





Multi-Class Positive and Unlabeled Learning for High Dimensional Data Based on Outlier Detection in a Low Dimensional Embedding Space


Abstract
:1. Introduction
2. Related Work
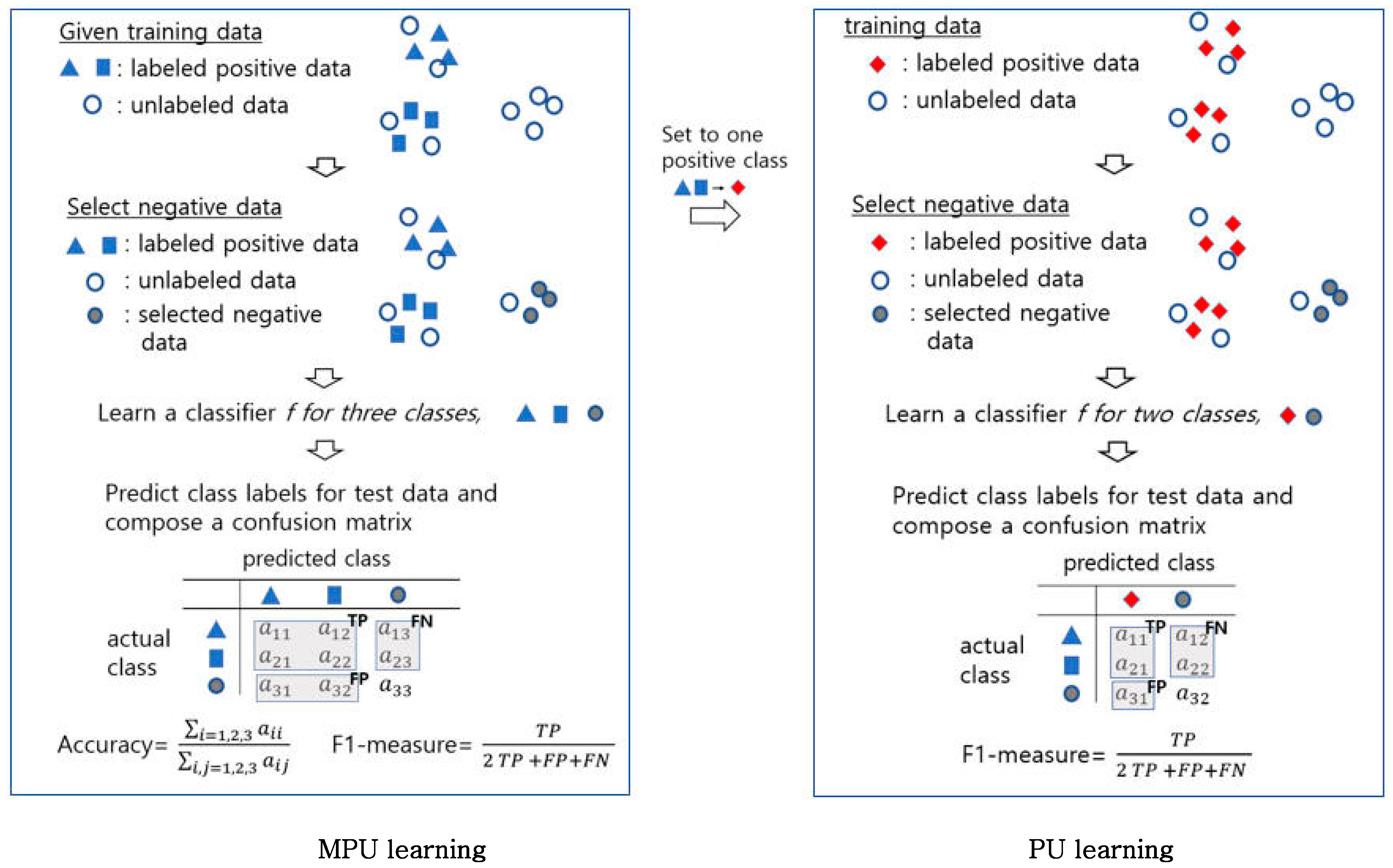
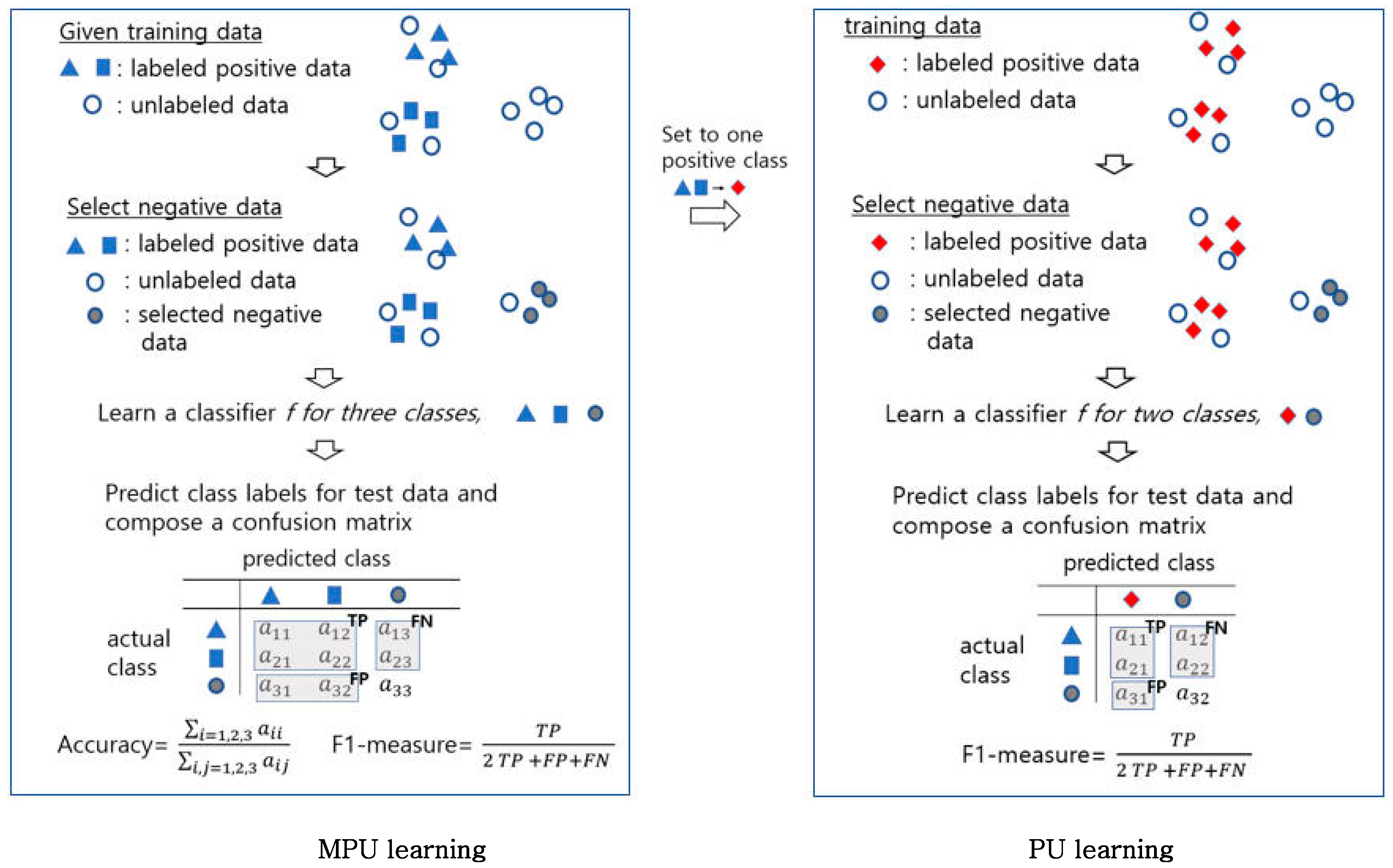
3. The Proposed MPU Learning Method Based on Outlier Detection in a Low Dimensional Embedding Space
3.1. Selection of Negative Samples Based on Binary Outlier Detection
- We construct the training set by randomly selecting 90% of the data samples from class i and set as the remaining 10% of data samples from class i.
- For each positive class j except i, 10% of the data samples are randomly selected to construct a set , and then a validation set is constructed with .
- For each data sample in , compute the sum of distances to k-nearest neighbors in the training set as the outlier score.
- Repeat the following procedure for p = 80, 85, 90, 95, 100 and determine the p-th percentile with the highest f1 score as the threshold for prediction to class i.
- -
- When setting a threshold as the p-th percentile of the outlier scores of the data samples in , if the outlier scores of the data samples in are less than the threshold, then we predict that they belong to class i. The f1 score is computed for the prediction of the data samples in to class i.
- After constructing and for each positive class i, the process of selecting negative samples from unlabeled data is as follows: For unlabeled data sample x, if the sum of distances to k-nearest neighbors among data samples in is greater than , then x is declared not to belong to class i. When x does not belong to any positive classes, it is chosen as the negative-class sample.
3.2. Learning a Multi-Class Classifier
| Algorithm 1. The proposed MPU learning algorithm based on outlier detection in the projected lower dimensional space |
| Input P: labeled positive data from class U: unlabeled data containing positive and negative data
|
| Algorithm 2. The proposed MPU learning algorithm based on outlier detection in the original data space |
| Input P: labeled positive data from class U: unlabeled data containing positive and negative data
|
4. Experiments
4.1. Data Description
4.2. Experimental Setup
- Paper [3]: Different convex loss functions are constructed for labeled and unlabeled data as in Equation (1), and the optimization of a discriminant function and the prediction of unlabeled data are performed alternately.
- Paper [4]: A risk estimator bounded below is proposed by using the modification of the hinge loss function as in Equation (2).
- U-Neg: This simple and naive approach assumes that the unlabeled data all belong to the negative class, commonly referred to as the closed-world assumption [2].
- Algo1: The proposed MPU learning method which performs outlier detection in a low dimensional embedding space.
- Algo2: The proposed MPU learning method which performs outlier detection in the original data space.
- nnPU [19]: A non-negative risk estimator for positive and unlabeled(PU) learning that explicitly constrains the training risk to be non-negative.
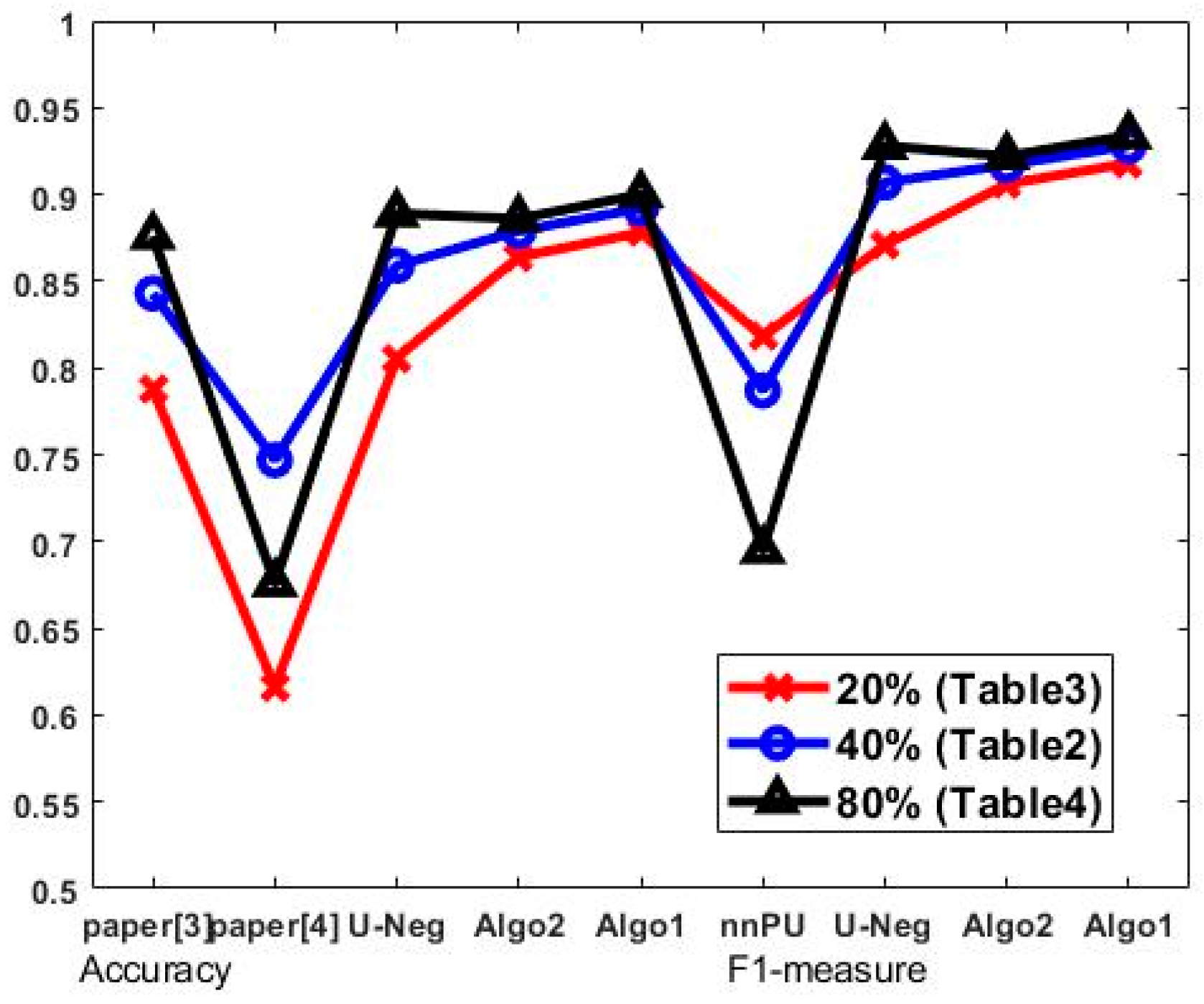
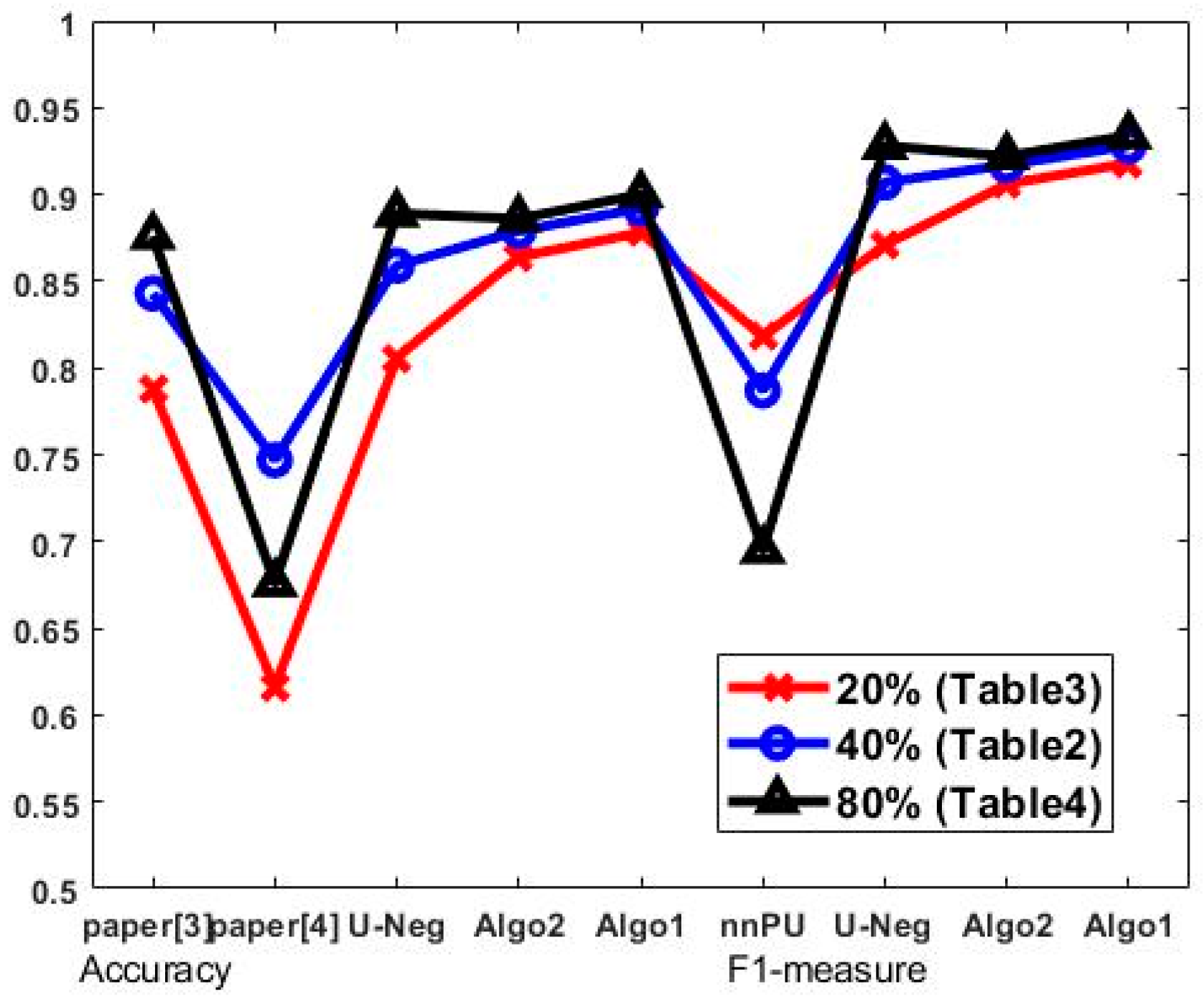
4.3. Performance Comparison
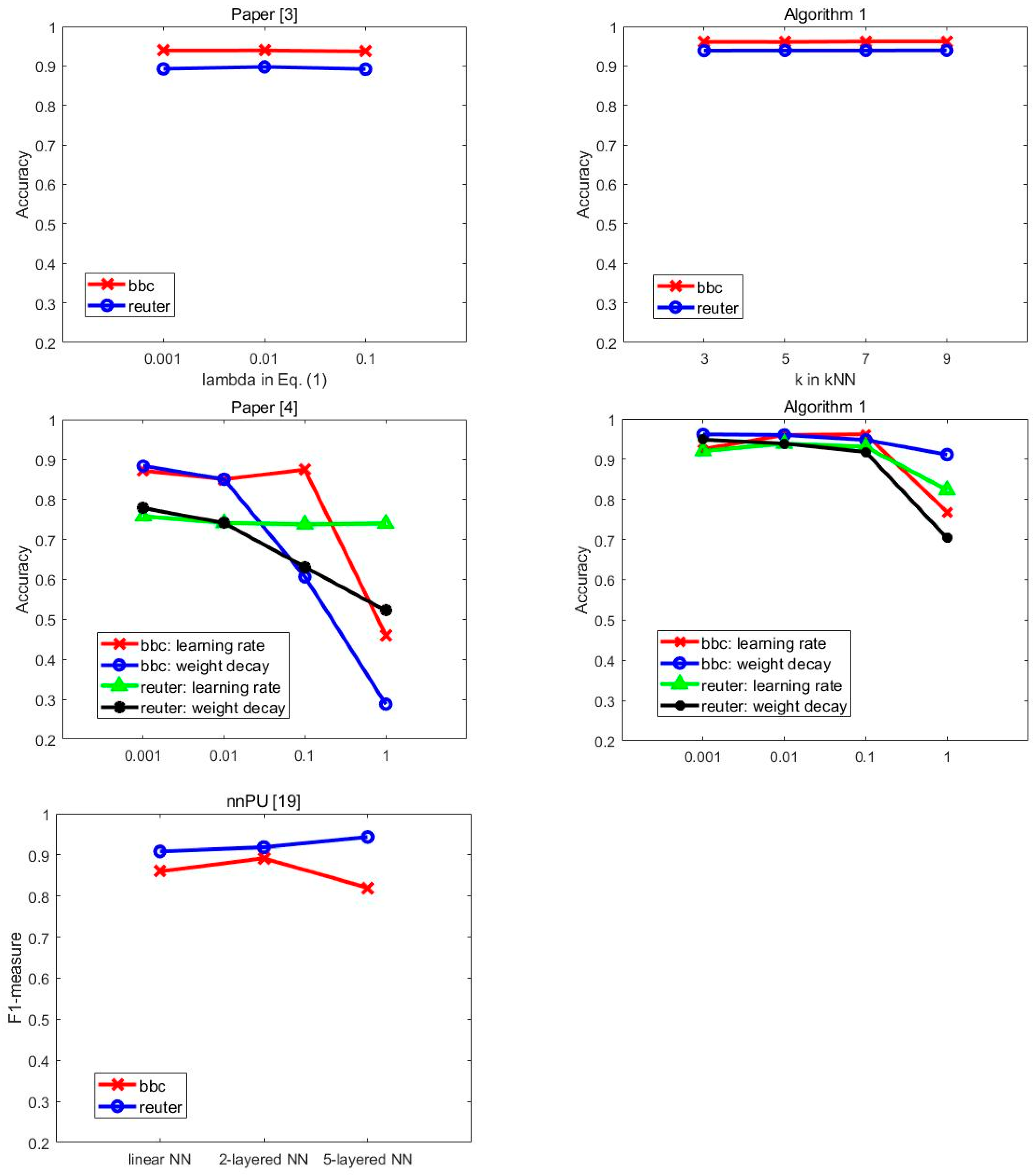
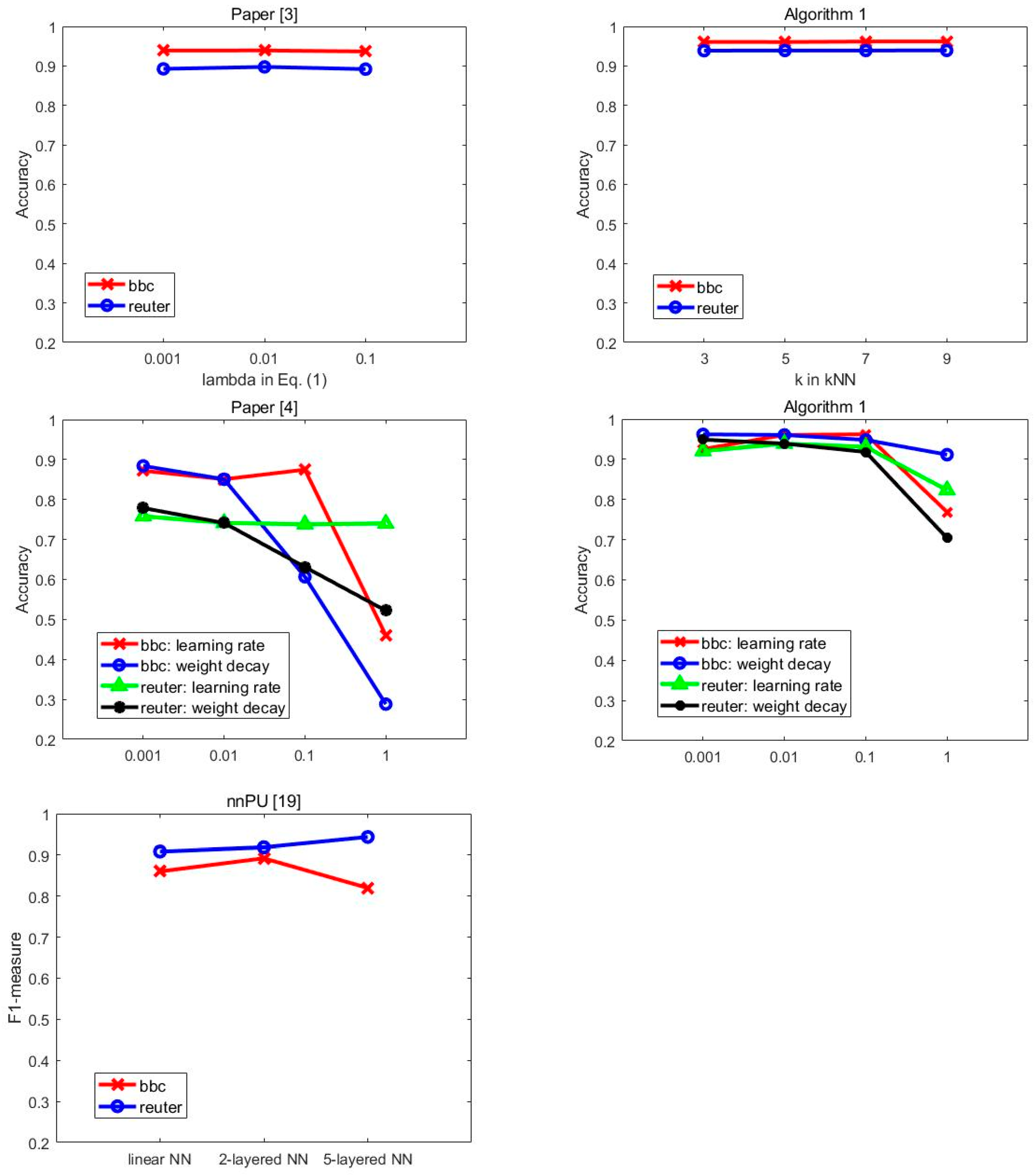
4.4. Ablation Study
5. Conclusions
Funding
Conflicts of Interest
References
- Jaskie, K.; Spanias, A. Positive and Unlabeled Learning Algorithms and Applications: A survey. In Proceedings of the International Conference on Information, Intelligence, Systems and Applications, Patras, Greece, 15–17 July 2019. [Google Scholar]
- Bekker, J.; Davis, J. Learning from Positive and Unlabeled Data: A survey. Mach. Learn. 2020, 109, 719–760. [Google Scholar] [CrossRef]
- Xu, Y.; Xu, C.; Xu, C.; Tao, D. Multi-Positive and Unlabeled Learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Shu, S.; Lin, Z.; Yan, Y.; Li, L. Learning from Multi-class Positive and Unlabeled Data. In Proceedings of the International Conference on Data Mining, Sorrento, Italy, 17–20 November 2020. [Google Scholar]
- Zhang, B.; Zuo, W. Learning from positive and unlabeled examples: A survey. In Proceedings of the International Symposiums on Information Processing, St. Louis, MI, USA, 22–24 April 2008. [Google Scholar]
- Liu, B.; Lee, S.; Yu, S.; Li, X. Partially Supervised Classification of Text Documents. In Proceedings of the International Conference on Machine Learning, Las Vegas, NV, USA, 24–27 June 2002. [Google Scholar]
- Chaudhari, S.; Shevade, S. Learning from Positive and Unlabeled Examples Using Maximum Margin Clustering. In Proceedings of the International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012. [Google Scholar]
- Liu, L.; Peng, T. Clustering-based Method for Positive and Unlabeled Text Categorization Enhanced by Improved TFIDF. J. Inf. Sci. Eng. 2014, 30, 1463–1481. [Google Scholar]
- Basil, M.; Di Mauro, N.; Esposito, F.; Ferilli, S.; Vegari, A. Density Estimators for Positive-Unlabeled Learning. In New Frontiers in Mining Complex Patterns; Appice, A., Loglisci, C., Manco, G., Masciari, E., Ras, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 18–22. [Google Scholar]
- Zhang, B.; Zuo, W. Reliable Negative Extracting based on kNN for Learning from Positive and Unlabeled Examples. J. Comput. 2009, 4, 94–101. [Google Scholar] [CrossRef]
- Aggarwal, C. Outlier Analysis, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Duda, R.; Hart, P.; Stork, D. Pattern Classification, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2001. [Google Scholar]
- Park, C.; Park, H. A Relationship Between Linear Discriminant Analysis and the Generalized Minimum Squared Error Solution. Siam J. Matrix Anal. Appl. 2005, 27, 474–492. [Google Scholar] [CrossRef] [Green Version]
- Park, C. A Comparative Study for Outlier Detection Methods in High Dimensional Data. J. Artif. Intell. Soft Comput. Res. 2022; submitted. [Google Scholar]
- Greene, D.; Cunningham, P. Practical Solutions to the Problem of Diagonal Dominance in Kernel Document Clustering. In Proceedings of the ICML, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- 20Newsgroups. Available online: http://qwone.com/~jason/20Newsgroups/ (accessed on 27 July 2021).
- Kim, H.; Holland, P.; Park, H. Dimension Reduction in Text Classification with Support Vector Machines. J. Mach. Learn. Res. 2005, 6, 37–53. [Google Scholar]
- KarypisLab. Available online: http://glaros.dtc.umn.edu/gkhome/index.php (accessed on 27 June 2022).
- Kiryo, R.; Niu, G.; Plessis, M.; Sugiyama, M. Positive-Unlabeled Learning with Non-Negative Risk Estimator. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Diamond, S.; Boyd, S. CVXPY: A Python-embedded Modeling Language for Convex Optimization. J. Mach. Learn. Res. 2016, 17, 2909–2913. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An Imperative Style, High-performance Deep Learning library. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Data | Terms | Samples | Classes |
|---|---|---|---|
| bbc | 17,005 | 2225 | 5 |
| reuter | 15,484 | 6656 | 3 |
| 20-ng | 44,713 | 18,774 | 20 |
| medline | 22,095 | 2500 | 5 |
| la12 | 21,604 | 6279 | 6 |
| sports | 18,324 | 8313 | 5 |
| classic | 12,009 | 7094 | 4 |
| ohscal | 11,465 | 11,162 | 10 |
| reviews | 23,220 | 3932 | 4 |
| Accuracy in Multi-Class Positive vs. Negative | F1-Measure in Positive vs. Negative | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Data | Paper [3] | Paper [4] | U-Neg | Algo2 | Algo1 | nnPU [19] | U-Neg | Algo2 | Algo1 |
| bbc | 0.939 | 0.851 | 0.941 | 0.955 | 0.961 | 0.892 | 0.961 | 0.961 | 0.975 |
| reuter | 0.885 * | 0.742 | 0.872 | 0.928 | 0.939 | 0.943 | 0.933 | 0.959 | 0.969 |
| 20-ng | * | 0.63 | 0.886 | 0.899 | 0.903 | 0.773 | 0.941 | 0.949 | 0.953 |
| medline | 0.616 | 0.816 | 0.812 | 0.811 | 0.833 | 0.811 | 0.891 | 0.891 | 0.903 |
| la12 | 0.808 | 0.69 | 0.833 | 0.861 | 0.874 | 0.625 | 0.862 | 0.882 | 0.894 |
| sports | 0.887 * | 0.721 | 0.968 | 0.973 | 0.973 | 0.903 | 0.976 | 0.979 | 0.978 |
| classic | 0.929 | 0.942 | 0.944 | 0.941 | 0.959 | 0.771 | 0.95 | 0.944 | 0.964 |
| ohscal | * | 0.603 | 0.575 | 0.655 | 0.668 | 0.732 | 0.736 | 0.78 | 0.788 |
| reviews | 0.839 | 0.73 | 0.899 | 0.88 | 0.918 | 0.73 | 0.91 | 0.897 | 0.928 |
| average | 0.843 | 0.747 | 0.859 | 0.879 | 0.892 | 0.787 | 0.907 | 0.917 | 0.928 |
| Accuracy in Multi-Class Positive vs. Negative | F1-Measure in Positive Vs. Negative | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Data | Paper [3] | Paper [4] | U-Neg | Algo2 | Algo1 | nnPU [19] | U-Neg | Algo2 | Algo1 |
| bbc | 0.903 | 0.636 | 0.894 | 0.943 | 0.946 | 0.806 | 0.926 | 0.961 | 0.963 |
| reuter | 0.866 | 0.718 | 0.81 | 0.924 | 0.937 | 0.924 | 0.897 | 0.956 | 0.967 |
| 20-ng | 0.775 * | 0.67 | 0.859 | 0.892 | 0.902 | 0.855 | 0.92 | 0.943 | 0.953 |
| medline | 0.544 | 0.563 | 0.769 | 0.789 | 0.802 | 0.766 | 0.864 | 0.879 | 0.883 |
| la12 | 0.775 | 0.569 | 0.767 | 0.836 | 0.861 | 0.738 | 0.813 | 0.862 | 0.883 |
| sports | 0.913 | 0.581 | 0.941 | 0.968 | 0.968 | 0.906 | 0.957 | 0.974 | 0.975 |
| classic | 0.875 | 0.631 | 0.877 | 0.927 | 0.947 | 0.856 | 0.895 | 0.932 | 0.951 |
| ohscal | 0.639 * | 0.581 | 0.511 | 0.631 | 0.638 | 0.744 | 0.703 | 0.766 | 0.77 |
| reviews | 0.798 | 0.592 | 0.83 | 0.865 | 0.902 | 0.771 | 0.861 | 0.881 | 0.914 |
| average | 0.788 | 0.616 | 0.806 | 0.864 | 0.878 | 0.818 | 0.871 | 0.906 | 0.918 |
| Accuracy in Multi-Class Positive vs. Negative | F1-Measure in Positive vs. Negative | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Data | Paper [3] | Paper [4] | U-Neg | Algo2 | Algo1 | nnPU [19] | U-Neg | Algo2 | Algo1 |
| bbc | 0.952 | 0.684 | 0.965 | 0.965 | 0.97 | 0.686 | 0.979 | 0.978 | 0.982 |
| reuter | 0.893 | 0.761 | 0.922 | 0.928 | 0.94 | 0.94 | 0.962 | 0.959 | 0.97 |
| 20-ng | * | 0.53 | 0.898 | 0.901 | 0.903 | 0.723 | 0.95 | 0.951 | 0.954 |
| medline | 0.666 | 0.499 | 0.848 | 0.828 | 0.853 | 0.306 | 0.914 | 0.903 | 0.917 |
| la12 | * | 0.684 | 0.869 | 0.866 | 0.881 | 0.525 | 0.891 | 0.886 | 0.9 |
| sports | 0.932 * | 0.79 | 0.979 | 0.977 | 0.976 | 0.869 | 0.985 | 0.982 | 0.981 |
| classic | 0.954 | 0.877 | 0.963 | 0.952 | 0.963 | 0.852 | 0.968 | 0.954 | 0.968 |
| ohscal | * | 0.504 | 0.628 | 0.672 | 0.685 | 0.749 | 0.765 | 0.79 | 0.797 |
| reviews | 0.857 | 0.755 | 0.929 | 0.896 | 0.929 | 0.606 | 0.936 | 0.898 | 0.937 |
| average | 0.876 | 0.676 | 0.889 | 0.886 | 0.9 | 0.695 | 0.928 | 0.922 | 0.934 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.H. Multi-Class Positive and Unlabeled Learning for High Dimensional Data Based on Outlier Detection in a Low Dimensional Embedding Space. Electronics 2022, 11, 2789. https://doi.org/10.3390/electronics11172789
Park CH. Multi-Class Positive and Unlabeled Learning for High Dimensional Data Based on Outlier Detection in a Low Dimensional Embedding Space. Electronics. 2022; 11(17):2789. https://doi.org/10.3390/electronics11172789
Chicago/Turabian StylePark, Cheong Hee. 2022. "Multi-Class Positive and Unlabeled Learning for High Dimensional Data Based on Outlier Detection in a Low Dimensional Embedding Space" Electronics 11, no. 17: 2789. https://doi.org/10.3390/electronics11172789
APA StylePark, C. H. (2022). Multi-Class Positive and Unlabeled Learning for High Dimensional Data Based on Outlier Detection in a Low Dimensional Embedding Space. Electronics, 11(17), 2789. https://doi.org/10.3390/electronics11172789