1. Introduction
At present, society is witnessing an unparalleled pace of technological development and global expansion of the Internet. An increasing number of ventures rely on network connectivity, both in the public sector and in business. Entities connected to the Internet range from those used for leisure purposes to elements of critical infrastructure, such as industrial process control or transportation management systems. In the background, a new technology paradigm known as Internet of Things (IoT) is evolving, which consists of objects that collect, process, and exchange data via diverse networks, often operating without direct human supervision [
1]. This automation is one of the reasons why people have been already surrounded by massive numbers of IoT devices; it is estimated that about 75 million IoT devices will be connected to the network by 2025 [
2].
In parallel, computer networks enable criminal activities named cybercrimes [
3]. Constantly, new cybercrime types are being developed [
4]. Some methods were previously associated only with mafia and now are a threat in the virtual world. This includes extortion using distributed denial of service (DDoS) attacks or ransomware—software that encrypts user data for ransom. According to the NETSCOUT Threat Intelligence Report [
5], 9.7 million DDoS attacks were encountered in 2021. As Cybersecurity Ventures estimates [
6], global cybercrime costs will grow yearly by 15%, reaching 10.5 trillion US dollars annually by 2025. Even though general awareness of various cybersecurity threats is increasing, as is the overall level of safety, constant effort to improve countermeasures is required. The growing number of targets, new attack vectors, and the fact that malware constantly evolves do not make this an easy task. It is estimated that over 450,000 new malicious programs and potentially unwanted applications (PUA) are registered every day [
7].
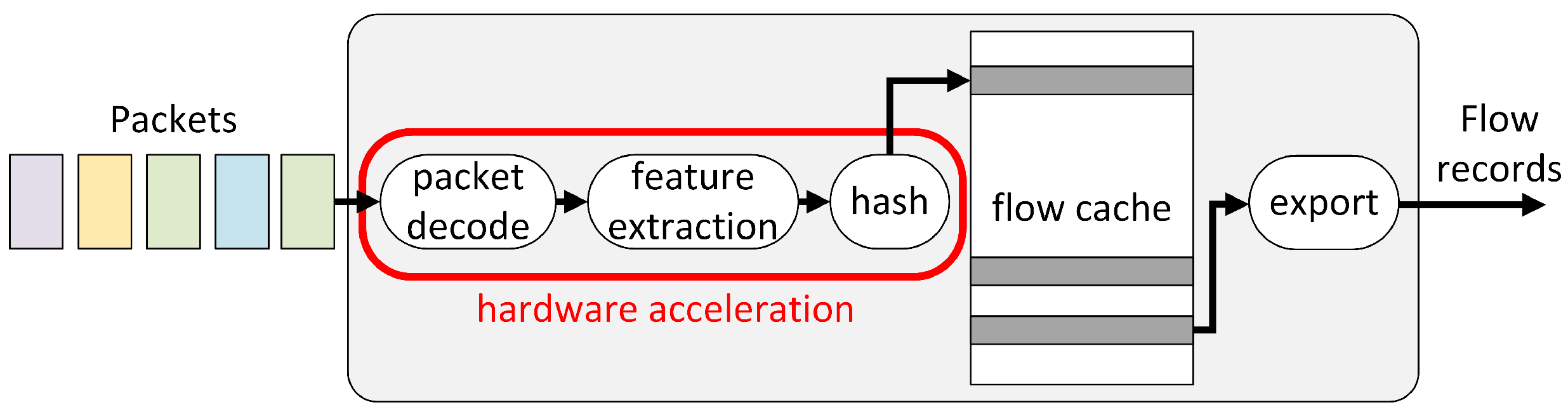
In response to numerous network threats, various cybersecurity methods have been proposed. The first safeguards of a network are firewalls and intrusion detection/prevention systems (ID/PS), whose task is to analyze incoming traffic and intercept packets when a malicious signature is detected. Collecting IP traffic information for network monitoring is a common practice of network operators and researchers. To build a coarse-grained understanding of network traffic, the concept of network flows is used. It records traffic statistics in the form of flow records. Each record contains important information about a flow, such as its source and destination Internet Protocol (IP) addresses, start and end timestamps, types of service, and application ports, along with the volume of packets or bytes, etc. IP packets are assigned into flows based on their characteristics, such as source or destination address, protocol type carried, and protocol port numbers (for TCP and UDP) that can be referred to as
flow keys. As a result of the analysis procedure, which often incorporates the most cutting-edge approaches, including machine learning [
8,
9,
10], disallowed flows can be eliminated.
Flow-based network monitoring is today the most widespread technology, and NetFlow [
11,
12,
13] is a widely used tool in network measurement and analysis. It is now gradually evolving into one of the most important means of ensuring network cybersecurity.
Performance of NetFlow monitoring tools has been identified as a crucial factor in network security allowing for the application of immediate countermeasures. It has been widely addressed, including the possibility for its hardware acceleration [
14,
15,
16,
17,
18]. However, it is important to note that also the monitoring device itself can be a target of a specialized cyberattack [
19], especially when the assailant has appropriate knowledge and is willing to spend their resources and time for initial reconnaissance.
Crossfire [
20] is an example of such a sophisticated attack (in comparison to the brute-force DDoS attack), tailored to a targeted enterprise, that can isolate a target area by flooding carefully selected network links.
NetFlow-like tools face great challenges when both the speed and complexity of the network traffic increase. To keep up with the multigigabit speed of network traffic, especially on high-bandwidth backbone links,
NetFlow probes incorporate advanced techniques to efficiently store and manipulate flow records [
21]. A fast local memory inside the probe, known as
flow cache, is used to store the active flows. The flow cache is organized in a data structure called a
flow table, which consists of a list of flow records, one for each active flow.
To efficiently process incoming packets and access the database gathered based on the flow key of the current packet often requires the use of sophisticated data structures, which vastly reduces computational complexity. Hash-based data structures are commonly proposed for this purpose as a solution allowing high-speed packet processing. Such data structures are usually coupled with a hashing function that maps a flow key to a flow cache location. Unfortunately, applying a perfect hashing function that maps each flow key to a distinct flow cache location is not possible in practice. Thus, it is crucial to select a hashing function that maps a small number of flow keys on to the same flow cache location, so-called hash buckets. If the number of collisions is sufficiently small, then hash tables work quite well and give search times. To ensure optimal utilization of the hash table and reduce the vulnerability of a NetFlow probe to cyberattacks, the hash function needs to be carefully chosen. If it is not, malicious traffic may be able to create collisions that degenerate the hash table to linked lists with worst-case lookup times of and greatly reduce the performance of the flow cache modules.
In [
19], the authors evaluated the resilience of hash functions used in the software-based NetFlow probes nProbe and Vermont. Theoretical analysis and real attacks proposed by the authors show how easily flow monitors can be overloaded if the hash algorithm has not been carefully chosen. The paper also presents a hash function that seems to offer protection against hash collision attacks and computes fast enough to be deployed in high-speed flow meters.
The obvious countermeasure against hash collision-based attacks (hash flooding or HashDoS) is a hash function for which collisions cannot easily be created. Cryptographic hash functions would provide such a feature; however, they are computationally expensive, which makes them difficult to use efficiently in NetFlow probes. The implementation of such network monitoring elements with rigorous throughput may be challenging. Hardware acceleration of their crucial functions can be an aid here. Still, to the best of our knowledge, there is a lack of publications discussing hardware-accelerated network probes for network traffic analysis with dedicated hash functions that would be resilient to targeted attacks.
Our article aims at filling up this gap. In this work, we propose a hardware-accelerated network probe that accelerates extraction of network packet characteristics and calculation of the hash identifier. In addition, we describe the application of the cryptographic hash functions SHA-1 and SHA-3 to map a flow key to a flow cache location. The efficiency of our approach will be compared with the solutions discussed in [
19].
Our article is organized as follows: First, in
Section 2 we present the concept of a hardware-accelerated network probe and review different hashing algorithms. Next, in
Section 3 we describe the experiments conducted. Their results are presented in
Section 4, followed by discussion and conclusions in
Section 5.
2. Materials and Methods
In this section, we outline the concept of a hardware-accelerated network probe (
Section 2.1). Different hash algorithms that can produce hash table keys are discussed in
Section 2.2. Details of hardware implementations and functional verification of the design are described in
Section 2.3.
2.1. Hardware-Accelerated Network Probe
A network probe is a tool which acquires parameters from network traffic for traffic-analysis purposes. In this work, we used a hardware-accelerated version of the software network probe proposed in [
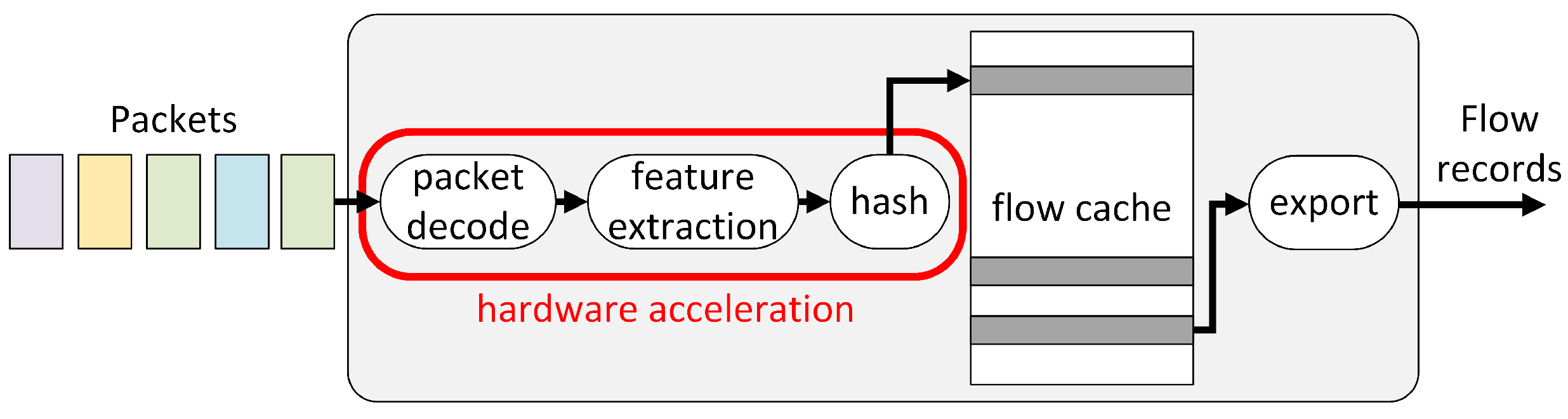
22], which is also briefly presented here. The block diagram of the probe is presented in
Figure 1. The network probe processes the traffic data in the following steps:
capture network packets from a specific interface,
analyze packets in chosen network stack layers,
extract flow key and other features from the current packet,
compute the hash value from the flow key,
create or update a network flow record in the active flow cache,
export inactive flows to the expired flow table,
calculate flow parameters for the expired flows,
store flow parameters in the output dataset.
The traffic captured from a network interface is analyzed and then a network flow record is created or an existing one is updated in the flow cache. Packet headers are analyzed in terms of second, third, and fourth ISO/OSI Reference Model layers. Assignment of new packets to flows is based on a hash function of the header parameters, which is calculated using the IP source address, the IP destination address, the source port number, the destination port number, and information on the transport layer protocol.
Considering the transport layer protocols, the conditions for classifying the stream as ended are RST or FIN flags in the case of TCP, and reaching a predefined inactivity time in the case of UDP. The flows considered as ended are statistically analyzed and their parameters extracted, as described in the next section. Expired flows are dumped to a file.
Captured packets are processed starting with the second ISO/OSI layer. From the data link layer, information about the timestamp and the packet length is fetched. The Ether_type field contains information about the higher-layer protocol used, which is, in the network probe’s case, IPv4. After receiving the IP header, it is possible to decode the source and destination IP addresses, along with the transport layer protocol. Knowing the values of the headers of transport layer protocols, it is possible to decode the recipient’s port, and the TCP flags, if applicable.
Current flows are stored in flow caches organized in buckets. For every incoming packet, a hash of the flow key is calculated and then checked against the existing flow keys in the appropriate bucket. If the hash does not exist, a new flow record is created in the given bucket, with parameters such as: source and destination IP addresses, source and destination port numbers, first packet timestamp, and transport layer protocol. If the hash already exists, the existing flow is updated. The packet count value is incremented, TCP flags are updated (if applicable), and a new timestamp and the packet size are added to the list.
In the case of the TCP protocol, the appearance of a FIN or RST flag means the end of the flow. Then, some of the flow’s parameters are updated. Furthermore, the flow is moved from the active flows map to the expired flows list. Post-processing of the parameters consists of converting source and destination IP addresses to ASCII format; marking last timestamp; and calculating the flow’s duration and total byte count, and its statistical parameters.
In the case of UDP packets, these are periodically checked by the application thread, which will be iterating through the active flows cache. The last packet’s arrival time in a flow is compared to the last packet’s arrival time on the network adapter, and if this exceeds the time difference by a predefined value (set in our case to 10 s), it is moved from the current flows cache to the expired flows list.
2.2. Hash Functions
Hashing is an extremely useful technique widely used to construct fast lookup methods to be able to quickly assign received packets to their corresponding flows. The hash functions used for mapping flow keys to hash values need to be chosen carefully to ensure optimal utilization of the hash table. Intuitively, a hash function is a function that maps every item to a hash value in a fashion that is somehow random. The most obvious model for a hash function is that it is fully random. Unfortunately, it is almost always impractical to construct fully random hash functions, as the space required to store such a function is essentially the same as that required to encode an arbitrary function as a lookupTable [
23]. Thus, the hashing applied is usually a compromise between the randomness properties that are desired in a hash function and the computational resources needed to store and evaluate such a function.
Hash functions utilized in network monitoring devices should have the following features:
good performance—hash calculation cannot become a bottleneck in the network monitor;
uniform distribution—when this condition is fulfilled, buckets of the hash table which stores data describing monitored flows are randomly selected for traffic that is not manipulated, and none of them is likely to contain long list of packets (or to overflow);
collision resistance—when the hash function has this feature, it is extremely hard for an attacker to forge two packets with different flow characteristics that will end in the same hash table bucket, a situation that might eventually lead to bucket overflow.
Report [
19] discusses hash algorithms used in two popular monitoring tools—nProbe [
24] and Vermont [
25]. The authors of the current paper have identified some flaws in both algorithms and proposed a modified version of Vermont. They also suggest that cryptographic hash functions might be best for such an application, if their implementations meet performance demands.
The network probe implements all three algorithms from [
19] in hardware. In addition, two cryptographic hash functions were implemented—the cryptographically broken but still widely used SHA-1 and the state-of-the-art SHA-3. All of the algorithms are described in following subsections.
For the proposed network probe, a hash width of 32 bits was considered. If the result of a given algorithm was wider, this was reduced accordingly to 32 bits. The network probe considers source IP address, destination IP address, protocol, and protocol (TCP/UDP) source/destination port numbers as flow keys.
2.2.1. Sum Modulo 32—nProbe
The nProbe [
24] monitoring tool utilizes simple sum modulo as its hash algorithm. For the proposed network probe, the calculation is presented as Equation (
1):
This algorithm is very simple; however, as the authors of [
19] point out, after testing it with a captured network packet trace, it does not have a perfectly uniform distribution—a number of buckets contain considerably more entries than others. Another drawback is relative ease of generating collisions, because an attacker can freely manipulate the values of the flow keys provided that their sum is constant.
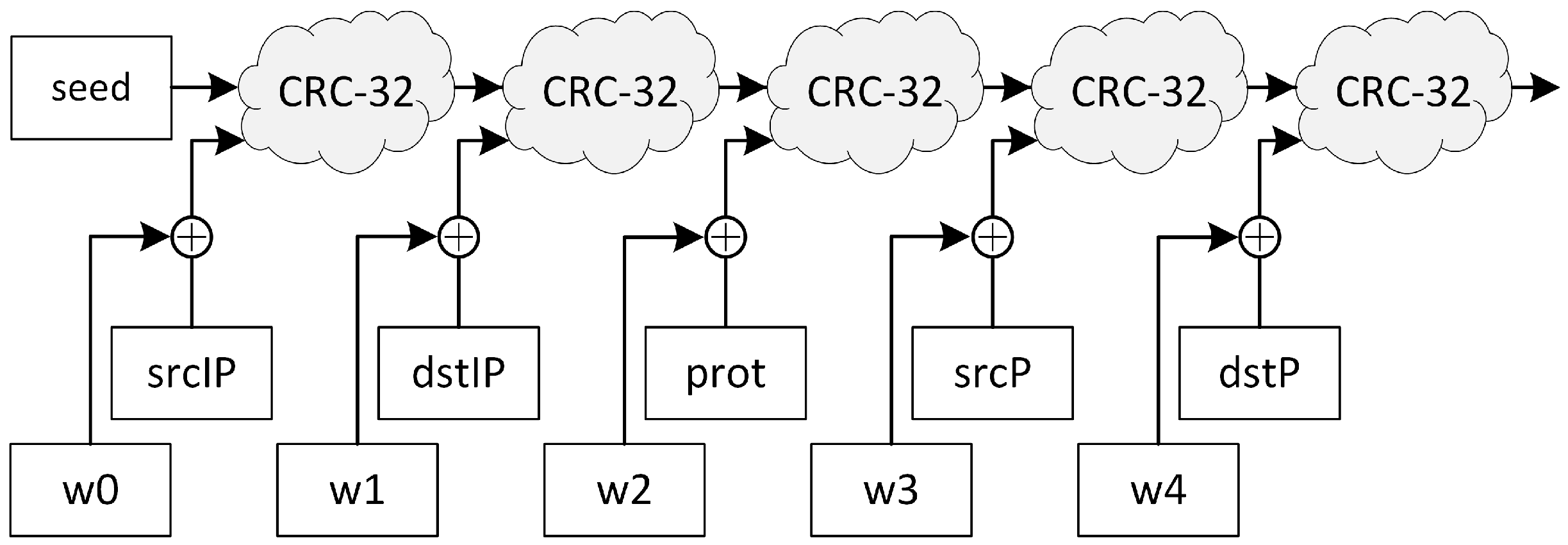
2.2.2. Nested CRC-32—Vermont
Cyclic redundancy checks or cyclic redundancy codes (CRC) have been utilized for error detection in computing for a long time. A digest is calculated from transmitted data and is appended to the frame. The same algorithm is applied to data upon frame reception, and when the result is the same as the code calculated by the transmitter, it means that the received packet is correct.
The actual algorithm can be described mathematically as polynomial division of binary data being interpreted as polynomial over GF(2) (every bit is a polynomial coefficient—zero or one) by generator polynomial G(x). The remainder of that division is treated as a check sequence, which is appended to the transmitted frame [
26].
The CRC-32 implementation used in the proposed network probe is based on IEEE 802.3 [
27] polynomial. Implementation parameters, according to [
26], are presented in
Table 1.
Vermont [
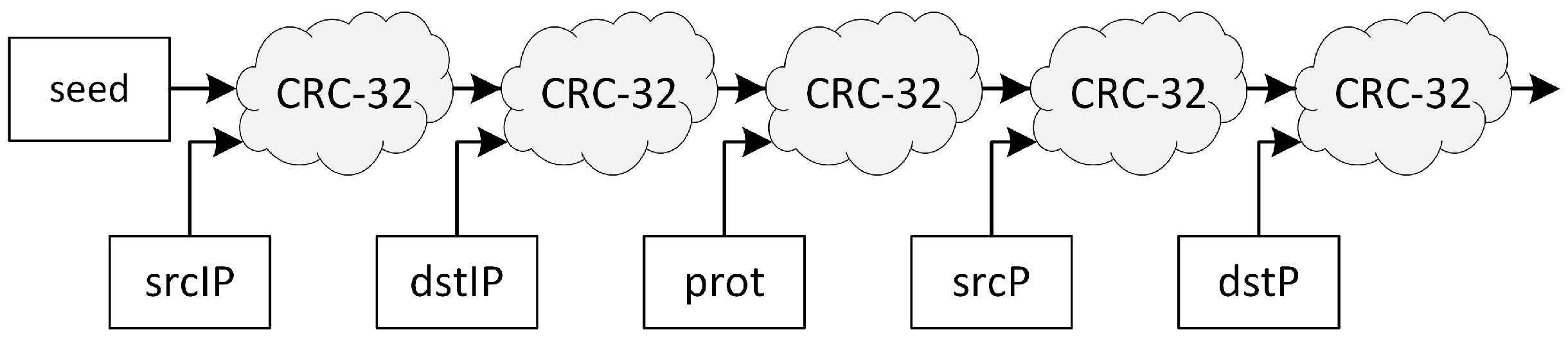
25] is built on nested CRC-32 invocations. The algorithm starts with a given initial seed, and
Figure 2 presents how CRC-32 is invoked five times to include flow keys in the hash calculation. The result of the preceding CRC-32 function is utilized as seed for the next one.
The authors of [
19] found that Vermont is computationally efficient and offers roughly uniform distribution; however, they also proved that an attacker is still able to create hash collisions on purpose.
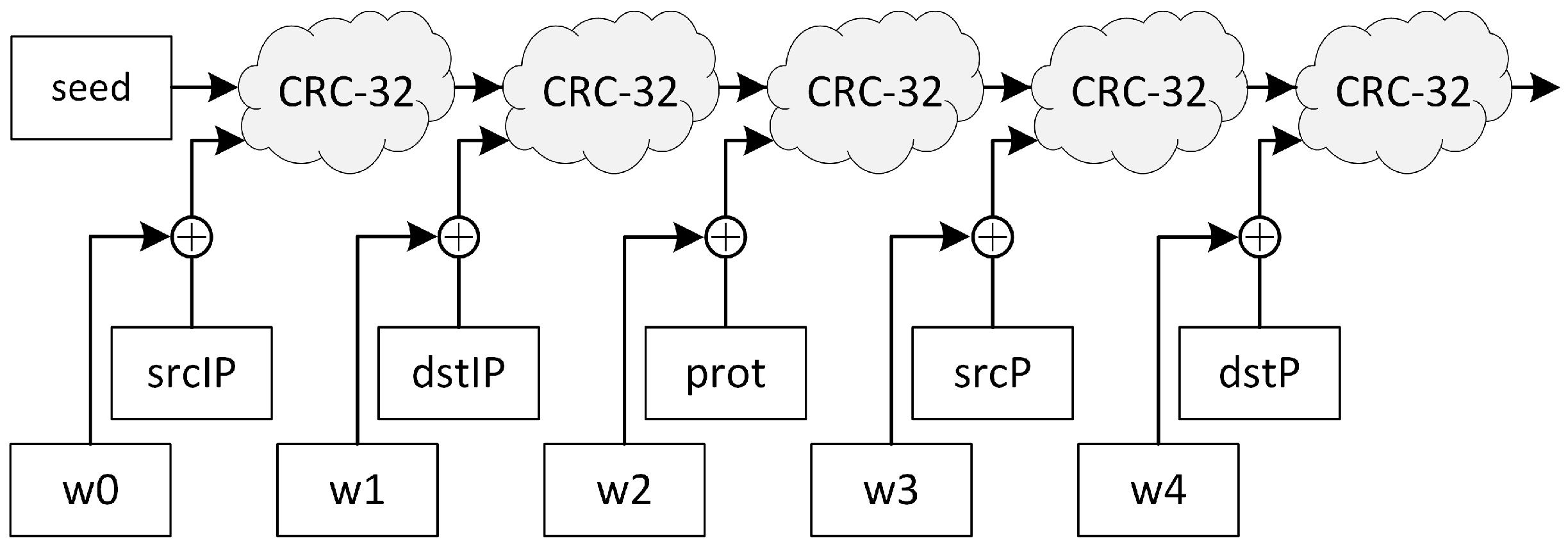
2.2.3. Nested CRC-32 with w Constants—Modified Vermont
Report [
19] proved that the CRC-based Vermont algorithm does not protect network monitoring devices from targeted collision attacks. The goal of the authors of this current paper was to design a function that does not have this flaw, but that offers the same statistical qualities. The result of their research is a modified Vermont algorithm, presented in
Figure 3.
To ensure that an attacker cannot create collisions in a simple way, a unique secret random value (w(i), initialized during network monitor activation) is added to every flow key before CRC-32 calculation. This significantly increases the cost of a targeted attack, but does not prevent it, since the CRC-32 scheme is still used.
2.2.4. SHA-1
SHA-1 is a cryptographic hash function created in 1995, described in [
28,
29]. In its cycle of life it is currently marked as deprecated, because it is prone to a variety of attacks. In 2015, a group of researchers was able to find a
freestart collision, where the SHA-1 initialization vector was chosen by themselves [
30], but soon the full SHA-1 algorithm was also cracked [
31,
32,
33].
An organized crime syndicate in possession of tens of thousands of dollars can create an SHA-1 collision in about two months, and for instance, forge an SSL certificate. That is the reason famous brands such as Microsoft, Google, and Mozilla abandoned the SHA-1 algorithm; however, it still may be useful in real-time applications such as network monitoring.
The SHA-1 function produces a 160-bit hash. It is capable of hashing messages as long as bits, which are divided into 512-bit blocks processed one by one.
The first step of the algorithm is padding, because the length of the message must be a multiple of 512 bits. During this process, the information about message length is encoded in 64 bits (hence the message length limit). This number is concatenated with exactly one “1” bit and an appropriate number of “0” bits, so when the padding bit string is appended to the message, the total length is a multiple of 512 bits. The temporary value of the hash is stored in five 32-bit variables H, initialized as in Listing 1.
Listing 1.
Initial values of H variables in SHA-1 algorithm.
Listing 1.
Initial values of H variables in SHA-1 algorithm.
| H_0(0) = 0x67452301 |
| H_1(0) = 0xEFCDAB89 |
| H_2(0) = 0x98BADCFE |
| H_3(0) = 0x10325476 |
| H_4(0) = 0xC3D2E1F0 |
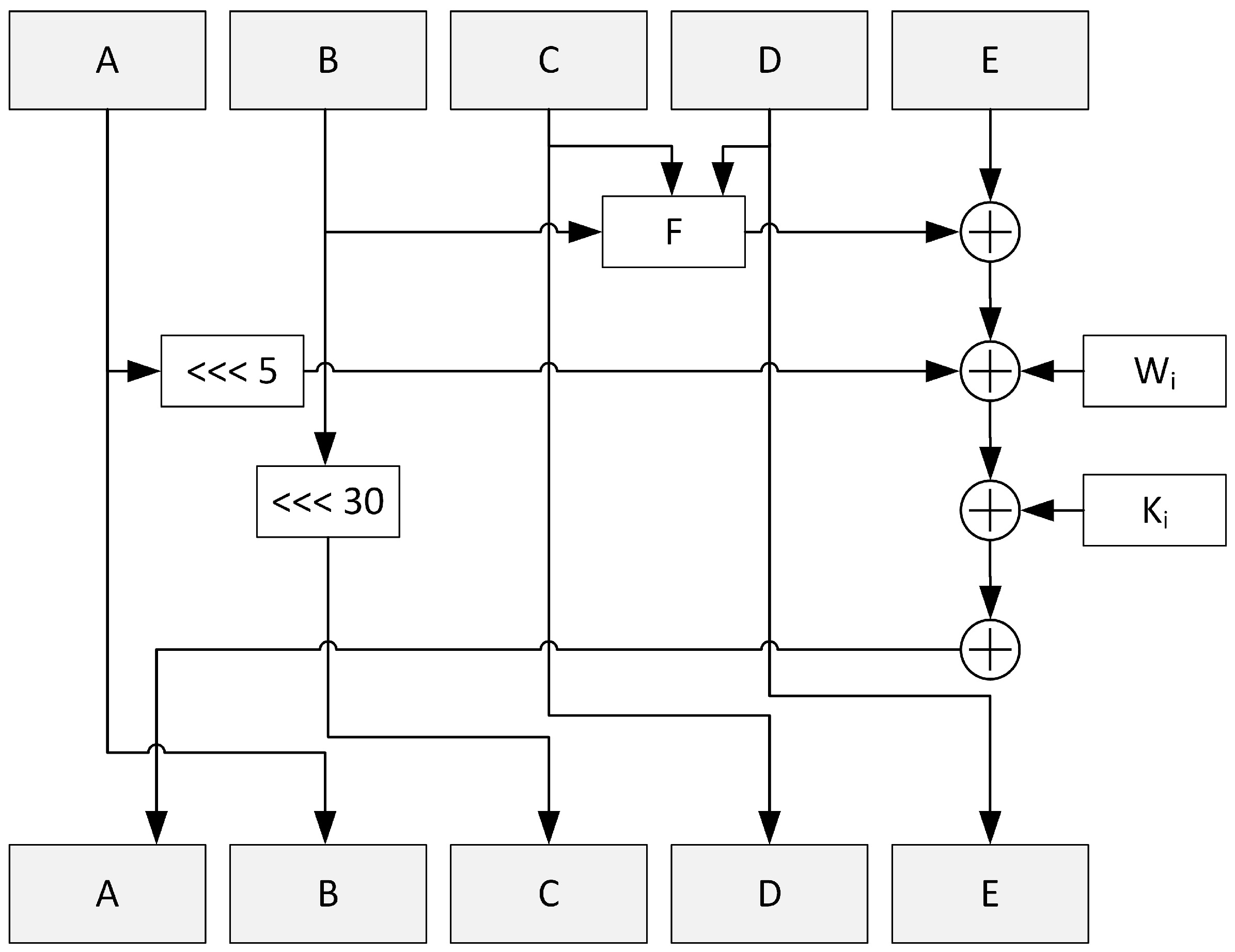
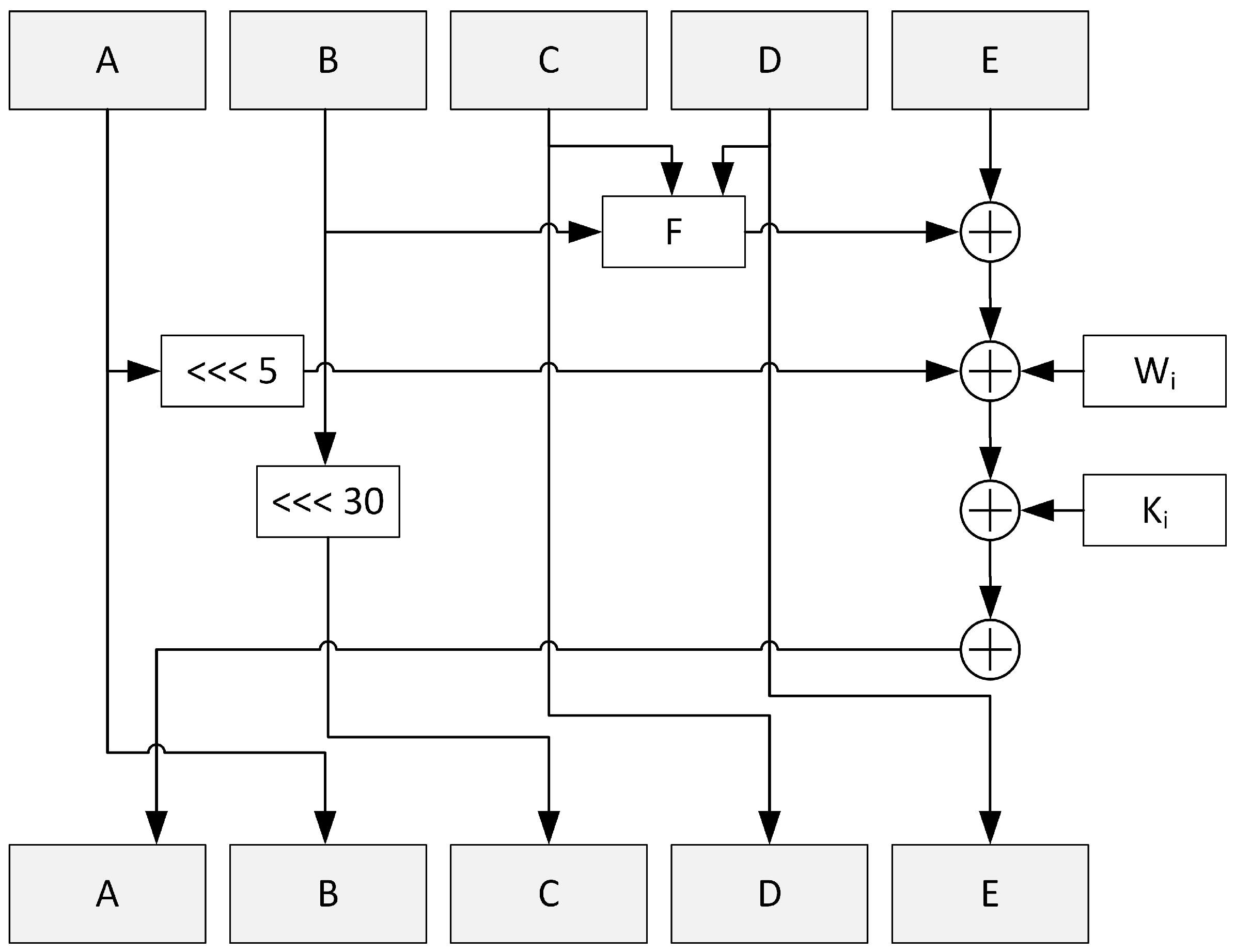
Every block of the message is processed through 80 rounds according to the scheme in
Figure 4.
Variables
A to
E are assigned values of corresponding
H registers from the previous block or
H(0) for the first block. The
W array is generated—the first 16 words are 32-bit chunks of the processed block and subsequent words are calculated with Equation (
2).
Function
F and the value of variable
K depend on the current round number as in Equations (
3) and (
4).
After 80 rounds for the given block, the H registers are updated as in Listing 2. When all blocks of the message are processed, the hash can be read as a concatenation of H variables.
Listing 2.
Update of H variables when block was processed in the SHA-1 algorithm.
Listing 2.
Update of H variables when block was processed in the SHA-1 algorithm.
| H_0(i) = H_0(i − 1) + A |
| H_1(i) = H_1(i − 1) + B |
| H_2(i) = H_2(i − 1) + C |
| H_3(i) = H_3(i − 1) + D |
| H_4(i) = H_4(i − 1) + E |
In the proposed network probe, SHA-1 is applied to a 104-bit string that consists of 32-bit IP source and destination addresses, 8-bit IP protocol information, and 16-bit source and destination ports of TCP/UDP. The 160-bit hash is reduced to 32-bit words by XORing (⊕) all H registers together.
2.2.5. SHA-3
SHA-3 [
34] is the newest hash standard issued by NIST. Unlike previous SHA algorithms, it is based on
sponge construction [
35] instead of the Merkle–Damgȧrd structure [
36]. SHA-3 is in fact a slightly modified
Keccak algorithm [
37], the winner of the NIST contest. SHA-3, like SHA-2, is capable of four hash length generations: 224, 256, 384, and 512 bits, depending on the underlying sponge construction configuration.
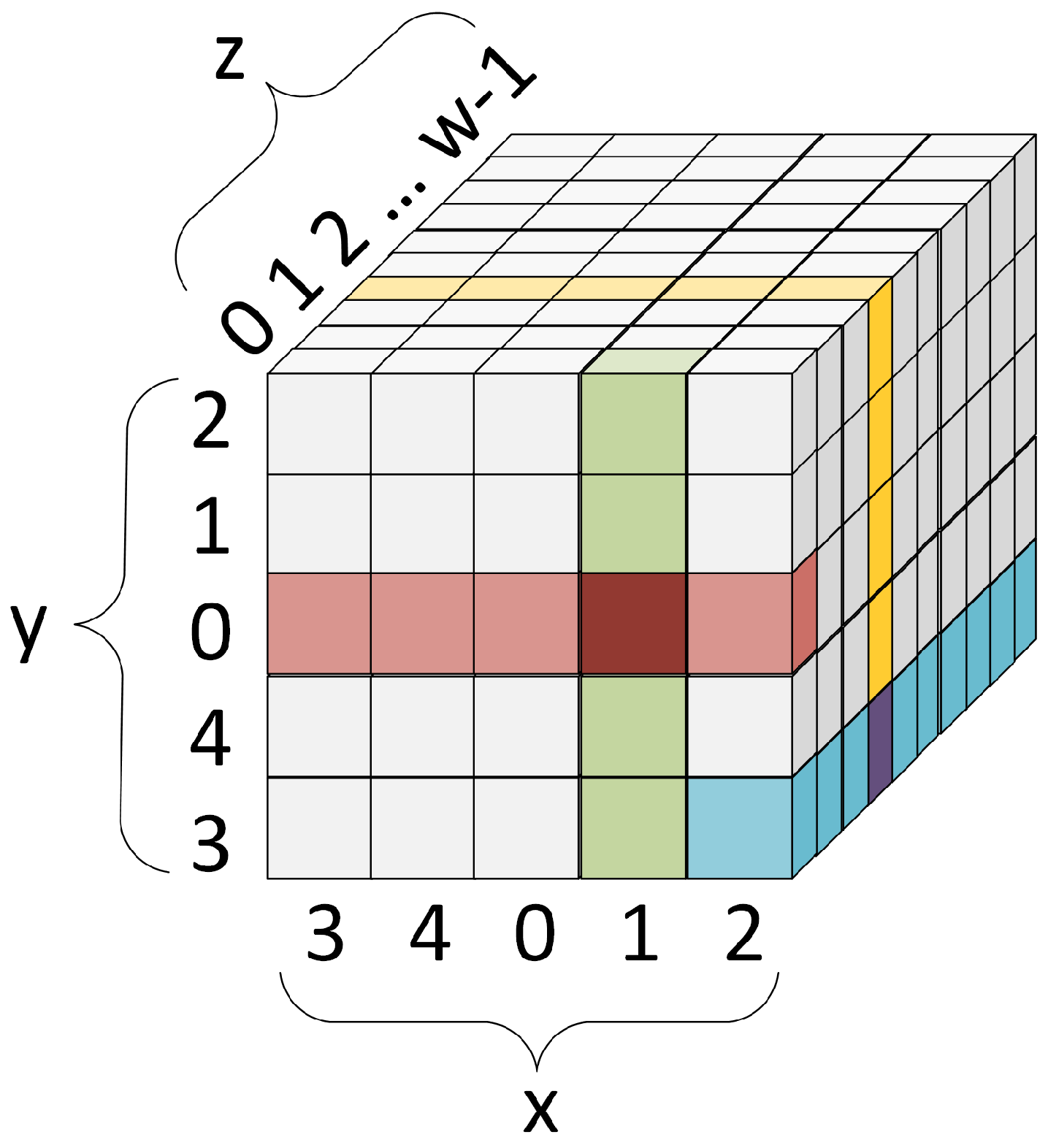
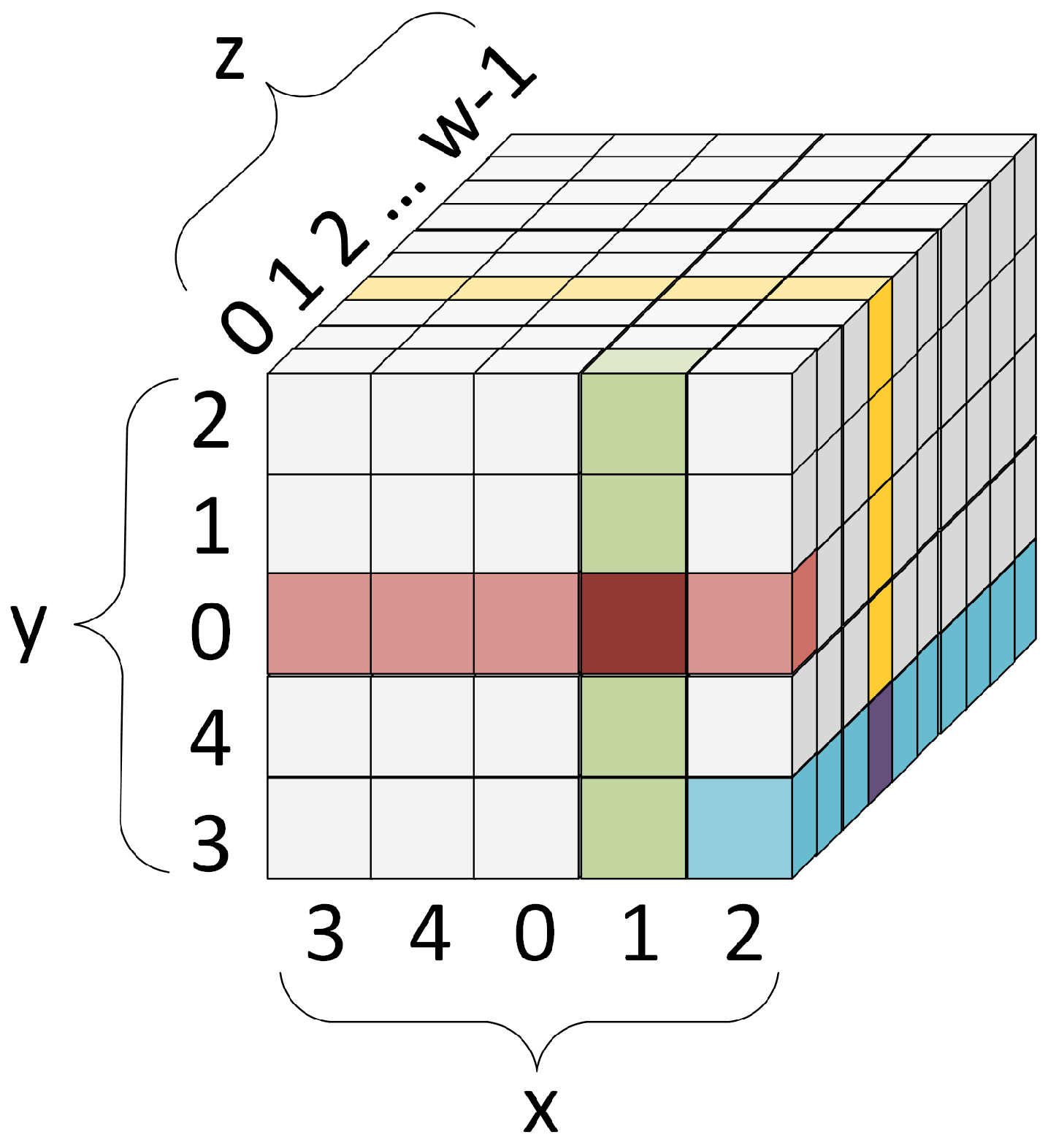
Keccak has an internal state which is
b-bit string
S; this can be also presented as a three-dimensional array (named
A,
Figure 5) with mapping as in Equation (
5). For SHA-3,
b = 1600 and two more helper variables are derived from this value:
w =
b/25 = 64 and
l =
(
w) = 6.
the color green marks an example column of the state array (x = 1, z = 0),
the color red marks an example row of the state array (y = 0, z = 0),
the color blue marks an example lane of the state array (x = 2, y = 3),
and the color yellow marks an example slice of the state array (z = 3).
An SHA-3 round consists of five step mappings denoted
,
,
,
, and
(Equation (
6)). Each of those mappings takes state array
A as an input and returns an updated state array
A’. The
mapping also takes round index
as an argument.
A detailed explanation of every step mapping can be found in [
34], and the descriptions below will give a brief idea of how each of these works.
The effect of is to XOR (⊕) each bit in the state with the parities of two columns in the array. The operation result is modification of the z coordinate for every bit in each lane by an offset (modulo lane size), which depends on fixed x and y coordinates of this lane. The operation effect is rearranged positions of lanes in every state array slice. In the operation, each bit of the state array is XORed (⊕) with a non-linear function of two other bits in its row. The effect of the operation is to modify some of the bits in Lane(0,0) (the exact center of the state array slice) in a way that depends on the round index . Lane(0,0) is XORed (⊕) with a w-bit string, where most of the bits are “0”, but a selected few are the result of rc(x) transformation dependent on round index .
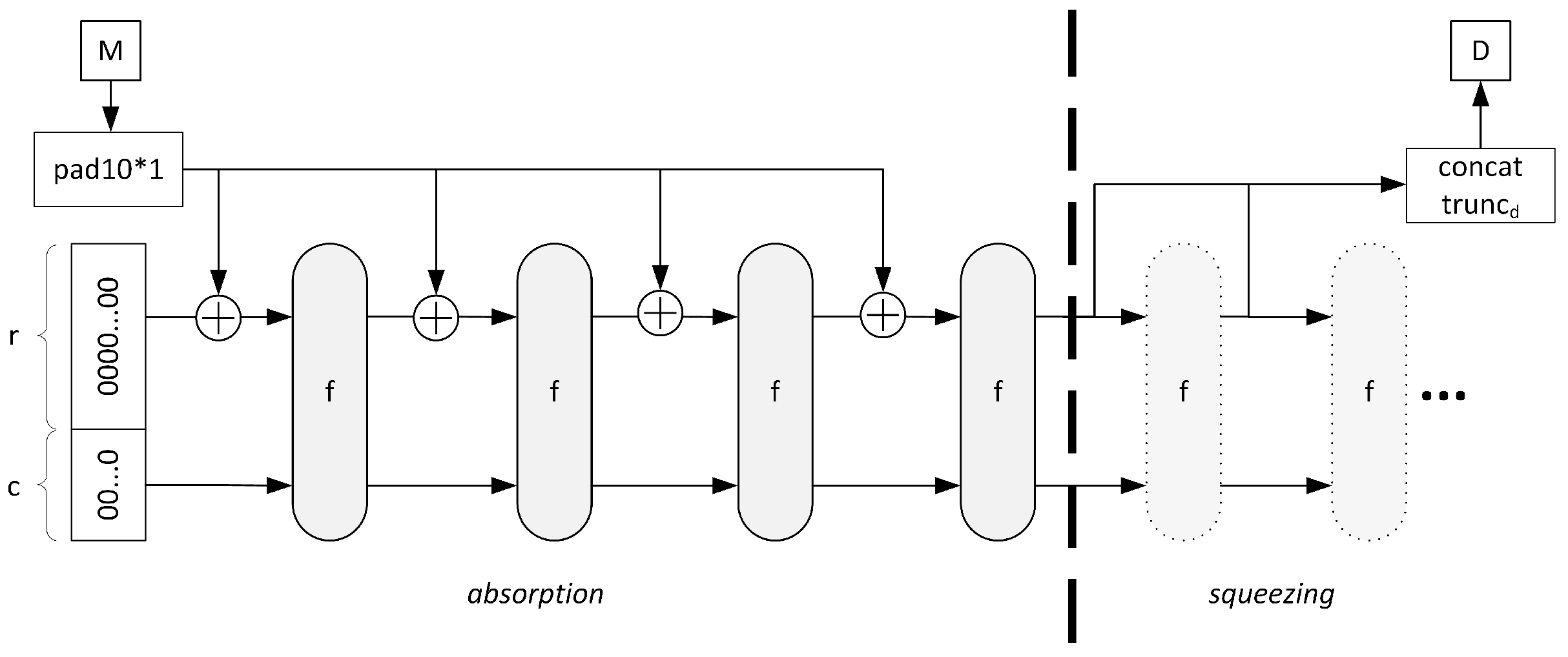
Before the message is fed into the sponge construction, a two-bit suffix “01” is appended to its end. It supports domain separation and allows us to distinguish the SHA-3 hash function from other algorithms. Now the message must be padded so its length is a multiple of rate (r) parameter, which essentially is the SHA-3 block width. SHA-3 utilizes a pad10*1 padding scheme, which generates a bit string starting and ending with “1” and filled with an appropriate number of 0s (hence the asterisk, which in regular expression notation indicates zero or more).
Figure 6 presents the SHA-3 sponge construction’s principle of operation. At the beginning, the SHA-3 state is initialized with a 1600-bit (
b = 1600) string of zeros. In the phase called
absorption, the padded message is divided into series of
r-bit blocks and XORed (⊕) into a state vector. Then
f transformation, which consists of 24 SHA-3 rounds, is applied to the state. This process is repeated until the whole message is absorbed. In the second stage, the actual hash is
squeezed from the sponge. For all SHA-3 hash lengths, the hash can be obtained without applying the
f transformation again—an appropriate number of bits is taken directly from the state vector as
r is always greater than the hash length (
Table 2). Variable
c is the
capacity of the sponge, and for SHA-3 it is double the hash length (
c = 2
d). As variables
r and
c satisfy relation
r +
c =
b, the selection of capacity determines the block width of the SHA-3 algorithm.
In the network probe, SHA-3 is applied to a 104-bit string that consists of 32-bit IP source and destination addresses, 8-bit IP protocol information, and 16-bit source and destination ports for TCP/UDP. The SHA-3 digest is trimmed to the 32 most significant bits, which are considered the flow hash.
2.3. Implementation and Verification
2.3.1. Implementation
The proposed network probe hardware accelerator was implemented with the hardware description language Verilog [
38]. The accelerator’s top module is depicted in
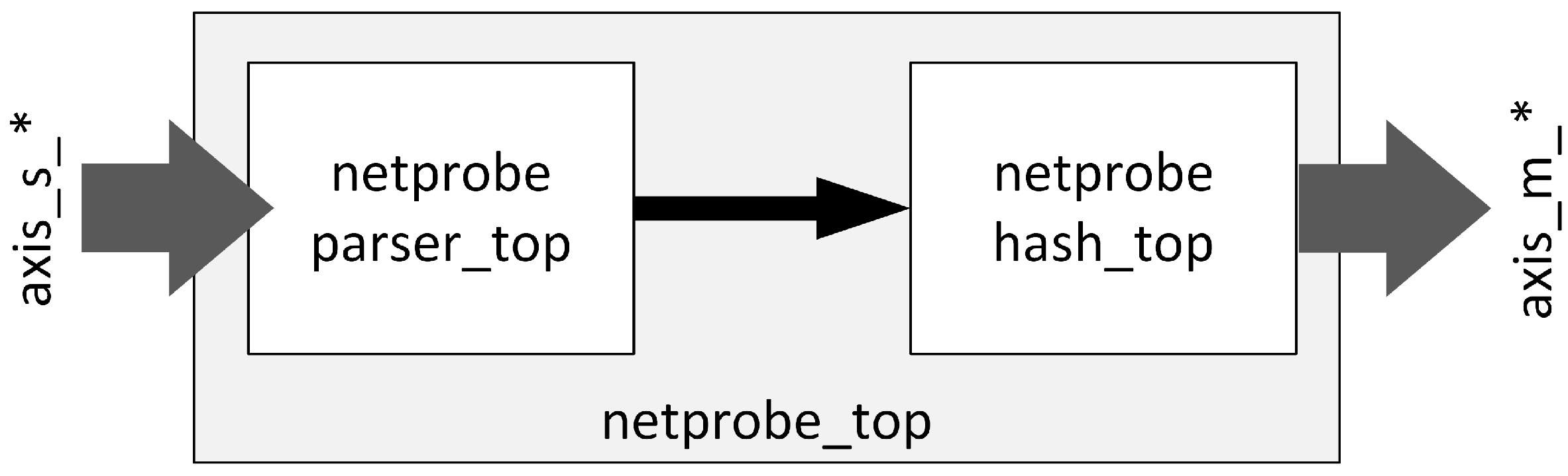
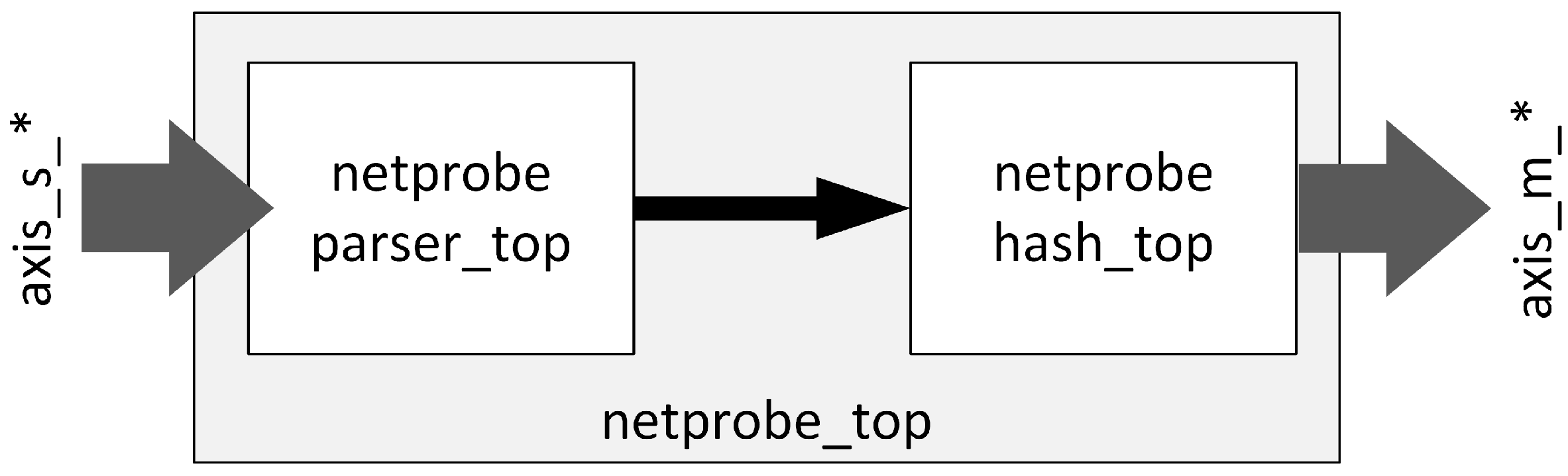
Figure 7. It has a 128-bit data path with two AXI4-Stream interfaces [
39], Slave and Master, used for data flow. Packets are processed sequentially, and their order is not changed. Block
netprobe_top consists of two submodules that implement the two main functions of the accelerator:
netprobe_parser_top, where IP packet parsing and extraction of flow keys along with some other parameters (e.g., payload length, TCP flags) is performed,
netprobe_hash_top, where calculation of the 32-bit hash over flow keys extracted from the IP packet header is carried out.
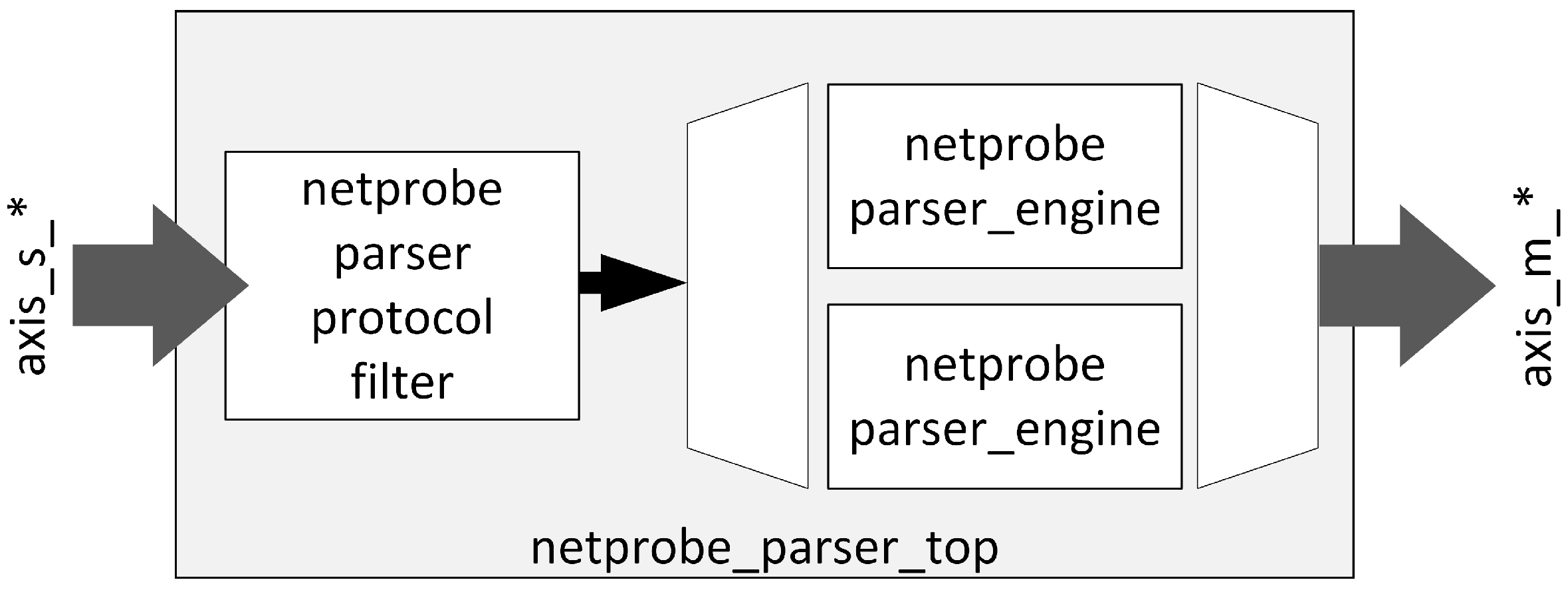
Figure 8 presents the structure of the packet parser module. The first block in the data path is a protocol filter, responsible for dropping IP packets that contain a protocol other than TCP or UDP. Packets that pass this protocol check are distributed in a round-robin manner between two parallel parser engines which extract flow keys and other information from the packet header.
These modules were parallelized to avoid empty cycles on the Master interface due to the unfavorable header structure of processed IP packets, e.g., such as IP header length (IHL), and as a result the TCP header offset that causes the TCP port and TCP flag fields to be in different packet beats for the 128-bit data path width. Parser engines process the IP packet header, extract flow keys and the rest of the features, and forward data in an internal format (two beats in a 128-bit data path). A placeholder for the hash is included, although it is calculated later in the pipeline.
Module
netprobe_hash_top is a block that wraps hash engines. It is parameterized with a HASH_ALGORITHM variable, which selects an appropriate algorithm submodule to be instantiated (
Table 3).
The module
netprobe_hash_top also has a set of strap ports used for modified Vermont and SHA-3 algorithm configuration as in
Table 4. In the network probe hardware accelerator,
w constant straps were tied off to random integers and a 512-bit hash was selected for the SHA-3 algorithm.
The nProbe hash algorithm (for HASH_ALGORITHM ) was implemented as a simple 32-bit adder, whose inputs are flow keys extracted from the internal packet format and left-padded with zeros to 32-bit width if necessary.
The Vermont hash algorithm (for HASH_ALGORITHM
) was implemented as 5-stage pipeline, similarly to the diagram in
Figure 2. Internal packet data are registered in parallel to CRC-32 logic, and at every stage an appropriate flow key is selected to be included in the hash.
The modified Vermont hash algorithm (for HASH_ALGORITHM
) was realized in a similar manner to regular Vermont. Flow keys are obfuscated with
w constants before being used in CRC-32 calculations, as in
Figure 3.
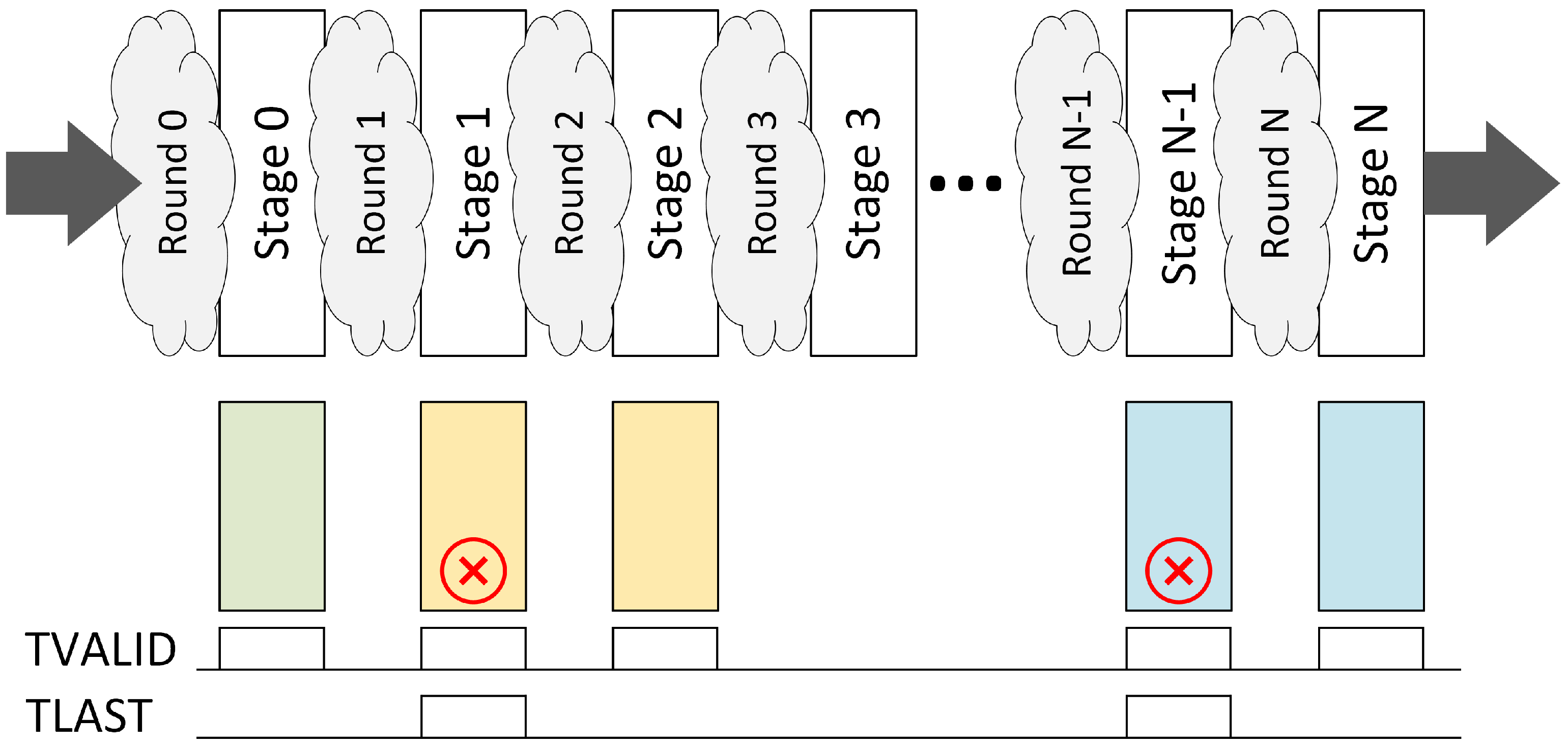
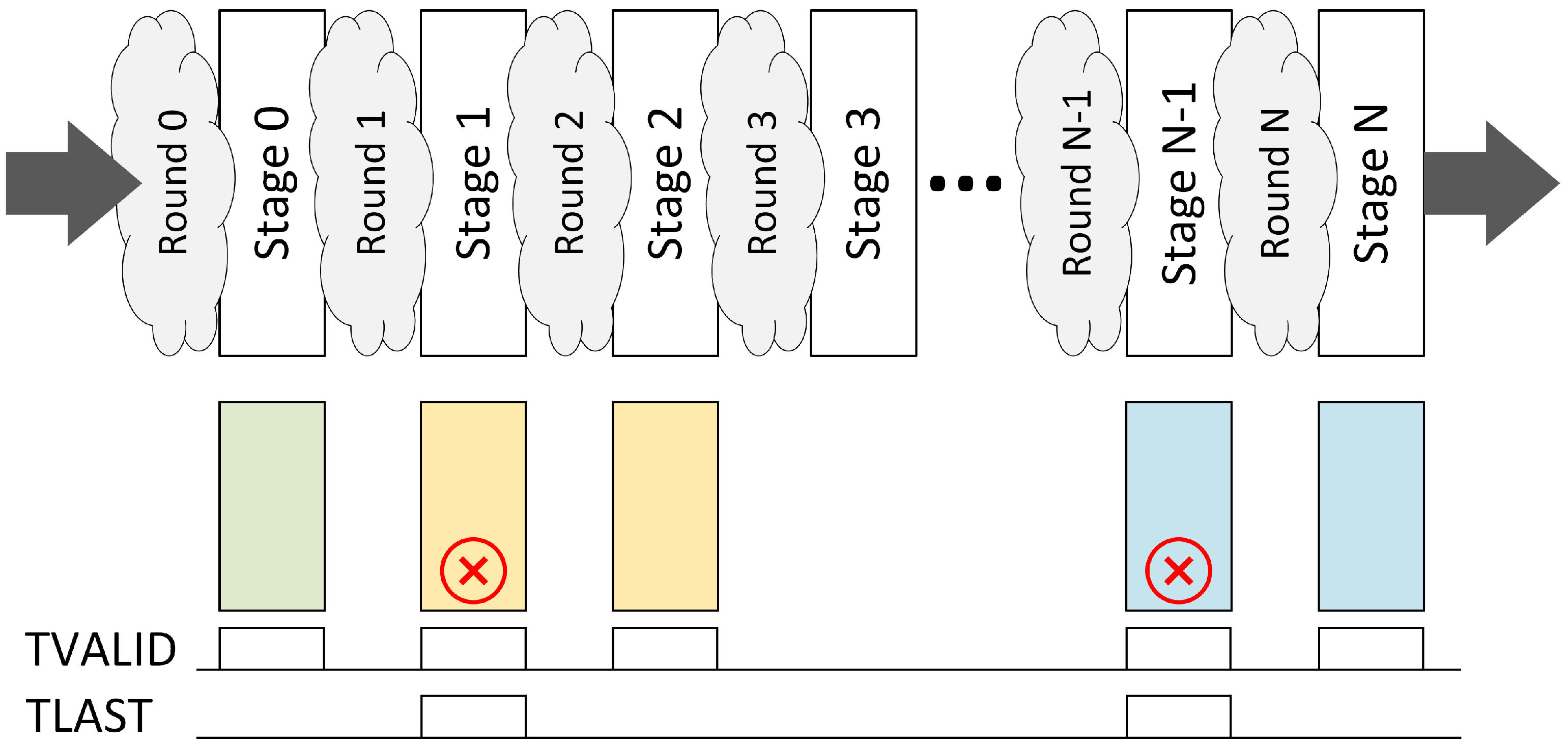
In the case of SHA-1 (for HASH_ALGORITHM ), concatenation of all flow keys forms a 104-bit word, which is considered input to the hash function. The length of the input word is less than 512 bits, which means that SHA-1 transformation (80 rounds) must be applied only to a single block. This makes pipelined algorithm implementation possible, as backpressure towards subsequent packets is not necessary.
Figure 9 presents an example of such a pipeline. Data with extracted flow keys are constantly fed to the input, and multiple packets are processed simultaneously. Since the internal packet format requires two cycles to be transmitted in a 128-bit data path, where only the first cycle carries valid flow keys, a valid hash is obtained at the final stage of the pipeline only for the first beat of this packet.
In regular SHA-1 implementation, the hash pipeline would have 80 stages—one per SHA-1 round. It is possible to reduce the number of stages by unfolding the algorithm loop and implementing two rounds between stage registers. This approach, however, leads to critical path extension of circuits and as a result decreases maximum clock frequency. The solution to this problem was proposed in [
40], where the authors described a method with the SHA-1 algorithm loop unfolding using additional variables. This technique allows us to perform two algorithm rounds within one clock cycle and reduces the required number of stages by half. It was incorporated in the network probe hardware accelerator SHA-1 implementation; therefore, its pipeline had 40 stages.
For SHA-3 (for HASH_ALGORITHM
), as previously, concatenation of all flow keys creates a 104-bit input word. Again, this is less than the SHA-3 block length, so the approach illustrated in
Figure 9 can be applied once more. The SHA-3 pipeline in the proposed network probe hardware accelerator has 24 stages, one per SHA-3 round.
In all cases, a 32-bit flow hash is inserted into the initial placeholder of the output accelerator packet.
2.3.2. Functional Verification
Functional verification of the proposed network probe hardware accelerator was conducted using cocotb—an open source, Python-based testbench environment for VHDL/Verilog RTL [
41]. It adopts the same concepts of constrained random verification as industry-standard UVM [
42]; however, it is implemented in Python rather than SystemVerilog. This enables swift and productive construction of the verification environment, as Python scripting is simple, and additionally, a huge library of existing code is available (e.g., packet generation libraries and cryptographic algorithm implementations).
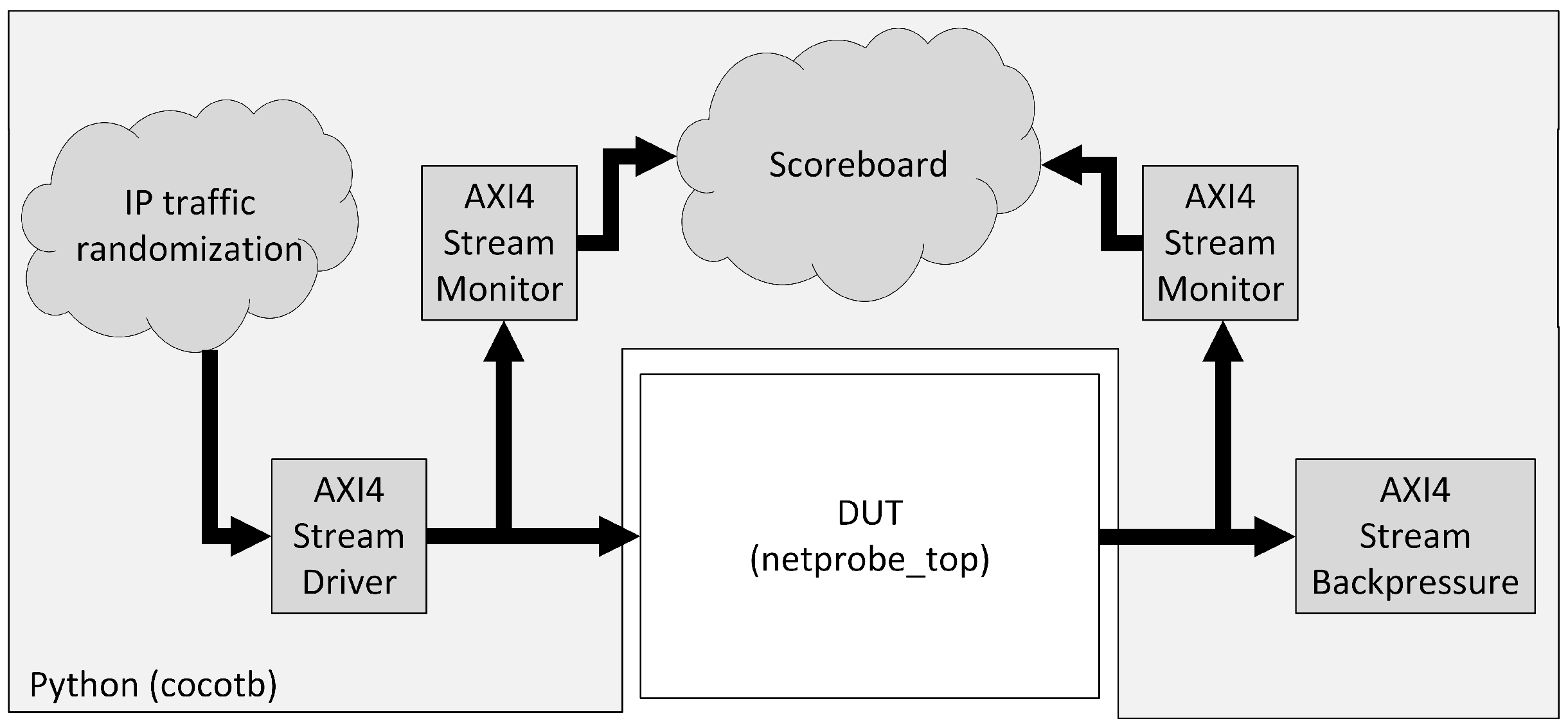
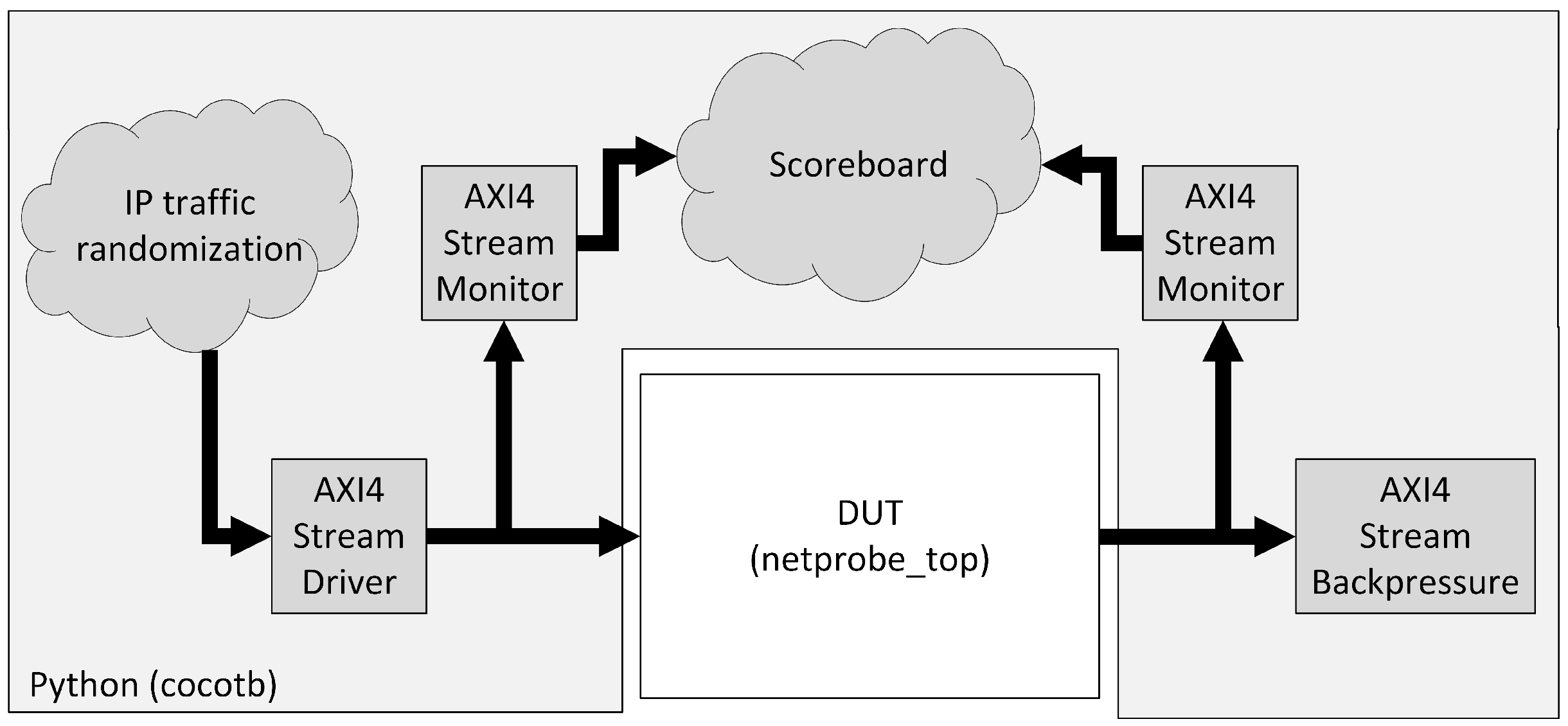
Figure 10 presents the structure of the
cocotb-based verification environment. DUT (Design Under Test, here
netprobe_top) was instantiated as top level in the simulator and was surrounded by verification environment components as drivers, monitors, and scoreboard, which were extended from infrastructure provided by cocotb. Ports of the tested module were stimulated directly from the Python function acting as a test case.
At the beginning, a number of transaction objects that mimic IP packets were created and randomized. The goal was to cover a broad space of possible network traffic, so multiple packet parameters were changed: packet length, addresses, encapsulated protocol, etc. These objects were passed to an AXI4-Stream driver, which transmitted them onto the Slave interface of the netprobe_top module. Both Slave and Master interfaces were watched by AXI4-Stream monitors, which were able to transform waveforms into transaction objects. Initial packets and those processed by DUT were fed to the scoreboard component. The DUT behavior model was applied to the stimulus packets there, and the result was compared with transactions processed by the netprobe_top module itself. They must be the same, and when this condition is not fulfilled, an error is reported.
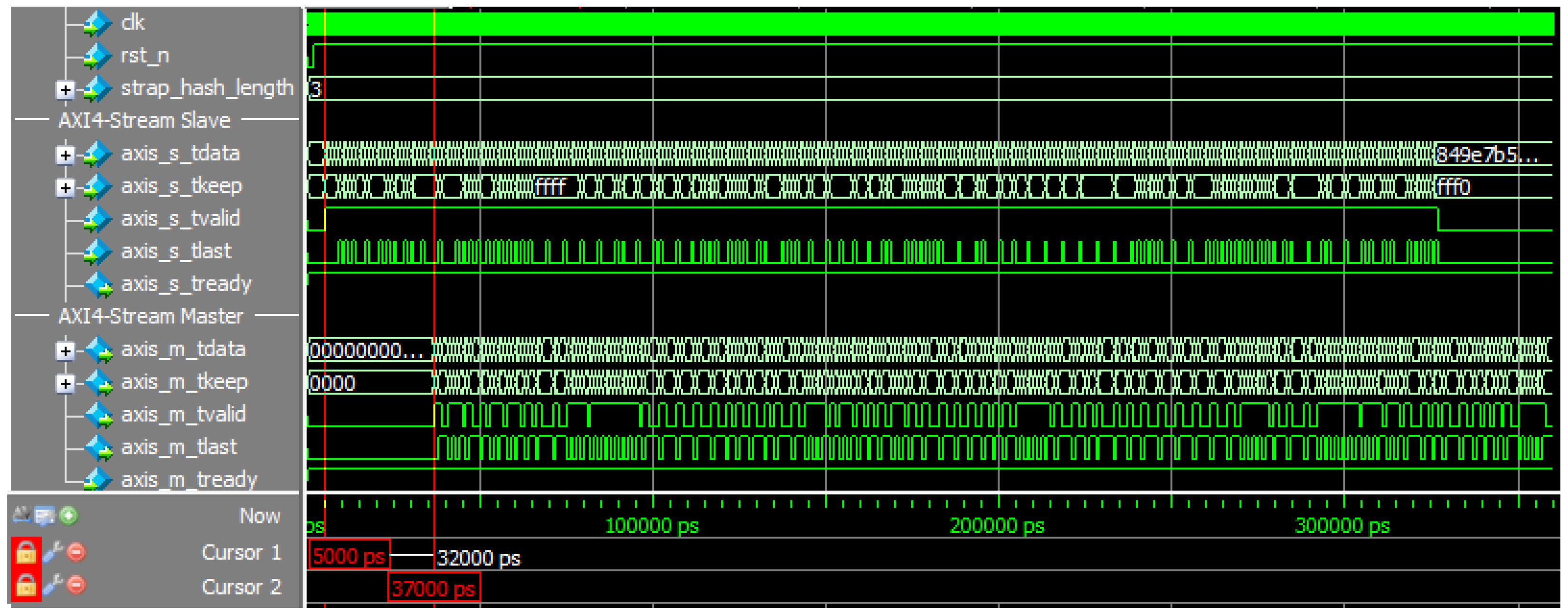
Figure 11 is a screen capture from a simulation of
netprobe_top module configured with the SHA-3 algorithm. The selected SHA-3 hash length was 512 bit (
strap_hash_length equals 2’d3). The goal of the executed test case was to check the performance of the design. Signal
axis_m_tready of the accelerator’s Master interface was tied off to high value, which indicates no backpressure. DUT was flooded with a number of short IP packets—signal
axis_s_tvalid went high at Cursor 1. After 32 clock cycles (latency for SHA-3 configuration), the first result packets were presented on the Master interface (Cursor 2,
axis_m_tvalid goes high). Checks implemented in the testbench verified whether the
axis_s_tready signal goes low. Module
netprobe_top does not introduce backpressure on its own, and even in these harsh conditions, DUT behaved as expected.
2.3.3. Synthesis Results
Synthesis of the network probe hardware accelerator was performed for Intel Stratix V GX FPGA (5SGXEA7N2F45C2), an element of the Terasic DE5-Net development kit [
43], using Intel Quartus Prime 18.1 software.
Table 5 summarizes the synthesis results of the
netprobe_top module for a range of hash algorithms. Since nProbe, Vermont, and modified Vermont are based on simple hashing schemes that use basic types of calculations (addition modulo 32 or CRC), hardware implementation of these algorithms requires little hardware resources (less than 1% of available resources of FPGA used in the experiment). Although SHA-1 and SHA-3 cryptographic functions are far more computationally expensive, the proposed implementation requires few enough resources to be efficiently used as a part of the hardware NetFlow probe. Even though SHA-1 and SHA-3 were optimized for performance, not for the area, the probe with the most complex SHA-3 algorithm utilized only 16.44% of resources, leaving enough of them to implement other functionalities of the NetFlow probe [
17]. It is no surprise that straightforward hash algorithms (such as nProbe, Vermont, or modified Vermont) implementations can sustain multigigabit throughput, but realizations of cryptographic functions (SHA-1, SHA-3) definitely match this. All investigated hash algorithms offer throughput over 20 Gbit/s.
It has been assumed that cryptographic hash functions such as SHA are computationally too expensive for efficient use in a flow monitor. The high bandwidth and low latency of the hardware accelerator based on the SHA-1 and SHA-3 functions definitely enables construction of a network probe working in a real-time manner—even when it is flooded with the smallest IP packets.
It is worth mentioning that the low percentage of logic utilization allows for further design optimization and parallelization [
44]. Utilizing such techniques, it should be even possible to reach a 100 Gbit/s bandwidth limit.
3. Experiments
In our experiments, we wanted to verify the following research hypotheses:
It is possible to realize a network traffic probe with a cryptographic hash function, working in a real-time regime.
Cryptographic hash functions SHA-1 and SHA-3 provide comparable distribution of flows to the reference methods.
In the experiments, the NetFlow probe was supplied with selected traffic, and the distribution of flow records in the flow cache buckets was analyzed. We conducted tests for five hardware-accelerated probes implementing different hash functions. Each probe was supplied with three different types of network traffic to analyze the impact of traffic type on flow record distribution over buckets in the flow cache.
3.1. Experimental Testbed
Verification and performance tests of the NetFlow probe hardware-accelerator designs were carried out using a dedicated testbed. The hardware part of the probe was implemented in the DE5-Net FPGA development platform. A general-purpose PC containing 10 Gbps Ethernet interfaces (Intel 82599 10 Gigabit Ethernet card) was connected to the DE5-Net kit. The Ethernet connectivity between the DE5-Net FPGA platform and the PC was established by means of multi-mode fiber optics, with SFP+ transceivers. The PC was used as a traffic generator running the tcreplay network driver and as a network monitor implementing the software part of the NetFlow probe.
3.2. Network Traffic Used
In our experiments, we used the CICIDS 2017 dataset [
45]. It contains the traffic captured during five days of activity in a simulated network. Both pcap and bidirectional flow formats have been published. These datasets cover various kinds of attack, such as botnets, (D)DoS, web application attacks, and SSH brute-force attempts. In total, 2,830,540 flows were collected over five days (from Monday to Friday).
In our experiments, we used the Monday, Wednesday, and Friday traffic. The traffic collected on Monday contained 496,943 flows, purely with benign network communication. The Wednesday traffic embraced 452,601 flows, which, apart from normal traffic, contained traffic captured during DoS, Heartbleed, slowloris, Slowhttptest, Hulk, and GoldenEye attacks. The Friday subset was the most numerous—it contained 792,487 flows with normal traffic and traffic with registered DDoS attacks, botnet communication, and various port scan attacks.
3.3. Metrics
The hardware-accelerated network flow probe was modified so that the flow cache stores records for all flows during a test session, i.e., flow records for terminated or expired flows, were not removed from the flow cache buckets. This allowed measurement of such values as:
minimal number of flow records in a nonempty bucket (hereinafter named as Min),
maximal number of flow records in a bucket (Max),
mean number of flow records in a bucket (Mean),
standard deviation (SD) of flow records in a bucket,
number of nonempty buckets (Buckets).
This gave us an overview of the distribution of flow records over all buckets in the flow cache for a given hash computation scheme and for the selected traffic type.
4. Results
In our experiments, each hash function was used in 16-bit and 32-bit versions, which organized the flow cache into
and
buckets, respectively. Every probe was supplied with three types of traffic from the CICIDS 2017 dataset labeled
Normal (Monday),
Normal + attacks (Wednesday), and
Normal + attacks (Friday) (see
Section 3.2). For each traffic type, the number of flows it contains was given as
N.
The results for hardware-accelerated probes using 16-bit hash functions have been presented in
Table 6. For every traffic type used to supply, all probe metrics proposed in
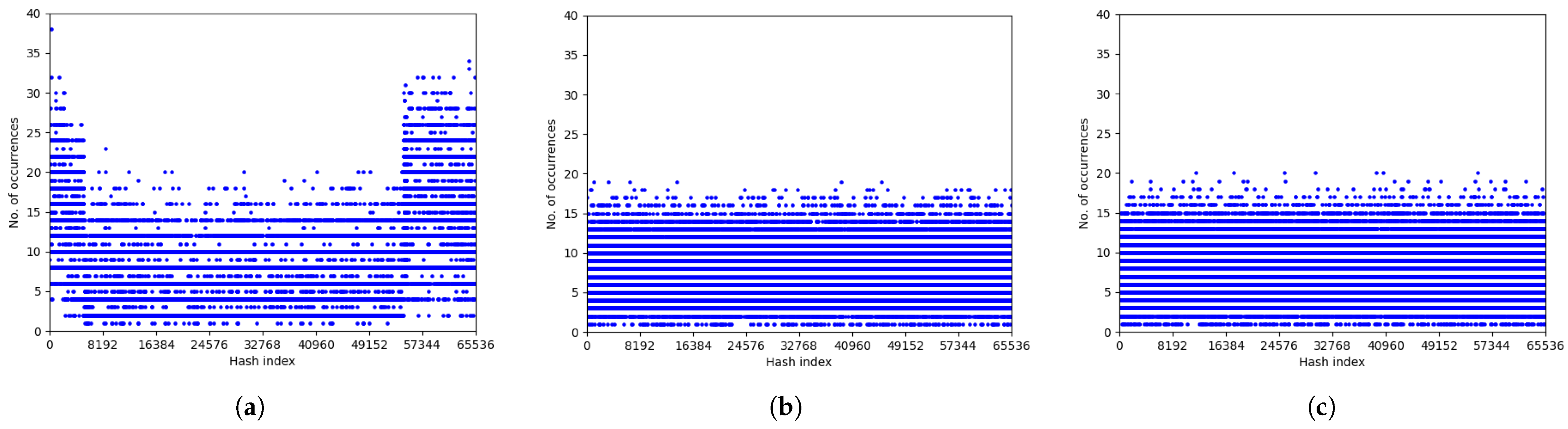
Section 3.3 were recorded. As can be seen, all hash functions except Mod32 yielded similar statistics over flow cache buckets. Mod32 function achieved noticeably worse Max, Mean, and SD values than the rest of the hash functions. We observed, however, that statistics for all functions were not much affected by anomalous traffic (DoS attacks, botnet communication, port scan attacks)—see the results for the Wednesday and Friday traffic. It can be noticed that traffic
Normal + attacks (Friday) generated larger values of recorded parameters for all functions than the other two traffic types. However, this can be explained by the fact that it contains much more flows than the other two traffic types used. Graphical presentation of the distribution of flow records over the flow cache buckets for a hash function based on a simple modulo operation (Mod32), modified Vermont, or the SHA-3 cryptographic function is shown in
Figure 12. It can be seen that the distribution produced by the simple modulo hash function is far from uniform. The modified Vermont hash function and that based on the cryptographic SHA-3 function offer much better distributions.
A more precise overview is given in
Table 7, where the results for the 32-bit version of hash functions are presented. Such a hash size greatly increases the flow cache capacity (up to
buckets). In this case, in addition to the metrics used in
Table 6, the number of nonempty buckets is also given (
Buckets column). Again, all hash functions, except Mod32, showed similar distribution over flow cache buckets, which was not affected by typical anomalous traffic. The Mod32 results significantly deviate from those obtained for the rest of the hash functions. It is worth noting that for Vermont, modified Vermont, and the two SHA hash functions, the mean value of flow records in a bucket was 1, and the number of nonempty buckets was almost equal to the number of all flows present in the traffic. This indicates that these functions put almost every flow record in a separate bucket, offering almost uniform distribution of flow records over flow cache buckets for normal traffic and typical anomalous traffic.
5. Discussion and Conclusions
A proper view of the statistics and the dynamics of a network is of great importance, since it enables us to detect network attacks. Thus, network monitors using the network flow concept are an important part of modern cybersecurity defense. As such, these devices themselves may be the targets of cyberattacks. One of the possible weak points of NetFlow probes is a network flow cache, which is usually implemented as a hash table. Due to the limited size of a hash table, it is inevitable that, sooner or later, two different flows will be mapped to the same hash bucket. It is essential that the hash function used for calculating the hash keys offers a uniform distribution of NetFlow records over available buckets, so that the lengths of all bucket lists would be almost equal. This makes it possible to use a reasonably sized hash data structure to make the flow lookup fast, because of minimal list lengths. The experiments conducted during this research show that even a relatively simple hash function may guarantee such characteristics.
However, nowadays, when components of cybersecurity systems themselves may be a targets of a cyberattack, a no less important feature of such systems is their resistance to attacks. In the case of a NetFlow probe, it should be impossible for an attacker to create directed collisions in the hash function. If an attacker is able to fabricate network traffic in such a way as to lead to a large number of collisions in the hash function, some buckets of the hash table may overflow, causing malfunction of the probe.
The results from
Section 4 show that only very simple hash functions (i.e., Mod32) are susceptible to common malicious traffic, such as DDoS or port scan attacks. More complex methods, such as Vermont, based on CRC32, offer relatively uniform distribution of flow records over flow cache buckets for normal traffic, and typical anomalous traffic. However, as demonstrated in [
19], it is possible to prepare a targeted attack exploiting a vulnerability of the implemented hash function.
Thus, it is crucial to select a hashing function that maps a small number of flow keys on to the same flow cache location. A hash function should therefore compute hash keys that are uniformly distributed, so that it should be impossible for an attacker to create directed collisions. At the same time, the hash function must be fast so that it does not become a bottleneck of the NetFlow probe.
The obvious countermeasure against hash collision-based attacks is the application of cryptographic hash functions, for which collisions cannot be created easily. The results presented in
Section 4 prove that the use of the cryptographic functions SHA-1 and SHA-3 offers comparable distribution of flows in the flow cache to the dedicated methods (Vermont, modified Vermont) used as reference. The advantage of implementing a hash function based on cryptographic functions in a NetFlow probe is that it is very difficult (or even impossible) to prepare a targeted attack on such a probe by fabricating network traffic to overflow flow cache buckets through systematically creating packets that lead to hash collisions.
Cryptographic functions, however, have not usually been candidates for hash functions in NetFlow probes, since they are considered to be computationally too expensive for efficient use in flow monitoring. Our concept presented in
Section 2.3 shows that it was possible to implement a hardware-accelerated network flow probe employing a cryptographic hash function that offered sufficient performance to construct a network probe working in real-time with multigigabit traffic, even when it was flooded with the smallest IP packets. Relatively low hardware resource utilization makes it possible to reach a 100 Gbit/s bandwidth limit by applying hardware-specific design optimization and parallelization.
It has to be emphasized that most available traffic datasets contain traffic with a relatively small number of flows. The set CICIDS 2017 used in our experiment contains, in total, 2,830,540 flows. Taking into account the fact that the flow cache of a probe that uses a 32-bit hash function contains buckets, the flow records fill only a small fraction of the flow cache. The use of datasets with significantly larger numbers of flows with normal and anomalous traffic might give a better view of possible differences in distribution of flow records over flow cache buckets for the evaluated hash functions. Such an approach, and the application of customized traffic containing flows intentionally constructed to produce hash collisions (which may not be a trivial task for some hash functions), could be the subject of future work.
To conclude, we can state that the resistance of cryptographic hash functions to collisions and the multigigabit efficiency of a hardware-accelerated implementation of hash computation allow the creation of an effective monitoring solution for modern cybersecurity systems while delivering a high level of resilience to targeted attacks.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}