
Research on Small Acceptance Domain Text Detection Algorithm Based on Attention Mechanism and Hybrid Feature Pyramid


Abstract
1. Introduction
2. Preliminaries
3. Methods
3.1. Lightweight Network Structure with a Mixed Attention Mechanism
3.1.1. Channel Domain Attention Mechanism
3.1.2. Spatial Domain Attention Mechanism
3.1.3. Hybrid Attention Mechanism Module
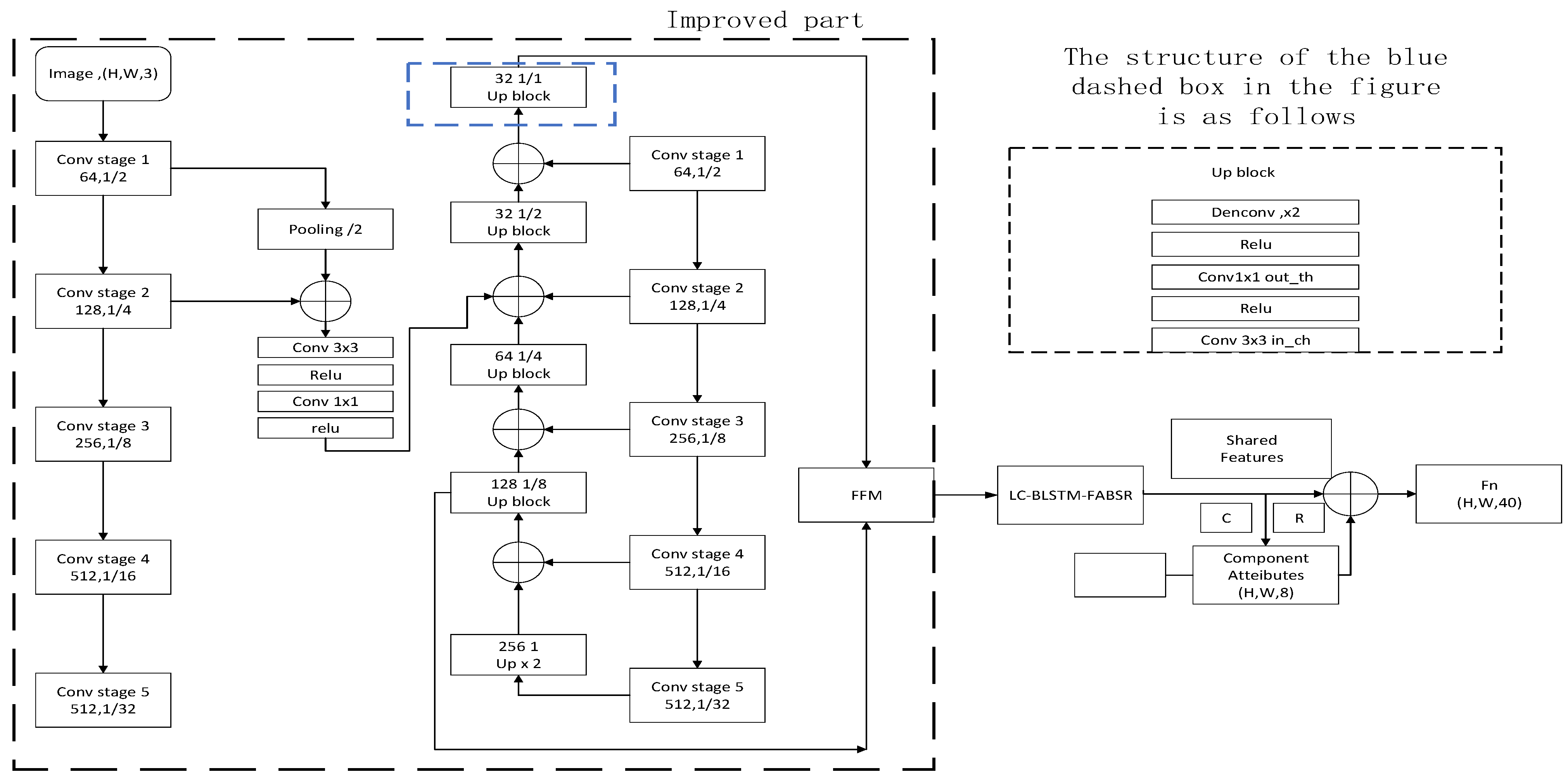
3.2. Optimization Way of Small Acceptance Domain Based on a Hybrid Feature Pyramid
Feature Extraction of Text Sequence Based on BLSTM Network
4. Experimental Results
4.1. Test Description
4.2. Comprehensive Comparison of Several Natural Scene Text Detection Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Short Name | Full Name |
| CBAM | Convolution Block Attention Module |
| EAST | Efficient and Accurate Scene Text |
| NMS | non-maximum suppression |
| FCN | full convolution network |
| LNMS | local perception non-maximum suppression |
| SE | squeeze-and-excitation |
| HS | h-swish |
| CAM | Channel Attention Module |
| SAM | Spatial Attention Module |
| BLSTM | bidirectional long short-term memory |
| ICDAR | International Conference on Document Analysis and Recognition |
| Faster-RCNN | Faster-Region-Convolutional Neural Network |
| CNN | Convolutional Neural Network |
| SSD | Single Shot MultiBoxDetector |
| CTPN | Connectionist Text Proposal Network |
| VGG | Visual Geometry Group |
| ReLU | Rectified Linear Unit |
| ResNet | Deep residual network |
| IoU | Intersection over Union |
| LSTM | Long Short Term Memory |
| ADAM | Adaptive Moment |
| RRPN | Rotation Region Proposal Network |
Appendix A




References
- Ren, S.; He, K.; Girshick, R.; Jian, S. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Hwang, Y.J.; Lee, J.G.; Moon, U.C.; Park, H.H. SSD-TSEFFM: New SSD Using Trident Feature and Squeeze and Extraction Feature Fusion. Sensors 2020, 20, 3630. [Google Scholar] [CrossRef] [PubMed]
- Li, X.B.; Chen, L. Face detection in natural scenes based on improved Faster-RCNN. J. Comput. Eng. 2021, 47, 210–216. [Google Scholar]
- Yun, N.; Lee, S. Analysis of effectiveness of tsunami evacuation principles in the 2011 Great East Japan tsunami by using text mining. Multimed. Tools Appl. 2016, 75, 12955–12966. [Google Scholar] [CrossRef]
- Huang, X. Automatic video scene text detection based on saliency edge map. Multimed. Tools Appl. 2019, 78, 34819–34838. [Google Scholar] [CrossRef]
- Zhou, B.; Liu, Y.Q.; Min, Z.; Jin, Y.J.; Ma, S.P. Retrieval effectiveness analysis for anchor texts. J. Softw. 2011, 22, 1714–1724. [Google Scholar] [CrossRef]
- Sun, J.; He, X.; Wu, M.; Wu, X.; Lu, B. Detection of tomato organs based on convolutional neural network under the overlap and occlusion backgrounds. Mach. Vis. Appl. 2020, 31, 15–22. [Google Scholar] [CrossRef]
- Chang, L.; Zhang, S.; Du, H.; You, Z.; Wang, S. Position-aware lightweight object detectors with depthwise separable convolutions. J. Real-Time Image Processing 2020, 34, 857–871. [Google Scholar] [CrossRef]
- Pang, Y.; Zhang, Y.J.; Lin, L.Z.; Cai, Y.Q. Improved scene text detection in any direction based on EAST. J. Chongqing Univ. Posts Telecommun. Nat. Sci. Ed. 2021, 33, 868–876. [Google Scholar]
- Yang, B.; Du, X.Y. Natural scene text localization algorithm based on improved EAST. J. Comput. Eng. Appl. 2019, 55, 161–165. [Google Scholar]
- Qiao, T.; Su, H.S.; Liu, G.H.; Wang, M. Object detection algorithm based on improved feature extraction network. J. Adv. Lasers Optoelectron. 2019, 56, 134–139. [Google Scholar]
- Saha, S.; Chakraborty, N.; Kundu, S.; Paul, S.; Mollah, A.F.; Basu, S.; Sarkar, R. Multi-lingual scene text detection and language identification. Pattern Recognit. Lett. 2020, 138, 16–22. [Google Scholar] [CrossRef]
- Wang, X.; Xue, F.; Wang, W.; Liu, A. A network model of speaker identification with new feature extraction ways and asymmetric BLSTM. Neurocomputing 2020, 403, 167–181. [Google Scholar] [CrossRef]
- Li, X.Q.; Liu, J.; Zhang, S.W.; Zhang, G.X.; Zheng, Y. Single shot multi-oriented text detection based on local and non-local features. Int. J. Doc. Anal. Recognit. 2020, 23, 241–252. [Google Scholar] [CrossRef]
- Naiemi, F.; Ghods, V.; Khalesi, H. Hassan Khalesi Scene text detection using enhanced Extremal region and convolutional neural network. Multimed. Tools Appl. Int. J. 2020, 79, 27137–27159. [Google Scholar] [CrossRef]
- Arunkumar, P.; Shantharajah, S.P.; Geetha, M. Improved canny detection construction for processing and segmenting text from the images. Clust. Comput. 2018, 22, 7015–7021. [Google Scholar] [CrossRef]
- Wang, D.F.; Chen, C.B.; Ma, T.L.; Li, C.H.; Miao, C.Y. YOLOv3 pedestrian detection algorithm based on depth-separable convolution. J. Comput. Appl. Softw. 2020, 37, 218–223. [Google Scholar]
- Liu, K.; Pan, G.Y.; Zheng, D.G.; Gu, J.J.; Meng, C.Y. An aviation forensics target detection algorithm based on RetinaNet and SE fusion. J. Mod. Def. Technol. 2022, 50, 25–32. [Google Scholar]
- Zhao, L.L.; Wang, X.Y.; Zang, Y.; Zhang, M.Y. Research on vehicle target detection technology based on YOLOv5s and SENet. J. J. Graphics. 2022, 4038, 1–8. [Google Scholar]
- Jlab, C.; Qza, B.; Yuan, Y.D.; Hai, S.E.; Bo, D. SemiText: Scene text detection with semi-supervised learning. Neurocomputing 2020, 407, 343–353. [Google Scholar]
- Basavaraju, H.T.; Aradhya, V.; Pavithra, M.S.; Guru, D.S.; Bhateja, V. Arbitrary oriented multilingual text detection and segmentation using level set and Gaussian mixture model. Evol. Intell. 2022, 14, 881–894. [Google Scholar] [CrossRef]
- Guo, Q.F.; Liu, L.; Zhang, C.; Xu, W.J.; Jing, W.F. Multi-scale feature fusion network based on feature pyramid. J. Eng. Math. 2020, 37, 521–530. [Google Scholar]
- Xu, C.Q.; Hong, X.H. Feature pyramid target detection network based on function preservation. J. Pattern Recognit. Artif. Intell. 2020, 33, 507–517. [Google Scholar]
- Guo, C.; Qiu, X.H. Improved EAST text detection algorithm based on BLSTM network. J. Comput. Technol. Dev. 2020, 30, 21–24. [Google Scholar]
- Liu, J.; Feng, K.; Pan, J.Z.; Deng, J.; Wang, L. MESD: Multi-Modal Web Rumor Detection Way. J. Comput. Res. Dev. 2020, 57, 2328–2336. [Google Scholar]
- Chakraborty, N.; Chatterjee, A.; Singh, P.K.; Mollah, A.F.; Sarkar, R. Application of daisy descriptor for language identification in the wild. Multimed. Tools Appl. 2020, 80, 323–344. [Google Scholar] [CrossRef]
- Bai, Z.C.; Li, Q.; Chen, P.; Guo, L.Q. Text detection in natural scenes: A literature review. Chin. J. Eng. 2020, 42, 1433–1448. [Google Scholar]
- Lu, L.; Wu, D.; Wu, T.; Huang, F.; Yi, Y. Anchor-free multi-orientation text detection in natural scene images. Appl. Intell. 2020, 50, 3623–3637. [Google Scholar] [CrossRef]
- Shiravale, S.S.; Jayadevan, R.; Sannakki, S.S. Devanagari Text Detection from Natural Scene Images. Int. J. Comput. Vis. Image Process. IJCVIP 2020, 10, 44–59. [Google Scholar] [CrossRef]
- Qin, X.; Chu, X.; Yuan, C.; Zhao, Q. Necklace: A novel long text detection model. J. Eng. 2020, 2020, 416. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Name | R (%) | P (%) | F (%) |
|---|---|---|---|
| EAST + VGG16 | 72.8 | 80.5 | 75.4 |
| Seglink [25] | 76.8 | 80.5 | 75 |
| CTPN + VGG16 [26] | 51.6 | 74.2 | 60.9 |
| EAST + resnet50 + BLSTM [27] | 78.07 | 85.10 | 81.64 |
| EAST + PVANET2 × MS [28] | 77.23 | 84.64 | 80.77 |
| TextSnke [29] | 83.20 | 73.90 | 78.72 |
| RRPN [30] | 86.00 | 70.00 | 77.00 |
| The algorithm in this paper | 80.02 | 86.04 | 82.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Li, B.; Zhang, W. Research on Small Acceptance Domain Text Detection Algorithm Based on Attention Mechanism and Hybrid Feature Pyramid. Electronics 2022, 11, 3559. https://doi.org/10.3390/electronics11213559
Liu M, Li B, Zhang W. Research on Small Acceptance Domain Text Detection Algorithm Based on Attention Mechanism and Hybrid Feature Pyramid. Electronics. 2022; 11(21):3559. https://doi.org/10.3390/electronics11213559
Chicago/Turabian StyleLiu, Mingzhu, Ben Li, and Wei Zhang. 2022. "Research on Small Acceptance Domain Text Detection Algorithm Based on Attention Mechanism and Hybrid Feature Pyramid" Electronics 11, no. 21: 3559. https://doi.org/10.3390/electronics11213559
APA StyleLiu, M., Li, B., & Zhang, W. (2022). Research on Small Acceptance Domain Text Detection Algorithm Based on Attention Mechanism and Hybrid Feature Pyramid. Electronics, 11(21), 3559. https://doi.org/10.3390/electronics11213559