1. Introduction
With the rapid development of mobile Internet and multimedia technology, screen content images (SCIs) have been widely used in various interactive scenarios, such as virtual screen sharing, online education, online meetings, cloud computing, and games [
1]. Especially in the global outbreak of COVID-19, many normal work and lifestyle cannot be carried out offline in order to prevent crowds from gathering, and people working at home must transmit information through screen content. SCIs generally refer to the interface presented on the screen of a digital viewing device, which usually contain computer-generated content, such as text, computer graphics, etc., as well as content captured by cameras. Examples of traditional natural images and SCIs are shown in
Figure 1. In contrast, SCIs typically consist of sharp edges, limited color variations, and repetitive patterns, while natural images usually present smoother edges, rich colors, and complex textures [
2,
3]. Similar to natural images, in the process of typical multimedia service chain, such as capture, compression, transmission, decompression, and reconstruction, a series of distortions will inevitably be introduced due to the interference of various factors, such as broadband constraint, resolution limitation of hardware devices, and color and contrast changes of remote sharing, which will lead to the decline of the perceived quality of SCIs at the receiving end [
4,
5,
6]. Therefore, as a basic technology in image engineering, image quality assessment (IQA) plays an irreplaceable role in the field of visual information processing and communication, and has profound theoretical significance and important application value.
Generally speaking, IQA methods can be divided into two categories: subjective and objective methods. The former represents the most realistic human perception of images and is the most reliable measure of visual quality among all available means. However, this method is time-consuming and not suitable for real-time processing. Therefore, most studies have focused on the automatic assessment of image quality, aiming to achieve the replacement of human vision in objective ways. Due to its advantages of high efficiency, stability, and integration, the objective research has gradually become a key topic in IQA studies. However, since the modeling of human visual system (HVS) is a very complex process, it is difficult to obtain the characteristics consistent with human vision. In addition, because of the significant differences of perceptual attributes between SCIs and natural images, the existing IQA methods for natural images cannot be directly applied to evaluate the perceptual quality of SCIs [
7,
8]. Therefore, in order to better meet the needs of practical applications, it is necessary to design an objective and accurate IQA method for SCIs that can fully reflect the characteristics of human visual perception.
2. Related Works
So far, there have been many full-reference (FR) quality assessment studies for SCIs that are able to obtain good performance [
9,
10,
11,
12,
13,
14,
15,
16]. However, in many practical applications (e.g., remote screen sharing systems and wireless transmission systems), it is often difficult for us to obtain the original versions of distorted SCIs, making such FR methods more limited. Therefore, we focus our research on no-reference (NR) approaches. Existing NR-IQA methods for SCIs can be roughly divided into the following two categories: manual feature extraction-based methods and machine learning-based methods. Gu et al. [
17] first proposed a blind quality measurement method (BQMS). Then, a unified framework is concluded and four types of descriptive features are extracted to design an IQA model (SIQE) [
18]. Fang et al. [
19] utilized histograms to represent statistical luminance and texture features extracted from local normalization and gradient information, respectively. Later on, an improved model (PQSC) [
20] was proposed by using a more accurate local ternary patterns (LTP) operator for texture feature extraction and introducing chromatic descriptors. Zheng et al. [
21] utilized the variance of local standard deviation to distinguish sharp edge patches (SEPes) and non-SEPes of SCIs. Yang et al. [
22] trained stacked autoencoders (SAEs) by a completely unsupervised method to process quality-awareness features extracted from pictorial and textual regions. The problem with these feature extraction-based methods is that those features are obviously subjective and one-sided, and cannot fully reflect the particularity of SCIs. The most typical machine-learning-based approach is the application of neural networks, which provides end-to-end features for better performance. Zuo et al. [
23] proposed a framework based on a convolutional neural network (CNN) to predict the quality scores of image patches. Yue et al. [
24] attempted to train a network with the entire image and divided the original image into prediction and non-prediction parts according to the internal generation mechanism theory. Chen et al. utilized a “normalization” module consisting of the up-sampling and convolutional layers, aiming to transform the SCIs to have more natural images-like features [
25]. Jiang et al. used multi-region local features to generate pseudo-global features, and proposed a novel ranking loss to predict quality scores [
26]. Neural networks make up for shortcomings of manual feature extraction methods to a certain extent, but these methods are completely black-box operations that lack interpretability and require a large amount of supervised data, which can easily lead to overfitting if the sample size of the training set is insufficient.
The HVS is critical to the perception of visual signals, and, therefore, we must consider relevant properties of the HVS when designing our model. When we observe the natural world through our eyes, visual signals are transmitted through the lateral geniculate nucleus (LGN) to the primary visual cortex (V1) for visual abstraction. During this process different neurons on the retina and LGN are activated, and these response properties can be successfully explained by the redundancy parsimony principle for interpretation [
27]. More theoretical studies have shown that for the perceptual information received by brains from the external world, the primitive visual cortex uses sparse coding to represent them, which is an effective strategy for the distributed representation of neural information populations [
28]. In summary, in order to better reflect the characteristics of information processing in HVS, we can use the sparse coding model to simulate the corresponding functions.
The applications of sparse coding in IQA designed for SCIs have also been extensively studied. Existing research shows that algorithms based on sparse coding can achieve data compression more efficiently, and we can use the redundancy property of dictionary to capture intrinsic essential features of signals, which makes it easier to obtain the information contained in signals and improves the effectiveness and completeness of artificial features. Shao et al. [
29] proposed a blind quality predictor (BLIQUP-SCI), which was based on the BRISQUE [
30] framework, and three features were extracted from both local and global perspectives for SCIs, including gradient magnitude (GM) maps, Gaussian Laplace operator response (GM-LOG) [
31], and local binary patterns (LBP). Yang et al. [
32] used features based on sparse coding coefficients of the histogram of oriented gradient (HOG) to predict image quality. Zhou et al. [
33] achieved a fused representation of images by training local and global feature dictionaries separately. Wu et al. [
34] designed a sparse representation model to extract local structural features and combined with global features consisting of luminance statistical features and LBP features. The above algorithms utilize sparse coding to deal with further local and global features, and optimize the artificial features to some extent. To enhance the correlation between features, a tensor domain dictionary-based BIQA method was proposed to better represent SCIs features and the working mechanism of HVS [
35].
In summary, current NR-IQA methods for SCIs are mainly considered from two perspectives: on the one hand, the model is applied to extract artificial features directly from the digital representation of images, which is highly subjective and largely depends on the prior knowledge of the quality degradation mechanism of SCIs. On the other hand, neural network-based methods do not have good interpretability, although they can achieve end-to-end training and obtain deep abstract feature representations. Therefore, considering the advantages and limitations of the above two types of approaches, this paper focuses on combining machine learning and manual feature extraction and proposes a NR quality assessment method for SCIs based on human visual perception characteristics. Specifically, we adopt dictionary learning and sparse coding methods in machine learning to simulate the information extraction process of human brains and then analyze the obtained sparse coefficients from multiple perspectives to define artificial features. Compared with previous algorithms, the proposed method extracts more comprehensive features. Additionally, we also introduce a decomposition mechanism of visual channels before simulating brains for sparse analysis to better capture the perception of image details towards human eyes under different viewing conditions. Furthermore, special consideration is given to color information by utilizing a closely related property of color perception as a description of color features. Finally, support vector regression (SVR) is adopted to learn the IQA model from perception features to human subjective scores. Experimental results have shown the performance improvement of the proposed method. In a word, the main contributions of this paper are summarized as follows:
Dictionary learning and sparse coding techniques were applied to obtain the quality perception characteristics and enhance the effectiveness and objectivity of the feature extraction process. The original samples were transformed into suitable sparse representation, which simplified the learning task and reduced complexity.
The multi-channel decomposition mechanism of visual system was introduced. Due to the HVS presenting different sensitivity to different frequency signals, details of images under different viewing conditions were captured by introducing multi-scale processing technique, which effectively improved the performance of the proposed model in quality prediction.
The results of sparse representation were described from several perspectives. Towards the luminance component, a local pooling scheme based on generalized Gaussian distribution and log-normal distribution was designed firstly by analyzing sparse coefficients. Secondly, the overall quality representation was obtained by extracting energy features of the image. Additionally, overall statistical features of SCIs about dictionary atoms were adopted to reduce the information loss in feature aggregation and effectively solve the one-sidedness of artificial features. Finally, we added the image saturation attribute to describe the color information to make extracted features more systematic and complete.
3. No-Reference Quality Assessment Model for Screen Content Images
Considering the characteristics of SCIs and HVS, a no-reference quality assessment model for SCIs is proposed in this paper based on perceptual characteristics of the human visual. The overall framework is shown in
Figure 2. On the whole, the proposed method firstly decomposes input images at multiple scales through Gaussian pyramids to simulate the multi-channel working mechanism of HVS. The respective quality contribution is then calculated at each scale, as shown in
Figure 3, which contains four stages of dictionary learning, sparse coding, feature extraction, and quality regression. The final quality score
Q is obtained by weighted fusion.
3.1. Multi-Scale Processing Technique
The multi-channel mechanism of HVS shows that neurons decompose visual information into different channels, such as color, frequency, orientation, etc. [
36]. According to the related research on the phenomenon of contrast sensitivity, human eyes are more sensitive to distortion in the mid-frequency region than in the low-frequency smooth region and the high-frequency texture region [
37]. Thus, multi-scale processing is introduced into our algorithm to improve the performance of the quality prediction. The degree of human perception of image details depends on several viewing conditions, such as display resolution, viewing distance, sampling density, etc. To eliminate the effect due to perceptibility differences as much as possible, the multi-scale processing technique simulates the working mechanism of HVS by weighting the relative importance between different scales.
A Gaussian pyramid is a kind of multi-scale representation that applies Gaussian blur and down-sampling several times to generate multiple sets of signals or images at different scales for subsequent processing. The principle of the Gaussian pyramid is shown in
Figure 4. In this paper, a Gaussian pyramid is used to process the images, as shown in
Figure 2. The proposed model iteratively applies a low-pass filter and down-samples the filtered image by a factor of 2. We denote the index of the original image as scale 1, and the index of the highest scale as scale
M, so the result is obtained after a total of
iterations. The quality score on the
kth scale is denoted as
, then the final quality prediction score is obtained by combining the results on different scales:
where
is used to adjust the relative importance of different scales, and we will discuss the values of parameters in detail in
Section 4.3.
3.2. Dictionary Learning
Dictionary learning is to capture the most common and essential features among thousands of targets, which can facilitate further processing. A learned representation matrix is used in the general model of dictionary learning to reflect the mapping relationship between the original signal space and the sub-signal space. This important representation matrix is the dictionary, and each column of the dictionary is called an atom. In the implementation, the K-SVD algorithm [
38] is adopted for dictionary learning to process input images by using the sequential dictionary update method and completing one dictionary update with K iterations, which has been widely used because of its good performance in various image processing applications. Specifically, we construct an initial dictionary through the dictionary learning objective function model:
where the first term indicates that the linear combination of the dictionary matrix
and the sparse representation
can restore the sample
as much as possible, and the second cumulative term indicates that the measurement vector
should be as sparse as possible. The dictionary learned in this paper is shown in
Figure 5, where each atom stands for a specific structural feature obtained from the training set, and its corresponding sparse coefficients represent the strength of structural features. Depending on the dictionary, we will obtain different reconstruction coefficients, that is, the values of atoms in the dictionary will directly affect the reconstruction effect of the images.
3.3. Sparse Coding
It has been shown that any given signal is sparse in some transform domain, which means any given signal can be expressed by some dictionary and the corresponding sparse representation [
39,
40,
41,
42]. From a biological point of view, sparse coding can be analogous to a neuronal response, while the dictionary atoms being used can be considered as the corresponding active neurons in the retina. Therefore, the existing metric with sparse coefficients can be considered as a measure of degradation of image quality by exploring the different responses given by the same neurons. Sparse coding aims to represent signals with as few useful elements as possible and can, therefore, be well used to describe the receptive fields of simple cells in V1 [
28].
Sparse coding simplifies subsequent learning tasks and reduces model complexity by representing the input signal as a sparse linear combination of atoms in a dictionary. In the target dictionary space, sparse reconstruction coefficients can be used to generate effective quality-aware features. In this paper, the optimal solution of Equation (
2) is obtained by OMP algorithm. All of the selected atoms are processed orthogonally at each step of decomposition, which enables the faster convergence of the OMP algorithm with the same accuracy requirements. We obtain the sparse coefficients matrix of each patch about dictionary atoms, which will be directly used for feature generation in subsequent modules. According to Equation (
3), we can use the learned dictionary
to perform a sparse representation of the target image:
where
,
denotes the input test SCIs, and
T denotes the error threshold. We set
T to 1 based on experimental comparison results and the effect of different
T values on performance will be analyzed in
Section 4.3.
3.4. Feature Extraction
After obtaining the sparse representation of images, we can perform feature extraction on the sparse coefficients of all patches, to explore the inherent features for subsequent calculation of quality scores. Considering the characteristics of human visual perception and the particularity of SCIs, five groups of features are selected to form the final feature vector. First, we analyze the sparse coefficient values by adopting different pooling schemes for zero and non-zero values separately to characterize their distribution. Second, we obtain the overall image quality representation by extracting the energy features of the images according to the relationship between sparse coefficient values and energy. Third, We combine the statistical properties of dictionary atoms to obtain the statistical features of images by calculating the probability of atoms in the dictionary. In addition, we add the image saturation property to describe color information of images, making the composition of features more comprehensive and complete. These features will be described one by one below.
3.4.1. Distribution of Sparse Coefficient Values
First, we investigate the distribution characteristics of sparse coefficients by analyzing their values to design a suitable pooling scheme. Since the sparse coefficients contain a large number of zero values and a small number of non-zero coefficients with positive and negative values, the process of reconstructing images using a small number of atoms is realized, which greatly improves the efficiency of image reconstruction. Depending on whether the sparse coefficients contain zero values, the frequency distribution histograms show different characteristics. Thus, we will analyze the regularity of sparse coefficients from these two perspectives in this paper. Taking
Figure 1c as an example,
Figure 6 shows the histogram of all sparse coefficients for atom 1 of the learned dictionary. We can observe that the distribution of sparse coefficients exhibits symmetry and it reaches a very sharp peak at zero with a heavy tail, which can be well approximated by the generalized Gaussian distribution (GGD) [
43]. The general definition of GGD is:
where
represents the gamma function, which is denoted as:
The GGD model parameters
are estimated with the method in [
44]. The constant
controls the shape and
determines the width of the model. Since the histograms of sparse coefficients and the corresponding GGD model parameters are subject to different distortions, these model parameters can be effectively used for distortion differentiation in quality assessment tasks.
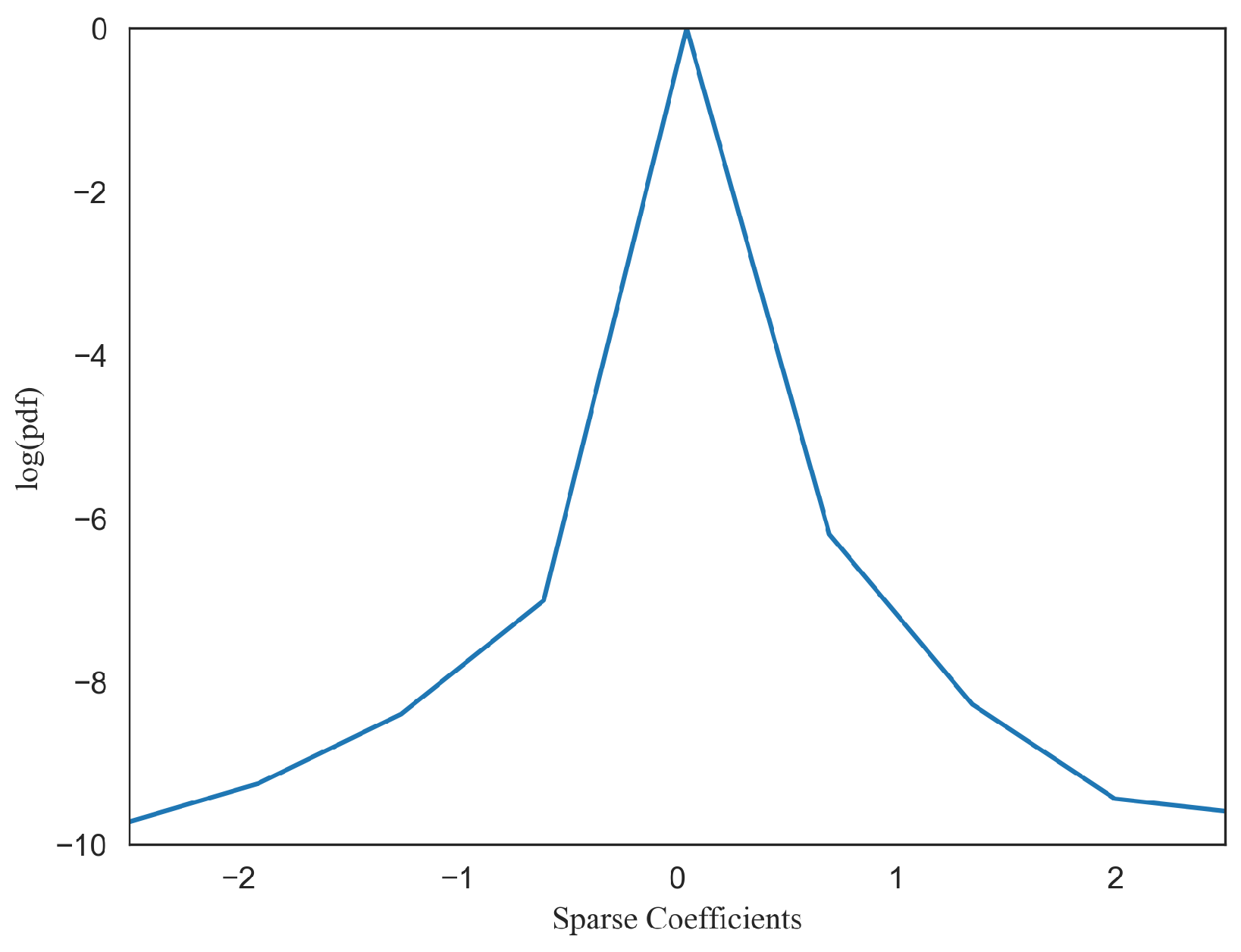
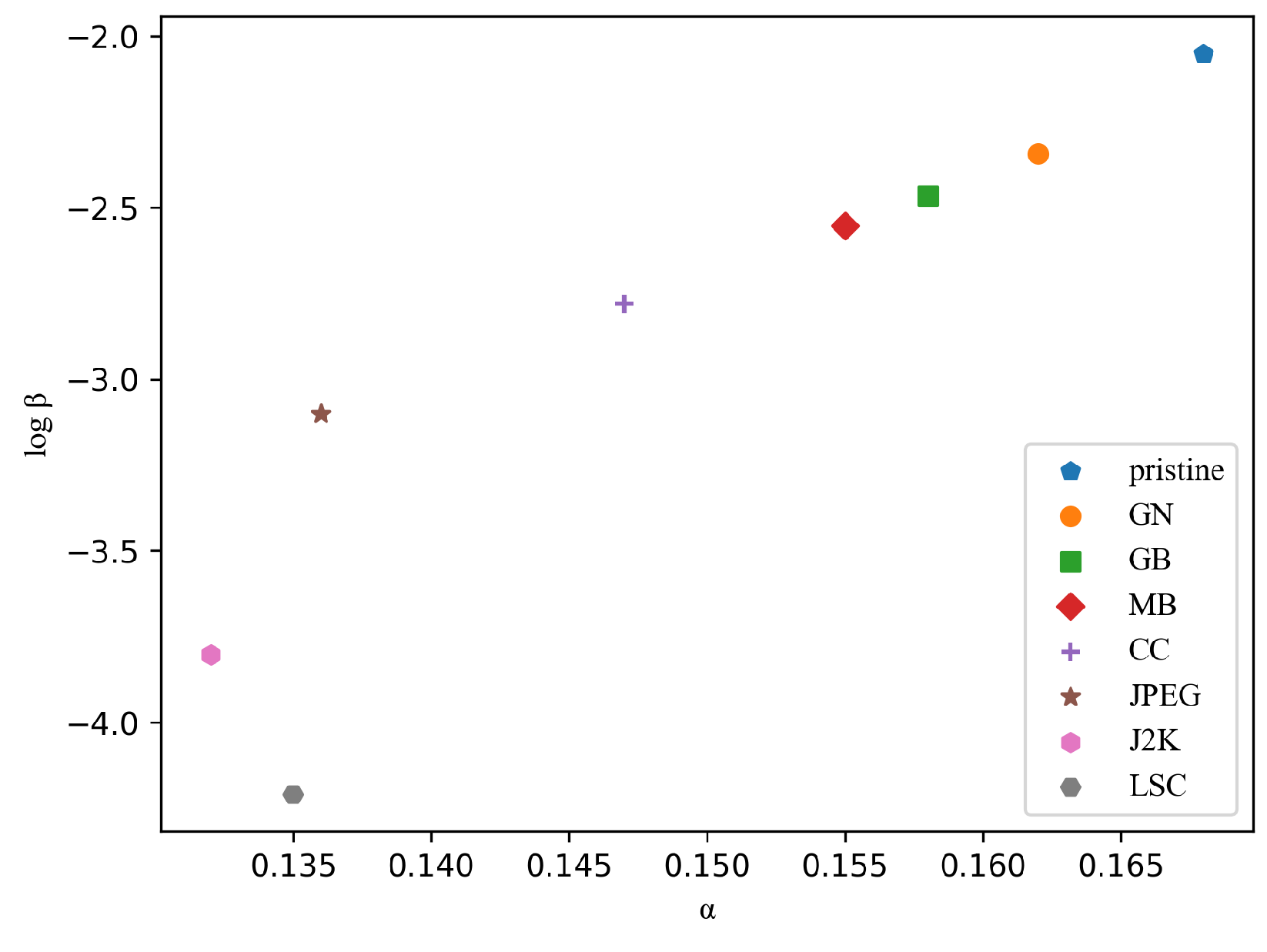
Figure 7 shows several sets of GGD parameters fitted by the histogram of sparse coefficients, where the y-axis represents log
and the x-axis represents
. We can find that there is large discrimination in model parameters for different image distortion types. A similar trend is observed for other atoms. Therefore, the GGD model parameters for each atom of the dictionary form a good set of features for distortion identification, which is denoted as
,
.
Since atoms with zero coefficients are not involved in the sparse reconstruction of each patch, and test images are reconstructed with partial non-zero sparse coefficient values, the main features of each image can still be accurately characterized [
35]. Therefore, we choose non-zero sparse coefficient values as the target object for the next pooling scheme.
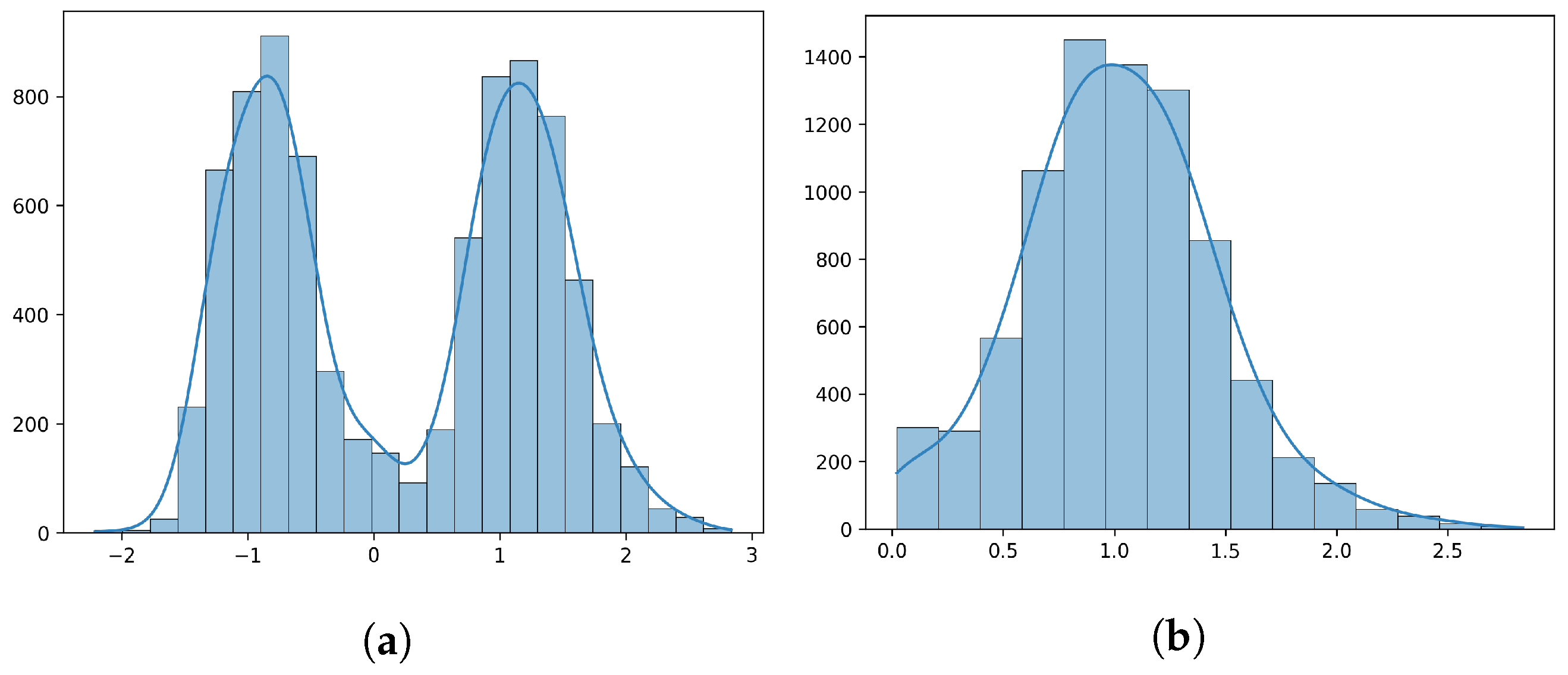
Figure 8 shows the histograms of sparse coefficients with original and absolute non-zero values.
From
Figure 8, it can be seen that values of absolute non-zero sparse coefficients usually follow a log-normal distribution with the probability density function:
where
and
are the mean and standard deviation of the logarithm of the variables. Therefore, our statistical feature model can be represented by the mathematical expectation of this log-normal distribution:
where
denotes feature vectors of all atoms in the learned dictionary.
3.4.2. Sparse Coefficients and Image Energy
We further consider energy distribution of the overall image. As mentioned above, all atoms in the learned dictionary can be directly used as basic elements to characterize images. Using the dictionary
, each patch can be sparsely represented as follows:
where
N is the patch number and
denotes the sparse coefficient matrix of
. Following the derivation in [
45], we can compute the energy
of the sparse coefficients for each image patch as:
where
.
Therefore, the energy of each patch can be represented by the corresponding sparse coefficients. If an image is divided into
N equal-sized patches, the degree of distortion of the image can be measured by calculating the average energy of all patches. By pooling the energies of all patches, we can obtain the quantity of visual information
of an image:
where
N is the number of patches contained in the test image.
Figure 9 shows three images distorted by Gaussian Blur, and the distortion level increases gradually from
Figure 9a–c, which means visual information contained in images is gradually reduced. Through calculation, we can obtain
of these three images to be 5.01, 4.73, and 4.31, which is following this decreasing trend.
Since different image patches possess different structural information [
46], we need to normalize the energy of each patch with the content change value
:
where
P is the number of pixels contained in a patch,
is the pixel value, and
is the average pixel value of an
image patch. Then, the quality calculation for the entire image can be expressed as:
The calculated results are shown in
Figure 9, which are 17447.85, 13406.79, and 9794.33, respectively. We denote this result as the energy feature
.
3.4.3. Statistical Features of Dictionary Atoms
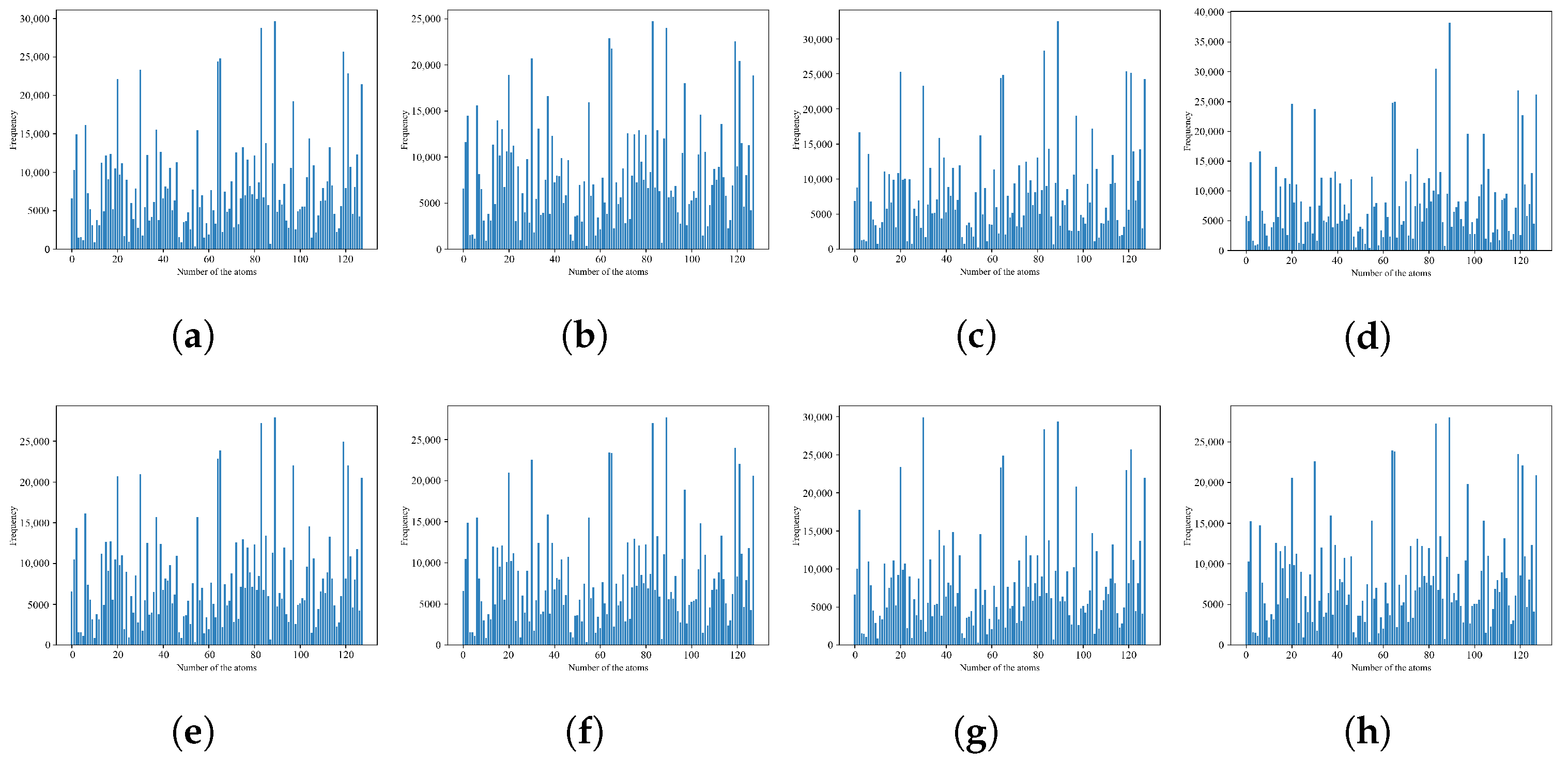
Natural scene statistical information has been widely studied and applied to process natural images, but cannot be directly used for SCIs due to their computer-generated parts. As mentioned above, only the non-zero sparse coefficients are needed to be considered when reconstruction, which means the image reconstruction process can be achieved with different numbers of partial dictionary atoms. We count the occurrence numbers of each atom with different distortion types for
Figure 1c,d. The result is shown in
Figure 10 and
Figure 11. Comparing
Figure 10a and
Figure 11a, it can be seen that when using the same dictionary to reconstruct images with different contents, the occurrence numbers of each atom in the dictionary are also different. Thus, the statistical features of the dictionary can be used to distinguish different images.
In addition, we further compare and analyze the occurrences of each atom in the dictionary for the same original image with different distortion types. From
Figure 11 we can observe that the distribution of occurrences of all atoms has a certain similarity on the whole, but there are still subtle differences due to different types of distortion. This finding shows that statistical features also have the ability to distinguish types of distortion. In summary, there is a certain statistical law in the sparse space of SCIs, which means we can describe the statistical features by counting occurrence numbers of atoms in the dictionary to characterize the changes in quality.
As we know, the occurrence numbers of all atoms are different according to the size of different images. To eliminate this kind of variability, this paper describes the statistical characteristics of SCIs by calculating the probability of atoms. Specifically, the occurrence number of each atom is calculated based on the sparse coefficient vector
, and then the probability value is obtained by normalization process, which is expressed as:
where
represents the statistical feature vectors of all atoms, and
represents the occurrence number of the
ith atom in the test image.
3.4.4. Image Color Features
Color information is very attractive to HVS. Existing IQA algorithms for natural images show that the color information contained in an image is also affected to varying degrees when its quality is impaired [
47,
48,
49]. Saturation and hue are properties of color, which are sensitive to color changes and, therefore, are useful to IQA investigations. In the proposed method, we consider the color characteristics of SCIs. We denote an image as
, thus the image saturation
S and hue
H can be calculated by:
where
and
are denoted as the minimum value and the sum of
R,
G, and
B, respectively. Apparently, the hue values of black and white pixels are zero, which need to be first removed before the color features extraction of input SCIs. Then, calculate the saturation of pixels with hue, and take their mean and quantile values, which are denoted as our image color features
.
3.5. Quality Regression
In summary, the final vector representation f of this paper is obtained by combining the above five sets of features, where . The number of dictionary atoms K is set to 128 in this paper, so each input image contains a total of 517 dimensions in its feature vector.
After obtaining the extracted feature vectors, the support vector regression (SVR) is applied to realize the quality regression at each scale. Specifically, an SVR model trained by the training subset is utilized to obtain the quality score of the testing subset. In this paper, we use SVR with a radial basis function (RBF) kernel as the mapping function to realize the transformation from feature vectors to human subjective quality scores.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}