
Online Trajectory Planning with Reinforcement Learning for Pedestrian Avoidance




Abstract
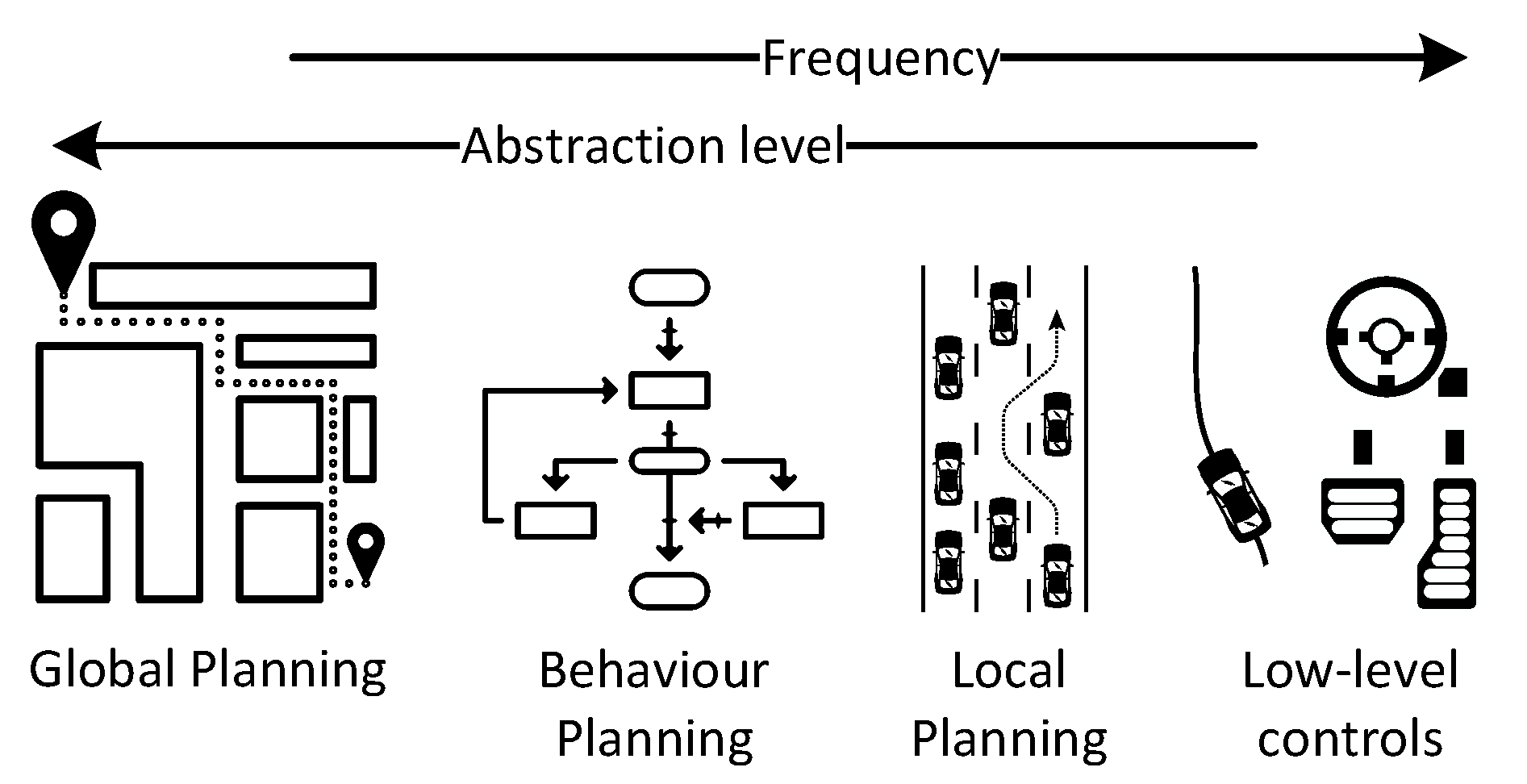
:1. Introduction
1.1. Related Work
1.2. Contributions of the Paper
2. Methodology
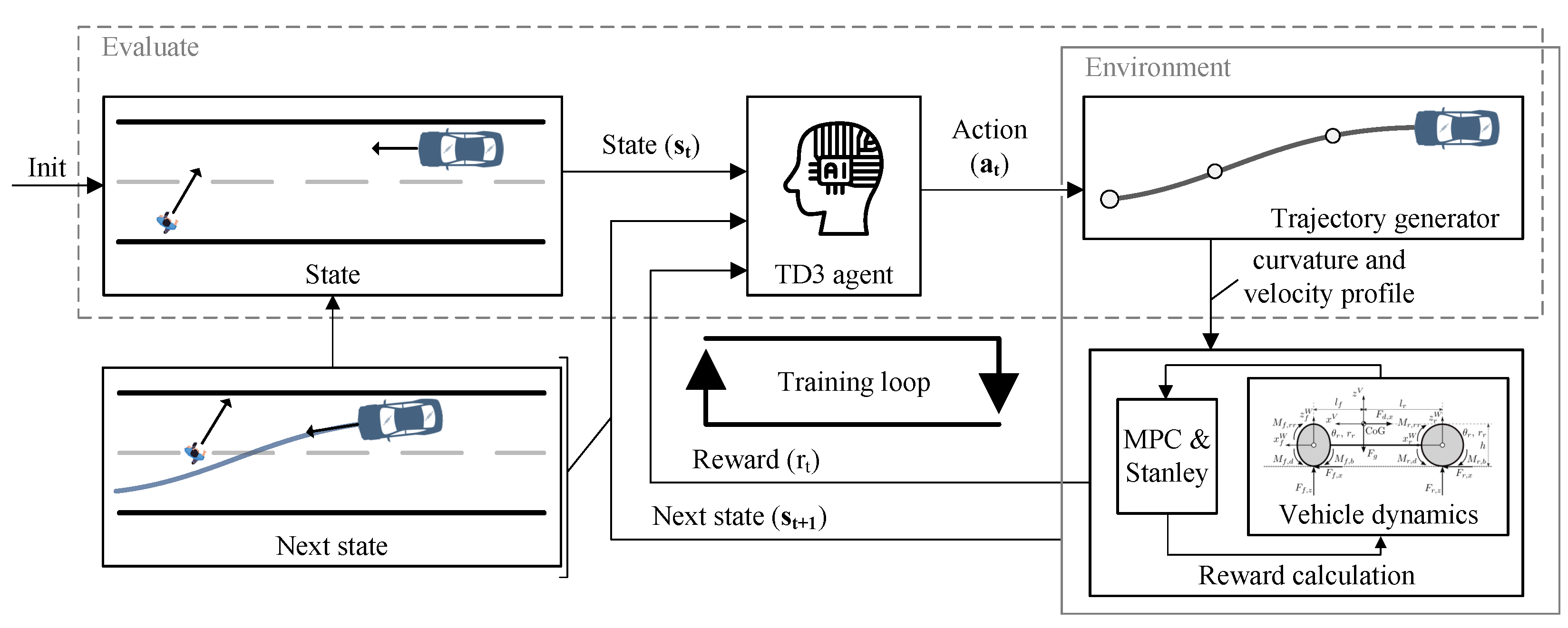
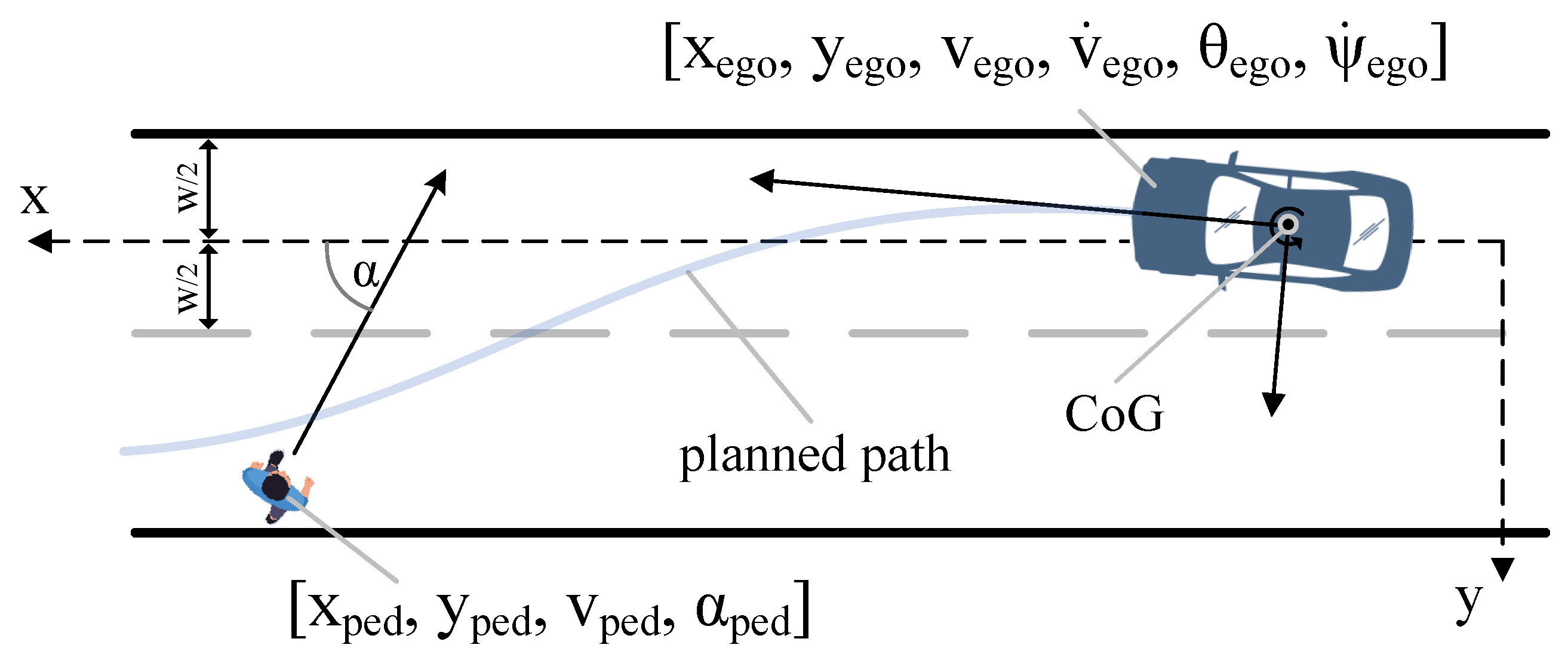
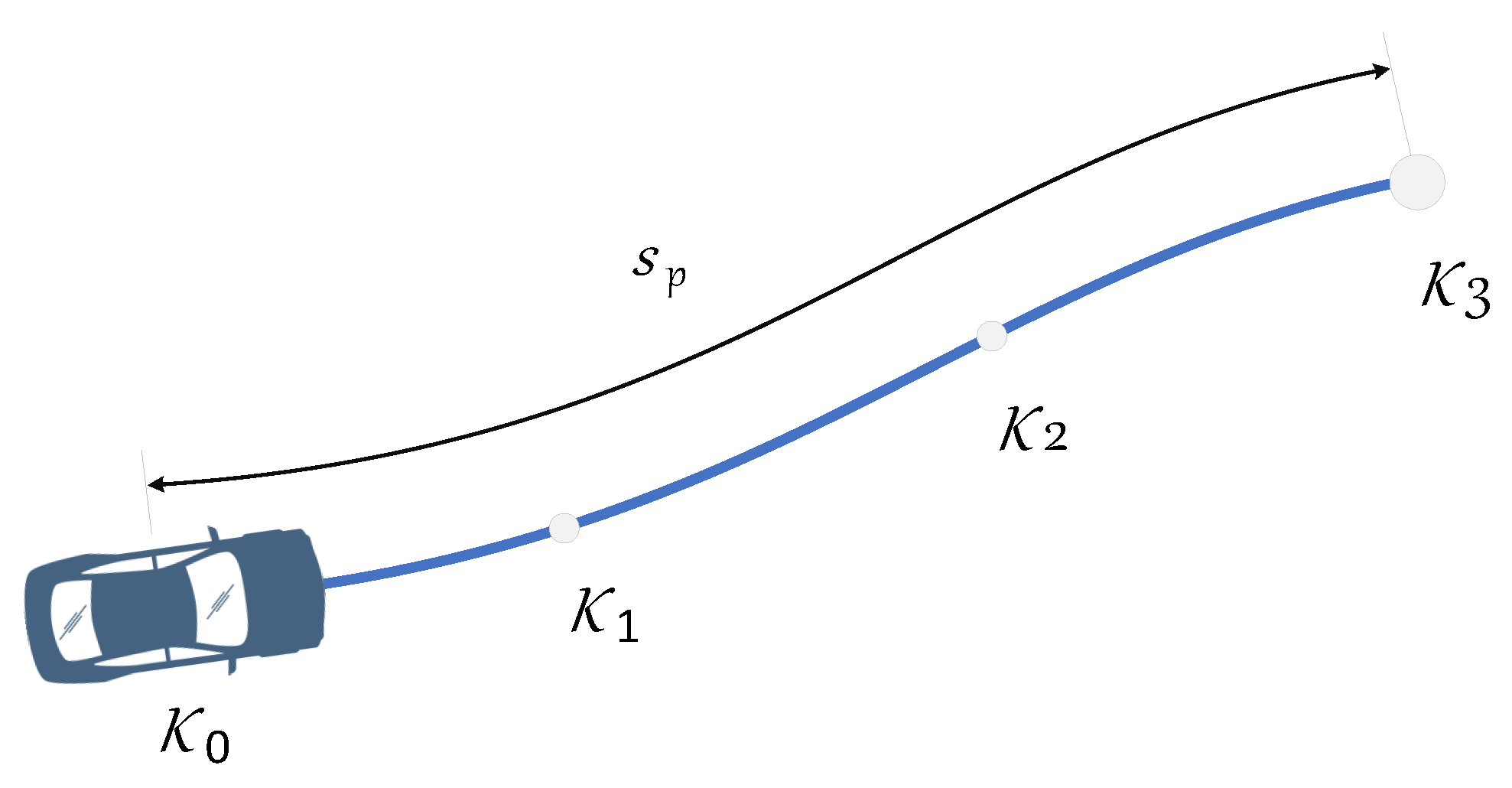
2.1. Problem Formulation
2.2. Proposed Method
- The maneuver is performed on a straight section of the road.
- The vehicle has ideal high-level sensor signals.
- Constant road–tire friction coefficient.
- The pedestrian makes a rectilinear motion.
- No other dynamic objects are considered.
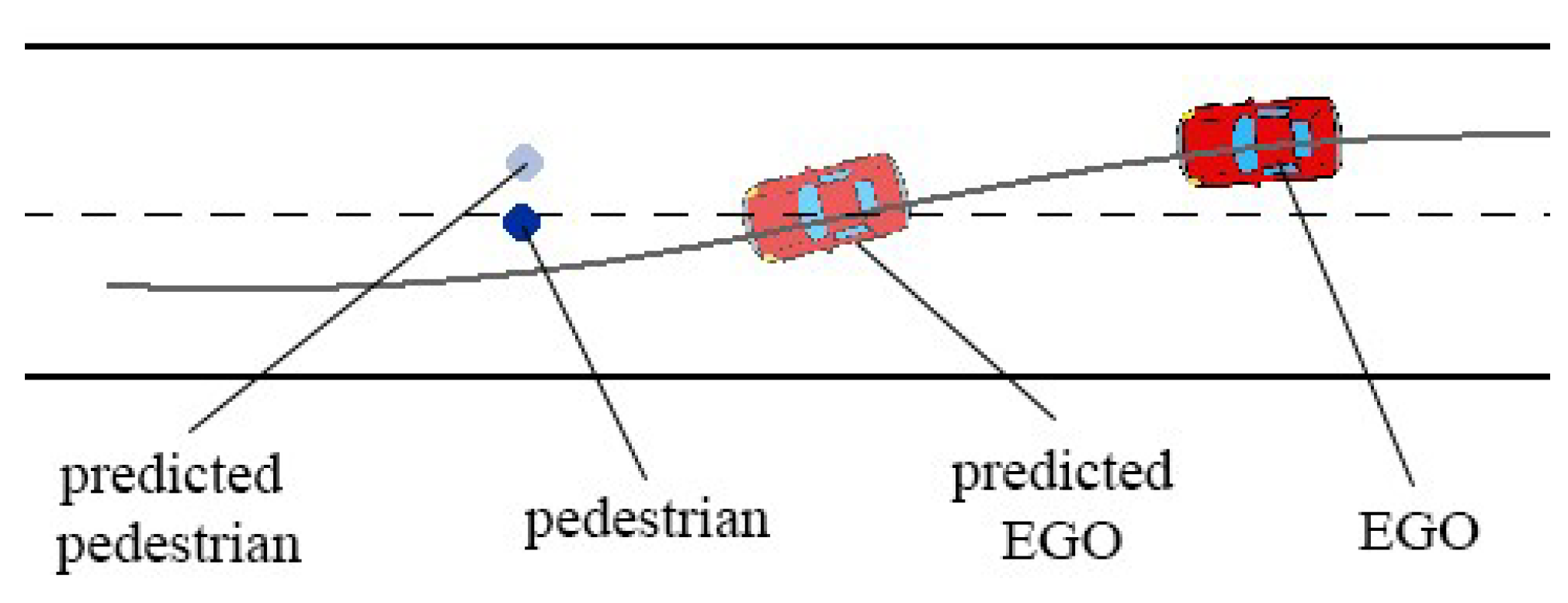
2.3. Environment
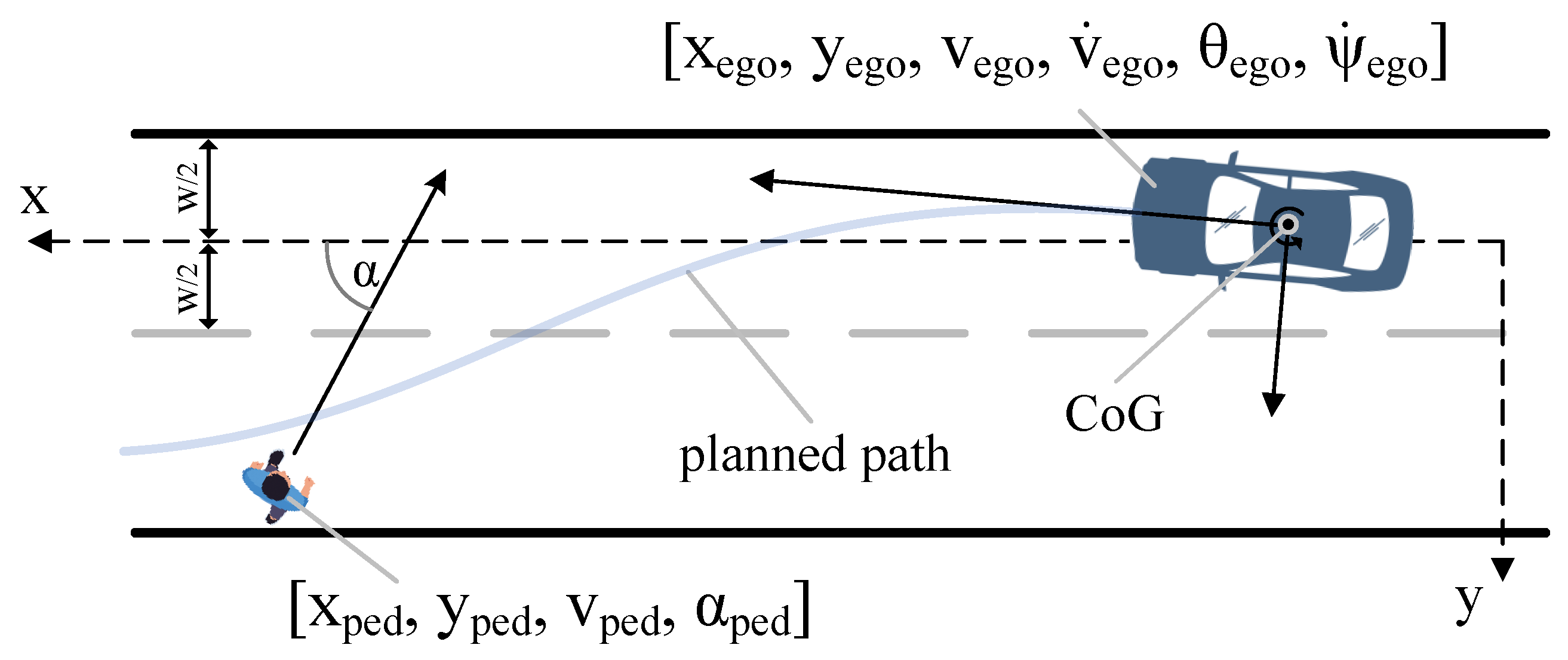
2.3.1. State Space
2.3.2. Action Space
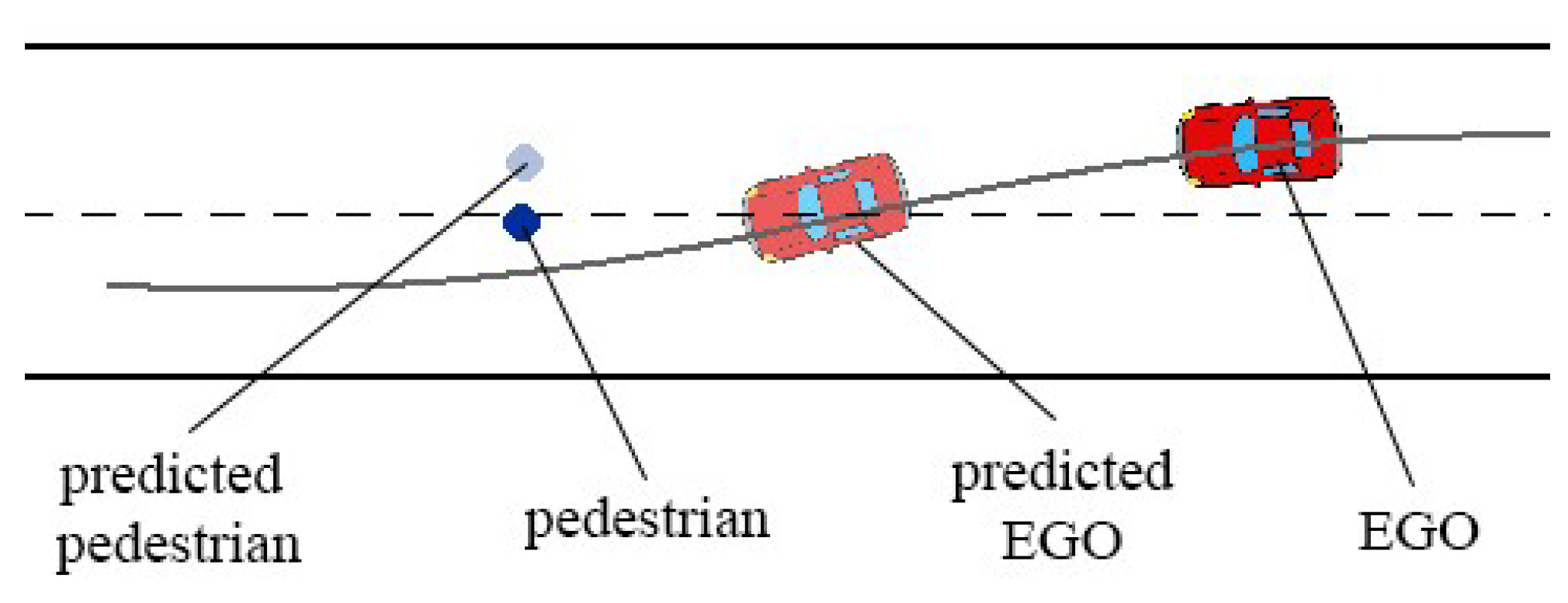
2.3.3. Models
2.3.4. Reward Function
- The euclidean distance between vehicle CoG and the nearest point of the path (distance error) greater than 1 m;
- The angle difference between at closest point of the path and vehicle (angle error) greater than 20 degrees;
- Longitudinal rear or front slip greater than 0.1;
- Lateral rear or front slip greater than 0.2 radians;
- The vehicle hit a pedestrian;
- The vehicle leaves the road.
2.3.5. Low-Level Controllers
2.3.6. Rendering and Carla Integration
2.4. Agent
- The overestimation can cause divergence in actor-critic solutions. As shown in Table 1 TD3 updates the weights of the actor network only every second step. It can reduce the error, resulting in a more stable and efficient training process.
- TD3 agent uses two critic networks with a clipped double Q learning method [28]. The smaller worst of the two critic networks is selected, which reduces underestimation bias.
- The action noise regularization can smooth the target policy and make it more robust. As also shown in Table 1, saturated noise is added to the selected action, which favors higher values for the action.
Network Architecture and Hyperparameters
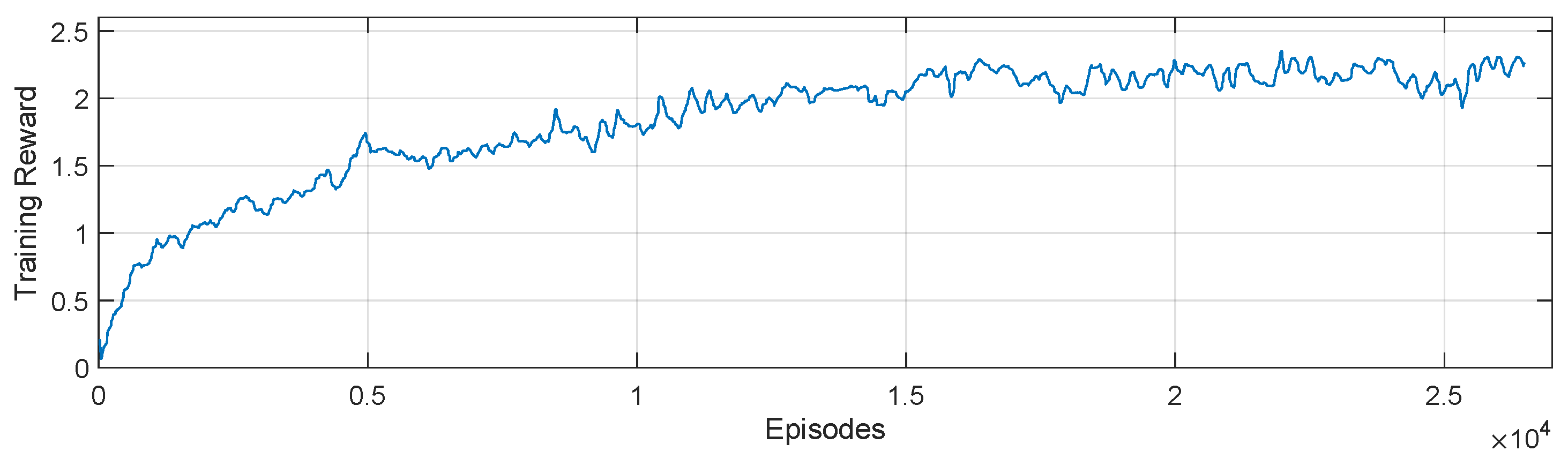
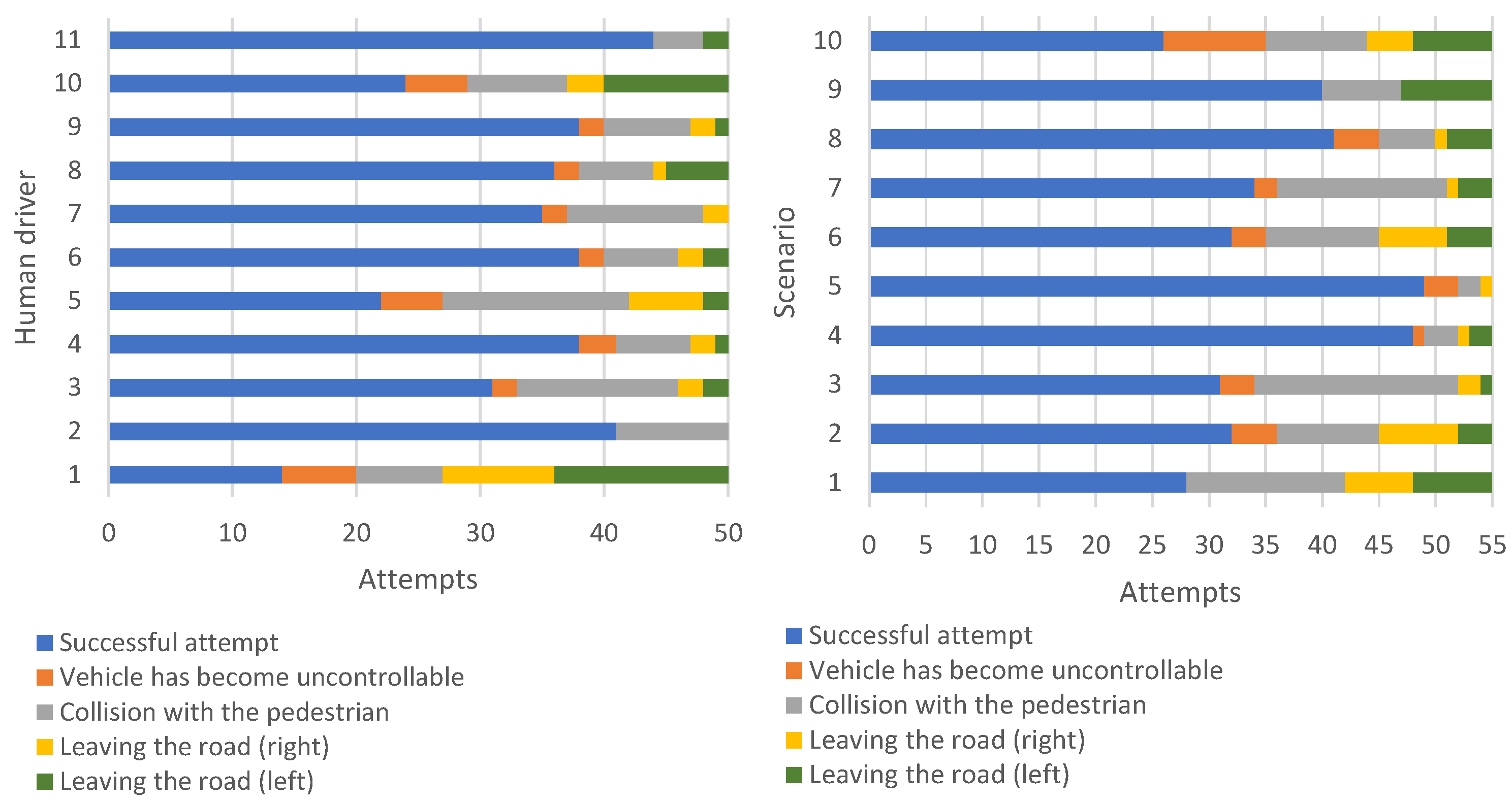
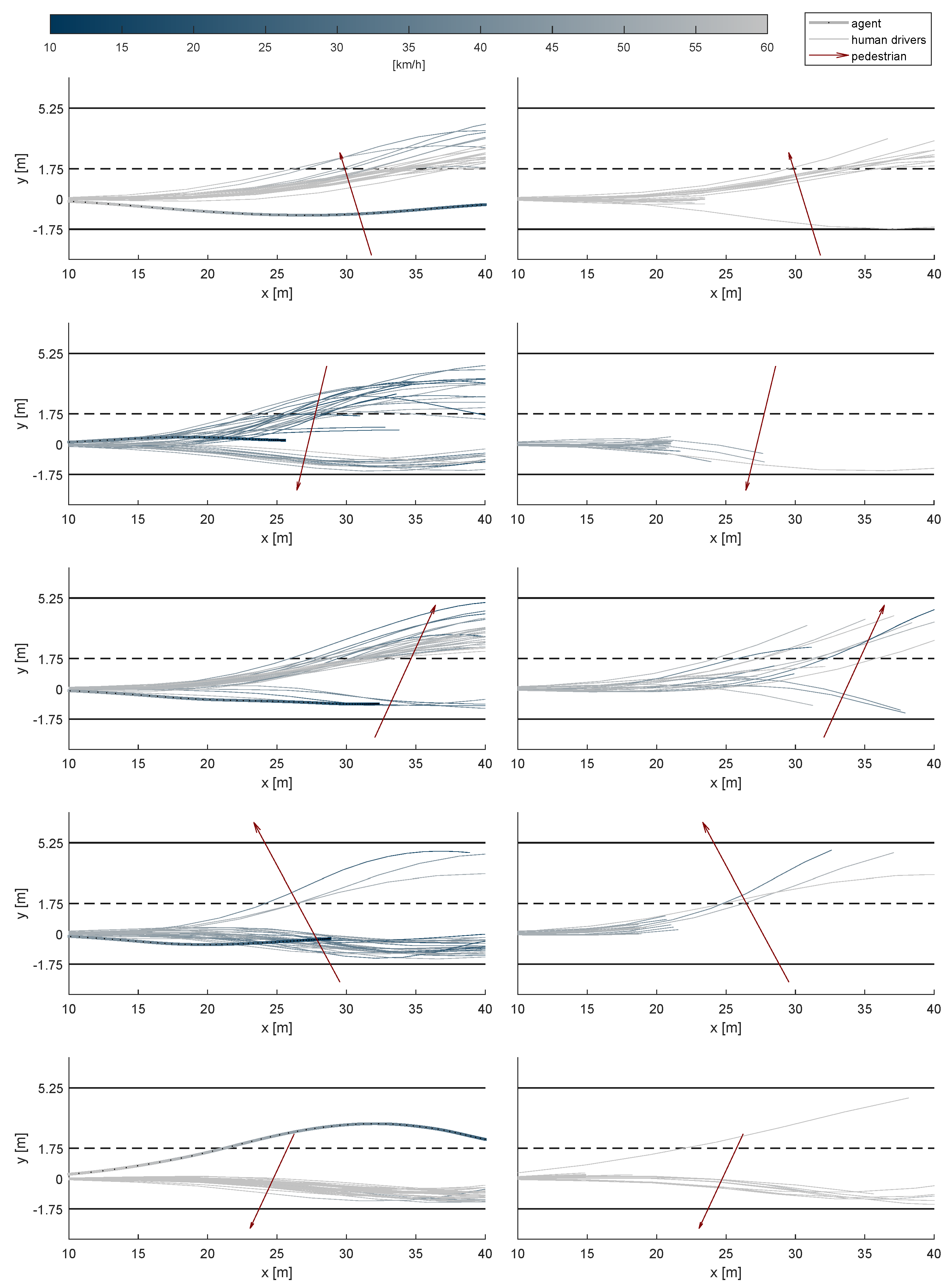
3. Results
- Logitech G29 Racing wheel with force feedback;
- High-end PC with powerful graphics card (Nvidia 2080Ti);
- CARLA Simulator (version 0.9.13);
- The developed Python environment.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| VRU | Vulnerable Road Users |
| ADAS | Advanced Driver Assistance Systems |
| AEB | Autonomous Emergency Braking |
| FCW | Forward Collision Warning |
| ESS | Emergency Steering Support |
| AES | Autonomous Emergency Steering |
| RL | Reinforcement Learning |
| RRT | Rapidly Exploring Random Trees |
| MDP | Markov Decision Process |
| POMDP | Partially Observable Markov Decision Process |
| PPO | Proximal Policy Optimization |
| DQN | Deep Q-Network |
| LSTM | Long Short-Term Memory |
| MPC | Model Predictive Control |
| CoG | Center of Gravity |
| PI | Proportional-Integral |
| TD3 | Twin-Delayed Deep Deterministic Policy Gradient |
| DDPG | Deep Deterministic Policy Gradient |
| ESP | Electronic Stability Program |
References
- Next Steps towards ‘Vision Zero’: EU Road Safety Policy Framework 2021–2030. Available online: https://op.europa.eu/en/publication-detail/-/publication/d7ee4b58-4bc5-11ea-8aa5-01aa75ed71a1 (accessed on 20 July 2022).
- Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2018.
- Haus, S.H.; Sherony, R.; Gabler, H.C. Estimated benefit of automated emergency braking systems for vehicle–pedestrian crashes in the United States. Traffic Inj. Prev. 2019, 20, S171–S176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eckert, A.; Hartmann, B.; Sevenich, M.; Rieth, P. Emergency steer & brake assist: A systematic approach for system integration of two complementary driver assistance systems. In Proceedings of the 22nd International Technical Conference on the Enhanced Safety of Vehicles (ESV), Washington, DC, USA, 13–16 June 2011; pp. 13–16. [Google Scholar]
- Euro NCAP 2025 Roadmap; EuroNCAP: Leuven, Belgium, 2017.
- Borenstein, J.; Koren, Y. The vector field histogram-fast obstacle avoidance for mobile robots. IEEE Trans. Robot. Autom. 1991, 7, 278–288. [Google Scholar] [CrossRef] [Green Version]
- Fulgenzi, C.; Spalanzani, A.; Laugier, C. Dynamic Obstacle Avoidance in uncertain environment combining PVOs and Occupancy Grid. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 1610–1616. [Google Scholar] [CrossRef] [Green Version]
- Shimoda, S.; Kuroda, Y.; Iagnemma, K. Potential Field Navigation of High Speed Unmanned Ground Vehicles on Uneven Terrain. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 2828–2833. [Google Scholar] [CrossRef] [Green Version]
- Gelbal, S.Y.; Arslan, S.; Wang, H.; Aksun-Guvenc, B.; Guvenc, L. Elastic band based pedestrian collision avoidance using V2X communication. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 270–276. [Google Scholar] [CrossRef]
- hwan Jeon, J.; Cowlagi, R.V.; Peters, S.C.; Karaman, S.; Frazzoli, E.; Tsiotras, P.; Iagnemma, K. Optimal motion planning with the half-car dynamical model for autonomous high-speed driving. In Proceedings of the 2013 American Control Conference, Washington, DC, USA, 17–19 June 2013; pp. 188–193. [Google Scholar] [CrossRef]
- Chen, Y.; Peng, H.; Grizzle, J.W. Fast Trajectory Planning and Robust Trajectory Tracking for Pedestrian Avoidance. IEEE Access 2017, 5, 9304–9317. [Google Scholar] [CrossRef]
- Wu, W.; Jia, H.; Luo, Q.; Wang, Z. Dynamic Path Planning for Autonomous Driving on Branch Streets With Crossing Pedestrian Avoidance Guidance. IEEE Access 2019, 7, 144720–144731. [Google Scholar] [CrossRef]
- Schratter, M.; Bouton, M.; Kochenderfer, M.J.; Watzenig, D. Pedestrian Collision Avoidance System for Scenarios with Occlusions. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1054–1060. [Google Scholar] [CrossRef] [Green Version]
- Yoshimura, M.; Fujimoto, G.; Kaushik, A.; Padi, B.K.; Dennison, M.; Sood, I.; Sarkar, K.; Muneer, A.; More, A.; Tsuchiya, M.; et al. Autonomous Emergency Steering Using Deep Reinforcement Learning For Advanced Driver Assistance System. In Proceedings of the 2020 59th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Chiang Mai, Thailand, 23–26 September 2020; pp. 1115–1119. [Google Scholar] [CrossRef]
- Yang, J.; Xi, M.; Wen, J.; Li, Y.; Song, H.H. A digital twins enabled underwater intelligent internet vehicle path planning system via reinforcement learning and edge computing. Digit. Commun. Netw. 2022. [Google Scholar] [CrossRef]
- Deshpande, N.; Spalanzani, A. Deep Reinforcement Learning based Vehicle Navigation amongst pedestrians using a Grid-based state representation. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, NZ, USA, 27–30 October 2019; pp. 2081–2086. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Yao, L.; Xu, X.; Cheng, B.; Ren, J. Deep reinforcement learning for pedestrian collision avoidance and human-machine cooperative driving. Inf. Sci. 2020, 532, 110–124. [Google Scholar] [CrossRef]
- Everett, M.; Chen, Y.F.; How, J.P. Collision Avoidance in Pedestrian-Rich Environments with Deep Reinforcement Learning. IEEE Access 2021, 9, 10357–10377. [Google Scholar] [CrossRef]
- Hegedüs, F.; Bécsi, T.; Aradi, S.; Gáspár, P. Model Based Trajectory Planning for Highly Automated Road Vehicles. IFAC-PapersOnLine 2017, 50, 6958–6964. [Google Scholar] [CrossRef]
- Pacejka, H.B. Chapter 8—Applications of Transient Tire Models. In Tire and Vehicle Dynamics, 3rd ed.; Pacejka, H.B., Ed.; Butterworth-Heinemann: Oxford, UK, 2012; pp. 355–401. [Google Scholar] [CrossRef]
- Mehta, B.; Reddy, Y. Chapter 19—Advanced process control systems. In Industrial Process Automation Systems; Mehta, B., Reddy, Y., Eds.; Butterworth-Heinemann: Oxford, UK, 2015; pp. 547–557. [Google Scholar] [CrossRef]
- Rajamani, R. Vehicle Dynamics and Control; Springer: Berlin, Germany, 2012; p. 27. [Google Scholar] [CrossRef]
- Hoffmann, G.M.; Tomlin, C.J.; Montemerlo, M.; Thrun, S. Autonomous automobile trajectory tracking for off-road driving: Controller design, experimental validation and racing. In Proceedings of the 2007 American Control Conference, New York, NY, USA, 9–13 July 2007; pp. 2296–2301. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. arXiv 2018, arXiv:1802.09477. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fehér, Á.; Aradi, S.; Bécsi, T. Hierarchical Evasive Path Planning Using Reinforcement Learning and Model Predictive Control. IEEE Access 2020, 8, 187470–187482. [Google Scholar] [CrossRef]
- Fehér, Á.; Aradi, S.; Hegedüs, F.; Bécsi, T.; Gáspár, P. Hybrid DDPG approach for vehicle motion planning. In Proceedings of the 16th International Conference on Informatics in Control, Automation and Robotics, ICINCO 2019, Prague, Czech Republic, 29–31 July 2019. [Google Scholar]
- Hasselt, H. Double Q-learning. Adv. Neural Inf. Process. Syst. 2010, 23, 2613–2621. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Soft-update parameter () | 0.005 |
| Batch size | 64 |
| Batch selection method | random choice |
| Warmup steps | 200 |
| Actor main, target networks | |
| Learning rate () | 0.001 |
| Hidden F.C. layer structure | [512, 512, 4] |
| Update steps | 2 |
| Critic main, target networks | |
| Learning rate () | 0.002 |
| Discount factor () | 0.99 |
| Hidden F.C. layer structure | [512, 512, 1] |
| Action and Target-action noise | |
| Mean () | 0.0 |
| Stddev () | 0.2 |
| Target action noise clip values | −0.5, 0.5 |
| Vehicle Speed (km/h) | Ped. Longitudinal Distace (m) | Ped. Velocity (km/h) | Ped. Moving Direction (°) | |
|---|---|---|---|---|
| 1 | 63.7 | 25.1 | 3.0 | 255.5 |
| 2 | 56.3 | 31.4 | 2.7 | 60.2 |
| 3 | 53.2 | 30.0 | 3.7 | 123.9 |
| 4 | 50.0 | 20.2 | 1.6 | 231.9 |
| 5 | 52.9 | 25.1 | 2.5 | 75.5 |
| 6 | 69.5 | 26.2 | 2.5 | 239.8 |
| 7 | 50.0 | 28.0 | 3.0 | 253.3 |
| 8 | 60.9 | 30.8 | 2.1 | 122.2 |
| 9 | 56.1 | 26.8 | 2.5 | 270.3 |
| 10 | 66.6 | 31.8 | 2.5 | 111.0 |
| Human Drivers | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | Sum | ||
| Scenarios | 1 | 1 | 5 | 3 | 3 | 1 | 3 | 0 | 4 | 3 | 1 | 4 | 28 |
| 2 | 1 | 4 | 2 | 3 | 2 | 3 | 3 | 4 | 4 | 1 | 5 | 32 | |
| 3 | 1 | 2 | 5 | 3 | 4 | 2 | 3 | 1 | 5 | 2 | 3 | 31 | |
| 4 | 2 | 5 | 3 | 5 | 4 | 5 | 5 | 5 | 5 | 4 | 5 | 48 | |
| 5 | 2 | 5 | 5 | 5 | 3 | 5 | 4 | 5 | 5 | 5 | 5 | 49 | |
| 6 | 2 | 5 | 2 | 4 | 1 | 4 | 2 | 2 | 3 | 3 | 4 | 32 | |
| 7 | 2 | 2 | 4 | 4 | 1 | 3 | 5 | 4 | 4 | 1 | 4 | 34 | |
| 8 | 2 | 5 | 3 | 4 | 3 | 4 | 5 | 5 | 3 | 2 | 5 | 41 | |
| 9 | 1 | 4 | 1 | 5 | 2 | 5 | 5 | 4 | 4 | 4 | 5 | 40 | |
| 10 | 0 | 4 | 3 | 2 | 1 | 4 | 3 | 2 | 2 | 1 | 4 | 26 | |
| Sum | 14 | 41 | 31 | 38 | 22 | 38 | 35 | 36 | 38 | 24 | 44 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fehér, Á.; Aradi, S.; Bécsi, T. Online Trajectory Planning with Reinforcement Learning for Pedestrian Avoidance. Electronics 2022, 11, 2346. https://doi.org/10.3390/electronics11152346
Fehér Á, Aradi S, Bécsi T. Online Trajectory Planning with Reinforcement Learning for Pedestrian Avoidance. Electronics. 2022; 11(15):2346. https://doi.org/10.3390/electronics11152346
Chicago/Turabian StyleFehér, Árpád, Szilárd Aradi, and Tamás Bécsi. 2022. "Online Trajectory Planning with Reinforcement Learning for Pedestrian Avoidance" Electronics 11, no. 15: 2346. https://doi.org/10.3390/electronics11152346
APA StyleFehér, Á., Aradi, S., & Bécsi, T. (2022). Online Trajectory Planning with Reinforcement Learning for Pedestrian Avoidance. Electronics, 11(15), 2346. https://doi.org/10.3390/electronics11152346