1. Introduction
In recent years, with the flourishing of low-cost sensors, such as Microsoft Kinect, Google Project Tango, and Intel RealSense, as well as high-speed computing systems, 3D data can be easily obtained, and the 3D computer vision area has been widely used in robots [
1], reverse engineering [
2], autopilot [
3] and biometric systems [
4,
5], and other fields. In these aforementioned 3D applications, the description of local features is a fundamental and crucial step. With the advancement of descriptors, a variety of techniques have been used to construct local feature descriptors, mainly based on manual design and deep learning. The research on methods based on deep learning is mainly focused on the representation of point cloud inputs, taking the local feature descriptor of point clouds as an input or regularizing direct point clouds, after which a network structure is designed for the inputs (i.e., ClusterNet [
6], SpinNet [
7], RPM-Net [
8], and PR-InvNet [
9]). Although it has developed rapidly, it is limited by the deficiency of large point cloud datasets for specific tasks, computer resources, which are very costly, and edge devices that still may not be equipped with GPUs. Therefore, in current practical applications, methods based on manual design still play an important role; they are mainly constructed through the statistics of spatial and geometric properties or the representation of the relationship between points. For details on the existing local feature descriptors, readers can refer to a recent survey [
10].
The research scope of this paper focuses on the local feature description of manual design. A local feature descriptor with good performance should have high descriptiveness and strong robustness, as well as efficient time performance [
11]. Descriptiveness represents a descriptor’s ability to distinguish between different surfaces, while robustness shows a descriptor’s ability to resist disturbances, including noise, varying resolutions, and occlusion; for the invariance of translation, scaling, and rotation, the time performance requires the computational efficiency of the descriptor [
12]. In the past two decades, many local feature descriptors have been designed, including FPFH [
13], SHOT [
14], and ROPS [
15]; the local frame and feature coding are the two main parts that determine their performance. The local frame is a local axis or coordinate system used to align with a local surface, enabling the rigid transformation invariance of local feature descriptors. Additionally, feature coding means converting the geometrical and spatial information of a local surface into a feature vector representation.
Local frames can be divided into a local reference frame (LRF) and a local reference axis (LRA). The LRF consists of three axes, while the LRA consists of the
z-axis. The repeatability of the
x-axis and
y-axis of the LRF is more easily affected by various disturbances (for example, noise, varying resolutions, and symmetric surfaces) than the
z-axis, and more time is required to construct it than is required for the LRA [
16]. The literature [
16] combines the method based on the LRA and the method based on the LRF with different coding methods, and performs a large number of comparative experiments to prove that the method based on the LRA, combined with radial information and elevation information, has stronger robustness against all kinds of interferences. For LRA-based descriptors, the repeatability of the LRA directly affects the performance of these descriptors. In order to achieve the high repeatability of local reference frames, many methods have been proposed to construct LRF/As; among these methods, the LRA usually uses covariance analysis techniques in its construction, which represent the LRA as a standardized eigenvector corresponding to the minimum eigenvalue of the covariance matrix [
17]. These methods have the problem of symbol ambiguity, for which Tombari et al. [
1] proposed a disambiguation technique. In addition, they introduced an LRA based on a linearly weighted covariance matrix, it is robust against noise but its vulnerability to varying data resolutions. Guo et al. [
15] proposed a new method to construct an LRA that needed to calculate the covariance matrix of each triangular mesh in the local neighborhood, so its efficiency was not high. Yang et al. [
17] used a subset of the radius neighborhood to construct a covariance matrix, which improved its robustness against occlusion, clutter, and mesh boundaries. Zhao et al. [
12] improved the LRA proposed by Yang, using a subset of radius neighborhoods to calculate directions and using all of the radius neighborhoods to eliminate symbolic ambiguity; although it reduces the robustness against grid boundaries, it improves the robustness against noise and varying resolutions. Therefore, the performance of the LRA calculated by different neighborhood scales was different, and the robustness against multiple disturbances cannot be obtained at the same time.
In a feature representation of a feature descriptor, the geometric information and spatial information of a local surface are usually encoded. Some existing descriptors only encode the geometric information of a local surface, and the angle of deviation between normals or LRAs and normals is an effective way to encode local geometric information; for example, Rusu et al. [
18] have proposed point characteristic histograms (PFHs) based on the relationship between points, their k-neighbors, and their estimated normals, which are relatively robust but computationally inefficient. In order to improve the efficiency, they simplified the features and constructed a fast point feature histogram (FPFH) [
13], which has a similar performance to the PFH and a higher efficiency, but only descriptors encoding geometric information usually show a poor performance in resisting noise, varying resolutions, etc. [
10]. In contrast, some descriptors encode only spatial information on a local surface. Johnson et al. proposed the spin image feature (SI) [
19], which uses normals as its LRA, after which each point within the support area is represented by two spatial distances, and, finally, the SI is generated by calculating the distribution of local points along both the spatial measures. The SI completely encodes local spatial information on an LRA but is sensitive to noise due to the low repeatability of its LRA [
10]. Tombari et al. [
20] proposed a unique shape context (USC) developed from a 3D shape context (3dsc) descriptor [
21]. The USC completely encodes the spatial information on the LRF by compartmentalizing it locally in a 3D spatial manner along the orientation, elevation, and radial directions, showing great robustness against noise, hetero waves, and occlusion, but showing sensitivity to variations in data resolution [
10]. There are also some descriptors that encode both geometric and spatial information, and Tombari et al. [
14] proposed an LRF-based direction histogram (SHOT) descriptor signature method, which is highly descriptive but very sensitive to variations in grid resolution. Some other local feature descriptors encode projection information based on different orientations of the LRF, which acquires redundant information (e.g., ROPS [
15] and TOLDI [
22]). Regardless of how to encode local information, due to the existence of symmetric objects or similar surfaces, encoding only local information will inevitably suffer from ambiguity, which in practical three-dimensional matching introduces a large number of false positives. Shah et al. [
23] proposed KSR encoded only between keypoints, independent of local surfaces, and realized three-dimensional modeling and recognition, demonstrating that information encoding between keypoints is also an effective way of expressing features, but is sensitive to occlusion comparisons with solely keypoint information.
For these concerns, we propose a novel local feature descriptor named deviation angle statistics of keypoints from local points and adjacent keypoints (DASKL). Specifically, we first calculated the LRA of different scales of keypoints and the normals of neighbor points; when calculating the LRA, we adopted a multiscale calculation strategy, and the appropriate LRA was selected according to the scale strategy in the matching stage, which made the LRA more robust against noise, varying resolutions, and boundary grids at the same time. When calculating the normals, Poisson-disk sampling was carried out on the local surfaces to remove redundant points and reduce the amount of calculation. Second, the geometric and spatial information of local spaces were encoded based on the LRA. Based on the local neighborhood of the keypoints subdivided by the LRA, the deviation angle between the normal of neighborhood points in each partition and the LRA was counted. The geometric information between keypoints was encoded; we calculated the distance between the keypoints of the local feature descriptor, obtained the two nearest neighbor keypoints of each keypoint, and then counted the deviation angle of the LRA between the keypoints. Finally, the statistical coding information was connected in the form of a histogram to generate the DASKL descriptor. The main contributions of this paper are summarized as follows:
- (1)
By encoding geometric information in subdivision spaces and combining the geometric information of keypoints and the last three keypoints, we propose the DASKL descriptor, which is highly descriptive and robust against occlusion, noise, and varying resolutions.
- (2)
The DASKL descriptor fully encodes the spatial and geometric information of local surfaces in addition to combining the geometric information of keypoints and adjacent keypoints, which improves the ability of the local feature descriptor to distinguish between similar surfaces.
The rest of this paper is organized as follows:
Section 2 describes the process of generating the DASKL descriptor in detail.
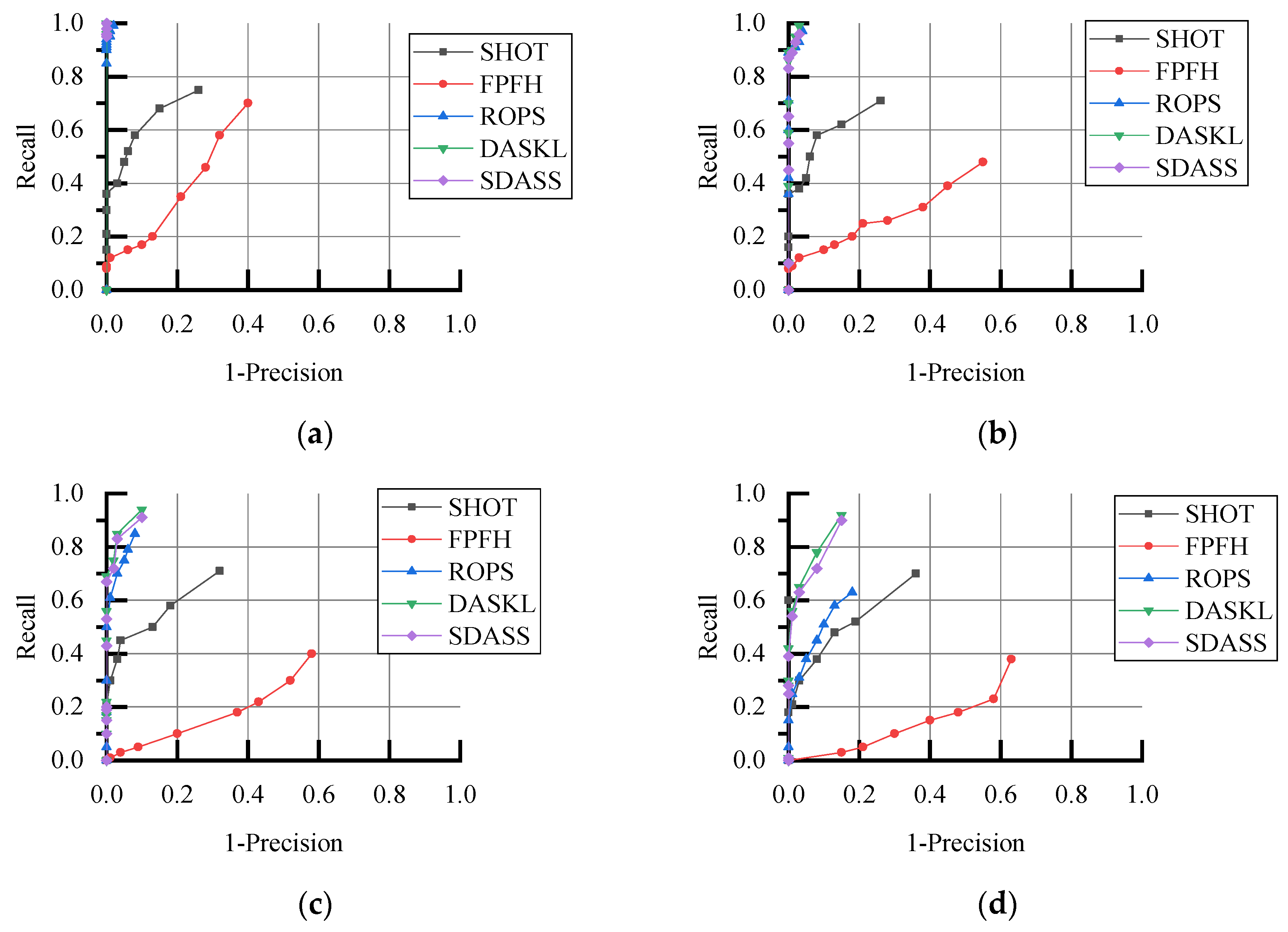
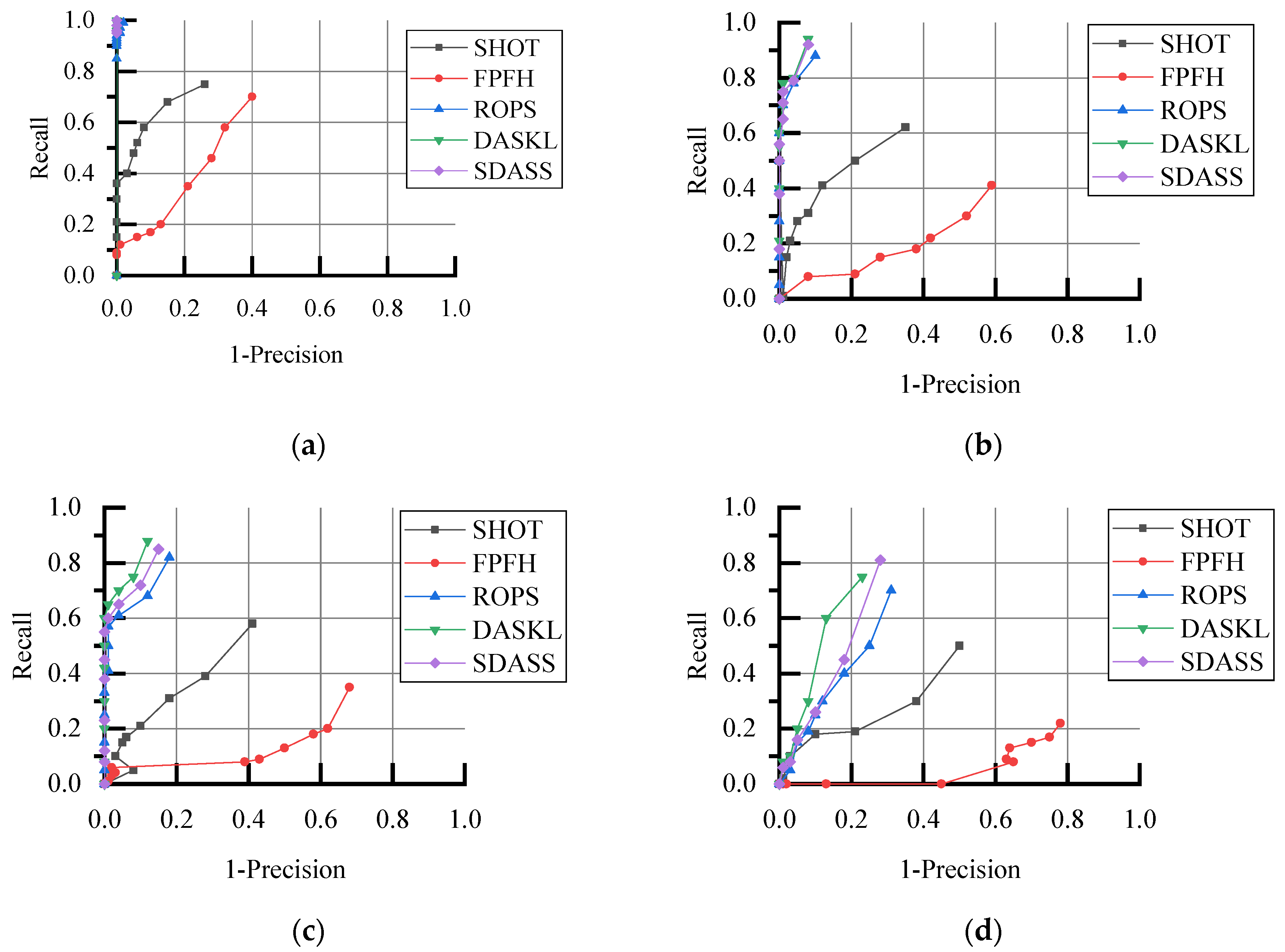
Section 3 presents the evaluation results of our approach for two public datasets and a LIDAR real-scene dataset. Finally, conclusions and future work are provided in
Section 4.
2. DASKL Local Feature Description
This section introduces some techniques involved in the DASKL descriptor in detail, including the construction of the LRA, the calculation of the normals, the coding between the keypoints and nearest neighbor keypoints, and the coding of the keypoints and local points, that is, to represent DASKL features by encoding the combination of the spatial and geometric information on the surface of an object.
2.1. Constructing the LRA
Our method chooses the LRA as the basis for space division at keypoints. Given a keypoint, p, and a support radius, R, all of the points in the radius range of the sphere are defined as neighborhood points of p points. These neighborhood points form a local surface:.
First, a subset of
Q is defined as
; to calculate the direction of the
z-axis, the covariance matrix
, based on
, is defined as:
where
n is the size of
,
is the center of gravity of
, and the eigenvector,
, corresponding to the smallest eigenvalue of
, is set to the
z-axis. However, the direction of the eigenvector is random. In order to eliminate the ambiguity of
, the LRA is generated by using the computational domain
:
where
n is the number of points in the computing field,
is the vector from
to
, and the “·” between the vectors represents the dot product. The scope of the subset of
is defined as the computing domain
is a scale factor for adjusting the size of the computing domain. It is proven in [
22] that the computational domain,
, used to estimate the
z-axis is smaller than the supporting radius,
R, which can improve the robustness of the LRA against clutter and occlusion, but it performs poorly in downsampled data. In [
12], all of the radius neighborhoods are used to determine the direction of the LRA, and high robustness of varying data resolutions against noise and variation is obtained, but it is less robust against grid boundaries. Therefore, the selection of different scales affects the performance of the LRA. How to determine the appropriate calculation radius is a challenging task.
For the neighborhood subsets of the same scale of different data, the number of neighborhood points involved in calculating the
z-axis is also different; for example, when LIDAR collects scenes’ data with long distances, the point clouds obtained are relatively sparse, that is, within the same radius the number of points in the scene is much smaller than that of the model, which is essentially related to the average data resolution of the point clouds. This is also reflected in the calculation of the LRF in [
14,
18]. The scene is consistent with the radius of the
z-axis calculated by the model. On this basis, the scale factor, λ, is introduced to adjust the model and scene to improve the robustness against varying resolutions [
24]:
m.mr and
s.mr are the average data resolutions of the model and the scene, respectively, and
c is constant. Based on the experience of previous methods, we think that when the average resolution of the scene and the model is about the same, λ takes 3 as the best parameter, and R is the upper limit of the threshold. It should be emphasized that when the model descriptor is generated in the offline phase, the scene resolution is unknown. Therefore, the indexing strategy proposed in reference [
24] is introduced to calculate the model descriptor of multiscale λ, and the model descriptor closest to λ, calculated by Formula (4), is selected in matching; thus, a nonfuzzy local reference frame LRA that is robust against scene interference is obtained.
2.2. Normal Calculation
At present, the common method of generating normals is to use principal component analysis (PCA) on the covariance matrix to calculate the normal of each point. The principal component analysis is based on the k-nearest neighbors of each point to create the covariance matrix. However, the normal direction calculated by PCA is not clear and is time-consuming. The local corresponding method in [
25,
26] is used to reorient the normal of each surface, such that the point is consistent with the direction of most normals in its radius neighborhood. For each point, pairi, and its original normal, nimi, as well as the k-nearest neighbors,
, calculate c_(pometi), that is, the centroid of the pairi neighborhood, as follows:
Next, define the normal after the ambiguity is eliminated:
Using the above method, it is not possible to uniformly orient normals across the entire object, but this does not affect performance because it ensures that the normal directions of the corresponding points in the model and the scene are consistent, which improves the robustness of normal-based descriptors.
The adjacent points on the local surface have similar characteristics, which leads to a certain degree of information redundancy; therefore, as shown in [
26,
27], the Poisson-disk sampling algorithm is used to sample the model to retain the necessary description information and simplify the model.
2.3. Descriptor Generation
After constructing the LRA and normals, the spatial and geometric information are encoded on the local surface, and the geometric information of the keypoints and the three nearest keypoints are counted. In general, the spatial information of the local surface can be fully encoded on the LRA in two ways. It is verified by different spatial information methods in reference [
1] that using projection radial distance and height distance to comprehensively encode the local spatial information of the LRA has the best performance. As shown in
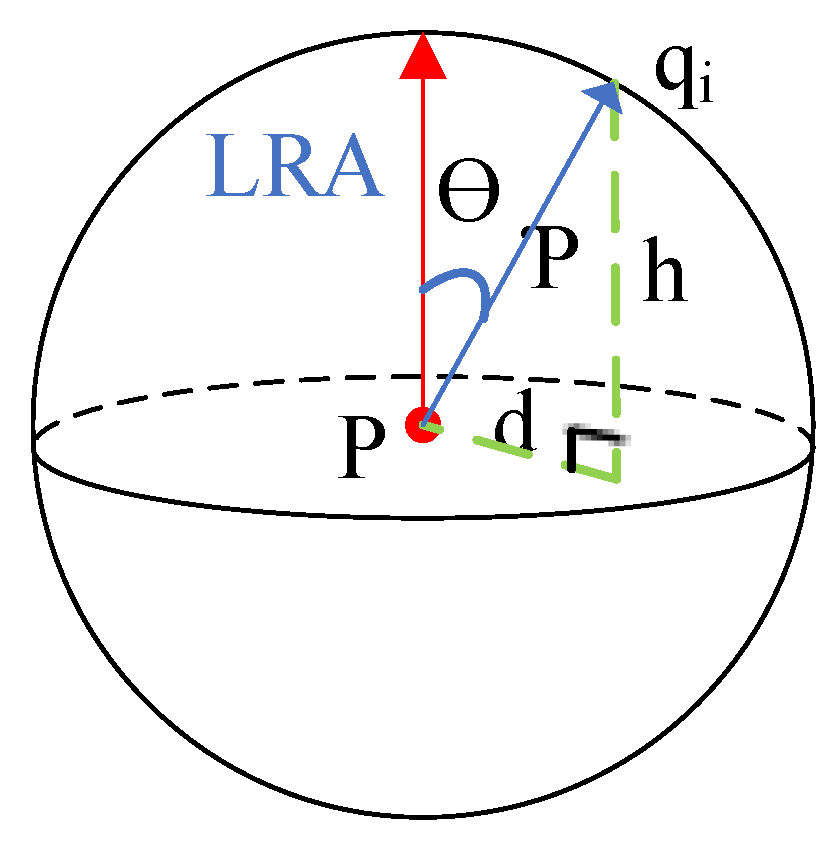
Figure 1, one method uses radial distance (ρ) and elevation (θ), and the other uses height distance (h) and projection radial distance (d). In this paper, projection radial distance and height distance are used to comprehensively encode the local spatial information of the LRA.
The local surface is determined by the feature point, p, and the support radius, R, and the local point cloud is defined as
, as shown in
Figure 2a. First, Q is transformed so that p coincides with the coordinate origin, and the LRA of the feature point is aligned with the
z-axis, as shown in
Figure 2b. Then, as shown in
Figure 2c, the spatial information of the transformed local space is encoded. The spatial information coding method is to segment the local space along the LRA and the projection radial direction;
and
are the number of partitions along the LRA and the projection radial direction, respectively, and
is the number of partitions used to count the deviation angle. The division ranges of the LRA and projection radial direction are [0, 2r] and [0, r], respectively. After the partition of the local space is completed, the geometric information is encoded into each partition, as shown in
Figure 2d.
In each partition, the geometric information is encoded using the statistics of the deviation angle between the feature point LRA and the normal of the adjacent points. The deviation angle between the normal and the LRA is calculated as follows:
where LRA(p) represents the LRA;
at the feature point, p, represents the normal at the local point,
;
represents the declination between the LRA (p) and n; and the range of
is [0,
]. Encode the geometric information into a partition to generate a subhistogram of the statistical offset angle in that partition, called
. As shown in
Figure 2e, after generating the subhistograms of all of the partitions, join all of the subhistograms into a single representation as
; the length of H is
.
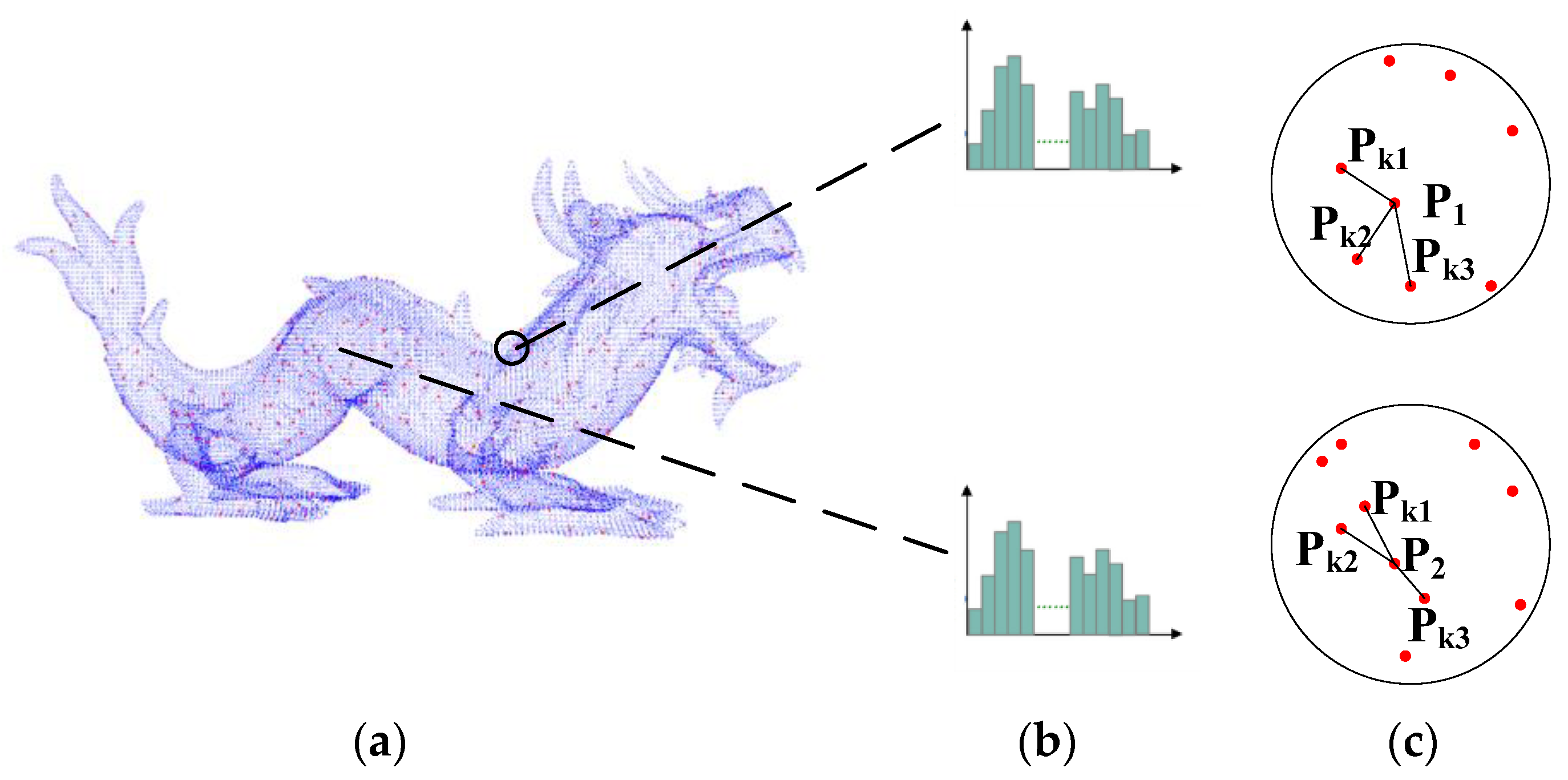
After coding the local surface of the feature points, as shown in (f) in
Figure 2, the geometric information of p and the three nearest keypoints is counted. This step can be synchronized with the local features framed by dotted lines in
Figure 2 to reduce the time overhead. Specifically, for the information coding between the keypoints, as shown in
Figure 3a, the local surface information of the model “dragon” is taken as an example. First of all, if we only calculate the local surface features of the model “dragon”, we will obtain several similar descriptors, such as
Figure 3b, which will lead to mismatching. However, as shown in
Figure 3c for the surface similar keypoints,
and
, the adjacent keypoints are
, n = 1, 2, 3;
and
are different from the recent three keypoints, which increases the differentiation of their similar surfaces.
The following equation is used to calculate the distance between keypoints and other keypoints:
In order to improve the search efficiency, this paper sets the search radius, , retrieves the nearest keypoints in the spherical domain within the search radius, and gradually expands the range of until the three nearest keypoints, , , and , are found.
After the three nearest keypoints are obtained, in order to further strengthen the differentiation between the keypoints, the deviation angle between the LRA at the keypoints is calculated to represent the geometric relationship between the keypoints. For a given feature point, (
), the angle of deviation between its LRA is:
where
indicates the deviation angle between the keypoints, and the range of the deviation angle is [0, π]. Finally, the information between the above keypoints is counted as a histogram, which is called
, and the dimension is
. The final length of the entire descriptor is
+
; in order to achieve robustness against point cloud resolution, the whole descriptor is normalized to 1.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
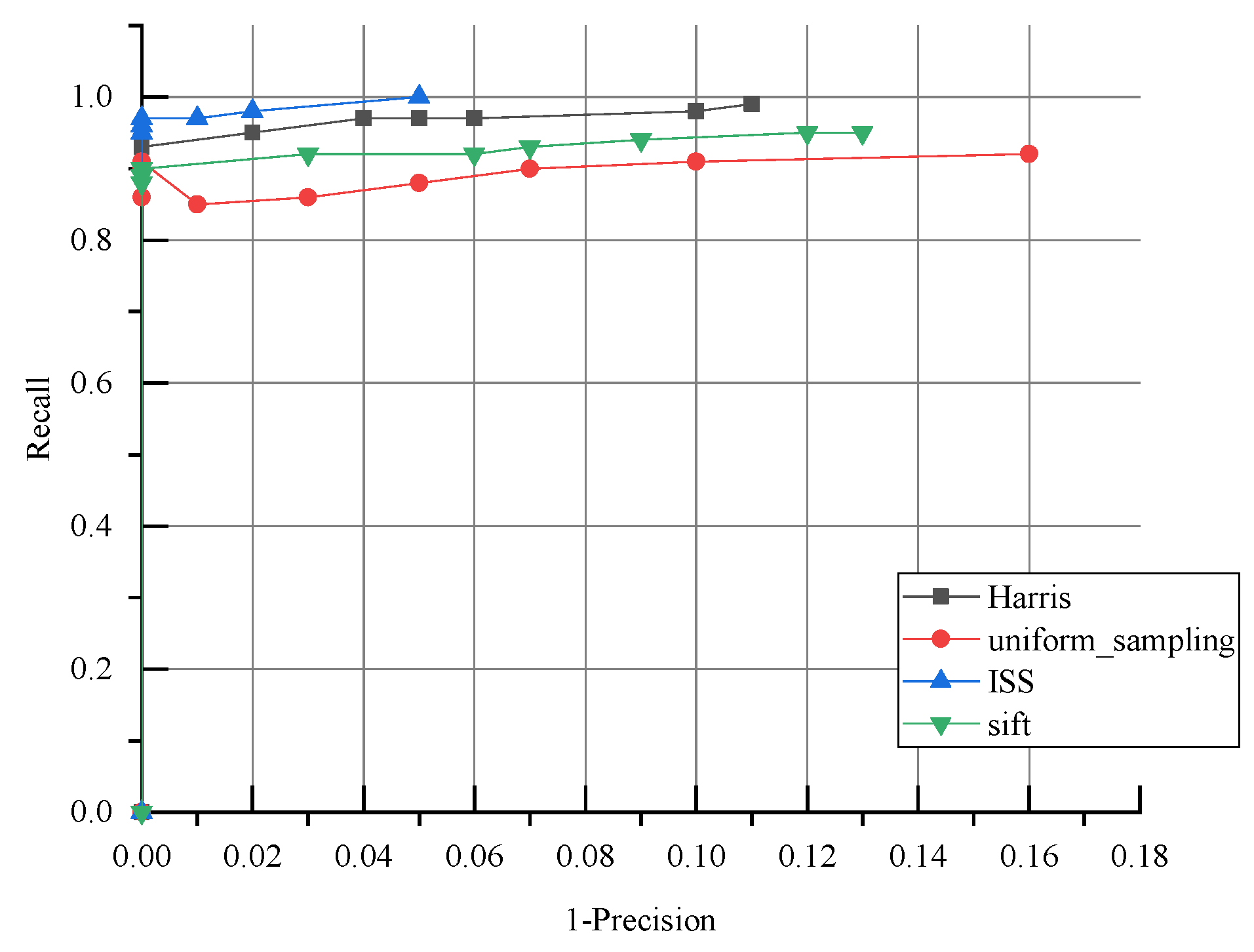{kind=link}
{kind=link}