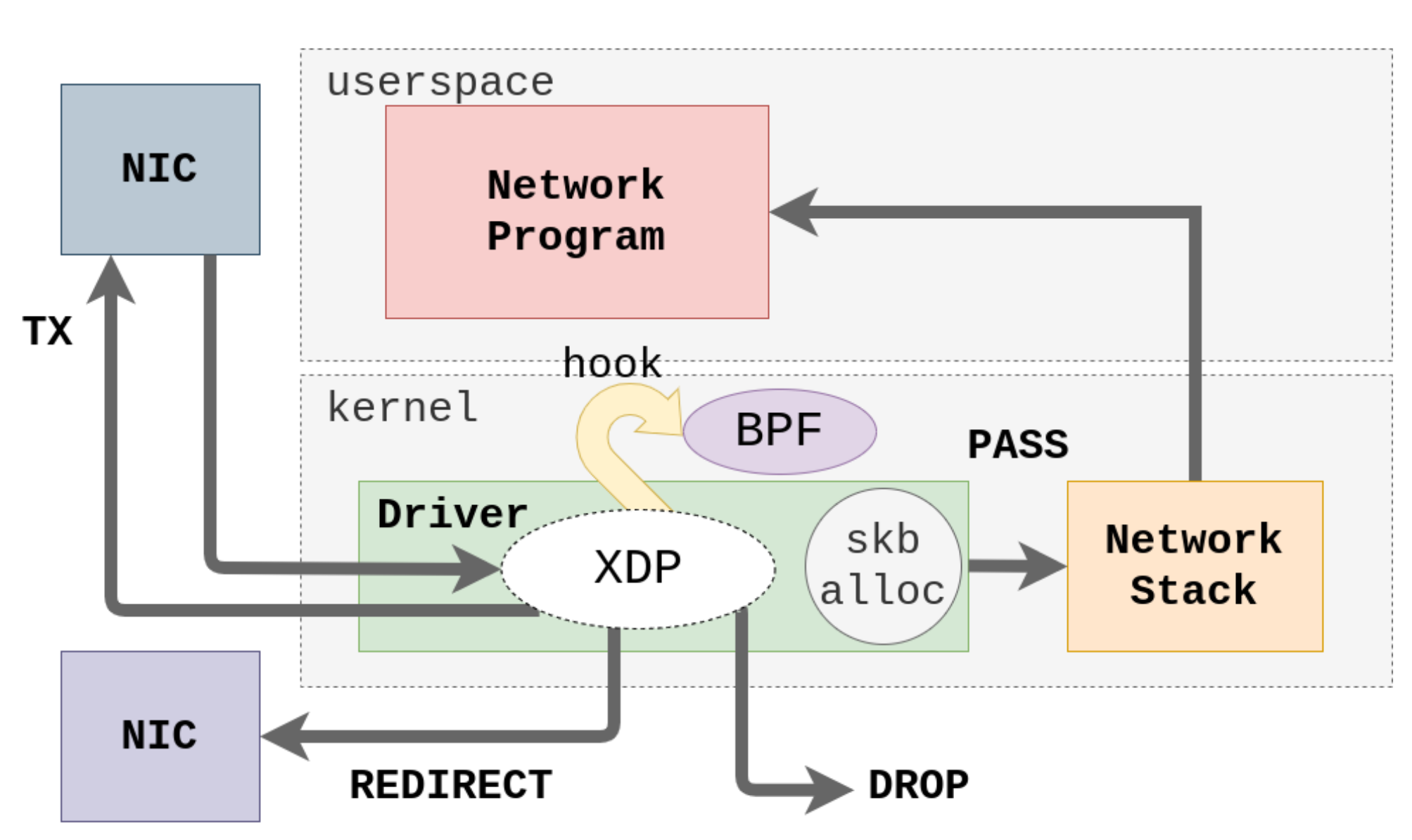
2.2. XDP
2.3. Libbpf
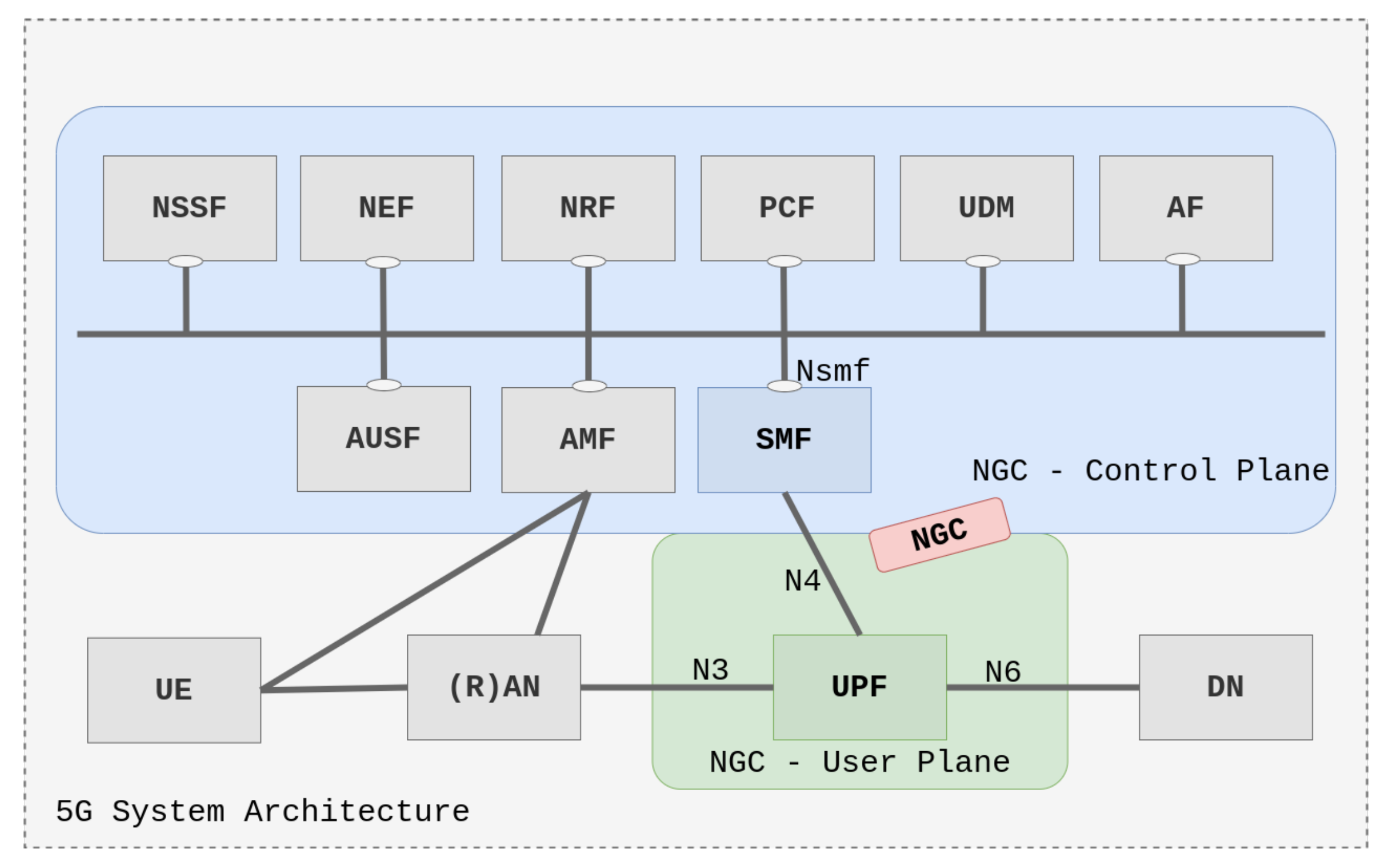
2.4. 5G Network Architecture
2.4.1. SMF
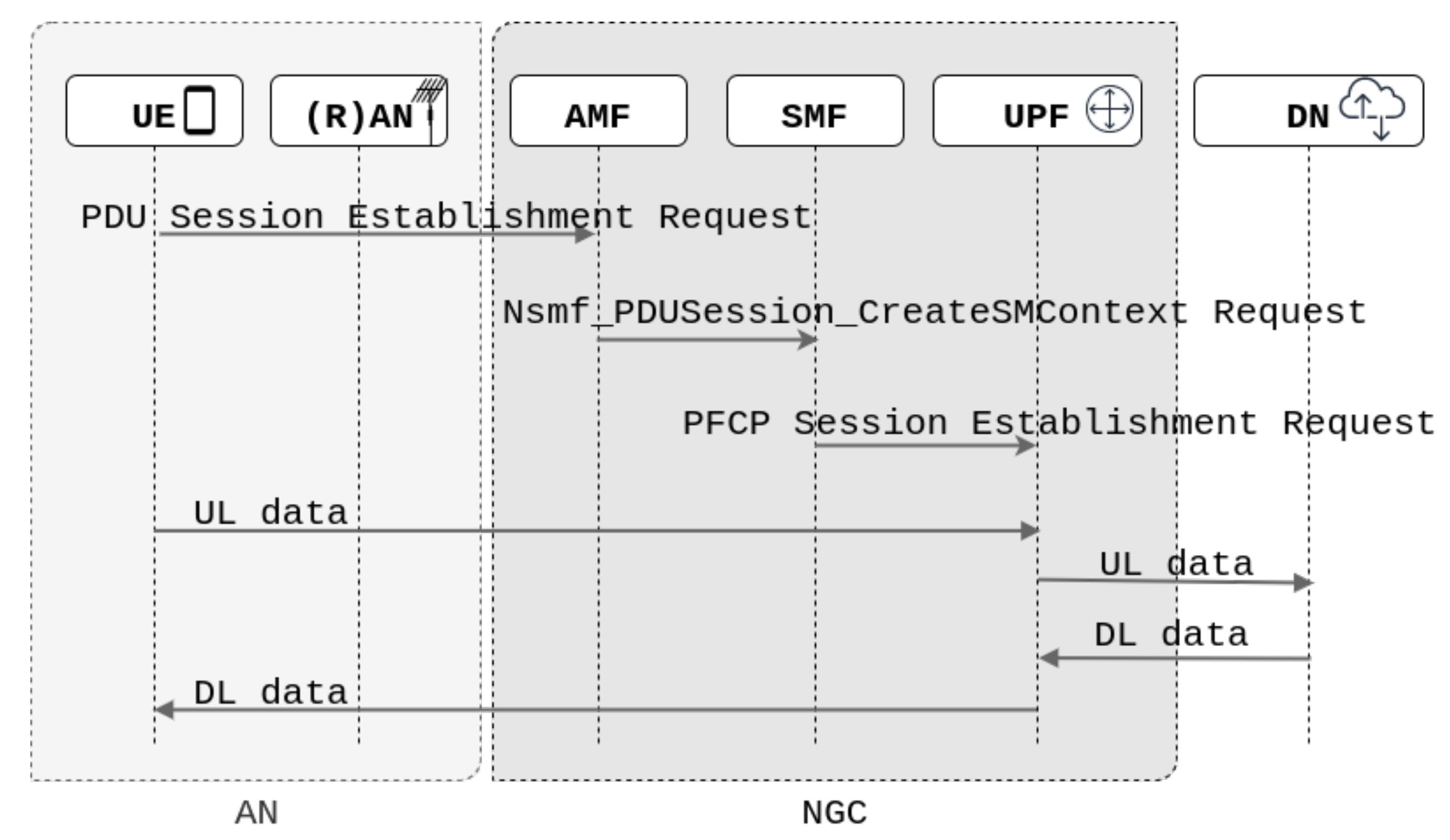
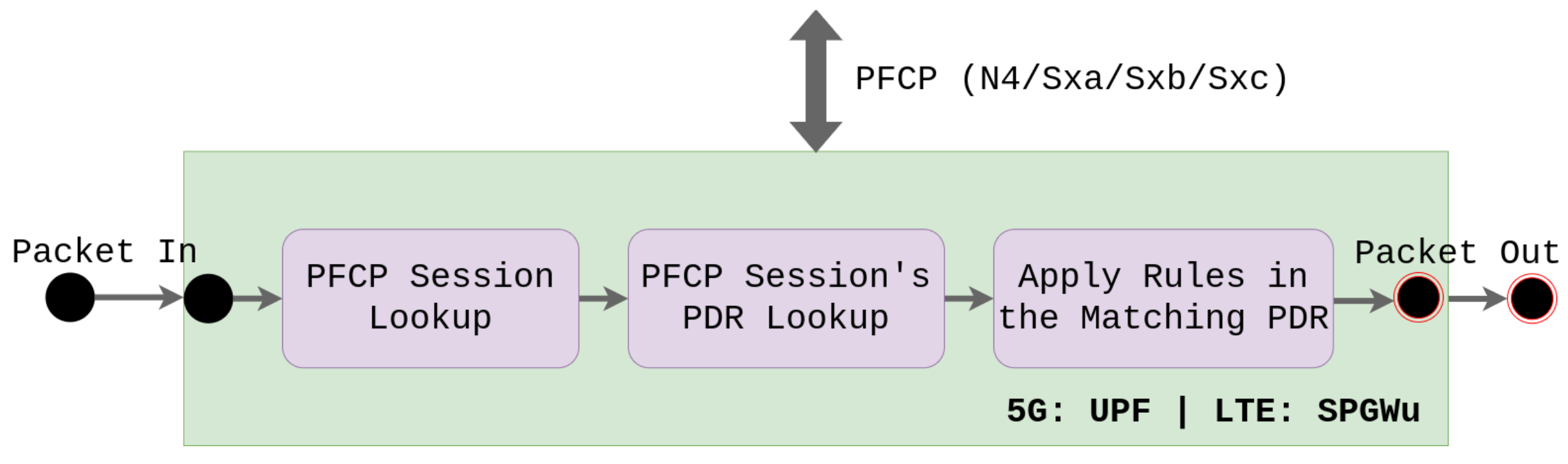
2.4.2. UPF
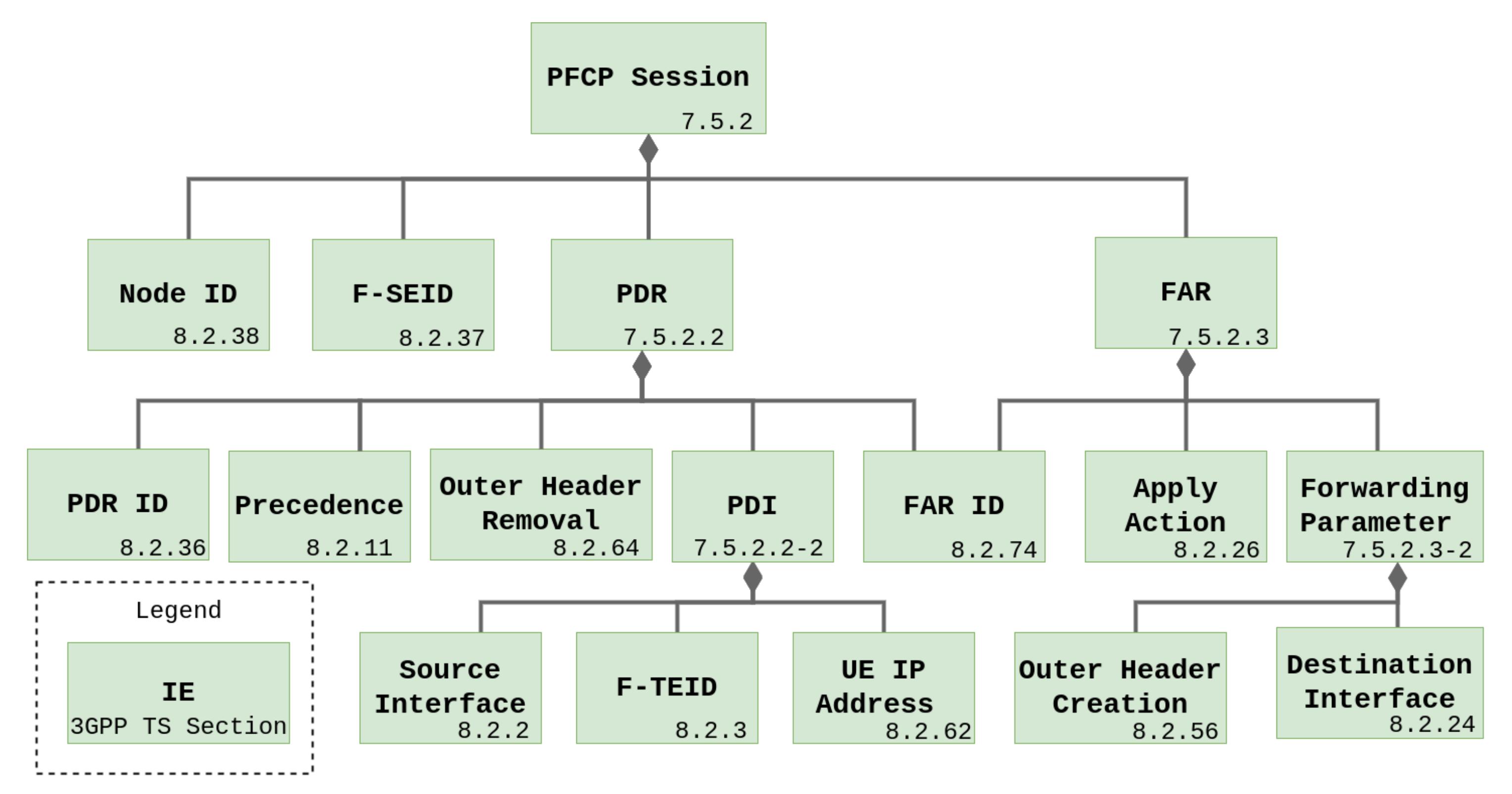
- Packet Detection Rules (PDRs)-Rules for packet detection;
- Forwarding Action Rules (FARs)-Rules for forwarding packets;
- QoS Enforcement Rules (QERs)-Rules for applying QoS;
- Usage Reporting Rules (URRs)-Rules for generating reports;
- Buffer Action Rules (BARs)-Rules for buffering packets;
- Multi-Access Rules (MARs)-Rules for traffic steering functionality.
2.5. The UPF-BPF Project
- i
- PFCP session management: create, read, update, and remove PFCP sessions, PDRs and FARs;
- ii
- Fast packet processing for uplink and downlink user data traffic: classify and forward UDP and GTP traffic based on PDR and FAR, respectively.
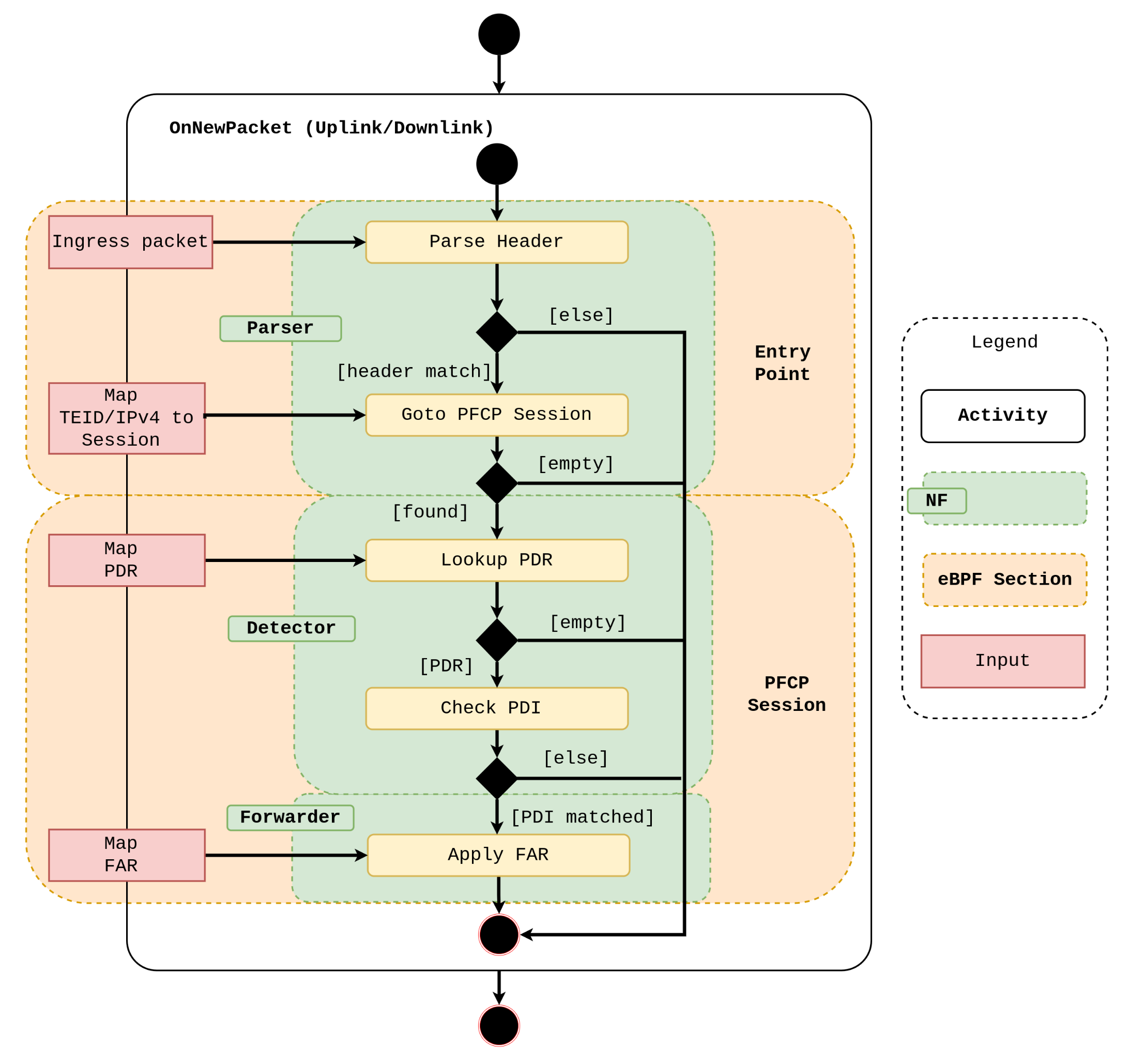
3. Current Limitations
3.1. Functionality Constraints
3.2. Flexibility Constraints
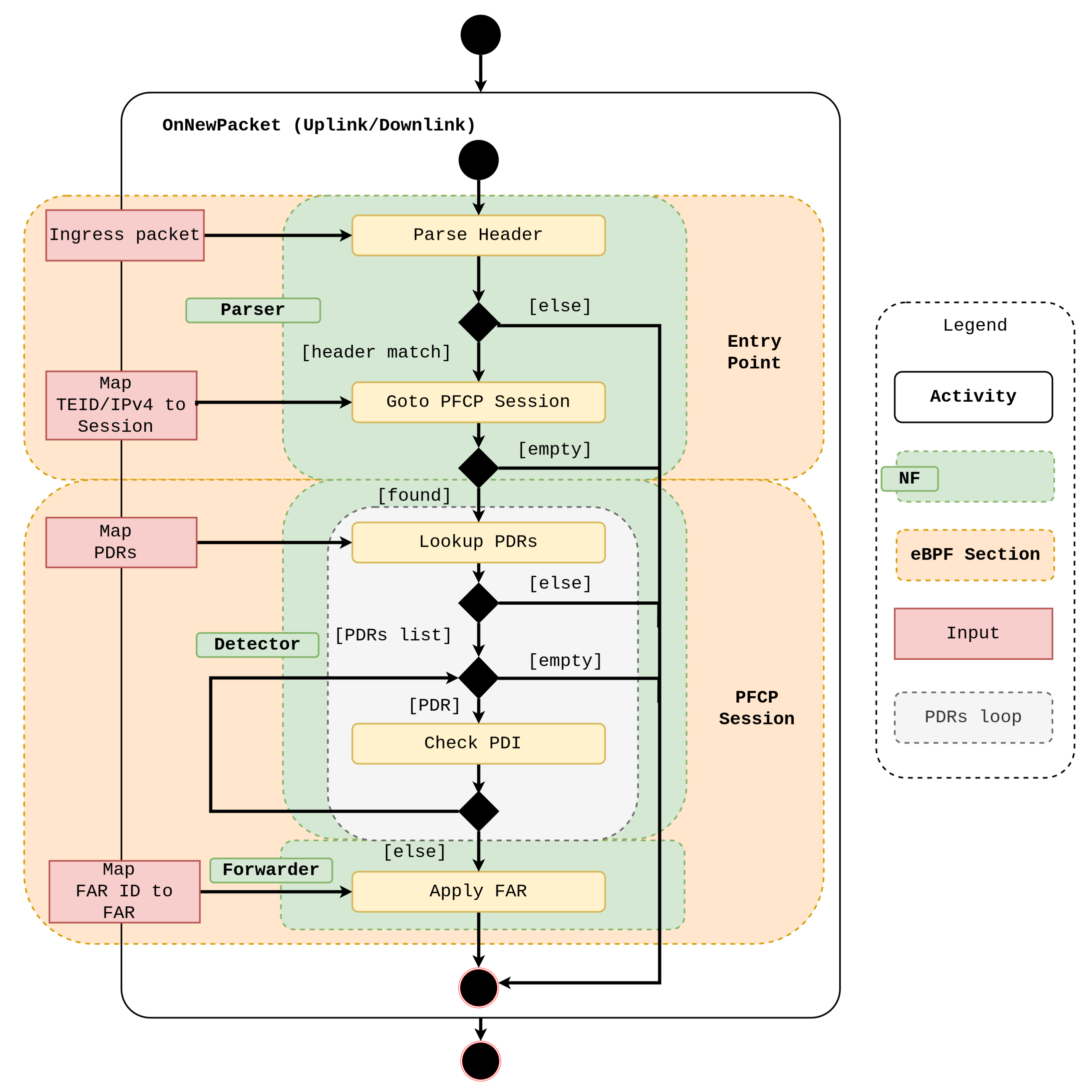
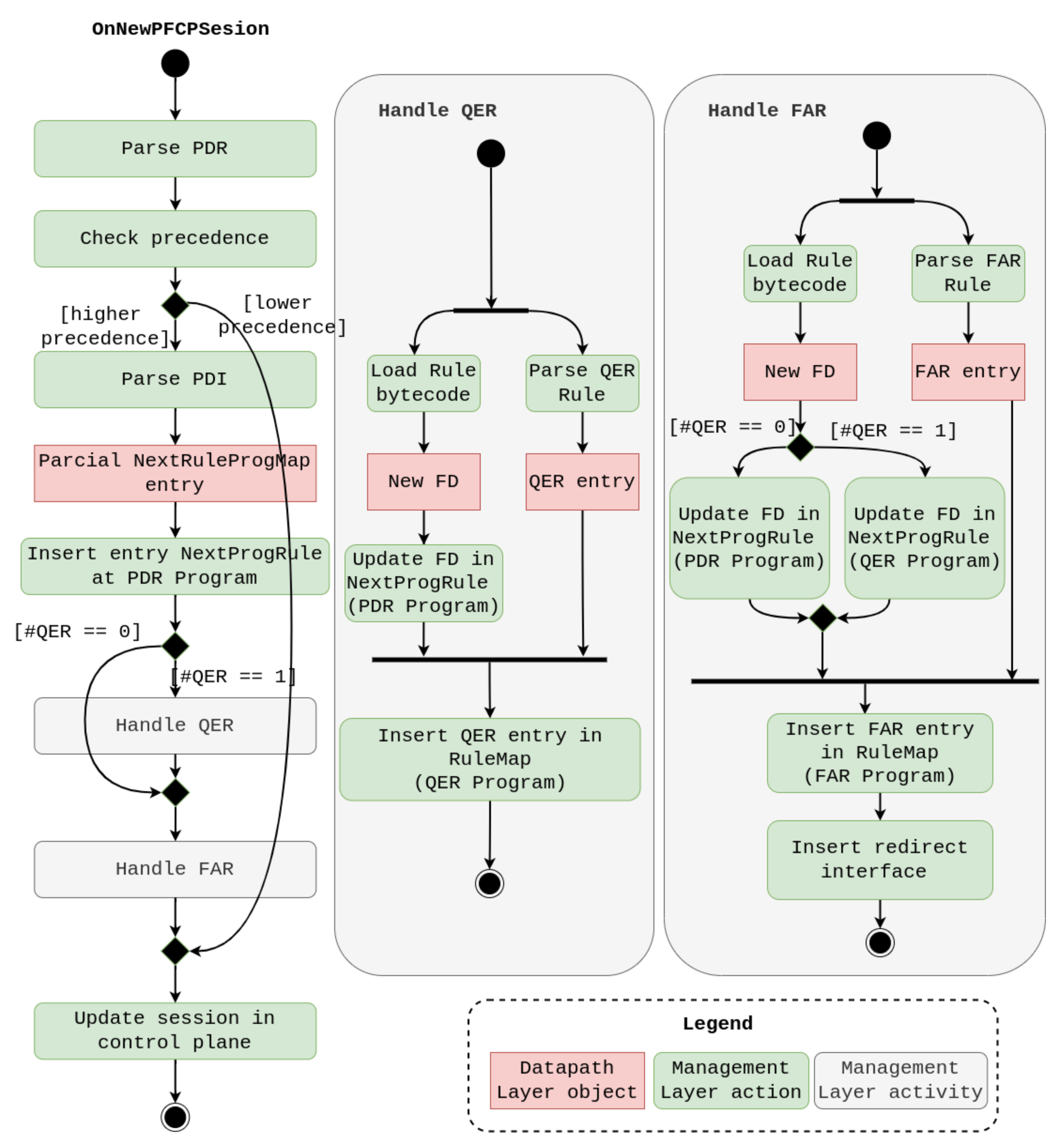
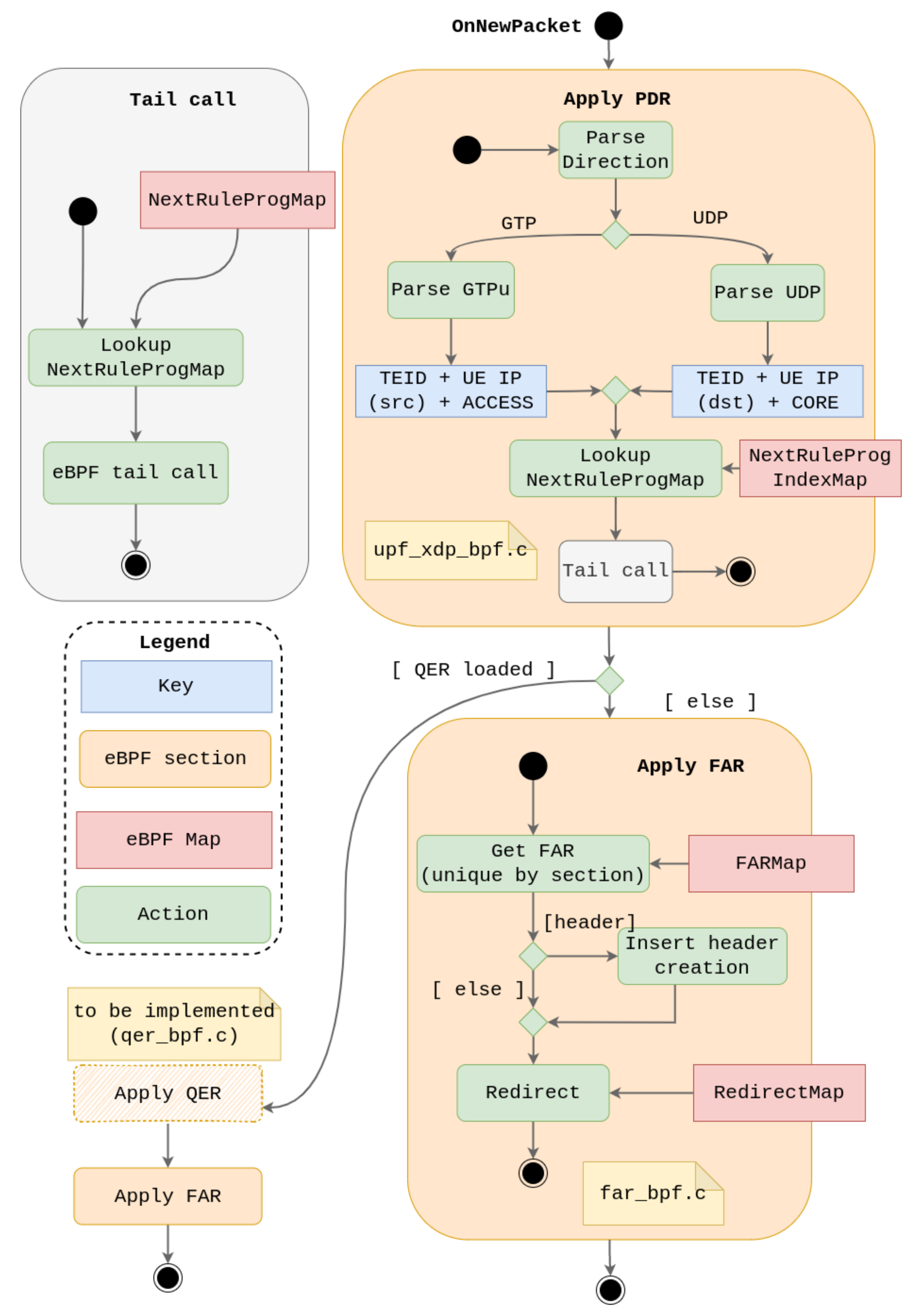
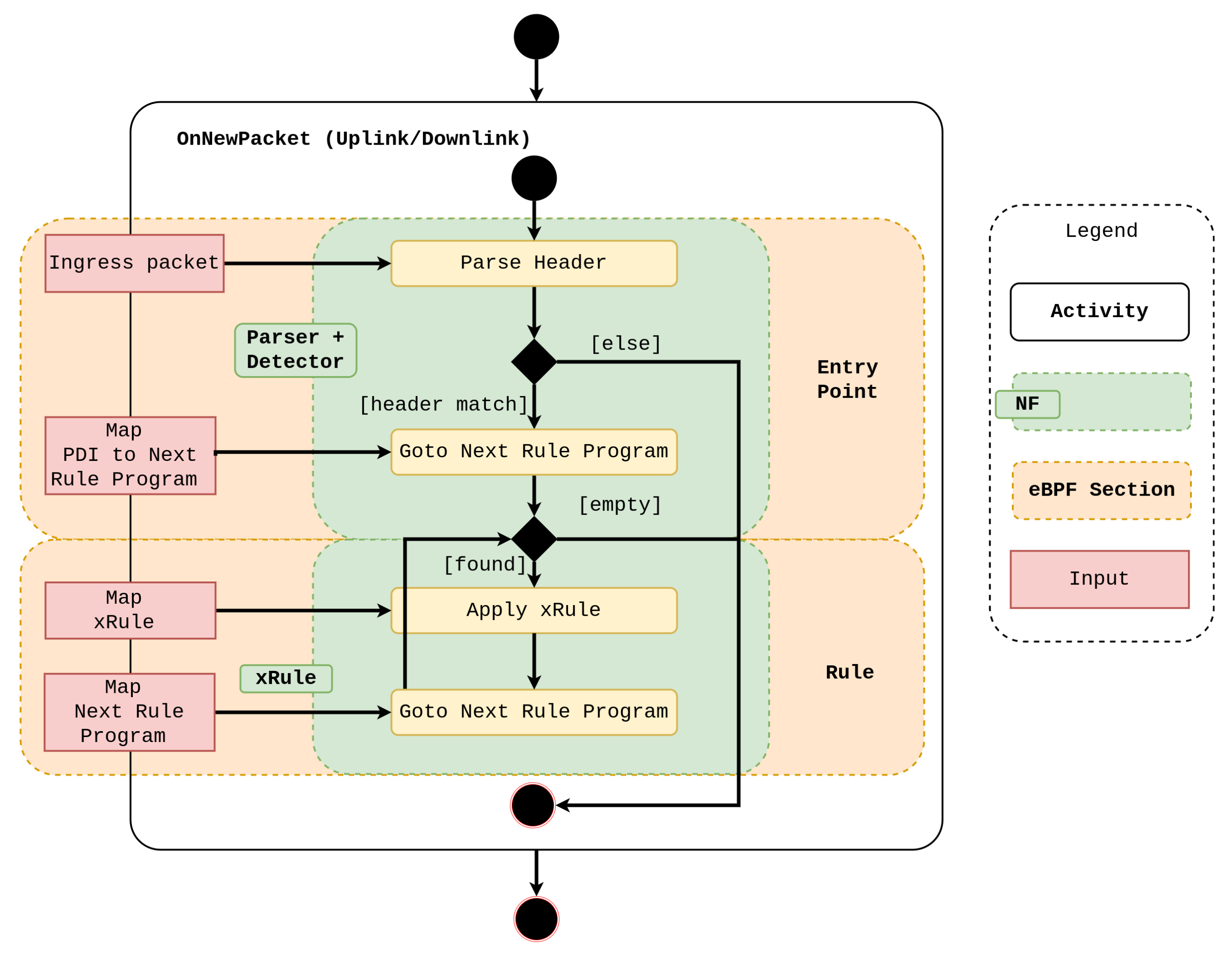
4. New Design
5. Performance Evaluation
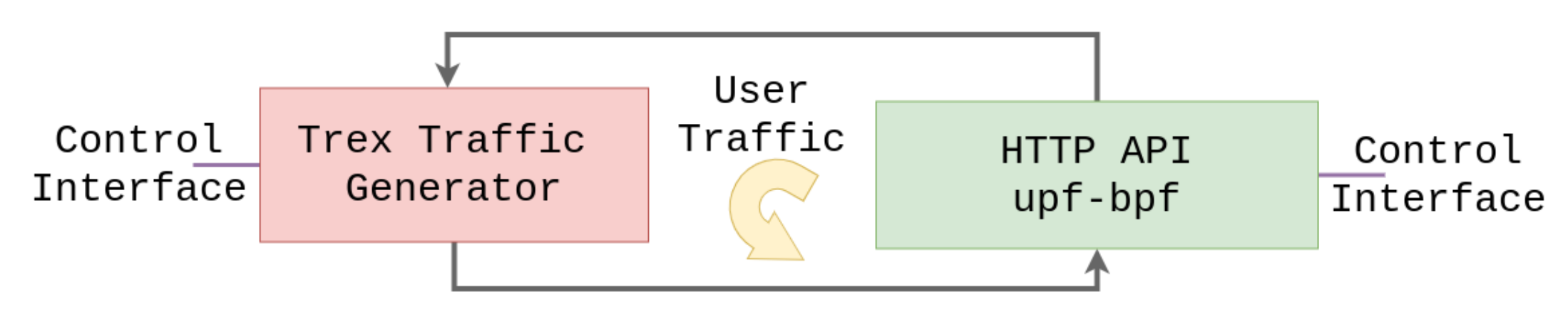
5.1. Setup
5.2. Scalability
5.3. Adaptation Time
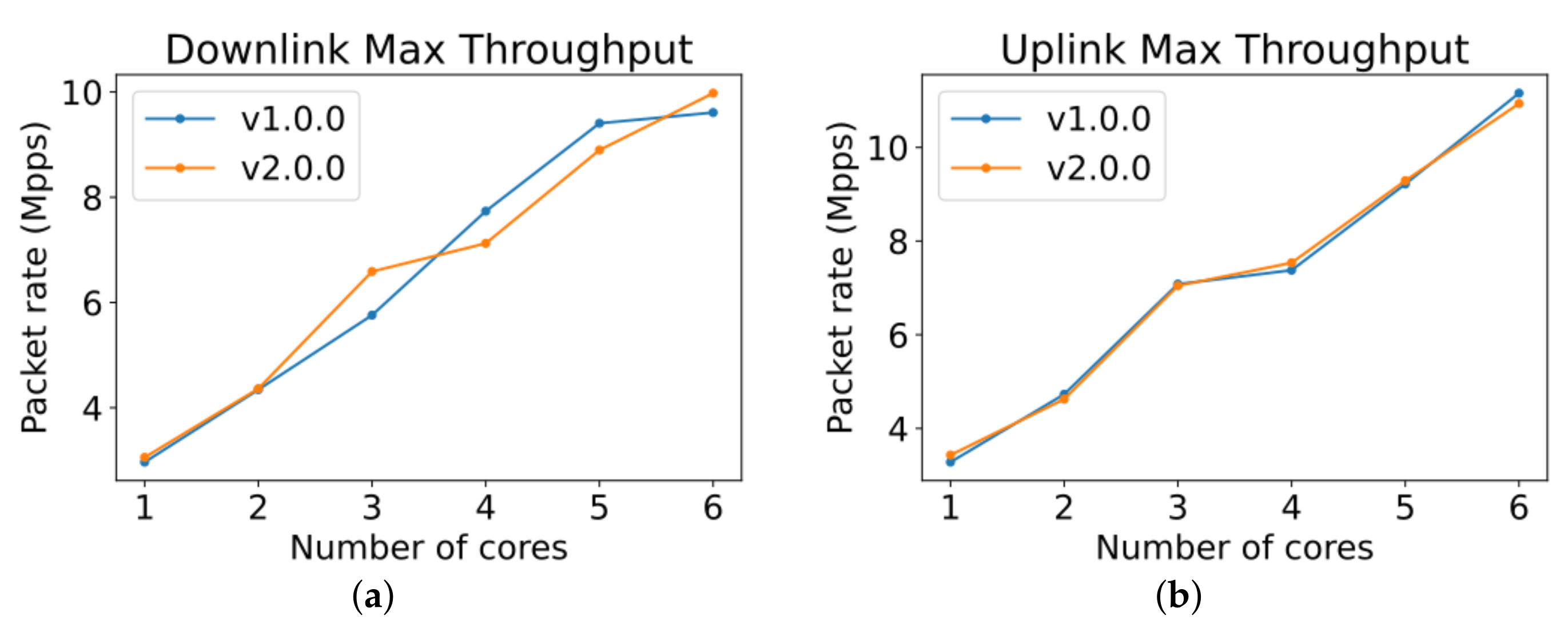
5.4. Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

6. Related Work
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kreutz, D.; Ramos, F.M.V.; Veríssimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-Defined Networking: A Comprehensive Survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef] [Green Version]
- NFV White Paper Network Functions Virtualisation: An Introduction, Benefits, Enablers, Challenges & Call for Action. Issue 1. 2012. Available online: https://portal.etsi.org/nfv/nfv_white_paper.pdf (accessed on 18 March 2022).
- Chowdhury, N.M.K.; Boutaba, R. A survey of network virtualization. Comput. Netw. 2010, 54, 862–876. [Google Scholar] [CrossRef]
- Lake, D.; Wang, N.; Tafazolli, R.; Samuel, L. Softwarization of 5G Networks–Implications to Open Platforms and Standardizations. IEEE Access 2021, 9, 88902–88930. [Google Scholar] [CrossRef]
- He, M.; Alba, A.M.; Basta, A.; Blenk, A.; Kellerer, W. Flexibility in Softwarized Networks: Classifications and Research Challenges. IEEE Commun. Surv. Tutor. 2019, 21, 2600–2636. [Google Scholar] [CrossRef]
- Abbas, K.; Khan, T.A.; Afaq, M.; Song, W.C. Network Slice Lifecycle Management for 5G Mobile Networks: An Intent-Based Networking Approach. IEEE Access 2021, 9, 80128–80146. [Google Scholar] [CrossRef]
- Do Amaral, T.A.N.; Vicente Rosa, R.; Moura, D.; Esteve Rothenberg, C. An In-Kernel Solution Based on XDP for 5G UPF: Design, Prototype and Performance Evaluation. In Proceedings of the 2021 1st International Workshop on Network Programmability (NetP 2021), Virtual, 25 October 2021. [Google Scholar]
- Høiland-Jørgensen, T.; Brouer, J.D.; Borkmann, D.; Fastabend, J.; Herbert, T.; Ahern, D.; Miller, D. The EXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel. In Proceedings of the 14th International Conference on Emerging Networking EXperiments and Technologies (CoNEXT ’18), Heraklion, Greece, 4–7 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 54–66. [Google Scholar] [CrossRef] [Green Version]
- A Thorough Introduction to eBPF. Available online: https://lwn.net/Articles/740157/ (accessed on 18 March 2022).
- Miano, S.; Bertrone, M.; Risso, F.; Tumolo, M.; Bernal, M.V. Creating Complex Network Services with eBPF: Experience and Lessons Learned. In Proceedings of the 2018 IEEE 19th International Conference on High Performance Switching and Routing (HPSR), Bucharest, Romania, 18–20 June 2018; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- eBPF-Introduction, Tutorials & Community Resources. Available online: https://ebpf.io/ (accessed on 18 March 2022).
- BPF CO-RE (Compile Once-Run Everywhere). Available online: https://nakryiko.com/posts/bpf-portability-and-co-re/ (accessed on 2 January 2022).
- Vieira, M.; Castanho, M.; Pacífico, R.; Santos, E.; Pinto, E.; Vieira, L. Fast Packet Processing with eBPF and XDP: Concepts, Code, Challenges, and Applications. ACM Comput. Surv. (CSUR) 2020, 53, 1–36. [Google Scholar] [CrossRef] [Green Version]
- SUSE-Introduction to eBPF and XDP. Available online: https://www2.slideshare.net/lcplcp1/introduction-to-ebpf-and-xdp (accessed on 2 January 2022).
- 5G; System Architecture for the 5G System (5GS), 3GPP TS 23.501 Version 16.6.0 Release 16; ESTI. Available online: https://www.etsi.org/deliver/etsi_ts/123500_123599/123501/16.06.00_60/ts_123501v160600p.pdf (accessed on 18 March 2022).
- Universal Mobile Telecommunications System (UMTS); LTE; Architecture Enhancements for Control and User Plane Separation of EPC Nodes, 3GPP TS 23.214 Version 16.2.0 Release 16; ESTI. Available online: https://www.etsi.org/deliver/etsi_ts/123200_123299/123214/16.02.00_60/ts_123214v160200p.pdf (accessed on 18 March 2022).
- LTE; 5G; Interface between the Control Plane and the User Plane Nodes, 3GPP TS 29.244 Version 16.5.0 Release 16; ESTI. Available online: https://www.etsi.org/deliver/etsi_ts/129200_129299/129244/16.05.00_60/ts_129244v160500p.pdf (accessed on 18 March 2022).
- Digital Cellular Telecommunications System (Phase 2+) (GSM); Universal Mobile Telecommunications System (UMTS); General Packet Radio Service (GPRS); GPRS Tunnelling Protocol (GTP) across the Gn and Gp Interface GPRS Tunnelling Protocol (GTP) across the Gn and Gp Interface, 3GPP TS 29.060 Version 16.0.0 Release; ESTI. Available online: https://www.3gpp.org/ftp/Specs/archive/29_series/29.060/29060-g00.zip (accessed on 18 March 2022).
- Girondi, M. Efficient Traffic Monitoring in 5G Core Network. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2020. [Google Scholar]
- Libbpf Linux Kernel Library. Available online: https://github.com/libbpf/libbpf (accessed on 2 January 2022).
- What are the Verifier Limits. Available online: https://www.kernel.org/doc/html/v5.2/bpf/bpf_design_QA.html#q-what-are-the-verifier-limits (accessed on 2 January 2022).
- TRex-Realistic Traffic Generator. Available online: https://trex-tgn.cisco.com/ (accessed on 2 January 2022).
- Linux Kernel Network-Receive Side Scaling. Available online: https://www.kernel.org/doc/Documentation/networking/scaling.txt (accessed on 18 March 2022).
- TRex Traffic Generator Stateless API Documentation. Available online: https://trex-tgn.cisco.com/trex/doc/cp_stl_docs/api/index.html (accessed on 2 January 2022).
- Fei, X.; Liu, F.; Zhang, Q.; Jin, H.; Hu, H. Paving the Way for NFV Acceleration: A Taxonomy, Survey and Future Directions; Association for Computing Machinery: New York, NY, USA, 2020; Volume 53. [Google Scholar] [CrossRef]
- Bonati, L.; Polese, M.; D’Oro, S.; Basagni, S.; Melodia, T. Open, Programmable, and Virtualized 5G Networks: State-of-the-Art and the Road Ahead. Comput. Netw. 2020, 182, 107516. [Google Scholar] [CrossRef]
- Ricart-Sanchez, R.; Malagon, P.; Alcaraz-Calero, J.M.; Wang, Q. Hardware-Accelerated Firewall for 5G Mobile Networks. In Proceedings of the 2018 IEEE 26th International Conference on Network Protocols (ICNP), Cambridge, UK, 25–27 September 2018; pp. 446–447. [Google Scholar] [CrossRef] [Green Version]
- Ricart-Sanchez, R.; Malagon, P.; Salva-Garcia, P.; Perez, E.C.; Wang, Q.; Alcaraz Calero, J.M. Towards an FPGA-Accelerated programmable data path for edge-to-core communications in 5G networks. J. Netw. Comput. Appl. 2018, 124, 80–93. [Google Scholar] [CrossRef] [Green Version]
- Openair-Cn: Evolved Core Network Implementation of OpenAirInterface. Available online: https://github.com/OPENAIRINTERFACE/openair-cn (accessed on 2 January 2022).
- Cloud Edge Computing: Beyond the Data Center. Available online: https://www.openstack.org/use-cases/edge-computing/cloud-edge-computing-beyond-the-data-center/ (accessed on 18 March 2022).
- Pinczel, B.; Géhberger, D.; Turányi, Z.; Formanek, B. Towards high performance packet processing for 5G. In Proceedings of the 2015 IEEE Conference on Network Function Virtualization and Software Defined Network (NFV-SDN), San Francisco, CA, USA, 18–21 November 2015; pp. 67–73. [Google Scholar] [CrossRef]
- Kohler, E.; Morris, R.; Chen, B.; Jannotti, J.; Kaashoek, M.F. The Click Modular Router. ACM Trans. Comput. Syst. 2000, 18, 263–297. [Google Scholar] [CrossRef]
- Rizzo, L. Netmap: A Novel Framework for Fast Packet I/O. In Proceedings of the 2012 USENIX Conference on Annual Technical Conference (USENIX ATC’12), Boston, MA, USA, 13–15 June 2012; p. 9. [Google Scholar]
- Chen, W.; Liu, C.H. Performance Enhancement of Virtualized Media Gateway with DPDK for 5G Multimedia Communications. In Proceedings of the 2019 International Conference on Intelligent Computing and its Emerging Applications (ICEA), Tainan, Taiwan, 30 August–1 September 2019; pp. 156–161. [Google Scholar] [CrossRef]
- Data Plane Development Kit (DPDK). Available online: https://dpdk.org (accessed on 2 January 2022).
- Building Enterprise-Level Cloud Solutions with Outscale. Available online: https://www.intel.com/content/dam/www/public/us/en/documents/case-studies/xeon-e5-2660-family-ssd-s3700-series-dpdk-case-study.pdf (accessed on 2 January 2022).
- Parola, F.; Miano, S.; Risso, F. A Proof-of-Concept 5G Mobile Gateway with eBPF. In Proceedings of the ACM SIGCOMM 2020 Conference on Posters and Demos (SIGCOMM ’20), Virtual Event, 10–14 August 2020. [Google Scholar]
- Polycube: eBPF/XDP-Based Software Framework for Fast Network Services Running in the Linux Kernel. Available online: https://github.com/polycube-network/polycube (accessed on 18 March 2022).
- BPF Compiler Collection (BCC). Available online: https://github.com/iovisor/bcc (accessed on 2 January 2022).
- USENIX Association. Runtime Programmable Switches. In Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), Renton, WA, USA, 4–6 April 2022.
- srsLTE-Open-Source 4G and 5G Software Radio Suite Developed by Software Radio Systems (SRS). Available online: https://github.com/srsLTE/srsLTE (accessed on 2 January 2022).
- Open5Gs-Open Source Project of 5GC and EPC (Release-16). Available online: https://github.com/open5gs/open5gs (accessed on 2 January 2022).
- UPF EPC-4G/5G Mobile Core User Plane. Available online: https://github.com/omec-project/upf-epc (accessed on 2 January 2022).
- Magma-Facebook Connectivity. Available online: https://connectivity.fb.com/magma/ (accessed on 2 January 2022).
- free5Gc-Open-Source Project for 5th Generation (5G) Mobile Core Networks. Available online: https://www.free5gc.org/ (accessed on 2 January 2022).
- Kernel Module for GTP Protocol. Available online: https://github.com/PrinzOwO/gtp5g (accessed on 2 January 2022).
- Han, S.; Jang, K.; Panda, A.; Palkar, S.; Han, D.; Ratnasamy, S. SoftNIC: A Software NIC to Augment Hardware; Technical Report UCB/EECS-2015-155; EECS Department, University of California: Berkeley, CA, USA, 2015. [Google Scholar]
- Pfaff, B.; Pettit, J.; Koponen, T.; Jackson, E.J.; Zhou, A.; Rajahalme, J.; Gross, J.; Wang, A.; Stringer, J.; Shelar, P.; et al. The Design and Implementation of Open VSwitch. In Proceedings of the 12th USENIX Conference on Networked Systems Design and Implementation, Oakland, CA, USA, 4–6 May 2015; pp. 117–130. [Google Scholar]
- Ryu-SDN Framework. Available online: https://ryu-sdn.org/ (accessed on 2 January 2022).
- Rosa, R.V.; Bertoldo, C.; Rothenberg, C.E. Take Your VNF to the Gym: A Testing Framework for Automated NFV Performance Benchmarking. IEEE Commun. Mag. 2017, 55, 110–117. [Google Scholar] [CrossRef]
- Gym. Available online: https://github.com/intrig-unicamp/gym (accessed on 2 January 2022).




| Rules | Interfaces | |||
|---|---|---|---|---|
| Sxa | Sxb | Sxc | N4 | |
| PDR | x | x | x | x |
| FAR | x | x | x | x |
| URR | x | x | x | x |
| QER | - | x | x | x |
| BAR | x | - | - | x |
| MAR | - | - | - | x |
| Version | BPF Section | BPF Insn | Injection (ms) |
|---|---|---|---|
| v1.0.0 | PFCP Session | 402 | 27 |
| v2.0.0 | FAR | 272 | 1 |
| Academic Research | |||||||
| 5GS | Fast Packet Processing | Experimental Evaluation | |||||
| Work | Location | Component | Based on | Technology | Environment | OSS CN | Application |
| [37] | Edge | UPF | SW | BPF, TC, XDP | Polycube | No | QoS, Traffic forward |
| [34] | N/A | N/A | SW | DPDK | Standalone | No | 5G Media Gateway |
| [31] | Core | UPF | SW | Netmap, Click | Docker Container | No | Context migration, service chain |
| [28] | Edge & Core | gNB & UPF | HW | NetFPGA, P4 | OAI | Yes | Multi-Tenancy, QoS, Multimedia |
| [27] | Edge & Core | gNB & UPF | HW | NetFPGA, P4 | Standalone | No | Firewall |
| This Work | Edge | UPF | SW | BPF, XDP | Standalone | Yes | Traffic forward |
| Open Source Software | |||||||
| 5GS | Fast Packet Processing | Details | |||||
| OSS | Location | Components | Based on | Technology | CUPS | Language | Application |
| [29] | Core | U/D | U | U | Yes | C/C++ | CN SA/NSA |
| [41] | Core | U | U | U | No | C++ | CN NSA |
| [44] | Core | U/D | U | OvS, Kernel module | No | C | CN NSA |
| [43] | Core | UPF | SW | BESS | Yes | C++ | CN SA |
| [42] | Core | U/D | U | U | Yes | C | CN SA |
| [45] | Core | All | SW | Kernel module | Yes | Go/C | CN SA/NSA |
| This Work (upf-bpf) | Core | UPF | SW | BPF, XDP | Yes | C++ | CN SA/NSA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Navarro do Amaral, T.A.; Rosa, R.V.; Moura, D.F.C.; Esteve Rothenberg, C. Run-Time Adaptive In-Kernel BPF/XDP Solution for 5G UPF. Electronics 2022, 11, 1022. https://doi.org/10.3390/electronics11071022
Navarro do Amaral TA, Rosa RV, Moura DFC, Esteve Rothenberg C. Run-Time Adaptive In-Kernel BPF/XDP Solution for 5G UPF. Electronics. 2022; 11(7):1022. https://doi.org/10.3390/electronics11071022
Chicago/Turabian StyleNavarro do Amaral, Thiago A., Raphael V. Rosa, David F. Cruz Moura, and Christian Esteve Rothenberg. 2022. "Run-Time Adaptive In-Kernel BPF/XDP Solution for 5G UPF" Electronics 11, no. 7: 1022. https://doi.org/10.3390/electronics11071022
APA StyleNavarro do Amaral, T. A., Rosa, R. V., Moura, D. F. C., & Esteve Rothenberg, C. (2022). Run-Time Adaptive In-Kernel BPF/XDP Solution for 5G UPF. Electronics, 11(7), 1022. https://doi.org/10.3390/electronics11071022