
A Modified RL-IGWO Algorithm for Dynamic Weapon-Target Assignment in Frigate Defensing UAV Swarms




Abstract
1. Introduction
- The “Attack-Observation-Attack” model (AOA). The AOA model is the most common in DWTA problems, in which said problems are directly decomposed into a series of SWTA problems, according to the current observation status. The AOA model is simple and effective, but it faces difficulties when handling large-scale DWTA problems in the long time-domain. Kong established a meaningful and effective DWTA model based on the AOA framework, which contains two practical and conflicting objectives, namely, maximizing combat benefits and minimizing weapon costs. Besides that, an improved multi-objective particle swarm optimization algorithm (IMOPSO) was proposed by Kong. Experimental results showed that IMOPSO has better convergence and distribution than other multi-objective optimization algorithms [8]. Lai supplemented the following two novel schemes into the original AOA model: the deterministic initialization scheme, and the target exchange scheme. The target exchange scheme is a local search updating feasible solutions, and it can be adopted when the battlefield situation varies drastically. Through the scheme, the robust performance of the AOA model was enhanced [9]. Hocaolu developed a constraint based nonlinear goal programming model for weapon assignment problem to minimize survival probability. The model not only gives optimum assignment but also results in engagement times and defense success for multi-defense sites. This model was exemplified by a land-based air defense example [10].
- The “Observe-Orient-Decide-Act” model (OODA). In the process of AOA modeling, the operational command process is not considered, and the combat command process is an “Observe-Oriented-Declare-Act” (OODA) loop [11]. AOA model only contains the “Observe-Act” stages, and the “Orient-Decide” stages are considered in the OODA model. Deriving from the AOA framework, an “Observe-Orient-Decide-Act” loop model for DWTA was established by Zhang. The receding horizon decomposition strategy was proposed and adopted to disassemble DWTA problems, thereby broadening the operational research space of each subproblem. A heuristic algorithm based on statistical marginal return (HA-SMR) was designed, which proposed a reverse hierarchical idea of an “asset value-target selected-weapon decision”. Experimental results show that HA-SMR solving DWTA has advantages of real-time and robustness [12]. A hybrid multi-target bi-level programming model was established by Zhao. The upper level takes the sum of the electronic jamming effects in the whole combat stage as an optimization objective, and the lower level takes the importance expectation value of the target subjected to interference and combat consumption as double optimization objectives to globally optimize the assignment scheme. To focus on solving this complex model, a hybrid multi-objective bi-level interactive fuzzy programming algorithm (HMOBIF) was proposed by Zhao; in this method, exponential membership function was used to describe the satisfaction degree of each level [13]. Although the weapon-target allocation problem is transformed into a two-layer optimization problem, in full consideration of the “Observe-Orient-Decide-Act” stages, there is no guarantee that the optimal solutions of subproblems can be the global optimal in the whole time-domain.
- The game theory model. All of the aforementioned DWTA models assume that antagonist targets are all passive defense objects without intelligence, without fully considering the dynamic game characteristics in actual battlefields. The introduction of game theory transforms the DWTA models from optimal control problems into game control problems. At present, there is a scarcity of research on the game theory model. The main idea of modeling is to calculate the operational benefits of the weapons and various target information on both sides, and to solve the Nash equilibrium solution according to the operational benefits at different operational moments [13]. A comprehensive mathematical dynamic game model based on both sides was established to solve DWTA problems, and a phased solution was provided based on Nash equilibrium algorithm and Pareto optimization. The results validated that combining the mathematical model with the game theory method can effectively deal with the problem of dynamic weapon-target assignment efficiently [14].
- The process of disassembling DWTA problems is not supported by effective analytical proof, and there is no guarantee that the optimal solutions of subproblems can be the global optimal in the whole time-domain.
- For solving each subproblem that is disassembled from DWTA problems, several imperfections exist in some state-of-the-art swarm intelligence algorithms, which can become trapped into the local optimum at times.
- For the process of multi-objective optimization of DWTA problems, various objective functions have intense conflicts with others in many cases, and traditional objective function design heavily relies on weight, for which there is no effective method.
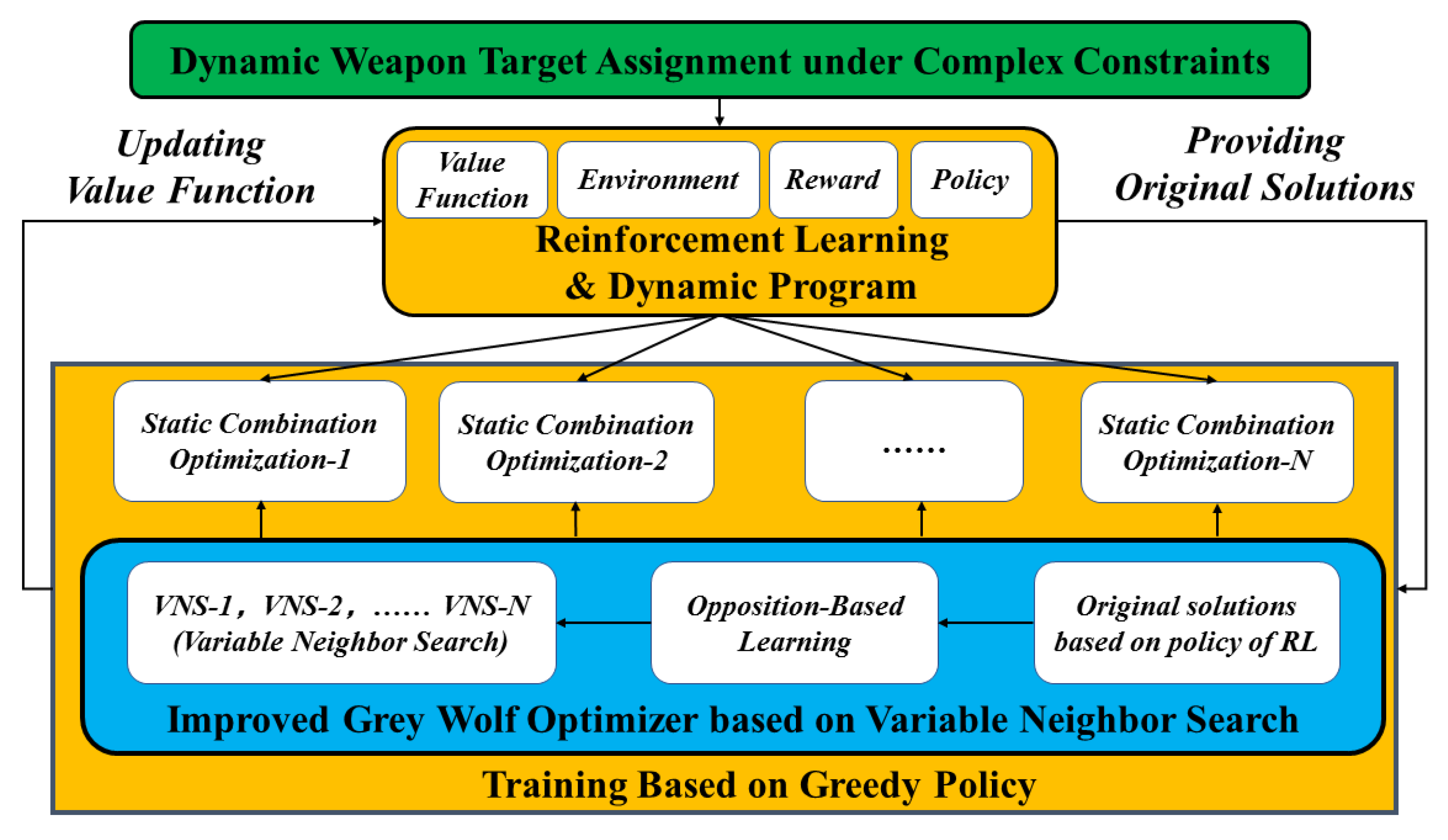
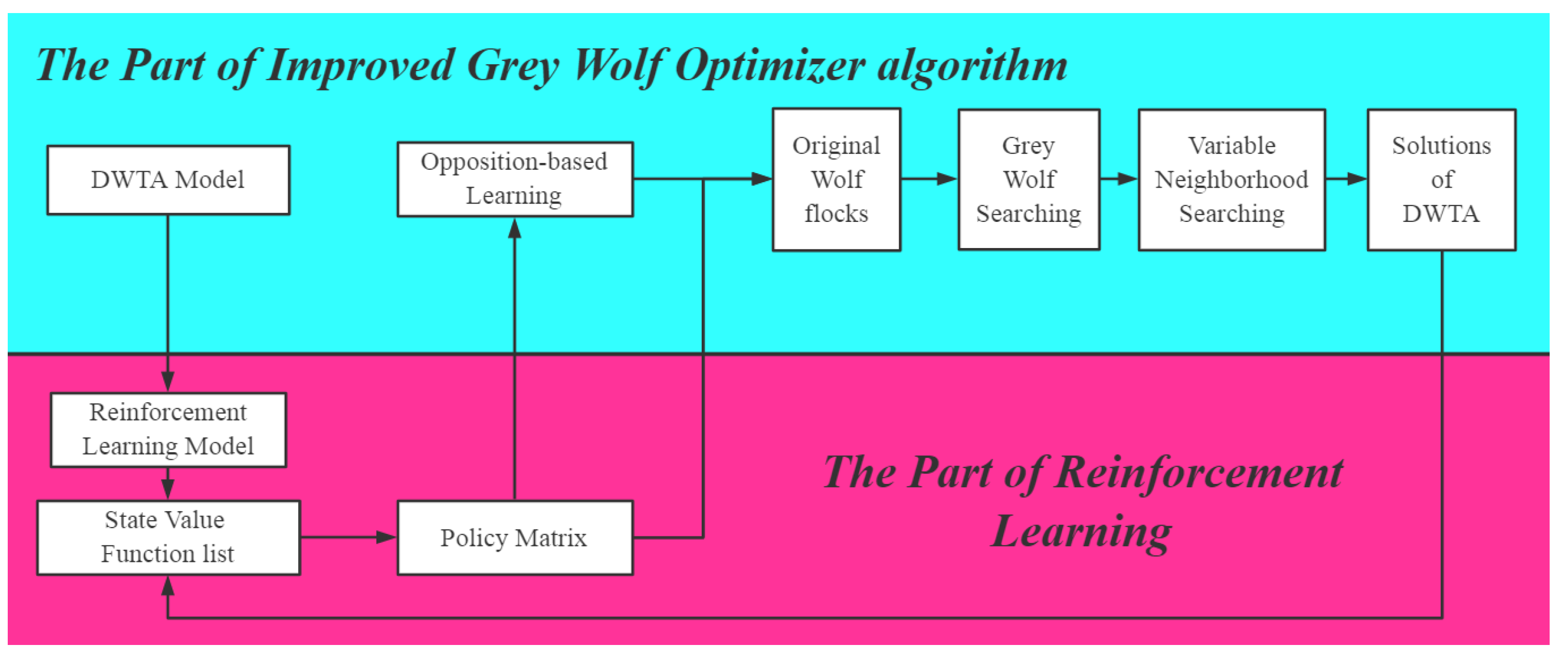
- In this paper, the DWTA problem was disassembled into several static combination optimization (SCO) problems by means of the dynamic programming method and reinforcement learning, with rigorous analytic proof.
- Several variable neighborhood search (VNS) operators and an opposition-based learning (OBL) operator were designed to enhance the global search ability of the grey wolf optimizer algorithm (GWO).
- This paper integrated reinforcement learning and the grey wolf optimizer algorithm. Reinforcement learning is adopted to help the grey wolf optimizer algorithm generate original solutions with high quality. The improved grey wolf optimizer algorithm can better execute greedy policy, which is beneficial to the state value function converge. Additionally, value state functions of reinforcement learning were considered to design objective functions.
2. DWTA Problems of Frigate Defensing UAVS
2.1. Combat Scenario
2.2. Model and Constraints
2.3. Objective Functions
3. RL-IGWO Algorithm
3.1. DWTA Disassembly
3.2. Improved Grey Wolf Optimizer (IGWO)
| Algorithm 1 Grey Wolf Optimizer |
| 1: for in range (): 2: for in range (): 3: 4: 5: 6: 7: 8: end for 9: end for |
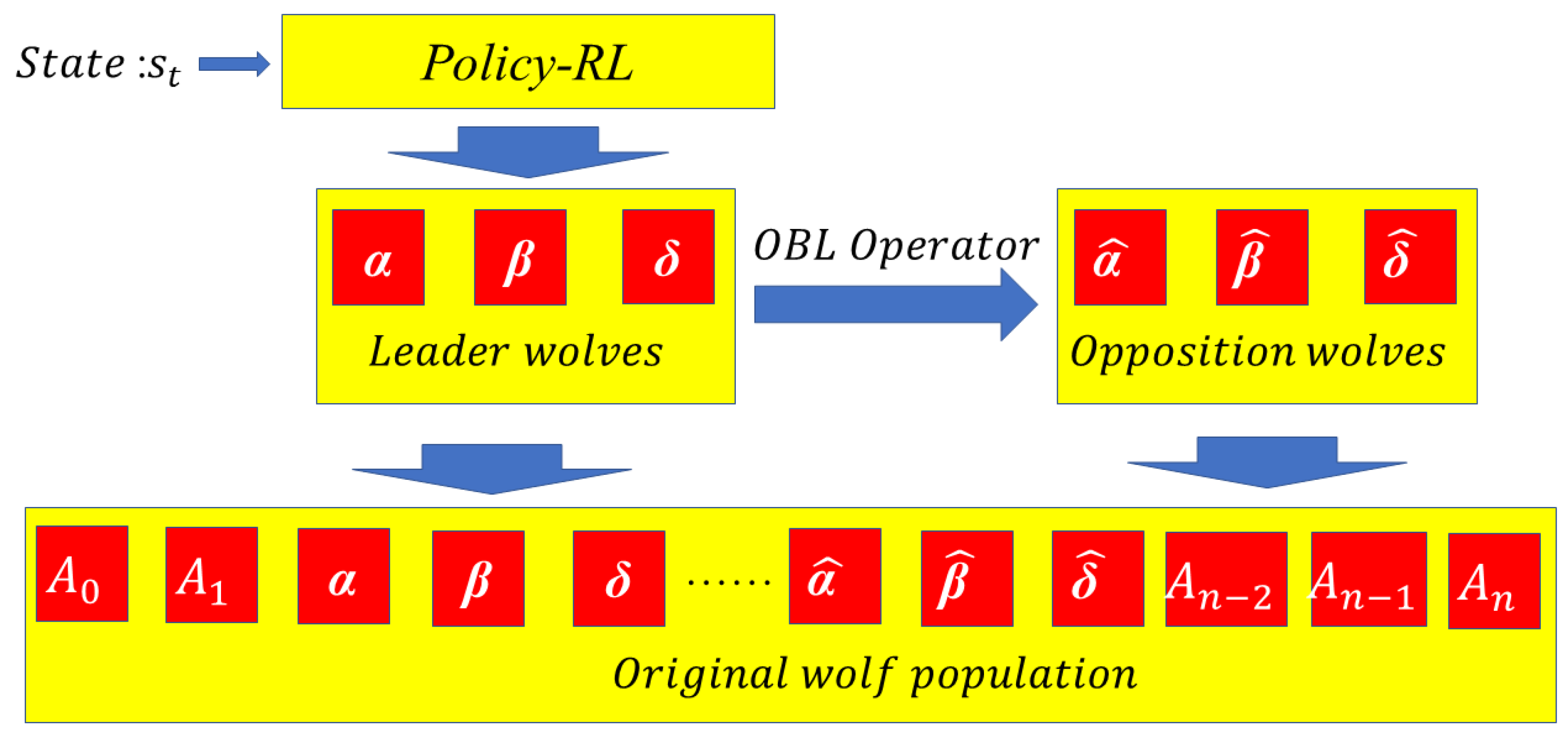
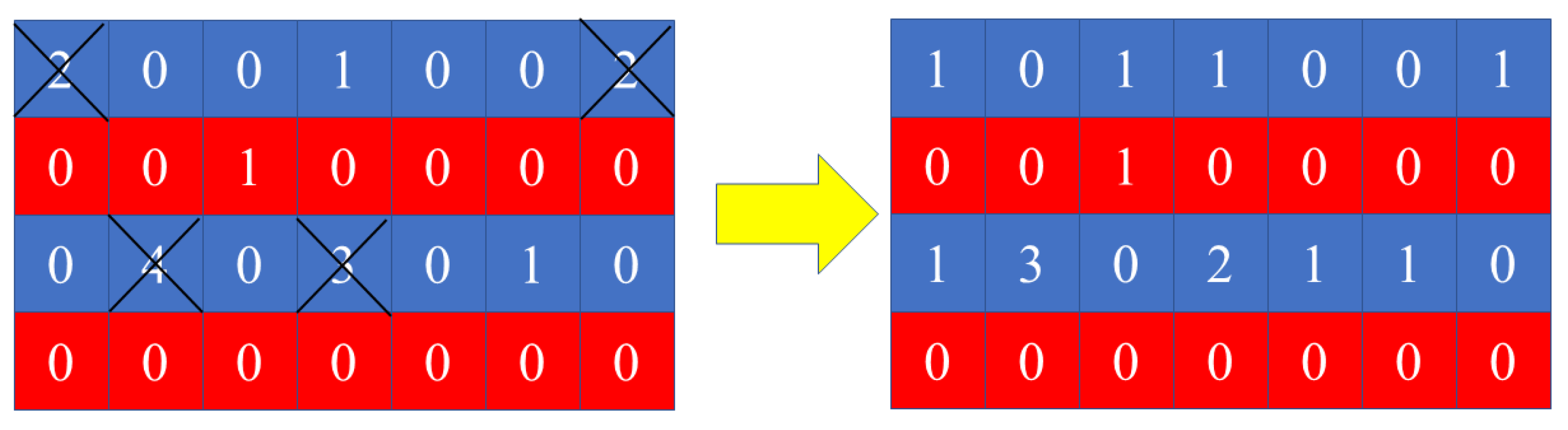
3.2.1. Opposition-based Learning Operator
| Algorithm 2 Opposition-Based Operator |
| 1: Determine the position of leader wolfs: 2:= 3: for in range (): 4: for in range (): 5: if ( > 0): 6: 7: if ( = 0): 8: 9: end for 10: end for 11: Output: |
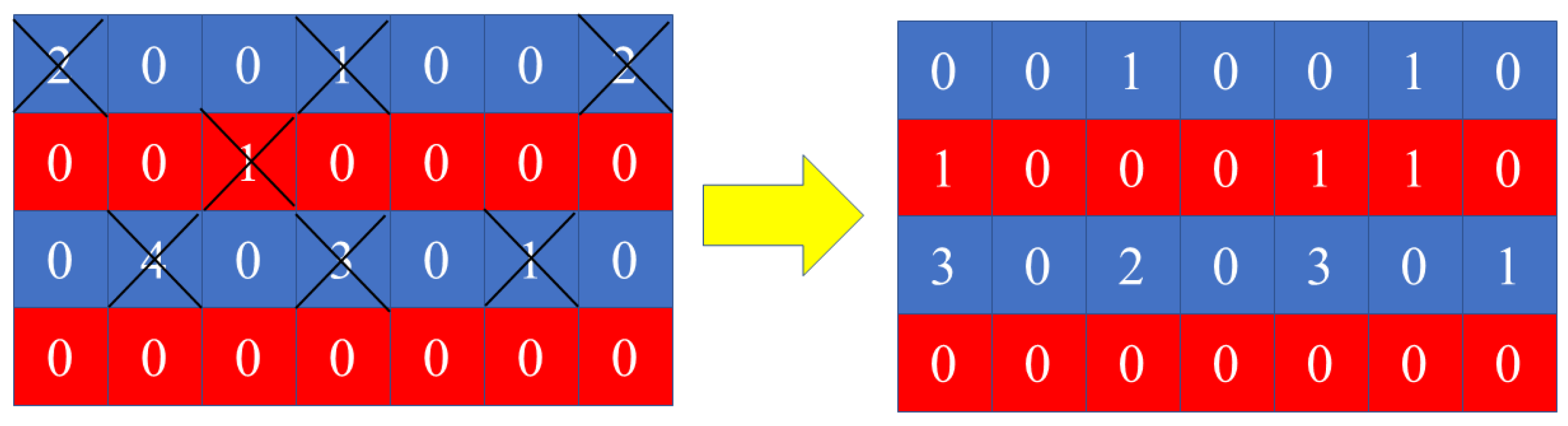
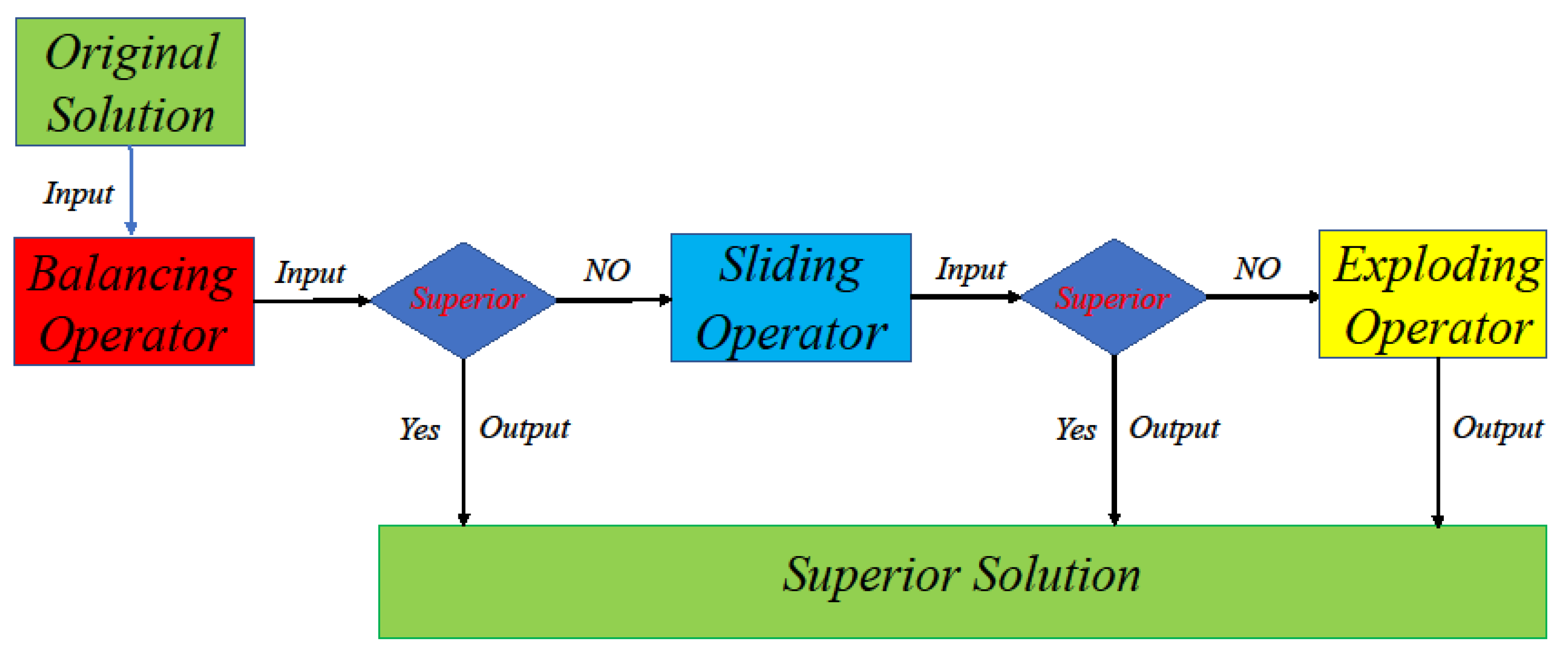
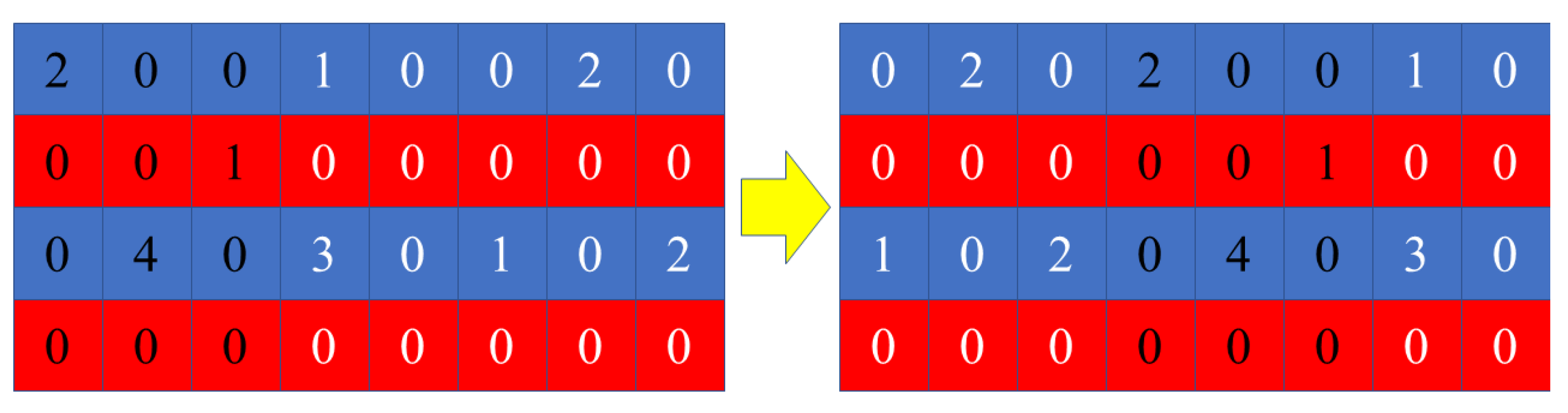
3.2.2. Variable Neighborhood Search Operator
| Algorithm 3 Balancing Operator |
| 1: Determine the position of wolfs: 2: == 3: for in range (): 4: for in range (): 5: if (>): 6: 7: Select k satisfies (<) 8: 9: end for 10: end for 11: Output: |
| Algorithm 4 Sliding Operator |
| 1: Determine the position of wolves: 2: = 3, = 1 3: == 4: =,=,= 5: for in range (): 6: for in range (0,): 7: = 8: end for 9: end for 10: Output: |
3.3. Flow of Improved Grey Wolf Optimizer Based on Reinforcement Learning (RL-IGWO)
4. Numerical Experiment
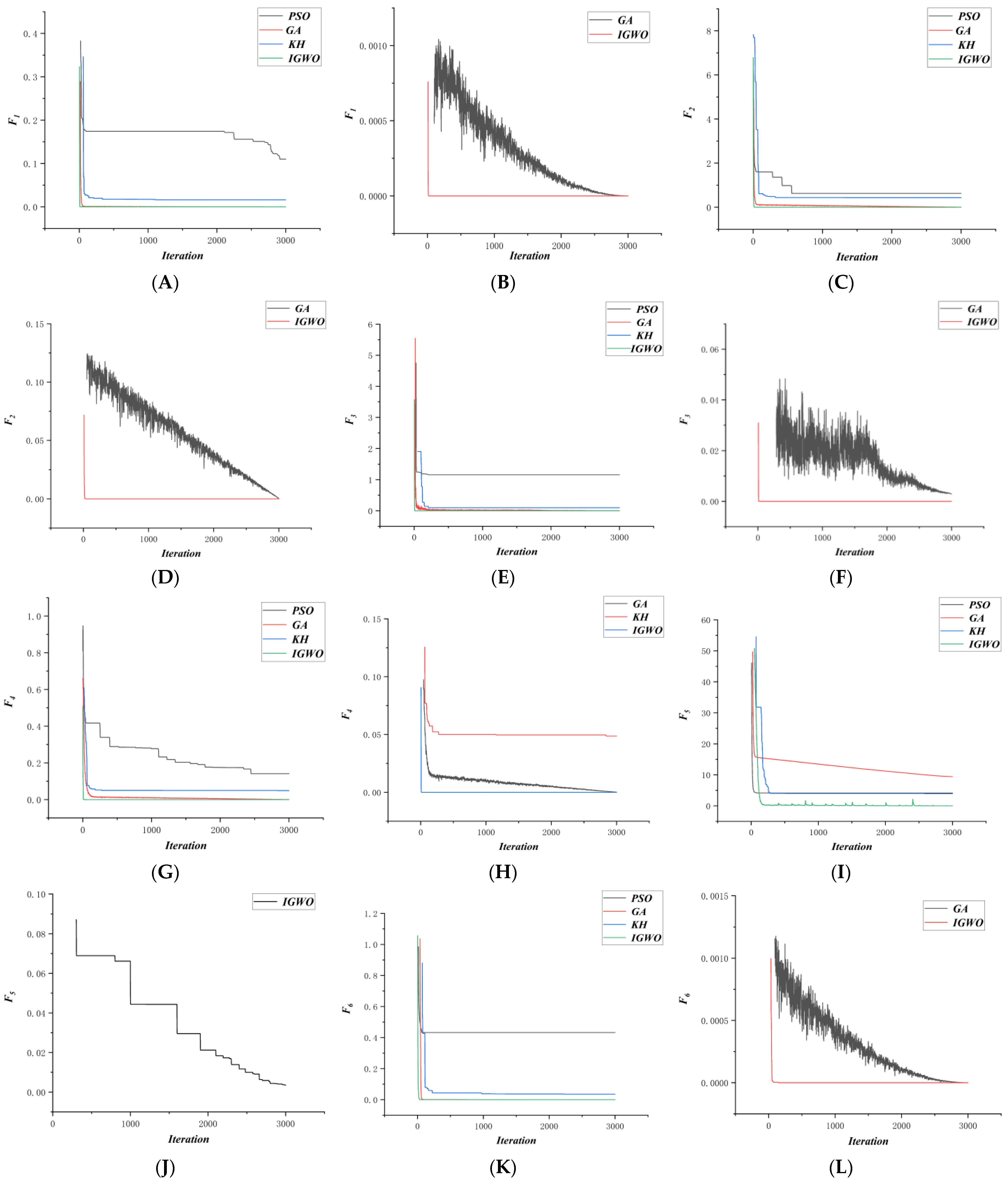
4.1. Simulation of Benchmark Functions
4.2. Numerical Experiment of DWTA Problems
4.2.1. Parameters of Numerical Experiment
4.2.2. Process of Reinforcement Learning
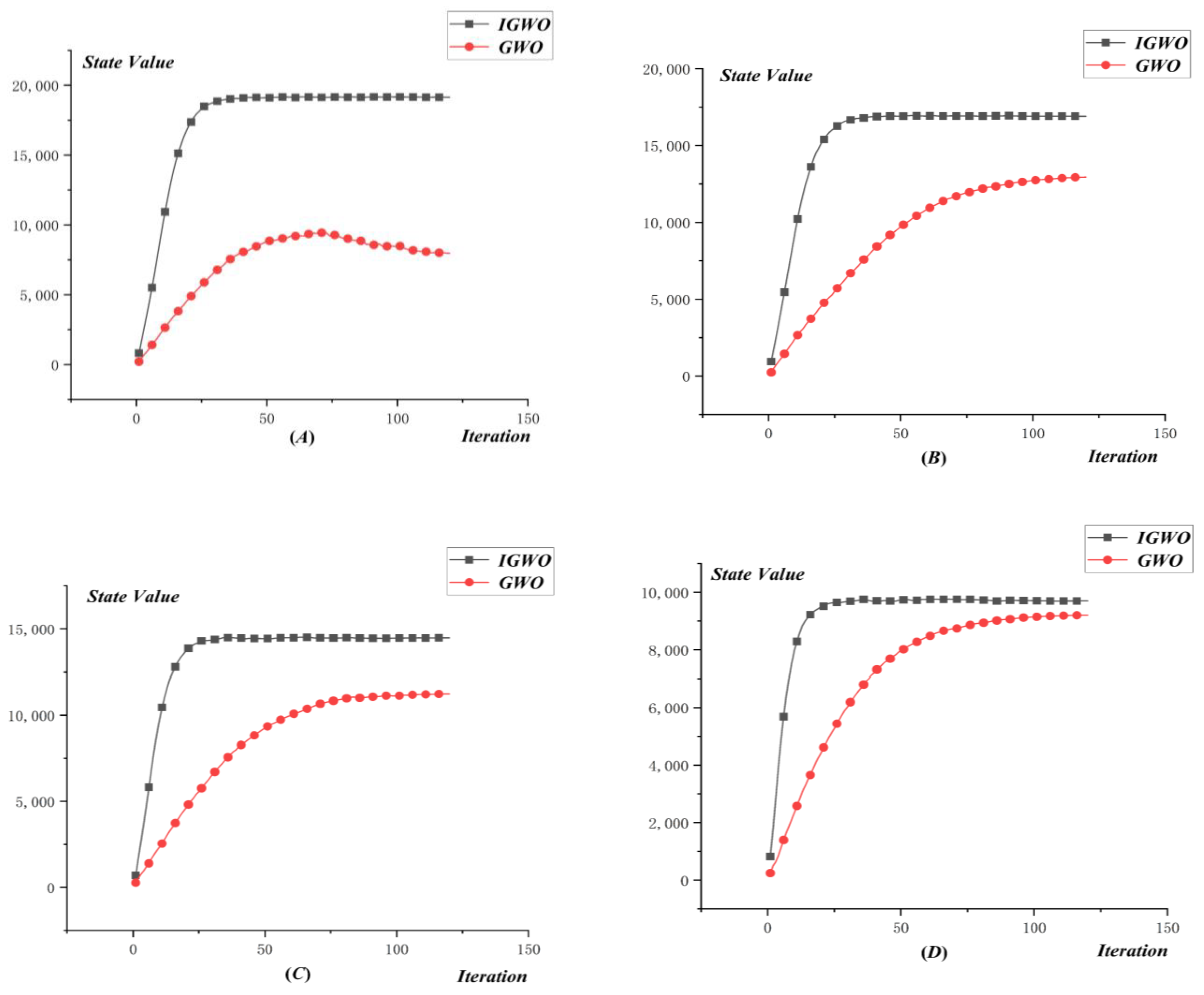
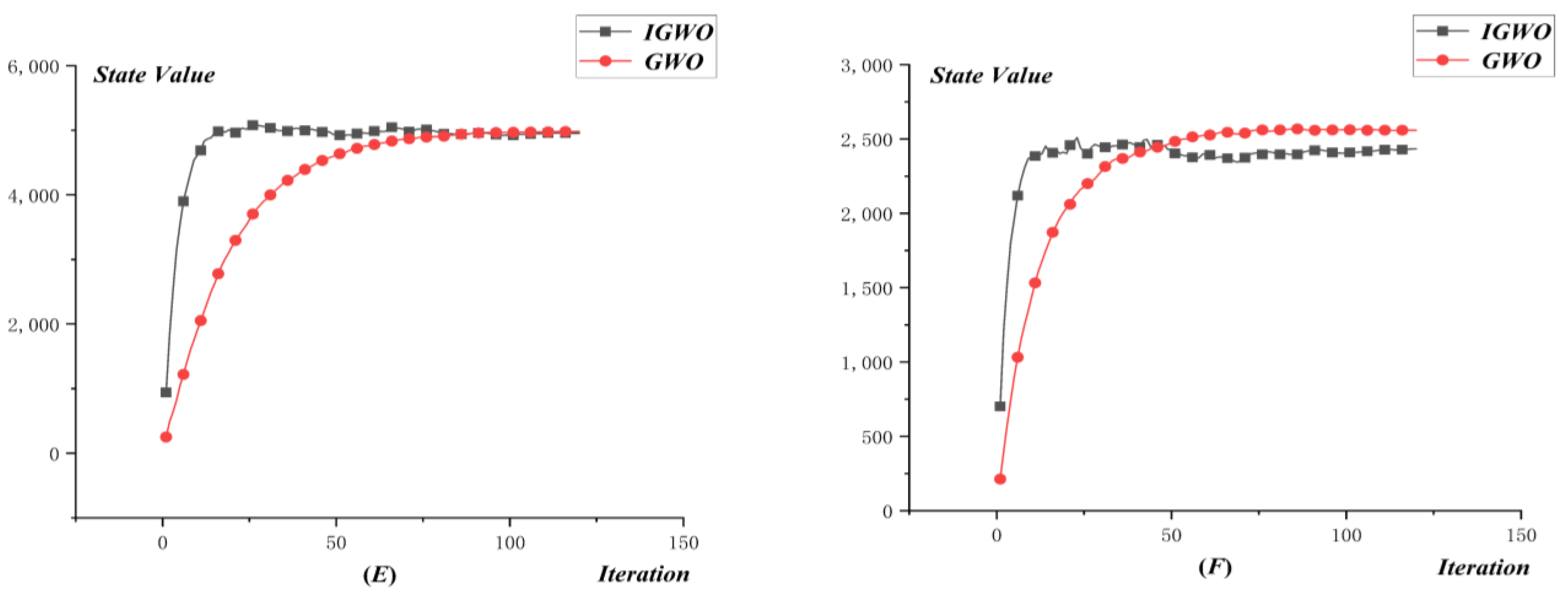
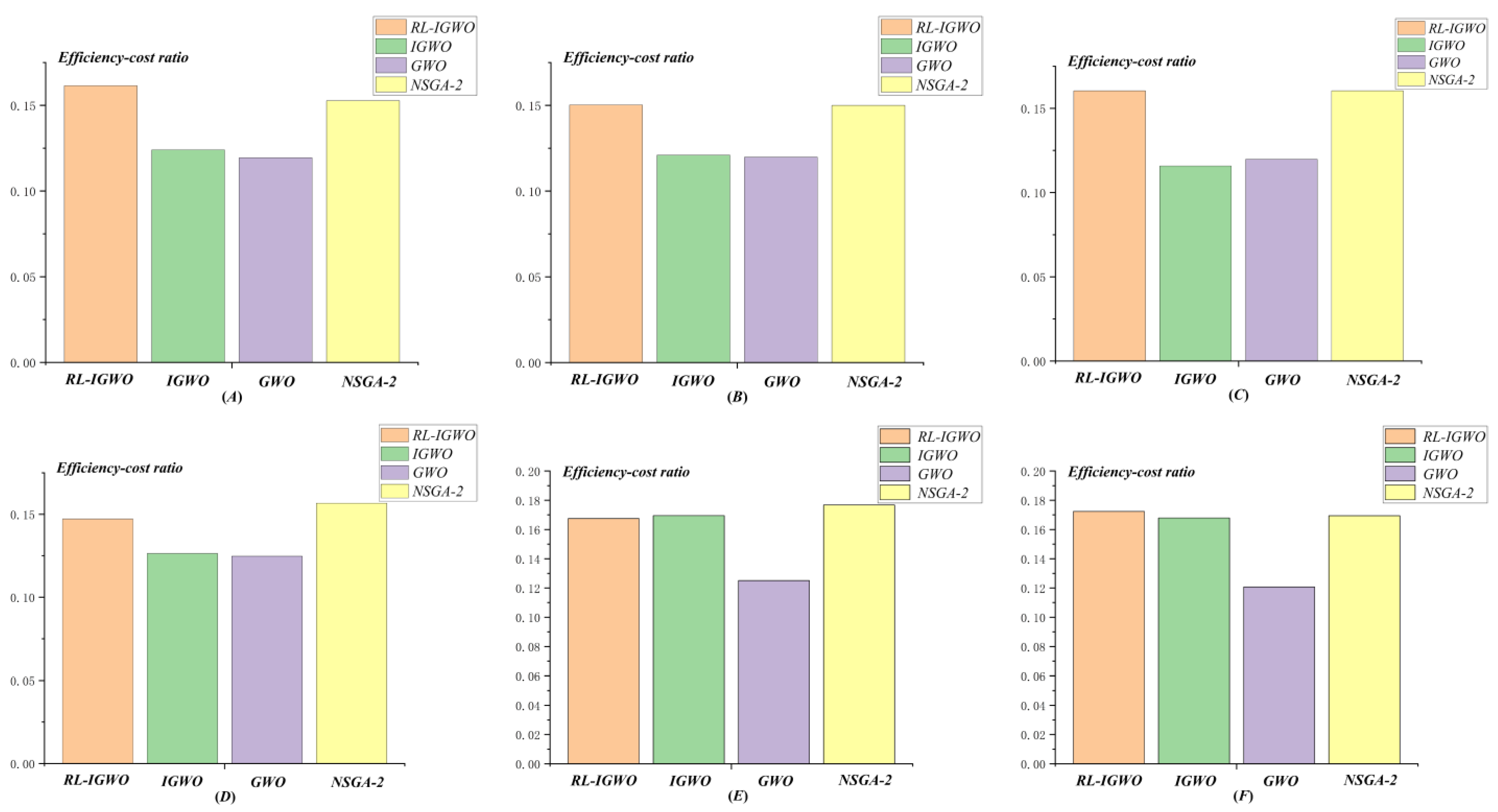
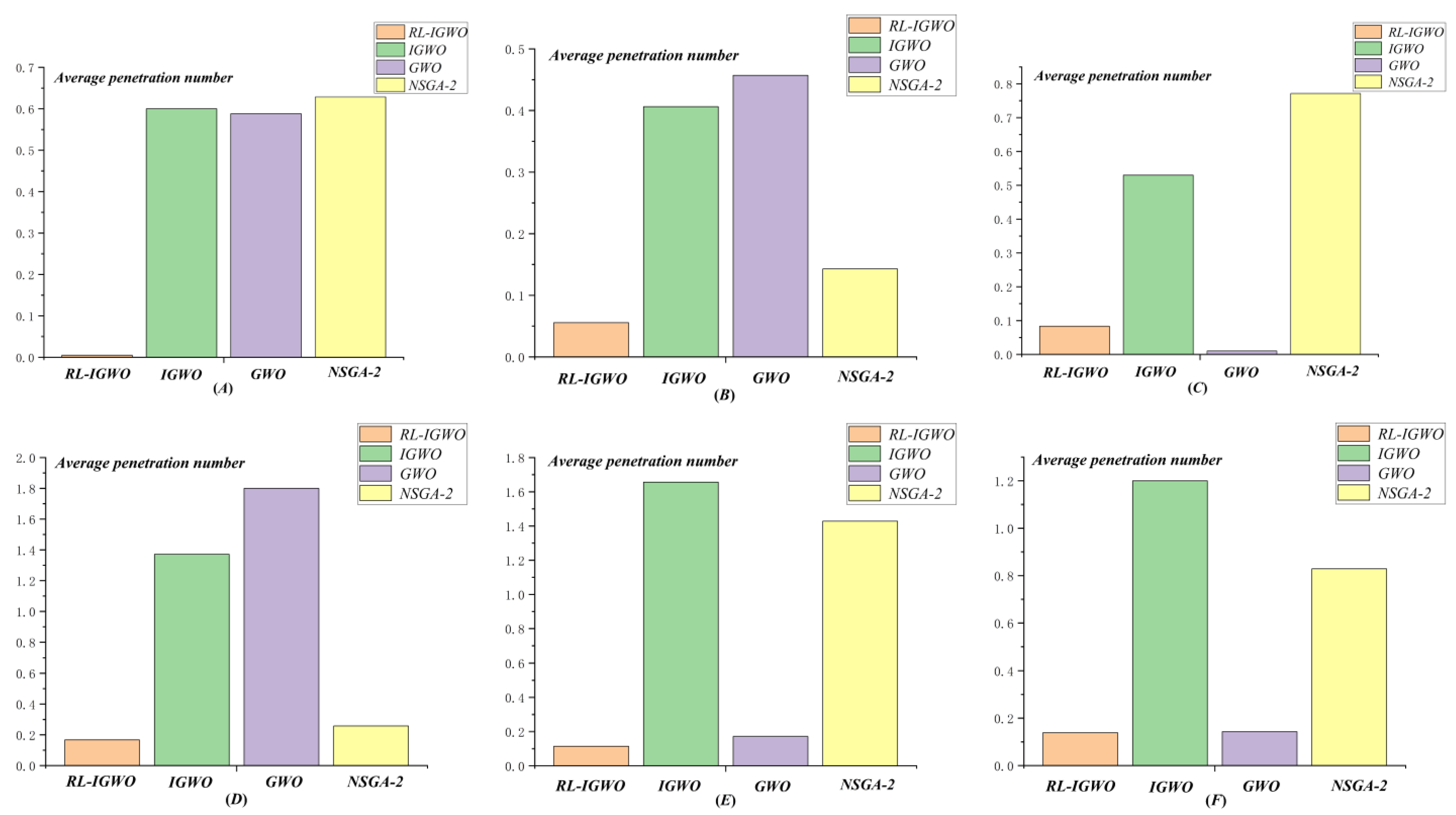
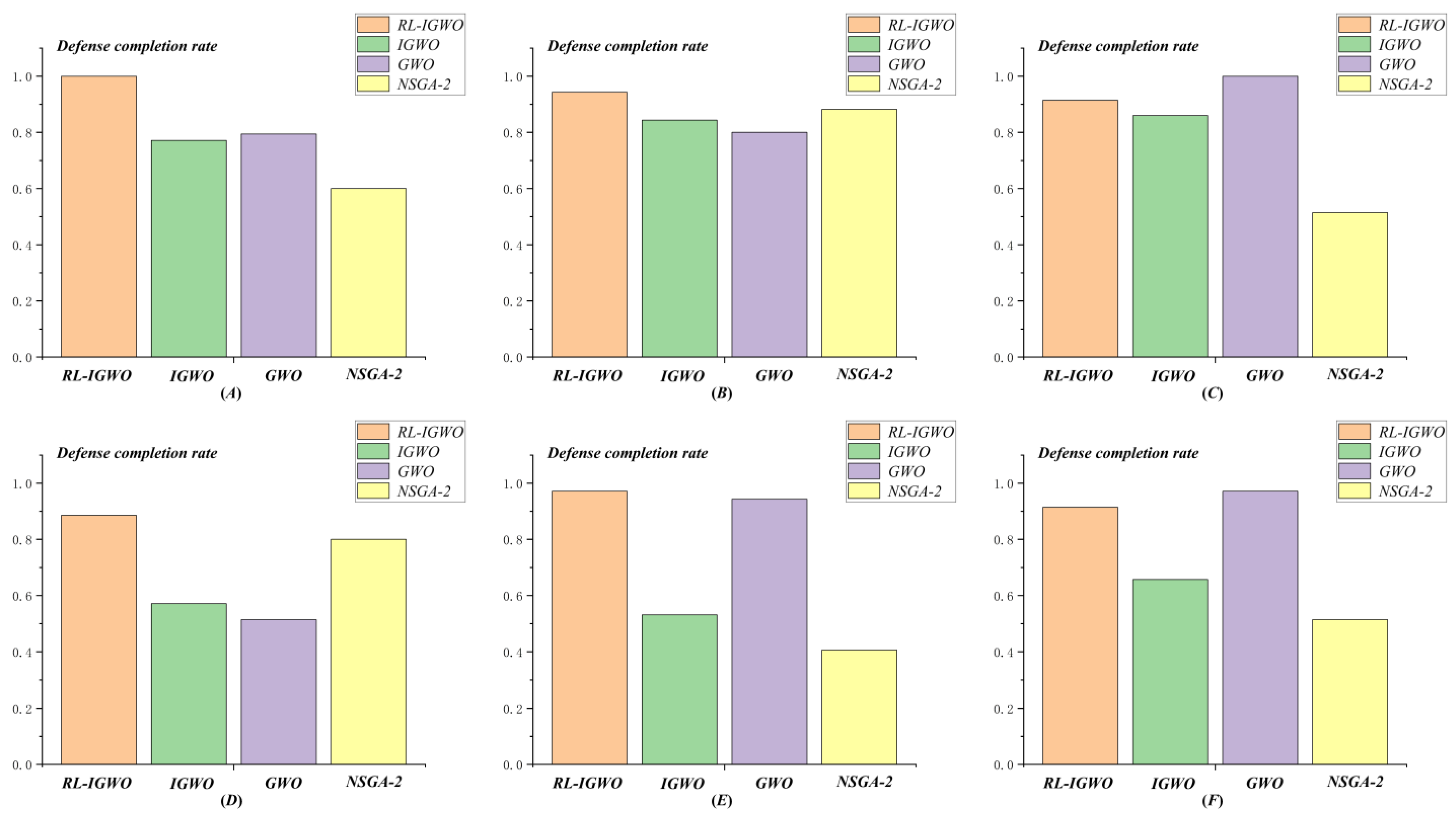
4.2.3. Results of DWTA
5. Discussion
- Based on the Markov decision process and the model-based reinforcement learning framework, the algorithm RL-IGWO decomposes a dynamic weapon-target assignment problem (DWTA) into static combinatorial optimization problems (SCO). In , is the number of the stages of the whole process of DWTA, and is the number of UAV swarms in the battlefield. The computational complexity of each SCO is , and the computational complexity of the RL-IGWO algorithm is . The assumption is that the IGWO algorithm transforms the computational complexity of each SCO problem from to , is a natural number, and the computational complexity of RL-IGWO algorithm is also . High computational complexity is a common problem in solving dynamic weapon-target assignment problems, and there is no doubt that certain effective optimization algorithms with low computational complexity are urgently needed. Distributed optimization and parallel computing are one of the crucial technologies for solving dynamic problems in the future.
- For certain scenarios, with the increase in iteration, the influence of high-quality initial population offered by a reinforcement learning policy on the whole optimization process will gradually weaken or even disappear. In the process of solving SCO problems, the addition of search operators to improve the performance of the original GWO algorithm should enhance the balance between local and global search, and work to maintain diversity
- Assuming that an algorithm has strong optimization capability, the same algorithm cannot also offer a good weapon-target assignment scheme. Objective functions are significant factors in the process of optimization, which influences the optimization process of DWTA, and, thus, a reasonable balance needs to be achieved under a variety of conflicting indicators.
6. Conclusions
- Based on the Markov decision process and the model-based reinforcement learning framework, the RL-IGWO algorithm decomposes a dynamic weapon-target assignment problem (DWTA) into a series of static combinatorial optimization problems (SCO). Multi-objective optimization was achieved in the global time-domain under the scenario of a frigate defending against UAV swarms. The algorithm proposed in this paper is applied for the model-based reinforcement learning, and it lays a foundation for the utilization of model-unknown reinforcement learning in future work.
- The policy based on reinforcement learning was designed to store the information of leader wolves , and in different states. The three leader wolves will be put into the original wolf population at the beginning of optimization process, which enhances solution quality greatly and reduces operation time significantly. A method combining reinforcement learning and heuristic algorithms was proposed in this paper, which provided an idea for solving the DWTA problem through reinforcement learning in the future.
- Facing the conflicts of different indicators, traditional objective function design heavily relies on weight to resolve conflicts between indicators. For the RL-IGWO algorithm, a new form of objective function was designed, in which value state functions of reinforcement learning are considered. The simulation results show that the contradictions between different indicators were well reconciled, illustrating the significance of the state value function of the reinforcement learning to the design of objective function in the problem of DWTA, raising the issue about the objective functions design covering the state value function in the future.
- The methods of an opposition-based learning operator and a variable neighbor search operator were adopted to significantly enhance the search ability of the grey wolf optimizer algorithm.
- Extend the utilization scope of the algorithm, especially for the scenario of model-unknown reinforcement learning.
- Propose more combination methods of heuristic algorithms and reinforcement learning, and improve the solution quality and optimization speed further.
- Design more appropriate objective functions problems in different scenarios, covering the state value function of the reinforcement learning.
Author Contributions
Funding
Conflicts of Interest
References
- Ca, O.M.; Fang, W. Swarm Intelligence Algorithms for Weapon-Target Assignment in a Multilayer Defense Scenario: A Comparative Study. Symmetry 2020, 12, 824. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, Y.; Zhen, Z.; Jiang, J. Multi-weapon multi-target assignment based on hybrid genetic algorithm in uncertain environment. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420905922. [Google Scholar] [CrossRef]
- Hu, X.; Luo, P.; Zhang, X.; Wang, J. Improved Ant Colony Optimization for Weapon-Target Assignment. Math. Probl. Eng. 2018, 2018, 6481635. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, J.; Kong, L. Decentralized Algorithms for Weapon-Target Assignment in Swarming Combat System. Math. Probl. Eng. 2019, 2019, 8425403. [Google Scholar] [CrossRef]
- Davis, M.T.; Robbins, M.J.; Lunday, B. Approximate dynamic programming for missile defense interceptor fire control. Eur. J. Oper. Res. 2017, 259, 873–886. [Google Scholar] [CrossRef]
- Zheng, X.; Zhou, D.; Li, N.; Wu, T.; Lei, Y.; Shi, J. Self-Adaptive Multi-Task Differential Evolution Optimization: With Case Studies in Weapon–Target Assignment Problem. Electronics 2021, 10, 2945. [Google Scholar] [CrossRef]
- Li, X.; Zhou, D.; Yang, Z.; Pan, Q.; Huang, J. A Novel Genetic Algorithm for the Synthetical Sensor-Weapon-Target Assignment Problem. Appl. Sci. 2019, 9, 3803. [Google Scholar] [CrossRef]
- Kong, L.; Wang, J.; Zhao, P. Solving the Dynamic Weapon Target Assignment Problem by an Improved Multi-objective Particle Swarm Optimization Algorithm. Appl. Sci. 2021, 11, 9254. [Google Scholar] [CrossRef]
- Lai, C.-M.; Wu, T.-H. Simplified swarm optimization with initialization scheme for dynamic weapon–target assignment problem. Appl. Soft Comput. 2019, 82, 105542. [Google Scholar] [CrossRef]
- Hocaolu, M.F. Weapon target assignment optimization for land based multi-air defense systems: A goal programming approach. Comput. Ind. Eng. 2019, 128, 681–689. [Google Scholar] [CrossRef]
- Zhang, K.; Zhou, D.; Yang, Z.; Li, X.; Zhao, Y.; Kong, W. A dynamic weapon target assignment based on receding horizon strategy by heuristic algorithm. J. Phys. Conf. Ser. 2020, 1651, 012062. [Google Scholar] [CrossRef]
- Zhang, K.; Zhou, D.; Yang, Z.; Zhao, Y.; Kong, W. Efficient Decision Approaches for Asset-Based Dynamic Weapon Target Assignment by a Receding Horizon and Marginal Return Heuristic. Electronics 2020, 9, 1511. [Google Scholar] [CrossRef]
- Zhao, L.; An, Z.; Wang, B.; Zhang, Y.; Hu, Y. A hybrid multi-objective bi-level interactive fuzzy programming method for solving ECM-DWTA problem. Complex Intell. Syst. 2022, 1–19. [Google Scholar] [CrossRef]
- Zhang, X.J. Land defense weapon versus target assignment against air attack. J. Natl. Univ. Def. Technol. 2019, 41, 6. [Google Scholar] [CrossRef]
- Hu, L.; Yi, G.; Huang, C.; Nan, Y.; Xu, Z. Research on Dynamic Weapon Target Assignment Based on Cross-Entropy. Math. Problem. Eng. 2020, 2020, 8618065. [Google Scholar] [CrossRef]
- Lu, X.; Di, H.; Jia, Z.; Zhang, X. Optimal weapon target assignment based on improved QPSO algorithm. In Proceedings of the 2019 International Conference on Information Technology and Computer Application (ITCA), Guangzhou, China, 20–22 December 2019; pp. 217–220. [Google Scholar]
- Li, J.; Chen, J.; Xin, B.; Dou, L. Solving multi-objective multistage weapon target assignment problem via adaptive NSGA-II and adaptive MOEA/D: A comparison study. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation, Sendai, Japan, 25–28 May 2015; pp. 3132–3139. [Google Scholar]
- Wang, C.; Fu, G.; Zhang, D.; Wang, H.; Zhao, J. Genetic Algorithm-Based Variable Value Control Method for Solving the Ground Target Attacking Weapon-Target Allocation Problem. Math. Probl. Eng. 2019, 9, 6761073. [Google Scholar] [CrossRef]
- Li, X.; Zhou, D.; Pan, Q.; Tang, Y.; Huang, J. Weapon-target assignment problem by multi-objective evolutionary algorithm based on decomposition. Complexity 2018, 2018, 8623051. [Google Scholar] [CrossRef]
- Huang, J.; Li, X.; Yang, Z.; Kong, W.; Zhao, Y.; Zhou, D. A Novel Elitism Co-Evolutionary Algorithm for Antagonistic Weapon-Target Assignment. IEEE Access 2021, 9, 139668–139684. [Google Scholar] [CrossRef]
- Wu, X.; Chen, C.; Ding, S. A Modified MOEA/D Algorithm for Solving Bi-Objective Multi-Stage Weapon-Target Assignment Problem. IEEE Access 2021, 9, 71832–71848. [Google Scholar] [CrossRef]
- Gupta, S.; Dalal, U.; Mishra, V.N. Novel Analytical Approach of Non Conventional Mapping Scheme with Discrete Hartley Transform in OFDM System. Am. J. Oper. Res. 2014, 04, 281–292. [Google Scholar] [CrossRef][Green Version]
- Gupta, S.; Dalal, U.; Mishra, V.N. Performance on ICI self cancellation in FFT-OFDM and DCT-OFDM system. J. Funct. Spaces 2015, 2015, 854753. [Google Scholar] [CrossRef]
- Shojaeifard, A.; Amroudi, A.N.; Mansoori, A.; Erfanian, M. Projection Recurrent Neural Network Model: A New Strategy to Solve Weapon-Target Assignment Problem. Neural Process. Lett. 2019, 50, 3045–3057. [Google Scholar] [CrossRef]
- Xie, J.; Fang, F.; Peng, D.; Ren, J.; Wang, C. Weapon-Target Assignment Optimization Based on Multi-attribute Decision-making and Deep Q-Network for Missile Defense System. J. Electron. Info. Technol. 2022, 42, 1–9. [Google Scholar] [CrossRef]
- Vieira, A. Reinforcement Learning and Robotics. In Introduction to Deep Learning Business Applications for Developers; Apress: Berkeley, CA, USA, 2018; pp. 137–168. [Google Scholar]
- Recht, B. A Tour of Reinforcement Learning: The View from Continuous Control. Annu. Rev. Control. Robot. Auton. Syst. 2019, 2, 253–279. [Google Scholar] [CrossRef]
- Ramírez, J.; Yu, W.; Perrusquía, A. Model-free reinforcement learning from expert demonstrations: A survey. Artif. Intell. Rev. 2022, 55, 3213–3241. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Soft. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.H.; Taghian, S.; Mirjalili, S. An improved grey wolf optimizer for solving engineering problems. Expert Syst. Appl. 2020, 166, 113917. [Google Scholar] [CrossRef]
- Hu, P.; Pan, J.S.; Chu, S.C. Improved binary grey wolf optimizer and its application for feature selection. Knowl. Based Syst. 2020, 195, 105746. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.H.; Taghian, S.; Mirjalili, S.; Zamani, H.; Bahreininejad, A. GGWO: Gaze cues learning-based grey wolf optimizer and its applications for solving engineering problems. J. Comput. Sci. 2022, 61, 101636. [Google Scholar] [CrossRef]
- Izci, D.; Ekinci, S.; Eker, E.; Kayri, M. Augmented Hunger Games Search Algorithm Using Logarithmic Spiral Opposition-based Learning for Function Optimization and Controller Design. J. King Saud Univ. Eng. Sci. 2022. [Google Scholar] [CrossRef]
- Mahdavi, S.; Rahnamayan, S.; Deb, K. Opposition based learning: A literature review. Swarm Evol. Comput. 2018, 39, 1–23. [Google Scholar] [CrossRef]
- Cheikh, M.; Ratli, M.; Mkaouar, O.; Jarboui, B. A variable neighborhood search algorithm for the vehicle routing problem with multiple trips. Electron. Notes Discret. Math. 2015, 47, 277–284. [Google Scholar] [CrossRef]
- Amous, M.; Toumi, S.; Jarboui, B.; Eddaly, M. A variable neighborhood search algorithm for the capacitated vehicle routing problem. Electron. Notes Discret. Math. 2017, 58, 231–238. [Google Scholar] [CrossRef]
- Baniamerian, A.; Bashiri, M.; Tavakkoli-Moghaddam, R. Modified variable neighborhood search and genetic algorithm for profitable heterogeneous vehicle routing problem with cross-docking. Appl. Soft Comput. 2019, 75, 441–460. [Google Scholar] [CrossRef]
- Awad, N.H.; Ali, M.Z.; Suganthan, P.N.; Liang, J.J.; Qu, B.Y. Problem Definitions and Evaluation Criteria for the CEC 2017 Special Session and Competition on Single Objective Real-Parameter Numerical Optimization; Technical Report; Nanyang Technological University: Singapore, 2017. [Google Scholar]
- Mallipeddi, R.; Suganthan, P.N. Problem Definitions and Evaluation Criteria for the CEC 2010 Competition on Constrained Real-Parameter Optimization; Nanyang Technological University: Singapore, 2010; p. 24. [Google Scholar]
- He, Y.; Xue, G.; Chen, W.; Tian, Z. Three-Dimensional Inversion of Semi-Airborne Transient Electromagnetic Data Based on a Particle Swarm Optimization-Gradient Descent Algorithm. Appl. Sci. 2022, 12, 3042. [Google Scholar] [CrossRef]
- Rytis, M. Agent State Flipping Based Hybridization of Heuristic Optimization Algorithms: A Case of Bat Algorithm and Krill Herd Hybrid Algorithm. Algorithms 2021, 14, 358. [Google Scholar]
- Zou, G. An Integrated Method for Modular Design Based on Auto-Generated Multi-Attribute DSM and Improved Genetic Algorithm. Symmetry 2021, 14, 48. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field of Fire | Hit Rate | Cost/Million Dollars | |
|---|---|---|---|
| Short-range missile-1 | 2–24 km | 82% | 1.15 |
| Short-range missile-2 | 2–9 km | 78% | 0.8 |
| Guided projectile | 2–6 km | 40% | 0.06 |
| Phalanx System | 0.5–2 km | 65% | 0.02 |
| Type | Maximum Attacking Range | Velocity | Price | Number |
|---|---|---|---|---|
| MALD-I | 926 km | 340 m/s | 0.2 million dollars | 40 |
| Sub-Area | D1 | D2 | D3 | D4 | D5 | D6 | D7 |
|---|---|---|---|---|---|---|---|
| Distance/km | 30–22 | 22–16 | 16–11 | 11–7.5 | 7.5–4.5 | 4.5–2 | 2–0 |
| Time-sensitive window/s | 26 | 19 | 14 | 11 | 8.5 | 6.5 | 5.5 |
| Name | Benchmark Function | Dimension | Variable Bounds | Theoretical Value |
|---|---|---|---|---|
| F1 | 20 | [−100,100] | 0 | |
| F2 | 20 | [−100,100] | 0 | |
| F3 | 20 | [−100,100] | 0 | |
| F4 | 20 | [−100,100] | 0 | |
| F5 | 20 | [−30,30] | 0 | |
| F6 | 20 | [−100,100] | 0 |
| Algorithm | Population Size | Iteration |
|---|---|---|
| PSO | 1500 | 3000 |
| GA | 1500 | 3000 |
| KH | 50 | 3000 |
| IGWO | 50 | 3000 |
| Test Problems | Statistic | PSO | GA | KH | IGWO |
|---|---|---|---|---|---|
| F1 | max | ||||
| min | |||||
| ave | |||||
| std | |||||
| F2 | max | ||||
| min | |||||
| ave | |||||
| std | |||||
| F3 | max | ||||
| min | |||||
| ave | |||||
| std | |||||
| F4 | max | ||||
| min | |||||
| ave | |||||
| std | |||||
| F5 | max | ||||
| min | |||||
| ave | |||||
| std | |||||
| F6 | max | ||||
| min | |||||
| ave | |||||
| std |
| Scenario | Scen1 | Scen2 | Scen3 | Scen4 | Scen5 | Scen6 | |
|---|---|---|---|---|---|---|---|
| Pop | RL-IGWO | 10 | 10 | 10 | 10 | 50 | 50 |
| Others | 10 | 10 | 50 | 50 | 50 | 50 | |
| Gen | 20 | 100 | 20 | 50 | 20 | 50 | |
| Parameters | Scen1 | Scen2 | Scen3 | Scen4 | Scen5 | Scen6 |
|---|---|---|---|---|---|---|
| Number | 40 | 39 | 38 | 37 | 36 | 35 |
| Region | D1 | D1 | D2 | D2 | D3 | D3 |
| Scenario | RL-IGWO | IGWO | GWO | NSGA-2 | |
|---|---|---|---|---|---|
| Scen1 | Average | 800 | 788.0 | 788.2 | 787.4 |
| Std. dev | 0 | 27.1 | 26.2 | 19.2 | |
| Median | 800 | 800.0 | 800.0 | 800.0 | |
| Maximum | 800 | 800.0 | 800.0 | 800.0 | |
| Minimum | 800 | 680.0 | 700.0 | 720.0 | |
| Scen2 | Average | 778.9 | 771.9 | 770.9 | 777.1 |
| Std. dev | 4.6 | 22.8 | 21.0 | 8.5 | |
| Median | 780.0 | 780.0 | 780.0 | 780.0 | |
| Maximum | 780.0 | 780.0 | 780.0 | 780.0 | |
| Minimum | 760.0 | 680.0 | 700.0 | 740.0 | |
| Scen3 | Average | 758.3 | 760 | 760.0 | 744.6 |
| Std. dev | 5.6 | 0.0 | 0.0 | 18.6 | |
| Median | 760.0 | 760 | 760.0 | 760.0 | |
| Maximum | 760.0 | 760 | 760.0 | 760.0 | |
| Minimum | 740.0 | 760 | 760.0 | 700.0 | |
| Scen4 | Average | 736.6 | 712.6 | 704.0 | 734.9 |
| Std. dev | 11.2 | 38.9 | 44.5 | 12.0 | |
| Median | 740.0 | 740.0 | 740.0 | 740.0 | |
| Maximum | 740.0 | 740.0 | 740.0 | 740.0 | |
| Minimum | 680.0 | 600.0 | 600.0 | 680.0 | |
| Scen5 | Average | 717.7 | 686.9 | 716.6 | 692.5 |
| Std. dev | 13.3 | 39.2 | 14.7 | 27.7 | |
| Median | 720.0 | 720.0 | 720.0 | 700.0 | |
| Maximum | 720.0 | 720.0 | 720.0 | 720.0 | |
| Minimum | 640.0 | 580.0 | 640.0 | 640.0 | |
| Scen6 | Average | 697.1 | 676.0 | 697.1 | 683.4 |
| Std. dev | 10.8 | 39.9 | 16.7 | 20.6 | |
| Median | 700.0 | 700.0 | 700.0 | 700.0 | |
| Maximum | 700.0 | 700.0 | 700.0 | 700.0 | |
| Minimum | 640.0 | 580.0 | 600.0 | 620.0 |
| Scenario | RL-IGWO | IGWO | GWO | NSGA-2 | |
|---|---|---|---|---|---|
| Scen1 | Average | 4953.3 | 6353.9 | 6600.6 | 5156.4 |
| Std. dev | 444.0 | 1580.8 | 706.8 | 236.3 | |
| Median | 4946.0 | 5786.0 | 6510.5 | 5176.0 | |
| Maximum | 5980.0 | 11,824.0 | 7997.0 | 5502.0 | |
| Minimum | 4212.0 | 4798.0 | 5274 | 4576.0 | |
| Scen2 | Average | 5182.5 | 6378.6 | 6432.4 | 5179.2 |
| Std. dev | 401.2 | 1147.0 | 838.4 | 175.9 | |
| Median | 5178.0 | 6187.5 | 6352.0 | 5199.0 | |
| Maximum | 6124.0 | 9993.0 | 9478.0 | 5506.0 | |
| Minimum | 4450.0 | 5007.0 | 5368.0 | 4721.0 | |
| Scen3 | Average | 4727.7 | 6562.5 | 6344.8 | 4640.8 |
| Std. dev | 484.6 | 985.8 | 638.2 | 220.2 | |
| Median | 4677.0 | 6239.5 | 6263.0 | 4636.0 | |
| Maximum | 6357.0 | 8791.0 | 8009.0 | 5179.0 | |
| Minimum | 3965.0 | 5060.0 | 5031.0 | 4212.0 | |
| Scen4 | Average | 5005.4 | 5636.4 | 5642.0 | 4688.6 |
| Std. dev | 446.9 | 2081.9 | 607.3 | 227.1 | |
| Median | 4989.0 | 5202.0 | 5446.0 | 4697.0 | |
| Maximum | 6333.0 | 14,450.0 | 6761.0 | 5156.0 | |
| Minimum | 4000.0 | 4183.0 | 4276.0 | 4209.0 | |
| Scen5 | Average | 4285.3 | 4051.8 | 5726.6 | 3916.5 |
| Std. dev | 383.6 | 498.5 | 688.2 | 214.7 | |
| Median | 4310.0 | 3993.5 | 5756.0 | 3888.0 | |
| Maximum | 5127.0 | 5269.0 | 7081.0 | 4303.0 | |
| Minimum | 3665.0 | 3125.0 | 4226.0 | 3485.0 | |
| Scen6 | Average | 4043.9 | 4025.4 | 5773.2 | 4033.6 |
| Std. dev | 354.7 | 1225.5 | 562.0 | 289.8 | |
| Median | 4072.0 | 3751.0 | 5731.0 | 4087.0 | |
| Maximum | 4730.0 | 10778.0 | 7161.0 | 4485.0 | |
| Minimum | 3200.0 | 3253.0 | 4742.0 | 3361.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nan, M.; Zhu, Y.; Kang, L.; Wang, T.; Zhou, X. A Modified RL-IGWO Algorithm for Dynamic Weapon-Target Assignment in Frigate Defensing UAV Swarms. Electronics 2022, 11, 1796. https://doi.org/10.3390/electronics11111796
Nan M, Zhu Y, Kang L, Wang T, Zhou X. A Modified RL-IGWO Algorithm for Dynamic Weapon-Target Assignment in Frigate Defensing UAV Swarms. Electronics. 2022; 11(11):1796. https://doi.org/10.3390/electronics11111796
Chicago/Turabian StyleNan, Mingyu, Yifan Zhu, Li Kang, Tao Wang, and Xin Zhou. 2022. "A Modified RL-IGWO Algorithm for Dynamic Weapon-Target Assignment in Frigate Defensing UAV Swarms" Electronics 11, no. 11: 1796. https://doi.org/10.3390/electronics11111796
APA StyleNan, M., Zhu, Y., Kang, L., Wang, T., & Zhou, X. (2022). A Modified RL-IGWO Algorithm for Dynamic Weapon-Target Assignment in Frigate Defensing UAV Swarms. Electronics, 11(11), 1796. https://doi.org/10.3390/electronics11111796