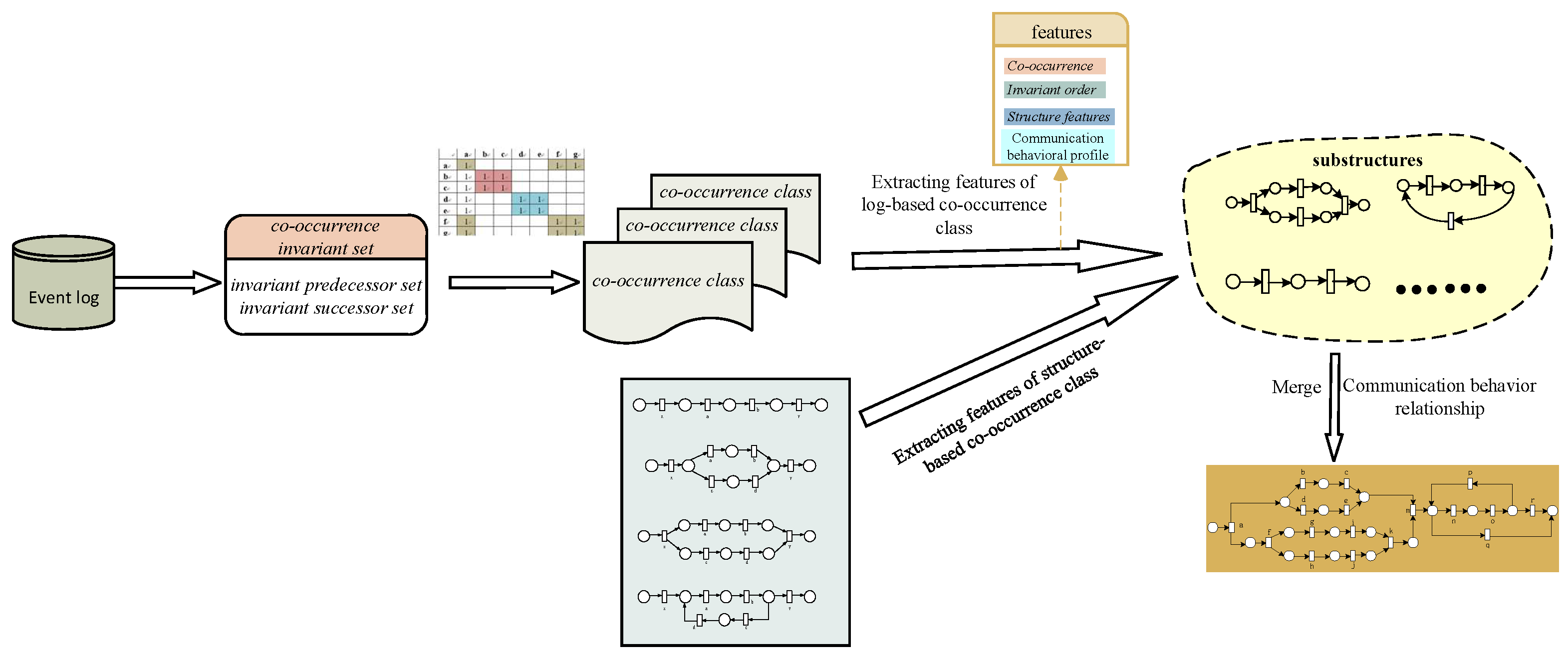
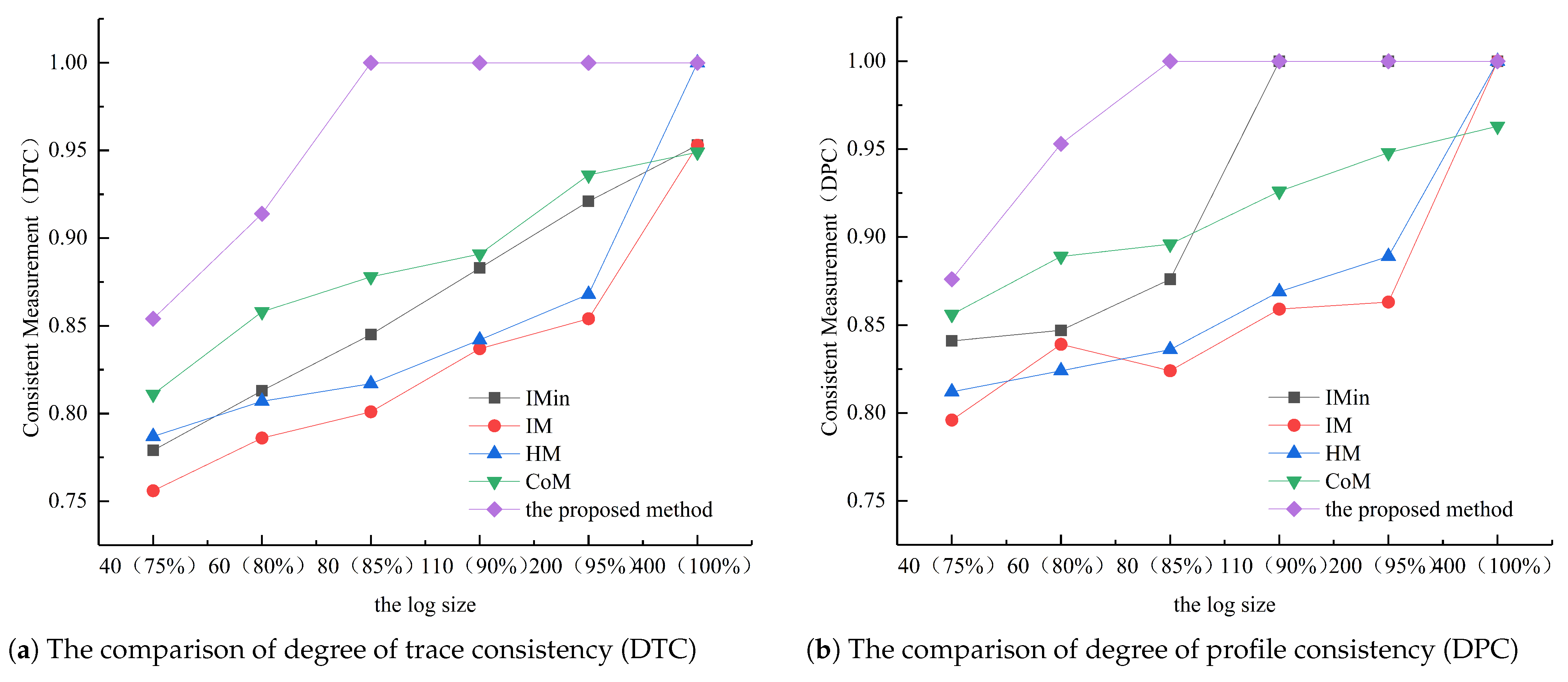
4.1. Discovery of Co-Occurrence Classes from Logs
The event log shows the actual execution of activities in the business process. By analyzing the occurrence dependencies between activities in each trace, the occurrence dependency between activities in the log can be found. In the following, the relevant definitions of trace handling operations are given.
Definition 1 (Trace handling operations [
6]).
Let L be an event log, is an activity set over L. For , if there exists a trace , such that , where :
(1) indicates that the k-th element in the trace σ is an activity a;
(2) such that ;
(3) The direct predecessor activity of the i-th activity in the trace σ is defined as ;
(4) The direct successor activity of the i-th activity in the trace σ is defined as ;
(5)
Invariant set of activities that appear before activity a in trace σ is denoted as ,
(6)
Invariant set of activities that appear after activity a in trace σ is denoted as , For example, considering a trace , using Definition 1, we obtain ,, , , , , , .
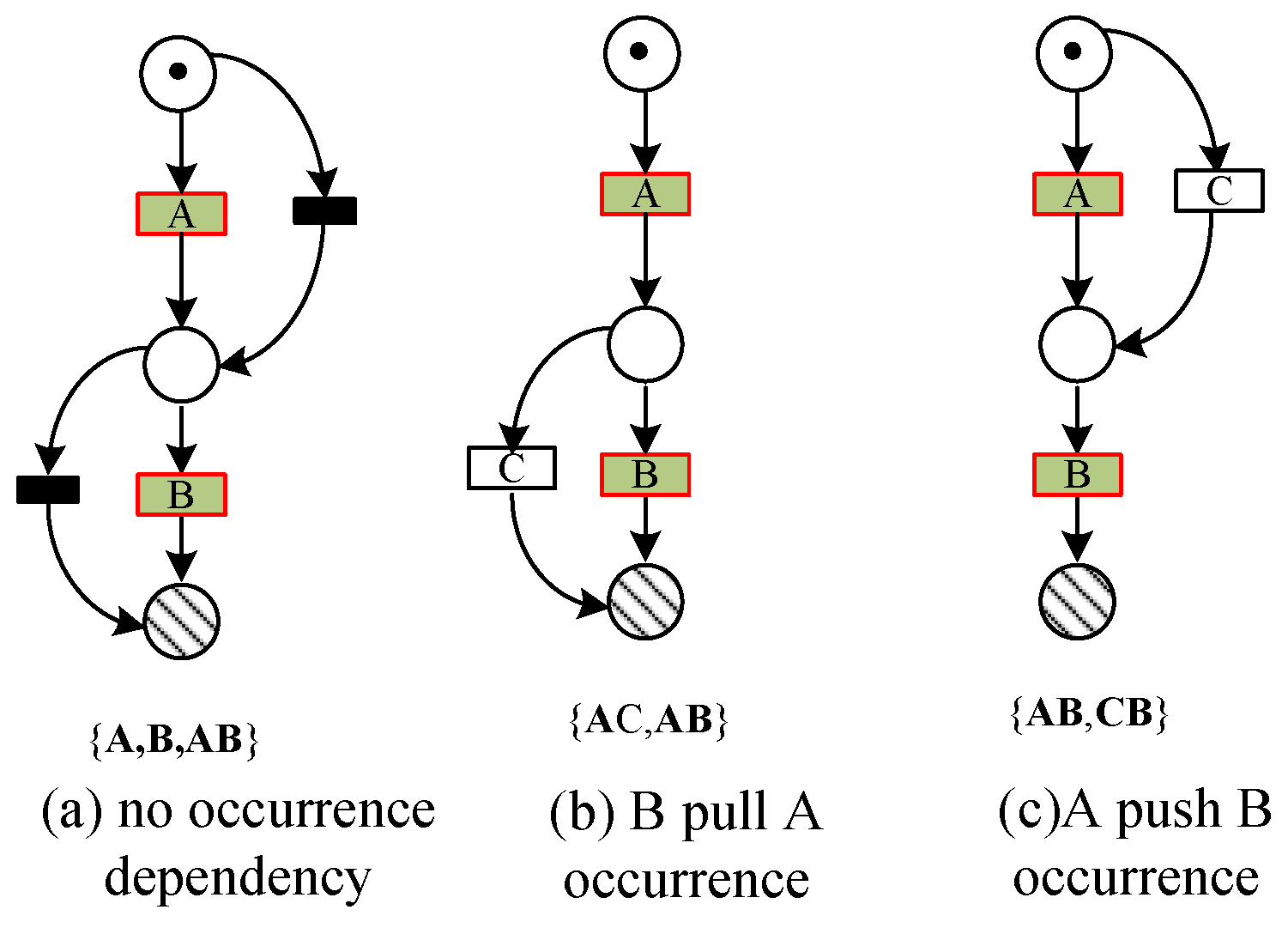
consists of activities appearing between two activities a together and before the first occurrence of the activity a. consists of activities appearing between two activities a together and after the last occurrence of the activity a. Therefore, and denote the set of possible activities that must occur before the activity a and after the activity a in any trace , respectively. To capture the predecessor and successor activities that have co-occurrence dependencies with an activity in the log, Definition 2 gives the invariant predecessor set and the invariant successor set of the activity in the log.
Definition 2 ((Log) Invariant predecessor set, Invariant successor set). Let L be an event log, is an activity set over L. For , invariant predecessor set of activity a is defined as , and invariant successor set of activity a is defined as .
The invariant predecessor set in Definition 2 represents the set of activities that always occur before the activity a in any trace of the log. Similarly, the invariant successor set represents the activity set that always occurs after the activity a in any trace of the log. The activities in the invariant predecessor set or the invariant successor set not only have a strict order relationship with the activity a but also have a co-occurrence relationship with the activity a. Definition 3 further gives the concept of a co-occurrence invariant set based on Definition 2.
Definition 3 ((Log) Co-occurrence invariant set). Let L be an event log, is an activity set over L. For , co-occurrence invariant set of activities a is denoted as .
In Definition 3, presents a set of activities that occur simultaneously with the activities a in any trace of the log L. There is not only a behavior dependency but also a co-occurrence dependency between them.
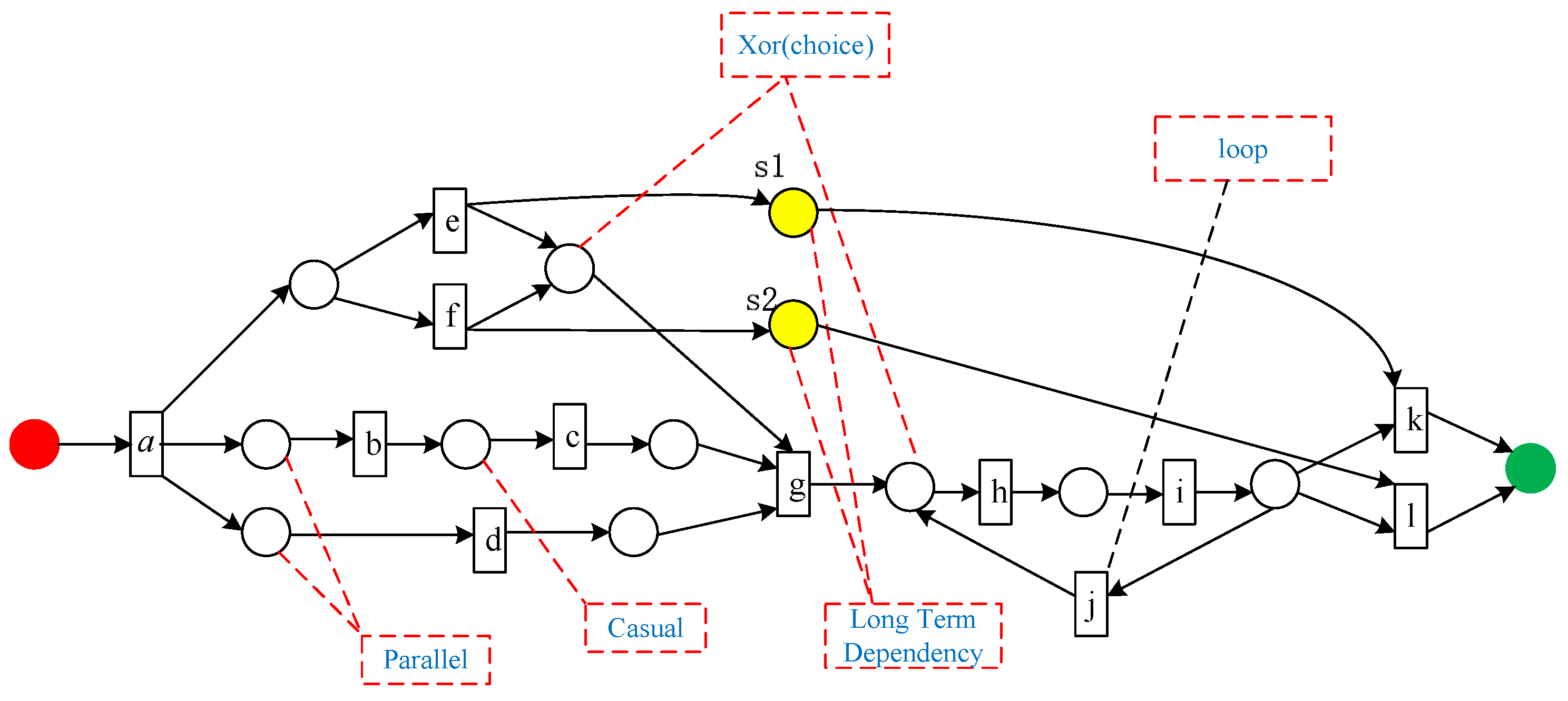
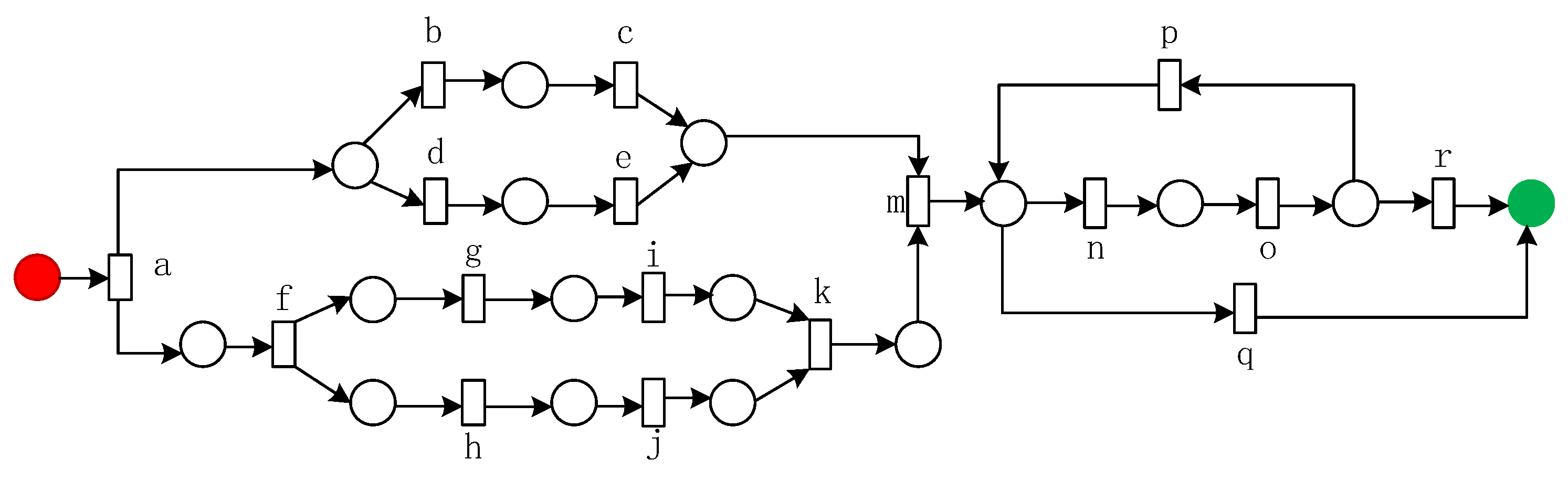
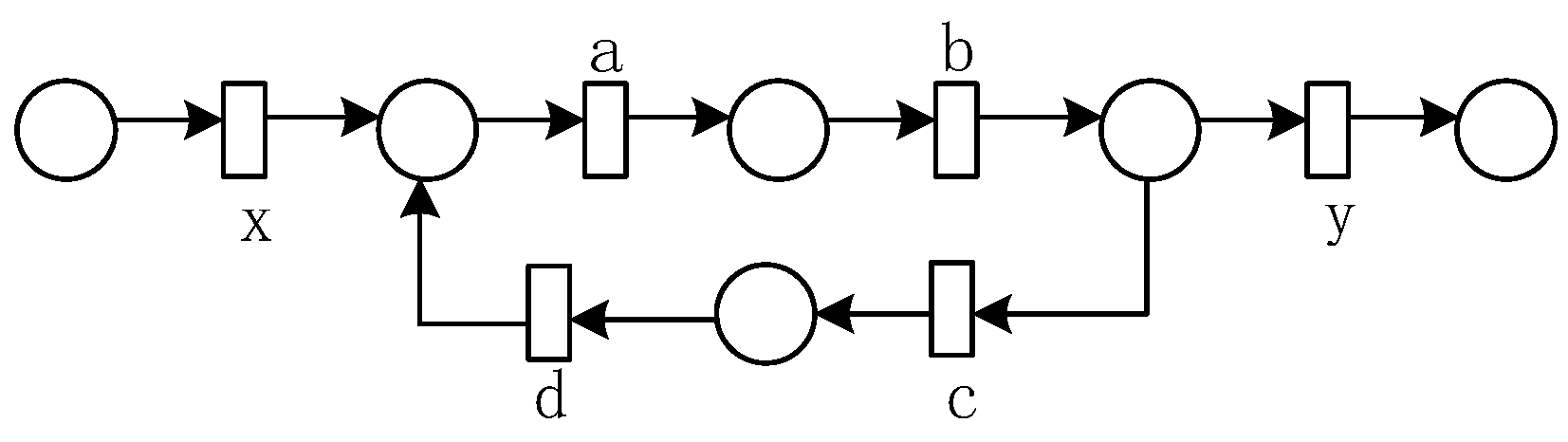
For example, given an activity log
as shown in
Table 3, the process model shown in
Figure 6 is the original model of the log
. This paper takes the event log
as an example to illustrate the solution process of our proposed method.
Table 4 presents the invariant predecessor set, invariant successor set, and co-occurrence invariant set for each activity in the event log
.
Since the co-occurrence invariant set represents the set of activities that appear simultaneously with the current activity in all traces of the log, based on this, this paper adopts the co-occurrence invariant set to capture the occurrence dependency between activities. To facilitate the discovery of a co-occurrence dependency among several activities, the activities in the log can be divided into several subsets with equivalent behavior by using the co-occurrence invariant set. Therefore, Definition 5 introduces the concept of co-occurrence classes.
Definition 4 (Co-occurrence matrix). Let L be an event log, and is an activity set over L and . Matrix is called as the co-occurrence matrix, where represents the co-occurrence relation between , if ; then, .
Definition 5 (Co-occurrence class). Let L be an event log, is an activity set over L. is a co-occurrence matrix of the log L. , an activity set is called a co-occurrence class if and only if ,where .
Definition 5 indicates that there exists a co-occurrence dependency between all activities in the co-occurrence class; that is, they always appear in a trace of the log together.
Table 5 shows the co-occurrence relationship matrix of the event log.
Using Definition 5, we can get co-occurrence classes from
Table 5:
, where , , , , , , , .
The co-occurrence class has some interesting properties. The relevant conclusions and proofs are given below.
Property 1 (Co-occurrence). Let L be an event log, is a co-occurrence class got from event log L. For , if such that , then for , holds.
Proof. If such that , then and . So and . Obviously, . Therefore, cannot both belong to . There exists a contradiction. □
Property 2 (Invariant order). Let L be an event log, is a co-occurrence class got from the event log L. If , activities satisfy partial order relation , for , if , then activities also satisfy partial order relation in a trace . i.e., if activities in occurred in a trace, they should occur in the same order.
Proof. Assume there exist two activities that appear in two different traces in different orders, and let two activities be , holds in trace , but holds in trace . Thus, , . Clearly, .Therefore, it is impossible for to belong to the same co-occurrence class at the same time. There exists a contradiction. □
Algorithm 1, Algorithm 2, and Algorithm 3, respectively, show how to obtain the invariant predecessor set, invariant successor set, and co-occurrence class of any activity from the log.
| Algorithm 1: An invariant predecessor set of any activity |
 |
| Algorithm 2: An invariant successor set of any activity |
 |
| Algorithm 3: Getting co-occurrence classes from the event log |
 |
In Algorithm 1, Step 2 initializes the invariant predecessor set to an empty set, Steps 3–9 solve the invariant predecessor set of the activity in each trace, Steps 10–15 get the invariant predecessor set of the activity in the log, and Steps 11–14 indicate that once the invariant predecessor set becomes an empty set, the algorithm is stopped.
In Algorithm 2, Step 2 initializes the invariant successor set to an empty set, Steps 3–9 solve the invariant successor set of the activity in each trace, Steps 10–15 obtain the invariant successor set of the activity in the log, and Steps 11–14 indicate that once the invariant successor activity set becomes an empty set, the algorithm is stopped.
Steps 1–5 in Algorithm 3 are used to find the invariant set of any activity, Steps 7–11 initialize each element in the co-occurrence relationship matrix to 0, Steps 12–20 update the value of the co-occurrence relationship matrix according to the invariant activity set, Steps 22–25 set each activity to an initial co-occurrence class, and Steps 21–37 construct all possible co-occurrence classes by merging the initial co-occurrence classes according to the co-occurrence relationship matrix.
4.2. Discovering Co-Occurrence Classes from Models
The co-occurrence invariant relationship of activities in the log is closely related to their structural relationship in the model. To facilitate the discovery of their structural relationship in the model according to the co-occurrence invariant relationship of activities in the log, we present some definitions related to the invariance of activity occurring in the model.
Definition 6 (Execution sequence). Execution sequence of the process model is defined as an executable sequence of the form from the start activity to the end activity of the process model. All execution sequences of the process modelN are denoted as .
Definition 7 ((Model) Invariant predecessor set, Invariant successor set). Let N be a process model, be an activity set of model, and be a set of executable sequences of the model. For , the invariant predecessor set of activity a is defined as , and the invariant successor set of activity a is defined as .
The set of invariant predecessors of activity a in model N represents the set of activities that occur before a in all executable sequences of the model N. Similarly, the set of invariant successors of activity a in the model represents the set of activities that occur after a in all executable sequences of the model N.
Definition 8 ((Model) co-occurrence invariant set). Let N be a process model and be an activity set of models. For , the co-occurrence invariant set of activity a is defined as .
Definition 8 denotes , which represents the set of activities that always occur simultaneously with the activity a in any execution sequence of the model.
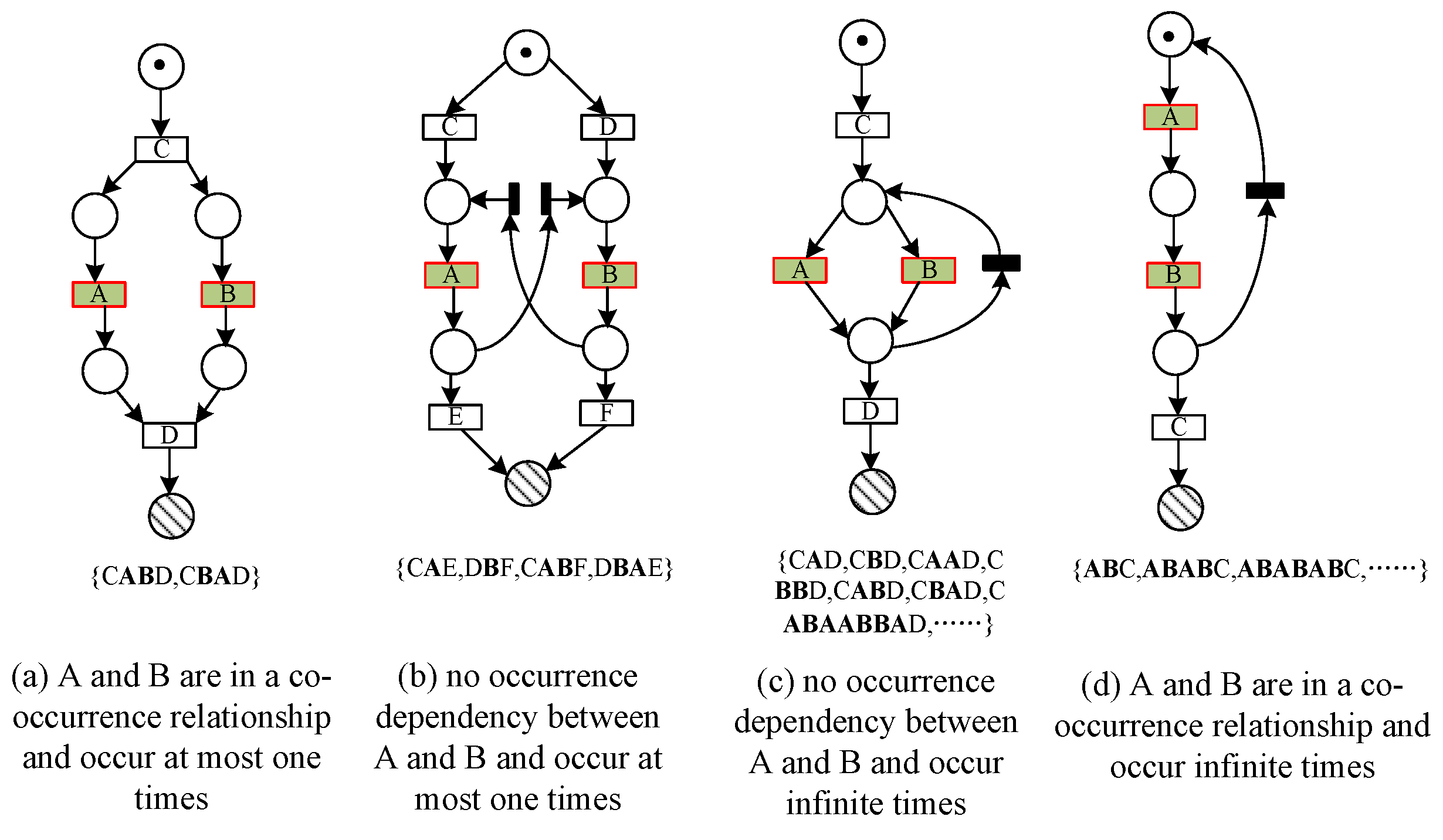
Definition 9 ((Model) co-occurrence class). Let N be a process model and be an activity set of the model, where , is the co-occurrence relationship matrix of the model N. For , a set of activities is called as a co-occurrence class if and only if , where .
Clearly, Definition 9 denotes , if , then , i.e., activities in a co-occurrence always occur simultaneously in an execution sequence.
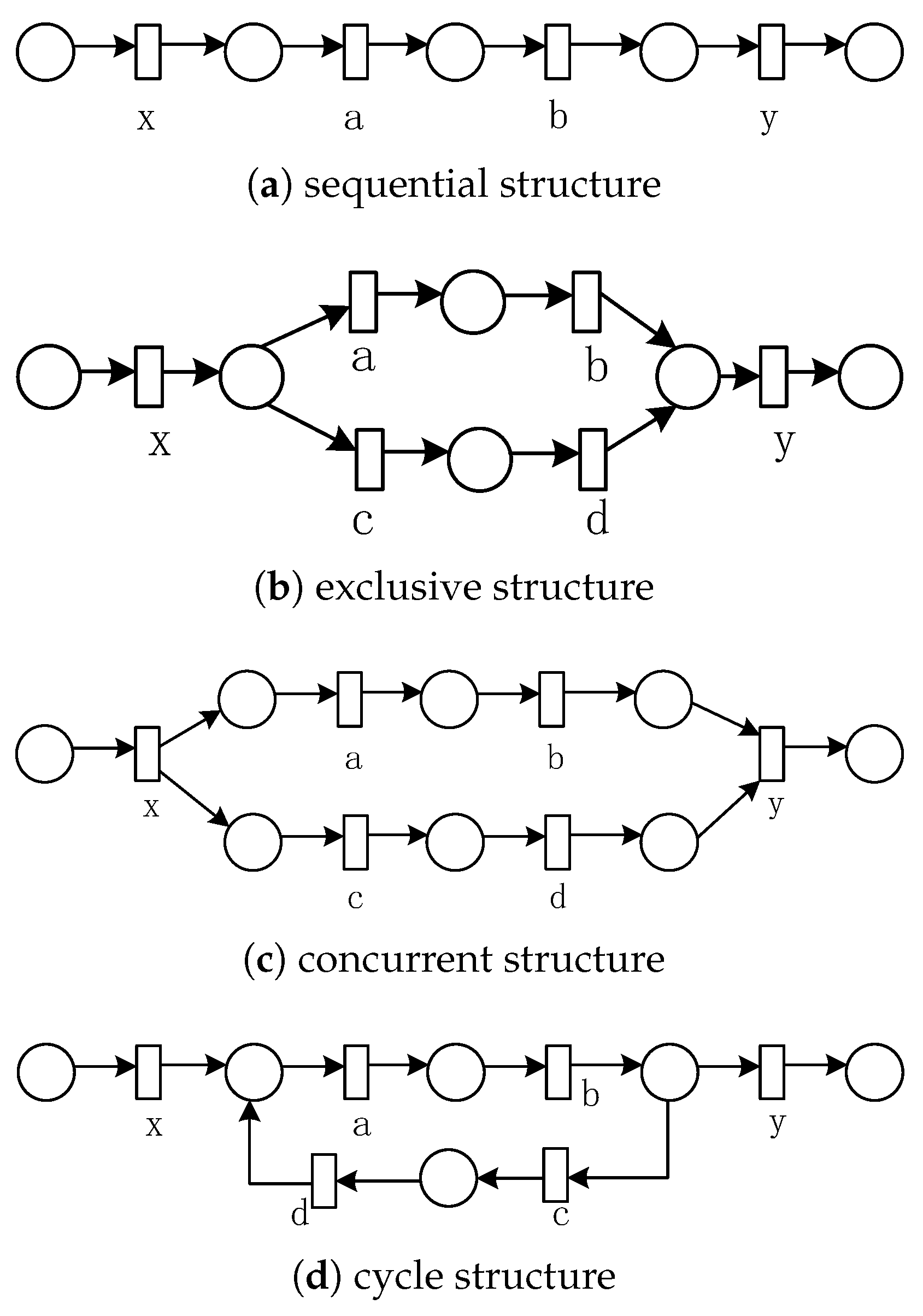
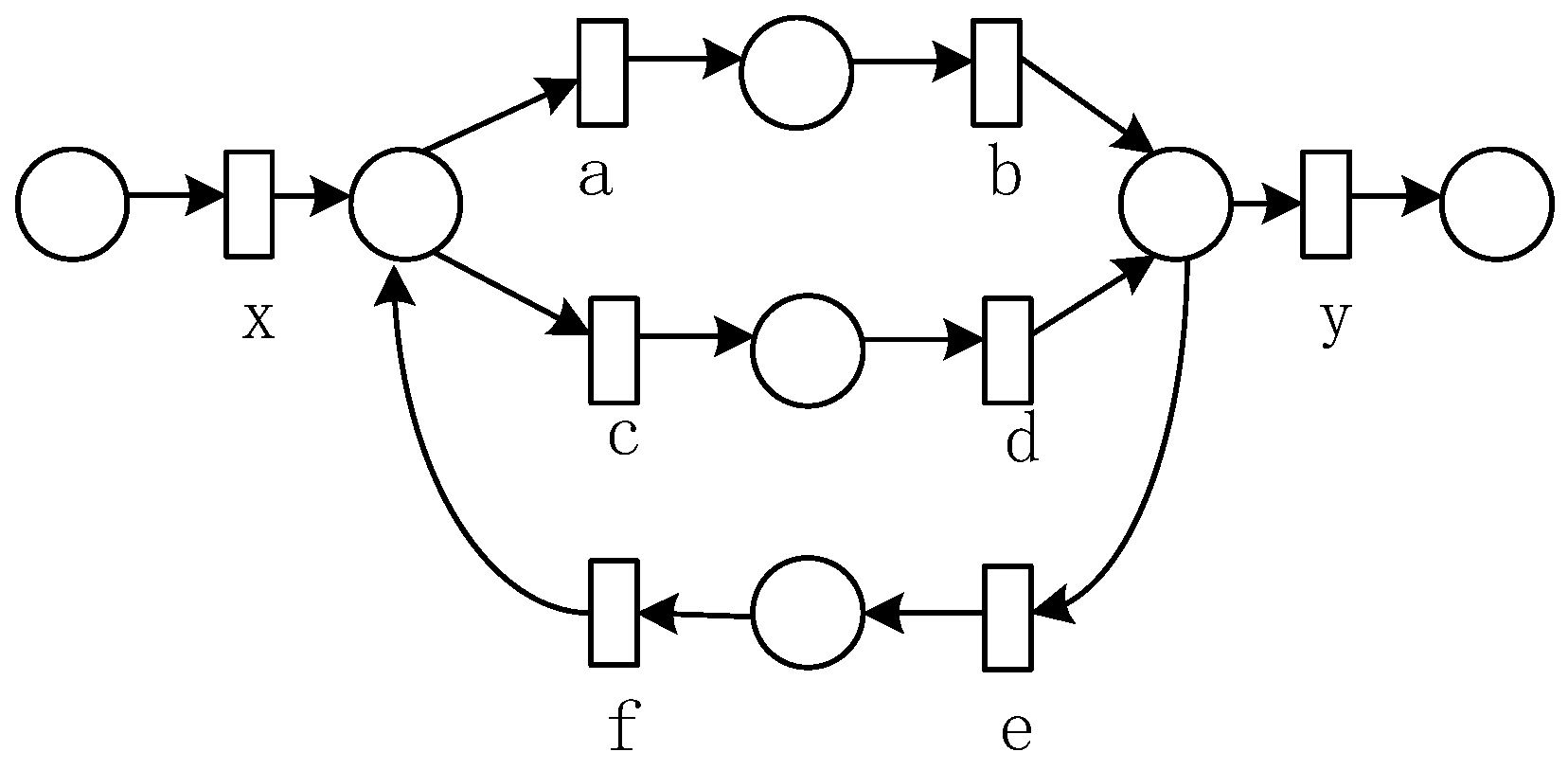
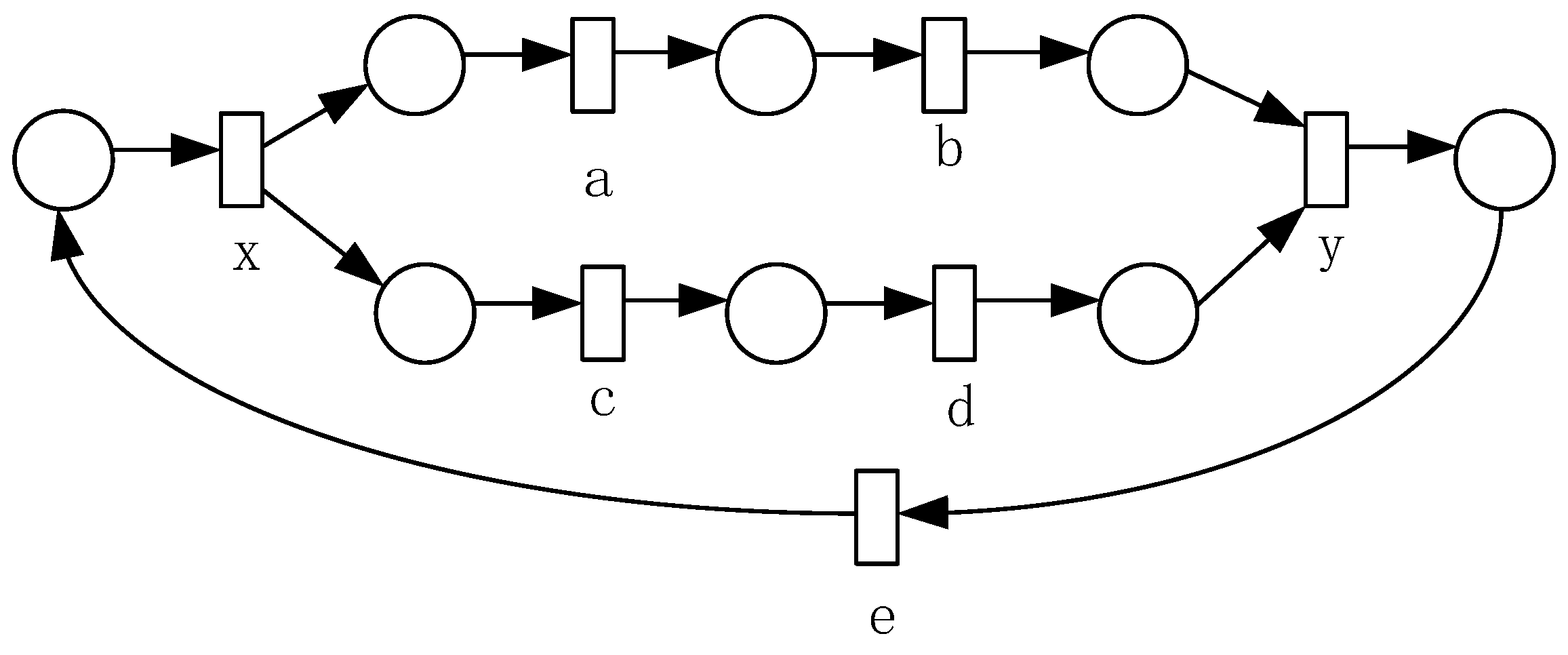
According to Definition 9,
Table 6 gives the invariant predecessor set, invariant successor set, and co-occurrence invariant set of each activity in the four basic structures (as shown in
Figure 7).
Table 7 presents co-occurrence classes of the four basic structures obtained from
Table 6.
Table 7 shows that the exclusive structure and the cyclic structure have the same set of co-occurrence classes, the sequential structure has only one co-occurrence class that contains all activities, and the concurrent structure is decomposed into two co-occurrence classes according to the concurrent branch, one of which contains the and-gateway activities.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}