
Power-Efficient Deep Neural Network Accelerator Minimizing Global Buffer Access without Data Transfer between Neighboring Multiplier—Accumulator Units



Abstract
:1. Introduction
- Proposal of a novel control sequence for reusing weight pixels by utilizing an LRF installed in each MAC unit in a 2-D MAC array.
- Analysis of global buffer access reduction ratio and power saving in comparison with that in the RS dataflow method as well as the methods involving no data owing to the reuse of weight pixels through the proposed control sequence.
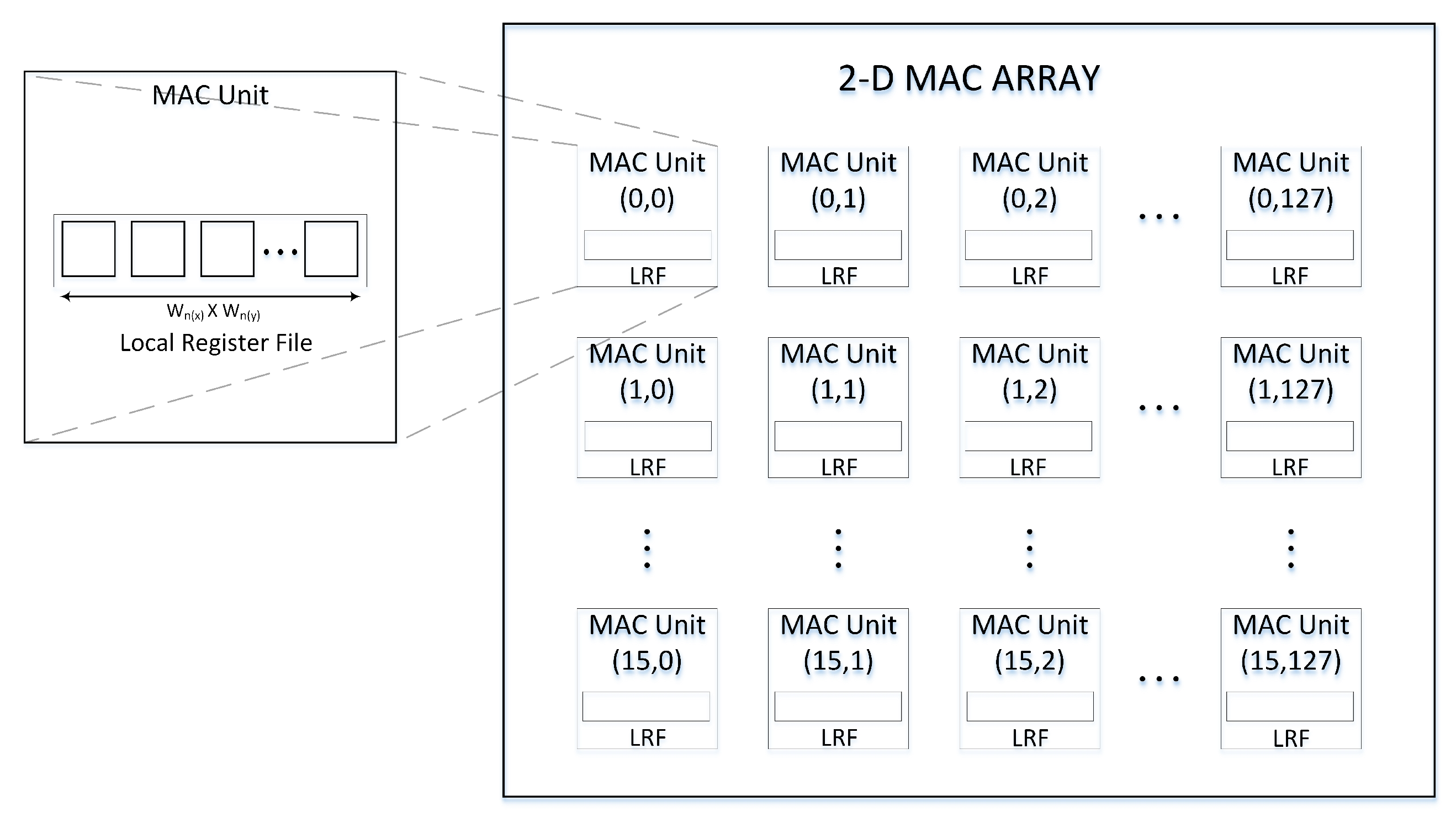
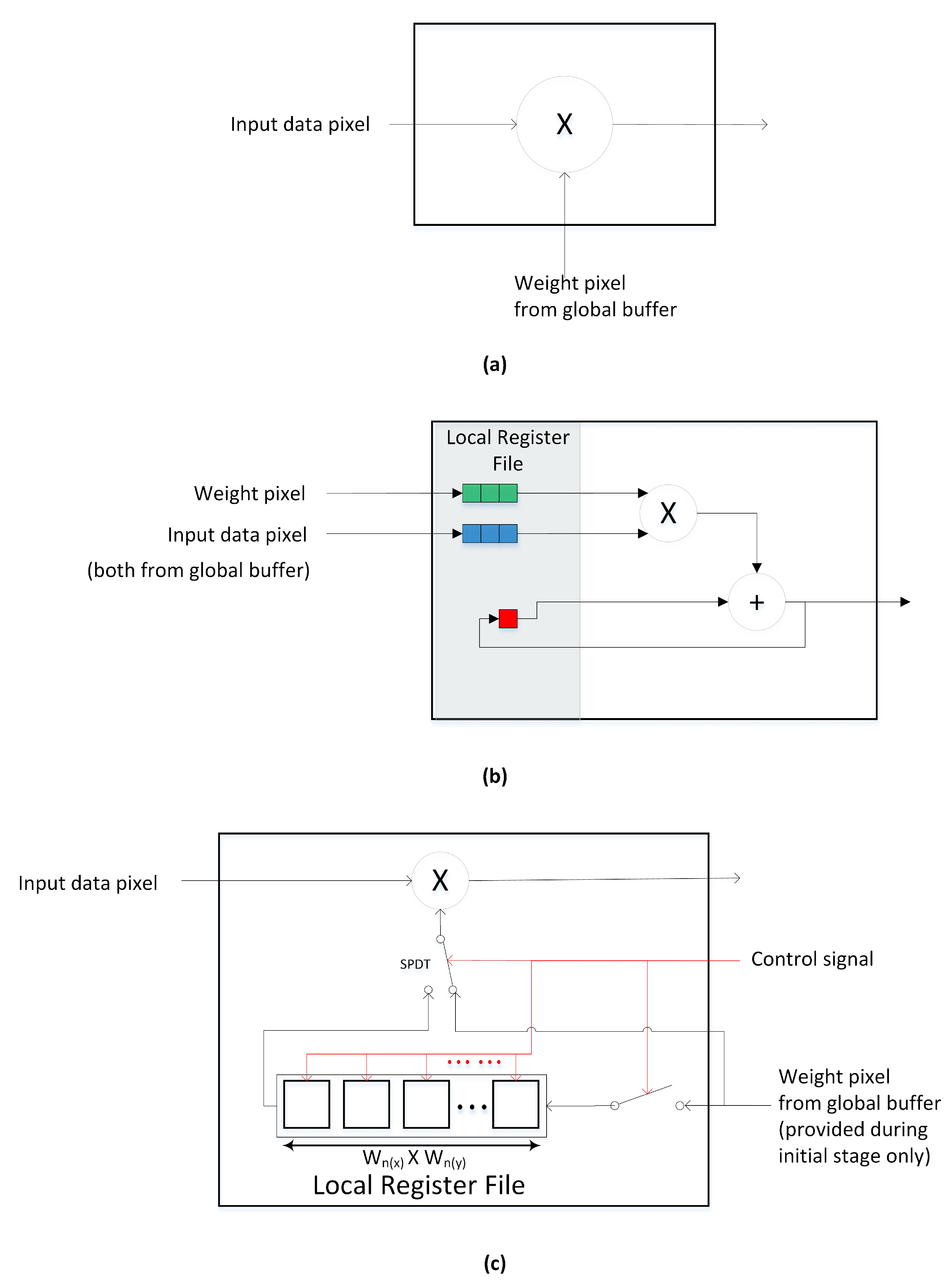
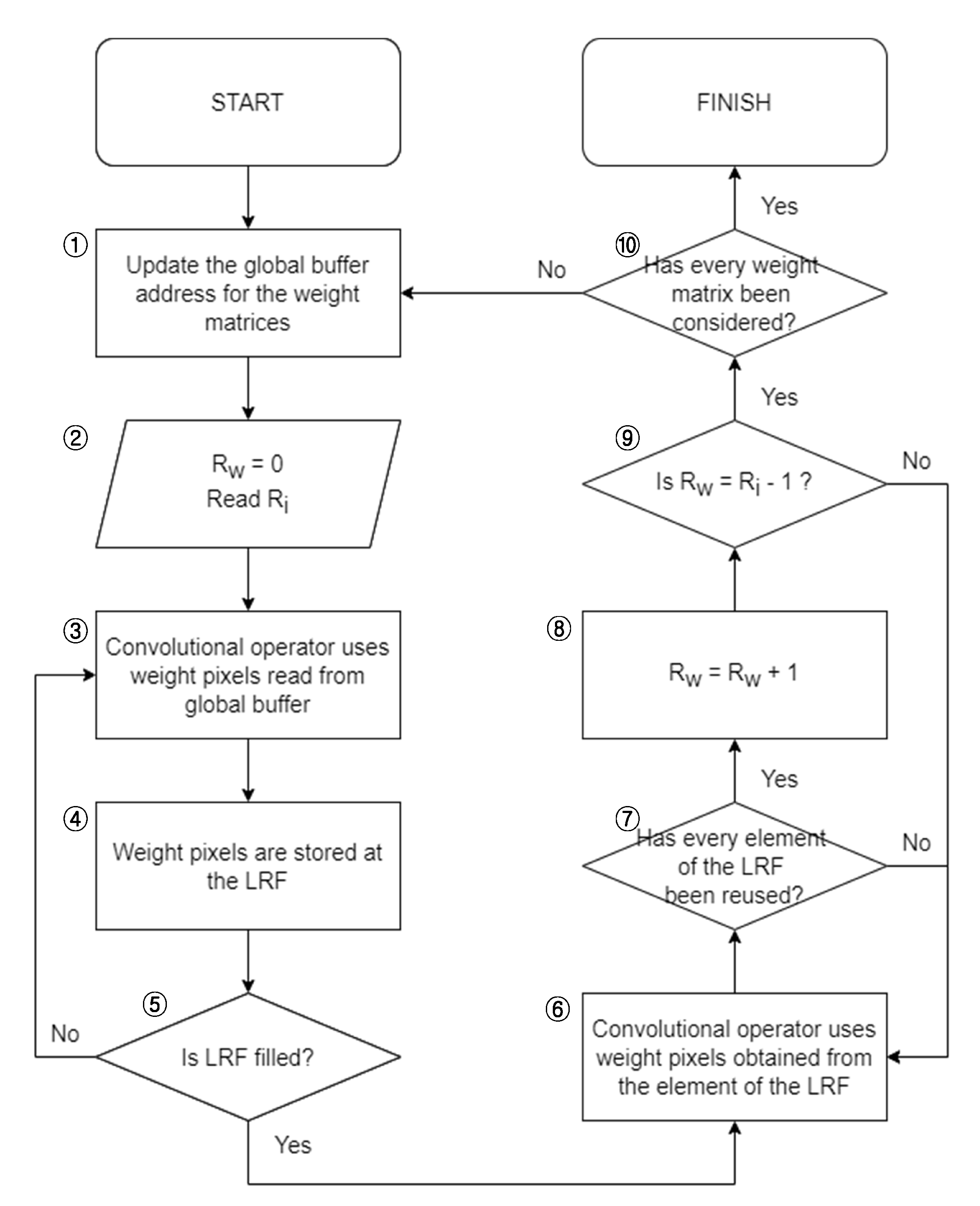
2. Proposed Method for Minimizing Global Buffer Access by Using a Local Register File
3. Numerical Results
3.1. Power Saving
3.2. Hardware Resources
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MAC | multiplier-accumulator |
| LRF | local register file |
| DNNs | deep neural networks |
| WS | weight stationary |
| OS | output stationary |
| RS | row stationary |
| HW | hardware |
| SPDT | single-pole double-throw |
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the IEEE International Conference Acoustic, Speech Signal Process, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Deng, L.; Li, J.; Huang, J.-T.; Yao, K.; Yu, D.; Seide, F.; Seltzer, M.; Zweig, G.; He, X.; Williams, J.; et al. Recent Advances in Deep Learning for Speech Research at Microsoft. In Proceedings of the International Conference on Acoustics [Speech], and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 8604–8608. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Yang, T.-J.; Chen, Y.-H.; Emer, J.; Sze, V. A Method to Estimate the Energy Consumption of Deep Neural Networks. In Proceedings of the 51st Asilomar Conference Signals, System, Computability, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 1916–1920. [Google Scholar]
- Mao, M.; Peng, X.; Liu, R.; Li, J.; Yu, S.; Chakrabarti, C. MAX2: An ReRAM-Based Neural Network Accelerator That Maximizes Data Reuse and Area Utilization. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 398–410. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Emer, J.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. ACM SIGARCH Comput. Archit. News 2016, 44, 367–379. [Google Scholar] [CrossRef]
- Sankaradas, M.; Jakkula, V.; Cadambi, S.; Chakradhar, S.; Durdanovic, I.; Cosatto, E.; Graf, H.P. A Massively Parallel Coprocessor for Convolutional Neural Networks. In Proceedings of the 2009 20th IEEE International Conference on Application-Specific Systems, Architectures and Processors, Boston, MA, USA, 7–9 July 2009. [Google Scholar]
- Sriram, V.; Cox, D.; Tsoi, K.H.; Luk, W. Towards an Embedded Biologically Inspired Machine Vision Processor. In Proceedings of the 2010 International Conference on Field-Programmable Technology, Beijing, China, 8–10 December 2010. [Google Scholar]
- Chakradhar, S.; Sankaradas, M.; Jakkula, V.; Cadambi, S. A Dynamically Configurable Coprocessor for Convolutional Neural Networks. In Proceedings of the 37th Annual International Symposium on Computer Architecture, Saint-Malo, France, 19–23 June 2010. [Google Scholar]
- Gokhale, V.; Jin, J.; Dundar, A.; Martini, B.; Culurciello, E. A 240 G-Ops/S Mobile Coprocessor for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 696–701. [Google Scholar]
- Park, S.; Bong, K.; Shin, D.; Lee, J.; Choi, S.; Yoo, H.-J. A 1.93TOPS/W Scalable Deep Learning/Inference Processor with Tetra-Parallel MIMD Architecture for Big-Data Applications. In Proceedings of the 2015 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 22–26 February 2015.
- Cavigelli, L.; Gschwend, D.; Mayer, C.; Willi, S.; Muheim, B.; Benini, L. Origami: A Convolutional Network Accelerator. In Proceedings of the 25th Edition on Great Lakes Symposium on VLSI, Pittsburgh, PA, USA, 20–22 May 2015. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep Learning with Limited Numerical Precision. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015. [Google Scholar]
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Li, L.; Luo, T.; Feng, X.; Chen, Y.; Temam, O. ShiDianNao: Shifting Vision Processing Closer to the Sensor. ISCA 2016, 43, 92–104. [Google Scholar] [CrossRef]
- Peemen, M.; Setio, A.A.A.; Mesman, B.; Corporaal, H. Memory-Centric Accelerator Design for Convolutional Neural Networks. In Proceedings of the 2013 IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013. [Google Scholar]
- Lee, M.; Zhang, Z.; Choi, S.; Choi, J. Minimizing Global Buffer Access in a Deep Learning Accelerator Using a Local Register File with Rearranged Computational Sequence. Sensors 2022, 22, 3095. [Google Scholar] [CrossRef] [PubMed]
- NVDLA. Unit Description [Online]. 2018. Available online: http://nvdla.org/hw/v1/ias/unit_description.html (accessed on 1 April 2022).
- Vivado Tools. Unit Description [Online]. 2021. Available online: https://www.xilinx.com/content/dam/xilinx/support/documents/sw_manuals/xilinx2021_2/ug910-vivado-getting-started.pdf (accessed on 1 April 2022).
- ZCU102 Board. Unit Description [Online]. 2019. Available online: https://www.xilinx.com/support/documents/boards_and_kits/zcu102/ug1182-zcu102-eval-bd.pdf (accessed on 1 April 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension of Input Data Matrix | 3 × 3 Weight | 5 × 5 Weight | 7 × 7 Weight | |||
|---|---|---|---|---|---|---|
| Global Buffer Access Reduction Ratio | Power Saving | Global Buffer Access Reduction Ratio | Power Saving | Global Buffer Access Reduction Ratio | Power Saving | |
| 32 × 32 | 99.79% | 83.16% | 99.78% | 83.15% | 99.76% | 83.13% |
| 64 × 64 | 99.97% | 83.31% | 99.96% | 83.30% | 99.96% | 83.30% |
| 128 × 128 | 99.99% | 83.33% | 99.99% | 83.33% | 99.99% | 83.33% |
| Dimension of Input Data Matrix | Required Number of Inter-MAC Unit Transmissions | ||
|---|---|---|---|
| 3 × 3 Weight | 5 × 5 Weight | 7 × 7 Weight | |
| 32 × 32 | 261 | 675 | 1225 |
| 64 × 64 | 549 | 1475 | 2793 |
| 128 × 128 | 1125 | 3075 | 5929 |
| Dimension of Input Data Matrix | Power Saving | ||
|---|---|---|---|
| 3 × 3 Weight | 5 × 5 Weight | 7 × 7 Weight | |
| 32 × 32 | 90.63% | 90% | 89.29% |
| 64 × 64 | 95.31% | 95.16% | 95% |
| 128 × 128 | 97.66% | 97.62% | 97.58% |
| Convolutional Layer | Power Saving Compared to Method of [11] |
|---|---|
| 1 | 98.63% |
| 2 | 88.89% |
| 3 | 76.92% |
| 4 | 76.92% |
| 5 | 72.92% |
| Dimension of Input Data Matrix | Size of Entire LRF Required for Storing Input Data Pixels (bytes) | |
|---|---|---|
| Method of [21] | Method of [11] | |
| 18 × 18 | 6.5 K | 36 K |
| 32 × 32 | 6.5 K | 64 K |
| 64 × 64 | 6.5 K | 128 K |
| 128 × 128 | 6.5 K | 256 K |
| Hardware Resources Required for Weight LRFs | Extra Hardware Value Compared to [21] | |
|---|---|---|
| FF | 8121 | 9.98% |
| LUT | 5768 | 7.93% |
| BRAM | 0 | 0 |
| DSP slice | 8 | 7.62% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Han, S.; Choi, S.; Choi, J. Power-Efficient Deep Neural Network Accelerator Minimizing Global Buffer Access without Data Transfer between Neighboring Multiplier—Accumulator Units. Electronics 2022, 11, 1996. https://doi.org/10.3390/electronics11131996
Lee J, Han S, Choi S, Choi J. Power-Efficient Deep Neural Network Accelerator Minimizing Global Buffer Access without Data Transfer between Neighboring Multiplier—Accumulator Units. Electronics. 2022; 11(13):1996. https://doi.org/10.3390/electronics11131996
Chicago/Turabian StyleLee, Jeonghyeok, Sangwook Han, Seungwon Choi, and Jungwook Choi. 2022. "Power-Efficient Deep Neural Network Accelerator Minimizing Global Buffer Access without Data Transfer between Neighboring Multiplier—Accumulator Units" Electronics 11, no. 13: 1996. https://doi.org/10.3390/electronics11131996
APA StyleLee, J., Han, S., Choi, S., & Choi, J. (2022). Power-Efficient Deep Neural Network Accelerator Minimizing Global Buffer Access without Data Transfer between Neighboring Multiplier—Accumulator Units. Electronics, 11(13), 1996. https://doi.org/10.3390/electronics11131996