3.1.1. Bloggers and Microblog Content Features
Commonly used microblog features for prediction in current research are mainly divided into two categories [
22,
23,
24]. The first one is features of users themselves, namely the blogger features, and the second one is features of blogs themselves, namely microblog content features. For Sina microblog, blogger features include the number of blogger’s fans, blogger influence, blogger’s recent microblog heat [
22,
25,
26], and for microblog content features, current research usually focuses on points including whether the original microblogs contain links, and its hashtags.
The blogger features and microblog content features specifically used in this paper are shown in
Table 1, including feature tags, specific meanings, and value ranges.
For some important features, their brief descriptions are as follows:
(1) The blogger’s recent microblog heat: There is a certain logical relationship between the heat of one microblog and the heat of its blogger’s other microblogs recently issued. Therefore, we use the heat of 10 other microblogs recently issued by the blogger as one basis of the calculation of the blogger’s recent microblog heat. The calculation is shown in Equation (
3):
where
h represents the required feature of the blogger’s recent microblog heat. For the
m-th other microblog recently issued by the blogger,
represents the reposting number of the microblog,
represents the number of microblog comments, and
represents the praise score of the microblog.
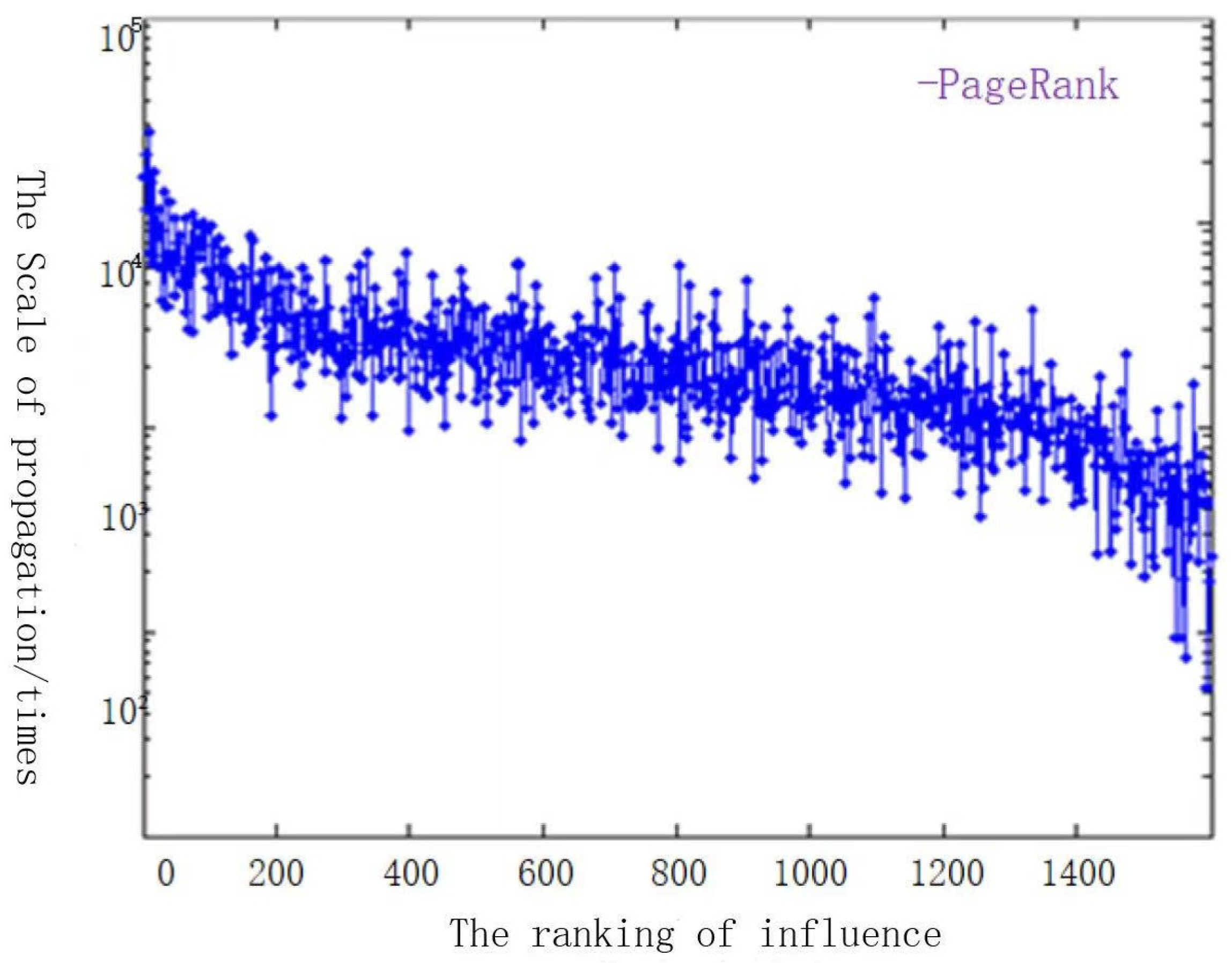
(2) Blogger influence: The microblog propagation trends will be directly affected by the strength of the influence of its blogger, namely, with larger blogger influence, it is easier for the microblog to be spread. Since the following relationship between microblog users is similar to the links between web pages in the Internet, the idea of PageRank algorithm can be used to evaluate the influence of users. The basic idea is that the user’s influence is larger followed by more influential users, the user’s influence is larger with more fans, and the user’s influence is larger with more fans and follow fewer users. According to the research on the topological structure and information propagation of Sina microblog [
23], it is found that it has an obvious small-world experiment, and its degree distribution obeys a power-law distribution. According to the idea that messages can be sent to other people on the network with fewer hops, the calculation of user influence is shown in Equation (
4):
where
represents the required influence of user
i.
d is the damping factor, which represents the probability of transferring from one given user to another random user, with its value range between 0 and 1, and the value of
d is usually 0.85.
represents all user nodes that have an outbound link to the blogger node, namely the user’s fan group.
N represents the number of all user nodes that have an outbound link to the blogger node, namely the number of user’s fans.
represents the out degree of user node
.
(3) Microblog length: Microblogs issued by most users are short and fragmented daily life and emotional catharsis, which is hard to result in widespread resonance and reposting. In contrast, those microblogs with more complete expression are more likely to gain the understanding and resonance of other users, and easier to spread. Therefore, we consider the microblog length as one of the microblog content features, and set the classification criteria as whether the length of microblog is more than 15 words.
(4) Whether to include usernames or hashtags: Regarding microblog content features, we consider the problem of whether usernames or hashtags is included. In a microblog, usernames are used to directly quote other users, or to address or talk about a certain user, and hashtags are used to mark specific topics.
(5) Special marks: We consider whether there is an exclamation mark “!” or a question mark “?” at the end of a microblog as part of microblog content features. The exclamation mark is used to mark emotional statements in the text, and the question mark represents a problem in the text. The existence of both marks is more likely to result in the blogger’s passing his own emotions to other users or arousing other users responding, which contributes to the spread of the blog.
3.1.2. Key Comment Features Based on Cluster and DCNN
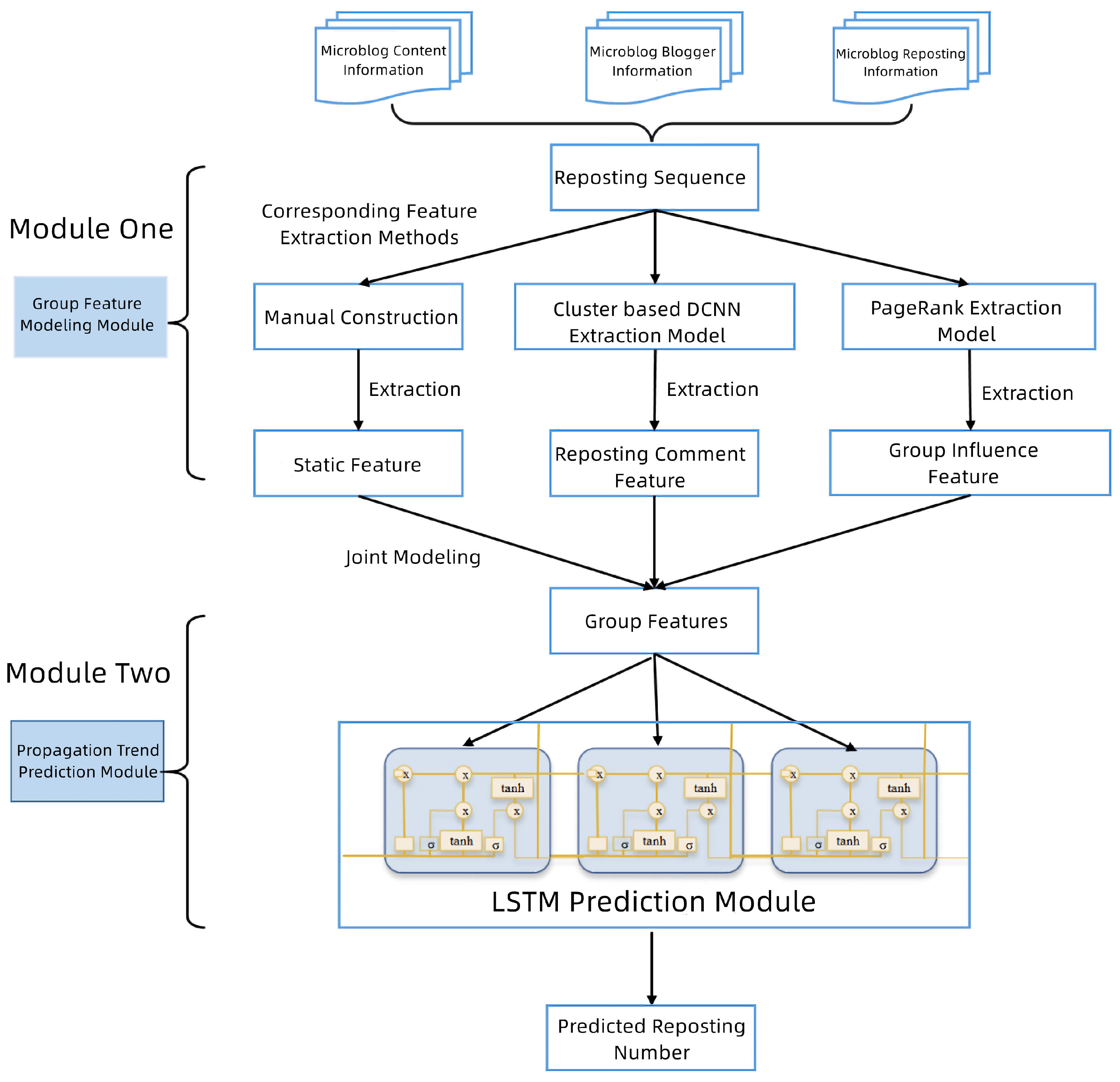
A microblog often expresses different meanings in different temporal and spatial contexts, and sometimes may even contain irony, metaphors, and other information. In this regard, forwarder comments are often needed as supplement to the information of the source microblog to provide temporal and spatial background information which the original microblog lacks. At the same time, users are usually susceptible to comments from other users. Therefore, in this paper, we consider extracting comment features of forwarder group to improve the accuracy of machine learning-based prediction methods.
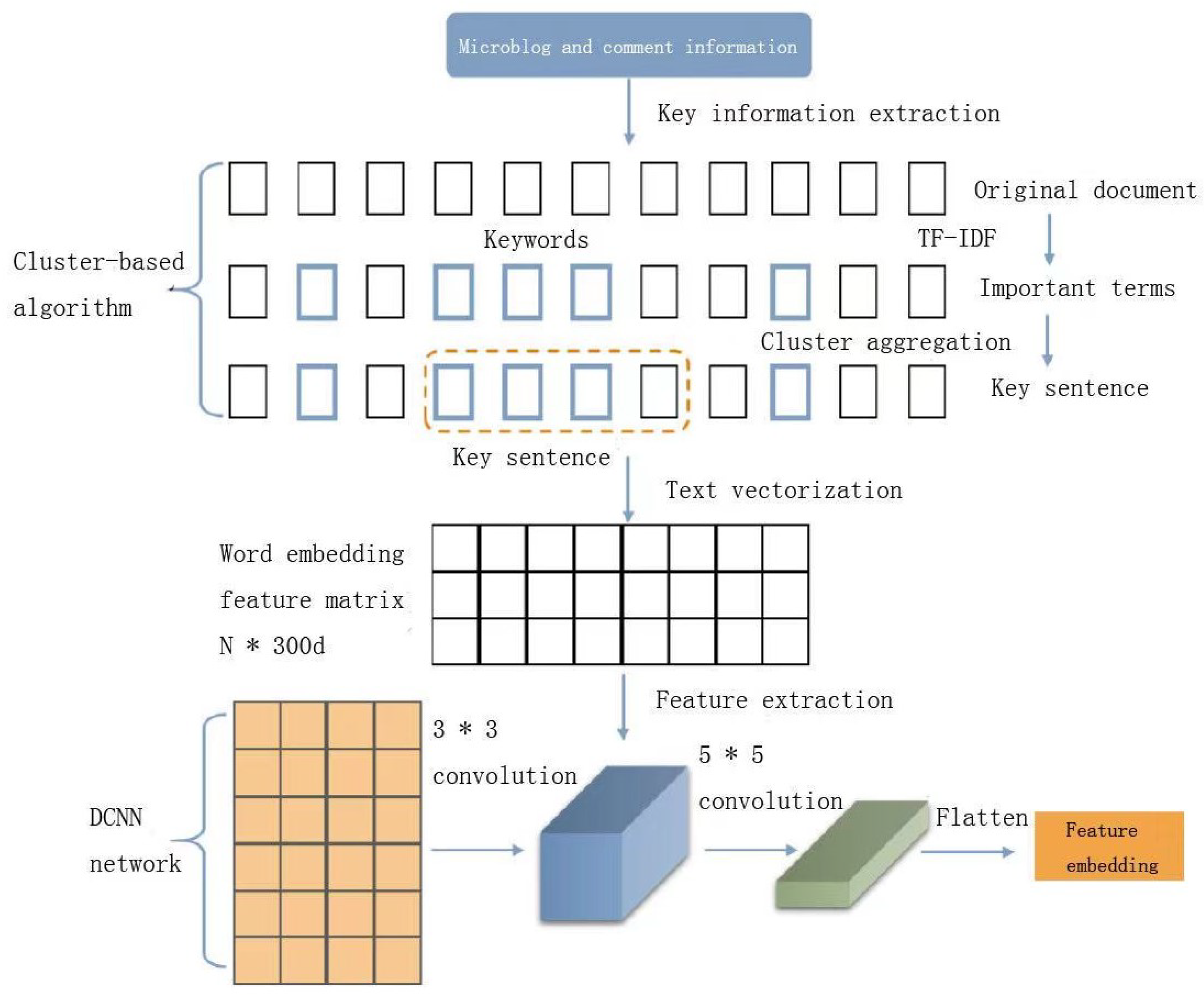
Since there are too many forwarder comments on a microblog, it is necessary to extract important information of the comments first, and then encode and vectorize them into group comment features of the blog. The process of feature extraction is shown in
Figure 3, where there are generally three steps: (1) First, we use the cluster-based key information extraction model to extract key information from the group comments of microblog forwarders; (2) Encoding and vectorizing group comment information into sentence embeddings; and (3) Inputting the sentence embeddings to the DCNN convolution layer for feature extraction and compression. Finally, feature embeddings of the forwarder group comments are extracted, which contains temporal and spatial background information and is a supplement to the source microblog.
The specific work of each step is as follows:
Step 1: Key information extraction based on clusters
Forwarder comments are composed of sentences. In the process of microblog propagation, forwarder group comments contain a large number of sentences, so key information of the comments needs to be extracted first. In this paper, we use the cluster-based key information extraction technology to extract the corresponding feature sentences [
27]. Our concept of “cluster” in this paper refers to the aggregation of keywords, namely, sentence fragments which contain multiple keywords.
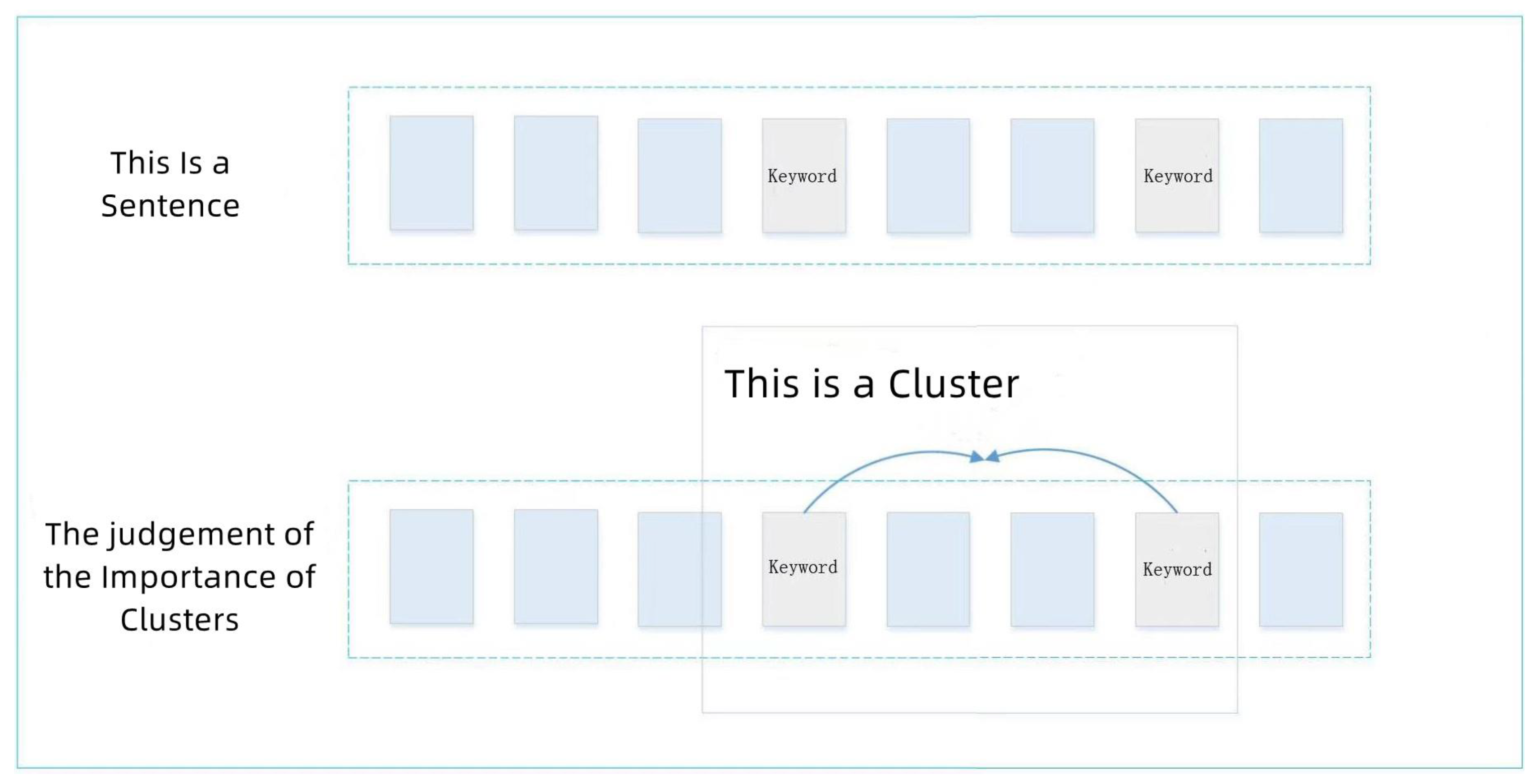
It can be seen in
Figure 4 that the framed part in the figure represents a cluster, where the keywords are obtained by calculating the TF-IDF score of terms of the comment sentences. If the distance between two keywords is less than the threshold, then these two keywords are classified into the same cluster. We set the threshold to 4 in this paper. In other words, if there are more than four other terms between two keywords, then these two keywords will be divided into two clusters. Then, we calculate the importance score of the clusters, the calculation of Equation (
5) is as follows:
where
represents the required importance score of clusters.
represents the number of keywords in the cluster.
represents the number of terms in the cluster. Taking
Figure 4 as an example, in the figure, the cluster in the frame has a total of four terms, two of which are keywords. Therefore, the importance score of this cluster is
. After that, we extract the 10 sentences with the highest cluster scores, and combine them together as the finally extracted comments containing key information which can be further processed later.
Step 2: Feature encoding and vectorization
Since the computer cannot directly understand the meanings of text information, it is necessary to encode and vectorize the extracted comment features containing key information into a multi-dimensional embedding to facilitate subsequent further processing. The basic idea of word embeddings originates from NNLM [
24] (Neural Network Language Model) proposed by Bengio. In this paper, we use open source tool Word2vec of Google in 2013 to solve the word embedding representation problem of microblog comments. Word2vec can quickly and effectively replace text sentences with multi-dimensional embeddings based on a given corpus.
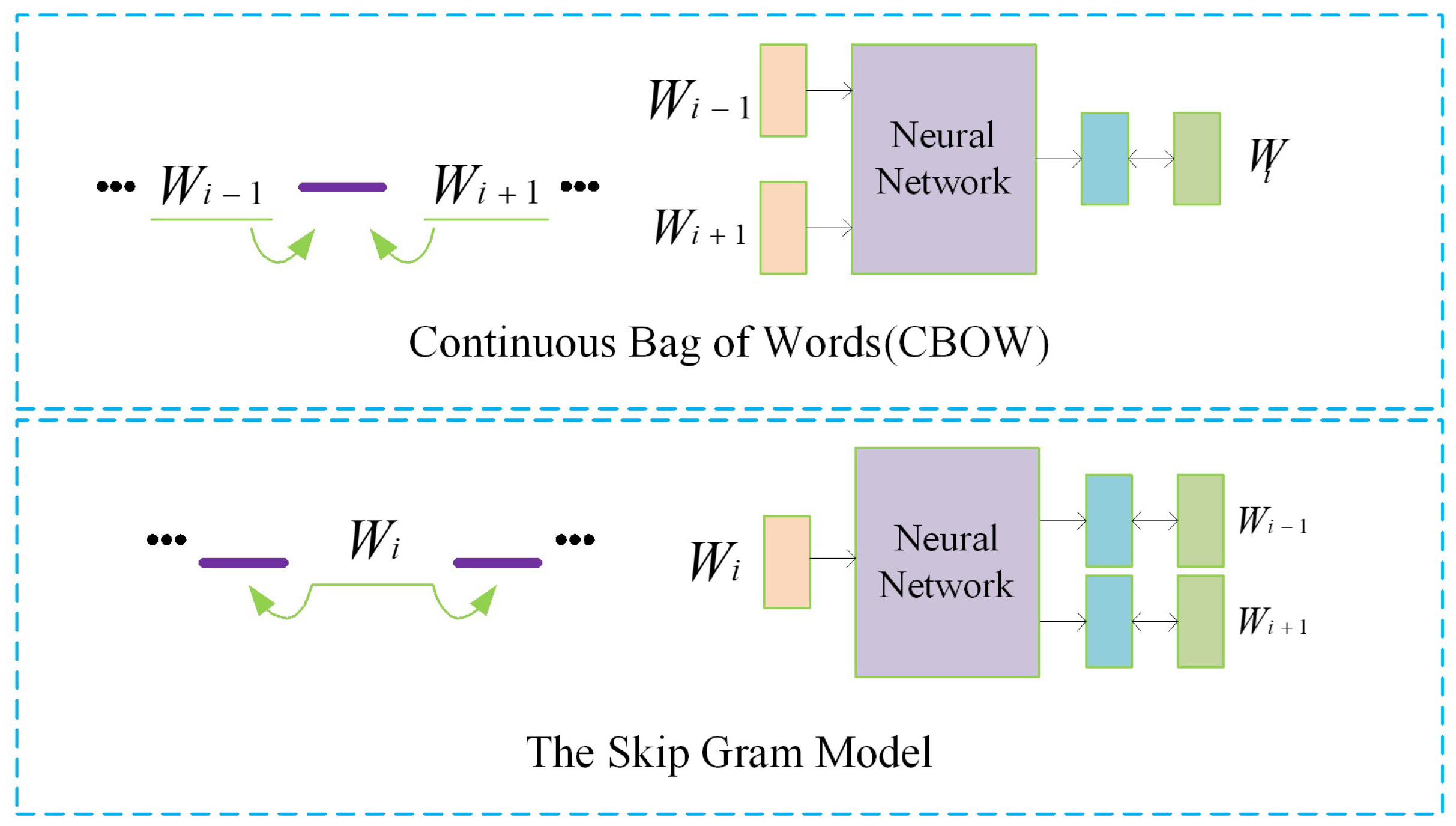
There are two models for Word2vec, which, respectively, are the Continuous Bag-of-Words (CBOW) model and the Skip-Gram (SG) model, whose structures are shown in
Figure 5. For a sentence containing L words, where …,
,
…
, respectively, represent the word embedding of each word in the sentence. In the CBOW model, a total of n words before and after the current word
(here n = 2) are used to predict the current word
. In contrast, the Skip-Gram model uses the word
to predict the n words before and after it. Both CBOW and Skip-Gram models include input layer [
24], hidden layer, and output layer.
After preprocessing reposting comments containing key information, Word2vec is used to encode them into multi-dimensional embeddings. We train the Word2vec model, update the weights through the backpropagation algorithm, and use the stochastic gradient descent method to reduce the loss value, and finally obtain the byproduct, word embeddings of the model. Based on the word embeddings trained by the tool word2vec, we convert the words into microblog forwarder comments into word embeddings, and finally convert the key sentences of the comments into sentence embeddings.
Step 3: Feature extraction and compression of DCNN convolutional layer
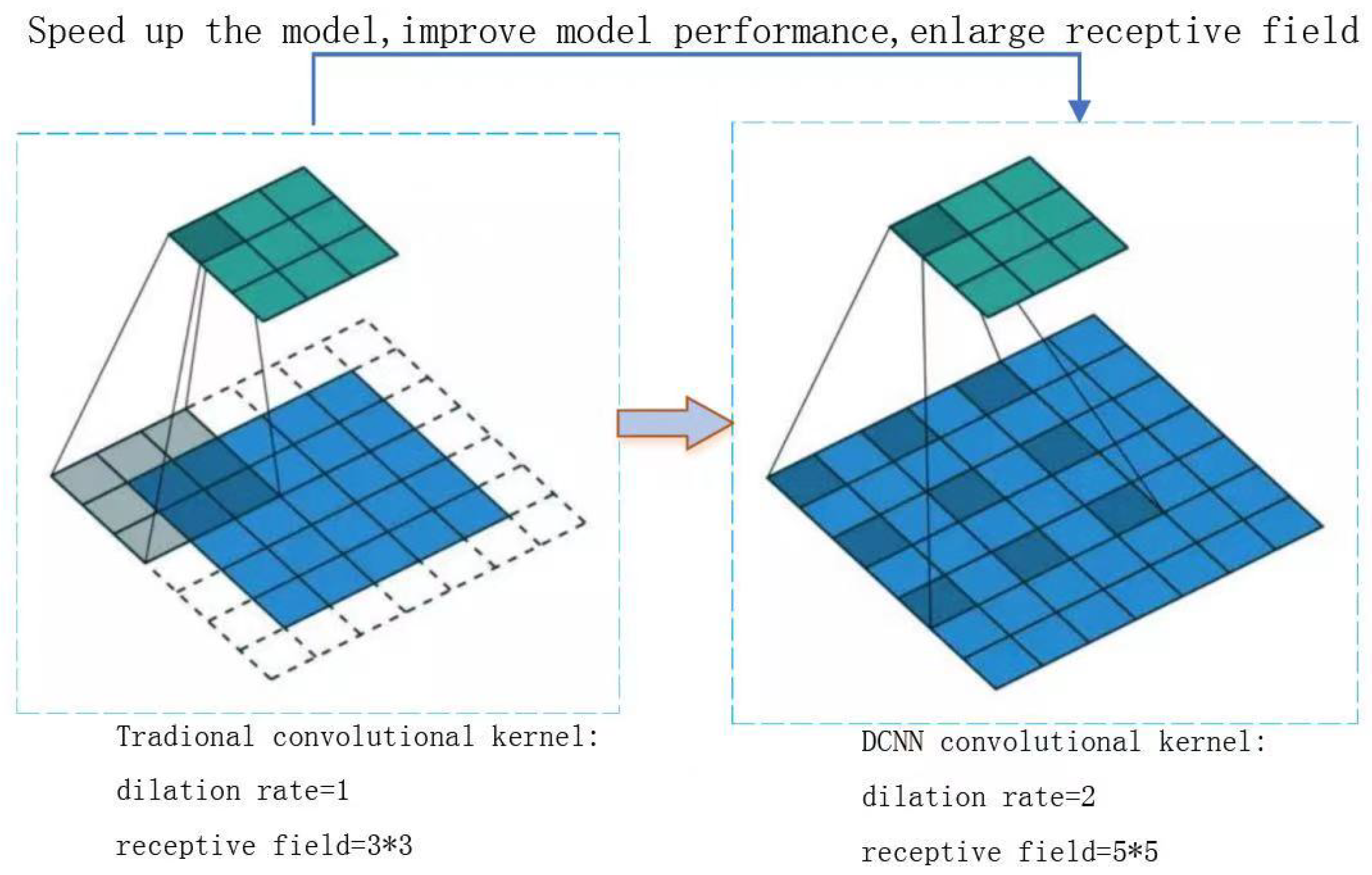
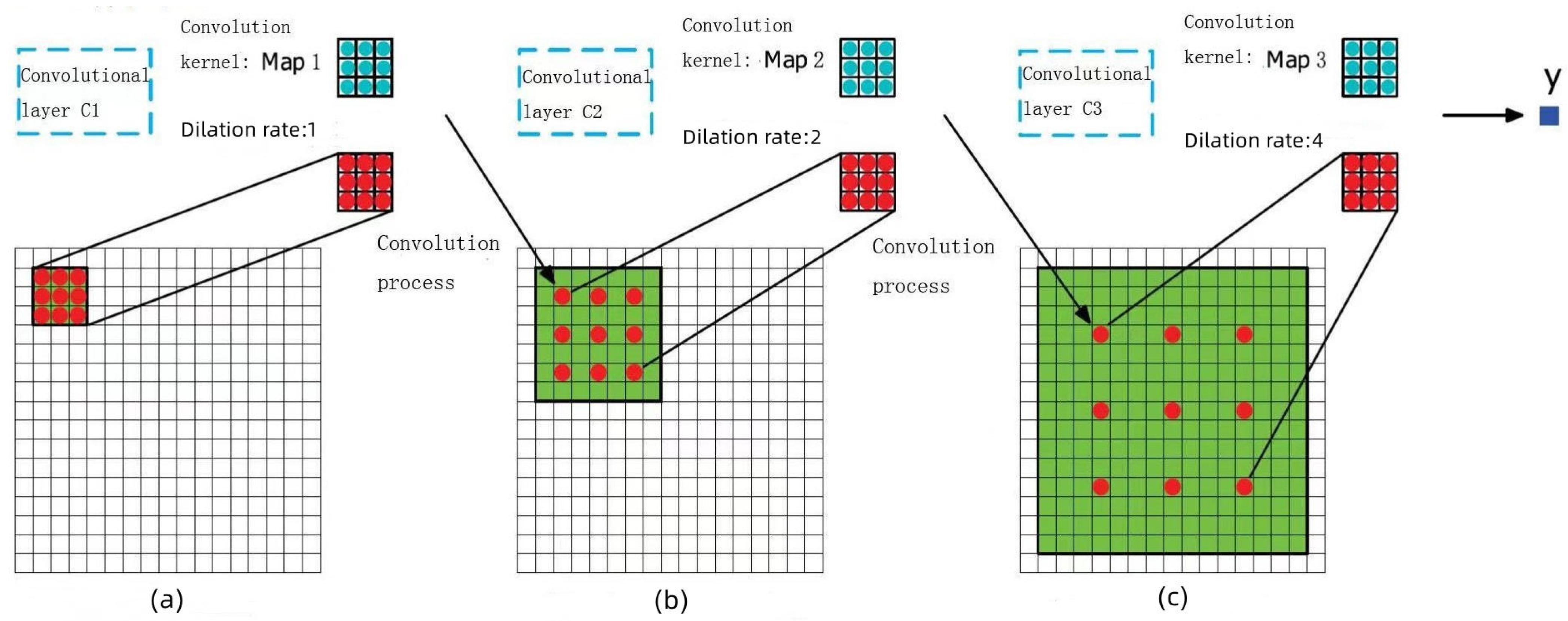
Finally, we conduct feature extraction and compression on the forwarder comment embeddings. Due to the complexity of microblog language, the effect of usage of ordinary convolutional networks for feature extraction and compression is limited, and there are too many model parameters. Therefore, we choose to use Dilated Convolutional Neural Network (DCNN) and input the sentence embedding representation of reposting comments into the DCNN convolutional layer for feature extraction and feature compression. The three dilated convolutional layers we use are shown in
Figure 6.
In the figure, for the three dilated convolutional layers C1, C2, and C3, their convolution kernels Map1, Map2, and Map3 are of the same size, which are all matrices, but the dilation rates of the three convolution kernels are different, with values of 1, 2, and 4. In subgraph (a), a convolution kernel with dilation rate of 1 is used to convolve the input embeddings, and we input the result feature map as the output of C1 to the convolutional layer C2. In subgraph (b), a convolution kernel with dilation rate of 2 is used to convolve the feature map output by the C1 layer, and we input the result feature map as the output of C2 to the convolutional layer C3. In subgraph (c), a convolution kernel with dilation rate of 4 is used to convolve the feature map output by the C2 layer. At this time, the receptive field of the elements in the output y of the convolutional layer C3 has reached , while, with the ordinary convolution operation, the receptive field will only be .
The calculation process of the DCNN convolutional layer is shown in Equation (
6).
For the forwarder comment embeddings, the convolution kernel
W of dilated convolutional layer is applied to a window of terms of length
h, and local features are generated after dilated convolution. In Equation (
6),
is the feature value calculated at position
t.
b is the deviation of the current filter, and
is the nonlinear activation function (ReLU). We use zero padding to ensure that the size of the matrix after convolution meets requirements of the calculation. Then, the pooling operation is performed on each feature map through the maximum pooling layer to perform feature compression on the feature embeddings, and output embedding
with a fixed length. The calculation is shown in Equation (
7):
As is shown in
Figure 6, our model uses multiple filters (with different window sizes) to obtain multiple features, and then outputs a multi-dimensional embedding at the maximum pooling layer network stage. The calculation is as shown in Equation (
8):
where
represents convolution and pooling operations. As a result, the feature embedding representation
of forwarder key comments is finally obtained, which contains spatial and temporal background information and is a supplement to the source microblog information.
3.1.3. Group Influence Features
User influence refers to the ability of a user’s opinions, comments, or behaviors to change the behaviors or opinions of other users. In microblog social networks, user influence has a direct impact on microblog propagation trends. Traditional machine learning-based prediction methods usually consider the personal influence of bloggers, without considering the influence of reposting users group in the process of microblog propagation. For example, if a celebrity user with huge influence reposts a microblog, then the propagation scale of this microblog is likely to be greatly improved [
24]. In this paper, we use the PageRank algorithm [
28] to calculate group influence to make up for the defect of blogger personal influence in traditional prediction methods.
Some scholars regard the microblog social network as a specific directed graph based on graph theory, each node of which corresponds to each user, and the directed edges in the graph represent the relationship “follow” and “followed” in the microblog network. Since the following relationship between users represented with directed edges is similar to the links between web pages on the Internet, we use the idea of PageRank algorithm to evaluate and calculate user influence. The main idea is that the user’s influence is larger followed by more influential users, the user’s influence is larger with more fans, and the user’s influence is larger with more fans and follow fewer users. The algorithm comprehensively considers the structure of the microblog social network, and the final calculated user influence value can also reflect the user’s influence objectively. The calculation Equation (
9) of the PageRank value of user influence is as follows:
where
represents the required influence of user
i.
d is the damping factor, which represents the probability of transferring from one given user to another random user, with its value range between 0 and 1, and the value of
d is usually
.
represents all user nodes that have an outbound link to the blogger node, namely the user’s fan group.
S represents the number of all user nodes that have an outbound link to the blogger node, namely the number of user’s fans.
represents the out degree of user node
.
After calculating the personal influence of reposting users through the PageRank algorithm in the microblog propagation process, we accumulate the individual PageRank values of the users in the reposting group, calculate the group influence of reposting users, and serve the combination of group influence features and blogger personal influence features as the final influence features. The calculation of full influence is shown in Equation (
10), which calculates the accumulation of the influence of all reposting users before time
:








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}