
An Interference-Resistant and Low-Consumption Lip Recognition Method

Abstract
1. Introduction
2. Related Work
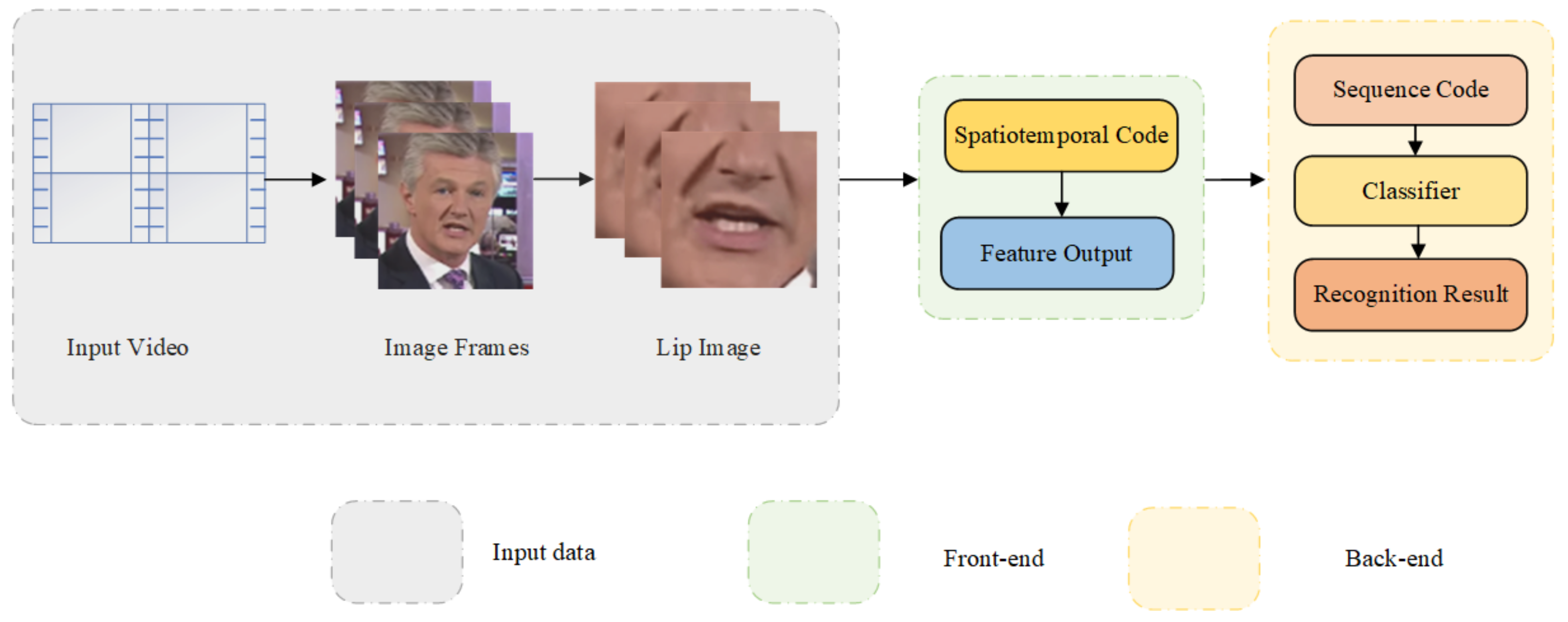
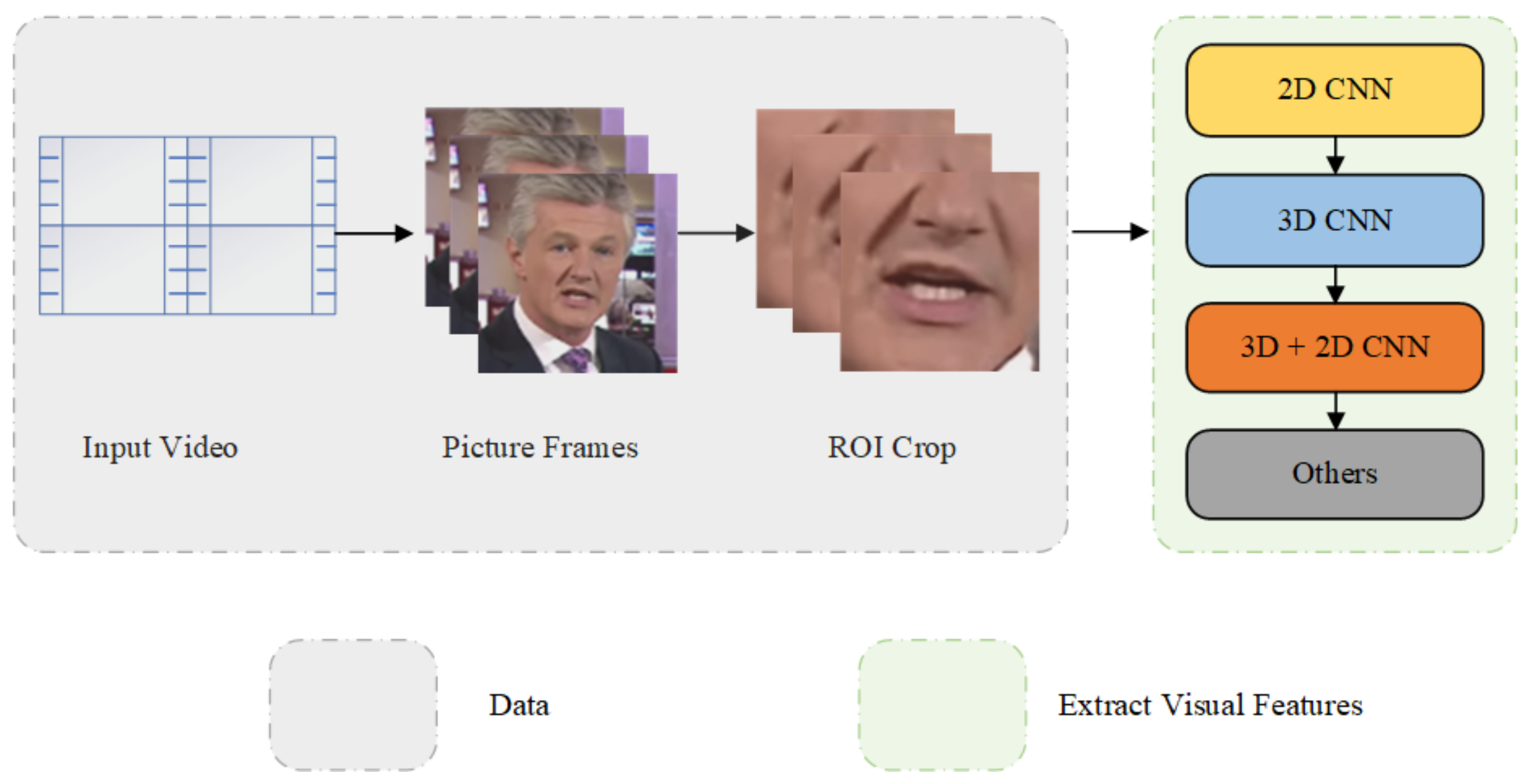
3. The Basic Pipeline
4. Proposed Methodology
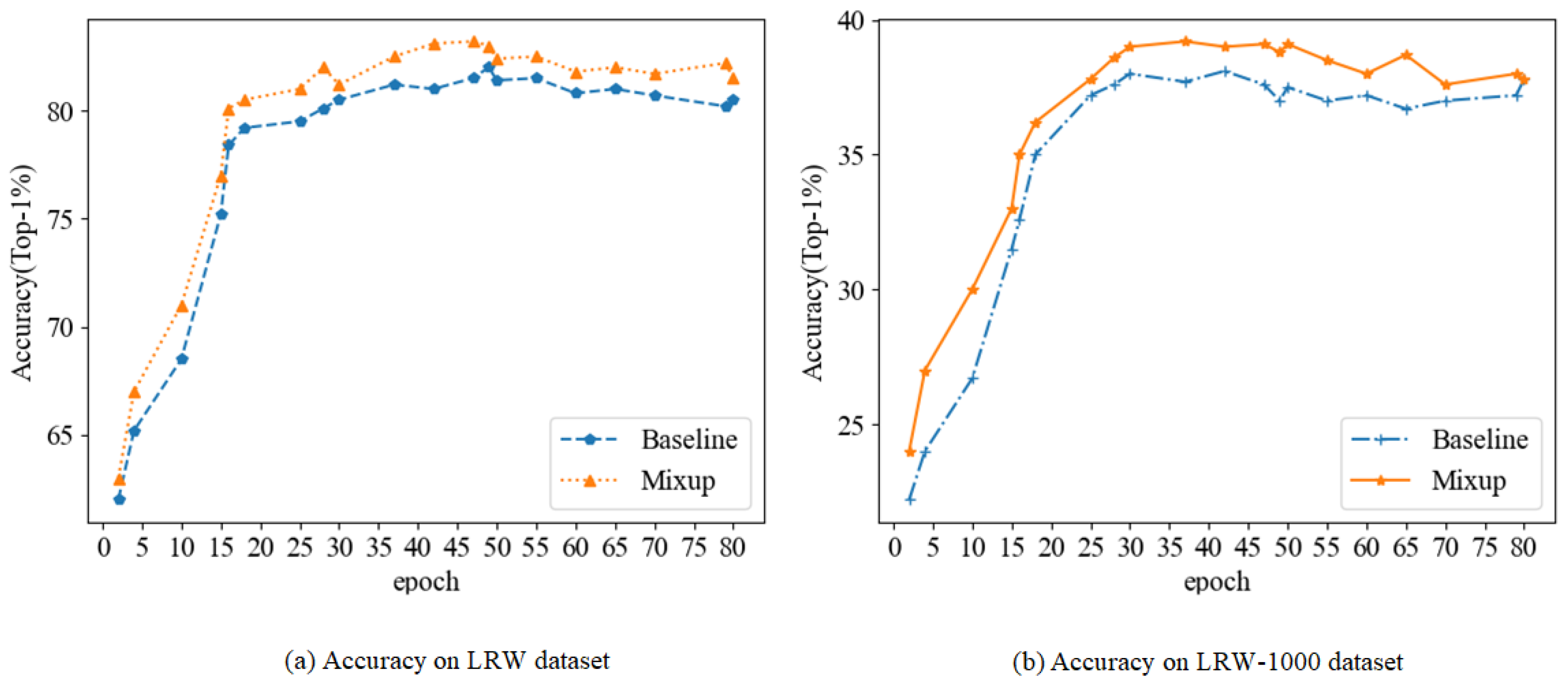
4.1. Mixup
4.1.1. Definition of Mixup
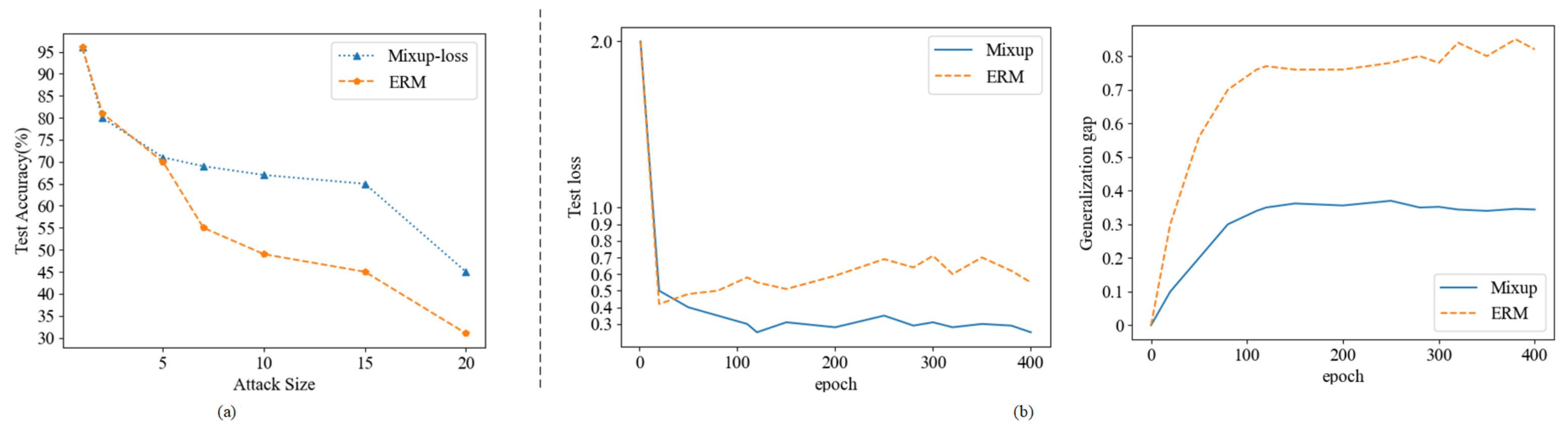
4.1.2. Robustness and Generalization
4.1.3. Mixup and Baseline Model
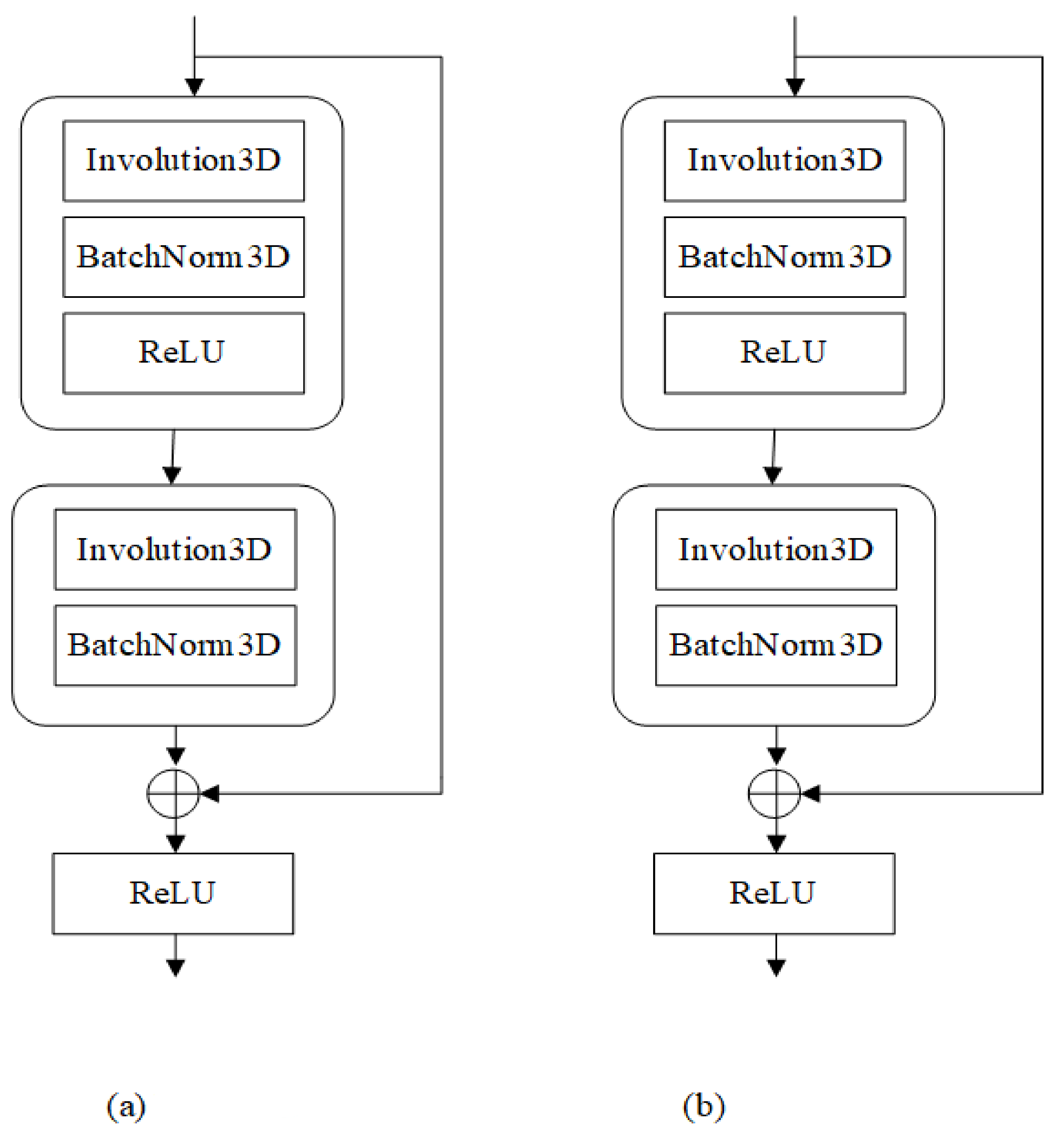
4.2. InvNet-18
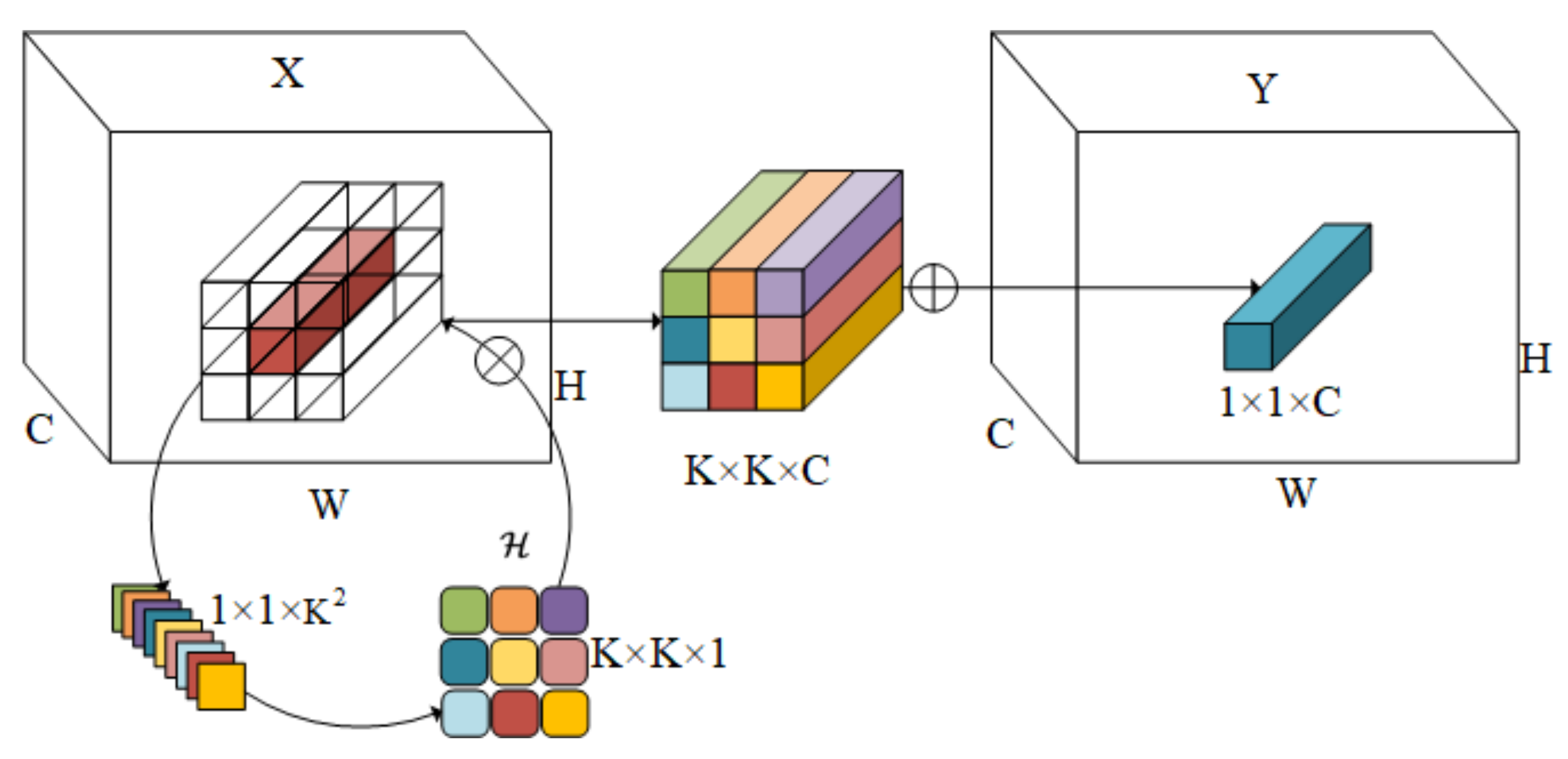
4.2.1. Design of Involution
| Algorithm 1 Pseudo code of involution in a PyTorch-like style. |
| Initialization: |
| o = nn.AvgPool2d(s, s) if s > 1 else nn.Identity() |
| reduce = nn.Conv2d(C, C//r, 1) |
| span = nn.Conv2d(C//r, K*K*G, 1) |
| unfold = nn.Unfold(k, dilation, padding, s) |
| Forward Pass: |
| x_unfolded = unfold(x), B, C*K*K. H*W |
| ×_unfolded = x_unfolded.view(B, G, C//G, K*K, H, W) |
| Kernel Generation, Equation (12): |
| kernel = span(reduce(o(x))), B, K*K*G, H, W |
| kernel = kernel.view(B, G, K*K, H, W).unsqueeze(2) |
| Multiply-Add Operation, Equation (10): |
| out = mul(kernel, x_unfolded).sum(dim = 3), B, G, C/G, H, W |
| out = out.view(B, C, H, W) |
| return out |
| B: batch size, H: height, W: width |
| C: channel number, G: group number |
| K: kernel size, s: stride, r: reduction ratio |
4.2.2. The Experimental Effect of Involution
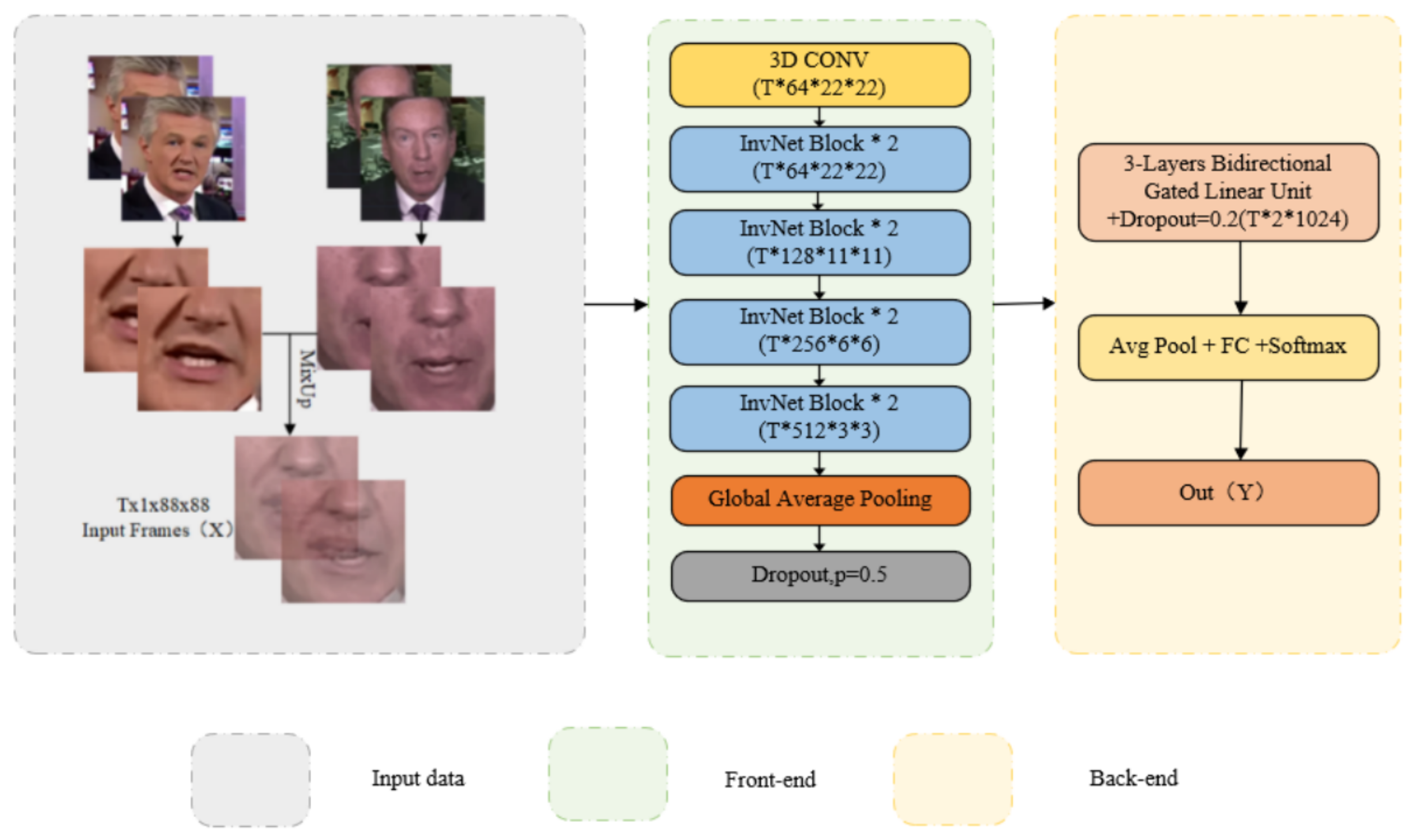
4.3. The Final Model
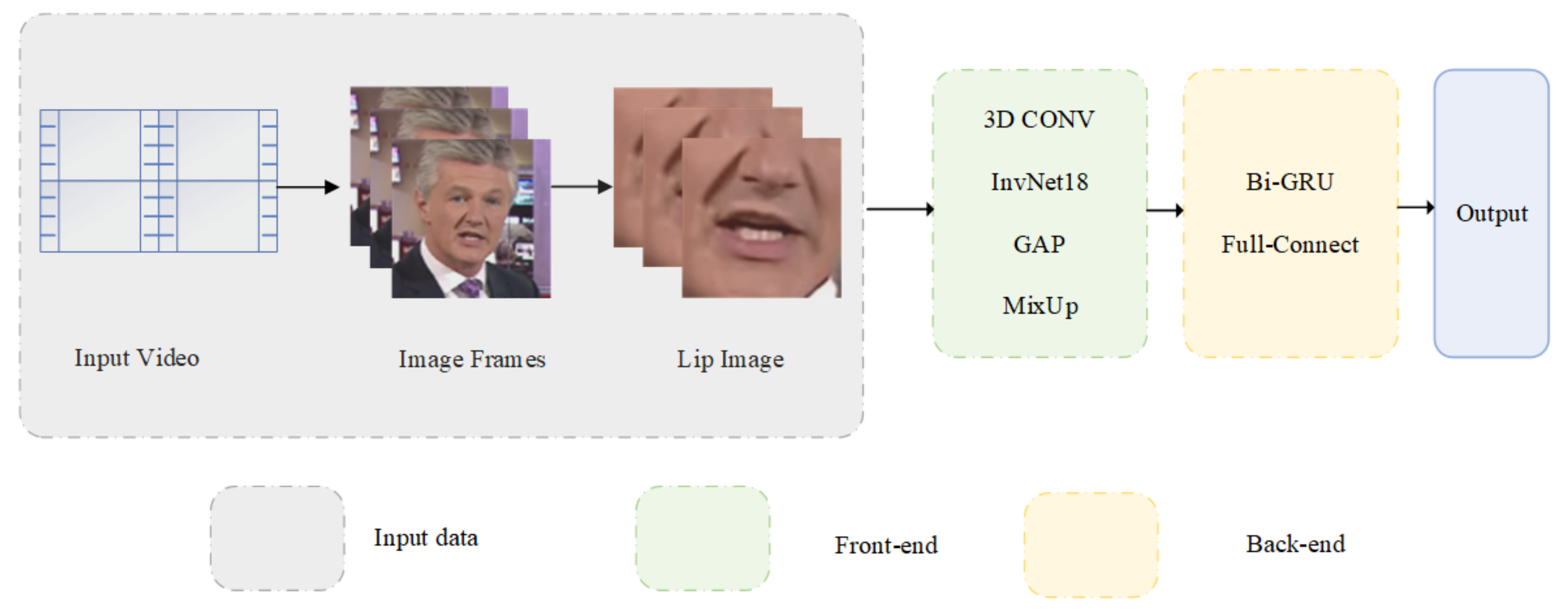
- The LRW and LRW-1000 video datasets were decomposed into picture frames and the 88 × 88 size lip image was cropped from them.
- The front-end module includes 3D Conv, InvNet-18, and GAP to obtain a 512-dimensional time feature sequence and use Mixup training for data enhancement. Mixup enables lip recognition models with high resistance to interference. The InvNet-18 network gives low consumption to lip recognition models. The combination of the two is suitable for constructing an interference-resistant and low-consumption lip recognition model with an accuracy comparable with the current state-of-the-art results.
- The back-end module includes Bi-GRU and the full connection layer, resulting in loss and classification results.
5. Experimental Result
5.1. DataSet
5.2. Experimental Setting
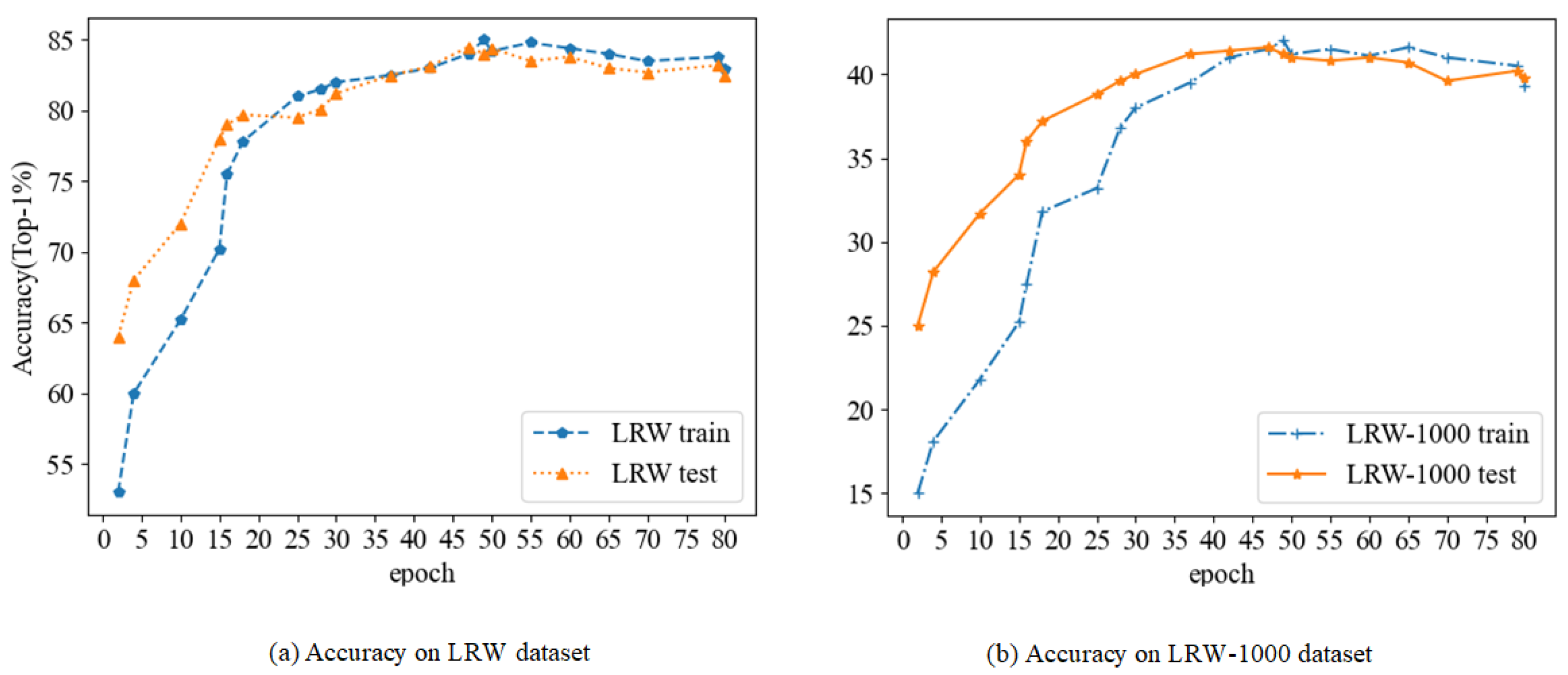
5.3. Experimental Results
6. Conclusions
- In this paper, we analyze the anti-interference capability of current state-of-the-art lip recognition models and find that they are not robust and generalized enough for adversarial examples, leading to a significant decrease in accuracy for adversarial examples. We experimentally demonstrate that Mixup training can also be applied to lip recognition models to improve their anti-interference ability effectively.
- Current lip recognition models generally improve the model’s accuracy by stacking neural networks, which leads to many parameters and consumes many resources. We propose the InvNet-18 network, which reduces 32% of parameters and consumes only 1/3 of GPU resources compared with the ResNet-18 network used by the advanced model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Petridis, S.; Stafylakis, T.; Ma, P.; Cai, F.; Pantic, M. End-to-end Audiovisual Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Lu, L.; Yu, J.; Chen, Y.; Liu, H.; Zhu, Y.; Kong, L.; Li, M. Lip Reading-Based User Authentication Through Acoustic Sensing on Smartphones. IEEE/ACM Trans. Netw. 2019, 27, 447–460. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhao, G.; Hong, X.; Pietikaeinen, M. A review of recent advances in visual speech decoding. Image Vis. Comput. 2014, 32, 590–605. [Google Scholar] [CrossRef]
- Mathulaprangsan, S.; Wang, C.Y.; Kusum, A.Z.; Tai, T.C.; Wang, J.C. A survey of visual lip reading and lip-password verification. In Proceedings of the 2015 International Conference on Orange Technologies (ICOT), Hong Kong, China, 19–22 December 2015. [Google Scholar]
- Wang, M. Lip feature selection based on BPSO and SVM. In Proceedings of the IEEE 2011 10th International Conference on Electronic Measurement & Instruments, Chengdu, China, 16–19 August 2011. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; McGuinness, K. Unsupervised label noise modeling and loss correction. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 312–321. [Google Scholar]
- Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Lip Reading Sentences in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yang, S.; Zhang, Y.; Feng, D.; Yang, M.; Chen, X. LRW-1000: A Naturally-Distributed Large-Scale Benchmark for Lip Reading in the Wild. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019. [Google Scholar]
- Jinlin, M.; Yanbin, Z.; Ziping, M.; Yuanwen, G.; Deguang, C.; Yuhao, L. A review of deep learning methods for lip recognition. Comput. Eng. Appl. 2021, 57, 13. [Google Scholar]
- Garg, A.; Noyola, J.; Bagadia, S. Lip Reading Using CNN and LSTM; Technical Report, CS231 n Project Report; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Noda, K.; Yamaguchi, Y.; Nakadai, K.; Okuno, H.G.; Ogata, T. Audio-visual speech recognition using deep learning. Appl. Intell. 2015, 42, 722–737. [Google Scholar] [CrossRef]
- Lee, D.; Lee, J.; Kim, K.E. Multi-view automatic lip-reading using neural network. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 290–302. [Google Scholar]
- Assael, Y.M.; Shillingford, B.; Whiteson, S.; De Freitas, N. Lipnet: Sentence-level lipreading. arXiv 2016, arXiv:1611.01599. [Google Scholar]
- Fung, I.; Mak, B. End-to-end low-resource lip-reading with maxout CNN and LSTM. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2511–2515. [Google Scholar]
- Xu, K.; Li, D.; Cassimatis, N.; Wang, X. LCANet: End-to-end lipreading with cascaded attention-CTC. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Calgary, AB, Canada, 15–20 April 2018; pp. 548–555. [Google Scholar]
- Weng, X.; Kitani, K. Learning spatio-temporal features with two-stream deep 3d cnns for lipreading. arXiv 2019, arXiv:1905.02540. [Google Scholar]
- Wiriyathammabhum, P. SpotFast networks with memory augmented lateral transformers for lipreading. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 18–22 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 554–561. [Google Scholar]
- Stafylakis, T.; Khan, M.H.; Tzimiropoulos, G. Pushing the boundaries of audiovisual word recognition using residual networks and LSTMs. Comput. Vis. Image Underst. 2018, 176, 22–32. [Google Scholar] [CrossRef]
- Feng, D.; Yang, S.; Shan, S.; Chen, X. Learn an effective lip reading model without pains. arXiv 2020, arXiv:2011.07557. [Google Scholar]
- Afouras, T.; Chung, J.S.; Zisserman, A. My lips are concealed: Audio-visual speech enhancement through obstructions. arXiv 2019, arXiv:1907.04975. [Google Scholar]
- Xu, B.; Lu, C.; Guo, Y.; Wang, J. Discriminative multi-modality speech recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14433–14442. [Google Scholar]
- Petridis, S.; Li, Z.; Pantic, M. End-to-end visual speech recognition with LSTMs. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2592–2596. [Google Scholar]
- Wand, M.; Koutník, J.; Schmidhuber, J. Lipreading with long short-term memory. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6115–6119. [Google Scholar]
- Shillingford, B.; Assael, Y.; Hoffman, M.W.; Paine, T.; Hughes, C.; Prabhu, U.; Liao, H.; Sak, H.; Rao, K.; Bennett, L.; et al. Large-scale visual speech recognition. arXiv 2018, arXiv:1807.05162. [Google Scholar]
- Afouras, T.; Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Petridis, S.; Stafylakis, T.; Ma, P.; Tzimiropoulos, G.; Pantic, M. Audio-visual speech recognition with a hybrid ctc/attention architecture. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 513–520. [Google Scholar]
- Xiao, J.; Yang, S.; Zhang, Y.; Shan, S.; Chen, X. Deformation flow based two-stream network for lip reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 364–370. [Google Scholar]
- Martinez, B.; Ma, P.; Petridis, S.; Pantic, M. Lipreading using temporal convolutional networks. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6319–6323. [Google Scholar]
- Lamb, A.; Verma, V.; Kawaguchi, K.; Matyasko, A.; Khosla, S.; Kannala, J.; Bengio, Y. Interpolated adversarial training: Achieving robust neural networks without sacrificing too much accuracy. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, Seoul, Korea, 15 November 2019. [Google Scholar]
- Zhang, L.; Deng, Z.; Kawaguchi, K.; Ghorbani, A.; Zou, J. How does mixup help with robustness and generalization? arXiv 2020, arXiv:2010.04819. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Tsipras, D.; Santurkar, S.; Engstrom, L.; Turner, A.; Madry, A. Robustness may be at odds with accuracy. arXiv 2018, arXiv:1805.12152. [Google Scholar]
- Xu, H.; Mannor, S. Robustness and generalization. Mach. Learn. 2012, 86, 391–423. [Google Scholar] [CrossRef]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Wang, H.; Zhu, Y.; Green, B.; Adam, H.; Yuille, A.; Chen, L.C. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 108–126. [Google Scholar]
- Zhao, X.; Yang, S.; Shan, S.; Chen, X. Mutual information maximization for effective lip reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 420–427. [Google Scholar]
- Yuanyuan, W.; Pei, W.; Kaicun, W. Research on lip language recognition based on self-attention sequence model. Electron. Dev. 2021, 3, 624–627. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block Name | Conv Channel | Input Size | Output Size |
|---|---|---|---|
| Conv_pre | 1->64 | [B,1,T,88,88] | [B,64,T,44,44] |
| MaxPool | 64->64 | [B,64,T,44,44] | [B,64,T,22,22] |
| ResBlock1 | 64->64 | [B,64,T,22,22] | [B,64,T,22,22] |
| ResBlock2 | 64->64 | [B,64,T,22,22] | [B,64,T,22,22] |
| ResDown1 | 64->128 | [B,64,T,22,22] | [B,64,T,22,22] |
| ResBlock3 | 128->128 | [B,128,T,11,11] | [B,128,T,11,11] |
| ResDown2 | 128->256 | [B,128,T,11,11] | [B,256,T,6,6] |
| ResBlock4 | 256->256 | [B,256,T,6,6] | [B,256,T,6,6] |
| ResDown3 | 256->512 | [B,256,T,6,6] | [B,512,T,3,3] |
| ResBlock5 | 512->512 | [B,512,T,3,3] | [B,512,T,3,3] |
| Average pool | 512->512 | [B,512,T,3,3] | [B,512,T,1,1] |
| Architecture | GPU Time (ms) | CPU Time (ms) | TOP-1 Acc. (%) |
|---|---|---|---|
| ResNet-50 [37] | 11.4 | 895.4 | 76.8 |
| ResNet-101 [37] | 18.9 | 967.4 | 78.5 |
| SAN19 [38] | 33.2 | N/A | 77.4 |
| Axial ResNet-S [39] | 35.9 | 377.0 | 78.1 |
| InvNet-18 | 11.2 | 156.0 | 77.6 |
| Front-End | Back-End | #Params (M) | LRW (%) | LRW-1000 (%) |
|---|---|---|---|---|
| VGGM | N/A | 11.6 | 61.1% | 25.7% |
| ResNet-18 | Bi-GRU | 10.6 | 83.0% | 38.2% |
| ResNet-34 | Bi-LSTM | 19.6 | 83.5% | N/A |
| InvNet-18 | Bi-GRU | 7.2 | 84.5% | 41.6% |
| Models | LRW (%) | LRW-1000 (%) |
|---|---|---|
| VGGM | 61.1% | 25.7% |
| D3D | 78.0% | 34.7% |
| GLMIM [40] | 84.4% | 38.7% |
| Baseline model (normal example) | 83.0% | 38.2% |
| Multi-Grained ResNet-18 + Conv BiLSTM | 83.3% | 36.9% |
| ResNet-34 + BiLSTM | 83.5% | 38.2% |
| Two-Stream ResNet-18 + BiLSTM | 84.1% | N/A |
| STCNN + Bi-GRU + Self-Attention [41] | 84.79% | 40.58% |
| Baseline model (adversarial example) | 75.2% | 31.9% |
| Mixup + Baseline model (adversarial example) | 85.0% | 40.2% |
| Mixup + 3D Conv + InvNet-18 + Bi-GRU (normal example) | 85.6% | 41.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, J.; Wang, Z.; Xu, L.; Dai, J.; Gu, M.; Huang, J. An Interference-Resistant and Low-Consumption Lip Recognition Method. Electronics 2022, 11, 3066. https://doi.org/10.3390/electronics11193066
Jia J, Wang Z, Xu L, Dai J, Gu M, Huang J. An Interference-Resistant and Low-Consumption Lip Recognition Method. Electronics. 2022; 11(19):3066. https://doi.org/10.3390/electronics11193066
Chicago/Turabian StyleJia, Junwei, Zhilu Wang, Lianghui Xu, Jiajia Dai, Mingyi Gu, and Jing Huang. 2022. "An Interference-Resistant and Low-Consumption Lip Recognition Method" Electronics 11, no. 19: 3066. https://doi.org/10.3390/electronics11193066
APA StyleJia, J., Wang, Z., Xu, L., Dai, J., Gu, M., & Huang, J. (2022). An Interference-Resistant and Low-Consumption Lip Recognition Method. Electronics, 11(19), 3066. https://doi.org/10.3390/electronics11193066