
MediaPipe’s Landmarks with RNN for Dynamic Sign Language Recognition

 ,
,  ,
,  ,
,  ,
, 
 and
and
Abstract
1. Introduction
- Build an end-to-end model using the MediaPipe framework combined with RNN to solve the issues of DSL recognition.
- Created a new video-based dataset (DSL10-Dataset) consisting of ten vocabularies.
2. Related Research
2.1. Dynamic Sign Language Recognition
2.1.1. Motion Trajectory and Hand Shapes Methodologies
2.1.2. Video Sequence Methodologies
2.2. Static Sign Language Recognition
3. Methodology
3.1. Input Data
3.2. Features Extraction Using MediaPipe
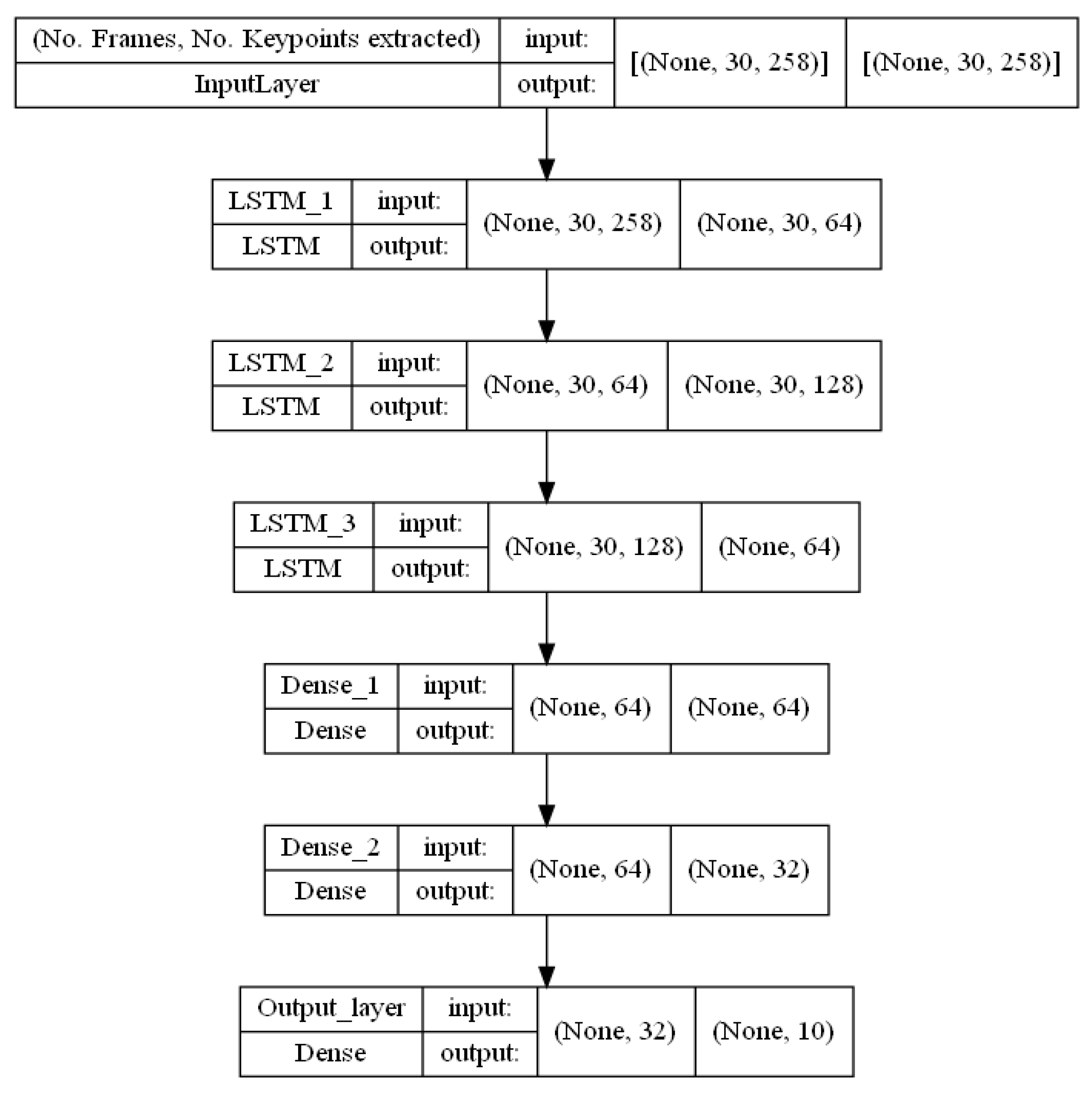
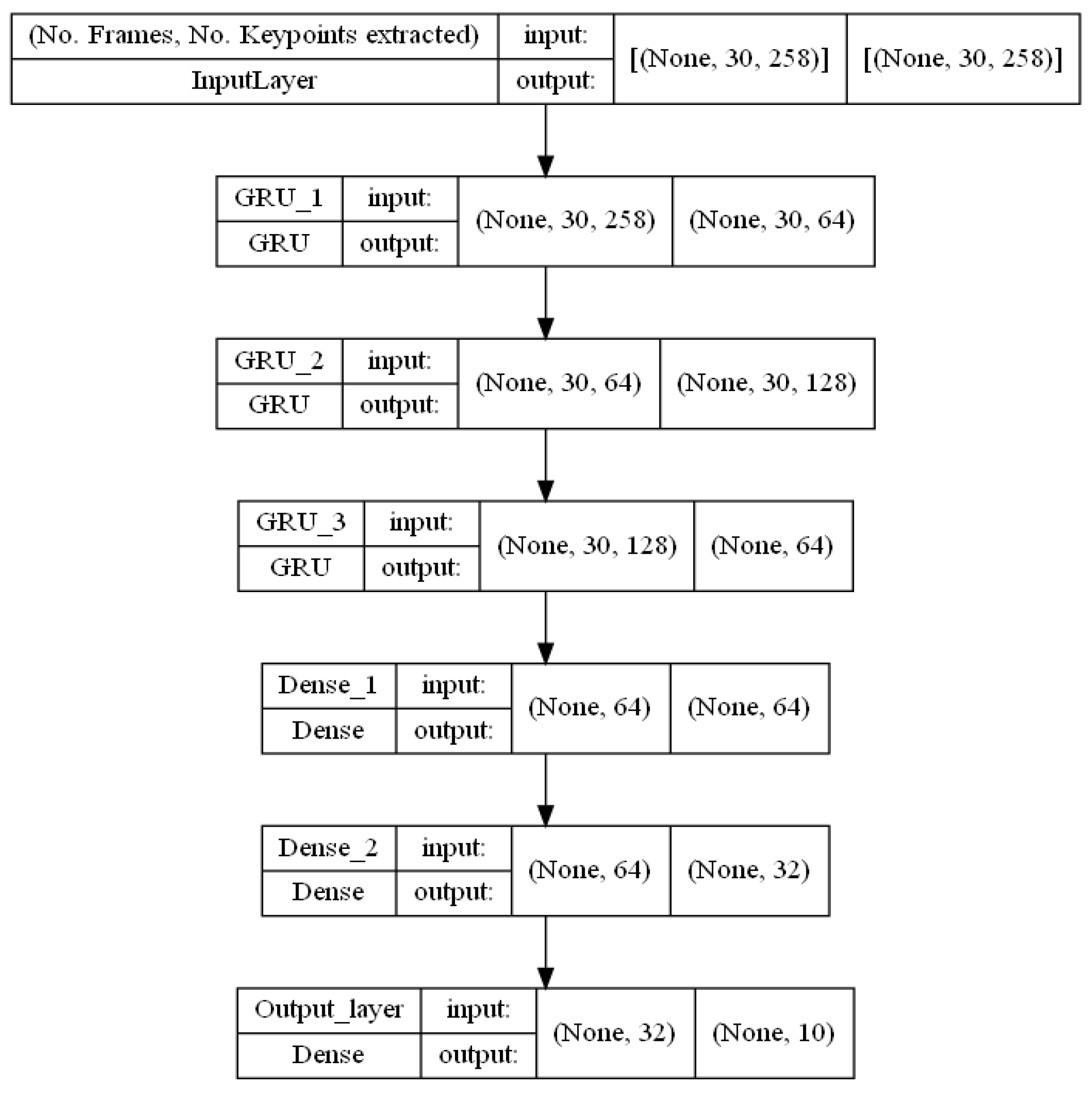
3.3. The Models
4. Datasets
- Signer body: the full signer’s body must appear in all the frames of the video as shown in Figure 8A.
- Signer movement: the whole movement details must be clear and bounded between the camera frame as shown in Figure 8B.
- Background: it is better to record the dataset in a stable background that does not contain any other hands or faces except those of the signer.
- Lighting: it is preferred to record in good lighting conditions to make sure all the keypoints will be clear as shown in Figure 8C.
- Camera: set up your camera on a fixed stand to ensure that the videos are as unshakable and focused as possible as shown in Figure 8D.
- Video duration and frame count: the clip duration and number of frames should be determined before the recording process.
- Quality: any camera with a 640 × 480 resolution sensor can be used for the recording process since the most common sensors on the market are available in this size or higher.
5. Experimental Results
5.1. MediaPipe without Including Face Keypoints
5.2. MediaPipe with Face Keypoints
6. Conclusions and Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abdalla, M.S.; Hemayed, E.E. Dynamic hand gesture recognition of arabic sign language using hand motion trajectory features. Glob. J. Comput. Sci. Technol. 2013, 13, 27–33. [Google Scholar]
- Liao, Y.; Xiong, P.; Min, W. Weiqiong Min, and Jiahao Lu. Dynamic sign language recognition based on video sequence with blstm-3d residual networks. IEEE Access 2019, 7, 38044–38054. [Google Scholar] [CrossRef]
- Escobedo, E.; Ramirez, L.; Camara, G. Dynamic sign language recognition based on convolutional neural networks and texture maps. In Proceedings of the 2019 32nd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Rio de Janeiro, Brazil, 28–30 October 2019; pp. 265–272. [Google Scholar]
- Chaikaew, A.; Somkuan, K.; Yuyen, T. Thai sign language recognition: An application of deep neural network. In Proceedings of the 2021 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunication Engineering, Cha-am, Thailand, 3–6 March 2021; pp. 128–131. [Google Scholar]
- Hoang, M.T.; Yuen, B.; Dong, X.; Lu, T.; Westendorp, R.; Reddy, K. Recurrent Neural Networks for Accurate RSSI Indoor Localization. IEEE Internet Things J. 2019, 6, 10639–10651. [Google Scholar] [CrossRef]
- Kim, T.; Keane, J.; Wang, W.; Tang, H.; Riggle, J.; Shakhnarovich, G.; Brentari, D.; Livescu, K. Lexicon-free fingerspelling recognition from video: Data, models, and signer adaptation. Comput. Speech Lang. 2017, 46, 209–232. [Google Scholar] [CrossRef]
- Mohandes, M.; Deriche, M.; Liu, J. Image-based and sensor-based approaches to Arabic sign language recognition. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 551–557. [Google Scholar] [CrossRef]
- Sonawane, T.; Lavhate, R.; Pandav, P.; Rathod, D. Sign language recognition using leap motion controller. Int. J. Adv. Res. Innov. Ideas Edu. 2017, 3, 1878–1883. [Google Scholar]
- Li, K.; Zhou, Z.; Lee, C.H. Sign transition modeling and a scalable solution to continuous sign language recognition for real-world applications. ACM Trans. Access. Comput. (TACCESS) 2016, 8, 1–23. [Google Scholar] [CrossRef]
- Yang, X.; Chen, X.; Cao, X.; Wei, S.; Zhang, X. Chinese sign language recognition based on an optimized tree-structure framework. IEEE J. Biomed. Health Inform. 2016, 21, 994–1004. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Zhou, W.; Li, H. Sign language recognition with long short-term memory. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2871–2875. [Google Scholar]
- Ma, Z.; Lai, Y.; Kleijn, W.B.; Song, Y.Z.; Wang, L.; Guo, J. Variational Bayesian learning for Dirichlet process mixture of inverted Dirichlet distributions in non-Gaussian image feature modeling. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 449–463. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Martinez, A. Three-Dimensional Shape and Motion Reconstruction for the Analysis of American Sign Language. In Proceedings of the 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006; p. 146. [Google Scholar] [CrossRef]
- Kumar, P.; Gauba, H.; Roy, P.P.; Dogra, D.P. A multimodal framework for sensor based sign language recognition. Neurocomputing 2017, 259, 21–38. [Google Scholar] [CrossRef]
- Zadghorban, M.; Nahvi, M. An algorithm on sign words extraction and recognition of continuous Persian sign language based on motion and shape features of hands. Pattern Anal. Appl. 2018, 21, 323–335. [Google Scholar] [CrossRef]
- Moussa, M.M.; Shoitan, R.; Abdallah, M.S. Efficient common objects localization based on deep hybrid Siamese network. J. Intell. Fuzzy Syst. 2021, 41, 3499–3508. [Google Scholar] [CrossRef]
- Abdallah, M.S.; Kim, H.; Ragab, M.E.; Hemayed, E.E. Zero-shot deep learning for media mining: Person spotting and face clustering in video big data. Electronics 2019, 8, 1394. [Google Scholar] [CrossRef]
- Cui, R.; Liu, H.; Zhang, C. Recurrent convolutional neural networks for continuous sign language recognition by staged optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7361–7369. [Google Scholar]
- Rao, G.A.; Syamala, K.; Kishore, P.; Sastry, A. Deep convolutional neural networks for sign language recognition. In Proceedings of the 2018 Conference on Signal Processing And Communication Engineering Systems (SPACES), Vijayawada, India, 4–5 January 2018; pp. 194–197. [Google Scholar]
- Kishore, P.; Kumar, D.A.; Goutham, E.; Manikanta, M. Continuous sign language recognition from tracking and shape features using fuzzy inference engine. In Proceedings of the 2016 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 23–25 March 2016; pp. 2165–2170. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning. PMLR, Lille, France, 7–9 July 2015; pp. 843–852. [Google Scholar]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for human action recognition. In Proceedings of the International Workshop on Human Behavior Understanding, Amsterdam, The Netherlands, 16 November 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 29–39. [Google Scholar]
- Yue-Hei Ng, J.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Bastos, I.L.; Angelo, M.F.; Loula, A.C. Recognition of static gestures applied to brazilian sign language (libras). In Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Bahia, Brazil, 26–29 August 2015; pp. 305–312. [Google Scholar]
- Hemayed, E.E.; Hassanien, A.S. Edge-based recognizer for Arabic sign language alphabet (ArS2V-Arabic sign to voice). In Proceedings of the 2010 International Computer Engineering Conference (ICENCO), Cairo, Egypt, 27–28 December 2010; pp. 121–127. [Google Scholar] [CrossRef]
- Althagafi, A.; Alsubait, G.T.; Alqurash, T. ASLR: Arabic sign language recognition using convolutional neural networks. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2020, 20, 124–129. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.L.; Yong, M.G.; Lee, J.; et al. Mediapipe: A framework for building perception pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. Mediapipe hands: On-device real-time hand tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Bazarevsky, V.; Grishchenko, I.; Raveendran, K.; Zhu, T.; Zhang, F.; Grundmann, M. Blazepose: On-device real-time body pose tracking. arXiv 2020, arXiv:2006.10204. [Google Scholar]
- Kartynnik, Y.; Ablavatski, A.; Grishchenko, I.; Grundmann, M. Real-time facial surface geometry from monocular video on mobile GPUs. arXiv 2019, arXiv:1907.06724. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The performance of LSTM and BiLSTM in forecasting time series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3285–3292. [Google Scholar]
- Cahuantzi, R.; Chen, X.; Güttel, S. A comparison of LSTM and GRU networks for learning symbolic sequences. arXiv 2021, arXiv:2107.02248. [Google Scholar]
- Khandelwal, S.; Lecouteux, B.; Besacier, L. Comparing GRU and LSTM for Automatic Speech Recognition. Ph.D. Thesis, LIG, Saint-Martin-d’Hères, France, 2016. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| RNN Model | GRU, LSTM or BiLSTM |
| Number of Nodes | Between (64,256) |
| Activation | ‘Relu’ or ’Softmax’ |
| Optimizer | ’Adagrad’, ‘Adamax’, ‘Adam’ or ‘RMSprop’ |
| GRU | LSTM | BILSTM | |
|---|---|---|---|
| Train accuracy | 100% | 99.9% | 99.9% |
| Test accuracy | 100% | 99.6% | 99.3% |
| Number of epochs | 241 | 65 | 75 |
| GRU | LSTM | BILSTM | |
|---|---|---|---|
| Train accuracy | 100% | 99% | 99.9% |
| Test accuracy | 100% | 99.6% | 99% |
| Number of epochs | 250 | 36 | 49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samaan, G.H.; Wadie, A.R.; Attia, A.K.; Asaad, A.M.; Kamel, A.E.; Slim, S.O.; Abdallah, M.S.; Cho, Y.-I. MediaPipe’s Landmarks with RNN for Dynamic Sign Language Recognition. Electronics 2022, 11, 3228. https://doi.org/10.3390/electronics11193228
Samaan GH, Wadie AR, Attia AK, Asaad AM, Kamel AE, Slim SO, Abdallah MS, Cho Y-I. MediaPipe’s Landmarks with RNN for Dynamic Sign Language Recognition. Electronics. 2022; 11(19):3228. https://doi.org/10.3390/electronics11193228
Chicago/Turabian StyleSamaan, Gerges H., Abanoub R. Wadie, Abanoub K. Attia, Abanoub M. Asaad, Andrew E. Kamel, Salwa O. Slim, Mohamed S. Abdallah, and Young-Im Cho. 2022. "MediaPipe’s Landmarks with RNN for Dynamic Sign Language Recognition" Electronics 11, no. 19: 3228. https://doi.org/10.3390/electronics11193228
APA StyleSamaan, G. H., Wadie, A. R., Attia, A. K., Asaad, A. M., Kamel, A. E., Slim, S. O., Abdallah, M. S., & Cho, Y.-I. (2022). MediaPipe’s Landmarks with RNN for Dynamic Sign Language Recognition. Electronics, 11(19), 3228. https://doi.org/10.3390/electronics11193228