
A Swarm Confrontation Method Based on Lanchester Law and Nash Equilibrium


Abstract
:1. Introduction
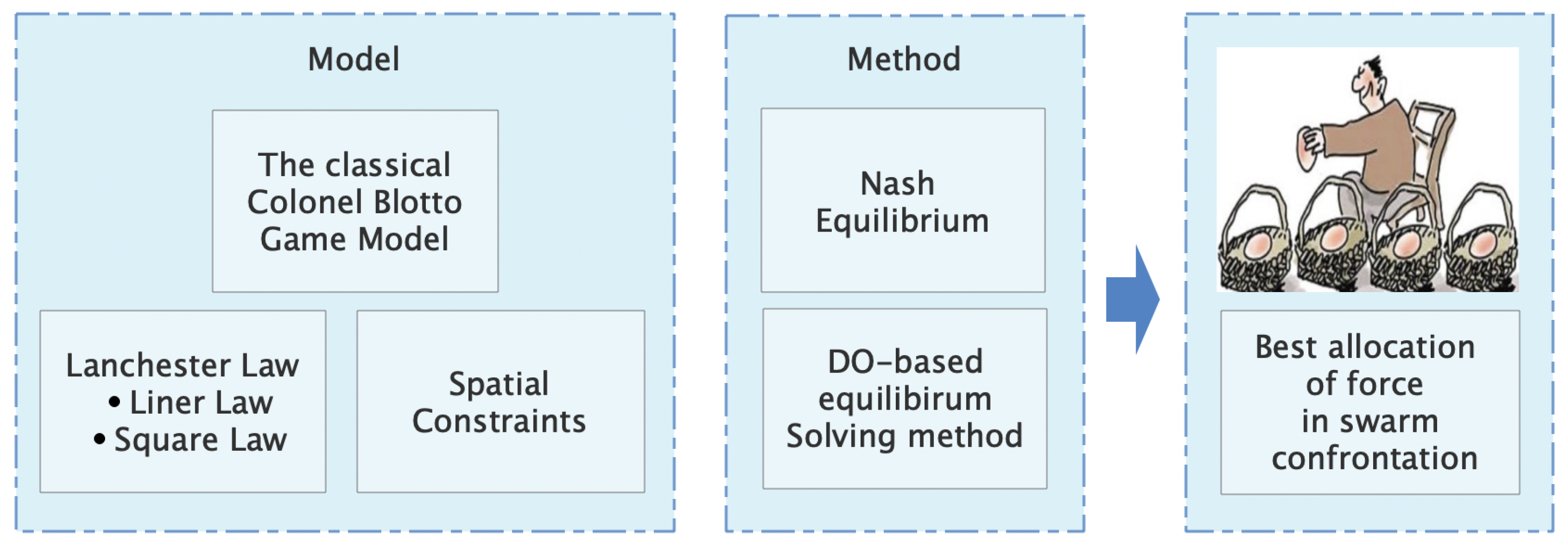
- We innovatively abstract swarm confrontation into a force allocation model, which greatly eases the control difficulty of the swarm confrontation. The concept of space constraint and the Lanchester law is creatively introduced into the UAV swarm confrontation model. Compared with the simple force comparison method to judge the result of the confrontation, the application of the Lanchester law makes the model closer to the actual confrontation scenario.
- We introduce the concept of approximate Nash equilibrium, and propose an equilibrium solving method based on the DO algorithm that can solve the equilibrium of the game more efficiently.
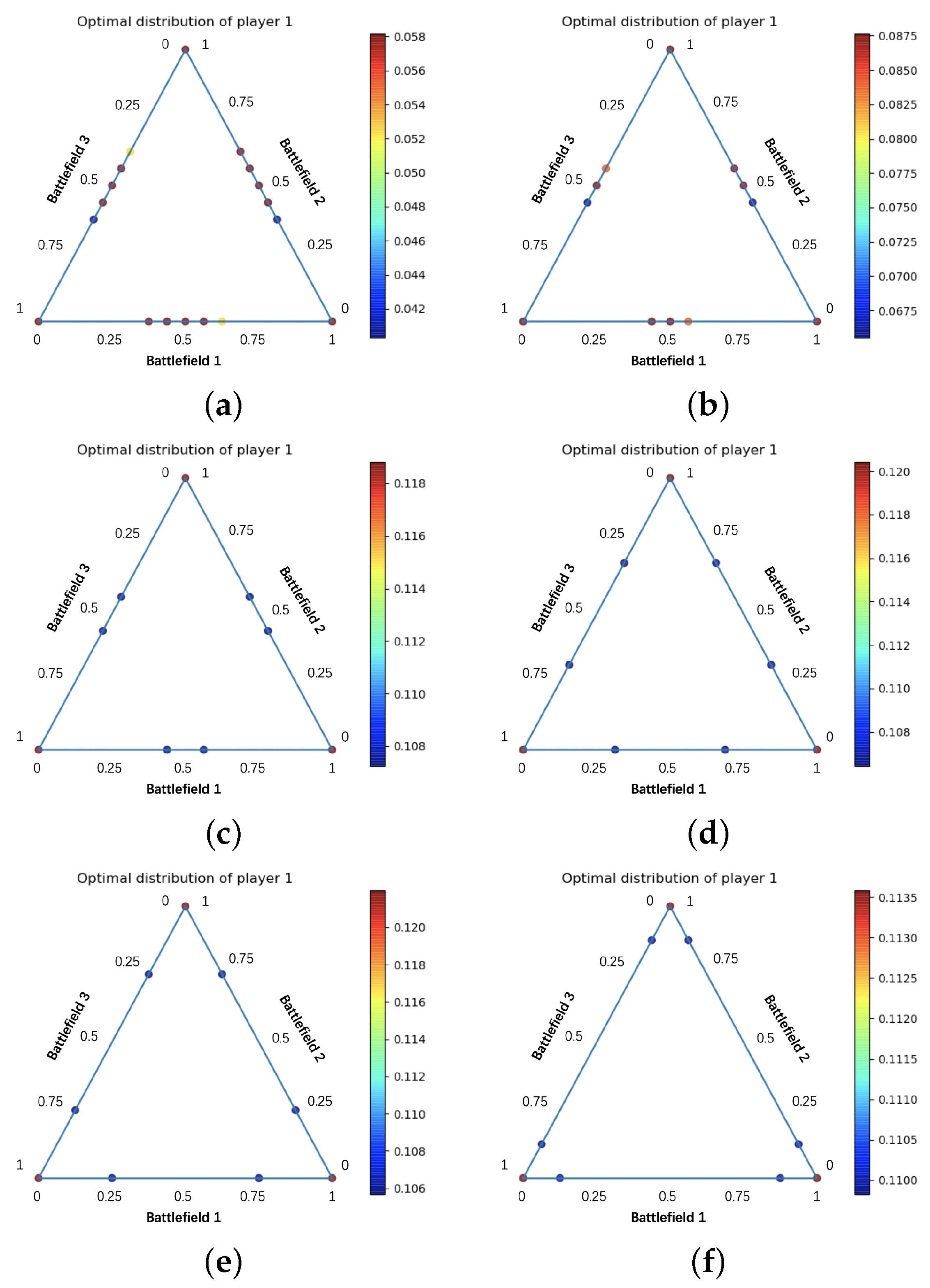
- Our analysis of the experimental results provides valuable guidance for the strategy design of swarm confrontation. In particular, as the confrontation space constraints change, the optimal strategy will vary between preferring an even allocation of force to different battlefields and preferring to concentrate the force on one or two battlefields.
2. Problem Formulation and Scheme Design
2.1. Problem Formulation
2.1.1. Attrition with Lanchester Law
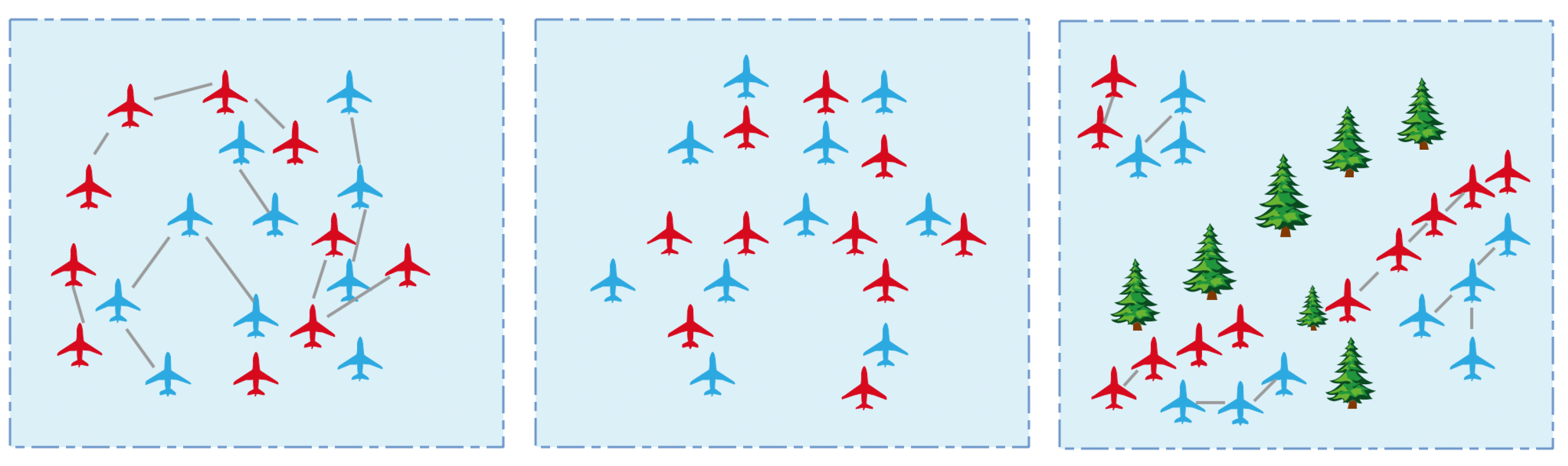
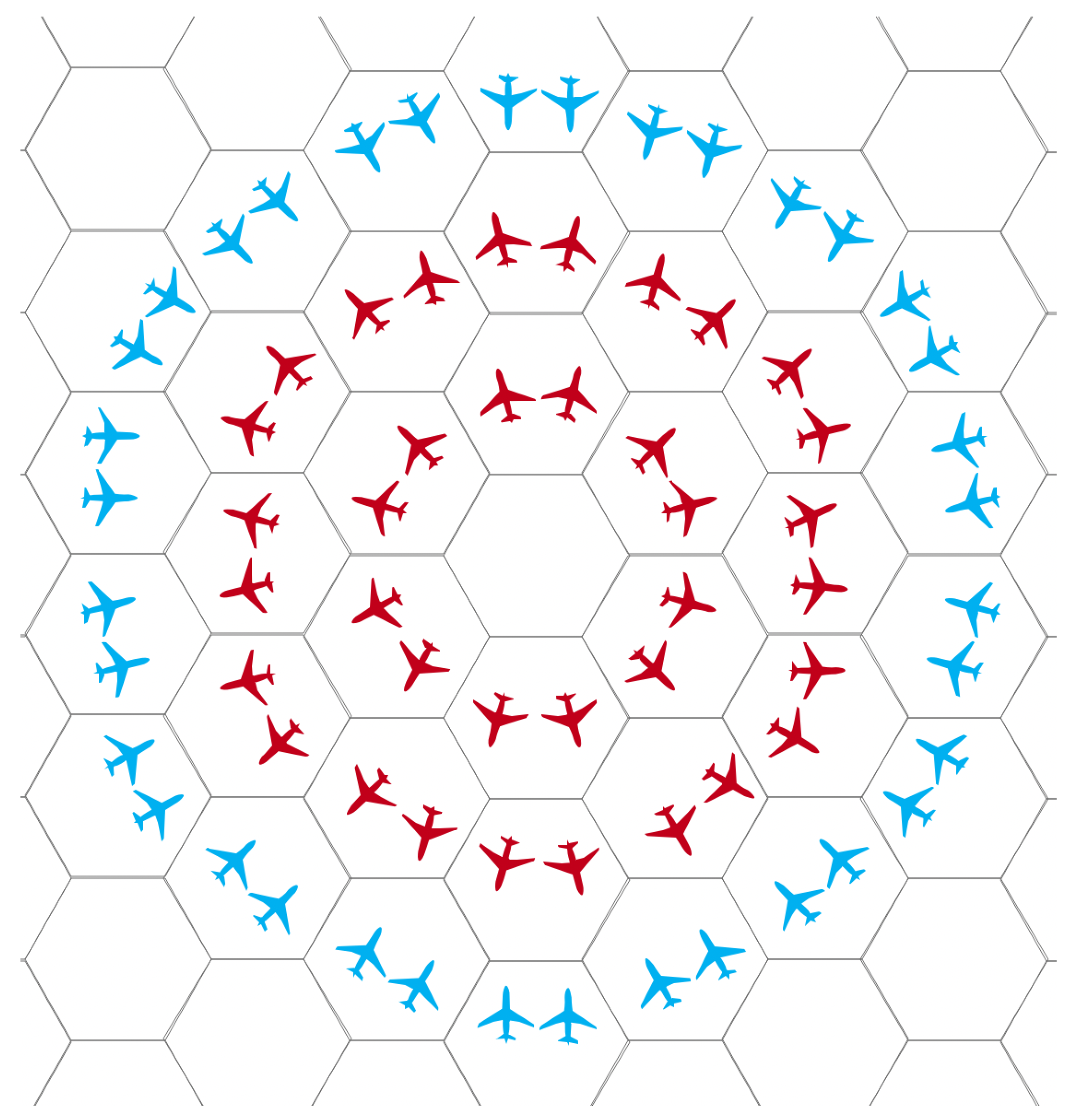
2.1.2. Constraints of the Confrontation Scenarios
2.1.3. UAV Swarm Game
2.2. The Equilibrium Solving Algorithm for Swarm Confrontation
2.2.1. Game Equilibrium
2.2.2. DO-Based Equilibrium Solving Algorithm
| Algorithm 1 DO-based Equilibrium Solving Algorithm. |
| Input: game , , , M, , nonempty subsets , , and Output: -equilibrium of game
|
3. Experiments
3.1. Experimental Settings
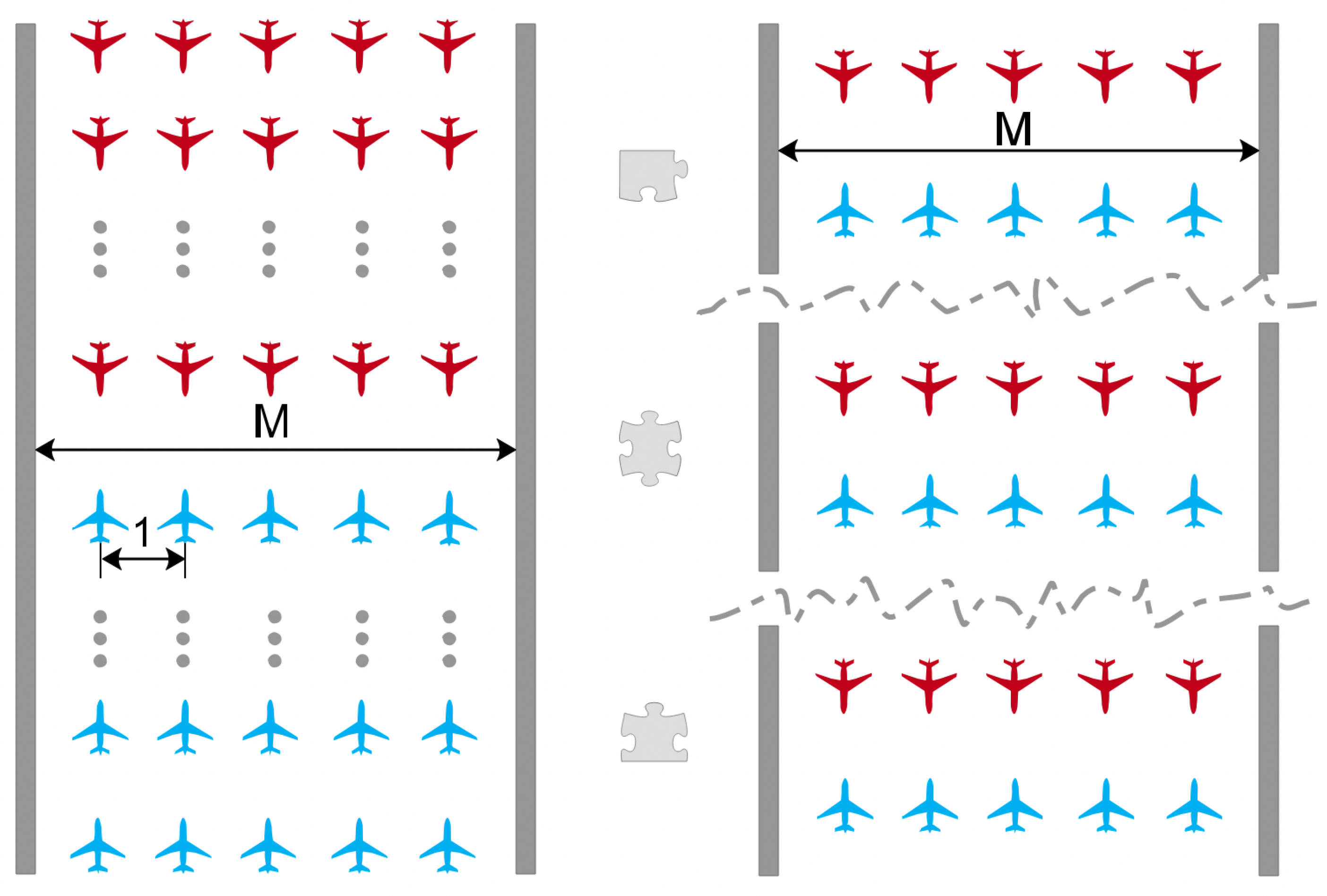
- Both sides of the game deploy force on three battlefields;
- Each battlefield has equal weights, which means ;
- Both sides are flying head-on on a 2D narrow passage with a width of M;
- Safe distance between UAVs is 1 and UAV swarm stays in neat formation in Figure 4;
- The attrition of the confrontation is calculated by the Lanchester law in Equation (3).
3.2. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| UAV | unmanned aerial vehicle |
| ECM | electronic countermeasure |
| MADDPG | Multi-Agent Deep Deterministic Policy Gradient |
| MBCN | Multi-Agent Bidirectionally Coordinated Nets |
| DO | double oracle |
References
- Coffey, V. High-energy lasers: New advances in defense applications. Opt. Photonics News 2014, 25, 28–35. [Google Scholar] [CrossRef]
- Hartmann, K.; Giles, K. UAV exploitation: A new domain for cyber power. In Proceedings of the 2016 8th International Conference on Cyber Conflict (CyCon), Tallinn, Estonia, 31 May–3 June 2016; pp. 205–221. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Peng, P.; Wen, Y.; Yang, Y.; Yuan, Q.; Tang, Z.; Long, H.; Wang, J. Multiagent bidirectionally-coordinated nets: Emergence of human-level coordination in learning to play starcraft combat games. arXiv 2017, arXiv:1703.10069. [Google Scholar]
- Zheng, L.; Yang, J.; Cai, H.; Zhou, M.; Zhang, W.; Wang, J.; Yu, Y. Magent: A many-agent reinforcement learning platform for artificial collective intelligence. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Xing, D.; Zhen, Z.; Gong, H. Offense–defense confrontation decision making for dynamic UAV swarm versus UAV swarm. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2019, 233, 5689–5702. [Google Scholar] [CrossRef]
- Grana, J.; Lamb, J.; O’Donoughue, N.A. Findings on Mosaic Warfare from a Colonel Blotto Game; Technical Report; RAND Corp.: Santa Monica, CA, USA, 2021. [Google Scholar]
- Bauer, H. Mathematical Models: The Lanchester Equations and the Zombie Apocalypse. Bachelor’s Thesis, University of Lynchburg, Lynchburg, VA, USA, April 2019. [Google Scholar]
- Brown, G.W. Iterative solution of games by fictitious play. Act. Anal. Prod. Alloc. 1951, 13, 374–376. [Google Scholar]
- McMahan, H.B.; Gordon, G.J.; Blum, A. Planning in the presence of cost functions controlled by an adversary. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 536–543. [Google Scholar]
- Adam, L.; Horcík, R.; Kasl, T.; Kroupa, T. Double oracle algorithm for computing equilibria in continuous games. arXiv 2020, arXiv:2009.12185. [Google Scholar]
- Bosansky, B.; Kiekintveld, C.; Lisy, V.; Pechoucek, M. An exact double-oracle algorithm for zero-sum extensive-form games with imperfect information. J. Artif. Intell. Res. 2014, 51, 829–866. [Google Scholar] [CrossRef] [Green Version]
- Vu, D.Q. Models and Solutions of Strategic Resource Allocation Problems: Approximate Equilibrium and Online Learning in Blotto Games. Ph.D. Thesis, Sorbonne Universites, UPMC University of Paris 6, Paris, France, 2020. [Google Scholar]
- Bixby, R.E.; Fenelon, M.; Gu, Z.; Rothberg, E.; Wunderling, R. Mixed-integer programming: A progress report. In The Sharpest Cut: The Impact of Manfred Padberg and His Work; SIAM: Philadelphia, PA, USA, 2004; pp. 309–325. [Google Scholar]
- Benazzoli, C.; Campi, L.; Di Persio, L. ε-Nash equilibrium in stochastic differential games with mean-field interaction and controlled jumps. Stat. Probab. Lett. 2019, 154, 108522. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Features | Description |
|---|---|---|
| MADDPG | Actor-critic framework; Real-time | Performs well in cooperative as well as competitive scenarios. |
| MBCN | Actor-critic framework; Real-time | Coordinate multiple agents as a team and defeat opponents in StarCraft. |
| Xing’s algorithm | Auction; Agent-based; Biological attraction | Allocate targets from the perspective of attack and defense in the swarm confrontation. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, X.; Zhang, W.; Xiang, F.; Yuan, W.; Chen, J. A Swarm Confrontation Method Based on Lanchester Law and Nash Equilibrium. Electronics 2022, 11, 896. https://doi.org/10.3390/electronics11060896
Ji X, Zhang W, Xiang F, Yuan W, Chen J. A Swarm Confrontation Method Based on Lanchester Law and Nash Equilibrium. Electronics. 2022; 11(6):896. https://doi.org/10.3390/electronics11060896
Chicago/Turabian StyleJi, Xiang, Wanpeng Zhang, Fengtao Xiang, Weilin Yuan, and Jing Chen. 2022. "A Swarm Confrontation Method Based on Lanchester Law and Nash Equilibrium" Electronics 11, no. 6: 896. https://doi.org/10.3390/electronics11060896
APA StyleJi, X., Zhang, W., Xiang, F., Yuan, W., & Chen, J. (2022). A Swarm Confrontation Method Based on Lanchester Law and Nash Equilibrium. Electronics, 11(6), 896. https://doi.org/10.3390/electronics11060896