
Resource- and Power-Efficient High-Performance Object Detection Inference Acceleration Using FPGA


Abstract
:1. Introduction
2. Related Works
3. Background
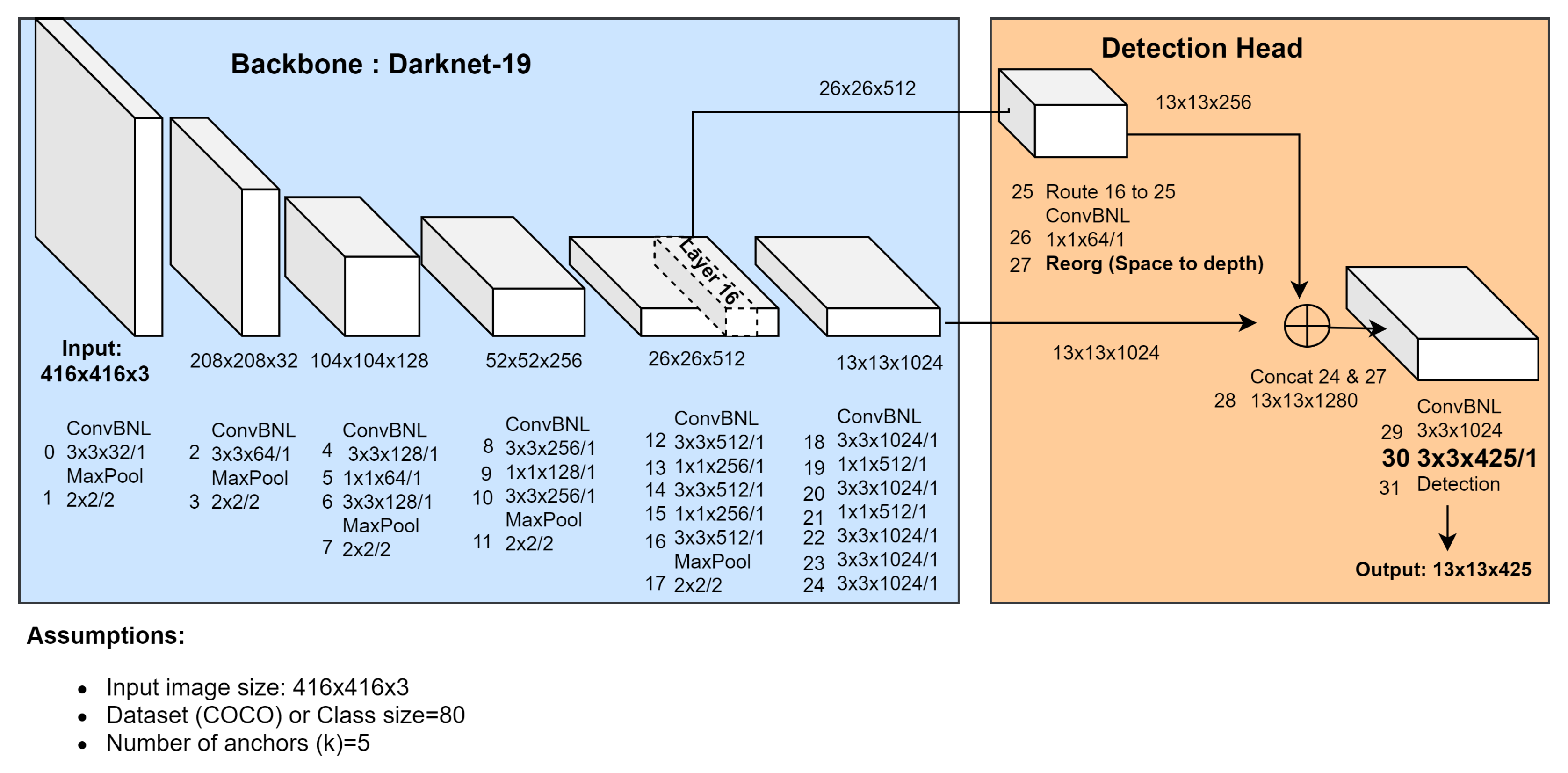
3.1. Overview of Object Detection Models
3.2. Convolution Layer
1 for (m=0; m<Nof;m++){
2 for (y=0; y<Noy;y+=S){
3 for (x=0; x<Nox;x+=S){
4 for (n=0; n<Nif;n++){
5 for (ky=0; ky<Nky;ky++){
6 for (kx=0; kx<Nkx;kx++){
7 O[m][x][y]+= X[ni][S*x+kx][S*y+ky] * W[m][n][kx][ky];
8 }
9 }
10 }
11 O[m][x][y] += B[m];
12 }
13 }
14 }
3.3. Pooling Layer
1 for (no=0; no<Nof;no++)
2 for (y=0; y<Noy;y+=S)
3 for (x=0; x<Nox;x+=S)
4 O[no][x][y]=Max(X[n0][x:x+S][y:y+S])
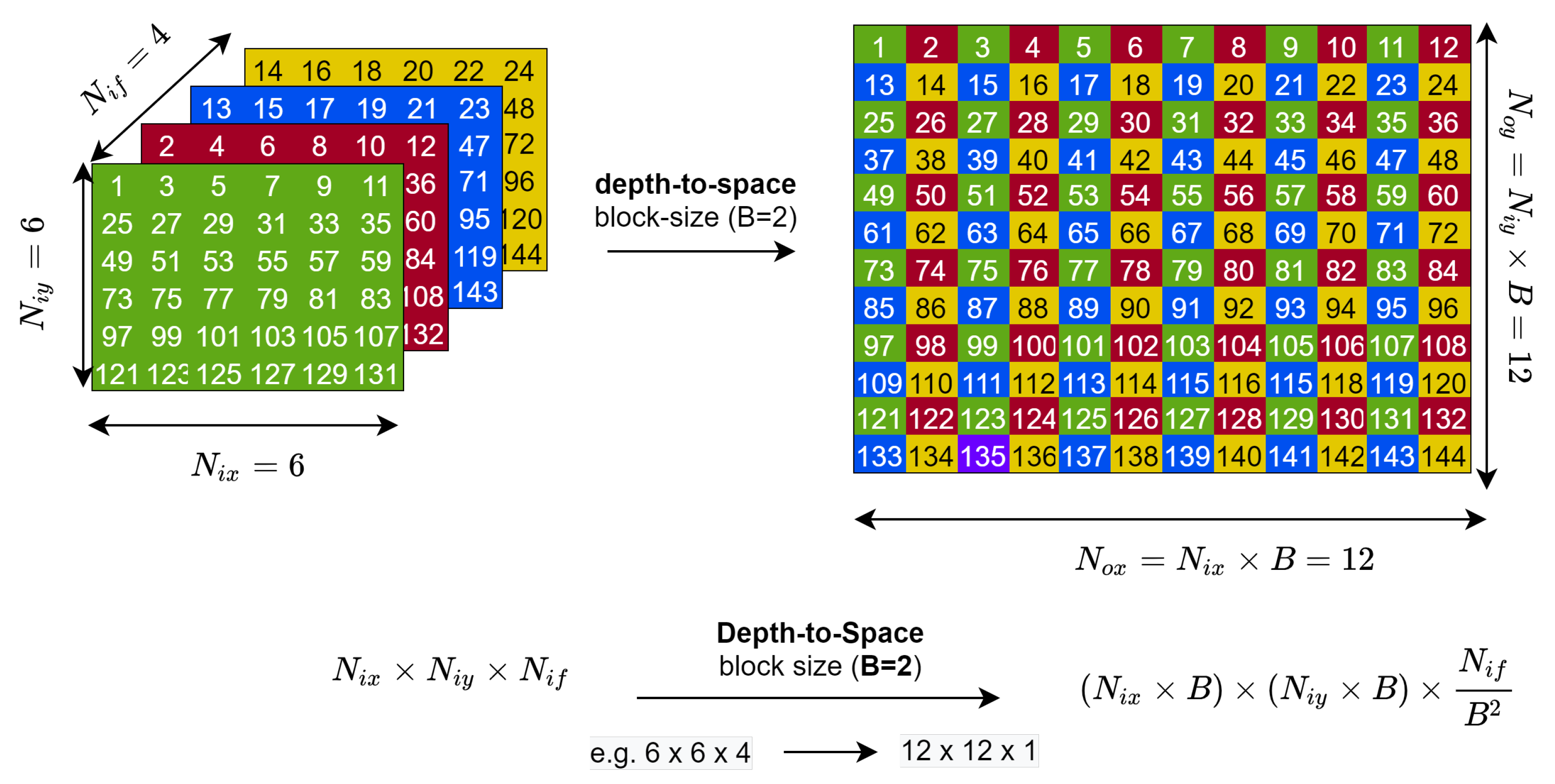
3.4. Depth-to-Space or Space-to-Depth Reorganization Layer
3.5. Batch Normalization Layer
3.6. Leaky Relu Activation Layer
4. The Proposed Hardware Acceleration of Object Detection Inference
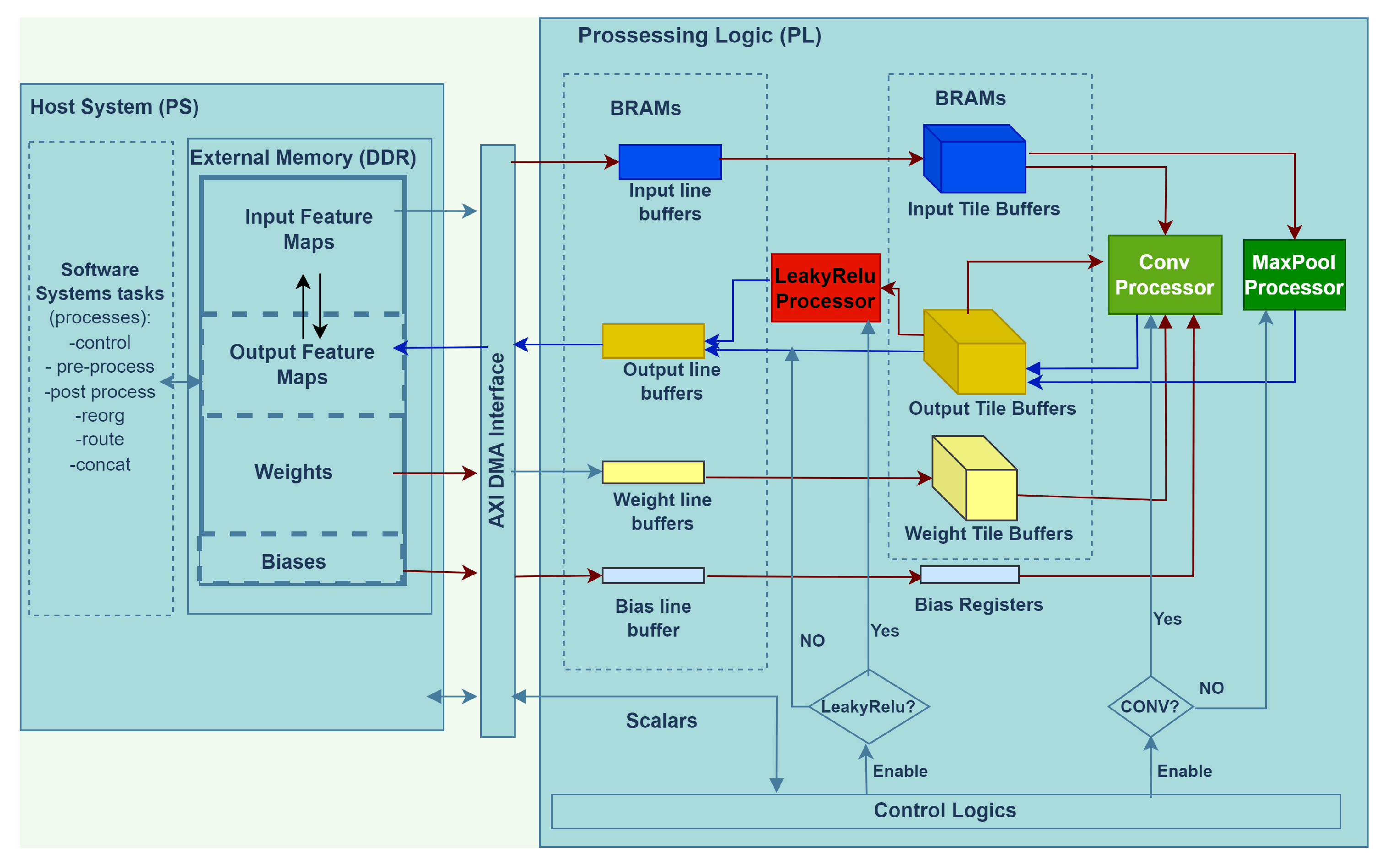
4.1. General Overview
- A highly hardware resource-efficient and optimized convolution and max-pool processors based on standard optimization techniques such as loop tiling, unrolling and convolution loop reordering;
- Per-layer dynamic 16-bit data quantization of the weight, bias, IFM and OFM;
- Double buffering-based memory read, computation and writeback for smooth convolution acceleration, one that avoids memory access from becoming its bottleneck.
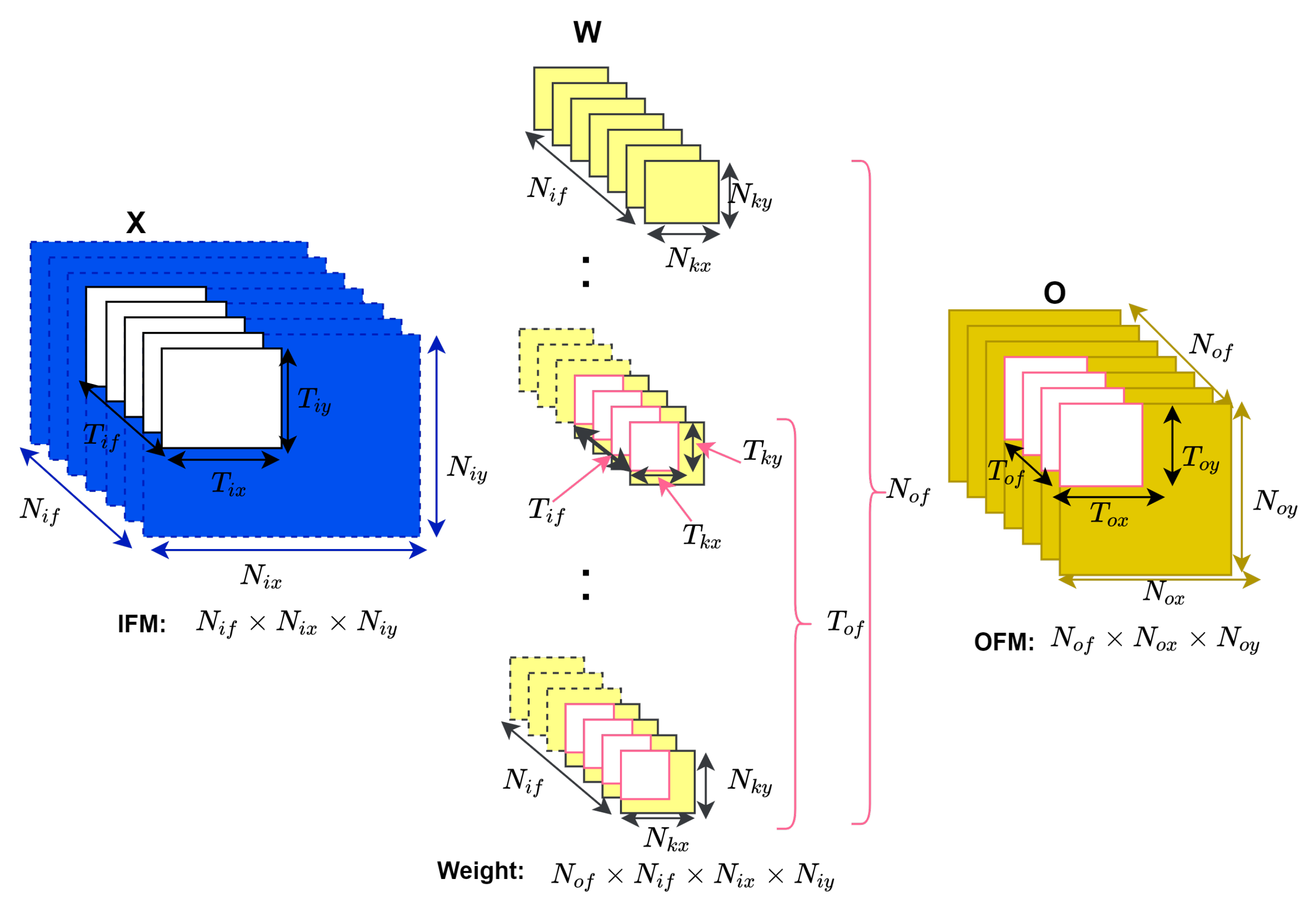
4.2. Loop Tiling
- For the efficient utilization of the scarce on-chip memory of the FPGA (that is, the BRAM or block random access memory), the max-pooling and convolution layers shall use the same memory blocks for buffering. This is possible since the two layers never happen simultaneously but one after another. Thus, we enforce resource-sharing among the two core processing elements.
- The bigger the data that we can fit on the on-chip memory through burst transfer is, the better it is to avoid frequent external memory access because external memory access is relatively slow compared to the actual computation.
- Determining the buffer sizes should not be solely based on the layers with the biggest width, height and/or depth. Instead, tile sizes should be a common divisor of all or most layers so as not to assign excessively-big buffers for most of layers, thereby wasting on-chip memory and energy or excessively small buffers, increasing external memory transaction frequencies.
4.3. Double Buffering
| Algorithm 1: Illustration of our double-buffering implementation |
 |
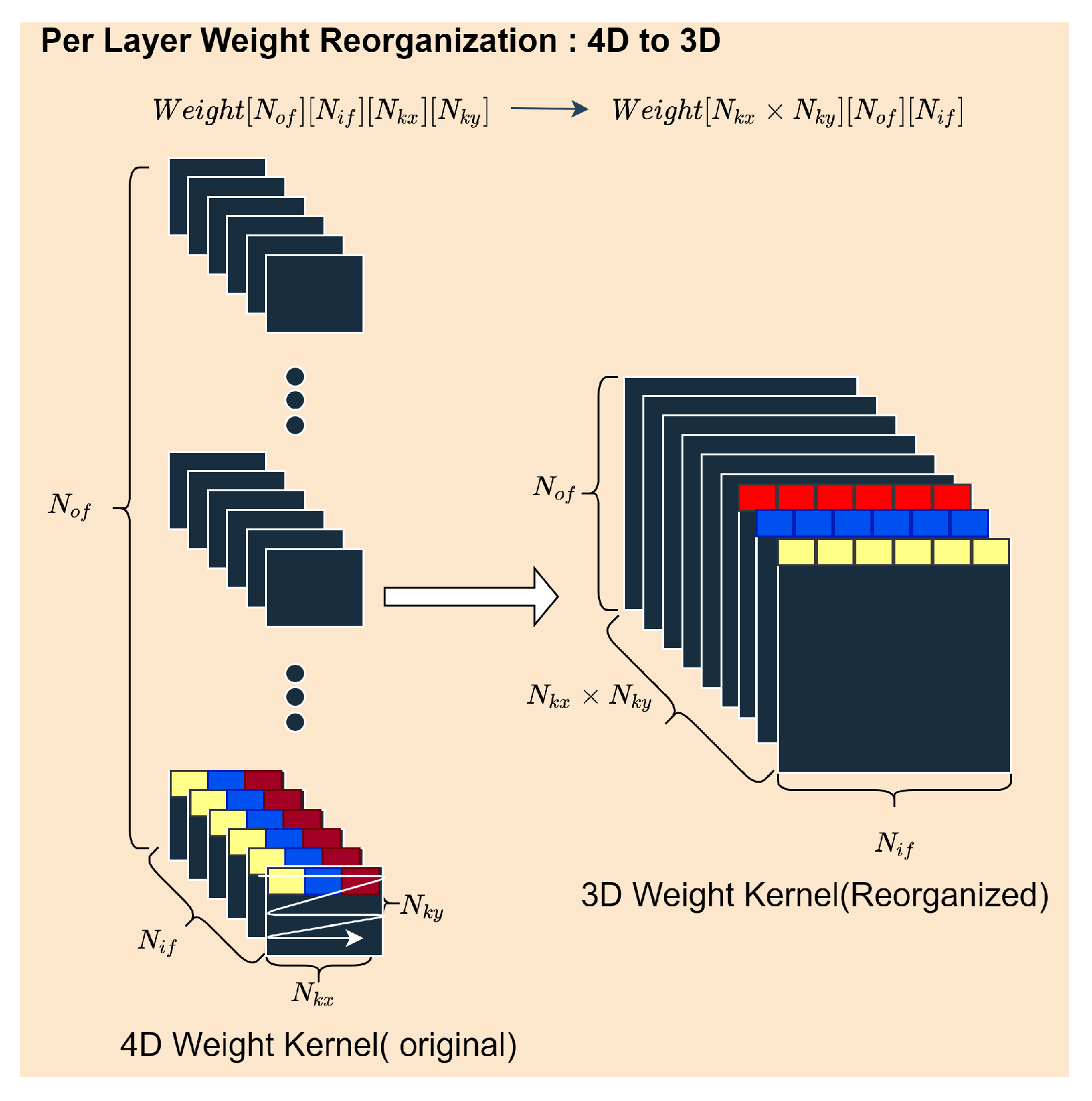
4.4. Data Quantization and Weight Reorganization
| Algorithm 2: Per-layer 16-bit dynamic quantization of weight |
 |
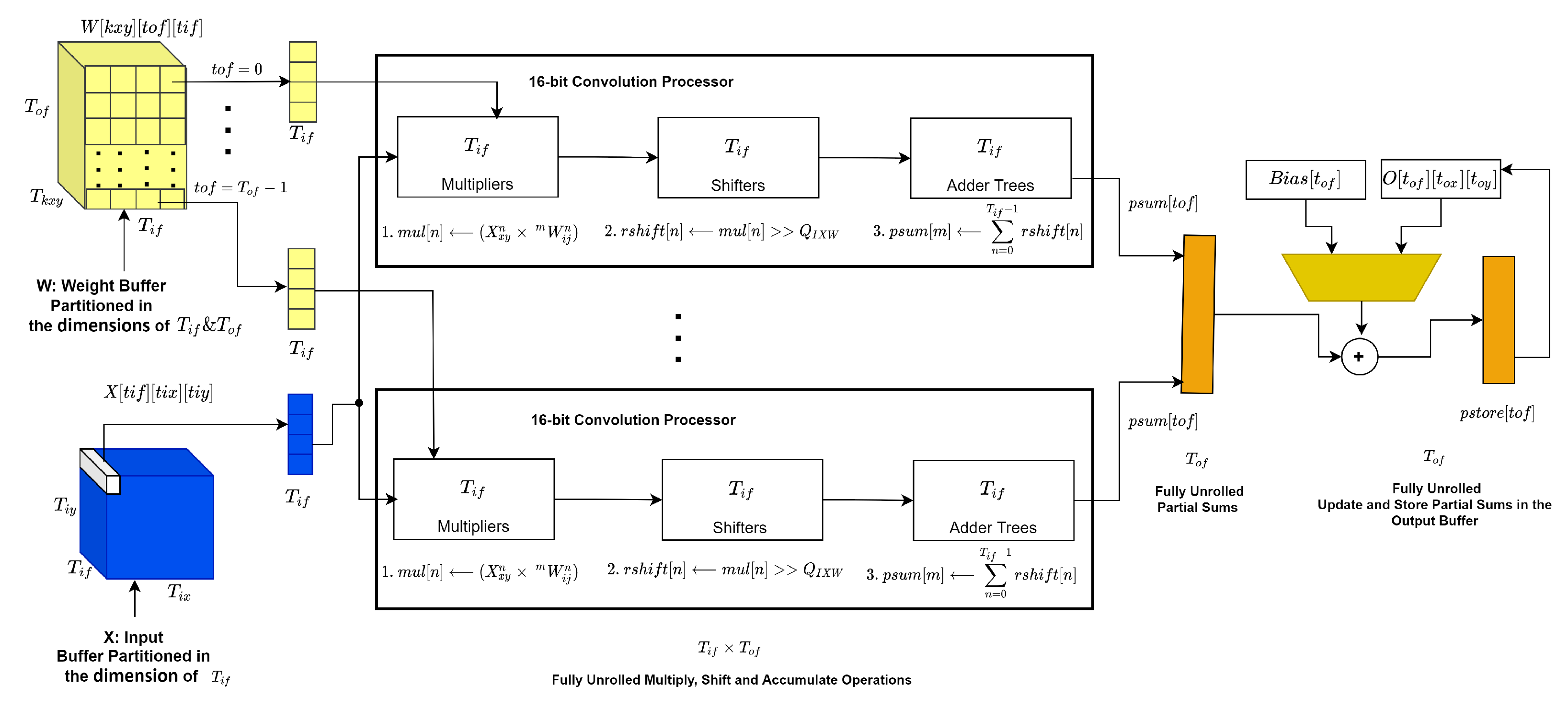
4.5. Convolution Processor
- Per block (tile), the convolution compute latency is given by the Equation (17) below:C stands for the ’constant’ referring to the number of cycles needed to perform the fully unrolled inner operations commented 1–4 in the pseudocode Listing 4 and loop iterations control logic. In our implementation, C is equal to either 13 or 21 based on the kernel types, or , respectively. stands for clock frequency.
- The total compute latency for a convolution layer is calculated as:
- The total number of multiply, shift and accumulate operations per convolution layer is calculated as:
1 int32_t lineinput[Tif];
2 int32_t pmul[Tif];
3 int32_t rshift[Tif];
4 int32_t psum[Tof];
5 int32_t pstore[Tof];
6 _trconv:for(tr = 0;tr < min(Tox,Nox);tr++){
7 _tcconv:for(tc = 0;tc < min(Toy,Noy);tc++){
8 //1. clear
9 _pmulclear:for(tm = 0;tm <Tof;tm++){
10 #pragma HLS unroll //PIPELINE II=1
11 psum[tm]=0;
12 }
13 //2. compute multiply, shift and accumulate
14 _nkiconv:for(i =0;i < Nkx; i++){
15 _nkjconv:for(j = 0;j < Nky; j++){
16 tix = tr*Kstride + i;
17 tiy = tc*Kstride + j;
18 tkxy = i*Ksize + j;
19 _tnminiInput:for(tn = 0;tn <Tn;tn++){
20 #pragma HLS unroll
21 lineinput[tn]= X[tn][tix][tiy];
22 }
23 _tmconv:for(tm = 0;tm < Tof;tm++){
24 #pragma HLS unroll
25 _tnconv1:for(tn = 0;tn <Tif;tn++){
26 #pragma HLS unroll
27 pmul[tn]= W[tkxy][tm][tn]*lineinput[tn];
28 }
29 _tnconv2:for(tn = 0;tn <Tif;tn++){
30 #pragma HLS unroll
31 rshift[tn]= pmul[tn]>>Qixw;
32 }
33 _tnconv3:for(tn = 0;tn <Tif;tn++){
34 #pragma HLS unroll
35 psum[tm]+= rshift[tn];
36 }
37 }
38 }
39 }
40 //3. update
41 _psupdate:for(tm = 0;tm <Tof;tm++){
42 #pragma HLS unroll
43 if(n==0){
44 pstore[tm] = B[tm] + (psum[tm]);
45 }
46 else{
47 pstore[tm] = O[tm][tr][tc]+ (psum[tm]);
48 }
49 }
50 //4. store
51 _psstore:for(tm = 0;tm <Tof;tm++){
52 #pragma HLS unroll
53 O[tm][tr][tc]= pstore[tm];
54 }
55 }
56 }
1 int32_t mul[Tif];
2 int32_t rshift[Tif];
3 int32_t psum[Tof];
4 int32_t pstore[Tm];
5 _nkiconv:for(i =0;i < Nkx; i++){
6 _nkjconv:for(j = 0;j < Nky; j++){
7 _trconv:for(tr = 0;tr < min(Tox,Nox);tr++){
8 _tcconv:for(tc = 0;tc < min(Toy,Noy);tc++){
9 //1. clear partial sum
10 _pmulclear:for(tm = 0;tm<Tof;tm++){
11 #pragma HLS unroll
12 msa[tm]=0;
13 }
14 //2. compute multiply, shift and accumulate
15 _tmconv:for(tm = 0;tm < Tof;tm++){
16 #pragma HLS unroll
17 //2.1 multiply
18 _tnmultiply:for(tn = 0;tn <Tif;tn++){
19 #pragma HLS unroll
20 mul[tn]= W[i*Nkx+j][tm][tn]*
21 X[tn][tr*S + i][tc*S + j];
22 }
23 //2.2 right-shift for decimal point consideration
24 _tnshift:for(tn = 0;tn <Tif;tn++){
25 #pragma HLS unroll
26 rshift[tn]= mul[tn]>>Qixw;
27 }
28 //2.3 accumulate to partial sum
29 _tnaccumulate:for(tn = 0;tn <Tif;tn++){
30 #pragma HLS unroll
31 psum[tm]+= rshift[tn];
32 }
33 }
34 //3. update stored partial sum
35 _pupdate:for(tm = 0;tm <Tof;tm++){
36 #pragma HLS unroll
37 if(i ==0 && j==0 && n==0){
38 pstore[tm] = B[tm] + (psum[tm]);
39 }
40 else{
41 pstore[tm] = O[tm][tr][tc]+ (psum[tm]);
42 }
43 }
44 //4. store partial sum
45 _pstore:for(tm = 0;tm <Tof;tm++){
46 #pragma HLS unroll
47 O[tm][tr][tc]= pstore[tm];
48 }
49 }
50 }
51 }
52 }
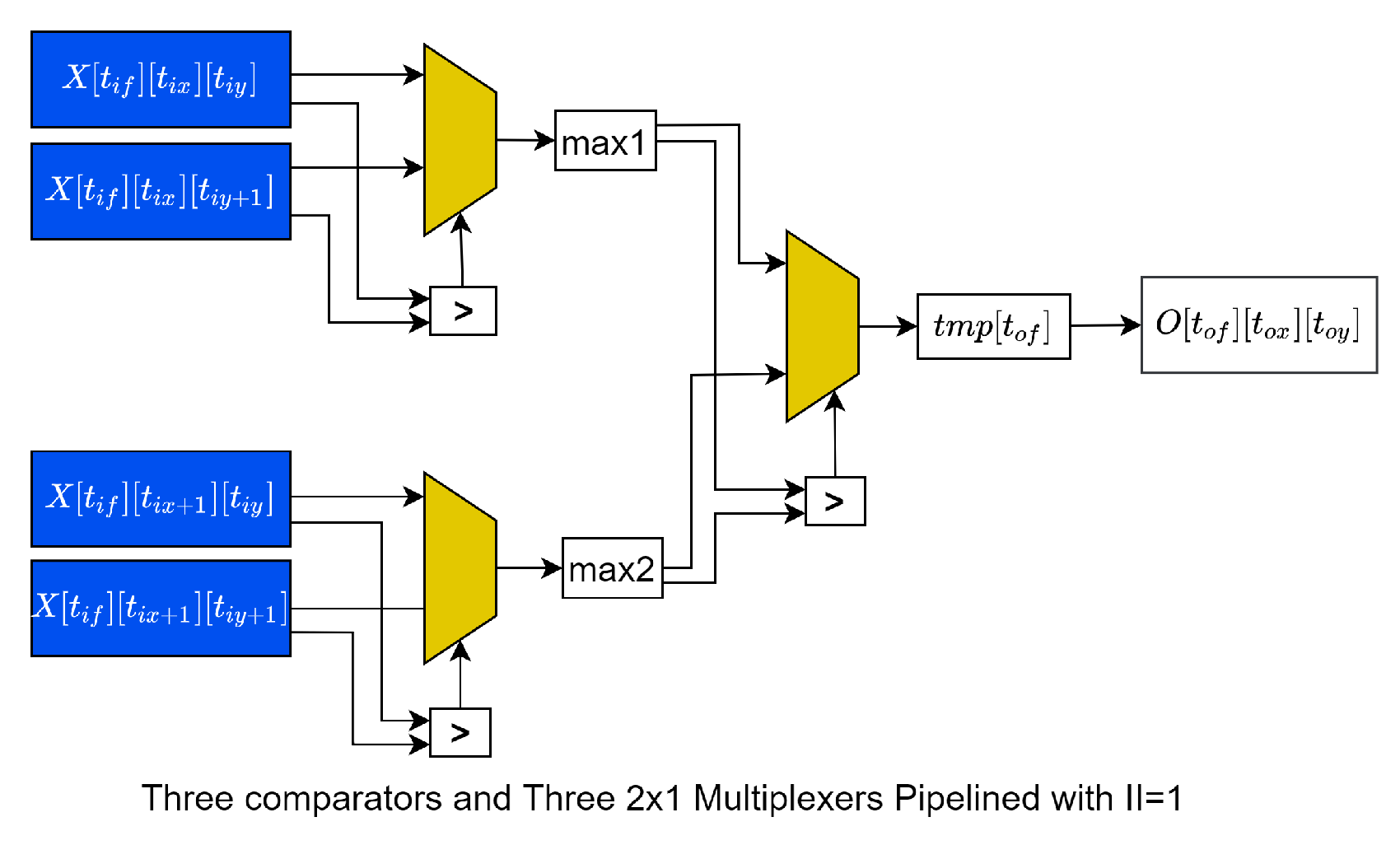
4.6. Max-Pooling Processor
1 int16_t tmp[Tif];
2 int16_t tmp1, tmp2,tmp3, tmp4, max1,max2;
3 _toxmax:for(_tox = 0;_tox < min(Tox,Nox);_tox++){
4 _toymax:for(_toy = 0;_toy < min(Toy,Noy);_toy++){
5 _tofmax:for(_tof = 0; _tof < min(Tif,N_{if}); _tof++){
6 #pragma HLS PIPELINE II=1
7 tmp1=X[_tof][_tox*S][_toy*S];
8 tmp2=X[_tof][_tox*S][_toy*S+1];
9 max1 = (tmp1 > tmp2) ? tmp1 : tmp2;
10
11 tmp3=X[_tof][_tox*S+1][_toy*S];
12 tmp4=X[_tof][_tox*S+1][_toy*S+1];
13 max2 = (tmp3 > tmp4) ? tmp3 : tmp4;
14
15 tmp[_tof] = max1 > max2 ? max1 : max2;
16
17 }
18 maxstore:for(_tof = 0; _tof < min(Tif,Nif); _tof++){
19 #pragma HLS PIPELINE II=1
20 O[_tof][_tox][_toy] = tmp[_tof];
21 }
22 }
23 }
4.7. Leaky Relu Hardware Processor
1 tmp_out[i]= (tmp_in[i] < 0) ? (tmp_in[i]*0xccc)>>15 : tmp_in[i];
5. Results and Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 525–542. [Google Scholar]
- Nakahara, H.; Yonekawa, H.; Fujii, T.; Sato, S. A lightweight YOLOv2: A binarized CNN with a parallel support vector regression for an FPGA. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; pp. 31–40. [Google Scholar]
- Suleiman, A.; Sze, V. Energy-efficient HOG-based object detection at 1080HD 60 fps with multi-scale support. In Proceedings of the 2014 IEEE Workshop on Signal Processing Systems (SiPS), Belfast, UK, 20–22 October 2014; pp. 1–6. [Google Scholar]
- IJzerman, J.; Viitanen, T.; Jääskeläinen, P.; Kultala, H.; Lehtonen, L.; Peemen, M.; Corporaal, H.; Takala, J. AivoTTA: An energy efficient programmable accelerator for CNN-based object recognition. In Proceedings of the 18th International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation, Pythagorion, Greece, 15–19 July 2018; pp. 28–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Cong, J.; Xiao, B. Minimizing computation in convolutional neural networks. In Proceedings of the International Conference on Artificial Neural Networks, Hamburg, Germany, 15–19 September 2014; pp. 281–290. [Google Scholar]
- Abdelouahab, K.; Pelcat, M.; Serot, J.; Berry, F. Accelerating CNN inference on FPGAs: A survey. arXiv 2018, arXiv:1806.01683. [Google Scholar]
- Zeng, K.; Ma, Q.; Wu, J.W.; Chen, Z.; Shen, T.; Yan, C. FPGA-based accelerator for object detection: A comprehensive survey. J. Supercomput. 2022, 1–41. [Google Scholar] [CrossRef]
- Zhang, C.; Prasanna, V. Frequency domain acceleration of convolutional neural networks on CPU-FPGA shared memory system. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 35–44. [Google Scholar]
- Zeng, H.; Chen, R.; Zhang, C.; Prasanna, V. A framework for generating high throughput CNN implementations on FPGAs. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; pp. 117–126. [Google Scholar]
- Bao, C.; Xie, T.; Feng, W.; Chang, L.; Yu, C. A power-efficient optimizing framework FPGA accelerator based on winograd for YOLO. IEEE Access 2020, 8, 94307–94317. [Google Scholar] [CrossRef]
- Aydonat, U.; O’Connell, S.; Capalija, D.; Ling, A.C.; Chiu, G.R. An OpenCLTM Deep Learning Accelerator on Arria 10. CoRR 2017. [Google Scholar] [CrossRef] [Green Version]
- Wai, Y.J.; bin Mohd Yussof, Z.; bin Salim, S.I.; Chuan, L.K. Fixed Point Implementation of Tiny-Yolo-v2 using OpenCL on FPGA. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 506–512. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing fpga-based accelerator design for deep convolutional neural networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 45–54. [Google Scholar]
- Wang, Z.; Xu, K.; Wu, S.; Liu, L.; Liu, L.; Wang, D. Sparse-YOLO: Hardware/software co-design of an FPGA accelerator for YOLOv2. IEEE Access 2020, 8, 116569–116585. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ma, Y.; Zheng, T.; Cao, Y.; Vrudhula, S.; Seo, J.s. Algorithm-hardware co-design of single shot detector for fast object detection on FPGAs. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Tesema, S.N.; Bourennane, E.B. Multi-Grid Redundant Bounding Box Annotation for Accurate Object Detection. In Proceedings of the 2021 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 25–28 October 2021; pp. 145–152. [Google Scholar]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A real-time object detection algorithm optimized for non-GPU computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Tesema, S.N.; Bourennane, E.B. DenseYOLO: Yet Faster, Lighter and More Accurate YOLO. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; pp. 0534–0539. [Google Scholar]
- Tesema, S.N.; Bourennane, E.B. Towards General Purpose Object Detection: Deep Dense Grid Based Object Detection. In Proceedings of the 2020 14th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 17–18 November 2020; pp. 227–232. [Google Scholar]
- Wei, X.; Yu, C.H.; Zhang, P.; Chen, Y.; Wang, Y.; Hu, H.; Liang, Y.; Cong, J. Automated systolic array architecture synthesis for high throughput CNN inference on FPGAs. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H.J. A high-throughput and power-efficient FPGA implementation of YOLO CNN for object detection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1861–1873. [Google Scholar] [CrossRef]
- Zhang, S.; Cao, J.; Zhang, Q.; Zhang, Q.; Zhang, Y.; Wang, Y. An fpga-based reconfigurable cnn accelerator for yolo. In Proceedings of the 2020 IEEE 3rd International Conference on Electronics Technology (ICET), Chengdu, China, 8–12 May 2020; pp. 74–78. [Google Scholar]
- Yu, Z.; Bouganis, C.S. A parameterisable FPGA-tailored architecture for YOLOv3-tiny. In International Symposium on Applied Reconfigurable Computing; Springer: Cham, Switzerland, 2020; pp. 330–344. [Google Scholar]
- Li, S.; Luo, Y.; Sun, K.; Yadav, N.; Choi, K.K. A novel FPGA accelerator design for real-time and ultra-low power deep convolutional neural networks compared with titan X GPU. IEEE Access 2020, 8, 105455–105471. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Layer Type | Filters | Size/Stride | Input Size | Output Size | |
|---|---|---|---|---|---|---|
| Darknet-19 Backbone | 0 | ConvBNL | 32 | |||
| 1 | Max Pool | |||||
| 2 | ConvBNL | 64 | ||||
| 3 | Max Pool | |||||
| 4 | ConvBNL | 128 | ||||
| 5 | ConvBNL | 64 | ||||
| 6 | ConvBNL | 128 | ||||
| 7 | Max Pool | |||||
| 8 | ConvBNL | 256 | ||||
| 9 | ConvBNL | 128 | ||||
| 10 | ConvBNL | 256 | ||||
| 11 | Max Pool | |||||
| 12 | ConvBNL | 512 | ||||
| 13 | ConvBNL | 256 | ||||
| 14 | ConvBNL | 512 | ||||
| 15 | ConvBNL | 256 | ||||
| 16 | ConvBNL | 512 | ||||
| 17 | Max Pool | |||||
| 18 | ConvBNL | 1024 | ||||
| 19 | ConvBNL | 512 | ||||
| 20 | ConvBNL | 1024 | ||||
| 21 | ConvBNL | 512 | ||||
| 22 | ConvBNL | 1024 | ||||
| 23 | ConvBNL | 1024 | ||||
| Detection Head | 24 | ConvBNL | 1024 | |||
| 25 | Route 16 | |||||
| 26 | ConvBNL | 64 | ||||
| 27 | Reorg | /2 | ||||
| 28 | Concat 24 and 27 | |||||
| 29 | ConvBNL | 1024 | ||||
| 30 | ConvBNL | 425 | ||||
| 31 | Detection-head (output post-processing) | |||||
| Tensors | Original Shape | Tile Sizes (Shapes) | Number of External Memory Access (Either to Read from or Write to DDR Memory) |
|---|---|---|---|
| IFM | |||
| OFM | |||
| Weights | |||
| Biases |
| Boards | Z-7020CGL484-1 | ZCU102-XCZU9EG-2FFVB1156E |
|---|---|---|
| Flip flops (FF) | 106,400 | 548,160 |
| LUT | 53,200 | 274,080 |
| BRAM_18Kb | 280 | 1824 |
| DSP | 220 | 2520 |
| Boards | ZYNQ 7020 | ZCU102 | |
|---|---|---|---|
| Tile sizes | 32 | 64 | |
| 4 | 4 | ||
| 26 | 52 | ||
| 26 | 52 | ||
| 52 | 104 | ||
| 52 | 104 | ||
| Resource utilization | FF | 22,239 (20.9%) | 34,076 (6%) |
| LUT | 28,333 (53.2%) | 97,971 (35%) | |
| BRAM (18 Kb) | 170 (60.7%) | 1008 (55%) | |
| DSP | 180 (81.8%) | 291 (11%) | |
| Clock (MHz) | 150 | 300 | |
| GOP | 44.36 | 44.96 | |
| GOPS | 51.06 | 184.06 | |
| Power (Watt) | 2.78 | 5.376 | |
| [30] | [31] | [32] | [33] | [23] | This Work | This Work | |
|---|---|---|---|---|---|---|---|
| Device | Virtex-7 VC707 | ZCU102 | Zedboard | Intel Arria 10 | Intel Stratix 10 | ZYNQ-7020 | ZCU102 |
| Models | Sim-YOLOv2 | YOLOv2 | YOLOv3 tiny | YOLOv2 | SSD300 | YOLOv2 | YOLOv2 |
| Design tool | OpenCL | Vivado HLS | Vivado HLS | OpenCL | RTL | Vitis HLS | Vitis HLS |
| Design scheme | HW | HW/SW | HW/SW | HW/SW | HW/SW | HW/SW | HW/SW |
| Precision (bits) | 1–6 | 16 | 16 | 8–16 | 8–16 | 16 | 16 |
| Frequency (MHz) | 200 | 300 | 100 | 200 | 300 | 150 | 300 |
| FF Utilization | 115 K (18.9%) | 90,589 | 46.7 K | 523.7 K | - | 22.2 K (20.9%) | 34,076 (6%) |
| LUT Utilization | 155.2 K (51.1%) | 95136 | 25.9 K | 360 K | 532 K | 28.3 K (53.2%) | 97,971 (35%) |
| DSP Utilization | 272 (9.7%) | 609 | 160 | 410 | 4363 | 180 (81.8%) | 291(11%) |
| BRAM(18Kb) utilizations | 1144 (55.5%) | 491 | 185 | 1366 * | 3844 * | 170 (60.7 %) | 1008 (55%) |
| Throughput (GOP/S) | 1877 | 102.5 | 464.7 | 740 | 2178 | 51.06 | 184.06 |
| Power | 18.29 | 11.8 | 3.36 | 27.2 | 100 | 2.78 | 5.376 |
| Latency (ms) | - | 288 | 532 | - | 29.11 | 868 | 244 |
| Accuracy (mAP) | 64.16 | - | - | 73.6 | 76.94 | 76.21 | 76.21 |
| Input image size | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tesema, S.N.; Bourennane, E.-B. Resource- and Power-Efficient High-Performance Object Detection Inference Acceleration Using FPGA. Electronics 2022, 11, 1827. https://doi.org/10.3390/electronics11121827
Tesema SN, Bourennane E-B. Resource- and Power-Efficient High-Performance Object Detection Inference Acceleration Using FPGA. Electronics. 2022; 11(12):1827. https://doi.org/10.3390/electronics11121827
Chicago/Turabian StyleTesema, Solomon Negussie, and El-Bay Bourennane. 2022. "Resource- and Power-Efficient High-Performance Object Detection Inference Acceleration Using FPGA" Electronics 11, no. 12: 1827. https://doi.org/10.3390/electronics11121827
APA StyleTesema, S. N., & Bourennane, E.-B. (2022). Resource- and Power-Efficient High-Performance Object Detection Inference Acceleration Using FPGA. Electronics, 11(12), 1827. https://doi.org/10.3390/electronics11121827