
A New Unsupervised Technique to Analyze the Centroid and Frequency of Keyphrases from Academic Articles

 , , ,
, , ,  and
and
Abstract
:1. Introduction
- the proposed approach is corpus, domain, and language agnostic;
- both supervised and unsupervised techniques can be benefited from the proposed technique;
- the proposed method is a document-length-agnostic approach;
- ten (10) standard datasets were utilized to analyze and evaluate the efficiency of the suggested technique.
2. Background Study
2.1. Unsupervised Techniques
2.2. Supervised Techniques
3. Methodology
3.1. Datasets Collection
3.2. Data Pre-Processing
3.2.1. Documents and Keys Extraction
3.2.2. Documents and Keys Pre-Processing
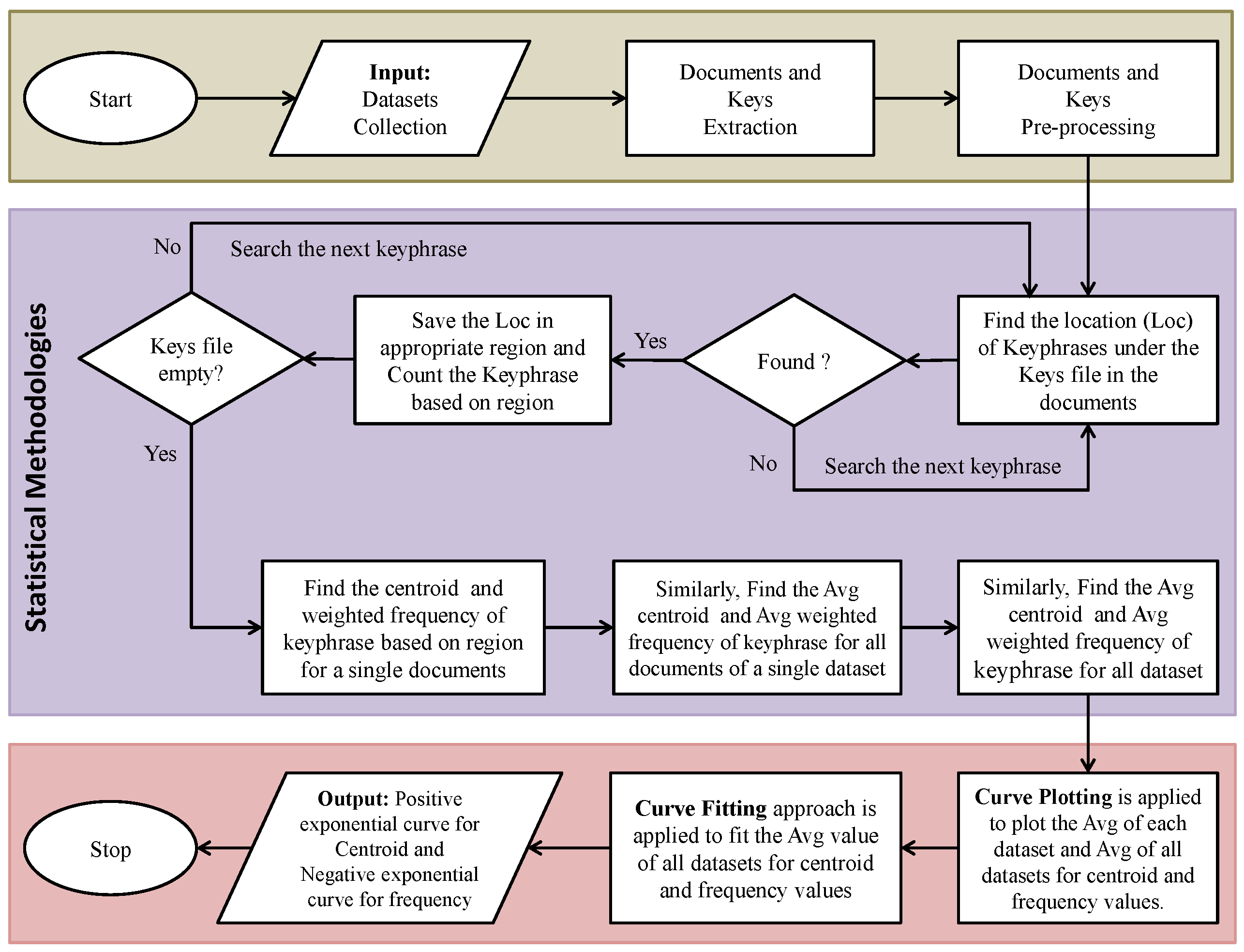
3.3. Statistical Methodologies
3.3.1. Keyphrase Searching, Saving, and Counting
3.3.2. Centroid and Weighted-Frequency Calculation and Averaging
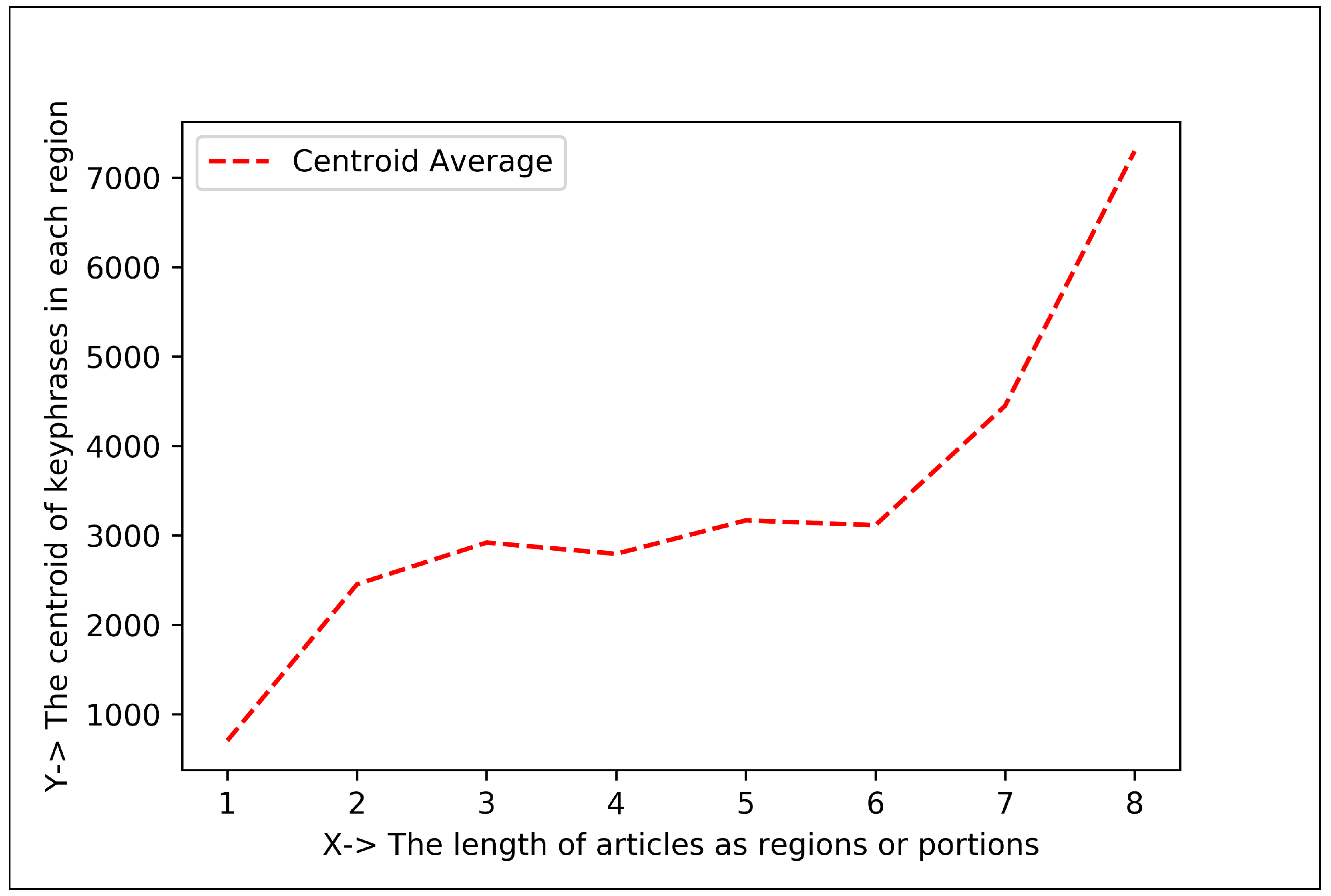
3.4. Curve Plotting Analysis (CPA)
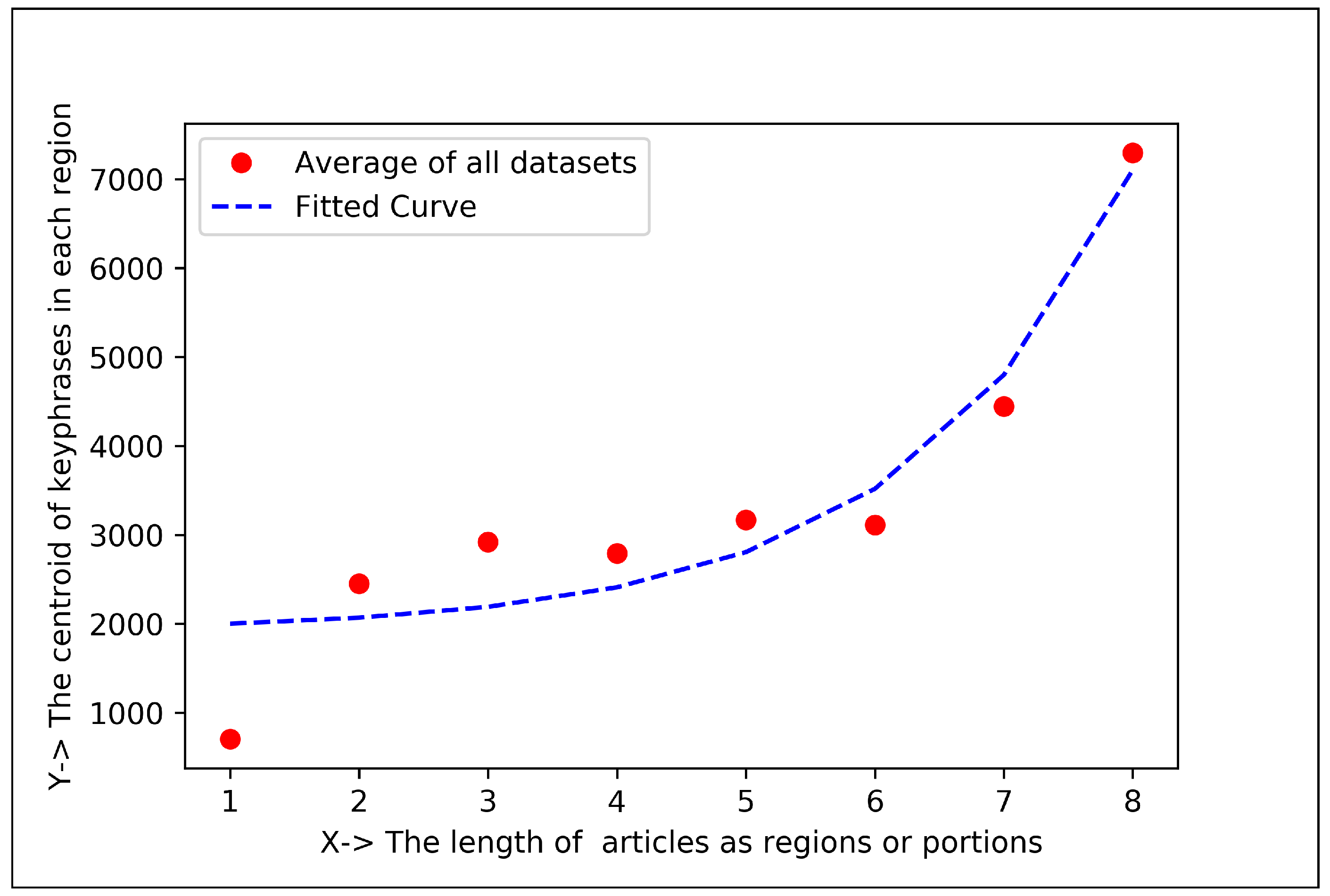
3.5. Curve Fitting Technique (CFT)
4. Experimental Setup
4.1. Corpus Details
4.2. Evaluation Metrics
4.3. Implementation Details
5. Results and Discussion
5.1. Results Analysis
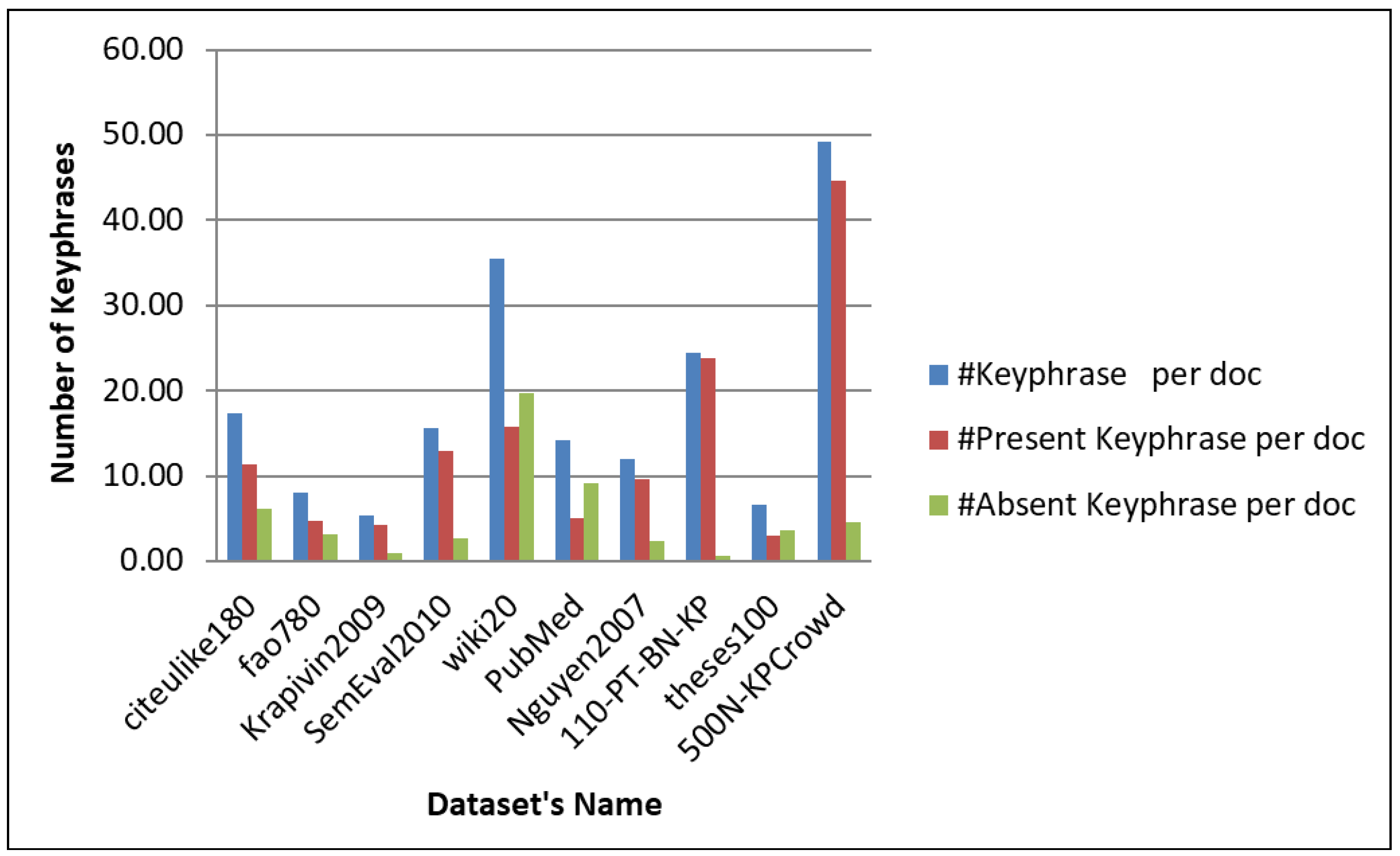
5.1.1. Dataset Analysis
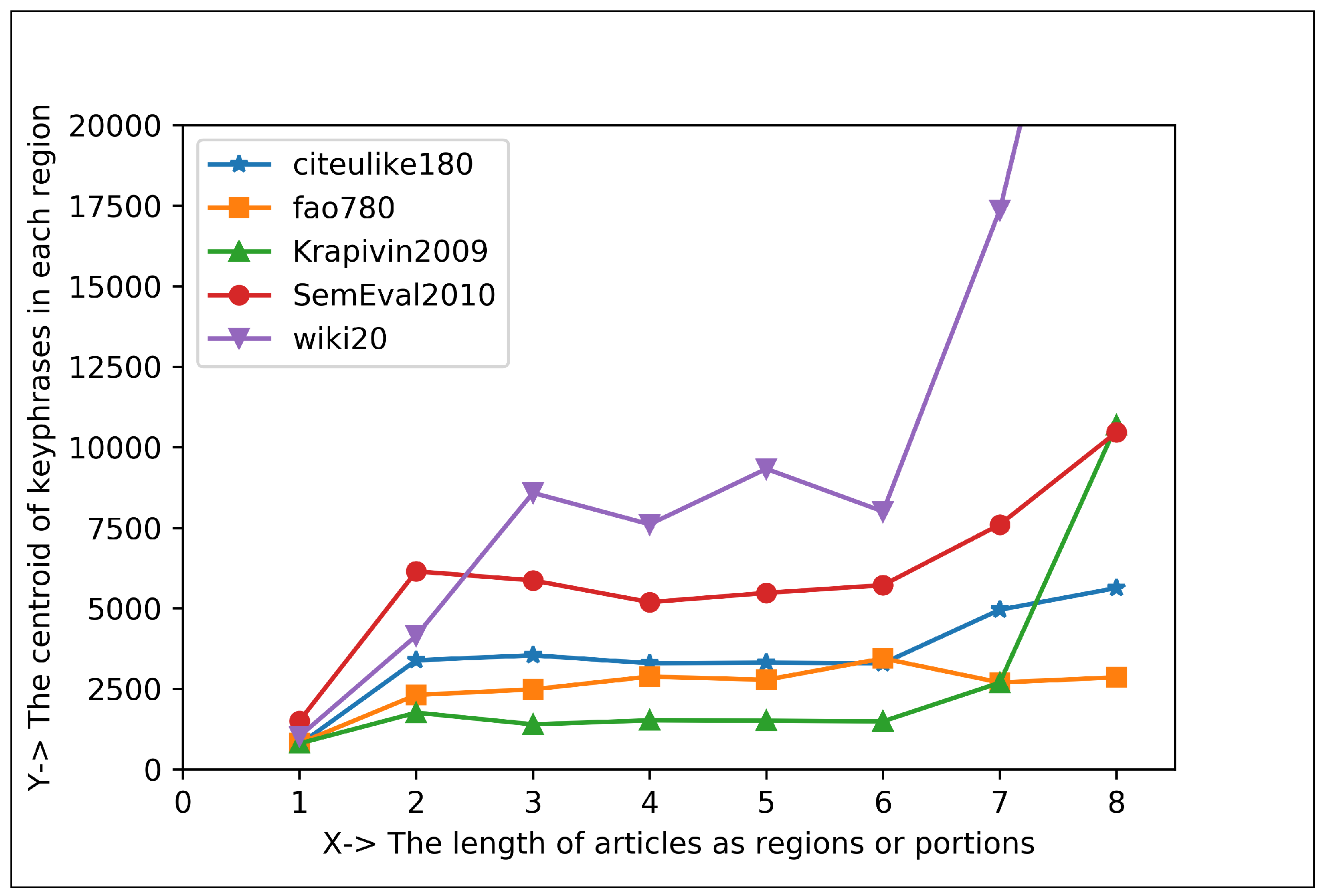
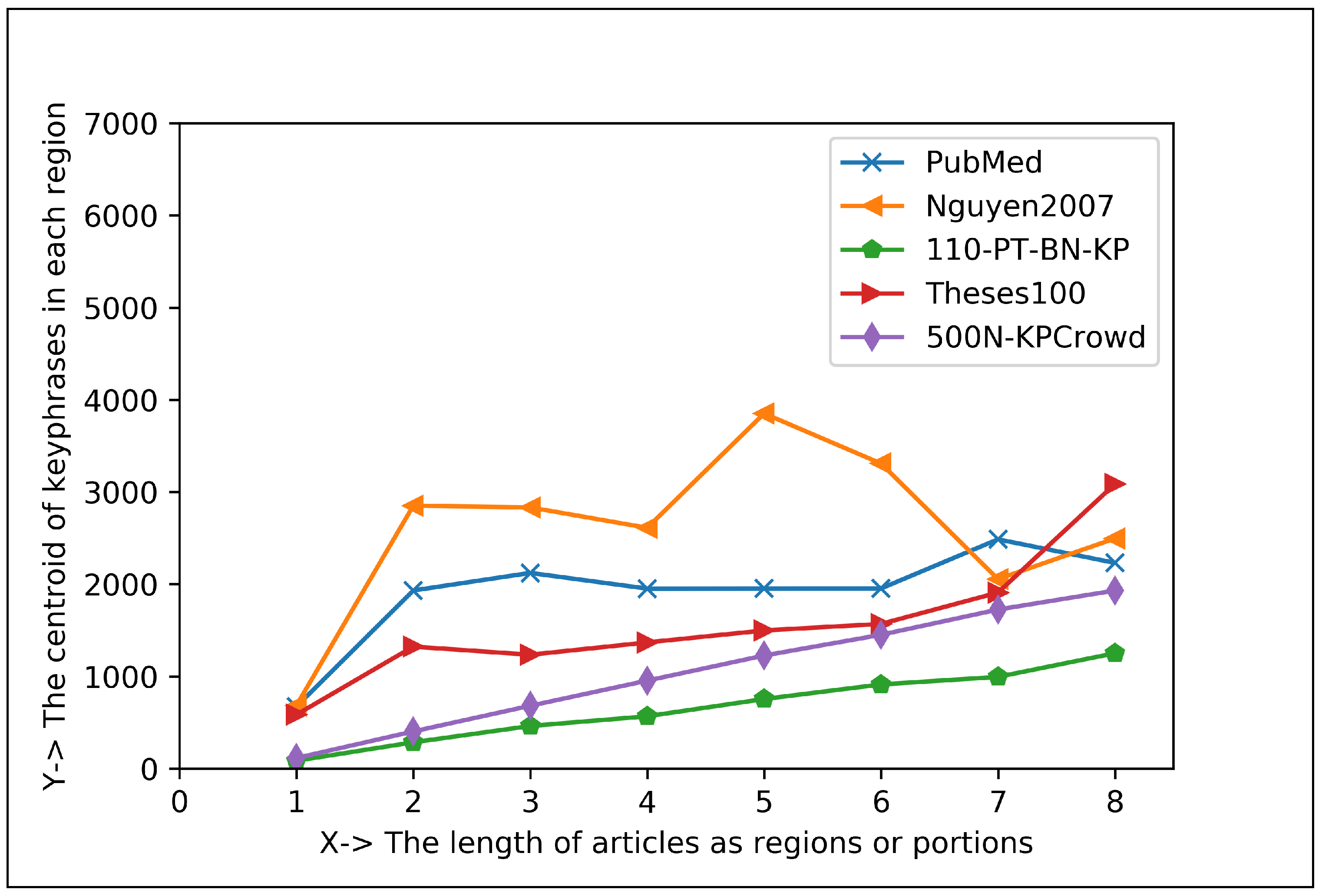
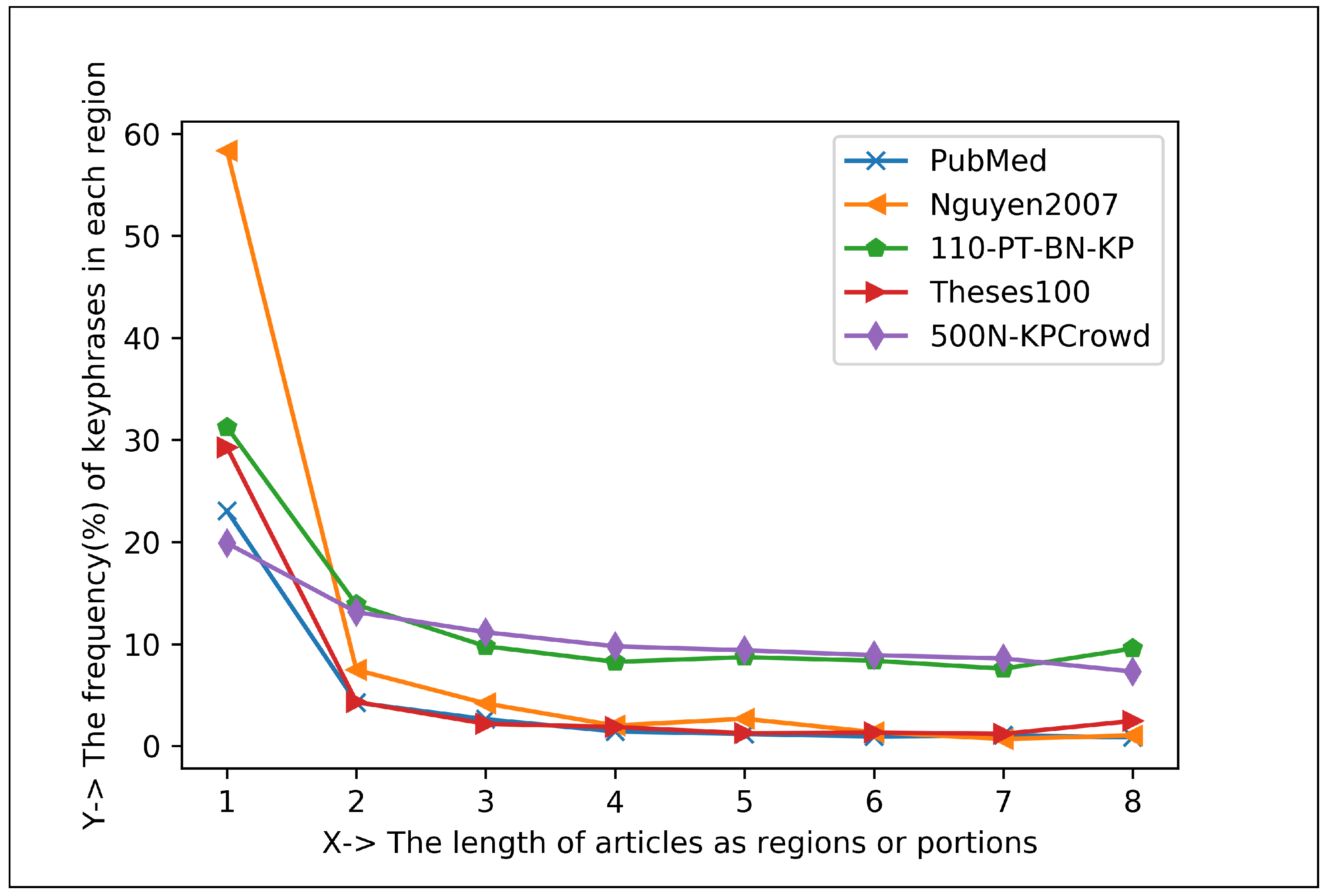
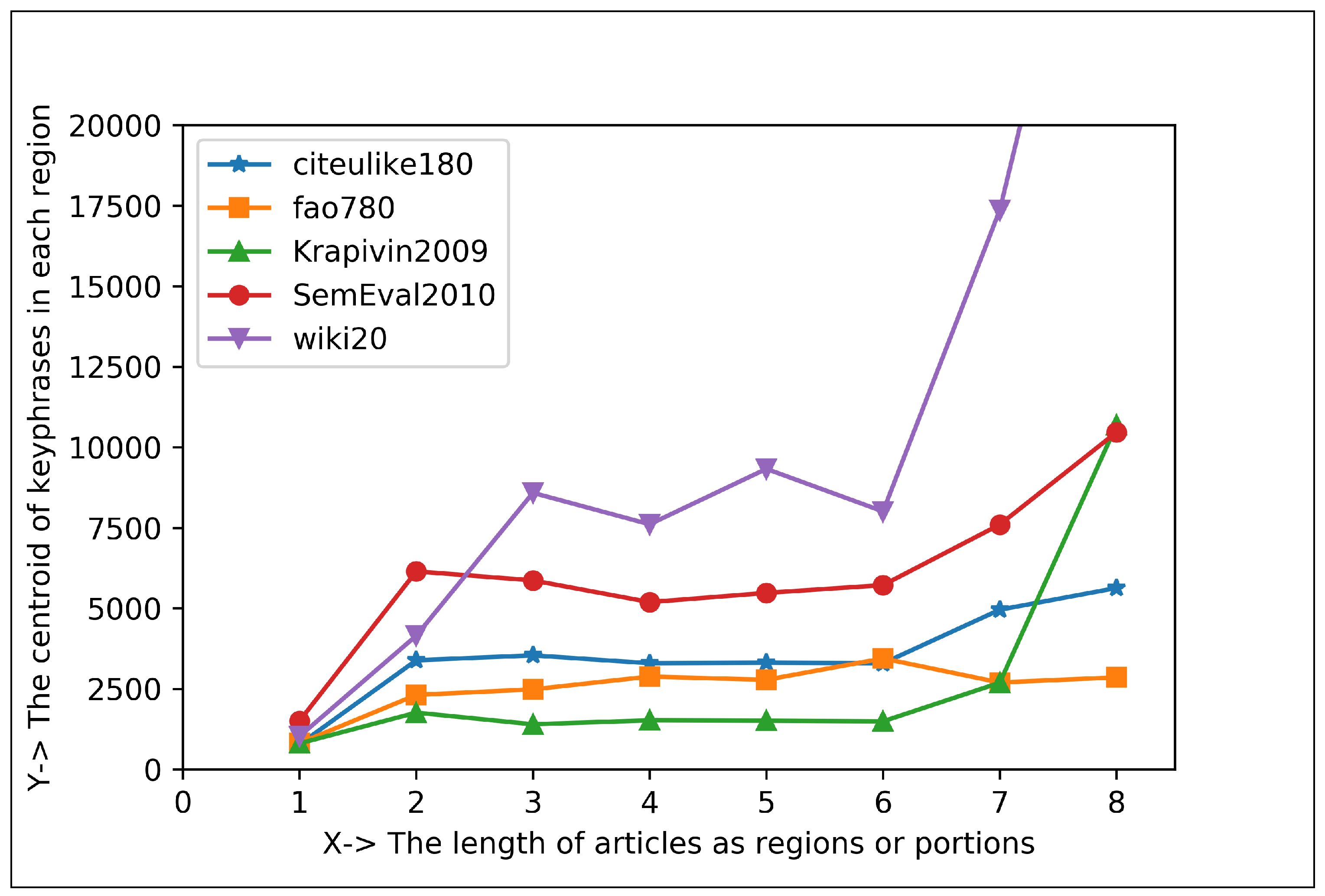
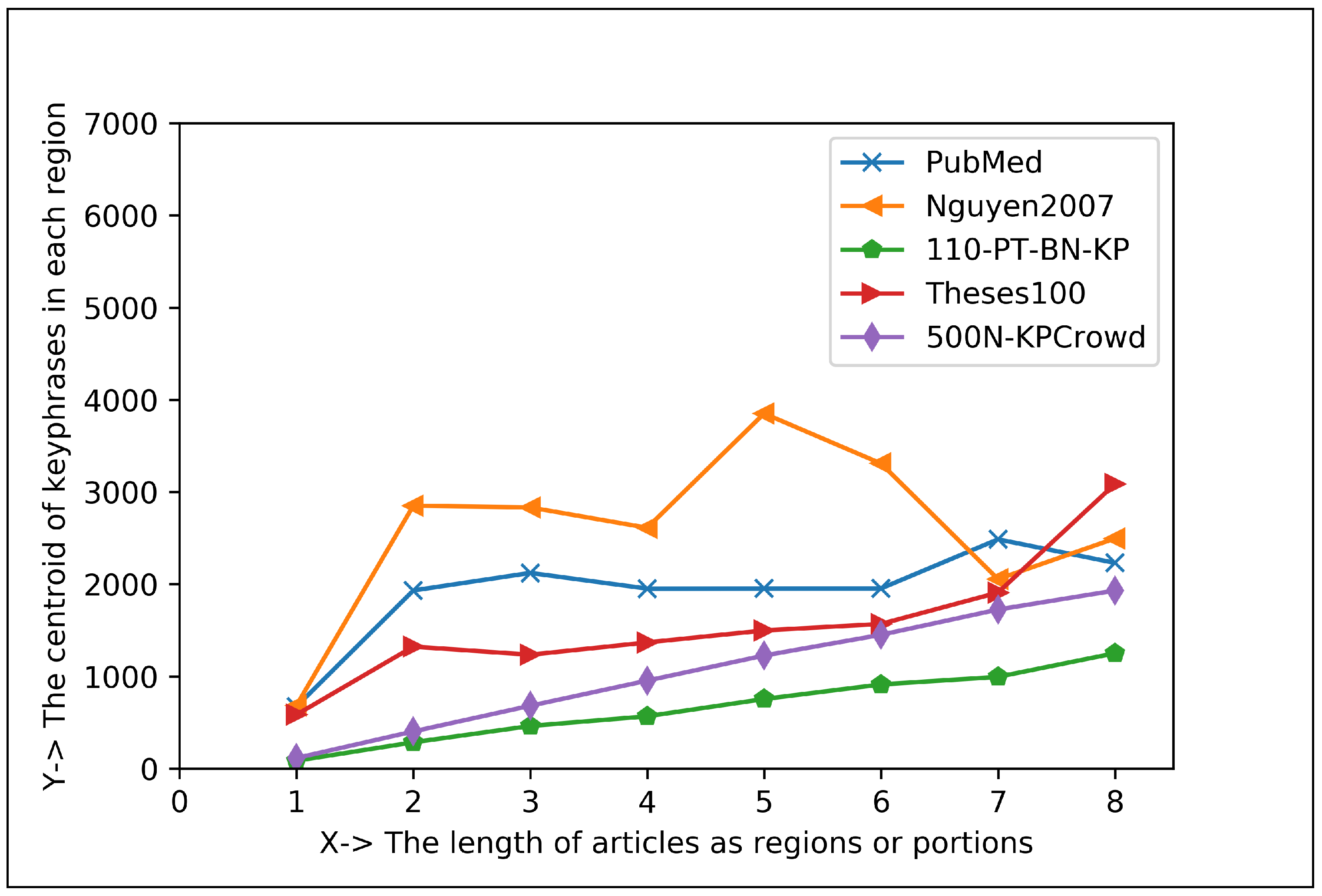
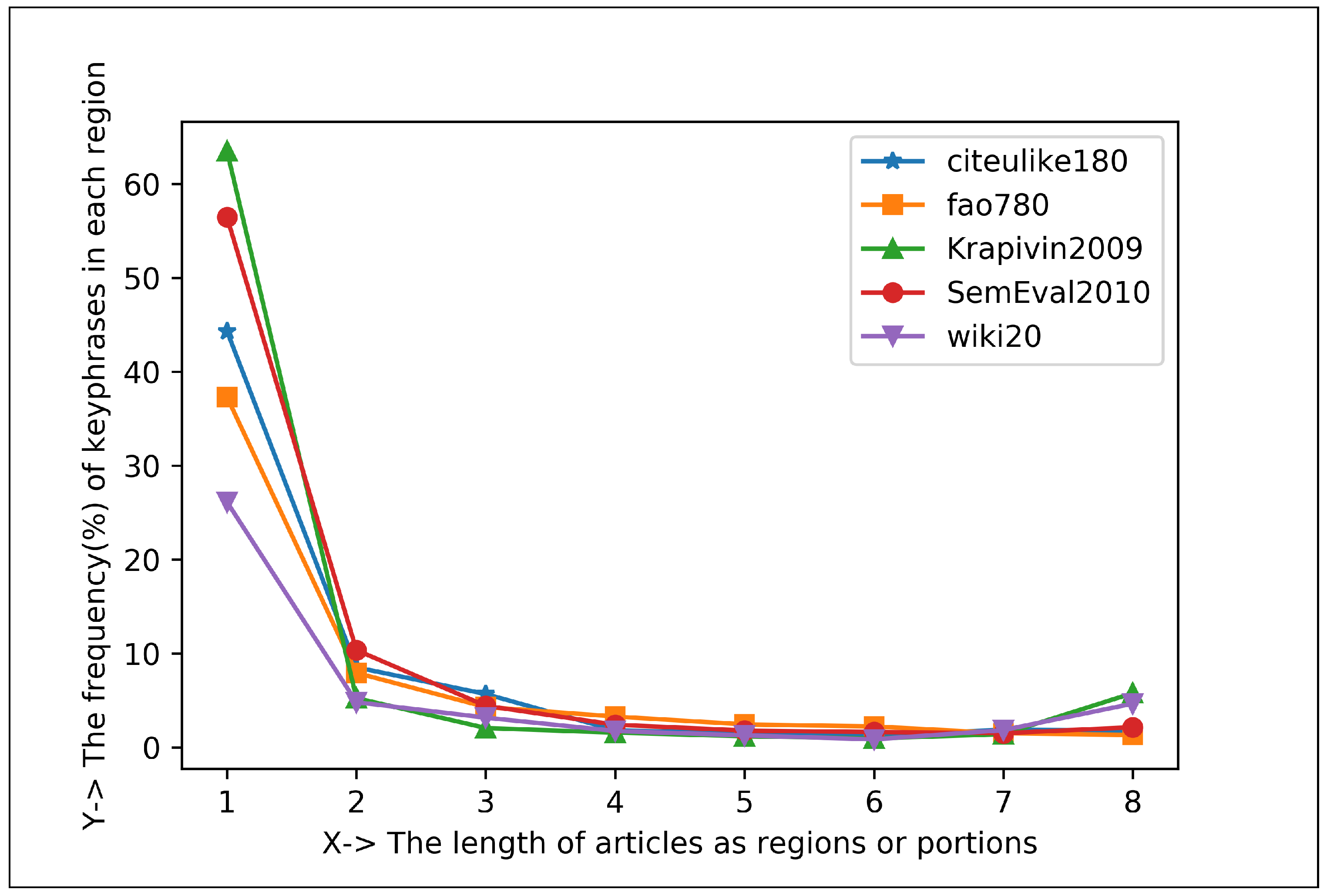
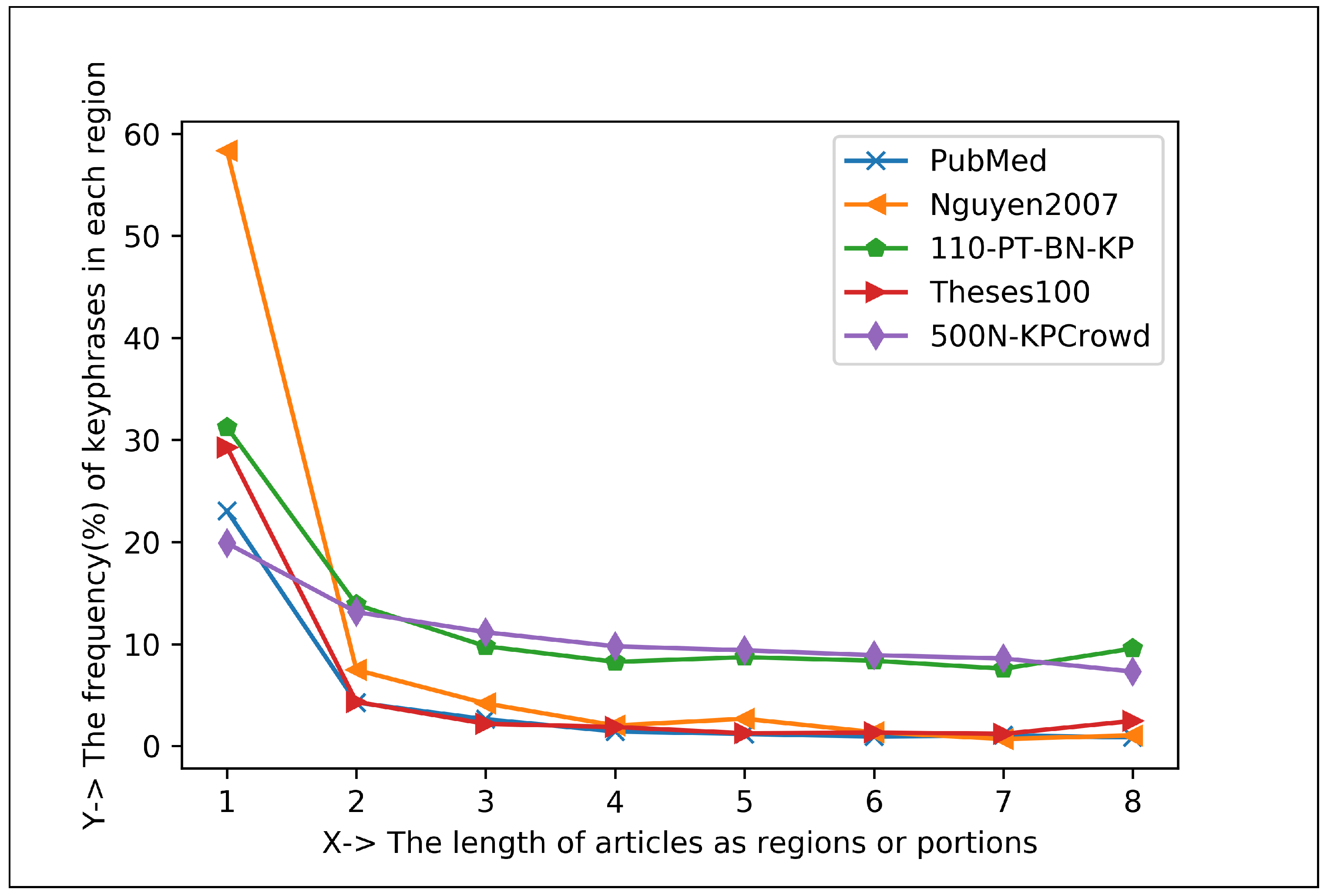
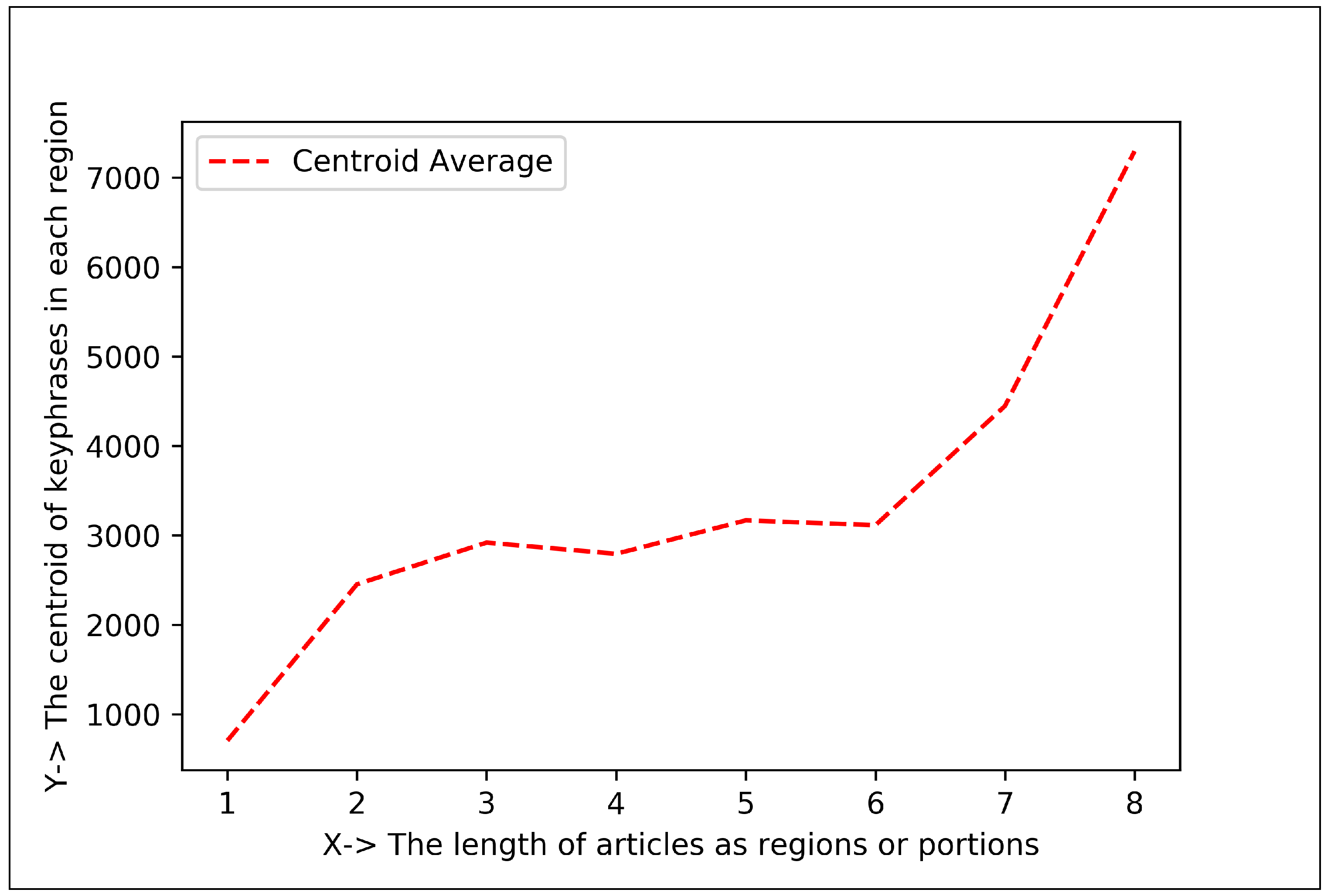
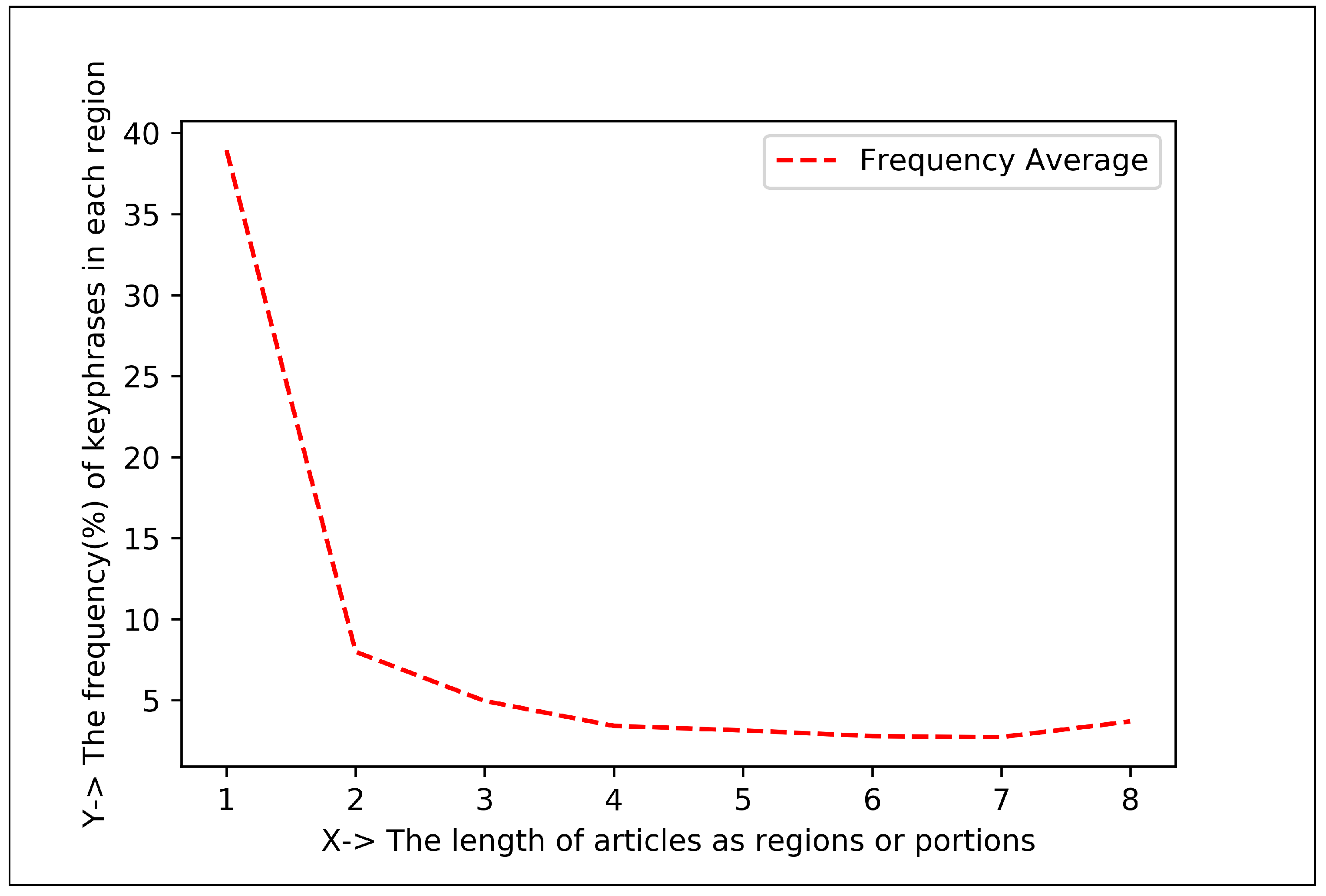
5.1.2. Plotting Analysis
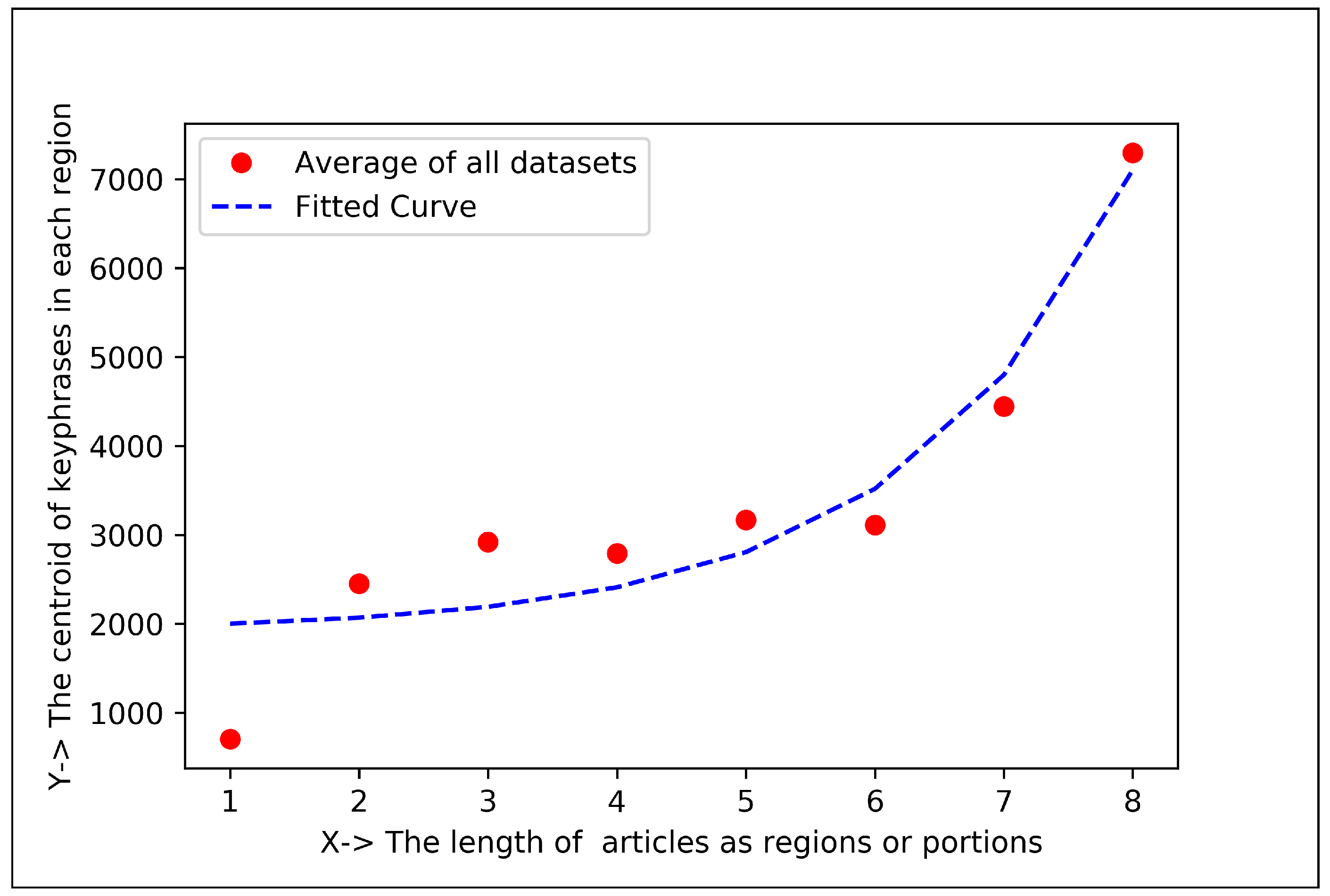
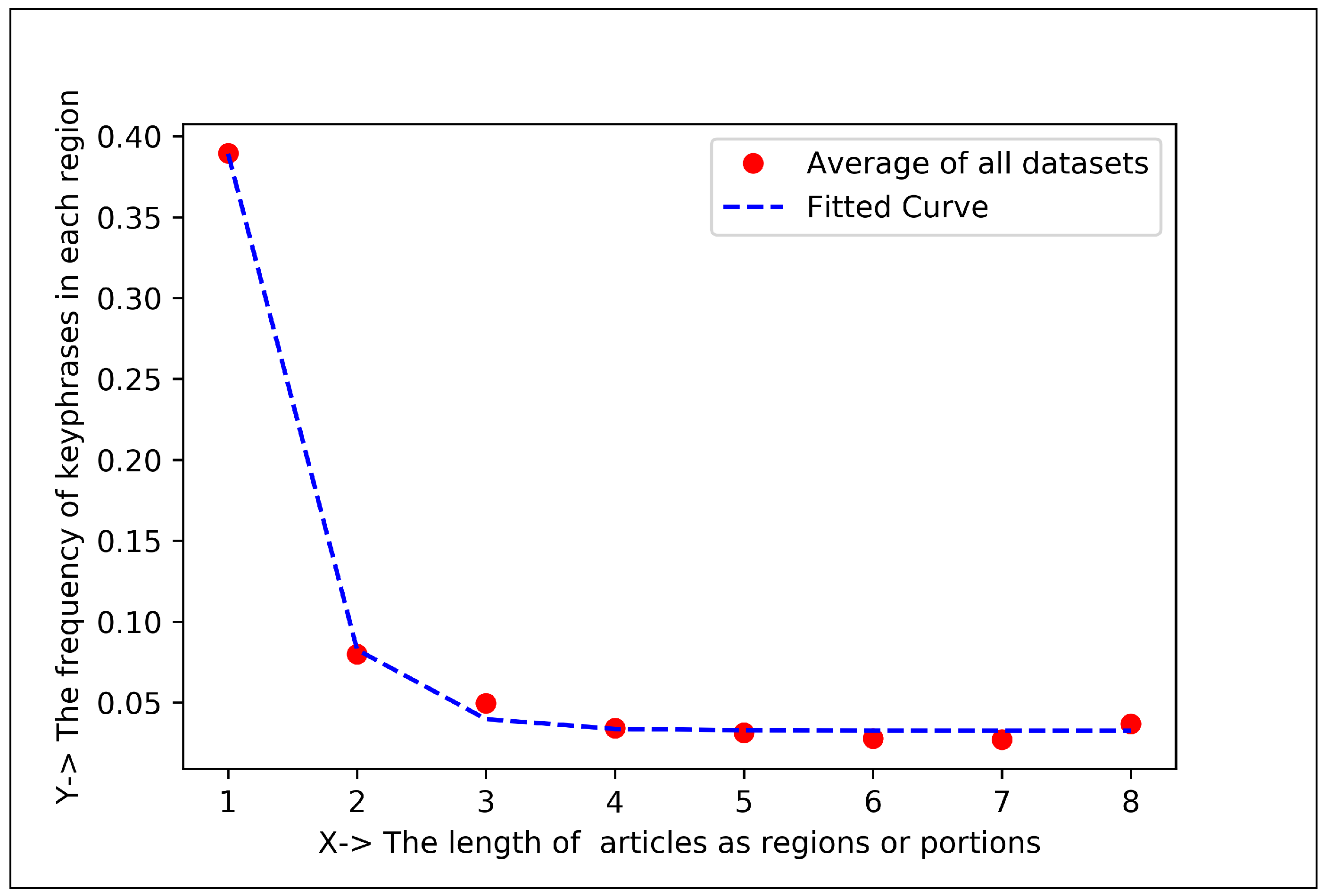
5.1.3. Curve Fitting Analysis
5.2. Comparison of Proposed Systems
5.2.1. Comparison for Choosing a Better Dataset
5.2.2. Comparison for Choosing a Better Technique
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| KCFA | Keyphrases Centroid and Frequency Analysis |
| SML | Supervised Machine Learning |
| NLP | Natural Language Processing |
| KCF | Keyphrase Centroid and Frequency |
| CPA | Curve Plotting Analysis |
| CFT | Cure Fitting Technique |
| TeKET | Tree-based Keyphrase Extraction Technique |
| YAKE | Yet Another Keyword Extractor |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| NN | Neural Networks |
| SVM | Support Vector Machines |
| DT | Decision Trees |
| KEA | Keyphrase Extraction Algorithm |
| GenEx | Genitor Extractor |
| POS | Part-of-speech |
| DPM | Document Phrase Maximality |
| CeKE | Citation-enhanced Keyphrase Extraction |
| AWF | Average Weighted Frequency |
| AC | average centroid |
| Loc | Location |
| Avg | Average |
| GRISP | General Research Insight in Scientific and technical Publications |
| HAL | Hyper Article en Ligne |
| GROBID | GeneRation Of BIbilographic Data |
| TEI | Text Encoding Initiative |
References
- Sarwar, T.B.; Noor, N.M.; Miah, M.S.U. Evaluating keyphrase extraction algorithms for finding similar news articles using lexical similarity calculation and semantic relatedness measurement by word embedding. PeerJ Comput. Sci. 2022, 8, e1024. [Google Scholar] [CrossRef] [PubMed]
- Miah, M.B.A.; Awang, S.; Azad, M.S.; Rahman, M.M. Keyphrases Concentrated Area Identification from Academic Articles as Feature of Keyphrase Extraction: A New Unsupervised Approach. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 788–796. [Google Scholar] [CrossRef]
- Sun, C.; Hu, L.; Li, S.; Li, T.; Li, H.; Chi, L. A Review of Unsupervised Keyphrase Extraction Methods Using Within-Collection Resources. Symmetry 2020, 12, 1864. [Google Scholar] [CrossRef]
- Miah, M.B.A.; Awang, S.; Azad, M.S. Region-Based Distance Analysis of Keyphrases: A New Unsupervised Method for Extracting Keyphrases Feature from Articles. In Proceedings of the 2021 International Conference on Software Engineering & Computer Systems and 4th International Conference on Computational Science and Information Management (ICSECS-ICOCSIM), Pekan, Malaysia, 24–26 August 2021; pp. 124–129. [Google Scholar]
- Zheng, W.; Xun, Y.; Wu, X.; Deng, Z.; Chen, X.; Sui, Y. A comparative study of class rebalancing methods for security bug report classification. IEEE Trans. Reliab. 2021, 70, 1658–1670. [Google Scholar] [CrossRef]
- Zheng, W.; Tian, X.; Yang, B.; Liu, S.; Ding, Y.; Tian, J.; Yin, L. A few shot classification methods based on multiscale relational networks. Appl. Sci. 2022, 12, 4059. [Google Scholar] [CrossRef]
- Shen, L.; Liu, Q.; Chen, G.; Ji, S. Text-based price recommendation system for online rental houses. Big Data Min. Anal. 2020, 3, 143–152. [Google Scholar] [CrossRef]
- Chen, H.; Yang, C.; Zhang, X.; Liu, Z.; Sun, M.; Jin, J. From Symbols to Embeddings: A Tale of Two Representations in Computational Social Science. J. Soc. Comput. 2021, 2, 103–156. [Google Scholar] [CrossRef]
- Nafis, N.S.M.; Awang, S. An Enhanced Hybrid Feature Selection Technique Using Term Frequency-Inverse Document Frequency and Support Vector Machine-Recursive Feature Elimination for Sentiment Classification. IEEE Access 2021, 9, 52177–52192. [Google Scholar] [CrossRef]
- Wu, Y.f.B.; Li, Q.; Bot, R.S.; Chen, X. Domain-specific keyphrase extraction. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 31 October–5 November 2005; pp. 283–284. [Google Scholar]
- Tomokiyo, T.; Hurst, M. A language model approach to keyphrase extraction. In Proceedings of the ACL 2003 Workshop on Multiword Expressions: Analysis, Acquisition and Treatment, Sapporo, Japan, 12 July 2003; pp. 33–40. [Google Scholar]
- Liu, F.; Zhang, G.; Lu, J. Multisource heterogeneous unsupervised domain adaptation via fuzzy relation neural networks. IEEE Trans. Fuzzy Syst. 2020, 29, 3308–3322. [Google Scholar] [CrossRef]
- Parida, U.; Nayak, M.; Nayak, A.K. Insight into diverse keyphrase extraction techniques from text documents. Intell. Cloud Comput. 2021, 194, 405–413. [Google Scholar]
- Rabby, G.; Azad, S.; Mahmud, M.; Zamli, K.Z.; Rahman, M.M. TeKET: A Tree-Based Unsupervised Keyphrase Extraction Technique. Cogn. Comput. 2020, 12, 811–833. [Google Scholar] [CrossRef] [Green Version]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.; Nunes, C.; Jatowt, A. YAKE! Keyword extraction from single documents using multiple local features. Inf. Sci. 2020, 509, 257–289. [Google Scholar] [CrossRef]
- Zhong, L.; Fang, Z.; Liu, F.; Yuan, B.; Zhang, G.; Lu, J. Bridging the theoretical bound and deep algorithms for open set domain adaptation. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Hasan, K.S.; Ng, V. Automatic keyphrase extraction: A survey of the state of the art. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 1262–1273. [Google Scholar]
- Marujo, L.; Gershman, A.; Carbonell, J.; Frederking, R.; Neto, J.P. Supervised topical key phrase extraction of news stories using crowdsourcing, light filtering and co-reference normalization. arXiv 2013, arXiv:1306.4886. [Google Scholar]
- Bennani-Smires, K.; Musat, C.; Hossmann, A.; Baeriswyl, M.; Jaggi, M. Simple unsupervised keyphrase extraction using sentence embeddings. arXiv 2018, arXiv:1801.04470. [Google Scholar]
- Miah, M.B.A.; Haque, S.; Rashed Mazumder, M.; Rahman, Z. A New Approach for Recognition of Holistic Bangla Word Using Neural Network. Int. J. Data Warehous. Min. 2011, 1, 139–141. [Google Scholar]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.M.; Nunes, C.; Jatowt, A. Yake! collection-independent automatic keyword extractor. In Proceedings of the European Conference on Information Retrieval, Grenoble, France, 26–29 March 2018; pp. 806–810. [Google Scholar]
- Giarelis, N.; Kanakaris, N.; Karacapilidis, N. A Comparative Assessment of State-Of-The-Art Methods for Multilingual Unsupervised Keyphrase Extraction. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Hersonissos, Greece, 25–27 June 2021; pp. 635–645. [Google Scholar]
- Zhang, M.; Li, X.; Yue, S.; Yang, L. An empirical study of TextRank for keyword extraction. IEEE Access 2020, 8, 178849–178858. [Google Scholar] [CrossRef]
- Bougouin, A.; Boudin, F.; Daille, B. Topicrank: Graph-based topic ranking for keyphrase extraction. In Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP), Nagoya, Japan, 14–19 October 2013; pp. 543–551. [Google Scholar]
- Sterckx, L.; Demeester, T.; Deleu, J.; Develder, C. Topical word importance for fast keyphrase extraction. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 121–122. [Google Scholar]
- Florescu, C.; Caragea, C. Positionrank: An unsupervised approach to keyphrase extraction from scholarly documents. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, ON, Canada, 30 July–4 August 2017; pp. 1105–1115. [Google Scholar]
- Boudin, F. Unsupervised keyphrase extraction with multipartite graphs. arXiv 2018, arXiv:1803.08721. [Google Scholar]
- Wu, D.; He, Y.; Luo, X.; Zhou, M. A latent factor analysis-based approach to online sparse streaming feature selection. IEEE Trans. Syst. Man Cybern. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Miah, M.B.A.; Awang, S.; Rahman, M.M.; Sanwar Hosen, A.S.M.; Ra, I.H. Keyphrases Frequency Analysis from Research Articles: A Region-Based Unsupervised Novel Approach. IEEE Access 2022, 10, 1. [Google Scholar] [CrossRef]
- Alami Merrouni, Z.; Frikh, B.; Ouhbi, B. Automatic keyphrase extraction: A survey and trends. J. Intell. Inf. Syst. 2020, 54, 391–424. [Google Scholar] [CrossRef]
- Thushara, M.; Mownika, T.; Mangamuru, R. A comparative study on different keyword extraction algorithms. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 969–973. [Google Scholar]
- Zhuohao, W.; Dong, W.; Qing, L. Keyword Extraction from Scientific Research Projects Based on SRP-TF-IDF. Chin. J. Electron. 2021, 30, 652–657. [Google Scholar] [CrossRef]
- Miah, M.B.A.; Yousuf, M.A. Detection of lung cancer from CT image using image processing and neural network. In Proceedings of the 2015 International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Savar, Bangladesh, 21–23 May 2015; pp. 1–6. [Google Scholar]
- Miah, M.B.A. A real time road sign recognition using neural network. Int. J. Comput. Appl. 2015, 114, 1–5. [Google Scholar]
- Li, J. A comparative study of keyword extraction algorithms for English texts. J. Intell. Syst. 2021, 30, 808–815. [Google Scholar] [CrossRef]
- Ünlü, Ö.; Çetin, A. A survey on keyword and key phrase extraction with deep learning. In Proceedings of the 2019 3rd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 11–13 October 2019; pp. 1–6. [Google Scholar]
- Gopan, E.; Rajesh, S.; Vishnu, M.G.; Raj R, A.; Thushara, M. Comparative study on different approaches in keyword extraction. In Proceedings of the 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 11–13 March 2020; pp. 70–74. [Google Scholar]
- Romary, P.L.L. Automatic key term extraction from scientific articles in grobid. In Proceedings of the SemEval 2010 Workshop, Uppsala, Sweden, 15–16 July 2010; p. 4. [Google Scholar]
- Haddoud, M.; Abdeddaïm, S. Accurate keyphrase extraction by discriminating overlapping phrases. J. Inf. Sci. 2014, 40, 488–500. [Google Scholar] [CrossRef]
- Bulgarov, F.; Caragea, C. A comparison of supervised keyphrase extraction models. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 13–14. [Google Scholar]
- Hulth, A. Improved automatic keyword extraction given more linguistic knowledge. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003; pp. 216–223. [Google Scholar]
- Xie, F.; Wu, X.; Zhu, X. Efficient sequential pattern mining with wildcards for keyphrase extraction. Knowl.-Based Syst. 2017, 115, 27–39. [Google Scholar] [CrossRef]
- Campos, R.; Mangaravite, V. Datasets of Automatic Keyphrase Extraction. 2020. Available online: https://github.com/LIAAD/KeywordExtractor-Datasets (accessed on 20 March 2022).
- Davydova, O. Text Preprocessing in Python: Steps, Tools, and Examples. Data Monsters. 2019. Available online: https://medium.com/product-ai/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908 (accessed on 25 March 2022).
- Wu, X.; Zheng, W.; Xia, X.; Lo, D. Data quality matters: A case study on data label correctness for security bug report prediction. IEEE Trans. Softw. Eng. 2021, 48, 2541–2556. [Google Scholar] [CrossRef]
- Xu, Y.; Xia, B.; Wan, Y.; Zhang, F.; Xu, J.; Ning, H. CDCAT: A multi-language cross-document entity and event coreference annotation tool. Tsinghua Sci. Technol. 2021, 27, 589–598. [Google Scholar] [CrossRef]
- Miah, M.B.A.; Hossain, M.Z.; Hossain, M.A.; Islam, M.M. Price prediction of stock market using hybrid model of artificial intelligence. Int. J. Comput. Appl. 2015, 111, 5–9. [Google Scholar]
- Marujo, L.; Viveiros, M.; Neto, J.P.d.S. Keyphrase cloud generation of broadcast news. arXiv 2013, arXiv:1306.4606. [Google Scholar]
- Jiang, S.; Fu, S.; Lin, N.; Fu, Y. Pretrained models and evaluation data for the Khmer language. Tsinghua Sci. Technol. 2021, 27, 709–718. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
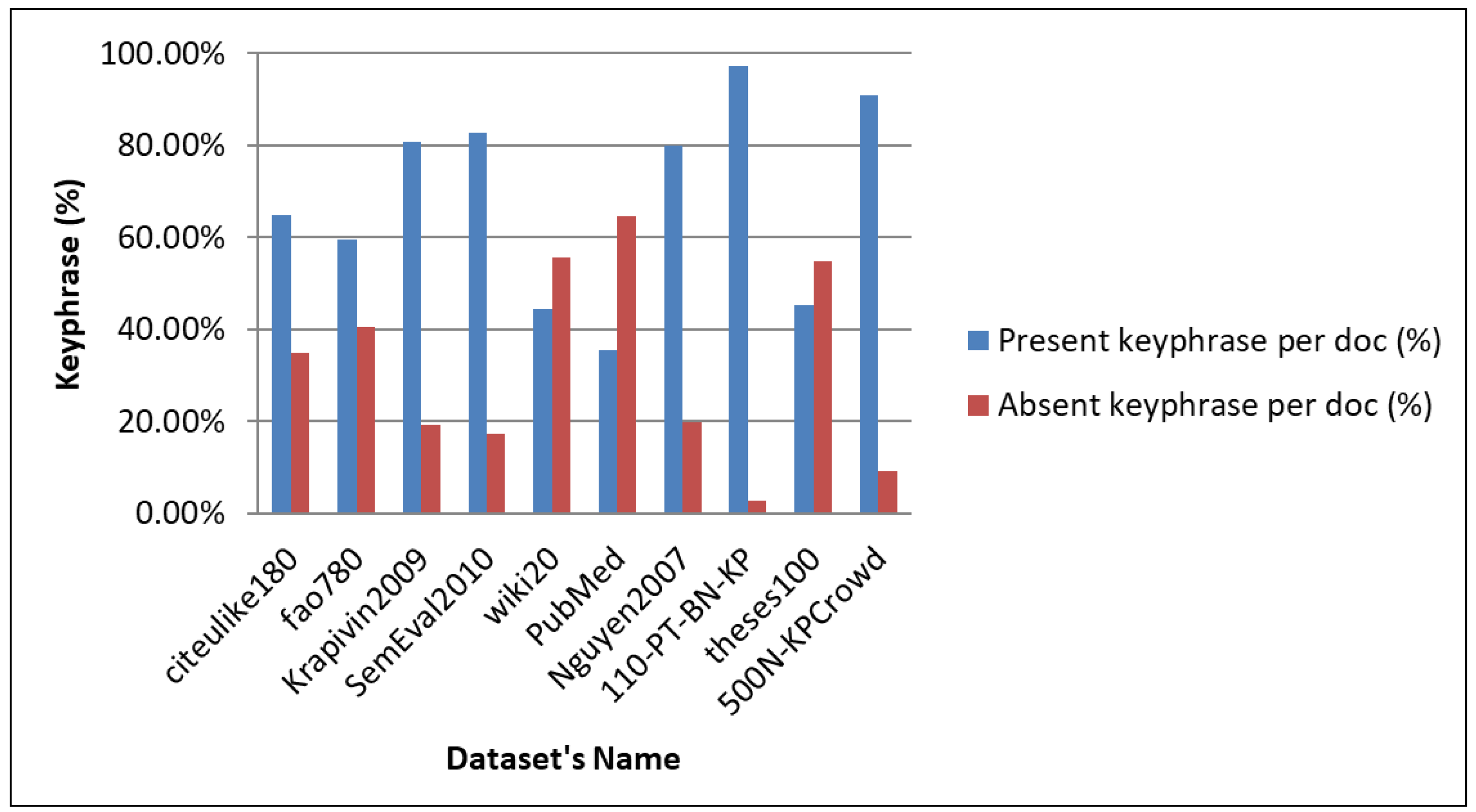
| Dataset Name | Language | Doc. Types | Domain Name | No. of Docs | No. of Keyphrases | No. of Present Keyphrases | No. of Absent Keyphrase | Processing Time (s) |
|---|---|---|---|---|---|---|---|---|
| citeulike-180 | ENG | Article | Misce. | 183 | 3187 | 2071 | 1116 | 0.531 |
| fao-780 | ENG | Article | Agri. | 779 | 6215 | 3702 | 2513 | 1.860 |
| Krapivin-2009 | ENG | Article | Computer Scien. | 2304 | 12,296 | 9933 | 2363 | 0.984 |
| SemEval-2010 | ENG | Article | Computer Scien. | 243 | 3785 | 3129 | 656 | 1.078 |
| wiki-20 | ENG | Research-Report | Computer Scien. | 20 | 710 | 315 | 395 | 0.016 |
| PubMed | ENG | Article | Life Science | 500 | 7120 | 2513 | 4607 | 0.266 |
| Nguyen-2007 | ENG | Article | Computer Scien. | 209 | 2507 | 2008 | 499 | 0.578 |
| 110-PT-BN-KP | ENG | News | Misce. | 110 | 2688 | 2616 | 72 | 0.047 |
| theses-100 | ENG | MSc/PhD-Thesis | Misce. | 100 | 667 | 302 | 365 | 0.234 |
| 500N-KPCrowd | ENG | News | Misce. | 500 | 24,610 | 22,345 | 2265 | 0.203 |
| Dataset’s Name | Performance Measurements | ||
|---|---|---|---|
| Precision | Recall | F1-Score | |
| citeulike180 | 100.00% | 64.98% | 78.78% |
| fao780 | 100.00% | 59.57% | 74.66% |
| Krapivin2009 | 100.00% | 80.78% | 89.37% |
| SemEval2010 | 100.00% | 82.67% | 90.51% |
| wiki20 | 100.00% | 44.37% | 61.46% |
| PubMed | 100.00% | 35.29% | 52.17% |
| Nguyen2007 | 100.00% | 80.10% | 88.95% |
| 110-PT-BN-KP | 100.00% | 97.32% | 98.64% |
| theses100 | 100.00% | 45.28% | 62.33% |
| 500N-KPCrowd | 100.00% | 90.80% | 95.18% |
| Articles Regions | Keyphrase Centroid and Frequency (%) in 1st Region | Keyphrase Centroid and Frequency (%) in 2nd Region | Co-Efficient for Positive Exponential () | Co-Efficient for Negative Exponential () |
|---|---|---|---|---|
| Eight Regions | 706.66 and 38.95% | 2454.21 and 7.98% | , , | , , |
| Sixteen Regions | 386.69 and 31.89% | 1223.87 and 7.05% | , , | , , |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miah, M.B.A.; Awang, S.; Rahman, M.M.; Hosen, A.S.M.S.; Ra, I.-H. A New Unsupervised Technique to Analyze the Centroid and Frequency of Keyphrases from Academic Articles. Electronics 2022, 11, 2773. https://doi.org/10.3390/electronics11172773
Miah MBA, Awang S, Rahman MM, Hosen ASMS, Ra I-H. A New Unsupervised Technique to Analyze the Centroid and Frequency of Keyphrases from Academic Articles. Electronics. 2022; 11(17):2773. https://doi.org/10.3390/electronics11172773
Chicago/Turabian StyleMiah, Mohammad Badrul Alam, Suryanti Awang, Md Mustafizur Rahman, A. S. M. Sanwar Hosen, and In-Ho Ra. 2022. "A New Unsupervised Technique to Analyze the Centroid and Frequency of Keyphrases from Academic Articles" Electronics 11, no. 17: 2773. https://doi.org/10.3390/electronics11172773
APA StyleMiah, M. B. A., Awang, S., Rahman, M. M., Hosen, A. S. M. S., & Ra, I.-H. (2022). A New Unsupervised Technique to Analyze the Centroid and Frequency of Keyphrases from Academic Articles. Electronics, 11(17), 2773. https://doi.org/10.3390/electronics11172773