
Android-SEM: Generative Adversarial Network for Android Malware Semantic Enhancement Model Based on Transfer Learning

 , ,
, ,
Abstract
:1. Introduction
- To the best of our knowledge, we are the first to use feature fusion vectors obtained from comments and source code to enhance the semantic information contained in malware. We propose Android-SEM, which is a generative adversarial pre-training model based on the transfer learning method. We effectively use the model for malicious Android code detection and classification.
- We transfer comment information that hardly exists in Android malicious code from a large number of Android source code datasets to the malicious code domain through transfer learning to enhance program-related semantic information.
- We propose a transfer learning-based filter, which can filter out bad comments without labels, and we use generative adversarial networks to improve the quality of generated comments, thereby effectively improving the classification abilities of our proposed model.
- To the best of our knowledge, we are the first to develop a model that uses QSVM combined with classical deep learning to detect malicious code in Android-based applications, and Android-SEM is more accurate than other detection models proposed in recent studies.
2. Related Work
2.1. Android Malware Detection and Classification
2.2. Source Code Comment Generation
2.3. Quantum Machine Learning

3. Method
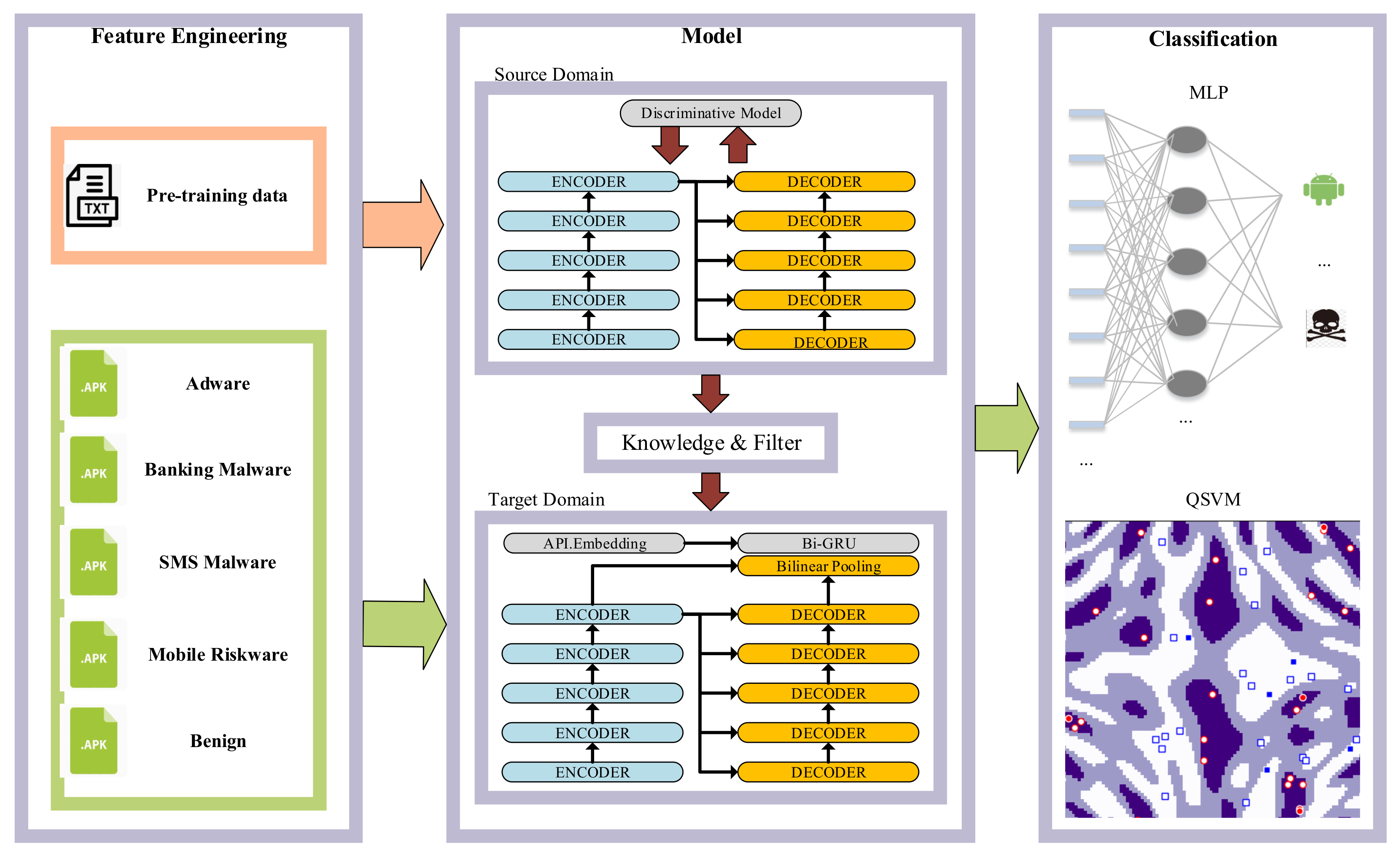
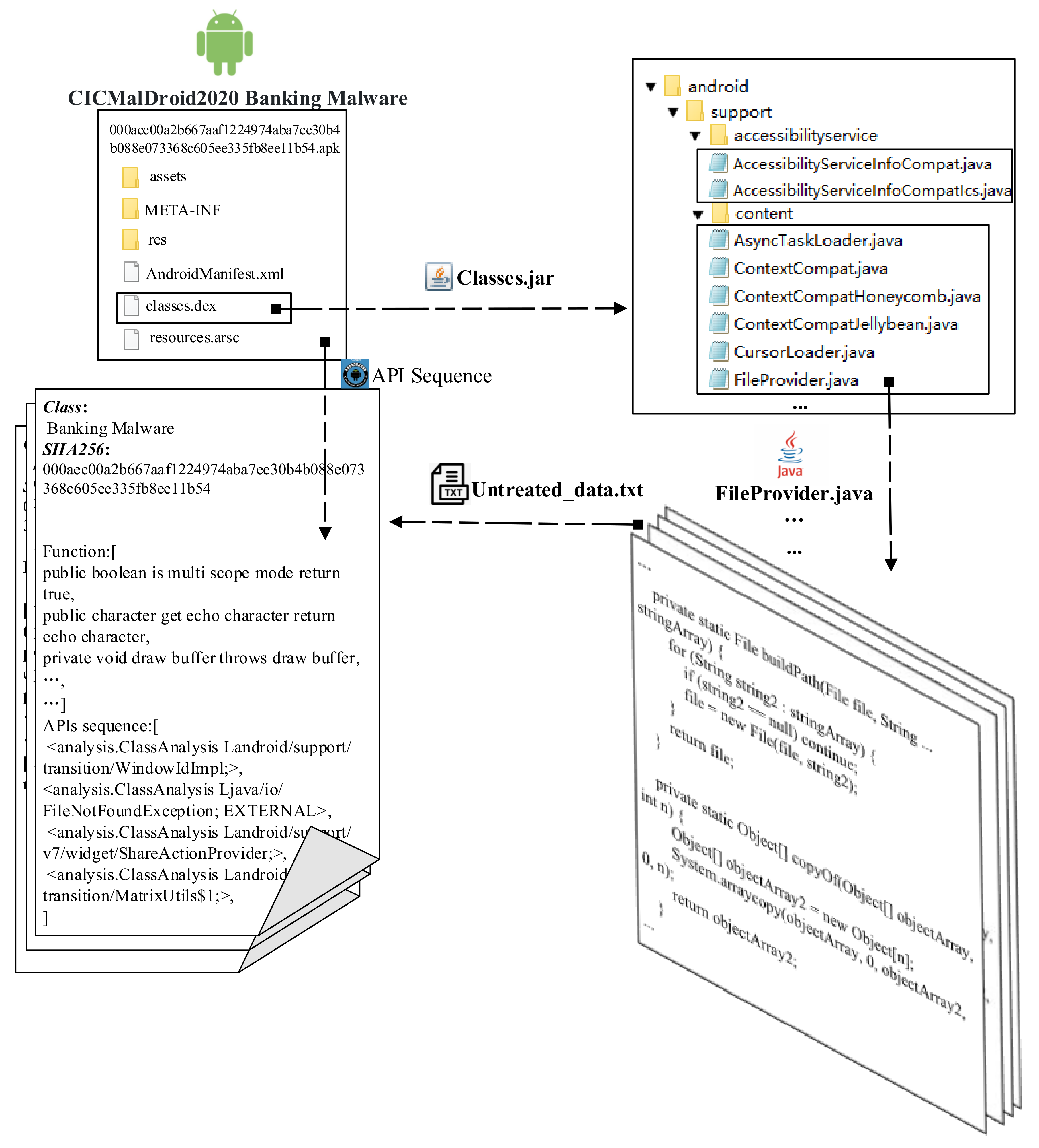
3.1. Feature Engineering
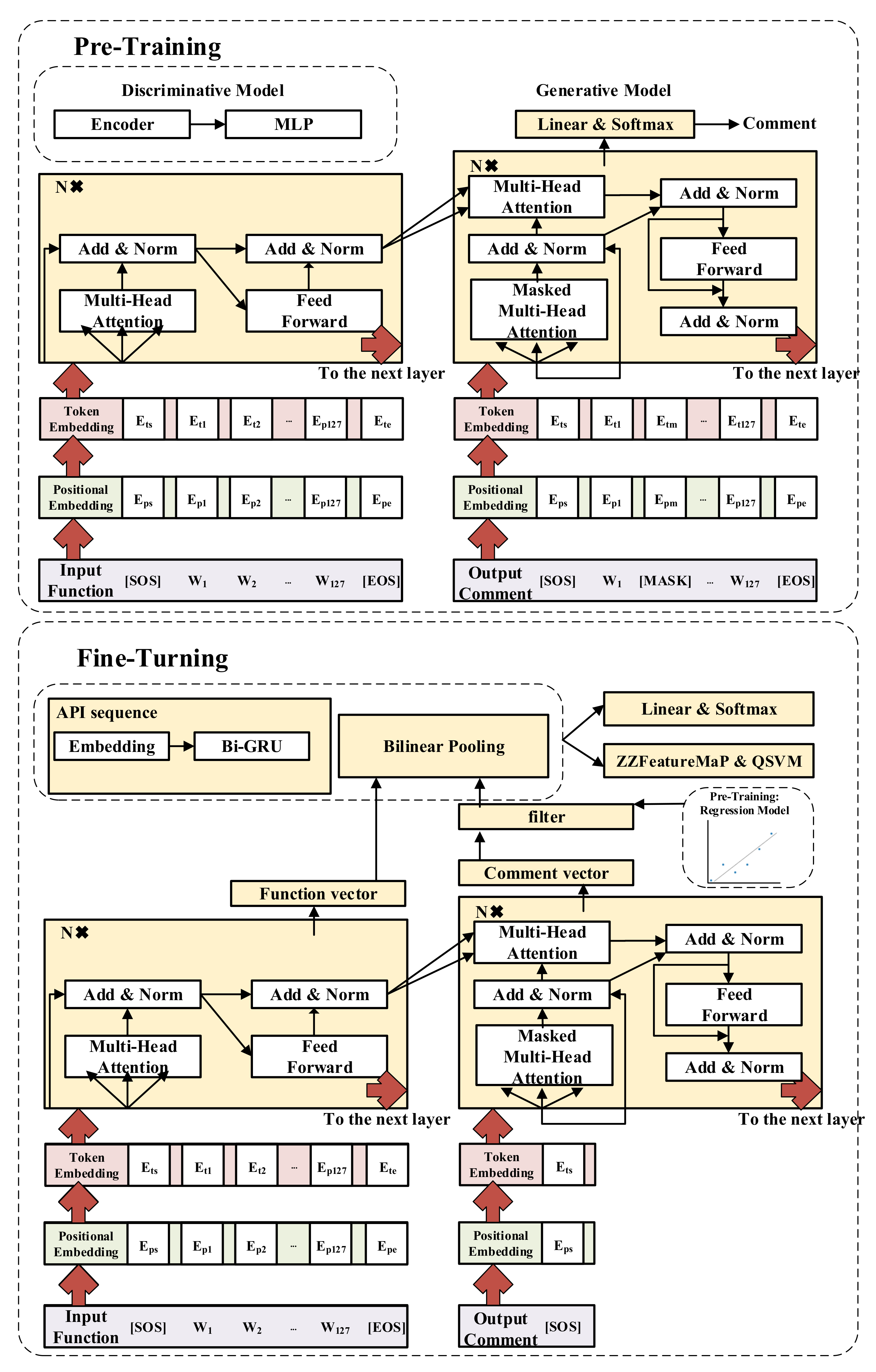
3.2. Model Design
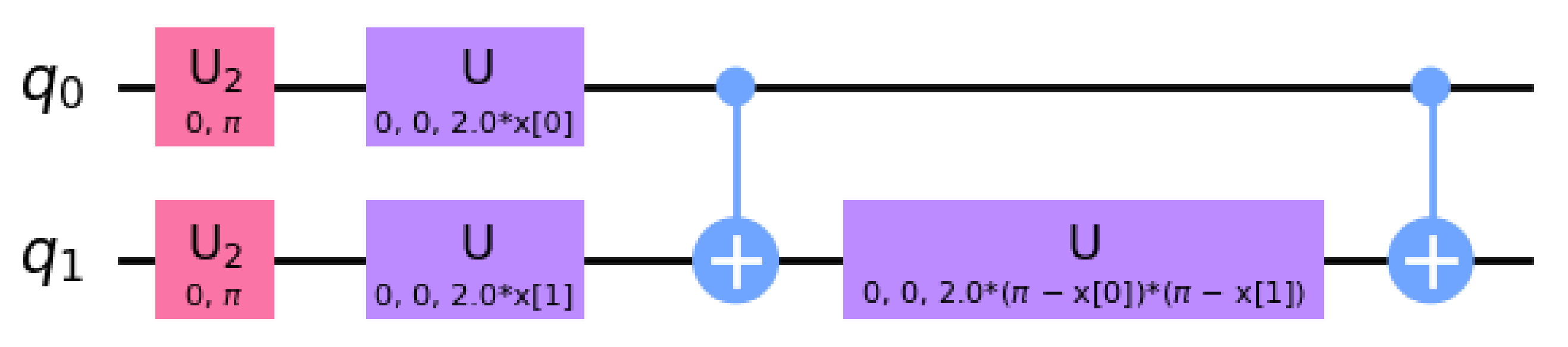
3.3. Quantum Classifier
4. Evaluation
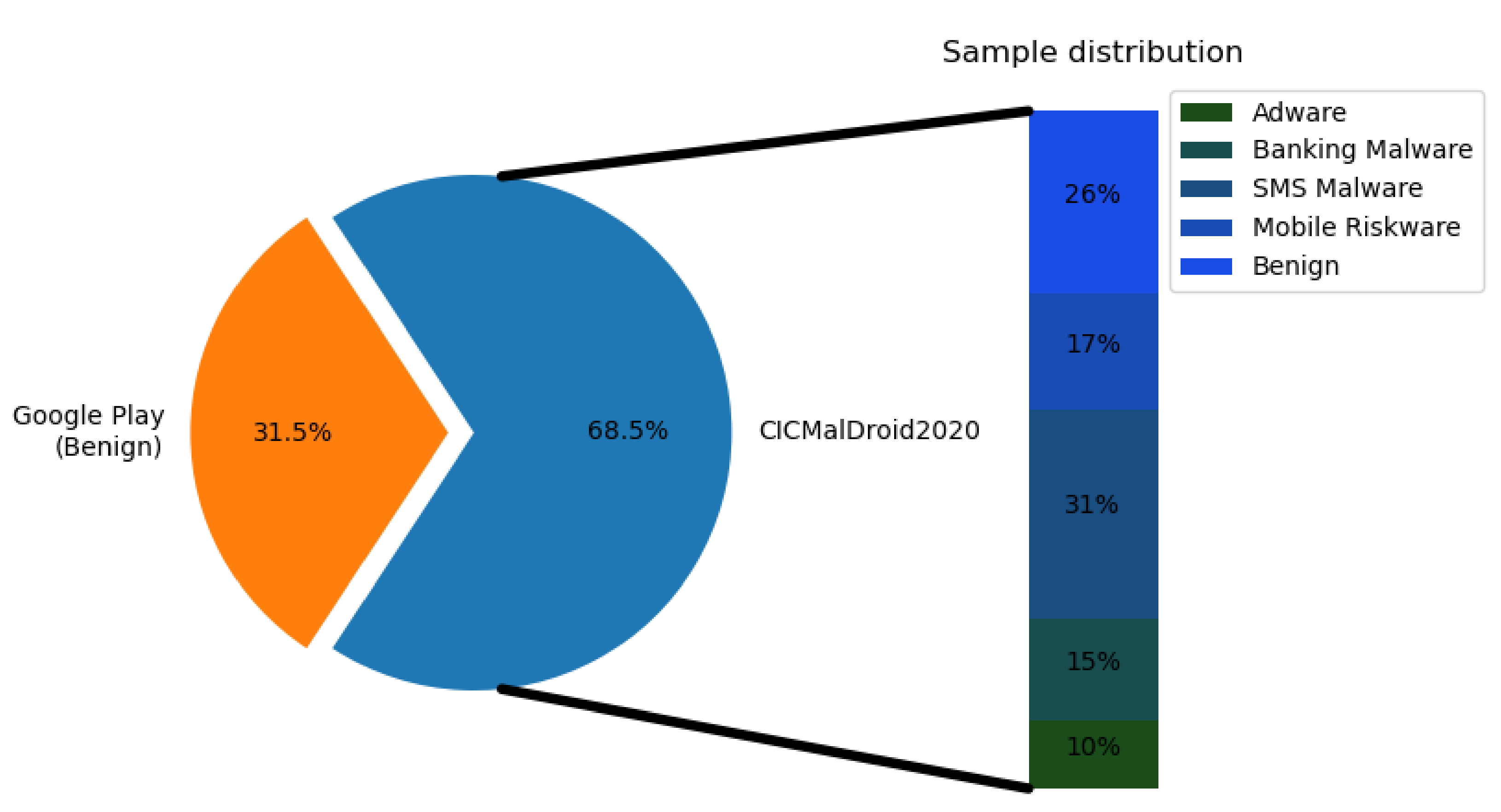
4.1. Datasets
4.2. Experimental Setup
4.3. Implementation
- 1.
- Is the semantic enhancement model based on transfer learning effective in solving the problem of malicious code classification?
- 2.
- Regarding the semantic enhancement model proposed in this study, how do we prove that it results in significant benefits and improvements for solving the problem of malicious code detection and classification?
- 3.
- Under different feature mapping methods, can QSVM complete the task of malicious code detection and classification like SVM?
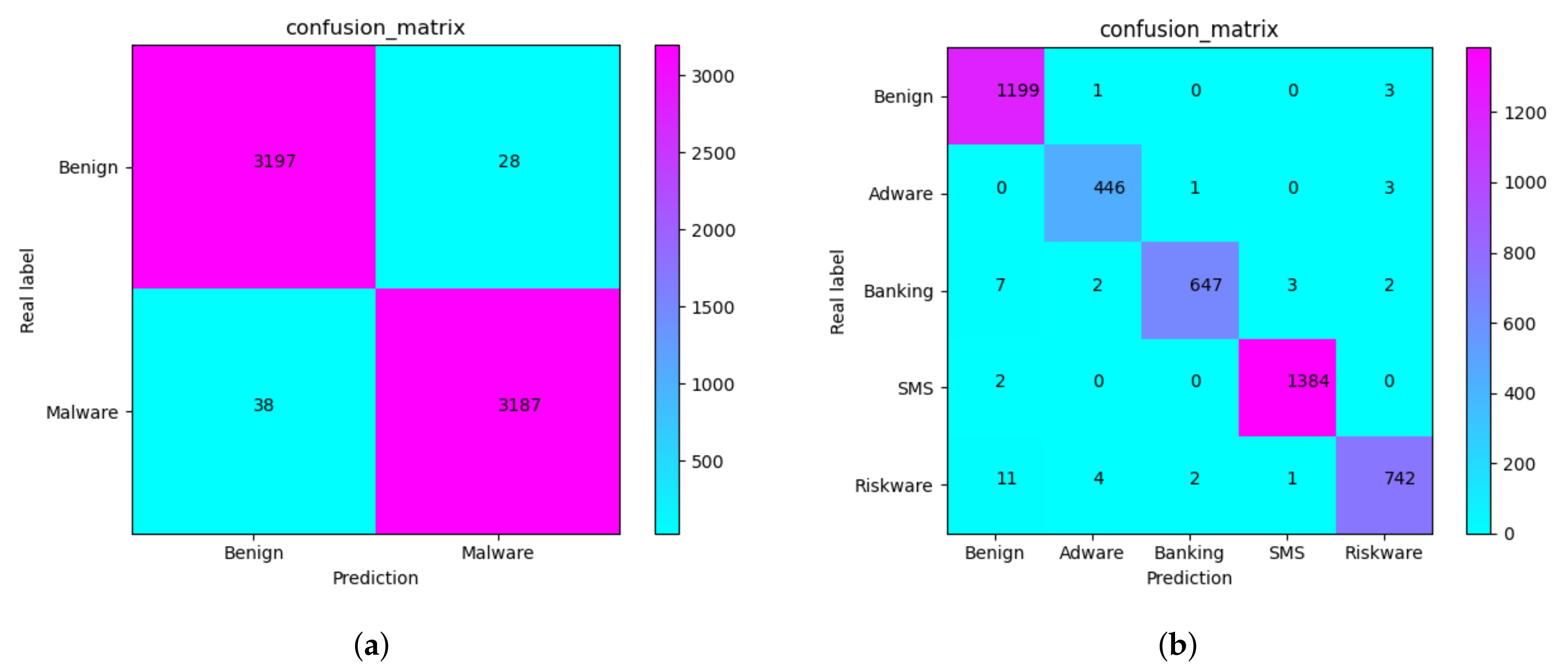
4.3.1. Model Classification Capabilities
4.3.2. Model Comparison Experiment
4.3.3. Quantum Classifiers with Different Encoding Methods
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Liu, Z.; Wang, R.; Japkowicz, N.; Tang, D.; Zhang, W.; Zhao, J. Research on unsupervised feature learning for Android malware detection based on Restricted Boltzmann Machines. Future Gener. Comput. Syst. 2021, 120, 91–108. [Google Scholar] [CrossRef]
- Chen, D.; Wawrzynski, P.; Lv, Z. Cyber security in smart cities: A review of deep learning-based applications and case studies. Sustain. Cities Soc. 2021, 66, 102655. [Google Scholar] [CrossRef]
- Shang, Y. Consensus of Hybrid Multi-Agent Systems With Malicious Nodes. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 685–689. [Google Scholar] [CrossRef]
- Fragkos, G.; Minwalla, C.; Plusquellic, J.; Tsiropoulou, E.E. Artificially Intelligent Electronic Money. IEEE Consum. Electron. Mag. 2021, 10, 81–89. [Google Scholar] [CrossRef]
- Wu, Q.; Zhu, X.; Liu, B. A Survey of Android Malware Static Detection Technology Based on Machine Learning. Mob. Inf. Syst. 2021, 2021, 8896013. [Google Scholar] [CrossRef]
- Kouliaridis, V.; Kambourakis, G. A Comprehensive Survey on Machine Learning Techniques for Android Malware Detection. Information 2021, 12, 185. [Google Scholar] [CrossRef]
- LeClair, A.; Jiang, S.; McMillan, C. A neural model for generating natural language summaries of program subroutines. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 795–806. [Google Scholar]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef]
- Cen, L.; Gates, C.S.; Si, L.; Li, N. A probabilistic discriminative model for android malware detection with decompiled source code. IEEE Trans. Dependable Secur. Comput. 2014, 12, 400–412. [Google Scholar] [CrossRef]
- Akram, J.; Mumtaz, M.; Jabeen, G.; Luo, P. DroidMD: An efficient and scalable android malware detection approach at source code level. Int. J. Inf. Comput. Secur. 2021, 15, 299–321. [Google Scholar] [CrossRef]
- LeClair, A.; McMillan, C. Recommendations for datasets for source code summarization. arXiv 2019, arXiv:1904.02660. [Google Scholar]
- Mahdavifar, S.; Kadir, A.F.A.; Fatemi, R.; Alhadidi, D.; Ghorbani, A.A. Dynamic Android Malware Category Classification using Semi-Supervised Deep Learning. In Proceedings of the 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 515–522. [Google Scholar]
- Zhang, X.; Zhang, Y.; Zhong, M.; Ding, D.; Cao, Y.; Zhang, Y.; Zhang, M.; Yang, M. Enhancing state-of-the-art classifiers with API semantics to detect evolved android malware. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020; pp. 757–770. [Google Scholar]
- Onwuzurike, L.; Mariconti, E.; Andriotis, P.; Cristofaro, E.D.; Ross, G.; Stringhini, G. Mamadroid: Detecting android malware by building markov chains of behavioral models (extended version). ACM Trans. Priv. Secur. 2019, 22, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Xu, K.; Li, Y.; Deng, R.; Chen, K.; Xu, J. DroidEvolver: Self-evolving Android malware detection system. In Proceedings of the 2019 IEEE European Symposium on Security and Privacy (EuroS&P), Stockholm, Sweden, 17–19 June 2019; pp. 47–62. [Google Scholar]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and explainable detection of android malware in your pocket. NDSS 2014, 14, 23–26. [Google Scholar]
- Suciu, O.; Coull, S.E.; Johns, J. Exploring adversarial examples in malware detection. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 19–23 May 2019; pp. 8–14. [Google Scholar]
- Idrees, F.; Rajarajan, M.; Conti, M.; Chen, T.M.; Rahulamathavan, Y. PIndroid: A novel Android malware detection system using ensemble learning methods. Comput. Secur. 2017, 68, 36–46. [Google Scholar] [CrossRef] [Green Version]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Wang, Q.; Garrity, G.M.; Tiedje, J.M.; Cole, J.R. Naive Bayesian classifier for rapid assignment of rRNA sequences into the new bacterial taxonomy. Appl. Environ. Microbiol. 2007, 73, 5261–5267. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.y.; Yu, H.; Yang, D. Decision table reduction based on conditional information entropy. Chin. J. Comput. Chin. Ed. 2002, 25, 759–766. [Google Scholar]
- Platt, J. Sequential minimal optimization: A fast algorithm for training support vector machines. Microsoft Res. 1998, 3, 88–95. [Google Scholar]
- Zanaty, E. Support vector machines (SVMs) versus multilayer perception (MLP) in data classification. Egypt. Inform. J. 2012, 13, 177–183. [Google Scholar] [CrossRef]
- Wang, Z.; Li, C.; Yuan, Z.; Guan, Y.; Xue, Y. DroidChain: A novel Android malware detection method based on behavior chains. Pervasive Mob. Comput. 2016, 32, 3–14. [Google Scholar] [CrossRef]
- Rathore, H.; Sahay, S.K.; Nikam, P.; Sewak, M. Robust Android Malware Detection System Against Adversarial Attacks Using Q-Learning. Inf. Syst. Front. 2020, 1–16. [Google Scholar] [CrossRef]
- Marquis-Boire, M.; Marschalek, M.; Guarnieri, C. Big Game Hunting: The Peculiarities in Nation-State Malware Research; Black Hat: Las Vegas, NV, USA, 2015. [Google Scholar]
- LeClair, A.; Haque, S.; Wu, L.; McMillan, C. Improved Code Summarization via a Graph Neural Network. In Proceedings of the ICPC ’20: 28th International Conference on Program Comprehension, Seoul, Korea, 13–15 July 2020; pp. 184–195. [Google Scholar] [CrossRef]
- Xu, K.; Wu, L.; Wang, Z.; Feng, Y.; Sheinin, V. Graph2Seq: Graph to Sequence Learning with Attention-based Neural Networks. arXiv 2018, arXiv:1804.00823. [Google Scholar]
- Xu, K.; Wu, L.; Wang, Z.; Yu, M.; Chen, L.; Sheinin, V. Exploiting Rich Syntactic Information for Semantic Parsing with Graph-to-Sequence Model. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 918–924. [Google Scholar] [CrossRef]
- Ahmad, W.U.; Chakraborty, S.; Ray, B.; Chang, K. A Transformer-based Approach for Source Code Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; pp. 4998–5007. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, H.; Lu, G.; Lyu, L.; Lyu, C. Fret: Functional Reinforced Transformer With BERT for Code Summarization. IEEE Access 2020, 8, 135591–135604. [Google Scholar] [CrossRef]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar] [CrossRef] [Green Version]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef]
- Anguita, D.; Ridella, S.; Rivieccio, F.; Zunino, R. Quantum optimization for training support vector machines. Neural Netw. 2003, 16, 763–770. [Google Scholar] [CrossRef]
- Park, J.E.; Quanz, B.; Wood, S.; Higgins, H.; Harishankar, R. Practical application improvement to Quantum SVM: Theory to practice. arXiv 2020, arXiv:2012.07725. [Google Scholar]
- Havlíček, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Arunachalam, S.; Temme, K. A rigorous and robust quantum speed-up in supervised machine learning. Nat. Phys. 2021, 17, 1013–1017. [Google Scholar] [CrossRef]
- Wang, Z.; Liang, Z.; Zhou, S.; Ding, C.; Shi, Y.; Jiang, W. Exploration of Quantum Neural Architecture by Mixing Quantum Neuron Designs: (Invited Paper). In Proceedings of the IEEE/ACM International Conference On Computer Aided Design, ICCAD 2021, Munich, Germany, 1–4 November 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Lin, T.; RoyChowdhury, A.; Maji, S. Bilinear CNN Models for Fine-Grained Visual Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar] [CrossRef]
- Al-Fawa’reh, M.; Saif, A.; Jafar, M.T.; Elhassan, A. Malware Detection by Eating a Whole APK. In Proceedings of the 15th International Conference for Internet Technology and Secured Transactions, ICITST 2020, London, UK, 8–10 December 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Blank, C.; Park, D.K.; Rhee, J.K.K.; Petruccione, F. Quantum classifier with tailored quantum kernel. NPJ Quantum Inf. 2020, 6, 1–7. [Google Scholar] [CrossRef]
- Haq, I.U.; Khan, T.A.; Akhunzada, A. A Dynamic Robust DL-Based Model for Android Malware Detection. IEEE Access 2021, 9, 74510–74521. [Google Scholar] [CrossRef]
- Sihag, V.; Choudhary, G.; Vardhan, M.; Singh, P.; Seo, J.T. PICAndro: Packet InspeCtion-Based Android Malware Detection. Secur. Commun. Netw. 2021, 2021, 9099476. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Formula | Metric | Formula |
|---|---|---|---|
| Accuracy | Recall | ||
| Precision | F1 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Batch Size | 64 | Optimization Algorithm | Adam |
| Epoch | 60 | Word embedding size | 512 |
| Learning | Dynamic change | Full connection layer dimension | 1024 |
| dropout | 0.1 | Multiple attention number | 8 |
| Loss Function | CrossEntropyLoss | decoder(encoder) layers | 4 |
| Classification Type | Work | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|---|
| 2 class | Vikas Sihag | 98.97 | 96.59 | 97.76 | 99.12 |
| Our | 99.50 | 99.35 | 99.43 | 99.55 | |
| 5 class | Haq | - | - | - | 96.4 |
| Vikas Sihag | 98.51 | 98.46 | 98.49 | 98.91 | |
| Our | 98.90 | 98.78 | 98.84 | 99.01 |
| Types | Model | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|---|
| 2 class | All modules have | 99.50 | 99.35 | 99.43 | 99.55 |
| Not included Bilinear pooling | 99.32 | 99.21 | 99.26 | 99.42 | |
| Not included filter | 94.75 | 94.69 | 94.71 | 94.87 | |
| Not included Decoder | 92.79 | 92.54 | 92.66 | 93.28 | |
| Embedding and LSTM | 87.26 | 87.43 | 87.35 | 87.97 | |
| 5 class | All modules have | 98.90 | 98.78 | 98.84 | 99.01 |
| Not included Bilinear pooling | 98.69 | 98.66 | 98.67 | 98.85 | |
| Not included filter | 94.01 | 94.18 | 94.01 | 94.21 | |
| Not included Decoder | 92.57 | 91.96 | 92.26 | 92.78 | |
| Embedding and LSTM | 87.25 | 87.14 | 87.20 | 87.34 |
| Classifier | Feature Maps (Function) | 2 Classification Score | 5 Classification Score |
|---|---|---|---|
| SVM | Linear | 0.96 | 0.94 |
| RBF | 0.99 | 0.97 | |
| QSVM | ZZFeatureMap linear | 0.96 | 0.94 |
| ZZFeatureMap circular | 0.99 | 0.94 | |
| PauliFeatureMap | 0.99 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Li, X.; Qiao, M.; Tang, K.; Zhang, C.; Gui, H.; Wang, P.; Liu, F. Android-SEM: Generative Adversarial Network for Android Malware Semantic Enhancement Model Based on Transfer Learning. Electronics 2022, 11, 672. https://doi.org/10.3390/electronics11050672
Huang Y, Li X, Qiao M, Tang K, Zhang C, Gui H, Wang P, Liu F. Android-SEM: Generative Adversarial Network for Android Malware Semantic Enhancement Model Based on Transfer Learning. Electronics. 2022; 11(5):672. https://doi.org/10.3390/electronics11050672
Chicago/Turabian StyleHuang, Yizhao, Xingwei Li, Meng Qiao, Ke Tang, Chunyan Zhang, Hairen Gui, Panjie Wang, and Fudong Liu. 2022. "Android-SEM: Generative Adversarial Network for Android Malware Semantic Enhancement Model Based on Transfer Learning" Electronics 11, no. 5: 672. https://doi.org/10.3390/electronics11050672
APA StyleHuang, Y., Li, X., Qiao, M., Tang, K., Zhang, C., Gui, H., Wang, P., & Liu, F. (2022). Android-SEM: Generative Adversarial Network for Android Malware Semantic Enhancement Model Based on Transfer Learning. Electronics, 11(5), 672. https://doi.org/10.3390/electronics11050672