
Microphone Array for Speaker Localization and Identification in Shared Autonomous Vehicles

 , , , , , , , , and
, , , , , , , , and
Abstract
:1. Introduction
- (1)
- a microphone array system to monitor sound events inside an SAV, which can be easily integrated with other sensor fusion strategies for automotive;
- (2)
- a hardware-based system with data acquisition and format conversion, i.e., Pulse Density Modulated (PDM) to Pulse Code Modulated (PCM) to interface the microphone array;
- (3)
- hardware-accelerated algorithms to localize different sound sources that can achieve good accuracy and performance metrics with real-time response.
2. Sensor System Architecture
- (1)
- the microphone array;
- (2)
- the processing platform; and
- (3)
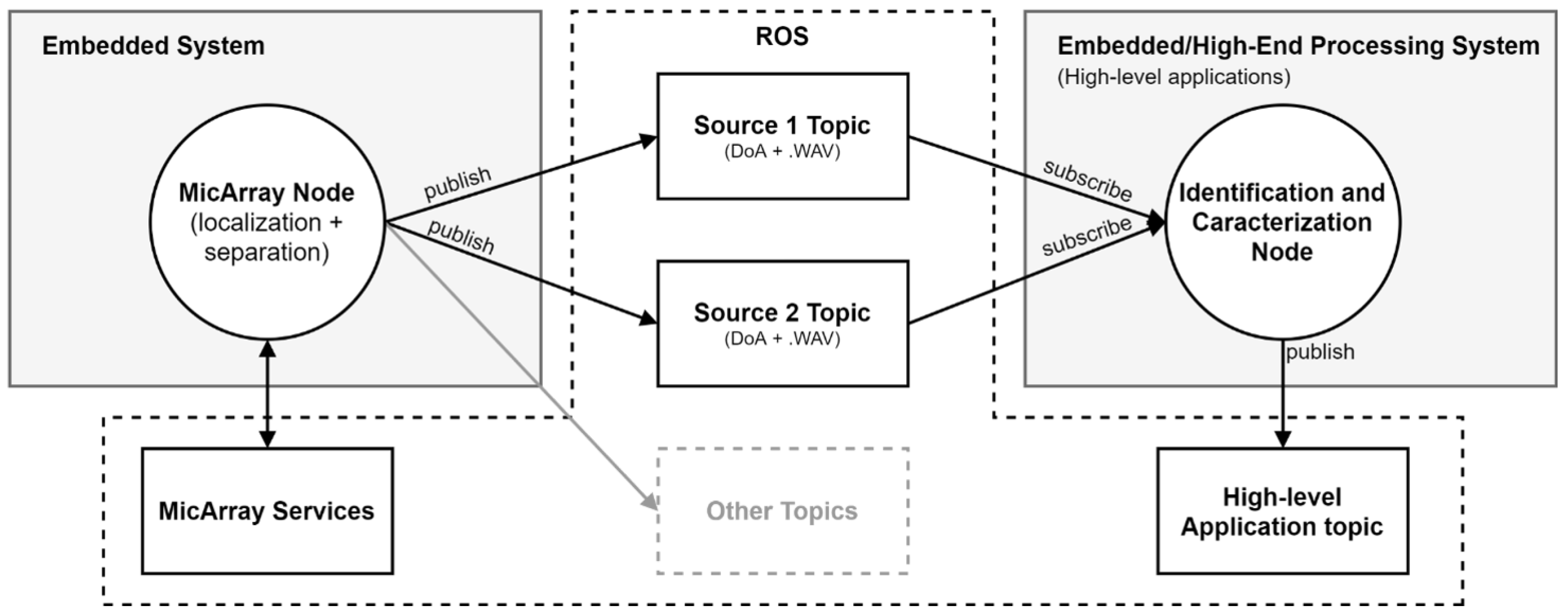
- the ROS environment.
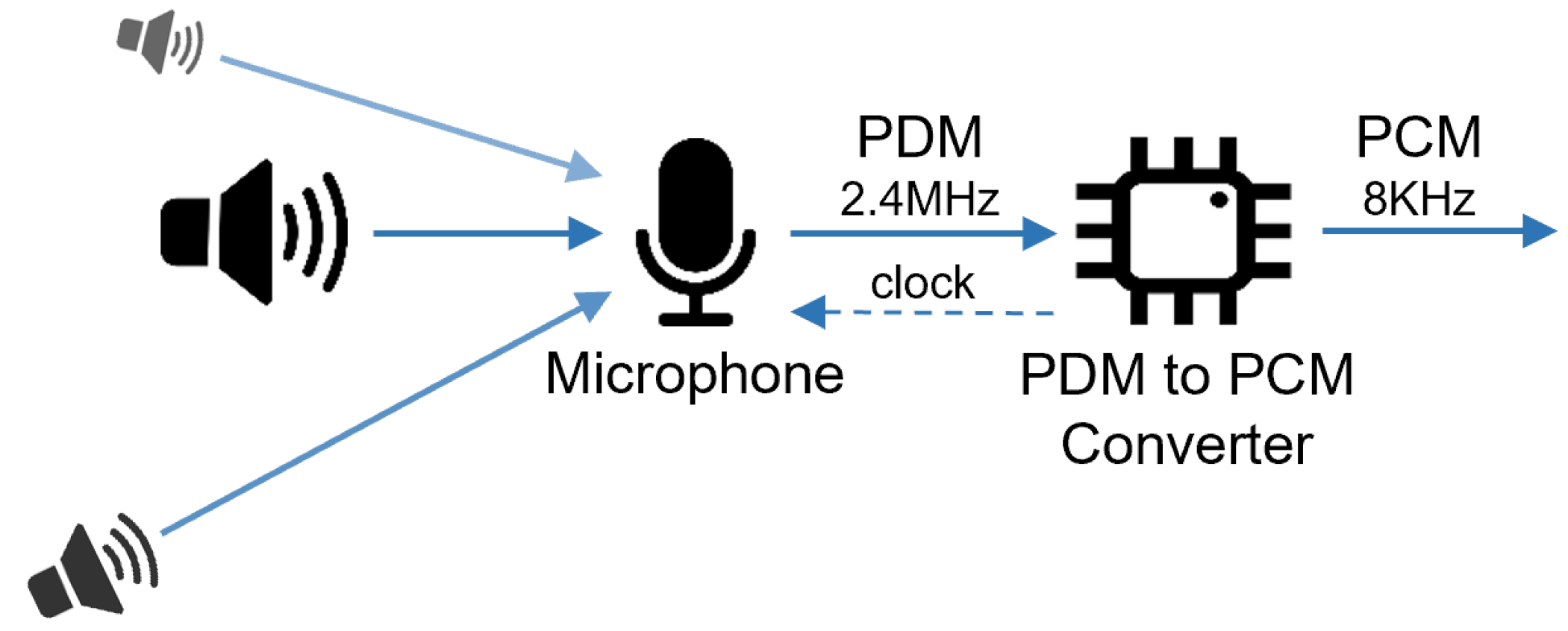
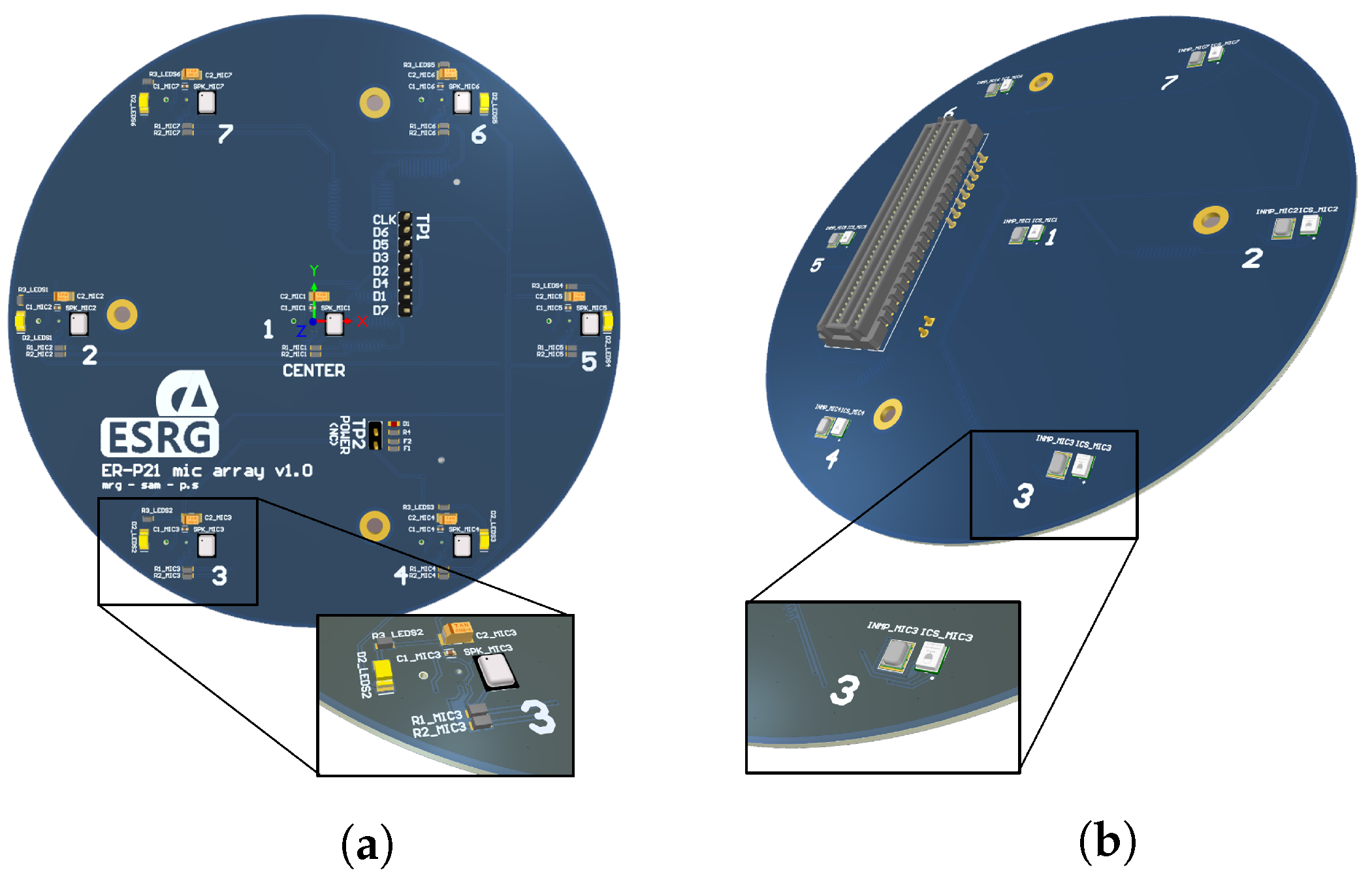
3. Microphone Array System
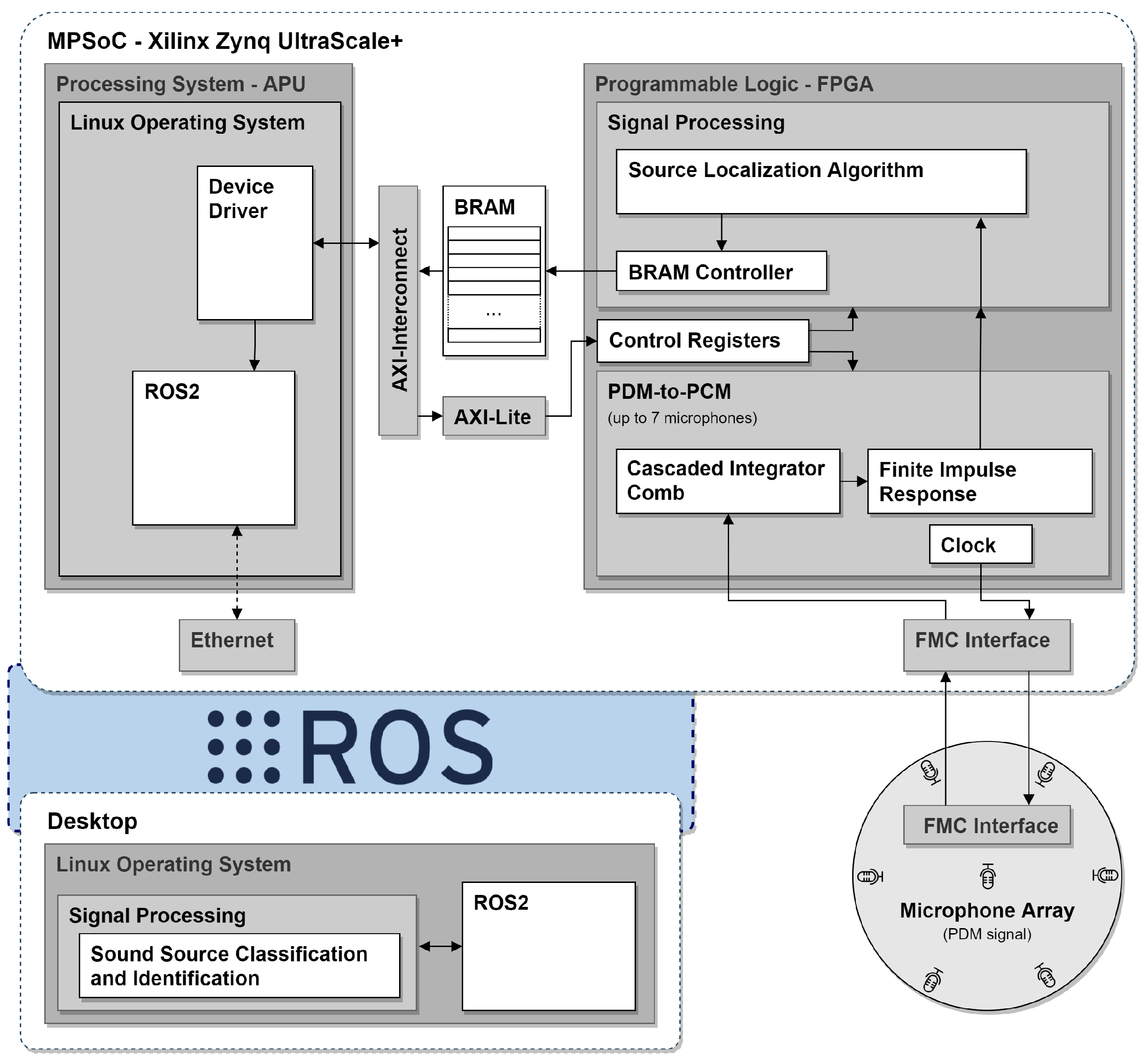
4. Processing Platform
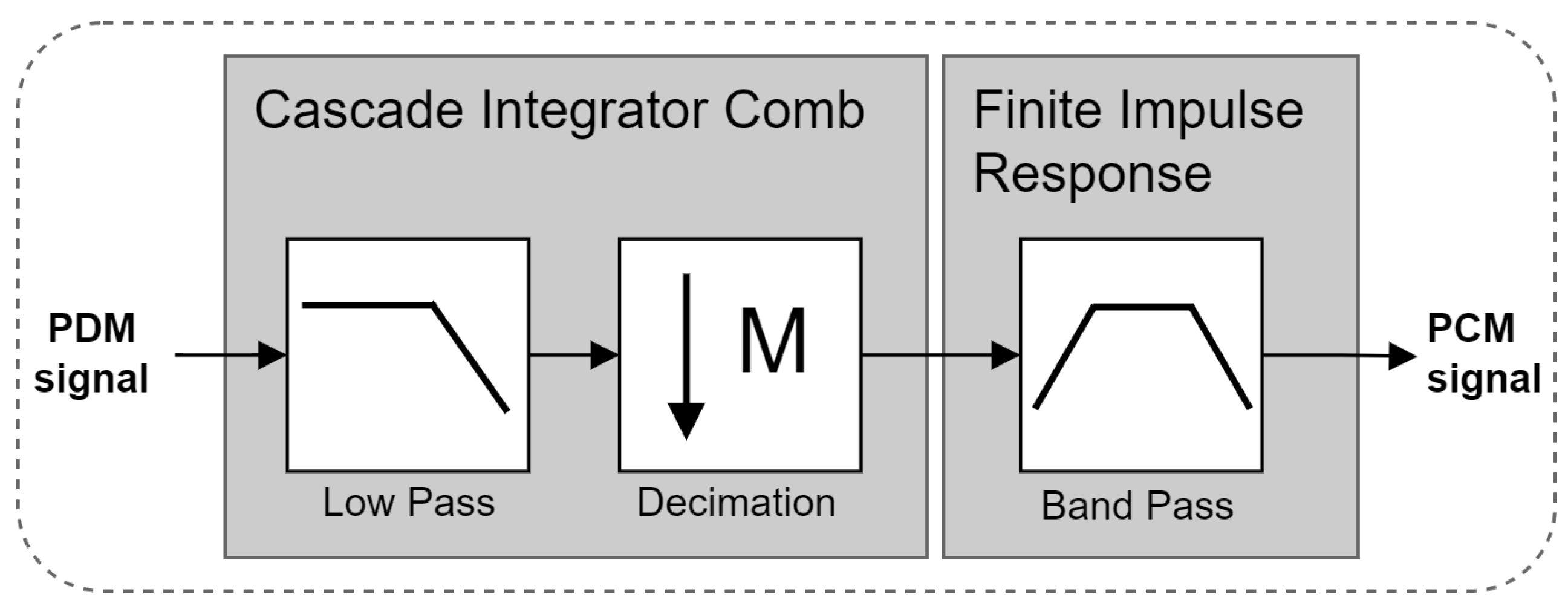
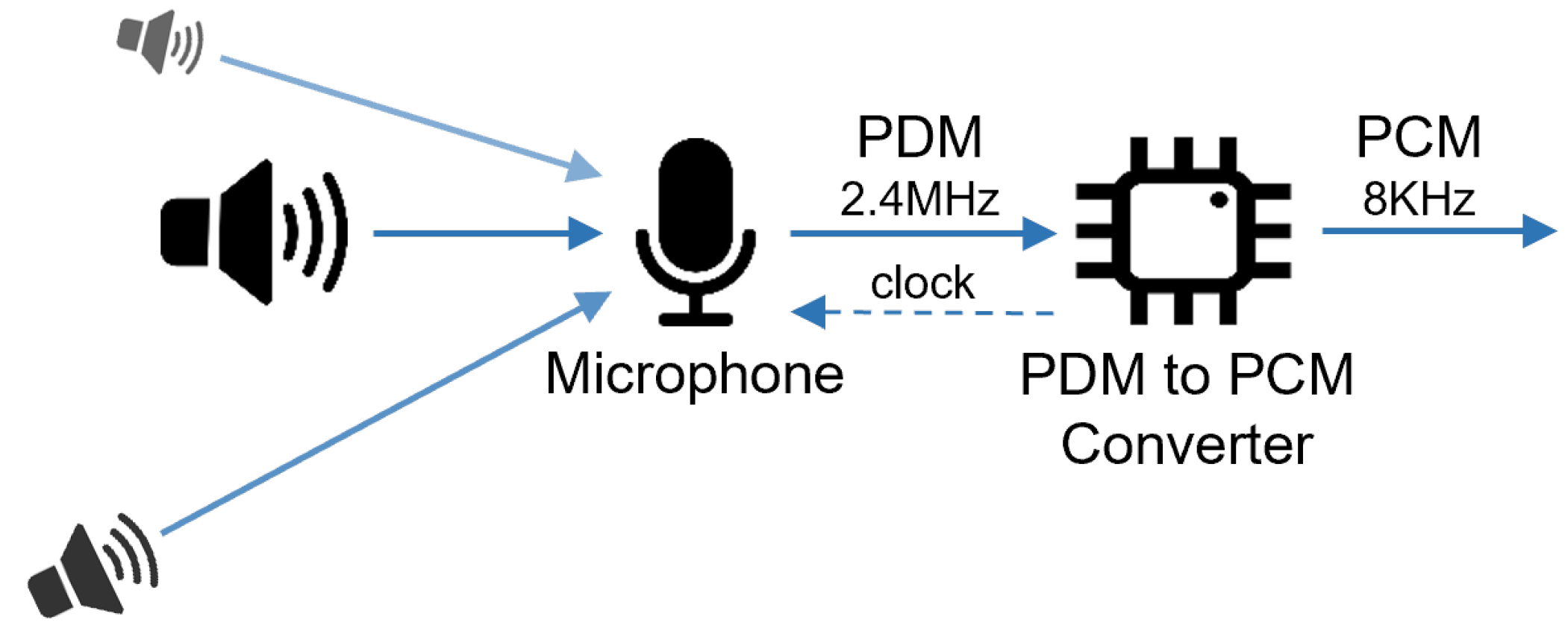
4.1. Signal Acquisition Module
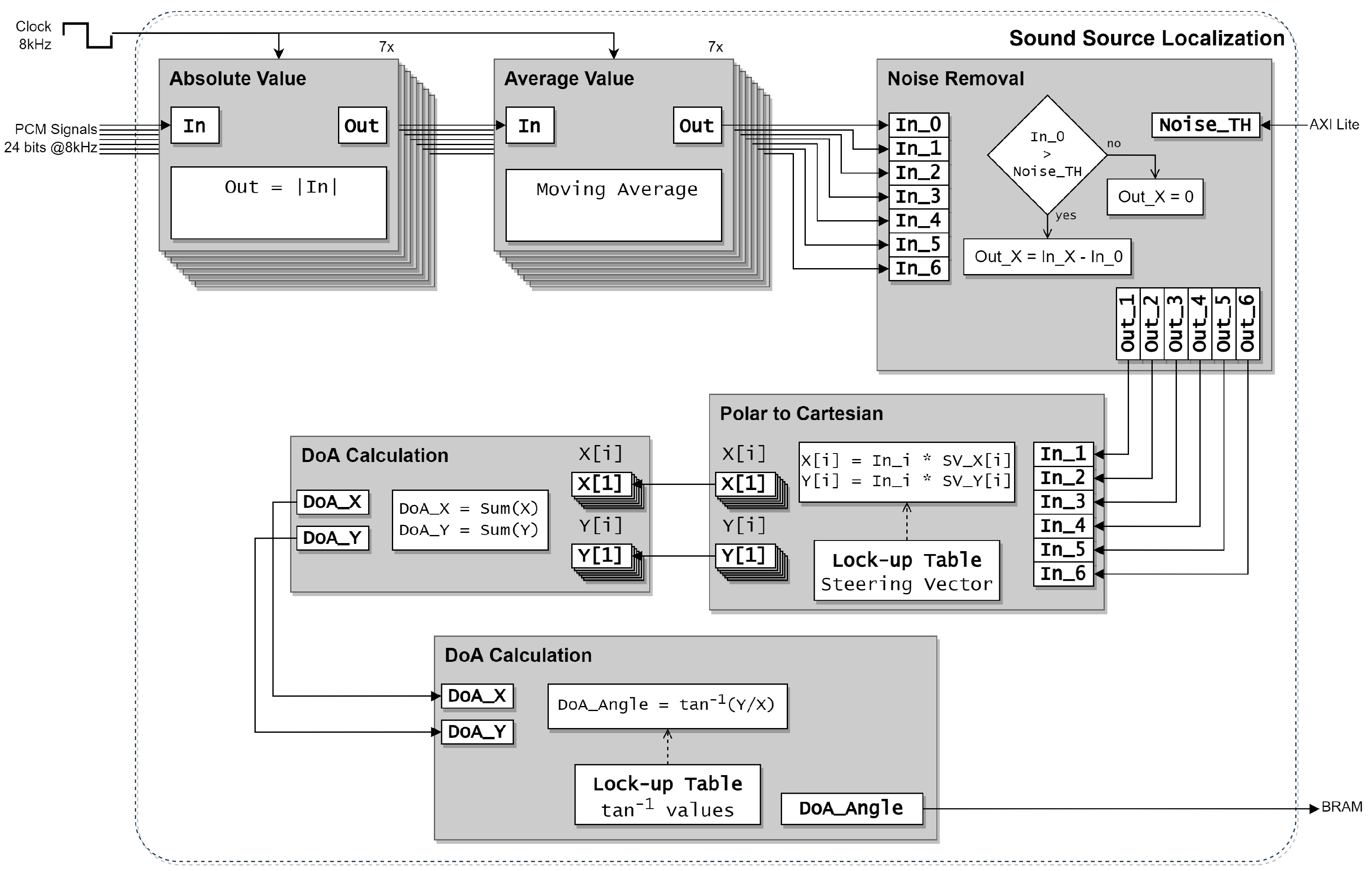
4.2. Sound Source Localization
- (1)
- Absolute Value: In this step, for each microphone, the input data (in PCM format) are received at the same frequency of the sampling frequency (8 kHz) to calculate its absolute value.
- (2)
- Average Value: This step receives data from the previous block and calculates the moving average for each microphone signal.
- (3)
- Noise Removal: This block receives the data from the previous step and a user-defined noise threshold signal (Noise Threshold). If the average value of the central microphone is less than the Noise Threshold, then it is considered only background noise in the environment, and the new average value for each microphone is set to zero. Otherwise, the average value of the central microphone is subtracted from the remaining microphone’s data.
- (4)
- Polar to Cartesian: This stage calculates, for each of the six UCA microphones, its cartesian position multiplied by its corresponding average value. The output from this block is the weight vector for each microphone according to the signal energy.
- (5)
- DoA Calculation: In this step, the resultant of all vectors to output a cartesian vector with the DoA estimation is calculated.
- (6)
- Get Angle: This stage calculates the DoA angle from the cartesian vector.
4.3. Interface between the PL and the PS
- (1)
- the PCM signal data are written to the Block Random Access Memory (BRAM) directly through a BRAM controller that defines the writing position. This data are accessed by the PS through an AXI interface connected to the BRAM;
- (2)
- the DoA data are directly set available to the PS via AXI-Lite interface.
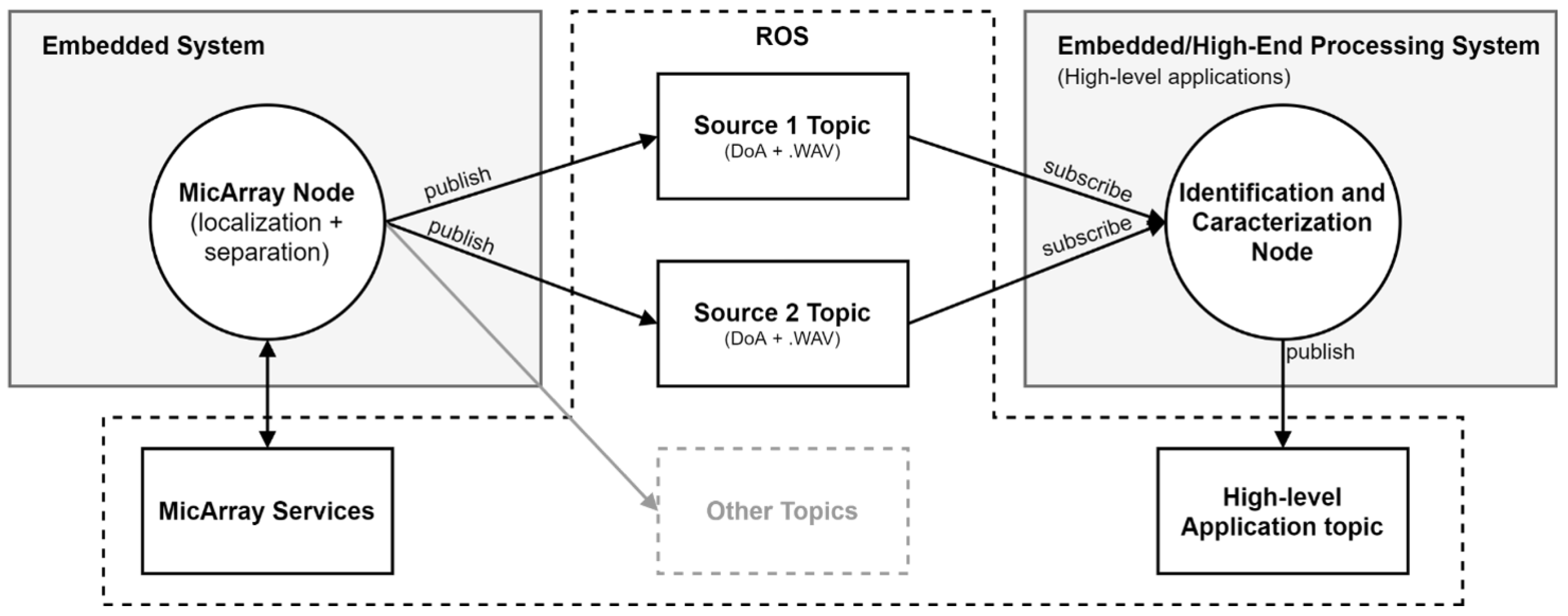
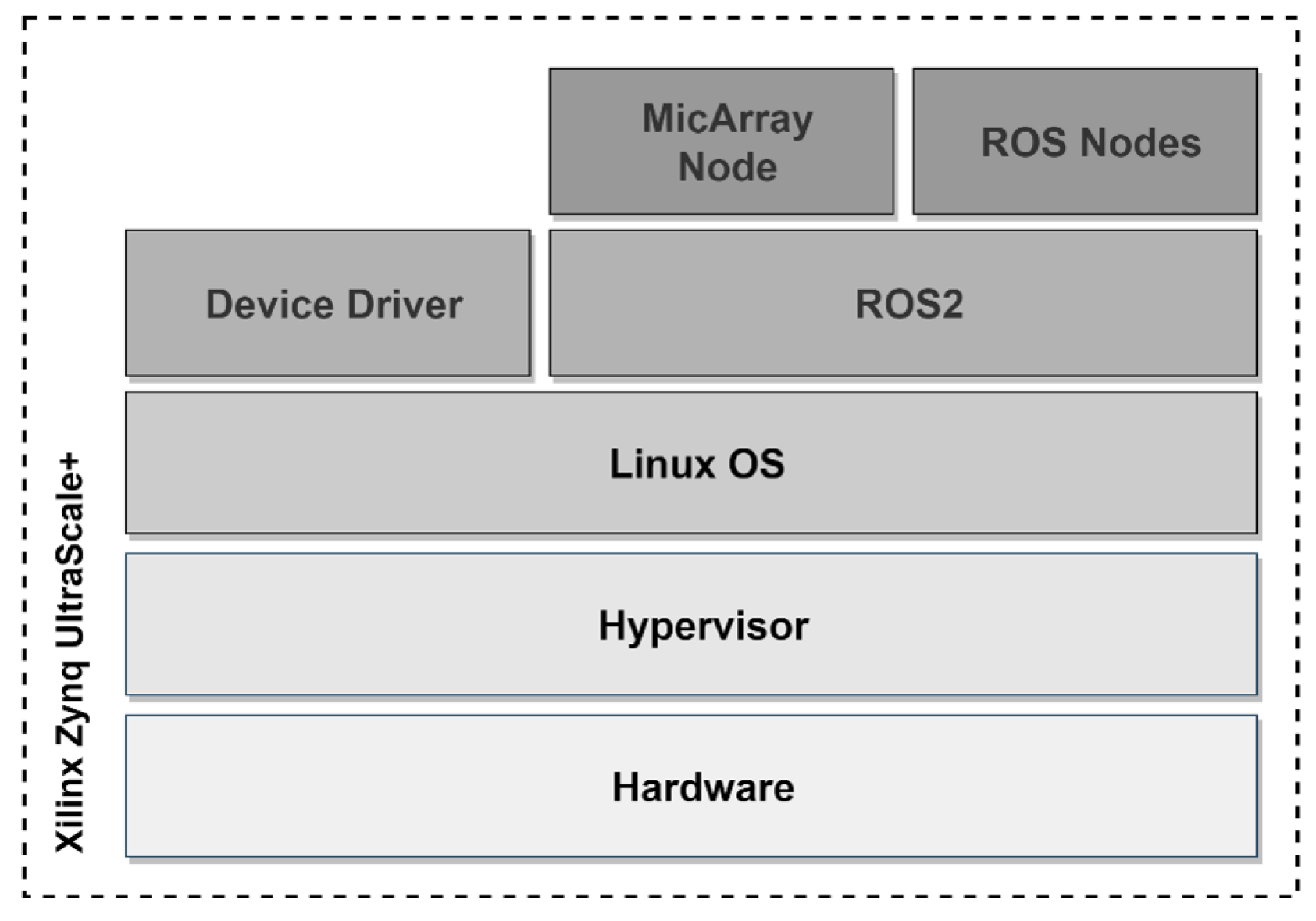
4.4. Software Stack
5. Evaluation
- (1)
- first step test evaluates and verifies the acquisition system, i.e., sampling, PDM to PCM format conversion, and data filtering;
- (2)
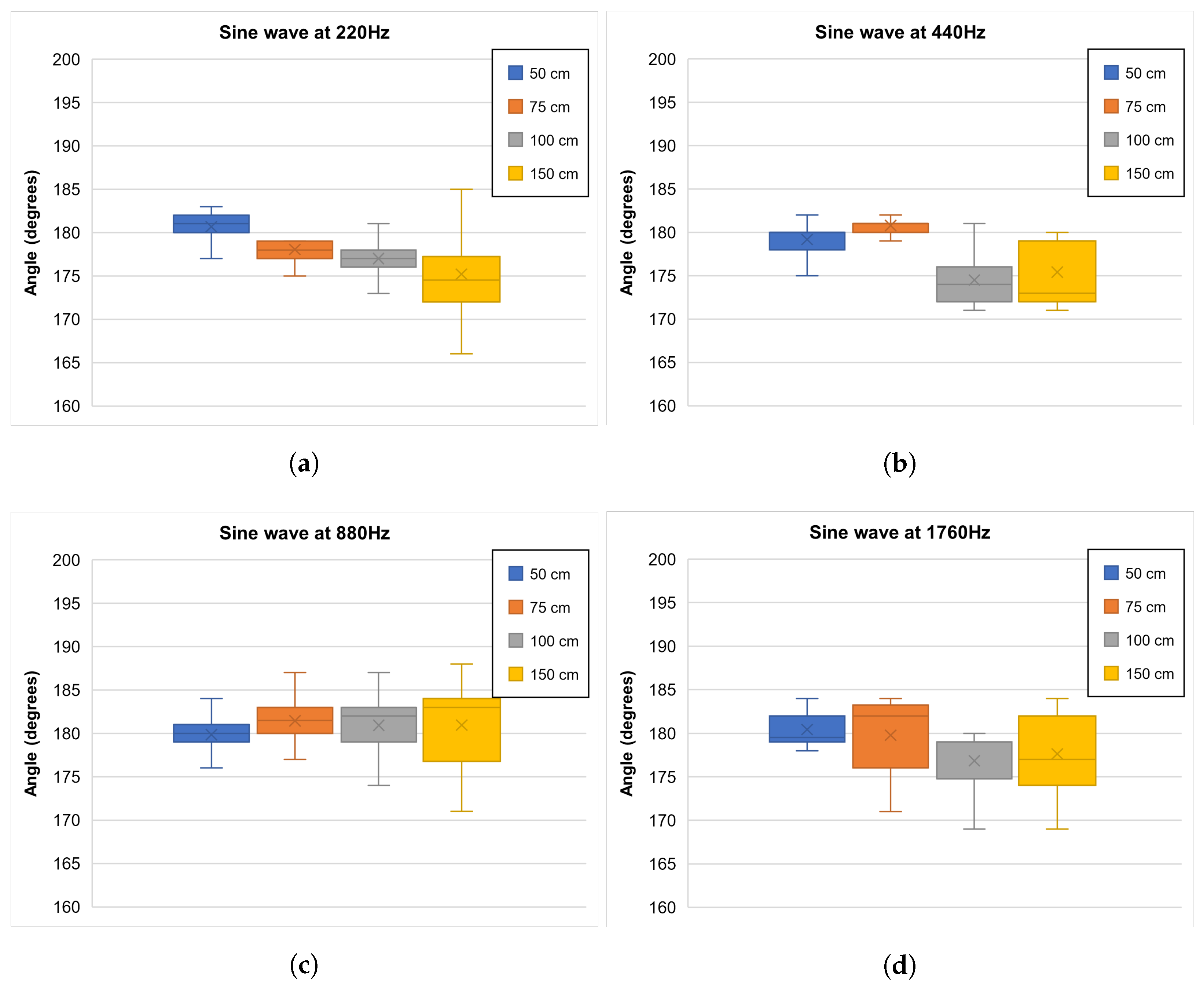
- second step evaluates the accuracy and precision of the localization system;
- (3)
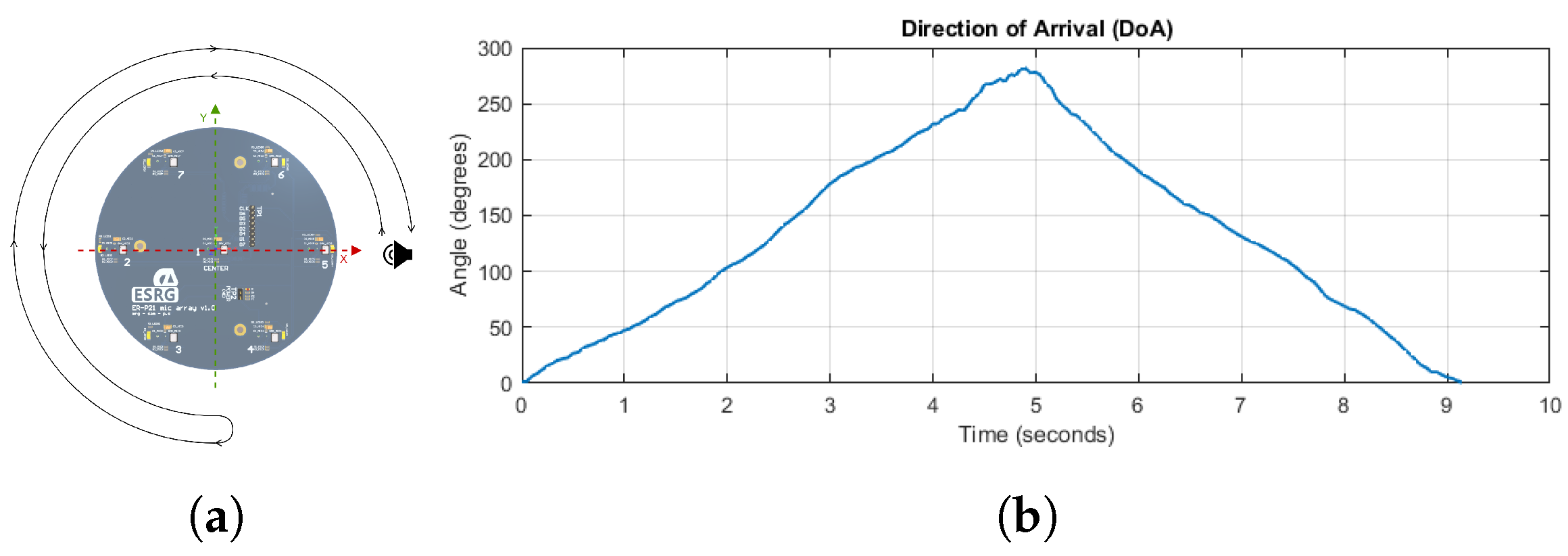
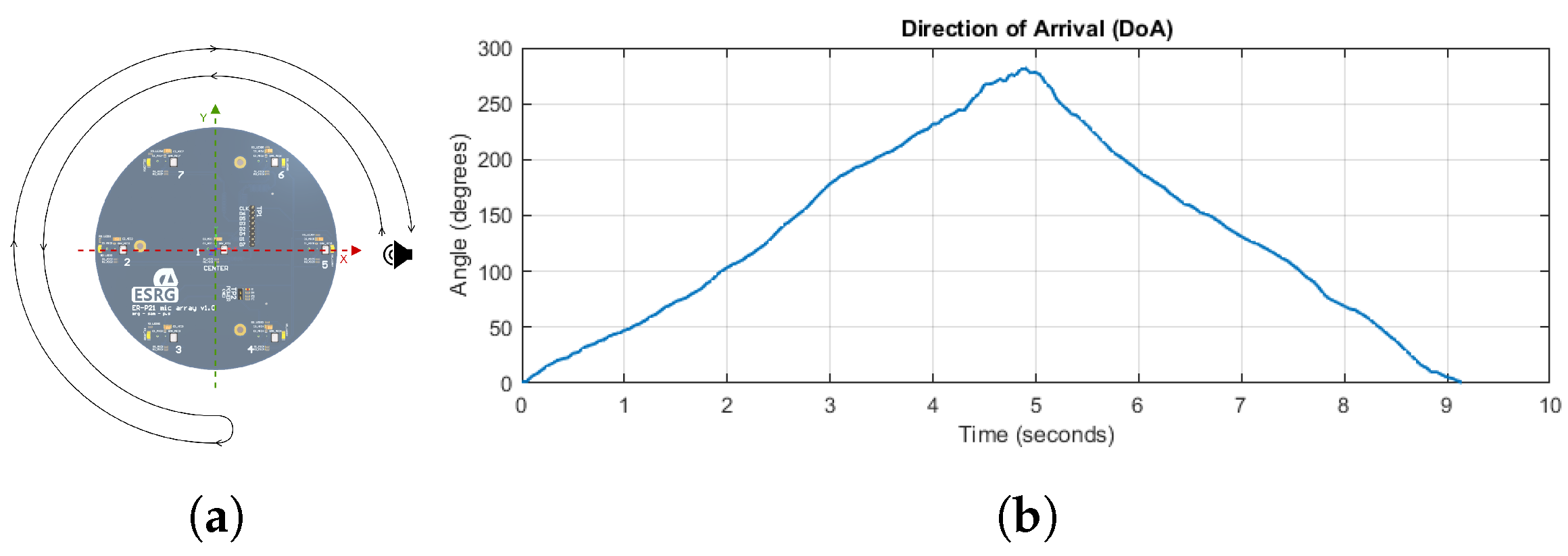
- lastly, the third step evaluates the localization system in the presence of a moving sound source, checking the DoA and verifying the resulting angle with the actual position of the sound source.
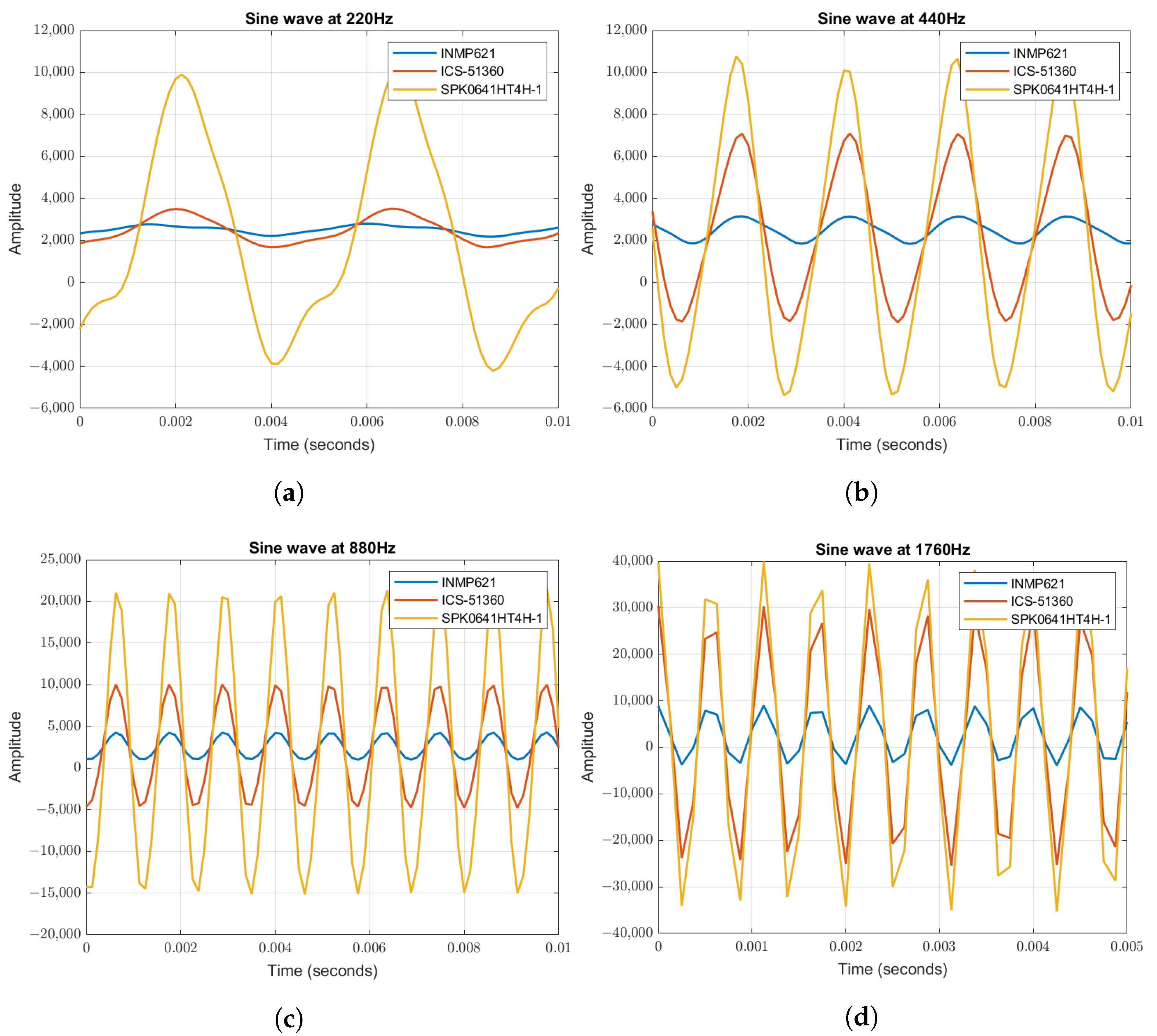
5.1. Data Acquisition
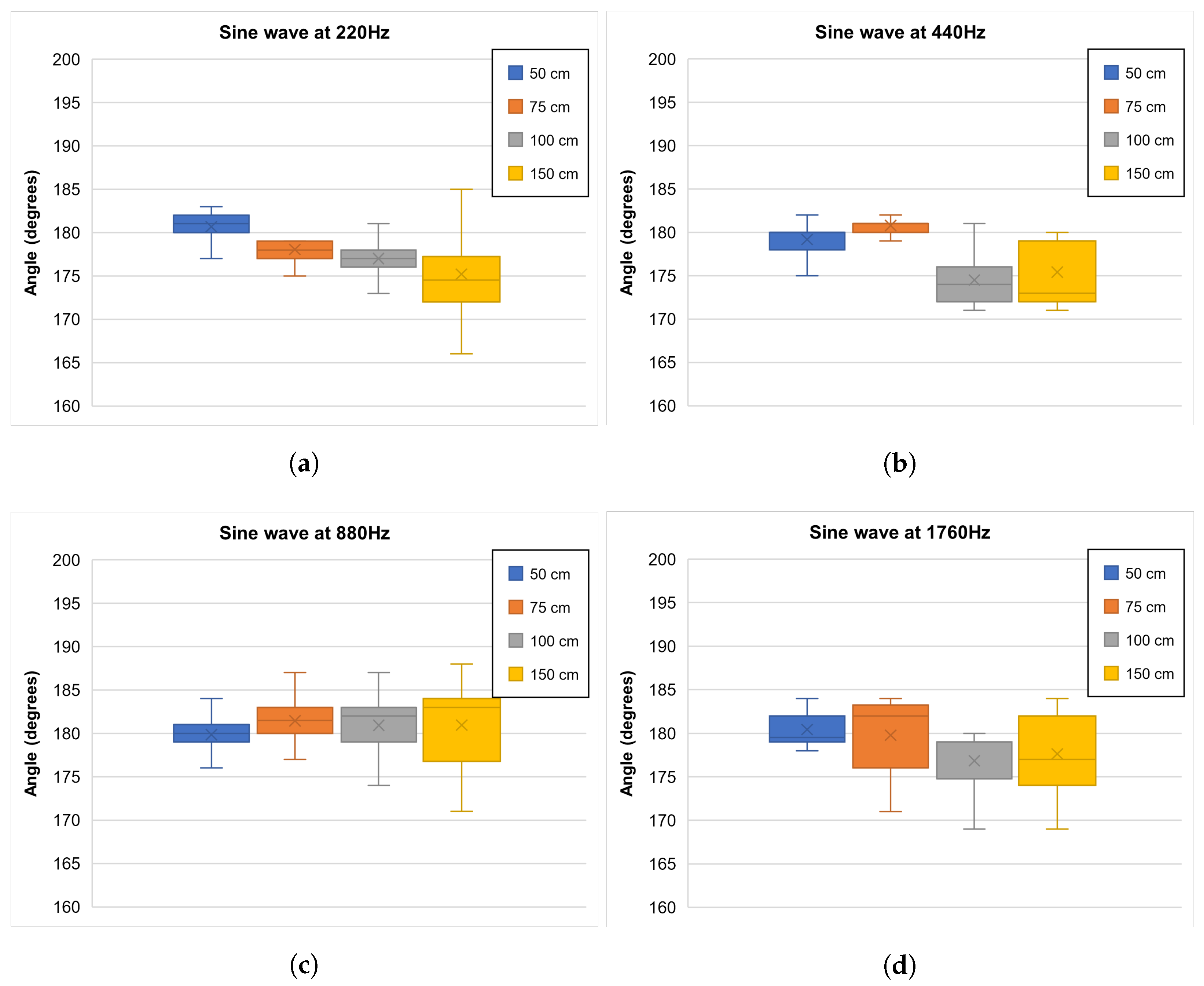
5.2. Sound Source Localization
5.3. FPGA Hardware Resources
6. Conclusions
7. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Litman, T. Autonomous Vehicle Implementation Predictions; Victoria Transport Policy Institute: Victoria, BC, Canada, 2021. [Google Scholar]
- Roriz, R.; Cabral, J.; Gomes, T. Automotive LiDAR Technology: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 1–16. [Google Scholar] [CrossRef]
- Liu, L.; Chen, C.; Pei, Q.; Maharjan, S.; Zhang, Y. Vehicular edge computing and networking: A survey. Mob. Netw. Appl. 2021, 26, 1145–1168. [Google Scholar] [CrossRef]
- Daily, M.; Medasani, S.; Behringer, R.; Trivedi, M. Self-Driving Cars. Computer 2017, 50, 18–23. [Google Scholar] [CrossRef] [Green Version]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixão, T.M.; Mutz, F.; et al. Self-driving cars: A survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar] [CrossRef]
- Rojas-Rueda, D.; Nieuwenhuijsen, M.J.; Khreis, H.; Frumkin, H. Autonomous vehicles and public health. Annu. Rev. Public Health 2020, 41, 329–345. [Google Scholar] [CrossRef] [Green Version]
- Jones, E.C.; Leibowicz, B.D. Contributions of shared autonomous vehicles to climate change mitigation. Transp. Res. Part D Transp. Environ. 2019, 72, 279–298. [Google Scholar] [CrossRef]
- Chaudhry, B.; El-Amine, S.; Shakshuki, E. Passenger safety in ride-sharing services. Procedia Comput. Sci. 2018, 130, 1044–1050. [Google Scholar] [CrossRef]
- Cartenì, A. The acceptability value of autonomous vehicles: A quantitative analysis of the willingness to pay for shared autonomous vehicles (SAVs) mobility services. Transp. Res. Interdiscip. Perspect. 2020, 8, 100224. [Google Scholar] [CrossRef]
- Paddeu, D.; Parkhurst, G.; Shergold, I. Passenger comfort and trust on first-time use of a shared autonomous shuttle vehicle. Transp. Res. Part C Emerg. Technol. 2020, 115, 102604. [Google Scholar] [CrossRef]
- Fouad, R.M.; Onsy, A.; Omer, O.A. Improvement of Driverless Cars’ Passengers on Board Health and Safety, using Low-Cost Real-Time Heart Rate Monitoring System. In Proceedings of the 2018 24th International Conference on Automation and Computing (ICAC), Newcastle upon Tyne, UK, 6–7 September 2018; pp. 1–6. [Google Scholar]
- Koojo, I.; Machuve, D.; Mirau, S.; Miyingo, S.P. Design of a Passenger Security and Safety System for the Kayoola EVs Bus. In Proceedings of the 2021 IEEE AFRICON, Arusha, Tanzania, 13–15 September 2021; pp. 1–6. [Google Scholar]
- Costa, M.; Oliveira, D.; Pinto, S.; Tavares, A. Detecting Driver’s Fatigue, Distraction and Activity Using a Non-Intrusive Ai-Based Monitoring System. J. Artif. Intell. Soft Comput. Res. 2019, 9, 247–266. [Google Scholar] [CrossRef] [Green Version]
- Chakravarty, P.; Mirzaei, S.; Tuytelaars, T.; Van hamme, H. Who’s Speaking? Audio-Supervised Classification of Active Speakers in Video. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, ICMI ’15, Seattle, WA, USA, 9–13 November 2005; pp. 87–90. [Google Scholar] [CrossRef]
- Qian, R.; Hu, D.; Dinkel, H.; Wu, M.; Xu, N.; Lin, W. Multiple sound sources localization from coarse to fine. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 292–308. [Google Scholar]
- Senocak, A.; Oh, T.H.; Kim, J.; Yang, M.H.; Kweon, I.S. Learning to localize sound source in visual scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–2 June 2018; pp. 4358–4366. [Google Scholar]
- Stachurski, J.; Netsch, L.; Cole, R. Sound source localization for video surveillance camera. In Proceedings of the 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance, Krakow, Poland, 27–30 August 2013; pp. 93–98. [Google Scholar]
- Pieropan, A.; Salvi, G.; Pauwels, K.; Kjellström, H. Audio-visual classification and detection of human manipulation actions. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 3045–3052. [Google Scholar]
- Tamai, Y.; Kagami, S.; Amemiya, Y.; Sasaki, Y.; Mizoguchi, H.; Takano, T. Circular microphone array for robot’s audition. In Proceedings of the SENSORS, 2004 IEEE, Vienna, Austria, 24–27 October 2004; pp. 565–570. [Google Scholar]
- Grondin, F.; Michaud, F. Lightweight and optimized sound source localization and tracking methods for open and closed microphone array configurations. Robot. Auton. Syst. 2019, 113, 63–80. [Google Scholar] [CrossRef] [Green Version]
- Wakabayashi, M.; Okuno, H.G.; Kumon, M. Multiple sound source position estimation by drone audition based on data association between sound source localization and identification. IEEE Robot. Autom. Lett. 2020, 5, 782–789. [Google Scholar] [CrossRef]
- Hulsebos, E.; Schuurmans, T.; de Vries, D.; Boone, R. Circular Microphone Array for Discrete Multichannel Audio Recording. Audio Engineering Society Convention 114. Audio Engineering Society. March 2003. Available online: http://www.aes.org/e-lib/browse.cfm?elib=12596 (accessed on 4 January 2022).
- Subramanian, A.S.; Weng, C.; Watanabe, S.; Yu, M.; Yu, D. Deep learning based multi-source localization with source splitting and its effectiveness in multi-talker speech recognition. Comput. Speech Lang. 2022, 10, 101360. [Google Scholar] [CrossRef]
- Danès, P.; Bonnal, J. Information-theoretic detection of broadband sources in a coherent beamspace MUSIC scheme. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 1976–1981. [Google Scholar] [CrossRef]
- Pavlidi, D.; Puigt, M.; Griffin, A.; Mouchtaris, A. Real-time multiple sound source localization using a circular microphone array based on single-source confidence measures. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 2625–2628. [Google Scholar]
- Rafaely, B.; Peled, Y.; Agmon, M.; Khaykin, D.; Fisher, E. Spherical Microphone Array Beamforming; Springer: Berlin, Germany, 2010; pp. 281–305. [Google Scholar]
- Kurc, D.; Mach, V.; Orlovsky, K.; Khaddour, H. Sound source localization with DAS beamforming method using small number of microphones. In Proceedings of the 2013 36th International Conference on Telecommunications and Signal Processing (TSP), Rome, Italy, 2–4 July 2013; pp. 526–532. [Google Scholar] [CrossRef]
- Dehghan Firoozabadi, A.; Irarrazaval, P.; Adasme, P.; Zabala-Blanco, D.; Játiva, P.P.; Azurdia-Meza, C. 3D Multiple Sound Source Localization by Proposed T-Shaped Circular Distributed Microphone Arrays in Combination with GEVD and Adaptive GCC-PHAT/ML Algorithms. Sensors 2022, 22, 1011. [Google Scholar] [CrossRef]
- Busso, C.; Hernanz, S.; Chu, C.W.; Kwon, S.i.; Lee, S.; Georgiou, P.G.; Cohen, I.; Narayanan, S. Smart room: Participant and speaker localization and identification. In Proceedings of the (ICASSP’05), IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005; Volume 2, pp. ii/1117–ii/1120. [Google Scholar]
- Chen, X.; Shi, Y.; Jiang, W. Speaker tracking and identifying based on indoor localization system and microphone array. In Proceedings of the 21st International Conference on Advanced Information Networking and Applications Workshops (AINAW’07), Niagara Falls, ON, Canada, 21–23 May 2007; Volume 2, pp. 347–352. [Google Scholar]
- Murthi, M.; Rao, B. Minimum variance distortionless response (MVDR) modeling of voiced speech. In Proceedings of the 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; Volume 3, pp. 1687–1690. [Google Scholar] [CrossRef]
- Gupta, P.; Kar, S. MUSIC and improved MUSIC algorithm to estimate direction of arrival. In Proceedings of the 2015 International Conference on Communications and Signal Processing (ICCSP), Melmaruvathur, India, 2–4 April 2015; pp. 757–761. [Google Scholar] [CrossRef]
- Roy, R.; Kailath, T. ESPRIT-estimation of signal parameters via rotational invariance techniques. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 984–995. [Google Scholar] [CrossRef] [Green Version]
- Das, A. Real-Valued Sparse Bayesian Learning for Off-Grid Direction-of-Arrival (DOA) Estimation in Ocean Acoustics. IEEE J. Ocean. Eng. 2021, 46, 172–182. [Google Scholar] [CrossRef]
- He, D.; Chen, X.; Pei, L.; Zhu, F.; Jiang, L.; Yu, W. Multi-BS Spatial Spectrum Fusion for 2-D DOA Estimation and Localization Using UCA in Massive MIMO System. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Yun, W.; Xiukun, L.; Zhimin, C. DOA Estimation of Wideband LFM Sources based on Narrowband Methods Integration Using Random Forest Regression. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; pp. 816–820. [Google Scholar] [CrossRef]
- Jalal, B.; Yang, X.; Igambi, D.; Ul Hassan, T.; Ahmad, Z. Low complex direction of arrival estimation method based on adaptive filtering algorithm. J. Eng. 2019, 2019, 6214–6217. [Google Scholar] [CrossRef]
- Tiete, J.; Domínguez, F.; Silva, B.D.; Segers, L.; Steenhaut, K.; Touhafi, A. SoundCompass: A Distributed MEMS Microphone Array-Based Sensor for Sound Source Localization. Sensors 2014, 14, 1918–1949. [Google Scholar] [CrossRef] [Green Version]
- Hoshiba, K.; Washizaki, K.; Wakabayashi, M.; Ishiki, T.; Kumon, M.; Bando, Y.; Gabriel, D.; Nakadai, K.; Okuno, H.G. Design of UAV-Embedded Microphone Array System for Sound Source Localization in Outdoor Environments. Sensors 2017, 17, 2535. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Motlicek, P.; Odobez, J.M. Deep Neural Networks for Multiple Speaker Detection and Localization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 74–79. [Google Scholar] [CrossRef] [Green Version]
- Purwins, H.; Li, B.; Virtanen, T.; Schlüter, J.; Chang, S.Y.; Sainath, T. Deep Learning for Audio Signal Processing. IEEE J. Sel. Top. Signal Process. 2019, 13, 206–219. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Jia, M.; Gao, S.; Li, L. Multiple Sound Source Separation by Using DOA Estimation and ICA. In Proceedings of the 2021 4th International Conference on Information Communication and Signal Processing (ICICSP), Shanghai, China, 24–26 September 2021; pp. 249–253. [Google Scholar] [CrossRef]
- Li, H.; Chen, K.; Wang, L.; Liu, J.; Wan, B.; Zhou, B. Sound Source Separation Mechanisms of Different Deep Networks Explained from the Perspective of Auditory Perception. Appl. Sci. 2022, 12, 832. [Google Scholar] [CrossRef]
- Butt, U.M.; Khan, S.A.; Ullah, A.; Khaliq, A.; Reviriego, P.; Zahir, A. Towards Low Latency and Resource-Efficient FPGA Implementations of the MUSIC Algorithm for Direction of Arrival Estimation. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 3351–3362. [Google Scholar] [CrossRef]
- Da Silva, B.; Braeken, A.; Touhafi, A. FPGA-based architectures for acoustic beamforming with microphone arrays: Trends, challenges and research opportunities. Computers 2018, 7, 41. [Google Scholar] [CrossRef] [Green Version]
- Jung, Y.; Jeon, H.; Lee, S.; Jung, Y. Scalable ESPRIT Processor for Direction-of-Arrival Estimation of Frequency Modulated Continuous Wave Radar. Electronics 2021, 10, 695. [Google Scholar] [CrossRef]
- Nsalo Kong, D.F.; Shen, C.; Tian, C.; Zhang, K. A New Low-Cost Acoustic Beamforming Architecture for Real-Time Marine Sensing: Evaluation and Design. J. Mar. Sci. Eng. 2021, 9, 868. [Google Scholar] [CrossRef]
- Ribeiro, Â.; Rodrigues, C.; Marques, I.; Monteiro, J.; Cabral, J.; Gomes, T. Deploying a Real-Time Operating System on a Reconfigurable Internet of Things End-device. In Proceedings of the IECON 2019-45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; Volume 1, pp. 2946–2951. [Google Scholar]
- Marques, I.; Rodrigues, C.; Tavares, A.; Pinto, S.; Gomes, T. Lock-V: A heterogeneous fault tolerance architecture based on Arm and RISC-V. Microelectron. Reliab. 2021, 120, 114120. [Google Scholar] [CrossRef]
- Brandstein, M.; Ward, D.; Lacroix, A.; Venetsanopoulos, A. (Eds.) Microphone Arrays: Signal Processing Techniques and Applications, 1st ed.; Digital Signal Processing; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- InvenSense. Wide Dynamic Range Microphone with PDM Digital Output Data Sheet ADMP62. In DS-INMP621-00 Datasheet Rev 1.3; InvenSense Inc.: San Jose, CA, USA, 2016. [Google Scholar]
- InvenSense. Bottom Port PDM Digital Output Multi-Mode Microphone. In ICS-51360 Datasheet Rev 1.0; InvenSense Inc.: San Jose, CA, USA, 2016. [Google Scholar]
- Knowles. Digital SiSonic Microphone With Multiple Performance Modes. In Datasheet SPK0641HT4H-1 Rev A; Knowles Electronics, LLC: Itasca, IL, USA, 2016. [Google Scholar]
- Hegde, N. Seamlessly interfacing MEMs microphones with blackfin processors. In EE-350 Engineer-to-Engineer Note; Analog Devices, Inc.: Norwood, MA, USA, 2010. [Google Scholar]
- Re, D.E.; O’Connor, J.J.; Bennett, P.J.; Feinberg, D.R. Preferences for very low and very high voice pitch in humans. PLoS ONE 2012, 7, e32719. [Google Scholar] [CrossRef] [Green Version]
- Martins, J.; Tavares, A.; Solieri, M.; Bertogna, M.; Pinto, S. Bao: A lightweight static partitioning hypervisor for modern multi-core embedded systems. In Proceedings of the Workshop on Next Generation Real-Time Embedded Systems (NG-RES 2020), Bologna, Italy, 21 January 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sound Source Distance | |||||
|---|---|---|---|---|---|
| 50 cm | 75 cm | 100 cm | 150 cm | ||
| Sine Wave Frequency | 220 Hz | 99.62% | 98.92% | 98.33% | 97.33% |
| 440 Hz | 99.54% | 99.56% | 96.94% | 97.45% | |
| 880 Hz | 99.92% | 99.20% | 99.48% | 99.46% | |
| 1760 Hz | 99.76% | 99.86% | 98.24% | 98.67% | |
| Resource | Utilization | Available | Utilization (%) |
|---|---|---|---|
| LUT | 18,628 | 230,400 | 8.09% |
| LUTRAM | 4550 | 101,760 | 4.47% |
| FF | 21,725 | 460,800 | 4.71% |
| BRAM | 191 | 312 | 61.22% |
| DSP | 49 | 1728 | 2.84% |
| IO | 14 | 360 | 3.89% |
| BUFG | 5 | 544 | 0.92% |
| MMCM | 1 | 8 | 12.50% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marques, I.; Sousa, J.; Sá, B.; Costa, D.; Sousa, P.; Pereira, S.; Santos, A.; Lima, C.; Hammerschmidt, N.; Pinto, S.; et al. Microphone Array for Speaker Localization and Identification in Shared Autonomous Vehicles. Electronics 2022, 11, 766. https://doi.org/10.3390/electronics11050766
Marques I, Sousa J, Sá B, Costa D, Sousa P, Pereira S, Santos A, Lima C, Hammerschmidt N, Pinto S, et al. Microphone Array for Speaker Localization and Identification in Shared Autonomous Vehicles. Electronics. 2022; 11(5):766. https://doi.org/10.3390/electronics11050766
Chicago/Turabian StyleMarques, Ivo, João Sousa, Bruno Sá, Diogo Costa, Pedro Sousa, Samuel Pereira, Afonso Santos, Carlos Lima, Niklas Hammerschmidt, Sandro Pinto, and et al. 2022. "Microphone Array for Speaker Localization and Identification in Shared Autonomous Vehicles" Electronics 11, no. 5: 766. https://doi.org/10.3390/electronics11050766
APA StyleMarques, I., Sousa, J., Sá, B., Costa, D., Sousa, P., Pereira, S., Santos, A., Lima, C., Hammerschmidt, N., Pinto, S., & Gomes, T. (2022). Microphone Array for Speaker Localization and Identification in Shared Autonomous Vehicles. Electronics, 11(5), 766. https://doi.org/10.3390/electronics11050766