
DFSGraph: Data Flow Semantic Model for Intermediate Representation Programs Based on Graph Network


Abstract
1. Introduction
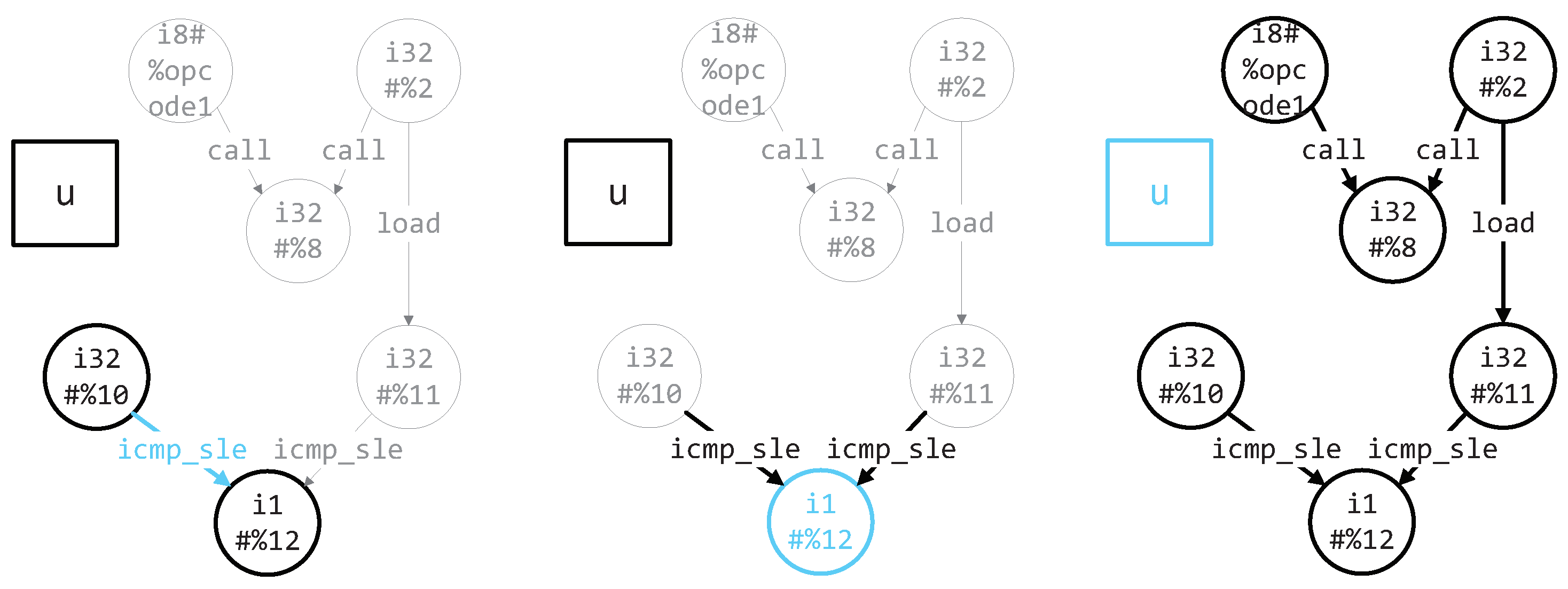
- We propose the Data Transformation Graph (DTG) for the first time, and it can express the data flow transformation relationships of the function completely and clearly.
- We redesign the message aggregation algorithm and update algorithm on the basis of graph network, making it can learn the semantic information from DTGs better.
- Experiments show that our proposed method can learn the semantic information of obfuscated code well and exhibits better performance than existing state-of-the-art methods in downstream tasks.
2. Related Works
2.1. Obfuscation Techniques
2.2. Intermediate Representation
2.3. Graph Neural Network
3. Proposed Approach
3.1. Data Transformation Graph
3.2. Graph Network
3.3. Model Training
4. Experiments
4.1. Dataset
4.2. Similarity Analysis of Obfuscated Code
4.3. Identification of Obfuscated Techniques
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tofighi-Shirazi, R.; Elbaz-Vincent, P.; Oppida, M.C.; Le, T.H. Dose: Deobfuscation based on semantic equivalence. In Proceedings of the ACM International Conference Proceeding Series, San Juan, PR, USA, 3–4 December 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Xu, D.; Ming, J.; Fu, Y.; Wu, D. VMhunt: A verifiable approach to partially-virtualized binary code simplification. In Proceedings of the ACM Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2018; pp. 442–458. [Google Scholar] [CrossRef]
- Menguy, G.; Bardin, S.; Bonichon, R.; Lima, C.D.S. Search-Based Local Black-Box Deobfuscation: Understand, Improve and Mitigate; Association for Computing Machinery: New York, NY, USA, 2021; Volume 1, pp. 2513–2525. [Google Scholar] [CrossRef]
- Blazytko, T.; Contag, M.; Aschermann, C.; Holz, T. Syntia: Synthesizing the semantics of obfuscated code. In Proceedings of the 26th USENIX Security Symposium, Vancouver, BC, Canada, 16–18 August 2017; pp. 643–659. [Google Scholar]
- Zhao, Y.; Tang, Z.; Ye, G.; Gong, X.; Fang, D. Input-Output Example-Guided Data Deobfuscation on Binary. Secur. Commun. Netw. 2021, 2021, 4646048. [Google Scholar] [CrossRef]
- David, R.; Coniglio, L.; Ceccato, M. QSynth—A Program Synthesis based approach for Binary Code Deobfuscation. In Proceedings of the BAR 2020 Workshop, San Diego, CA, USA, 23 February 2020. [Google Scholar] [CrossRef]
- Eyrolles, N.; Goubin, L.; Videau, M. Defeating MBA-based Obfuscation. In Proceedings of the 2016 ACM Workshop on Software Protection (SPRO ’16), Vienna, Austria, 28 October 2016; pp. 27–37. [Google Scholar]
- Ming, J.; Xu, D.; Wang, L.; Wu, D. LOOP: Logic-oriented opaque predicate detection in obfuscated binary code. In Proceedings of the ACM Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 757–768. [Google Scholar] [CrossRef]
- Kim, J.; Kang, S.; Cho, E.S.; Paik, J.Y. LOM: Lightweight Classifier for Obfuscation Methods; Springer International Publishing: New York, NY, USA, 2021; Volume 13009, pp. 3–15. [Google Scholar] [CrossRef]
- Peng, D.; Zheng, S.; Li, Y.; Ke, G.; He, D.; Liu, T.Y. How could Neural Networks Understand Programs? arXiv 2021, arXiv:2105.04297. [Google Scholar]
- Yu, Z.; Cao, R.; Tang, Q.; Nie, S.; Huang, J.; Wu, S. Order matters: Semantic-aware neural networks for binary code similarity detection. In Proceedings of the AAAI 2020—34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1145–1152. [Google Scholar] [CrossRef]
- Ding, S.H.; Fung, B.C.; Charland, P. Asm2Vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 19–23 May 2019; pp. 472–489. [Google Scholar] [CrossRef]
- Wang, S.; Wang, P.; Wu, D. Semantics-aware machine learning for function recognition in binary code. In Proceedings of the 2017 IEEE International Conference on Software Maintenance and Evolution, ICSME, Shanghai, China, 17–22 September 2017; pp. 388–398. [Google Scholar] [CrossRef]
- Tofighi-Shirazi, R.; Asavoae, I.M.; Elbaz-Vincent, P.; Le, T.H. Defeating Opaque Predicates Statically through Machine Learning and Binary Analysis. In Proceedings of the 3rd ACM Workshop on Software Protection (SPRO 2019), Los Angeles, CA, USA, 7–11 November 2019; pp. 3–14. [Google Scholar] [CrossRef]
- You, I.; Yim, K. Malware Obfuscation Techniques: A Brief Survey. In Proceedings of the 2010 International Conference on Broadband, Wireless Computing, Communication and Applications, Fukuoka, Japan, 4–6 November 2010; pp. 297–300. [Google Scholar] [CrossRef]
- Yu, Z.; Zheng, W.; Wang, J.; Tang, Q.; Nie, S.; Wu, S. CodeCMR: Cross-modal retrieval for function-level binary source code matching. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Online, 6 December 2020; pp. 1–12. [Google Scholar]
- Cummins, C.; Petoumenos, P.; Wang, Z.; Leather, H. End-to-End Deep Learning of Optimization Heuristics. In Proceedings of the 2017 26th International Conference on Parallel Architectures and Compilation Techniques (PACT), Portland, OR, USA, 9–13 September 2017; pp. 219–232. [Google Scholar] [CrossRef]
- Ben-Nun, T.; Jakobovits, A.S.; Hoefler, T. Neural code comprehension: A learnable representation of code semantics. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montreal, QC, Canada, 3 December 2018; pp. 3585–3597. [Google Scholar]
- Altinay, A.; Nash, J.; Kroes, T.; Rajasekaran, P.; Zhou, D.; Dabrowski, A.; Gens, D.; Na, Y.; Volckaert, S.; Giuffrida, C.; et al. BinRec: Dynamic binary lifting and recompilation. In Proceedings of the 15th European Conference on Computer Systems, EuroSys 2020, Heraklion, Greece, 27–30 April 2020. [Google Scholar] [CrossRef]
- Jain, P.; Jain, A.; Zhang, T.; Abbeel, P.; Gonzalez, J.; Stoica, I. Contrastive Code Representation Learning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 5954–5971. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Venkatakeerthy, S.; Aggarwal, R.; Jain, S.; Desarkar, M.S.; Upadrasta, R.; Srikant, Y.N. IR2Vec: LLVM IR Based Scalable Program Embeddings. ACM Trans. Archit. Code Optim. 2020, 17, 1–27. [Google Scholar] [CrossRef]
- Garba, P.; Favaro, M. SATURN—Software Deobfuscation Framework Based on LLVM. In Proceedings of the 3rd ACM Workshop on Software Protection (SPRO 2019), London, UK, 15 November 2019; pp. 27–38. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Casanova, A.; Liò, P.; Cucurull, G.; Romero, A.; Bengio, Y. Graph attention networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April 2018; pp. 1–12. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4 December 2017; pp. 1025–1035. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Łukasz, K.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4 December 2017; pp. 5999–6009. [Google Scholar] [CrossRef]
- Yun, S.; Jeong, M.; Kim, R.; Kang, J.; Kim, H.J. Graph Transformer Networks. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8 December 2019. [Google Scholar]
- Rong, Y.; Bian, Y.; Xu, T.; Xie, W.; Wei, Y.; Huang, W.; Huang, J. Self-Supervised Graph Transformer on Large-Scale Molecular Data. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Online, 6 December 2020. [Google Scholar]
- Ying, C.; Cai, T.; Luo, S.; Zheng, S.; Ke, G.; He, D.; Shen, Y.; Liu, T.Y. Do Transformers Really Perform Badly for Graph Representation? In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Montreal, QC, Canada, 6 December 2021. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In European Semantic Web Conference; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10843, pp. 593–607. [Google Scholar]
- Corso, G.; Cavalleri, L.; Beaini, D.; Liò, P.; Veličković, P. Principal Neighbourhood Aggregation for Graph Nets. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Online, 6 December 2020. [Google Scholar]
- Xie, T.; Grossman, J.C. Crystal Graph Convolutional Neural Networks for an Accurate and Interpretable Prediction of Material Properties. Phys. Rev. Lett. 2018, 120, 145301. [Google Scholar] [CrossRef] [PubMed]
- Gong, L.; Cheng, Q. Exploiting edge features for graph neural networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9203–9211. [Google Scholar] [CrossRef]
- Jiang, X.; Ji, P.; Li, S. CensNet: Convolution with Edge-Node Switching in Graph Neural Networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence; International Joint Conferences on Artificial Intelligence Organization: Macao, China, 2019; pp. 2656–2662. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Chen, H. EGAT: Edge-Featured Graph Attention Network. In Artificial Neural Networks and Machine Learning—ICANN 2021; Farkaš, I., Masulli, P., Otte, S., Wermter, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 253–264. [Google Scholar]
- Yang, Y.; Li, D. NENN: Incorporate Node and Edge Features in Graph Neural Networks. In Proceedings of the 12th Asian Conference on Machine Learning, Bangkok, Thailand, 15 April 2020; Volume 129, pp. 593–608. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Operators |
|---|---|
| Zero-element | ret, unreachable, fence, call, landingpad, catchpad, cleanuppad |
| Unary | resume, fneg, alloca, load, freeze |
| Binary | catchret, cleanupret, add, fadd, sub, fsub, mul, fmul, udiv, sdiv, fdiv, urem, srem, frem, shl, lshr, ashr, and, or, xor, extractelement, extractvalue, store, trunc..to, zext..to, sext..to, fptrunc..to, fpext..to, fptoui..to, fptosi..to, uitofp..to, sitofp..to, ptrtoint..to, inttoptr..to, bitcast..to, addrspacecast..to, icmp, fcmp, select |
| Multivariate | br, switch, indirectbr, invoke, callbr, catchswitch, insertelement, shufflevector, insertvalue, cmpxchg, atomicrmw, getelementptr, phi, va_arg |
| Obfuscator | Options | Composite Options |
|---|---|---|
| O-LLVM | sub, fla, bcf | sub+fla, sub+bcf, fla+bcf, sub+fla+bcf |
| Tigress | addOpaque4, A, V, EA, EL, F | A+EL, A+V, EA+A, EA+F, EA+V, EL+EA, EL+F, EL+V, F+A, F+EA, F+EL, F+V, V+A, V+EL, V+F, V+V, V+EA |
| Obfuscator | Options | P@1 | P@2 | P@3 | P@5 | P@10 |
|---|---|---|---|---|---|---|
| O-LLVM | sub | 0.909 | 0.970 | 0.993 | 0.997 | 1.000 |
| fla | 0.910 | 0.975 | 0.992 | 0.997 | 1.000 | |
| bcf | 0.903 | 0.974 | 0.986 | 0.995 | 0.999 | |
| sub+bcf | 0.899 | 0.972 | 0.991 | 0.995 | 0.999 | |
| sub+fla | 0.913 | 0.978 | 0.989 | 0.994 | 0.999 | |
| bcf+fla | 0.872 | 0.962 | 0.985 | 0.993 | 0.997 | |
| sub+bcf+fla | 0.870 | 0.948 | 0.977 | 0.992 | 0.998 | |
| Tigress | addOpaque4 | 0.818 | 0.921 | 0.964 | 0.989 | 0.998 |
| A | 0.809 | 0.928 | 0.963 | 0.992 | 1.000 | |
| EA | 0.797 | 0.935 | 0.966 | 0.989 | 0.997 | |
| EL | 0.892 | 0.972 | 0.987 | 0.995 | 0.998 | |
| F | 0.893 | 0.965 | 0.988 | 0.993 | 0.999 | |
| V | 0.761 | 0.901 | 0.945 | 0.983 | 0.996 | |
| A+EL | 0.735 | 0.878 | 0.927 | 0.966 | 0.991 | |
| A+V | 0.528 | 0.703 | 0.793 | 0.892 | 0.974 | |
| EA+A | 0.722 | 0.876 | 0.932 | 0.974 | 0.997 | |
| EA+F | 0.824 | 0.944 | 0.980 | 0.994 | 1.000 | |
| EA+V | 0.641 | 0.809 | 0.892 | 0.957 | 0.993 | |
| EL+EA | 0.821 | 0.937 | 0.978 | 0.993 | 0.999 | |
| EL+F | 0.897 | 0.978 | 0.995 | 0.998 | 1.000 | |
| EL+V | 0.718 | 0.862 | 0.935 | 0.978 | 0.997 | |
| F+A | 0.817 | 0.917 | 0.963 | 0.987 | 0.997 | |
| F+EA | 0.813 | 0.924 | 0.969 | 0.994 | 0.999 | |
| F+EL | 0.903 | 0.980 | 0.993 | 0.999 | 1.000 | |
| F+V | 0.749 | 0.885 | 0.938 | 0.982 | 0.998 | |
| V+A | 0.630 | 0.795 | 0.885 | 0.953 | 0.991 | |
| V+EL | 0.760 | 0.894 | 0.951 | 0.986 | 0.996 | |
| V+F | 0.725 | 0.885 | 0.947 | 0.989 | 0.987 | |
| V+V | 0.654 | 0.800 | 0.877 | 0.948 | 0.987 | |
| V+EA | 0.591 | 0.771 | 0.862 | 0.952 | 0.995 |
| sub | fla | bcf | sub+bcf | sub+fla | bcf+fla | sub+fla+bcf | |
|---|---|---|---|---|---|---|---|
| Asm2Vec | 0.921 | 0.871 | 0.856 | 0.820 | 0.782 | 0.729 | 0.653 |
| DFSGraph | 0.909 | 0.910 | 0.903 | 0.899 | 0.913 | 0.872 | 0.870 |
| addOpaque4 | addOpaque16 | EncodeArithmetic | EncodeLiterals | |
|---|---|---|---|---|
| DefeatOP | 98.2% | 96.3% | 95.8% | 94.7% |
| DFSGraph | 99.2% | 95.8% | 97.2% | 98.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, K.; Shan, Z.; Zhang, C.; Xu, L.; Qiao, M.; Liu, F. DFSGraph: Data Flow Semantic Model for Intermediate Representation Programs Based on Graph Network. Electronics 2022, 11, 3230. https://doi.org/10.3390/electronics11193230
Tang K, Shan Z, Zhang C, Xu L, Qiao M, Liu F. DFSGraph: Data Flow Semantic Model for Intermediate Representation Programs Based on Graph Network. Electronics. 2022; 11(19):3230. https://doi.org/10.3390/electronics11193230
Chicago/Turabian StyleTang, Ke, Zheng Shan, Chunyan Zhang, Lianqiu Xu, Meng Qiao, and Fudong Liu. 2022. "DFSGraph: Data Flow Semantic Model for Intermediate Representation Programs Based on Graph Network" Electronics 11, no. 19: 3230. https://doi.org/10.3390/electronics11193230
APA StyleTang, K., Shan, Z., Zhang, C., Xu, L., Qiao, M., & Liu, F. (2022). DFSGraph: Data Flow Semantic Model for Intermediate Representation Programs Based on Graph Network. Electronics, 11(19), 3230. https://doi.org/10.3390/electronics11193230