

Camera Animation for Immersive Light Field Imaging
 ,
,  , , and
, , and
Abstract
:1. Introduction
2. Light Field Capture and Visualization
2.1. Brief Historical Overview of Light Field
- Leonardo da Vinci described light rays filling space as “radiant pyramids” that intersect and cross one another [21].
- Michael Faraday used the term “lines of force” to describe light rays, claiming that LFs are more or less analogous to magnetic fields [22].
- Frederic E. Ives managed to record parallax stereograms in 1903 by means of a single-lens apparatus [23].
- LF photography was first introduced by Gabriel Lippmann in 1908. He provided the theoretical foundations for LF photography under the name of “integral photography” [24], and proposed a setup where multiple crystalline lenses are placed hexagonally—similarly to a beehive.
- In 1939, Arun Gershun introduced the term “light field” to describe light rays filling space by their radiometric properties [25].
- The first plenoptic camera was proposed by Edward Adelson and John Wang in 1992, consisting of a single lens and a sensor plane, in front of which a lenticular array was planted [26].
2.2. Classification of Light Field Displays
2.3. Camera Setups for Light Field Displays
3. Camera Animation
3.1. General Camera Animation
3.1.1. Cinematography Camera Animations
3.1.2. Simulation Camera Animations
3.2. Camera Animation Design for 3D Displays
3.3. Light Field Camera Animation
- General visibility of the scene along the observer line during animations.
- Frequency of immersion-breaking occluders.
- Frequency of collisions and course corrections within the scene.
- Frequency of depth-related artefacts.
- Occurrence of depth of field changes.
4. Visualization of Light Field Camera Animation Used in Cinematography
4.1. Simulation Camera Animations
Discussion and Assessment
4.2. Realistic Physical Camera Animations
- Collision camera: The first scenario consists of a car and a set of columns, into which the car is moving. The car accelerates on its way towards the columns, resulting in its collision with one of them. The camera is mounted twice on the car as an FP and as a TP camera, and once on the collided column.
- Suspension camera: In this scenario, the camera is mounted once on a suspension object with the car placed in front of the suspension element and once on the car itself, looking towards the suspension element.
- Falling camera: In this scenario, a camera is falling from an altitude towards the ground until it collides with the latter. There is a total of 50 objects (boxes and cylinders) on the ground.
4.2.1. Metrics
- Collisions: Since we used physical camera motions in our study, there was the possibility of the collision of the camera with the objects from the scene. Counting the number of collisions between the camera and the objects was carried out to decide whether or not this camera motion would provide plausible results.
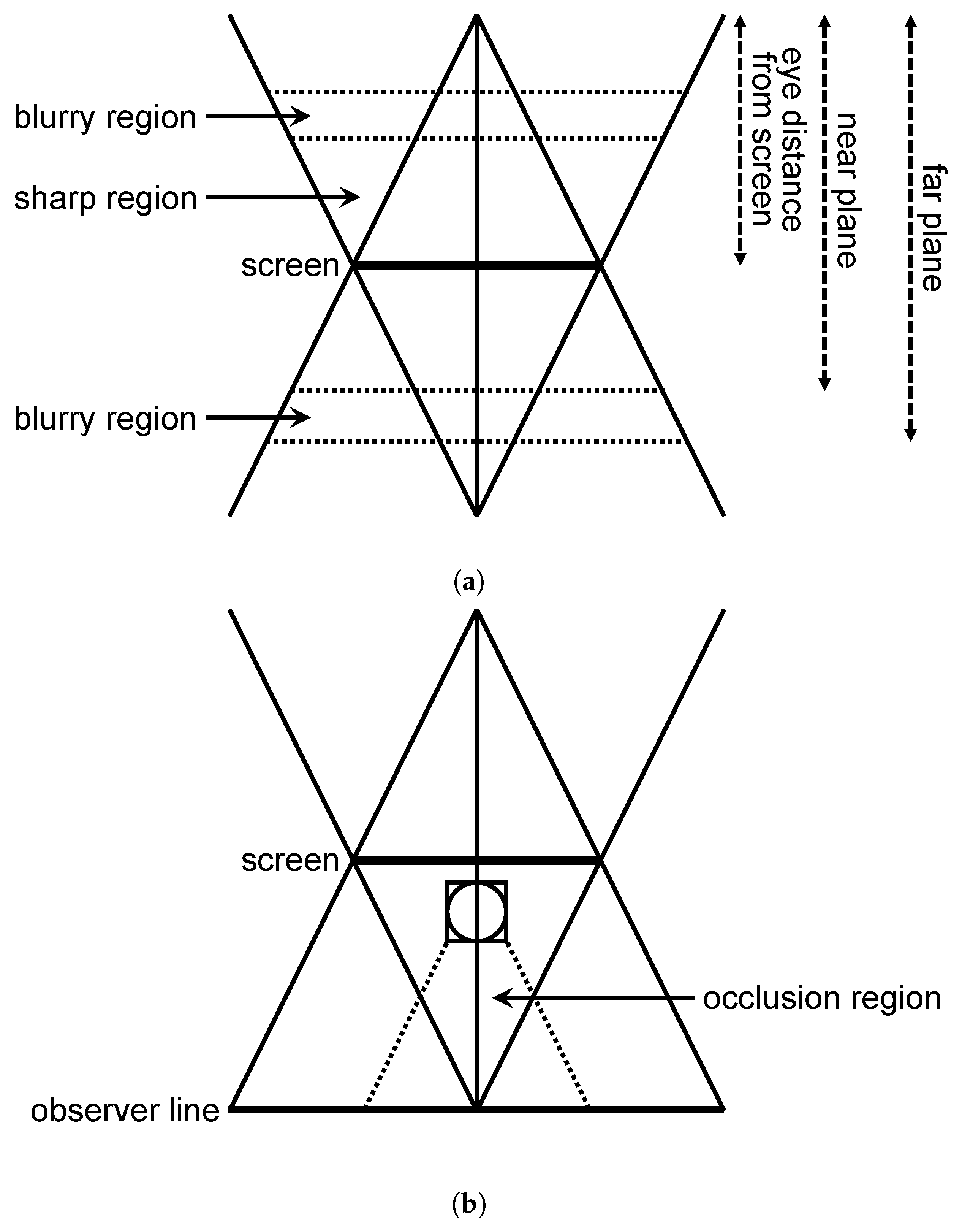
- Blurry region: Figure 7a shows the top view taken from the LFD setup. Unlike conventional displays, LFDs have double frustums placed in front of and behind the screen, illustrated with the black line. The viewing angles enclosing the frustums are depicted by the blue lines. Considering LFDs, the area enclosing the screen contains the objects that are sharply rendered. In this metric, we calculated the number of objects that were rendered outside the sharp region.
- Occlusion region: When using TP cameras, this metric is used to count the number of objects occluding the main entity with respect to the camera. Figure 7b shows the top view of the setup illustrating this metric, where the main entity is shown as the yellow circle. The main entity is enclosed by an axis-aligned bounding box (AABB), illustrated with the red square. In order to measure the number of objects in the occlusion region, the latter should be set up prior to the assessment. The occlusion region is depicted by the frustum drawn in front of the main entity, illustrated with blue lines. The back plane of the frustum is the same plane as that of the front of the AABB of the main entity. The right and left planes enclosing the frustum are parallel to the viewing angle planes of the LFD. However, they enclose the main entity. Finally, the top and bottom planes are constructed starting from the top and bottom lines of the AABB of the main entity and passing by the observer line. Once the occlusion region is constructed, the number of objects within are calculated by counting the number of intersections between the frustum depicting the occlusion region and the AABBs of the elements in the scene.
4.2.2. Evaluation and Testing
4.2.3. Discussion and Assessment
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Lindström, J.; Hulthén, M.; Sandborg, M.; Carlsson-Tedgren, Å. Development and assessment of a quality assurance device for radiation field–light field congruence testing in diagnostic radiology. SPIE J. Med. Imaging 2020, 7, 063501. [Google Scholar] [CrossRef] [PubMed]
- Cserkaszky, A.; Kara, P.A.; Barsi, A.; Martini, M.G. The potential synergies of visual scene reconstruction and medical image reconstruction. In Novel Optical Systems Design and Optimization XXI; SPIE: Bellingham, WA, USA, 2018; Volume 10746, pp. 1–7. [Google Scholar]
- Zhang, X.; Braley, S.; Rubens, C.; Merritt, T.; Vertegaal, R. LightBee: A self-levitating light field display for hologrammatic telepresence. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Scotland, UK, 4–9 May 2019; pp. 1–10. [Google Scholar]
- Cserkaszky, A.; Barsi, A.; Nagy, Z.; Puhr, G.; Balogh, T.; Kara, P.A. Real-time light-field 3D telepresence. In Proceedings of the 7th European Workshop on Visual Information Processing (EUVIP), Tampere, Finland, 26–28 November 2018; pp. 1–5. [Google Scholar]
- Kara, P.A.; Martini, M.G.; Nagy, Z.; Barsi, A. Cinema as large as life: Large-scale light field cinema system. In Proceedings of the International Conference on 3D Immersion (IC3D), Brussels, Belgium, 11–12 December 2017; pp. 1–8. [Google Scholar]
- Balogh, T.; Barsi, A.; Kara, P.A.; Guindy, M.; Simon, A.; Nagy, Z. 3D light field LED wall. In Proceedings of the Digital Optical Technologies 2021, Online. 21–25 June 2021; Volume 11788, pp. 1–11. [Google Scholar]
- Brunnström, K.; Beker, S.A.; De Moor, K.; Dooms, A.; Egger, S.; Garcia, M.N.; Hossfeld, T.; Jumisko-Pyykkö, S.; Keimel, C.; Larabi, M.C.; et al. Qualinet White Paper on Definitions of Quality of Experience. 2013. Available online: https://hal.archives-ouvertes.fr/hal-00977812/ (accessed on 9 August 2022).
- Liu, Y.; Ge, Z.; Yuan, Y.; Su, X.; Guo, X.; Suo, T.; Yu, Q. Study of the Error Caused by Camera Movement for the Stereo-Vision System. Appl. Sci. 2021, 11, 9384. [Google Scholar] [CrossRef]
- Flueckiger, B. Aesthetics of stereoscopic cinema. Projections 2012, 6, 101–122. [Google Scholar] [CrossRef]
- Shi, G.; Sang, X.; Yu, X.; Liu, Y.; Liu, J. Visual fatigue modeling for stereoscopic video shot based on camera motion. In Proceedings of the International Symposium on Optoelectronic Technology and Application 2014: Image Processing and Pattern Recognition, Beijing, China, 13–15 May 2014; pp. 709–716. [Google Scholar]
- Oh, H.; Son, W. Cybersickness and Its Severity Arising from Virtual Reality Content: A Comprehensive Study. Sensors 2022, 22, 1314. [Google Scholar] [CrossRef]
- Keshavarz, B.; Hecht, H. Axis rotation and visually induced motion sickness: The role of combined roll, pitch, and yaw motion. Aviat. Space Environ. Med. 2011, 82, 1023–1029. [Google Scholar] [CrossRef] [PubMed]
- Singla, A.; Fremerey, S.; Robitza, W.; Raake, A. Measuring and comparing QoE and simulator sickness of omnidirectional videos in different head mounted displays. In Proceedings of the 2017 Ninth International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 31 May–2 June 2017; pp. 1–6. [Google Scholar]
- Cserkaszky, A.; Kara, P.A.; Tamboli, R.R.; Barsi, A.; Martini, M.G.; Balogh, T. Light-field capture and display systems: Limitations, challenges, and potentials. In Proceedings of the Novel Optical Systems Design and Optimization XXI, San Diego, CA, USA, 20 August 2018; Volume 10746, pp. 1–9. [Google Scholar]
- Levoy, M.; Hanrahan, P. Light field rendering. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 31–42. [Google Scholar]
- Bimber, O.; Schedl, D.C. Light-Field Microscopy: A Review. J. Neurol. 2019, 4, 1–6. [Google Scholar] [CrossRef]
- Dai, F.; Chen, X.; Ma, Y.; Jin, G.; Zhao, Q. Wide Range Depth Estimation from Binocular Light Field Camera. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018; pp. 1–11. [Google Scholar]
- Ng, R.; Levoy, M.; Brédif, M.; Duval, G.; Horowitz, M.; Hanrahan, P. Light Field Photography with a Hand-Held Plenoptic Camera. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2005. [Google Scholar]
- Wetzstein, G.; Lanman, D.; Hirsch, M.; Raskar, R. Real-time Image Generation for Compressive Light Field Displays. Proc. J. Phys. Conf. Ser. 2013, 415, 012045. [Google Scholar] [CrossRef]
- Balogh, T.; Kovács, P.T.; Barsi, A. Holovizio 3D display system. In Proceedings of the 3DTV Conference, Kos, Greece, 7–9 May 2007; pp. 1–4. [Google Scholar]
- Richter, J.P. The Notebooks of Leonardo da Vinci; Courier Corporation: North Chelmsford, MA, USA, 1970; Volume 2. [Google Scholar]
- Faraday, M. LIV. Thoughts on ray-vibrations. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1846, 28, 345–350. [Google Scholar] [CrossRef]
- Ives, F.E. Parallax Stereogram and Process of Making Same. U.S. Patent 725,567, 14 April 1903. [Google Scholar]
- Lippmann, G. Epreuves reversibles Photographies integrals. Comptes-Rendus Acad. Des Sci. 1908, 146, 446–451. [Google Scholar]
- Gershun, A. The light field. J. Math. Phys. 1939, 18, 51–151. [Google Scholar] [CrossRef]
- Adelson, E.H.; Wang, J.Y. Single lens stereo with a plenoptic camera. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 99–106. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, H.; Omura, T.; Okaichi, N.; Kano, M.; Sasaki, H.; Arai, J. Full-parallax three-dimensional display based on light field reproduction. Opt. Rev. 2022, 29, 366–374. [Google Scholar] [CrossRef]
- Wang, P.; Sang, X.; Yu, X.; Gao, X.; Xing, S.; Liu, B.; Gao, C.; Liu, L.; Du, J.; Yan, B. A full-parallax tabletop three dimensional light-field display with high viewpoint density and large viewing angle based on space-multiplexed voxel screen. Opt. Commun. 2021, 488, 126757. [Google Scholar] [CrossRef]
- Liu, L.; Sang, X.; Yu, X.; Gao, X.; Wang, Y.; Pei, X.; Xie, X.; Fu, B.; Dong, H.; Yan, B. 3D light-field display with an increased viewing angle and optimized viewpoint distribution based on a ladder compound lenticular lens unit. Opt. Express 2021, 29, 34035–34050. [Google Scholar] [CrossRef]
- Bae, S.I.; Kim, K.; Jang, K.W.; Kim, H.K.; Jeong, K.H. High contrast ultrathin light-field camera using inverted microlens arrays with metal–insulator–metal optical absorber. Adv. Opt. Mater. 2021, 9, 2001657. [Google Scholar] [CrossRef]
- Fan, Q.; Xu, W.; Hu, X.; Zhu, W.; Yue, T.; Zhang, C.; Yan, F.; Chen, L.; Lezec, H.J.; Lu, Y.; et al. Trilobite-inspired neural nanophotonic light-field camera with extreme depth-of-field. Nat. Commun. 2022, 13, 2130. [Google Scholar] [CrossRef]
- Kim, H.M.; Kim, M.S.; Chang, S.; Jeong, J.; Jeon, H.G.; Song, Y.M. Vari-Focal Light Field Camera for Extended Depth of Field. Micromachines 2021, 12, 1453. [Google Scholar] [CrossRef]
- Liu, D.; Huang, X.; Zhan, W.; Ai, L.; Zheng, X.; Cheng, S. View synthesis-based light field image compression using a generative adversarial network. Inf. Sci. 2021, 545, 118–131. [Google Scholar] [CrossRef]
- Singh, M.; Rameshan, R.M. Learning-Based Practical Light Field Image Compression Using A Disparity-Aware Model. In Proceedings of the 2021 Picture Coding Symposium (PCS), Bristol, UK, 29 June–2 July 2021; pp. 1–5. [Google Scholar]
- Hu, X.; Pan, Y.; Wang, Y.; Zhang, L.; Shirmohammadi, S. Multiple Description Coding for Best-Effort Delivery of Light Field Video using GNN-based Compression. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Gul, M.S.K.; Mukati, M.U.; Bätz, M.; Forchhammer, S.; Keinert, J. Light-field view synthesis using a convolutional block attention module. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3398–3402. [Google Scholar]
- Wang, H.; Yan, B.; Sang, X.; Chen, D.; Wang, P.; Qi, S.; Ye, X.; Guo, X. Dense view synthesis for three-dimensional light-field displays based on position-guiding convolutional neural network. Opt. Lasers Eng. 2022, 153, 106992. [Google Scholar] [CrossRef]
- Bakir, N.; Hamidouche, W.; Fezza, S.A.; Samrouth, K.; Deforges, O. Light Field Image Coding Using VVC standard and View Synthesis based on Dual Discriminator GAN. IEEE Trans. Multimed. 2021, 23, 2972–2985. [Google Scholar] [CrossRef]
- Salem, A.; Ibrahem, H.; Kang, H.S. Light Field Reconstruction Using Residual Networks on Raw Images. Sensors 2022, 22, 1956. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Shi, J.; Hong, Y.; Lin, L.; Kuruoglu, E.E. Robust dense light field reconstruction from sparse noisy sampling. Signal Process. 2021, 186, 108121. [Google Scholar] [CrossRef]
- Hu, Z.; Yeung, H.W.F.; Chen, X.; Chung, Y.Y.; Li, H. Efficient light field reconstruction via spatio-angular dense network. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- PhiCong, H.; Perry, S.; Cheng, E.; HoangVan, X. Objective Quality Assessment Metrics for Light Field Image Based on Textural Features. Electronics 2022, 11, 759. [Google Scholar] [CrossRef]
- Qu, Q.; Chen, X.; Chung, V.; Chen, Z. Light field image quality assessment with auxiliary learning based on depthwise and anglewise separable convolutions. IEEE Trans. Broadcast. 2021, 67, 837–850. [Google Scholar] [CrossRef]
- Meng, C.; An, P.; Huang, X.; Yang, C.; Shen, L.; Wang, B. Objective quality assessment of lenslet light field image based on focus stack. IEEE Trans. Multimed. 2021, 24, 3193–3207. [Google Scholar] [CrossRef]
- Simon, A.; Guindy, M.; Kara, P.A.; Balogh, T.; Szy, L. Through a different lens: The perceived quality of light field visualization assessed by test participants with imperfect visual acuity and color blindness. In Proceedings of the Big Data IV: Learning, Analytics, and Applications; SPIE: Bellingham, WA, USA, 2022; Volume 12097, pp. 212–221. [Google Scholar]
- Kara, P.A.; Guindy, M.; Balogh, T.; Simon, A. The perceptually-supported and the subjectively-preferred viewing distance of projection-based light field displays. In Proceedings of the International Conference on 3D Immersion (IC3D), Brussels, Belgium, 8 December 2021; pp. 1–8. [Google Scholar]
- Guindy, M.; Kara, P.A.; Balogh, T.; Simon, A. Perceptual preference for 3D interactions and realistic physical camera motions on light field displays. In Virtual, Augmented, and Mixed Reality (XR) Technology for Multi-Domain Operations III; SPIE: Bellingham, WA, USA, 2022; Volume 12125, pp. 156–164. [Google Scholar]
- Perra, C.; Mahmoudpour, S.; Pagliari, C. JPEG pleno light field: Current standard and future directions. In Optics, Photonics and Digital Technologies for Imaging Applications VII; SPIE: Bellingham, WA, USA, 2022; Volume 12138, pp. 153–156. [Google Scholar]
- Kovács, P.T.; Lackner, K.; Barsi, A.; Balázs, Á.; Boev, A.; Bregović, R.; Gotchev, A. Measurement of perceived spatial resolution in 3D light-field displays. In Proceedings of the International Conference on Image Processing, Paris, France, 27–30 October 2014; pp. 768–772. [Google Scholar]
- Kovács, P.T.; Bregović, R.; Boev, A.; Barsi, A.; Gotchev, A. Quantifying Spatial and Angular Resolution of Light-Field 3-D Displays. IEEE J. Sel. Top. Signal Process. 2017, 11, 1213–1222. [Google Scholar] [CrossRef]
- Dricot, A.; Jung, J.; Cagnazzo, M.; Pesquet, B.; Dufaux, F.; Kovács, P.T.; Adhikarla, V.K. Subjective evaluation of Super Multi-View compressed contents on high-end light-field 3D displays. Signal Process. Image Commun. 2015, 39, 369–385. [Google Scholar] [CrossRef]
- Tamboli, R.R.; Appina, B.; Channappayya, S.; Jana, S. Super-multiview content with high angular resolution: 3D quality assessment on horizontal-parallax lightfield display. Signal Process. Image Commun. 2016, 47, 42–55. [Google Scholar] [CrossRef]
- Cserkaszky, A.; Barsi, A.; Kara, P.A.; Martini, M.G. To interpolate or not to interpolate: Subjective assessment of interpolation performance on a light field display. In Proceedings of the IEEE International Conference on Multimedia & Expo (ICME) Workshops, Hong Kong, China, 10–14 July 2017; pp. 55–60. [Google Scholar]
- Kara, P.A.; Tamboli, R.R.; Cserkaszky, A.; Barsi, A.; Simon, A.; Kusz, A.; Bokor, L.; Martini, M.G. Objective and subjective assessment of binocular disparity for projection-based light field displays. In Proceedings of the International Conference on 3D Immersion (IC3D), Brussels, Belgium, 11 December 2019; pp. 1–8. [Google Scholar]
- Kara, P.A.; Tamboli, R.R.; Shafiee, E.; Martini, M.G.; Simon, A.; Guindy, M. Beyond perceptual thresholds and personal preference: Towards novel research questions and methodologies of quality of experience studies on light field visualization. Electronics 2022, 11, 953. [Google Scholar] [CrossRef]
- Alam, M.Z.; Gunturk, B.K. Hybrid light field imaging for improved spatial resolution and depth range. Mach. Vis. Appl. 2018, 29, 11–22. [Google Scholar] [CrossRef]
- Leistner, T.; Schilling, H.; Mackowiak, R.; Gumhold, S.; Rother, C. Learning to Think Outside the Box: Wide-Baseline Light Field Depth Estimation with EPI-Shift. In Proceedings of the International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 249–257. [Google Scholar]
- Kara, P.A.; Barsi, A.; Tamboli, R.R.; Guindy, M.; Martini, M.G.; Balogh, T.; Simon, A. Recommendations on the viewing distance of light field displays. In Digital Optical Technologies; SPIE: Bellingham, WA, USA, 2021; Volume 11788, pp. 1–14. [Google Scholar]
- Monteiro, N.B.; Marto, S.; Barreto, J.P.; Gaspar, J. Depth range accuracy for plenoptic cameras. Comput. Vis. Image Underst. 2018, 168, 104–117. [Google Scholar] [CrossRef]
- Ng, R. Digital Light Field Photography; Stanford University: Stanford, CA, USA, 2006. [Google Scholar]
- Doronin, O.; Barsi, A.; Kara, P.A.; Martini, M.G. Ray tracing for HoloVizio light field displays. In Proceedings of the International Conference on 3D Immersion (IC3D), Brussels, Belgium, 11–12 December 2017; pp. 1–8. [Google Scholar]
- Schell, J. The Art of Game Design: A Book of Lenses; CRC Press, Taylor & Francis: Boca Raton, FL, USA, 2008. [Google Scholar]
- Callenbach, E. The Five C’s of Cinematography: Motion Picture Filming Techniques Simplified by Joseph V. Mascelli; Silman-James Press: West Hollywood, CA, USA, 1966. [Google Scholar]
- Bercovitz, J. Image-side perspective and stereoscopy. In Stereoscopic Displays and Virtual Reality Systems V; SPIE: Bellingham, WA, USA, 1998; Volume 3295, pp. 288–298. [Google Scholar]
- Balázs, A.; Barsi, A.; Kovács, P.T.; Balogh, T. Towards mixed reality applications on light-field displays. In Proceedings of the 3DTV Conference, Tokyo, Japan, 8–11 December 2014; pp. 1–4. [Google Scholar]
- Agus, M.; Gobbetti, E.; Iglesias Guitian, J.; Marton, F.; Pintore, G. GPU Accelerated Direct Volume Rendering on an Interactive Light Field Display. Comput. Graph. Forum 2008, 27, 231–240. [Google Scholar] [CrossRef]
- Coumans, E. Bullet 3.05 Physics SDK Manual. Available online: https://github.com/bulletphysics/bullet3/raw/master/docs/Bullet_User_Manual.pdf (accessed on 1 August 2022).
- Guindy, M.; Barsi, A.; Kara, P.A.; Balogh, T.; Simon, A. Realistic physical camera motion for light field visualization. In Proceedings of the Holography: Advances and Modern Trends VII. SPIE, Online. 19–30 April 2021; Volume 11774, pp. 1–8. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Narrow-Baseline Light Field Cameras | Wide-Baseline Light Field Cameras | |
|---|---|---|
| Length | Measured in centimeters (less than 1 m) | More than 1 m |
| Reconstruction accuracy | Limited and can lead to sub-pixel feature disparities | Better |
| Depth map estimation | Limited | Better |
| Spatial resolution | Deteriorated | Enhanced |
| Portability | Relatively portable | Not portable |
| Camera Animation | General Visibility | Occluder Frequency | Collision Frequency | Depth-Related Artefacts’ Frequency | Expected Depth of Field Changes Not Occuring |
|---|---|---|---|---|---|
| Pan | Good | Low | None | Low | N/A |
| Tilt | Mediocre | None | Medium | High | N/A |
| Zoom in | Mediocre | None | High | High | Yes |
| Zoom out | Mediocre | Low | Low | Low | Yes |
| Dolly in | Mediocre | None | High | High | N/A |
| Dolly out | Mediocre | None | Low | Low | N/A |
| Truck | Good | Low | None | Low | N/A |
| Pedestal | Mediocre | High | Medium | Medium | N/A |
| FP | Bad | None | High | High | N/A |
| TP | Mediocre | None | High | High | N/A |
| Scenario | Number of Objects Colliding | Number of Objects in Blurry Region | Number of Objects in Occlusion Region |
|---|---|---|---|
| Collision camera scenario (FPC on car) | 2 | 4 | 3 |
| Collision camera scenario (TPC on car) | 0 | 3 | 3 |
| Collision camera scenario (FPC on column) | 2 | 3 | 3 |
| Suspension camera scenario (FPC on suspension) | 0 | 5 | 0 |
| Suspension camera scenario (TPC on car) | 0 | 2 | 0 |
| Falling camera scenario | 0 | 17 | 51 (All) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guindy, M.; Barsi, A.; Kara, P.A.; Adhikarla, V.K.; Balogh, T.; Simon, A. Camera Animation for Immersive Light Field Imaging. Electronics 2022, 11, 2689. https://doi.org/10.3390/electronics11172689
Guindy M, Barsi A, Kara PA, Adhikarla VK, Balogh T, Simon A. Camera Animation for Immersive Light Field Imaging. Electronics. 2022; 11(17):2689. https://doi.org/10.3390/electronics11172689
Chicago/Turabian StyleGuindy, Mary, Attila Barsi, Peter A. Kara, Vamsi K. Adhikarla, Tibor Balogh, and Aniko Simon. 2022. "Camera Animation for Immersive Light Field Imaging" Electronics 11, no. 17: 2689. https://doi.org/10.3390/electronics11172689
APA StyleGuindy, M., Barsi, A., Kara, P. A., Adhikarla, V. K., Balogh, T., & Simon, A. (2022). Camera Animation for Immersive Light Field Imaging. Electronics, 11(17), 2689. https://doi.org/10.3390/electronics11172689