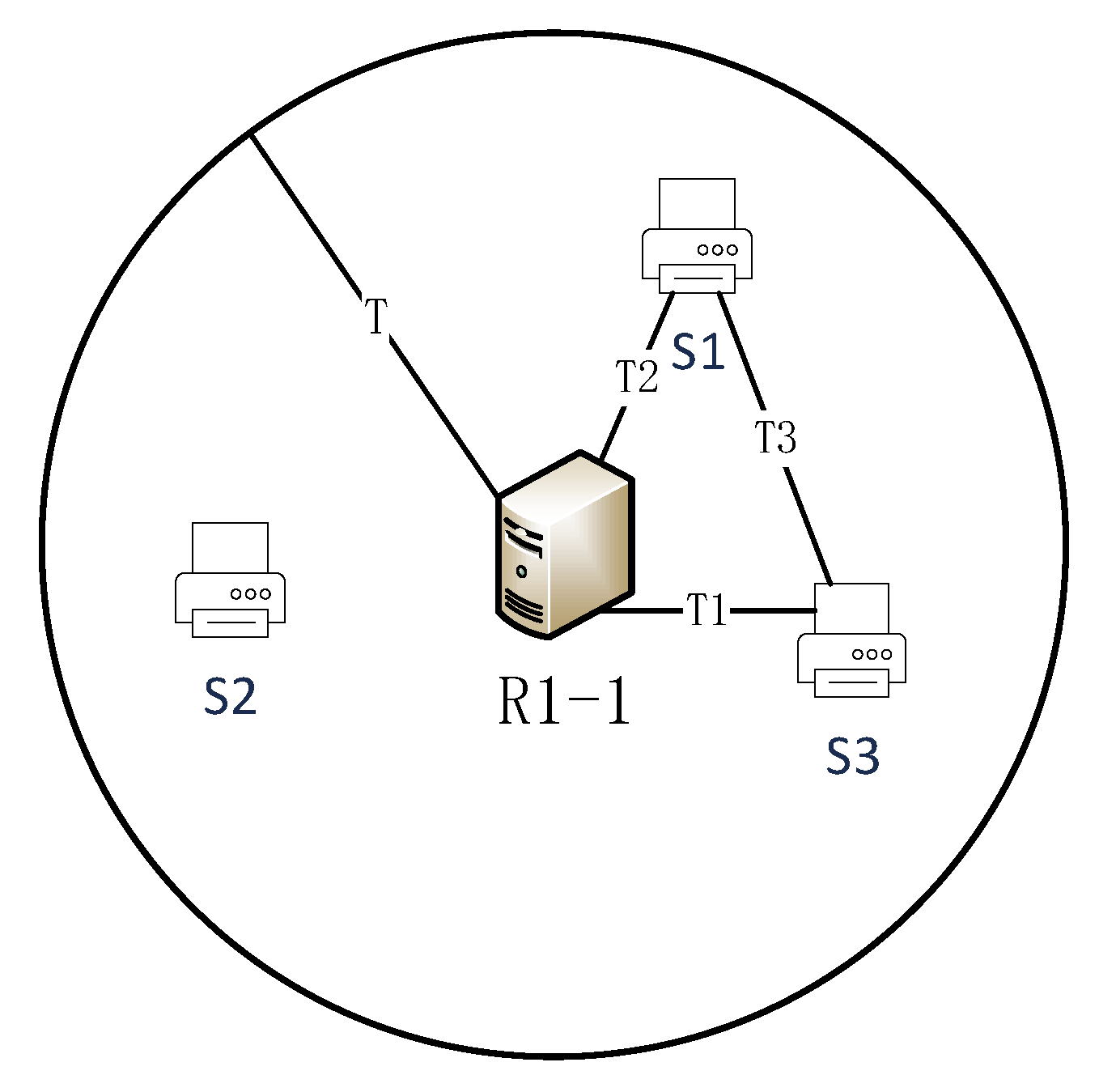
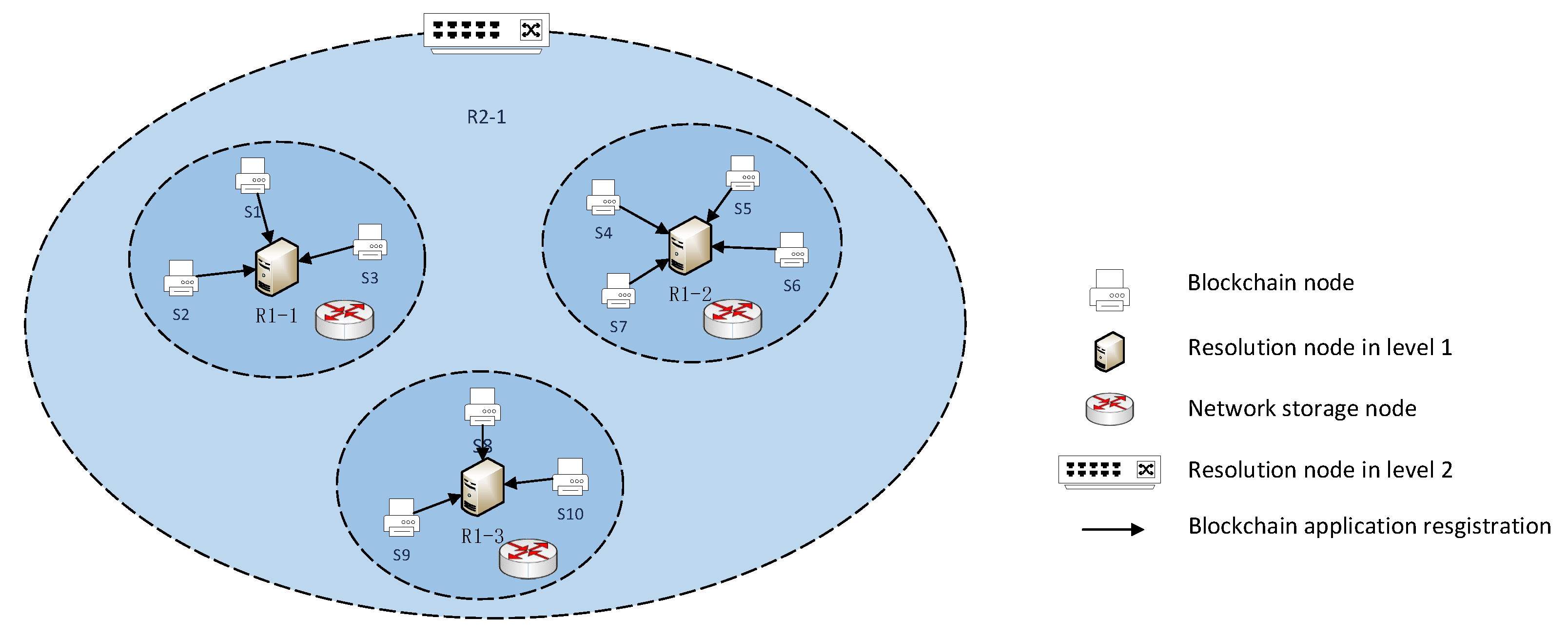
Community partitioning based on network characteristics can guarantee proximity access to the blockchain ledger. However, each partition must pay for an entire blockchain ledger’s storage and maintenance overhead. Full ledger replica storage has a high level redundancy. Existing blockchain replica management schemes use segmentation or compression to reduce the data amount and randomly delete the block data in the ledger. The result is that blockchain users cannot access some blocks locally, which impacts blockchain data availability and increases ledger access reaction time. Therefore, how to optimize the block replica management becomes the next work. We have discovered that blockchain users have an uneven accessing probability for each block in the ledger, with a typical skew feature.
3.4.1. Block Replica Number Decision Mechanism
Existing replica number decision mechanisms require statistical accesses and probabilistic transfer models, including Markov chains or gray Markov models, to forecast the accesses distribution in the next period and make replica number decisions [
19,
27,
28,
29]. This method is statistically expensive and ignores the unique characteristics of blockchain ledgers.
According to the latest Bitcoin data analysis paper [
30], the blockchain users’ access frequency to block data is correlated with the block generation time. We can see that more than 80% of user access is for blocks generated within one day, and the probability of accessing blocks with longer generation time decreases rapidly. The phenomenon is more evident in transactional blockchains, where the record content involves logistics, bills, and other financial transactions.
Analyzing the blockchain content, blockchain is essentially a ledger, which is internally linked in the form of blocks according to the temporal relationship. Each block contains a part of the ledger data. The transaction records within the block are generally contracts, stocks, notes, transaction information, and other data. Blockchain users strongly desire to access newly generated blocks and will regularly generate new transactions or blocks based on that block. As the generation time passes, the users’ interest falls considerably. Blockchain users’ access to the blockchain follows the network information life cycle theory. The utility value of new block data enters the peak phase quickly when it first appears, then it will undergo rapid decay with time and finally enter the decline phase.
We summarize this behavior pattern of blockchain users accessing blocks as the decay characteristics of blockchain ledger access. For modeling this decay relationship, academics have proposed many similar theories. The Ebbinghaus curve [
31] models the information retention is a decaying relationship in the brain and claims that data forgetting has exponential features as
Figure 8, which is then used to construct a forgetting model.
The Ebbinghaus forgetting model curve has been widely used in recommender systems [
32] and collaborative filtering [
33]. The basic expressions are as following:
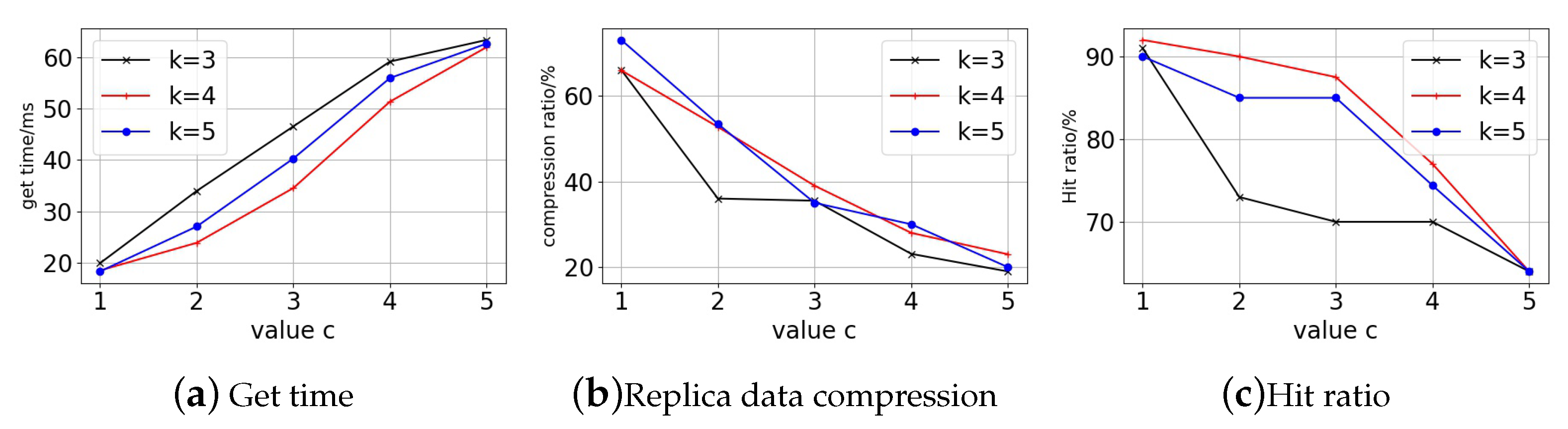
where
t denotes the time interval.
c and
k are the decay coefficient.
We find that the blockchain access interest decay follows a similar pattern, so we apply the forgetting model to the decay of blockchain access interest, using interest decay as the basis for replica number decisions.
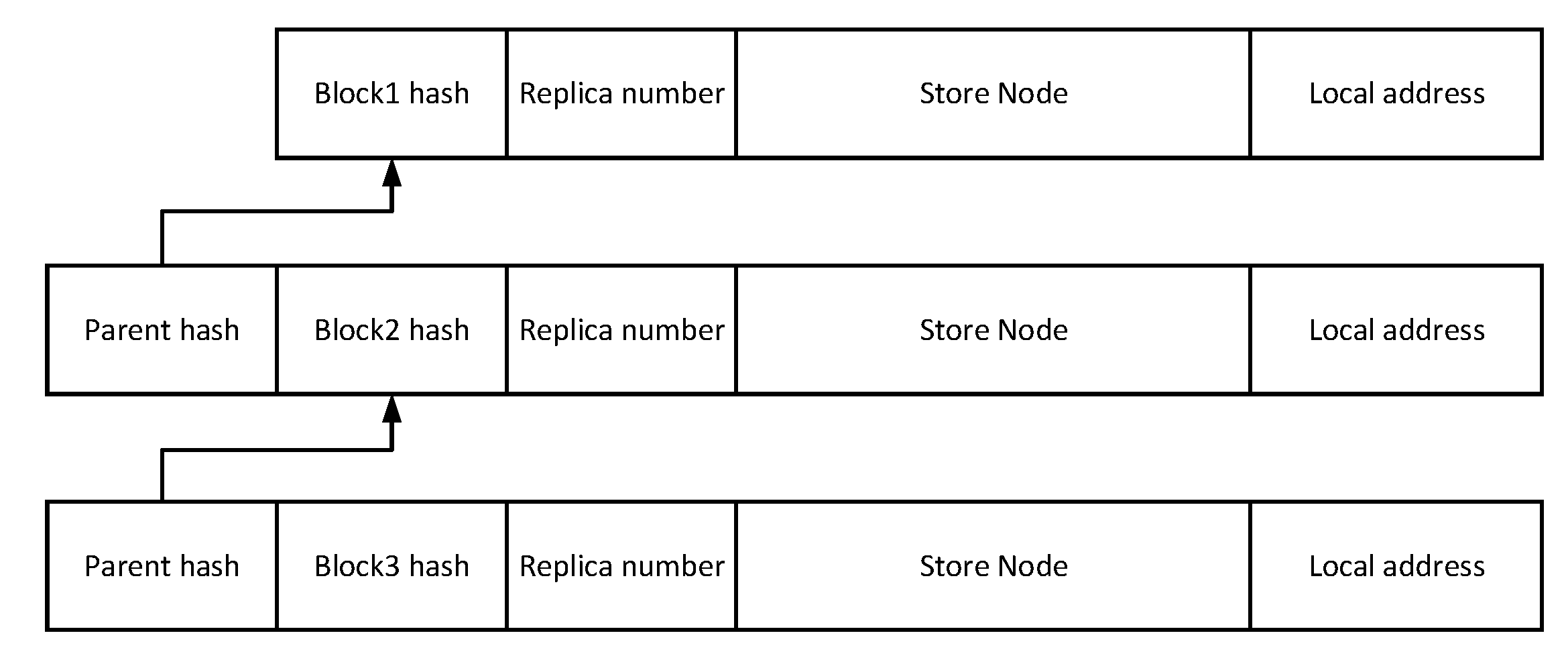
The following is the specific implementation. It is assumed that the block files in same blockchain have similar access interest decay relationship. The block is then labeled with a decay factor when stored in the network, based on the timestamp information in the block and the forgetting model. The block decay factor fluctuates over time, showing that interest in accessing the block changes over time, which we use to determine the replica number. The calculation is as follows:
where
represents the decay factor of block
t,
represents the creation timestamp of the latest block,
represents the creation timestamp of block
t,
represents the reliability requirement on the replicas number,
represents the static replica factor, which is calculated based on the topology information, and
represents the current replica number.
The decay factor indicates that as the block generation time passes, the interest of blockchain users in the block declines. This interest affects the block replica number, which is highest at first and then progressively drops. We can see that newly generated blocks are allocated more replicas, while old blocks are maintained with fewer replicas. Using the blockchain ledger access decay relationship for replica number decisions can greatly reduce the statistics burden in the existing replica number decision method and guarantee the user access performance to the ledger.
3.4.2. Replica Deletion Algorithm
After obtaining the replica number by the decay factor, how to select a deletion replica becomes a new problem. The following issues need to be considered when deleting replica:
- (1)
Deleting a replica directly affects the blockchain user’s access performance to the ledger by adding extra access time.
- (2)
Each partition can withstand a certain number of requests, and inappropriate deletion of replicas concentrates the load on specific partition. As a result, these partitions become overloaded, resulting in high data locality and excessive network utilization, thus lowering system performance.
For the load resource relationship of replica deletion selection, we perform a modeling analysis to minimize the replica deletion loss, representing the user access time added by the replica deletion. The loss is expressed as follows:
where
represents the total loss when deleting a block
k replica in partition
j,
represents the access number from partition
i to partition
j for block
k,
represents the loss under that access behavior, and
S represents the partitions number. We perform a summation analysis for the single replica deletion loss, with the following overall objective equation:
Expand it as:
where
represents whether to delete the block
k replica in partition
j,
k’s range includes the genesis block to the newly generated block in this blockchain,
represents the access number to block
k from partition
i to partition
j,
represents the partitions number that currently stores the block
k replica, and
indicates the deleted block
k replica in (
8a). Equations (8b) and (8c) represent the partition load capacity constraint,
denotes the request to access partition
j is shifted to partition
m, and
denotes the partition
m load capacity.
Based on the above block replica deletion model, we evaluate the associated models and discover that the replica deletion problem is a subset of the replica placement problem, which has been proven to be an NP-hard problem that is difficult to solve in polynomial time [
34,
35,
36]. Heuristic algorithms have been used to solve the problem and approximate the optimal solution. However, this technique is typically challenging to implement, and when replicas are deleted, the same replicas will affect each other between partitions, and the effect will change dynamically.
For the replica deletion model, we approximate the optimal replica deletion distribution by deleting the replica greedily. The core idea is deleting the minor loss replica based on the replica deletion loss and the partition load state at each iteration. The specific implementation process includes message design, state calculation, and cooperative deletion algorithms.
We expand the blockchain node synchronous interaction messages to meet the collaboration requirements by adding
Delete Flag, Replica Number, State, and Regional Identifier, as shown in
Table 2. The
Delete Flag field is used to identify the block deletion phase. The
Replica Number field identifies the target deleted replica number. The
State field is used to identify the loss status when partition deleting block replica. The
Regional Identifier field is used to identify whether the partition has participated in the collaboration process.
This algorithm selects the delete partition based on the partition states and uses the greed algorithm idea to delete the replica with the worst states. The state calculation includes the deletion replica loss and load condition.
First is the replica deletion loss calculation, which is the increase in access time when a replica is deleted and requires consideration of access number, access distribution, distance received by the partition supernode, and the partition load condition.
where
represents the loss of partition
j deleting block
k replica,
represents the behavior of partition
i requesting block
k from partition
j,
k’s range includes the genesis block to the newly generated block in this blockchain,
represents the partition set of deleted block
k replica,
represents the partition where the block
k replica is stored,
represents bandwidth, and
represents the block
k data amount.
where
represents the load limit of partition j supernode.
The above two are then weighted and summed to indicate the partition current state, which is used as the basis for replica deletion.
The collaborative block replica deletion algorithm consists of three phases: the deletion message construction phase, the partition deletion state interaction, and the block replica deletion and update. SN represents the supernode.
The first phase builds the delete message phase and initiates the collaborative deletion process. As shown in Algorithm 1, the target block k replica number is first calculated based on the decay factor in Formula (
4) and then compared with the current block
k replica number in the local virtual chain. If the target number is less than the current number, the block replica deletion phase is entered. In the message, set the
Deletion Flag field to 1 and the
Replica Number field to the target replica number, and fill in the
State field with its own partition status value according to Formula (
11). Initialize all partition
Regional Identifiers fields containing block
k replica to 0 and set its own
Regional Identifier field to 1, representing that the partition has participated in the block replica deleting. After the message is constructed, the supernode forwards it to other supernodes that have stored block
k replicas that are not involved in the collaboration.
| Algorithm 1 Deletion message construction phase. |
- 1:
for block k in blockchain do - 2:
The SN retrieval block k’s replica number in virtual chain - 3:
Compute the block k target replica number according to Formula ( 11) - 4:
if block k target replica number is smaller than current replica number then - 5:
Set Replica Number to block k target replica number, set Delete Flag to 1, set State Field to SN’s state - 6:
Set Regional Identifier for current SN to 1, other Regional Identifier to 0 - 7:
Forward the packet to other SN contains block k replica - 8:
end if - 9:
end for
|
The second phase, comparing the states of the individual partition, is used to assess each partition, deleting replica loss. As shown in Algorithm 2, after receiving the message, other supernodes calculate the block replica number according to the Formula (
4), and if the target replica number is the same, they enter the deletion process. Set the
Regional Identifier field representing itself to 1. It also calculates its state value according to the Formula (
11) and compares it with the
State field in the message. If the status value is less than the
State field in the message, the
State field updates. Keep forwarding messages until the
Regional Identifiers of all replicas of storage block
k are set to 1 and the second phase is completed.
| Algorithm 2 Block deletion state interaction. |
- 1:
The SN receives a deletion message - 2:
if some Regional Identifier is 0 then - 3:
The SN retrieval block k’s replica number in virtual chain - 4:
Compute the block k target replica number according to Formula ( 11) - 5:
if block k target replica number is equal to Replica Number then - 6:
if The current SN state is smaller than State Field then - 7:
Update the State field to current SN state - 8:
end if - 9:
Set Regional Identifier for SN contains block k replica to 1 - 10:
end if - 11:
Forward the packet to other SN contains block k replica - 12:
end if
|
The third phase consists of block replica deletion state updates. According to Algorithms 3 and 4, the supernode updates its own virtual chain after deleting replica, while setting the Deletion Flag field to 2, then setting its own the Regional Identifier field to 1 and the other Regional Identifier field to 0. Forward this message to all other supernodes that store block k replica. Other supernodes receive this message and update virtual chain.
| Algorithm 3 Block replica deletion and update. |
- 1:
The SN receives partition deletion state interaction message - 2:
if SN state is equal to State field then - 3:
SN delete the block k replica and update virtual chain for block k - 4:
Set the Delete Flag to 2 - 5:
Set Region Flag to 1, other Region Flag to 0 - 6:
Forward the packet to all SN contains block k replica - 7:
end if
|
| Algorithm 4 Block replica deletion and update response. |
- 1:
The SN receives a block replica deletion and update message - 2:
Update virtual chain for block k
|















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}