This section presents the architecture, components, and interconnections used in the design of the proposed tool. It also includes a discussion about main features, instrumentation modes, and output file structure that contains the data measured and collected by the proposed tool.
3.1. Architecture
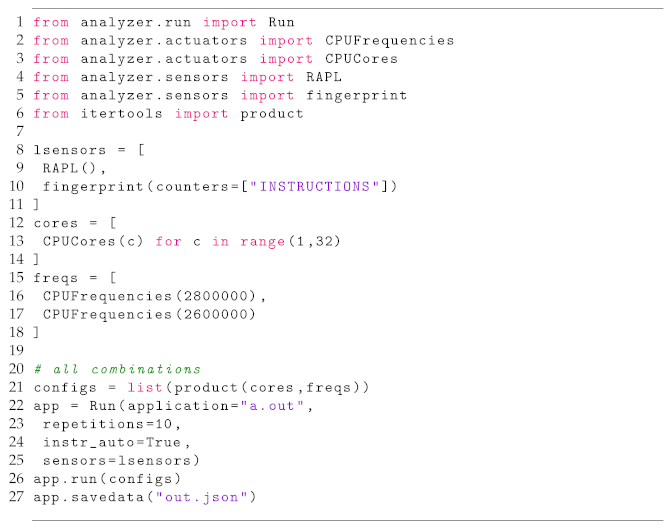
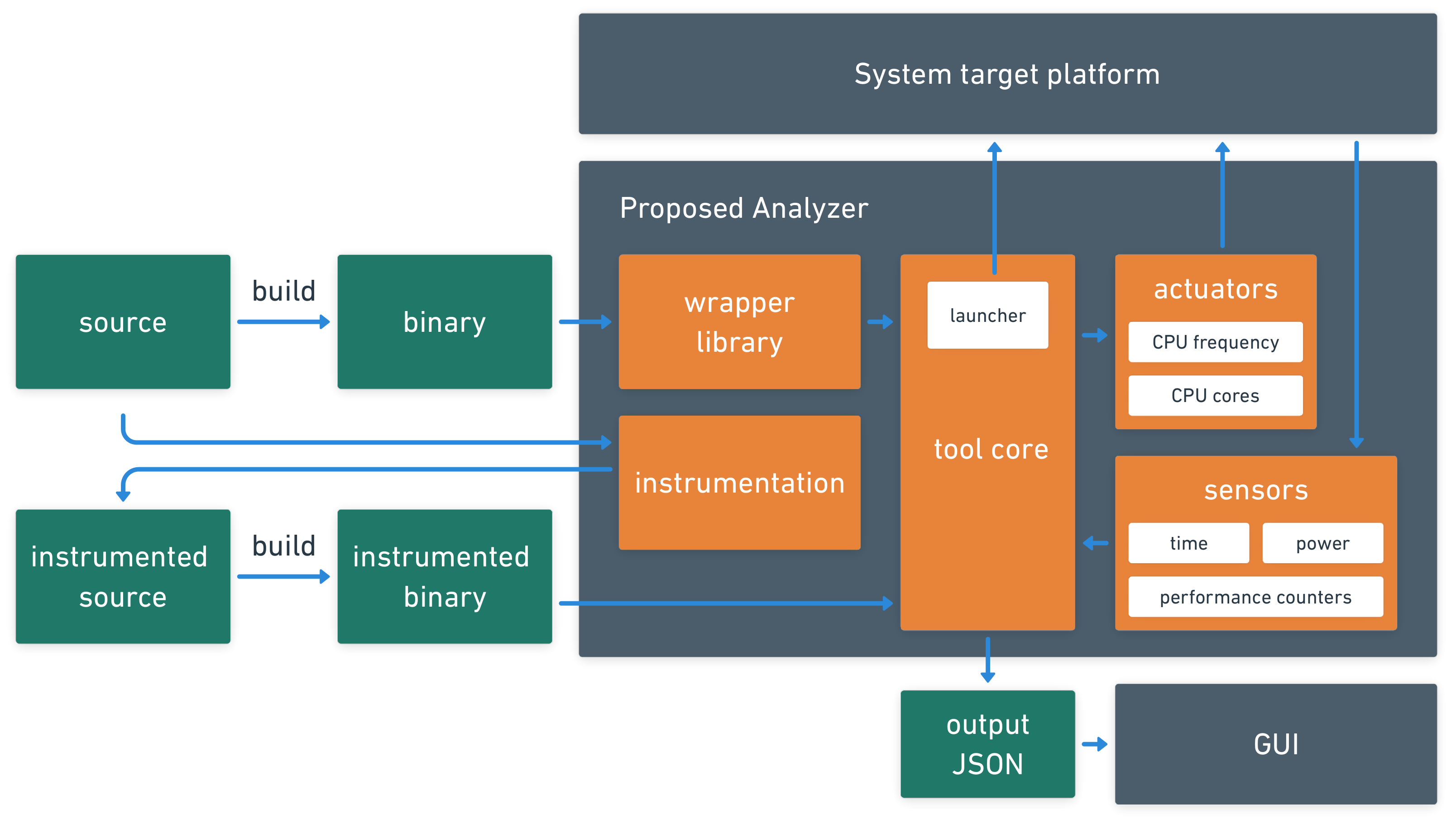
The tool we propose to measure, combine and compare multiple runs of a parallel application implements two main concepts to achieve this goal: actuators and sensors.
Actuators characterize the parameters we intend to observe. They are variables representing elements external to the program and which, when changed, can influence aspects such as the performance and efficiency of the running application. Therefore, analyzing the result of actuators’ variation is essential to understand how these elements impact program behavior, especially scalability and power consumption. By default, the tool implements actuators controlling the number of active cores and threads, the program input, and the CPU operating frequency.
The sensor is the concept we use to represent the elements addressed to measure and monitor the variation of actuators. Both sensors and actuators are plugged into the tool core as modules. Currently, the tool implements three types of sensors:
Begin/end: collects data at launch and end of each program run.
Time sample: periodically collects data.
Events-based: collects data when a specific event happens.
Currently, there are sensors to measure time, energy, and performance counters. The default sensor is a begin/end type used to collect the execution time of the whole application. To measure energy consumption, we developed sampling sensors capable of retrieving data from RAPL (Running Average Power Limit) and IPMI (Intelligent Platform Management Interface), which are interfaces that provide power information from the CPU and the entire system. Apart from that, there are time sample and begin/end sensors to gather performance counters data.
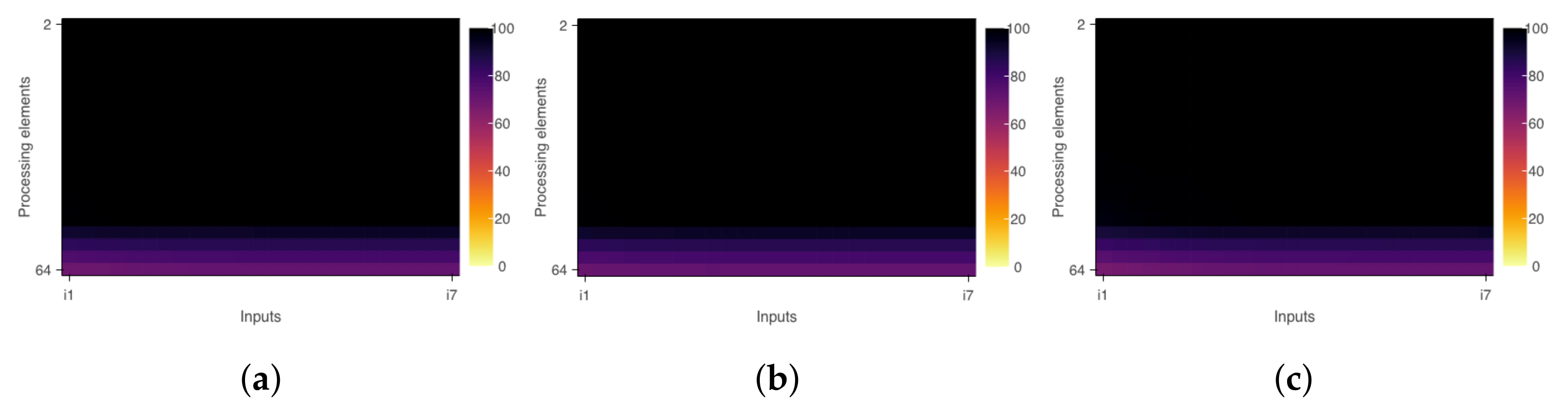
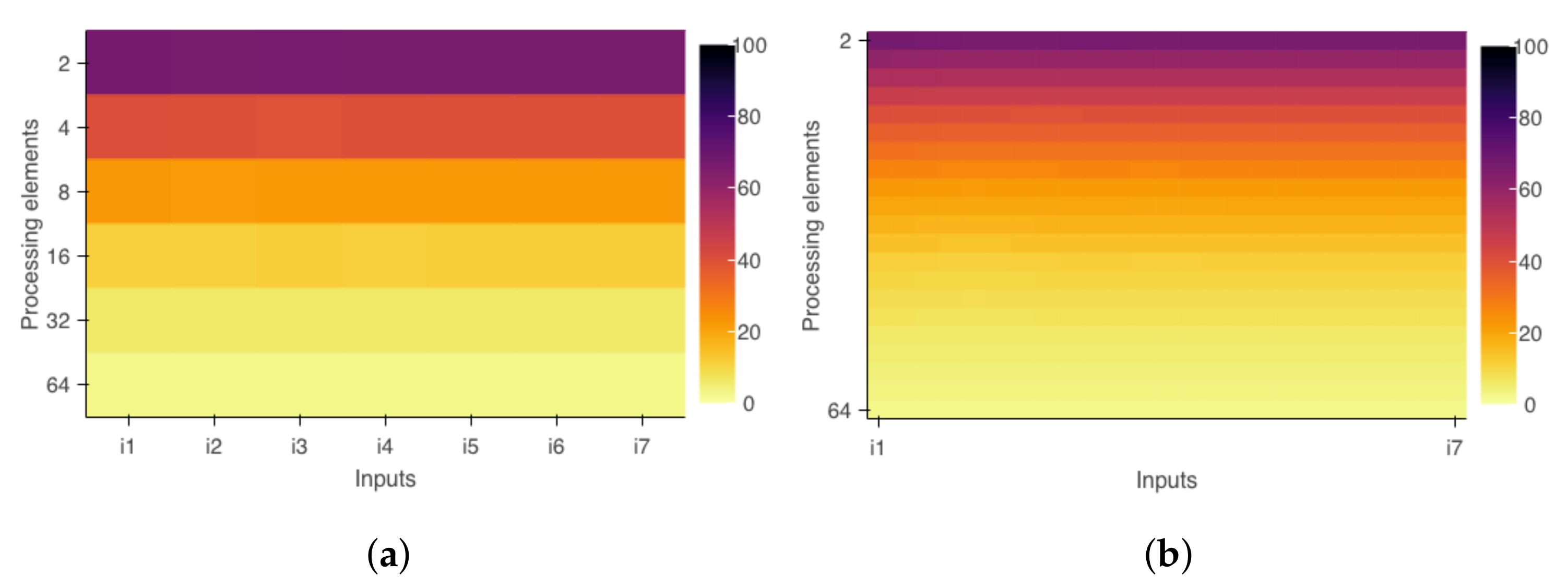
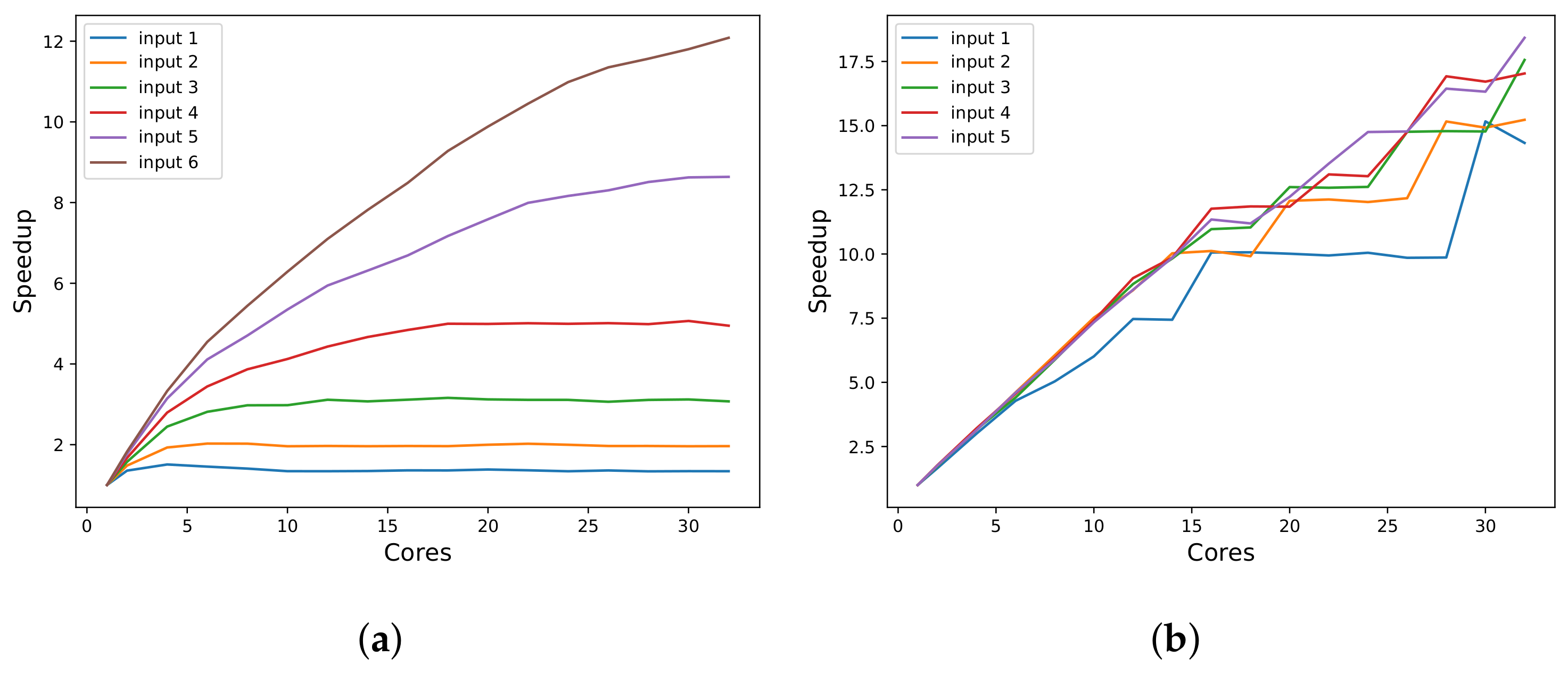
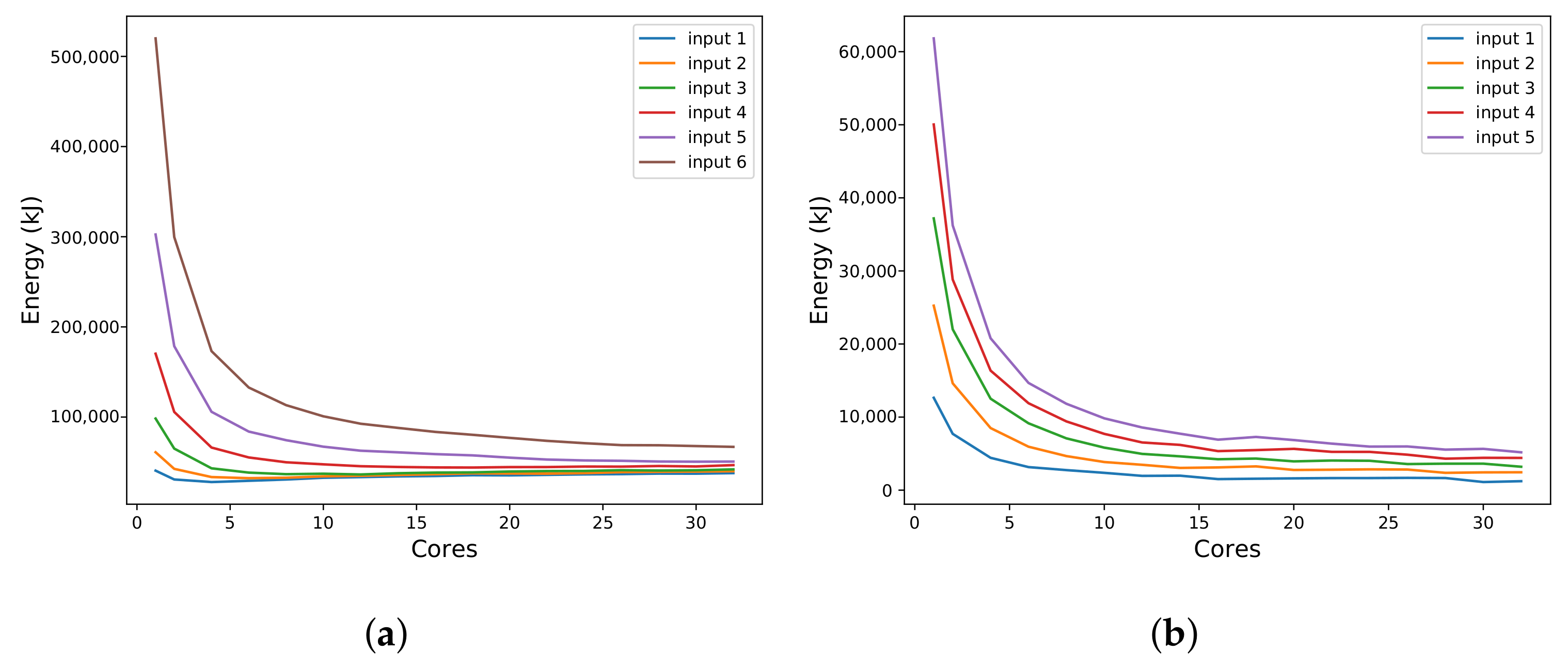
Measurements that support scalability analysis are taken from event-based sensors. For this, the tool includes markers that trigger events to automatically identify the boundaries of parallel regions defined by developers in codes that use POSIX Threads or OpenMP. This feature is essential for relating parallel code sections to analysis regions and measuring execution times directly from binary code. The triggers for this measurement mode are implemented in a wrapper library and therefore already available in the system. The tool also provides manual marks that can be inserted into the source code to monitor specific parts of the program. Furthermore, any system event can be set as a trigger.
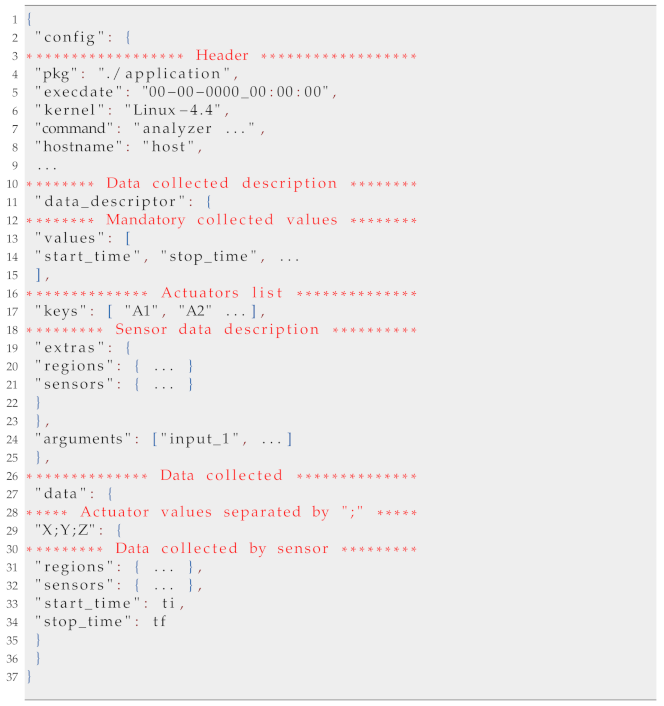
Figure 1 describes the integration of each part of the proposed software. The idea is that actuators and sensors are modular parts that can easily be added or removed. The tool’s core is responsible for all operations, launching the application, and data gathering.
3.2. Instrumentation and Intrusiveness
The instrumentation module is one of the most crucial. In addition to automating the instrumentation, it determines the overload and level of intrusiveness of the instrumentation process. This module is designed to execute the fewest instructions possible in the most optimized manner. Currently, there is instrumentation support for C/C++ languages through shared libraries that work with either automatic or manual instrumentation. Manual instrumentation is preferred when it is necessary to examine the application program in specific code sections, regardless of the type of content.
The manual instrumentation mode is implemented in three routines: one for initialization, another to mark the beginning of the region of interest (analyzer_start), and finally, a routine to mark the end of that region (analyzer_stop). The initialization routine is called when loading the library to create the necessary data structures and set up the data exchange communication. The routines analyzer_start and analyzer_stop identify threads in a region and store timestamps. These routines are implemented in such a way that only one thread at a time writes in a designated position of a two-dimensional array, thus ensuring thread safety and eliminating the necessity of locks.
The automatic instrumentation includes a routine allowing us to intercept the creation of threads via the LD_PRELOAD environment variable. This routine overwrites parts of an existing native library. In this manner, the functions responsible for thread spawning, such as pthread_create in the pthread library, GOMP_parallel (GCC implementation), __kmpc_fork_call (Clang implementation) in the OpenMP framework, and similar functions for other compilers, are intercepted to identify the parallel regions automatically. This approach is less intrusive than other tools, such as using a debugger interface with breakpoints or performing binary code instrumentation.
A key point of performance analysis tools, particularly important when analyzing real-time program execution, is that instrumentation must have a negligible impact on program behavior and execution time. Indeed, as mentioned in
Section 3.1, we support three types of sensors, each of which has a different degree of intrusion. There is hardly any sensors intrusion at the start and then at the end of the program execution since it is simply the invocation of both data collection routines.
With sampling sensors, the degree of intrusion depends on the sampling rate and the total execution time of the application under study. Therefore, the intrusion needs to be assessed on a case-by-case basis with this type of sensor.
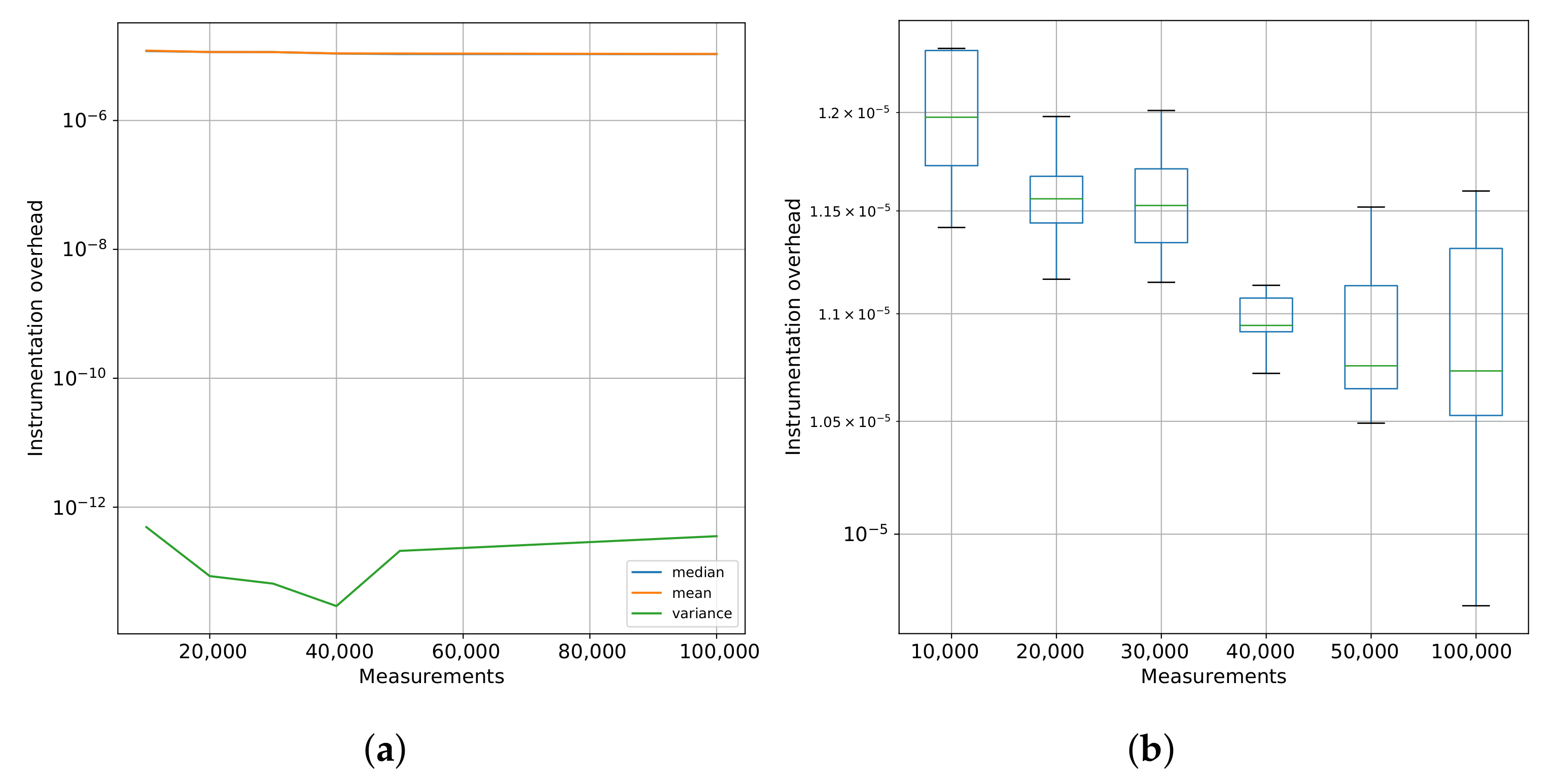
The instrumentation overhead does not depend on the number of instructions or the runtime required to process the set of instructions to be analyzed. However, it varies according to the number of processing units used and measurements taken. To estimate the order of magnitude of the overhead (
), we measured recurring calls to the proposed sampling functions delimiting the regions in a simple benchmark code. This experiment was carried out in the same target architecture described in the experimental results of
Section 4.2, and the code structure is presented on Listing 1.
| Listing 1. Code used to measure the overhead of instrumentation functions (analyzer_start and analyzer_stop) defined as . |
![Electronics 11 00689 i001]() |
The time required to execute
N calls to the
analyzer_start and
analyzer_stop functions was obtained by the routine
gettimeofday, from the
sys/time.h library. The algorithm ran with 1
, 2
, 3
, 4
, 5
, and 1
calls to the pair of functions, each test repetited ten times, and the mean, median, and variance values computed.
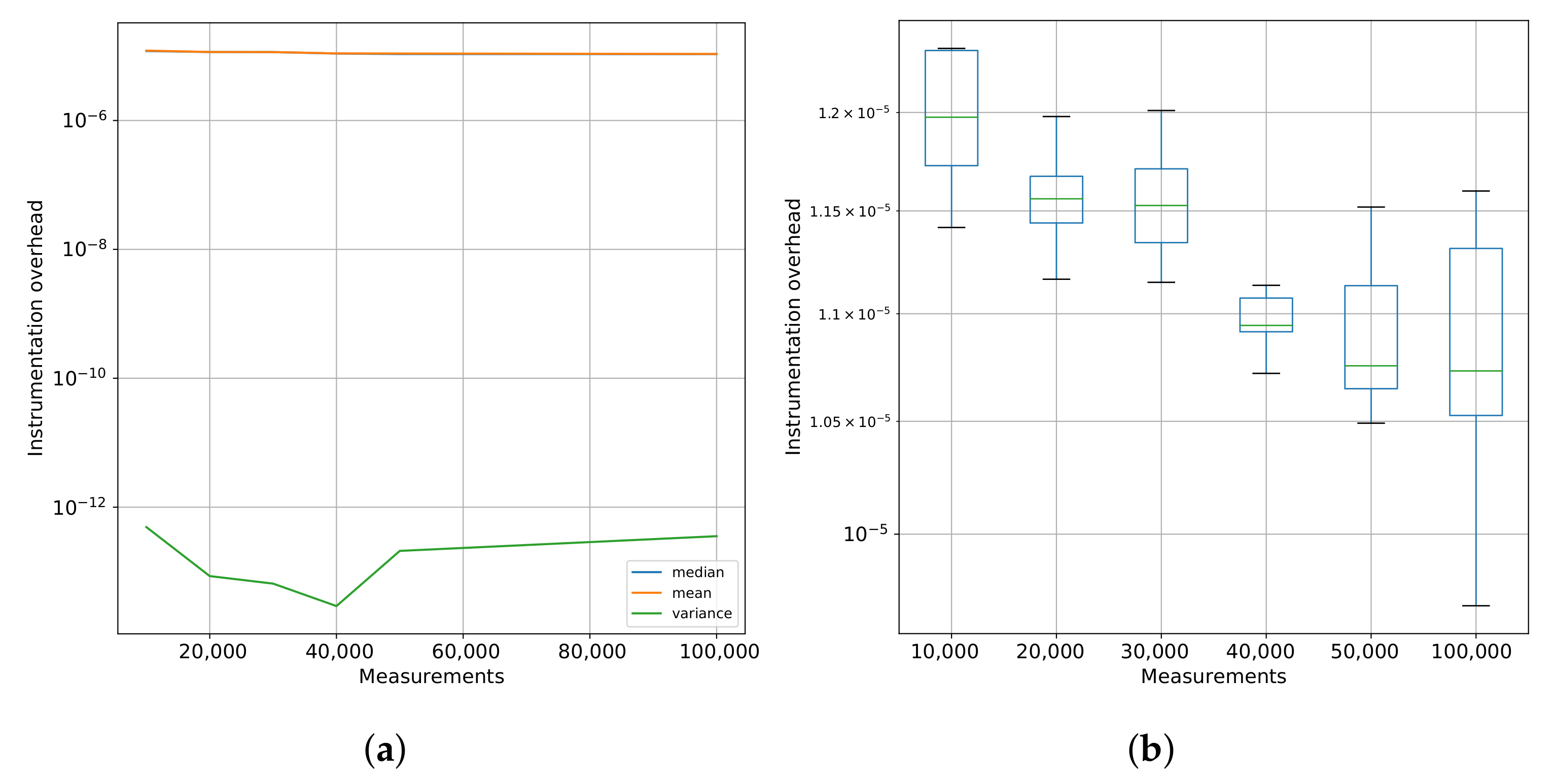
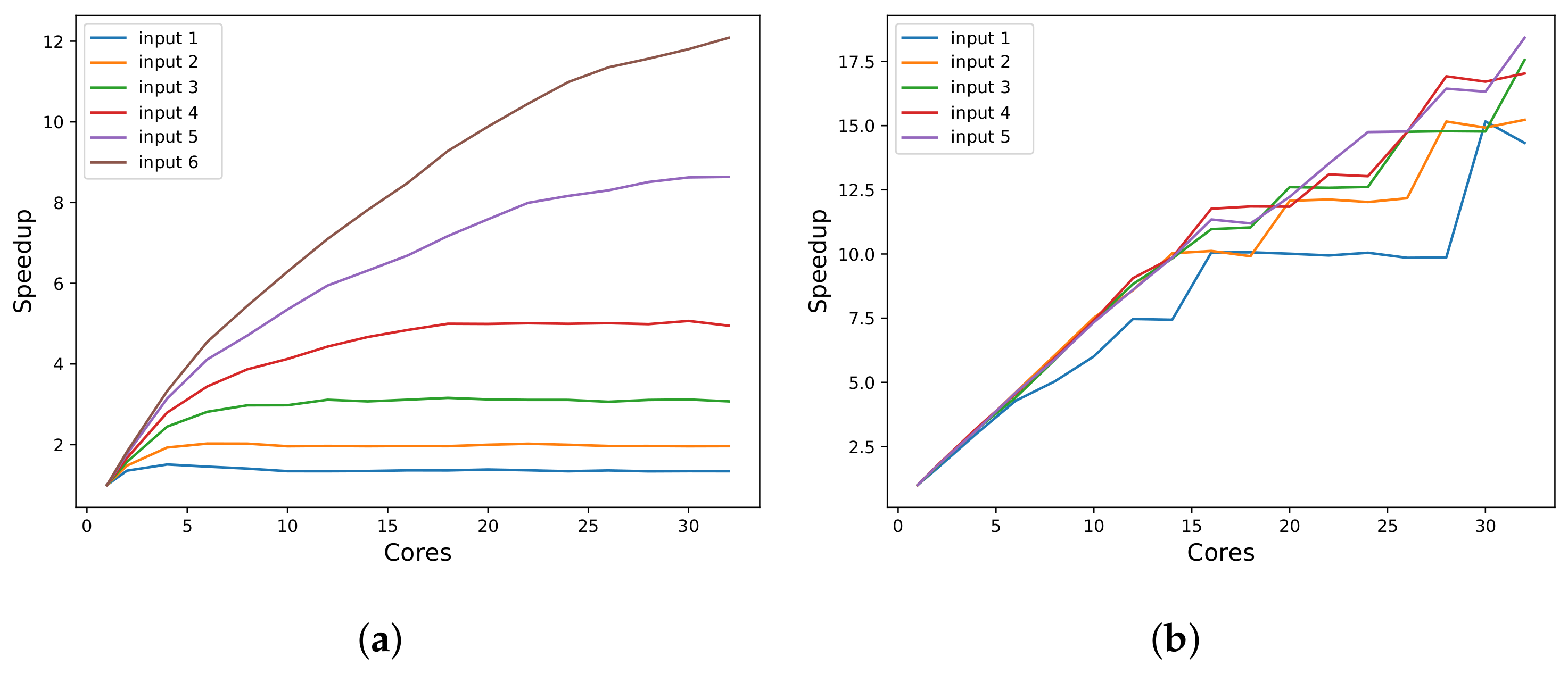
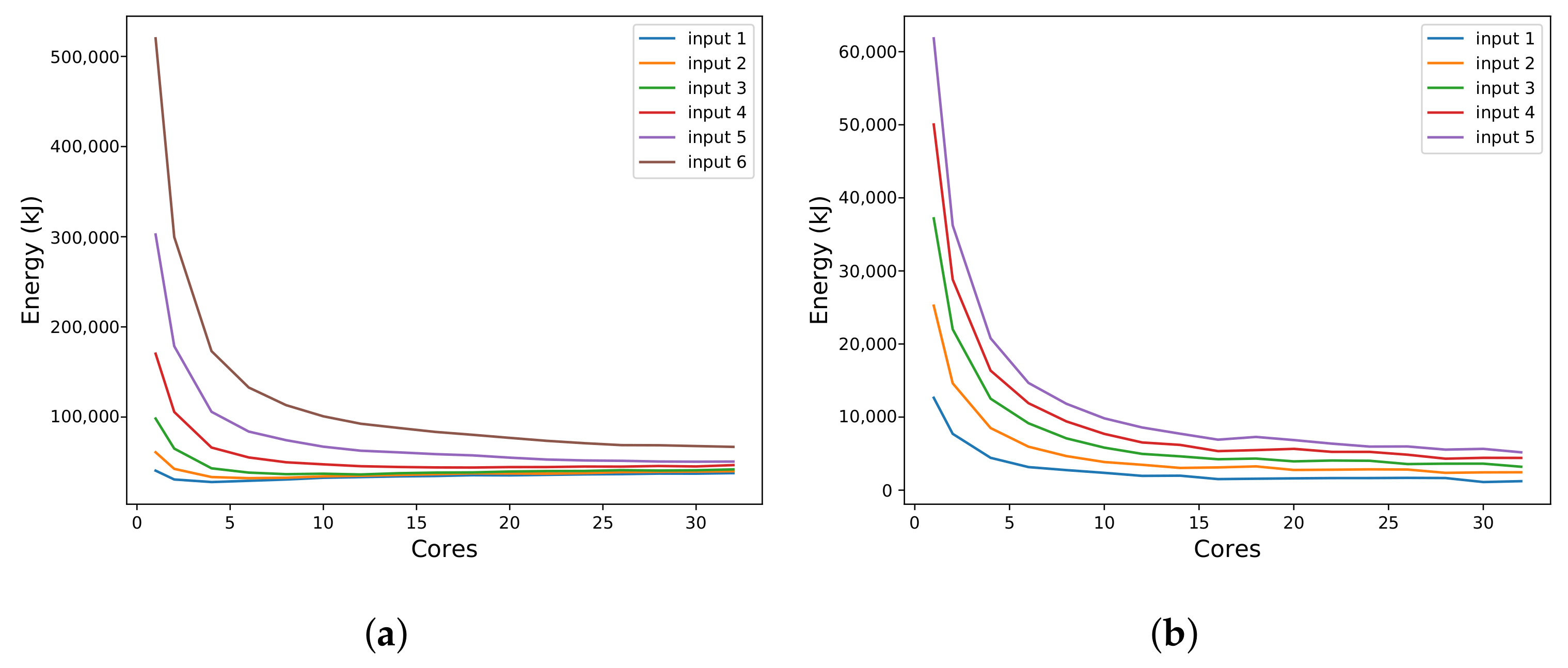
Figure 2 shows these results.
In
Figure 2a, we can see the mean, median, and variance of the time for a single call to our instrumentation function while varying the number of calls/measurements. The
Figure 2a complements these results showing the variance in each execution.
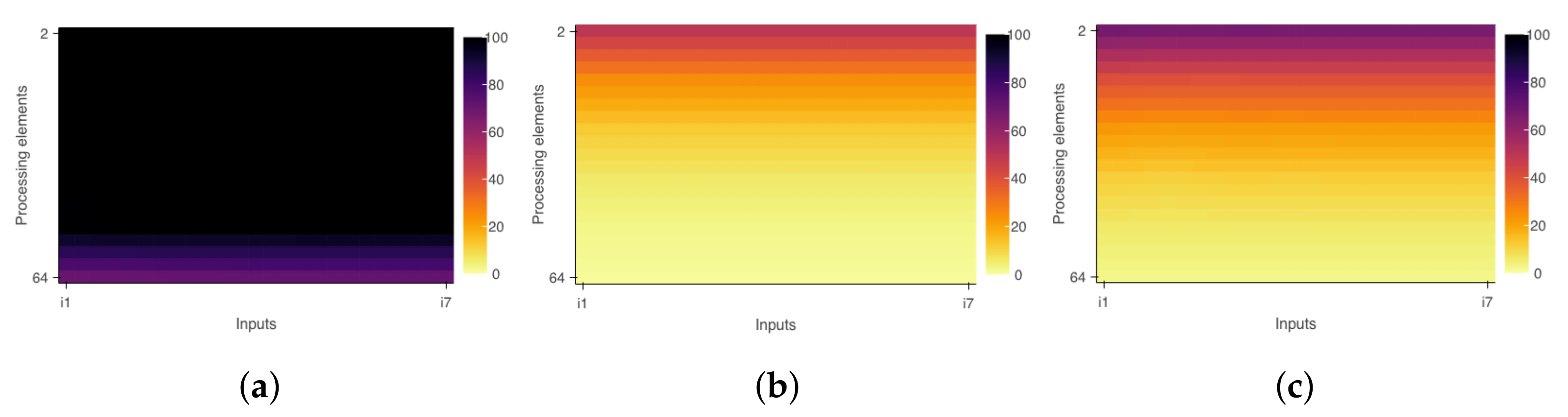
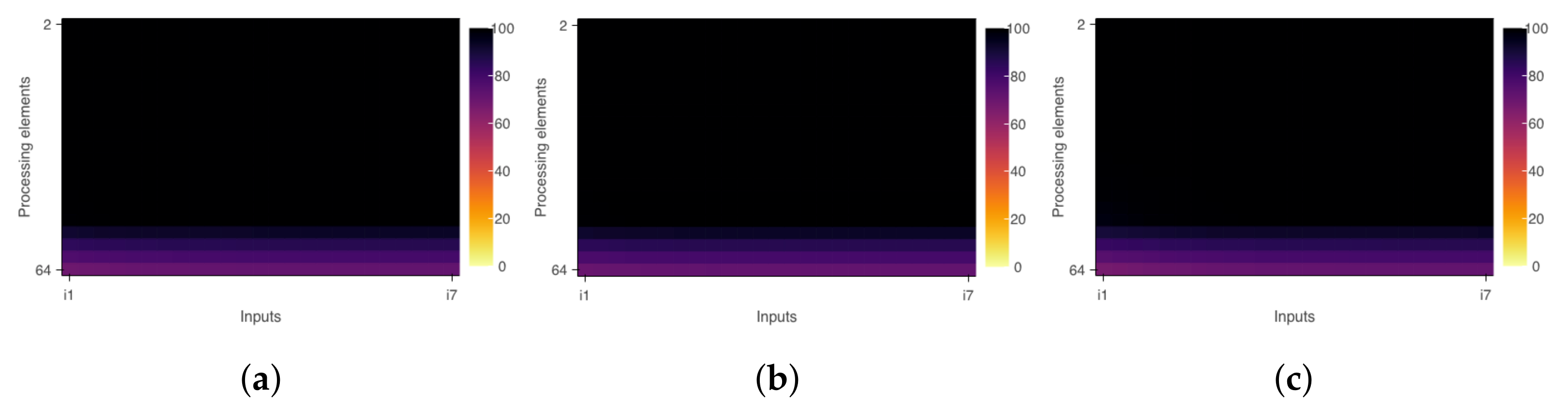
Table 1 shows the results from the same experiment above comparing the time with and without the analyzer. We can observe that proportional impact (overhead) was constant while the number of interactions increased.
Table 1 also presents the data referring to the simulation using the TAU profiling tool. For this simulation, we replaced the analyzer directives with the time measurement directives (
TAU_PROFILE_START and
TAU_PROFILE_STOP) of TAU, which allowed us to approximate the measurement and analysis conditions.
From the results, it is possible to see that the tool proposed in this work has a higher overhead than that presented by the TAU, but the analysis capabilities are distinct. TAU adds the individual runtime of each thread to define the execution time of a parallel region. This strategy does not consider the simultaneous action of threads in processing instructions and can count the same period of time more than once, damaging a precise measurement of the parallel region. The analyzer works around this problem because the intersection periods are counted just once. In this sense, although the TAU has lower overhead, a scalability analysis depends on a more accurate measurement like the one proposed in this work.
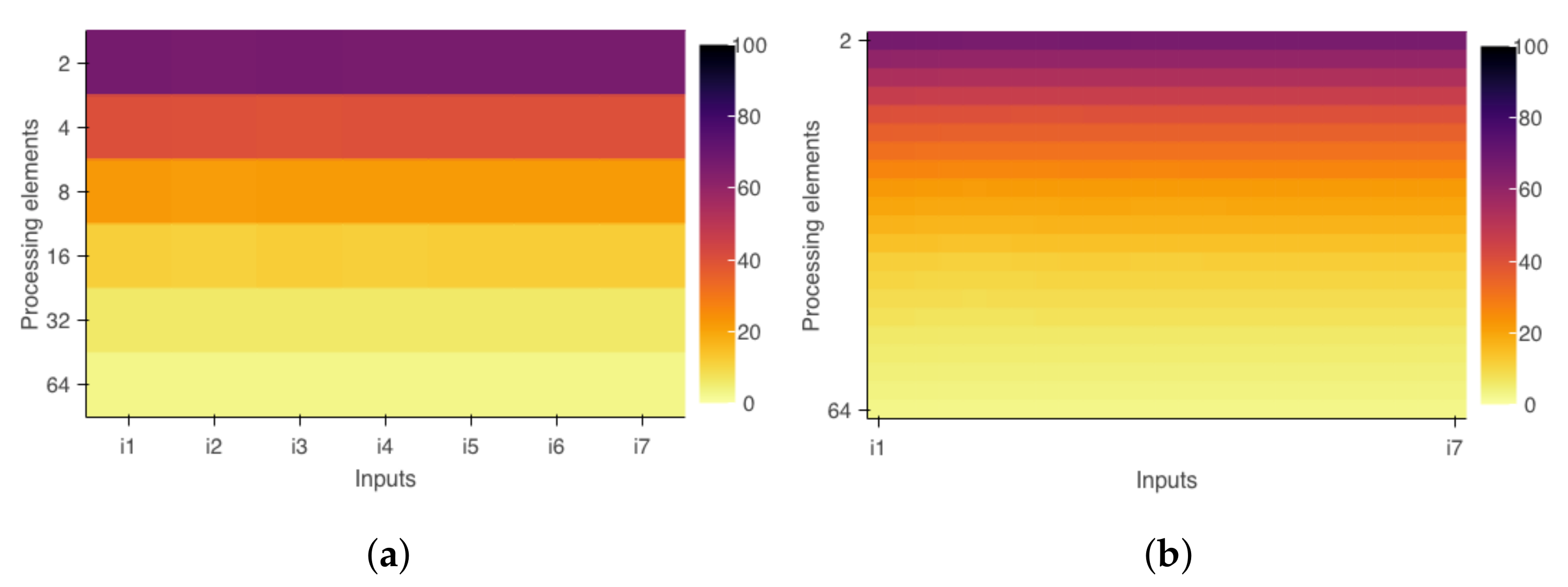
Varying the number of threads impacts the cost of instrumentation. As shown in
Table 2, there is a trend for the percentage of overhead to increase concerning the application’s runtime. However, it is also possible to see that this increase is negligible, considering the exponential increase in the number of threads. The increase in the processing load, on the other hand, has a beneficial impact on the relationship between execution time and the percentage of overhead. This behavior occurs because the runtime will increase with the greater need for processing, and the overhead will only change if the number of threads is also changed.
For pluggable sensors, overhead is generally not a concern as they run on a separate thread and have very low CPU usage, which presents only a few scenarios where they can cause interference.
One of these scenarios is where the application needs all the machine’s resources at the same time that we have sensors that can respond faster than the processing speed at a given sample rate. In this case, the overhead would be directly associated with the sample rate and how the system handles concurrency. In general, this is rarer to happen in HPC (High-performance computing) since it would require an application with a perfect linear scaling.
Another possible scenario is I/O overhead, where some network, disk, or memory resource becomes unavailable due to high sensor usage. However, this scenario is even rarer as sensors seldom produce data that quickly and, in all the performed tests, this was not close to being an issue.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}