
GSCINet: Gradual Shrinkage and Cyclic Interaction Network for Salient Object Detection

Abstract
:1. Introduction
2. Related Work
2.1. Traditional-Based SOD Methods
2.2. FCNs-Based SOD Methods
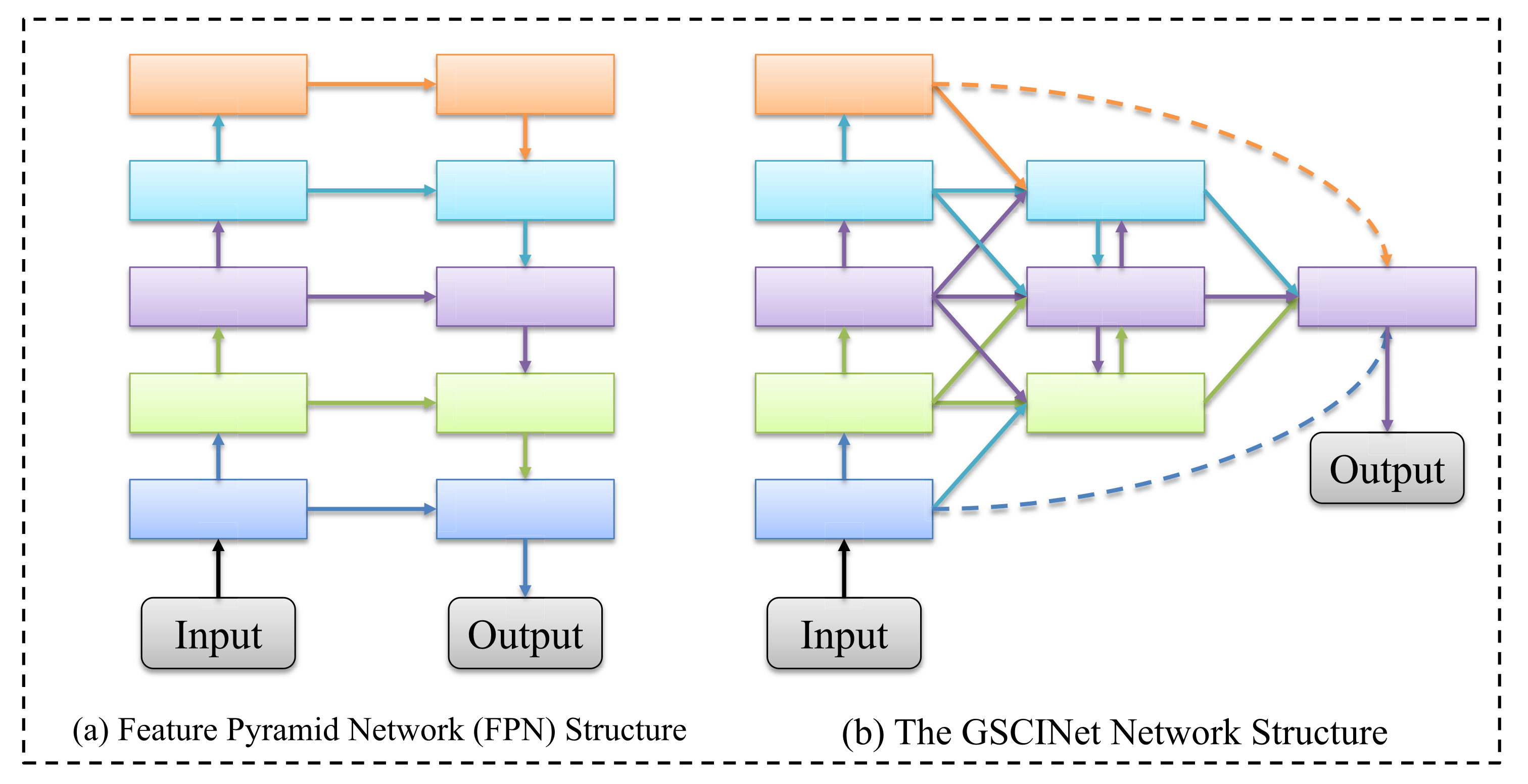
3. The Proposed GSCINet Methods
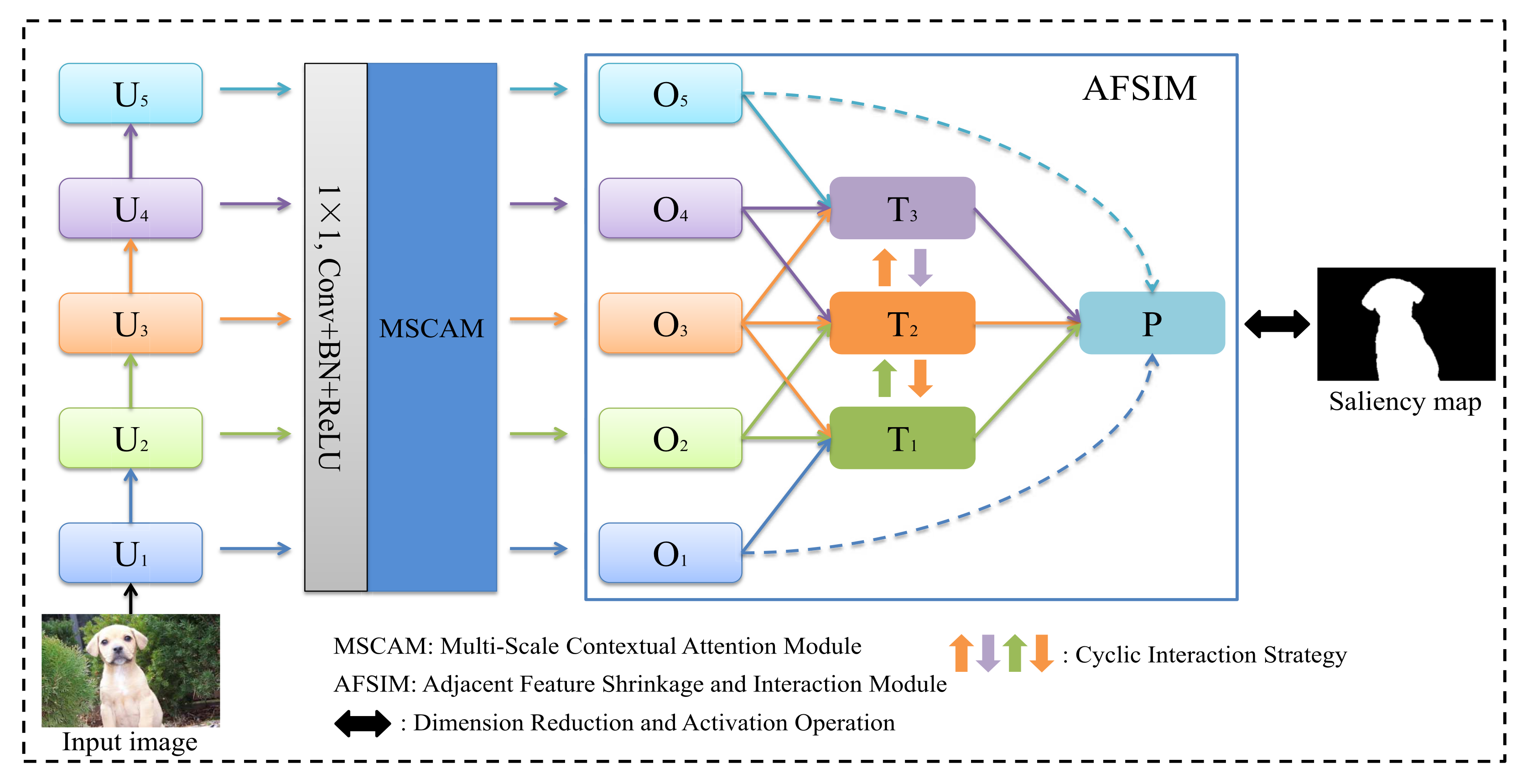
3.1. Overall Architecture
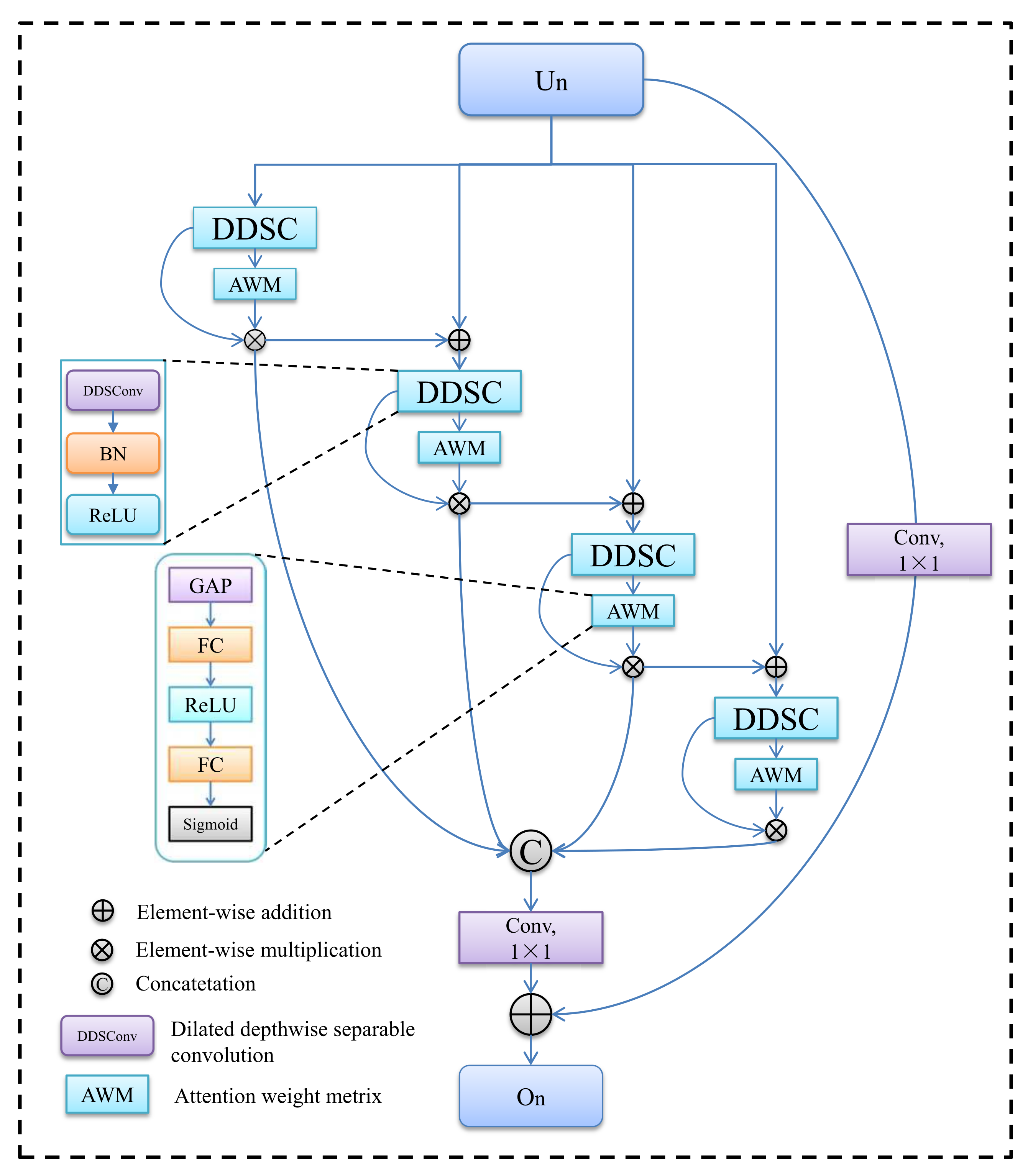
3.2. Multi-Scale Contextual Attention Module (MSCAM)
3.3. Adjacent Feature Shrinkage and Interaction Module (AFSIM)
3.4. Loss Function
4. Experiment
4.1. Datasets
4.2. Experimental Details
4.3. Evaluation Metrics
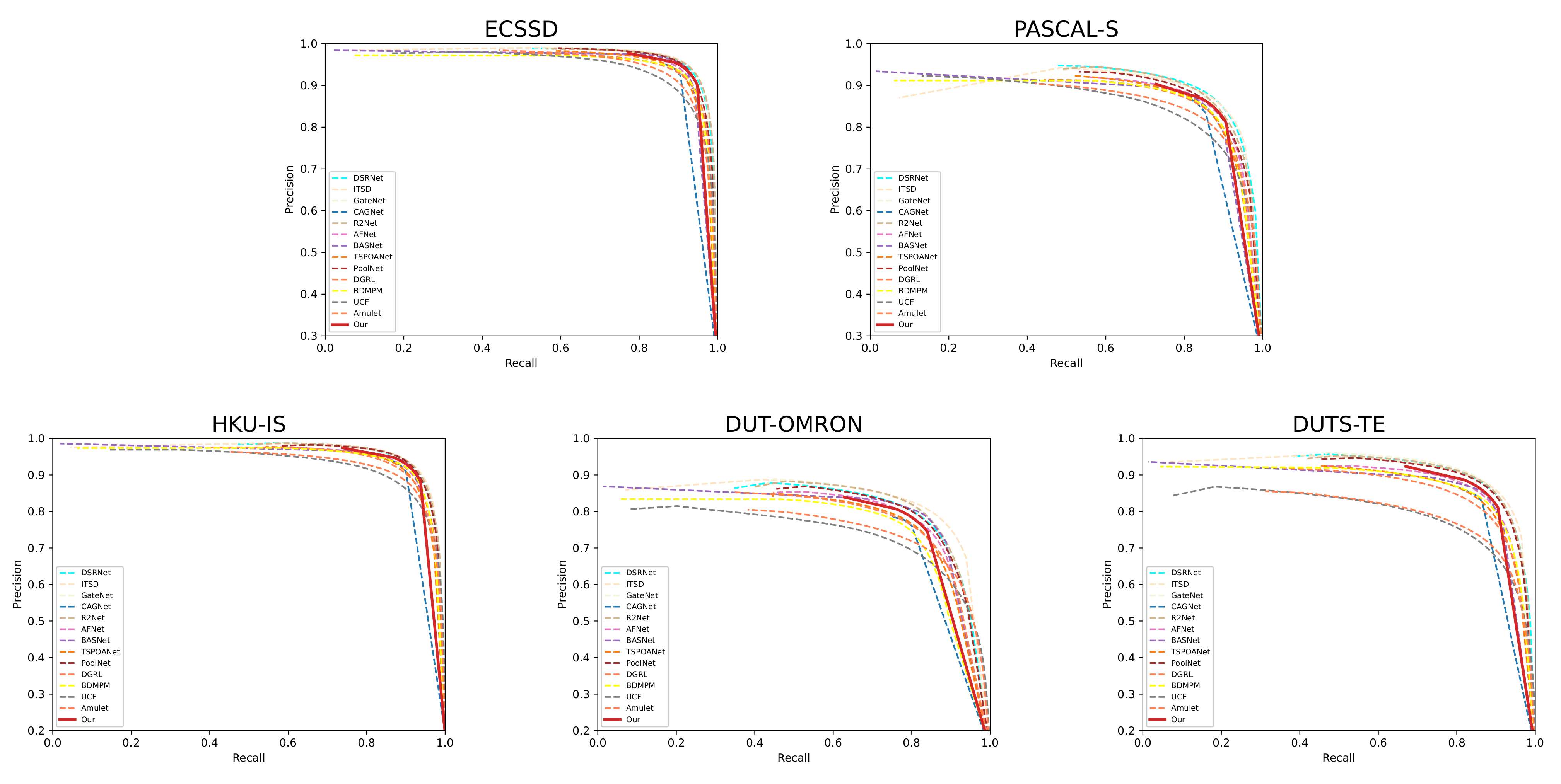
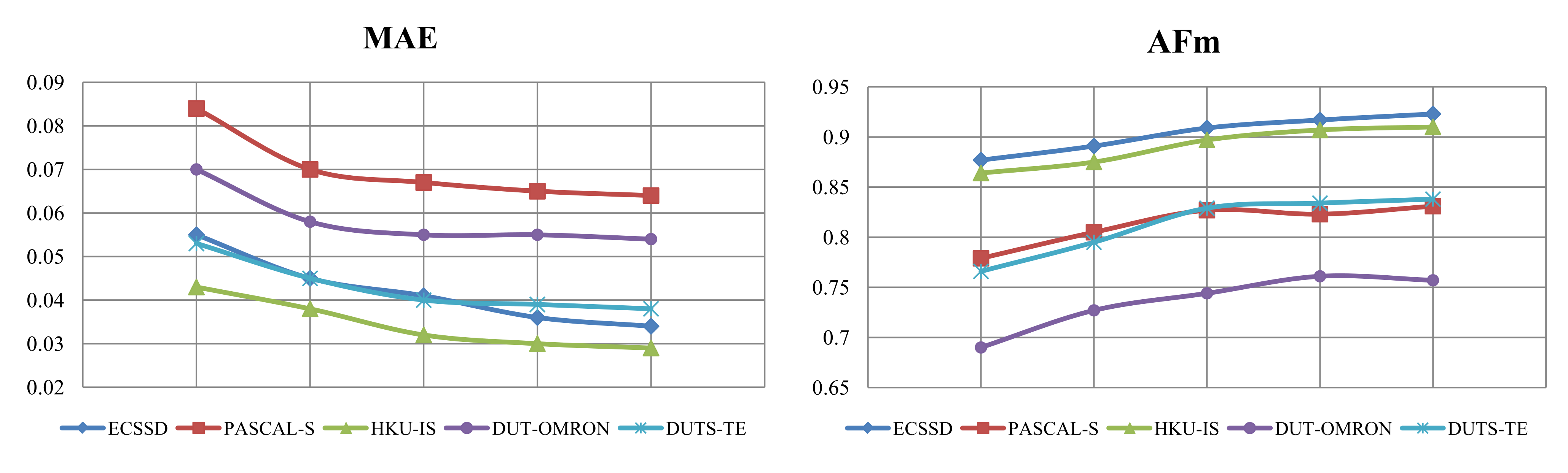
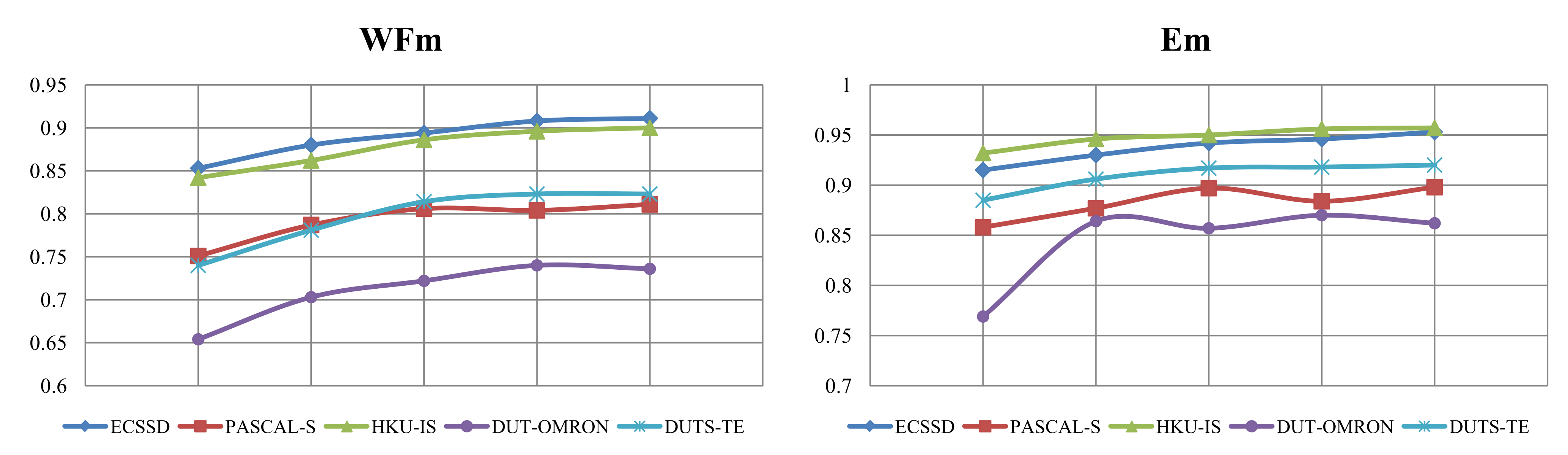
4.4. Comparison With State-of-the-Arts
4.4.1. Quantitative Evaluation
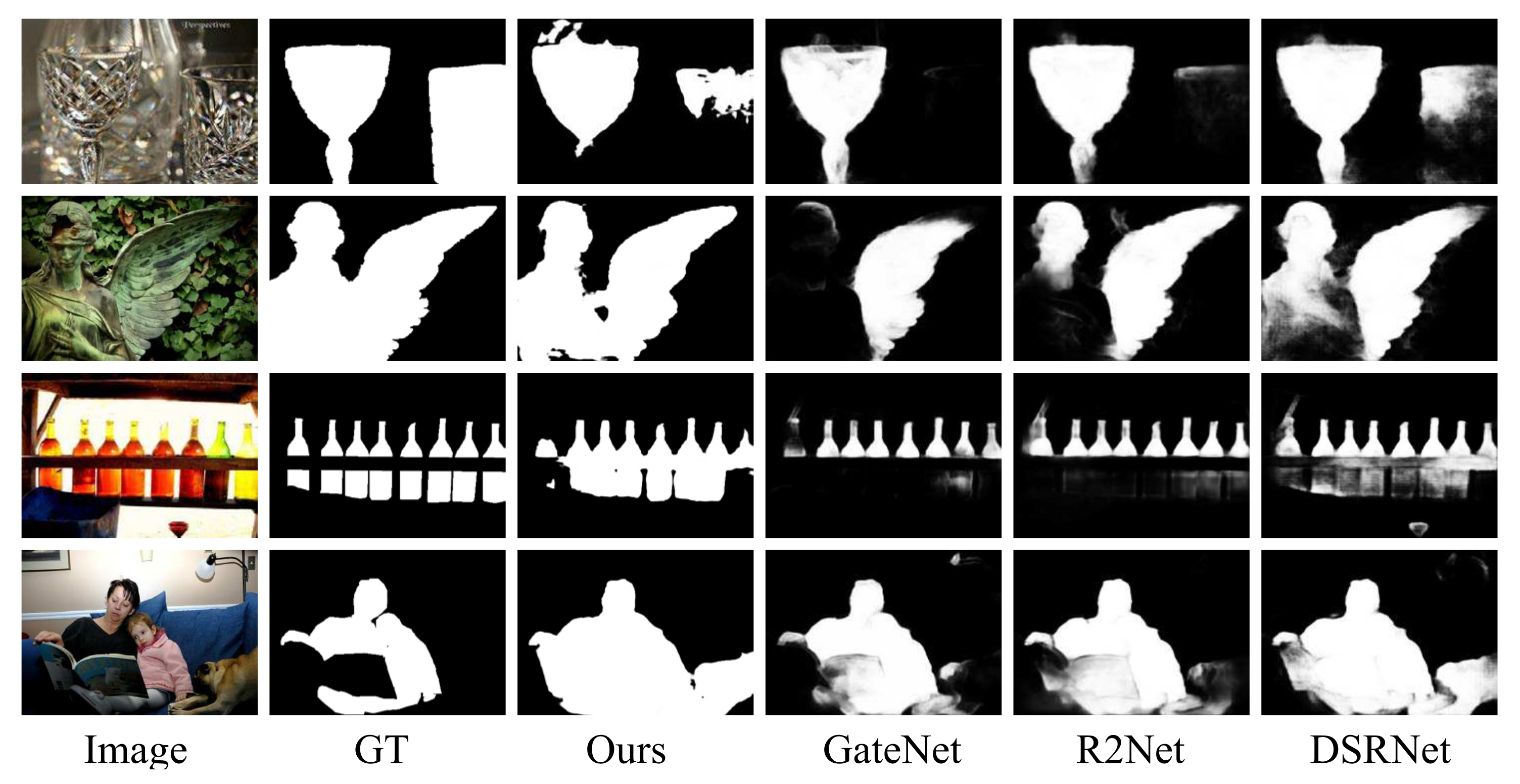
4.4.2. Qualitative Evaluation
4.4.3. Efficiency Evaluation
4.5. Ablation Studies
4.5.1. The Effectiveness of MSCAM
4.5.2. The Effectiveness of AFSIM
4.6. Analysis and Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, J.; Feng, J.; Liu, X.; Cheng, T.; Lin, T.H.; Chung, H.; Chang, S.F. Mobile product search with bag of hash bits and boundary reranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3005–3012. [Google Scholar]
- Zhang, P.; Zhuo, T.; Huang, W.; Chen, K.; Kankanhalli, M. Online object tracking based on CNN with spatial-temporal saliency guided sampling. Neurocomputing 2017, 257, 115–127. [Google Scholar] [CrossRef]
- Cheng, M.M.; Liu, X.C.; Wang, J.; Lu, S.P.; Lai, Y.K.; Rosin, P.L. Structure-preserving neural style transfer. IEEE Trans. Image Process. 2019, 29, 909–920. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, C.; Zhang, L. A Novel Multiresolution Spatiotemporal Saliency Detection Model and Its Applications in Image and Video Compression. IEEE Trans. Image Process. 2010, 19, 185–198. [Google Scholar] [PubMed]
- Margolin, R.; Tal, A.; Zelnik-Manor, L. What Makes a Patch Distinct? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 1139–1146. [Google Scholar]
- Klein, D.A.; Frintrop, S. Center-surround divergence of feature statistics for salient object detection. In Proceedings of the IEEE International Conference on computer vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2214–2219. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xia, C.; Gao, X.; Fang, X.; Li, K.C.; Su, S.; Zhang, H. RLP-AGMC: Robust label propagation for saliency detection based on an adaptive graph with multiview connections. Signal Process. Image Commun. 2021, 98, 116372. [Google Scholar] [CrossRef]
- Xia, C.; Zhang, H.; Gao, X.; Li, K. Exploiting background divergence and foreground compactness for salient object detection. Neurocomputing 2020, 383, 194–211. [Google Scholar] [CrossRef]
- Wang, L.; Lu, H.; Ruan, X.; Yang, M.H. Deep networks for saliency detection via local estimation and global search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3183–3192. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Yin, B. Learning uncertain convolutional features for accurate saliency detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 212–221. [Google Scholar]
- Zhang, L.; Dai, J.; Lu, H.; He, Y.; Wang, G. A Bi-Directional Message Passing Model for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1741–1750. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect Globally, Refine Locally: A Novel Approach to Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3127–3135. [Google Scholar]
- Feng, M.; Lu, H.; Ding, E. Attentive Feedback Network for Boundary-Aware Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 19–20 June 2019; pp. 1623–1632. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-Aware Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 19–20 June 2019; pp. 7471–7481. [Google Scholar]
- Ren, G.; Dai, T.; Barmpoutis, P.; Stathaki, T. Salient object detection combining a self-attention module and a feature pyramid network. Electronics 2020, 9, 1702. [Google Scholar] [CrossRef]
- Da, Z.; Gao, Y.; Xue, Z.; Cao, J.; Wang, P. Local and Global Feature Aggregation-Aware Network for Salient Object Detection. Electronics 2022, 11, 231. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 19–20 June 2019; pp. 3912–3921. [Google Scholar]
- Feng, M.; Lu, H.; Yu, Y. Residual Learning for Salient Object Detection. IEEE Trans. Image Process. 2020, 29, 4696–4708. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and Balance: A Simple Gated Network for Salient Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2020; pp. 35–51. [Google Scholar]
- Mei, H.; Liu, Y.; Wei, Z.; Zhou, D.; Xiaopeng, X.; Zhang, Q.; Yang, X. Exploring dense context for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1378–1389. [Google Scholar] [CrossRef]
- Tong, N.; Lu, H.; Zhang, L.; Ruan, X. Saliency detection with multi-scale superpixels. IEEE Signal Process. Lett. 2014, 21, 1035–1039. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Li, J.; Pan, Z.; Liu, Q.; Wang, Z. Stacked U-Shape Network With Channel-Wise Attention for Salient Object Detection. IEEE Trans. Multimed. 2021, 23, 1397–1409. [Google Scholar] [CrossRef]
- Peng, H.; Li, B.; Ling, H.; Hu, W.; Xiong, W.; Maybank, S.J. Salient object detection via structured matrix decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 818–832. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borji, A.; Cheng, M.M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar] [CrossRef] [Green Version]
- Sina, M.; Mehrdad, N.; Ali, B.; Sina, G.; Mohammad, H. CAGNet: Content-Aware Guidance for Salient Object Detection. Pattern Recognit. 2020, 103, 107303. [Google Scholar]
- Wang, L.; Chen, R.; Zhu, L.; Xie, H.; Li, X. Deep Sub-Region Network for Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 728–741. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded Partial Decoder for Fast and Accurate Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 19–20 June 2019; pp. 3902–3911. [Google Scholar]
- Ren, Q.; Lu, S.; Zhang, J.; Hu, R. Salient Object Detection by Fusing Local and Global Contexts. IEEE Trans. Multimed. 2021, 23, 1442–1453. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H.S. Deeply Supervised Salient Object Detection with Short Connections. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 815–828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Máttyus, G.; Luo, W.; Urtasun, R. Deeproadmapper: Extracting road topology from aerial images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3438–3446. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The Secrets of Salient Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency Detection via Graph-Based Manifold Ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to Detect Salient Objects with Image-Level Supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3796–3805. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 1597–1604. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment Measure for Binary Foreground Map Evaluation. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 698–704. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse attention for salient object detection. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Liu, Y.; Zhang, Q.; Zhang, D.; Han, J. Employing deep part-object relationships for salient object detection. In Proceedings of the IEEE International Conference on computer vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1232–1241. [Google Scholar]
- Zhou, H.; Xie, X.; Lai, J.H.; Chen, Z.; Yang, L. Interactive Two-Stream Decoder for Accurate and Fast Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9138–9147. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year, Pub | ECSSD (1000) | PASCAL-S (850) | HKU-IS (4447) | DUT-OMRON (5168) | DUTS-TE (5019) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ↓ | ↑ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | ||
| UCF | 2017, ICCV | 0.069 | 0.844 | 0.806 | 0.896 | 0.116 | 0.726 | 0.689 | 0.807 | 0.062 | 0.823 | 0.779 | 0.904 | 0.120 | 0.621 | 0.574 | 0.768 | 0.112 | 0.631 | 0.596 | 0.770 |
| Amulet | 2017, CVPR | 0.059 | 0.868 | 0.840 | 0.912 | 0.100 | 0.757 | 0.728 | 0.827 | 0.051 | 0.841 | 0.817 | 0.914 | 0.098 | 0.647 | 0.626 | 0.784 | 0.085 | 0.678 | 0.658 | 0.803 |
| DGRL | 2018, CVPR | 0.046 | 0.893 | 0.871 | 0.935 | 0.077 | 0.794 | 0.772 | 0.869 | 0.041 | 0.875 | 0.851 | 0.943 | 0.066 | 0.711 | 0.688 | 0.847 | 0.054 | 0.755 | 0.748 | 0.873 |
| BDMPM | 2018, CVPR | 0.045 | 0.869 | 0.871 | 0.916 | 0.074 | 0.758 | 0.774 | 0.845 | 0.039 | 0.871 | 0.859 | 0.938 | 0.064 | 0.692 | 0.681 | 0.839 | 0.049 | 0.746 | 0.761 | 0.863 |
| RASNet | 2018, ECCV | 0.056 | 0.889 | 0.857 | 0.922 | 0.101 | 0.777 | 0.731 | 0.838 | - | - | - | - | 0.062 | 0.713 | 0.695 | 0.849 | 0.059 | 0.751 | 0.740 | 0.864 |
| PoolNet | 2019, CVPR | 0.039 | 0.915 | 0.896 | 0.945 | 0.075 | 0.815 | 0.793 | 0.876 | 0.032 | 0.900 | 0.883 | 0.955 | 0.056 | 0.739 | 0.721 | 0.864 | 0.040 | 0.809 | 0.807 | 0.904 |
| BASNet | 2019, CVPR | 0.037 | 0.880 | 0.904 | 0.921 | 0.076 | 0.771 | 0.793 | 0.853 | 0.032 | 0.896 | 0.889 | 0.946 | 0.057 | 0.756 | 0.751 | 0.869 | 0.048 | 0.791 | 0.803 | 0.884 |
| AFNet | 2019, CVPR | 0.042 | 0.908 | 0.886 | 0.941 | 0.070 | 0.815 | 0.792 | 0.885 | 0.036 | 0.888 | 0.869 | 0.948 | 0.057 | 0.739 | 0.717 | 0.860 | 0.046 | 0.793 | 0.785 | 0.895 |
| CPD | 2019, CVPR | 0.037 | 0.917 | 0.898 | 0.950 | 0.071 | 0.820 | 0.794 | 0.887 | 0.033 | 0.895 | 0.879 | 0.952 | 0.056 | 0.747 | 0.719 | 0.873 | 0.043 | 0.805 | 0.795 | 0.904 |
| TSPOANet | 2019, ICCV | 0.046 | 0.900 | 0.876 | 0.935 | 0.077 | 0.804 | 0.775 | 0.871 | 0.038 | 0.882 | 0.862 | 0.902 | 0.061 | 0.716 | 0.697 | 0.850 | 0.049 | 0.776 | 0.767 | 0.885 |
| R2Net | 2020, TIP | 0.038 | 0.914 | 0.899 | 0.946 | 0.069 | 0.817 | 0.793 | 0.880 | 0.033 | 0.896 | 0.880 | 0.954 | 0.054 | 0.744 | 0.728 | 0.866 | 0.041 | 0.801 | 0.804 | 0.901 |
| CAGNet | 2020, PR | 0.042 | 0.914 | 0.892 | 0.939 | 0.076 | 0.819 | 0.789 | 0.882 | 0.034 | 0.905 | 0.885 | 0.947 | 0.057 | 0.744 | 0.718 | 0.859 | 0.045 | 0.822 | 0.797 | 0.904 |
| ITSD | 2020, CVPR | 0.040 | 0.875 | 0.897 | 0.918 | 0.068 | 0.773 | 0.811 | 0.854 | 0.035 | 0.890 | 0.881 | 0.945 | 0.063 | 0.745 | 0.734 | 0.858 | 0.042 | 0.798 | 0.814 | 0.893 |
| GateNet | 2020, ECCV | 0.040 | 0.916 | 0.894 | 0.943 | 0.067 | 0.819 | 0.797 | 0.884 | 0.033 | 0.899 | 0.880 | 0.953 | 0.055 | 0.746 | 0.729 | 0.868 | 0.040 | 0.807 | 0.809 | 0.903 |
| DSRNet | 2021, TCSVT | 0.039 | 0.910 | 0.891 | 0.942 | 0.067 | 0.819 | 0.801 | 0.883 | 0.035 | 0.893 | 0.873 | 0.951 | 0.061 | 0.727 | 0.711 | 0.855 | 0.043 | 0.791 | 0.794 | 0.892 |
| CANet | 2021, TMM | 0.044 | 0.900 | 0.878 | 0.936 | 0.073 | 0.813 | 0.792 | 0.879 | 0.037 | 0.882 | 0.866 | 0.946 | 0.058 | 0.730 | 0.720 | 0.859 | 0.044 | 0.785 | 0.788 | 0.890 |
| SUCA | 2021, TMM | 0.036 | 0.915 | 0.906 | 0.948 | 0.067 | 0.818 | 0.803 | 0.886 | 0.031 | 0.897 | 0.890 | 0.955 | - | - | - | - | 0.044 | 0.803 | 0.802 | 0.903 |
| Ours | - | 0.034 | 0.923 | 0.911 | 0.953 | 0.064 | 0.831 | 0.811 | 0.898 | 0.029 | 0.910 | 0.900 | 0.957 | 0.054 | 0.757 | 0.736 | 0.862 | 0.038 | 0.838 | 0.823 | 0.920 |
| Method | Input Size | #Param (M) | Inference Speed (FPS) | Model Memory (M) |
|---|---|---|---|---|
| Amulet | 320 × 320 | 33.15 | 8 | 132 |
| DGRL | 384 × 384 | 161.74 | 8 | 631 |
| BDMPM | 256 × 256 | - | 22 | 259 |
| AFNet | 224 × 224 | 37.11 | 26 | 128 |
| BASNet | 256 × 256 | 87.06 | 25 | 332 |
| PoolNet | 384 × 384 | 68.26 | 17 | 410 |
| R2Net | 224 × 224 | - | 33 | 117 |
| GateNet | 384 × 384 | 128.63 | 30 | 503 |
| DSRNet | 400 × 400 | 75.29 | 15 | 290 |
| CANet | 256 × 256 | - | 32 | - |
| Ours | 320 × 320 | 24.46 | 40 | 96 |
| Method | ECSSD (1000) | PASCAL-S (850) | HKU-IS (4447) | DUT-OMRON (5168) | DUTS-TE (5019) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ↓ | ↑ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | |
| Backbone | 0.055 | 0.877 | 0.853 | 0.915 | 0.084 | 0.779 | 0.751 | 0.858 | 0.043 | 0.864 | 0.842 | 0.932 | 0.070 | 0.690 | 0.654 | 0.769 | 0.053 | 0.766 | 0.740 | 0.885 |
| Backbone+FPN | 0.045 | 0.891 | 0.880 | 0.930 | 0.070 | 0.805 | 0.787 | 0.877 | 0.038 | 0.875 | 0.862 | 0.946 | 0.058 | 0.727 | 0.703 | 0.864 | 0.045 | 0.795 | 0.781 | 0.906 |
| Backbone+AFSIM | 0.041 | 0.909 | 0.894 | 0.942 | 0.067 | 0.827 | 0.806 | 0.897 | 0.032 | 0.897 | 0.886 | 0.950 | 0.055 | 0.744 | 0.722 | 0.857 | 0.040 | 0.829 | 0.815 | 0.917 |
| Backbone+ASPP+FPN | 0.039 | 0.908 | 0.896 | 0.945 | 0.067 | 0.814 | 0.795 | 0.888 | 0.034 | 0.884 | 0.872 | 0.948 | 0.056 | 0.738 | 0.718 | 0.862 | 0.042 | 0.809 | 0.796 | 0.912 |
| Backbone+MSCAM+FPN | 0.039 | 0.917 | 0.908 | 0.946 | 0.065 | 0.823 | 0.804 | 0.884 | 0.030 | 0.907 | 0.896 | 0.956 | 0.055 | 0.761 | 0.740 | 0.870 | 0.039 | 0.834 | 0.823 | 0.918 |
| Backbone+MSCAM+AFSIM | 0.034 | 0.923 | 0.911 | 0.953 | 0.064 | 0.831 | 0.811 | 0.898 | 0.029 | 0.910 | 0.900 | 0.957 | 0.054 | 0.757 | 0.736 | 0.862 | 0.038 | 0.838 | 0.823 | 0.920 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Gao, X.; Xia, C.; Ge, B.; Duan, S. GSCINet: Gradual Shrinkage and Cyclic Interaction Network for Salient Object Detection. Electronics 2022, 11, 1964. https://doi.org/10.3390/electronics11131964
Sun Y, Gao X, Xia C, Ge B, Duan S. GSCINet: Gradual Shrinkage and Cyclic Interaction Network for Salient Object Detection. Electronics. 2022; 11(13):1964. https://doi.org/10.3390/electronics11131964
Chicago/Turabian StyleSun, Yanguang, Xiuju Gao, Chenxing Xia, Bin Ge, and Songsong Duan. 2022. "GSCINet: Gradual Shrinkage and Cyclic Interaction Network for Salient Object Detection" Electronics 11, no. 13: 1964. https://doi.org/10.3390/electronics11131964
APA StyleSun, Y., Gao, X., Xia, C., Ge, B., & Duan, S. (2022). GSCINet: Gradual Shrinkage and Cyclic Interaction Network for Salient Object Detection. Electronics, 11(13), 1964. https://doi.org/10.3390/electronics11131964