
JR-TFViT: A Lightweight Efficient Radar Jamming Recognition Network Based on Global Representation of the Time–Frequency Domain

Abstract
:1. Introduction
- The research questions addressed in this paper are as follows. To address the problem that the existing CNN-based radar jamming recognition network cannot fully utilize the global representation of jamming signals in the time–frequency domain, the JR-TFViT is proposed that can fuse the global representation of jamming in the time–frequency domain with local information to improve jamming recognition performance.
- For the lightweight requirement of the jamming recognition network, the traditional convolutional operation mechanism is adjusted and ViT is fused into the convolutional structure between, which significantly reduces the number of parameters in the jamming recognition network.
2. Radar Jamming Signal Data Preparation
2.1. Generating Jamming Signals
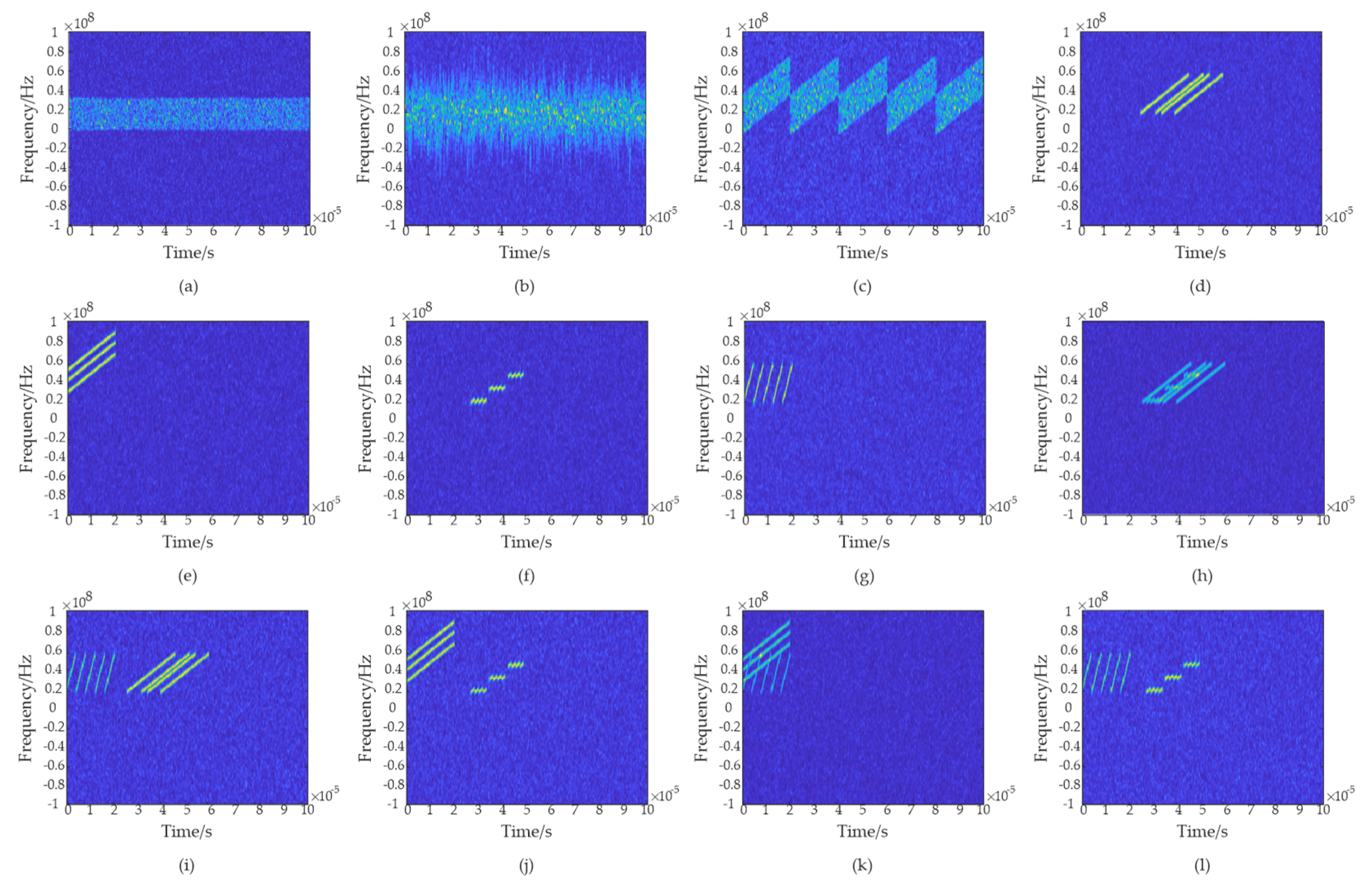
2.2. Time Frequency Transformation
3. Methods
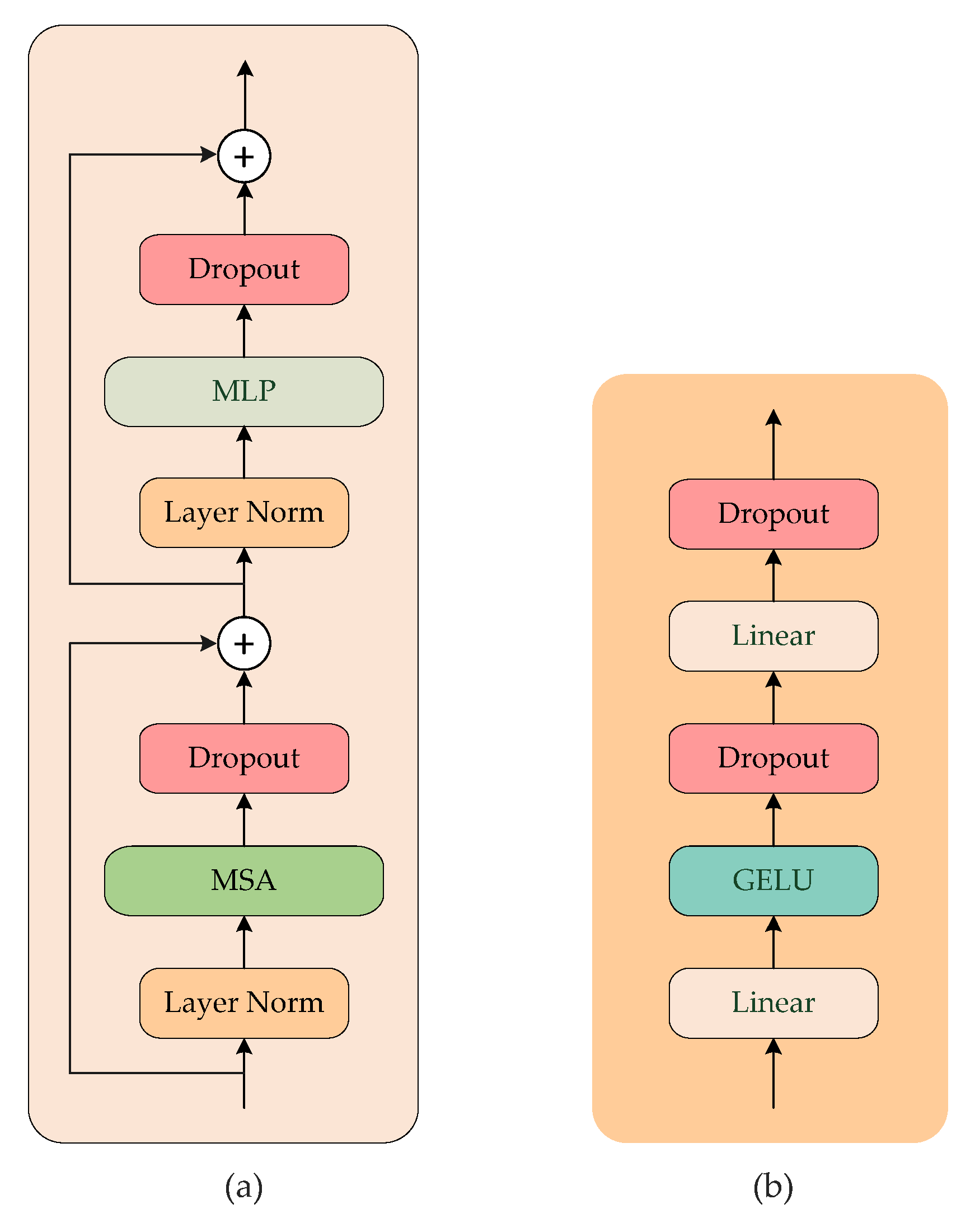
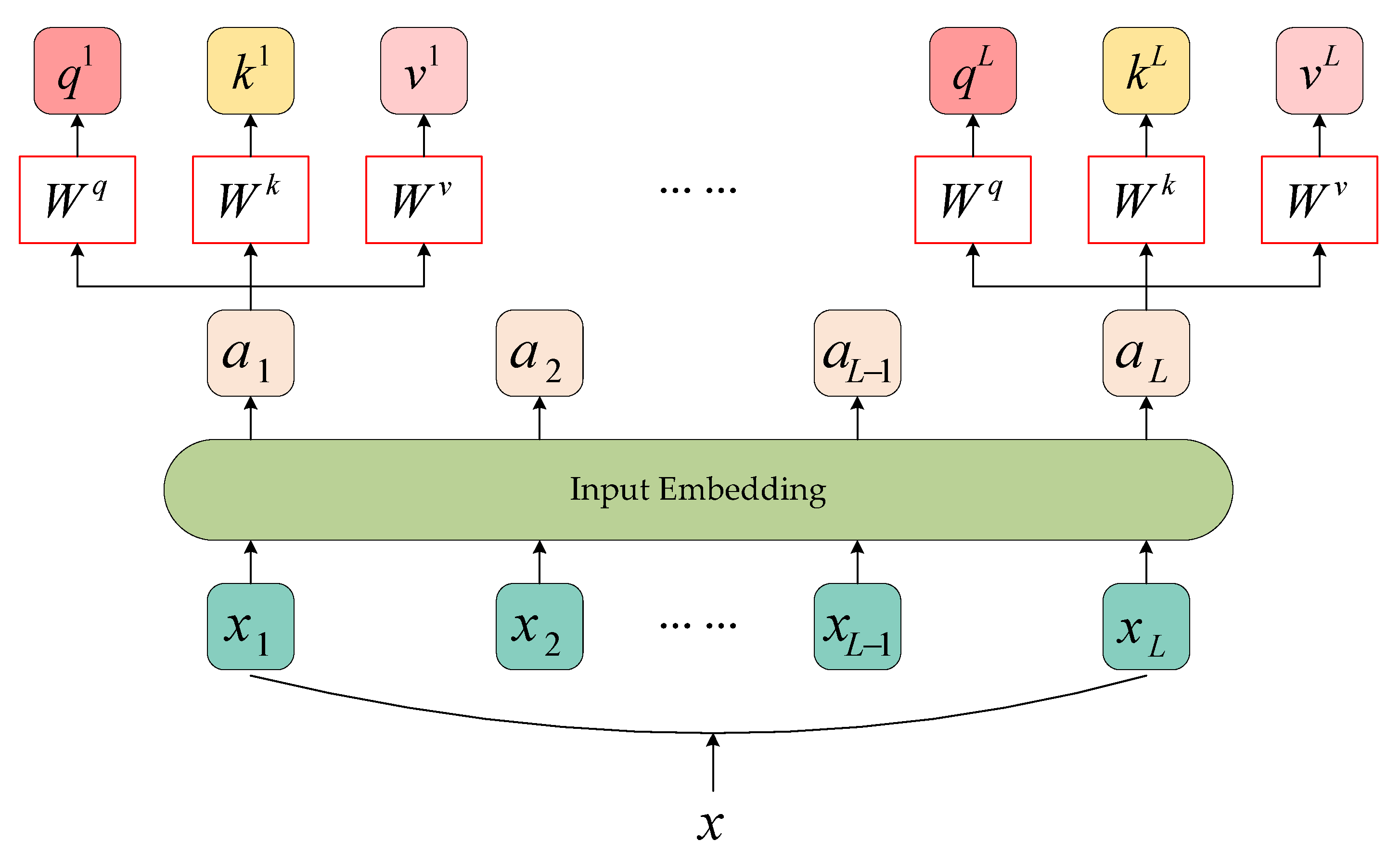
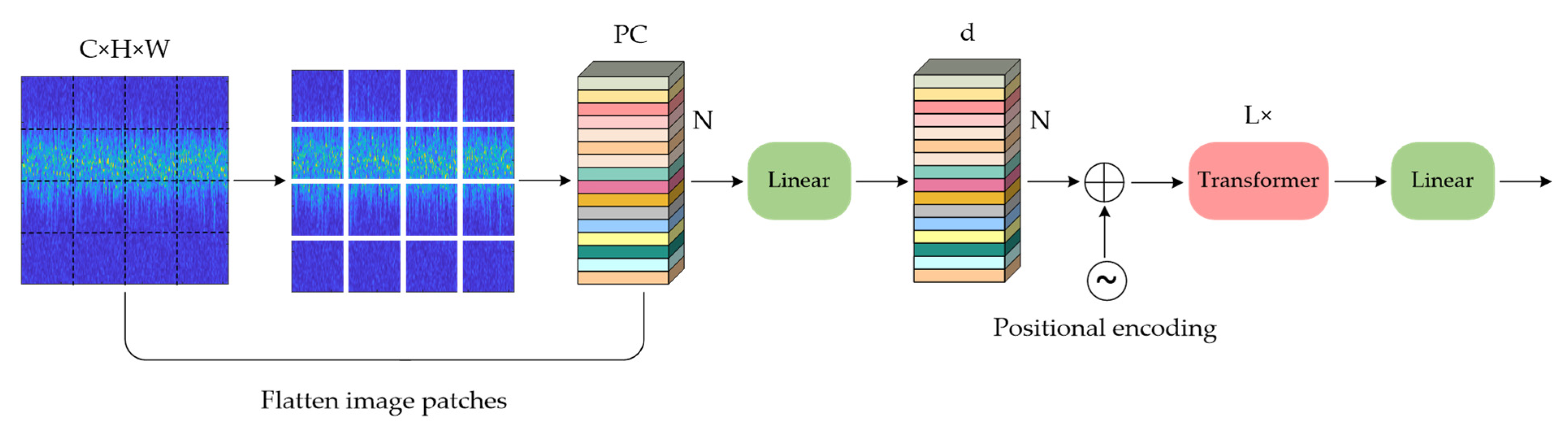
3.1. Global Representation and MSA
3.2. Lightweight Improvements
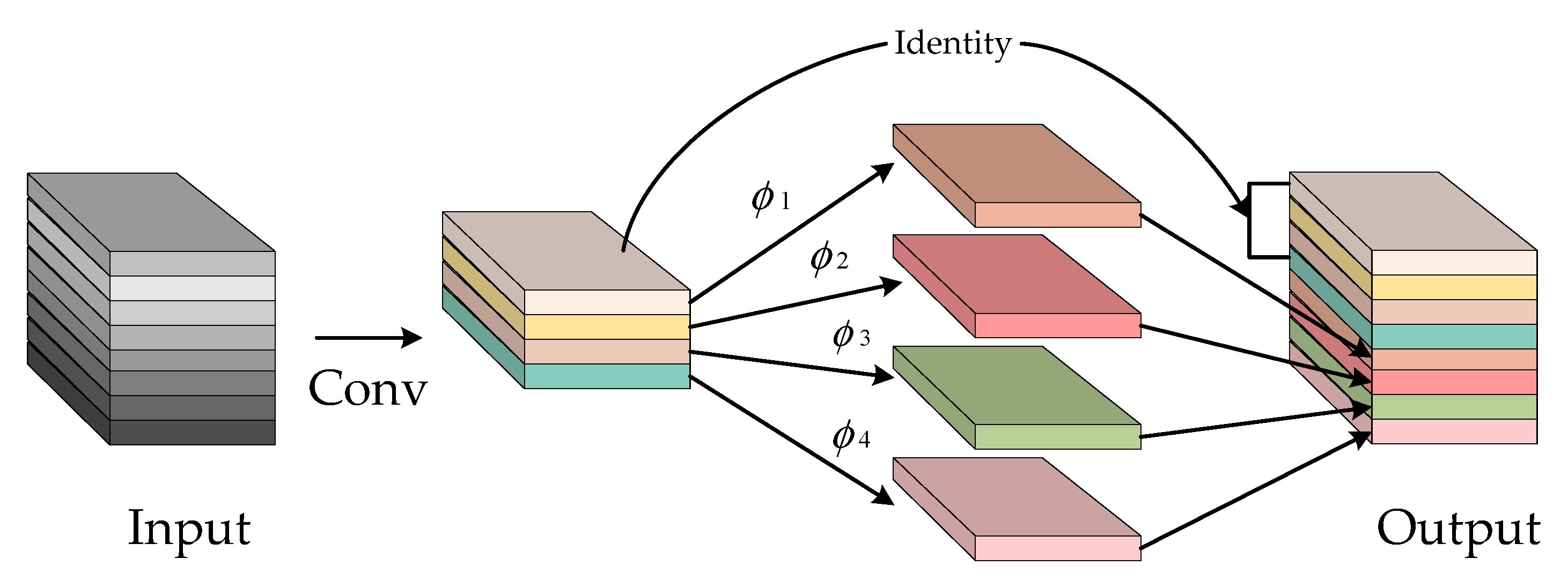
3.2.1. Ghost Convolution
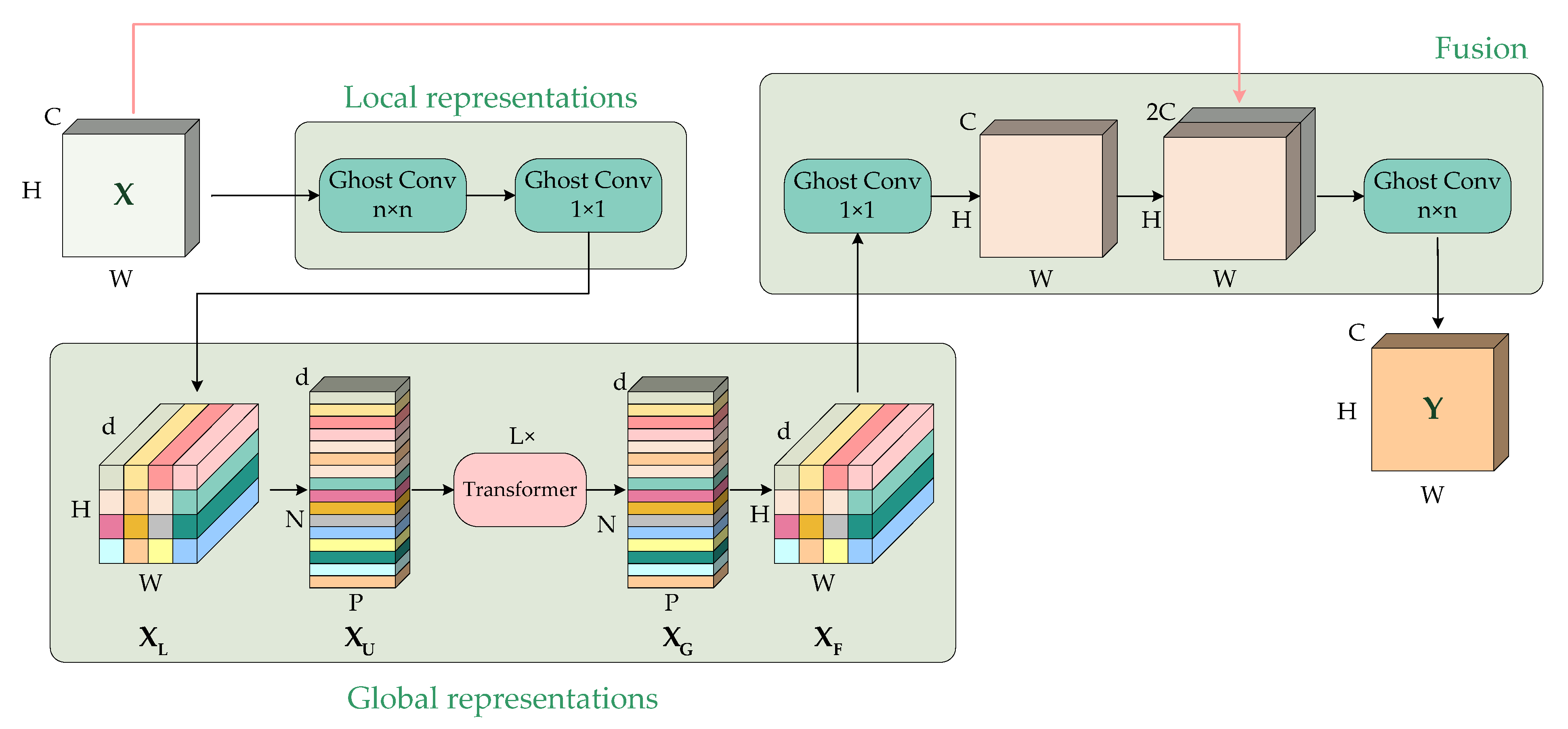
3.2.2. Ghost–MobileViT
3.3. JR-TFViT
4. Experiments and Results
4.1. Experiment Settings
4.2. Evaluation Metrics
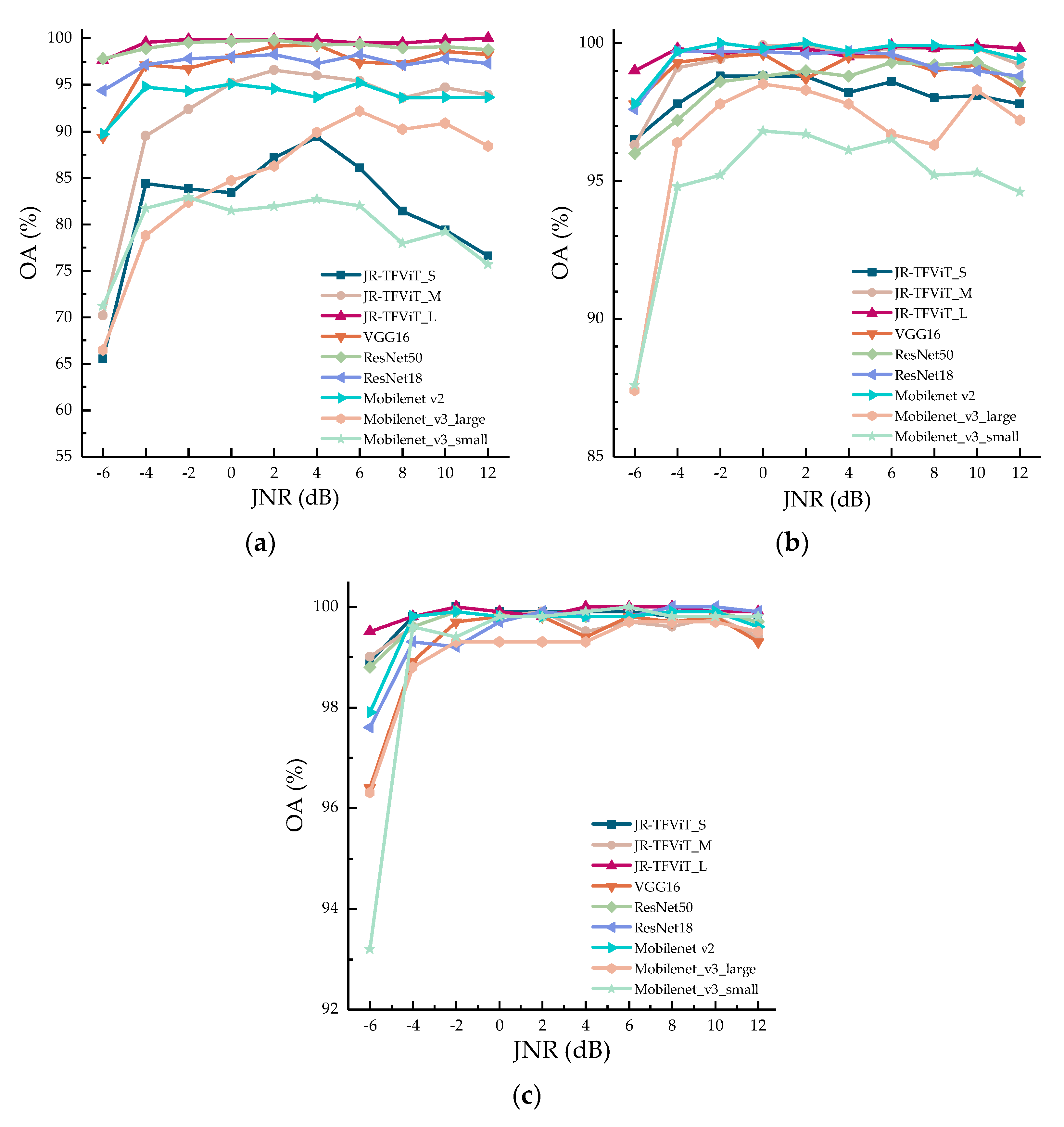
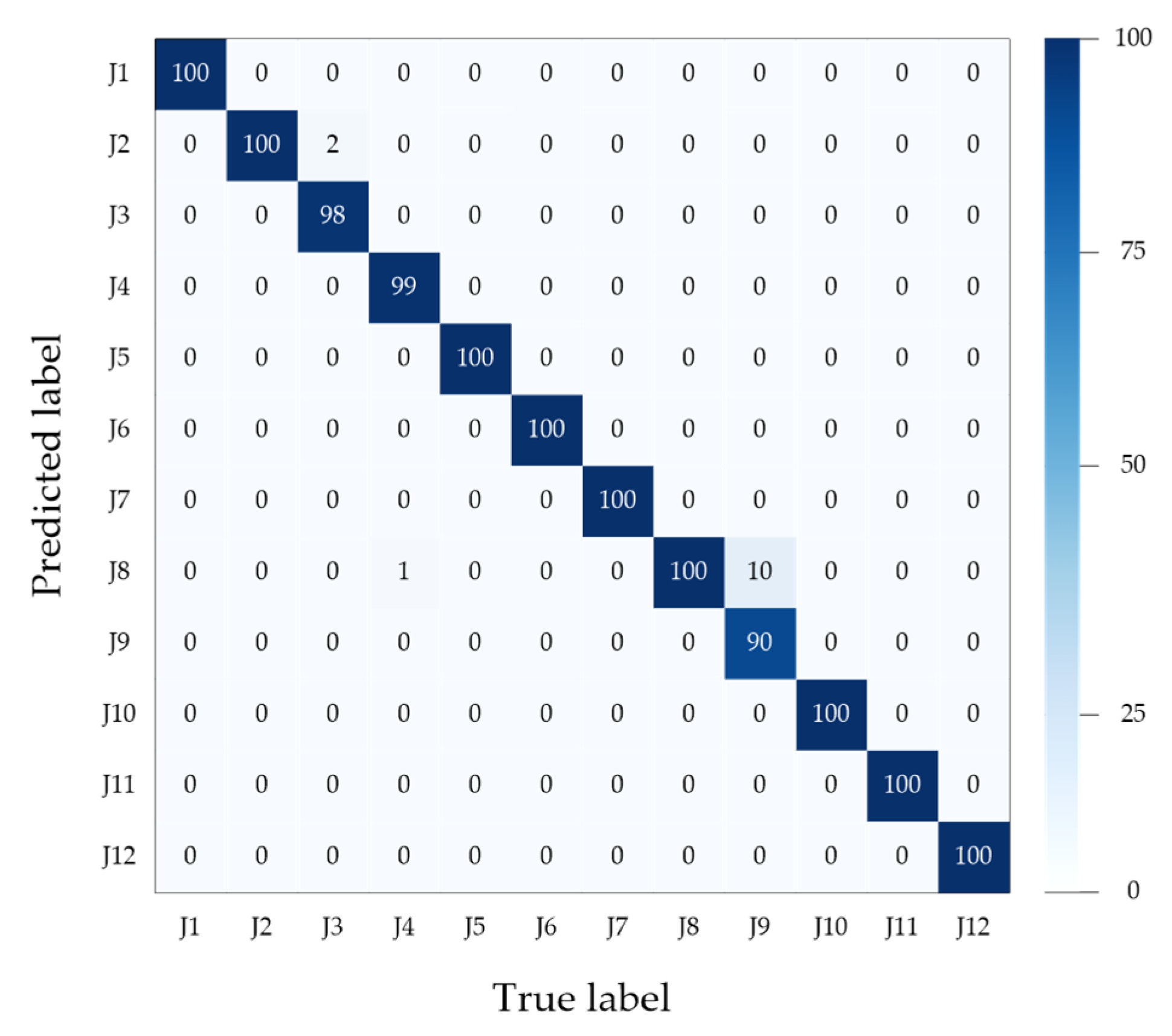
4.3. Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tan, M.; Wang, C.; Xue, B.; Xu, J. A Novel Deceptive Jamming Approach Against Frequency Diverse Array Radar. IEEE Sens. J. 2021, 21, 8323–8332. [Google Scholar] [CrossRef]
- Li, N.J.; Zhang, Y.T. A survey of radar ECM and ECCM. IEEE Trans. Aerosp. Electron. Syst. 1995, 31, 1110–1120. [Google Scholar]
- Futong, Q.; Jie, M.; Jing, D.; Fujiang, A.; Ying, Z. Radar jamming effect evaluation based on AdaBoost combined classification mode. In Proceedings of the 2013 IEEE 4th International Conference on Software Engineering and Service Science, Beijing, China, 23–25 May 2013. [Google Scholar]
- Gao, M.; Li, H.; Jiao, B.; Hong, Y. Simulation research on classification and identification of typical active jamming against LFM radar. In Proceedings of the Eleventh International Conference on Signal Processing Systems, Chengdu, China, 15–17 December 2019. [Google Scholar]
- Su, D.; Gao, M. Research on Jamming Recognition Technology Based on Characteristic Parameters. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 23–25 October 2020. [Google Scholar]
- Zhao, J.; Hu, T.; Zheng, R.; Ba, P.; Mei, C.; Zhang, Q. Defect Recognition in Concrete Ultrasonic Detection Based on Wavelet Packet Transform and Stochastic Configuration Networks. IEEE Access. 2021, 9, 9284–9295. [Google Scholar] [CrossRef]
- Thayaparan, T.; Stankovic, L.; Amin, M.; Chen, V.; Cohen, L.; Boashash, B. Time-Frequency Approach to Radar Detection, Imaging, and Classification. IET Signal Process. 2010, 4, 325–328. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, W. Deep learning and recognition of radar jamming based on CNN. In Proceedings of the 2019 12th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 14–15 December 2019. [Google Scholar]
- Qian, J.; Teng, X.; Qiu, Z. Recognition of radar deception jamming based on convolutional neural network. In Proceedings of the IET International Radar Conference, Online, 4–6 November 2021. [Google Scholar]
- Lv, Q.; Quan, Y.; Feng, W.; Sha, M.; Dong, S.; Xing, M. Radar Deception Jamming Recognition Based on Weighted Ensemble CNN With Transfer Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5107511. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local Features Coupling Global Representations for Visual Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Si, C.; Yu, W.; Zhou, P.; Zhou, Y.; Wang, X.; Yan, S. Inception Transformer. arXiv 2022, arXiv:2205.12956. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Zhang, H.; Yu, L.; Chen, Y.; Wei, Y. Fast Complex-Valued CNN for Radar Jamming Signal Recognition. Remote Sens. 2021, 13, 2867. [Google Scholar] [CrossRef]
- Campbell, F.W.; Robson, J.G. Application of Fourier analysis to the visibility of gratings. Physiology 1968, 197, 551–556. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Yan, S.; Feng, J. Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Park, N.; Kim, S. How Do Vision Transformers Work. arXiv 2022, arXiv:2202.06709. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. arXiv 2021, arXiv:2108.11539. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sumaiya, M.N.; Kumari, R.S.S. Logarithmic Mean-Based Thresholding for SAR Image Change Detection. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1726–1728. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Signal Parameter | Value Ranges |
|---|---|
| JNR | −6:1:12 dB |
| center frequency | 10~15 MHz |
| pulse repetition period | 100 μs |
| bandwidth | 40 MHz |
| sampling frequency | 200 MHz |
| number of false targets | 4 |
| Params | d | |||
|---|---|---|---|---|
| JR-TFViT_S | 0.67 M | [16,16,24,48,48,64,64,80,80,320] | [2,4,3] | [64,80,96] |
| JR-TFViT_M | 1.5 M | [16,32,48,64,64,80,80,96,96,384] | [2,4,3] | [96,120,144] |
| JR-TFViT_L | 3.66 M | [16,32,64,96,96,128,128,160,120,640] | [2,4,3] | [144,192,240] |
| VGG16 | ResNet50 | ResNet18 | Mobilenet v2 | Mobilenet_v3_small | Mobilenet_v3_large | |
|---|---|---|---|---|---|---|
| Params | 134.91 M | 23.53 M | 11.18 M | 2.24 M | 1.53 M | 4.22 M |
| Network | Params | JNR | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| −6 | −4 | −2 | 0 | 2 | 4 | 6 | 8 | 10 | 12 | ||
| JR-TFViT_S | 0.67 M | 98.9 | 99.8 | 100 | 99.9 | 99.9 | 99.9 | 99.9 | 99.8 | 99.8 | 99.8 |
| JR-TFViT_M | 1.5 M | 99 | 99.6 | 99.9 | 99.8 | 99.9 | 99.5 | 99.7 | 99.6 | 99.8 | 99.4 |
| JR-TFViT_L | 3.66 M | 99.5 | 99.8 | 100 | 99.9 | 99.8 | 100 | 100 | 100 | 99.9 | 99.9 |
| VGG16 | 134.91 M | 96.4 | 98.9 | 99.7 | 99.8 | 99.8 | 99.4 | 99.8 | 99.7 | 99.8 | 99.3 |
| ResNet50 | 23.53 M | 98.8 | 99.6 | 99.9 | 99.8 | 99.8 | 99.8 | 99.8 | 99.9 | 99.9 | 99.7 |
| ResNet18 | 11.18 M | 97.6 | 99.3 | 99.2 | 99.7 | 99.9 | 99.8 | 99.8 | 100 | 100 | 99.9 |
| Mobilenet v2 | 2.24 M | 97.9 | 99.8 | 99.9 | 99.8 | 99.8 | 99.8 | 99.8 | 99.9 | 99.9 | 99.6 |
| Mobilenet_v3_small | 1.53 M | 96.3 | 98.8 | 99.3 | 99.3 | 99.3 | 99.3 | 99.7 | 99.7 | 99.7 | 99.5 |
| Mobilenet_v3_large | 4.22 M | 93.2 | 99.6 | 99.4 | 99.8 | 99.8 | 99.9 | 100 | 99.8 | 99.8 | 99.8 |
| Network | Params | JNR | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| −6 | −4 | −2 | 0 | 2 | 4 | 6 | 8 | 10 | 12 | ||
| JR-TFViT_S | 0.67 M | 98.8 | 99.8 | 100 | 99.9 | 99.9 | 99.9 | 99.9 | 99.8 | 99.8 | 99.8 |
| JR-TFViT_M | 1.5 M | 98.9 | 99.5 | 99.9 | 99.8 | 99.9 | 99.5 | 99.6 | 99.5 | 99.7 | 99.4 |
| JR-TFViT_L | 3.66 M | 99.5 | 99.8 | 100 | 99.9 | 99.8 | 100 | 100 | 100 | 99.9 | 99.9 |
| VGG16 | 134.91 M | 96.1 | 98.8 | 99.6 | 99.8 | 99.8 | 99.4 | 99.7 | 99.6 | 99.8 | 99.2 |
| ResNet50 | 23.53 M | 98.6 | 99.5 | 99.9 | 99.7 | 99.7 | 99.8 | 99.8 | 99.9 | 99.9 | 99.6 |
| ResNet18 | 11.18 M | 97.4 | 99.3 | 99.1 | 99.6 | 99.9 | 99.8 | 99.8 | 100 | 100 | 99.9 |
| Mobilenet v2 | 2.24 M | 97.7 | 99.7 | 99.9 | 99.8 | 99.7 | 99.7 | 99.8 | 99.9 | 99.9 | 99.5 |
| Mobilenet_v3_small | 1.53 M | 96 | 98.6 | 99.2 | 99.2 | 99.2 | 99.2 | 99.6 | 99.6 | 99.6 | 99.5 |
| Mobilenet_v3_large | 4.22 M | 92.6 | 99.5 | 99.4 | 99.7 | 99.8 | 99.9 | 100 | 99.8 | 99.8 | 99.8 |
| Network | Params | JNR | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| −6 | −4 | −2 | 0 | 2 | 4 | 6 | 8 | 10 | 12 | ||
| JR-TFViT_S | 0.67 M | 0.989 | 0.998 | 1 | 0.999 | 0.999 | 0.999 | 0.999 | 0.998 | 0.998 | 0.998 |
| JR-TFViT_M | 1.5 M | 0.99 | 0.995 | 0.999 | 0.998 | 0.999 | 0.995 | 0.997 | 0.996 | 0.997 | 0.994 |
| JR-TFViT_L | 3.66 M | 0.995 | 0.998 | 1 | 0.999 | 0.998 | 1 | 1 | 1 | 0.999 | 0.999 |
| VGG16 | 134.91 M | 0.962 | 0.989 | 0.997 | 0.998 | 0.997 | 0.995 | 0.997 | 0.997 | 0.998 | 0.993 |
| ResNet50 | 23.53 M | 0.987 | 0.996 | 0.999 | 0.997 | 0.998 | 0.998 | 0.998 | 0.999 | 0.999 | 0.997 |
| ResNet18 | 11.18 M | 0.975 | 0.992 | 0.992 | 0.995 | 0.999 | 0.998 | 0.998 | 1 | 1 | 0.999 |
| Mobilenet v2 | 2.24 M | 0.978 | 0.997 | 0.999 | 0.998 | 0.997 | 0.997 | 0.998 | 0.999 | 0.999 | 0.996 |
| Mobilenet_v3_small | 1.53 M | 0.963 | 0.988 | 0.992 | 0.993 | 0.993 | 0.993 | 0.996 | 0.996 | 0.997 | 0.995 |
| Mobilenet_v3_large | 4.22 M | 0.93 | 0.996 | 0.994 | 0.997 | 0.998 | 0.999 | 1 | 0.998 | 0.998 | 0.998 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lang, B.; Gong, J. JR-TFViT: A Lightweight Efficient Radar Jamming Recognition Network Based on Global Representation of the Time–Frequency Domain. Electronics 2022, 11, 2794. https://doi.org/10.3390/electronics11172794
Lang B, Gong J. JR-TFViT: A Lightweight Efficient Radar Jamming Recognition Network Based on Global Representation of the Time–Frequency Domain. Electronics. 2022; 11(17):2794. https://doi.org/10.3390/electronics11172794
Chicago/Turabian StyleLang, Bin, and Jian Gong. 2022. "JR-TFViT: A Lightweight Efficient Radar Jamming Recognition Network Based on Global Representation of the Time–Frequency Domain" Electronics 11, no. 17: 2794. https://doi.org/10.3390/electronics11172794
APA StyleLang, B., & Gong, J. (2022). JR-TFViT: A Lightweight Efficient Radar Jamming Recognition Network Based on Global Representation of the Time–Frequency Domain. Electronics, 11(17), 2794. https://doi.org/10.3390/electronics11172794