
Controller Design of Tracking WMR System Based on Deep Reinforcement Learning



Abstract
:1. Introduction
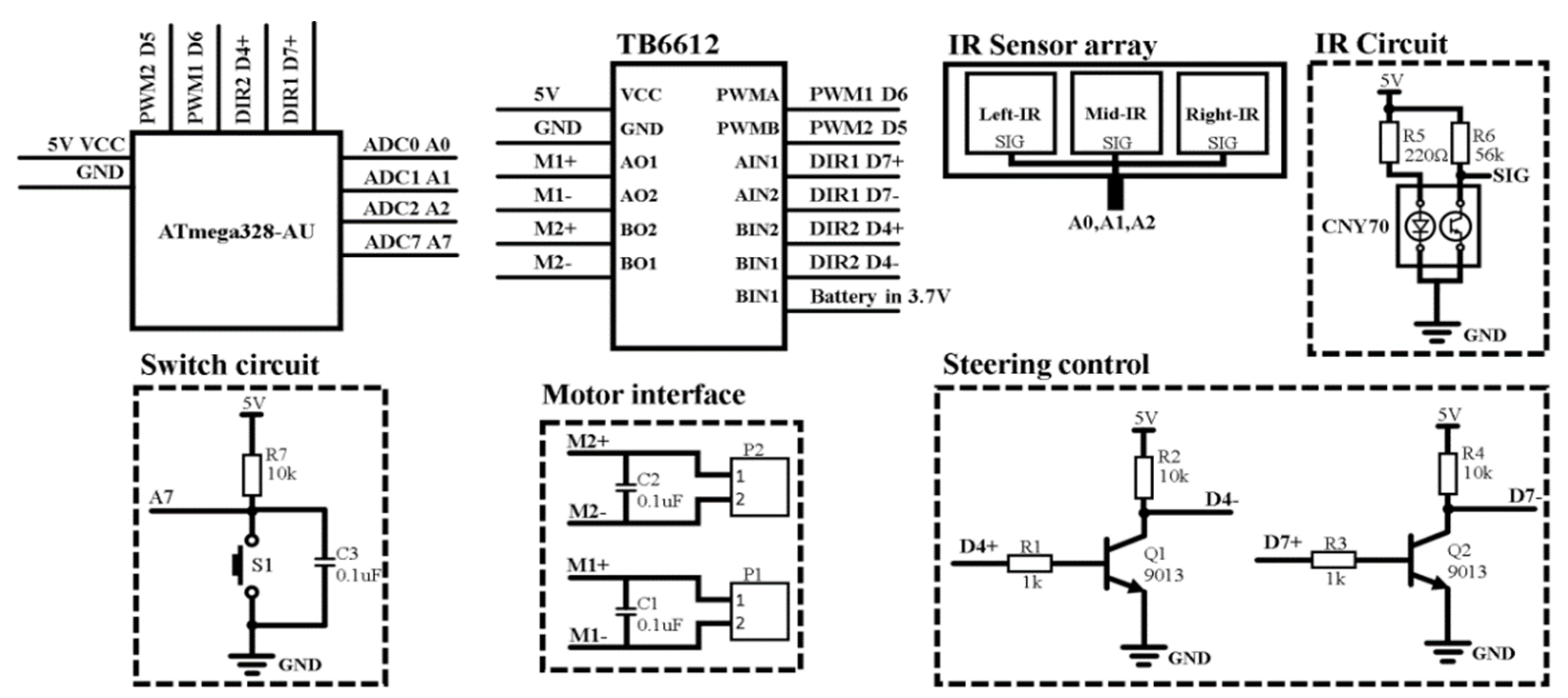
2. System Architecture and Device
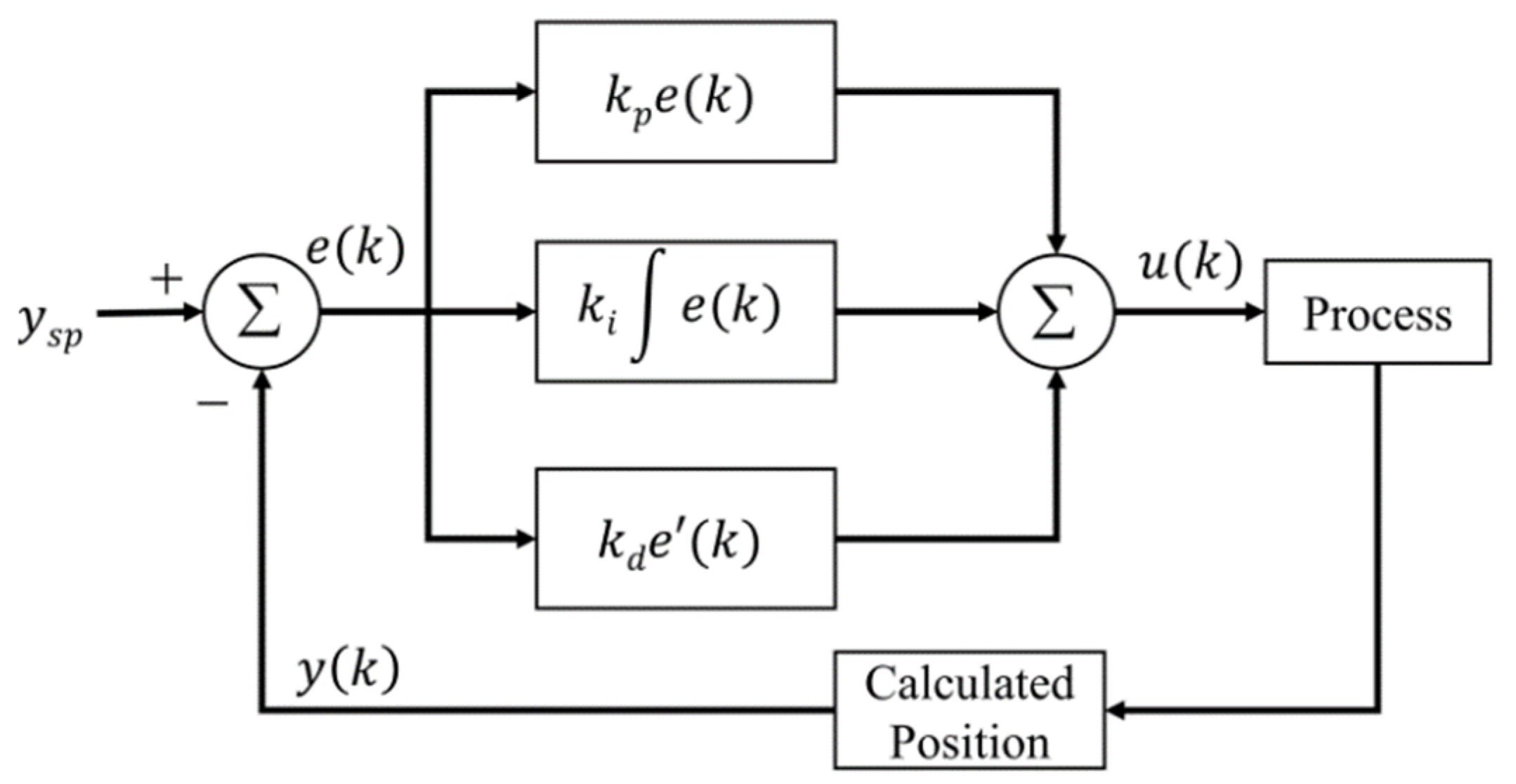
2.1. Conventional PID Controller
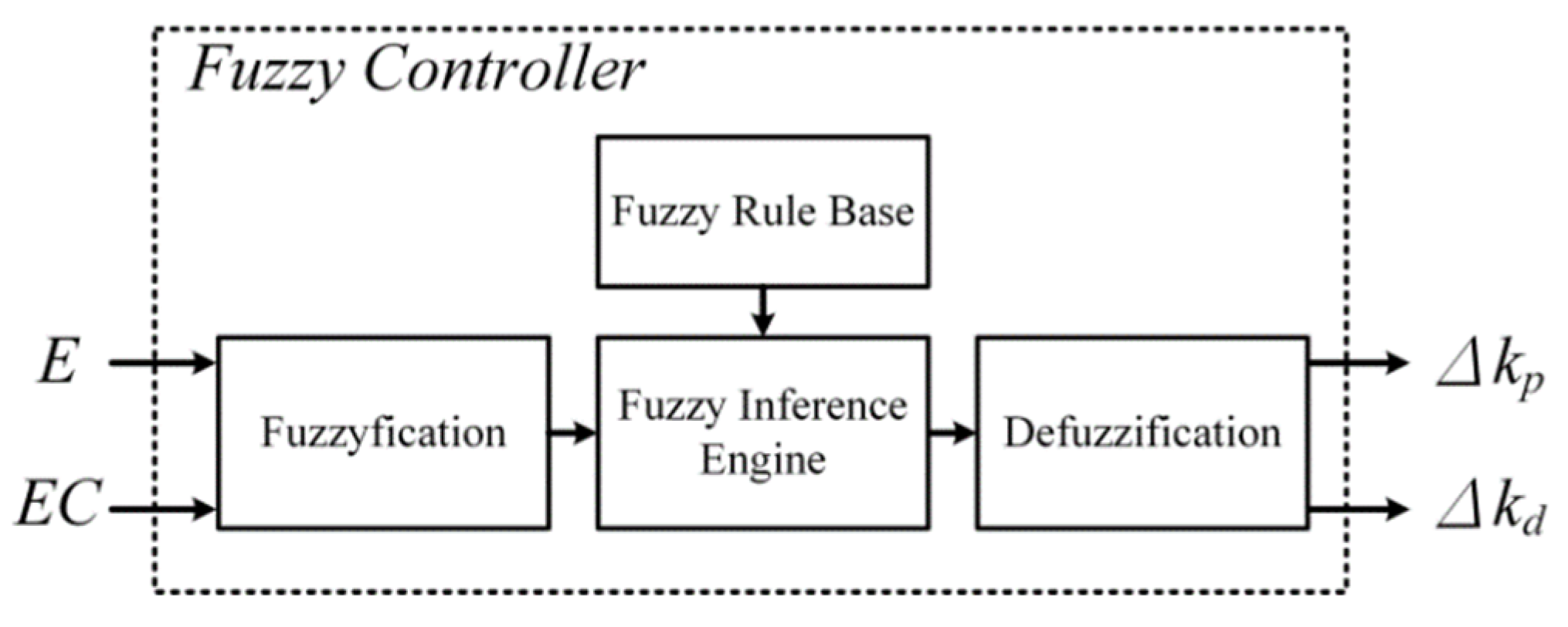
2.2. Fuzzy Controller
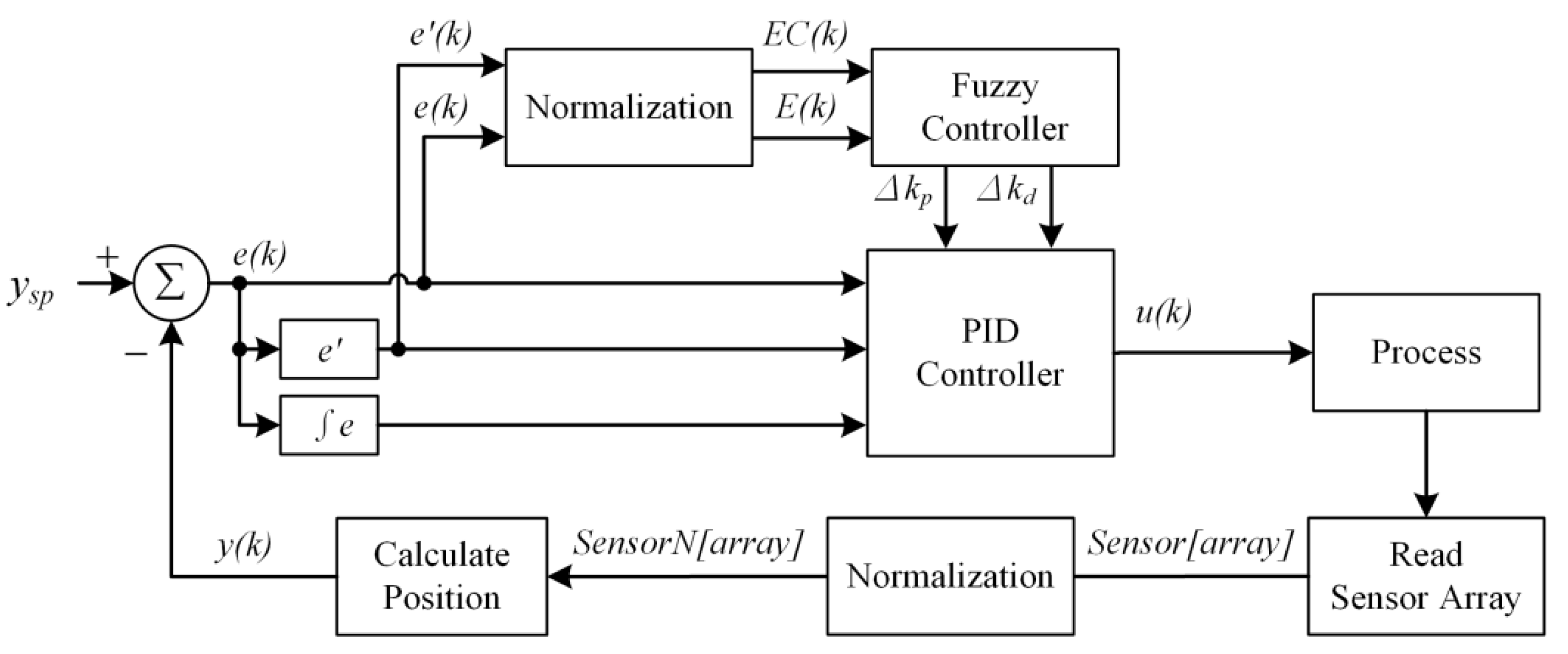
2.3. Fuzzy-PID Controller
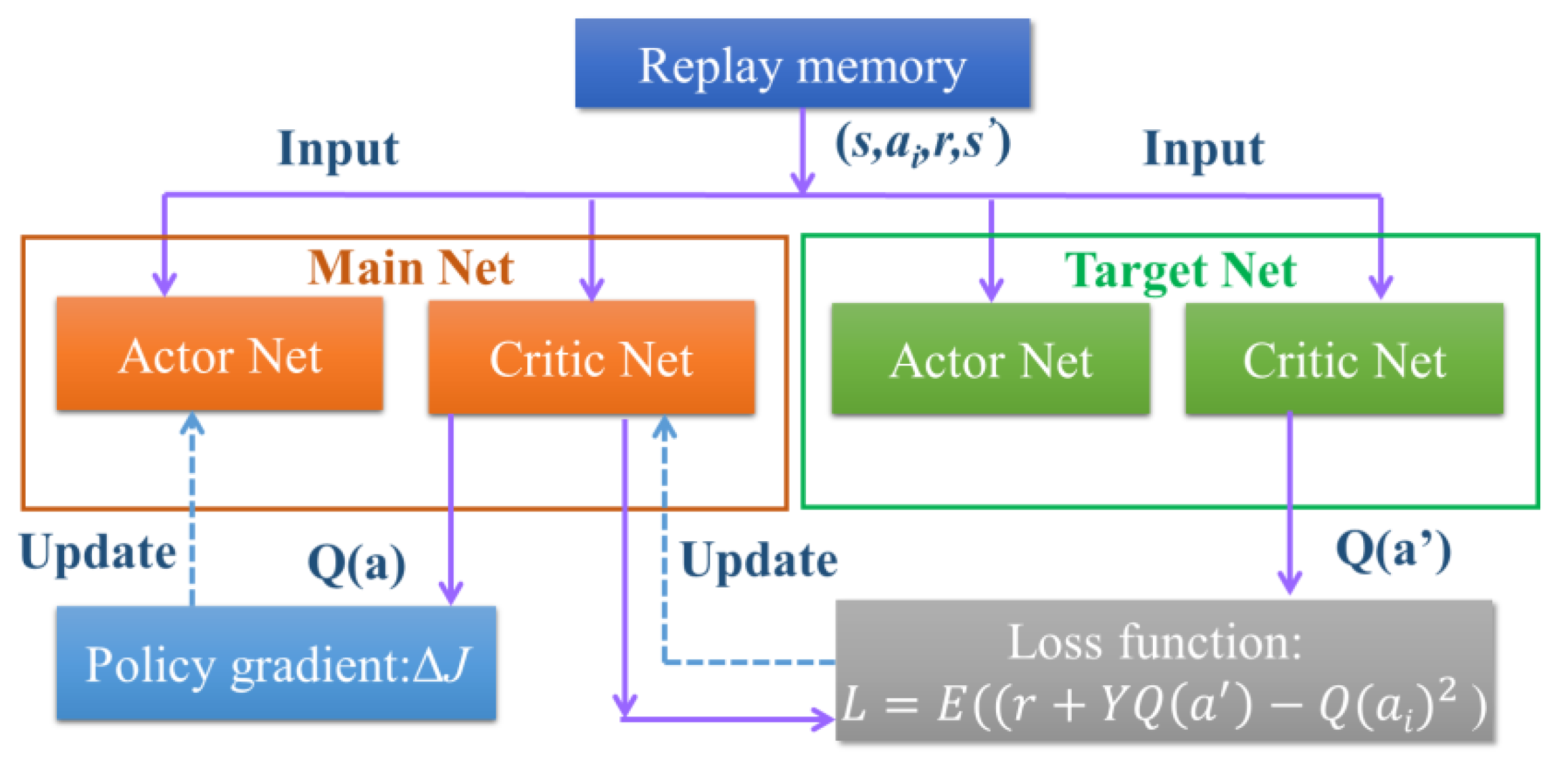
2.4. Deep Reinforcement Learning(DRL)
2.5. MBot Robot
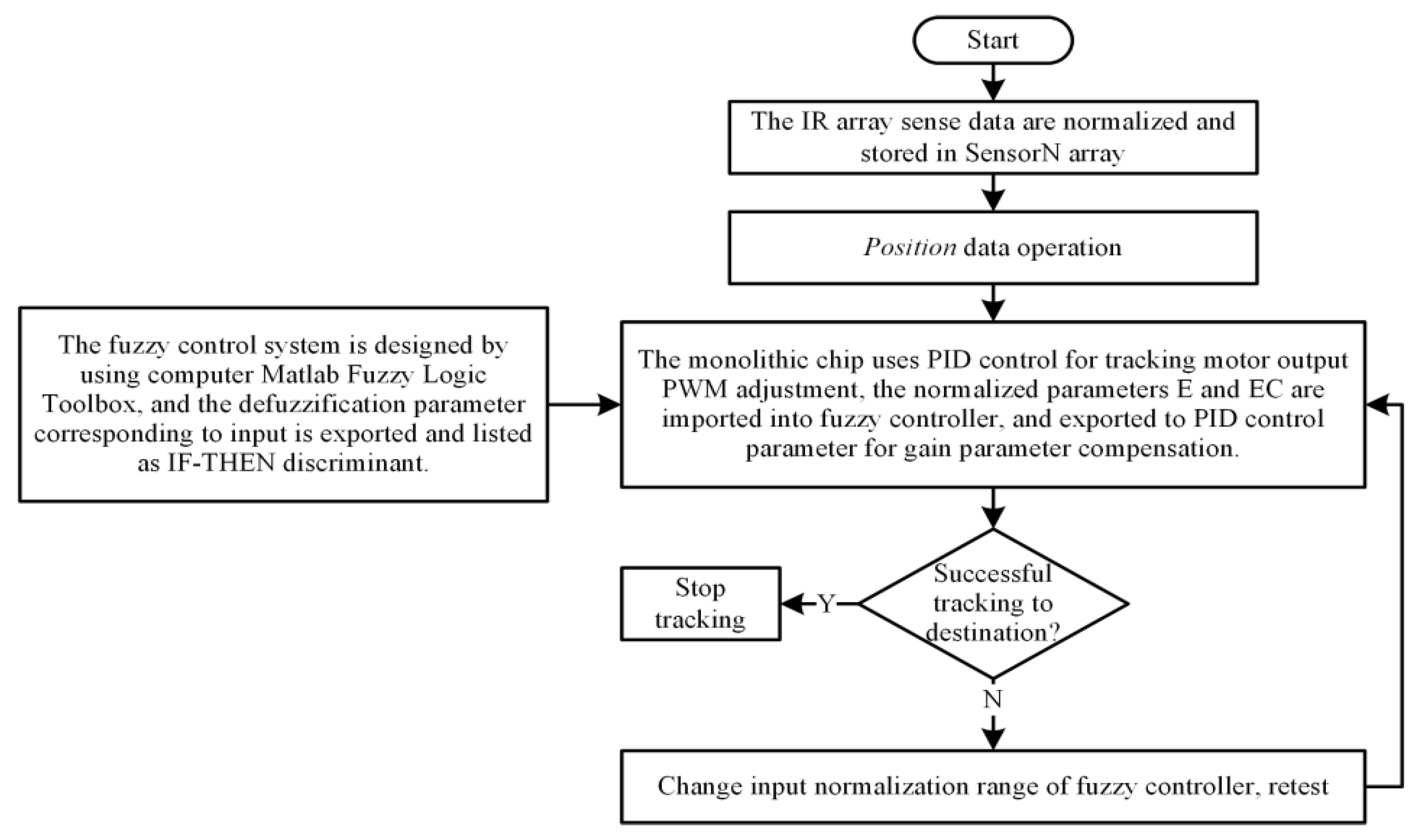
3. Experimental Methods
3.1. Normalization
3.2. Position Calculation
- Read Sensor Array voltage from Sensor[array] = [Left-IR, Mid-IR, Right-IR]
- Normalize Sensor Output SensorN[array]
- Count = 0, Sum = 0, Weighted = 0
- WHILE(Count < 3)Sum = Sum + (SensorN[Count] × Count × 1000)Weighted = Weighted + SensorN[Count]Count = Count + 1END WHILE
- Position = Sum/Weighted
3.3. Regression of Tracking Path
- IF Position is 0 value THEN
- IF LastPosition < 1000 THENPosition = 0
- ELSE IF LastPosition > 1000 THENPosition = 2000END IF
- ELSE THENLastPosition = PositionEND IF
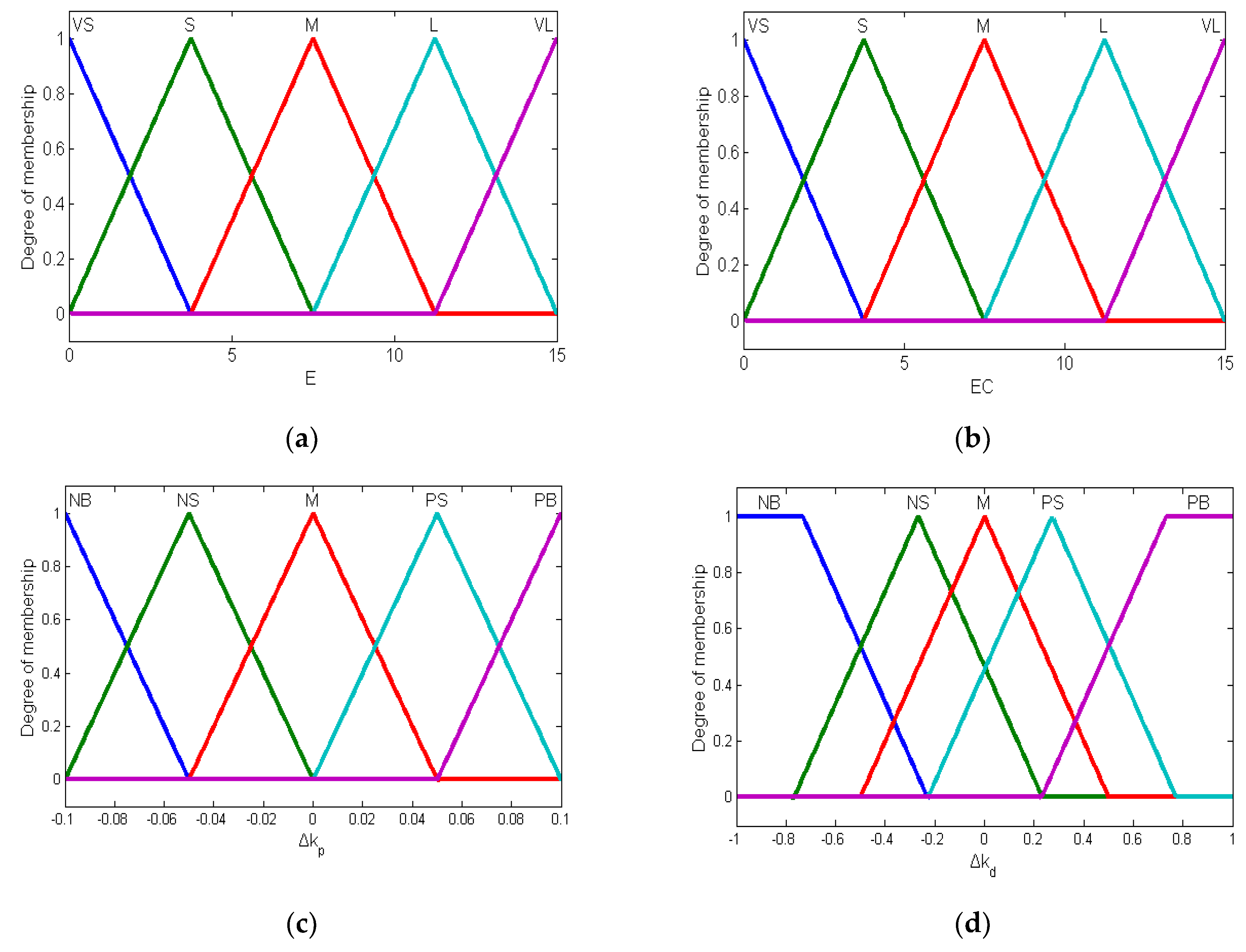
3.4. Fuzzy-PID Gain Parameter System Design
3.5. Design of Tracking Experiment
4. Results and Discussion
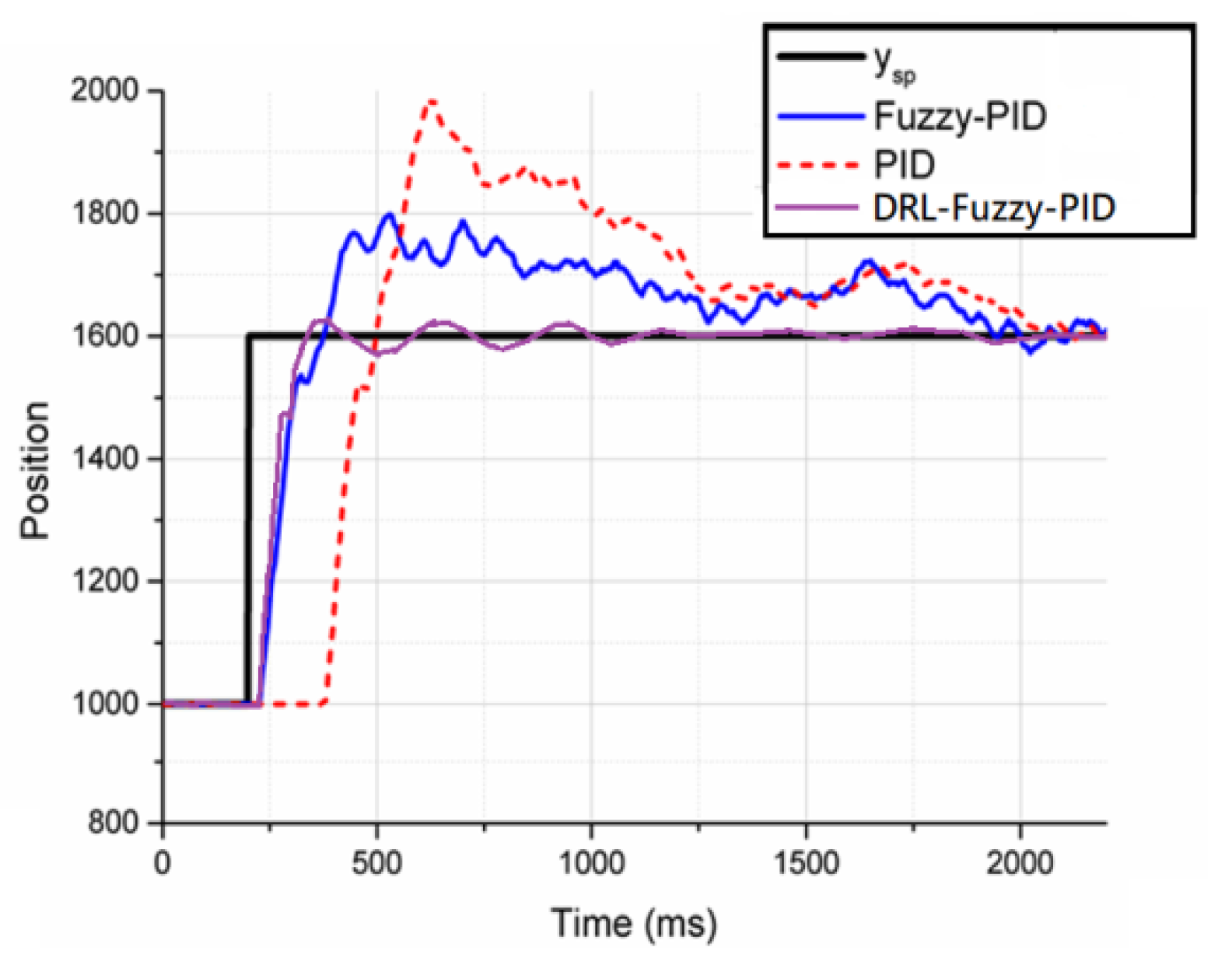
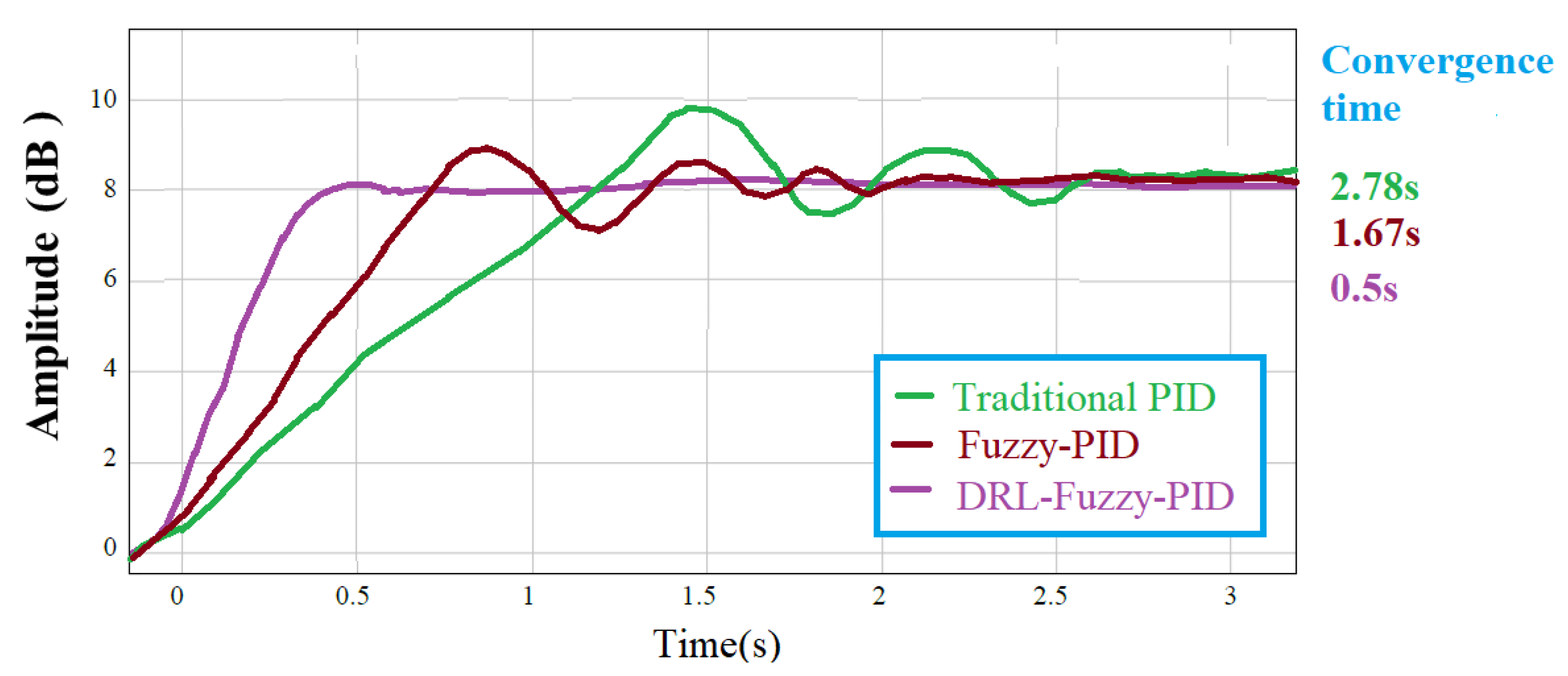
4.1. Comparison of DRL-Fuzzy PID, Fuzzy PID and Traditional PID Control in the Step Response of mBot
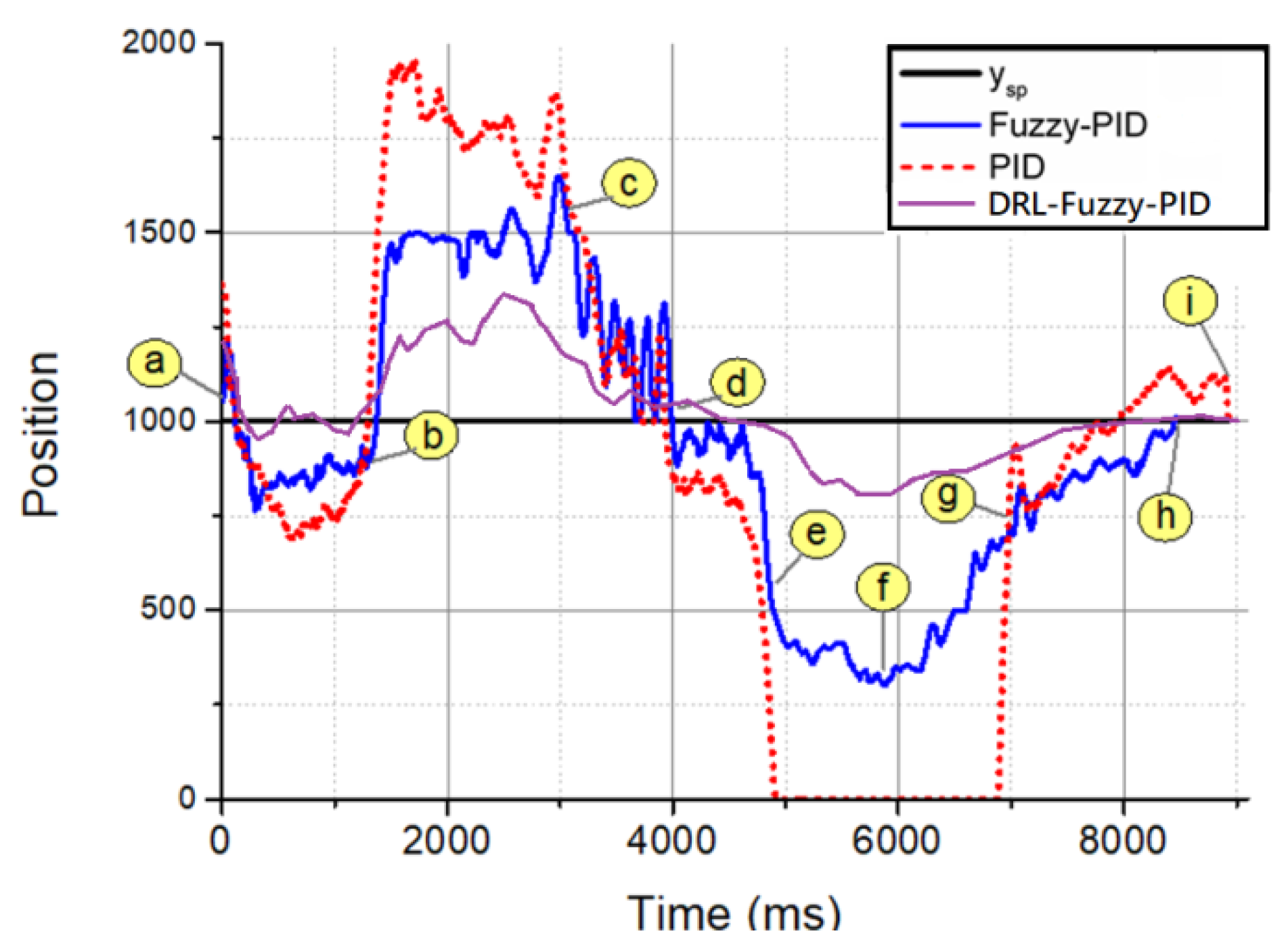
4.2. Comparison of DRL-Fuzzy PID, Fuzzy PID Control and Traditional PID Control in mBot Field Tracking
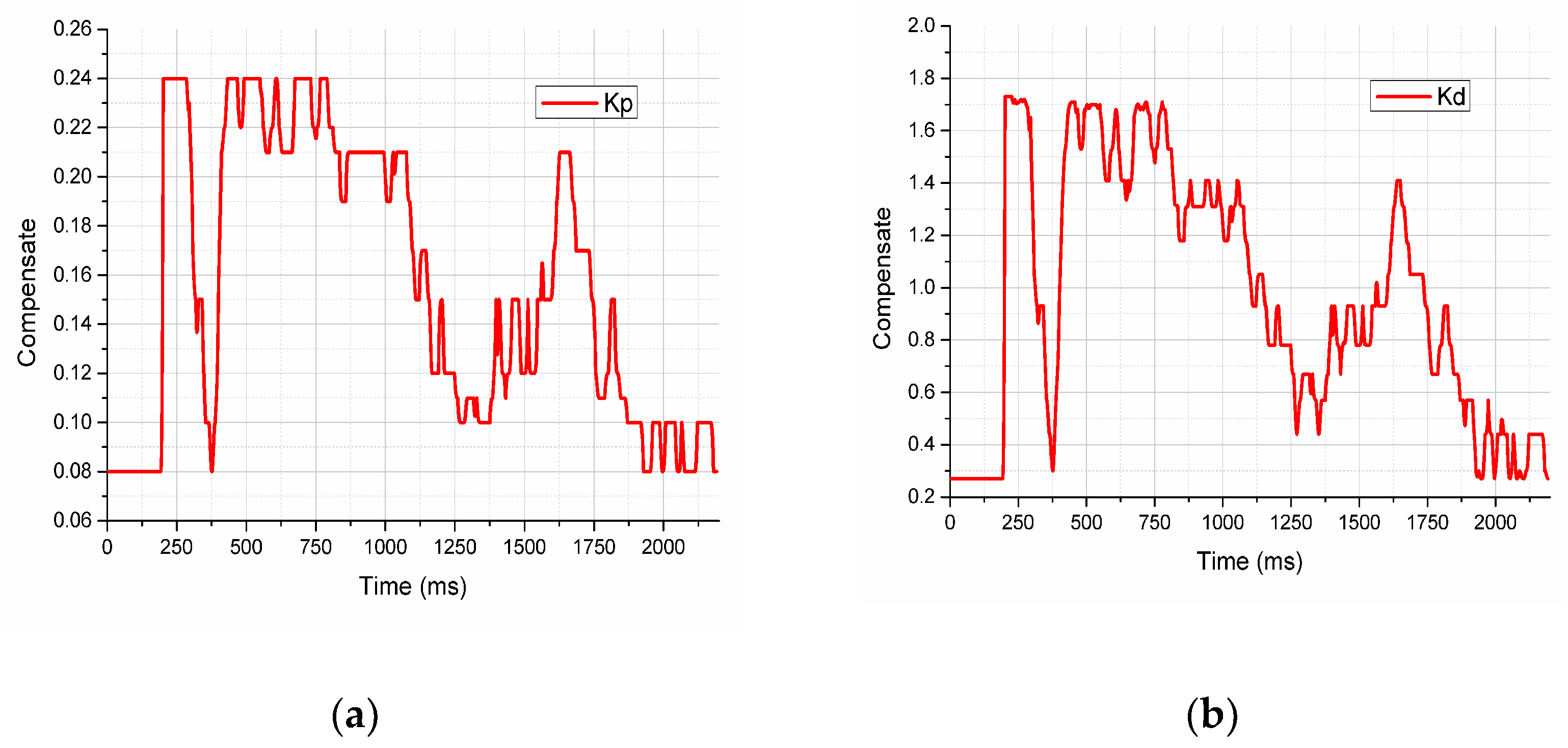
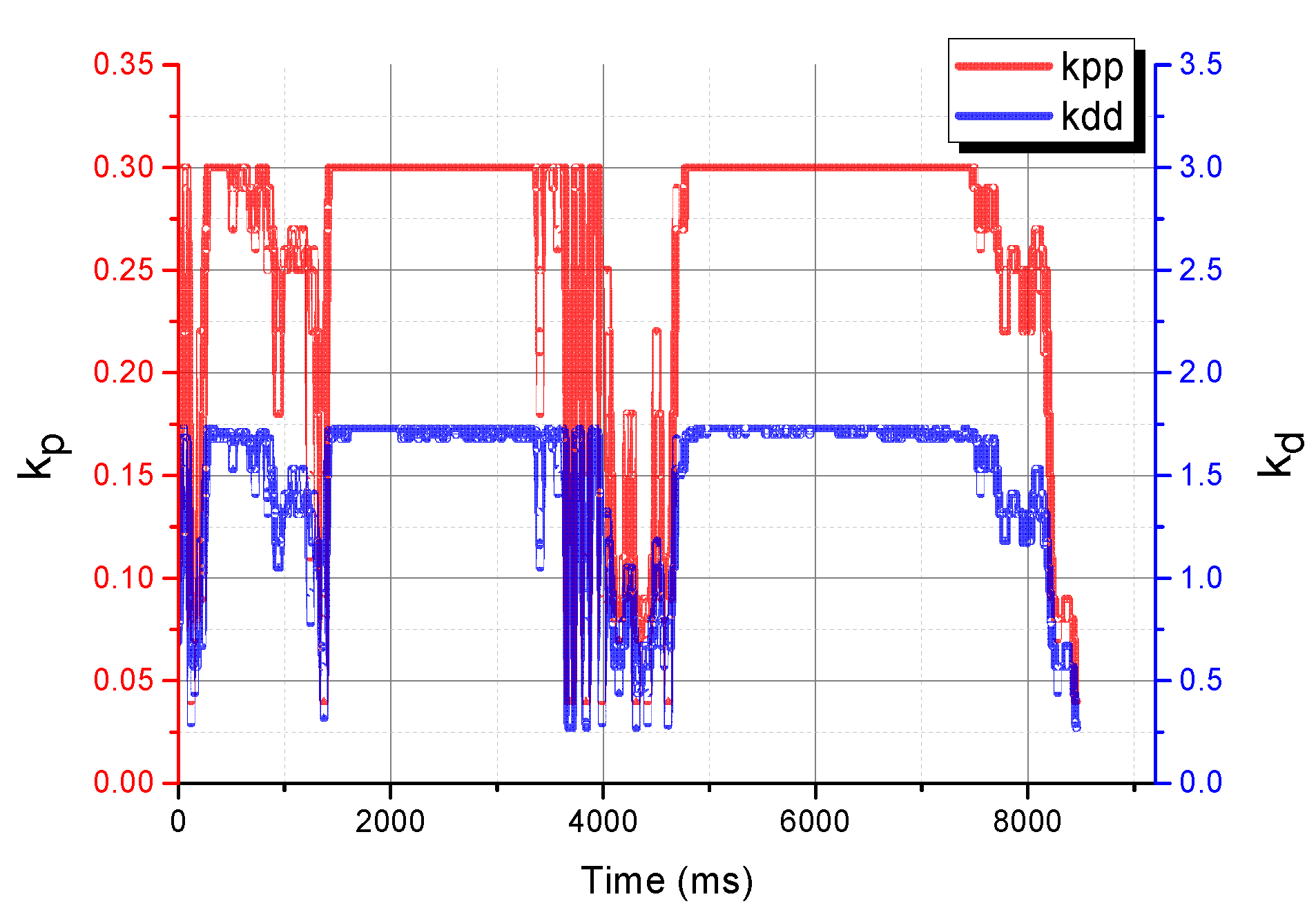
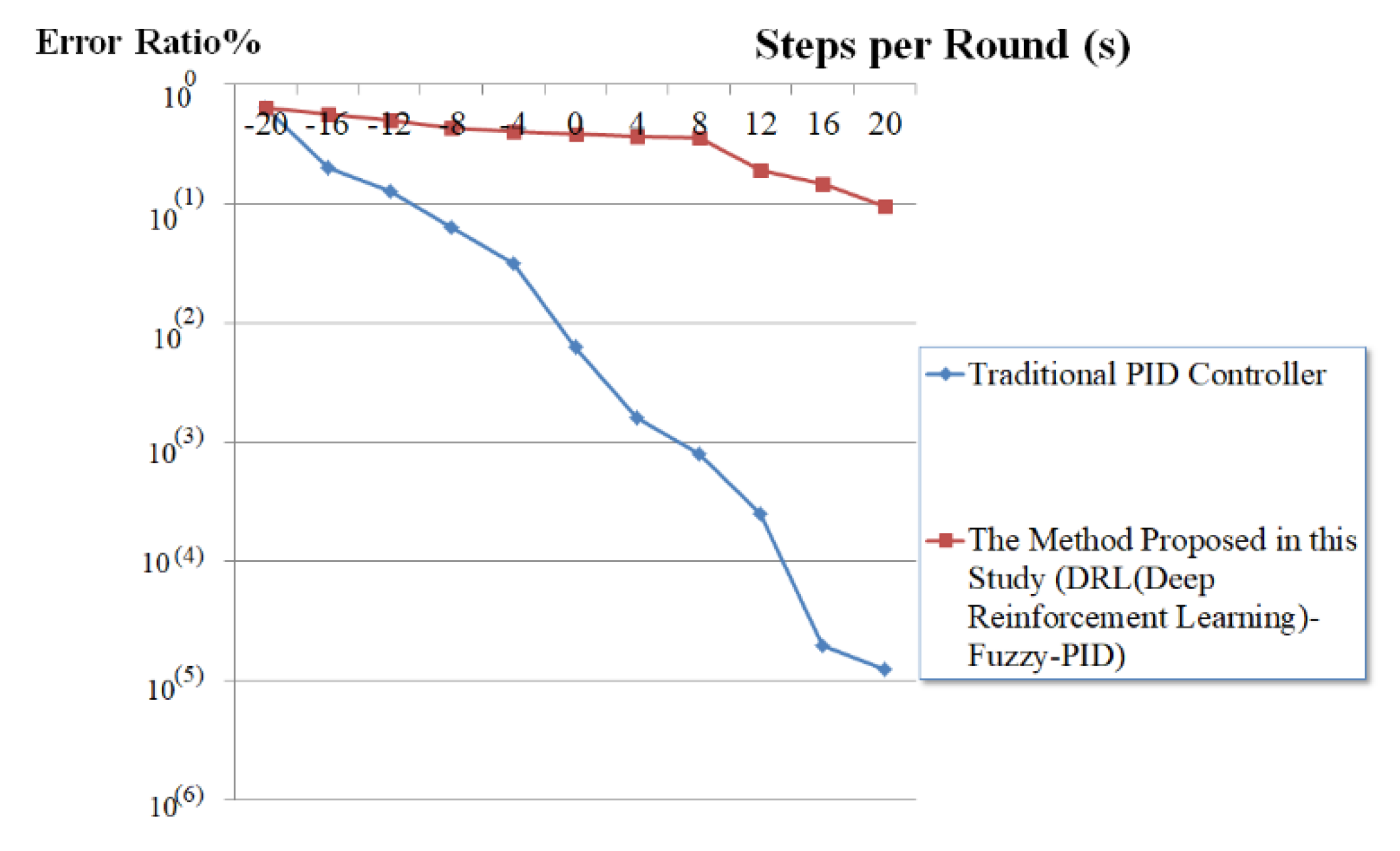
4.3. Experiments and Discussions Based on Deep Reinforcement Learning(DRL)
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Möller, R.; Krzykawski, M.; Gerstmayr-Hillen, L.; Horst, M.; Fleer, D.; De Jong, J. Cleaning robot navigation using panoramic views and particle clouds as landmarks. Robot. Auton. Syst. 2013, 61, 1415–1439. [Google Scholar] [CrossRef]
- Backman, J.; Oksanen, T.; Visala, A. Navigation system for agricultural machines: Nonlinear model predictive path tracking. Comput. Electron. Agric. 2012, 82, 32–43. [Google Scholar] [CrossRef]
- Poongodi, C.; Premalatha, J.; Lalitha, K.; Vijay, A.D. Region based find and spray scheme for co-operative data communication in vehicular cyber-physical systems. Intell. Autom. Soft Comput. 2017, 23, 501–507. [Google Scholar]
- Matveev, A.S.; Hoy, M.C.; Savkin, A.V. The problem of boundary following by a unicycle-like robot with rigidly mounted sensors. Robot. Auton. Syst. 2013, 61, 312–327. [Google Scholar] [CrossRef]
- Santos, M.C.P.; Santana, L.V.; Brandão, A.S.; Sarcinelli-Filho, M.; Carelli, R. Indoor low-cost localization system for controlling aerial robots. Control Eng. Pract. 2017, 61, 93–111. [Google Scholar] [CrossRef]
- Kaliński, K.J.; Mazur, M. Optimal control at energy performance index of the mobile robots following dynamically created trajectories. Mechatronics 2016, 37, 79–88. [Google Scholar] [CrossRef]
- Iacca, G.; Caraffini, F.; Neri, F. Memory-saving memetic computing for path-following mobile robots. Appl. Soft Comput. 2013, 13, 2003–2016. [Google Scholar] [CrossRef]
- Alvarez-Santos, V.; Pardo, X.M.; Iglesias, R.; Canedo-Rodriguez, A.; Regueiro, C.V. Feature analysis for human recognition and discrimination: Application to a person-following behaviour in a mobile robot. Robot. Auton. Syst. 2012, 60, 1021–1036. [Google Scholar] [CrossRef]
- Yang, L.; Noguchi, N.; Takai, R. Development and application of a wheel-type robot tractor. Eng. Agric. Environ. Food 2016, 9, 131–140. [Google Scholar] [CrossRef]
- Lei, W.; Li, C.; Chen, M.Z.Q. Robust adaptive tracking control for quadrotors by combining pi and self-tuning regulator. IEEE Trans. Control Syst. Technol. 2019, 27, 2663–2671. [Google Scholar] [CrossRef]
- Lin, X.-L.; Wu, C.-F.; Chen, B.-S. Robust H∞ adaptive fuzzy tracking control for MIMO nonlinear stochastic poisson jump diffusion systems. IEEE Trans. Cybern. 2019, 49, 3116–3130. [Google Scholar] [CrossRef] [PubMed]
- Resnick, M.; Maloney, J.; Monroy-Hernández, A.; Rusk, N.; Eastmond, E.; Brennan, K.; Millner, A.; Rosenbaum, E.; Silver, J.; Silverman, B.; et al. Scratch: Programming for all. Commun. ACM 2009, 52, 60–67. [Google Scholar] [CrossRef]
- Benitti, F.B.V. Exploring the educational potential of robotics in schools: A systematic review. Comput. Educ. 2012, 58, 978–988. [Google Scholar] [CrossRef]
- Chen, J.; Wu, C.; Yu, G.; Narang, D.; Wang, Y. Path following of wheeled mobile robots using online-optimization-based guidance vector field. IEEE/ASME Trans. Mechatron. 2021, 26, 1737–1744. [Google Scholar] [CrossRef]
- Hermand, E.; Nguyen, T.W.; Hosseinzadeh, M.; Garone, E. Constrained control of UAVs in geofencing applications. In Proceedings of the 2018 26th Mediterranean Conference on Control and Automation (MED), Zadar, Croatia, 19–22 June 2018; pp. 217–222. [Google Scholar]
- Wang, C.; Liu, X.; Yang, X.; Hu, F.; Jiang, A.; Yang, C. Trajectory tracking of an omni-directional wheeled mobile robot using a model predictive control strategy. Appl. Sci. 2018, 8, 231. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, P.R.; Pano, V.; Dam, T. PID position domain control for contour tracking. Int. J. Syst. Sci. 2015, 46, 111–124. [Google Scholar] [CrossRef]
- Wang, W.; Xu, L.; Hu, H. Neuron adaptive PID control for greenhouse environment. J. Ind. Prod. Eng. 2015, 32, 291–297. [Google Scholar] [CrossRef]
- Iqbal, A.; Abu-Rub, H.; Nounou, H. Adaptive fuzzy logic-controlled surface mount permanent magnet synchronous motor drive. Syst. Sci. Control Eng. 2014, 2, 465–475. [Google Scholar] [CrossRef]
- Santos, B.R.; Fonseca, T.; Barata, M.; Ribeiro, R.A.; Sousa, P. A method for automatic fuzzy set generation using sensor data. Intell. Autom. Soft Comput. 2008, 14, 279–294. [Google Scholar] [CrossRef]
- Zhang, Q.; Lin, J.; Sha, Q.; He, B.; Li, G. Deep interactive reinforcement learning for path following of autonomous underwater vehicle. IEEE Access 2020, 8, 2169–3536. [Google Scholar] [CrossRef]
- Kim, T.; Lee, J.-H. Reinforcement learning-based path generation using sequential pattern reduction and self-directed curriculum learning. IEEE Access 2020, 8, 147790–147807. [Google Scholar] [CrossRef]
- Cao, Z.; Wong, K.-C.; Lin, C.-T. Weak human preference supervision for deep reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5369–5378. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Wang, D.; Gao, J. Learning automata-based multiagent reinforcement learning for optimization of cooperative tasks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4639–4652. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Li, H. Research on fuzzy enhanced learning model of multienhanced signal learning automata. IEEE Trans. Ind. Inf. 2019, 15, 5980–5987. [Google Scholar] [CrossRef]
- Voštinár, P. Using mBot robots for the motivation of studying computer science. In Proceedings of the 2020 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020; pp. 653–657. [Google Scholar]
- Wang, R.; Liang, M.; He, Y.; Wang, X.; Cao, W. A normalized adaptive filtering algorithm based on geometric algebra. IEEE Access 2020, 8, 92861–92874. [Google Scholar]
- Dounis, A.I.; Kofinas, P.; Alafodimos, C.; Tseles, D. Adaptive fuzzy gain scheduling PID controller for maximum power point tracking of photovoltaic system. Renew. Energy 2013, 60, 202–214. [Google Scholar] [CrossRef]
- Premkumar, K.; Manikandan, B.V. Fuzzy PID supervised online ANFIS based speed controller for brushless DC motor. Neurocomputing 2015, 157, 76–90. [Google Scholar] [CrossRef]
- Devi, T.M.; Kasthuri, N.; Natarajan, A.M. Environmental noise reduction system using fuzzy neural network and adaptive fuzzy algorithms. Int. J. Electron. 2013, 100, 205–226. [Google Scholar] [CrossRef]
- Feng, G.; Guo, X.; Wang, G. Infrared motion sensing system for human-following robots. Sens. Actuators A Phys. 2012, 185, 1–7. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Δkp, Δkd. | EC(K) | |||||
|---|---|---|---|---|---|---|
| VS | S | M | L | VL | ||
| E(K) | VS | NB | NB | NB | NB | NB |
| S | NS | NS | NS | NS | NB | |
| M | PS | PS | M | M | NS | |
| L | PB | PB | PS | PS | M | |
| VL | PB | PB | PB | PB | PS | |
| PID Controller Parameters | |||||
| Speedmax = 210 | kp = 0.16 | ki = 0.00001 | kd = 1.0 | ||
| Fuzzy-PID Controller Parameters | |||||
| Speedmax = 210 | kp = 0.16 | ki = 0.00001 | kd = 1.0 | Δkp [−0.1 0.1] | Δkd [−1.0 1.0] |
| DRL-Fuzzy-PID Controller Parameters | |||||
| Speedmax = 210 | kp = 0.16 | ki = 0.00001 | kd = 1.0 | Δkp [−0.1 0.1] | Δkd [−1.0 1.0] |
| Controller | Compare Ps | Compare MO |
|---|---|---|
| PID | 181.4 | 97% |
| Fuzzy-PID | 98 | 49.5% |
| DRL-Fuzzy-PID | 75 | 32.3% |
| PID Controller Parameters | |||||
| Speedmax = 210 | kp = 0.16 | ki = 0.00001 | kd = 1.0 | ||
| Fuzzy-PID Controller Parameters | |||||
| Speedmax = 210 | kp = 0.16 | ki = 0.00001 | kd = 1.0 | Δkp [−0.1 0.1] | Δkd [−1.0 1.0] |
| DRL-Fuzzy-PID Controller Parameters | |||||
| Speedmax = 210 | kp = 0.16 | ki = 0.00001 | kd = 1.0 | Δkp [−0.1 0.1] | Δkd [−1.0 1.0] |
| Controller | Compare Ps | Compare MO | Compare Follow Time |
|---|---|---|---|
| PID | 640.8 | 100% (3541 ms) | 7387 ms |
| Fuzzy-PID | 398.8 | 100% (606 ms) | 6775 ms |
| DRL-Fuzzy-PID | 256.4 | 100% (238 ms) | 427 ms |
| Parameter | Number of Rounds | Steps per Round | Learning Rate | Number of Training Batches | Reward Decay Rate |
|---|---|---|---|---|---|
| Value | 300 | 100 | 0.02 | 72 | 0.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.-T.; Sung, W.-T. Controller Design of Tracking WMR System Based on Deep Reinforcement Learning. Electronics 2022, 11, 928. https://doi.org/10.3390/electronics11060928
Lee C-T, Sung W-T. Controller Design of Tracking WMR System Based on Deep Reinforcement Learning. Electronics. 2022; 11(6):928. https://doi.org/10.3390/electronics11060928
Chicago/Turabian StyleLee, Chin-Tan, and Wen-Tsai Sung. 2022. "Controller Design of Tracking WMR System Based on Deep Reinforcement Learning" Electronics 11, no. 6: 928. https://doi.org/10.3390/electronics11060928
APA StyleLee, C.-T., & Sung, W.-T. (2022). Controller Design of Tracking WMR System Based on Deep Reinforcement Learning. Electronics, 11(6), 928. https://doi.org/10.3390/electronics11060928