Abstract
In view of the intelligent requirements of spatial non-cooperative target detection and recognition tasks, this paper applies the deep learning method YOLOX_L to the task and draws on YOLOF (You Only Look One-Level Feature) and TOOD (Task-Aligned One-Stage Object Detection), which optimize and improve its detection accuracy to meet the needs of space Task Accuracy Requirements. We improve the FPN (Feature Pyramid Networks) structure and decoupled prediction network in YOLOX_L and perform a validation comparative analysis of the improved YOLOX_L on the VOC2007+2012 and spacecraft dataset. Our experiments conducted on the VOC2007+2012 benchmark show that the proposed method can help YOLOX_L achieve 88.86 mAP, which is higher than YOLOX_L, running at 50 FPS under the image size of 608 × 608. The spatial target detection method based on the improved YOLOX has a detection accuracy rate of 96.28% and a detection speed of 50 FPS on our spacecraft dataset, which prove that the method has certain practical significance and practical value.
1. Introduction
With the rapid development of space technology, human activities in space are becoming more and more frequent, and various countries have successively launched satellites with various functions into space. However, due to the particularity of the space environment and the insufficiency of its own design and manufacture, some satellites will inevitably have problems such as falling off of battery plates and running out of fuel, resulting in the downgrading of problematic satellites, or becoming space junk. In order to avoid or reduce losses and waste, On-Orbit Servicing (OOS) has emerged to realize the assembly, maintenance and service functions of on-orbit space vehicles [1,2].
The detection and recognition of spatial non-cooperative targets is the prerequisite for OOS. Therefore, the technology of target feature detection and recognition is the key technology for the autonomous operation control of OOS. For the complex and special space environment, the visual sensor has a simple structure, rich applicable scenes, low price and strong real-time performance. It has become the main sensor of the space manipulator, which is equivalent to the eye of the manipulator, and plays an important role in the operation of the space manipulator. Therefore, the research and application of the spatial target feature detection and recognition algorithm based on vision are of great significance [3].
Visual perception techniques range from simple to complex, including cooperative target vision measurement and non-cooperative target vision measurement [4]. The cooperative objective refers to how the target can transmit relative motion state information to the service spacecraft or provide the service spacecraft with convenient conditions for capturing and other operations. Usually, a cooperative identifier or a known grasping device of a robotic arm is installed for measurement. The non-cooperative target refers to the unknown form of the target itself, which is unable to transmit relative motion state information to the service spacecraft, and which has no corresponding cooperative identifier or known manipulator grasping device [5]. Currently, the perceptual technology mature cooperation targets, rather than the awareness of cooperation target research beginning from the end of the 20th century, as most of the research in the theoretical analysis and experimental ground, the failure of the spacecraft in orbit garbage removal service and maintenance, space and even space attack–defense tasks to target mostly non-cooperative targets. Therefore, in space missions, the research on the visual perception of non-cooperative targets has more important significance and broader prospects. The visual perception of the non-cooperative target is more difficult than the visual perception of the cooperative target [6,7]. The main reasons are:
- The target feature is unknown in the complex space environment. So, traditional model-based methods (such as contour edge features, template matching, geometric features, etc.) have considerable difficulty in feature recognition, and artificially designed features are difficult to generalize and apply to other targets, resulting in poor adaptability and robustness.
- The target state changes rapidly, and the accuracy and real-time performance of the traditional algorithm cannot be guaranteed. As for feature detection, there is little research on non-cooperative objects in space, and the feature detection methods of ground robots can be compared and used for reference. Due to the high requirement of autonomy, various machine learning methods are mainly considered.
The detection and recognition algorithm can be divided into traditional methods and deep learning methods according to whether a deep neural network is used. Traditional methods mainly learn from the existing prior data, and then classify and identify specific feature parts after mastering certain rules, which can be roughly divided into comparison-based methods and feature-based methods. In general, traditional machine learning methods often need to manually design and find features, and they are less universal. The deep learning method does not depend on the target model, does not need to manually design features, has better generalization ability when the training data are good enough, has better universality for different targets and scenarios and is more robust than traditional methods. In recent years, with the rapid iteration of deep learning methods, there have been breakthroughs in target detection technology in the field of computer vision, which can also meet the requirements of spatial target detection and recognition in terms of accuracy and real-time performance [8,9].
Reference [10] proposes datasets for spatial object detection, segmentation and part recognition. Due to the difficulty in obtaining real images of spatial targets, there are not many real images published. To enrich the dataset, the researchers collect 3117 images of satellites and space stations from real images and videos and generate complete datasets with space targets including space stations and satellites. In addition, benchmark datasets are provided for evaluating the state-of-the-art in object detection and instance segmentation algorithms. Reference [11] uses the YOLO model to identify satellites and their components, and it uses the three-dimensional model image sets of the two satellite models for training. The results show that the accuracy of the model is above 90%, but the recognition of the satellite model does not consider different motions, different illuminations and different orientations. Reference [12] proposes to apply MASK-RCNN to the problem of feature detection and recognition of space satellites, and it uses RFCN and Light-Header R-CNN to optimize and improve it to meet the real-time requirements of space satellite recognition tasks. However, there is still a big difference between building a virtual environment and a real space environment, and the more complex space lighting environment, complex nutation and precession and other movements are not considered.
In recent research, YOLOX [13], a new high-performance detector, has been proposed with some experienced improvements to the YOLO series. YOLOF [14] points out that the divide-and-conquer strategy is the key reason for the success of FPN rather than multi-scale feature fusion. Task-Aligned One-Stage Object Detection (TOOD) [15] proposes an overall pipeline of backbone-FPN-head, authors propose to align the two tasks more explicitly using a designed Task-aligned head (T-head) with a new Task Alignment Learning (TAL). DetectoRS [16] propose a Recursive Feature Pyramid, which incorporates extra feedback connections from Feature Pyramid Networks into the bottom-up backbone layers.
Meanwhile, YOLOX, YOLOF, TOOD and DetectoRS provide many other details on the specific operations so that they can achieve state-of-the-art performances.
Therefore, this paper proposes to apply the deep learning method YOLOX_L to the detection and recognition of non-cooperative targets in space, and it makes some detailed improvements to the algorithms that require high accuracy in the detection process in space tasks. At the same time, deep learning algorithms require large-scale sample data for network training. Aiming at the difficulty of constructing a space target sample dataset, this paper simulates the space environment and generates satellite sample data under different scenarios and working conditions.
In a nutshell, the major contributions of this paper are:
- We use three one-level feature maps instead of FPN as the input of detection part to detect large, medium and small objects.
- We propose an adaptive feedback connection with the one-level feature maps.
- We utilize the improvement TOOD head to replace the decoupled head used in official YOLOX, and this allows the classification and regression tasks to work more collaboratively, which in turn aligns their predictions more accurately.
- We create a new available space non-cooperative images dataset, as the first step to develop new deep learning algorithms for spacecraft object detection, and recognition tasks.
- Extensive experiments on the dataset indicate the importance of each component.
2. Related Works
Object detection: A branch of computer vision. Given an image, we can detect the position of the object in the image by object detection, which usually returns a four-tuple of coordinates in the top left and bottom right corner and the category number of the object in the box. At present, object detection has multiple application backgrounds, such as face recognition [17], intelligent transportation [18], industrial detection [19] and so on. Face recognition is a biometric identification technology based on human facial features. By collecting images or video streams containing faces, it automatically detects and tracks faces, and then recognizes the detected faces. Industrial inspection is to use the target detection algorithm in computer vision technology to detect the appearance defects such as cracks, deformation and parts loss in the production process of products, so as to achieve the purpose of improving product quality stability and production efficiency. Intelligent traffic detects various abnormal traffic events through visual algorithms, including non-motor vehicles entering the motor vehicle lane, vehicles occupying the emergency lane, monitoring the driving behavior of dangerous goods transport vehicle drivers and real-time traffic accident alarms. There are two main categories of object detection methods: one-stage methods, and two-stage methods. One-stage detectors have attracted a lot of attention from researchers because of their simple pipeline and fast inference time. The YOLO series algorithms are a high-precision algorithm that can meet the real-time detection requirements (FPS > 30), so they are favored by the majority of engineering application personnel, and they have a very wide range of applications in practical projects. Currently, YOLOX has become the most popular detection framework due to its detection accuracy and detection speed. In this paper, we apply object detection technology to the space background, use the one-stage detector YOLOX as our baseline and realize our methods of space non-cooperative target detection on it to prove its effectiveness.
One-level feature detector and multiple-level feature detectors: Multiple-level feature detectors are a conventional technique for object detection. The main method is to construct a feature pyramid through multiple features. The single shot detectors (SSD) [20] first use the pyramidal feature to perform object detection on different scales. However, this method does not use enough low-level features (in SSD, the feature of the lowest layer is conv4_3 of VGG network), which are very helpful for detecting small objects. Then, a feature pyramid network (FPN) [21] is proposed to use the high semantic information of low-level features and high-resolution features and high-level features at the same time, which achieves the prediction effect by fusing the features of these different layers. After the FPN, many works follow it and obtain better performance.
In the initial stage of target detection technology based on deep learning, the R-CNN series [22,23] and R- FCN [24] only use a single feature to detect various scale objects. Similarly, the one-stage detectors, YOLO [25] and YOLOv2 [26], also use the last output feature of the backbone. They all have a low performance on accuracy. In recent research, YOLOF points out that the most successful part of the FPN lies in the strategy of dividing and conquering optimization problems rather than multi-scale feature fusion. From an optimization point of view, the authors introduce an alternative solution to this optimization problem without using a complex feature pyramid, they only need to use a single-layer feature map. Based on this simple and efficient solution, the author designs the You Only Look One-Level Feature (YOLOF) detection framework. In this framework, there are two core components, namely Dilated Encoder and Uniform Matching, which bring huge performance improvements.
Different from the above works, our method uses a three-single-level feature detector, instead of the FPN, as the input of detection part to detect large, medium and small objects.
Task-aligned head: We all know, the contradiction between classification and regression tasks is a big problem in object detection [27]. So, most of the one-stage and two-stage detectors use a decoupled head for classification and localization [28]. YOLOX replaces the YOLO detect head with a decoupled head, which brings additional accuracy and speed improvement. In recent research, Task-Aligned One-Stage Object Detection (TOOD) proposes an overall pipeline of backbone-FPN-head, authors propose to align the two tasks more explicitly using a designed Task-aligned head (T-head) with a new Task Alignment Learning (TAL). Qualitative results also demonstrate the effectiveness of TOOD for better aligning the tasks of object classification and localization. In this paper, we utilize the TOOD head to replace the decoupled head used in the official YOLOX, and this allows the classification and regression tasks to work more collaboratively, which in turn aligns their predictions more accurately.
Non-cooperative space target dataset: The large amount of training data in the non-cooperative spatial target dataset is the basis of deep learning methods, but for spatial targets, the construction of the dataset is more difficult. The main reasons are: space target images are difficult to obtain, and for the same target, when its scale, attitude and working conditions (such as shooting angle, distance, lighting, etc.) are different, the characteristics will also change; however, the dataset must contain images of the same target under different scales, attitudes and working conditions, which is difficult to collect. In this paper, we select 1000 images and make data enhancement and annotation from the satellite dataset, which collects 3117 satellite and space station images. Finally, we use the dataset to verify the advancement of the improved algorithm.
3. Method
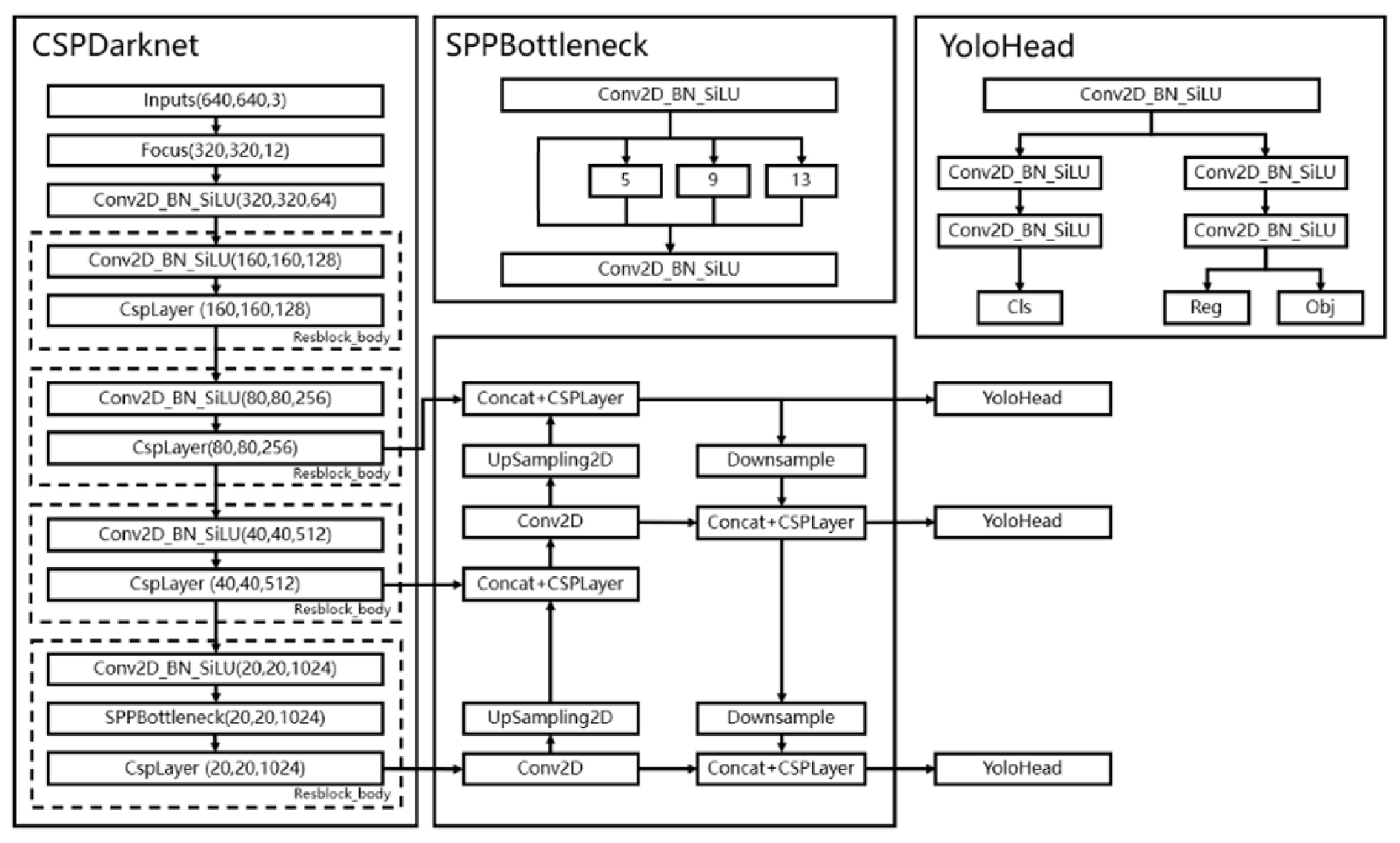
In this paper, we use the one-stage detector YOLOX_L as our baseline and realize our methods on it to prove its effectiveness due to YOLOX_L having a high performance. According to the different network structure functions, YOLOX_L can be divided into three parts, namely CSPDarknet, FPN and YoloHead. CSPDarknet can be called the backbone feature extraction network of YOLOX. In the backbone part, we obtain three feature layers for the next network construction. The FPN can be called the enhanced feature extraction network. The three effective feature layers obtained in the backbone part will be the feature fusion in this part. The purpose of feature fusion is to combine feature information of different scales. YoloHead is the classifier and regressor of YOLOX_L, and what YoloHead actually does is to judge and determine whether the feature points have objects. Although YOLOX_L has become the most popular detection framework due to its detection accuracy and detection speed, in terms of non-cooperative spatial target detection and recognition, improvements to its network can also improve accuracy and speed.
Therefore, in this section, we will first introduce the details of YOLOX_L, and then introduce our design and application to the YOLOX_L detector. As shown in Figure 1, we replace the FPN and YoloHead with the Dilated Encoder and Head, as detailed below.
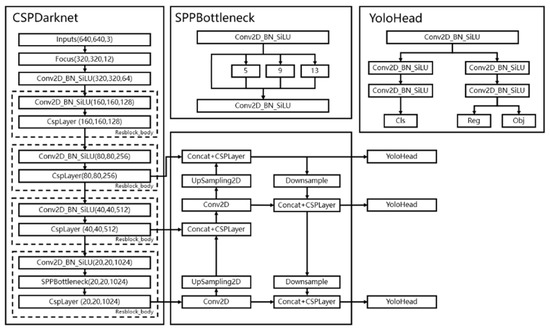
Figure 1.
The structure of YOLOX_L.
3.1. Introduction of YOLOX_L
The YOLOX series model is a network designed for object detection. Different from the traditional YOLO series, the YOLOX_L model adopts the current mainstream methods of target detection, such as decoupling the prediction head, removing the anchor frame and switching to the anchor-free mode and using advanced label assignment SimOTA. The rest of YOLOX’s models have been improved in much the same way. This improvement makes YOLOX-L reduce the number of parameters and calculation amount and improve the prediction accuracy while maintaining the speed advantage of YOLO series. As shown in Figure 1, YOLOX_L can be divided into three parts, namely CSPDarknet, FPN and YoloHead.
CSPDarknet: Firstly, it uses the focus structure to extract separated pixels in the direction of rows and columns in an image to form a new feature layer. Each image can be reconstituted into four feature layers, and then the four feature layers are stacked to expand the input channel by four times. The stacked feature layer has 12 channels, compared with the original 3 channels. Secondly, it uses SPPBottleneck to pool images through pooling cores of different sizes to increase the network receptive field and extract more features. Finally, the backbone network uses the CSP structure, and the main feature extraction in the CspLayer uses the residual structure. However, the CspLayer divides the feature map into two parts: one part enters the residual block for feature extraction, and the other part performs the concat operation with the feature map after feature extraction for information fusion.
FPN: It can fuse the feature layers of different shapes, which is conducive to extracting better features. In the feature utilization, YOLOX_L extracts multiple feature layers for target detection, and a total of three feature layers are extracted. The three feature layers are located in different positions of the main part of CSPdarknet, namely, the middle layer, the middle layer and the bottom layer. When the input is (640,640,3), the shapes of the three feature layers are (80,80,256),(40,40,512) and (20,20,1024).
After obtaining the three effective feature layers, YOLOX_L uses these three effective feature layers to construct the FPN layer, which fuses the feature maps of the three dimensions, but each output has a certain focus, in order to have a better detection effect on targets of different scales.
YoloHead: Using the FPN, YOLOX_L can obtain three strengthening features, whose shapes are (20,20,1024), (40,40,512) and (80,80,256), respectively. Then, YOLOX_L uses the feature layers of these three shapes to pass into the YoloHead to obtain the prediction results.
For each feature layer, YOLOX_L can obtain three prediction results, which are:
- Reg(H,w,4) is used to judge the regression parameters of each feature point, and the prediction box can be obtained after adjusting the regression parameters.
- Obj(h,w,1) is used to judge whether each feature point contains an object.
- Cls(H, W, NUM_classes) is used to determine the types of objects contained in each feature point.
3.2. Solution of YOLOF
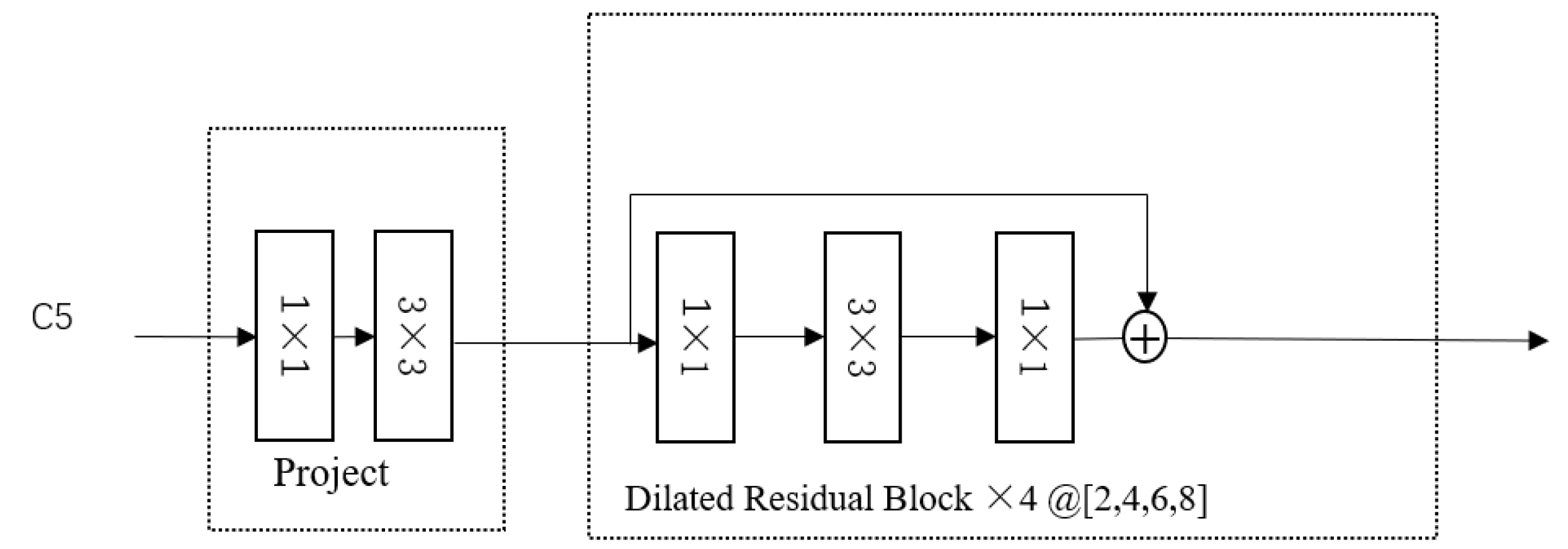
YOLOF is a fast and straightforward framework with a single-level feature. YOLOF starts with finding an alternative to the optimization problem of the feature FPN, which can obtain comparable precision and speed using only a single-layer feature map compared to the FPN. It can be divided into three parts: the backbone, the encoder and the decoder. The backbone uses ResNet [29] and ResNeXt [30] series. Then, to enable the encoder’s output feature to cover all objects on various scales, four different dilated rates’ residual blocks are stacked. For the decoder, it adapts the main design of RetinaNet, which is composed of two task-specific heads: the classification head and the regression head. As shown in Figure 2, we show the single-layer feature map of YOLOF.
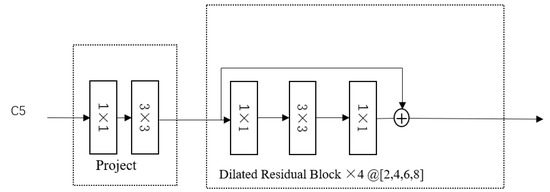
Figure 2.
The single-layer feature map of YOLOF. C5 is a feature map from backbone in YOLOF.
3.3. Dilated Encoder Network: Three One-Level Feature Maps with Feedback Connection
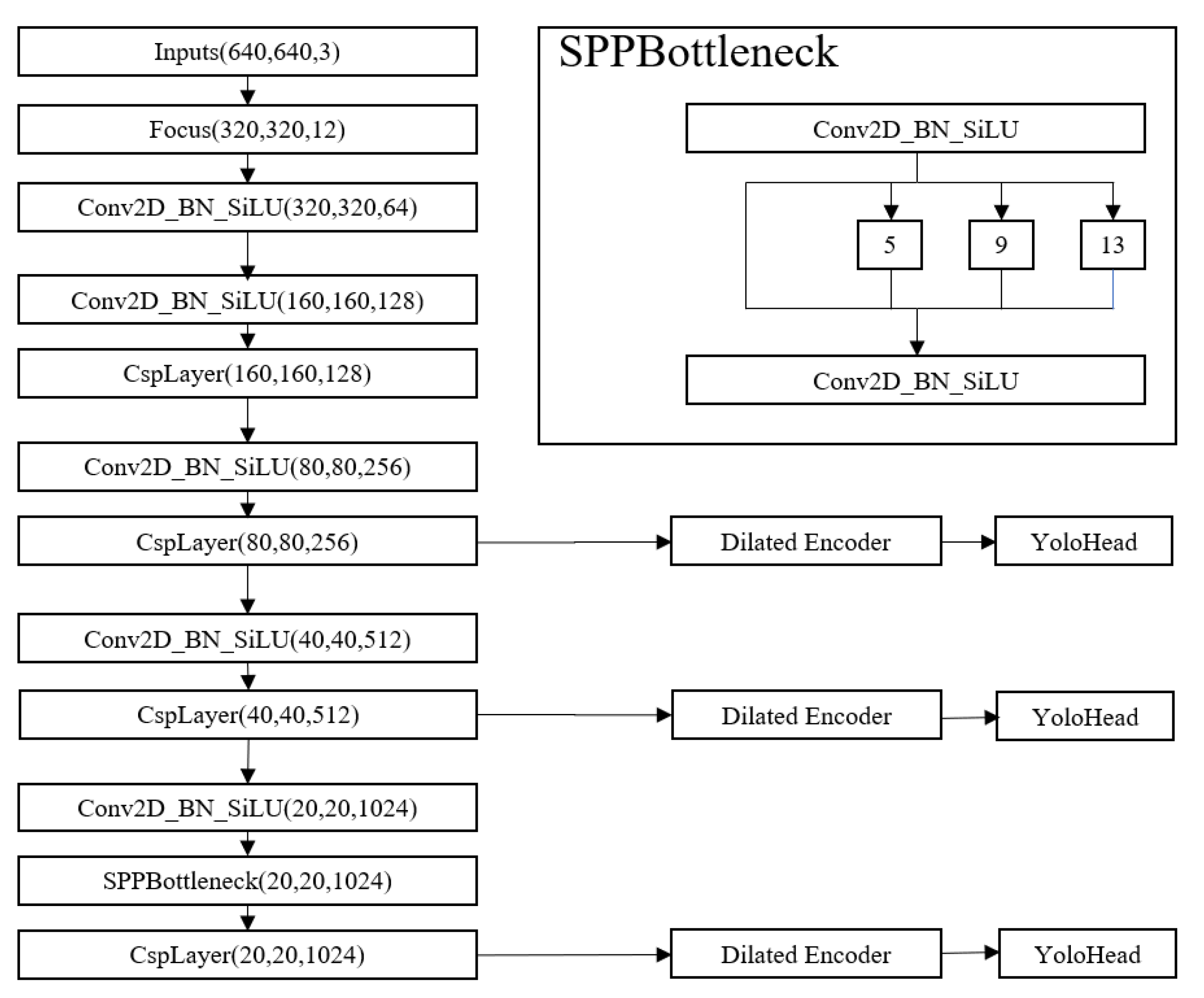
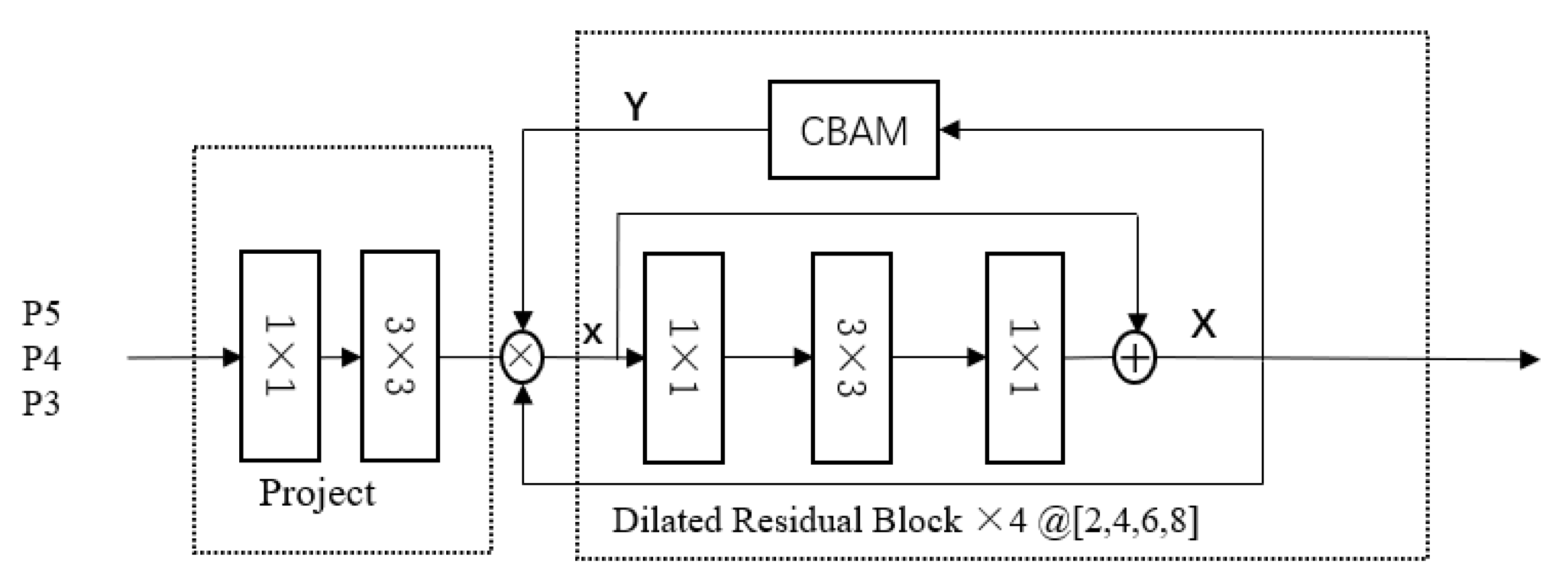
After reviewing YOLOF’s solution, we compare with the YOLOX_L detector and discover potential optimization methods. As shown in Figure 1, YOLOX_L uses the feature fusion of different layers as an enhanced feature extraction network. However, YOLOF points out that the success of FPN is due to its divide-and-conquer solution rather than multi-scale feature fusion. With this solution, we believe that the three effective feature layers obtained by the feature extraction network can be separately processed by YOLOF’s solution and realize the detection and recognition of large, medium and small targets. As shown in Figure 3, driven by YOLOF, we propose our Dilated Encoder Network: three one-level feature maps with feedback connection.
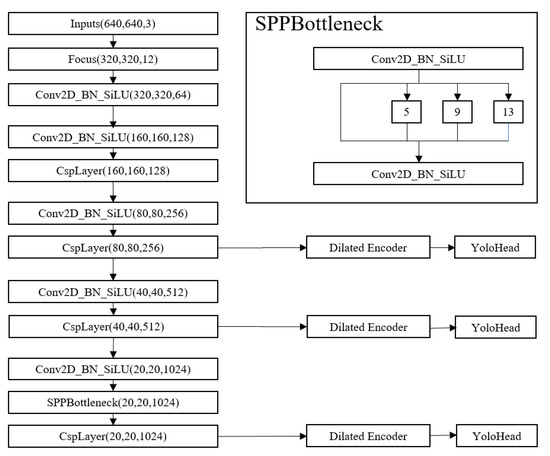
Figure 3.
The structure of three one-level feature maps with feedback connection.
As shown in Figure 4, the Dilated Encoder Network contains three main components: the initial convolution module, residual module and attention mechanism module. Firstly, to build the initial convolutional module, use a 1 × 1 convolutional layer to reduce the channel dimension, then add a 3 × 3 convolutional layer to refine the semantic context. After that, stack four consecutive dilated residual blocks with an attention mechanism module. The dilated residual blocks consist of a 3 × 3 convolutional layer with a different dilation rate and generate multiple receptive fields, covering the scale of all objects. The attention mechanism module is established to compensate for the performance between the single-in-single-out structure and the multiple-in-single-out structure gap.
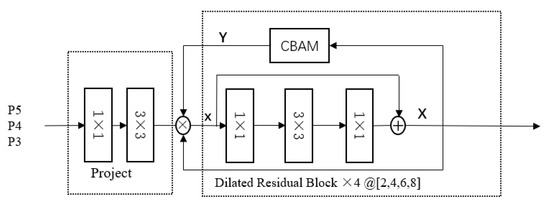
Figure 4.
The sketch of Dilated Encoder Network. P3, P4, P5 are feature maps that form CSPDarknet in YOLOX_L.
We take P5 as an example to expand the calculation process. The calculation of P3 and P4 is the same as P5. The initial convolutional module is constructed as:
where is the feature map from CSPDarknet; and are two convolutional layers. Then, we stack four consecutive dilated residual blocks with an attention mechanism module:
where is the input of the dilated residual block and it is the output of initial convolutional module; is the output of the dilated residual block; and refer to two 1×1 convolutional layers; refers to the dilated convolution; and the dilation rates of the four dilated convolutions are 2, 4, 6 and 8, and correspond to the four dilated residual blocks, respectively. Then, we establish an attention mechanism feedback module CBAM, which combines spatial and channel attention mechanisms to bridge the performance gap between the single-in-single-out structure and the multiple-in-single-out structure:
where is the output of channel attention; is the output of spatial attention; is the output of the feedback attention module CBAM; is the input feature map; and are the average pooling and max pooling operations, respectively; and refer to the convolution operations and the activation function; σ is the function; is the concatenation operation based on one dimension. Finally, we build a recursive Dilated Encoder Network:
3.4. Improvement Head for YOLOX_L
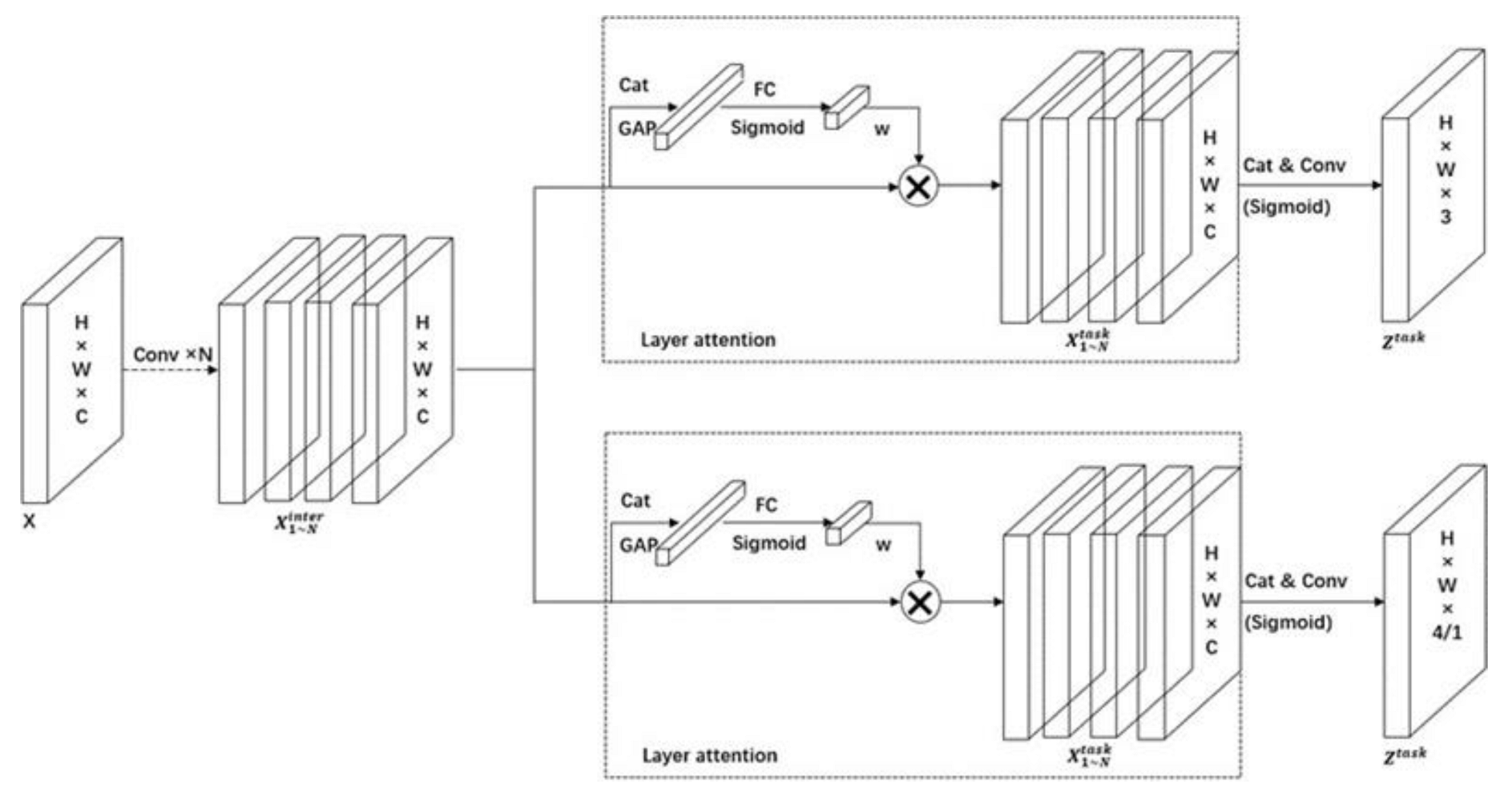
The YoloHead uses two branches in parallel to complete classification and localization tasks separately; we design a new head to enhance an interaction between the classification and localization tasks for YOLOX_L. The new head makes the two tasks work more mutually, which in turn adjusts their predictions more accurately. The detailed structure is presented in Figure 5.
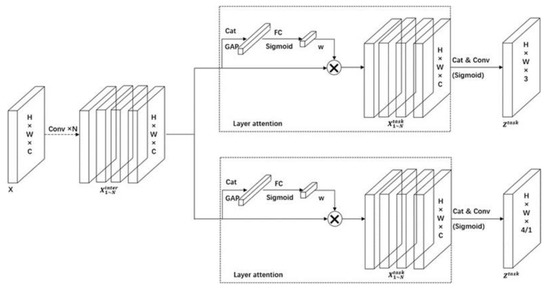
Figure 5.
The improvement head for YOLOX_L.
We use a new feature extractor to enhance the interaction between classification and localization, which learns a series of task interaction features from multiple convolutional layers. This new feature extractor not only facilitates task interaction, but also provides multi-level effective receptive fields with multi-scale features. We calculate task interaction features with four consecutive convolutional layers, which include activation functions. The brief process can be presented as follows:
where is a single feature layer; X ∈ R × H ×W ×C, R, H, W and C, respectively, denote the number of images, batch size, image height, image width and number of channels of each input model; and refer to the k-th conv layer and a relu function, respectively. Therefore, we use a single branch to extract rich multi-scale features from the input features. Then, two branches will be established with task interaction features for classification and localization.
We use a layer attention mechanism to resolve a certain level of feature conflicts that exist between classification and localization and compute such task-specific features at the layer level dynamically. This process computes as:
where is the k-th element of the layer attention mechanism; is the task interaction feature we obtained in the previous step; is calculated from task interaction features:
where and refer to two convolutional layers; is a sigmoid function; is a relu function. At last, we use to calculate the result of classification and localization:
where and refer to two convolutional layers; is the stitched feature map of ; is a sigmoid function, and finally generates the category prediction parameter, the target box parameter and the foreground or background parameter for target detection.
3.5. Non-Cooperative Space Target Dataset
We know the large amount of training data in the non-cooperative spatial target dataset is the basis of the deep learning methods, but for spatial targets, the construction of the dataset is more difficult. We select 1000 clear images from the satellite dataset, which collects 3117 satellite and space station images, and the images are composite or real images of satellites and space stations. However, in this spatial target dataset, the number of positive samples generated by the small target and the contribution of the small target for the loss are far less than the large target, making the convergence direction tend to the large target. In order to alleviate this problem, we copy and reduce the target in the image, and then we use the enhancement image in the training process. This process increases the number of tiny objects in the image and the number of images containing tiny objects, increases the contribution to the loss of tiny objects and makes the training more balanced. Finally, we annotate all the images with labeling, an annotation tool, and the space targets are divided into three categories, including satellite, windsurfing and cabin. Figure 6 shows the selected clear images in our dataset.

Figure 6.
The selected clear images.
4. Experimental Results and Analysis
In order to verify the feasibility of the algorithm in this paper, we perform end-to-end training on the two datasets; the server configuration used in the experiment is shown in Table 1.

Table 1.
Server configuration.
4.1. Experiments Details
The network is trained on the above server, and each minibatch size is 8, the learning rate is initially 0.00002 and each training is in 20 increments of 0.00002 until the increment is 0.001, for a total of iterative training 20,000 times.
4.2. Evaluation Index
In this paper, the mAP (mean average accuracy) and FPS are used as the evaluation index in target detection. The mAP is defined as the average of the AP (Average Precision) rate of all categories. The AP rate is defined as:
Among them, R represents the recall rate; P represents the accuracy rate.
4.3. Effectiveness of Our Method on YOLO_L
At first, in order to verify the feasibility of the algorithm in this paper, we perform end-to-end training on the PASCAL-VOC2007+2012 dataset, which has a total of 20 types of target images.
We experiment through training of the VOC2007 and VOC2012 dataset, and test on the dataset. Then, the experimental results are shown in Table 2 and Table 3.
Table 2.
Effectiveness of our method on YOLO_L.
Table 3.
Test results of different algorithms for target categories.
4.4. Effectiveness of Three Single-Level Features with Improvement Head on YOLO_L
The motivation for our work is the desire to port the methods from YOLOF and TOOD to our model. However, based on the theoretical analysis, we believe that the solution must take into account different expansion rates. Therefore, we conduct ablation experiments to evaluate the effect of each component. Following the spirit of YOLOX_L, which is simplicity and speed, we choose three convolutional blocks for our design. Furthermore, three are the minimum blocks that can make the receptive field cover the entire feature map. Then, we perform end-to-end training on our space target dataset, which has a total of 1120 target images.
Dilation rates: The purpose of adding a dilation convolutional block is to enlarge the receptive field of a single feature to cover all scales. Therefore, we abandon YOLOF’s solution. We show experimental results for different dilation rates in convolutional blocks in Table 4: (1, 4, 8) achieves the best performance, while larger dilation rates cannot improve YOLO.
Table 4.
Comparison of different dilation rates.
Improvement head: In the official YOLOX_L, YoloHead uses two branches in parallel to complete classification and localization tasks separately; we design a new head to enhance an interaction between the classification and localization tasks for YOLOX_L. The new head makes the two tasks work more mutually, which in turn adjusts their predictions more accurately. The results in Table 5 show that our head is enough to perform well and efficiently.
Table 5.
Effectiveness of our head on YOLO_L.
4.5. Effectiveness of Three Single-Level Features with Feedback Connection and Improvement Head on YOLO_L
To reach a comparable performance with the original YOLO on accuracy, we propose adaptive feedback connection, and we perform end-to-end training on our space target dataset. The results in Table 6 show that our head is enough to perform well and efficiently.
Table 6.
Effectiveness of Dilated Encoder Network on YOLO_L.
4.6. Effectiveness of Our Improvement YOLO_L
To better evaluate the effectiveness of the proposed method, we conduct additional experiments with multiple object detectors on our spatial object dataset. The results in Table 7 show that our design is enough to perform well.
Table 7.
Effectiveness of our improvement YOLO_L.
5. Conclusions
To increase the accuracy of the YOLOX_L detector with comparable speed, this work proposes an adaptive feedback connection with the three single-level features for object detection, which are motivated by YOLOF. We follow the basic single-in-single-out structure of the YOLOF, while bringing some significant modifications to the encoder to make it effective on the YOLOX_L. Based on the single-in-single-out structure, the proposed method helps YOLOX_L keep the high speed while improving accuracy about 3.2% higher than before, and the detection model can converge much earlier in the training stage. We prove that the proposed method is an efficient and effective solution for the YOLOX_L detector. Although the proposed method can achieve a reasonable performance for the space target, it cannot detect the smaller target well in some of the more complex scenes. The focus of future research should be to choose the smaller space target to improve the detection performance for more complex scenes.
Author Contributions
Conceptualization, H.Z.; funding acquisition, H.Z.; investigation, J.F.; methodology, H.A. and L.R.; software, H.A.; writing—original draft, H.A.; writing—review and editing, S.G. and H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the West Light Foundation of the Chinese Academy of Sciences: grant No. XAB2021YN15.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cui, N.G.; Wang, P.; Guo, J.F.; Cheng, X. A Review of On-Orbit Servicing. J. Chin. Soc. Astronaut. 2007, 28, 805–811. [Google Scholar]
- Zhang, Q.-X.; Sun, F.-C.; Ye, W.; Chen, J. On-orbit Servicing Task Allocation for Spacecrafts Using Discrete Particle Swarm Optimization Algorithm. In Proceedings of the International Conference on Computational Materials Science (CMS 2011), Guangzhou, China, 17–18 April 2011; pp. 574–580. [Google Scholar]
- Liu, D.; Li, J. Spectral-spatial target detection based on data field modeling for hyperspectral data. Chin. J. Aeronaut. 2018, 31, 795–805. [Google Scholar] [CrossRef]
- Guo, X.; Chen, T.; Liu, J.; Liu, Y.; An, Q. Dim Space Target Detection via Convolutional Neural Network in Single Optical Image. IEEE Access 2022, 10, 52306–52318. [Google Scholar] [CrossRef]
- Dumitrescu, F.; Ceachi, B.; Truica, C.-O.; Trascau, M.; Florea, A.M. A Novel Deep Learning-Based Relabeling Architecture for Space Objects Detection from Partially Annotated Astronomical Images. Aerospace 2022, 9, 520. [Google Scholar] [CrossRef]
- Fitzmaurice, J.; Bedard, D.; Lee, C.H.; Seitzer, P. Detection and correlation of geosynchronous objects in NASA’s Wide-field Infrared Survey Explorer images. Acta Astronaut. 2021, 183, 176–198. [Google Scholar] [CrossRef]
- Zhang, R.; Yang, K.; Rongzhi, Z.; Kaizhong, Y. Space Object Detection Technology; Academic Press: Cambridge, MA, USA, 2020; pp. 35–72. [Google Scholar]
- Han, L.; Tan, C.; Liu, Y.; Song, R. Research on the On-orbit Real-time Space Target Detection Algorithm. Spacecr. Recovery Remote Sens. 2021, 42, 122–131. [Google Scholar]
- Li, Y.S.; Wan, L. Role of Radar in Deep Space Target Detection. Mod. Radar. 2005, 27, 1–4. [Google Scholar]
- Hoang Anh, D.; Chen, B.; Chin, T.-J.; Soc, I.C. A Spacecraft Dataset for Detection, Segmentation and Parts Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Nashville, TN, USA, 19–25 June 2021; pp. 2012–2019. [Google Scholar]
- Wang, L. Research on Spatial Multi-objective Recognition Based on Deep Learning. Unmanned Syst. Technol. 2019, 3, 49–55. [Google Scholar]
- Chen, Y.; Gao, J.; Zhang, K. R-CNN-Based Satellite Components Detection in Optical Images. Int. J. Aerosp. Eng. 2020, 2020, 8816187. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2017, arXiv:0843. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-aligned One-stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11 October 2021. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Wu, Q.; Gao, X. Face Recognition in Non-ideal Environment Based on Sparse Representation and Support Vector Machine. Comput. Sci. 2020, 47, 121–125. [Google Scholar]
- Mingwei, L.; Lin, L. Intelligent transportation system in China: The optimal evaluation period of transportation’s application performance. J. Intell. Fuzzy Syst. 2020, 38, 6979–6990. [Google Scholar] [CrossRef]
- Liang, W.; Li, K.-C.; Long, J.; Kui, X.; Zomaya, A.Y. An Industrial Network Intrusion Detection Algorithm Based on Multifeature Data Clustering Optimization Model. IEEE Trans. Ind. Inform. 2020, 16, 2063–2071. [Google Scholar] [CrossRef]
- Wei, L.; Dragomir, A.; Dumitru, E.; Christian, S.; Scott, R.; Cheng-Yang, F.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the Sibling Head in Object Detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Fu, Y. Rethinking Classification and Localization for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).