


Privacy-Preserving Top-k Query Processing Algorithms Using Efficient Secure Protocols over Encrypted Database in Cloud Computing Environment

Abstract
:1. Introduction
- We present an architecture for outsourcing both the encrypted data and index.
- We propose new secure protocols based on arithmetic operations (e.g., ASC, ASRO, and ASPE) to protect original data, user query, and access patterns.
- We propose a new Top-k query processing algorithm that can support both security and efficiency.
- We propose a new parallel Top-k query processing algorithm using a random value pool to improve the efficiency of Top-k query processing.
- We also present the comprehensive performance analysis of our algorithms with a synthetic and real dataset.
2. Background and Related Work
2.1. Background
- Homomorphic addition: The multiplication of two ciphertexts E() and E() generates the ciphertext of the sum of their plaintexts and (Equation (1)).
- Homomorphic multiplication: The th power of ciphertext E() generates the ciphertext of the multiplication of and (Equation (2)).
- Semantic security: Encryptions of the same plaintexts generate different ciphertexts in the same public key (Equation (3)).
2.2. Related Work
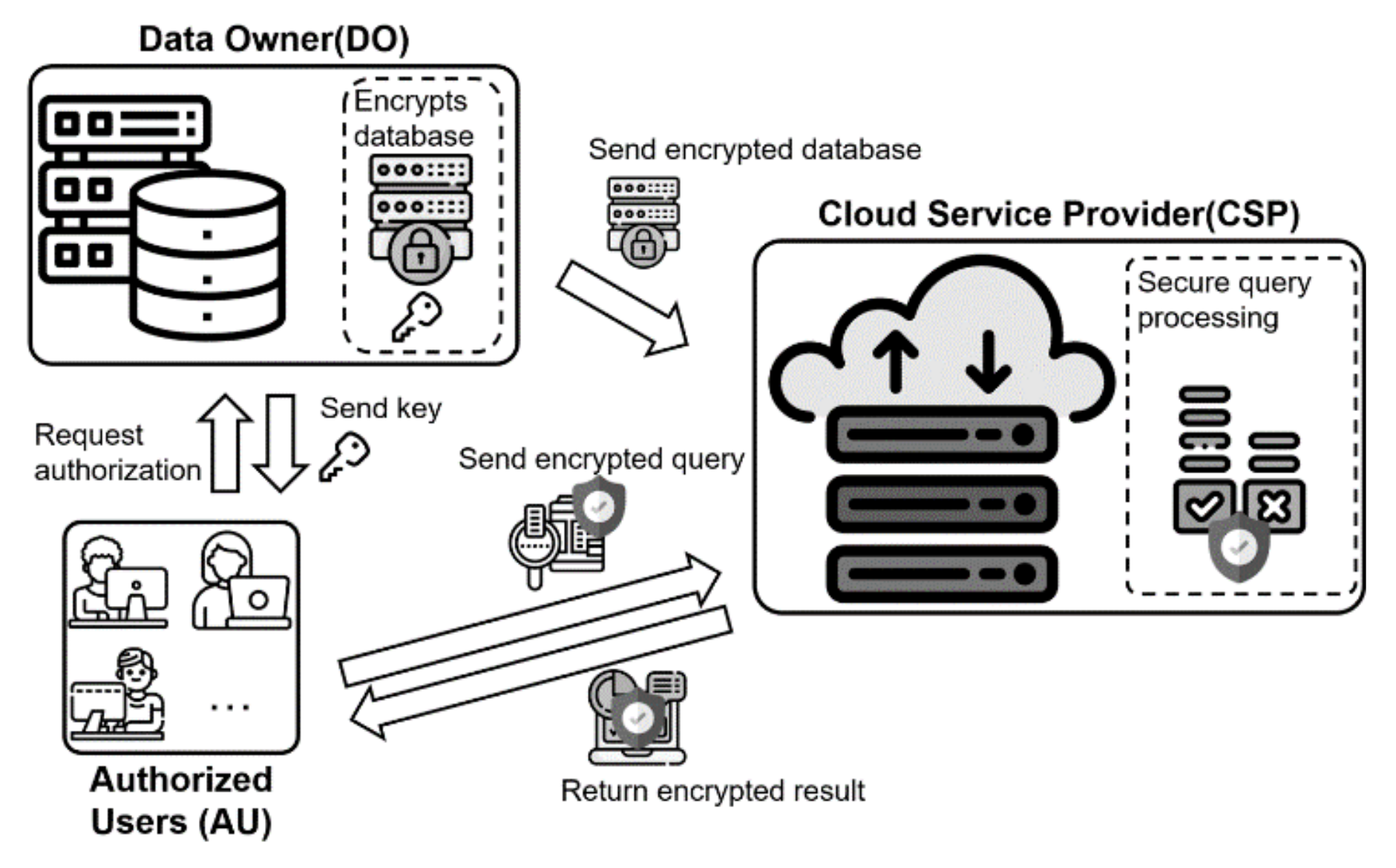
3. Overall System Architecture
3.1. System Architecture
3.2. Secure Protocol
| Algorithm 1 ASC Protocol. |
Input: Output: if , return E(1), otherwise, return E(0) : 01. pick two pairs <, E()> and <, E()> in random value pool 02. E() ← 03. E() ← 04. randomly selected or 05. if is selected then 06. Transmit <E(), E()> to 07. else if is selected then 08. Transmit <E(), E()> to 09. receive E(), E() // cannot know any information from . 10. D(E()) 11. D(E()) 12. if 13. E() ← E(1) 14. else 15. E() ← E(0) 16. Transmit to 17. receive 18. if is selected, then 19. return E() 20. else 21. return SBN(E()) |
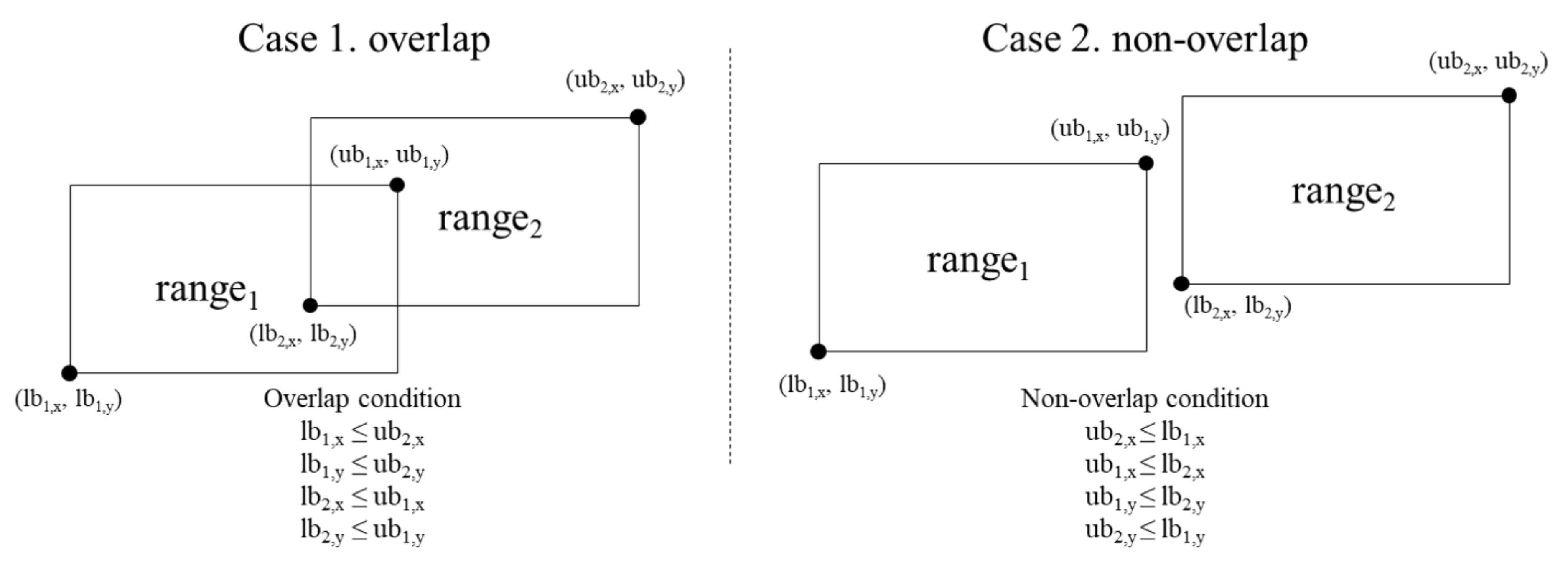
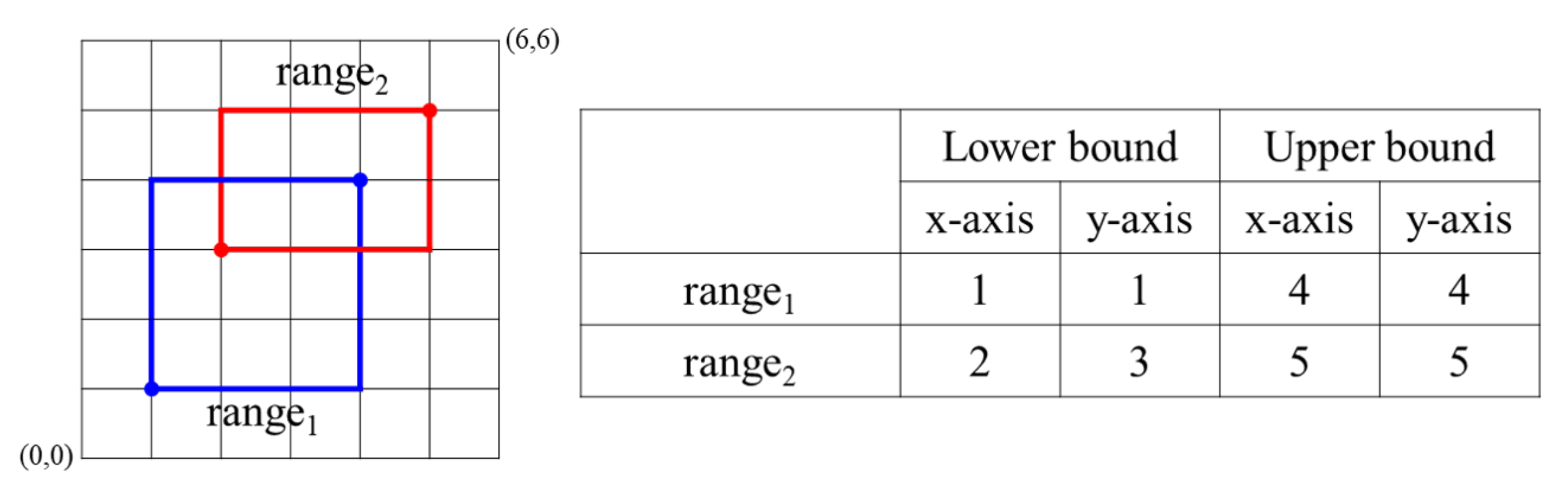
| Algorithm 2 ASRO Protocol. |
Input: E(), E() (range consists of <> , m is the number of dimension) Output: if and is overlapped, return E(1), otherwise, return E(0) : 01. E() ← E(1) 02. for 03. E() ← ASC(E(), E()) 04. E() ← SM(E(), E()) 05. for 06. E() ← ASC(E(), E()) 07. E() ← SM(E(), E()) 08. return E() |
| Algorithm 3 ASPE Protocol. |
Input: E(p), E(range) (range consists of <> , m is the number of dimension) Output: if range includes p, return E(1), otherwise, return E(0) : 01. E() ← E(1) 02. for 03. E() ← ASC(E(p), E()) 04. E() ← SM(E(), E()) 05. E() ← ASC(E(), E(p)) 06. E() ← SM(E(), E()) 07. return E() |
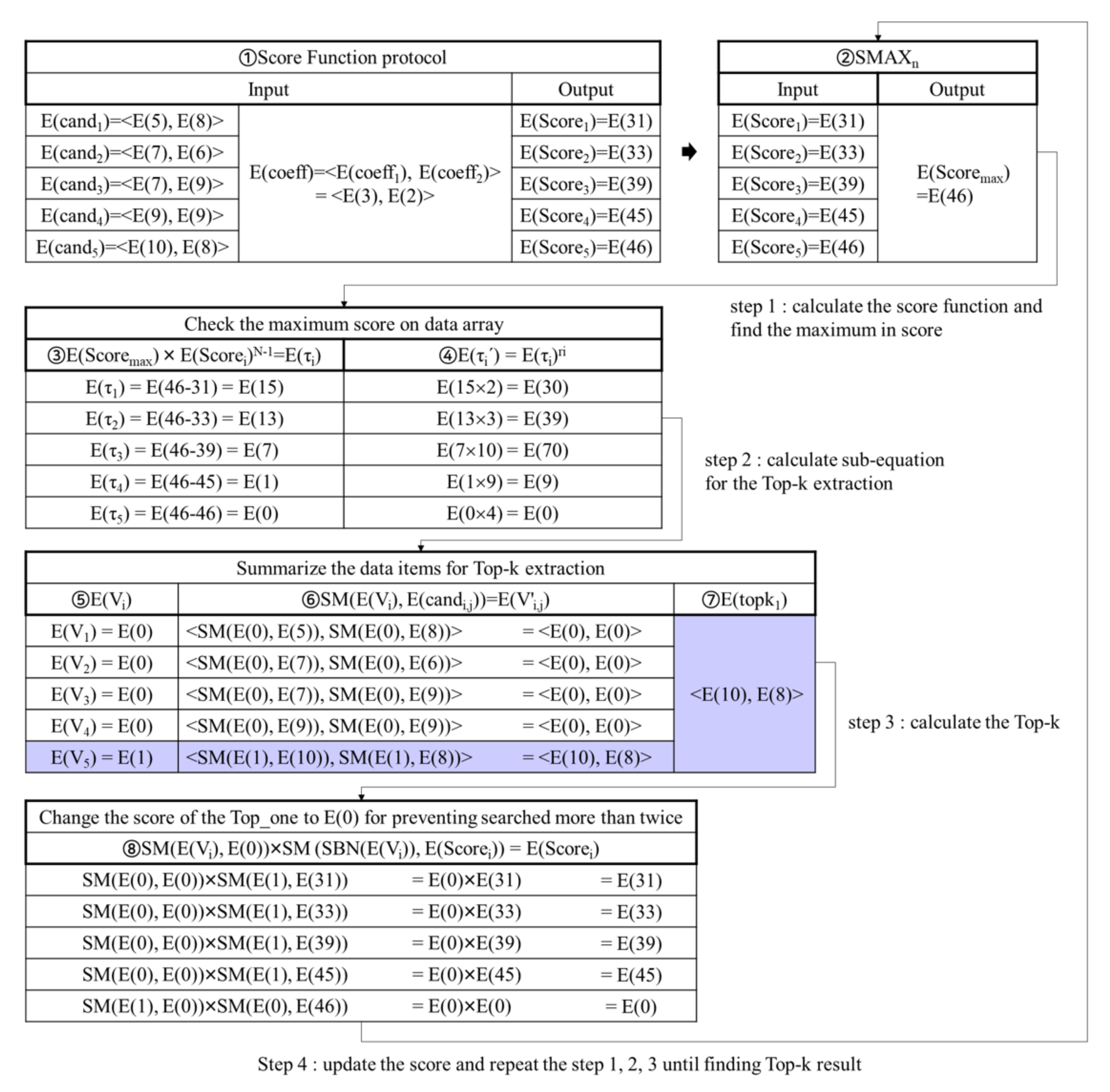
4. Privacy-Preserving Top- Query Processing Algorithm
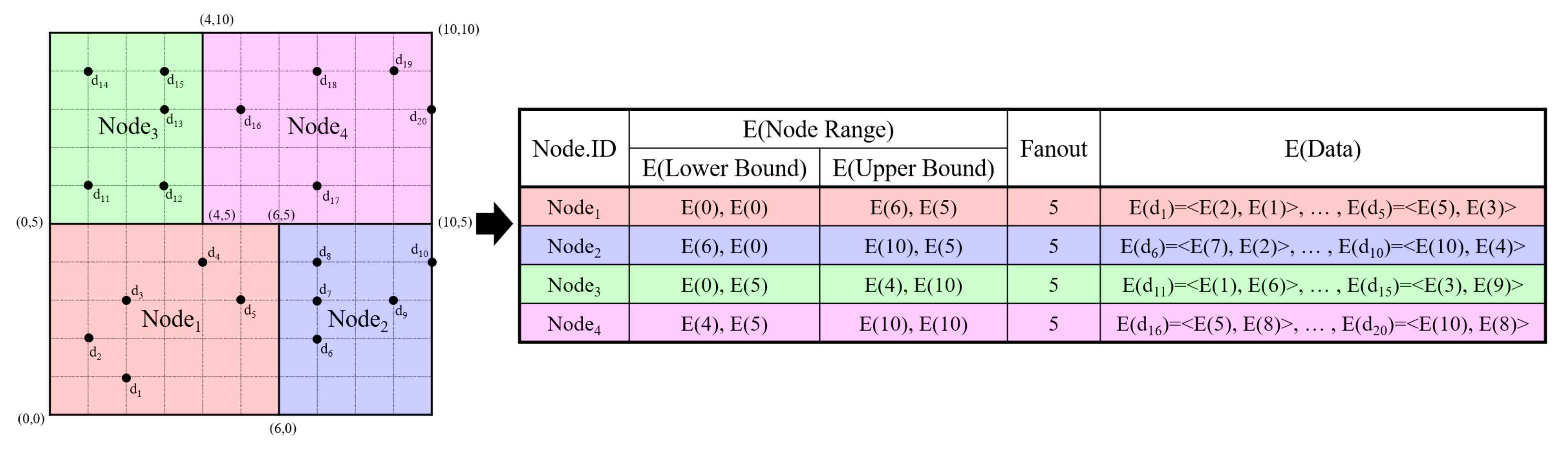
4.1. Node Data Search Phase
| Algorithm 4 Node data search phase. |
Input: <E(), E(), …, E() | >, E()=<E(), E(), …, E() | means coefficient of score function and >, <E(), E(), …, E() | is the maximum data domain of i dimension >, E() // hint means the largest of the absolute values among coefficients Output: <E(), E(), …, E()> // all candidates inside nodes being related to a query : 01. for 02. E() ← E()×E() 03. E() ← ASC(E(), E()) 04. E() ← SM(E(), E(0)) × SM(SBN(E()), E()) 05. for // where h means the level of the kd-tree 06. E() ← ASPE(E(), E()) 07. E() ←(E()) // shuffle the order of array E() = <E(), E(), …, E()> 08. send E() to : 09. ← D(E()) 10. the number of ’1’ in 11. generate c number of Node Group such that = <, , …, > 12. for 13. assign into a node with = 1 and nodes with = 0 14. shuffle the ids of nodes in 15. send = <, , …, > to : 16. 0 // is # of data items extracted from the encrypted leaf nodes of kd-tree 17. for 18. shuffle node ids using for each // = <, , …, > 19. for 20. for // in the selected 21. id of jth nodes of 22. for //: # of data items in each nodes 23. for 24. if (s 1) 25. E() ← E(0) where // E() = <E(), E(), …, E()> 26. E() ← E()×SM(, E()) 27. 28. send <E(), E(), …, E()> |
4.2. Top-k Retrieval Phase
| Algorithm 5 Top-k retrieval phase. |
Input: <E(), E(), …, E() | = >, E(), k // means coefficient of score function and k means the number of Top-k Output: <E(), E(), …, E()> // temporary Top-k results : 01. for 02. E() ← SF(E(), E()) // SF is a score function for Top-k 03. for 04. E() ← SMAX(E(), E(), …, E()) 05. for 06. E() ← E()×E() 07. E() ← // means random value for i 08. E() ←() // =<, , …, > 09. send E()=<E(), E(), …, E()> to : 10. for 11. if D() = 0 then E() ← E(1) 12. else E() ← E(0) 13. send E(U)=<E(), E(), …, E()> to : 14. E(V) ←(U) // E(V)=<E(), E(), …, E()> 15. for 16. for // m means 17. E() ← SM(E(), E()) // E()=<E(), E(), …,E()> 18. if 19. E() ← SM(E(), E(0))×SM(SBN(E()), E()) 20. for 21. E() ← // E()=<E(), E(), …, E()> 22. E() ← E() ∪ E() 23. Return E()=<E(), E(), …, E()> |
4.3. Top-k Result Refinement Phase
| Algorithm 6 Top-k result refinement phase. |
Input: <E(), E(), …, E() | >, <E(), E(), …, E()>, E(), k // means coefficient of score function and k means the number of Top-k Output:=<, , …, > // final Top-k results : 01. E(criteria) = SF(E(), E()) 02. for 03. for 04. E()←SM(E(), E())×SM(SBN(E()), E()) // E() is value returned by ASPE protocol in line 6 of Algorithm 4 05. E() ← SF(E(), E()) 06. E() ← SM(E(), E(0))× SM(SBN(E()), E()) // E() is value returned by ASPE protocol in line 6 of Algorithm 4 07. E() ← ASC(E(criteria), E()) 08. E() ← perform 7 ∼ 27 lines of Algorithm 4 with <E(), E(), …, E()>, E() = <E(), E(), …, E()> 09. E() ← E()∪<E(), E(), …, E()> 10. E() ← perform Algorithm 5 with E(), E() and k 11. for 12. for 13. pick up the random value // =<, , …, > 14. E() ← E()×E() // E()=<E(), E(), …, E()> and E()=<E(), E(), …,E()> 15. send <E(), E(), …, E() > to and <, , …, > to // means authorized user : 16. for 17. for 18. ← D(E()) // = <, , …,> 19. send <, , …, > to : 20. for 21. for 22. ← - // = <, , …, > |
5. Privacy-Preserving Parallel Top- Query Processing Algorithm
5.1. Parallel Node Data Search Phase
| Algorithm 7 Parallel node data search phase. |
Input: <E(), E(), …, E() | >, E()=<E(), E(), …, E() | means coefficient of score function and >, <E(), E(), …, E() | is the maximum data domain of i dimension >, E() // hint means the largest of the absolute values among coefficients Output: <E(), E(), …, E()> // all candidates inside nodes being related to a query : 01. for 02. E() ← E()×E() 03. E() ← ASC(E(), E()) 04. E() ← SM(E(), E(0)) × SM(SBN(E()), E()) 05. generate thread_pool // create a thread and wait in the pool until a task is given 06. for 07. call thread_pool_push(Proc_ASPE(E(), E(), E())) // assign the task to an available thread 08. E() ←(E()) // shuffle the order of array E() = <E(), E(), …, E()> 09. send E() to : 10. perform line 9∼15 in Algorithm 4 : 11. perform line 16∼18 in Algorithm 4 12. for 13. for // in the selected 14. id of jth nodes of 15. for //: the number of data items in each nodes 16. call thread_pool_push(Extract_candidate(E(), E(), m, s, , E())) 17. 18. return <E(), E(), …, E()> procedure 1. Proc_ASPE(E(), E()) Begin Procedure 01. E() ← ASPE(E(), E()) 02. return E() End Procedure end procedure procedure 2. Extract_candidate(E() = <E(), E(), …, E()>, E()) Begin Procedure 01. for 02. if (s 1) 03. E() ← E(0) where // E() = <E(), E(), …,E()> 04. E() ← E()×SM(, E()) 05. return E() = <E(), E(), …, E()> End Procedure end procedure |
5.2. Parallel Top-k Retrieval Phase
5.3. Parallel Top-k Result Refinement Phase
| Algorithm 8 Parallel Top-k retrieval phase. |
Input: <E(), E(), …, E() | = >, E(), k // means coefficient of score function and k means the number of Top-k Output: <E(), E(), …, E()> // temporary Top-k results : 01. for 02. call thread_pool_push(Proc_SF(E(), E(), E())) 03. for 04. E() ← SMAX(E(), E(), …, E()) 05. for 06. call thread_pool_push(Mark_Top_one(E(), E(), E())) 07. E() ←() // =<, , …, > 08. send E()=<E(), E(), …, E()> to : 09. perform line 10∼13 in Algorithm 5 : 10. E(V) ←(U) // E(V) = <E(), E(), …, E()> 11. for 12. call thread_pool_push(Pruneout_From_Top2(E(), E(), E(), E())) 13. for 14. call thread_pool_push(Find_Top_one(E(), , E())) 15. E() ← E() ∪ E() 16. return E() = <E(), E(), …, E()> procedure 3. Proc_SF(E(), E()) Begin Procedure 01. E() ← SF(E(), E()) 02. return E() End Procedure end procedure procedure 4. Mark_Top_one(E(), E()) Begin Procedure 01. E() ← E()×E() 02. E() ← // r means random value 03. return E() End Procedure end procedure procedure 5. Pruneout_From_Top2(E(), E(), E()) Begin Procedure 01. for // m = dimension 02. E() ← SM(E(), E()) 03. if s < k // k = topk and s is from 1 to k 04. E() ← SM(E(), E(0))×SM(SBN(E()), E()) 05. return E(), E() End Procedure end procedure procedure 6. Find_Top_one(E(), , E()) Begin Procedure 01. for // = candidates 02. E() ← E()×E() // s = index of loop from 1 to k, k = topk 03. return E() End Procedure end procedure |
| Algorithm 9 Parallel Top-k result refinement phase. |
Input: <E(), E(), …, E() | >, <E(), E(), …, E()>, E(), k // means coefficient of score function and k means the number of Top-k Output: = <, , …, > // final Top-k results : 01. E(criteria) = SF(E(), E()) 02. for 03. call thread_pool_push(check_node_expansion(E(), E(), E(), E(), E(criteria), m), E()) 04. E() ← perform 7 ∼ 27 lines of Algorithm 6 with <E(), E(), …, E()>, E() = <E(), E(), …, E()> 05. E() ← E()∪<E(), E(), …, E()> 06. E() ← perform Algorithm 8 with E(), E() and k 07. for 08. for 09. pick up the random value // = <, , …, > 10. E() ← E()×E() // E()=<E(), E(), …, E()> and E() = <E(), E(), …,E()> 11. send <E(), E(), …, E() > to and <, , …, > to : 12. for 13. for 14. ← D(E()) // = <, , …,> 15. send <, , …, > to : 16. for 17. for 18. ← - // = <, , …, > procedure 7. Check_node_expansion(E() = <E(),E(), …, E()>, E(), E(), E(), E(criteria), m = dimension) Begin Procedure 01. for 02. E()←SM(E(), E())×SM(SBN(E()), E()) // E() is value returned by ASPE protocol in Algorithm 6 03. E() ← SF(E(), E()) 04. E() ← SM(E(), E(0))× SM(SBN(E()), E()) // E() is value returned by ASPE protocol in Algorithm 6 05. E() ← ASC(E(criteria), E()) 06. return E() End Procedure end procedure |
6. Security Proof
6.1. Security Proof of the Secure Protocols
6.2. Security Proof of the Proposed Top-k Query Processing Algorithm
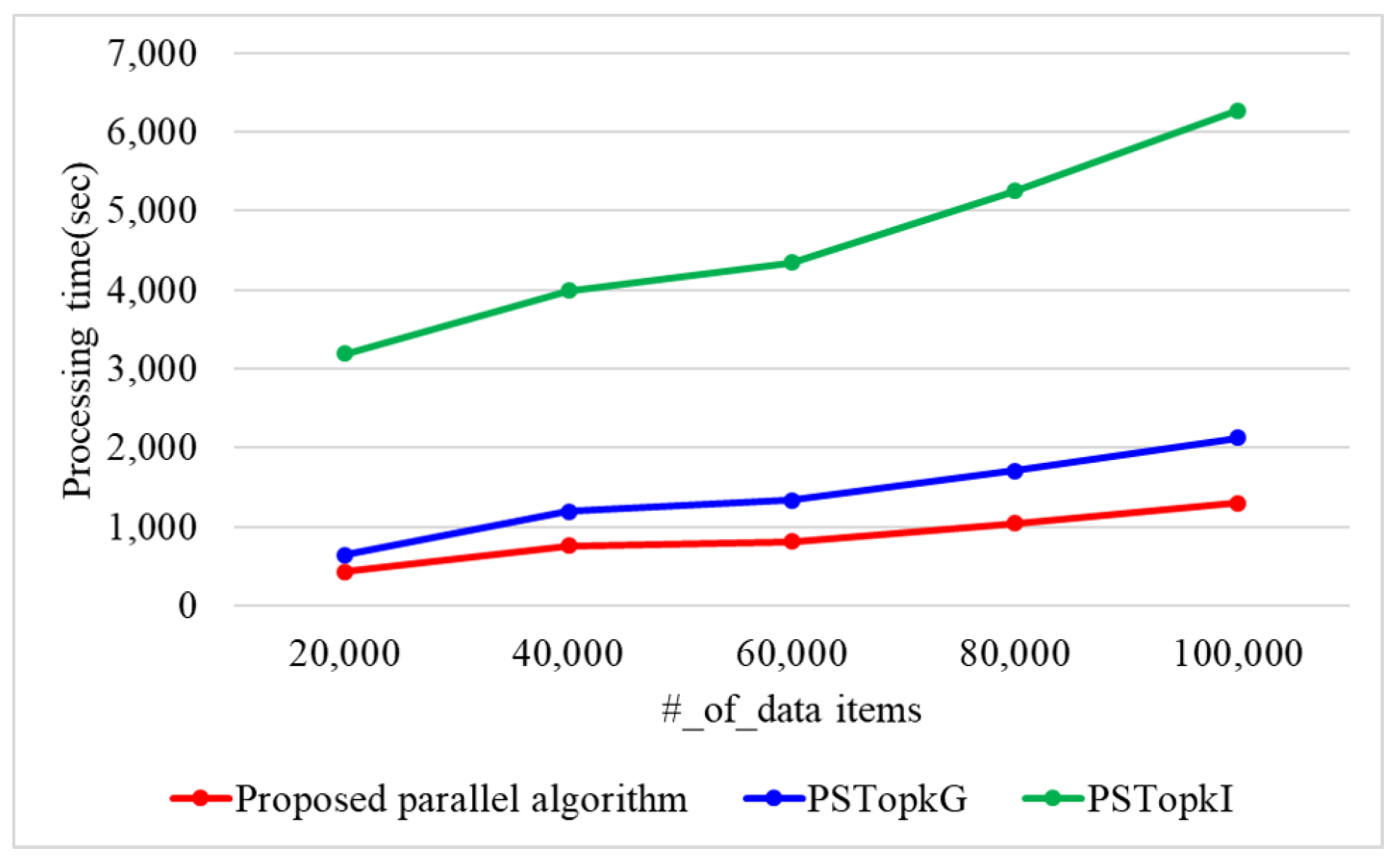
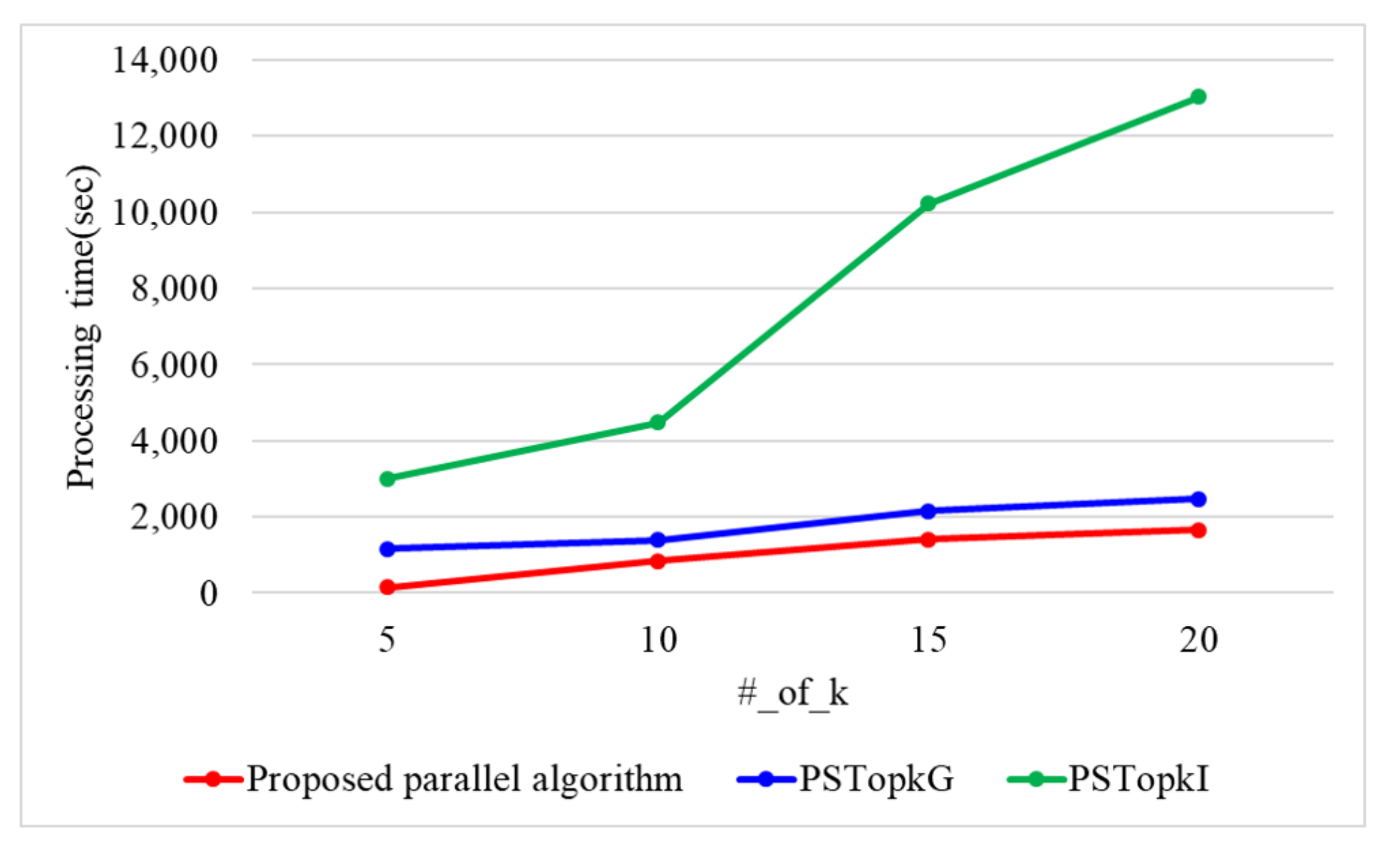
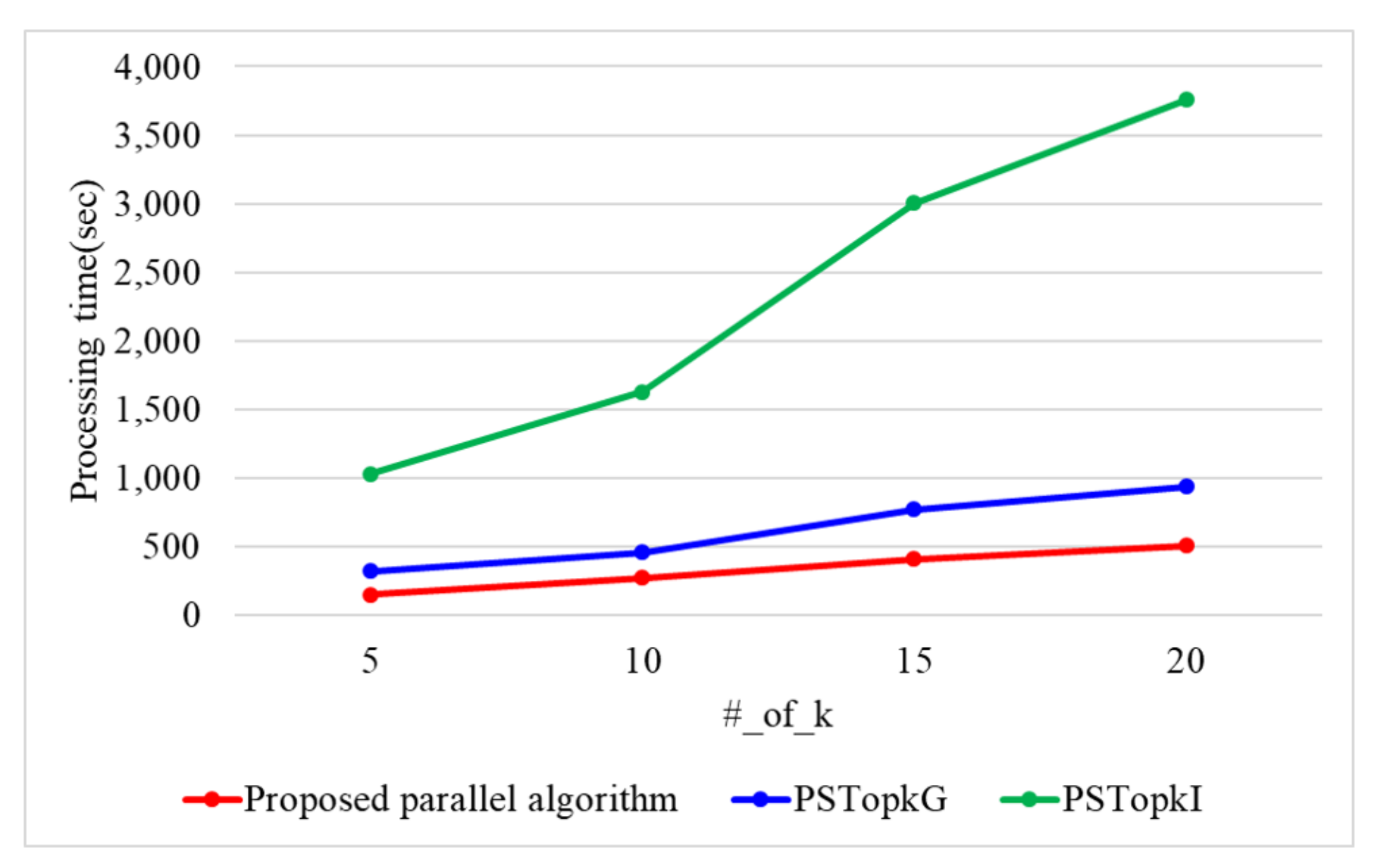
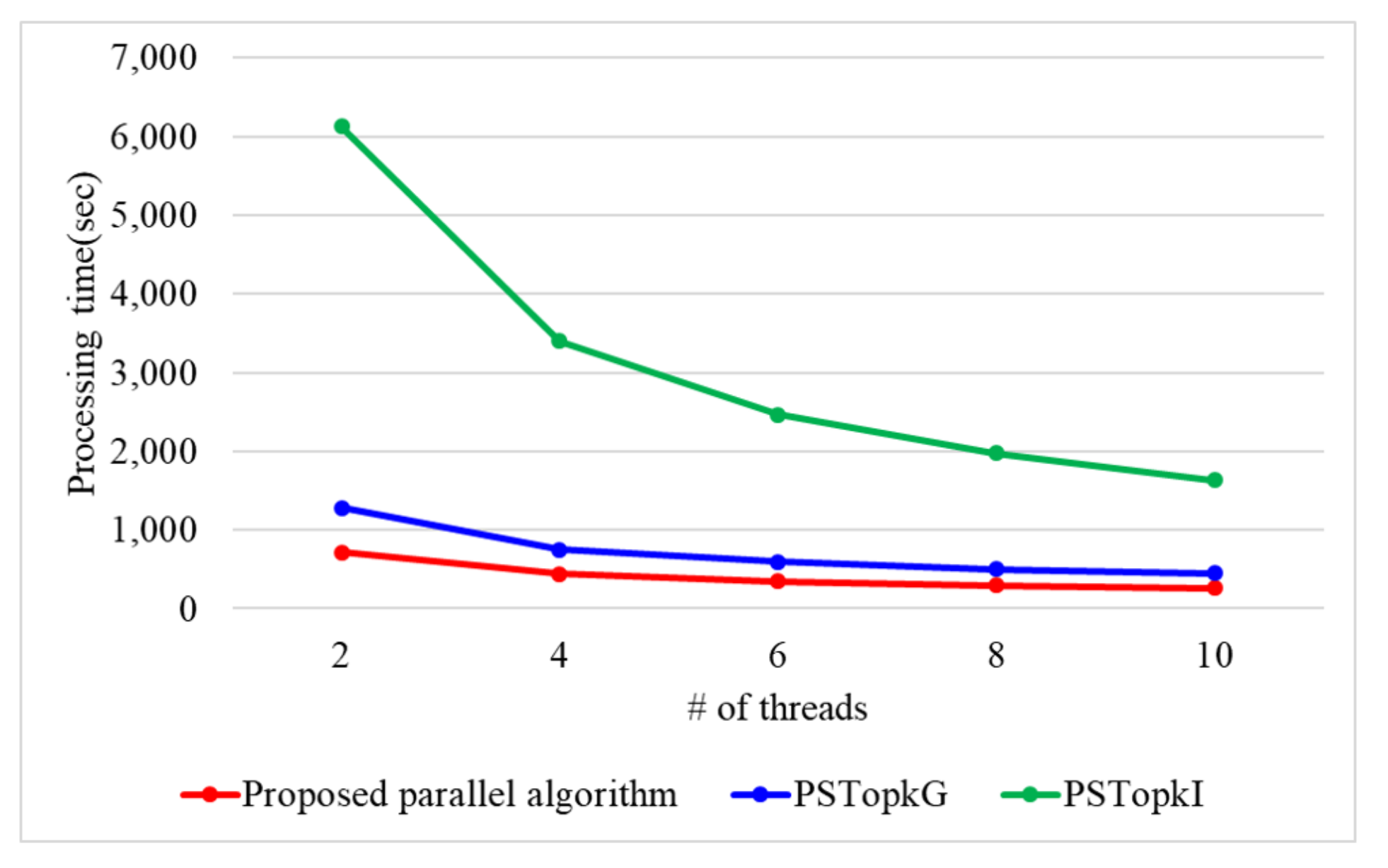
7. Performance Analysis
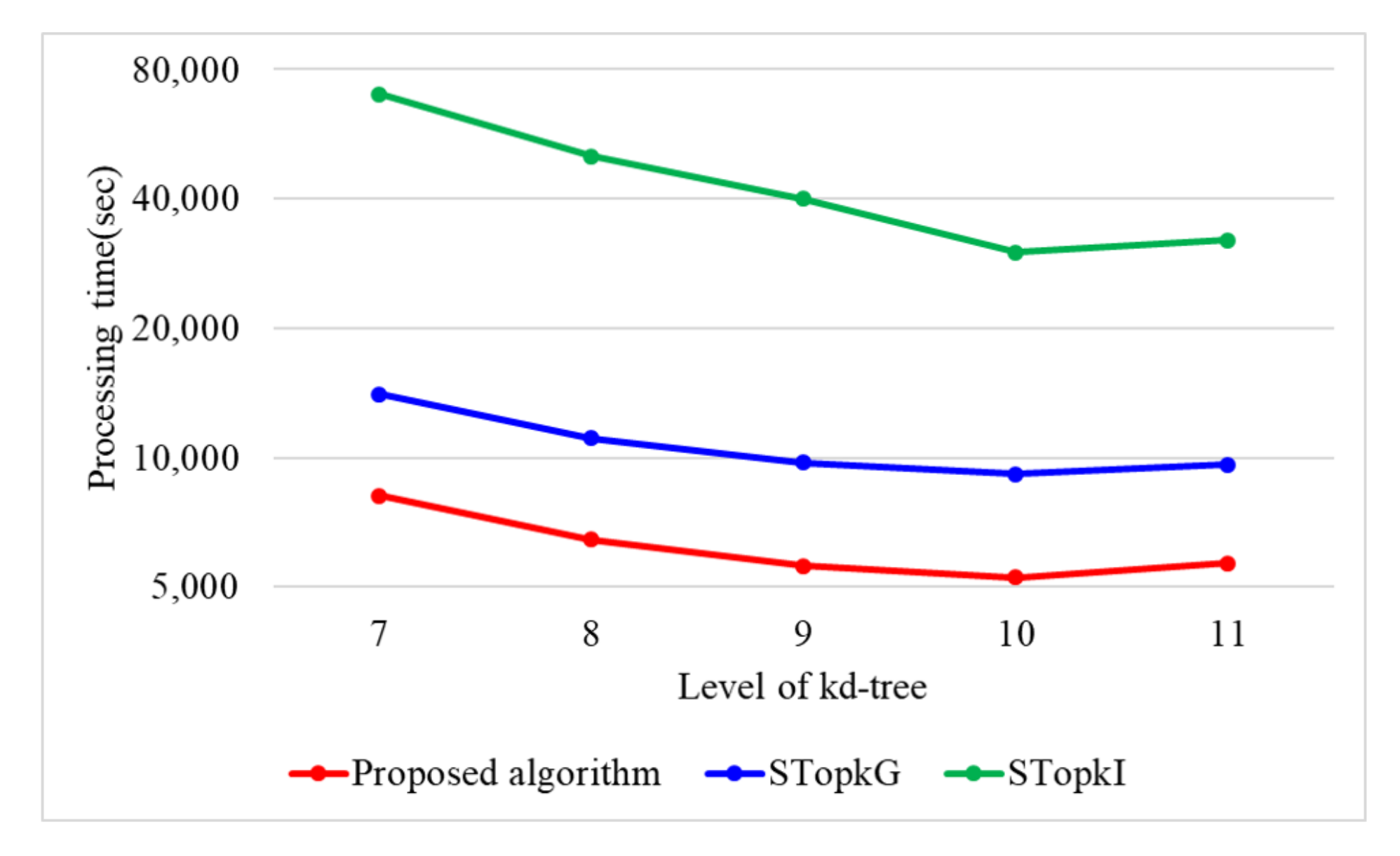
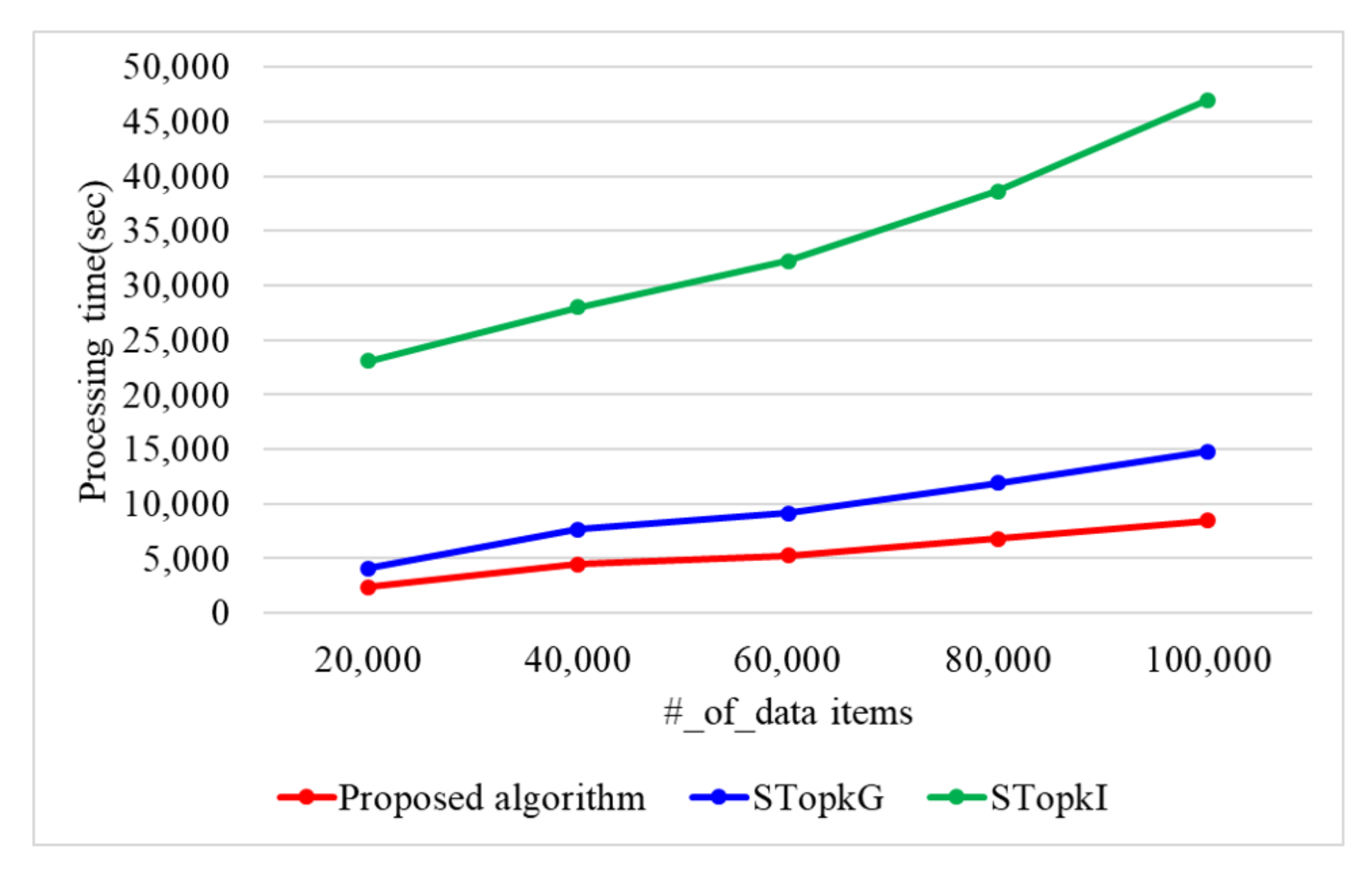
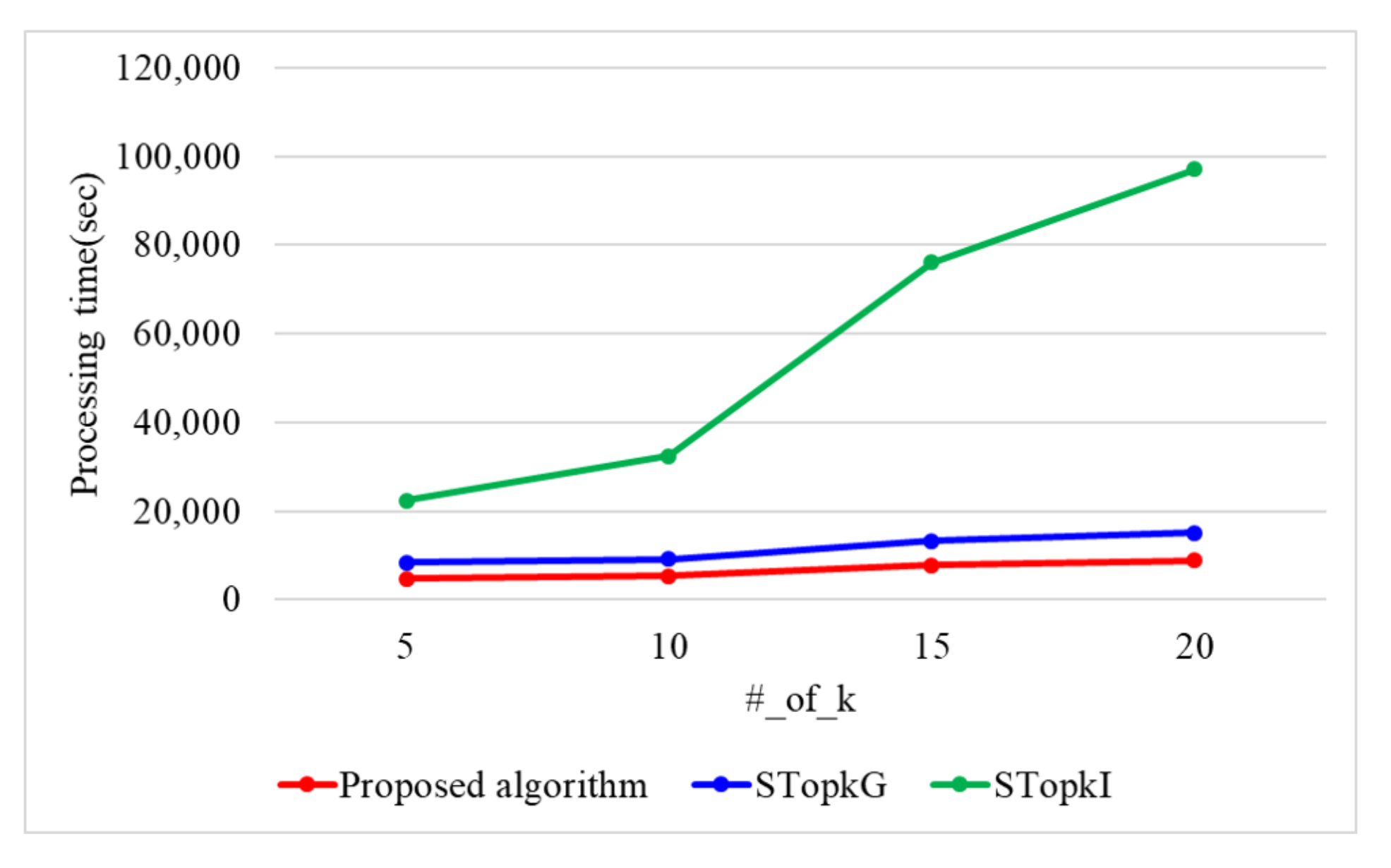
7.1. Performance Evaluation of the Proposed Top-k Query Processing Algorithm in a Single-Core Environment
7.2. Performance Evaluation of the Proposed Top-k Query Processing Algorithm in a Multi-Core Environment
8. Discussion
9. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hayes, B. Cloud computing. Commun. ACM 2008, 51, 9–11. [Google Scholar] [CrossRef]
- Qian, L.; Luo, Z.; Du, Y.; Guo, L. Cloud computing: An overview. In Proceedings of the IEEE International Conference on Cloud Computing, Bangalore, India, 21–25 September 2009; pp. 626–631. [Google Scholar]
- Grolinger, K.; Higashino, W.A.; Tiwari, A.; Capretz, M.A. Data management in cloud environments: NoSQL and NewSQL data stores. J. Cloud Comput. Adv. Syst. Appl. 2013, 2, 1–24. [Google Scholar] [CrossRef]
- Zhao, L.; Sakr, S.; Liu, A.; Bouguettaya, A. Cloud Data Management; Springer: Berlin/Heidelberg, Germany, 2014; 189p. [Google Scholar]
- Agrawal, D.; Das, S.; Abbadi, A.E. Data management in the cloud: Challenges and opportunities. In Synthesis Lectures on Data Management; Springer: Nature/Cham, Switzerland, 2012; Volume 4, 138p. [Google Scholar]
- Sun, Y.; Zhang, J.; Xiong, Y.; Zhu, G. Data security and privacy in cloud computing. Int. J. Distrib. Sens. Netw. 2014, 10, 190903. [Google Scholar] [CrossRef]
- Sharma, Y.; Gupta, H.; Khatri, S.K. A security model for the enhancement of data privacy in cloud computing. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 898–902. [Google Scholar]
- Garigipati, N.; Krishna, R.V. A study on data security and query privacy in cloud. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 337–341. [Google Scholar]
- Cao, N.; Yang, Z.; Wang, C.; Ren, K.; Lou, W. Privacy-preserving query over encrypted graph-structured data in cloud computing. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems, Minneapolis, MN, USA, 20–24 June 2011; pp. 393–402. [Google Scholar]
- Islam, M.S.; Kuzu, M.; Kantarcioglu, M. Access pattern disclosure on searchable encryption: Ramification, attack and mitigation. In Proceedings of the 19th Annual Network and Distributed System Security Symposium, San Diego, CA, USA, 5–8 February 2012; p. 12. [Google Scholar]
- Williams, P.; Sion, R.; Carbunar, B. Building castles out of mud: Practical access pattern privacy and correctness on untrusted storage. In Proceedings of the 15th ACM Conference on Computer and Communications Security, Alexandria, VI, USA, 27–31 August 2008; pp. 139–148. [Google Scholar]
- Cui, S.; Belguith, S.; Zhang, M.; Asghar, M.R.; Russello, G. Preserving access pattern privacy in sgx-assisted encrypted search. In Proceedings of the 2018 27th International Conference on Computer Communication and Networks (ICCCN), Hangzhou, China, 30 July–2 August 2018; pp. 1–9. [Google Scholar]
- Yiu, M.L.; Ghinita, G.; Jensen, C.S.; Kalnis, P. Enabling search services on outsourced private spatial data. VLDB J. 2010, 19, 363–384. [Google Scholar] [CrossRef]
- Boldyreva, A.; Chenette, N.; Lee, Y.; Oneill, A. Order-preserving symmetric encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cologne, Germany, 26–30 April 2009; pp. 224–241. [Google Scholar]
- Boldyreva, A.; Chenette, N.; O’Neill, A. Order-preserving encryption revisited: Improved security analysis and alternative solutions. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; pp. 578–595. [Google Scholar]
- Qi, Y.; Atallah, M.J. Efficient privacy-preserving k-nearest neighbor search. In Proceedings of the 28th International Conference on Distributed Computing Systems, Beijing, China, 17–20 June 2008; pp. 311–319. [Google Scholar]
- Shaneck, M.; Kim, Y.; Kumar, V. Privacy preserving nearest neighbor search. In Machine Learning in Cyber Trust; Springer: Berlin/Heidelberg, Germany, 2009; pp. 247–276. [Google Scholar]
- Vaidya, J.; Clifton, C. Privacy-preserving top-k queries. In Proceedings of the 21st International Conference on Data Engineering (ICDE’05), Tokyo, Japan, 5–8 April 2005; pp. 545–546. [Google Scholar]
- Elmehdwi, Y.; Samanthula, B.K.; Jiang, W. Secure k-nearest neighbor query over encrypted data in outsourced environments. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 664–675. [Google Scholar]
- Kim, H.J.; Kim, H.I.; Chang, J.W. A privacy-preserving kNN classification algorithm using Yao’s garbled circuit on cloud computing. In Proceedings of the 2017 IEEE 10th International Conference on Cloud Computing (CLOUD), Honolulu, HI, USA, 25–30 June 2017; pp. 766–769. [Google Scholar]
- Zhou, L.; Zhu, Y.; Castiglione, A. Efficient k-NN query over encrypted data in cloud with limited key-disclosure and offline data owner. Comput. Secur. 2017, 69, 84–96. [Google Scholar] [CrossRef]
- Kim, H.I.; Kim, H.J.; Chang, J.W. A secure kNN query processing algorithm using homomorphic encryption on outsourced database. Data Knowl. Eng. 2019, 123, 101602. [Google Scholar] [CrossRef]
- Sun, X.; Wang, X.; Xia, Z.; Fu, Z.; Li, T. Dynamic multi-keyword top-k ranked search over encrypted cloud data. Int. J. Secur. Its Appl. 2014, 8, 319–332. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, S.; Xia, Z. A distributed privacy-preserving data aggregation scheme for smart grid with fine-grained access control. J. Inf. Secur. Appl. 2022, 66, 103118. [Google Scholar] [CrossRef]
- Hozhabr, M.; Asghari, P.; Javadi, H.H.S. Dynamic secure multi-keyword ranked search over encrypted cloud data. J. Inf. Secur. Appl. 2021, 61, 102902. [Google Scholar] [CrossRef]
- Ilyas, I.F.; Beskales, G.; Soliman, M.A. A survey of top-k query processing techniques in relational database systems. ACM Comput. Surv. 2008, 40, 1–58. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.I.; Kim, H.J.; Chang, J.W. A privacy-preserving top-k query processing algorithm in the cloud computing. In Proceedings of the International Conference on the Economics of Grids, Clouds, Systems, and Services, Athens, Greece, 20–22 September 2016; pp. 277–292. [Google Scholar]
- Kim, H.J.; Chang, J.W. A new Top-k query processing algorithm to guarantee confidentiality of data and user queries on outsourced databases. Int. J. Syst. Assur. Eng. Manag. 2019, 10, 898–904. [Google Scholar] [CrossRef]
- Yao, A.C.C. How to generate and exchange secrets. In Proceedings of the 27th Annual Symposium on Foundations of Computer Science, Toronto, ON, Canada, 27–28 October 1986; pp. 162–167. [Google Scholar]
- Lindell, Y.; Pinkas, B. A proof of security of Yao’s protocol for two-party computation. J. Cryptol. 2009, 22, 161–188. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Lindell, Y. Secure multiparty computation for privacy preserving data mining. In Encyclopedia of Data Warehousing and Mining; IGI Global: Hershey, PA, USA, 2005; pp. 1005–1009. [Google Scholar]
- Hazay, C.; Lindell, Y. Efficient Secure Two-Party Protocols: Techniques and Constructions; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Cramer, R.; Damgård, I.B. Secure Multiparty Computation; Cambridge University Press: Cambridige, UK, 2015. [Google Scholar]
- Hazay, C.; Lindell, Y. A note on the relation between the definitions of security for semi-honest and malicious adversaries. Available online: https://eprint.iacr.org/2010/551.pdf (accessed on 6 September 2022).
- Veugen, T.; Blom, F.; de Hoogh, S.J.; Erkin, Z. Secure comparison protocols in the semi-honest model. IEEE J. Sel. Top. Signal Process. 2015, 9, 1217–1228. [Google Scholar] [CrossRef]
- Vaidya, J.; Clifton, C.W. Privacy-preserving kth element score over vertically partitioned data. IEEE Trans. Knowl. Data Eng. 2008, 21, 253–258. [Google Scholar] [CrossRef]
- Fagin, R. Combining fuzzy information from multiple systems. J. Comput. Syst. Sci. 1999, 58, 83–99. [Google Scholar] [CrossRef]
- Burkhart, M.; Dimitropoulos, X. Fast privacy-preserving top-k queries using secret sharing. In Proceedings of 19th International Conference on Computer Communications and Networks, Zurich, Switzerland, 2–5 August 2010; pp. 1–7. [Google Scholar]
- Zheng, Y.; Lu, R.; Yang, X.; Shao, J. Achieving efficient and privacy-preserving top-k query over vertically distributed data sources. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Goldreich, O. Foundations of Cryptography: Volume 2, Basic Applications; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Chess (King-Rookvs.King) DataSet. Available online: http://archive.ics.uci.edu/ml/datasets/Chess+%28King-Rook+vs.+King%29 (accessed on 7 July 2022).
- Kim, H.J.; Lee, H.; Kim, Y.K.; Chang, J.W. Privacy-preserving kNN query processing algorithms via secure two-party computation over encrypted database in cloud computing. J. Supercomput. 2022, 78, 9245–9284. [Google Scholar] [CrossRef]
- Kim, Y.K.; Kim, H.J.; Lee, H.; Chang, J.W. Privacy-preserving parallel kNN classification algorithm using index-based filtering in cloud computing. PLoS ONE 2022, 17, e0267908. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Data Privacy | Query Privacy | Hiding Data Access Pattern | Index | Computation Overhead | Encryption | User Involvement in Computation | Security Risk | |
|---|---|---|---|---|---|---|---|---|---|
| Schemes | |||||||||
| J. Vaidya and C. Clifton’s work [38] | Support | Not support | Not support | None | Low | None | Involved | High | |
| M. Burkhart and X. Dimitropoulos’s work [40] | Support | Not support | Not support | None | Low | None | Involved | High | |
| Y. Zheng et al. [41] | Support | Not support | Not support | None | Moderate | AES | Involved | High | |
| H-I. Kim et al. [27] | Support | Support | Support | Encrypted kd-tree | Very high | Paillier | Not involved | Low | |
| H-J. Kim et al. [28] | Support | Support | Not support | Encrypted kd-tree | High | Paillier | Not involved | Low | |
| Proposed | Support | Support | Support | Encrypted kd-tree | Low | Paillier | Not involved | Low | |
| Parameter | Values | Default |
|---|---|---|
| Number of data items (n) | 20 k, 40 k, 60 k, 80 k, 100 k | - |
| Level of kd-tree | 7, 8, 9, 10, 11 | 10 |
| Number of dimensions | 2, 3, 4, 5, 6 | 6 |
| Key size | 512, 1024 | - |
| Data domain (bit length) |
| Parameter | Values | Default |
|---|---|---|
| Number of data items (n) | 20 k, 40 k, 60 k, 80 k, 100 k | - |
| Number of k | 5, 10, 15, 20 | 10 |
| Number of threads | 2, 4, 6, 8, 10 | 10 |
| Key size | 1024 | - |
| Data domain (bit length) |
| Parameter | Values | Default |
|---|---|---|
| Number of data items (n) | 28,056 | - |
| Level of kd-tree | 5, 6, 7, 8, 9, 10, 11, 12 | 10 |
| Number of dimensions | 6 | 6 |
| Number of threads | 2, 4, 6, 8, 10 | 10 |
| Number of k | 5, 10, 15, 20 | 10 |
| Key size | 512 | - |
| Data domain (bit length) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.-J.; Kim, Y.-K.; Lee, H.-J.; Chang, J.-W. Privacy-Preserving Top-k Query Processing Algorithms Using Efficient Secure Protocols over Encrypted Database in Cloud Computing Environment. Electronics 2022, 11, 2870. https://doi.org/10.3390/electronics11182870
Kim H-J, Kim Y-K, Lee H-J, Chang J-W. Privacy-Preserving Top-k Query Processing Algorithms Using Efficient Secure Protocols over Encrypted Database in Cloud Computing Environment. Electronics. 2022; 11(18):2870. https://doi.org/10.3390/electronics11182870
Chicago/Turabian StyleKim, Hyeong-Jin, Yong-Ki Kim, Hyun-Jo Lee, and Jae-Woo Chang. 2022. "Privacy-Preserving Top-k Query Processing Algorithms Using Efficient Secure Protocols over Encrypted Database in Cloud Computing Environment" Electronics 11, no. 18: 2870. https://doi.org/10.3390/electronics11182870
APA StyleKim, H.-J., Kim, Y.-K., Lee, H.-J., & Chang, J.-W. (2022). Privacy-Preserving Top-k Query Processing Algorithms Using Efficient Secure Protocols over Encrypted Database in Cloud Computing Environment. Electronics, 11(18), 2870. https://doi.org/10.3390/electronics11182870