
Deepsign: Sign Language Detection and Recognition Using Deep Learning

 ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
2. Related Work
3. Methodology
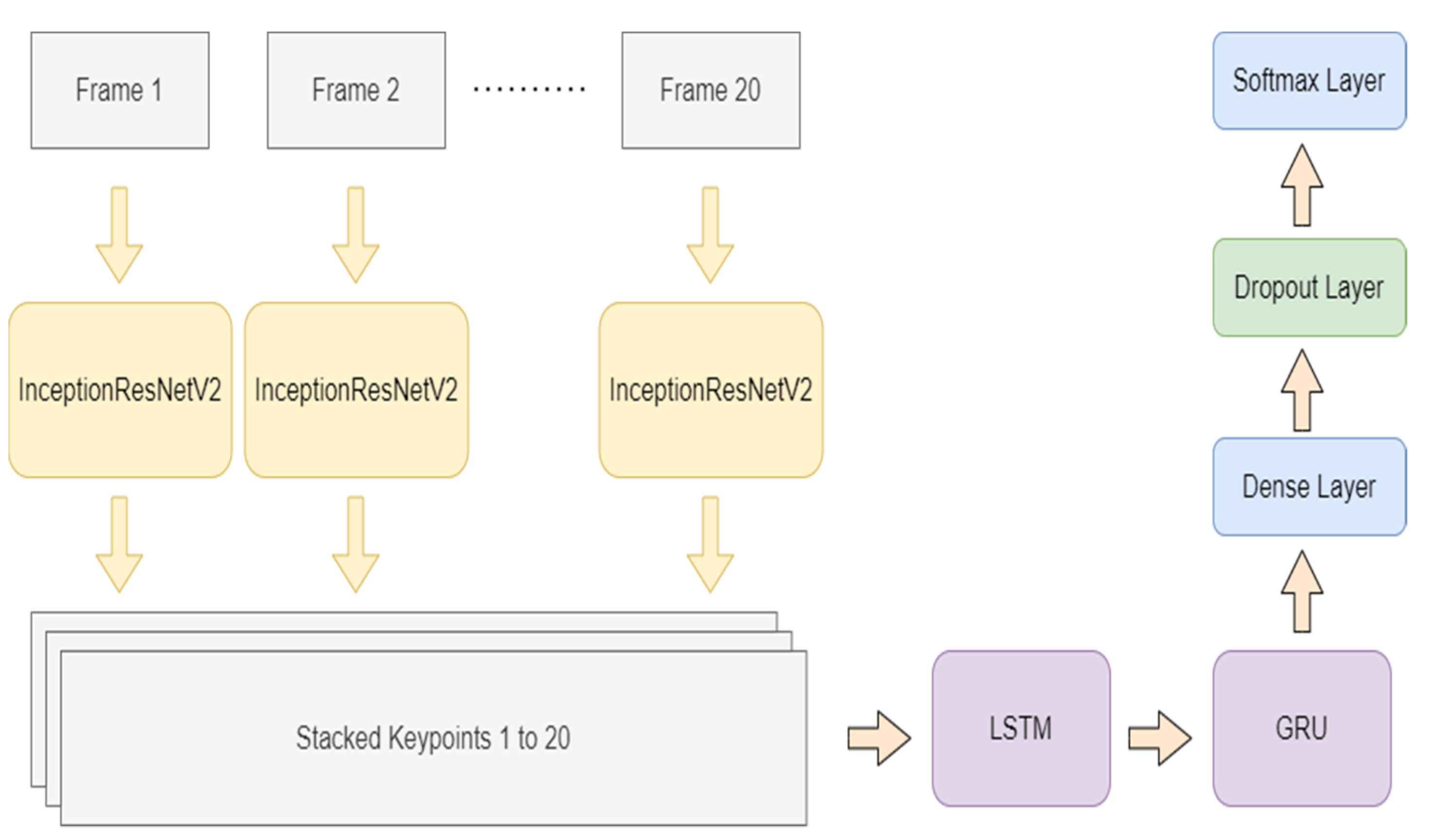
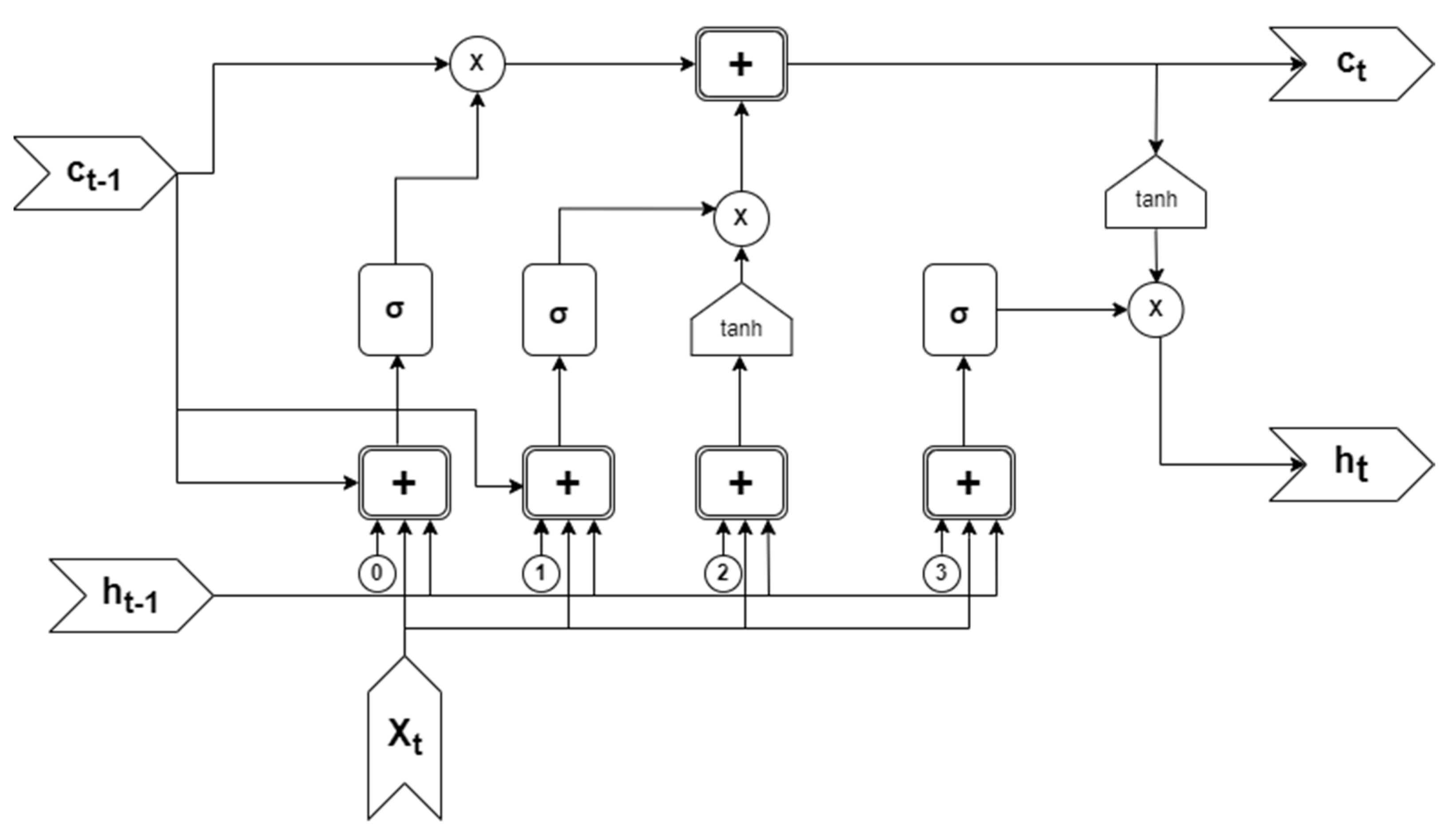
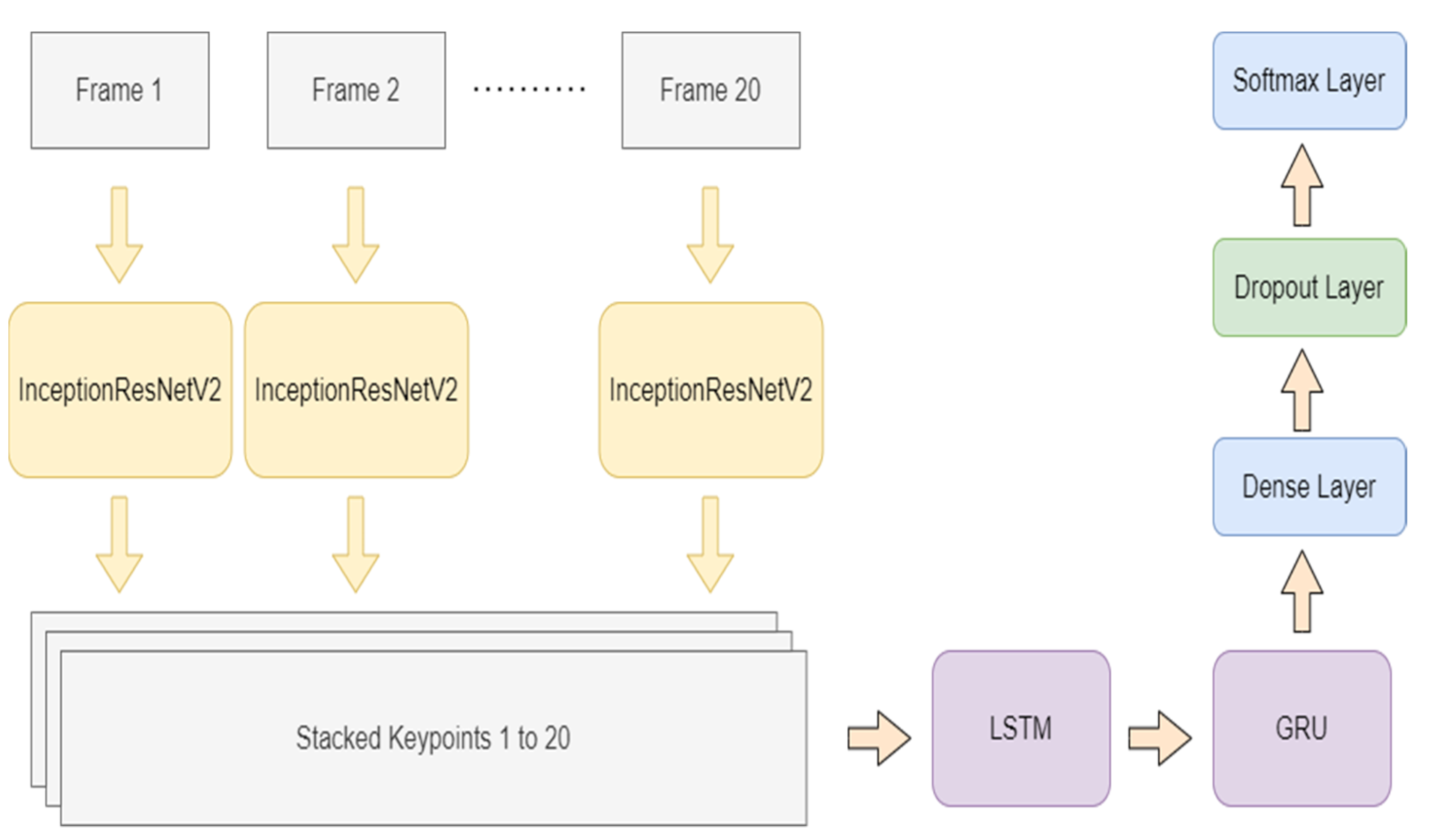
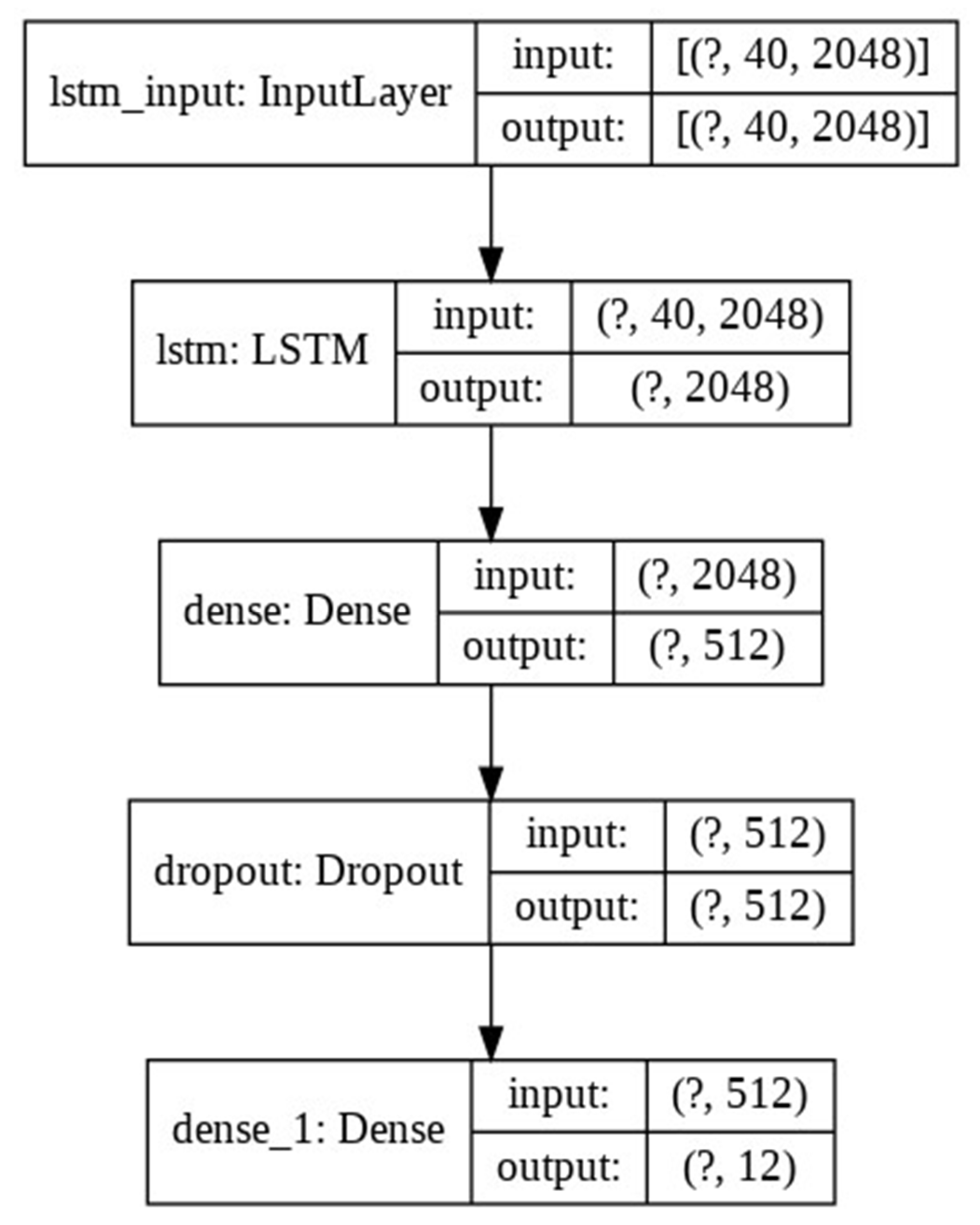
Proposed LSTM-GRU-Based Model
- The feature vectors are extracted using InceptionResNetV2 and passed to the model. Here, the video frames are classified into objects with InceptionResNet-2; then, the task is to create key points stacked for video frames;
- The first layer of the neural network is composed of a combination of LSTM and GRU. This composition can be used to capture the semantic dependencies in a more effective way;
- The dropout is used to reduce overfitting and improve the model’s generalization ability;
- The final output is obtained through the ‘softmax’ function.
- The LSTM layer of 1536 units, 0.3 dropouts, and a kernel regularizer of ′l2′ receive data from the input layer;
- Then, the data are passed from the GRU layer using the same parameters;
- Results are passed to a fully connected dense layer;
- The output is fed to the dropout layer, with an effective value of 0.3.
4. Experiments and Results
4.1. Dataset
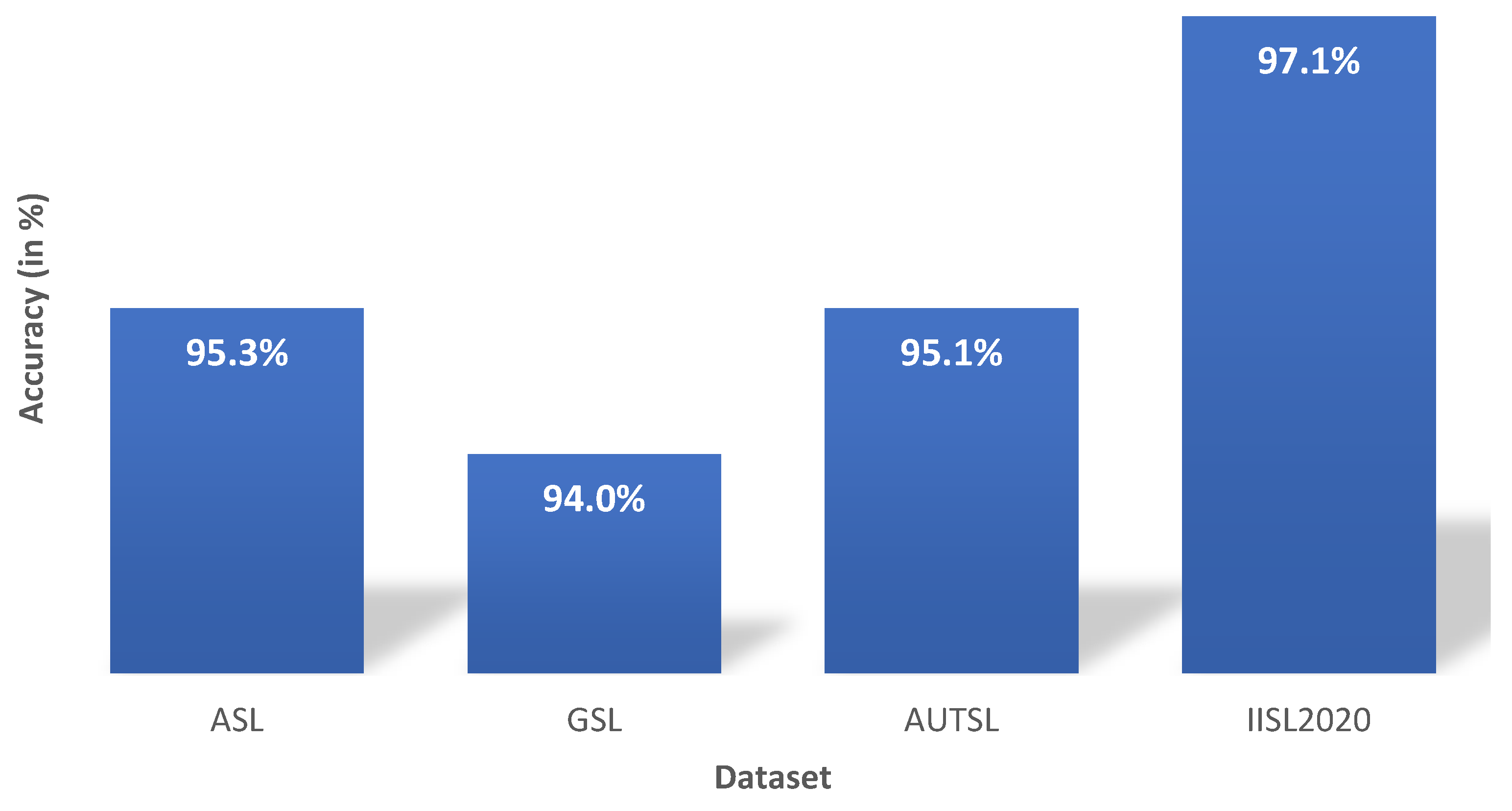
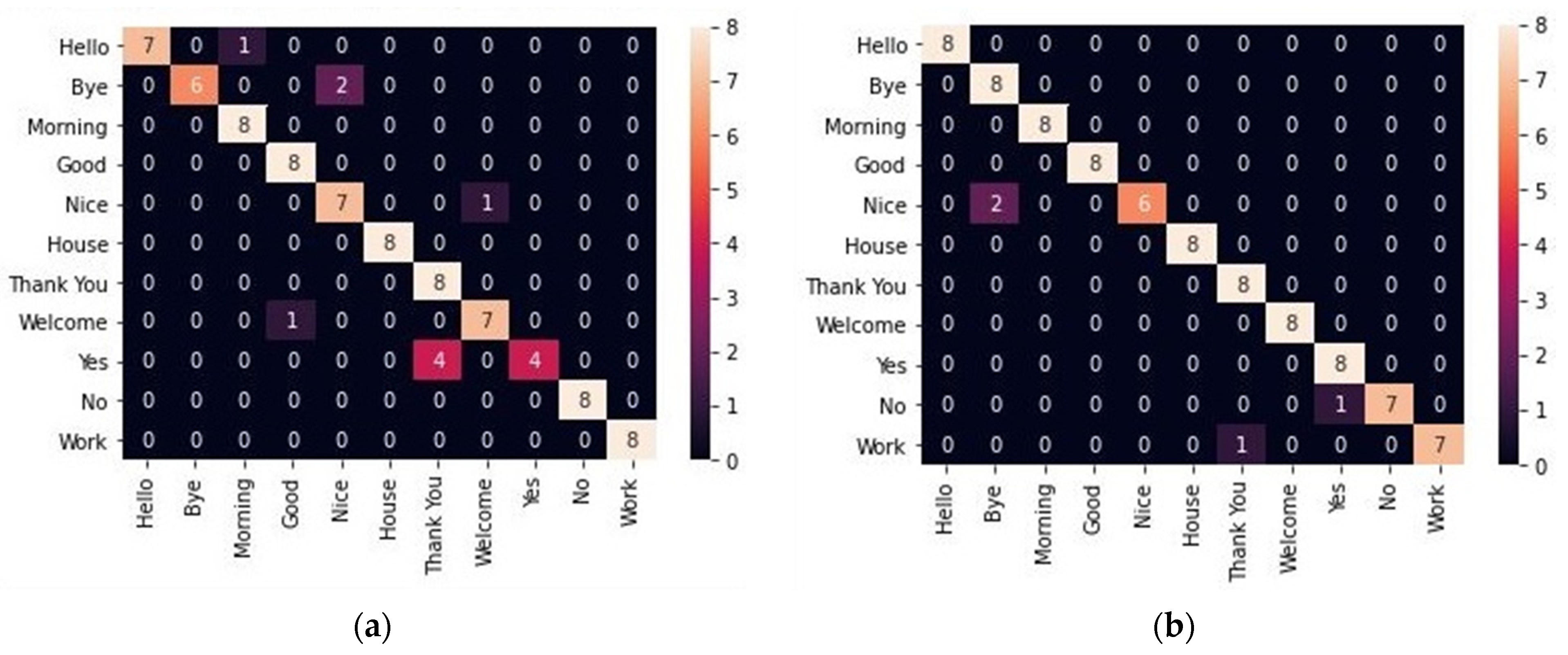
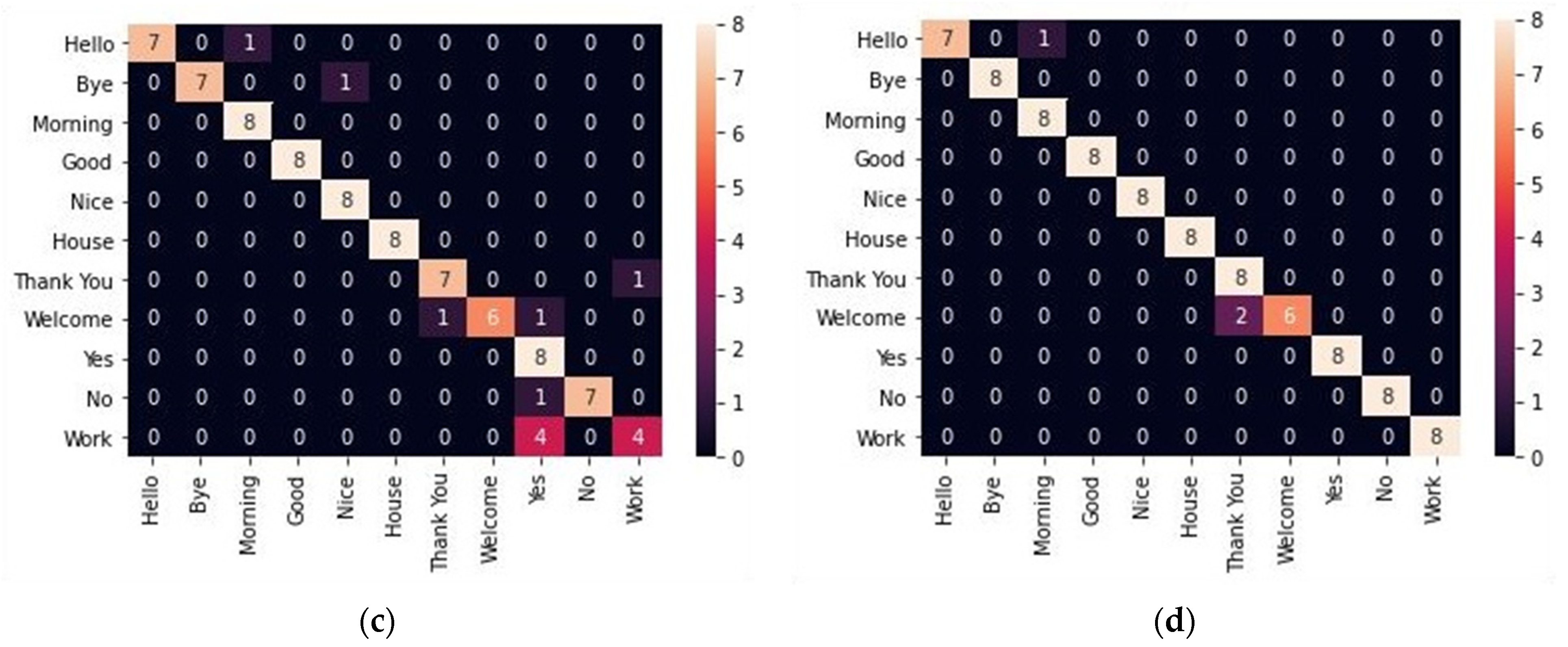
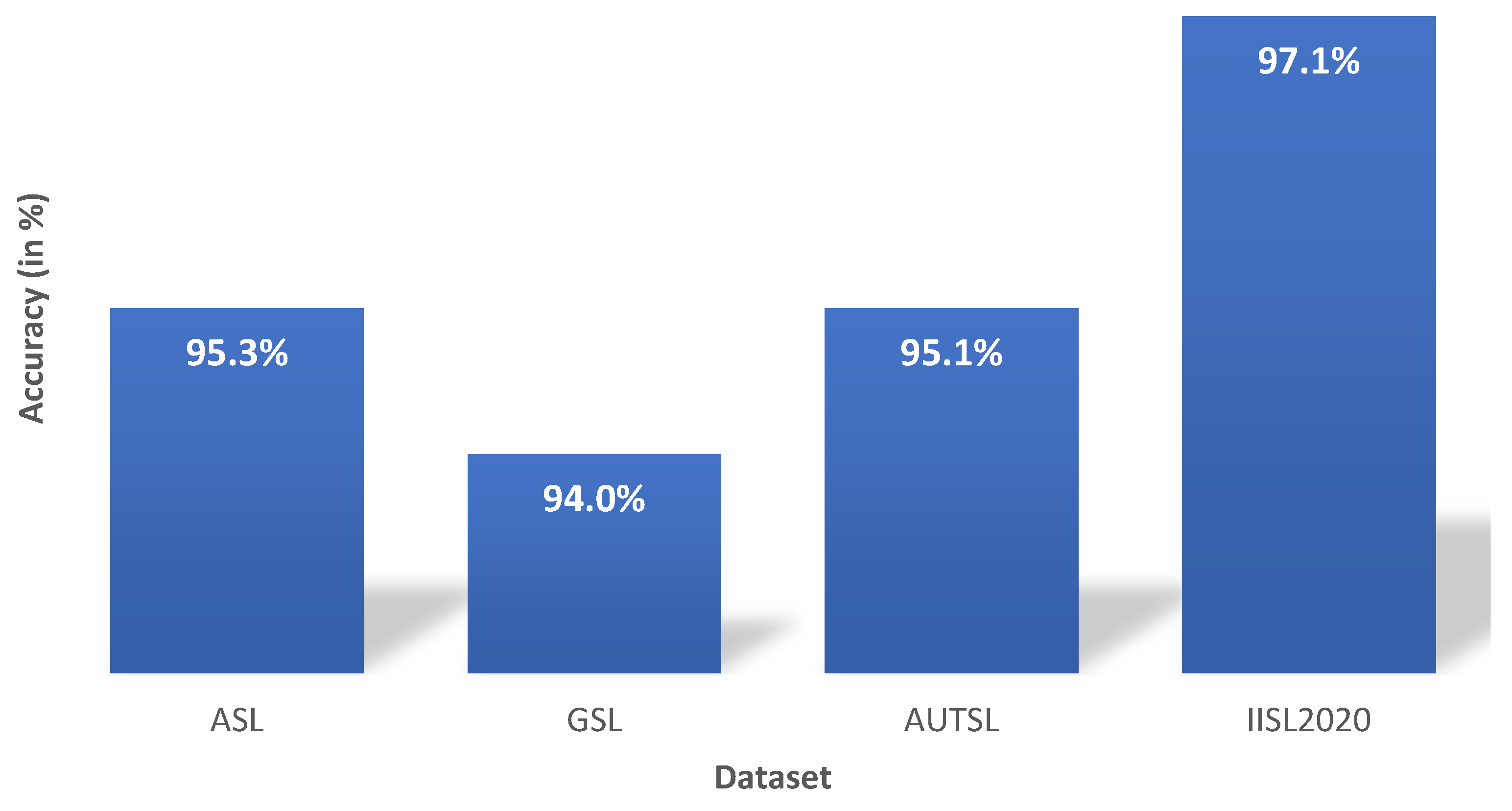
4.2. Results
5. Discussion and Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ministry of Statistics & Programme Implementation. Available online: https://pib.gov.in/PressReleasePage.aspx?PRID=1593253 (accessed on 5 January 2022).
- Manware, A.; Raj, R.; Kumar, A.; Pawar, T. Smart Gloves as a Communication Tool for the Speech Impaired and Hearing Impaired. Int. J. Emerg. Technol. Innov. Res. 2017, 4, 78–82. [Google Scholar]
- Wadhawan, A.; Kumar, P. Sign language recognition systems: A decade systematic literature review. Arch. Comput. Methods Eng. 2021, 28, 785–813. [Google Scholar] [CrossRef]
- Papastratis, I.; Chatzikonstantinou, C.; Konstantinidis, D.; Dimitropoulos, K.; Daras, P. Artificial Intelligence Technologies for Sign Language. Sensors 2021, 21, 5843. [Google Scholar] [CrossRef] [PubMed]
- Nandy, A.; Prasad, J.; Mondal, S.; Chakraborty, P.; Nandi, G. Recognition of Isolated Indian Sign Language Gesture in Real Time. Commun. Comput. Inf. Sci. 2010, 70, 102–107. [Google Scholar]
- Mekala, P.; Gao, Y.; Fan, J.; Davari, A. Real-time sign language recognition based on neural network architecture. In Proceedings of the IEEE 43rd Southeastern Symposium on System Theory, Auburn, AL, USA, 14–16 March 2011. [Google Scholar]
- Chen, J.K. Sign Language Recognition with Unsupervised Feature Learning; CS229 Project Final Report; Stanford University: Stanford, CA, USA, 2011. [Google Scholar]
- Sharma, M.; Pal, R.; Sahoo, A. Indian sign language recognition using neural networks and KNN classifiers. J. Eng. Appl. Sci. 2014, 9, 1255–1259. [Google Scholar]
- Agarwal, S.R.; Agrawal, S.B.; Latif, A.M. Article: Sentence Formation in NLP Engine on the Basis of Indian Sign Language using Hand Gestures. Int. J. Comput. Appl. 2015, 116, 18–22. [Google Scholar]
- Wazalwar, S.S.; Shrawankar, U. Interpretation of sign language into English using NLP techniques. J. Inf. Optim. Sci. 2017, 38, 895–910. [Google Scholar] [CrossRef]
- Shivashankara, S.; Srinath, S. American Sign Language Recognition System: An Optimal Approach. Int. J. Image Graph. Signal Process. 2018, 10, 18–30. [Google Scholar]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural Sign Language Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Muthu Mariappan, H.; Gomathi, V. Real-Time Recognition of Indian Sign Language. In Proceedings of the International Conference on Computational Intelligence in Data Science, Haryana, India, 6–7 September 2019. [Google Scholar]
- Mittal, A.; Kumar, P.; Roy, P.P.; Balasubramanian, R.; Chaudhuri, B.B. A Modified LSTM Model for Continuous Sign Language Recognition Using Leap Motion. IEEE Sens. J. 2019, 19, 7056–7063. [Google Scholar] [CrossRef]
- De Coster, M.; Herreweghe, M.V.; Dambre, J. Sign Language Recognition with Transformer Networks. In Proceedings of the Conference on Language Resources and Evaluation (LREC 2020), Marseille, France, 13–15 May 2020; pp. 6018–6024. [Google Scholar]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton aware multi-modal sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21–24 June 2021; pp. 3413–3423. [Google Scholar]
- Liao, Y.; Xiong, P.; Min, W.; Min, W.; Lu, J. Dynamic Sign Language Recognition Based on Video Sequence with BLSTM-3D Residual Networks. IEEE Access 2019, 7, 38044–38054. [Google Scholar] [CrossRef]
- Adaloglou, N.; Chatzis, T. A Comprehensive Study on Deep Learning-based Methods for Sign Language Recognition. IEEE Trans. Multimed. 2022, 24, 1750–1762. [Google Scholar] [CrossRef]
- Aparna, C.; Geetha, M. CNN and Stacked LSTM Model for Indian Sign Language Recognition. Commun. Comput. Inf. Sci. 2020, 1203, 126–134. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Yang, D.; Martinez, C.; Visuña, L.; Khandhar, H.; Bhatt, C.; Carretero, J. Detection and Analysis of COVID-19 in medical images using deep learning techniques. Sci. Rep. 2021, 11, 19638. [Google Scholar] [CrossRef] [PubMed]
- Likhar, P.; Bhagat, N.K.; Rathna, G.N. Deep Learning Methods for Indian Sign Language Recognition. In Proceedings of the 2020 IEEE 10th International Conference on Consumer Electronics (ICCE-Berlin), Berlin, Germany, 9–11 November 2020; pp. 1–6. [Google Scholar] [CrossRef]
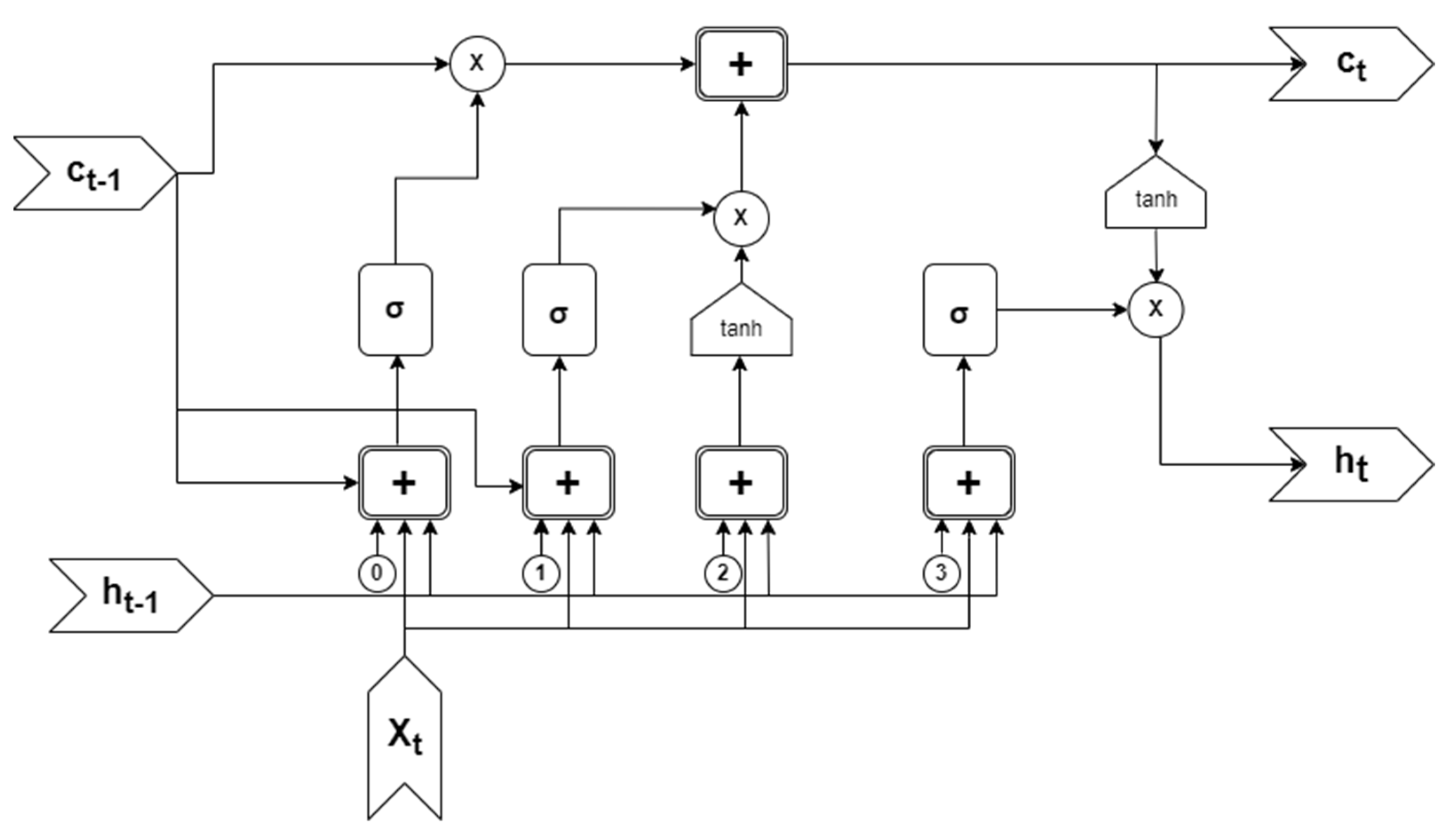
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Le, X.-H.; Hung, V.; Ho, G.L.; Sungho, J. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef] [Green Version]
- Yan, S. Understanding LSTM and Its Diagrams. Available online: https://medium.com/mlreview/understanding-lstm-and-its-diagrams-37e2f46f1714 (accessed on 19 January 2022).
- Chen, J. CS231A Course Project Final Report Sign Language Recognition with Unsupervised Feature Learning. 2012. Available online: http://vision.stanford.edu/teaching/cs231a_autumn1213_internal/project/final/writeup/distributable/Chen_Paper.pdf (accessed on 15 March 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Methodology | Dataset | Accuracy |
|---|---|---|---|
| Mittal et al. (2019) [14] | 2D-CNN and Modified LSTM, with Leap motion sensor | ASL | 89.50% |
| Aparna and Geetha (2019) [19] | CNN and 2layer LSTM | Custom Dataset (6 signs) | 94% |
| Jiang et al. (2021) [16] | 3DCNN with SL-GCN using RGB-D modalities | AUTSL | 98% |
| Liao et al. (2019) [17] | 3D- ConvNet with BLSTM | DEVISIGN_D | 89.8% |
| Adaloglou et al. (2021) [18] | Inflated 3D ConvNet with BLSTM | RGB + D | 89.74% |
| IISL2020 (Our Dataset) | AUTSL | GSL | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| GRU-GRU | 0.92 | 0.90 | 0.90 | 0.93 | 0.90 | 0.90 | 0.93 | 0.92 | 0.93 |
| LSTM-LSTM | 0.96 | 0.96 | 0.95 | 0.89 | 0.89 | 0.89 | 0.90 | 0.89 | 0.89 |
| GRU-LSTM | 0.91 | 0.89 | 0.89 | 0.90 | 0.89 | 0.89 | 0.91 | 0.90 | 0.90 |
| LSTM-GRU | 0.97 | 0.97 | 0.97 | 0.95 | 0.94 | 0.95 | 0.95 | 0.94 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kothadiya, D.; Bhatt, C.; Sapariya, K.; Patel, K.; Gil-González, A.-B.; Corchado, J.M. Deepsign: Sign Language Detection and Recognition Using Deep Learning. Electronics 2022, 11, 1780. https://doi.org/10.3390/electronics11111780
Kothadiya D, Bhatt C, Sapariya K, Patel K, Gil-González A-B, Corchado JM. Deepsign: Sign Language Detection and Recognition Using Deep Learning. Electronics. 2022; 11(11):1780. https://doi.org/10.3390/electronics11111780
Chicago/Turabian StyleKothadiya, Deep, Chintan Bhatt, Krenil Sapariya, Kevin Patel, Ana-Belén Gil-González, and Juan M. Corchado. 2022. "Deepsign: Sign Language Detection and Recognition Using Deep Learning" Electronics 11, no. 11: 1780. https://doi.org/10.3390/electronics11111780
APA StyleKothadiya, D., Bhatt, C., Sapariya, K., Patel, K., Gil-González, A.-B., & Corchado, J. M. (2022). Deepsign: Sign Language Detection and Recognition Using Deep Learning. Electronics, 11(11), 1780. https://doi.org/10.3390/electronics11111780