
A Data-Efficient Training Method for Deep Reinforcement Learning


Abstract
1. Introduction
- Curriculum design for the agent in a simulation environment.
- 2.
- Data efficiency analysis for the DRL.
- 3.
- Transferring the learned policy from the simulation scenario to a real environment.
2. Related Work
2.1. Hindsight Experience Replay
2.2. Multi-Level Hierarchical Reinforcement Learning
3. Methods
3.1. Curriculum in Simulation Scenario
3.2. Experience Replay Buffers
| Algorithm 1. Data-efficient DQN |
| Initialize: Experience replay buffer for win trajectories Experience replay buffer for lose trajectories A temp buffer The count of win trajectories The network for action-value function with random weights and the target action-value function with random weights For episode = 1, do If : Sample initial state Else: Set the distribution of initial state farther from the goal, and sample For t = 1, T do Select a random action by probability Otherwise, select Interact with the environment using and record reward and the next state Add transition into the temp buffer If the episode terminates and wins the task: Copy the temp buffer to Elseif the episode terminates and lose the task: Copy the temp buffer to Sample random minibatch of transitions from with probability otherwise, sample the transitions from Set Perform a gradient descent step on with respect to the network parameters Set every steps End For Decay the probability of sample from win buffer according to Function (1) End For |
3.3. Transfer from Simulation to Reality
4. Experiment of UAV Maneuver Control
4.1. Problem Formulation
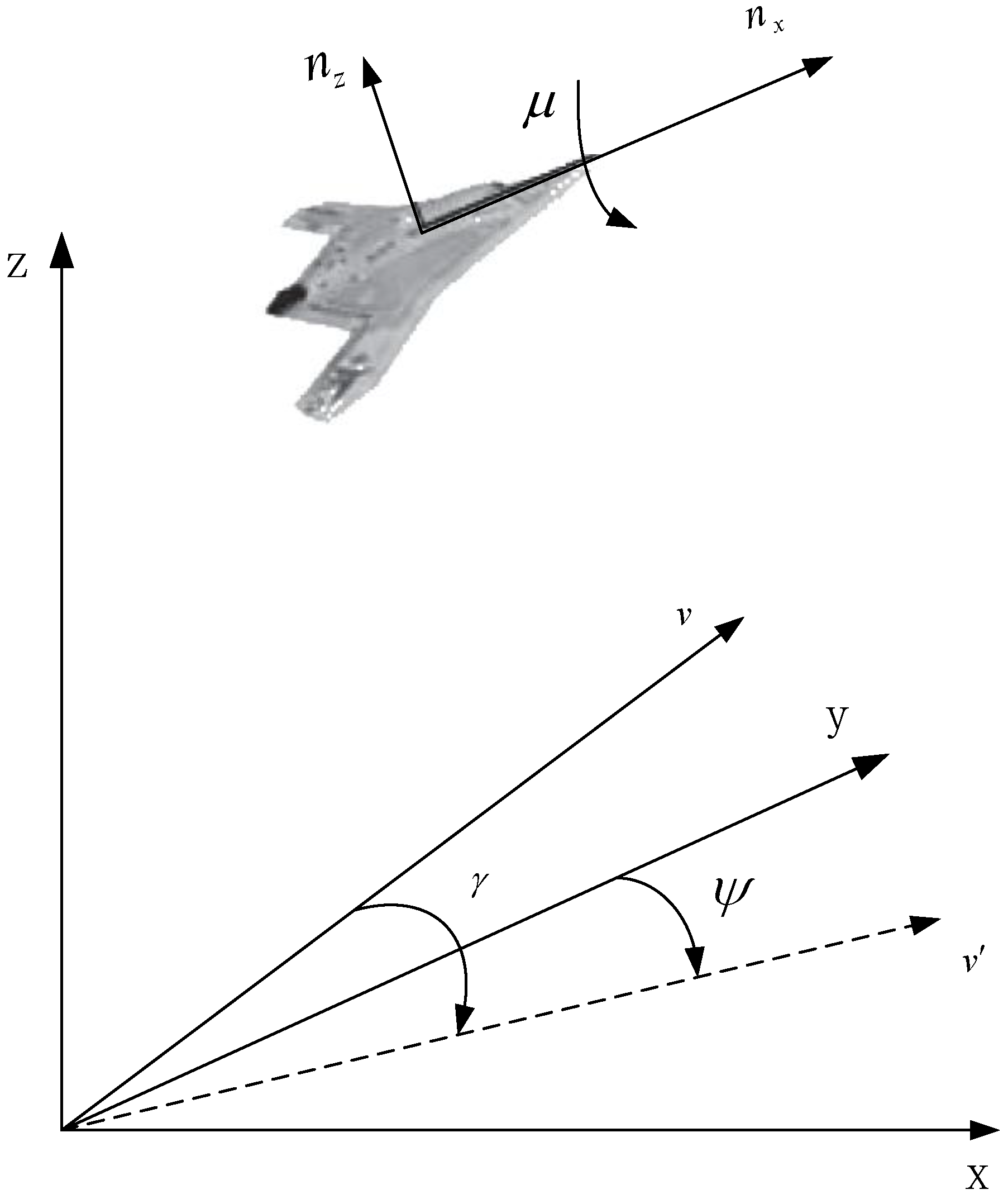
4.2. Dynamic Model for UAV
4.3. State Space
4.4. Action Space
4.5. Reward Function
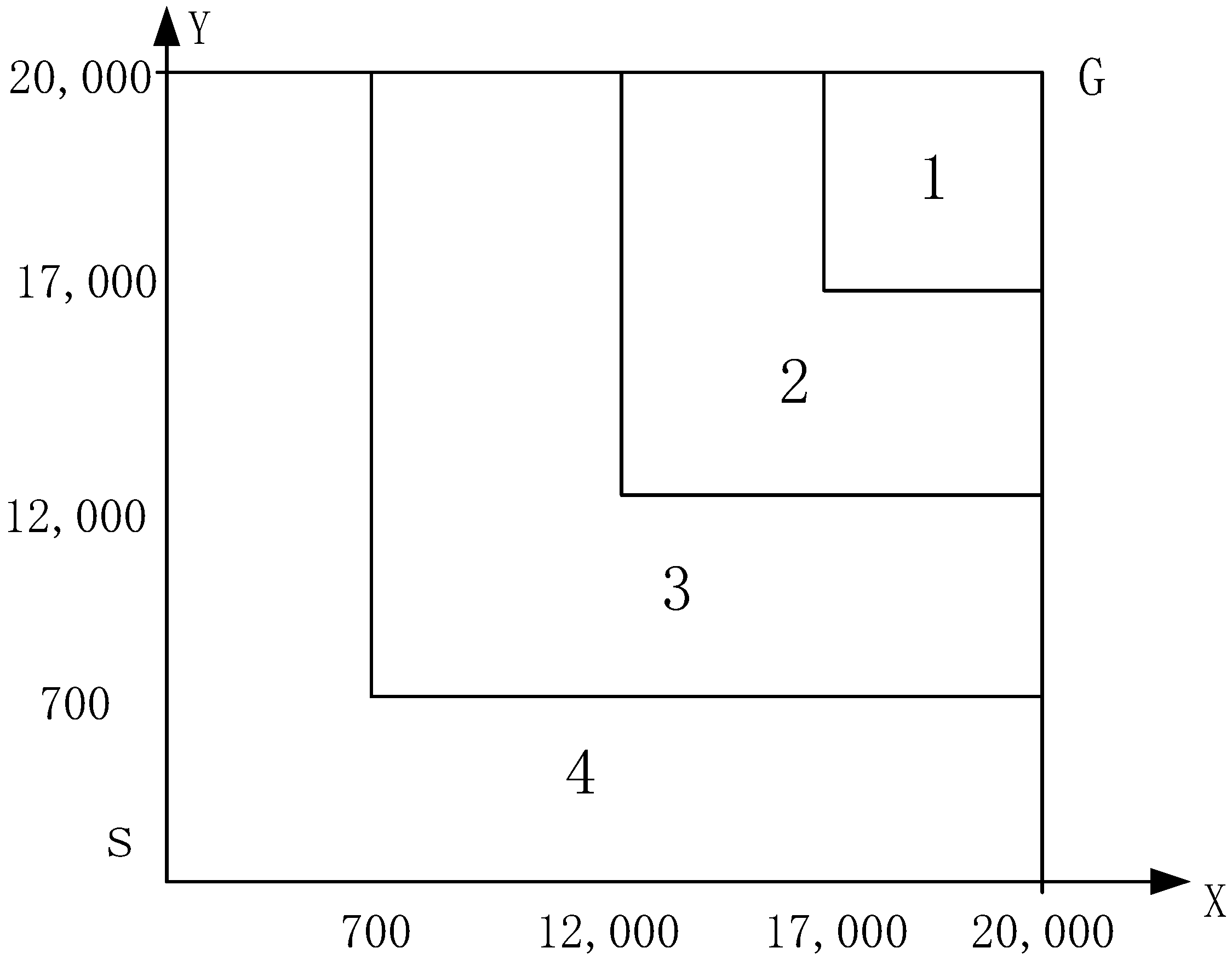
4.6. The Distributions of the Initial State
4.7. Network Architecture for the Value Function
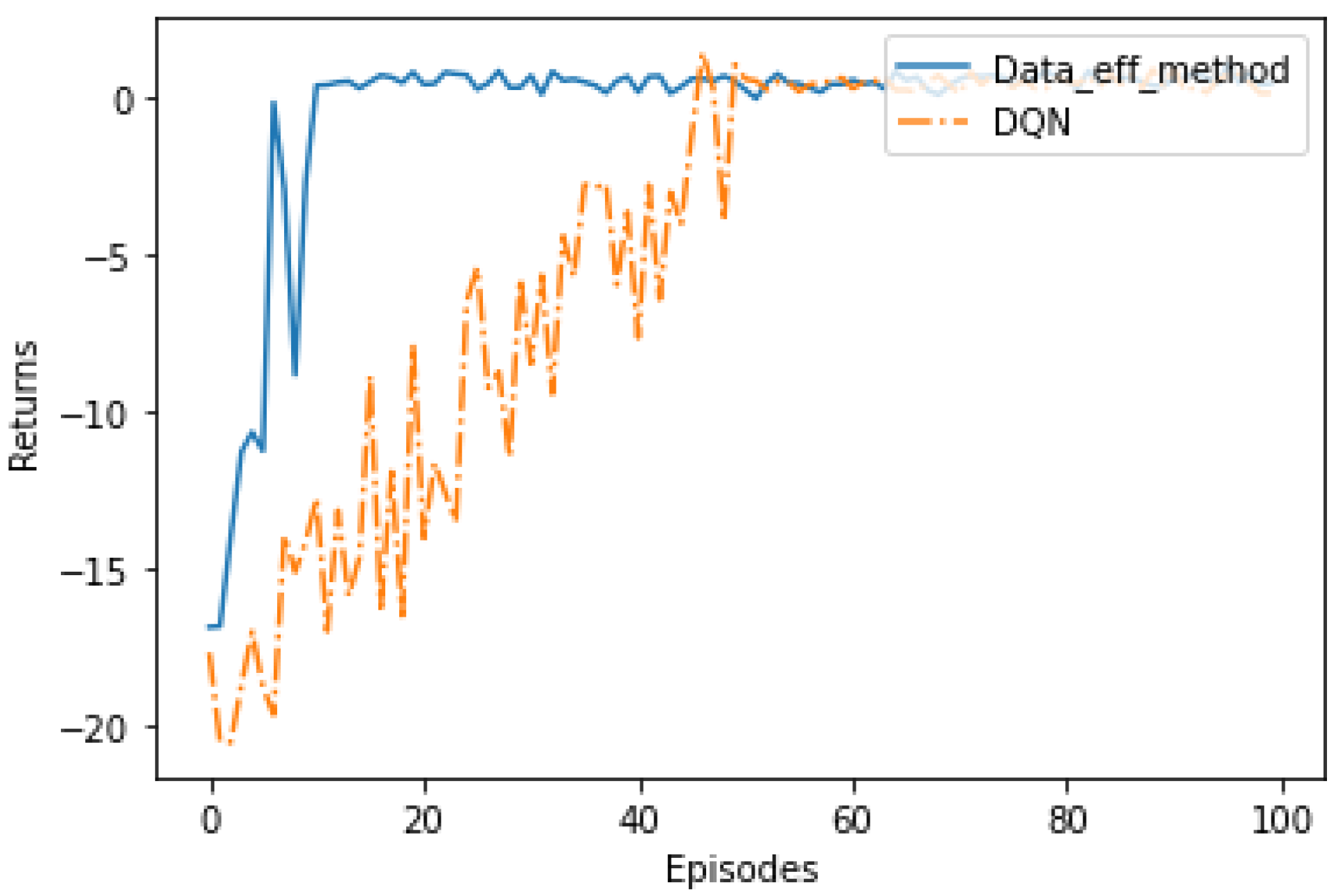
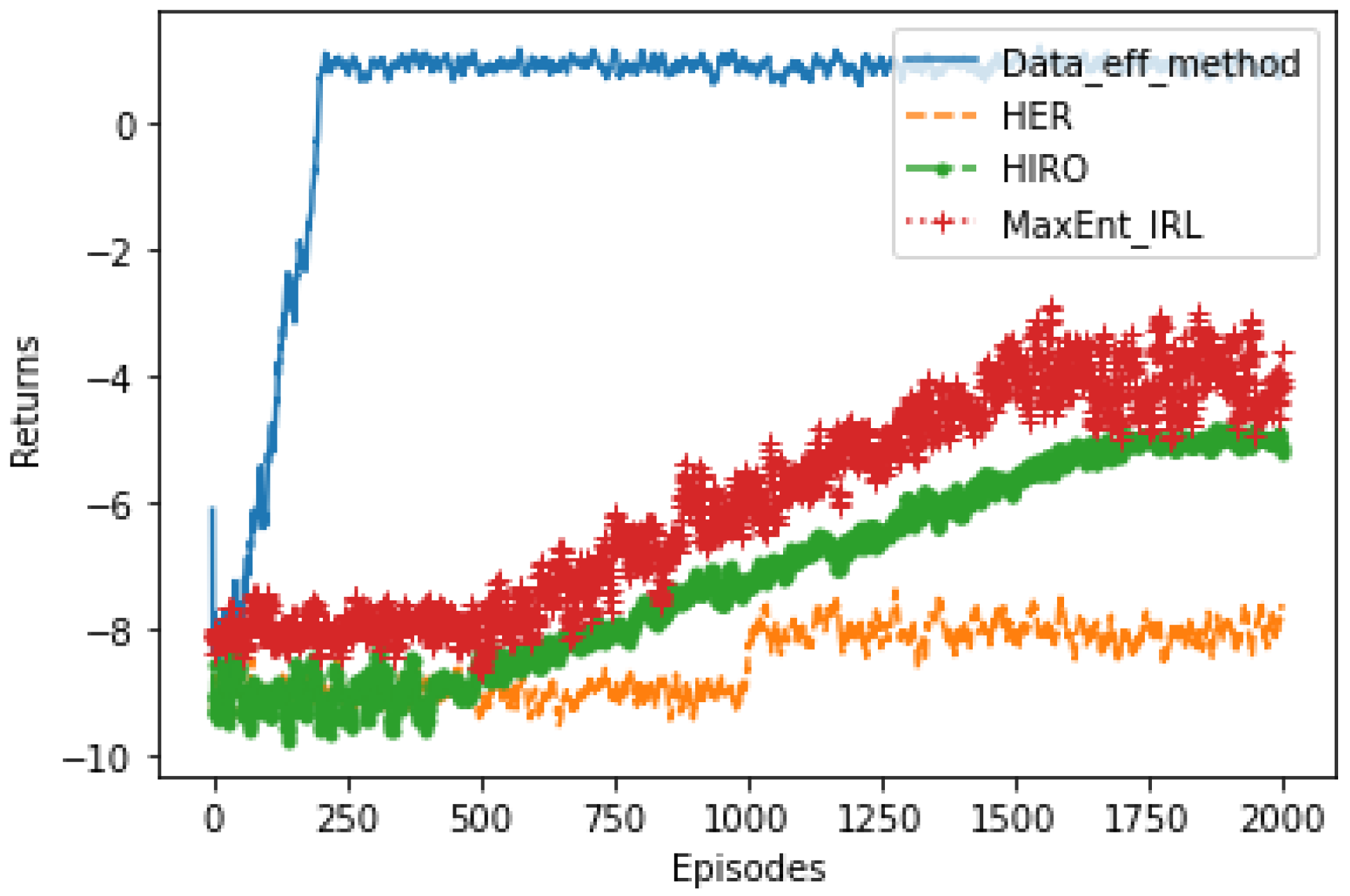
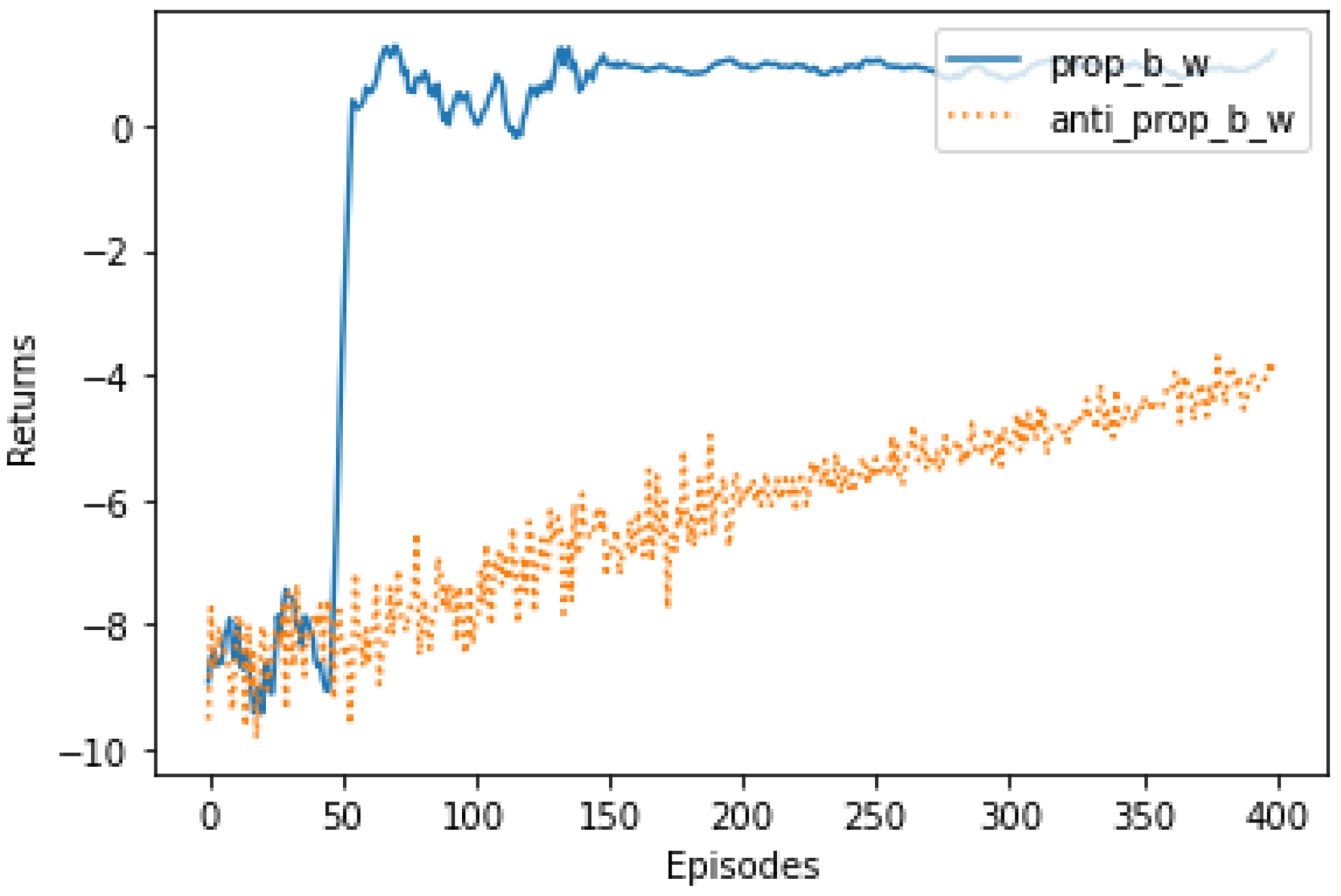
5. Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Mnih, V.; Badia, A.P. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef]
- Moravčík, M.; Schmid, M.; Burch, N.; Lisý, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M. DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker. Scence 2017, 356, 508–513. [Google Scholar] [CrossRef]
- Brown, N.; Sandholm, T. Safe and nested subgame solving for imperfect-information games. arXiv 2017, arXiv:1705.02955. [Google Scholar]
- Jaderberg, M.; Czarnecki, W.M.; Dunning, I.; Marris, L.; Lever, G.; Castañeda, A.G.; Beattie, C.; Rabinowitz, N.; Morcos, A.; Ruderman, A.; et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science 2019, 364, 859–865. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-End Training of Deep Visuomotor Policies. J. Mach. Lean. Res. 2016, 17, 1334–1373. [Google Scholar]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation. arXiv 2018, arXiv:1806.10293. [Google Scholar]
- Pinto, L.; Gupta, A. Supersizing self-supervision: Learning to grasp from 50K tries and 700 robot hours. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar]
- Nagabandi, A.; Konoglie, K.; Levine, S.; Kumar, V. Deep Dynamics Models for Learning Dexterous Manipulation. In Proceedings of the 2020 Conference on Robot Learning, Virtual, 16–18 November 2020; pp. 1101–1112. [Google Scholar]
- Kalashnikov, D.; Varley, J.; Chebotar, Y.; Swanson, B.; Jonschkowski, R.; Finn, C.; Levine, S.; Hausman, K. MT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale. arXiv 2021, arXiv:2104.08212. [Google Scholar]
- Gupta, A.; Yu, J.; Zhao, T.Z.; Kumar, V.; Rovinsky, A.; Xu, K.; Devlin, T.; Levine, S. Reset-Free Reinforcement Learning via Multi-Task Learning: Learning Dexterous Manipulation Behaviors without Human Intervention. arXiv 2021, arXiv:2104.11203. [Google Scholar]
- Degrave, J.; Felici, F.; Buchli, J.; Neunert, M.; Tracey, B.; Carpanese, F.; Ewalds, T.; Hafner, R.; Abdolmaleki, A.; de las Casas, D.; et al. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature 2022, 602, 414–419. [Google Scholar] [CrossRef] [PubMed]
- Mirhoseini, A.; Goldie, A.; Yazgan, M.; Jiang, J.W.; Songhori, E.; Wang, S.; Lee, Y.; Johnson, E.; Pathak, O.; Nazi, A.; et al. A graph placement methodology for fast chip design. Nat. Int. Wkly. J. Sci. 2021, 594, 207–212. [Google Scholar] [CrossRef]
- Hu, J.; Wang, L.; Hu, T.; Guo, C.; Wang, Y. Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning. Electronics 2022, 11, 467. [Google Scholar] [CrossRef]
- Rusu, A.A.; Vecerik, M.; Rothörl, T.; Heess, N.; Pascanu, R.; Hadsell, R. Sim-to-Real Robot Learning from Pixels with Progressive Nets. arXiv 2016, arXiv:1610.042868. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents. J. Artif. Intell. Res. 2012, 47, 253–279. [Google Scholar] [CrossRef]
- Machado, M.C.; Bellemare, M.G.; Talvitie, E.; Veness, J.; Hausknecht, M.; Bowling, M. Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents. J. Artif. Intell. Res. 2018, 61, 523–562. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hessel, M.; Modayil, J.; van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining Improvements in Deep Reinforcement Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Tsividis, P.A.; Tenenbaum, J.B.; Pouncy, T.; Xu, J.; Gershman, S. Human learning in atari. In Proceedings of the AAAI Spring Symposium—Technical Report, Standford, CA, USA, 27–29 March 2017. [Google Scholar]
- Fedus, W.; Ramachandran, P.; Agarwal, R.; Bengio, Y.; Larochelle, H.; Rowland, M.; Dabney, W. Revisiting Fundamentals of Experience Replay. In Proceedings of the International Conference on Machine Learning, Virtual, 12–18 July 2020; pp. 3061–3071. [Google Scholar]
- Zhang, S.; Sutton, R.S. A Deeper Look at Experience Replay. arXiv 2017, arXiv:1712.01275. [Google Scholar]
- Silver, D.; Singh, S.; Precup, D.; Sutton, R.S. Reward is enough. Artif. Intell. 2021, 299, 103535. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Ng, A.Y.; Harada, D.; Russell, S. Policy Invariance under Reward Transformations: Theory and Application to Reward Shaping; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1999. [Google Scholar]
- Burda, Y.; Edwards, H.; Storkey, A.; Klimov, O. Exploration by Random Network Distillation. arXiv 2018, arXiv:1810.128948. [Google Scholar]
- Badia, A.P.; Sprechmann, P.; Vitvitskyi, A.; Guo, D.; Piot, B.; Kapturowski, S.; Tieleman, O.; Arjovsky, M.; Pritzel, A.; Bolt, A.; et al. Never Give Up: Learning Directed Exploration Strategies. arXiv 2022, arXiv:2002.060388. [Google Scholar]
- Yengera, G.; Devidze, R.; Kamalaruban, P.; Singla, A. Curriculum Design for Teaching via Demonstrations: Theory and Applications. In Proceedings of the 35th Conference in Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Wang, X.; Chen, Y.; Zhu, W. A Survey on Curriculum Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 49, 4555–4576. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Lai, J.; Chen, X.; Cao, L.; Wang, J. Learning to Utilize Curiosity: A New Approach of Automatic Curriculum Learning for Deep RL. Mathematics 2022, 10, 2523. [Google Scholar] [CrossRef]
- Zhipeng, R.; Daoyi, D.; Huaxiong, L.; Chunlin, C. Self-paced prioritized curriculum learning with coverage penalty in deep reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2216–2226. [Google Scholar]
- Gehring, J.; Synnaeve, G.; Krause, A.; Usunier, N. Hierarchical Skills for Efficient Exploration. In Proceedings of the 35th Conference in Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Vezhnevets, A.S.; Osindero, S.; Schaul, T.; Heess, N.; Jaderberg, M.; Silver, D.; Kavukcuoglu, K. FeUdal networks for hierarchical reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3540–3549. [Google Scholar]
- Nachum, O.; Gu, S.; Lee, H.; Levine, S. Data-Efficient Hierarchical Reinforcement Learning. arXiv 2018, arXiv:1805.08296. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, P.; Zaremba, W. Hindsight Experience Replay. arXiv 2017, arXiv:1707.01495. [Google Scholar]
- Vecchietti, L.F.; Seo, M.; Har, D. Sampling Rate Decay in Hindsight Experience Replay for Robot Control. IEEE Trans. Cybern. 2022, 52, 1515–1526. [Google Scholar] [CrossRef]
- Schaul, T.; Horgan, D.; Gregor, K.; Silver, D. Universal value function approximators. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1312–1320. [Google Scholar]
- Levy, A.; Konidaris, G.; Platt, R.; Saenko, K. Learning multi-level hierarchies with hindsight. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, J.X.; Kurth-Nelson, Z.; Tirumala, D.; Soyer, H.; Leibo, J.Z.; Munos, R.; Blundell, C.; Kumaran, D.; Botvinick, M. Learning to reinforcement learn. arXiv 2016, arXiv:1611.05763. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maneuver | Control Values | ||
|---|---|---|---|
| nx | nz | μ | |
| forward maintain | 0 | 1 | 0 |
| forward accelerate | 2 | 1 | 0 |
| forward decelerate | −1 | 1 | 0 |
| left turn maintain | 0 | 8 | −arccos(1/8) |
| left turn accelerate | 2 | 8 | −arccos(1/8) |
| left turn decelerate | −1 | 8 | −arccos(1/8) |
| right turn maintain | 0 | 8 | arccos(1/8) |
| right turn accelerate | 2 | 8 | arccos(1/8) |
| right turn decelerate | −1 | 8 | arccos(1/8) |
| upward maintain | 0 | 8 | 0 |
| upward accelerate | 2 | 8 | 0 |
| upward decelerate | −1 | 8 | 0 |
| downward maintain | −1 | 8 | |
| downward accelerate | 2 | 8 | |
| downward decelerate | −1 | 8 | |
| Hyperparameter | Value |
|---|---|
| Threshold for win trajectories | 50 |
| Parameter for | 0.005 |
| Parameter for decay | 0.95 |
| Discounting rate | 0.98 |
| Units for the NN | (14, 128, 512, 64, 15) |
| Learning rate | 0.002 |
| Update the target net every d steps | 100 |
| Buffer size for the two experiment replays | 5000 |
| Minibatch size | 64 |
| Max velocity for the UAV | 200 m/s |
| Min velocity for the UAV | 80 m/s |
| Method | Time Cost | Total Return |
|---|---|---|
| Proposed data-efficient framework | 28 m | 0.95 |
| HER | 43 m | −7.3 |
| HIRO | 47 m | −5.4 |
| MaxEntIRL | 21 m | −3.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, W.; Han, C.; Lian, F.; Liu, X. A Data-Efficient Training Method for Deep Reinforcement Learning. Electronics 2022, 11, 4205. https://doi.org/10.3390/electronics11244205
Feng W, Han C, Lian F, Liu X. A Data-Efficient Training Method for Deep Reinforcement Learning. Electronics. 2022; 11(24):4205. https://doi.org/10.3390/electronics11244205
Chicago/Turabian StyleFeng, Wenhui, Chongzhao Han, Feng Lian, and Xia Liu. 2022. "A Data-Efficient Training Method for Deep Reinforcement Learning" Electronics 11, no. 24: 4205. https://doi.org/10.3390/electronics11244205
APA StyleFeng, W., Han, C., Lian, F., & Liu, X. (2022). A Data-Efficient Training Method for Deep Reinforcement Learning. Electronics, 11(24), 4205. https://doi.org/10.3390/electronics11244205