
Sequential Clique Optimization for Unsupervised and Weakly Supervised Video Object Segmentation


Abstract
:1. Introduction
- We propose the SCO process to extract multiple primary objects effectively. It determines a clique efficiently with complexity, where T is the number of frames in a video, and N is the number of instances in each frame.
- The proposed algorithm can extract multiple primary objects effectively, whereas most conventional algorithms assume a single primary object.
- We extend the preliminary work [18] of this paper to achieve weakly supervised VOS using the SD-Net, which yields segmentation results using only a few point clicks instead of dense masks for target objects. The proposed SD-Net also improves the unsupervised VOS results of the preliminary work.
- We develop two segmentation refinement methods to improve the unsupervised VOS results based on MRF optimization and the SD-Net.
2. Related Work
2.1. Unsupervised VOS
2.2. Semi-Supervised VOS
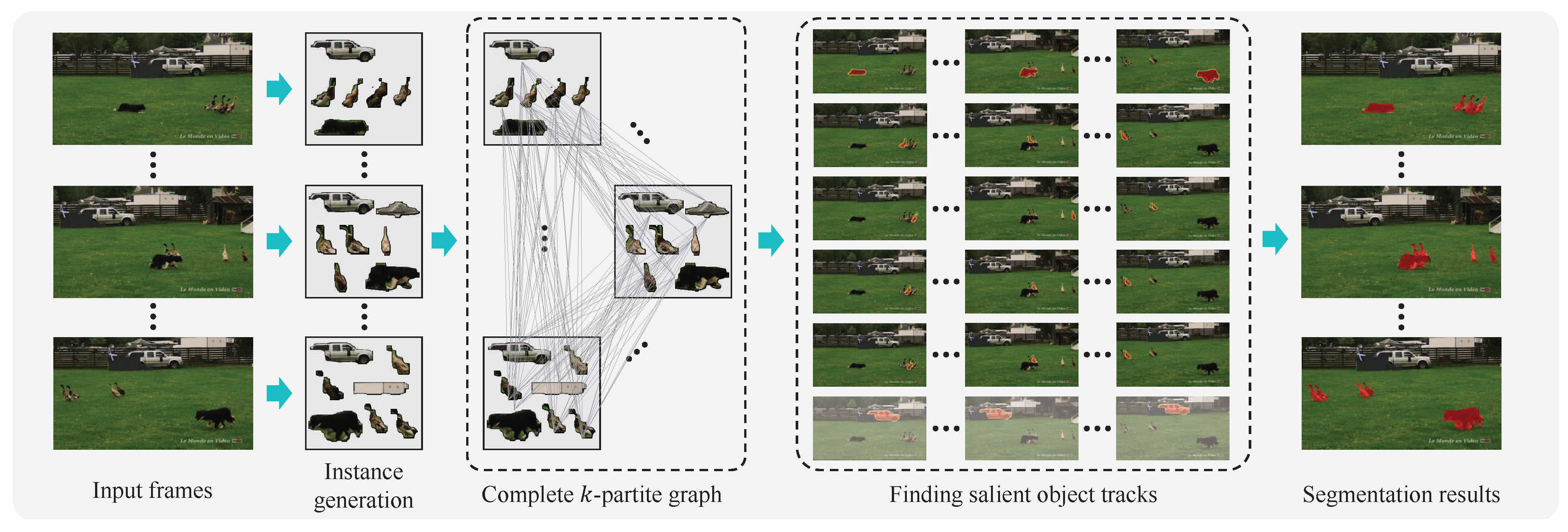
3. Proposed Unsupervised VOS Algorithm
3.1. Generating Object Instances
3.2. Finding Salient Object Tracks
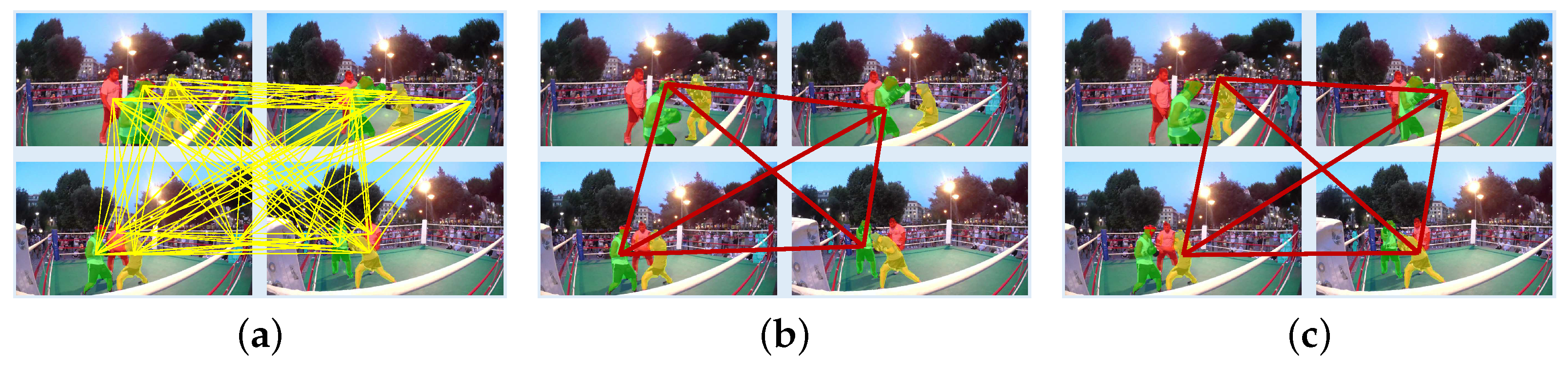
3.2.1. Problem Formulation
3.2.2. SCO
| Algorithm 1(SCO) Sequential Clique Optimization |
Input: Sets of object instances
Output: Optimized clique |
3.2.3. Salient Object Track Refinement
3.2.4. Disappearance Detection
3.3. Segmentation Results
3.3.1. Object Track Selection
- SCO-F: The first track extracts the primary object in a video in general. Thus, SCO-F selects . However, it may fail to extract spatially connected objects. For example, given a motorbike and its rider, it may detect only one of them. Therefore, SCO-F additionally picks another salient object track , only when and are spatially adjacent in most frames in a video.
- SCO-M: To handle multiple primary objects, which may not be spatially connected, we choose multiple tracks from . To this end, we compute the mean saliency score of the object instances in each track and discard the tracks whose mean scores are lower than a pre-specified threshold . We fix in all experiments.
- SCO-OF: The aforementioned SCO-F is an offline approach that constructs the global T-partite graph for an entire video. In contrast, SCO-OF is an online approach that uses the t-partite graph for frames to obtain the segmentation result for the current frame . In other words, SCO-O uses the information in the current and past frames only to achieve VOS.
- SCO-OM: SCO-OM is an online approach of SCO-M.
3.3.2. Pixel-Wise Segmentation Refinement
3.4. Complexity Analysis
4. Proposed Weakly Supervised Algorithm
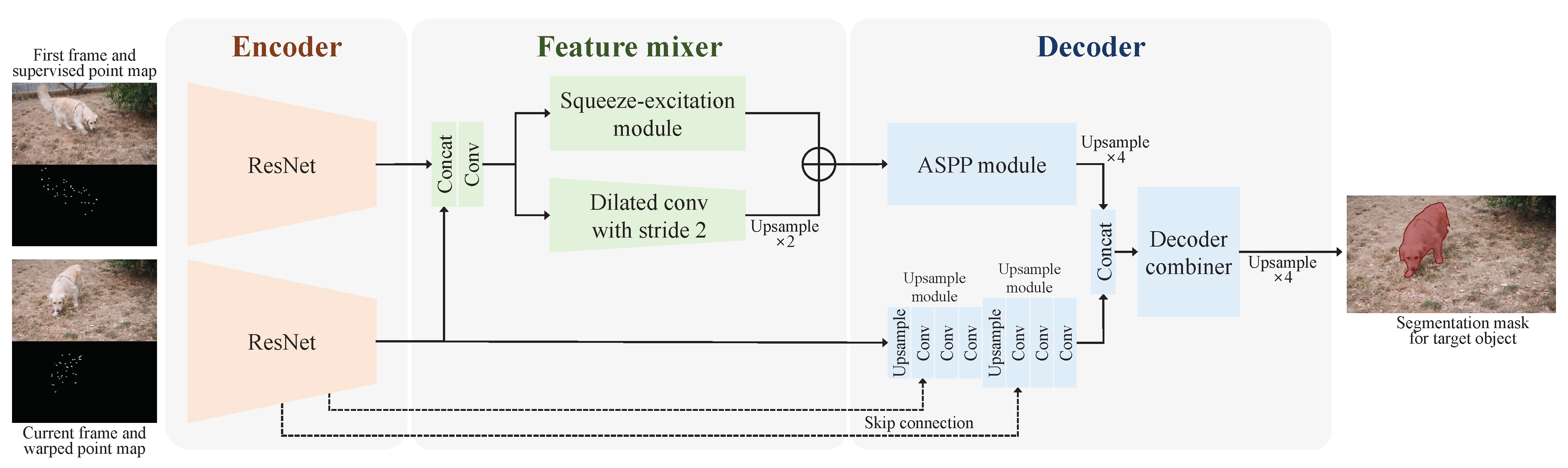
4.1. Network Architecture
4.2. SD-Net for Weakly Supervised VOS
4.3. SD-Net for Segmentation Refinement in Unsupervised VOS
5. Experimental Results
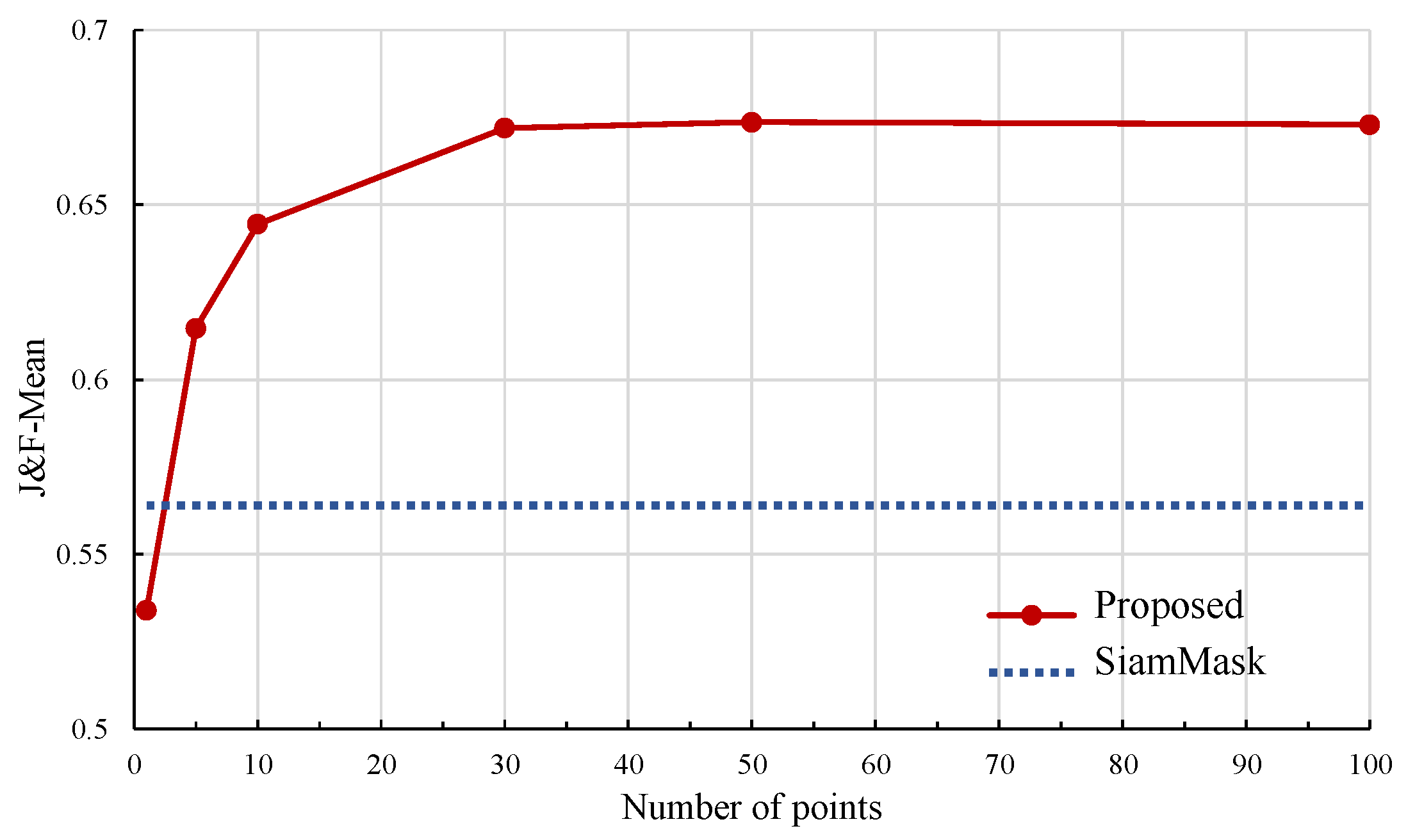
5.1. Ablation Studies
5.2. Assessment of Unsupervised VOS Algorithm
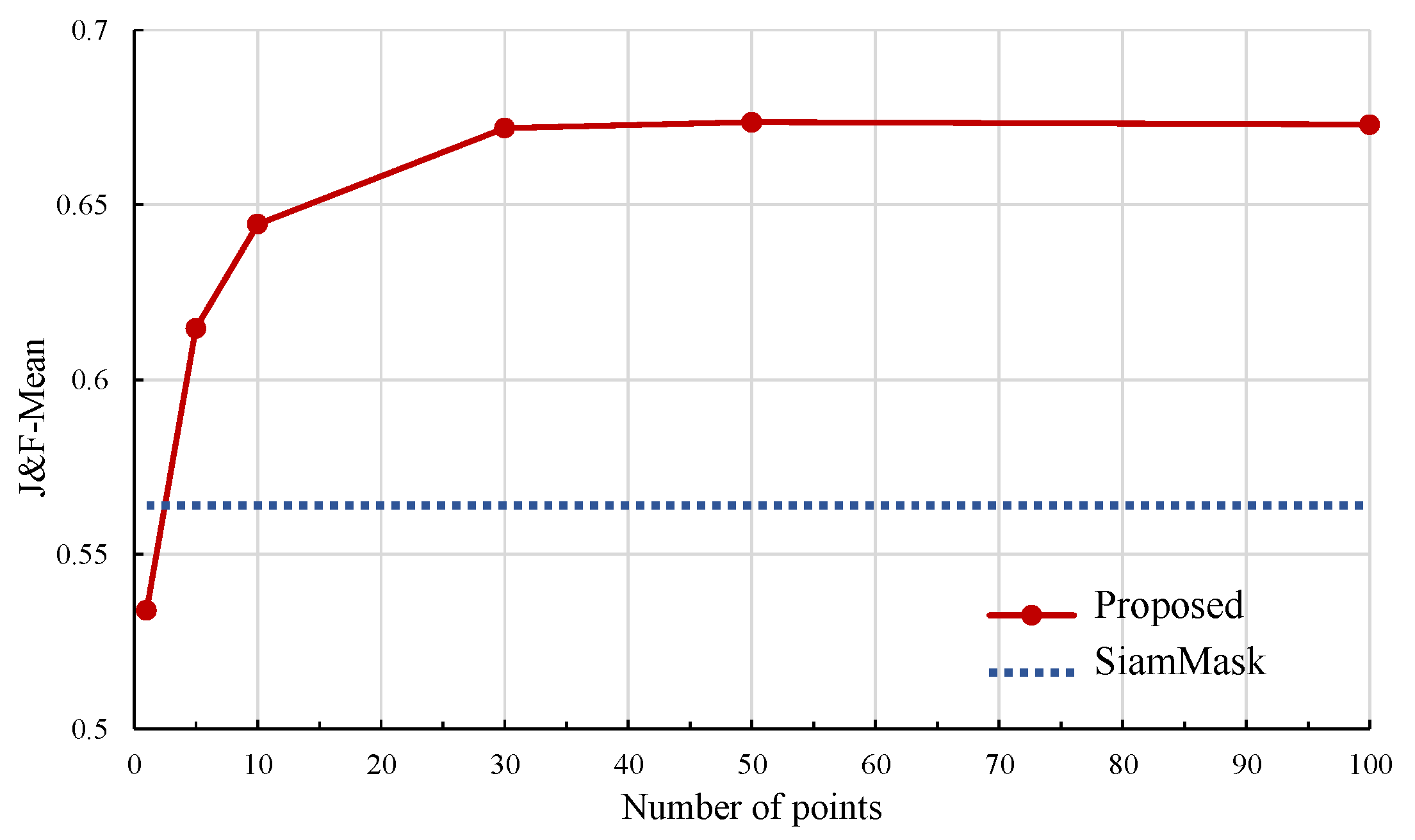
5.3. Assessment of Weakly Supervised VOS Algorithm
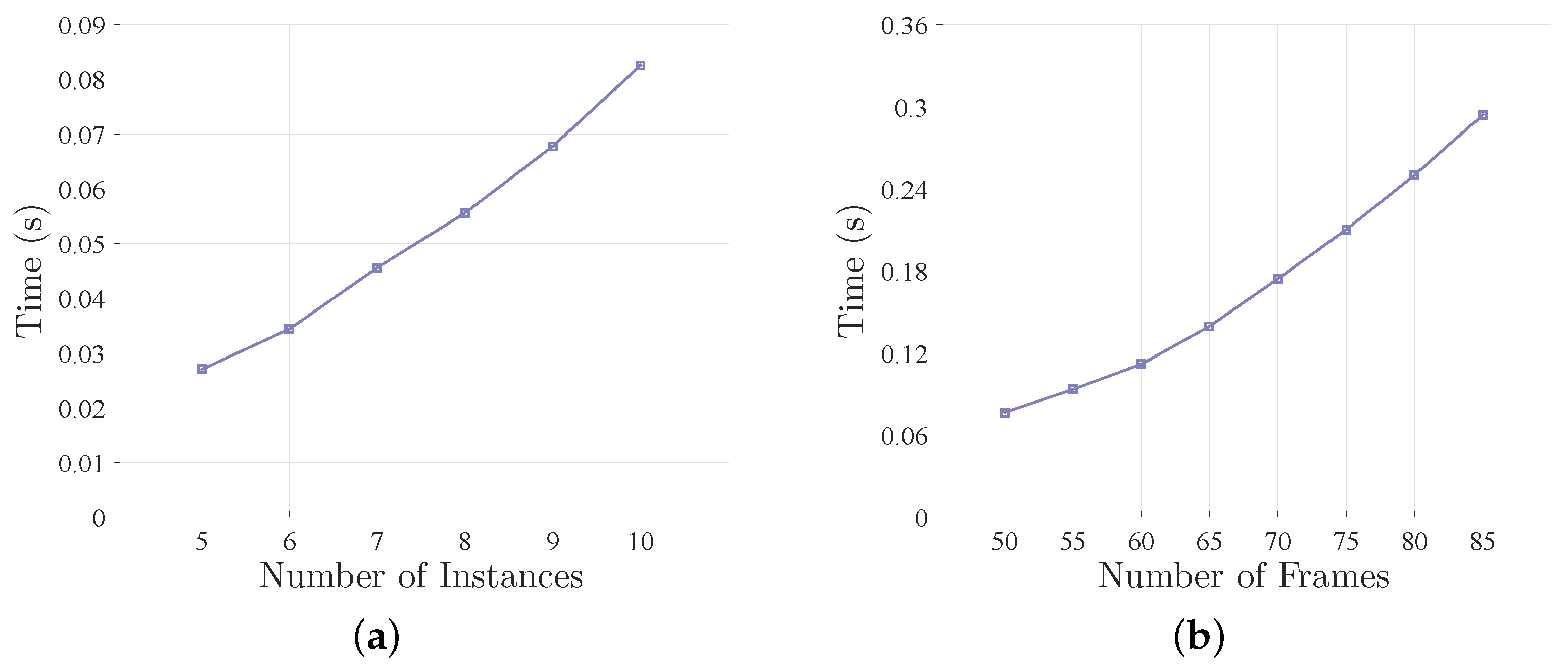
5.4. Running Time Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Koh, Y.J.; Jang, W.D.; Kim, C.S. POD: Discovering primary objects in videos based on evolutionary refinement of object recurrence, background, and primary object models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Cecognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1068–1076. [Google Scholar]
- Maninis, K.K.; Caelles, S.; Pont-Tuset, J.; Van Gool, L. Deep extreme cut: From extreme points to object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 616–625. [Google Scholar]
- Zhang, Z.; Hua, Y.; Song, T.; Xue, Z.; Ma, R.; Robertson, N.; Guan, H. Tracking-assisted Weakly Supervised Online Visual Object Segmentation in Unconstrained Videos. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 941–949. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H.S. Fast Online Object Tracking and Segmentation: A Unifying Approach. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar]
- Wei, L.; Lang, C.; Liang, L.; Feng, S.; Wang, T.; Chen, S. Weakly Supervised Video Object Segmentation via Dual-attention Cross-branch Fusion. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–20. [Google Scholar] [CrossRef]
- En, Q.; Duan, L.; Zhang, Z. Joint Multisource Saliency and Exemplar Mechanism for Weakly Supervised Video Object Segmentation. IEEE Trans. Image Process. 2021, 30, 8155–8169. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Yang, J.; Zhang, Q.; Zhang, X. Improvement of generalization ability of deep CNN via implicit regularization in two-stage training process. IEEE Access 2018, 6, 15844–15869. [Google Scholar] [CrossRef]
- Zhao, M.; Chang, C.H.; Xie, W.; Xie, Z.; Hu, J. Cloud shape classification system based on multi-channel cnn and improved fdm. IEEE Access 2020, 8, 44111–44124. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Gonçalves, N. Deep facial diagnosis: Deep transfer learning from face recognition to facial diagnosis. IEEE Access 2020, 8, 123649–123661. [Google Scholar] [CrossRef]
- Zheng, Q.; Zhao, P.; Li, Y.; Wang, H.; Yang, Y. Spectrum interference-based two-level data augmentation method in deep learning for automatic modulation classification. Neural Comput. Appl. 2021, 33, 7723–7745. [Google Scholar] [CrossRef]
- Jain, S.D.; Xiong, B.; Grauman, K. FusionSeg: Learning to Combine Motion and Appearance for Fully Automatic Segmentation of Generic Objects in Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3664–3673. [Google Scholar]
- Koh, Y.J.; Kim, C.S. Primary Object Segmentation in Videos Based on Region Augmentation and Reduction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3442–3450. [Google Scholar]
- Lu, X.; Wang, W.; Ma, C.; Shen, J.; Shao, L.; Porikli, F. See More, Know More: Unsupervised Video Object Segmentation With Co-Attention Siamese Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3618–3627. [Google Scholar]
- Caelles, S.; Maninis, K.K.; Pont-Tuset, J.; Leal-Taixe, L.; Cremers, D.; Van Gool, L. One-Shot Video Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 221–230. [Google Scholar]
- Voigtlaender, P.; Leibe, B. Online adaptation of convolutional neural networks for video object segmentation. arXiv 2017, arXiv:1706.09364. [Google Scholar]
- Chen, Y.; Pont-Tuset, J.; Montes, A.; Van Gool, L. Blazingly Fast Video Object Segmentation with Pixel-Wise Metric Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1189–1198. [Google Scholar]
- Voigtlaender, P.; Chai, Y.; Schroff, F.; Adam, H.; Leibe, B.; Chen, L.C. FEELVOS: Fast end-to-end embedding learning for video object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9481–9490. [Google Scholar]
- Koh, Y.J.; Lee, Y.Y.; Kim, C.S. Sequential clique optimization for video object segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Seoul, Korea, 22–26 October 2018; pp. 537–556. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully Convolutional Instance-Aware Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Chartrand, G.; Zhang, P. Chromatic Graph Theory; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 724–732. [Google Scholar]
- Papazoglou, A.; Ferrari, V. Fast object segmentation in unconstrained video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1777–1784. [Google Scholar]
- Jang, W.D.; Lee, C.; Kim, C.S. Primary Object Segmentation in Videos via Alternate Convex Optimization of Foreground and Background Distributions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 696–704. [Google Scholar]
- Tokmakov, P.; Schmid, C.; Alahari, K. Learning to segment moving objects. Int. J. Comput. Vis. 2019, 127, 282–301. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, Q.; Bertinetto, L.; Bai, S.; Hu, W.; Torr, P.H.S. Anchor Diffusion for Unsupervised Video Object Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 931–940. [Google Scholar]
- Zhou, T.; Wang, S.; Zhou, Y.; Yao, Y.; Li, J.; Shao, L. Motion-Attentive Transition for Zero-Shot Video Object Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Wang, W.; Song, H.; Zhao, S.; Shen, J.; Zhao, S.; Hoi, S.C.; Ling, H. Learning unsupervised video object segmentation through visual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3064–3074. [Google Scholar]
- Zhuo, T.; Cheng, Z.; Zhang, P.; Wong, Y.; Kankanhalli, M. Unsupervised online video object segmentation with motion property understanding. IEEE Trans. Image Process. 2019, 29, 237–249. [Google Scholar] [CrossRef]
- Ventura, C.; Bellver, M.; Girbau, A.; Salvador, A.; Marques, F.; Giro-i Nieto, X. RVOS: End-to-end recurrent network for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5277–5286. [Google Scholar]
- Qi, G.; Zhang, Y.; Wang, K.; Mazur, N.; Liu, Y.; Malaviya, D. Small Object Detection Method Based on Adaptive Spatial Parallel Convolution and Fast Multi-Scale Fusion. Remote. Sens. 2022, 14, 420. [Google Scholar] [CrossRef]
- Lazarow, J.; Xu, W.; Tu, Z. Instance Segmentation With Mask-Supervised Polygonal Boundary Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4382–4391. [Google Scholar]
- Jang, W.D.; Kim, C.S. Online Video Object Segmentation via Convolutional Trident Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5849–5858. [Google Scholar]
- Sun, M.; Xiao, J.; Lim, E.G.; Xie, Y.; Feng, J. Adaptive ROI Generation for Video Object Segmentation Using Reinforcement Learning. Pattern Recog. 2020, 106, 107465. [Google Scholar] [CrossRef]
- Yin, Y.; Xu, D.; Wang, X.; Zhang, L. AGUnet: Annotation-guided U-net for fast one-shot video object segmentation. Pattern Recog. 2021, 110, 107580. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar]
- Zamir, A.R.; Dehghan, A.; Shah, M. GMCP-Tracker: Global multi-object tracking using generalized minimum clique graphs. In Proceedings of the European Conference on Computer Vision, Providence, RI, USA, 16–21 June 2012; pp. 343–356. [Google Scholar]
- Dehghan, A.; Modiri Assari, S.; Shah, M. GMMCP Tracker: Globally optimal generalized maximum multi clique problem for multiple object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4091–4099. [Google Scholar]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 1999; Volume 1, pp. 377–384. [Google Scholar]
- Fan, Q.; Zhong, F.; Lischinski, D.; Cohen-Or, D.; Chen, B. JumpCut: Non-successive mask transfer and interpolation for video cutout. ACM Trans. Graphics 2015, 34, 195:1–195:10. [Google Scholar] [CrossRef]
- Jang, W.D.; Kim, C.S. Interactive Image Segmentation via Backpropagating Refinement Scheme. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5297–5306. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Xu, N.; Yang, L.; Fan, Y.; Yang, J.; Yue, D.; Liang, Y.; Price, B.; Cohen, S.; Huang, T. YouTube-VOS: Sequence-to-sequence video object segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018 2018; pp. 585–601. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Zhao, Z.; Zhao, S.; Shen, J. Real-time and light-weighted unsupervised video object segmentation network. Pattern Recognit. 2021, 120, 108120. [Google Scholar] [CrossRef]
- Zhou, Y.; Xu, X.; Shen, F.; Zhu, X.; Shen, H.T. Flow-edge guided unsupervised video object segmentation. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- Wang, Y.; Choi, J.; Chen, Y.; Li, S.; Huang, Q.; Zhang, K.; Lee, M.S.; Kuo, C.C.J. Unsupervised video object segmentation with distractor-aware online adaptation. J. Vis. Commun. Image Represent. 2021, 74, 102953. [Google Scholar] [CrossRef]
- Gao, S.H.; Tan, Y.Q.; Cheng, M.M.; Lu, C.; Chen, Y.; Yan, S. Highly Efficient Salient Object Detection with 100K Parameters. In Proceedings of the European Conference on Computer Vision (ECCV), Online Conference, 23–28 August 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Li, F.; Kim, T.; Humayun, A.; Tsai, D.; Rehg, J.M. Video segmentation by tracking many figure-ground segments. In Proceedings of the IEEE International Conference on Computer Vision, Portland, OR, USA, 23–28 June 2013; pp. 2192–2199. [Google Scholar]
- Oh, S.W.; Lee, J.Y.; Sunkavalli, K.; Kim, S.J. Fast Video Object Segmentation by Reference-Guided Mask Propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7376–7385. [Google Scholar]
- Zeng, X.; Liao, R.; Gu, L.; Xiong, Y.; Fidler, S.; Urtasun, R. DMM-Net: Differentiable mask-matching network for video object segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3929–3938. [Google Scholar]
- Hu, P.; Liu, J.; Wang, G.; Ablavsky, V.; Saenko, K.; Sclaroff, S. Dipnet: Dynamic identity propagation network for video object segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 2–5 March 2020; pp. 1904–1913. [Google Scholar]
- Yu, S.; Xiao, J.; Zhang, B.; Lim, E.G.; Zhao, Y. Fast pixel-matching for video object segmentation. Signal Process. Image Commun. 2021, 98, 116373. [Google Scholar] [CrossRef]
- Li, Y.; Hong, Y.; Song, Y.; Zhu, C.; Zhang, Y.; Wang, R. SiamPolar: Semi-supervised realtime video object segmentation with polar representation. Neurocomputing 2022, 467, 491–503. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Refinement | Region Similarity | Contour Accuracy | ||||
|---|---|---|---|---|---|---|
| Algorithm | MRF | SD-Net | Mean | Recall | Mean | Recall |
| SCO-F | 0.788 | 0.958 | 0.757 | 0.867 | ||
| ✓ | 0.809 | 0.957 | 0.770 | 0.877 | ||
| ✓ | 0.815 | 0.962 | 0.796 | 0.885 | ||
| ✓ | ✓ | 0.819 | 0.962 | 0.799 | 0.881 | |
| SCO-OF | 0.751 | 0.885 | 0.736 | 0.852 | ||
| ✓ | 0.772 | 0.887 | 0.749 | 0.855 | ||
| ✓ | 0.776 | 0.892 | 0.766 | 0.855 | ||
| ✓ | ✓ | 0.781 | 0.894 | 0.773 | 0.856 | |
| SCO-M | 0.743 | 0.851 | 0.727 | 0.823 | ||
| ✓ | 0.763 | 0.860 | 0.740 | 0.831 | ||
| ✓ | 0.766 | 0.857 | 0.761 | 0.833 | ||
| ✓ | ✓ | 0.771 | 0.865 | 0.764 | 0.837 | |
| Refinement | Region Similarity | Contour Accuracy | ||||
|---|---|---|---|---|---|---|
| Algorithm | MRF | SD-Net | Mean | Recall | Mean | Recall |
| SCO-M | 0.518 | 0.615 | 0.552 | 0.640 | ||
| ✓ | 0.532 | 0.620 | 0.557 | 0.644 | ||
| ✓ | 0.533 | 0.618 | 0.567 | 0.646 | ||
| ✓ | ✓ | 0.537 | 0.623 | 0.568 | 0.651 | |
| SCO-OM | 0.474 | 0.561 | 0.510 | 0.577 | ||
| ✓ | 0.483 | 0.562 | 0.514 | 0.580 | ||
| ✓ | 0.486 | 0.565 | 0.523 | 0.589 | ||
| ✓ | ✓ | 0.490 | 0.568 | 0.524 | 0.587 | |
| Region Similarity | Contour Accuracy | ||||
|---|---|---|---|---|---|
| Algorithm | Saliency | Mean | Recall | Mean | Recall |
| SCO-M | CSF [50] | 0.512 | 0.597 | 0.549 | 0.625 |
| w/o OF | 0.509 | 0.594 | 0.543 | 0.618 | |
| Proposed | 0.537 | 0.623 | 0.568 | 0.651 | |
| SCO-OM | CSF [50] | 0.485 | 0.557 | 0.523 | 0.592 |
| w/o OF | 0.472 | 0.543 | 0.511 | 0.569 | |
| Proposed | 0.490 | 0.568 | 0.524 | 0.587 | |
| Region Similarity | Contour Accuracy | ||||
|---|---|---|---|---|---|
| Algorithm | Setting | Mean | Recall | Mean | Recall |
| SCO-M | Proposed | 0.537 | 0.623 | 0.568 | 0.651 |
| w/o SOTR | 0.525 | 0.611 | 0.562 | 0.642 | |
| w/o DD | 0.522 | 0.607 | 0.559 | 0.637 | |
| Feature | Distance | Region Similarity | Contour Accuracy | |||
|---|---|---|---|---|---|---|
| Algorithm | Type | Metric | Mean | Recall | Mean | Recall |
| SCO-M | VGG16 | Chi-square | 0.504 | 0.580 | 0.551 | 0.616 |
| VGG16 | Cosine | 0.512 | 0.600 | 0.557 | 0.636 | |
| ResNet50 | Chi-square | 0.514 | 0.597 | 0.552 | 0.623 | |
| ResNet50 | Cosine | 0.516 | 0.603 | 0.560 | 0.639 | |
| BoW | Chi-square | 0.537 | 0.623 | 0.568 | 0.651 | |
| SCO-OM | VGG16 | Chi-square | 0.470 | 0.545 | 0.519 | 0.569 |
| VGG16 | Cosine | 0.469 | 0.543 | 0.514 | 0.571 | |
| ResNet50 | Chi-square | 0.475 | 0.549 | 0.520 | 0.571 | |
| ResNet50 | Cosine | 0.477 | 0.552 | 0.523 | 0.578 | |
| BoW | Chi-square | 0.490 | 0.568 | 0.524 | 0.587 | |
| Region Similarity | Contour Accuracy | |||
|---|---|---|---|---|
| Algorithm | Mean | Recall | Mean | Recall |
| FST [22] | 0.558 | 0.649 | 0.511 | 0.516 |
| FSEG [11] | 0.707 | 0.835 | 0.653 | 0.738 |
| ARP [12] | 0.762 | 0.911 | 0.706 | 0.835 |
| LSMO [24] | 0.782 | 0.891 | 0.759 | 0.847 |
| AGS [27] | 0.797 | 0.911 | 0.774 | 0.858 |
| COSNet [13] | 0.805 | 0.931 | 0.795 | 0.895 |
| AnDiff [25] | 0.817 | 0.909 | 0.805 | 0.851 |
| MATNet [26] | 0.824 | 0.945 | 0.807 | 0.902 |
| UOVOS [28] | 0.739 | 0.885 | 0.680 | 0.806 |
| Zhao [47] | 0.634 | 0.703 | 0.602 | 0.627 |
| FEM-Net [48] | 0.799 | 0.939 | 0.769 | 0.883 |
| Wang [49] | 0.816 | - | 0.797 | - |
| SCO-F | 0.819 | 0.962 | 0.799 | 0.881 |
| SCO-OF | 0.781 | 0.894 | 0.773 | 0.856 |
| SCO-M | 0.771 | 0.865 | 0.764 | 0.837 |
| Mean & | |||||
|---|---|---|---|---|---|
| Attr. | ARP | FSEG | LSMO | AGS | SCO-F |
| LR | 0.722 | 0.712 | 0.772 | 0.815 | 0.861 |
| SV | 0.698 | 0.603 | 0.724 | 0.744 | 0.779 |
| FM | 0.728 | 0.660 | 0.734 | 0.775 | 0.805 |
| CS | 0.754 | 0.756 | 0.817 | 0.831 | 0.845 |
| DB | 0.693 | 0.482 | 0.556 | 0.640 | 0.697 |
| MB | 0.689 | 0.607 | 0.721 | 0.735 | 0.751 |
| OCC | 0.725 | 0.628 | 0.767 | 0.769 | 0.768 |
| OV | 0.728 | 0.629 | 0.696 | 0.754 | 0.766 |
| AC | 0.759 | 0.674 | 0.766 | 0.800 | 0.840 |
| Region Similarity | Contour Accuracy | |||
|---|---|---|---|---|
| Algorithm | Mean | Recall | Mean | Recall |
| RVOS [29] | 0.368 | 0.402 | 0.457 | 0.464 |
| SCO-OM | 0.490 | 0.568 | 0.524 | 0.587 |
| SCO-M | 0.537 | 0.623 | 0.568 | 0.651 |
| Region Similarity | Contour Accuracy | ||||
|---|---|---|---|---|---|
| Algorithm | Annotation | Mean | Recall | Mean | Recall |
| A. DAVIS2016 | |||||
| BBOX [3] | Box | 0.803 | 0.952 | – | – |
| SiamMask [4] | Box | 0.717 | 0.868 | 0.678 | 0.798 |
| DEXTR [2] | 4 points | 0.795 | – | – | – |
| per frame | |||||
| En [6] | category label | 0.769 | 0.927 | 0.720 | 0.870 |
| Proposed | 50 points | 0.815 | 0.955 | 0.795 | 0.886 |
| B. DAVIS2017 | |||||
| SiamMask [4] | Box | 0.543 | 0.628 | 0.585 | 0.675 |
| Proposed | # of targets | 0.537 | 0.630 | 0.566 | 0.650 |
| Proposed | 50 points | 0.658 | 0.781 | 0.688 | 0.804 |
| The Number of Interaction Rounds | ||||||
|---|---|---|---|---|---|---|
| Metric | 1 | 2 | 3 | 4 | 5 | 6 |
| Mean | 0.655 | 0.676 | 0.685 | 0.696 | 0.713 | 0.718 |
| Mean | 0.690 | 0.707 | 0.719 | 0.735 | 0.750 | 0.758 |
| 0.673 | 0.692 | 0.702 | 0.716 | 0.732 | 0.738 | |
| Semi-Supervised | Weakly Supervised | |||||
|---|---|---|---|---|---|---|
| RGMP [53] | DMM-Net [54] | DIPNet [55] | NPMCA-net [56] | SiamPolar [57] | Proposed | |
| Mean | 0.711 | 0.767 | 0.738 | 0.761 | 0.728 | 0.726 |
| Optical | Saliency | Feature | |||||
|---|---|---|---|---|---|---|---|
| FCIS | Flow | Estimation | Extraction | MRF | SD-Net | Total | |
| Time | 0.24 | 0.19 | 0.30 | 0.15 | 0.76 | 0.15 | 1.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koh, Y.J.; Heo, Y.; Kim, C.-S. Sequential Clique Optimization for Unsupervised and Weakly Supervised Video Object Segmentation. Electronics 2022, 11, 2899. https://doi.org/10.3390/electronics11182899
Koh YJ, Heo Y, Kim C-S. Sequential Clique Optimization for Unsupervised and Weakly Supervised Video Object Segmentation. Electronics. 2022; 11(18):2899. https://doi.org/10.3390/electronics11182899
Chicago/Turabian StyleKoh, Yeong Jun, Yuk Heo, and Chang-Su Kim. 2022. "Sequential Clique Optimization for Unsupervised and Weakly Supervised Video Object Segmentation" Electronics 11, no. 18: 2899. https://doi.org/10.3390/electronics11182899
APA StyleKoh, Y. J., Heo, Y., & Kim, C.-S. (2022). Sequential Clique Optimization for Unsupervised and Weakly Supervised Video Object Segmentation. Electronics, 11(18), 2899. https://doi.org/10.3390/electronics11182899