
TweezBot: An AI-Driven Online Media Bot Identification Algorithm for Twitter Social Networks



Abstract
:1. Introduction
- Our proposed TweezBot model aims at revealing the automated tweeting behavior of online Twitter bots.
- The proposed classifier is a multi-layer condition-based model developed using artificial intelligence for bot identification.
- Several string-based and numeric profile-centric attributes, such as profile name, description, location, listed count, verification status, etc. form the condition base.
- The comparative study is performed with the benchmark machine and deep learning models, including the following: decision tree, random forest, Bernoulli Naïve-Bayes classifier, categorical Naïve-Bayes, support vector machine, and multi-layer perceptron.
- Performance analysis is also conducted with publicly available standard automation identifier APIs, such as Botometer, BotSentinel, and TweetBotOrNot.
- Results obtained from the existing classifiers and APIs are used for comparative examination and performance of TweezBot in terms of accuracy, recall, precision, F1-score, Cohen-Kappa score, area under ROC curve, and other.
2. Related Work
3. Research Methodologies
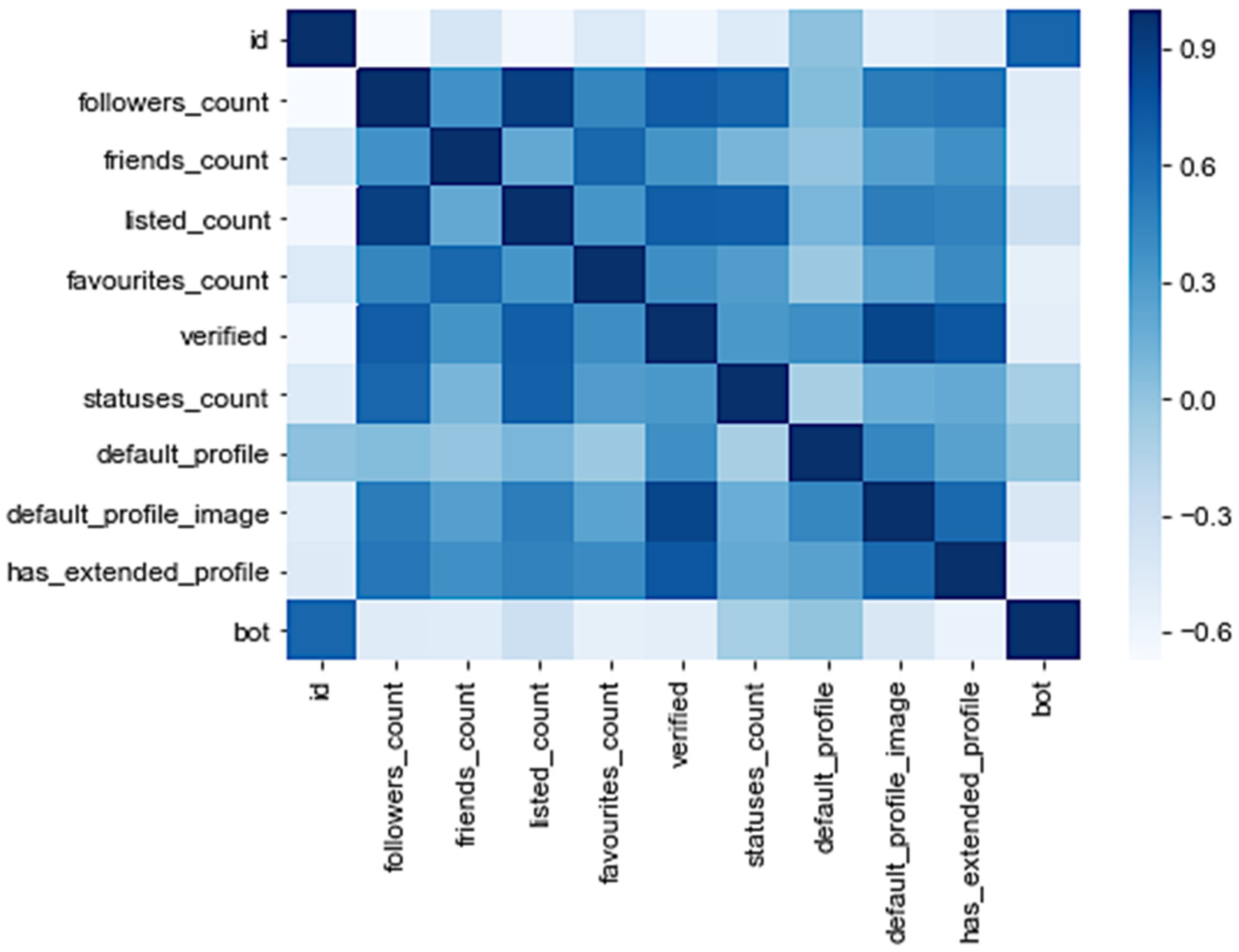
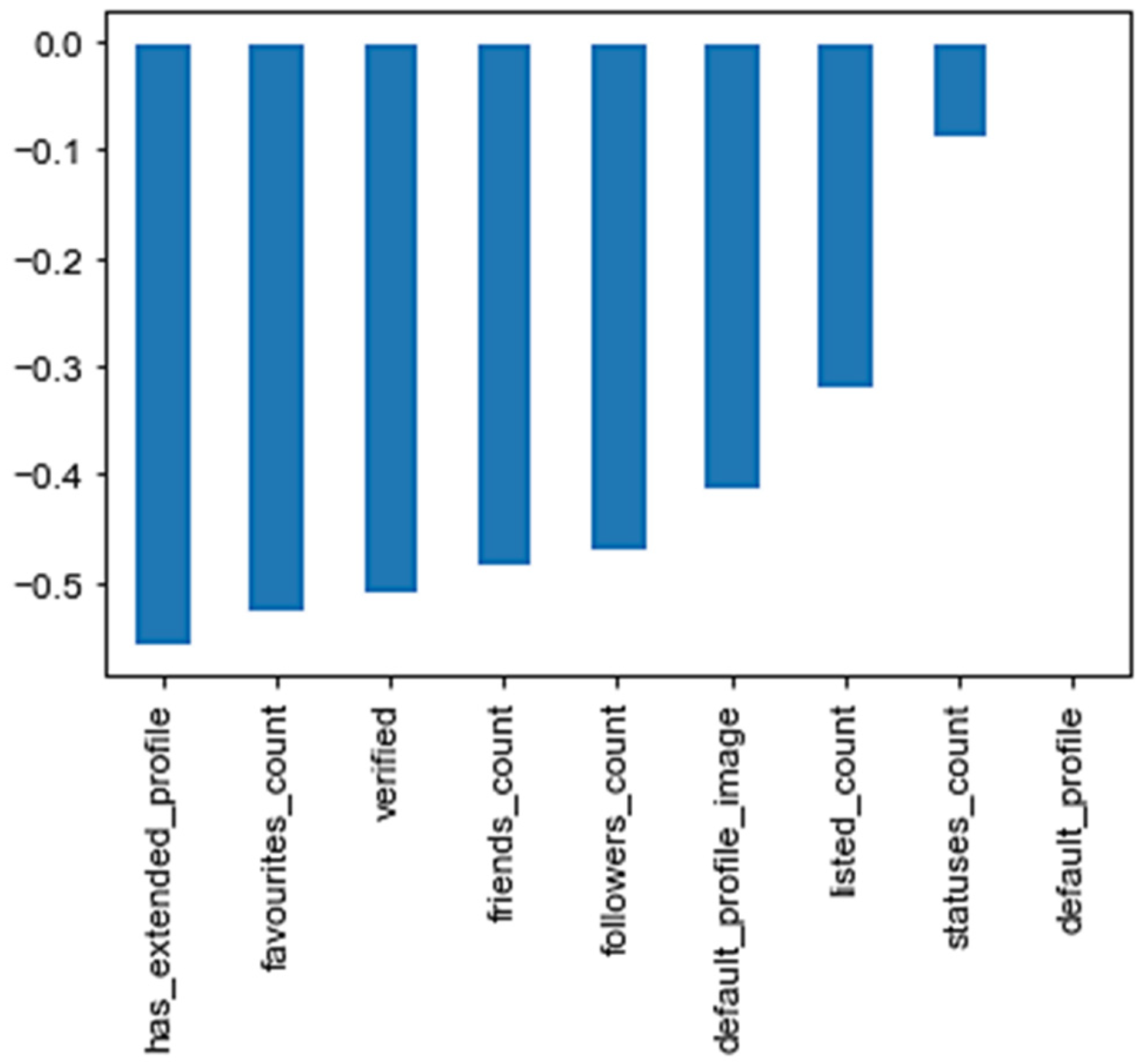
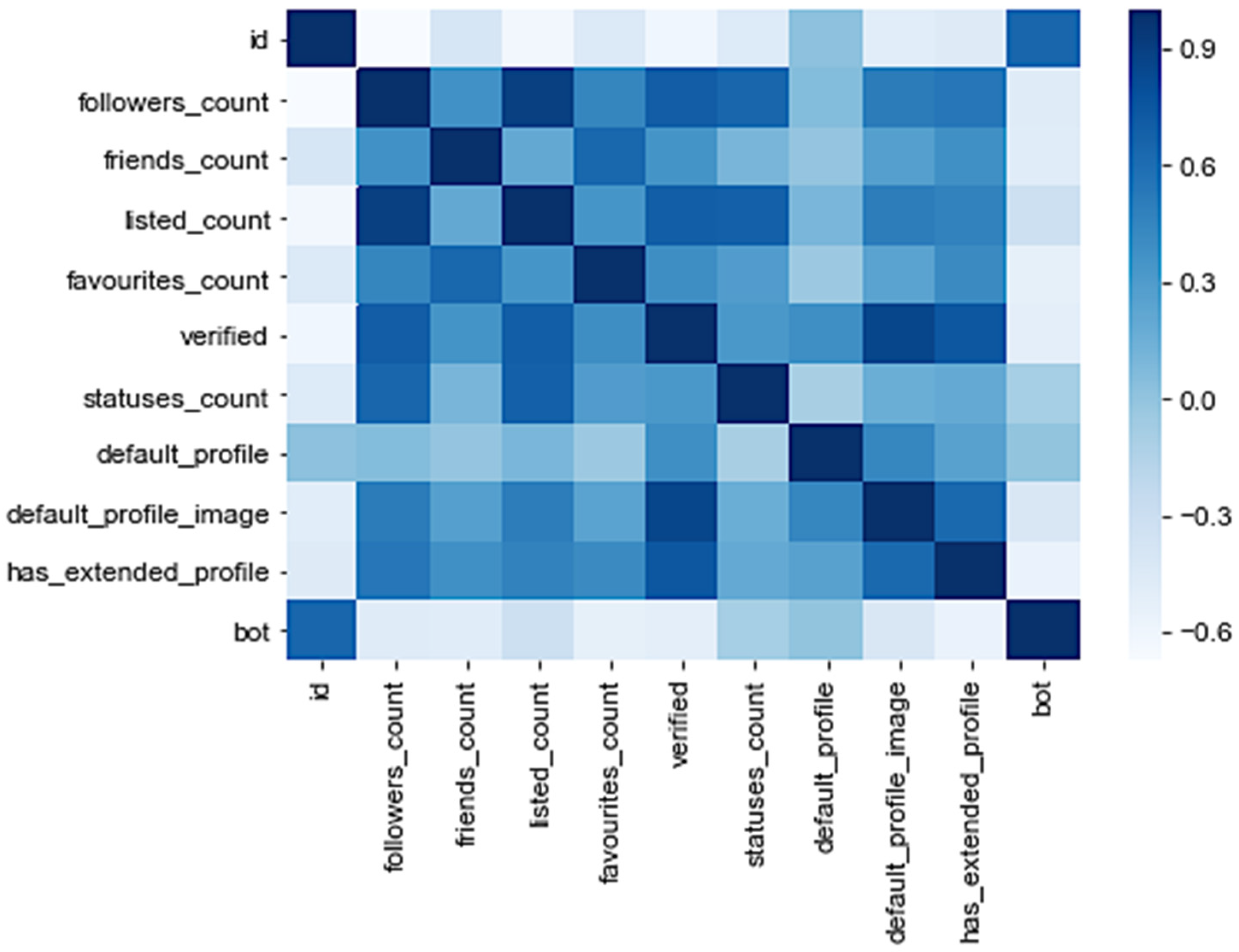
3.1. Correlation Statistics
3.2. Decision Trees
3.3. Random Forest Classifier
3.4. Bernoulli Naïve Bayes
3.5. Categorical Naïve-Bayes
3.6. Support Vector Machine
3.7. Multi-Layer Perceptron
4. Proposed Framework: TweezBot Model
| Algorithm 1: Proposed TweezBot Algorithm. |
| Input: Twitter dataset Procedure:
|
| Output: for each user |
5. Experimental Outcomes
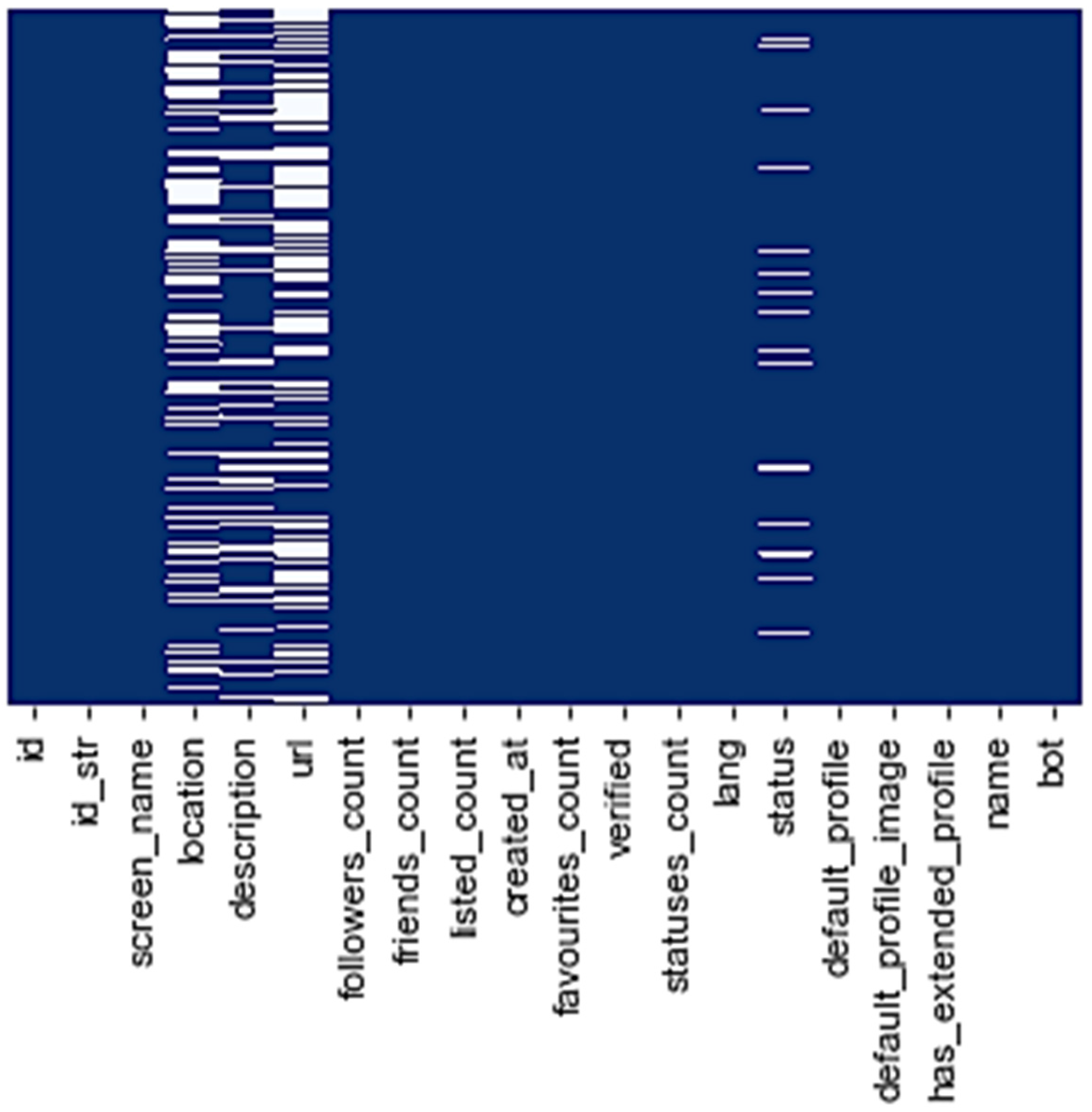
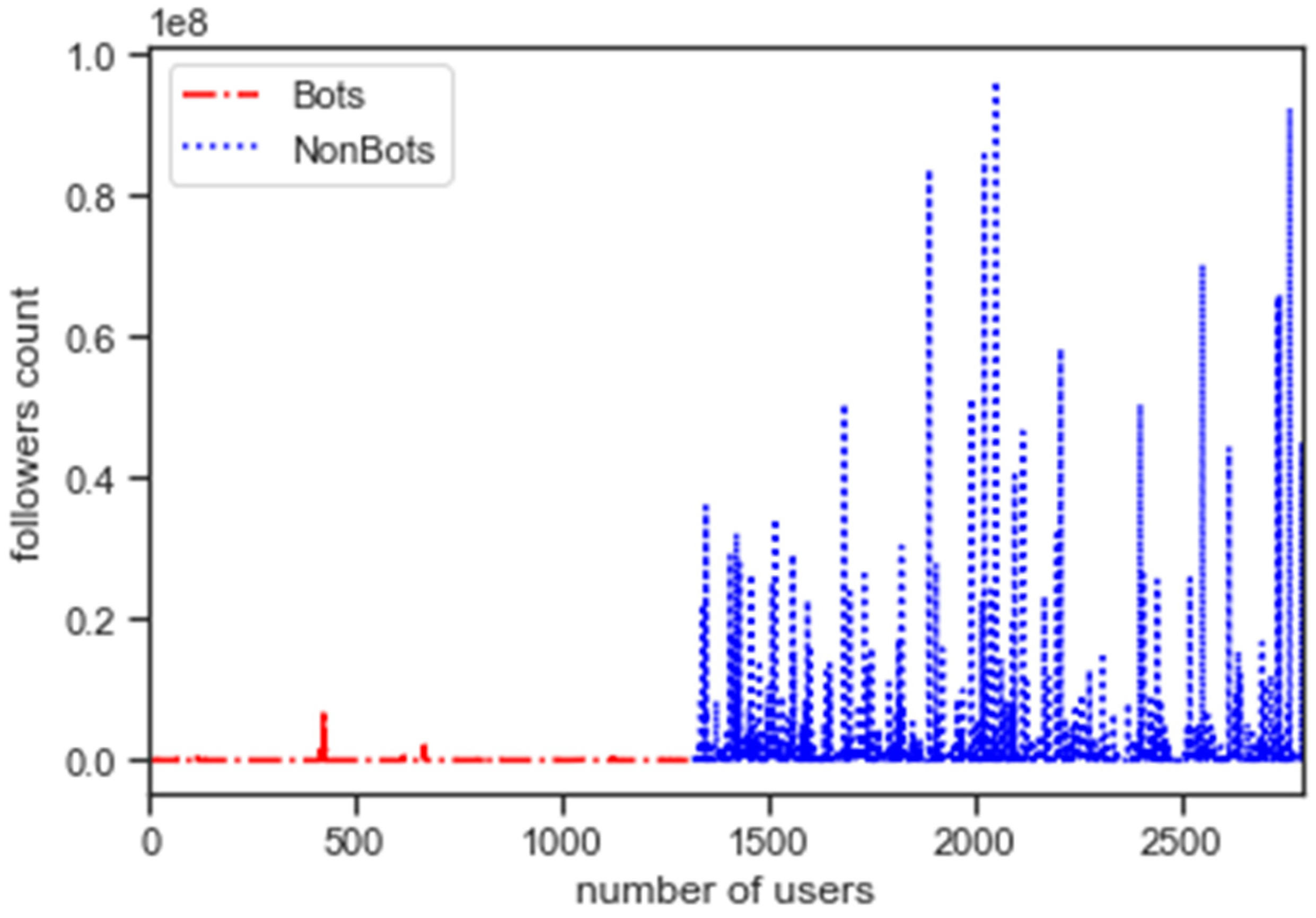
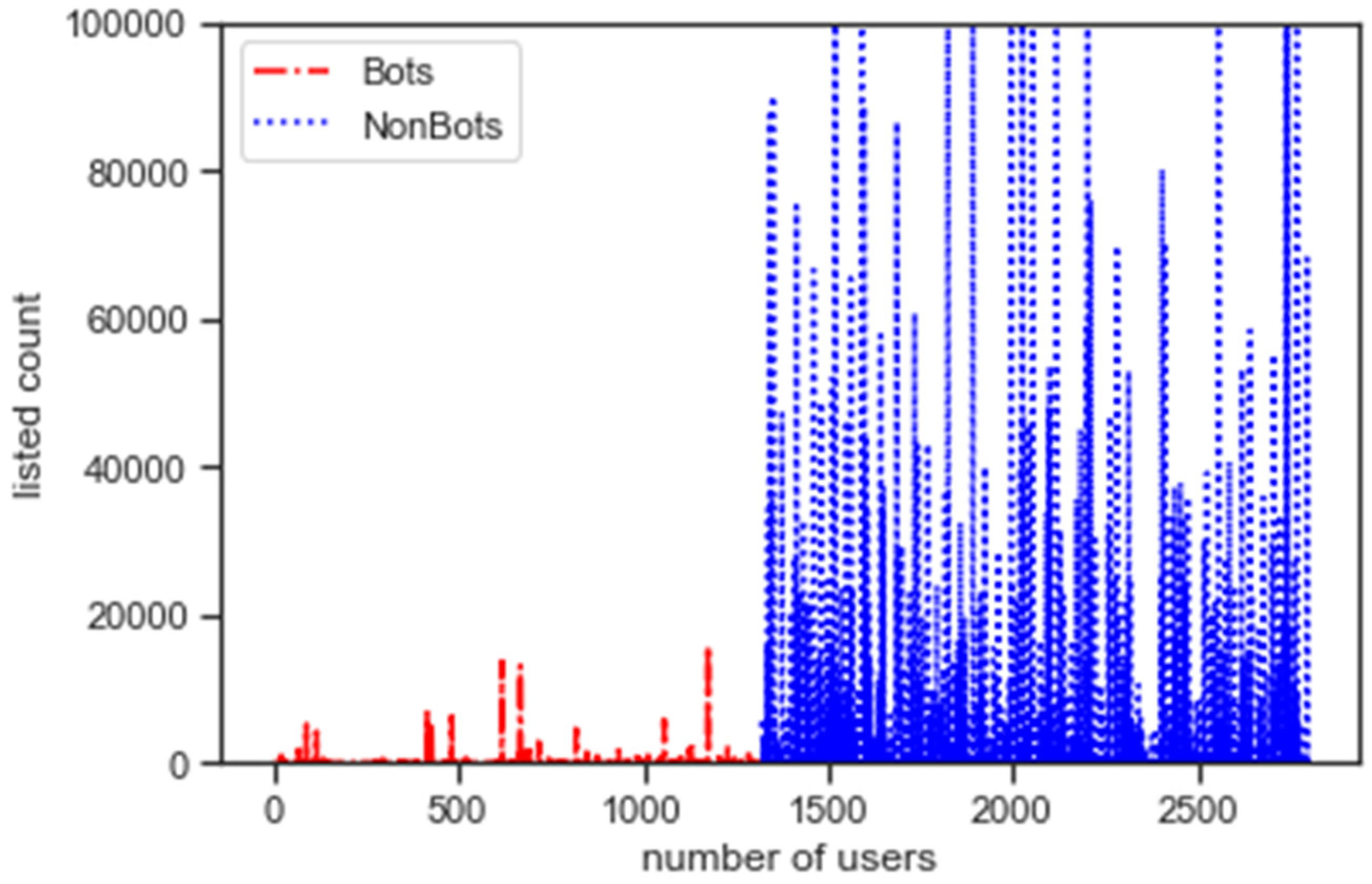
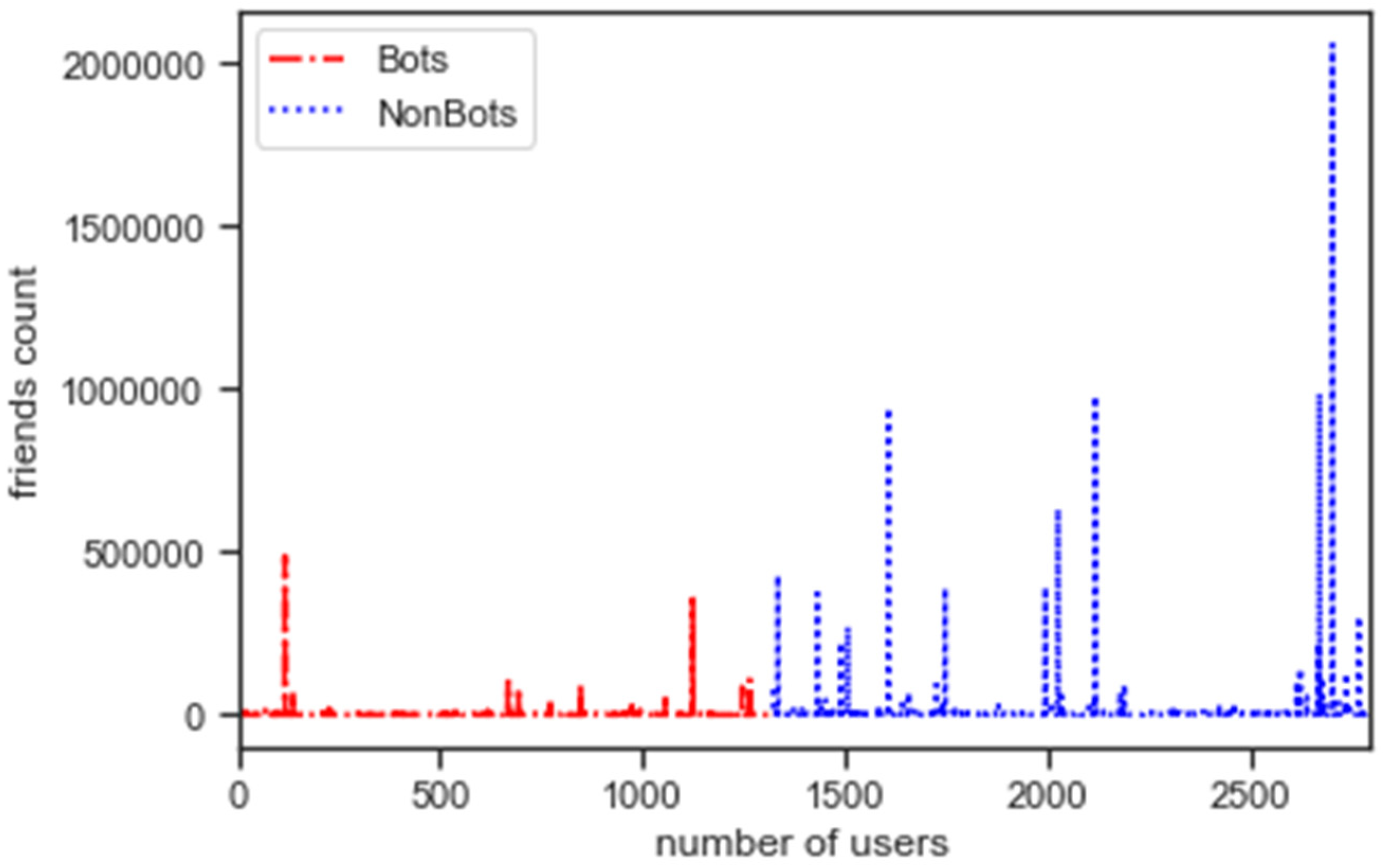
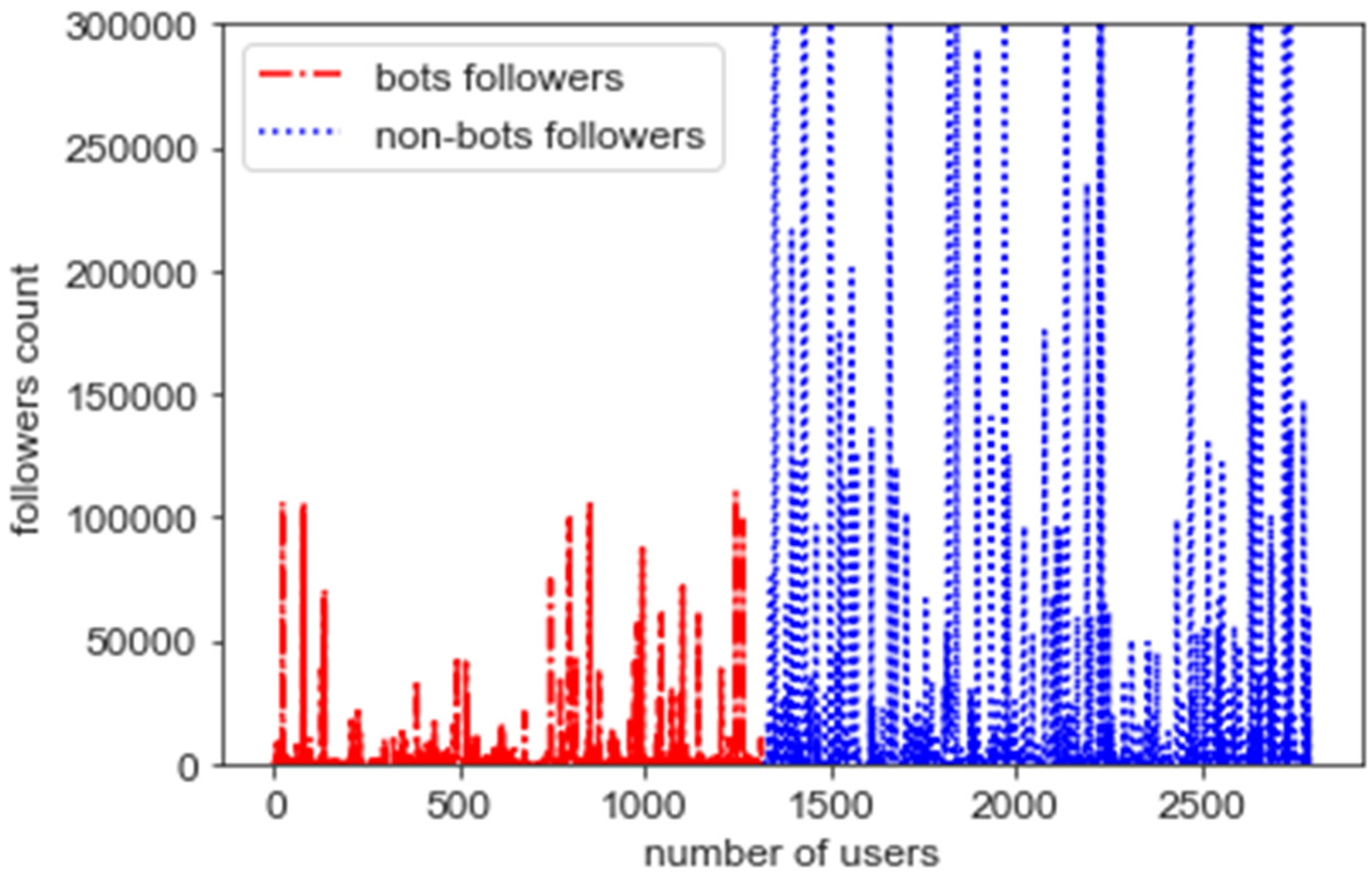
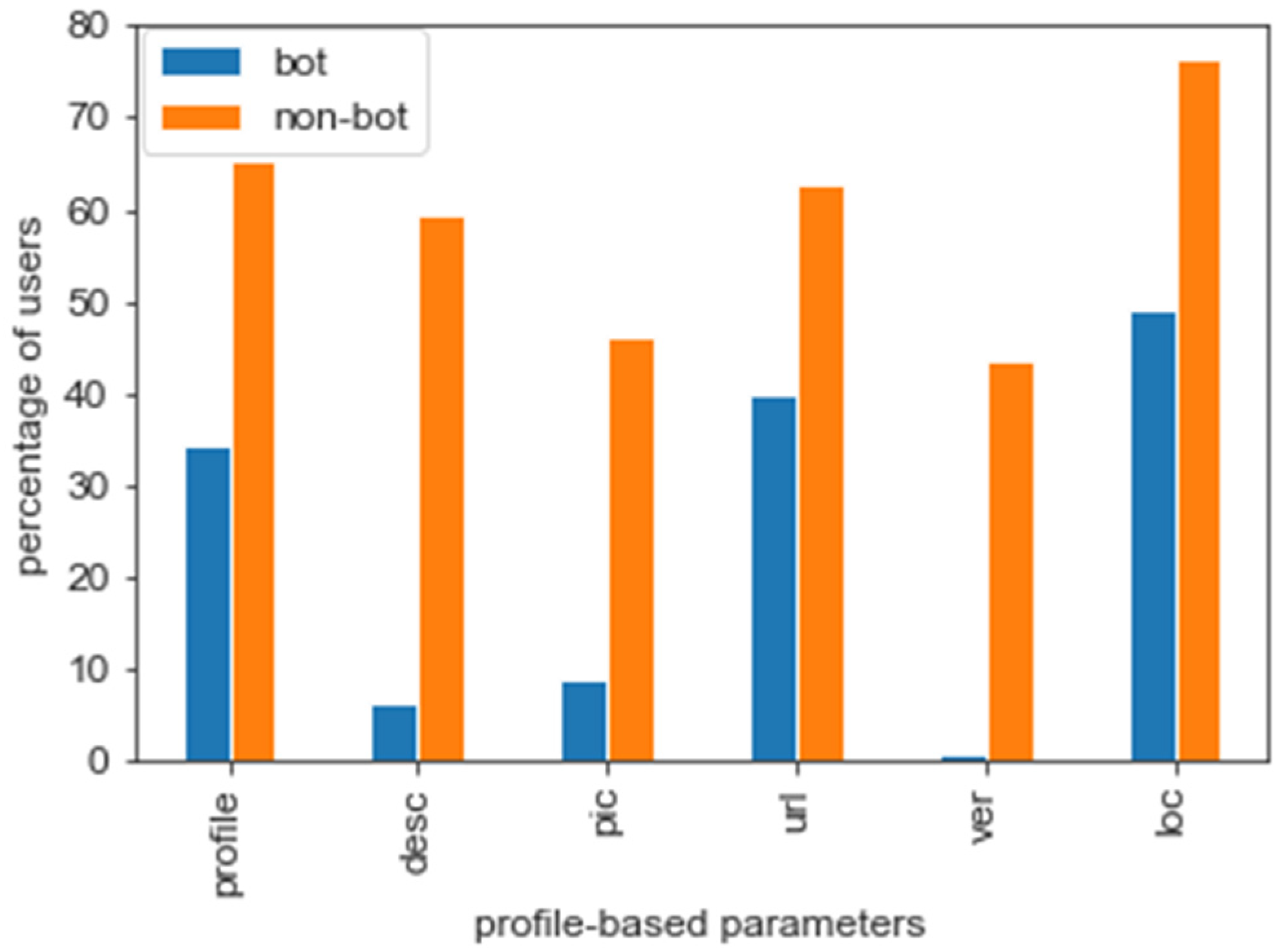
5.1. Feature Analysis
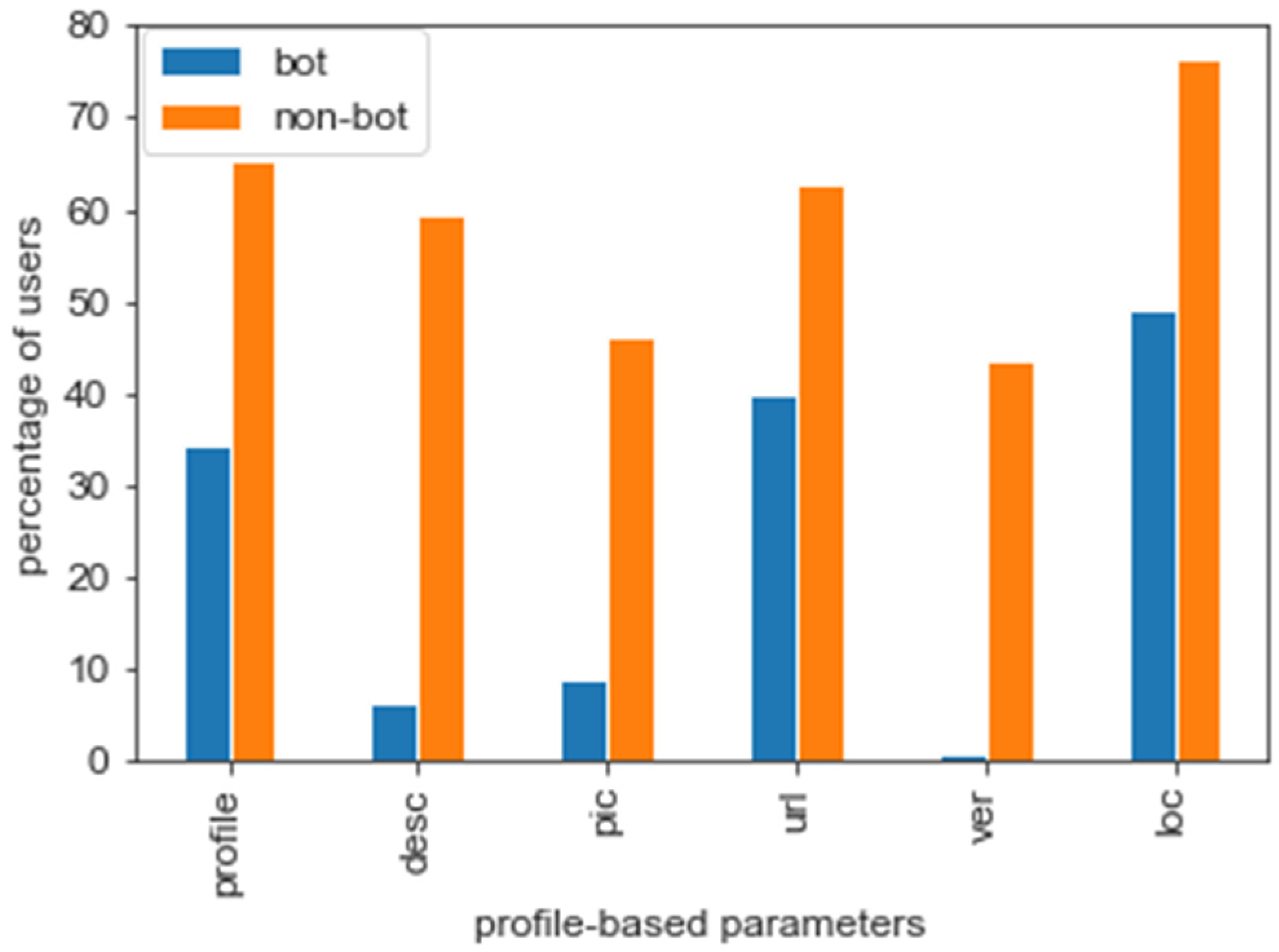
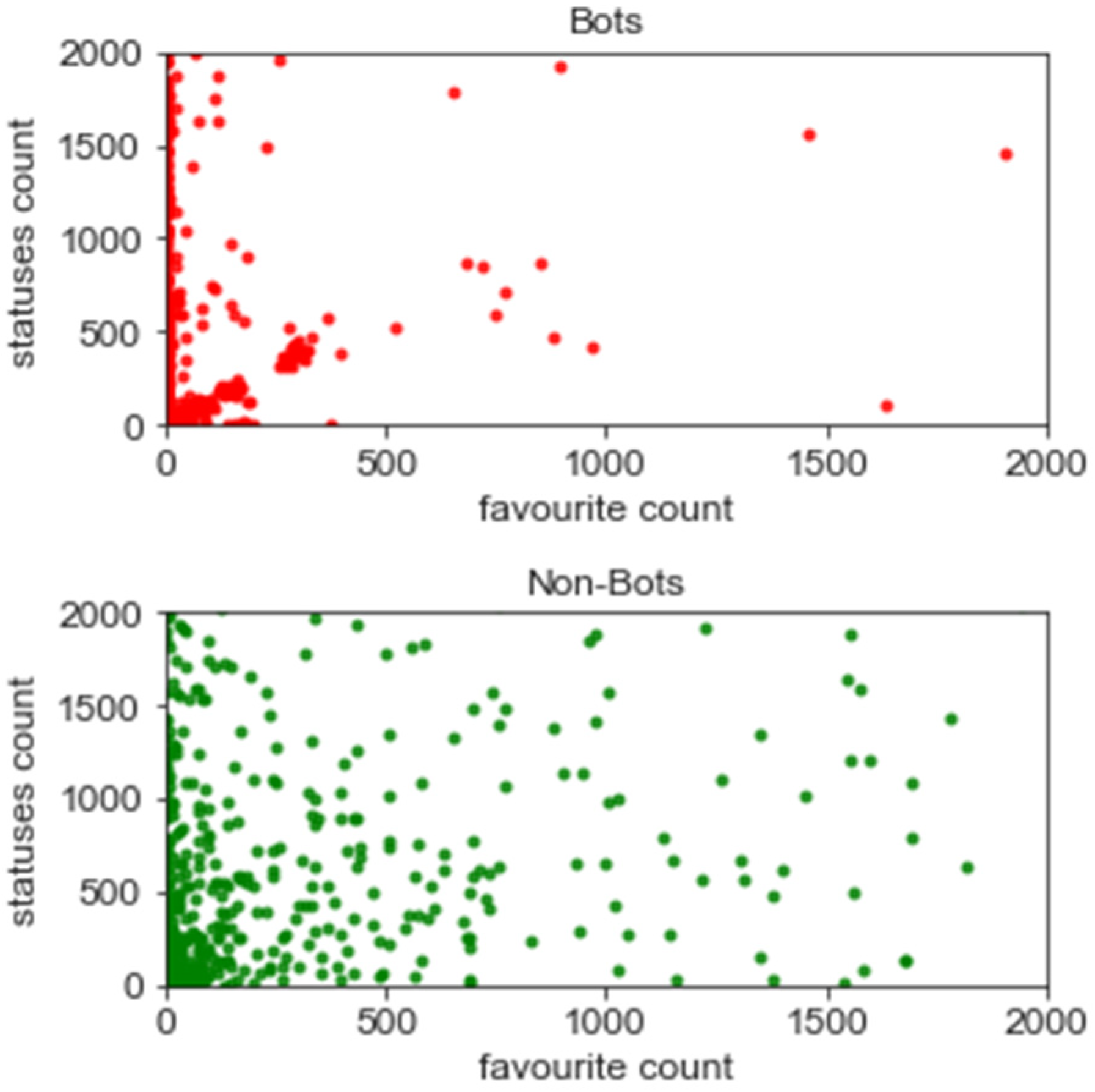
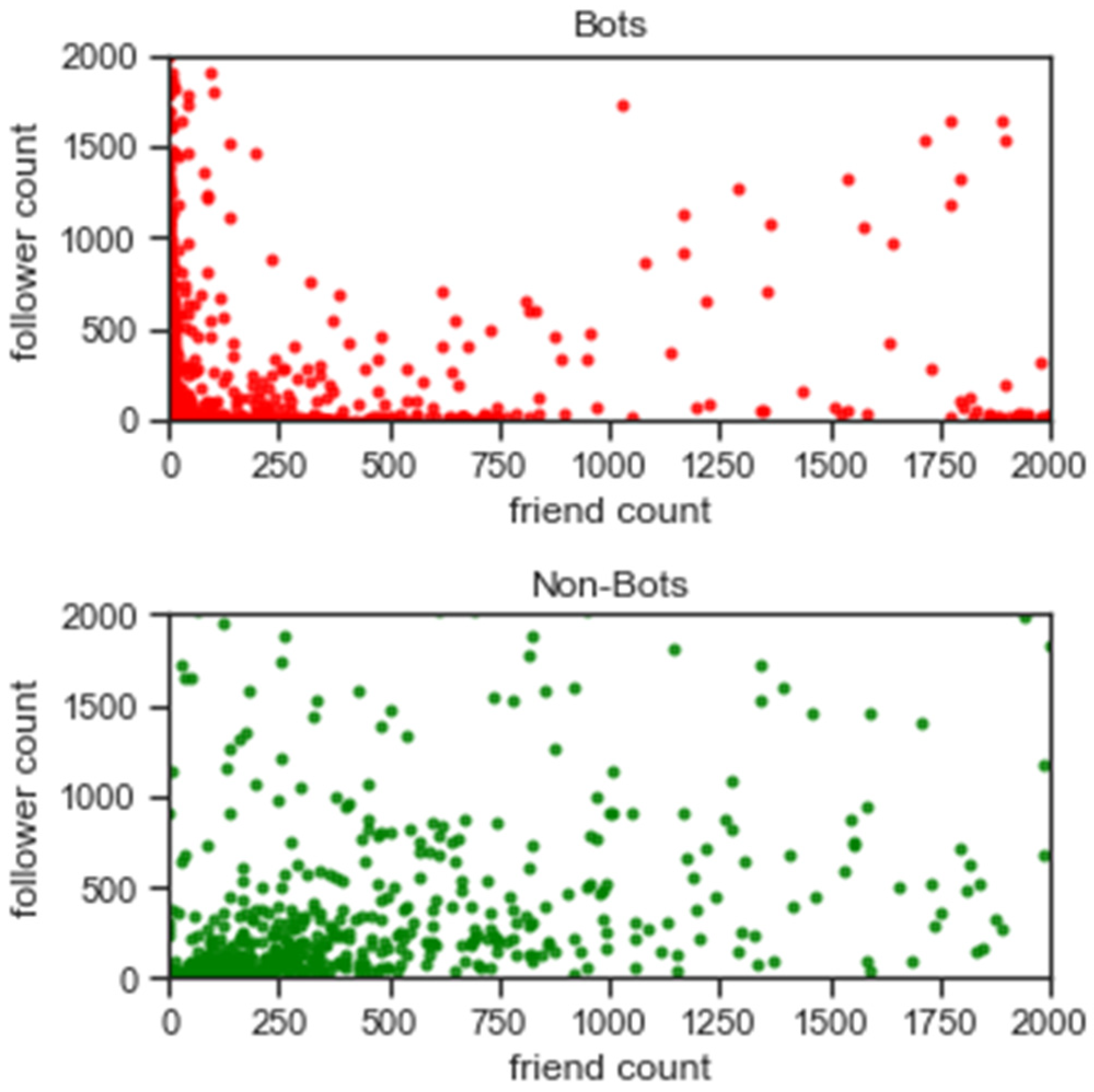
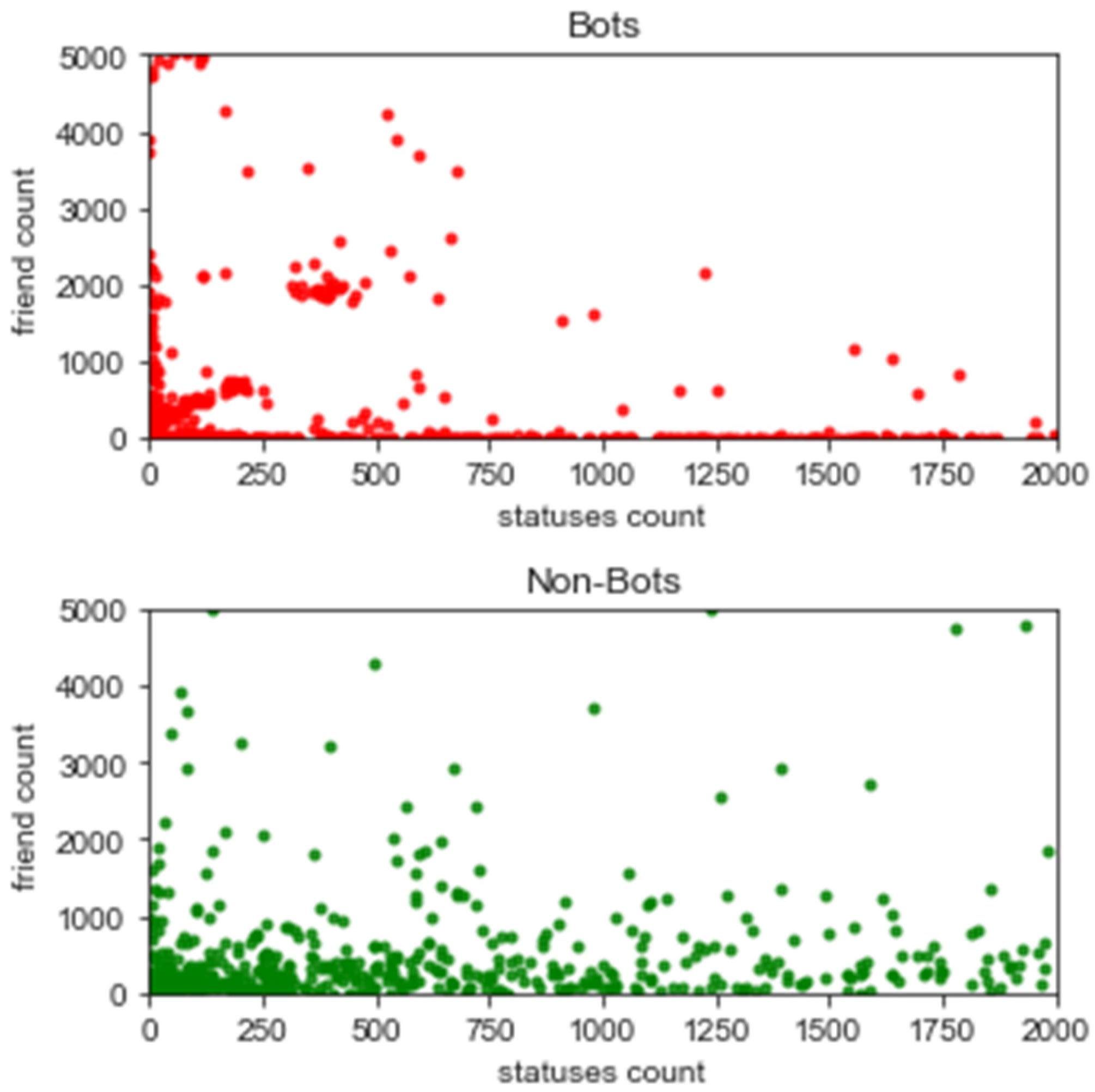
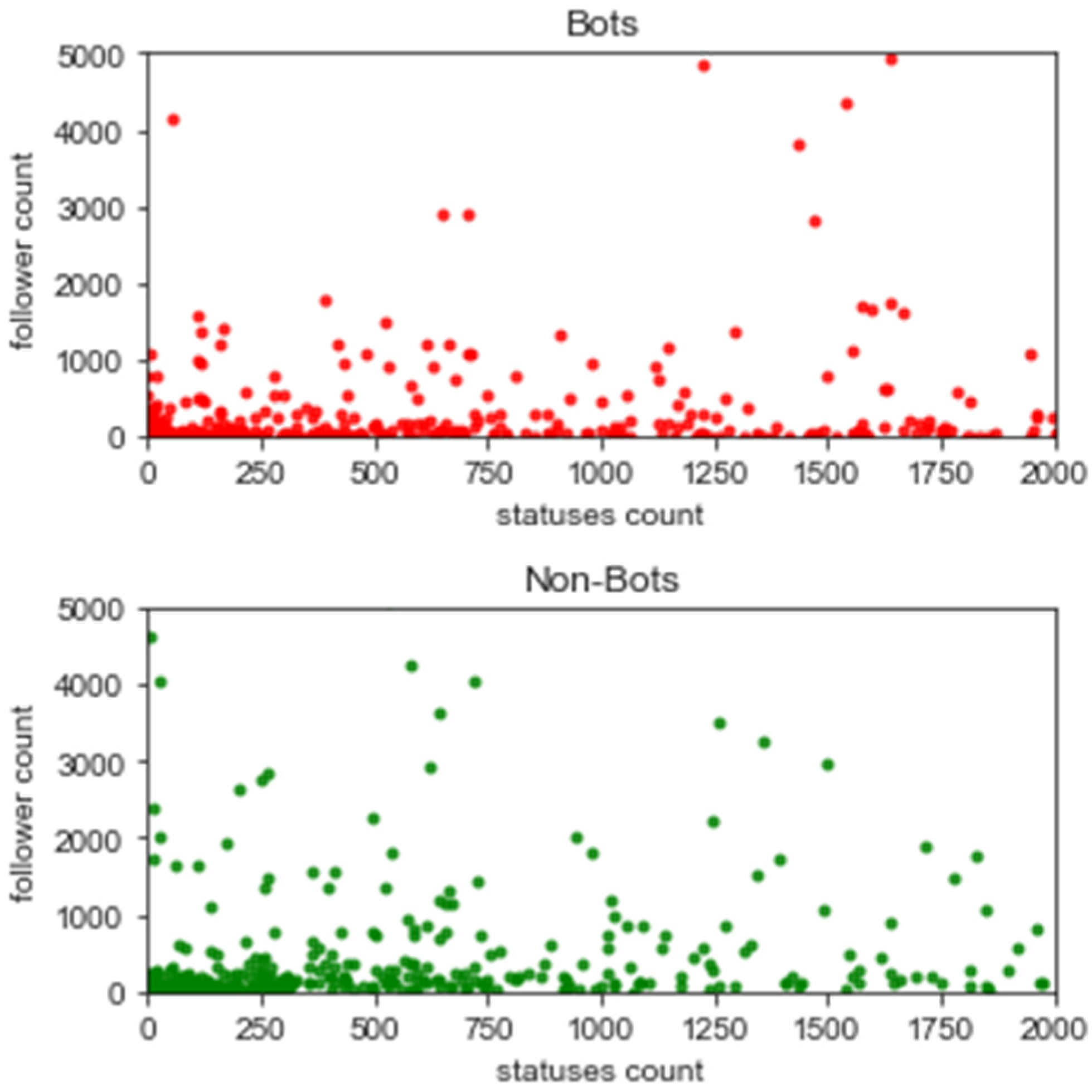
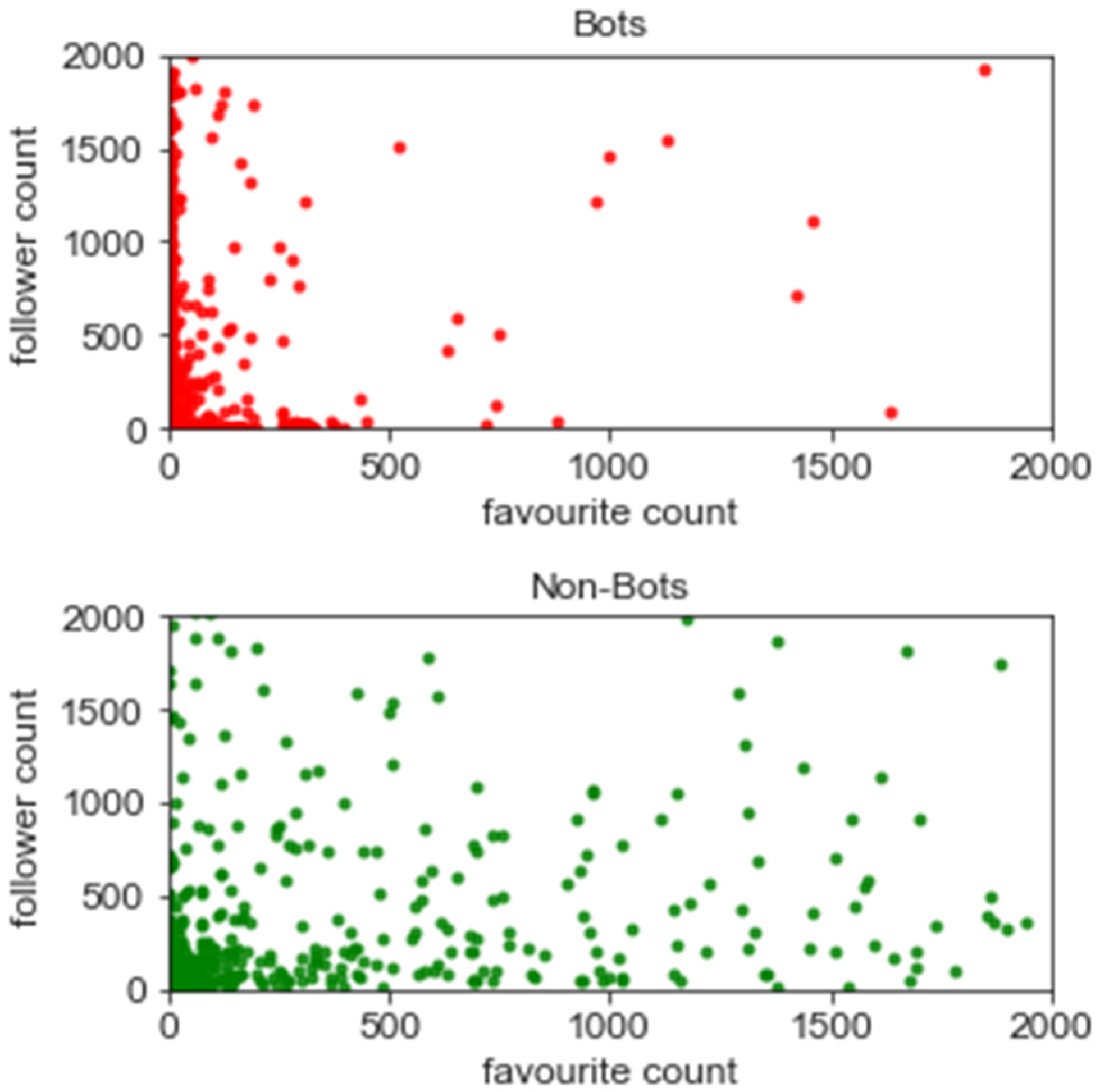
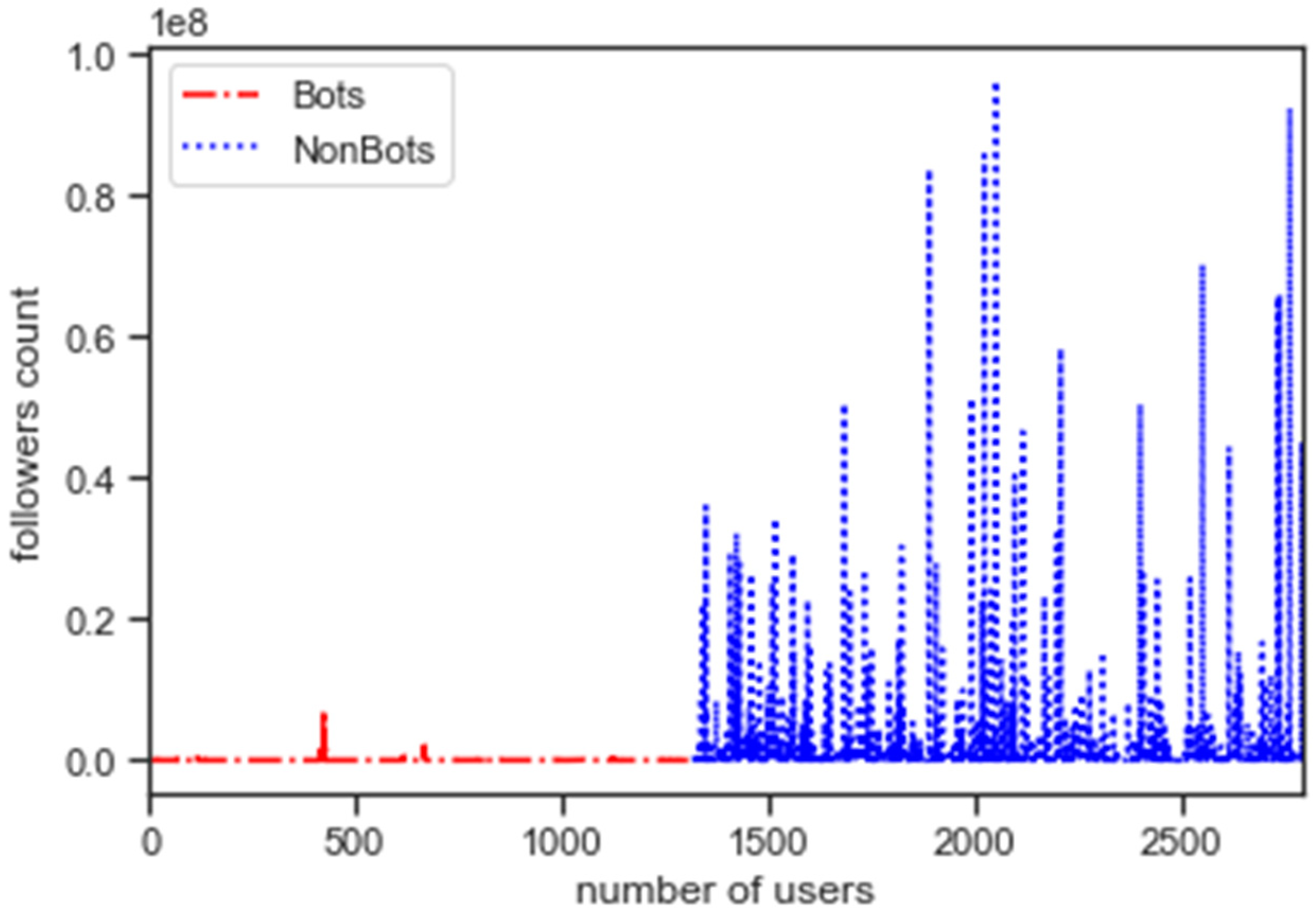
5.2. Exploratory Data Analysis
5.3. Assessing Bot Behaviour
5.4. Comparative Performance Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Clark, E.M.; Williams, J.R.; Jones, C.A.; Galbraith, R.A.; Danforth, C.M.; Dodds, P.S. Sifting robotic from organic text: A natural language approach for detecting automation on Twitter. J. Comput. Sci. 2016, 16, 1–7. [Google Scholar] [CrossRef] [Green Version]
- He, D.; Liu, X. Novel competitive information propagation macro mathematical model in online social network. J. Comput. Sci. 2020, 41, 101089. [Google Scholar] [CrossRef]
- Jain, S.; Sinha, A. Identification of influential users on Twitter: A novel weighted correlated influence measure for COVID-19. In Chaos, Solitons Fractals; Elsevier: Amsterdam, The Netherlands, 2020; Volume 139, pp. 1–8. [Google Scholar] [CrossRef]
- Kantepe, M.; Ganiz, M.C. Preprocessing framework for Twitter bot detection. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 630–634. [Google Scholar]
- Anwar, A.; Yaqub, U. Bot detection in twitter landscape using unsupervised learning. In Proceedings of the 21st Annual International Conference on Digital Government Research, Seoul, Korea, 15–19 June 2020; pp. 329–330. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Chen, Z.; Subramanian, D. An unsupervised approach to detect spam campaigns that use botnets on twitter. arXiv 2018, arXiv:1804.05232. [Google Scholar]
- Beskow, D.M.; Carley, K.M. Bot-Match: Social Bot Detection with Recursive Nearest Neighbors Search. arXiv 2020, arXiv:2007.07636. [Google Scholar]
- Ilias, L.; Roussaki, I. Detecting malicious activity in Twitter using deep learning techniques. Appl. Soft Comput. 2021, 107, 107360. [Google Scholar] [CrossRef]
- Miller, S.J. (Ed.) Benford’s Law; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Kalameyets, M.; Levshun, D.; Soloviev, S.; Chechulin, A.; Kotenko, I. Social networks bot detection using Benford’s law. In Proceedings of the 13th International Conference on Security of Information and Networks, Merkez, Turkey, 4–7 November 2020; pp. 1–8. [Google Scholar]
- Barhate, S.; Mangla, R.; Panjwani, D.; Gatkal, S.; Kazi, F. Twitter bot detection and their influence in hashtag manipulation. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 11–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Lundberg, J.; Nordqvist, J.; Laitinen, M. Towards a language independent Twitter bot detector. In Proceedings of the Digital Humanities in the Nordic Countries, Copenhagen, Denmark, 5–8 March 2019; pp. 308–319. [Google Scholar]
- Wei, F.; Nguyen, U.T. Twitter Bot Detection Using Bidirectional Long Short-Term Memory Neural Networks and Word Embeddings. In Proceedings of the 2019 First IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Los Angeles, CA, USA, 12–14 December 2019; pp. 101–109. [Google Scholar]
- Rauchfleisch, A.; Kaiser, J. The False positive problem of automatic bot detection in social science research. PLoS ONE 2020, 15, e0241045. [Google Scholar] [CrossRef] [PubMed]
- Moosavi, A.; Rao, V.; Sandu, A. Machine learning based algorithms for uncertainty quantification in numerical weather prediction models. J. Comput. Sci. 2021, 50, 101295. [Google Scholar] [CrossRef]
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In Proceedings of the AAAI-98 Workshop on Learning for Text Categorization, Menlo Park, CA, USA, 27 July 1998; Volume 752, pp. 41–48. [Google Scholar]
- Metsis, V.; Androutsopoulos, I.; Paliouras, G. Spam filtering with naive bayes-which naive bayes? In Proceedings of the CEAS 2006—The Third Conference on Email and Anti-Spam, Mountain View, CA, USA, 27–28 July 2006; Volume 17, pp. 28–69. [Google Scholar]
- Shrivastava, A.; Tripathy, A.K.; Dalal, P.K. A SVM-based classification approach for obsessive compulsive disorder by oxidative stress biomarkers. J. Comput. Sci. 2019, 36, 101023. [Google Scholar] [CrossRef]
- Cinar, A.C. Training Feed-Forward Multi-Layer Perceptron Artificial Neural Networks with a Tree-Seed Algorithm. Arab. J. Sci. Eng. 2020, 45, 10915–10938. [Google Scholar] [CrossRef]
- Samper-Escalante, L.; Loyola-González, O.; Monroy, R.; Medina-Pérez, M. Bot Datasets on Twitter: Analysis and Challenges. Appl. Sci. 2021, 11, 4105. [Google Scholar] [CrossRef]
- Loyola-Gonzalez, O.; Monroy, R.; Rodríguez, J.; Lopez-Cuevas, A.; Mata-Sanchez, J.I. Contrast Pattern-Based Classification for Bot Detection on Twitter. IEEE Access 2019, 7, 45800–45817. [Google Scholar] [CrossRef]
- Charvi Jain. 2018. Available online: Kaggle.com/charvijain27/training-data-2-csv-utfcsv (accessed on 20 January 2022).
- Subrahmanian, V.S.; Azaria, A.; Durst, S.; Kagan, V.; Galstyan, A.; Lerman, K.; Zhu, L.; Ferrara, E.; Flammini, A.; Menczer, F. The DARPA Twitter Bot Challenge. Computer 2016, 49, 38–46. [Google Scholar] [CrossRef] [Green Version]
- Bouzy, C. Towards a Language Independent Twitter Bot Detector. 2018. Available online: Botsentinel.com (accessed on 10 December 2021).
- Kearney, M.W. TweetBotOrNot. 2018. Available online: github.com/mkearney/tweetbotornot (accessed on 1 December 2021).
- Shuja, J.; Humayun, M.A.; Alasmary, W.; Sinky, H.; Alanazi, E.; Khan, M.K. Resource Efficient Geo-Textual Hierarchical Clustering Framework for Social IoT Applications. IEEE Sens. J. 2021, 21, 25114–25122. [Google Scholar] [CrossRef]
- Aftab, H.; Shuja, J.; Alasmary, W.; Alanazi, E. Hybrid DBSCAN based Community Detection for Edge Caching in Social Media Applications. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 2038–2043. [Google Scholar] [CrossRef]
- Fan, J.; Lee, J.; Lee, Y. A Transfer Learning Architecture Based on a Support Vector Machine for Histopathology Image Classification. Appl. Sci. 2021, 11, 6380. [Google Scholar] [CrossRef]
- Nalbantov, G.; Bioch, J.C.; Groenen, P.J.F. Solving and Interpreting Binary Classification Problems in Marketing with SVMs. In From Data and Information Analysis to Knowledge Engineering; Springer: Berlin/Heidelberg, Germany, 2006; pp. 566–573. [Google Scholar] [CrossRef] [Green Version]
- Otani, N.; Otsubo, Y.; Koike, T.; Sugiyama, M. Binary classification with ambiguous training data. Mach. Learn. 2020, 109, 2369–2388. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Number of users in dataset | |
| Twitter dataset collected | |
| Training Dataset | |
| Testing Dataset | |
| Dataframe used for attributes of a Twitter object | |
| Id of a twitter user in a dataframe | |
| Followers count of a twitter user | |
| Friends count of a twitter user | |
| Location of user profile | |
| Verification status imparted by Twitter | |
| Name of the twitter user in the dataset | |
| Description of the twitter user | |
| Screen name of the twitter user | |
| Statuses count of the twitter user | |
| Bag of words containing objectionable phrases | |
| Existence of profile image of Twitter user | |
| Existence of extended profile of Twitter user | |
| Listed count of Twitter user | |
| Predicted status of profile as bot or non-bot | |
| Actual labelled status of a profile as bot or non-bot | |
| Training accuracy computation | |
| Testing accuracy computation |
| S.No. | Dataset Size | Fraction of Bot & Non-Bot | Training Accuracy | Testing Accuracy | |
|---|---|---|---|---|---|
| 1 | 25% | Bot | 42.23% | 0.979729 | 0.97009 |
| 2 | Non-Bot | 57.77% | |||
| 3 | 50% | Bot | 52.34% | 0.970833 | 0.985621 |
| 4 | Non-Bot | 47.66% | |||
| 5 | 75% | Bot | 54.03% | 0.984137 | 0.989867 |
| 6 | Non-Bot | 45.97% | |||
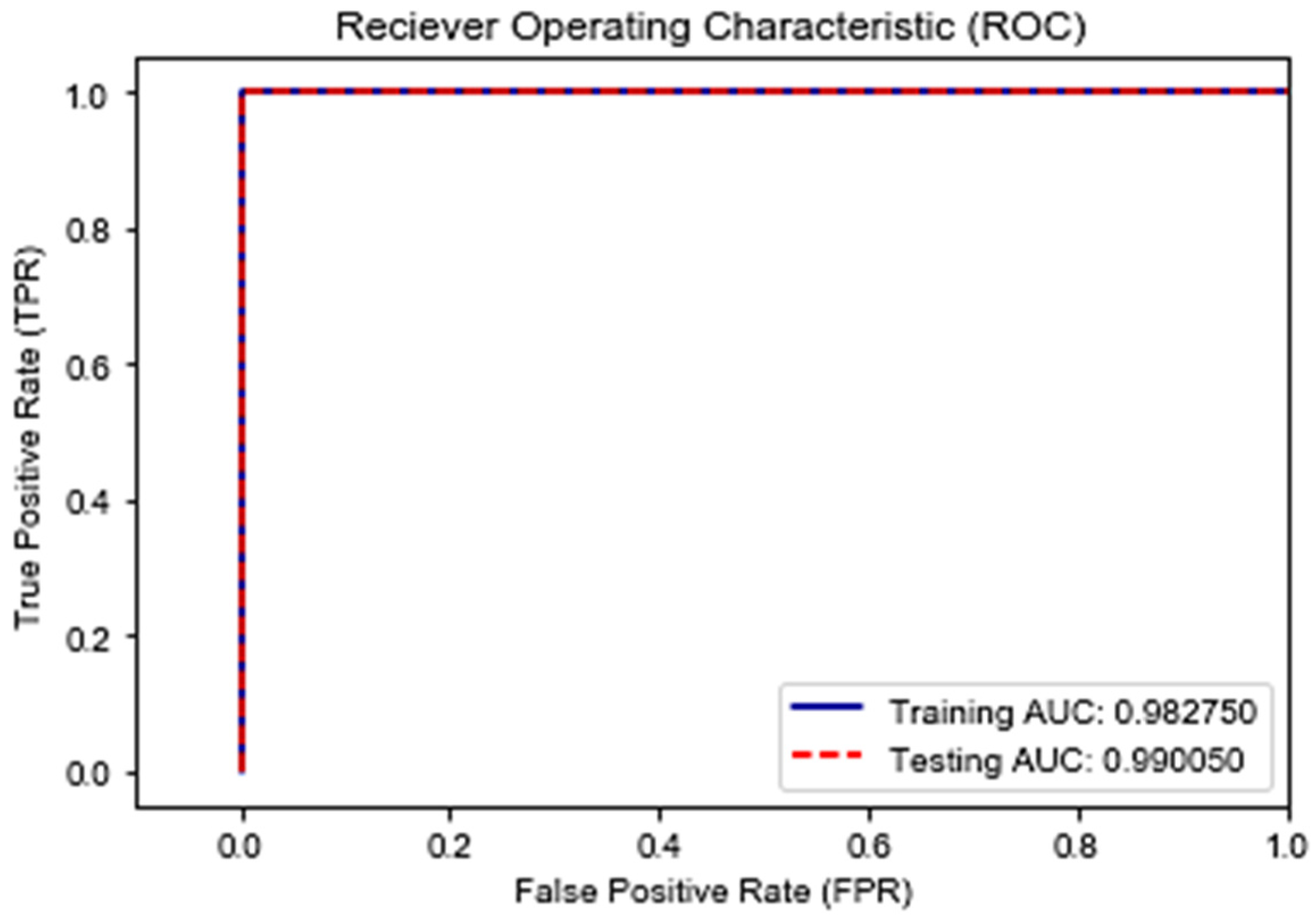
| 7 | 100% | Bot | 47.22% | 0.982749 | 0.990049 |
| 8 | Non-Bot | 52.78% | |||
| S.No. | Classifier | Training Accuracy † | Training AUROC * | Testing Accuracy † | Testing AUROC * |
|---|---|---|---|---|---|
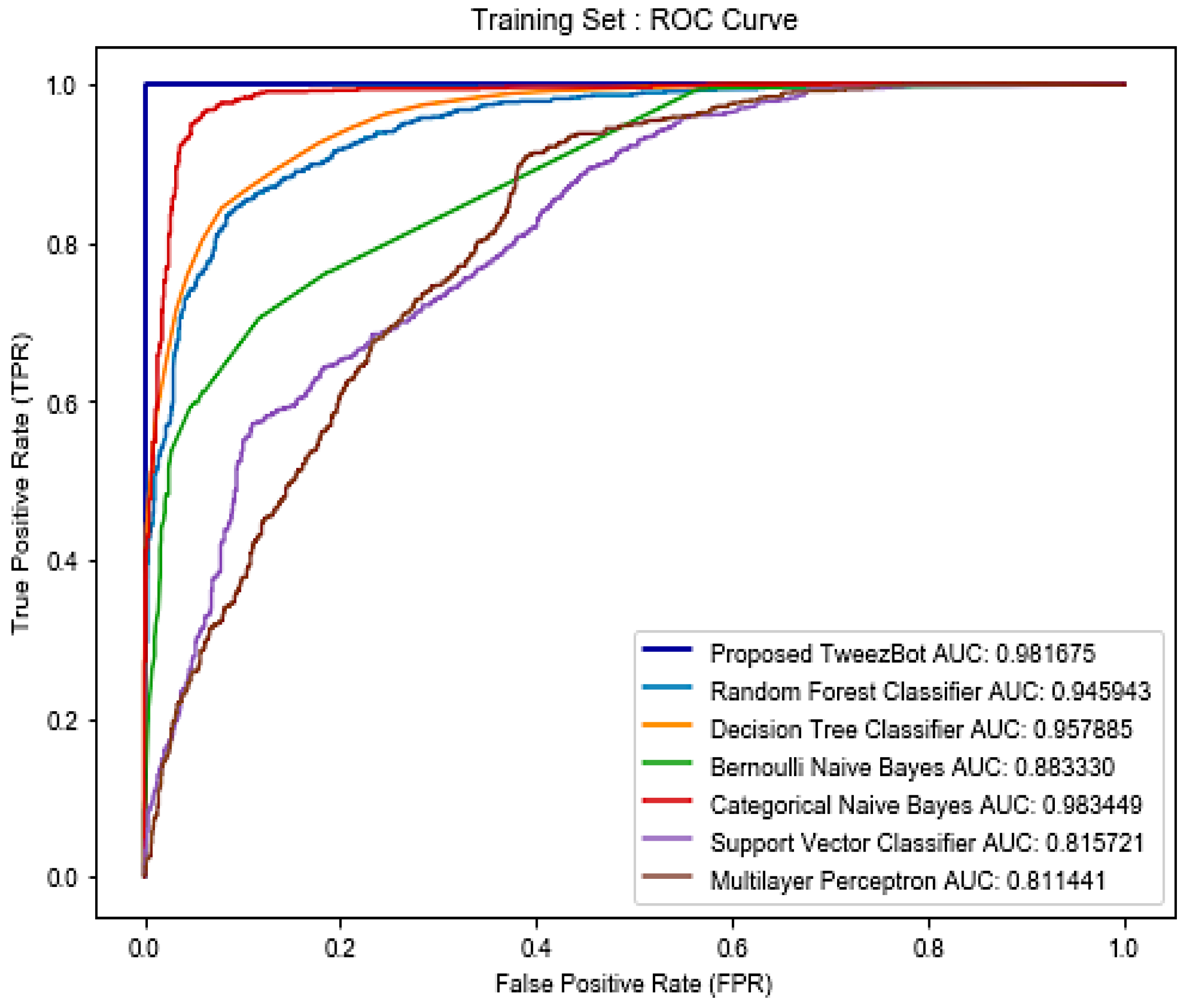
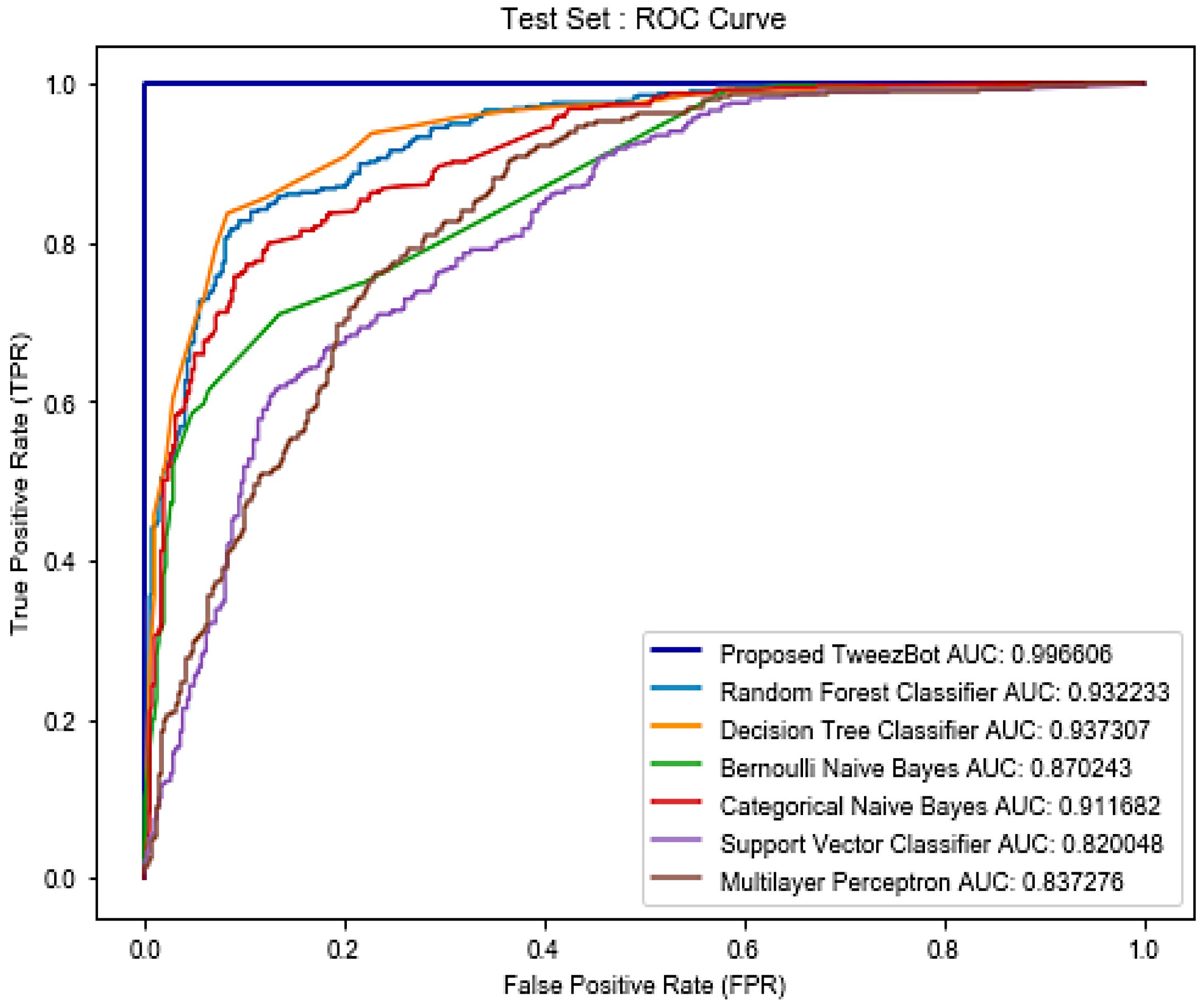
| 1. | Decision Tree | 88.5539 | 0.957885 | 87.7381 | 0.937313 |
| 2. | Random Forest | 87.2253 | 0.945545 | 86.0714 | 0.931360 |
| 3. | Bernoulli Naïve Bayes | 80.0715 | 0.883330 | 78.8095 | 0.870243 |
| 4. | Categorical Naïve Bayes | 95.0945 | 0.983449 | 81.7857 | 0.911682 |
| 5. | Support Vector Machine | 87.2253 | 0.815790 | 86.0714 | 0.820042 |
| 6. | Multi-layer Perceptron | 63.1068 | 0.811441 | 62.1428 | 0.837276 |
| 7. | Proposed TweezBot | 98.2749 | 0.981675 | 99.0049 | 0.996606 |
| Parameters | Decision Tree | Random Forest | Bernoulli Naïve Bayes | Categorical Naïve Bayes | SVM | Multilayer Perceptron Layer (ANN) | Proposed TweezBot |
|---|---|---|---|---|---|---|---|
| Training Precision | 0.901891 | 0.895238 | 0.838157 | 0.9307036 | 0.895238 | 0.8181818 | 0.999899 |
| Testing Precision | 0.908854 | 0.891472 | 0.838526 | 0.7959641 | 0.891472 | 0.8510638 | 0.992443 |
| Training Recall | 0.844026 | 0.831858 | 0.704646 | 0.945708 | 0.831858 | 0.2588496 | 0.950369 |
| Testing Recall | 0.836930 | 0.827338 | 0.709832 | 0.8513189 | 0.827338 | 0.2877698 | 0.938574 |
| Training F1_Score | 0.872000 | 0.862385 | 0.765625 | 0.9478827 | 0.862385 | 0.3932773 | 0.995689 |
| Testing F1 Score | 0.871410 | 0.858209 | 0.768831 | 0.8227115 | 0.858209 | 0.4301075 | 0.989361 |
| Training Cohen Kappa Score | 0.768693 | 0.752054 | 0.594537 | 0.9015805 | 0.752054 | 0.2201130 | 0.988734 |
| Testing Cohen Kappa Score | 0.754611 | 0.728419 | 0.575707 | 0.6358753 | 0.728419 | 0.2392474 | 0.990504 |
| Training ROC AUC Score | 0.882602 | 0.874143 | 0.793918 | 0.9519898 | 0.874143 | 0.6047334 | 0.987283 |
| Testing ROC AUC Score | 0.877094 | 0.864023 | 0.787540 | 0.8180945 | 0.864023 | 0.6190622 | 0.995192 |
| S.No. | Actual Bot Status | Twitter Screen Name | Existing Social Media Bot Identifiers | Proposed TweezBot Automation Outcome ‡ | ||
|---|---|---|---|---|---|---|
| Botometer Automation (Score) * | BotSentinel Automation (Score) † | TweetBotOrNot Automation (Score) † | ||||
| 1 | Bot | @2181chrom_bot | Bot (4.6) | Non-Bot (0) | Bot (0.992) | 1 |
| 2 | @2LA1R_bot | Non-Bot (4.1) | Non-Bot (0) | Non-Bot (0.561) | 1 | |
| 3 | @3pei_bot | Bot (4.7) | Non-Bot (0) | Bot (0.957) | 1 | |
| 4 | @joe_ghinn_ITBot | Bot (4.3) | Non-Bot (0.13) | Bot (0.820) | 1 | |
| 5 | @misheardly | Bot (4.6) | Bot (0.23) | Bot (0.873) | 1 | |
| 6 | @stevehssb_ITBot | Bot (4.6) | Non-Bot (0.39) | Bot (0.764) | 1 | |
| 7 | Non-Bot | @KellySchuberth | Non-Bot (0) | Non-Bot (0.03) | Non-Bot (0.320) | 0 |
| 8 | @KylieJenner | Non-Bot (0) | Non-Bot (0.03) | Non-Bot (0.254) | 0 | |
| 9 | @Meg_Cramer | Non-Bot (0.1) | Non-Bot (0.01) | Non-Bot (0.439) | 0 | |
| 10 | @mitchprothero | Non-Bot (0.1) | Non-Bot (0.1) | Bot (0.770) | 0 | |
| 11 | @o_tilli_a | Non-Bot (0) | Non-Bot (0.02) | Non-Bot (0.191) | 0 | |
| 12 | @jasonhall8675 | Non-Bot (0.4) | Non-Bot (0.09) | Bot (0.683) | 0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shukla, R.; Sinha, A.; Chaudhary, A. TweezBot: An AI-Driven Online Media Bot Identification Algorithm for Twitter Social Networks. Electronics 2022, 11, 743. https://doi.org/10.3390/electronics11050743
Shukla R, Sinha A, Chaudhary A. TweezBot: An AI-Driven Online Media Bot Identification Algorithm for Twitter Social Networks. Electronics. 2022; 11(5):743. https://doi.org/10.3390/electronics11050743
Chicago/Turabian StyleShukla, Rachit, Adwitiya Sinha, and Ankit Chaudhary. 2022. "TweezBot: An AI-Driven Online Media Bot Identification Algorithm for Twitter Social Networks" Electronics 11, no. 5: 743. https://doi.org/10.3390/electronics11050743
APA StyleShukla, R., Sinha, A., & Chaudhary, A. (2022). TweezBot: An AI-Driven Online Media Bot Identification Algorithm for Twitter Social Networks. Electronics, 11(5), 743. https://doi.org/10.3390/electronics11050743