1. Introduction
Modern power systems have become more complex, while suffering from various uncertainties attributed to the high penetration of distributed renewable energy resources [
1]. It is essential to ensure reliable power-system and market operation by accurately forecasting techniques [
2]. Load forecasting is one of the most effective methods to fight against uncertainty in modern power-system operation and management [
3] and plays an important role in economic dispatch, demand response and power market transactions [
4]. Traditionally, utility companies focus on the system level or the aggregation level in load forecasting [
5]. This aggregated load forecasting is used to arrange the daily startup/shutdown plans of centralized power generation [
6].
Nowadays, load forecasting for an individual residential customer has become increasingly important in smart-grid planning and operation [
7]. To better use renewable energy, load forecasting for residential customers can help energy storage systems to make the best decisions on charging/discharging operation. A home energy-management system can improve energy efficiency by shifting the flexible load such as air-conditioner systems and balancing demand with the fluctuating supply of renewable energy. Furthermore, residential load forecasting can support utilities to develop more reasonable demand-response strategies, and reduce grid operating costs [
8]. With the volatility in distributed energy and load in households, it is quite challenging to precisely predict an individual load, which hinders the applications of residential load forecasting, i.e., peer-to-peer energy trading [
9].
The availability of smart meters that provide fine-grained data facilitates residential load forecasting [
10]. Many open data sources have also promoted this research. Compared with the aggregated load, the electric load of a individual household not only depends on external environmental factors such as weather and special events [
11], but is also highly related to the lifestyle and consumption patterns of residents [
12]. The load curve of an individual household will inevitably show greater volatility [
13]. In addition, due to the sparse deployment of data collection sensors and inevitable errors, collected data may often be approximate or inaccurate. At the same time, load series often have long-term dependence, such as weekly or daily seasonal patterns. There are complex or even uncertain nonlinear relationships between internal or external factors and future load demand. It is difficult to accurately capture these relationships in a model for prediction.
As the amount and dimensions of smart-grid data increase, the performance of traditional machine-learning methods is becoming worse [
3]. Traditional machine-learning methods find it difficult to obtain good accuracy in residential load forecasting, where most of these methods use pre-defined nonlinear forms and may not be able to accurately capture nonlinear relationships [
14]. Recently, deep neural networks (DNN) have been increasingly used for residential load forecasting. Shi et al. [
15] proposed an LSTM neural network based on pooling for residential load forecasting. They studied a 920-customer case in Ireland and proved that the recurrent neural network(RNN)-based forecasting method is better than the benchmark method, including autoregressive integrated moving average (ARIMA) model and support vector regression (SVR). Kong et al. [
3] also proposed a deep-learning prediction framework based on LSTM to predict single-step household load. Wang et al. [
16] proposed a gated recurrent unit (GRU) model to predict the residential load of the next day. Wang et al. [
5] took residential and small-and-medium-enterprise customers as the research object and proposed a probabilistic individual load forecasting model based on the pinball loss function and LSTM, aiming to quantify the uncertainty of individual user load. Yang et al. [
17] proposed a probabilistic-load forecasting framework based on deep ensemble learning, which uses customer classification and multi-task representation learning to improve the quantitative performance of the uncertainty of an individual load. The above results show that the use of deep-learning technology can provide better performance on this issue. In particular, RNNs specifically designed for sequence modeling have powerful performance improvements on this issue.
A key factor for a successful deep neural network is its capability of highly nonlinear approximation with multiple layers [
18]. However, this makes it difficult to explain how the model reaches its expressive performance. If a forecasting model cannot provide an explanation understandable by humans, it will be difficult for end users to trust the prediction result, which creates an obstacle for load shifting. Therefore, in order to make the residential load-forecasting model based on deep learning trustworthy, it is critical to develop a new technique for explanations that are understandable by humans.
Currently, an attention mechanism [
19] is often used to explain predictions for various temporal prediction tasks. The naive attention mechanism only has a certain degree of interpretability [
20]. When the attention layer is used for each time step, the attention scores can be interpreted as the importance of different time steps. Ma et al. [
21] proposed a vessel collision risk early-warning model based on an attention mechanism and bidirectional LSTM. The attention mechanism was used to quantify the impact of motor behavioral characteristics at a certain time step, on future risk. When the attention layer is used for each variable, the attention scores can be interpreted as the importance of different features. Liao et al. [
22] proposed a graph neural network model combining multimodal information for taxi demand prediction. An attention mechanism is used to model the correlation between multimodal features (weather, events or text, etc.) and taxi demand. However, time-series prediction contains many different types of input features at each time step. Single attention mechanism does not allow us to understand the importance of each feature at each time step, and cannot distinguish the contribution of a single variable to the prediction result. To address this, a new interpretable time-series model based on two sets of attention was developed by Choi et al. [
23]. The model trains two RNN sequences in reverse time sequence, and each sequence takes temporal importance and variable importance into consideration, respectively. Guo et al. [
24] proposed an interpretable MV-LSTM with a mixture attention mechanism for multi-variate time-series forecasting. A mixture attention mechanism firstly determines the variable-wise temporal importance, and then weighs the last hidden state that belongs to each variable to determine the importance of every variable. Li et al. [
25] implemented a multi-variate LSTM on a memristor system for residential load forecasting. However, these methods can only predict one time step and cannot realize interpretable multi-step load forecasting. Lim et al. [
26] proposed a temporal fusion transformer for multi-step time-series forecasting. Toubeau et al. [
27] proposed a model based on an attention mechanism and encoder–decoder structure for area control-error prediction. This two models use a variable selection network to choose important variables, but cannot capture the variable-wise temporal dynamics.
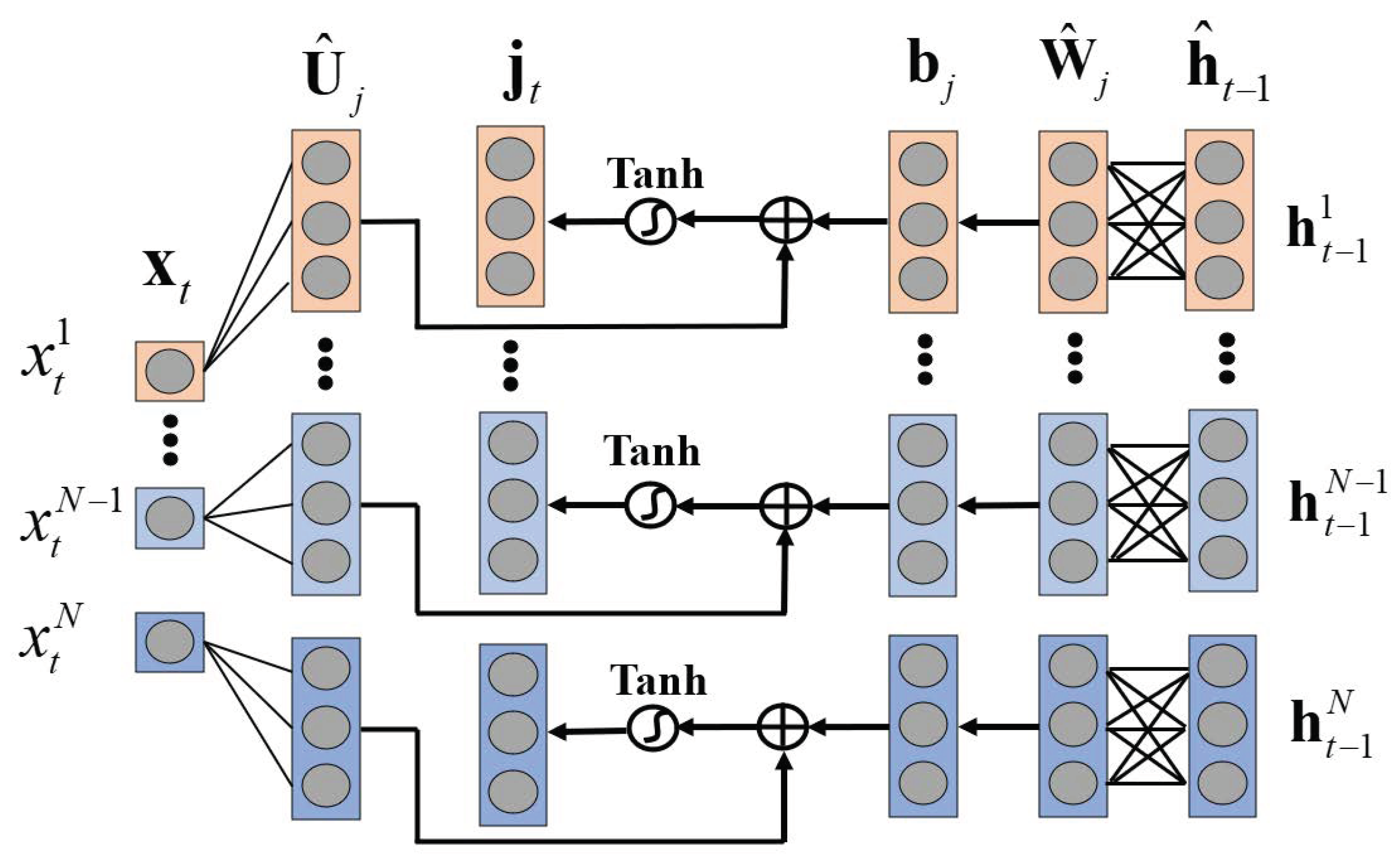
In this paper, we use a mixture attention mechanism to explain the forecasting results of residential load that can characterize the temporal dynamics of different input variables and improve the prediction performance. More importantly, the leverage of the mixture attention mechanism provides two valuable interpretations of variables and time steps for residential load forecasting. Due to the popularity of distributed energy in households, future load demand fluctuates significantly. Traditional point forecasting cannot fully quantify the uncertainty of residential load demand. Therefore, we use probabilistic forecasting to output the quantiles of future residential load. Unlike traditional point forecasting, which only outputs the expected value of future loads, quantile forecasting can explore the distribution of future loads [
28]. In addition, in order to work with long-term future time series, the encoder–decoder architecture was established to implement multi-step ahead forecasting, in which the quantile outputs for future multiple time steps can be predicted simultaneously. The established interpretable multi-step probabilistic forecasting model expands the capacity of the learning model for future decision making.
The remainder of this paper is structured as follows. The multi-step residential load forecasting problem is described in
Section 2.
Section 3 introduces the working principle of the interpretable multi-step load forecasting model.
Section 4 introduces the experiments for residential load forecasting and discusses the experimental results and model interpretability for residential load forecasting.
Section 5 draws a conclusion.
2. Problem Formulation
Let the time-series observation of the residential load of the i-th customer at time step t be represented by . The general load forecasting aims to predict the future load time series given its past with respect to customer i. is the reference time from which the actual is unknown at prediction time. In addition, are covariates that are known for the entire time period , e.g., hour of the day or weather forecasting.
Quantile regression can predict the conditional distribution of a target variable without assuming specific parametric distribution. It can flexibly represent the uncertainty of future loads and give different possible load demands. Therefore, quantile load forecasting is useful to optimize decision making for home energy-management systems. In this paper, we use probabilistic quantile regression to perform quantile prediction
for target quantile set
Q at each prediction time step
. Multi-step quantile prediction is obtained by the following equation:
For notation simplicity, we omit the subscript
i of the customer unless explicitly required. Then, to easily manage different types of variables, we represent the input at each time step as follows:
where
represents concatenation. We try to predict the quantile of next
time steps from
for all time series. To train a forecasting model, multiple training samples were created by choosing a window
with consecutive starting time slots. To illustrate it clearly, the time ranges
and
corresponding to
are called the condition and the prediction windows, respectively.
4. Case Study
4.1. Data Description and Preparation
In this paper, we used one residential load consumption data set without missing values collected from 78 residential customers near the airport in Western Victoria, Australia to evaluate the performance of proposed model for residential load forecasting. Each customer contains 35,040 measurements with half-hour resolution from 1 January 2017 to 31 December 2018. In addition, we obtained weather observations and forecasting data from the nearest weather station. A linear interpolation technique was used to estimate missing measurements.
In our proposed model, we consider three types of input: auto-regressive variable—i.e., load consumption observation, time-related variables, and weather information. We take month, day of the week, hour and holiday, etc. to be four variables as the time-related variables, each of which is a real-valued input. The weather information includes seven real-valued variables: temperature, relative humidity, dew point, wind speed, cloud type, visibility and precipitation. In view of the magnitude difference between the load series of different customers, we separately applied 0–1 standardization to input the variables of each customer.
4.2. Baseline Methods and Training Procedure
We compared our proposed method with multiple multi-step forecasting methods.
- (1)
Gradient boosting quantile regression (GBQR): GBQR is a tree ensemble method based on boosting. We used the Python package Scikit-learn [
31] to implement GBQR with quantile loss function and the number of trees was set to 500. MultiOutputRegressor of Scikit-learn was used to obtain multistep forecasting results. It is worth noting that MultiOutputRegressor trains a model for each step of prediction.
- (2)
Quantile regression forest (QRF): QRF is also an ensemble learning approach for regression and classification tasks which obtains prediction results by creating different decision trees. QRF is implemented by the Python package Scikit-garden [
32] and the number of trees was also set to 500. QRF was used to build a model for each prediction step.
- (3)
Multi-layer perceptron (MLP): An MLP with three hidden layers and a Relu activation function was used for load forecasting for all future time steps. The loss function is the average pinpall loss function.
- (4)
Encoder–decoder: The encoder–decoder model contains two LSTMs, an encoder LSTM and a decoder LSTM [
33]. The encoder LSTM encodes the input sequence as a feature representation. The decoder LSTM uses the context vector generated by the encoder LSTM as its initial hidden state and extracts its own input combined with the previous step estimate to iteratively generate predictions at each time step.
- (5)
Attention encoder–decoder: The attention encoder–decoder model is a prediction model that combines encoder–decoder and temporal attention mechanism [
33].
In our experiment, we focused on the load forecasting of the next day (i.e., 48 time steps) using the information of the previous day (i.e., 48 time steps) and we computed quantiles with . We implemented our proposed method and other deep-learning baseline methods using Pytorch. We divided the data set into training, validation, and test sets with a ratio of 70/15/15. We used the Adam algorithm with a mini-batch size of 32 to train the model. We used gradient clipping to avoid large gradients in the iteration. The maximum training epoch was 100, and we used early stopping on the validation data set to avoid overfitting. The performance of deep models is heavily dependent on hyperparameter selection. We selected the best hyperparameters through a grid search. The following is the search scope of all hyperparameters:
The size of a fully connected layer or LSTM of baseline methods .
LSTM size of our proposed method .
Dropout rate .
Learning rate .
Maximum gradient norm .
In this paper, the loss function is defined as the average pinball loss over the quantiles of all prediction time steps, which was calculated as follows:
where
represents the training set,
represents one sample of the training set,
is the size of quantile set, and
P is the pinball loss function.
4.3. Evaluation Criteria
4.3.1. Point Forecasting
Point forecasting is the primary objective of residential load forecasting, and is very critical to the day-ahead scheduling of home energy-management systems. The quantile regression model can obtain the prediction results of different quantiles. Among them, when
,
is equivalent to the mean absolute error (
MAE) loss. Accordingly, the prediction result of the
-th quantile
can be approximated as the point forecasting value. We employed three metrics to measure the performance of point forecasting on the test set, including the root mean square error (
RMSE), the
MAE, and the mean absolute percentage error (
MAPE). They were formulated as follows:
where
is the total number of time steps of test set.
4.3.2. Probabilistic Forecasting
Probabilistic forecasting based on quantile regression can obtain the variation interval of the quantity to be predicted. Interval prediction is usually evaluated in terms of reliability and sharpness. Reliability measures how far the quantile deviates from the actual observed value. Sharpness describes the width of the prediction interval. The average pinball score on the test set is a composite measure of reliability and sharpness and is expressed as follows:
In addition, the average Winkler score is also a composite index that takes into account both the coverage probability and width of the prediction interval. For a confidence interval of
, the Winkler score for one time step can be computed as follows:
where
is the width of interval at time step
t, and
and
are the lower and upper bounds, respectively.
were considered for computing the Winkler score in this paper. A lower Winkler score means better interval estimation.
4.4. Forecasting Results
In this subsection, we present the performance comparison results of the proposed method with other baseline methods in point forecasting and probabilistic forecasting.
Table 1 shows the comparison results of the point forecasting performance of different methods. Compared with the baseline methods, our proposed model obtains the best prediction performance, which shows the superiority of mixture attention on the variable-wise hidden states. Since the multi-step forecasting strategy along the time direction can easily utilize the known information in the future, the encoder–decoder model provides the second-best result. It is worth noting that the attention encoder–decoder model does not improve prediction performance relative to the encoder–decoder model. This shows that the temporal attention mechanism acting on a recurrent layer cannot extract the variable-wise important information and find salient features. Compared to MLP, GBQR and QRF provides better results. We built a prediction model for each future time step for tree models, which is inefficient and time-consuming, so they are not very applicable in practical applications.
Quantile forecasting at different probability levels show insights into future demand scenarios, which have important implications for electricity risk management. To quantify the performance of probabilistic forecasting, we present the average pinball scores and Winkler scores at different reliability levels of different methods in
Table 2. Likewise, our proposed method can generate better quantile predictions, showing high reliability and sharpness. This is because the mixture attention mechanism can effectively capture the uncertainty brought by different variables and very suitable for highly fluctuating residential load data. It can also be seen that the performance of the deep-learning models is better compared to the tree models. This suggests that deep learning is well-suited for probabilistic forecasting, producing tighter and more reliable prediction intervals.
In
Figure 3, we show the results of quantile forecasting for a randomly selected residential customer in a week. The black point shows the actual load consumption values and the red curve shows the median (0.5 quantile) prediction result. Dark blue and light blue represent the
and
prediction intervals, respectively. This customer has a high load demand in the morning and evening, and low load demand at other times, which may be due to sleeping or going out. The consumption profile of this household customer has high volatility in the high-load-demand time due to the variability in residential consumer behavior. It can be seen that the prediction interval basically covers the actual load, and the median is very close to the actual load. It is worth emphasizing that the accurate prediction of peak load is an important factor for the operation of home energy-management systems, and satisfactory prediction results can be obtained using the proposed forecasting model based on the mixture attention mechanism. This indicates that the load volatility and temporal pattern of the load consumption profile are well-captured by the model.
4.5. Interpretability Analysis on Variable Importance
After analyzing the performance of the model, we elaborated on the interpretability of the proposed model. To interpret the prediction results, we first calculated the global variable importance of the mixture attention mechanism by Equation (
15). Variable attention can distinguish the significance of variables by the attention score. The global variable importance results are shown in
Figure 4. The horizontal axis represents the input variable, and the vertical axis is the global feature importance score of the input variable. It can be seen that the three factors that have the greatest impact on load forecasting are the autoregressive variable—load (accounting for 0.27), temperature (accounting for 0.15) and hour (accounting for 0.09). As expected, historical load is the most important input variable, as these values contain the richest information about the prediction. Temperature is also an important factor affecting the electrical behavior of residential customers.The higher the temperature, the less comfortable the living environment is. As a result, the air-conditioning system will be turned on to meet comfort demands, increasing electricity usage. In addition, time-related variables also contribute to model predictions. In fact, the residential load profile has a certain degree of periodicity, especially the daily periodicity. Therefore, the hour variable can represent a fixed behavioral pattern of customers. In contrast, the information contained in other external variables, such as wind speed, visibility, dew point, etc., is of little value.
To show the difference in variable importance between different times of the day, we visualize the variable importance for 48 forecasting time steps in
Figure 5, where yellow indicates a high-importance variable and blue indicates less influential variable. It can be seen that the history load is the most important at each moment. At the peak time, the effect of the history load becomes larger. During the trough period of electricity consumption, the influence of temperature and hour becomes greater. During peak hours, load consumption is more dependent on consumer behavior, so the importance of load consumption at the previous moments is more prominent. During off-peak hours, people mainly sleep or go out to work. Residential electricity consumption mainly depends on the appliances that must be operated, and the pattern is relatively fixed, and the importance of time-related external factors becomes greater.
4.6. Interpretability Analysis on Temporal Importance
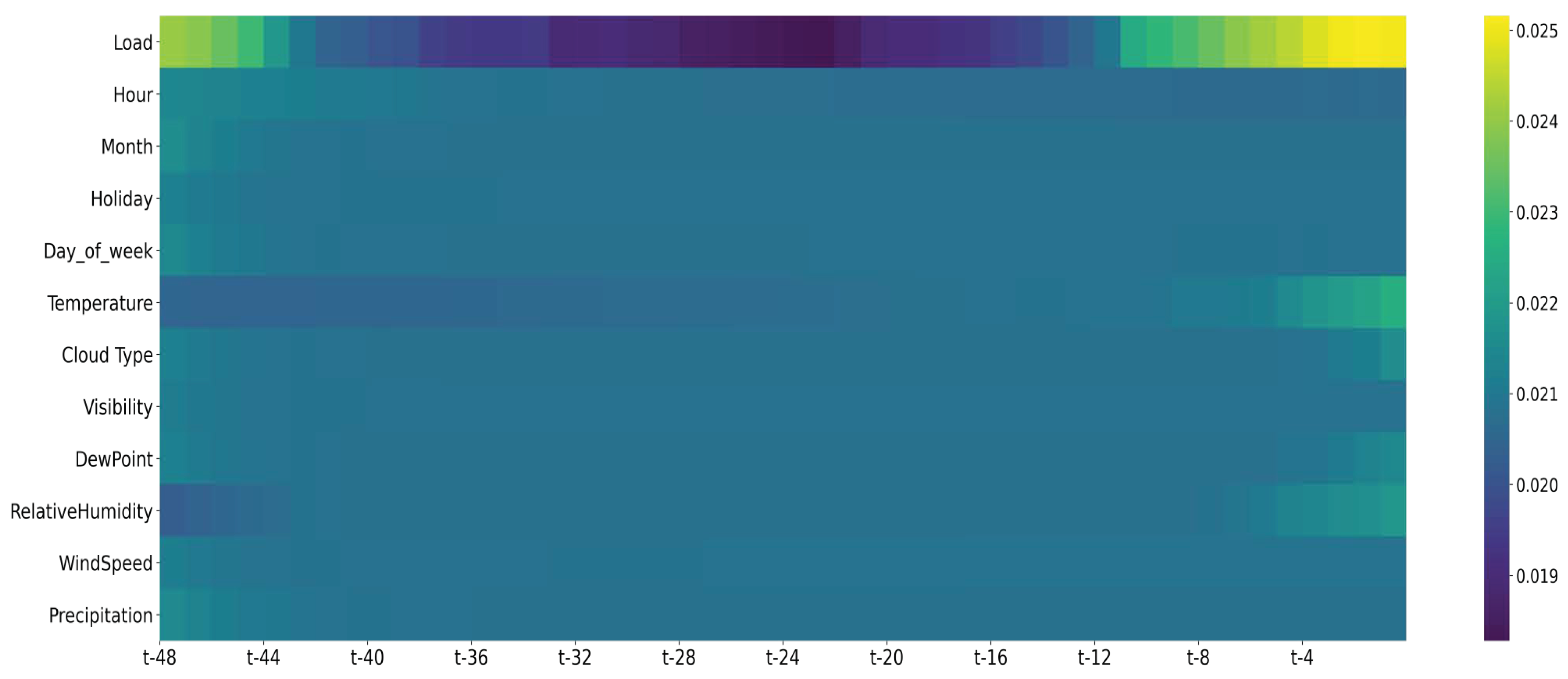
Next, we analyzed the variable-wise temporal importance of the mixture attention mechanism in load forecasting.
Figure 6 shows the variable-wise temporal importance results calculated by Equation (
16). The rows of the matrix represent the past time steps of the predicted point, and the columns represent the input variables. It can be seen that the importance of the load changed dramatically over time. The load in the last few hours contributed the most to the prediction. This is because the power consumption has a significant lag effect. At the same time, the load at the same moment of the previous day also has a great influence on the prediction. This is related to the periodicity of residential electricity consumption behavior. Changes in temperature also have a greater influence on the load prediction. The temporal importance of temperature increases gradually and the lag effect of temperature is not as large as the load. These show that our model can capture the dynamic changes in different features. The mixture attention mechanism indeed learns useful information for load forecasting, which is consistent with domain knowledge.
5. Conclusions
Due to the flexibility of model development and the availability of fine-grained smart-meter data, the application of deep-learning technology in residential load forecasting has gradually increased. Despite the powerful representational power of deep learning, the complexity of the model reduces interpretability. In this paper, we proposed an interpretable deep-learning method for residential load forecasting, which focuses on mitigating black-box characteristic while improving accuracy. We extended traditional one-step point forecasting to multi-step probabilistic forecasting by employing an encoder–decoder architecture and pinball loss function. The mixture attention mechanism used in each prediction time step can capture different temporal dynamics in a multivariate sequence, which not only improves the prediction performance, but also makes the model inherently interpretable. The experimental results on the real-world data set show that the proposed method has good prediction performance and provides two valuable interpretability aspects: (i) global variable importance and variable importance at different time steps, and (ii) the variable-wise temporal importance. These insights into variable importance and temporal importance reveal the underlying mechanism by which the model works, helping users understand patterns and relationships in the data. They are important for the practical deployment of residential load forecasting models. In addition, by detecting whether these interpretations conflict with the actual electricity load-variation law, it can help decision makers judge the reliability of forecasting results. Finally, these explanations can further help model developers to further improve prediction performance by feature engineering.
The main goal of this work is to train a well-performing interpretable deep-learning prediction model of residential load. A centralized learning approach was used to train a general model, where a large amount of load data was collected by smart meters in different households and shared in a server. However, there are potential privacy leakage issues during communication transmission, as the model can easily infer the living habits of customers, even with the type and usage time of household appliances based on fine-grained load data. Subsequent research should consider combining federated learning [
34] to achieve privacy protection. On the other hand, the algorithm complexity is inevitably increased due to the introduction of MV-LSTM. Future methods need to be proposed to compress models, such as feature selection, model distillation, for deployment in home IoT devices with limited computational requirements.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}