
Application of Generative Adversarial Network to Optimize Vehicle Allocation at Dispatch Stations of Paratransit Services

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Types of Dial-a-Ride Problems
2.2. Heuristic Algorithms for Dial-a-Ride Problems
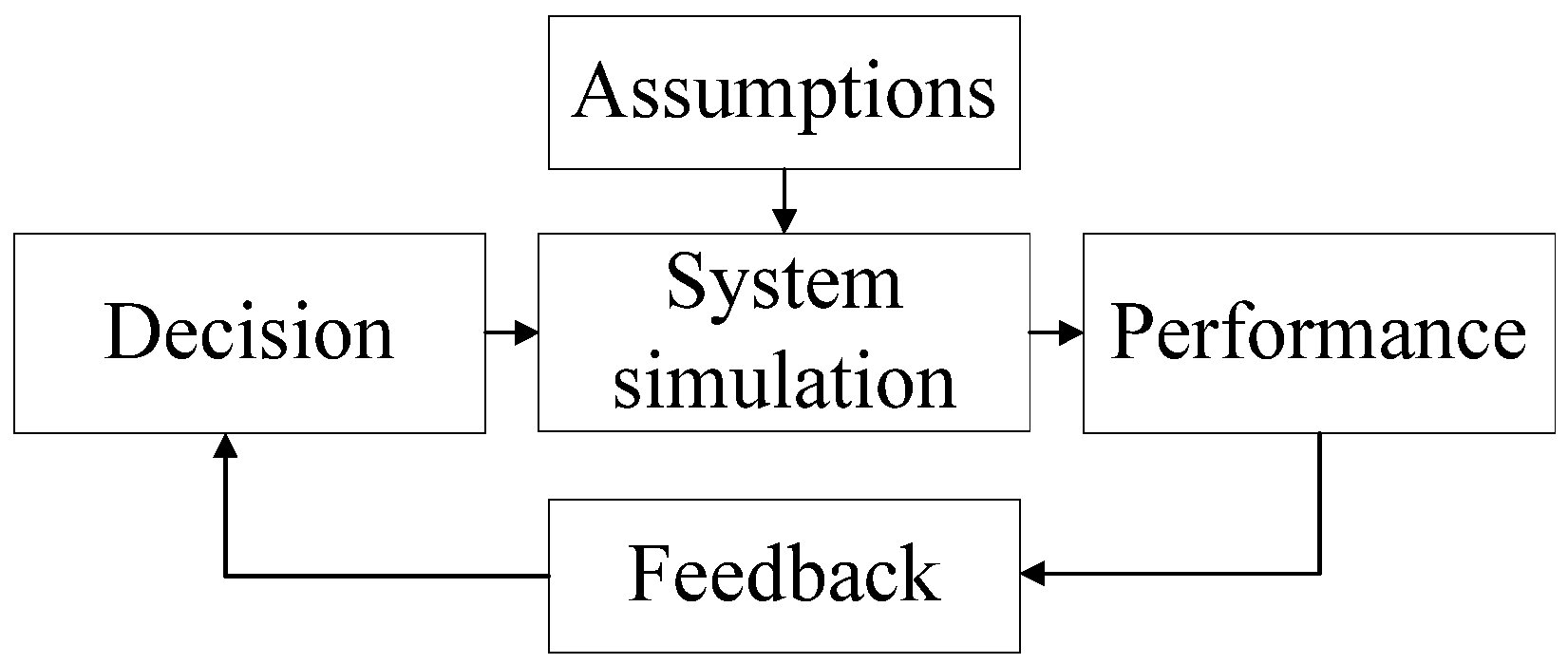
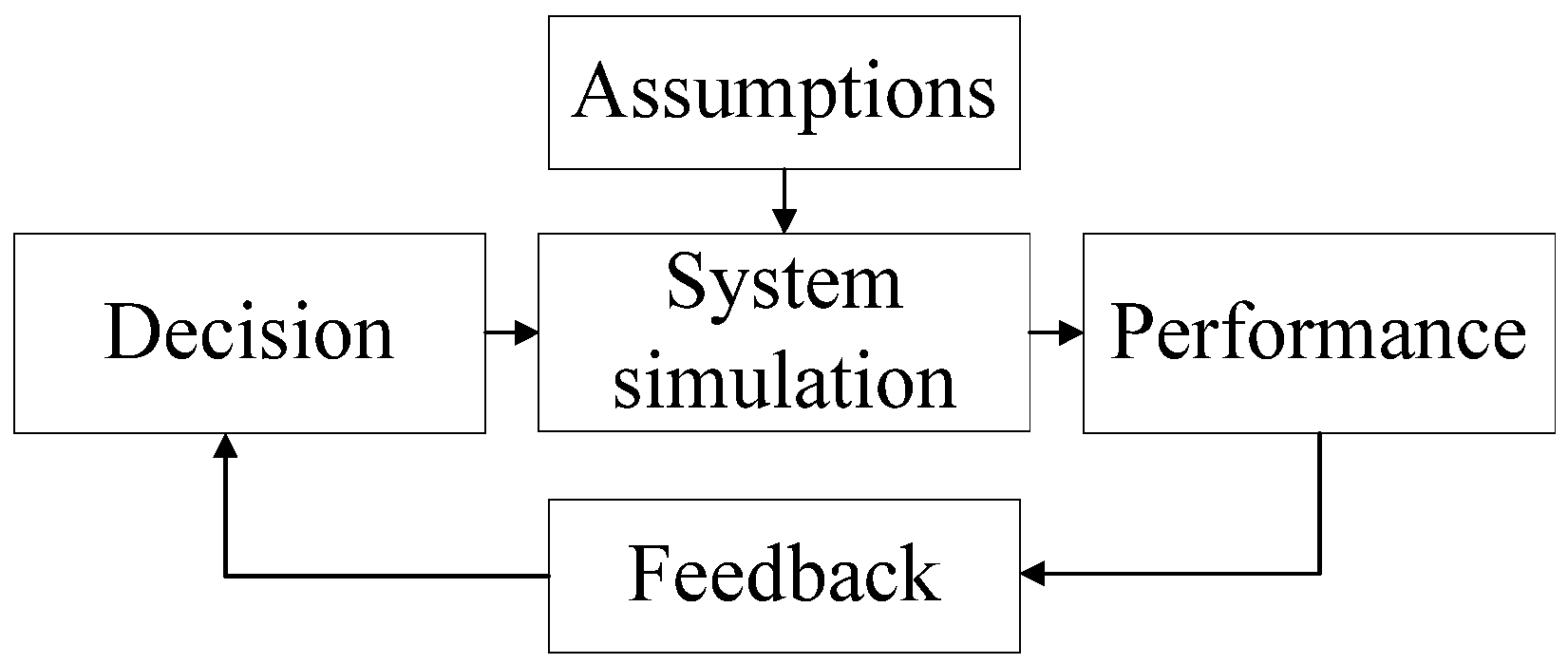
2.3. Definition of System Simulation and Related Work
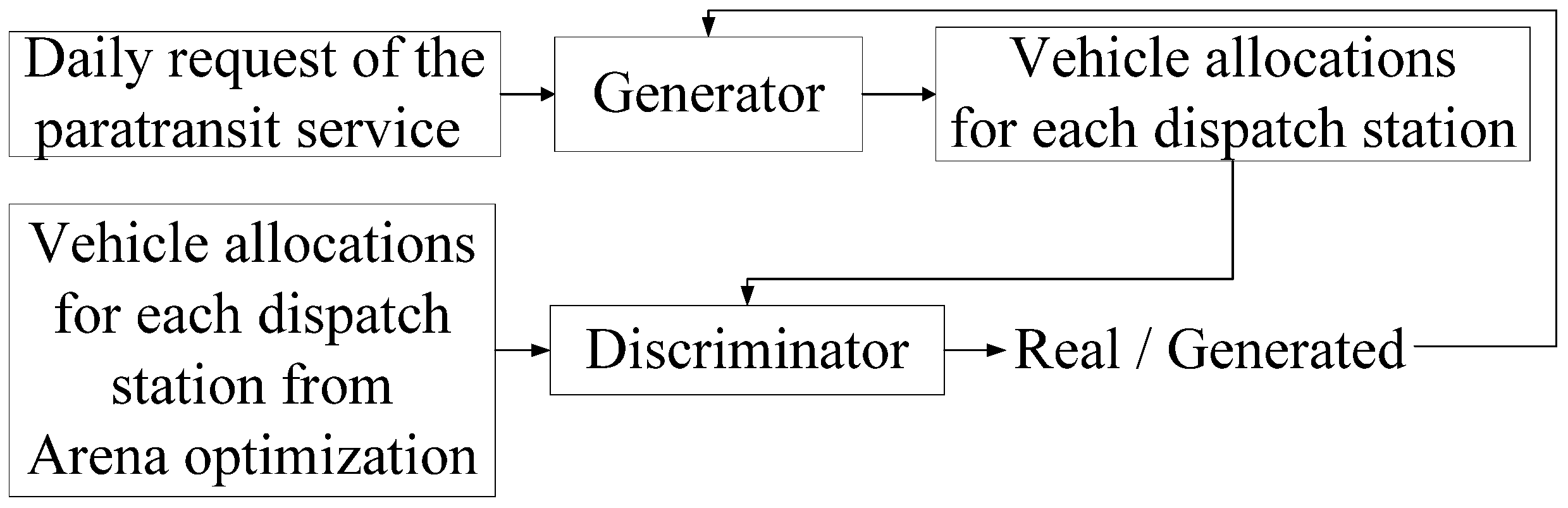
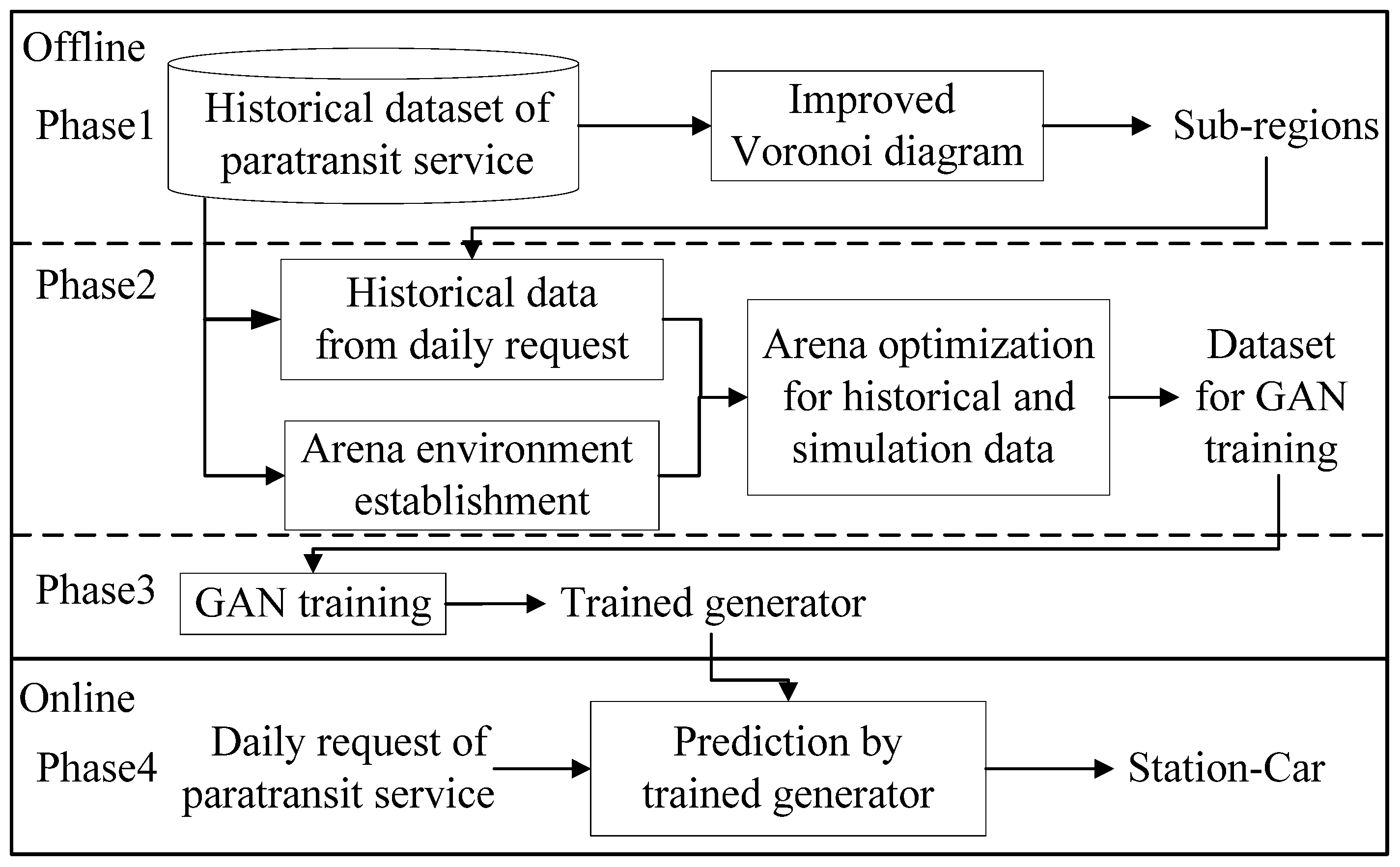
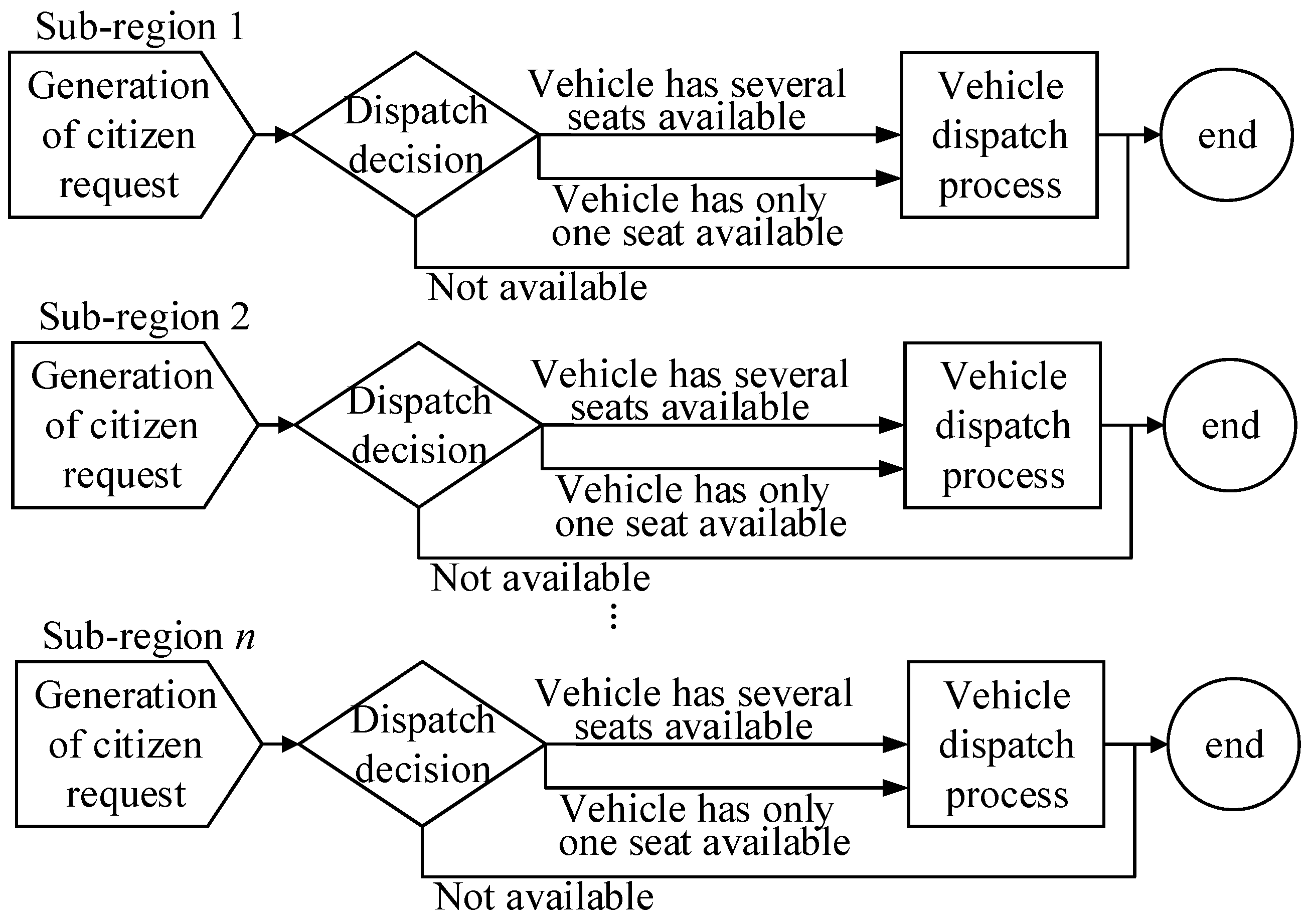
3. GAN-Based Framework for Vehicle Allocation Problems (GAN-VAPS) in the Context of Paratransit Services
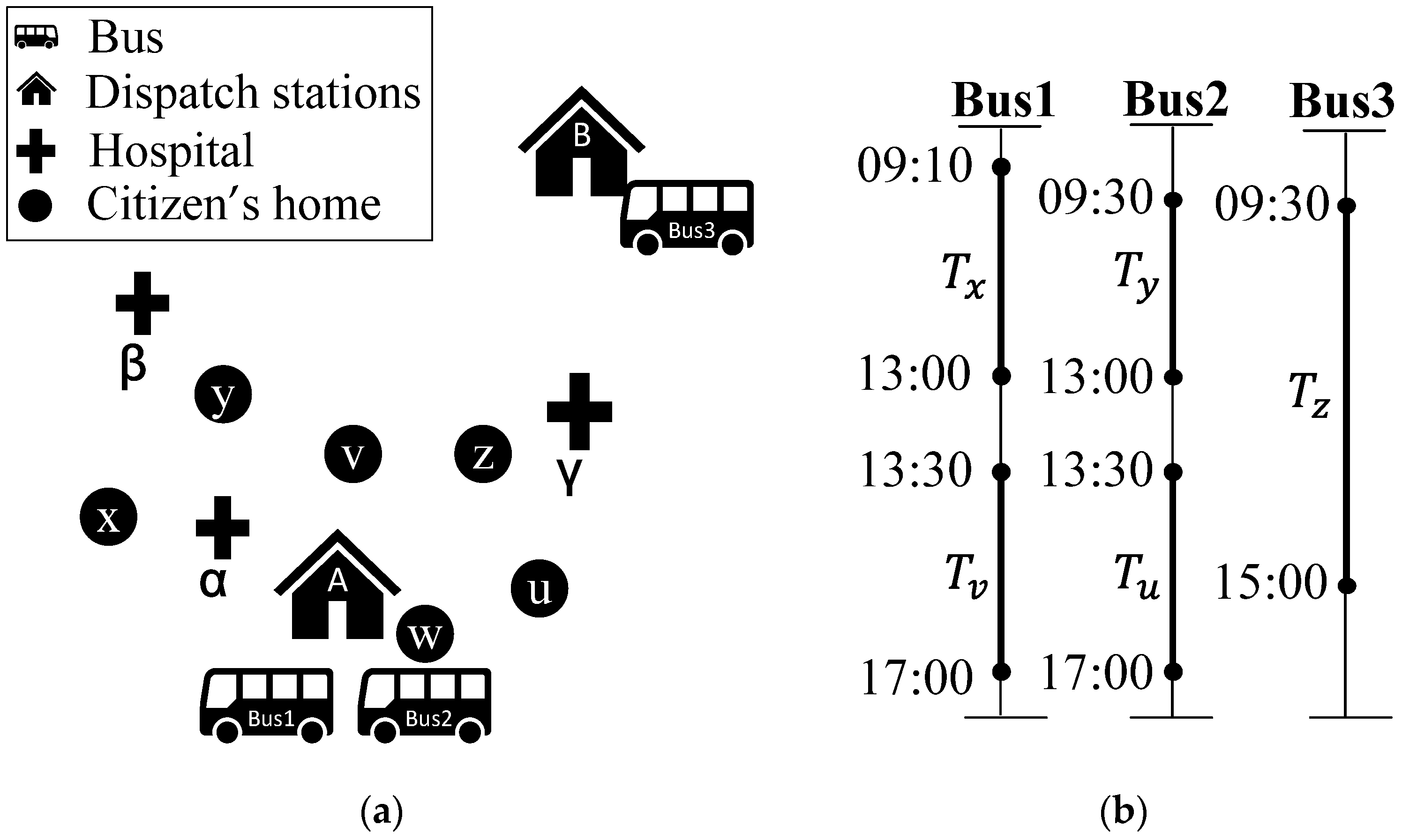
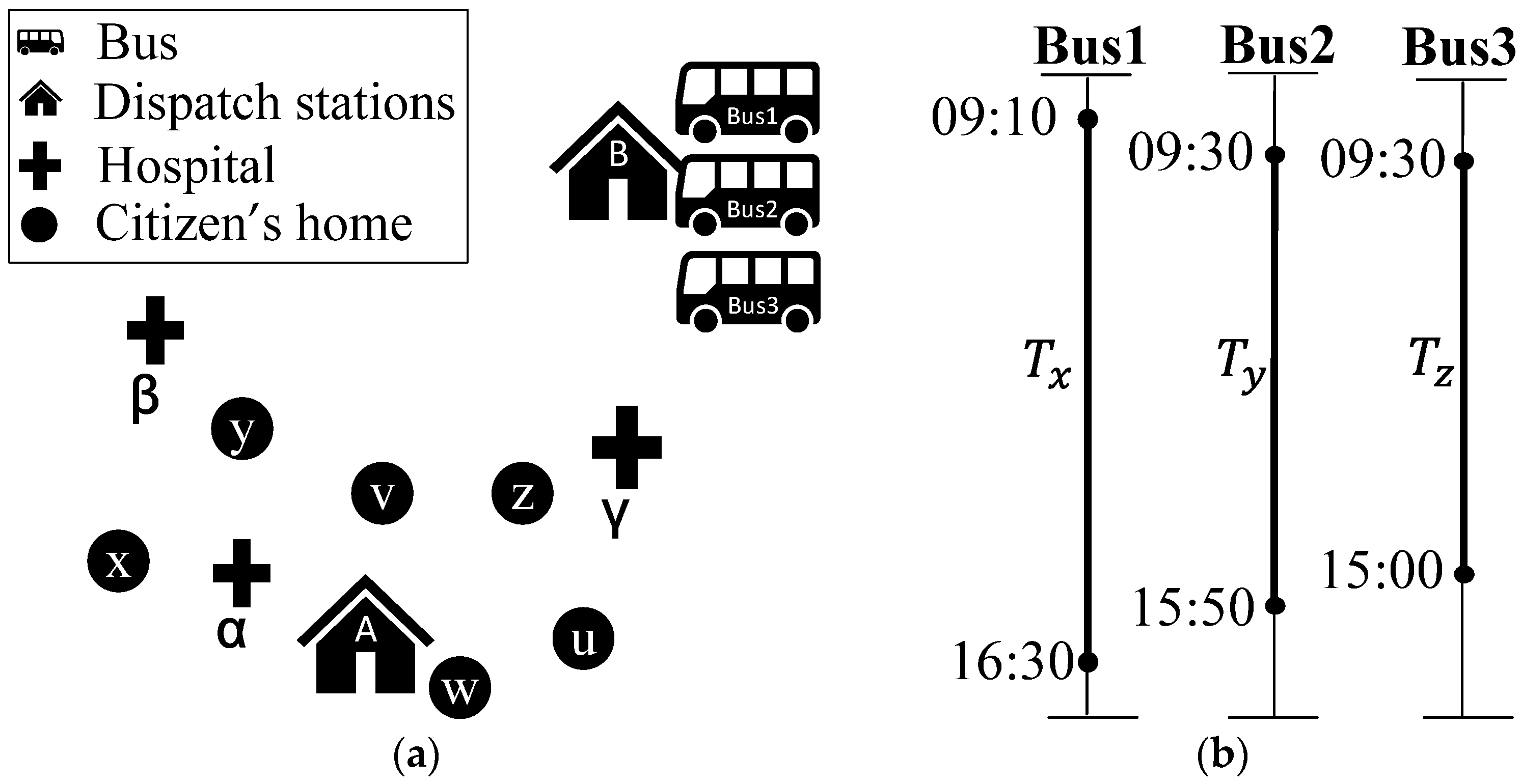
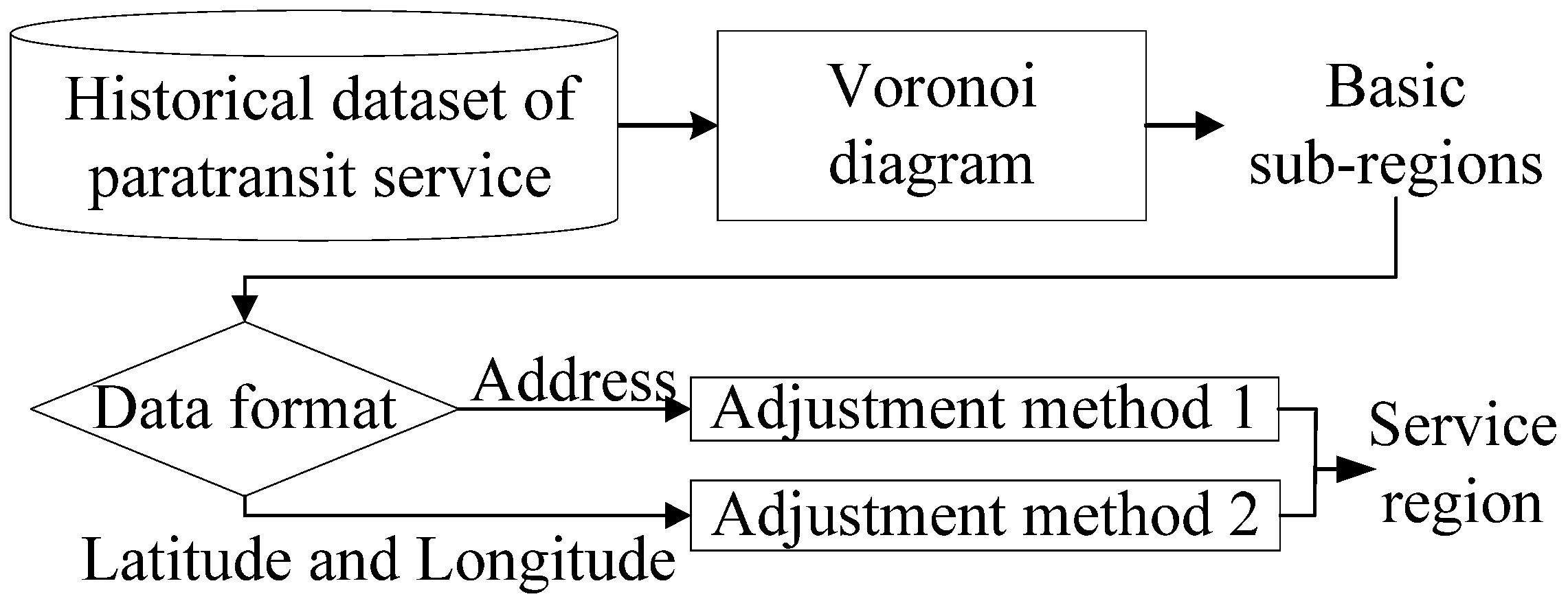
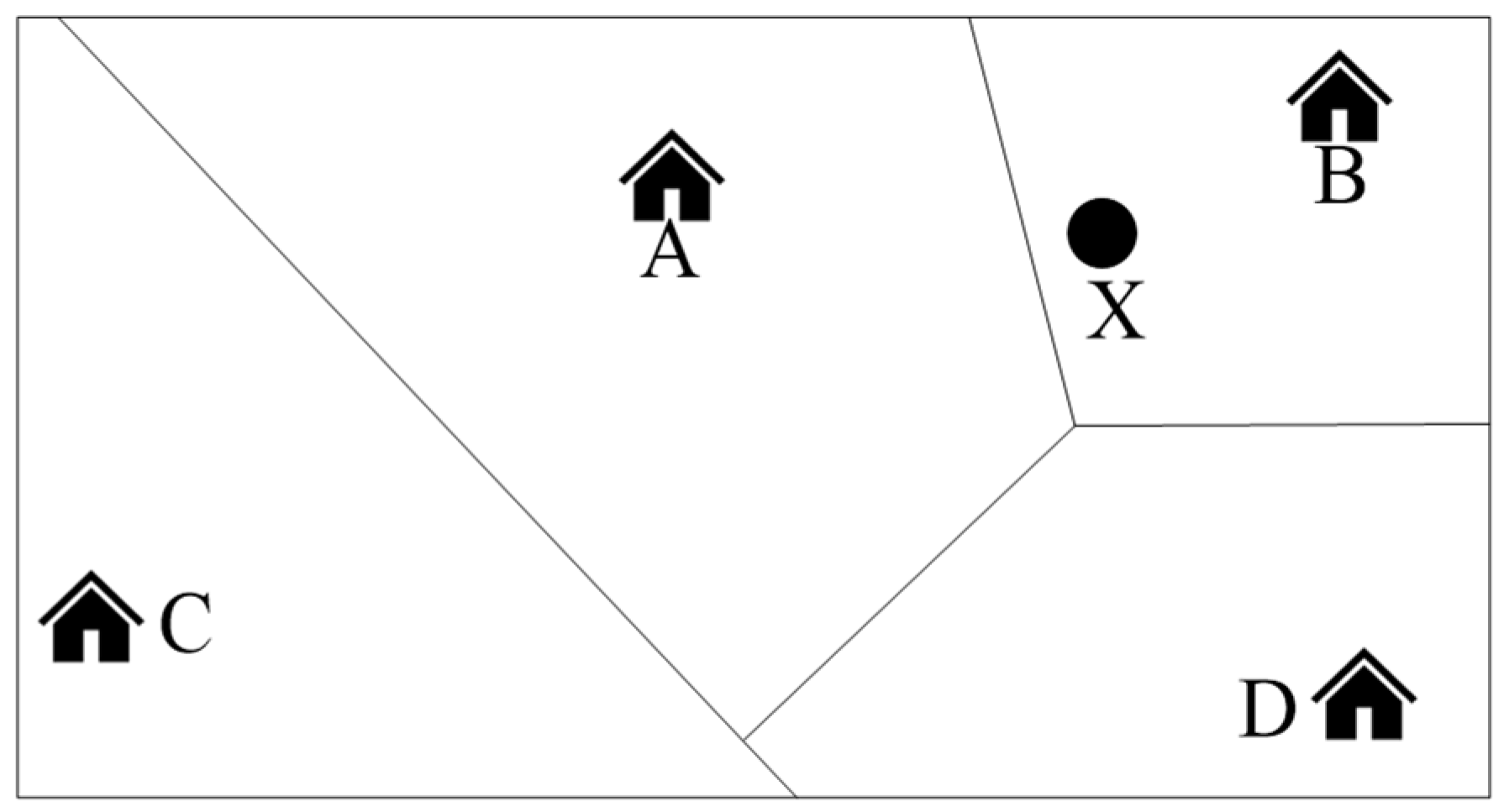
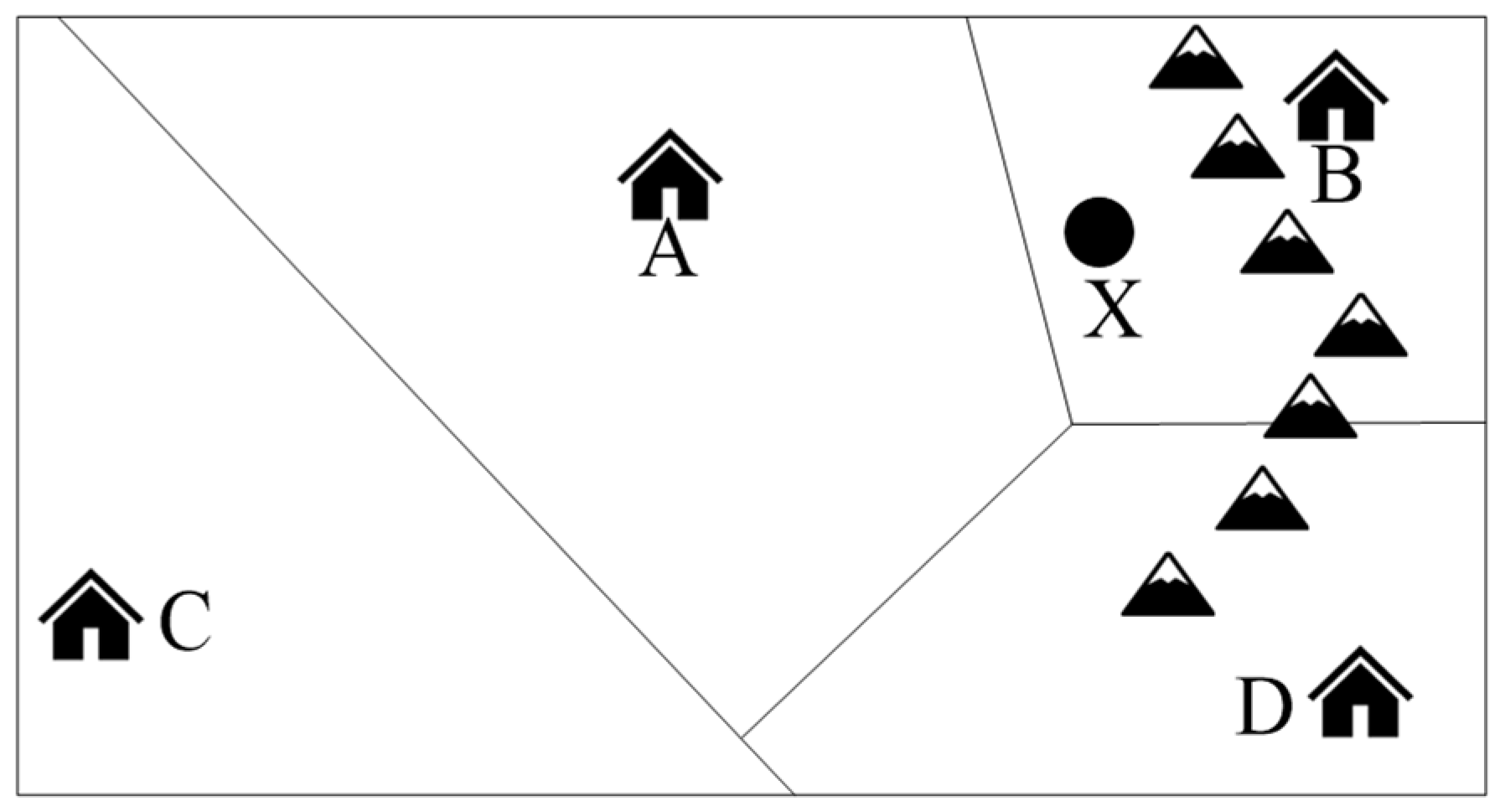
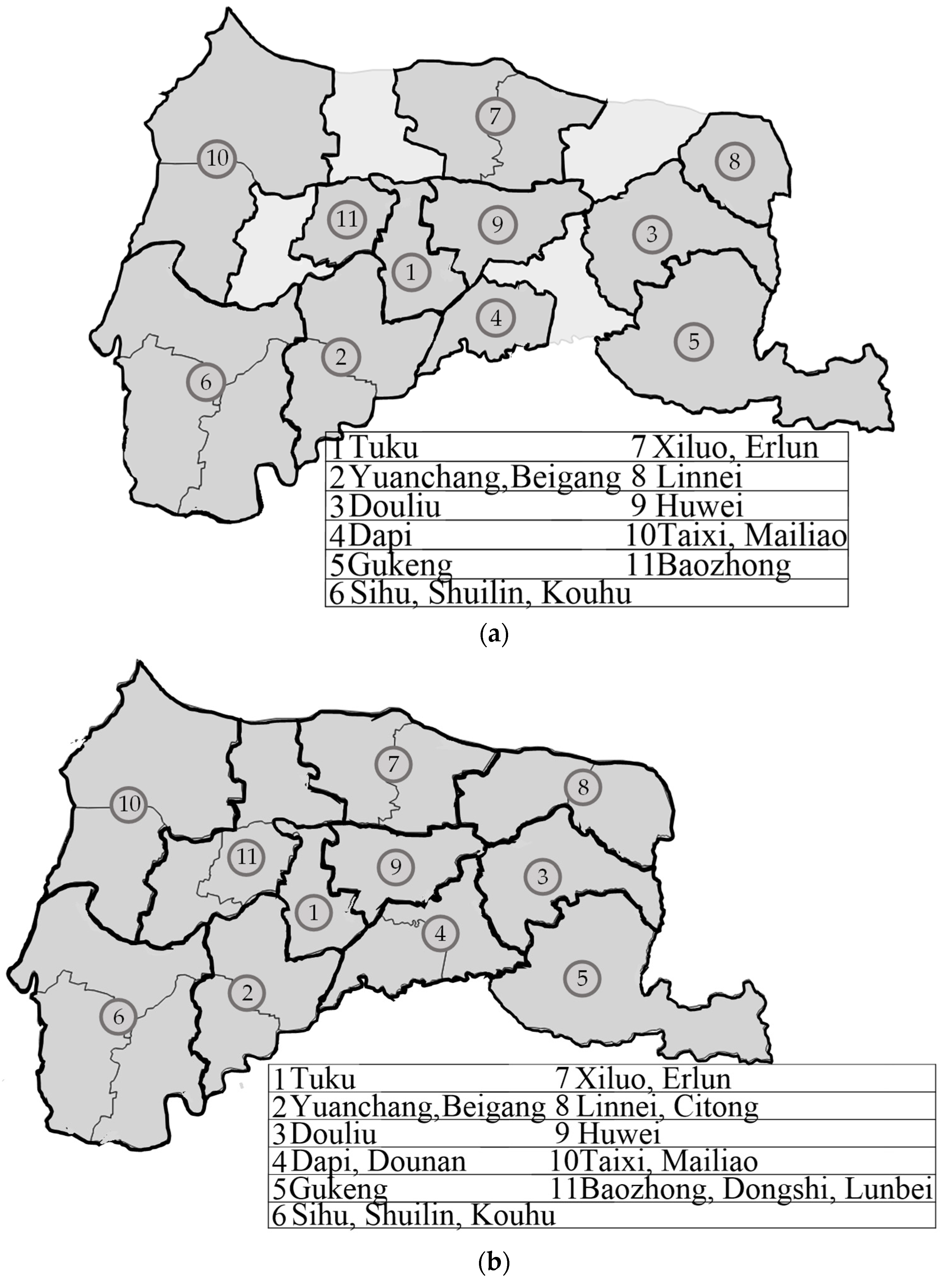
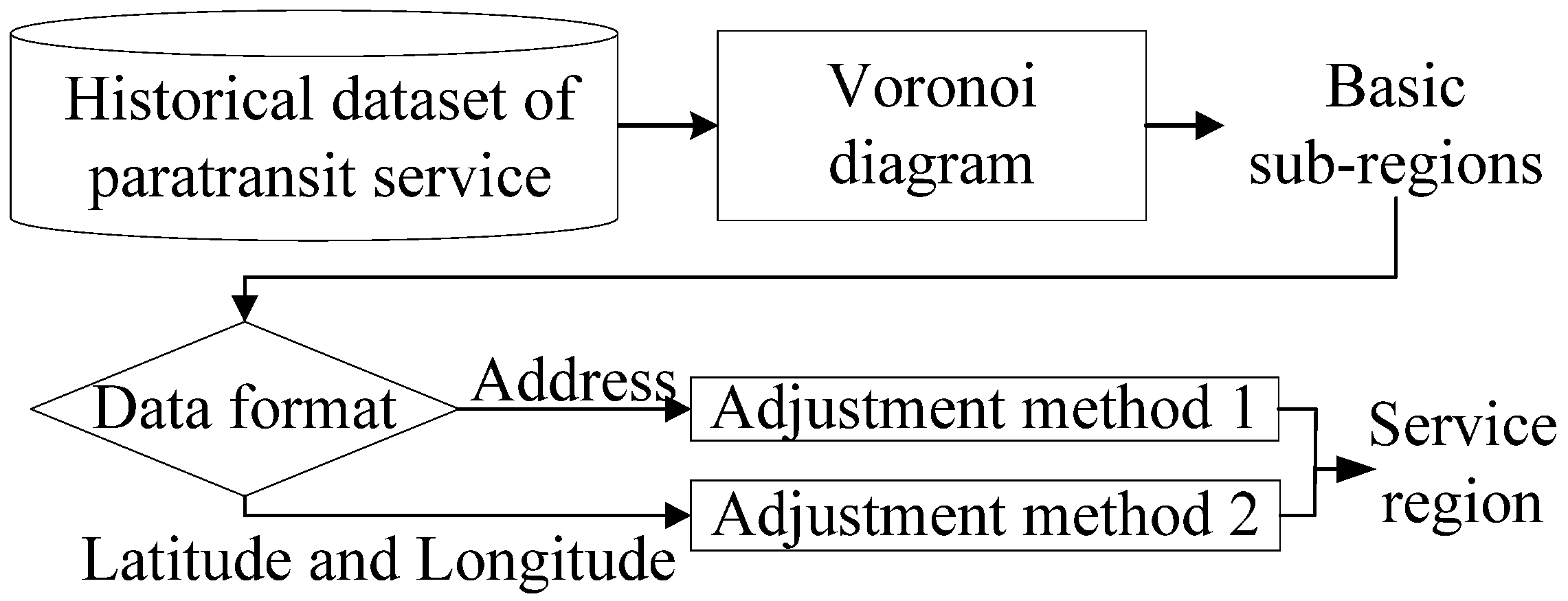
3.1. Division of Paratransit Service Region
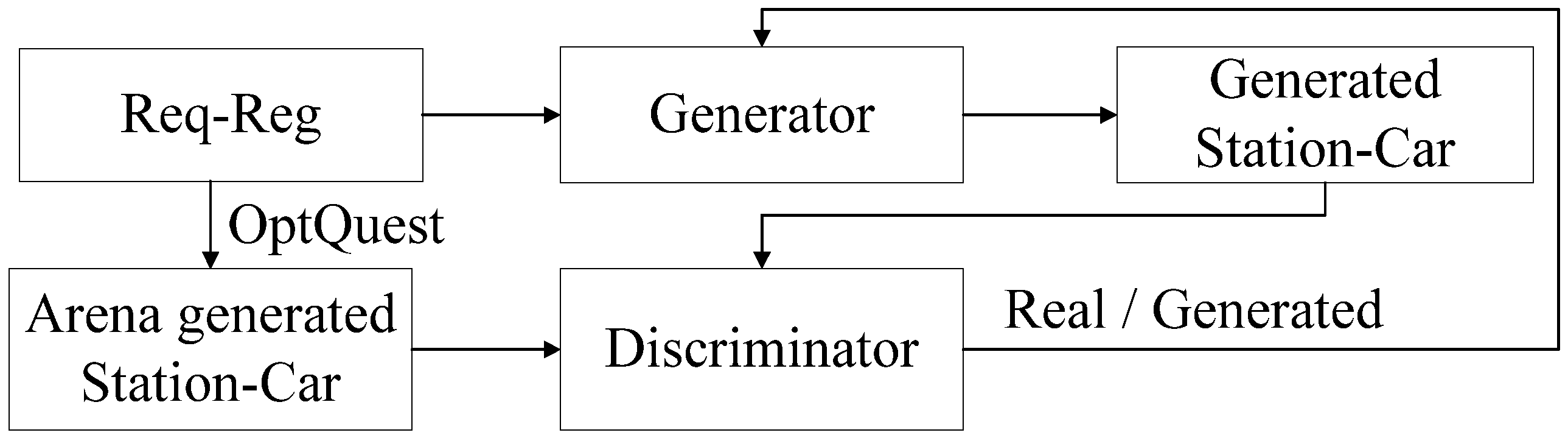
3.2. Training Data Set of GAN Established by Arena
3.3. GAN Training
4. Simulations
4.1. Introduction to Data Sets and Experimental Parameters
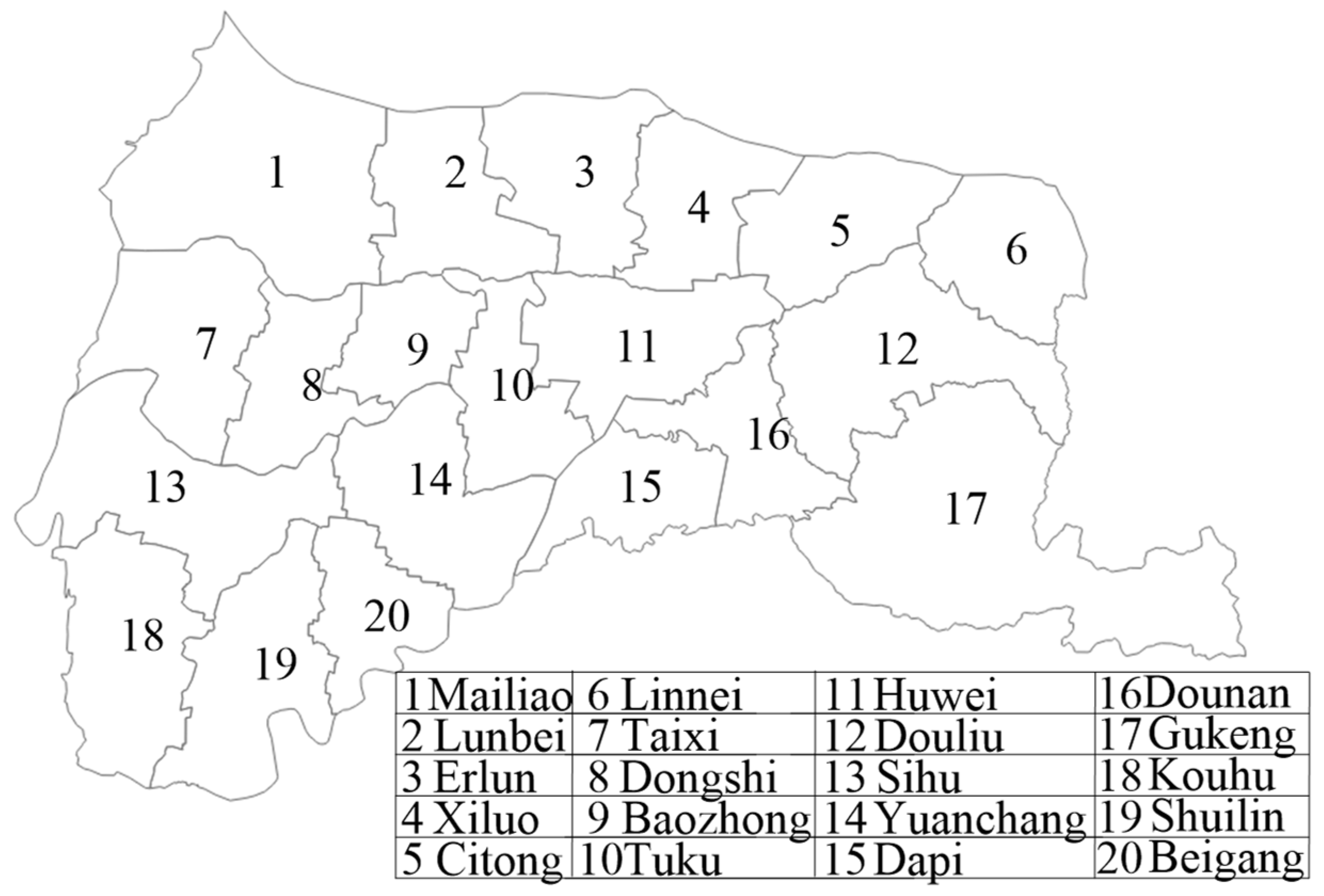
4.2. Division of Service Region
4.3. Arena Environment Configuration and Optimized Solution Results
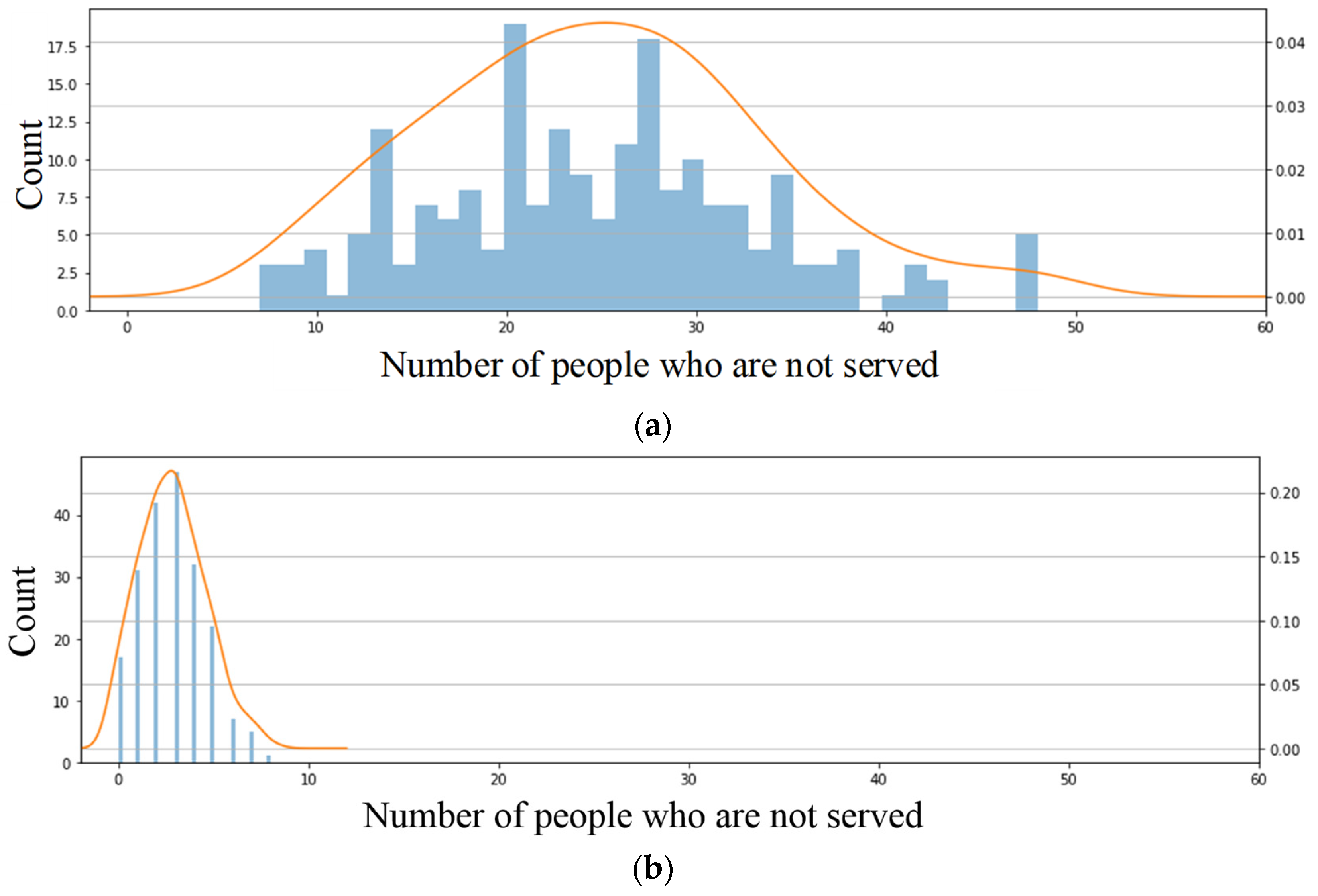
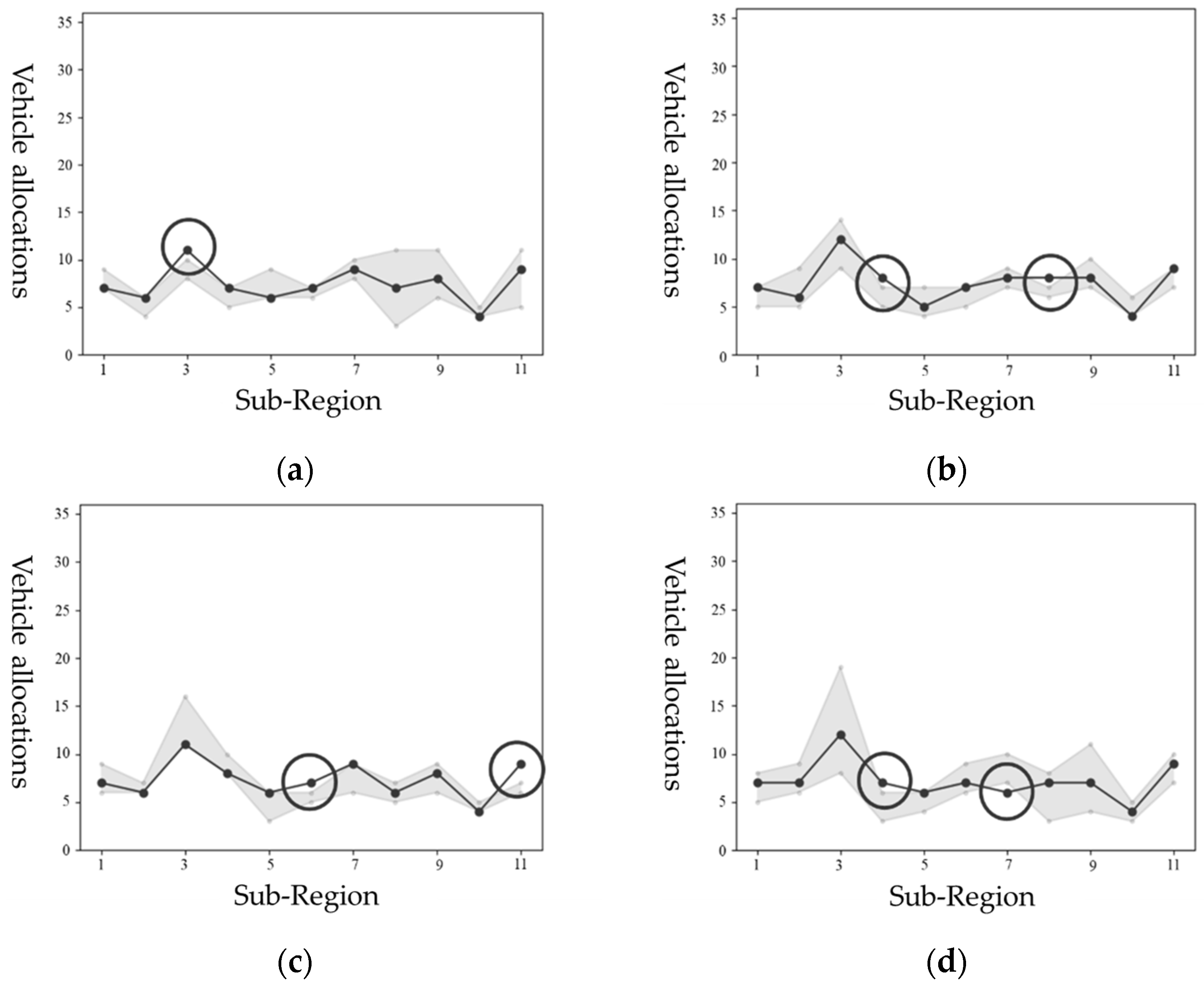
4.4. Station-Car Results Inferred by GAN
5. Conclusions and Directions for Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fu, L.-P.; Ishkhanov, G. Fleet Size and Mix Optimization for Paratransit Services. Transp. Res. Rec. J. Transp. Res. Board 2004, 1884, 39–46. [Google Scholar] [CrossRef] [Green Version]
- Gupta, D.; Chen, H.-W.; Miller, L.; Surya, F. Improving the efficiency of demand-responsive paratransit services. Transp. Res. Part A Policy Pract. 2010, 44, 201–217. [Google Scholar] [CrossRef]
- Cordeau, J.-F.; Laporte, G. The Dial-a-Ride problem (DARP): Variants, modeling issues and algorithms. Q. J. Oper. Res. 2003, 1, 89–101. [Google Scholar] [CrossRef]
- Psaraftis, H.N. A dynamic programming approach to the single-vehicle, many-to-many immediate request Dial-a-Ride problem. Transp. Sci. 1980, 14, 130–154. [Google Scholar] [CrossRef]
- Psaraftis, H.N. An exact algorithm for the single-vehicle many-to-many Dial-a-Ride problem with time windows. Transp. Sci. 1983, 17, 351–357. [Google Scholar] [CrossRef]
- Jaw, J.-J.; Odoni, A.R.; Psaraftis, H.N.; Wilson, N.H.M. A heuristic algorithm for the multi-vehicle advance-request Dial-a-Ride problem with time windows. Transp. Res. Part B Methodol. 1986, 20, 243–257. [Google Scholar] [CrossRef]
- Bodin, L.D.; Sexton, T. The multi-vehicle subscriber Dial-a-Ride problem. TIMS Stud. Manag. Sci. 1986, 2, 73–86. [Google Scholar]
- Desrosiers, J.; Dumas, Y.; Soumis, F. A dynamic programming solution of the large-scale single vehicle Dial-a-Ride problem with time windows. Am. J. Math. Manag. Sci. 1986, 6, 301–325. [Google Scholar] [CrossRef]
- Cordeau, J.-F.; Laporte, G. A tabu search heuristic for the static multi-vehicle Dial-a-Ride problem. Transp. Res. B 2003, 37, 579–594. [Google Scholar] [CrossRef] [Green Version]
- Samuel, W.L. Autonomous Dial-a-Ride Transit Benefit-Cost Evaluation; Volpe National Transportation System Center: Cambridge, MA, USA, 1998. [Google Scholar]
- Teodorovic, D.; Radivojevic, G. A fuzzy logic approach to dynamic Dial-a-Ride problem. Fuzzy Sets Syst. 2000, 116, 23–33. [Google Scholar] [CrossRef]
- Madsen, O.B.G.; Ravn, H.F.; Rygaard, J.M. A heuristic algorithm for the a Dial-a-Ride problem with time windows, multiple capacities, and multiple objectives. Ann. Oper. Res. 1995, 60, 193–208. [Google Scholar] [CrossRef]
- Toth, P.; Vigo, D. Fast local search algorithms for the handicapped persons transportation problem. In Meta-Heuristics: Theory and Applications; Osman, I.H., Kelly, J.P., Eds.; Kluwer: Boston, MA, USA, 1996; pp. 677–690. [Google Scholar]
- Toth, P.; Vigo, D. Heuristic algorithms for the handicapped persons transportation problem. Transp. Sci. 1997, 31, 60–71. [Google Scholar] [CrossRef]
- Borndörfer, R.; Klostermeier, F.; Grötschel, M.; Küttner, C. Telebus Berlin: Vehicle scheduling in a Dial-a-Ride system. In Computer-Aided Transit Scheduling. Lecture Notes in Economics and Mathematical Systems; Wilson, N.H.M., Ed.; Springer: Berlin/Heidelberg, Germany, 1999; Volume 471, pp. 391–422. [Google Scholar]
- Jih, W.R.; Kao, C.Y.; Hsu, F.Y.J. Using Family Competition Genetic Algorithm in Pickup and Delivery Problem with Time Window Constraints. In Proceedings of the IEEE International Symposium on Intelligent Control, Vancouver, BC, Canada, 27–30 October 2002; pp. 496–501. [Google Scholar]
- Jorgensen, R.M.; Larsen, J.; Bergvinsdottir, K.B. Solving the Dial-a-Ride problem using genetic algorithms. J. Oper. Res. Soc. 2007, 58, 1321–1331. [Google Scholar] [CrossRef]
- Parragh, S.N.; Doerner, K.F.; Hartl, R.F. Variable neighborhood search for the dial-a-ride problem. Comput. Oper. Res. 2010, 37, 1129–1138. [Google Scholar] [CrossRef]
- Parragh, S.N.; Schmid, V. Hybrid column generation and large neighborhood search for the dial-a-ride problem. Comput. Oper. Res. 2013, 40, 490–497. [Google Scholar] [CrossRef] [Green Version]
- Masson, R.; Lehuédé, F.; Péton, O. The dial-a-ride problem with transfers. Comput. Oper. Res. 2014, 41, 12–23. [Google Scholar] [CrossRef] [Green Version]
- Ritzinger, U.; Puchinger, J.; Hartl, R.F. Dynamic programming based metaheuristics for the dial-a-ride problem. Ann. Oper. Res. 2016, 236, 341–358. [Google Scholar] [CrossRef] [Green Version]
- Molenbruch, Y.; Braekers, K.; Caris, A. Benefits of horizontal cooperation in dial-a-ride services. Transp. Res. Part E Logist. Transp. Rev. 2017, 107, 97–119. [Google Scholar] [CrossRef]
- Chassaing, M.; Duhamel, C.; Lacomme, P. An ELS-based approach with dynamic probabilities management in local search for the dial-a-ride problem. Eng. Appl. Artif. Intell. 2016, 48, 119–133. [Google Scholar] [CrossRef]
- Masmoudi, M.A.; Braekers, K.; Masmoudi, M.; Dammak, A. A hybrid genetic algorithm for the heterogeneous dial-a-ride problem. Comput. Oper. Res. 2017, 81, 1–13. [Google Scholar] [CrossRef]
- Gschwind, T.; Drexl, M. Adaptive Large Neighborhood Search with a Constant-Time Feasibility Test for the Dial-a-Ride Problem. Transp. Sci. 2019, 53, 480–491. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Aaron, C.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–5 May 2018. [Google Scholar]
- Zhang, F.; Ma, Y.; Yuan, G.; Zhang, H.; Ren, J. Multiview image generation for vehicle reidentification. Appl. Intell. 2021, 51, 5665–5682. [Google Scholar] [CrossRef]
- Aggarwal, A.; Guibas, L.J.; Saxe, J.; Shor, P. A linear-time algorithm for computing the Voronoi diagram of a convex polygon. Discret. Comput. Geom. 1989, 4, 591–604. [Google Scholar] [CrossRef]
- Alitappeh, R.J.; Jeddisaravi, K. Multi-robot exploration in task allocation problem. Appl. Intell. 2022, 52, 2189–2211. [Google Scholar] [CrossRef]
- Toth, P.; Vigo, D. The Vehicle Routing Problem; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2002. [Google Scholar]
- Masmoudi, M.A.; Hosny, M.; Braekers, K.; Dammak, A. Three effective metaheuristics to solve the multi-depot multi-trip heterogeneous Dial-a-Ride problem. Transp. Res. Part E Logist. Transp. Rev. 2016, 96, 60–80. [Google Scholar] [CrossRef]
- Detti, P.; Papalini, F.; de Lara, G.Z.M. A multi-depot Dial-a-Ride problem with heterogeneous vehicles and compatibility constraints in healthcare. Omega 2017, 70, 1–14. [Google Scholar] [CrossRef]
- Tellez, O.; Vercraene, S.; Lehuédé, F.; Péton, O.; Monteiro, T. The fleet size and mix Dial-a-Ride problem with reconfigurable vehicle capacity. Transp. Res. Part C Emerg. Technol. 2018, 91, 99–123. [Google Scholar] [CrossRef]
- Paquay, C.; Crama, Y.; Pironet, T. Recovery management for a Dial-a-Ride system with real-time disruptions. Eur. J. Oper. Res. 2020, 280, 953–969. [Google Scholar] [CrossRef] [Green Version]
- Marković, N.; Kim, M.E.; Schonfeld, P. Statistical and machine learning approach for planning Dial-a-Ride systems. Transp. Res. Part A Policy Pract. 2016, 89, 41–55. [Google Scholar] [CrossRef]
- Riedler, M.; Raidl, G. Solving a selective Dial-a-Ride problem with logic-based Benders decomposition. Comput. Oper. Res. 2018, 96, 30–54. [Google Scholar] [CrossRef]
- Ho, S.C.; Szeto, W.Y.; Kuo, Y.-H.; Leung, J.M.Y.; Petering, M.; Tou, T.W.H. A survey of dial-a-ride problems: Literature review and recent developments. Transp. Res. Part B Methodol. 2018, 111, 395–421. [Google Scholar] [CrossRef]
- Glover, F.; Laguna, M. Tabu Search; Springer: Boston, MA, USA, 1997. [Google Scholar]
- Guerriero, F.; Bruni, M.E.; Greco, F. A hybrid greedy randomized adaptive search heuristic to solve the dial-a-ride problem. Asia-Pac. J. Oper. Res. 2013, 30, 1250046. [Google Scholar] [CrossRef]
- Paquette, J.; Cordeau, J.-F.; Laporte, G.; Pascoal, M.M.B. Combining multicriteria analysis and tabu search for dial-a-ride problems. Transp. Res. Part B Methodol. 2013, 52, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Zidi, I.; Mesghouni, K.; Zidi, K.; Ghedira, K. A multi-objective simulated annealing for the multi-criteria dial a ride problem. Eng. Appl. Artif. Intell. 2012, 25, 1121–1131. [Google Scholar] [CrossRef]
- Reinhardt, L.B.; Clausen, T.; Pisinger, D. Synchronized dial-a-ride transportation of disabled passengers at airports. Eur. J. Oper. Res. 2013, 225, 106–117. [Google Scholar] [CrossRef]
- Braekers, K.; Caris, A.; Janssens, G.K. Exact and meta-heuristic approach for a general heterogeneous dial-a-ride problem with multiple depots. Transp. Res. Part B Methodol. 2014, 67, 166–186. [Google Scholar] [CrossRef]
- Muelas, S.; LaTorre, A.; Peña, J.-M. A variable neighborhood search algorithm for the optimization of a dial-a-ride problem in a large city. Expert Syst. Appl. 2013, 40, 5516–5531. [Google Scholar] [CrossRef]
- Muelas, S.; LaTorre, A.; Peña, J.-M. A distributed VNS algorithm for optimizing dial-a-ride problems in large-scale scenarios. Transp. Res. Part C Emerg. Technol. 2015, 54, 110–130. [Google Scholar] [CrossRef]
- Souza, A.L.S.; Bernardo, M.; Penna, P.H.V.; Pannek, J.; Souza, M.J.F. Bi-objective optimization model for the heterogeneous dynamic dial-a-ride problem with no rejects. Optim. Lett. 2022, 16, 355–374. [Google Scholar] [CrossRef]
- Chen, R.; Chen, S.; Cui, H.; Meng, Q. The container drayage problem for heterogeneous trucks with multiple loads: A revisit. Transp. Res. Part E Logist. Transp. Rev. 2021, 147, 102241. [Google Scholar] [CrossRef]
- Kaleche, R.; Bendaoud, Z.; Bouamrane, K. An Improved Biogeography-Based Optimization for the Long-Term Carpooling Problem. Appl. Artif. Intell. 2021, 35, 745–764. [Google Scholar] [CrossRef]
- Ropke, S.; Pisinger, D. An adaptive large neighborhood search heuristic for the pickup and delivery problem with time windows. Transp. Sci. 2006, 40, 455–472. [Google Scholar] [CrossRef] [Green Version]
- Braekers, K.; Kovacs, A.A. A multi-period dial-a-ride problem with driver consistency. Transp. Res. Part B Methodol. 2016, 94, 355–377. [Google Scholar] [CrossRef] [Green Version]
- Hungerländer, P.; Maier, K.; Pachatz, V.; Truden, C. Improving Sharing Rates of a Dial-a-Ride Problem implemented for an Austrian Mobility Provider. Transp. Res. Procedia 2021, 52, 525–532. [Google Scholar] [CrossRef]
- Masmoudi, M.A.; Hosny, M.; Demir, E.; Pesch, E. Hybrid adaptive large neighborhood search algorithm for the mixed fleet heterogeneous dial-a-ride problem. J. Heuristics 2020, 26, 83–118. [Google Scholar] [CrossRef]
- Galarza Montenegro, B.D.; Sörensen, K.; Vansteenwegen, P. A large neighborhood search algorithm to optimize a demand-responsive feeder service. Transp. Res. Part C Emerg. Technol. 2021, 127, 103102. [Google Scholar] [CrossRef]
- Ma, B.; Hu, D.; Chen, X.; Wang, Y.; Wu, X. The vehicle routing problem with speed optimization for shared autonomous electric vehicles service. Comput. Ind. Eng. 2021, 161, 107614. [Google Scholar] [CrossRef]
- Truden, C.; Ruthmair, M.; Kollingbaum, M.J. Analysis of Schedules for Rural First and Last Mile Microtransit Services. In Computational Logistics; ICCL 202; Mes, M., Lalla-Ruiz, E., Voß, S., Eds.; Springer: Cham, Switzerland, 2021; pp. 332–346. [Google Scholar]
- Vamanan, M.; Wang, Q.; Batta, R.; Szczerba, R.J. Integration of COTS software products ARENA & CPLEX for an inventory/logistics problem. Comput. Oper. Res. 2004, 31, 533–547. [Google Scholar]
- Dinu, O.; Rosca, E.; Dragu, V.; Rosca, M.; Ilie, A. Optimization of the transfer function through handling productivity control in port container terminals. Procedia Manuf. 2018, 22, 856–863. [Google Scholar] [CrossRef]
- Tasoglu, G.; Yildiz, G. Simulated annealing based simulation optimization method for solving integrated berth allocation and quay crane scheduling problems. Simul. Model. Pract. Theory 2019, 97, 101948. [Google Scholar] [CrossRef]
- AlKheder, S.; Alomair, A.; Aladwani, B. Hold baggage security screening system in Kuwait International Airport using Arena software. Ain Shams Eng. J. 2020, 11, 687–696. [Google Scholar] [CrossRef]
- Okeke, O.B. The impacts of shared autonomous vehicles on car parking space. Case Stud. Transp. Policy 2020, 8, 1307–1318. [Google Scholar] [CrossRef]
- Karimi, A.; Sepehri, M.M.; Yavari, E. A simulation model approach to decrease the length of stay of patients undergoing cataract surgery. Perioper. Care Oper. Room Manag. 2020, 21, 100133. [Google Scholar] [CrossRef]
- Azcarate, C.; Esparza, L.; Mallor, F. The problem of the last bed: Contextualization and a new simulation framework for analyzing physician decisions. Omega 2020, 96, 102120. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. K-means properties on six clustering benchmark datasets. Appl. Intell. 2018, 48, 4743–4759. [Google Scholar] [CrossRef]
- Hamerly, G.; Elkan, C. Learning the k in k-means. In Proceedings of the 16th International Conference on Neural Information Processing Systems, Whistler, BC, Canada, 9–11 December 2003; Thrun, S., Saul, L.K., Schölkopf, B., Eds.; MIT Press: Cambridge, MA, USA, 2014; pp. 281–288. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X.-W. DBSCAN Revisited, Revisited: Why and How You Should (Still) Use DBSCAN. ACM Trans. Database Syst. 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Ahlgren, P.; Jarneving, B.; Rousseau, R. Requirements for a cocitation similarity measure, with special reference to Pearson’s correlation coefficient. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 550–560. [Google Scholar] [CrossRef]
- Ly, A.; Marsman, M.; Wagenmakers, E.-J. Analytic posteriors for Pearson’s correlation coefficient. Stat. Neerl. 2018, 72, 4–13. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Zhang, Y.; Xian, M.; Chen, H.D.; Tang, X.-L. SMOTE-WENN: Solving class imbalance and small sample problems by oversampling and distance scaling. Appl. Intell. 2021, 51, 1394–1409. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Chiu, S.-M.; Chen, Y.-C.; Lee, C. Estate price prediction system based on temporal and spatial features and lightweight deep learning model. Appl. Intell. 2021, 52, 808–834. [Google Scholar] [CrossRef]
- Li, J.-H.; Zhang, M.; Martins, J.R.R.; Shu, C. Efficient Aerodynamic Shape Optimization with Deep-learning-based Geometric Filtering. AIAA J. 2020, 58, 4243–4259. [Google Scholar] [CrossRef]
- The Entrusted Technical Service for Designation of the Urban Renewal Area in Xiluo Town, Yunlin County and Drafting of Urban Renewal Plan. 2019. Available online: https://twur.cpami.gov.tw/zh/urban/govplan/view/314 (accessed on 31 December 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
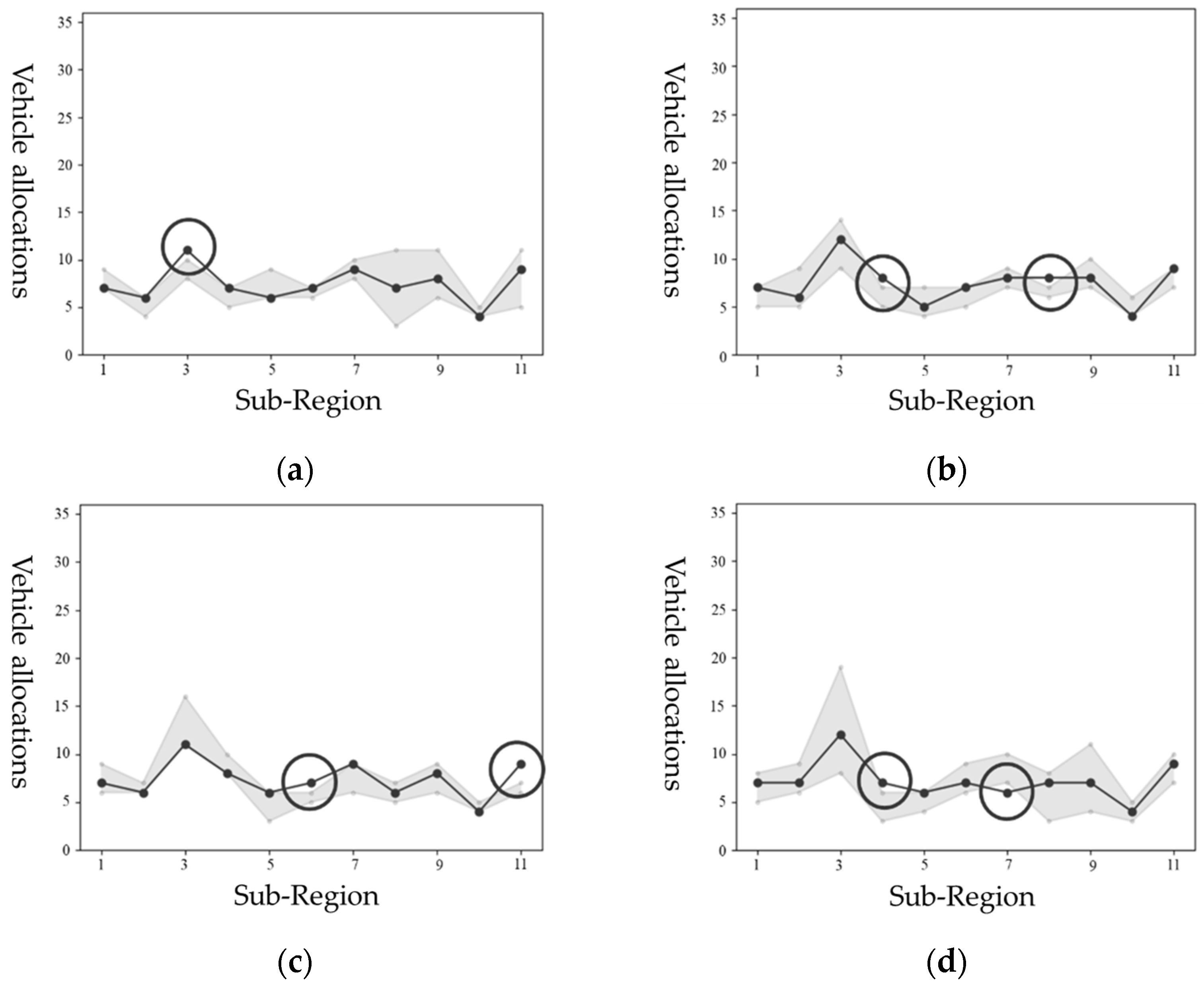{kind=link}
{kind=link}
| Author | Algorithm | Number of Cars | Number of Requests | CPU Time (min) |
|---|---|---|---|---|
| Jih et al. [16] | Genetic algorithms | 1 | 70 | 10.00 |
| Cordeau and Laporte [9] | Tabu Search | 11 | 120 | 46.24 |
| Jorgensen et al. [17] | Genetic algorithms | 11 | 120 | 58.23 |
| Parragh et al. [18] | Variant Neighborhood Search | 11 | 120 | 154.47 |
| Parragh and Schmid [19] | Column generation + Large Neighborhood Search | 11 | 120 | 26.70 |
| Masson et al. [20] | Adaptive Large Neighborhood Search | 11 | 120 | 44.00 |
| Ritzinger et al. [21] | Large Neighborhood Search + Dynamic Programming | 11 | 120 | 41.22 |
| Molenbruch et al. [22] | Large Neighborhood Search | 11 | 120 | 107.80 |
| Chassaing [23] | Evolutionary Local Search | 11 | 120 | 9.87 |
| Masmoudi et al. [24] | Genetic algorithms + Local Search | 11 | 120 | 1.90 |
| Gschwind and Drexl [25] | Adaptive Large Neighborhood Search | 11 | 120 | 1.27 |
| Gschwind and Drexl [25] | Heuristic Adaptive Large Neighborhood Search | 11 | 120 | 4.46 |
| Number of Neurons | Activation Function | |
|---|---|---|
| Input layer | 11 | - |
| Fully connected layer 1 | 256 | tanh |
| Fully connected layer 2 | 128 | tanh |
| Fully connected layer 3 | 64 | tanh |
| Fully connected layer 4 | 32 | tanh |
| Output layer | 11 | - |
| Number of Neurons | Normalization | Activation Function | |
|---|---|---|---|
| Input layer | 22 | - | - |
| Convolutional layer 1 | 128 | - | LeakyReLU |
| Convolutional layer 2 | 128 | BatchNormalization | LeakyReLU |
| Convolutional layer 2 | 64 | BatchNormalization | LeakyReLU |
| Convolutional layer 2 | 64 | BatchNormalization | LeakyReLU |
| Output layer | 1 | - | - |
| Target Administrative Region | Central Administrative Region of the Sub-Region | Similarity | Final Division Result |
|---|---|---|---|
| Dounan | Dabei Gukeng | 0.9671 0.9605 | Dabei |
| Citong | Linnei Xiluo | 0.9730 0.9359 | Linnei |
| Dongshi | Sihu Taixi Baozhong | 0.8334 0.7905 0.8333 | Baozhong |
| Lunbei | Taixi Baozhong | 0.9391 0.9601 | Baozhong |
| Sub-Region | Time Distribution |
|---|---|
| 1 | −0.001 + 7 ∗ BETA (0.316, 1.06) |
| 2 | −0.001 + LOGN (1.47, 2.54) |
| 3 | LOGN (0.609, 0.575) |
| 4 | −0.001 + LOGN (1.41, 2.49) |
| 5 | EXPO (1.35) |
| 6 | −0.001 + LOGN (1.51, 3.05) |
| 7 | 7.88 ∗ BETA (0.687, 2.64) |
| 8 | LOGN (1.34, 2.19) |
| 9 | −0.001 + LOGN (1.22, 1.67) |
| 10 | −0.001 + 7 ∗ BETA (0.588, 1.81) |
| 11 | −0.001 + 7 ∗ BETA (0.345, 1.04) |
| Sub-Region | Delay Type | Minimum | Value | Maximum |
|---|---|---|---|---|
| 1 | Triangular | 46 | 52 | 66 |
| 2 | Triangular | 58 | 80 | 100 |
| 3 | Triangular | 6 | 18 | 36 |
| 4 | Triangular | 20 | 28 | 56 |
| 5 | Triangular | 20 | 32 | 120 |
| 6 | Triangular | 72 | 96 | 114 |
| 7 | Triangular | 42 | 54 | 86 |
| 8 | Triangular | 28 | 42 | 64 |
| 9 | Triangular | 32 | 42 | 62 |
| 10 | Triangular | 72 | 80 | 98 |
| 11 | Triangular | 58 | 68 | 88 |
| Sub-Region | Low Bound | High Bound |
|---|---|---|
| 1 | 1 | 9 |
| 2 | 1 | 9 |
| 3 | 8 | 19 |
| 4 | 2 | 11 |
| 5 | 1 | 10 |
| 6 | 1 | 9 |
| 7 | 1 | 10 |
| 8 | 1 | 11 |
| 9 | 2 | 11 |
| 10 | 1 | 6 |
| 11 | 1 | 11 |
| Type | Case | R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 | R11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Real | 1 | 19 | 10 | 32 | 14 | 9 | 9 | 17 | 11 | 6 | 13 | 19 |
| 2 | 17 | 5 | 42 | 15 | 8 | 10 | 18 | 6 | 10 | 8 | 17 | |
| 3 | 12 | 15 | 37 | 30 | 8 | 10 | 9 | 6 | 12 | 8 | 14 | |
| 4 | 7 | 10 | 13 | 14 | 17 | 11 | 14 | 13 | 8 | 9 | 16 | |
| Assuming | 5 | 3 | 2 | 7 | 3 | 2 | 2 | 4 | 2 | 2 | 4 | 3 |
| 6 | 30 | 25 | 82 | 43 | 24 | 27 | 38 | 34 | 33 | 23 | 41 | |
| 7 | 3 | 17 | 33 | 8 | 5 | 18 | 211 | 16 | 10 | 13 | 13 | |
| 8 | 30 | 25 | 82 | 43 | 24 | 27 | 260 | 34 | 33 | 23 | 41 |
| Case | Method | R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 | R11 | No. of Persons Not Served |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Arena-Upper bound | 9 | 6 | 10 | 7 | 9 | 7 | 10 | 11 | 11 | 5 | 11 | Min: 3 |
| Arena-Lower bound | 7 | 4 | 8 | 5 | 6 | 6 | 8 | 3 | 6 | 4 | 5 | ||
| GAN | 7 | 6 | 11 | 7 | 6 | 7 | 9 | 7 | 8 | 4 | 9 | 3 | |
| 2 | Arena-Upper bound | 7 | 9 | 14 | 7 | 7 | 7 | 9 | 7 | 10 | 6 | 9 | Min: 0 |
| Arena-Lower bound | 5 | 5 | 9 | 5 | 4 | 5 | 7 | 6 | 7 | 4 | 8 | ||
| GAN | 7 | 6 | 12 | 8 | 5 | 7 | 8 | 8 | 8 | 4 | 9 | 0 | |
| 3 | Arena-Upper bound | 9 | 7 | 16 | 10 | 6 | 6 | 9 | 7 | 9 | 5 | 7 | Min: 0 |
| Arena-Lower bound | 6 | 6 | 11 | 8 | 3 | 5 | 6 | 5 | 6 | 4 | 6 | ||
| GAN | 7 | 6 | 11 | 8 | 6 | 7 | 9 | 6 | 8 | 4 | 9 | 0 | |
| 4 | Arena-Upper bound | 8 | 9 | 19 | 6 | 6 | 9 | 10 | 8 | 10 | 5 | 10 | Min: 4 |
| Arena-Lower bound | 5 | 6 | 9 | 3 | 4 | 6 | 7 | 3 | 4 | 3 | 7 | ||
| GAN | 7 | 7 | 12 | 7 | 6 | 7 | 6 | 7 | 7 | 4 | 9 | 4 |
| Case | Method | R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 | R11 | No. of Persons Not Served |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | Arena-Upper bound | 7 | 7 | 19 | 11 | 8 | 7 | 8 | 10 | 11 | 6 | 7 | Min: 0 |
| Arena-Lower bound | 5 | 5 | 8 | 3 | 2 | 4 | 5 | 3 | 4 | 4 | 4 | ||
| GAN | 7 | 8 | 11 | 11 | 6 | 8 | 5 | 5 | 6 | 3 | 9 | 0 | |
| 6 | Arena-Upper bound | 6 | 8 | 10 | 7 | 7 | 8 | 10 | 7 | 9 | 5 | 11 | Min:4 |
| Arena-Lower bound | 5 | 6 | 9 | 5 | 5 | 5 | 9 | 4 | 7 | 4 | 9 | ||
| GAN | 4 | 8 | 10 | 8 | 6 | 9 | 12 | 2 | 6 | 4 | 12 | 26 | |
| 7 | Arena-Upper bound | 2 | 2 | 1 | 1 | 7 | 5 | 31 | 18 | 18 | 2 | 1 | Min:56 |
| Arena-Lower bound | 2 | 2 | 1 | 1 | 5 | 5 | 26 | 12 | 14 | 2 | 1 | ||
| GAN | 3 | 3 | 1 | 1 | 5 | 4 | 27 | 21 | 13 | 1 | 0 | 56 | |
| 8 | Arena-Upper bound | 4 | 4 | 10 | 7 | 6 | 4 | 33 | 5 | 8 | 6 | 5 | Min: 122 |
| Arena-Lower bound | 1 | 3 | 8 | 5 | 4 | 4 | 32 | 3 | 4 | 1 | 1 | ||
| GAN | 2 | 2 | 5 | 4 | 4 | 6 | 25 | 18 | 10 | 2 | 5 | 210 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-C.; Loh, C.-H.; Wang, F.-C.; Chen, Z.-J.; Fu, S.-H.; Wang, C.-Y. Application of Generative Adversarial Network to Optimize Vehicle Allocation at Dispatch Stations of Paratransit Services. Electronics 2022, 11, 423. https://doi.org/10.3390/electronics11030423
Chen Y-C, Loh C-H, Wang F-C, Chen Z-J, Fu S-H, Wang C-Y. Application of Generative Adversarial Network to Optimize Vehicle Allocation at Dispatch Stations of Paratransit Services. Electronics. 2022; 11(3):423. https://doi.org/10.3390/electronics11030423
Chicago/Turabian StyleChen, Yi-Chung, Chee-Hoe Loh, Fu-Cheng Wang, Zi-Jing Chen, Shau-Huai Fu, and Chen-Yu Wang. 2022. "Application of Generative Adversarial Network to Optimize Vehicle Allocation at Dispatch Stations of Paratransit Services" Electronics 11, no. 3: 423. https://doi.org/10.3390/electronics11030423
APA StyleChen, Y.-C., Loh, C.-H., Wang, F.-C., Chen, Z.-J., Fu, S.-H., & Wang, C.-Y. (2022). Application of Generative Adversarial Network to Optimize Vehicle Allocation at Dispatch Stations of Paratransit Services. Electronics, 11(3), 423. https://doi.org/10.3390/electronics11030423