
Explainable Artificial Intelligence for Intrusion Detection System

 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
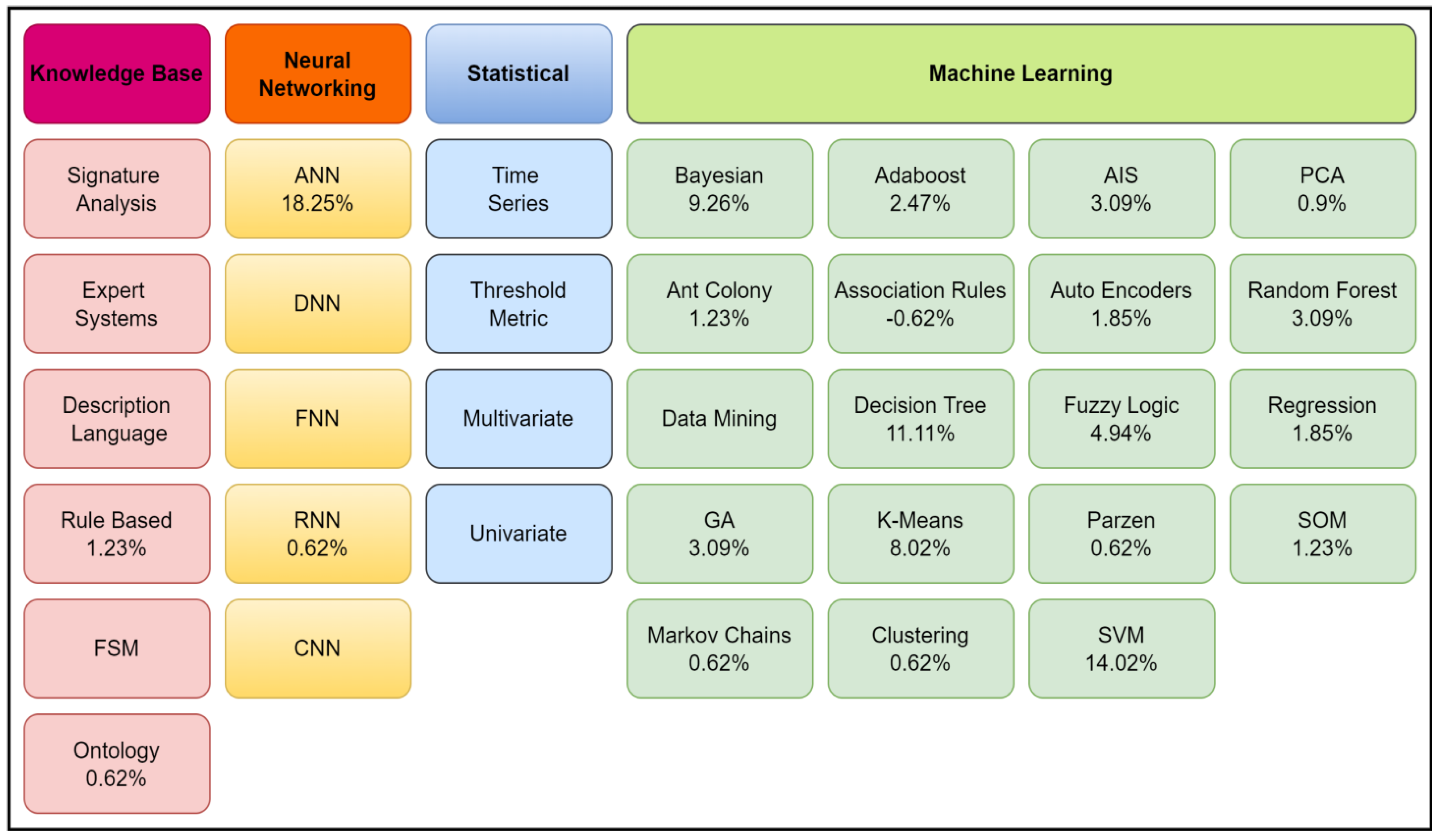
2. Literature Review
3. Significance of the Study
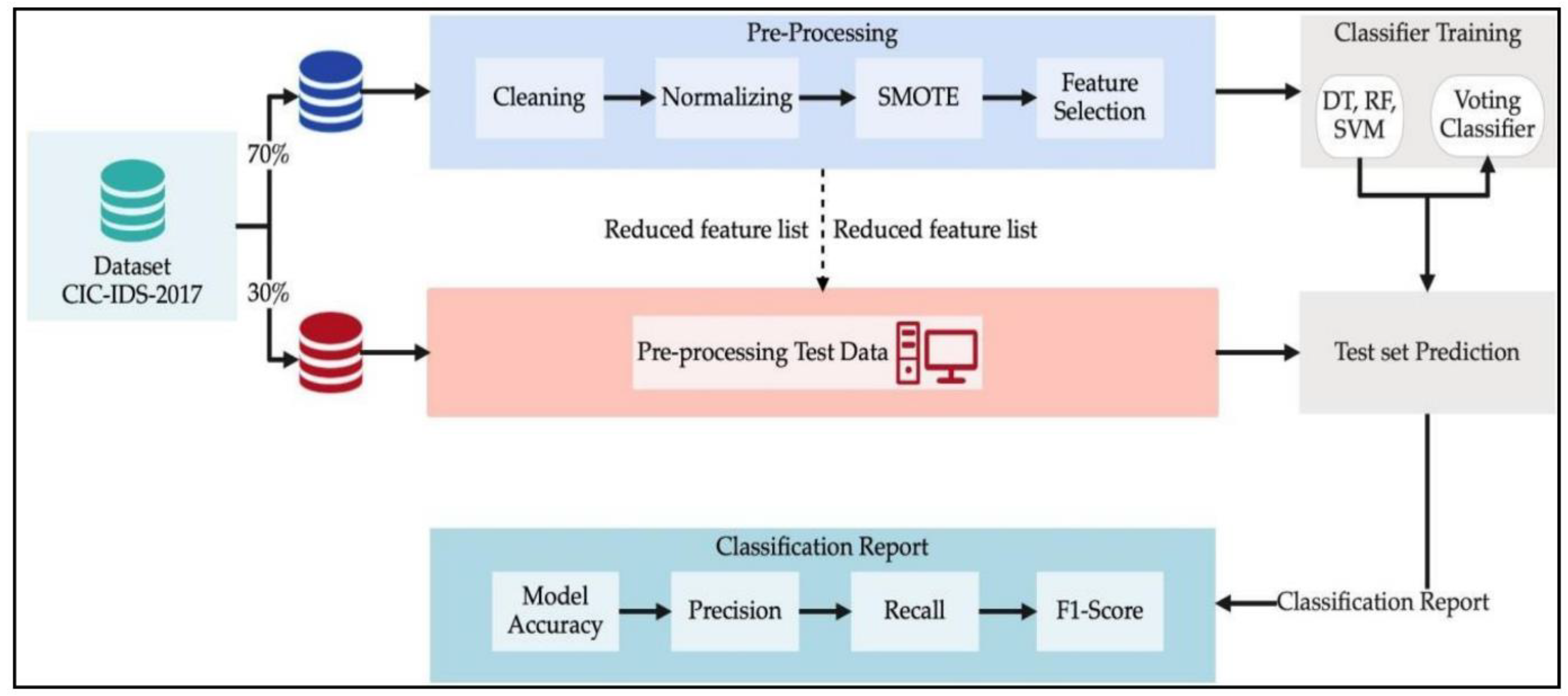
4. Methodology
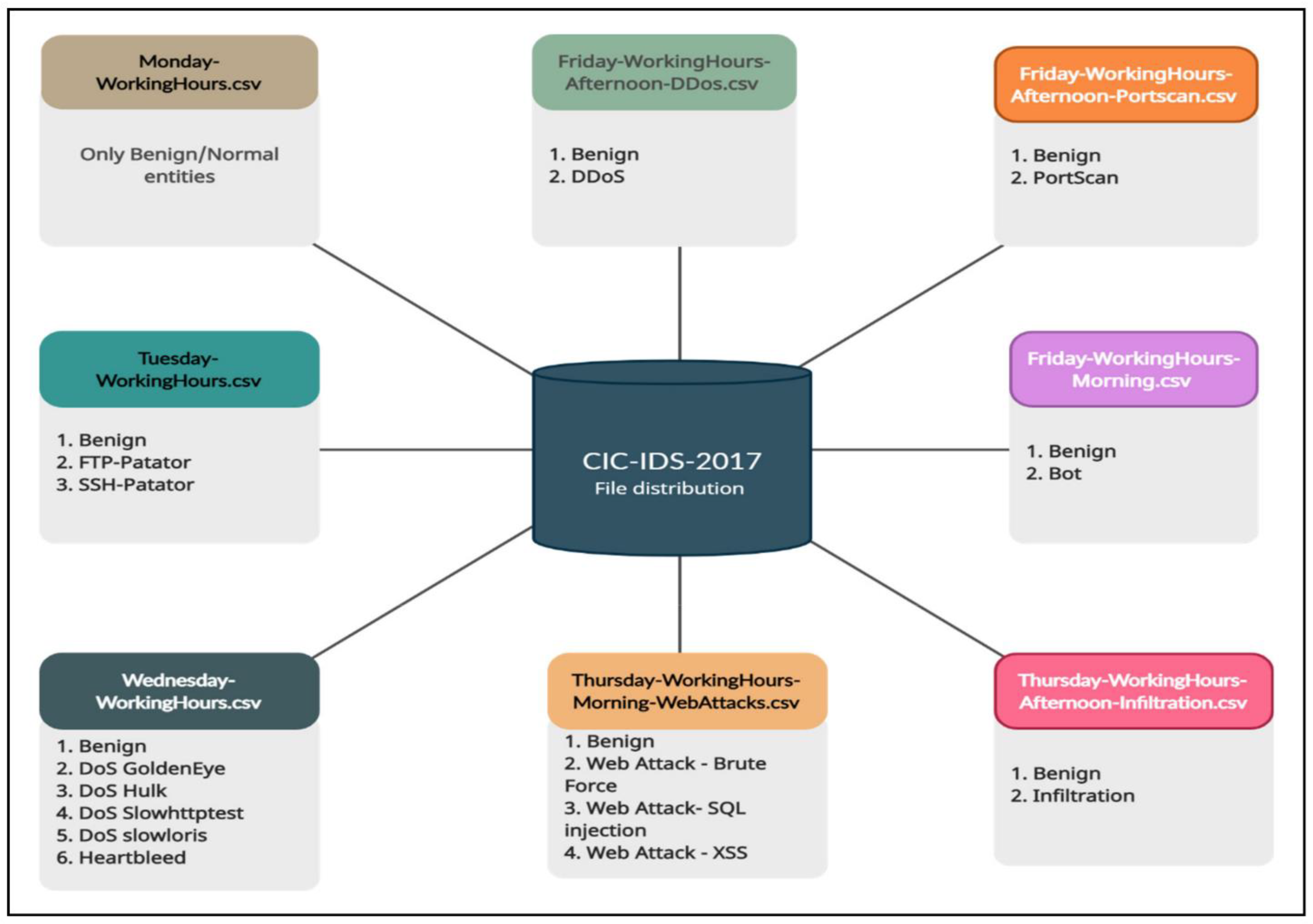
4.1. DATASET
4.2. Feature Selection
4.3. Machine Learning Pipeline
4.3.1. Random Forest (RF)
- 1:
- Acquire all the features of the random forest model
- 2:
- Calculate the RMSE and rank the importance of features.
- 3:
- Let i = 1 to n do
- 4:
- Remove the features with the smallest importance
- 5:
- Train the RF model with the tunes subset
- 6:
- Calculate RMSE and measure model performance
- 7:
- Rank the importance of features
- 8:
- End
- 9:
- Identify the optimal length of the features and the rank of each.
4.3.2. Decision Tree (DT)
- The whole training set is considered the root in the beginning.
- Categorical values are preferred for feature values.
- Recursively, records are distributed based on attribute values.
- According to some statistical methods, nodes or root attributes are ranked according to their importance in a tree.
4.3.3. Support Vector Machine (SVM)
4.3.4. Voting Classifier
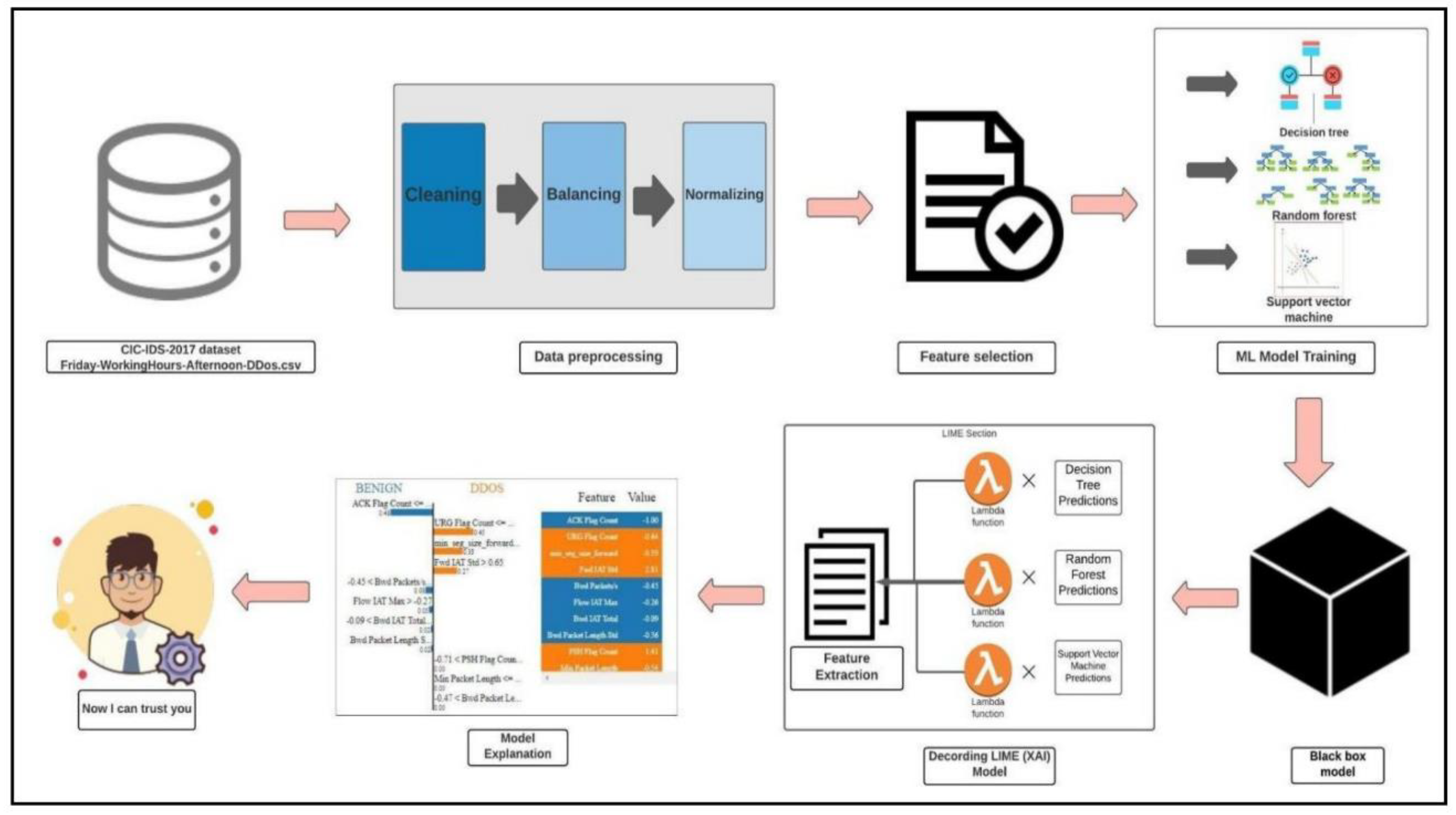
5. Generation of Explanations Using X-AI Model (LIME)
- A TabularExplainer is initially initialized with the data used to train it (or with the statistics of the training data if no training data are present), details about the features, and several class names (if classification is possible).
- In the class explain_instance, a method called explain_instance accepts a reference to the instance for which an explanation is needed, along with the trained model’s prediction method and the number of features to be included in the explanation.
- The prediction probabilities are displayed in the left section.
- The middle section presents 13 of the most important features. The binary classification task would be done in two colors, orange and blue. Class 1 attributes are in orange, and class 0 attributes are in blue. Horizontal bars indicate the relative importance of these features based on floating-point numbers.
- The color-coding is consistent across sections. A list containing the actual values of the top 13 variables.
- If an explanation is needed, n times of perturbation must occur without a small change in value. Using this fake data, LIME constructs a local linear model around the perturbed observation.
- Outcomes of perturbed data are predicted.
- Measure the distance between each perturbed observation and the original observation.
- Calculate the similarity score based on distance.
- Then determine m features to best represent the predictions from the perturbed data.
- The perturbed data are fitted with a simple model using the selected features.
- The coefficients (feature weights) of the simple model describe the observations.
6. Prediction and Evaluation
6.1. Confusion Matrix
6.2. Accuracy
6.3. Precision
6.4. Recall
7. Experimental Results and Discussions
7.1. Result Comparison
7.1.1. Decision Tree
7.1.2. Random Forest
7.1.3. Support Vector Machine
7.1.4. Voting Classifier
- A decision tree was used to determine the importance of features on a classification problem involving 1000 samples and 10 features. The importance of split points is estimated using decision tree algorithms, such as classification and regression trees (CARTs), which use standard metrics, such as Gini and entropy, to select split points. Similarly, algorithms such as random forest and stochastic gradient boosting can be applied to ensembles of decision trees. It is possible to use this algorithm as the BasisTreeRegressor and BasisTreeClassifier classes of scikit-learn. After a model has been fitted, the feature_importances property can be accessed, to retrieve the relative importance scores for each input feature. Figure 13 represents the calculated scores for each feature.
- 2.
- The random forest method was used to determine the significance of features in regression problems, as represented in Figure 14. Random forest was implemented as the Random Forest Classifier class and Random Forest Regressor class in scikit-learn, to determine the feature importance. After a model has been fitted, its property of feature importance can be accessed, to retrieve the relative importance of each feature. The bagging and extra trees algorithms can also be used with this approach.



8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An explainable machine learning framework for intrusion detection systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Vigneswaran, R.K.; Vinayakumar, R.; Soman, K.; Poornachandran, P. Evaluating shallow and deep neural networks for network intrusion detection systems in cyber security. In Proceedings of the 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–6. [Google Scholar]
- Tran, M.-Q.; Elsisi, M.; Liu, M.-K.; Vu, V.Q.; Mahmoud, K.; Darwish, M.M.F.; Abdelaziz, A.Y.; Lehtonen, M. Reliable deep learning and IoT-based monitoring system for secure computer numerical control machines against cyber-attacks with experimental verification. IEEE Access 2022, 10, 23186–23197. [Google Scholar] [CrossRef]
- Elsisi, M.; Tran, M.-Q. Development of an IoT architecture based on a deep neural network against cyber attacks for automated guided vehicles. Sensors 2021, 21, 8467. [Google Scholar] [CrossRef]
- Scott, S.-l.l.; Lundberg, M. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?”: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Ribeiro, M.T.C. Lime. 2020. Available online: https://github.com/marcotcr/lime (accessed on 17 July 2022).
- Sahu, S.K.; Sarangi, S.; Jena, S.K. A detail analysis on intrusion detection datasets. In Proceedings of the 2014 IEEE International Advance Computing Conference (IACC), Gurgaon, India, 21–22 February 2014. [Google Scholar]
- AI Explainability 360 (v0.2.0). 2019. Available online: https://github.com/Trusted-AI/AIX360 (accessed on 17 July 2022).
- Mane, S.; Rao, D. Explaining network intrusion detection system using explainable AI framework. arXiv 2021, arXiv:2103.07110t. [Google Scholar]
- Ando, S. Interpreting Random Forests. 2019. Available online: http://blog.datadive.net/interpreting-random-forests/ (accessed on 17 July 2022).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, J.; Li, K.; Tang, Z.; Bilal, K.; Yu, S.; Weng, C.; Li, K. A parallel random forest algorithm for big data in a spark cloud computing environment. IEEE Transact. Parallel Distrib. Syst. 2016, 28, 919–933. [Google Scholar] [CrossRef]
- DeJong, G. Generalizations based on explanations. IJCAI 1981, 81, 67–69. [Google Scholar]
- Dong, B.; Wang, X. Comparison deep learning method to traditional methods using for network intrusion detection. In Proceedings of the 8th IEEE International Conference on Communication Software and Networks (ICCSN), Beijing, China, 4–6 June 2016; pp. 581–585. [Google Scholar]
- Hooman, A.; Marthandan, G.; Yusoff, W.F.W.; Omid, M.; Karamizadeh, S. Statistical and data mining methods in credit scoring. J. Dev. Areas 2016, 50, 371–381. [Google Scholar] [CrossRef]
- Islam, S.R.; Eberle, W.; Bundy, S.; Ghafoor, S.K. Infusing domain knowledge in ai-based ”black box” models for better explainability with application in bankruptcy prediction. arXiv 2019, arXiv:1905.11474. [Google Scholar]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection systems. In Proceedings of the 9th EAI International Conference on Bio-Inspired Information and Communications Technologies (Formerly BIONETICS), New York, NY, USA, 3–5 December 2016; pp. 21–26. [Google Scholar]
- Li, Z.; Sun, W.; Wang, L. A neural network-based distributed intrusion detection system on a cloud platform. In Proceedings of the IEEE 2nd International Conference on Cloud Computing and Intelligence Systems, Hangzhou, China, 30 October–1 November 2012; Volume 1, pp. 75–79. [Google Scholar]
- Lipovetsky, S.; Conklin, M. Analysis of regression in game theory approach. Appl. Stoch. Models Bus. Ind. 2001, 17, 319–330. [Google Scholar] [CrossRef]
- Lundberg, S. Shap vs. Lime. 2019. Available online: https://github.com/slundberg/shap/issues/19 (accessed on 17 July 2022).
- Ferdiana, R. A systematic literature review of intrusion detection system for network security: Research trends, datasets and methods. In Proceedings of the 4th International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 10–11 November 2020; pp. 1–6. [Google Scholar]
- Peddabachigari, S.; Abraham, A.; Grosan, C.; Thomas, J. Modeling intrusion detection system using hybrid intelligent systems. J. Netw. Comput. Appl. 2007, 30, 114–132. [Google Scholar] [CrossRef]
- Li, T.; Hu, S.; Beirami, A.; Smith, V. Ditto: Fair and robust federated learning through personalization. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 6357–6368. [Google Scholar]
- Mohseni, S.; Wang, H.; Yu, Z.; Xiao, C.; Wang, Z.; Yadawa, J. Practical machine learning safety: A survey and primer. arXiv 2021, arXiv:2106.04823. [Google Scholar]
- Kishore, R. Evaluating Shallow and Deep Neural Networks for Intrusion Detection Systems Cyber Security. Doctoral Dissertation, Amrita School of Engineering, Amritapuri, India, 2020. [Google Scholar]
- Hoque, M.S.; Mukit, M.; Bikas, M.; Naser, A. An implementation of intrusion detection system using genetic algorithm. arXiv 2012, arXiv:1204.1336. [Google Scholar]
- Maseer, Z.K.; Yusof, R.; Bahaman, N.; Mostafa, S.A.; Foozy, C.F.M. Benchmarking of machine learning for anomaly based intrusion detection systems in the CICIDS2017 dataset. IEEE Access 2021, 9, 22351–22370. [Google Scholar] [CrossRef]
- Laqtib, S.; El Yassini, K.; Hasnaoui, M.L. A technical review and comparative analysis of machine learning techniques for intrusion detection systems in MANET. Int. J. Electr. Comput. Eng. 2020, 10, 2701. [Google Scholar] [CrossRef]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Transact. Emerg. Telecommun. Technol. 2021, 32, e4150. [Google Scholar] [CrossRef]
- Mukherjee, S.; Sharma, N. Intrusion detection using naive Bayes classifier with feature reduction. Procedia Technol. 2012, 4, 119–128. [Google Scholar] [CrossRef]
- Kumar, V.; Chauhan, H.; Panwar, D. K-means clustering approach to analyze NSL-KDD intrusion detection dataset. Int. J. Soft Comput. Eng. 2013, 4, 2231–2307. [Google Scholar]
- Sharafaldin. Intrusion Detection Evaluation Dataset (CICIDS2017), Canadian Institute for Cybersecurity, January, 2018. Available online: https://www.unb.ca/cic/datasets/ids2017.html (accessed on 17 July 2022).
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Radoglou-Grammatikis, P.I.; Sarigiannidis, P.G. Securing the smart grid: A comprehensive compilation of intrusion detection and prevention systems. IEEE Access 2019, 7, 46595–46620. [Google Scholar] [CrossRef]
- Gamage, S.; Samarabandu, J. Deep learning methods in network intrusion detection: A survey and an objective comparison. J. Netw. Comput. Appl. 2020, 169, 102767. [Google Scholar] [CrossRef]
- Mohammadi, M.; Rashid, T.A.; Karim, S.H.; Aldalwie, A.H.M.; Tho, Q.T.; Bidaki, M.; Rahmani, A.M.; Hosseinzadeh, M. A comprehensive survey and taxonomy of the SVM-based intrusion detection systems. J. Netw. Comput. Appl. 2021, 178, 102983. [Google Scholar] [CrossRef]
- Chaabouni, N.; Mosbah, M.; Zemmari, A.; Sauvignac, C.; Faruki, P. Network intrusion detection for IoT security based on learning techniques. IEEE Commun. Surv. Tutor. 2019, 21, 2671–2701. [Google Scholar] [CrossRef]
- Da Costa, K.A.; Papa, J.P.; Lisboa, C.O.; Munoz, R.; de Albuquerque, V.H.C. Internet of things: A survey on machine learning-based intrusion detection approaches. Comput. Netw. 2019, 151, 147–157. [Google Scholar] [CrossRef]
- Shone, N.; Ngoc, T.N.; Phai, V.D.; Shi, Q. A deep learning approach to network intrusion detection. IEEE Transact. Emerg. Topics Comput. Intell. 2018, 2, 41–50. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-agnostic interpretability of machine learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.Z. XAI—Explainable artificial intelligence. Sci. Robot. 2019, 4, eaay7120. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (XAI): Toward medical XAI. IEEE Transact. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef]
- Wolf, C.T. Explainability scenarios: Towards scenario-based XAI design. In Proceedings of the 24th International Conference on Intelligent User Interfaces, Marina del Ray, CA, USA, 17–20 March 2019; pp. 252–257. [Google Scholar]
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (XAI): A survey. arXiv 2020, arXiv:2006.11371. [Google Scholar]
- Byrne, R.M.J. Counterfactuals in explainable artificial intelligence (XAI): Evidence from human reasoning. IJCAI 2019, 6276–6282. [Google Scholar]
- Booij, T.M.; Chiscop, I.; Meeuwissen, E.; Moustafa, N.; Hartog, F.T.H.d. ToN_IoT: The role of heterogeneity and the need for standardization of features and attack types in IoT network intrusion data sets. IEEE Internet Things J. 2022, 9, 485–496. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Dataset Used | Techniques Used | Research Findings |
|---|---|---|---|
| [28] | NSL-KDD | This paper proposes a different explainable AI framework that provides the capabilities for transparency in every stage of the machine learning pipeline, including SHAP, LIME, CEM, ProtoDash, and Boolean Decision Rules. They also employed deep neural networks for intrusion detection. | This approach uses a variety of explainability techniques, these approaches are applied on the NSL-KDD dataset. This is a dataset which is based on KDD99, an older dataset. |
| [29] | KDDCup-99 | This paper proposes different machine learning classifiers on top of kdd99 This research paper also elaborately covered the application of DNNs in intrusion detection comprehensively. | This approach used many classical machine learning classifiers, as well as deep neural networks of layer 1 to 5; however, the approach used the KDD99 dataset. |
| [30] | KDDCup-99 | Using genetic algorithms to detect several types of network intrusions, the paper discusses the implementation of an intrusion detection system (IDS). Utilizing the standard KDD99 benchmark dataset, we implemented our system and obtained a good detection rate. | In intrusion detection, many approaches have been adopted, but none of the systems have been completely error-free. Thus, the quest for betterment continues. KDDcup-99 was yet another limitation to this approach. |
| [31] | NSL-KDD | An application of self-taught learning (STL) for classification was proposed in this paper. STL employs two stages for deep learning. Accuracy, precision, recall, and F-measure values are among the metrics compared. | The use of a deep-learning-based NIDS with a sparse autoencoderand softmax regression was demonstrated. It is a limitation of this approach that NSL- KDD does not apply. |
| [32] | CIC-IDS- 2017 | Several analysis methods involving artificial neural networks and ML were proposed in this paper for the CIC-IDS-2017 data set. | This paper proposes pros and cons of using CIC-IDS-2017 for domain research and implementation. It was found that the data were not completely reliable in the high required working processes. Many cases where data cells read “NaN” and “Infinity” ceased to exist. |
| [33] | NSL-KDD | A paper presented different deep learning techniques that have the ability to adapt to dynamic environments. Three models were used: bidirectional long short-term memory, Inception-CNN, and deep belief network. | A number of practical problems with existing intrusion detection were addressed in this work, and different deep learning models were compared to solve the problems. The model has been developed and tested on the NSL-KDD dataset. |
| [34] | KDD99, NSL- KDD | Ten machine learning approaches were presented for IDS, which include decision tree, hybrid with locally weighted learning, rotation forest, and Bayesian belief network, and then combination of J48 and NB with AdaBoost was implemented for IDS. | The results of this research suggest that the proposed approach utilizing a variety of machine learning methods using the NSL-KDD dataset performed well in all major categories of attacks. However, a low detection rate was reported. It is inevitable to detect minority attacks such as U2R and R2L, which results in large bias in the dataset. |
| [35] | NSL-KDD | A combined approach is proposed by combining NB with feature vitality based feature selection method for accuracy improvement. | The FVBRM method achieved 97.78% overall classifier accuracy, with 98.7 TPR for DoS, 97% for normal, 98.8% for probe, 96.1 for r2l, and 64% for u2r, which was higher than others compared. |
| [36] | NSL-KDD | Clustering algorithm was used to group dataset samples into a set representing four attack classes, and then classification was done. | The K-means algorithm took 9.25 s to build cluster models and the mean squared error in this process was 19,308.72. |
| [37] | DARPA1998, KDD99, NSL-KDD, UNSW-NB15 | Survey on machine learning and deep learning algorithms used for intrusion detection. | The paper proposed an IDS taxonomy over various machine learning algorithms used in this field. It discusses the various data sources, i.e., logs, packets, flow, and sessions. The paper emphasized ML for IDs |
| [38] | Examine 37 cases | The paper examined the contribution of the IDPSs in the SG paradigm, providing an analysis of 37 cases. | Timely detecting of IDs was given stress in the paper. The cases the paper deals with are on the advanced metering infrastructure (AMI), supervisory control, and data acquisition (SCADA) systems, substations, and synchrophasors. Based on a comparative analysis, the limitations and the shortcomings of the current IDPS systems were identified, and appropriate recommendations were provided for future research efforts. |
| [39] | KDD 99, NSL-KDD, CIC-IDS2017, CIC-IDS2018 | Evaluated four deep learning models on four intrusion detection datasets. | Gave a taxonomy and survey of deep learning models for intrusion detection. Evaluated four deep learning models on four intrusion detection datasets. Feed-forward neural networks performed best across all metrics, on all datasets. |
| [40] | 14 different datasets were used | Evaluated the performance of SVM for IDS approaches. | This paper presented a comprehensive study and investigation of the SVM-based intrusion detection and feature selection systems. |
| [41] | KDDCUP99, NSL-KDD | IoT NIDS based on machine learning techniques. | This paper reviewed existing NIDS implementation tools and datasets, as well as free and open-source network sniffing software. Then, it surveyed, analyzed, and compared state-of-the-art NIDS proposals in the IoT context, in terms of architecture, detection methodologies, validation strategies, treated threats, and algorithm deployments. |
| [42] | Comparison result on various dataset | The work focused on the newest studies in intrusion detection and intelligent techniques applied to IoT, to keep data secure. | The research focused on rigorous state-of-the-art literature on machine learning techniques applied in internet-of-things and intrusion detection for computer network security. |
| MODEL | ACCURACY | PRECISION | RECALL | F1-SCORE |
|---|---|---|---|---|
| Decision Tree | 0.95551413679 | 0.88 | 0.88 | 0.88 |
| Random Forest | 0.9603538146 | 0.89 | 0.88 | 0.88 |
| Support vector machine | 0.9557731796 | 0.89 | 0.8 | 0.8 |
| Voting classifier | 0.9625651556 | 0.89 | 0.89 | 0.89 |
| 1 | Bwd Packet Length Min |
| 2 | Bwd Packet Length Std |
| 3 | Flow IAT Max |
| 4 | Fwd IAT Std |
| 5 | Bwd IAT Total |
| 6 | Bwd Packets/s |
| 7 | Min Packet Length |
| 8 | PSH Flag Count |
| 9 | ACK Flag Count |
| 10 | URG Flag Count |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patil, S.; Varadarajan, V.; Mazhar, S.M.; Sahibzada, A.; Ahmed, N.; Sinha, O.; Kumar, S.; Shaw, K.; Kotecha, K. Explainable Artificial Intelligence for Intrusion Detection System. Electronics 2022, 11, 3079. https://doi.org/10.3390/electronics11193079
Patil S, Varadarajan V, Mazhar SM, Sahibzada A, Ahmed N, Sinha O, Kumar S, Shaw K, Kotecha K. Explainable Artificial Intelligence for Intrusion Detection System. Electronics. 2022; 11(19):3079. https://doi.org/10.3390/electronics11193079
Chicago/Turabian StylePatil, Shruti, Vijayakumar Varadarajan, Siddiqui Mohd Mazhar, Abdulwodood Sahibzada, Nihal Ahmed, Onkar Sinha, Satish Kumar, Kailash Shaw, and Ketan Kotecha. 2022. "Explainable Artificial Intelligence for Intrusion Detection System" Electronics 11, no. 19: 3079. https://doi.org/10.3390/electronics11193079
APA StylePatil, S., Varadarajan, V., Mazhar, S. M., Sahibzada, A., Ahmed, N., Sinha, O., Kumar, S., Shaw, K., & Kotecha, K. (2022). Explainable Artificial Intelligence for Intrusion Detection System. Electronics, 11(19), 3079. https://doi.org/10.3390/electronics11193079