
Data Enhancement of Underwater High-Speed Vehicle Echo Signals Based on Improved Generative Adversarial Networks

 ,
, 
Abstract
:1. Introduction
2. Background
2.1. Traditional Underwater Target Recognition
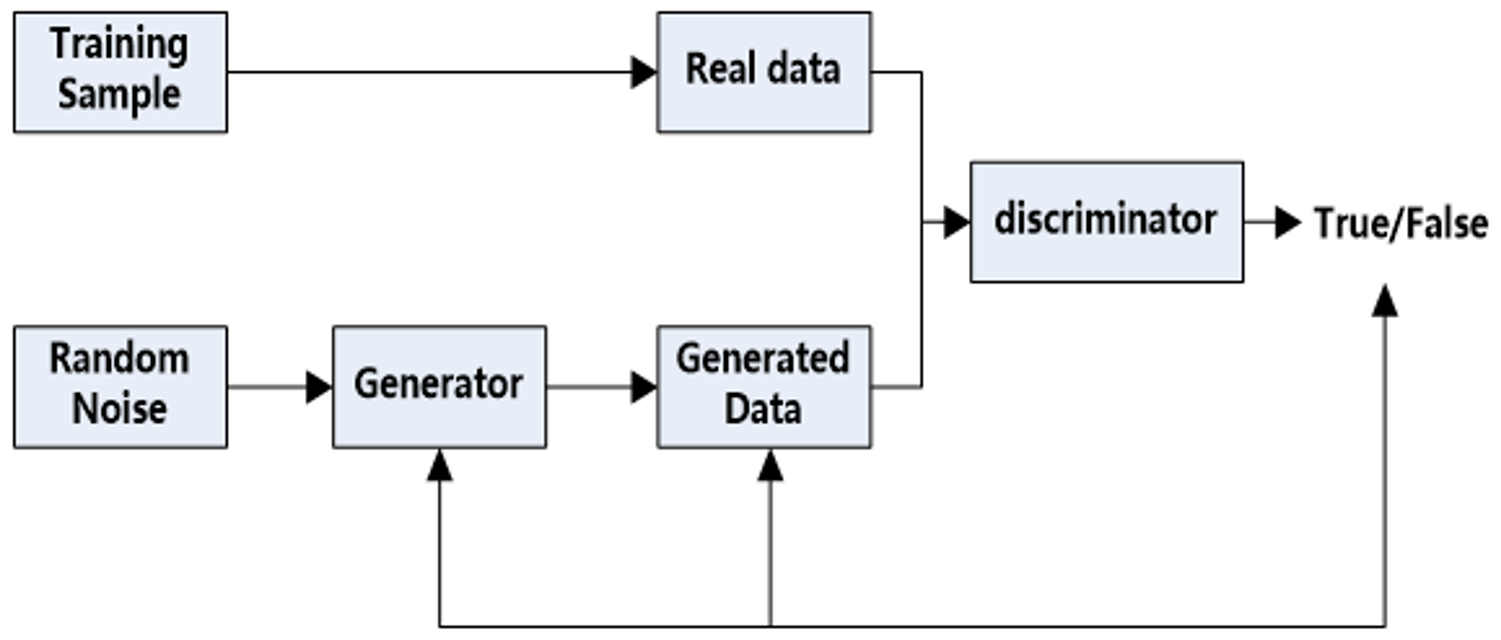
2.2. Generative Adversarial Network
2.2.1. Network Structure
2.2.2. Network Principle
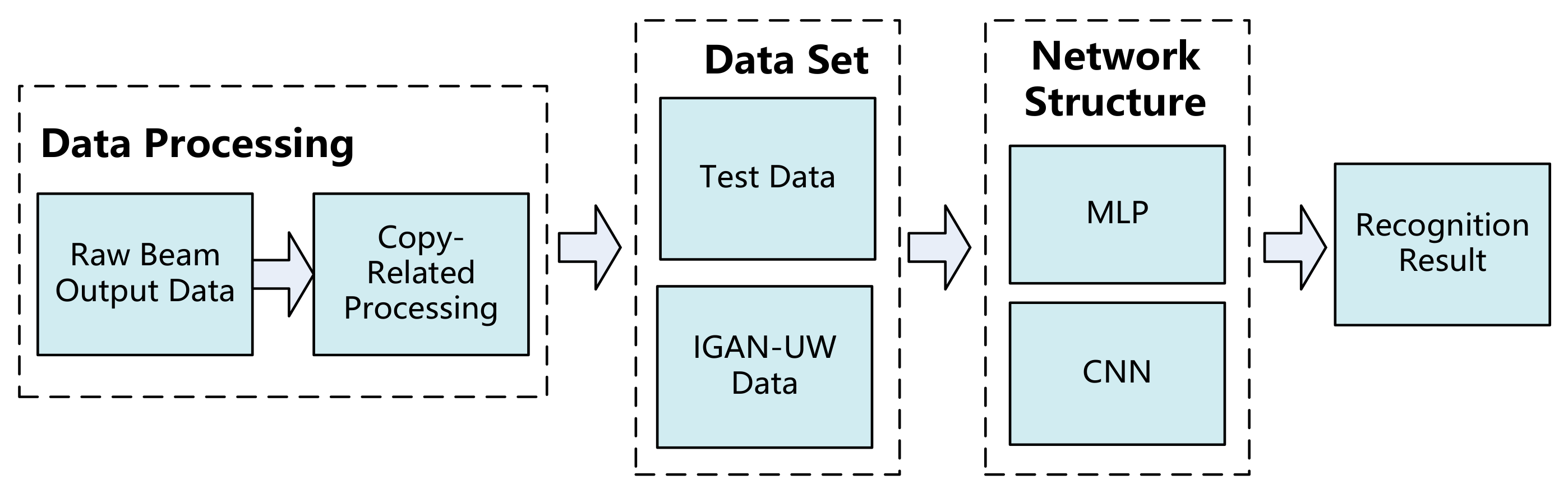
3. Methodology
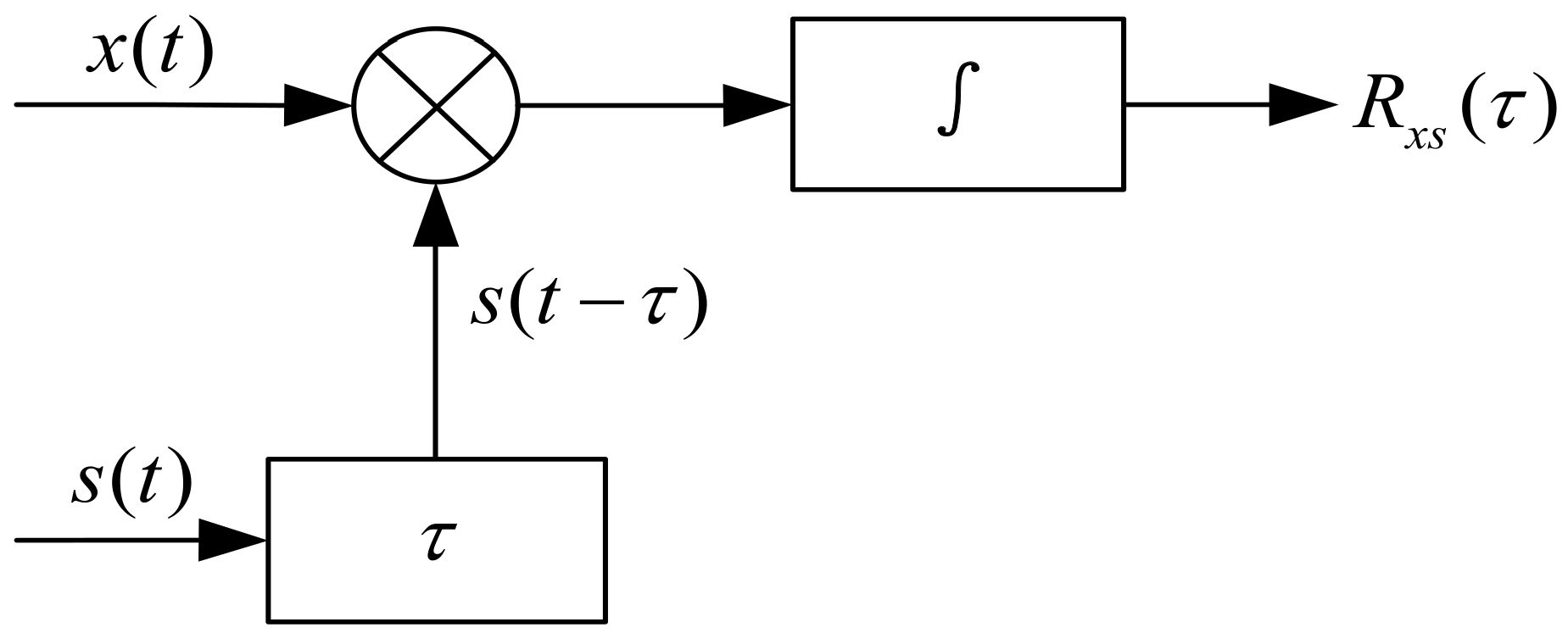
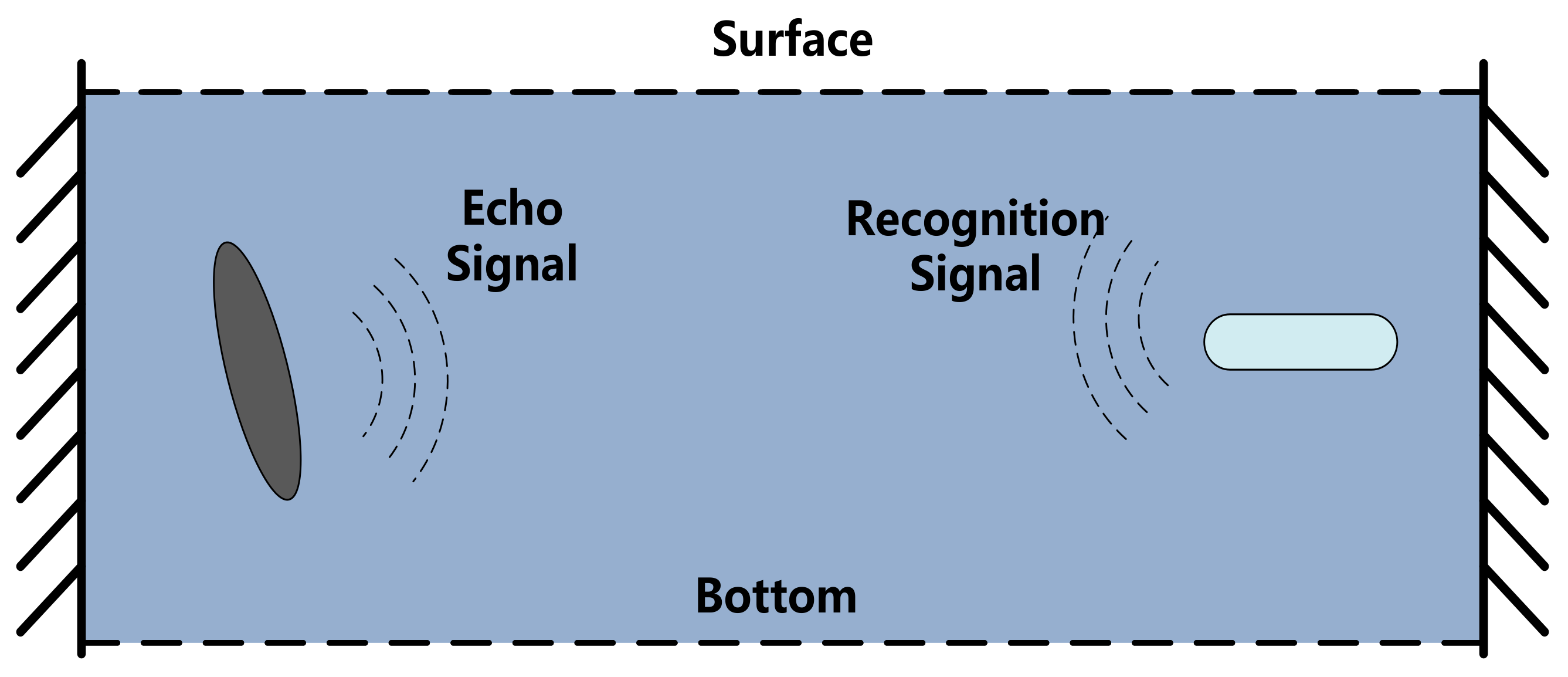
3.1. Underwater Target Water Wave Data Processing
3.2. Framework of Underwater Target Recognition Based on the GAN
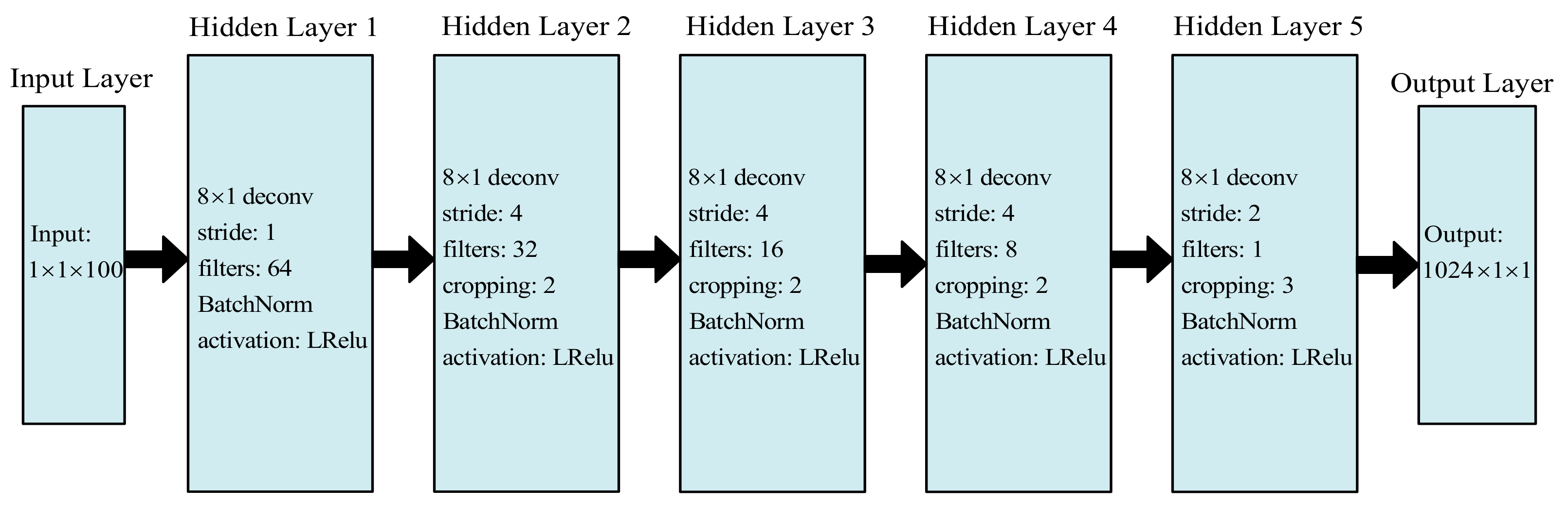
3.3. IGAN-UW for Underwater Target Recognition
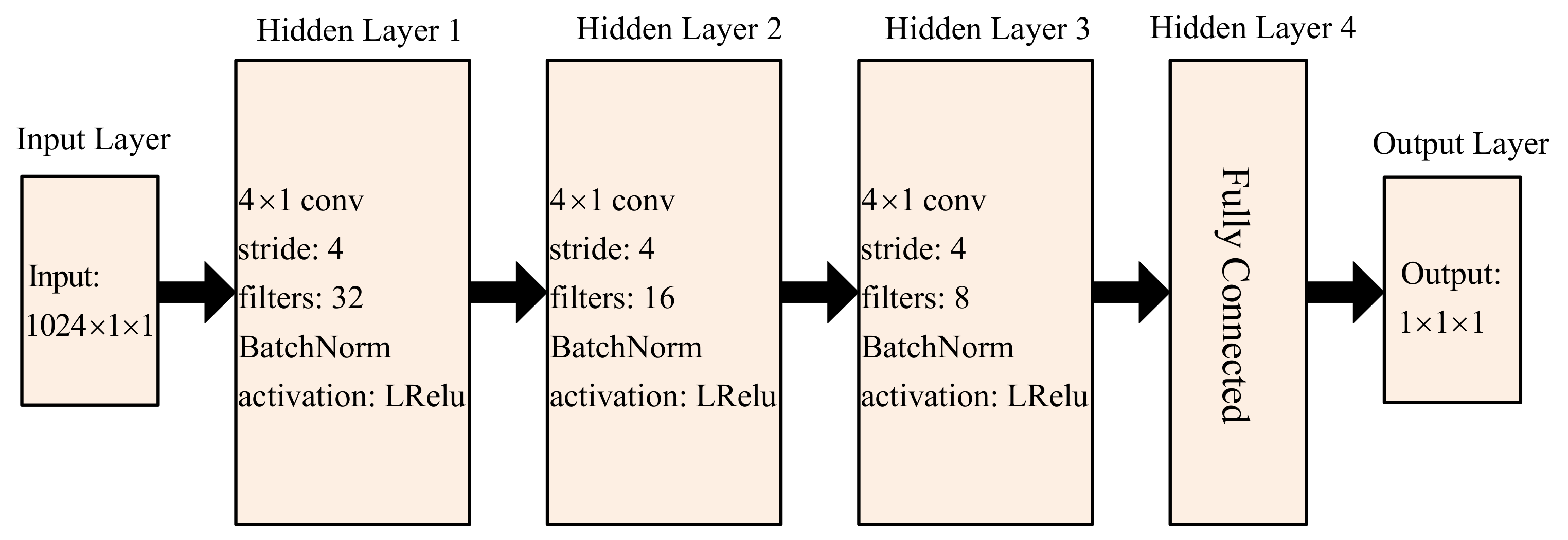
3.3.1. Structural Design of the Network
3.3.2. Training Process
- Train the generated network. A generated network (generator) tries its best to generate false pictures that are approximately true from random noise. As illustrated in Figure 8, the discriminant network’s parameter training process is frozen, and only the generated network is updated (a). The generated network’s input is random noise, and its label is true (1). The output is either true or false information (0/1); to be more specific, the generator generates a false signal, sends it to the discriminator, and trains the generator according to the determination result (note that the parameters of the discriminator should not be updated at this time);
- Train the discriminant network. A discriminant network (decision maker) tries its best to distinguish between real pictures and false signals (signals generated by the generator). The parameters of the generated network are frozen, and only the discriminant network’s parameter training process is updated, as illustrated in Figure 8b. A discriminant network has two types of input. One is the signal generated by random noise passing through the generated network, and its associated label is false (0). One is a real signal, and the label to which it corresponds is real (1). The output is either true or false information (0/1). To be more specific: first, send a real signal to the discriminator, mark the sample as true, and train the discriminator; second, the generator generates a false signal, sends it to the discriminator, marks the sample as false, and trains the discriminator;
- Repeat steps 1 and 2 in sequence until convergence occurs. The generated signal becomes increasingly close to the real signal through continuous confrontation between the generated network and the discriminant network.
- (1)
- Randomly sample the noise data distribution, input the generation model, and obtain a set of false data, which is recorded as D(z);
- (2)
- Randomly sample the distribution of real data as real data and record it as X;
- (3)
- Take the data generated in one of the first two steps as the input of the discrimination network (so the input of the discrimination model is two types of data: true/false), and the output value of the discrimination network is the probability that the input belongs to the real data. Real is 1, and fake is 0;
- (4)
- Then, calculate the loss function according to the obtained probability value;
- (5)
- According to the loss function of the discriminant model and the generated model, the parameters of the model can be updated by using the back propagation algorithm. (First, update the parameters of the discrimination model, and then update the parameters of the generator through the noise data obtained by resampling).
4. Experimental Verification and Result Analysis
4.1. Experimental Data
4.2. IGAN-UW Experimental Verification and Analysis
4.3. Recognition of Experimental Verification and Analysis Based on a CNN Model
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, L.; Zheng, M.; Duan, S.; Luo, W.; Yao, L. Underwater Target Recognition Based on Improved YOLOv4 Neural Network. Electronics 2021, 10, 1634. [Google Scholar] [CrossRef]
- Kamal, S.; Mohammed, S.K.; Pillai, P.R.S.; Supriya, M.H. Deep learning architectures for underwater target recognition. Ocean. Electron. 2013, 48–54. [Google Scholar]
- Jiang, X.-D.; Yang, D.-S.; Shi, S.-G.; Li, S.-C. The research on high speed underwater target recognition based on fuzzy logic inference. J. Mar. Sci. Appl. 2006, 5, 19–23. [Google Scholar] [CrossRef]
- Jiang, J.; Wu, Z.; Lu, J.; Huang, M.; Xiao, Z. Interpretable features for underwater acoustic target recognition. Measurement 2021, 173, 108586. [Google Scholar] [CrossRef]
- Liu, J.; Gong, S.; Guan, W.; Li, B.; Li, H.; Liu, J. Tracking and Localization based on Multi-angle Vision for Underwater Target. Electronics 2020, 9, 1871. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Teng, B.; Zhao, H. Underwater target recognition methods based on the framework of deep learning: A survey. Int. J. Adv. Robot. Syst. 2020, 17. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Li, J.; Zhao, Y.; Gong, M.; Zhang, Y.; Liu, T. Cost-Sensitive Self-Paced Learning with Adaptive Regularization for Classification of Image Time Series. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11713–11727. [Google Scholar] [CrossRef]
- Rahmani, M.H.; Almasganj, F.; Seyyedsalehi, S.A. Audio-visual feature fusion via deep neural networks for automatic speech recognition. Digit. Signal Process. 2018, 82, 54–63. [Google Scholar] [CrossRef]
- McLaren, M.; Lei, Y.; Scheffer, N.; Ferrer, L. Application of convolutional neural networks to speaker recognition in noisy conditions. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Zhang, Z.; Geiger, J.; Pohjalainen, J.; Mousa, A.E.; Jin, W.; Schuller, B. Deep learning for environmentally robust speech recognition: An overview of recent developments. ACM Trans. Intell. Syst. Technol. (TIST) 2018, 9, 1–28. [Google Scholar] [CrossRef]
- Zhang, Y.; Marshall, I.; Wallace, B.C. Rationale-augmented convolutional neural networks for text classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 16–20 November 2016; p. 795. [Google Scholar]
- Mirończuk, M.M.; Protasiewicz, J. A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 2018, 106, 36–54. [Google Scholar] [CrossRef]
- Li, H.; Gong, M.; Wang, C.; Miao, Q. Self-paced stacked denoising autoencoders based on differential evolution for change detection. Appl. Soft Comput. 2018, 71, 698–714. [Google Scholar] [CrossRef]
- Li, H.; Gong, M.; Zhang, M.; Wu, Y. Spatially self-paced convolutional networks for change detection in heterogeneous images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4966–4979. [Google Scholar] [CrossRef]
- Xu, J.; Bi, P.; Du, X.; Li, J.; Chen, N. Generalized robust PCA: A new distance metric method for underwater target recognition. IEEE Access 2019, 7, 51952–51964. [Google Scholar] [CrossRef]
- Zhang, Q.; Da, L.; Zhang, Y.; Hu, Y. Integrated Neural Networks based on Feature Fusion for Underwater Target Recognition. Appl. Acoust. 2021, 182, 108261. [Google Scholar] [CrossRef]
- Wang, X.; Wang, G.; Wu, Y. An adaptive particle swarm optimization for underwater target tracking in forward looking sonar image sequences. IEEE Access 2018, 6, 46833–46843. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, X.; Yu, Y.; Niu, L. Deep learning-based recognition of underwater target. In Proceedings of the IEEE International Conference on Digital Signal Processing (DSP), Beijing, China, 16–18 October 2016; pp. 89–93. [Google Scholar]
- Wang, J.; Chen, Y.; Gu, Y.; Xiao, Y.; Pan, H. SensoryGANs: An effective generative adversarial framework for sensor-based human activity recognition. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Suh, S.; Lee, H.; Lukowicz, P.; Lee, Y.O. CEGAN: Classification Enhancement Generative Adversarial Networks for unraveling data imbalance problems. Neural Netw. 2021, 133, 69–86. [Google Scholar] [CrossRef]
- Latifi, S.; Torres-Reyes, N. Audio enhancement and synthesis using generative adversarial networks: A survey. Int. J. Comput. Appl. 2019, 182, 27. [Google Scholar]
- Fu, S.W.; Liao, C.F.; Tsao, Y.; Lin, S. Metricgan: Generative adversarial networks based black-box metric scores optimization for speech enhancement. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 2031–2041. [Google Scholar]
- Kataoka, Y.; Matsubara, T.; Uehara, K. Image generation using generative adversarial networks and attention mechanism. In Proceedings of the IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar]
- Singh, N.K.; Raza, K. Medical image generation using generative adversarial networks: A review. Health Inform. A Comput. Perspect. Healthc. 2021, 77–96. [Google Scholar]
- Mao, X.; Wang, S.; Zheng, L.; Huang, Q. Semantic invariant cross-domain image generation with generative adversarial networks. Neurocomputing 2018, 293, 55–63. [Google Scholar] [CrossRef]
- Pascual, S.; Bonafonte, A.; Serra, J. SEGAN: Speech enhancement generative adversarial network. arXiv 2017, arXiv:1703.09452. [Google Scholar]
- Li, H.; Gong, M. Self-paced Convolutional Neural Networks. In Proceedings of the IJCAI, Melbourne, VIC, Australia, 19–25 August 2017; pp. 2110–2116. [Google Scholar]
- Yang, H.; Li, J.; Shen, S.; Xu, G. A deep convolutional neural network inspired by auditory perception for underwater acoustic target recognition. Sensors 2019, 19, 1104. [Google Scholar] [CrossRef] [Green Version]
- Cao, X.; Togneri, R.; Zhang, X.; Yang, Y. Convolutional neural network with second-order pooling for underwater target classification. IEEE Sens. J. 2018, 19, 3058–3066. [Google Scholar] [CrossRef]
- Hu, G.; Wang, K.; Liu, L. Underwater Acoustic Target Recognition Based on Depthwise Separable Convolution Neural Networks. Sensors 2021, 21, 1429. [Google Scholar] [CrossRef]
- Wang, K.F.; Gou, C.; Duan, Y.J.; Yilun, L.; Zheng, X.-H.; Wang, F.-Y. Generative adversarial networks: The state of the art and beyond. Acta Autom. Sin. 2017, 43, 321–332. [Google Scholar]
- Zhang, C.; Liang, M.; Song, X.; Liu, L.; Wang, H.; Li, W.; Shi, M. Generative adversarial network for geological prediction based on TBM operational data. Mech. Syst. Signal Processing 2022, 162, 108035. [Google Scholar] [CrossRef]
- Song, S.; Mukerji, T.; Hou, J. Geological facies modeling based on progressive growing of generative adversarial networks (GANs). Comput. Geosci. 2021, 25, 1251–1273. [Google Scholar] [CrossRef]
- Hershey, J.R.; Olsen, P.A. Approximating the Kullback Leibler divergence between Gaussian mixture models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV−317–IV−320. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Neural Information Processing Systems; MIT Press: Boston, MA, USA, 2014. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Feature Map | Kernels | Steps | Pooling Strategy |
|---|---|---|---|---|---|
| 1 | Input Layer | 1 | ~ | ~ | ~ |
| 2 | Convolution Layer | 32 | 12 × 1 | 3 | ~ |
| 3 | Pooling Layer | 32 | 4 × 1 | 4 | Ave |
| 4 | Convolution Layer | 64 | 12 × 1 | 1 | ~ |
| 5 | Pooling Layer | 64 | 4 × 1 | 4 | Ave |
| 6 | Convolution Layer | 128 | 12 × 1 | 1 | ~ |
| 7 | Fulling Connection Layer | 32 | 1 × 1 | 1 | ~ |
| 8 | Softmax | 3 | 1 × 1 | 1 | ~ |
| Optimizer | Adam |
|---|---|
| L2 Punish Coefficient | 0.001 |
| Batch Size | 4 |
| Leaky ReLU Slope Coefficient | 0.2 |
| Generative Network Learning Rate | 0.0003 |
| Discriminative Network Learning Rate | 0.0001 |
| Feature Type | Body Target | Point Target | Line Target | Average Recognition Rate |
|---|---|---|---|---|
| Copy-Related Samples | 87.8% | 61.3% | 94.8% | 81.3% |
| Model Type | Input Data | Body Target | Point Target | Line Target | Average Recognition Rate |
|---|---|---|---|---|---|
| MLP | Before | 85.1% | 67.4% | 89.8% | 80.7% |
| After | 91.8% | 88.3% | 90.1% | 90.1% | |
| CNN | Before | 87.8% | 61.3% | 94.8% | 81.3% |
| After | 91.8% | 96.8% | 94.8% | 94.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Liu, L.; Wang, C.; Deng, J.; Zhang, K.; Yang, Y.; Zhou, J. Data Enhancement of Underwater High-Speed Vehicle Echo Signals Based on Improved Generative Adversarial Networks. Electronics 2022, 11, 2310. https://doi.org/10.3390/electronics11152310
Wang Z, Liu L, Wang C, Deng J, Zhang K, Yang Y, Zhou J. Data Enhancement of Underwater High-Speed Vehicle Echo Signals Based on Improved Generative Adversarial Networks. Electronics. 2022; 11(15):2310. https://doi.org/10.3390/electronics11152310
Chicago/Turabian StyleWang, Zhong, Liwen Liu, Chenyu Wang, Jianjing Deng, Kui Zhang, Yunchuan Yang, and Jianbo Zhou. 2022. "Data Enhancement of Underwater High-Speed Vehicle Echo Signals Based on Improved Generative Adversarial Networks" Electronics 11, no. 15: 2310. https://doi.org/10.3390/electronics11152310
APA StyleWang, Z., Liu, L., Wang, C., Deng, J., Zhang, K., Yang, Y., & Zhou, J. (2022). Data Enhancement of Underwater High-Speed Vehicle Echo Signals Based on Improved Generative Adversarial Networks. Electronics, 11(15), 2310. https://doi.org/10.3390/electronics11152310