
Framing Network Flow for Anomaly Detection Using Image Recognition and Federated Learning




Abstract
:1. Introduction
- Reduced computational power and training time. Overall, 96 times fewer images are required for deep neural network (DNN) training while adopting the proposed pre-processing method merging a specific amount of NTF records into frames and transforming frames into images;
- Preserved data privacy. To ensure data privacy, the FL method was used to share trained models between participants without the need to publicly centralize training data in a data centre. As an example of trained model sharing, GitHub may be used as a distributed version control system, which implies that every developer’s computer has access to the whole codebase and history, therefore making branching and merging simple;
- The detailed experimental analysis. Experiments of the proposed approach presented in three use cases for the DNN training on the classification of DDoS network attack type: (i) traditional transfer learning (TL) method with mandatory training data centralization, (ii) federated transfer learning (FTL) method when participants share only trained models to continue training, (iii) federated learning (FL) method when trained models aggregated in a data centre to create the Global Model for sharing;
- Empirical quantification. In the presented experimental use cases, the testing accuracy of Global Models is strong, ranging from 88.42 per cent to 93.95 per cent. Although the majority class in our instance is normal traffic, the fundamental challenge of identifying normal traffic is being resolved. In our experimental results, high F1 score values of Global Models testing from 93.78% to 96.86% were obtained.
2. Related Works
- FL allows devices, such as mobile phones, to share a common prediction model by keeping training data on the device rather than downloading and storing the data on a central server;
- It shifts model training to the peripheral, namely to devices like smartphones, tablets, the Internet of Things, or even “organizations” like hospitals that must function under strict secrecy constraints. Keeping personal data in situ provides significant security benefits;
- Since forecasting occurs on the device itself, real-time forecasting is feasible. FL decreases the time lag that occurs when raw data is transferred back to a central server and the results are sent to the device;
- As the models are stored on the device, the forecasting process may continue even if there is no Internet connection;
- FL decreases the amount of hardware infrastructure required. FL makes use of minimum hardware, and what is available on mobile devices is more than sufficient to operate the FL models.
3. Materials and Methods
3.1. Framing Network Flow for Anomaly Detection Using Image Recognition and Federated Learning
3.1.1. Proposed Approach for Network Flow Anomaly Detection
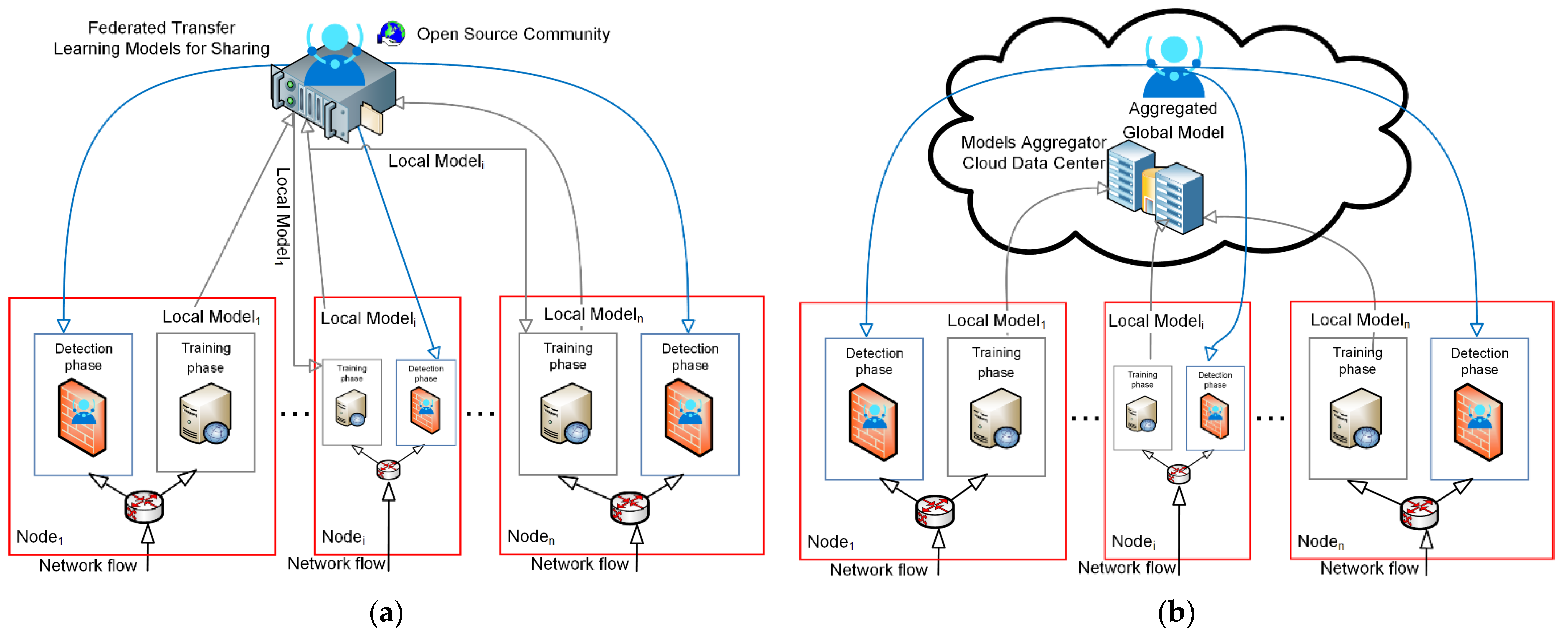
- Stage 1. Participants (in our case nodes) register to an open source community and get the registration number;
- Stage 2. First Local Model training process—the first node1 trains the model using its own local dataset and then shares the trained local model1 with the second participant of an open source community;
- Stage 3. Second Local Model training process—the second node2 downloads the trained local model1 and uses that model to retrain it with its own local dataset and then shares the trained local model2 with the next participant of an open source community;
- Stage 4. Next Local Model training process—the next nodei downloads the trained local model2 and uses that model2 to retrain it with its own local dataset and then shares the trained local modeli with another participant of an open source community;
- Stage 5. Continuous model retraining process—each participant retrains the model, obtained from its neighbour with its own dataset, and shares the trained model; the process continues until the last registered participant is reached;
- Stage 6. Last Local model training—the last noden downloads the trained local modeln-1 and uses that modeln-1 to retrain it with its own local dataset and then shares the trained local modeln for sharing with an open source community as a Global Model;
- Stage 1. Participant Selection—the server (in our case, Cloud Data Center Model Aggregator) selects a group of participants (in our case, nodes) who meet the prerequisites to participate in the training process;
- Stage 2. Local Models Computation—participants train the local model using their own device’s local dataset. This step is carried out at local nodes;
- Stage 3. Aggregation of Local Models—the server collects enough locally trained deep learning models from participants to update the global deep learning model (the next stage). To prevent the server from analyzing individual deep learning model parameters, this aggregation process must incorporate some privacy-preserving techniques such as safe aggregation, differential privacy, and sophisticated encryption approaches;
- Stage 4. Global Model Update—based on the aggregated model parameters collected in Stage 3, the server updates the current global deep learning model. This revised global model will be sent to participants.
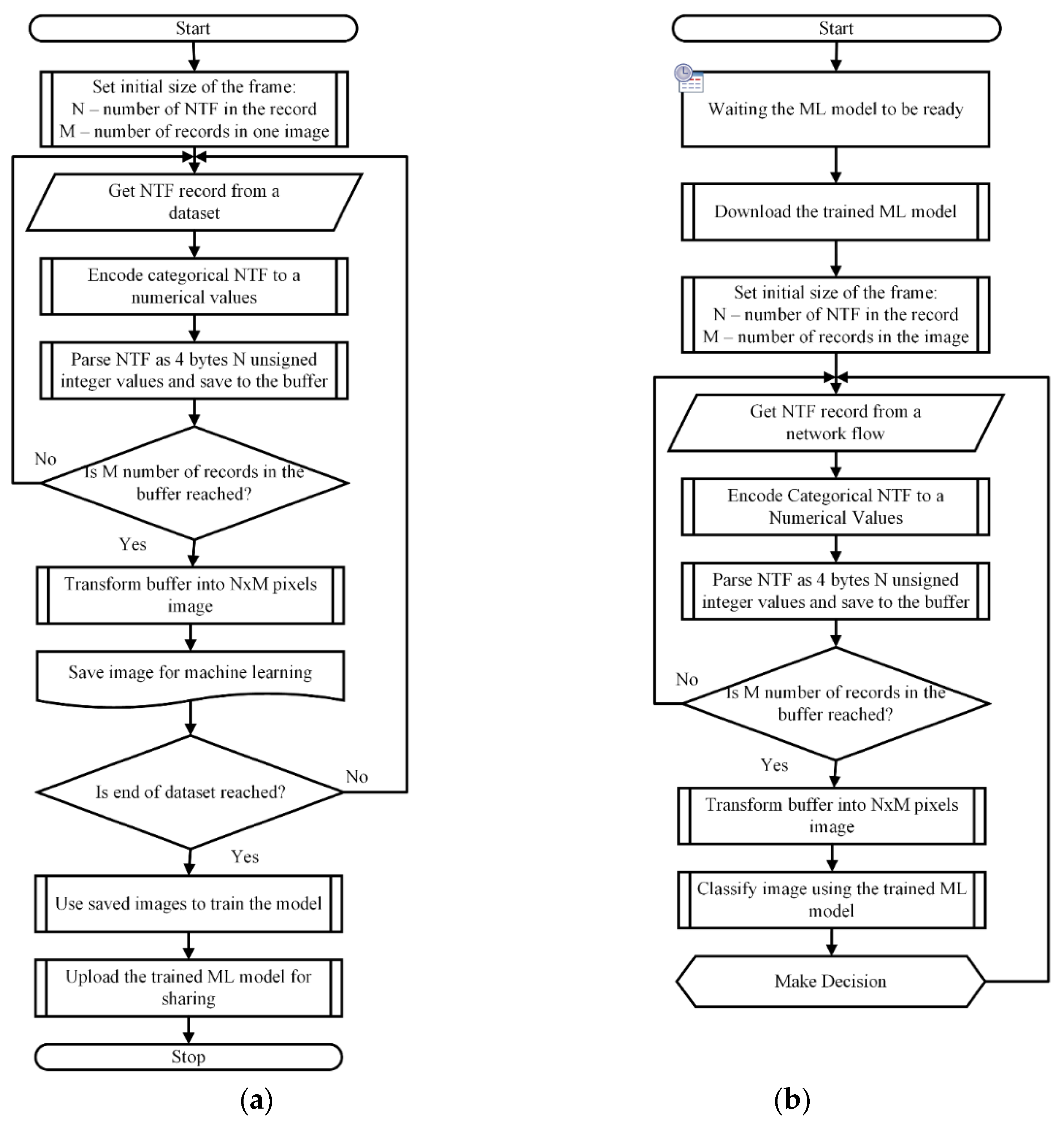
3.1.2. Proposed Method for Framing Network Flow and Representing Frames as Images
- 1. Traditional transfer learning. Mandatory centralization of training data. Employed DNN with ResNet50 architecture, which allows comparing widely used ML practice with our proposed FTL and FL methods;
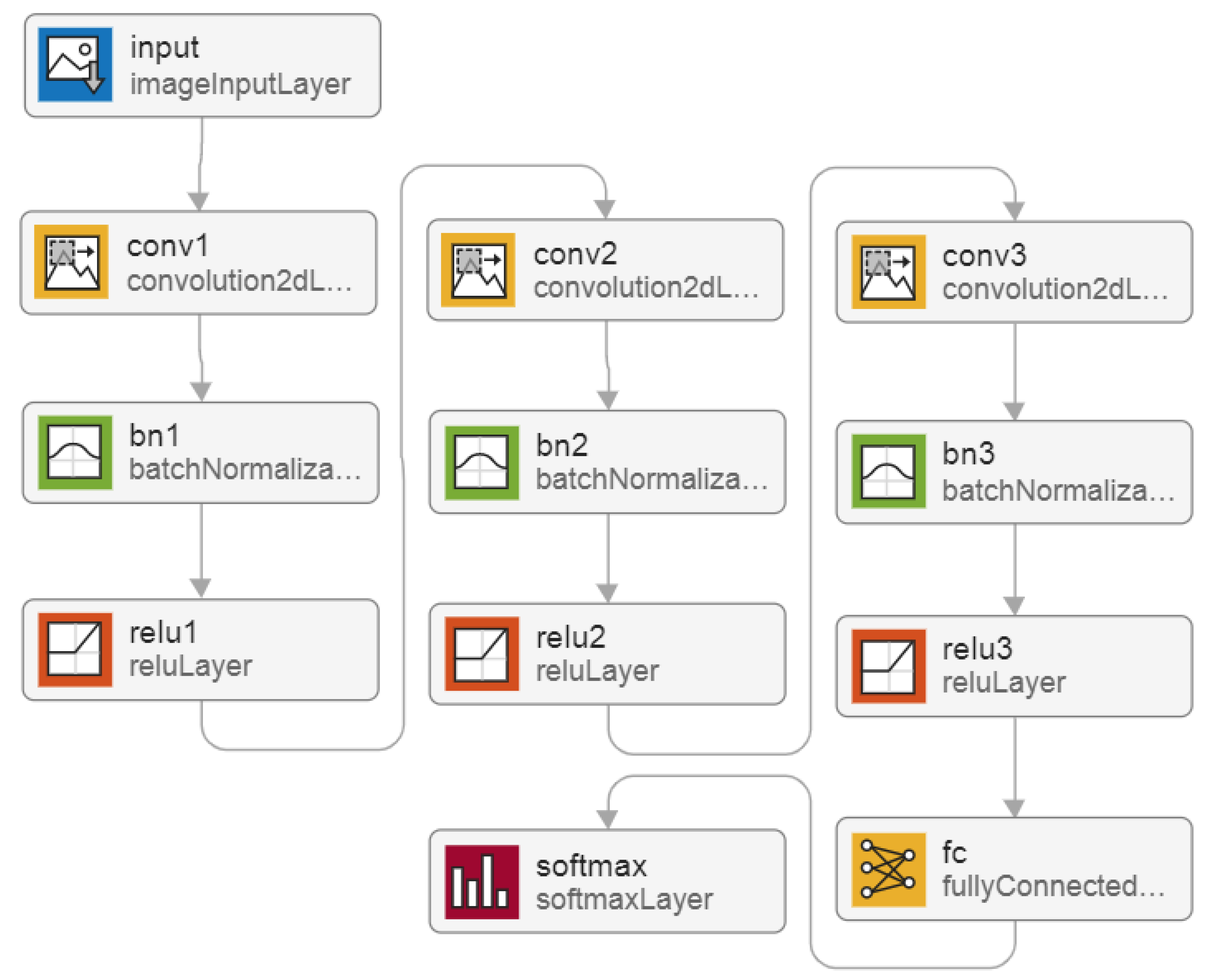
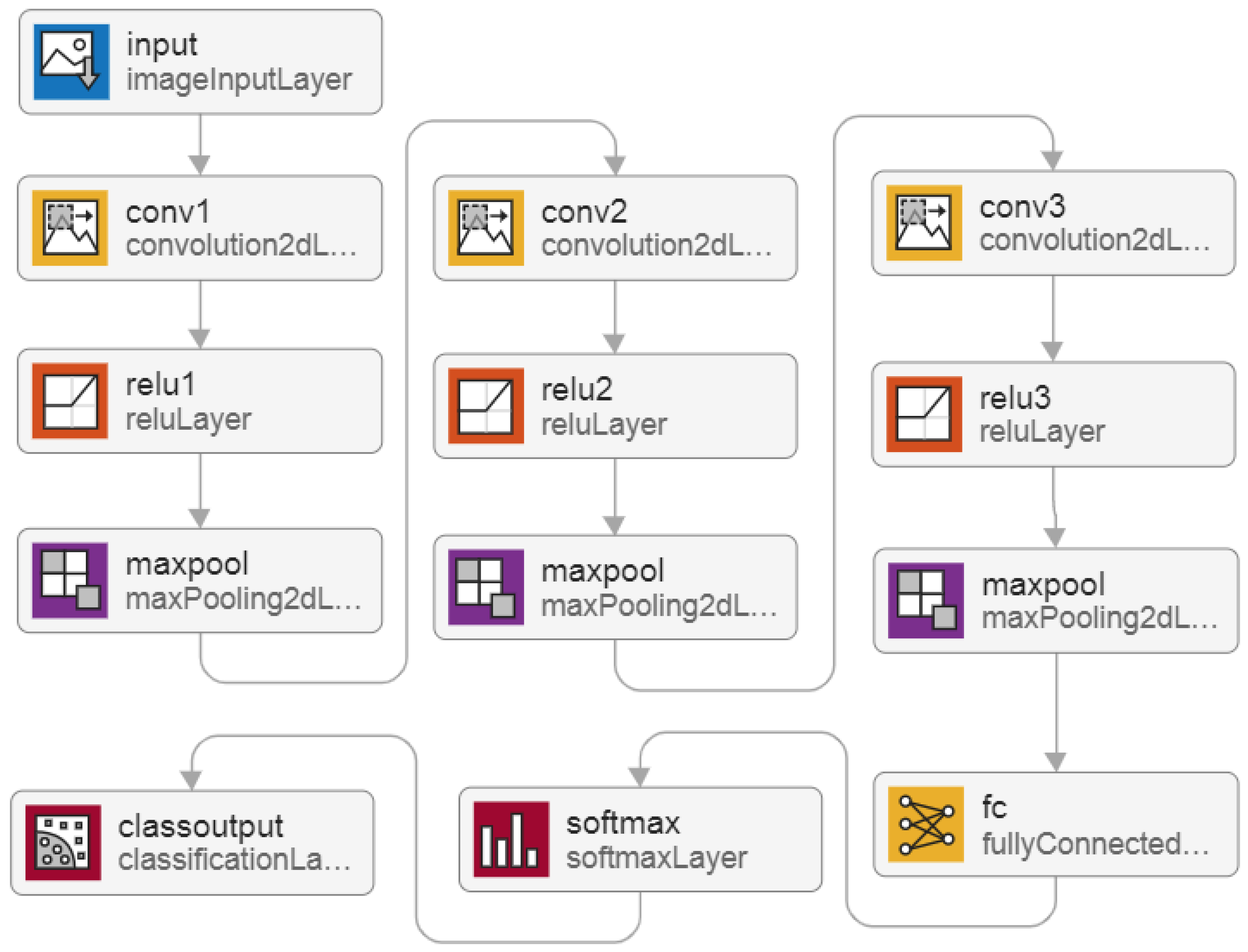
- 2. Federated transfer learning. Training data is disposed at local nodes. Proposed 13-layer DNN architecture. The MATLAB trainNetwork function is used, which trains the models according to the proposed FTL method, as shown in Figure 1a;
- 3. Federated learning. Training data is disposed at local nodes. Proposed 12-layer DNN architecture. The stochastic gradient descent with momentum (SGDM) algorithm is used with a custom training loop, which trains the models according to the proposed FL method, as shown in Figure 1b.
4. Experimental Results
4.1. Dataset for Proposed Approach Implementation
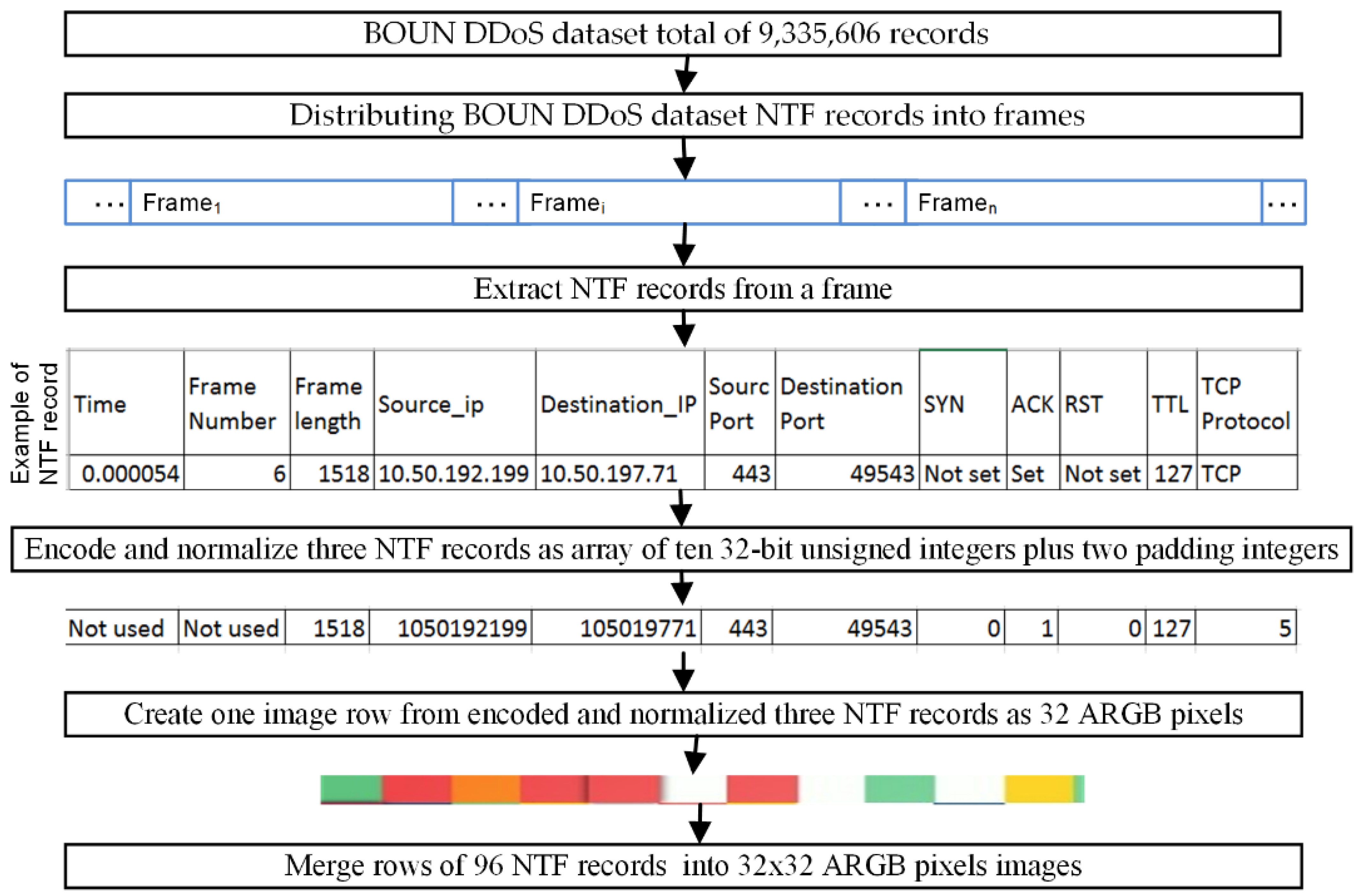
4.2. BOUN-DDoS Dataset Preparation for Experiments
4.2.1. Transformation of NTF Records of the BOUN-DDoS Dataset
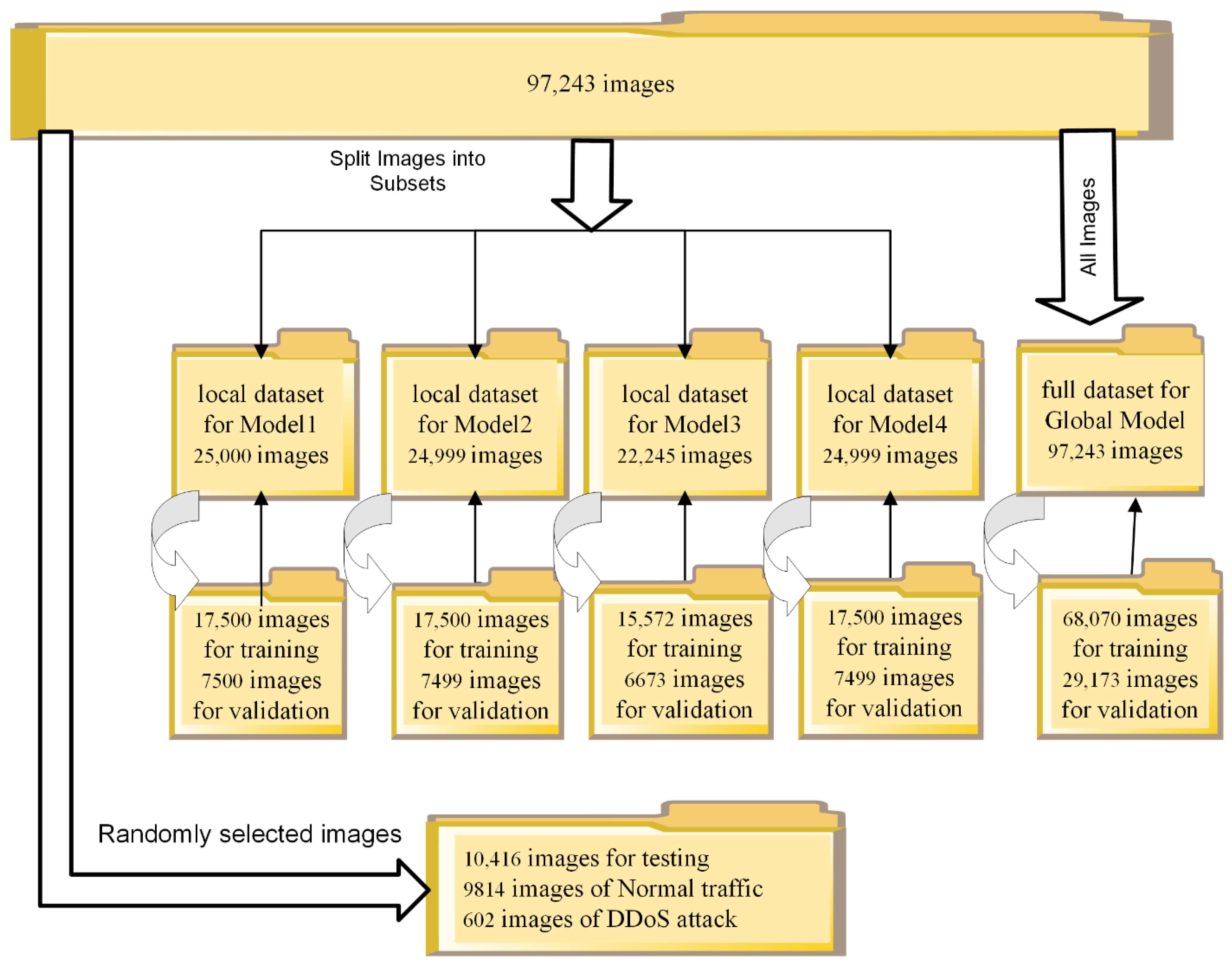
4.2.2. Dataset Partitions for Traditional Transfer Learning Method
- Training set. A partition of the dataset used to train, fit, and select the parameters of the model is referred to as the training set. It must reflect the complexity and diversity of the model and often comprises 60 to 70 per cent of the dataset data;
- Validation set. A partition of the dataset used to evaluate the performance of the model while tuning the hyperparameters of the model is referred to as the validation set. The validation set indirectly influences the model, since these data, which typically comprise between 30 and 40% of the dataset data, are used for more frequent evaluation and hyperparameter updates. Although it is typically advised, tuning a model’s hyperparameters is not strictly necessary;
- Testing set. This dataset serves as an objective assessment of how well the model fits the data from the training set. This set is only used after the model has completed the training and does not have a bearing on the model; it is only used to determine performance.
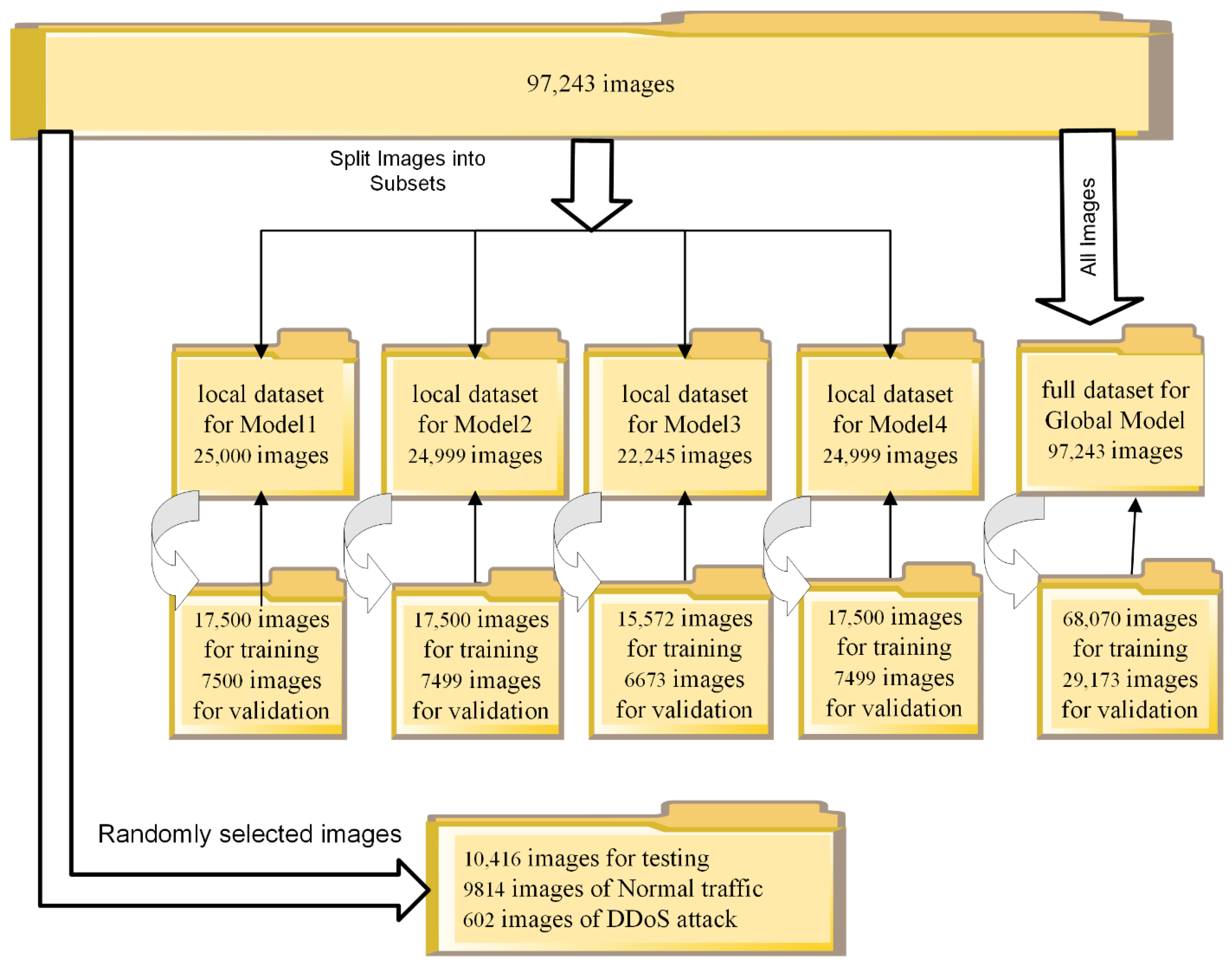
4.2.3. Dataset Partitions for Federated Transfer Learning Method
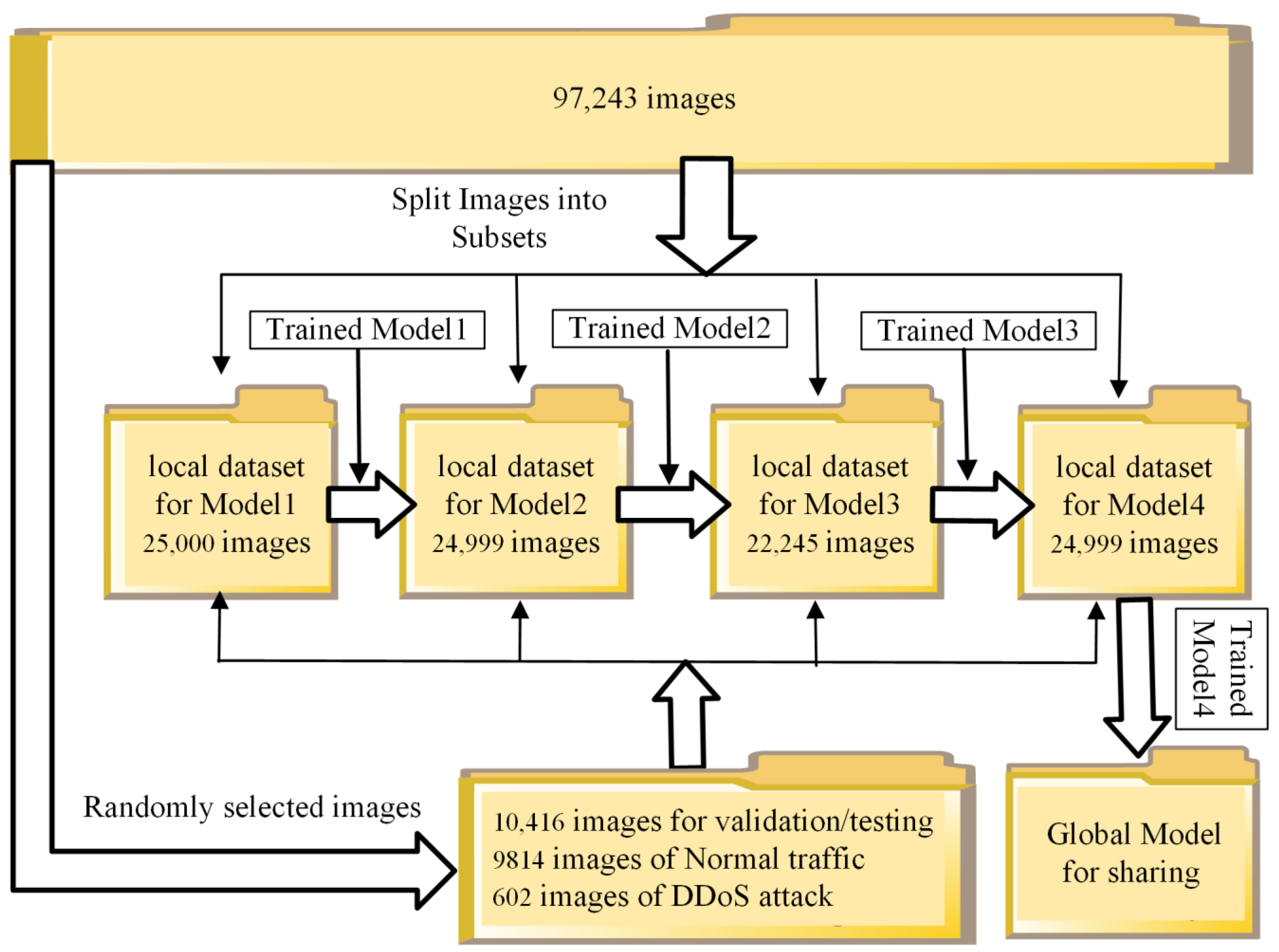
4.2.4. Dataset Partitions for Federated Learning Method
4.3. Experimental Results and Evaluation
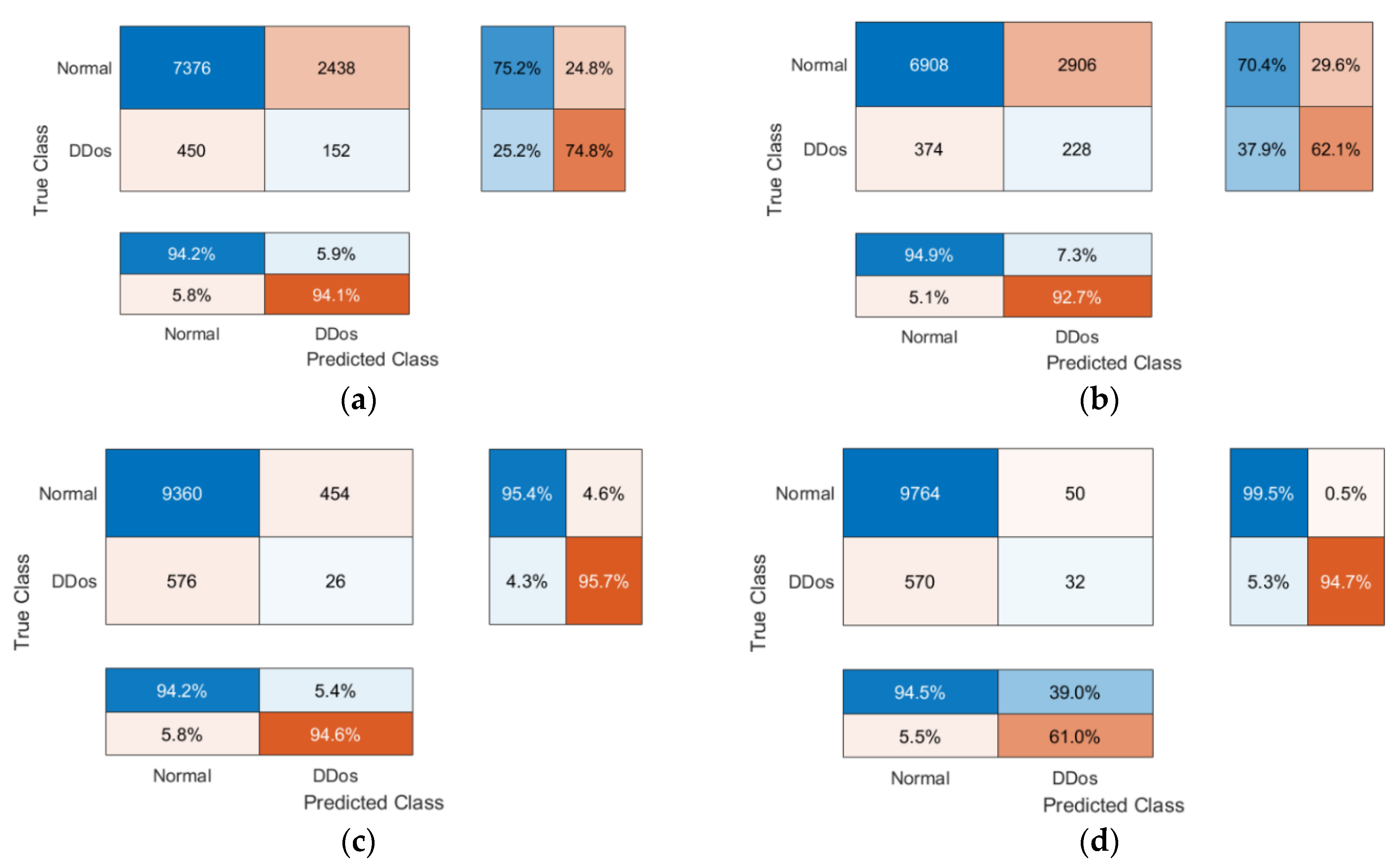
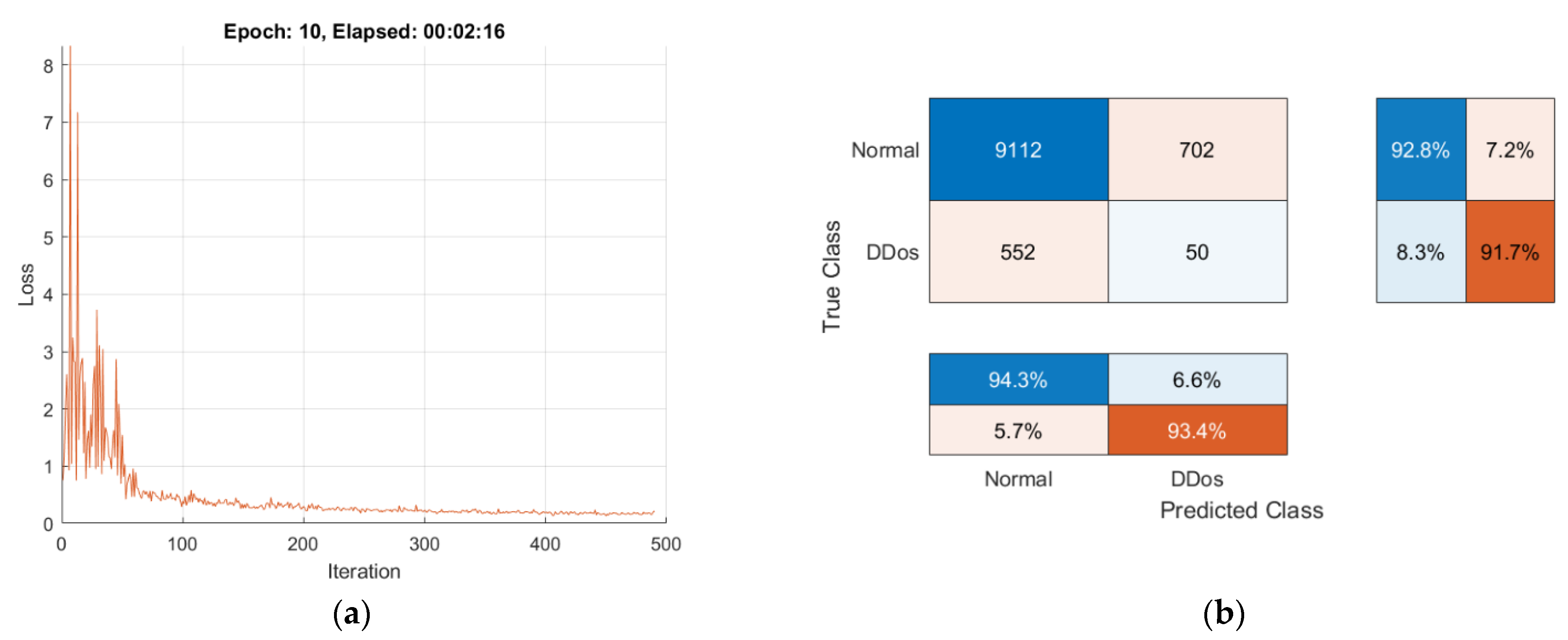
4.3.1. Experimental Results of Traditional Transfer Learning Method
- Distributions of NTF records and combination into frames lead to an overwhelming burst in every frame that distributes 96 NTF records, and thus, each frame can contain normal and DDoS NTF records in any random proportion;
- The ResNet50 architecture contains 50 layers and is very complex and redundant for training a recognition network for the proposed types of images.
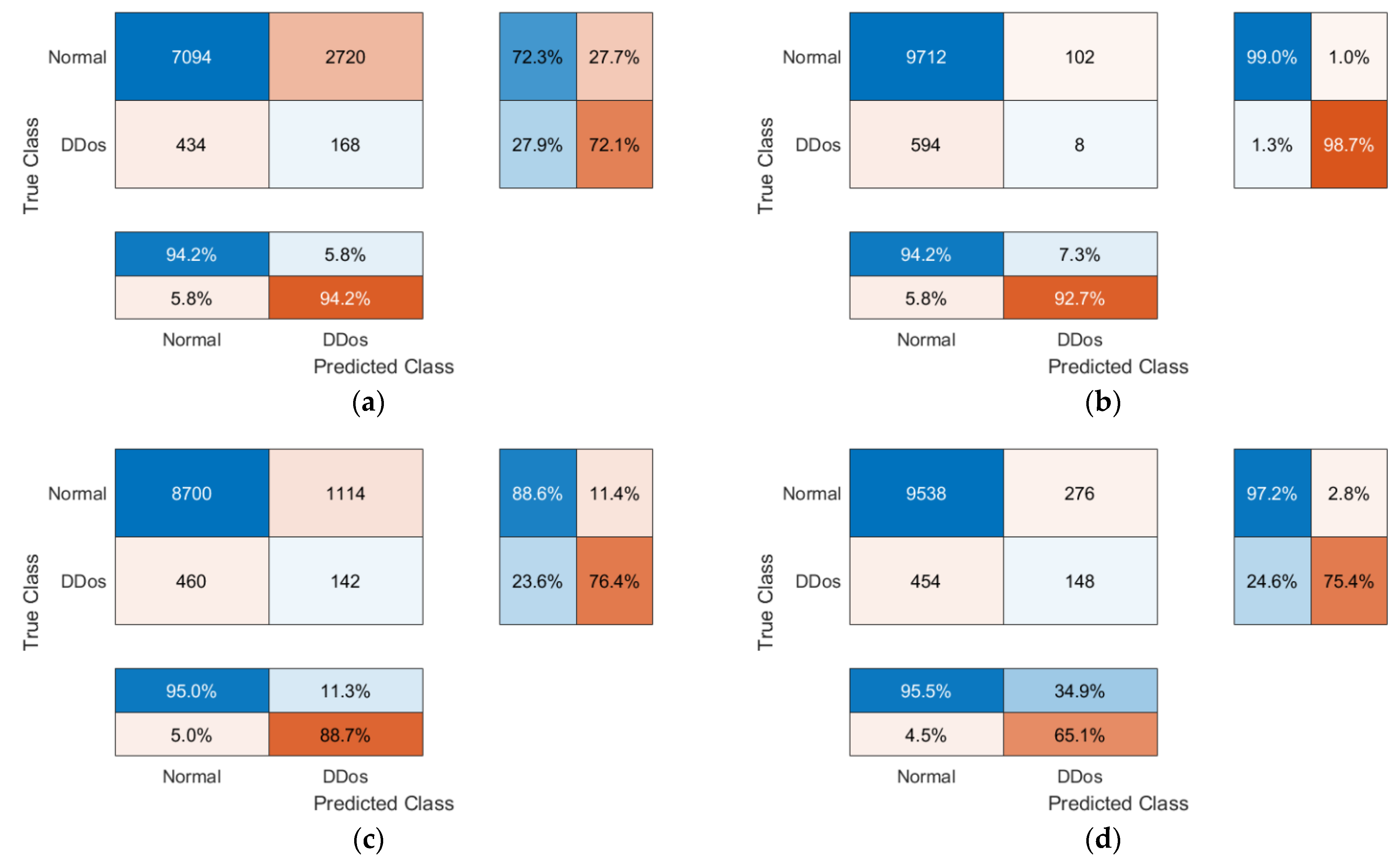
4.3.2. Experimental Results of Federated Transfer Learning Method
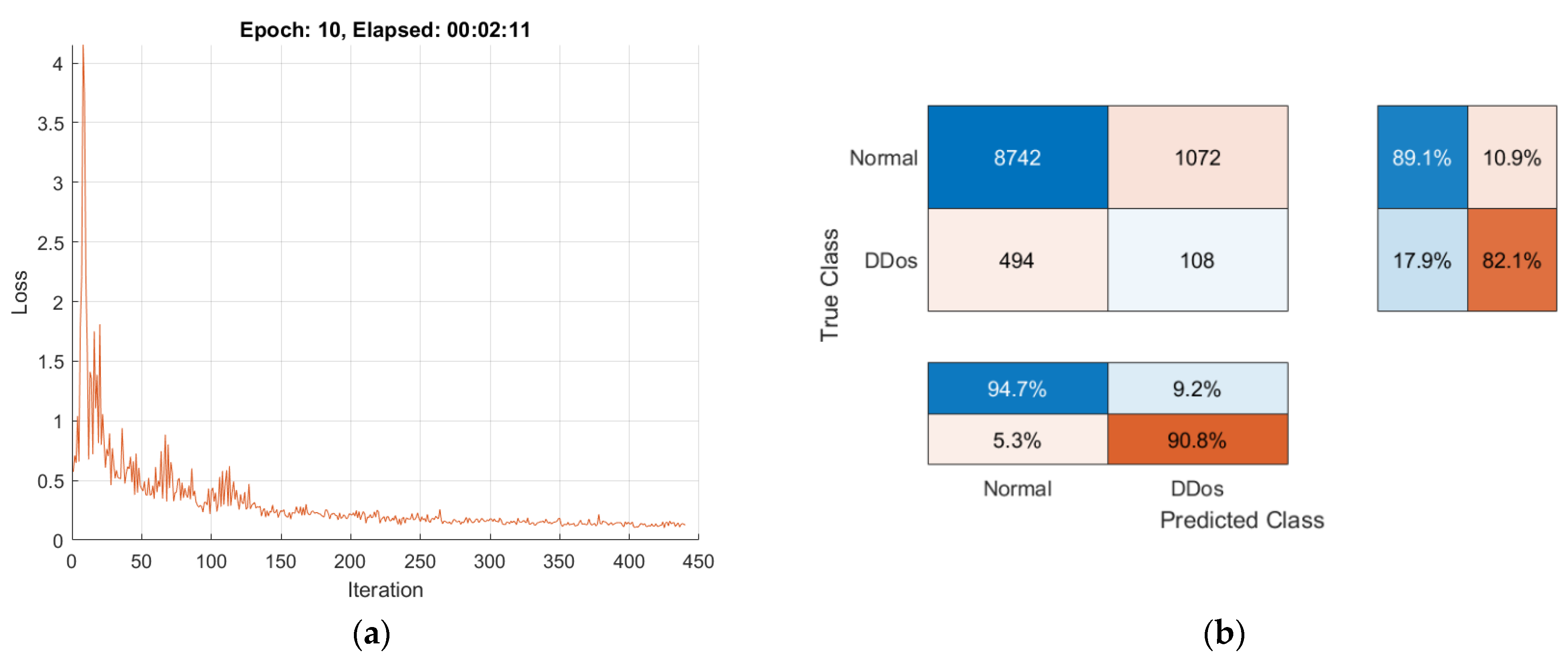
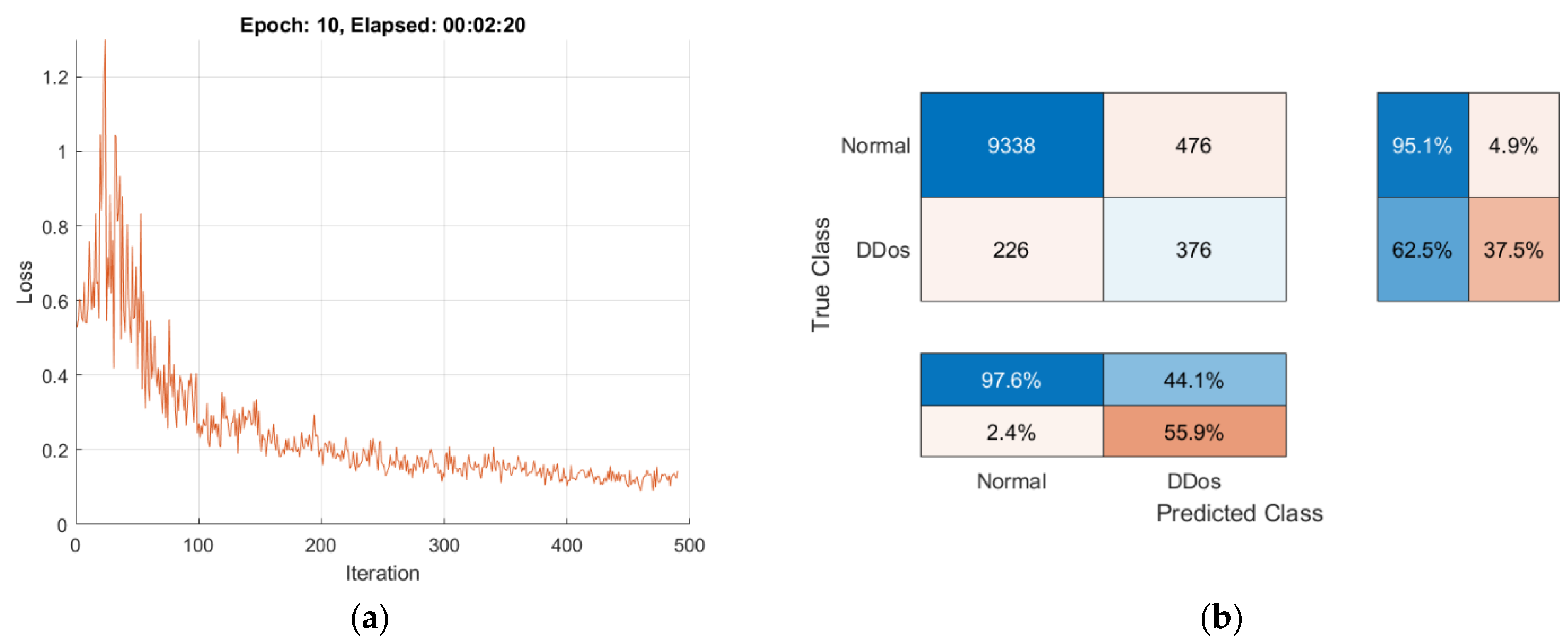
4.3.3. Experimental Results of Federated Learning Method
5. Discussion
- The BOUN-DDoS dataset (total number of NTF records 9,335,605) is highly imbalanced (this is true for other network intrusion datasets as well) because there is a very small number of NTF records with DDoS attack (125,557) represented as 1.34% compared to NTF records with normal traffic (9,210,048) represented as 98.66%;
- Framing NTF records into one image reduces the number of images compared to images of NTF records created on a one-to-one basis (in such a case for BOUN DDoS we would have 9,335,605 images). The framing approach reduces the number of images to 97,243–that is, 96 times less;
- On the other hand, framing NTF records into one image makes the ML process complicated because some images represent only NTF records with normal traffic, while others incorporate normal traffic and an unpredictable number of NTF records with DDoS attack. If a DDoS attack takes more than 96 NTF records consistently, such a frame image only represents a DDoS attack.
- Compared to FL, the training time for models that utilize TTL with ResNet50 architecture requires more time. It takes roughly 43 min to train a Global Model using a dataset with all 97,243 images when employing TTL. Training local models using the TTL method took more than an hour in total (see Table 2), compared to 12 min when using the FTL method with the 13-layer DNN architecture (see Table 3) and 9 min when using the FL method with the 12-layer DNN architecture (see Table 4). As a result, that is about five times faster than utilizing TTL with ResNet50 architecture.
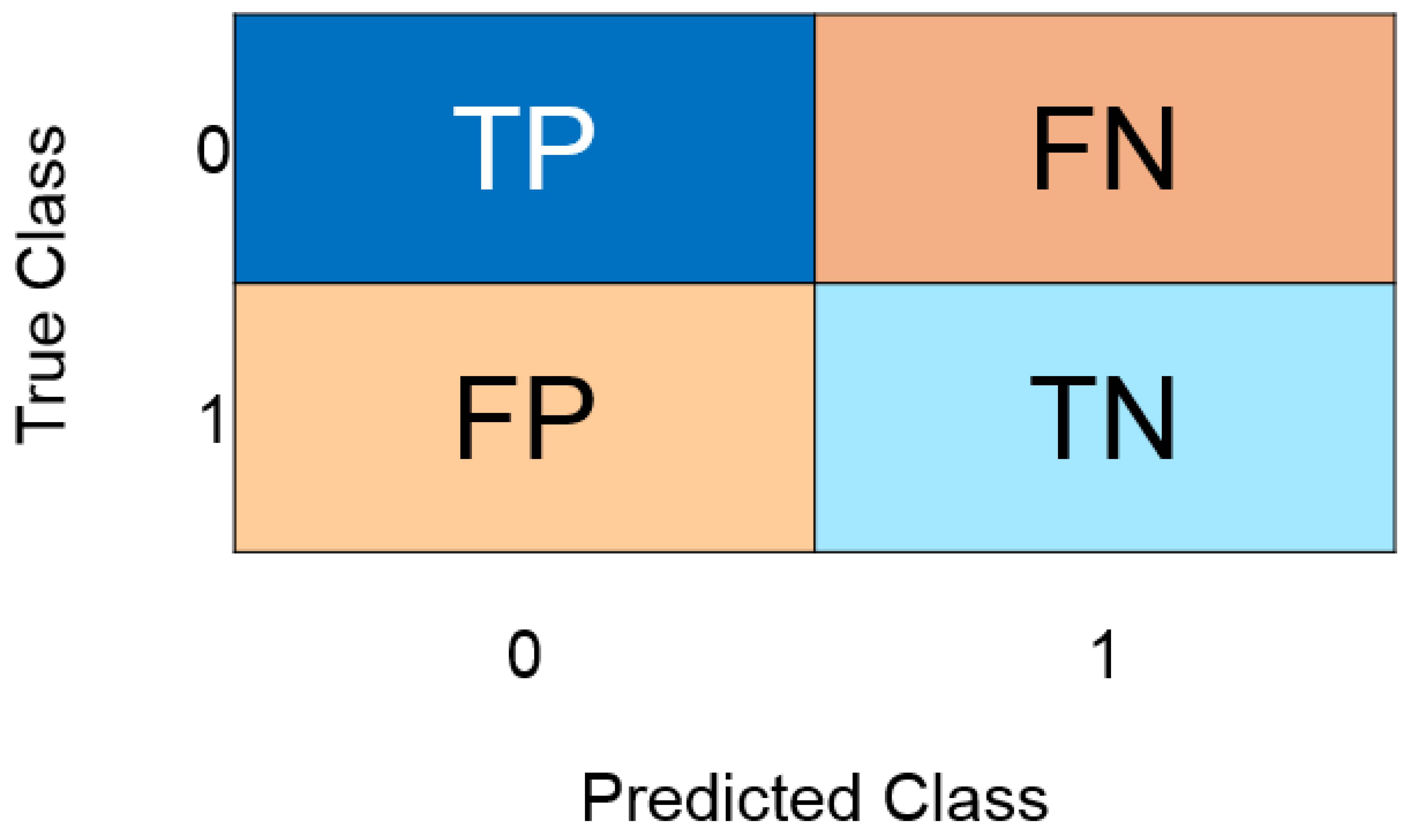
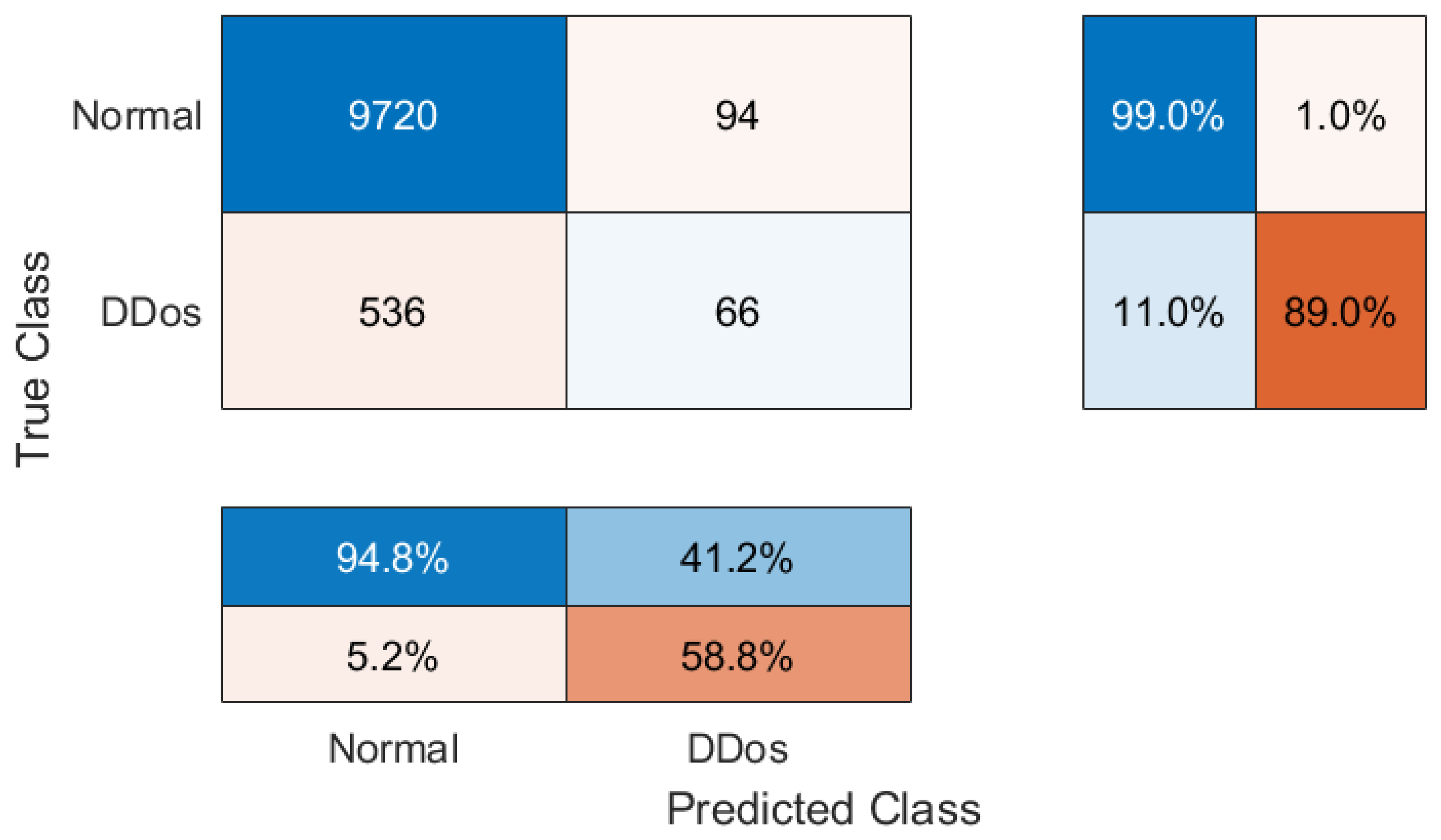
- The number of observations, both positive and negative, that were correctly identified depends on the accuracy. It is a measurement of how closely the model’s forecast matches the actual data. It is simple to obtain a high accuracy score when using accuracy on imbalanced problems by categorizing all observations as belonging to the majority class. Since the testing accuracy of Global Models is strong, ranging from 88.42% to 93.95%, the majority class in our instance is NTF records of normal traffic, and the fundamental challenge to identify normal traffic is being resolved;
- The F1 score, which accounts for both false positives and false negatives, is the weighted average of precision and recall. In most cases, the F1 score is more helpful than accuracy, particularly when the class distribution is imbalanced. The high F1 scores of the Global Models for the suggested FTL method (96.31%) and the FL method (93.78%) are extremely similar to the F1 score for the TTL with ResNet50 architecture (96.86%).
- Using the proposed FTL and FL methods for training does not require data centralization and preserves participant data privacy while obtaining nearly the same Global Models testing results in accuracy and F1 score as using the TTL method.
- We can notice that local model testing occasionally yields better testing results when we compare the results of testing local models with those of testing Global Models. When all participants use the Global Model instead of their local models, participant privacy is guaranteed, even though the use of the global model may be superior for some participants while being poorer for others.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network Anomaly Detection: Methods, Systems and Tools. IEEE Commun. Surv. Tutor. 2014, 16, 303–336. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.; Liu, X.; Dong, C. Multi-dimensional feature fusion and stacking ensemble mechanism for network intrusion detection. Future Gen. Comput. Syst. 2021, 122, 130–143. [Google Scholar] [CrossRef]
- Aljanabi, M.; Ismail, M.A.; Ali, A.H. Intrusion Detection Systems, Issues, Challenges, and Needs. Int. J. Comput. Intell. Syst. 2021, 14, 560–571. [Google Scholar] [CrossRef]
- Pontes, C.; Souza, M.; Gondim, J.; Bishop, M.; Marotta, M. A new method for flow-based network intrusion detection using the inverse Potts model. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1125–1136. [Google Scholar] [CrossRef]
- Umer, M.; Sher, M.; Bi, Y. Flow-based intrusion detection: Techniques and challenges. Comput. Secur. 2017, 70, 238–254. [Google Scholar] [CrossRef]
- Song, S.; Ling, L.; Manikopoulo, C.N. Flow-based Statistical Aggregation Schemes for Network Anomaly Detection. In Proceedings of the 2006 IEEE International Conference on Networking, Sensing and Control, Ft. Lauderdale, FL, USA, 23–25 April 2006; pp. 786–791. [Google Scholar] [CrossRef]
- Cisco Annual Internet Report (2018–2023) White Paper. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 11 August 2022).
- Das, A.; Balakrishnan, S.G. A Comparative Analysis of Deep Learning Approaches in Intrusion Detection System. In Proceedings of the 2021 International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bangalore, India, 27–28 August 2021; pp. 555–562. [Google Scholar] [CrossRef]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Tel. Tech 2021, 32, e4150. [Google Scholar] [CrossRef]
- Albulayhi, K.; Smadi, A.A.; Sheldon, F.T.; Abercrombie, R.K. IoT intrusion detection taxonomy, reference architecture, and analyses. Sensors 2021, 21, 6432. [Google Scholar] [CrossRef]
- Lee, S.; Mohammed sidqi, H.; Mohammadi, M.; Rashidi, S.; Rahmani, A.M.; Masdari, M.; Hosseinzadeh, M. Towards secure intrusion detection systems using deep learning techniques: Comprehensive analysis and review. J. Netw. Comput. Appl. 2021, 187, 103111. [Google Scholar] [CrossRef]
- Rabbani, M.; Wang, Y.; Khoshkangini, R.; Jelodar, H.; Zhao, R.; Ahmadi, S.B.B.; Ayobi, S. A review on machine learning approaches for network malicious behavior detection in emerging technologies. Entropy 2021, 23, 529. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Zhao, S. Advances and Open Problems in Federated Learning; Now Foundations and Trends: Boston, MA, USA, 2021. [Google Scholar] [CrossRef]
- Lo, S.K.; Lu, Q.; Wang, C.; Paik, H.; Zhu, L. A systematic literature review on federated machine learning: From a software engineering perspective. ACM Comput. Surv. 2022, 54, 1–39. [Google Scholar] [CrossRef]
- Yin, X.; Zhu, Y.; Hu, J. A comprehensive survey of privacy-preserving federated learning: A taxonomy, review, and future directions. ACM Comput. Surv. 2022, 54, 1–36. [Google Scholar] [CrossRef]
- Zerka, F.; Barakat, S.; Walsh, S.; Bogowicz, M.; Leijenaar, R.T.H.; Jochems, A.; Lambin, P. Systematic review of privacy-preserving distributed machine learning from federated databases in health care. JCO Clin. Cancer Inform. 2020, 3, 184–200. [Google Scholar] [CrossRef]
- Jiang, J.C.; Kantarci, B.; Oktug, S.; Soyata, T. Federated learning in smart city sensing: Challenges and opportunities. Sensors 2020, 20, 6230. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Marchal, S.; Miettinen, M.; Fereidooni, H.; Asokan, N.; Sadeghi, A. DÏoT: A federated self-learning anomaly detection system for IoT. In Proceedings of the International Conference on Distributed Computing Systems, Dallas, TX, USA, 7–10 July 2019; pp. 756–767. [Google Scholar] [CrossRef]
- Qu, Y.; Pokhrel, S.R.; Garg, S.; Gao, L.; Xiang, Y. A blockchained federated learning framework for cognitive computing in industry 4.0 networks. IEEE Trans. Ind. Inform. 2021, 17, 2964–2973. [Google Scholar] [CrossRef]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated learning: A survey on enabling technologies, protocols, and applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- Sheth, A.P.; Larson, J.A. Federated database systems for managing distributed, heterogeneous, and autonomous databases. ACM Comput. Surv. (CSUR) 1990, 22, 183–236. [Google Scholar] [CrossRef]
- Kurze, T.; Klems, M.; Bermbach, D.; Lenk, A.; Tai, S.; Kunze, M. Cloud federation. In Proceedings of the CLOUD COMPUTING 2011: The Second International Conference on Cloud Computing, GRIDs, and Virtualization, Rome, Italy, 25–30 September 2011; pp. 32–38. [Google Scholar]
- Xu, S.; Qian, Y.; Hu, R.Q. Data-driven edge intelligence for robust network anomaly detection. IEEE Trans. Netw. Sci. Eng. 2019, 7, 1481–1492. [Google Scholar] [CrossRef]
- Preuveneers, D.; Rimmer, V.; Tsingenopoulos, I.; Spooren, J.; Joosen, W.; Ilie-Zudor, E. Chained anomaly detection models for federated learning: An intrusion detection case study. NATO Adv. Sci. Inst. Ser. E Appl. Sci. 2018, 8, 2663. [Google Scholar] [CrossRef]
- Aliyu, I.; Feliciano, M.C.; Van Engelenburg, S.; Kim, D.O.; Lim, C.G. A blockchain-based federated forest for SDN-enabled in-vehicle network intrusion detection system. IEEE Access 2021, 9, 102593–102608. [Google Scholar] [CrossRef]
- Cetin, B.; Lazar, A.; Kim, J.; Sim, A.; Wu, K. Federated wireless network intrusion detection. In Proceedings of the 2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 6004–6006. [Google Scholar] [CrossRef]
- Huong, T.T.; Bac, T.P.; Long, D.M.; Thang, B.D.; Binh, N.T.; Luong, T.D.; Phuc, T.K. LocKedge: Low-complexity cyberattack detection in IoT edge computing. IEEE Access 2021, 9, 29696–29710. [Google Scholar] [CrossRef]
- Li, K.; Zhou, H.; Tu, Z.; Wang, W.; Zhang, H. Distributed network intrusion detection system in satellite-terrestrial integrated networks using federated learning. IEEE Access 2020, 8, 214852–214865. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Vincent Poor, H. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Qin, Q.; Poularakis, K.; Leung, K.K.; Tassiulas, L. Line-speed and scalable intrusion detection at the network edge via federated learning. In Proceedings of the IFIP Networking 2020 Conference and Workshops, Paris, France, 22–26 June 2020; pp. 352–360. [Google Scholar]
- Shi, J.; Ge, B.; Liu, Y.; Yan, Y.; Li, S. Data privacy security guaranteed network intrusion detection system based on federated learning. In Proceedings of the IEEE Conference on Computer Communications Workshops, INFOCOM WKSHPS 2021, Vancouver, BC, Canada, 10–13 May 2021. [Google Scholar] [CrossRef]
- Tian, Q.; Guang, C.; Chen, W.; Si, W. A lightweight residual networks framework for DDoS attack classification based on federated learning. In Proceedings of the IEEE Conference on Computer Communications Workshops, INFOCOM WKSHPS 2021, Vancouver, BC, Canada, 10–13 May 2021. [Google Scholar] [CrossRef]
- Xie, B.; Dong, X.; Wang, C. An improved K-means clustering intrusion detection algorithm for wireless networks based on federated learning. Wirel. Commun. Mob. Comput. 2021, 2021, 9322368. [Google Scholar] [CrossRef]
- Rahman, S.A.; Tout, H.; Talhi, C.; Mourad, A. Internet of things intrusion detection: Centralized, on-device, or federated learning? IEEE Netw. 2020, 34, 310–317. [Google Scholar] [CrossRef]
- Saadat, H.; Aboumadi, A.; Mohamed, A.; Erbad, A.; Guizani, M. Hierarchical federated learning for collaborative IDS in IoT applications. In Proceedings of the 10th Mediterranean Conference on Embedded Computing, MECO 2021, Budva, Montenegro, 7–10 June 2021. [Google Scholar] [CrossRef]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damaševičius, R. An efficient densenet-based deep learning model for malware detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef]
- Awan, M.J.; Masood, O.A.; Mohammed, M.A.; Yasin, A.; Zain, A.M.; Damaševičius, R.; Abdulkareem, K.H. Image-based malware classification using vgg19 network and spatial convolutional attention. Electronics 2021, 10, 2444. [Google Scholar] [CrossRef]
- Azeez, N.A.; Odufuwa, O.E.; Misra, S.; Oluranti, J.; Damaševičius, R. Windows PE malware detection using ensemble learning. Informatics 2021, 8, 10. [Google Scholar] [CrossRef]
- Damaševičius, R.; Venčkauskas, A.; Toldinas, J.; Grigaliūnas, Š. Ensemble-based classification using neural networks and machine learning models for windows pe malware detection. Electronics 2021, 10, 485. [Google Scholar] [CrossRef]
- Toldinas, J.; Venčkauskas, A.; Damaševičius, R.; Grigaliūnas, Š.; Morkevičius, N.; Baranauskas, E. A novel approach for network intrusion detection using multistage deep learning image recognition. Electronics 2021, 10, 1854. [Google Scholar] [CrossRef]
- Alharbi, A.; Alosaimi, W.; Alyami, H.; Rauf, H.T.; Damaševičius, R. Botnet attack detection using local global best bat algorithm for industrial internet of things. Electronics 2021, 10, 1341. [Google Scholar] [CrossRef]
- Islam, A.; Al Amin, A.; Shin, S.Y. FBI: A Federated Learning-Based Blockchain-Embedded Data Accumulation Scheme Using Drones for Internet of Things. IEEE Wirel. Commun. Lett. 2022, 11, 972–976. [Google Scholar] [CrossRef]
- Chen, J.; Li, J.; Huang, R.; Yue, K.; Chen, Z.; Li, W. Federated Transfer Learning for Bearing Fault Diagnosis With Discrepancy-Based Weighted Federated Averaging. IEEE Trans. Instrum. Meas. 2022, 71, 3514911. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Voigt, P.; von dem Bussche, A. The EU General Data Protection Regulation (GDPR). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Pardau, S.L. The California Consumer Privacy Act: Towards A European-Style Privacy Regime in the United States? J. Technol. Law Policy 2018, 23, 68. Available online: https://scholarship.law.ufl.edu/jtlp/vol23/iss1/2 (accessed on 26 September 2022).
- Hegedűs, I.; Danner, G.; Jelasity, M. Decentralized learning works: An empirical comparison of gossip learning and federated learning. J. Parallel Distrib. Comput. 2021, 148, 109–124. [Google Scholar] [CrossRef]
- Damasevicius, R.; Venckauskas, A.; Grigaliunas, S.; Toldinas, J.; Morkevicius, N.; Aleliunas, T.; Smuikys, P. LITNET-2020: An Annotated Real-World Network Flow Dataset for Network Intrusion Detection. Electronics 2020, 9, 800. [Google Scholar] [CrossRef]
- Erhan, D.; Anarım, E. Boğaziçi University distributed denial of service dataset. Data Brief. 2020, 32, 106187. [Google Scholar] [CrossRef] [PubMed]
- Train Network Using Custom Training Loop. Available online: https://se.mathworks.com/help/deeplearning/ug/train-network-using-custom-training-loop.html (accessed on 26 May 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | No. of Features and Classes | Model Details | Attack Type (No. of Records) | Dataset | Limitations | Accuracy |
|---|---|---|---|---|---|---|
| Aliyu et al. [29] | 1000 statistical and entropy features 4 classes | Federated Forest Model | Fuzzy (50,000) DoS (50,000) Impersonation (50,000) Attack-free (50,000) | CAN-intrusion dataset (OTIDS) Training 60% Testing 40% | Employed multiple statics and entropy features to handle the high complexity and non-linearity in CAN bus traffic | 98.1% |
| Cetin et al. [30] | 74 dataset attributes 4 classes | Stacked Autoencoders Merging local models by averaging their weights on the central server | Injection (82,061) Impersonation (68,601) Flooding (56,581) Normal (205,285) | Aegean Wi-Fi Intrusion Dataset (AWID) | For Wi-Fi network only Balancing procedure applied | 73.12–99.99% |
| Huong et al. [31] | Features extracted by principal component analysis (PCA) 11 classes | Neural network | DoS-HTTP (1485) DoS-TCP (615,800) DoS-UDP (1,032,975) DDoS-HTTP (989) DDoS-TCP (977,380) DDoS-UDP (948,255) OS Fingerprinting (17,914) Server Scanning (73,168) Keylogging (73) Data Theft (6) Normal (477) | BoT-IoT | Cyberattack detection in IoT edge computing | 56.098–99.973% |
| Li et al. [32] | 15 Flow-level features 9 classes | Deep CNN | SAT20 dataset (82,320): DDoS-Syn (39,076) DDoS-UDP (43,244) TER20 dataset (88,063): Botnets (14,622) Web Attacks (13,017) Backdoor (12,762) DDoS-LDAP (15,694) DDoS-MSSQL (15,688) DDoS-NetBIOS (11,530) DDoS-Portmap (4750) | SAT20 and TER20 datasets Training 80% Testing 20% | For Satellite-Terrestrial integrated networks only | 85–90% |
| Qin et al. [34] | Packet-level features 5-tuple (IP addresses, layer-4 protocol and ports) and IP packet length | The BNN implemented inside the data plane contains one fully connected hidden layer with 120 neurons and a single-neuron output. | Attack (43.92%) Normal (56.08%) | ISCX Botnet 2014 | Only 5-tuple packet-level features used and a single-neuron output | 94.5% 98.3% |
| Shi et al. [35] | Netflow features (49 features from UNSW-NB15, 80 features from CICIDS2018) | Centralized CNN compared with Federated CNN | UNSW-NB15 (Analysis, Backdoor, DoS, Exploits, Fuzzers, Generic, Nor-mal, Reconnaissance, Shellcode, Worms) CICIDS2018 (HeartBleed, DoS, Botnet, DDoS, Brute Force, Infiltration, Web) | UNSW-NB15 Training 150,000 Validation 20,000 CICIDS2018 Training 100,000 Validation 50,000 Testing 50,000 | Datasets were used partially Example: UNSW-NB15 full training set 175,341 and full testing set 82,332 | Centralized CNN 83.46% Federated CNN 81.19% Centralized CNN 98.77% Federated CNN 78.46% |
| Tian et al. [36] | 87 netflow features 7 classes | Custom-made lightweight residual network (LwResnet) | 6 types of DDoS attacks (UDP flood, MSSQL attack; LDAP and NetBIOS attacks; TFTP and NTP attacks) | CICDDoS2019 | 600 epochs used for classification | 91–99% |
| Xie et al. [37] | Features extracted by principal component analysis (PCA) from the AWID 154 attribute values 4 classes | Modified K-means clustering | Flooding (56,581) Impersonation (68,601) Injection (82,061) Normal (2,163,975) | AWID | For Wi-Fi network only | 86–95% |
| Rahman et al. [38] | 41 features such as duration, protocol type, service, flag 2 classes | The FL model using 122 input variables, 288 neurons for the hidden layer, and 2 neurons in the output layer to represent the abnormal and normal decision. | Attack (71,363) Normal (77,154) | NSL-KDD | Complexity of the network Legacy dataset | 73.34–80.47% |
| Saadat et al. [39] | 41 network features 5 classes | NN is composed of 122-neuron input layer, and two hidden layers of 80 and 40 neurons, respectively, and 5-neuron output layer. | DoS (53,385) User to Root (252), Remote to Local (3649) Probe attacks (14,077) Normal (77,154) | NSL-KDD | Complexity of the net-work Legacy dataset | 75–80% |
| Images Dataset | Most Observations | Fewest Observations | Observations (70%) | Maximum Iterations | Validation Accuracy | Validation Loss | Testing Accuracy | Training Time |
|---|---|---|---|---|---|---|---|---|
| Local Model1 | Normal (14,657) | DDoS (2843) | 17,500 | 680 | 86.80% | 0.3396 | 72.27% | 9 min 9 s |
| Local Model2 | Normal (14,179) | DDoS (3320) | 17,499 | 680 | 62.72% | 0.4268 | 68.51% | 9 min 23 s |
| Local Model3 | Normal (12,327) | DDoS (3245) | 15,572 | 600 | 77.64% | 0.4419 | 90.11% | 8 min 4 s |
| Local Model4 | Normal (14,668) | DDoS (2832) | 17,500 | 680 | 83.54% | 0.4244 | 94.05% | 9 min 12 s |
| Global Model | Normal (55,831) | DDoS (12,239) | 68,070 | 2650 | 80.94% | 0.4256 | 93.95% | 43 min 31 s |
| Images Dataset | Most Observations | Fewest Observations | Observations (100%) | Maximum Iterations | Validation Accuracy | Training Error | Testing Accuracy | Training Time |
|---|---|---|---|---|---|---|---|---|
| Local Model1 | Normal (20,939) | DDoS (4061) | 25,000 | 1950 | 69.72% | 13.18% | 69.72% | 2 min 50 s |
| Local Model2 | Normal (20,256) | DDoS (4743) | 24,999 | 1950 | 93.32% | 18.63% | 93.32% | 2 min 55 s |
| Local Model3 | Normal (17,610) | DDoS (4635) | 22,245 | 1730 | 84.89% | 15.37% | 84.89% | 2 min. 37 s |
| Local Model4 | Normal (20,954) | DDoS (4045) | 24,999 | 1950 | 92.99% | 14.63% | 92.99% | 2 min 53 s |
| Images Dataset | Most Observations | Fewest Observations | Observations (100%) | Maximum Iterations | Validation Accuracy | Validation Loss | Testing Accuracy | Training Time |
|---|---|---|---|---|---|---|---|---|
| Local Model1 | Normal (20,939) | DDoS (4061) | 25,000 | 500 | 65.57% | 0.1873 | 65.57% | 1 min 54 s |
| Local Model2 | Normal (20,256) | DDoS (4743) | 24,999 | 500 | 87.96% | 0.2105 | 87.96% | 2 min 16 s |
| Local Model3 | Normal (17,610) | DDoS (4635) | 22,245 | 500 | 84.97% | 0.1260 | 84.97% | 2 min 11 s |
| Local Model4 | Normal (20,954) | DDoS (4045) | 24,999 | 500 | 93.26% | 0.1436 | 93.26% | 2 min 20 s |
| Global Average Model | Normal (79,759) | DDoS (17,484) | 97,243 | - | - | - | 88.42% | - |
| Parameter | Local Model1 | Local Model2 | Local Model3 | Local Model4 | Global Model |
|---|---|---|---|---|---|
| Total No. of images | 25,000 | 24,999 | 22,245 | 24,999 | 97,243 |
| No. of images of Normal traffic | 20,939 | 20,256 | 17,610 | 20,954 | 79,759 |
| No. of images of DDoS attack traffic | 4061 | 4743 | 4635 | 4045 | 17,484 |
| Use case | 1. Traditional transfer learning (TTL) | ||||
| Testing accuracy Equation (1) in % | 72.27 | 68.51 | 90.11 | 94.05 | 93.95 |
| Precision Equation (2) in % | 94.25 | 94.86 | 94.2 | 94.48 | 94.77 |
| Recall Equation (3) in % | 75.16 | 70.39 | 95.37 | 99.49 | 99.04 |
| F1 score Equation (4) in % | 83.63 | 80.81 | 94.78 | 96.92 | 96.86 |
| Training time | 9 min 9 s | 9 min 23 s | 8 min 4 s | 9 min 12 s | 43 min 31 s |
| Use case | 2. Federated transfer learning (FTL) | ||||
| Testing accuracy Equation (1) in % | 69.72 | 93.32 | 84.89 | 92.99 | 92.99 |
| Precision Equation (2) in % | 94.23 | 94.24 | 94.98 | 95.46 | 95.46 |
| Recall Equation (3) in % | 72.28 | 98.96 | 88.65 | 97.19 | 97.19 |
| F1 score Equation (4) in % | 81.81 | 96.54 | 91.7 | 96.31 | 96.31 |
| Training time | 2 min 50 s | 2 min 55 s | 2 min 37 s | 2 min 53 s | - |
| Use case | 3. Federated learning (FL) | ||||
| Testing accuracy Equation (1) in % | 65.57 | 87.96 | 84.97 | 93.26 | 88.42 |
| Precision Equation (2) in % | 93.47 | 94.29 | 94.65 | 97.64 | 95 |
| Recall Equation (3) in % | 68.23 | 92.85 | 89.08 | 95.15 | 92.58 |
| F1 score Equation (4) in % | 78.88 | 93.56 | 91.78 | 96.38 | 93.78 |
| Training time | 1 min 54 s | 2 min 16 s | 2 min 11 s | 2 min 20 s | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toldinas, J.; Venčkauskas, A.; Liutkevičius, A.; Morkevičius, N. Framing Network Flow for Anomaly Detection Using Image Recognition and Federated Learning. Electronics 2022, 11, 3138. https://doi.org/10.3390/electronics11193138
Toldinas J, Venčkauskas A, Liutkevičius A, Morkevičius N. Framing Network Flow for Anomaly Detection Using Image Recognition and Federated Learning. Electronics. 2022; 11(19):3138. https://doi.org/10.3390/electronics11193138
Chicago/Turabian StyleToldinas, Jevgenijus, Algimantas Venčkauskas, Agnius Liutkevičius, and Nerijus Morkevičius. 2022. "Framing Network Flow for Anomaly Detection Using Image Recognition and Federated Learning" Electronics 11, no. 19: 3138. https://doi.org/10.3390/electronics11193138
APA StyleToldinas, J., Venčkauskas, A., Liutkevičius, A., & Morkevičius, N. (2022). Framing Network Flow for Anomaly Detection Using Image Recognition and Federated Learning. Electronics, 11(19), 3138. https://doi.org/10.3390/electronics11193138