1. Introduction
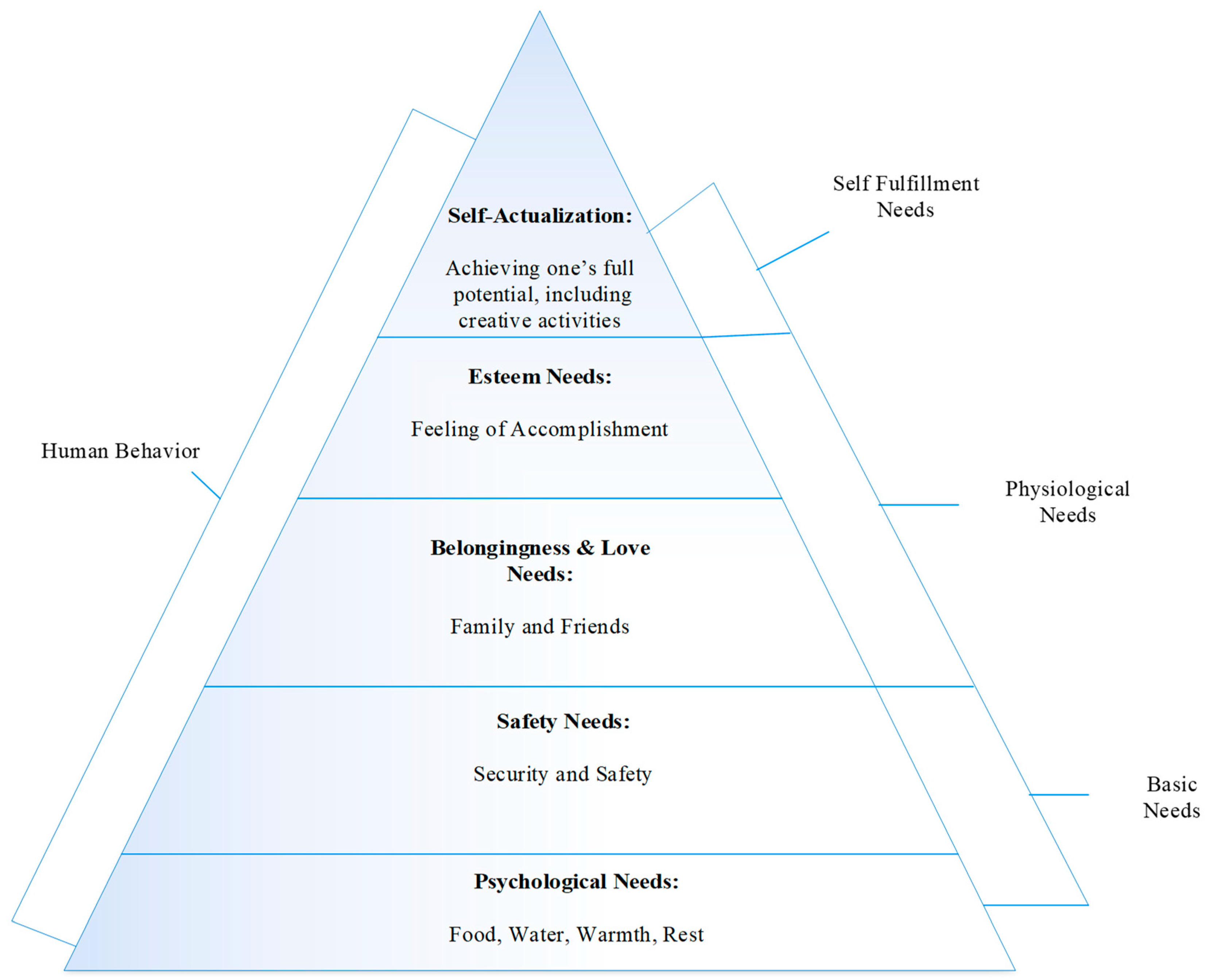
The study of human behavior is a crucial process. It exhibits the needs of the human mind. ‘Human needs’ consist of five levels, which are physiological needs, safety needs, love needs, esteem needs and self-actualization [
1]. If these needs are fulfilled accurately, it leads to positive behavior in a person. On the other hand, if these needs are not fulfilled in a constructive way, the negative behavior is accelerated, according to Maslow’s hierarchy (
Figure 1).
The behavior of a person is built as a result of the particular events or actions that happen in his/her life. Environments, disasters, family conflicts or [
2] events have an immense effect on human behavior. It is an amalgam of a person’s nature, face expressions, surroundings and physical gestures, according to Zhang et al. [
3] and Albu [
4]. It is also defined as the state which is achieved after a series of events and actions [
5]. Two types of behaviors can be categorized while studying different fields of society: routine behaviors and political behaviors [
6,
7]. The daily routine of a person defines routine behavior. On the other hand, the political activities of a person define political behaviors [
8].
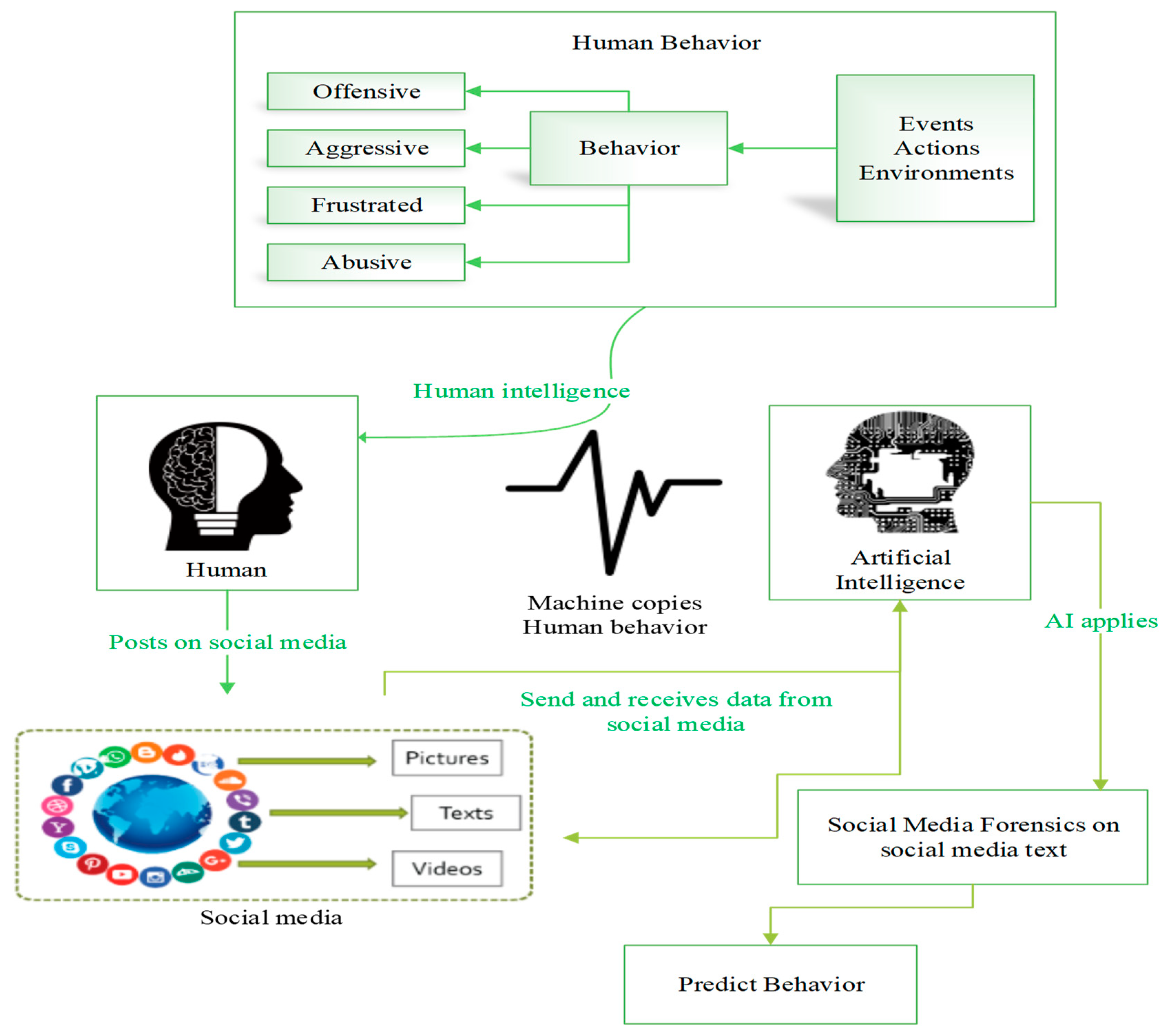
As human behavior is a vast field of study, machines are training to mimic human behaviors by make them learn to perform human-like actions [
9]. The process of mimicking a human behavior is called artificial intelligence (
Figure 2).
Humans are social by nature, so in this electronic era of the world, the acceptance of social media platforms has increased significantly; nearly everyone socializes here [
10]. The use of social media platforms can be used to harm other people through negative comments, abusive language, hate speech and bullying online [
11]. Such aggrieved behavior can harm anyone in electronic means [
12]. Aggression is a behavior that represents hate. This aggression can be because of gender discrimination, color biasness, nationality, religious conflicts, etc. Aggressive behavior leads to criminal activities. An example is the case of shooting on the mosque in New Zealand, where the shooter played live footage on social media while shooting, which shows his aggression toward the Muslim community. Before the attack, he posted the pictures of the gun and later on he used same guns for attack on the mosque [
13]. It is important to identify the threats before something worse happens. This critical situation can be handled by using the concept of social media forensics. The process of cyber investigation of people from their social media profiles and collecting relevant information by applying learning algorithms to prevent crimes is called social media forensics [
13].
The research focuses on the identification of criminal behavior from social media by analyzing the state of the art work and proposing a better approach. This research helps with shortlisting the text containing certain behaviors, which can help with prevention of the crimes in the future. The proposed research intends to help cybercrime and cyber-security agencies with shortlisting the profiles indicating a certain behavior of individuals who could become involved in any criminal activities in the future.
The major contributions in the research are:
Optimized modeling of framework for criminal behavior detection focusing.
Optimal hybridization of NLP mechanisms during feature engineering process for robust results.
Combining multi-features in neural network architecture optimally.
The improvement of results in finding the context of the text by training the model on unigram, bigram and trigrams.
The paper is organized as follows.
Section 2 explains the critical analysis of state of the art work related to behaviors on social media. In
Section 3, materials and methods proposed for the detection of criminal behavior are explained.
Section 4 explains experimental setup and results are presented in
Section 5. Finally,
Section 6 concludes this work.
2. Literature Review
The zeta byte of data is available on social media [
14] and can be helpful in the detection of behaviors of people. Recent research shows that there has been an enormous amount of work on behavior detection from social media platforms (
Table 1).
In [
15], a cyber-troll dataset was used for the identification of aggression from tweets. The dataset had 20,001 tweets in total. Multilayer perceptron with TF-IDF was proposed, and researchers compared its performance with DNN models, i.e., CNN-LSTM and CNN-BiLSTM. Statistical results showed that the proposed model detects better aggressive behavior with 92% accuracy in less training time and with a small number of layers. However, experimental results were tested on a single feature, which was TF-IDF. Different features and combinations of features must be identified for better performance.
In [
16], a first, practical, real-time framework was introduced for aggression detection. Multiple machine learning classifiers were adapted in an incremental fashion using the bag of words explained in
Table 1. The proposed framework was able to achieve the same performance in comparison with base learning models, with almost 93% accuracy, 92% precision, 91% recall, and an F1 score of 90%. The proposed model only uses bag-of-words, which may cause class imbalance. If more features are explored, more accurate detection can be achieved.
A Web-based plug-in user interface [
17] was developed by using the pre-trained Google AI model BERT. It visualized and detected aggressive and non-aggressive comments within twitter and Facebook text on the TRAC dataset [
18]. Multiple classifiers were used that included XGBoost, LR, NB, SVM and FFNN. The proposed model was evaluated on the basis of F1 score and ROC-AUC: 0.64 and 0.62 F1 scores were attained on the TRAC English and Hindi Facebook datasets, respectively. For the English and Hindi twitter datasets, F1 scores of 0.58 and 0.50 were achieved. However, the complexity of a sentence was unsolved because it was neglected. More pre-trained models must be explored to reduce sentence complexity.
In [
19], suicide notes were detected from social media blogs by using datasets: the Genuine suicide notes dataset [
20], Reddit depression data [
21] and Neutral Blog data. In the first part, LIWC was used for the extraction of suicide notes from the datasets. In the second part, a dilated-LSTM model was used for the detection of suicide notes. The proposed model achieved an 88.26% F1 score and 96.1% accuracy. At the end, features were visualized by emoticons such as love. In the proposed research, language patterns were identified on datasets for real-time data; accurate language patterns may not be detected. This problem can be resolved by enhancing LIWC analysis.
Depression behavior was studied in [
22] by a manually created dataset from VKontakt users. In total, 6000 users were considered for this purpose. Preprocessing was completed by using MyStemAPI. Sentiment features were extracted by using the Linis-Crowd sentiment dictionary. Moreover, unigram and bigram features were extracted using TF-IDF. For classification, multiple models were tested, and results showed that random forest with PCA gave the best results with an AUC of 0.74, precision of 0.59, recall of 0.71 and F1 score of 0.65. However, the results must be improved by applying more feature fusion techniques. Moreover, neural networks can also be applied in the future in order to achieve better results.
In [
23], an online hate classifier was developed for multiple social media platforms using machine learning classifiers. Data were gathered from YouTube, Reddit, twitter and Wikipedia. Binary labels were given as hateful and non-hateful comments. Multiple features were applied that included LIWC, bag-of-words, TF-IDF, Word2Vec and BERT. Multiple classification models were compared including LR. NB, SVM, XGBoost, FFNN and NB. Performance was evaluated on the basis of F1 Score and ROC-AUC. Results showed that XGBoost performed the best in the proposed model. However, a comparison of classification models was made without hyperparameter optimization; if applied, some classifiers may give different results.
Sentiment analysis of reviews of customers was conducted in [
24] on four datasets by using Co-LSTM; the researchers compared the performance using a confusion matrix with SVM, Naïve Bayes, LR, CNN and RNN. The results showed that the proposed model performed well in terms of AUC in an air-line dataset with AUC = 0.084. However, the word-embedding model was trained on a limited pre-trained dataset, whereas deep learning models need a huge amount of data. Moreover, in capturing text information, Co-LSTM was unable to capture some important sequence of words. This problem occurs because of the use of connected layers without memory. If connected layers are used with memory, this problem can be resolved.
A hate speech detection model [
25] among vulnerable minorities was proposed by web crawling in the Amharic language. Preprocessing was completed using the tool HornMorpho. N-gram features were extracted using Word2Vec and Tf-IDF. Deep learning classifiers, i.e., GBT, RNN-LSTM, RRF and NN-GRU, were used for classification. Performance of the model was evaluated on the basis of ACC, ROC and AUC. The results showed that RNN-GRU performed best with an ACC of 92%, ROC of 0.97% and AUC of 0.97%. However, language peculiarities may not be captured by a pre-trained model due to the use of generalized model.
Two datasets, DWMW17 [
26] and FDCL18 [
27], were used in [
28] for hate speech detection. Features were extracted by using a combination of features and given names from M1 to M7, where M1 was the baseline feature with the TF-IDF. Experiments were conducted on both datasets separately based on these features. The results showed that M7 outperformed when applied on both datasets. For DWMW17 [
26], the results were better, i.e., accuracy of 94.8%, precision of 97.1%, recall of 96.7% and F1 score of 96.9%. However, polysemy words with multiple meanings can give wrong interpretations regarding hate speech. The proposed model can be applied for multi-lingual hate speech detection in future.
Hate speech text was detected from twitter by comparing pre-trained feature extractors with CNN in [
29]. Data were collected from twitter API. It had 4575 Hindi–English code-mixed words. Pre-trained features included RoBERTA, XLNet, DistilBERT and BERT. These features were used with a CNN model. Results were generated for each pre-trained embedding. XLNET performed the best for hate class with precision = 0.69, recall = 0.42 and F1 score = 0.53. However, as the comparison was among pre-trained models, some Hindi–English interpretations may be neglected by these embeddings.
Detection of hate speech in Hindi–English code-mix text of social media is discussed in [
30]. Data were collected from three different resources [
31,
32]. Features were extracted on the word, document and character level. For the document level, Doc2Vec was used along with SVM-Linear, SVM-RBF and RF. The results showed that RF performed the best in this scenario with an accuracy of 0.64. In the second experiment, Word2Vec was used along with the same models; the results showed that SVM-RBF performed the best with an accuracy of 0.75. In the third experiment, characters were extracted on the basis of the same models by using FastText. The results showed that SVM-RBF outperformed in this scenario with an accuracy of 85.81. It is seen that character-level features provide more information than document-level and word-level features. However, for better performance, more features must be explored.
The focus of [
33] was to identify hate from datasets of multiple classes. For this purpose, the SP-MTL (Shared Private Multitask Learning) model [
33] was proposed. The model was based on deep neural network classifiers, i.e., CNN, LSTM, CNN + GRU and CNNa + GRU. This model was implemented on five datasets with classes hate, aggression, offensive, harassment, racist and sexist [
18,
34]. Features were extracted by CBOW and Word2ec. Results showed that the proposed model CNNa + GRU outperformed by macro-F1 = 84.92 and weighted-F1 = 88.31. However, there were some classes that were misclassified. To overcome this problem, domain-specific embedding should be explored. Multi-verse optimizer, group search optimizer, harmony search optimizer, krill herd algorithm and other genetic algorithms can be explored for better performance.
Hate speech was detected using deep neural network and machine learning techniques in [
35] by using the Arabic Abusive Language dataset [
36]. Arabic text features were extracted on the basis of n-grams, i.e., 1, 2, 3, 4, 5 and 6 g after preprocessing. Feature extraction was completed by using TF-IDF in the SVM, Naïve Bayes and logistic regression cases. For the CNN, LSTM and GRU models, mBert was used. The results showed that SVM with a binary class outperformed with F1-Macro: 85.16, and in DNN, CBB + mBert outperformed for the two-class case with F1-Macro: 87.05. However, in this research, some classes were misclassified, which can have a huge impact on results. If classified correctly, the results may differ.
In [
37], the Vine social network dataset [
26] was used. Features were extracted by BoW after preprocessing. For classification, RF, Ada-Boost AB, Logistic Regression (LR), linear Support Vector Classification (SVC) and Extra-Tree (ET) were applied. Evaluation was made on the basis of ERDE, F1, precision and recall. Experimental results showed that the threshold model improved the baseline of the detection model by 26%. Duel models increases the improvement of cyber-bullying detection up to 42%.
The challenge of cyber bullying detection from text embedding images and infographics is discussed in [
38]. Data contained 10,000 comments and posts in the form of text and images. Comments and posts were divided into 60% text, 20% images and 20% infographics. Features were extracted by using Google lens. The data were fed to the model depending on the type of input data. The textual data were fed to the CapsNet model, and image data were fed to the ConNet model. The final prediction was made by adding a multilayer perceptron with the sigmoid activation function for decision-level fusion. The results showed that AUC-ROC achieved a score of 0.98. However, due to the complexity of language, real-time data can be of high dimensions, and it can be imbalanced.
In [
39], two sub-categories of abusive language, i.e., aggressive language and offensive language, were detected from the online social media platform using word embedding with word2Vec. A simple CNN model was use for the detection of text. The Sentiment-Dataset [
40] was considered as a dictionary, which had 50,000 words. CNN with Word2Vec was implemented using this dictionary on two datasets, i.e., the Aggressive-language dataset [
41] and Offensive-Language Dataset [
42], respectively. Experimental results showed that the model pre-trained on sentiments showed better performance with an F1 score of 64%. However, the proposed model had variations with spellings. By using more word embeddings, the problem of spelling variations can be resolved.
A sentiment analysis framework was proposed in [
43] by the self-development of a military sentiment dictionary. The main focus of this study was on two things: One was to make a military dictionary that was MILSentic. The second was to compare MILSentic with existing dictionaries, i.e., NTUD and HowNet. Sigmoid, Tanh and ReLu were used with LSTM and Bi-LSTM models to check performance. Results showed that the self-developed dictionary (MILSentic + HowNet + NTUD) with (Bi-LSTM + Tanh) gave the best results with accuracy of 92.68%. This study was based on sentiment analysis of text only. More research is required for the development of refined dictionary for sentiment analysis of images, videos and cross-lingual characteristics.
Abusive comments were classified in [
44] by using deep learning approaches. For this purpose, the toxic comments from the kaggle dataset were labeled as ‘Toxic’, ‘Obscene’, ‘Insult’ and ‘Severe toxic’ comments. Features were extracted on the basis of two main models; one was Glove with CNN and the other was Glove and LSTM with CNN. The results showed that the Glove + CNN model outperformed with an accuracy of 97.27.
Table 1.
Evaluation Table Literature Review.
Table 1.
Evaluation Table Literature Review.
| Research Challenges | Literature References |
|---|
| Dataset limitations | [15,18,21] |
| Imbalanced data annotation | [43,44] |
| Limited features extraction | [15,17,19,20,25] |
| Ambiguity in learning models | [37,38,39] |
| Text context misclassification | [37,44] |
3. Materials and Methods
In today’s era, crimes are rapidly increasing. It is important to make a scenario in which criminals can be identified before crimes. For this purpose, a framework is proposed for the prevention of crimes by the early detection of criminal behaviors.
3.1. Proposed Framework
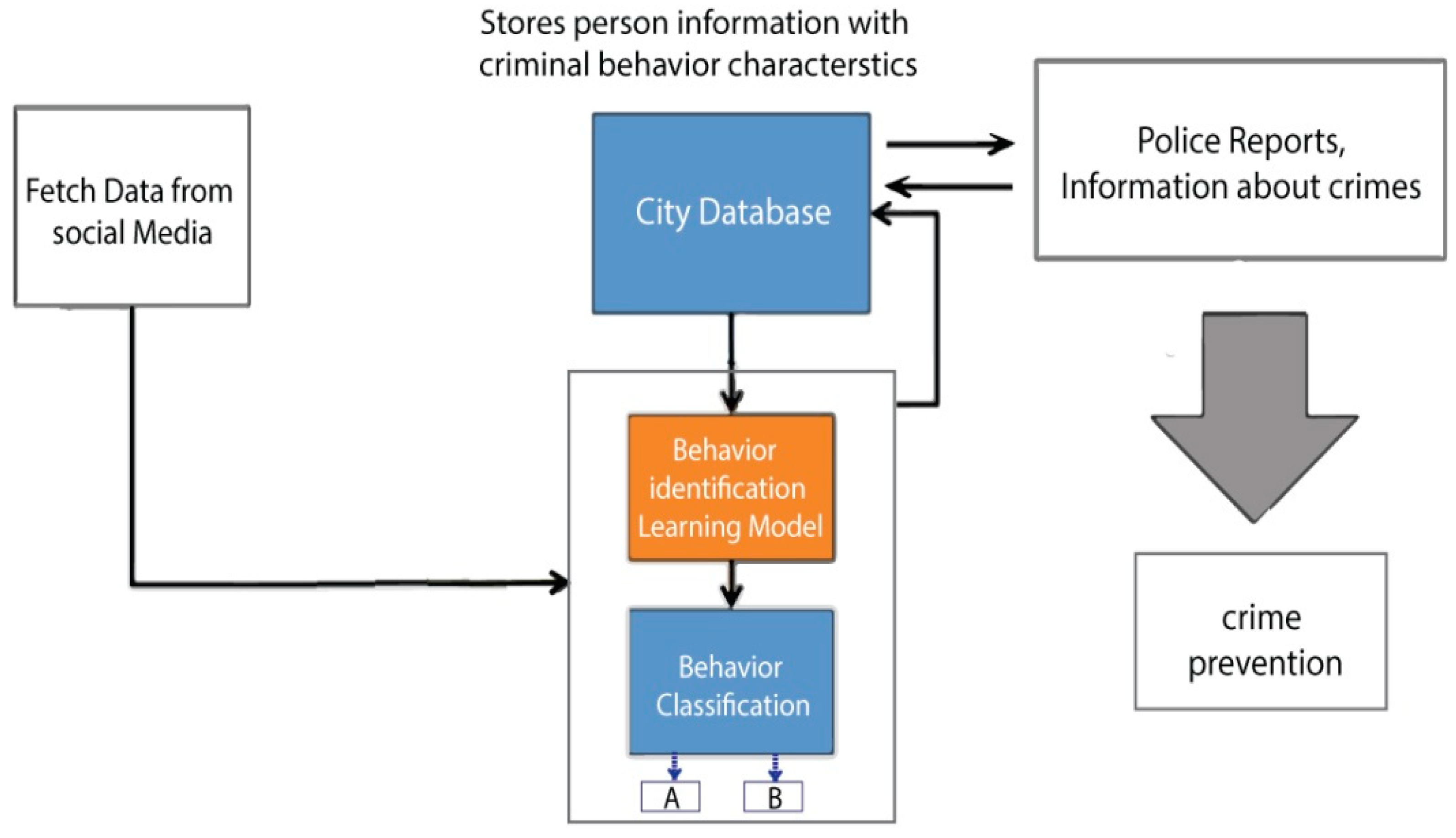
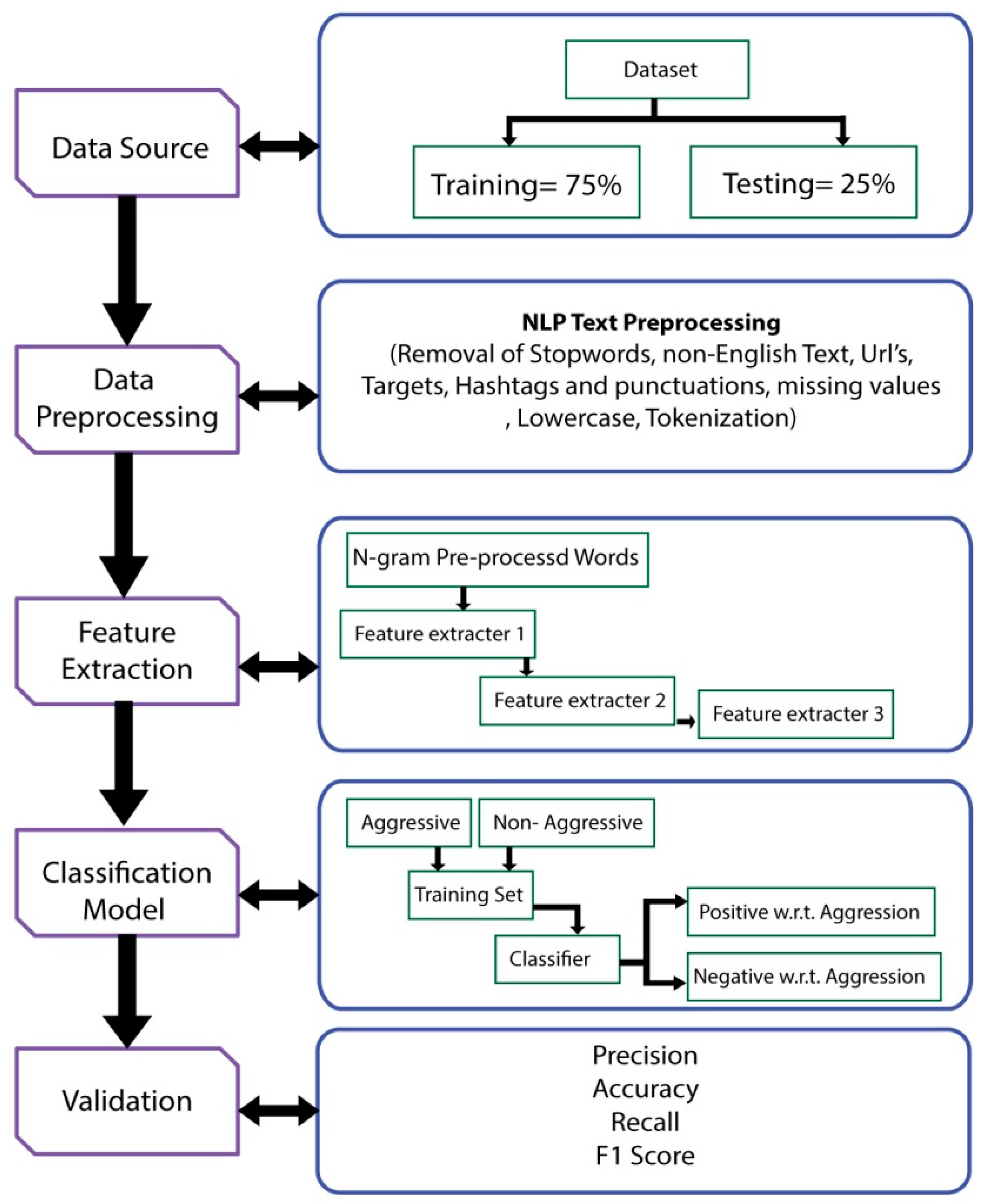
For crime prevention, it is important to keep an eye on people with a criminal mindset, so that quick actions can be taken accordingly by law enforcement agencies. In this research, a novel behavior detection framework is proposed for crime prevention, as shown in
Figure 3. In this framework, real-time data are fetched from social media. The system detects the type of data. It then separates the data that are relevant to the behavior of a person. After that, it classifies the behavior regarding whether the data belong to class ‘A’ or class ‘B’.
If it belongs to class ‘A’, it means these data have nothing to do with the behavior of a person. On the other hand, if it belongs to class ‘B’, it means that the data are relevant to the behavior of a person. The ‘B’ class is further divided into other behavioral classes. These behavioral classes identify the behavioral traits of a person that can have a criminal mindset by observing the text posted on social media. After fetching information related to criminal behavior, those social media profiles containing a criminal nature of behavior are stored in the city database.
This database is accessible to law enforcement agencies. They can keep an eye on people with a criminal mindset by accessing the shortlisted profiles of people having criminal behavior. Moreover, they can also use this system to compare the shortlisted profiles with their own records for finding criminals.
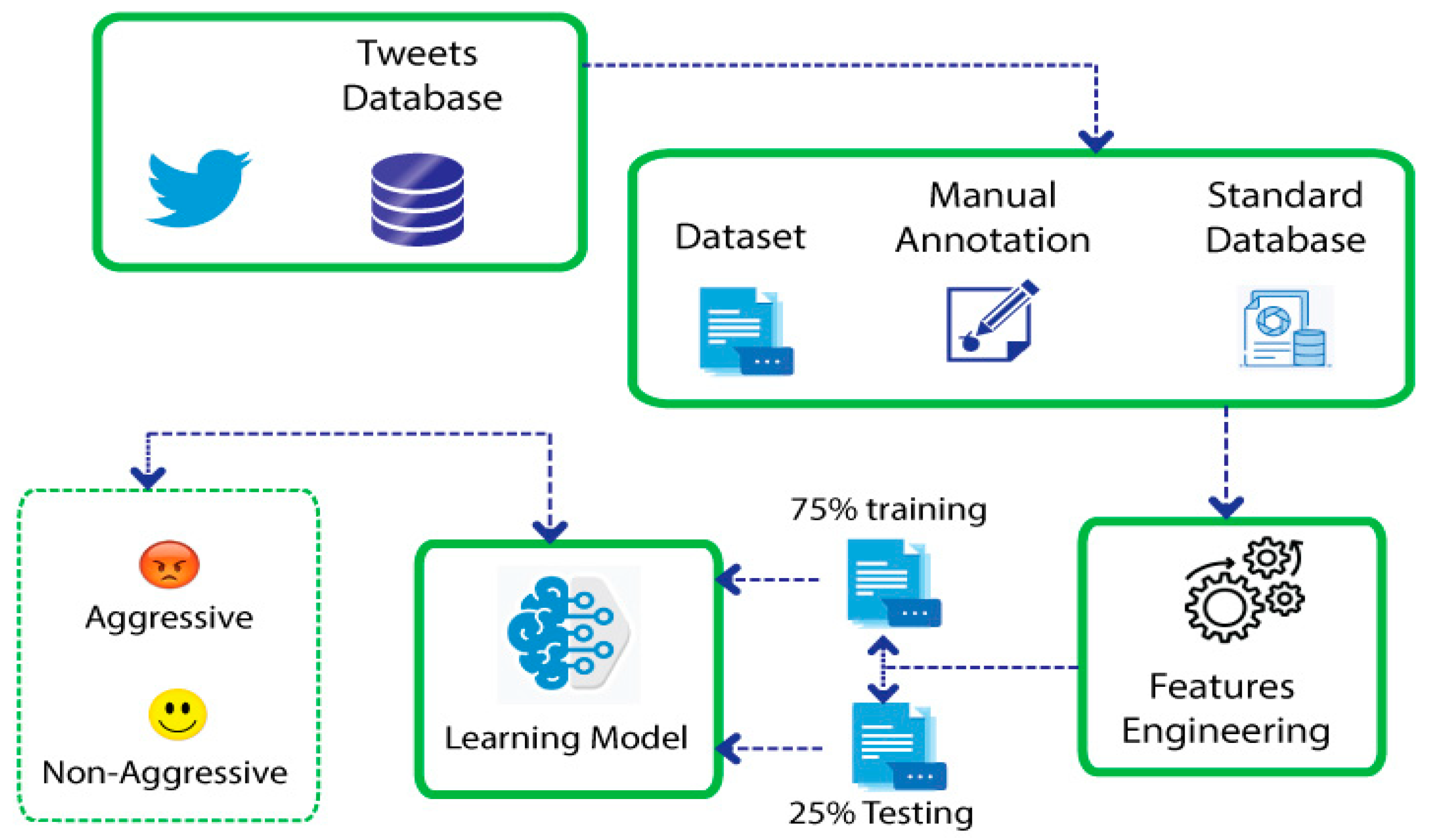
The black box of
Figure 3 is explained further in
Figure 4 where a behavioral model is implemented. The fetched data from social media are saved in a database. From this database, the dataset is extracted. After that, manual annotation is performed to extract more relevant data. After extracting relevant data, a standard database is made. On this standard dataset, feature engineering is applied. After that, data splitting is completed with 75% training and 25% testing. At the end, a learning model is applied to check the performance of the claimed model in terms of finding criminal behavior. The process is visualized in
Figure 4.
3.2. Proposed Methodology
System architecture is presented in this section. The architecture is shown in
Figure 5. The environment for the proposed model implementation is Jupyter, and the language is python. Data are gathered from twitter. After that, a data-splitting process is initiated. Splitting the whole data into training and testing portions is essential to see how accurately the model performs on unseen data (testing data). It also prevents from overfitting. In the proposed model, data are divided into 75% training data and 25% testing data. After that, data preprocessing is completed on a dataset where it cleans the unclean data. Data cleaning is necessary to obtain accurate results from the model. In the proposed model, NLP text preprocessing techniques are implemented. Moreover, text is converted into lowercase, and tokenization is completed. After data preprocessing, feature extraction is completed, where important and relevant features are extracted without losing important information. It also helps in reducing the redundant data to increase the process-time efficiency. Multi-feature extraction techniques are implemented in order to increase the diversity of information produced from text data. In the proposed model, features are extracted on unigram, bigrams and trigrams by using bag of words, TF-IDF and GloVe feature extractors to improve the performance of the model. At first, count of word occurrence is calculated by using BoW. After that, important lexical features of the text are extracted using TF-IDF. At the end, GloVe is used to extract the semantic relatedness of words by learning meaningful vector similarities. Furthermore, feature fusion operation is performed by taking a summation of each feature extractor. This idea becomes clearer by considering the following feature extraction and feature fusion process, as shown in.
Figure 5.
The proposed methodology is shown in
Figure 5. The environment for the implementation of the proposed model is Jupyter, and the language is python. Data are gathered from twitter. After that, the data-splitting process is initiated. Splitting the whole data into training and testing portions is essential to see how accurately the model performs on unseen data (testing data). It also prevents from overfitting. In the proposed model, data are divided into 75% training data and 25% testing data. After that, data preprocessing is performed on a dataset where it cleans the unclean data. Data cleaning is necessary for accurate results of the model. In the proposed model, NLP text preprocessing is performed by the removal of stop words, removal of non-English text, removal of URLs, targets, hashtags, punctuation and missing values. Moreover, text is converted into lowercase, and tokenization is completed. After data preprocessing, feature extraction is performed where important and relevant features are extracted without losing important information. It also helps by reducing the redundant data to increase the process-time efficiency. Multi-feature extraction techniques are implemented in order to increase the diversity of information produced from text data. In the proposed model, features are extracted on unigrams, bigrams and trigrams by using bag of words, TF-IDF and GloVe feature extractors to improve the performance of the model. At first, count of word occurrence is calculated by using BoW. After that, important lexical features of the text are extracted using TF-IDF. At the end, GloVe is used to extract the semantic relatedness of words by learning meaningful vector similarities. Furthermore, feature fusion operation is performed by taking a summation of each feature extractor.
After features extraction, classification is performed. It recognizes and separates the relevant text into relevant class automatically with the help of the learning model. In the proposed DNN model, multilayer perceptron is used for the detection of behavior. Aggressive behavior tweets are directed to the aggressive class, and non-aggressive or neutral tweets are directed to the non-aggressive class.
In the end, the proposed model is validated on the basis of accuracy, precision, recall, loss and F1 score. It is important to validate the model to see the performance. Validation parameters show the scale of the proposed model. The scale defines how well the model has performed. The results of the proposed model are evaluated by comparing it with state of the art work.
3.3. Dataset Description
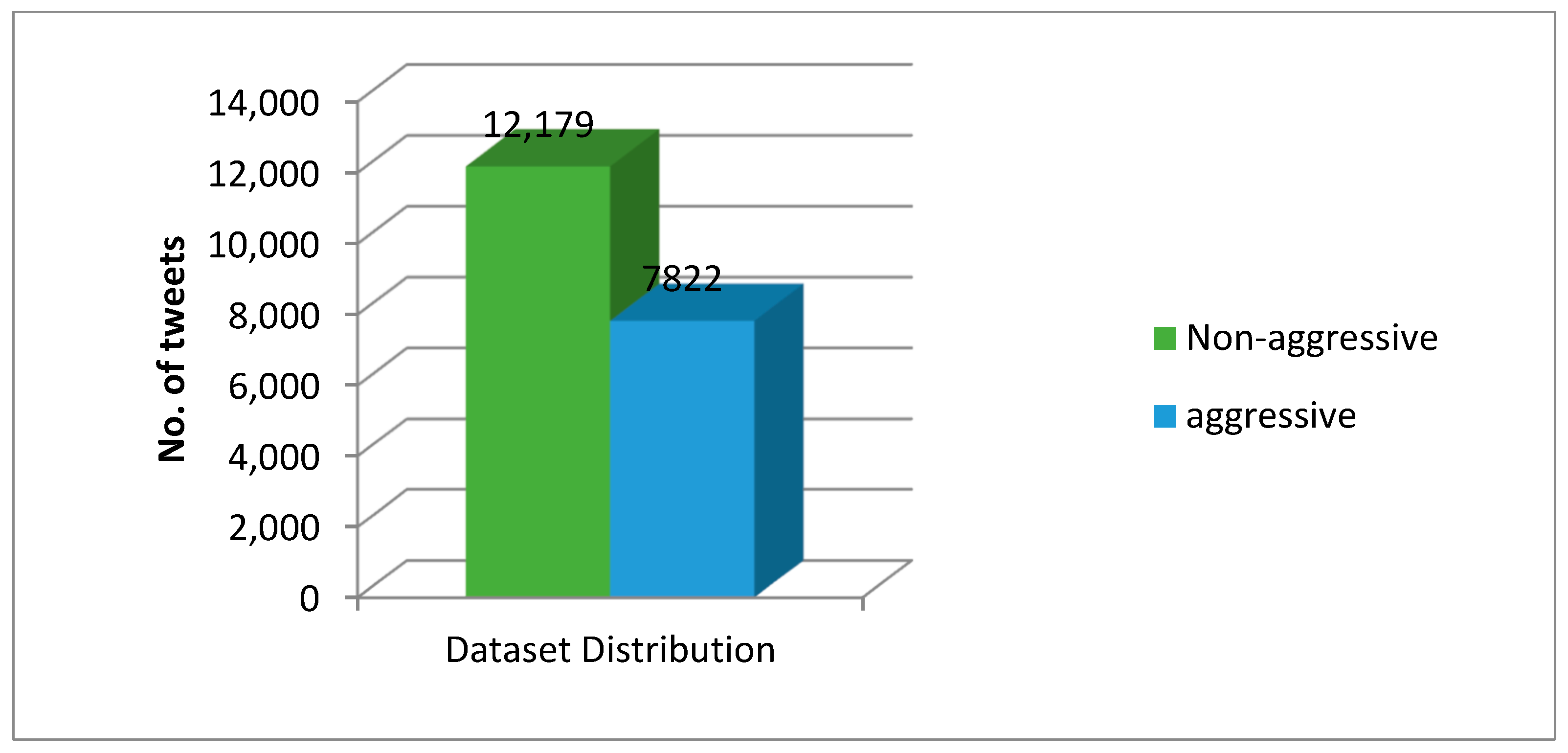
For this research, a cyber-troll dataset is used [
45]. It was created for the classification of text by Data Turks. It is a human labeled dataset, as shown in
Figure 6. It has 20,001 tweets in it of which 7822 are aggressive and 12,179 are non-aggressive. Aggressive tweets are labeled as 1, and non-aggressive tweets are labeled as 0.
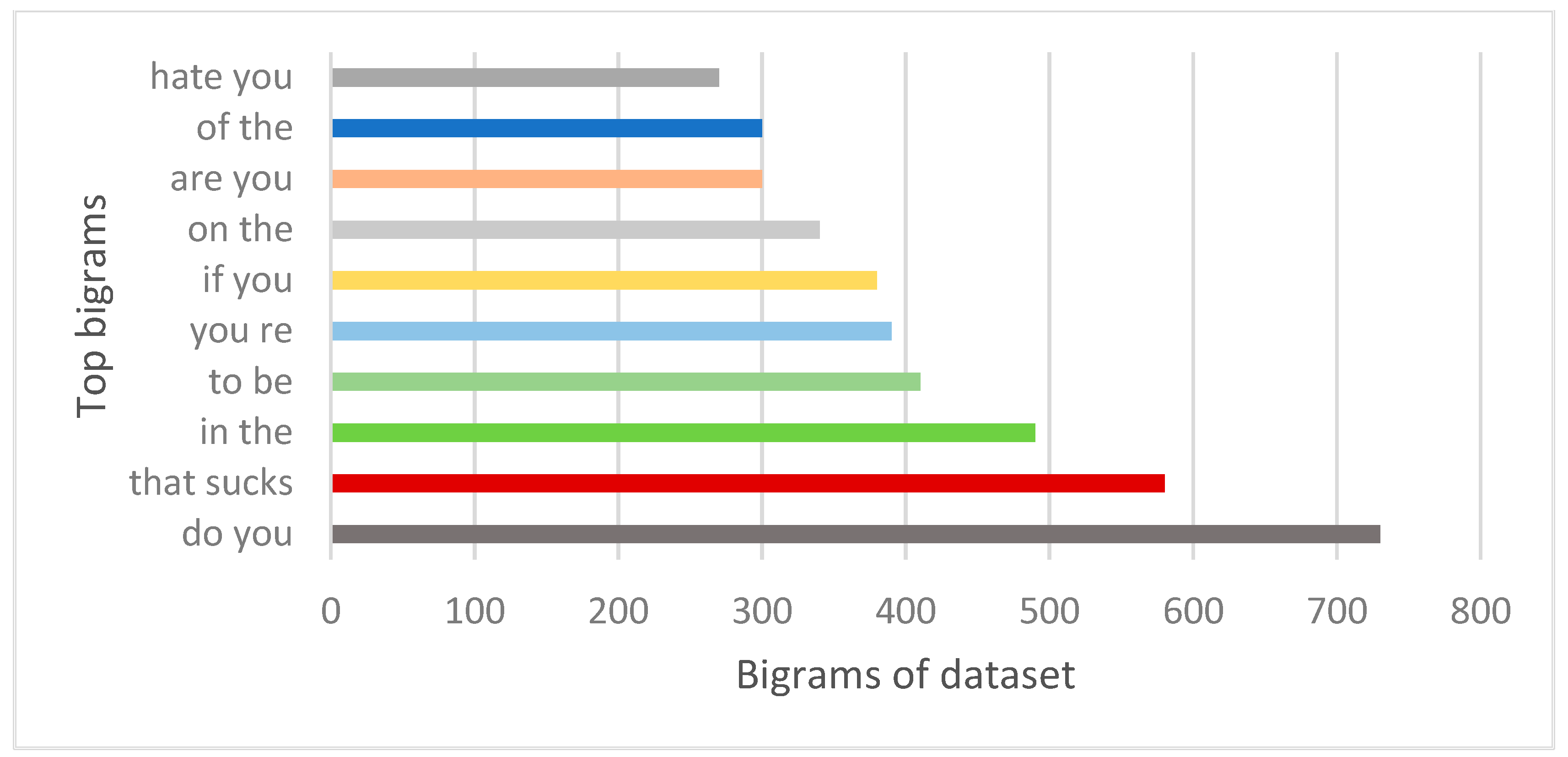
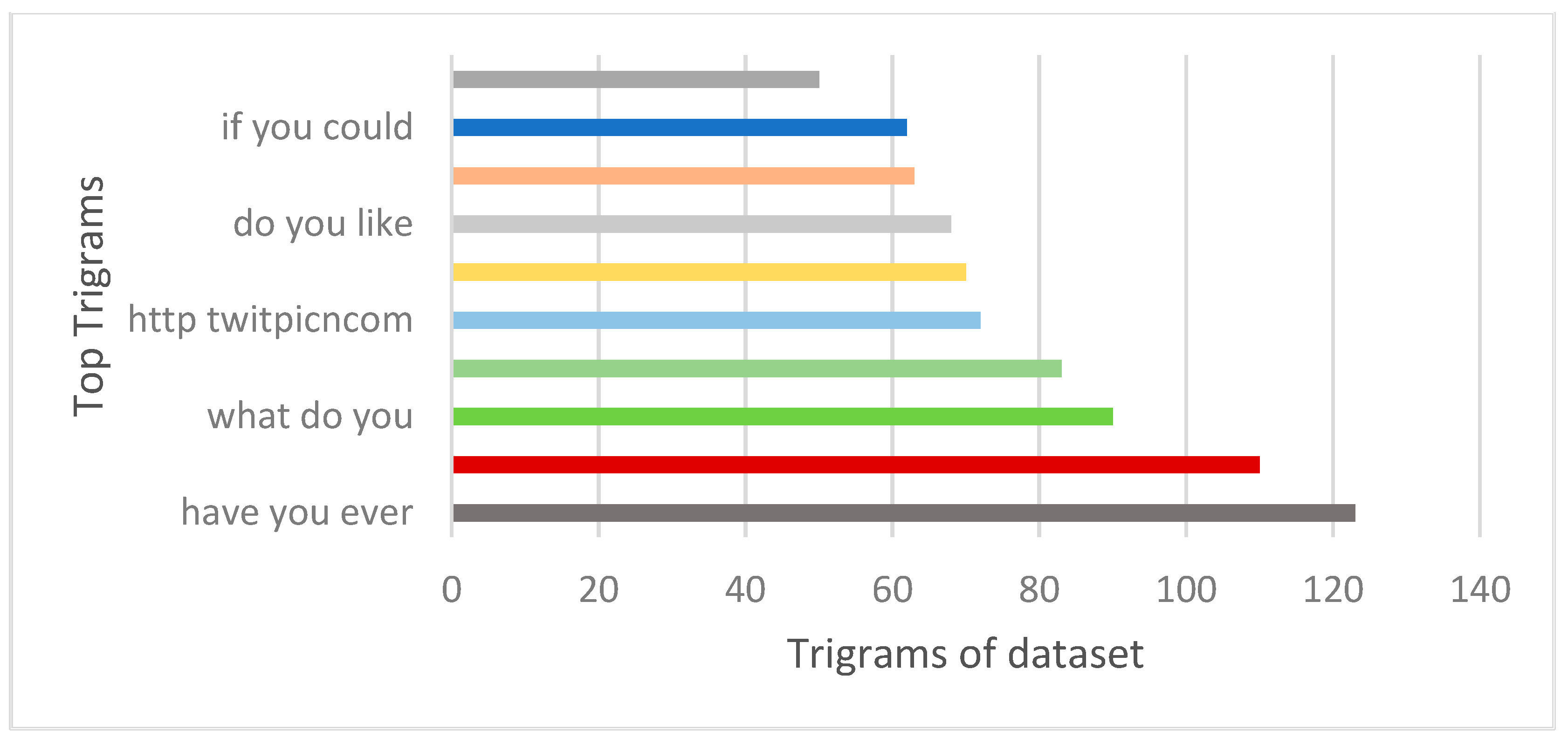
The number of characters with respect to length is almost the same, as shown in
Figure 7. The green bar shows the non-aggressive class and the blue bar shows the aggressive class. Data are divided into 25% testing and 75% training.
3.4. Classification Models and Validations
In model classification, fully connected dense layers are used. The experimentation is completed in python using TensorFlow as the back end and Keras as the front end. The framework used for implementation is Jupyter python. In the model, four hidden layers are implemented. In the first three layers, the Relu (Rectified Linear unit) activation function is used, and in the output layer, the sigmoid activation function is used. There are two neurons in the output layer just as in the classes of the dataset. After performing some experimentation, training hyper parameters are set accordingly. Drop out is equal to 0.2, and the batch size is set to 128. The learning rate is le-3. For identification of loss function, we used binary cross entropy. For optimization, Adam optimizer was used. For comparison purposes, the base model is implemented as well. After that, it is compared with the proposed model with respect to the performance.
Evaluation metrics include accuracy, recall, f measure and precision. These measures are calculated by TP (True Positive) TN (True Negative), FN (False Negative) and FP (False Positive). Those tweets in which aggressive behavior is classified correctly are TP. Those tweets that are not classified correctly are FN. On the other hand, those tweets that are not related to aggressive behavior and classified correctly are TN, and on the other hand, those tweets that are not related to aggressive behavior and are misclassified are FP. F1 score is use to balance the recall and precision and embed in a single value. In this research, the F1 score is used as a main evaluation parameter. The system used for this experimentation is core-I7 with 16 GB of RAM, Keras R, TensorFlow R and python R 3.6.7.
5. Results and Analysis
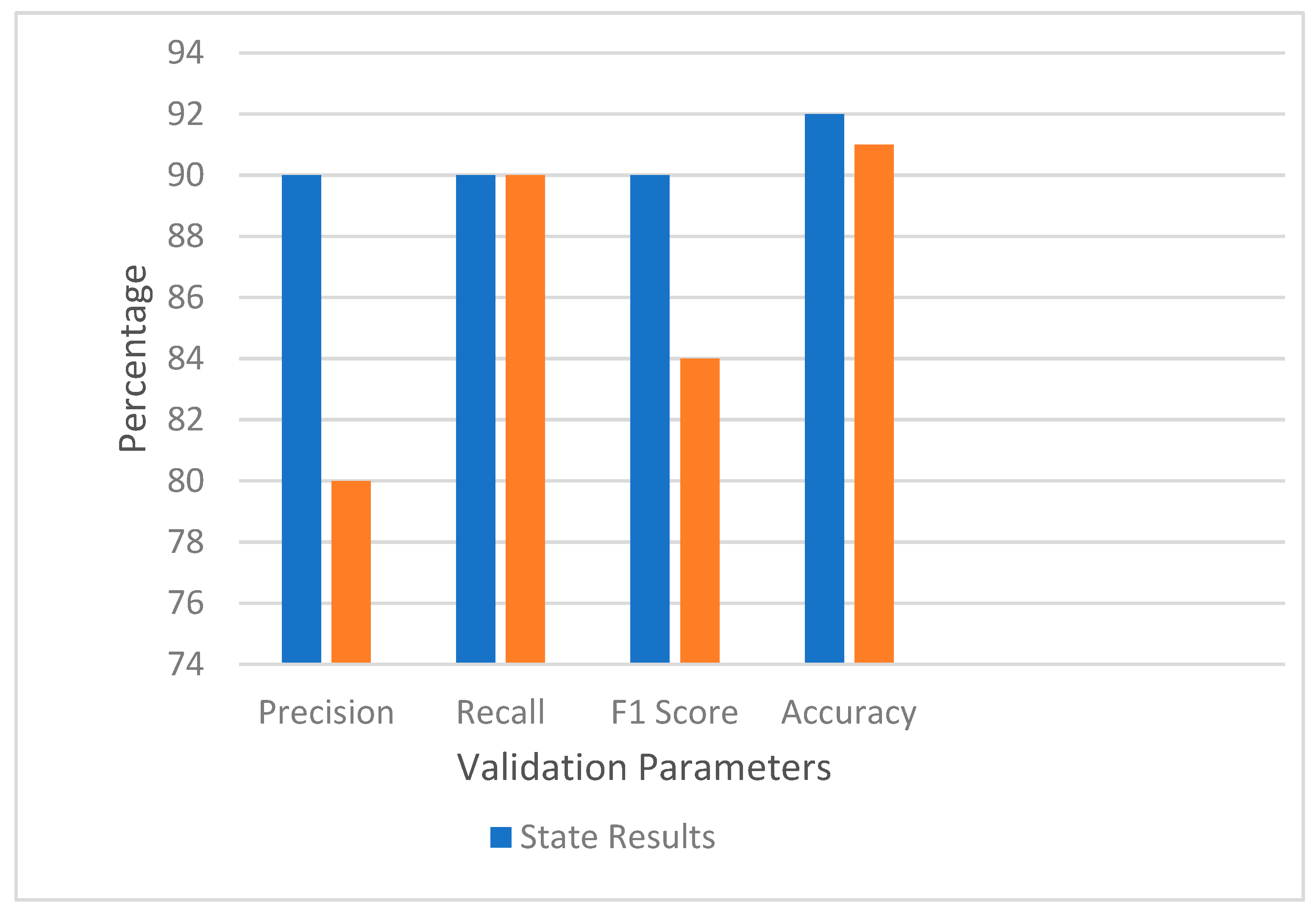
The performance evaluation of models on the basis of feature hybridization and classification is presented on the basis of a cyber troll dataset. At first, state of the art work [
15] is implemented with the same settings as explained. They obtained an accuracy of 92% and precision, recall and F1 score of 90% (
Figure 14).
However, when the same parameters were implemented with the same model, settings and dataset, the achieved results were quite different. The results were precision of 80%, recall of 90%, accuracy of 91% and F1 score of 84%. This is also shown in
Table 1.
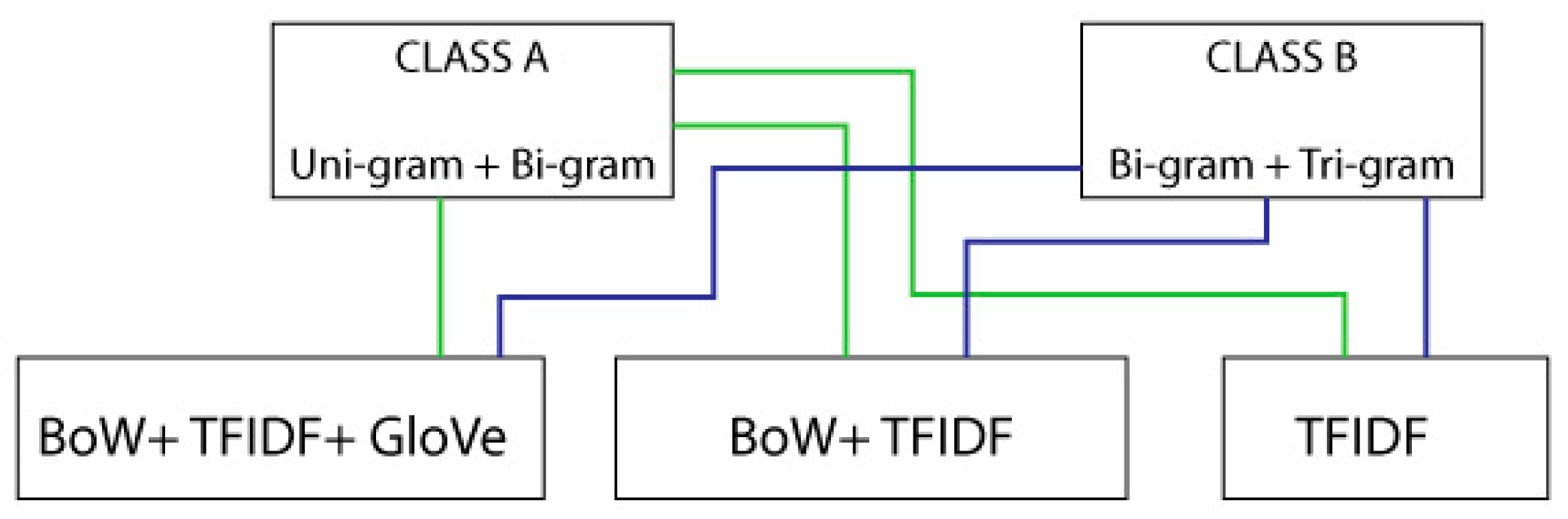
The MLP performance is tested with combinations of feature extraction models to make a competitive comparison between all approaches.
As the F1 score is considered as the main evaluation measure, it is evident from
Table 2 that the proposed model MLP using (BoW + TF-IDF + GloVe) and MLP using (BoW + TF-IDF) outperformed the base model with 86% and 87% F1 scores, respectively, in the unigram + bigram case. Similarly, it has 83% and 86% F1 scores in the bigram + trigram case.
On the other hand, the F1 score of MLP using TF-IDF, which was a base model, had an 84% f1 score in the unigram case and 83% in the bigram case when implemented.
Table 2 shows the accuracy, precision, recall and F1 score of MLP using the proposed features extraction model.
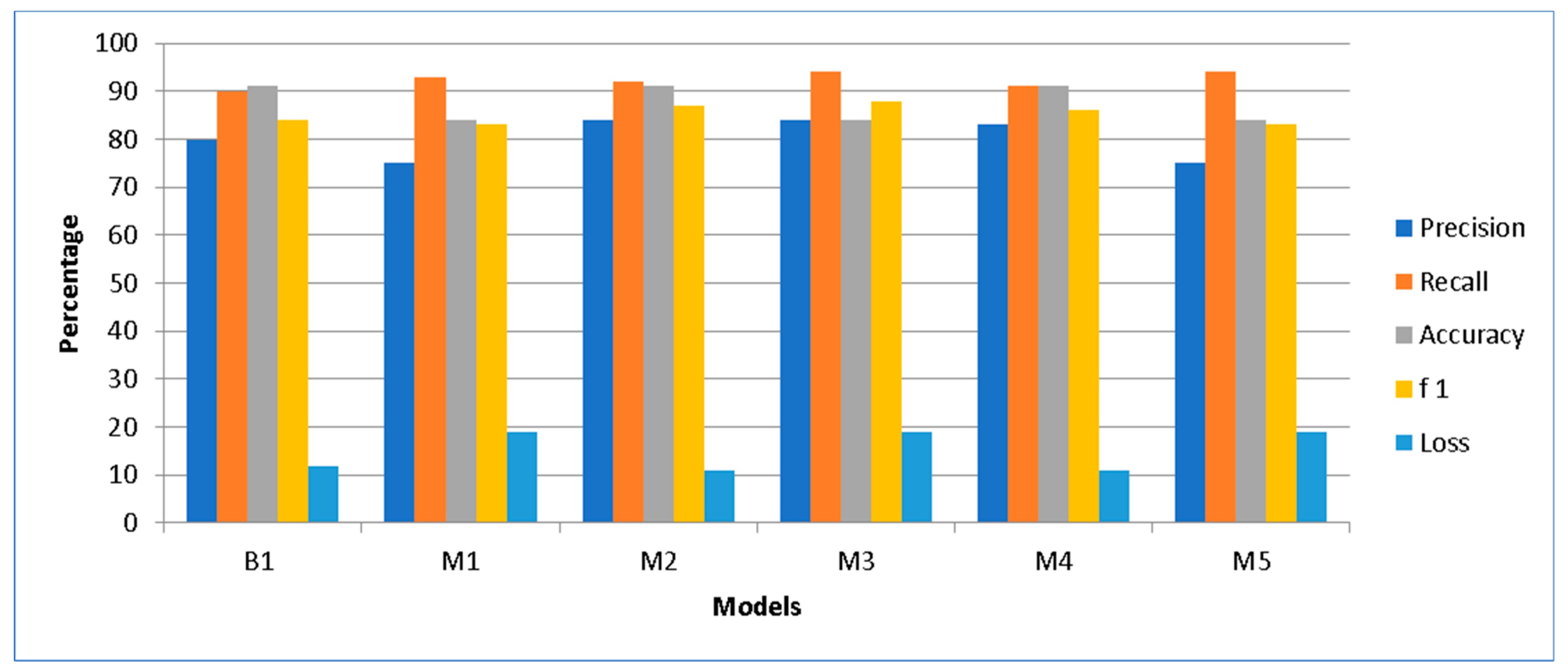
As shown in
Table 3, BoW + TF-IDF the 1 + 2 g and 2 + 3 g cases outperformed with F1 scores of 87% and 88%, respectively. This is also shown in
Figure 15. On the
x-axis, all models are placed, and the
y-axis shows the percentage of evaluation parameters. B1 defines the base model and M1 to M5 explain the proposed model results. In the figure, it can be seen that M2 and M3 showed the best results. The main contribution of the proposed research is an introduction of a hybrid model which gives the best results in comparison with the model implemented in state of the art work.
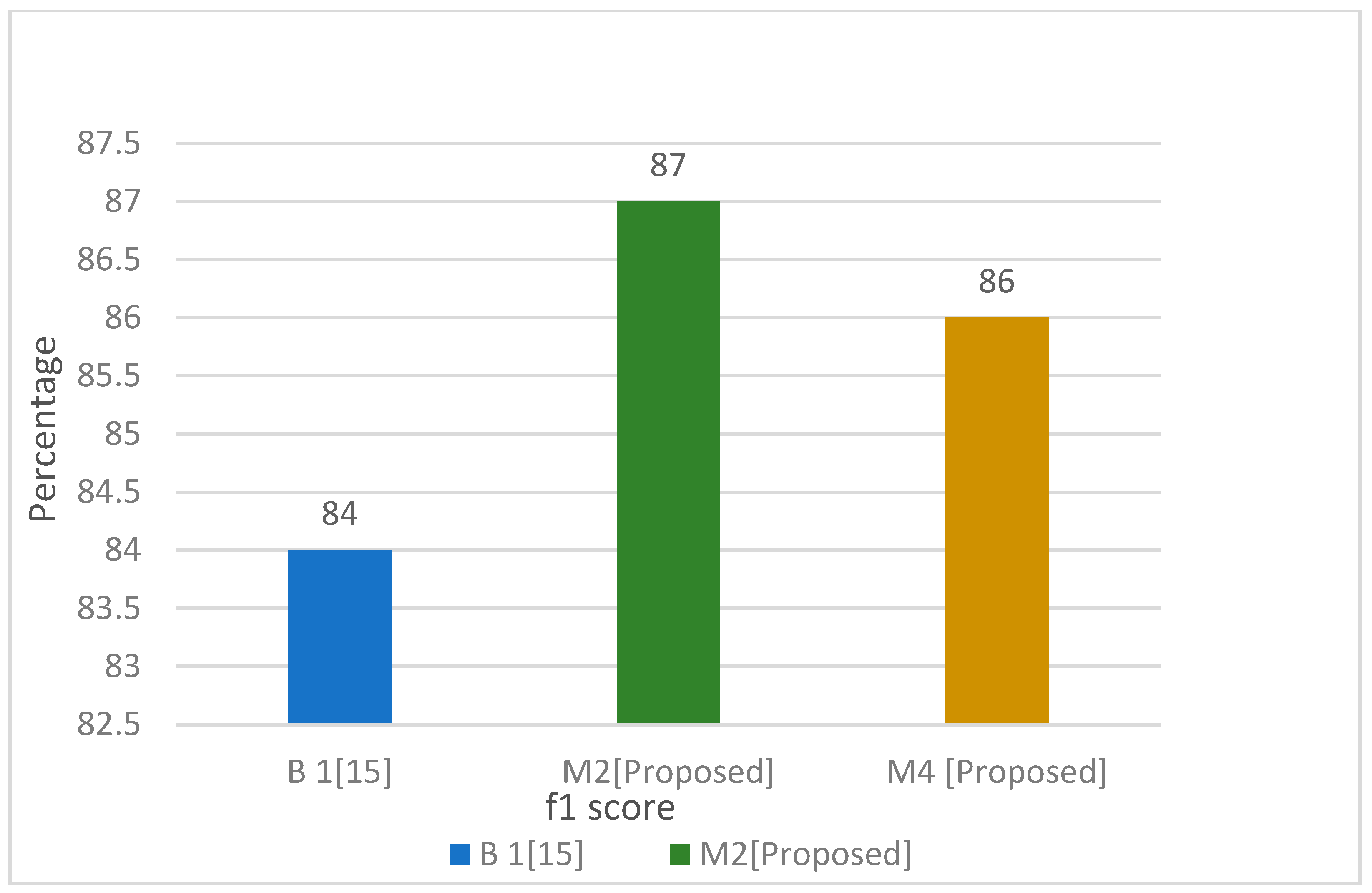
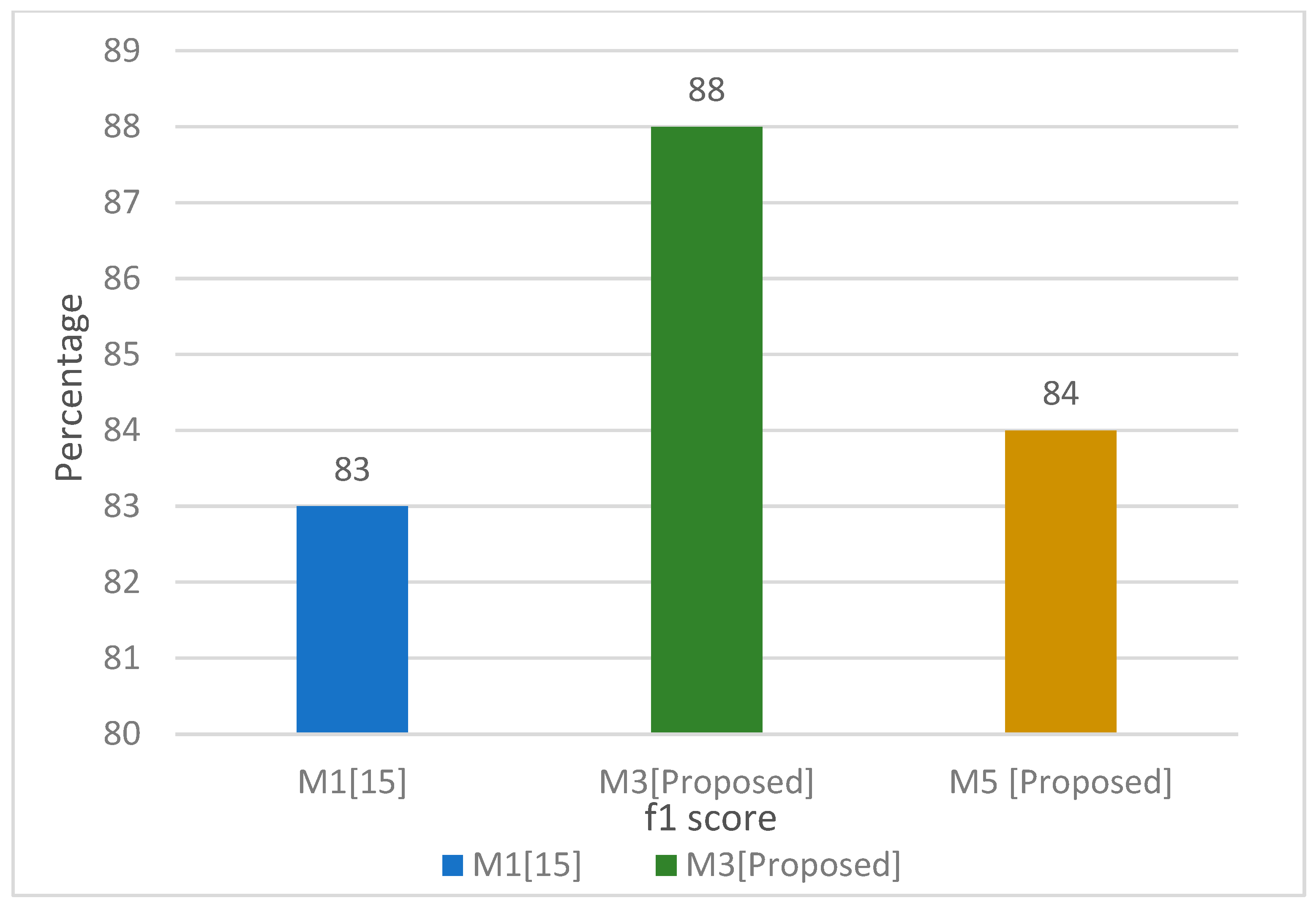
In
Figure 16 and
Figure 17, the best fit proposed model is compared with the base model to see the results in terms of F1 score, and it can be seen clearly, the proposed model M2 (bag of words, TF-IDF, MLP, 1 + 2 g) outperformed the base model B1.
The proposed model results are compared with state of the art models in the published results, and it is seen that the proposed model outperformed in terms of F1 score in that case as well. This is shown in
Table 4.
From the implementation of models, it is clear that the proposed deep learning model outperformed the base model. Sparsity of data is one of the main problems that occurs while dealing with tweets because of the short length of text. To resolve this problem, a dense layer is added which extracts more accurate features. An approach is presented in this research for identifying aggressive behavior by introducing a hybrid feature extraction approach in a simple neural network architecture.
This methodology is applied by obtaining vectors in the form of one, two and three grams of words. In DNN, the number of hidden layers has a direct impact on the training time. If there are more hidden layers, the network becomes more complex; hence, it increases the training time. The proposed methodology reduces the training time by empowering the neural network system to learn important features from the proposed features hybridization technique. The proposed study contributed in the field of research by (i) modeling a framework for criminal behavior detection; (ii) building a model for aggressive behavior detection by combining multi-features in neural network architecture; and (iii) the improvement of results in finding the context of the text by training the model on unigrams, bigrams and trigrams. The results in
Table 1 and
Table 2 clearly portray a correlation of state of the art work with the proposed techniques and show that the proposed techniques achieved better results in terms of F1 score in finding aggression. Looking into the dataset for experimentation, it is seen that there are more tweets in the non-aggressive behavior class as compared to the aggressive behavior class. If class balancing is applied by including more tweets in the aggressive class, the results may improve. For this purpose, SMOT can be explored. The proposed research implemented methodology proposed in state of the art work [
15], and the results stated were different when the same methodology with the same dataset was applied. They have stated 92% accuracy and 90% precision, recall and F1 score. However, when implementing the same model, the reproduced results were different, i.e., F1 score of 84%. The proposed model outperforms because of the multi-feature hybridization approach for extraction before feeding to the DNN model multilayer perceptron. The proposed model increased the efficiency and gave better results. The proposed model (bag of words, TF-IDF, MLP, 1 + 2 g) gave outstanding results with an 87% F1 score in the unigram + bigram case and 88% F1 score in the bigram + trigram case.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















