
Survey of Software-Implemented Soft Error Protection


Abstract
:1. Introduction
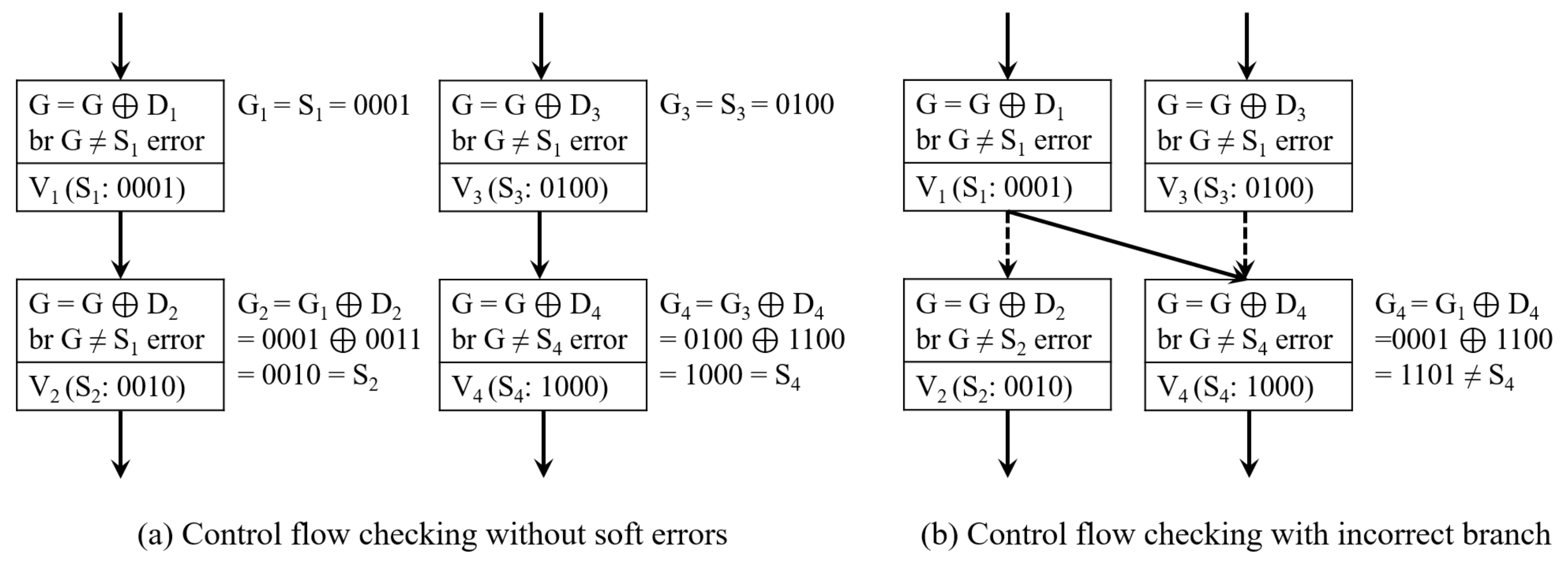
2. Purely Software-Implemented Fault-Tolerant Techniques
3. Software-Based Fault-Tolerant Techniques Considering Hardware
4. Discussion
5. Conclusions
Funding
Conflicts of Interest
References
- Narayanan, V.; Xie, Y. Reliability concerns in embedded system designs. Computer 2006, 39, 118–120. [Google Scholar] [CrossRef]
- Shivakumar, P.; Kistler, M.; Keckler, S.W.; Burger, D.; Alvisi, L. Modeling the effect of technology trends on the soft error rate of combinational logic. In Proceedings of the International Conference on Dependable Systems and Networks, 2002 (DSN 2002), Bethesda, MD, USA, 23–26 June 2002; pp. 389–398. [Google Scholar] [CrossRef] [Green Version]
- Fiala, D.; Mueller, F.; Engelmann, C.; Riesen, R.; Ferreira, K.; Brightwell, R. Detection and Correction of Silent Data Corruption for Large-scale High-performance Computing. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; IEEE Computer Society Press: Los Alamitos, CA, USA, 2012. SC ’12. pp. 78:1–78:12. [Google Scholar]
- Khudia, D.S.; Wright, G.; Mahlke, S. Efficient Soft Error Protection for Commodity Embedded Microprocessors Using Profile Information. In Proceedings of the 13th ACM SIGPLAN/SIGBED International Conference on Languages, Compilers, Tools and Theory for Embedded Systems, Beijing, China, 12–13 June 2012; ACM: New York, NY, USA, 2012. LCTES ’12. pp. 99–108. [Google Scholar] [CrossRef] [Green Version]
- Baleani, M.; Ferrari, A.; Mangeruca, L.; Sangiovanni-Vincentelli, A.; Peri, M.; Pezzini, S. Fault-tolerant Platforms for Automotive Safety-critical Applications. In Proceedings of the 2003 International Conference on Compilers, Architecture and Synthesis for Embedded Systems, San Jose, CA, USA, 30 October–1 November 2003; ACM: New York, NY, USA, 2003. CASES ’03. pp. 170–177. [Google Scholar] [CrossRef]
- Hazucha, P.; Karnik, T.; Walstra, S.; Bloechel, B.A.; Tschanz, J.W.; Maiz, J.; Soumyanath, K.; Dermer, G.E.; Narendra, S.; De, V.; et al. Measurements and analysis of SER-tolerant latch in a 90-nm dual-VT CMOS process. IEEE J. Solid-State Circuits 2004, 39, 1536–1543. [Google Scholar] [CrossRef]
- Mukherjee, S.S.; Emer, J.; Reinhardt, S.K. The soft error problem: An architectural perspective. In Proceedings of the 11th International Symposium on High-Performance Computer Architecture, San Francisco, CA, USA, 12–16 February 2005; pp. 243–247. [Google Scholar] [CrossRef]
- Chen, C.L.; Hsiao, M.Y. Error-Correcting Codes for Semiconductor Memory Applications: A State-of-the-Art Review. IBM J. Res. Dev. 1984, 28, 124–134. [Google Scholar] [CrossRef] [Green Version]
- Koren, I.; Krishna, C.M. Fault-Tolerant Systems; Morgan Kaufmann: Burlington, MA, USA, 2020. [Google Scholar]
- Lyons, R.E.; Vanderkulk, W. The Use of Triple-Modular Redundancy to Improve Computer Reliability. IBM J. Res. Dev. 1962, 6, 200–209. [Google Scholar] [CrossRef] [Green Version]
- Sadler, N.N.; Sorin, D.J. Choosing an Error Protection Scheme for a Microprocessor’s L1 Data Cache. In Proceedings of the 2006 International Conference on Computer Design, San Jose, CA, USA, 1–4 October 2006; pp. 499–505. [Google Scholar] [CrossRef]
- Shim, B.; Shanbhag, N. Energy-efficient soft error-tolerant digital signal processing. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2006, 14, 336–348. [Google Scholar] [CrossRef]
- Martinez-Alvarez, A.; Cuenca-Asensi, S.; Restrepo-Calle, F.; Palomo Pinto, F.R.; Guzman-Miranda, H.; Aguirre, M.A. Compiler-Directed Soft Error Mitigation for Embedded Systems. IEEE Trans. Dependable Secur. Comput. 2012, 9, 159–172. [Google Scholar] [CrossRef]
- Chen, L.; Avizienis, A. N-version programming: A fault-tolerance approach to reliability of software operation. In Proceedings of the Digest of Papers FTCS-8: Eighth Annual International Conference on Fault Tolerant Computing, Toulouse, France, 3–9 June 1978; pp. 3–9. [Google Scholar]
- Che, S.; Li, J.; Sheaffer, J.W.; Skadron, K.; Lach, J. Accelerating Compute-Intensive Applications with GPUs and FPGAs. In Proceedings of the 2008 Symposium on Application Specific Processors, Anaheim, CA, USA, 8–9 June 2008; pp. 101–107. [Google Scholar] [CrossRef]
- Oh, N.; Shirvani, P.P.; McCluskey, E.J. Error detection by duplicated instructions in super-scalar processors. IEEE Trans. Reliab. 2002, 51, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Oh, N.; Shirvani, P.P.; McCluskey, E.J. Control-flow checking by software signatures. IEEE Trans. Reliab. 2002, 51, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Reis, G.A.; Chang, J.; Vachharajani, N.; Rangan, R.; August, D.I. SWIFT: Software Implemented Fault Tolerance. In Proceedings of the International Symposium on Code Generation and Optimization, San Jose, CA, USA, 20–23 March 2005; IEEE Computer Society: Washington, DC, USA, 2005. CGO ’05. pp. 243–254. [Google Scholar] [CrossRef]
- Didehban, M.; Shrivastava, A. nZDC: A compiler technique for near Zero Silent Data Corruption. In Proceedings of the 2016 53nd ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 5–9 June 2016; pp. 1–6. [Google Scholar] [CrossRef]
- So, H.; Didehban, M.; Jung, J.; Shrivastava, A.; Lee, K. CHITIN: A Comprehensive In-thread Instruction Replication Technique Against Transient Faults. In Proceedings of the 2021 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 1440–1445. [Google Scholar] [CrossRef]
- Reis, G.A.; Chang, J.; August, D.I. Automatic Instruction-Level Software-Only Recovery. IEEE Micro 2007, 27, 36–47. [Google Scholar] [CrossRef]
- Feng, S.; Gupta, S.; Ansari, A.; Mahlke, S. Shoestring: Probabilistic Soft Error Reliability on the Cheap. In Proceedings of the Fifteenth Edition of ASPLOS on Architectural Support for Programming Languages and Operating Systems, Pittsburgh, PA, USA, 13–17 March 2010; ACM: New York, NY, USA, 2010. ASPLOS XV. pp. 385–396. [Google Scholar] [CrossRef]
- Wang, C.; Kim, H.S.; Wu, Y.; Ying, V. Compiler-Managed Software-based Redundant Multi-Threading for Transient Fault Detection. In Proceedings of the International Symposium on Code Generation and Optimization (CGO’07), San Jose, CA, USA, 11–14 March 2007; pp. 244–258. [Google Scholar] [CrossRef]
- Zhang, Y.; Lee, J.W.; Johnson, N.P.; August, D.I. DAFT: Decoupled acyclic fault tolerance. Int. J. Parallel Program. 2012, 40, 118–140. [Google Scholar] [CrossRef] [Green Version]
- Mitropoulou, K.; Porpodas, V.; Jones, T.M. COMET: Communication-optimised multi-threaded error-detection technique. In Proceedings of the 2016 International Conference on Compliers, Architectures, and Sythesis of Embedded Systems (CASES), Pittsburgh, PA, USA, 2–7 October 2016; pp. 1–10. [Google Scholar]
- So, H.; Didehban, M.; Ko, Y.; Shrivastava, A.; Lee, K. EXPERT: Effective and flexible error protection by redundant multithreading. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 533–538. [Google Scholar] [CrossRef]
- So, H.; Didehban, M.; Shrivastava, A.; Lee, K. A software-level Redundant MultiThreading for Soft/Hard Error Detection and Recovery. In Proceedings of the 2019 Design, Automation Test in Europe Conference Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 1559–1562. [Google Scholar] [CrossRef]
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach; Morgan Kaufmann: Burlington, MA, USA, 2011. [Google Scholar]
- Faraboschi, P.; Brown, G.; Fisher, J.A.; Desoli, G.; Homewood, F. Lx: A Technology Platform for Customizable VLIW Embedded Processing; ACM: New York, NY, USA, 2000; Volume 28. [Google Scholar]
- Kim, Y.; Mahapatra, R.N. Hierarchical Reconfigurable Computing Arrays for Efficient CGRA-based Embedded Systems. In Proceedings of the 46th Annual Design Automation Conference, San Francisco, CA, USA, 26–31 July 2009; ACM: New York, NY, USA, 2009. DAC ’09. pp. 826–831. [Google Scholar] [CrossRef]
- Clemons, J.; Jones, A.; Perricone, R.; Savarese, S.; Austin, T. EFFEX: An embedded processor for computer vision based feature extraction. In Proceedings of the 2011 48th ACM/EDAC/IEEE Design Automation Conference (DAC), San Diego, CA, USA, 5–9 June 2011; pp. 1020–1025. [Google Scholar]
- Reis, G.A.; Chang, J.; Vachharajani, N.; Mukherjee, S.S.; Rangan, R.; August, D.I. Design and evaluation of hybrid fault-detection systems. In Proceedings of the 32nd International Symposium on Computer Architecture (ISCA’05), Madison, Wisconsin, 4–8 June 2005; pp. 148–159. [Google Scholar] [CrossRef] [Green Version]
- Boyer, M.; Tarjan, D.; Acton, S.T.; Skadron, K. Accelerating leukocyte tracking using CUDA: A case study in leveraging manycore coprocessors. In Proceedings of the IPDPS 2009, IEEE International Symposium on Parallel Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–12. [Google Scholar] [CrossRef]
- Maitre, O.; Baumes, L.A.; Lachiche, N.; Corma, A.; Collet, P. Coarse Grain Parallelization of Evolutionary Algorithms on GPGPU Cards with EASEA. In Proceedings of the Conference on Genetic and Evolutionary Computation, Montreal, QC, Canada, 8–12 July 2009; pp. 1403–1410. [Google Scholar]
- Park, H.; Fan, K.; Mahlke, S.A.; Oh, T.; Kim, H.; Kim, H.S. Edge-centric Modulo Scheduling for Coarse-grained Reconfigurable Architectures. In Proceedings of the International Conference on Parallel Architectures and Compilation Techniques, Toronto, ON, Canada, 25–29 October 2008; pp. 166–176. [Google Scholar]
- Tan, J.; Goswami, N.; Li, T.; Fu, X. Analyzing soft-error vulnerability on GPGPU microarchitecture. In Proceedings of the IEEE International Symposium on Workload Characterization, Austin, TX, USA, 6–8 November 2011; pp. 226–235. [Google Scholar]
- Lee, J.; Ko, Y.; Lee, K.; Youn, J.M.; Paek, Y. Dynamic Code Duplication with Vulnerability Awareness for Soft Error Detection on VLIW Architectures. ACM Trans. Archit. Code Optim. 2013, 9, 48. [Google Scholar] [CrossRef]
- Ko, Y.; Kang, J.; Lee, J.; Kim, Y.; Kim, J.; So, H.; Lee, K.; Paek, Y. Software-Based Selective Validation Techniques for Robust CGRAs Against Soft Errors. ACM Trans. Embed. Comput. Syst. 2016, 15, 20. [Google Scholar] [CrossRef]
- Leveugle, R.; Calvez, A.; Maistri, P.; Vanhauwaert, P. Statistical fault injection: Quantified error and confidence. In Proceedings of the 2009 Design, Automation Test in Europe Conference Exhibition, Nice, France, 20–24 April 2009; pp. 502–506. [Google Scholar] [CrossRef]
- Chatzidimitriou, A.; Bodmann, P.; Papadimitriou, G.; Gizopoulos, D.; Rech, P. Demystifying Soft Error Assessment Strategies on ARM CPUs: Microarchitectural Fault Injection vs. Neutron Beam Experiments. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019; pp. 26–38. [Google Scholar] [CrossRef]
- Yang, W.; Li, Y.; Zhang, W.; Guo, Y.; Zhao, H.; Wei, J.; Li, Y.; He, C.; Chen, K.; Guo, G.; et al. Electron inducing soft errors in 28 nm system-on-Chip. Radiat. Eff. Defects Solids 2020, 175, 745–754. [Google Scholar] [CrossRef]
- Ko, Y.; Jeyapaul, R.; Kim, Y.; Lee, K.; Shrivastava, A. Protecting Caches from Soft Errors: A Microarchitect’s Perspective. ACM Trans. Embed. Comput. Syst. 2017, 16, 93. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Techniques | Key Idea | Pros | Cons |
|---|---|---|---|
| N-Version Programming [14] | Independently generating N > 1 functionally equivalent programs | Reducing the probability of identical software faults | Different programming teams can make similar mistakes |
| EDDI [16] | Duplicating instructions during compilation and using different registers and variables for the new instructions | Providing high fault coverage Performance overhead can be reduced by using instruction-level parallelism | Huge performance overhead Only detection, not correction No protection mechanism for branch instruction |
| CFCSS [17] | Monitoring assigned signatures for inter-block control flow checking using instructions | High fault coverage (for control flow checking) Low performance overhead | Only detection, not correction Errors in computation parts cannot be caught by CFCSS |
| SWIFT [18] | EDDI + ECC (for memory parts) + CFCSS + optimization skills | Performance overhead can be reduced by using instruction-level parallelism | The ratio of correct output is smaller than no protection due to too-conservative error detection Only detection, not correction |
| SWIFT-R [21] | Intertwining three copies of a program and adding majority voting before critical instructions | Correcting soft errors, not just detecting them | Performance overhead due to instruction triplication |
| Shoestring [22] | Symptom-based fault detection + software-based instruction duplication | Low performance overhead by selective duplication | Fault coverage of selective protection is not validated |
| Profile-based solution [4] | Value profiling for generating software symptoms | Low performance overhead by selective duplication Memory profiling can be performed at the compilation stage | Experiments were performed in an in-order processor, not in an out-of-order one Multi-core, multi-thread can change memory profiling methods |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ko, Y. Survey of Software-Implemented Soft Error Protection. Electronics 2022, 11, 456. https://doi.org/10.3390/electronics11030456
Ko Y. Survey of Software-Implemented Soft Error Protection. Electronics. 2022; 11(3):456. https://doi.org/10.3390/electronics11030456
Chicago/Turabian StyleKo, Yohan. 2022. "Survey of Software-Implemented Soft Error Protection" Electronics 11, no. 3: 456. https://doi.org/10.3390/electronics11030456
APA StyleKo, Y. (2022). Survey of Software-Implemented Soft Error Protection. Electronics, 11(3), 456. https://doi.org/10.3390/electronics11030456