
Fuzzy Local Information and Bhattacharya-Based C-Means Clustering and Optimized Deep Learning in Spark Framework for Intrusion Detection




Abstract
:1. Introduction
2. Literature Review
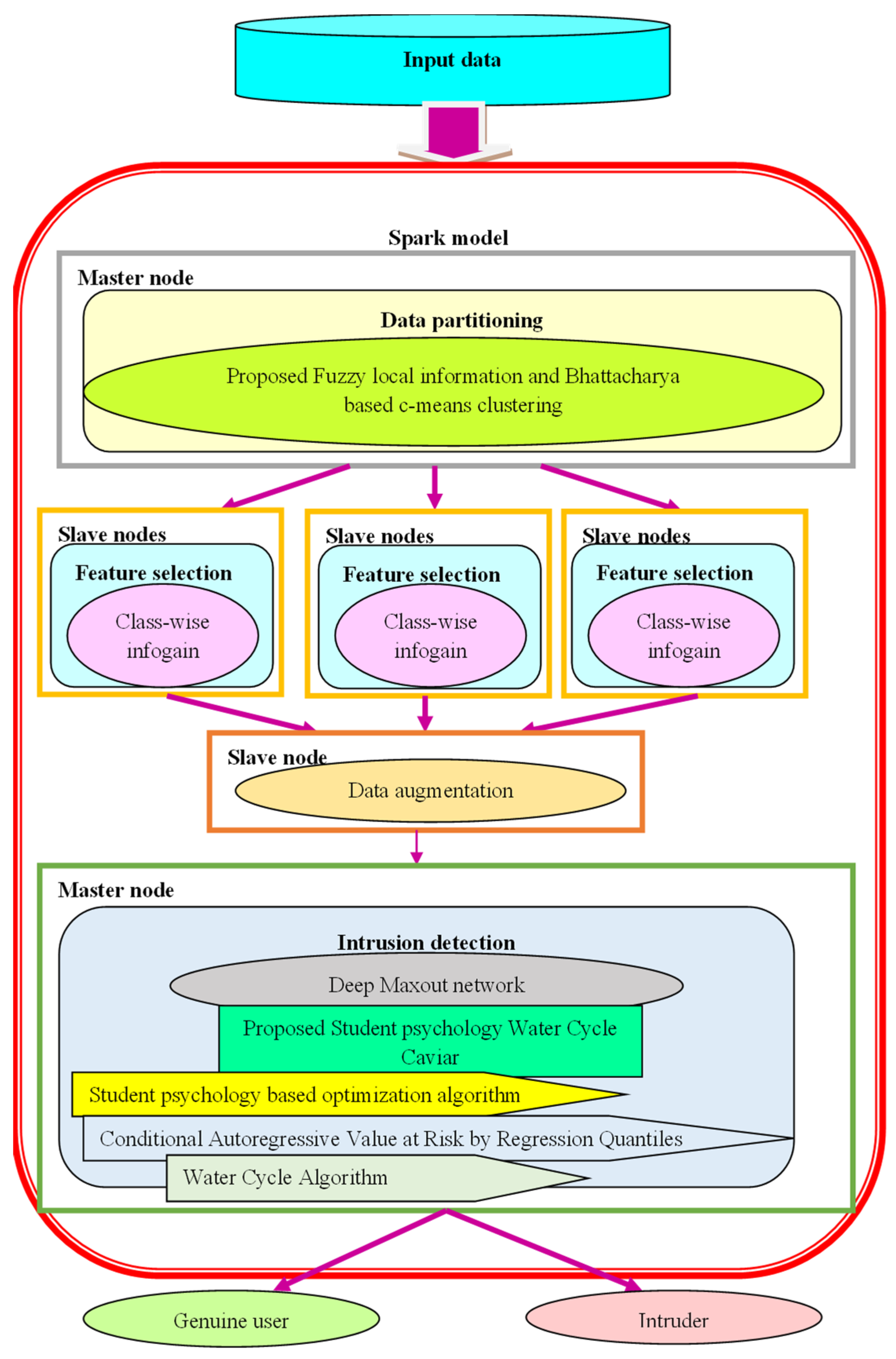
3. Materials and Methods
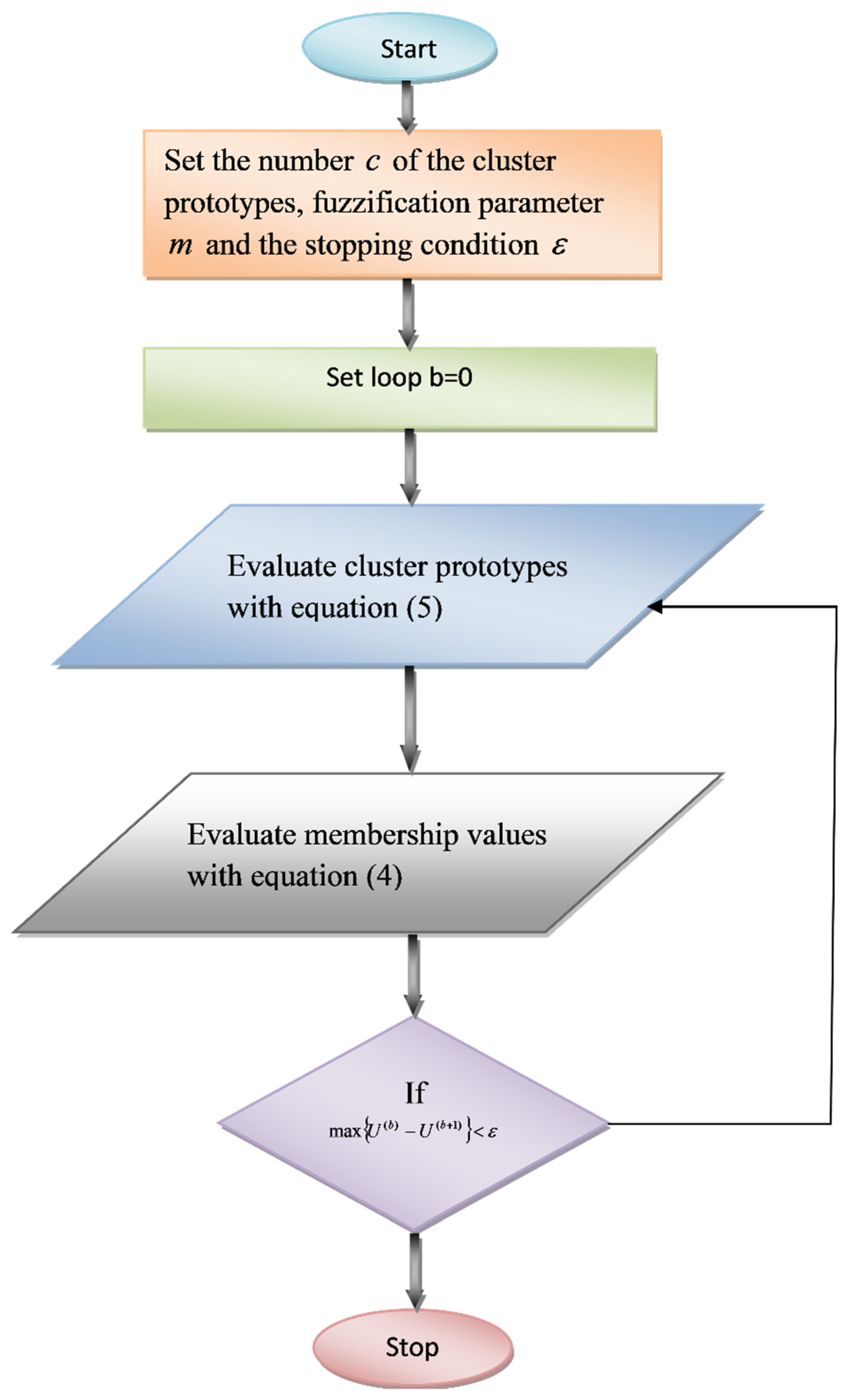
3.1. Methods
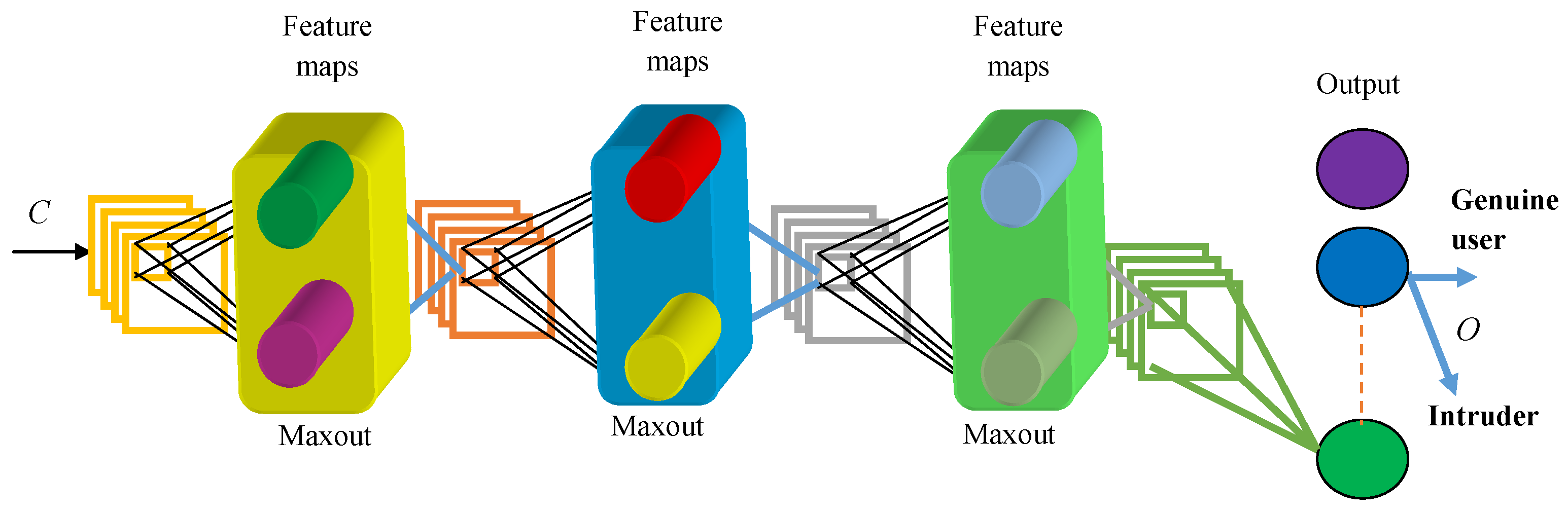
3.2. Proposed SPWCC-Based DMN for Intrusion Detection
4. Results
4.1. Evaluation Metrics
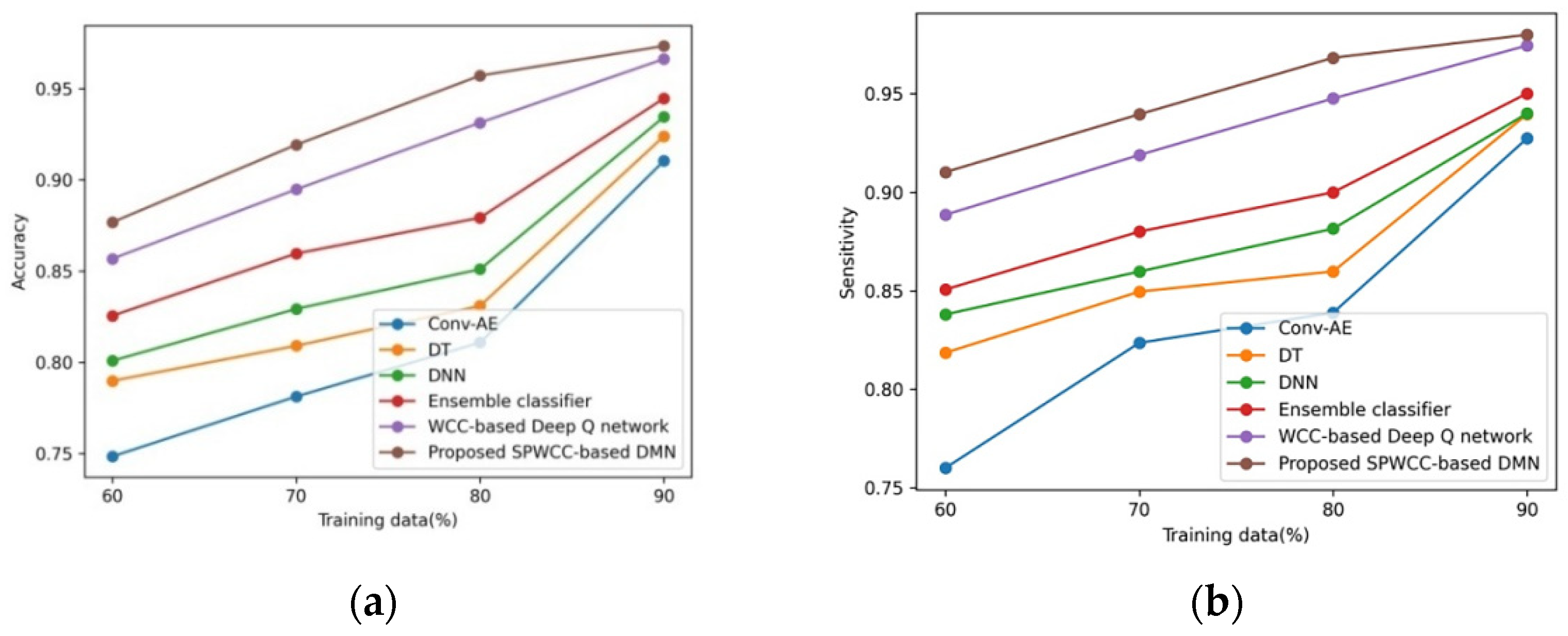
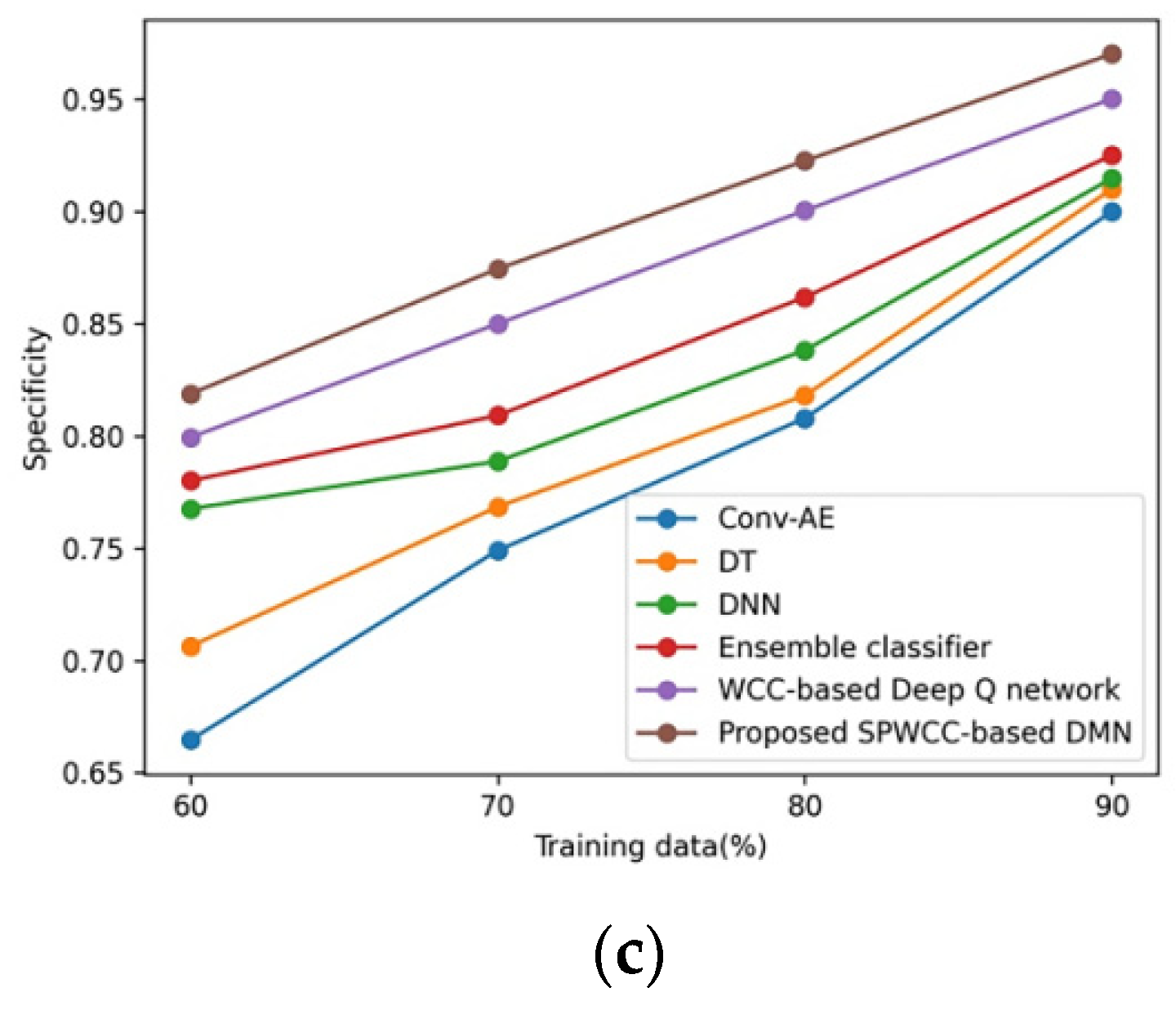
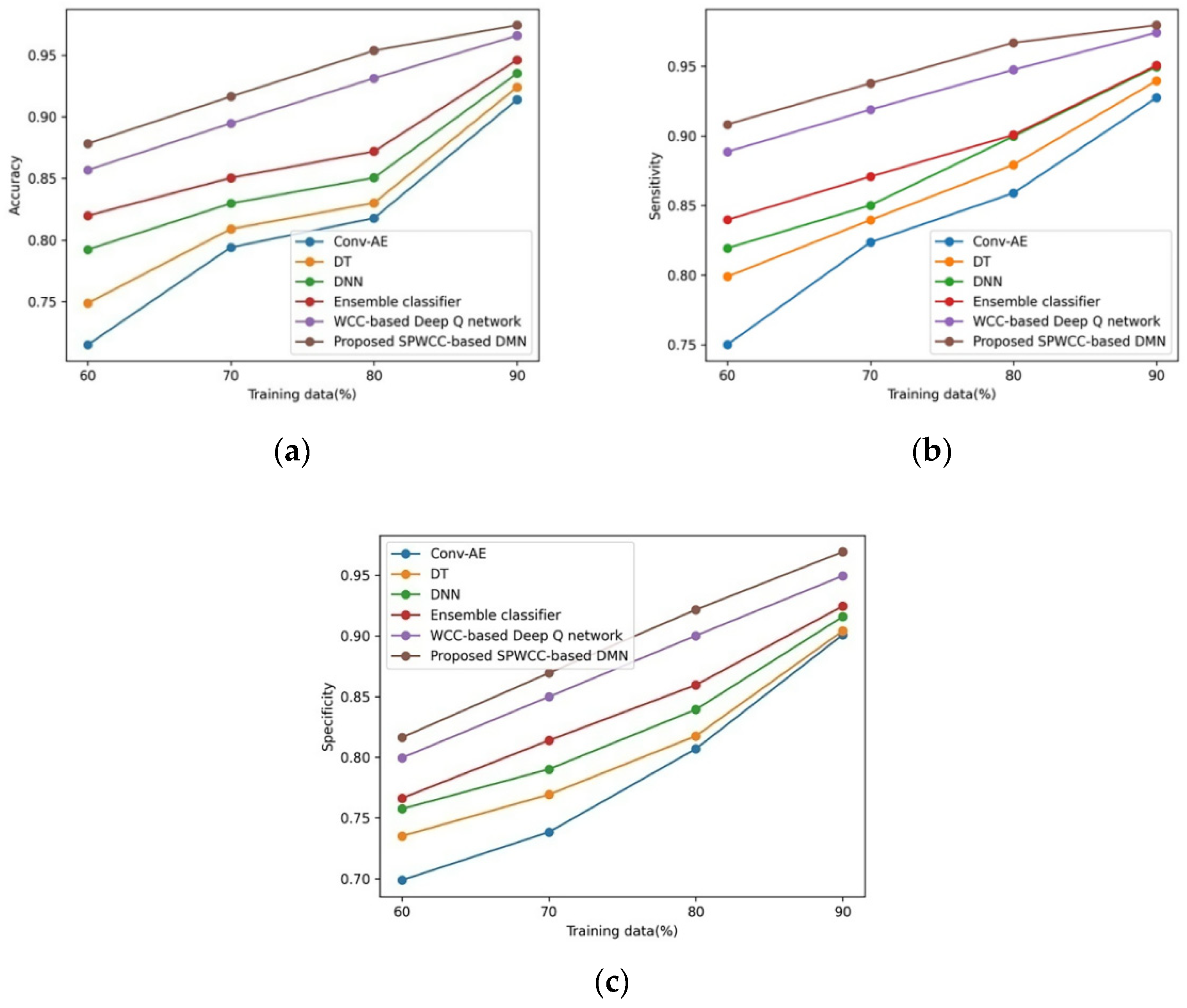
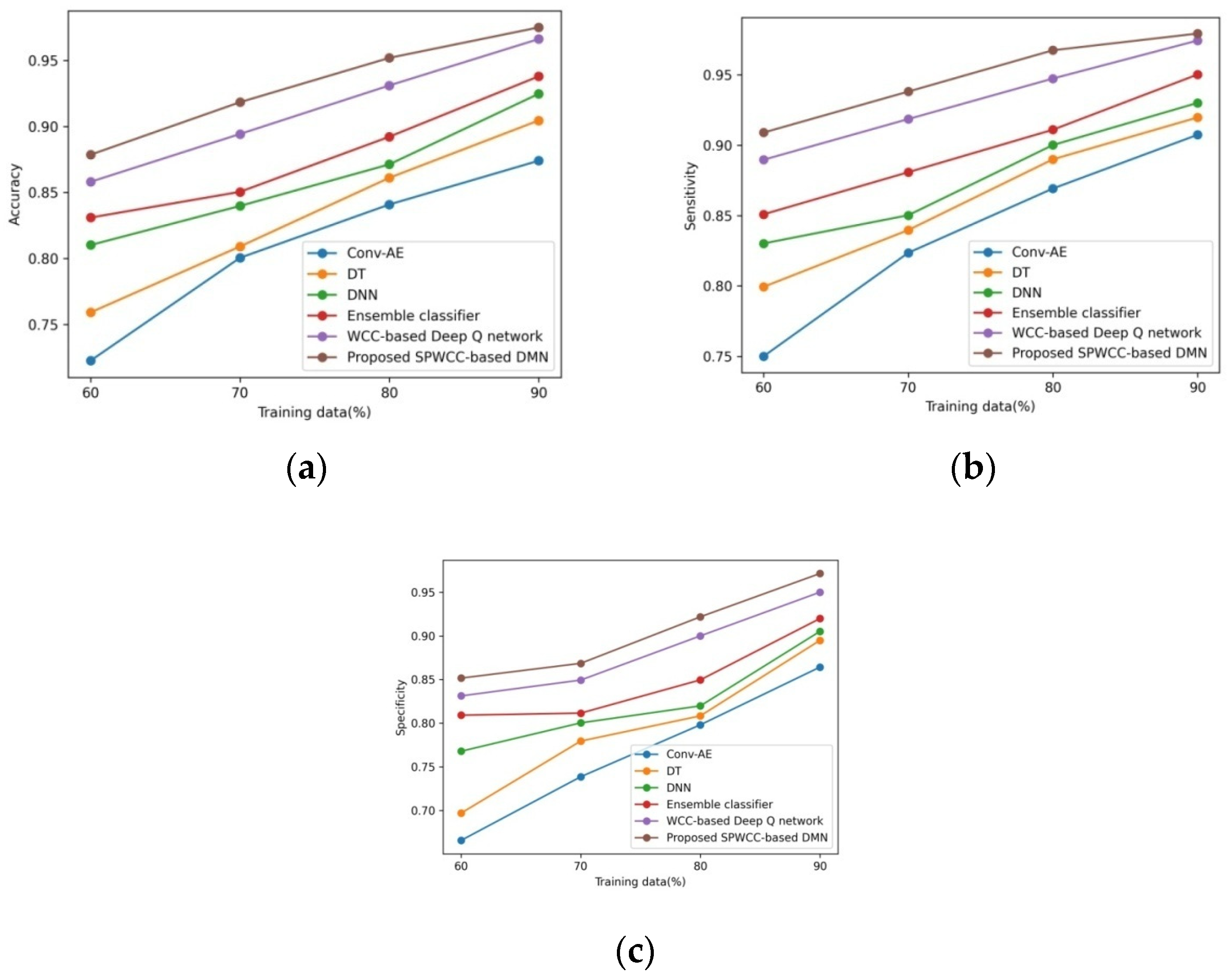
4.1.1. Accuracy
4.1.2. Sensitivity
4.1.3. Specificity
5. Discussion
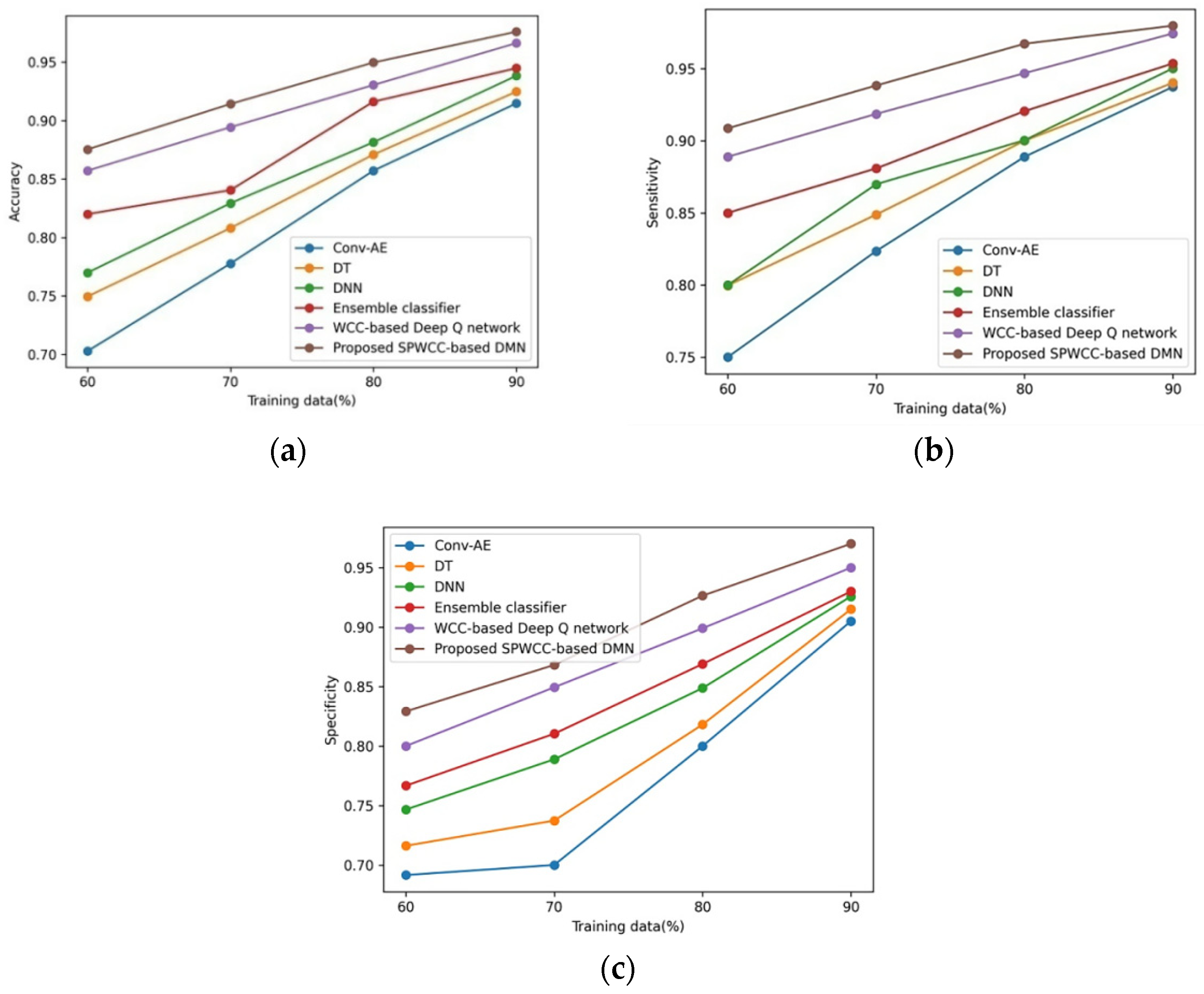
5.1. Comparative Analysis
5.1.1. Assessment without Attack
5.1.2. Assessment with DoS Attack
5.1.3. Assessment with Probe Attack
5.1.4. Assessment of Other Attacks
5.2. Discussion Based on the Best Performance
6. Conclusions
Abbreviation
| HDFS | Hadoop Distributed File System |
| WDLSTM | Weight-Dropped, Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| SQL | Structured Query language |
| ML | Machine Learning |
| KNN | K-nearest neighbors |
| Conv-AE | convolutional-auto encoder |
| SVMs | Support Vector Machines |
| BDHDLS | Big Data-based Hierarchical Deep Learning System |
| PSO | Particle Swarm Optimization |
| GA | Genetic Algorithm |
| FLIBCM | fuzzy local information and Bhattacharya-based C-Means clustering |
| DLS-IDS | Deep Learning Spark Intrusion Detection System |
| BLSTM | Bidirectional Long Short-term memory |
| RBF | Radial Basis function |
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dahiya, P.; Srivastava, D.K. Network intrusion detection in big dataset using spark. Procedia Comput. Sci. 2018, 132, 253–262. [Google Scholar] [CrossRef]
- Azeroual, O.; Nikiforova, A. Apache spark and MLlib-based intrusion detection system or how the big data technologies can secure the data. Information 2022, 13, 58. [Google Scholar] [CrossRef]
- Abushwereb, M.; Alkasassbeh, M.; Almseidin, M.; Mustafa, M. An accurate IoT intrusion detection framework using Apache Spark. arXiv 2022, arXiv:2203.04347. [Google Scholar]
- Ramkumar, M.P.; Bhaskar Reddy, P.V.; Thirukrishna, J.T.; Vidyadhari, C. Intrusion detection in big data using hybrid feature fusion and optimization enabled deep learning based on spark architecture. Comput. Secur. 2022, 116, 102668. [Google Scholar]
- Gupta, G.P.; Kulariya, M. A framework for fast and efficient cyber security network intrusion detection using Apache Spark. Procedia Comput. Sci. 2016, 93, 824–831. [Google Scholar] [CrossRef] [Green Version]
- Mahdy, A.M.S.; Lotfy, K.; El-Bary, A.A. Use of optimal control in studying the dynamical behaviors of fractional financial awareness models. Soft Comput. 2022, 26, 3401–3409. [Google Scholar] [CrossRef]
- Li, R.; Shen, M.; Yu, H.; Li, C.; Duan, P.; Zhu, L. A survey on cyberspace search engines. In CNCERT: Cyber Security, Proceedings of the China Cyber Security Annual Conference, Beijing, China, 12 August 2020; Springer: Singapore, 2020; pp. 206–214. [Google Scholar]
- Daskevics, A.; Nikiforova, A. IoTSE-based open database vulnerability inspection in three Baltic countries: ShoBEVODSDT sees you. In Proceedings of the 8th international Conference on Internet of Things: Systems, Management and Security (IOTSMS), Gandia, Spain, 6–9 December 2021; pp. 1–8. [Google Scholar]
- Faker, O.; Dogdu, E. Intrusion detection using big data and deep learning techniques. In Proceedings of the 2019 ACM Southeast Conference, Kennesaw, GA, USA, 18–20 April 2019; pp. 86–93. [Google Scholar] [CrossRef]
- Hafsa, M.; Jemili, F. Comparative study between big data analysis techniques in intrusion detection. Big Data Cogn. Comput. 2019, 3, 1. [Google Scholar] [CrossRef] [Green Version]
- Mahdy, A.M.S.; Youssef, E.S.M. Numerical solution technique for solving isoperimetric variational problems. Int. J. Mod. Phys. C 2021, 32, 2150002. [Google Scholar] [CrossRef]
- Kulariya, M.; Saraf, P.; Ranjan, R.; Gupta, G.P. Performance analysis of network intrusion detection schemes using Apache Spark. In Proceedings of the 2016 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 6–8 April 2016; pp. 1973–1977. [Google Scholar]
- Veeraiah, N.; Krishna, B.T. Intrusion detection based on piecewise fuzzy C-means clustering and fuzzy naive bayes rule. Multimed. Res. 2018, 1, 27–32. [Google Scholar]
- Yi, Y.; Wu, J.; Xu, W. Incremental SVM based on reserved set for network intrusion detection. Expert Syst. Appl. 2011, 38, 7698–7707. [Google Scholar] [CrossRef]
- Muda, Z.; Yassin, W.; Sulaiman, M.N.; Udzir, N.I. Intrusion detection based on K-Means clustering and Naïve Bayes classification. In Proceedings of the 2011 7th International Conference on Information Technology in Asia, Sarawak, Malaysia, 12–13 July 2011; pp. 1–6. [Google Scholar]
- Syarif, A.R.; Gata, W. Intrusion detection system using hybrid binary PSO and K-nearest neighborhood algorithm. In Proceedings of the 11th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 31 October 2017; pp. 181–186. [Google Scholar]
- Aslahi-Shahri, B.M.; Rahmani, R.; Chizari, M.; Maralani, A.; Eslami, M.; Golkar, M.J.; Ebrahimi, A. A hybrid method consisting of GA and SVM for intrusion detection system. Neural Comput. Appl. 2016, 27, 1669–1676. [Google Scholar] [CrossRef]
- Aburomman, A.A.; Reaz, M.B.I. A novel SVM-KNN-PSO ensemble method for intrusion detection system. Appl. Soft Comput. 2016, 38, 360–372. [Google Scholar] [CrossRef]
- Zhang, H.; Dai, S.; Li, Y.; Zhang, W. Real-time distributed-random-forest-based network intrusion detection system using Apache Spark. In Proceedings of the 37th IEEE international performance computing and communications conference (IPCCC), Orlando, FL, USA, 17–19 November 2018; pp. 1–7. [Google Scholar]
- Kalyani, G.; Lakshmi, A.J. Performance assessment of different classification techniques for intrusion detection. IOSR J. Comput. Eng. (IOSRJCE) 2012, 7, 25–29. [Google Scholar] [CrossRef]
- Chauhan, H.; Kumar, V.; Pundir, S.; Pilli, E.S. A comparative study of classification techniques for intrusion detection. In Proceedings of the International Symposium on Computer and Business Intelligent, New Delhi, India, 24–26 August 2013; pp. 40–43. [Google Scholar]
- Khan, M.A.; Kim, J. Toward developing efficient conv-AE-based intrusion detection system using heterogeneous dataset. Electronics 2020, 9, 1771. [Google Scholar] [CrossRef]
- Morfino, V.; Rampone, S. Towards near-real-time intrusion detection for IoT devices using supervised learning and Apache Spark. Electronics 2020, 9, 444. [Google Scholar] [CrossRef] [Green Version]
- Atefinia, R.; Ahmadi, M. Network intrusion detection using multi-architectural modular deep neural network. J. Supercomput. 2020, 77, 3571–3593. [Google Scholar] [CrossRef]
- Mahfouz, A.; Abuhussein, A.; Venugopal, D.; Shiva, S. Ensemble classifiers for network intrusion detection using a novel network attack dataset. Future Internet 2020, 12, 180. [Google Scholar] [CrossRef]
- Hassan, M.M.; Gumaei, A.; Alsanad, A.; Alrubaian, M.; Fortino, G. A hybrid deep learning model for efficient intrusion detection in big data environment. Inf. Sci. 2020, 513, 386–396. [Google Scholar] [CrossRef]
- Zhong, W.; Yu, N.; Ai, C. Applying big data based deep learning system to intrusion detection. Big Data Min. Anal. 2020, 3, 181–195. [Google Scholar] [CrossRef]
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep learning methods on network intrusion detection using NSL-KDD dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Haggag, M.; Tantawy, M.M.; El-Soudani, M.M. Implementing a deep learning model for intrusion detection on Apache Spark platform. IEEE Access 2020, 8, 163660–163672. [Google Scholar] [CrossRef]
- Ayyagari, M.R.; Kesswani, N.; Kumar, M.; Kumar, K. Intrusion detection techniques in network environment: A systematic review. Wirel. Netw. 2021, 27, 1269–1285. [Google Scholar] [CrossRef]
- Ahmad, Z.; Khan, A.S.; Shiang, C.W.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2020, 32, e4150. [Google Scholar] [CrossRef]
- Krinidis, S.; Chatzis, V. A robust fuzzy local information C-means clustering algorithm. IEEE Trans. Image Process. 2010, 19, 1328–1337. [Google Scholar] [CrossRef] [PubMed]
- Mukherjee, S.; Sharma, N. Intrusion detection using naive bayes classifier with feature reduction. Procedia Technol. 2012, 4, 119–128. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Su, F.; Wang, L. Improving deep neural networks with multi-layer maxout networks and a novel initialization method. Neurocomputing 2018, 278, 34–40. [Google Scholar] [CrossRef]
- Eskandar, H.; Sadollah, A.; Bahreininejad, A.; Hamdi, M. Water cycle algorithm—A novel metaheuristic optimization method for solving constrained engineering optimization problems. Comput. Struct. 2012, 110, 151–166. [Google Scholar]
- Engle, R.F.; Manganelli, S. CAViaR: Conditional autoregressive value at risk by regression quantiles. J. Bus. Econ. Stat. 2004, 22, 367–381. [Google Scholar] [CrossRef]
- Das, B.; Mukherjee, V.; Das, D. Student psychology based optimization algorithm: A new population based optimization algorithm for solving optimization problems. Adv. Eng. Softw. 2020, 146, 102804. [Google Scholar] [CrossRef]
- The NSL-KDD Dataset. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 22 June 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attacks | Metrics | Conv-AE | DT | DNN | Ensemble Classifier | WCC-Based Deep Q Network | Proposed SPWCC-Based DMN |
|---|---|---|---|---|---|---|---|
| Without attack | Accuracy | 0.915 | 0.925 | 0.938 | 0.945 | 0.966 | 0.976 |
| Sensitivity | 0.937 | 0.940 | 0.950 | 0.954 | 0.974 | 0.980 | |
| Specificity | 0.905 | 0.915 | 0.926 | 0.930 | 0.950 | 0.970 | |
| With DoS attack | Accuracy | 0.910 | 0.924 | 0.934 | 0.945 | 0.966 | 0.973 |
| Sensitivity | 0.927 | 0.940 | 0.940 | 0.950 | 0.974 | 0.980 | |
| Specificity | 0.900 | 0.910 | 0.915 | 0.925 | 0.950 | 0.970 | |
| With probe attack | Accuracy | 0.914 | 0.924 | 0.935 | 0.946 | 0.966 | 0.974 |
| Sensitivity | 0.927 | 0.940 | 0.950 | 0.951 | 0.974 | 0.980 | |
| Specificity | 0.901 | 0.904 | 0.916 | 0.924 | 0.949 | 0.969 | |
| With other attack | Accuracy | 0.874 | 0.904 | 0.925 | 0.938 | 0.966 | 0.975 |
| Sensitivity | 0.907 | 0.920 | 0.930 | 0.950 | 0.974 | 0.979 | |
| Specificity | 0.864 | 0.895 | 0.905 | 0.920 | 0.950 | 0.971 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouya-Moko, B.E.; Boahen, E.K.; Wang, C. Fuzzy Local Information and Bhattacharya-Based C-Means Clustering and Optimized Deep Learning in Spark Framework for Intrusion Detection. Electronics 2022, 11, 1675. https://doi.org/10.3390/electronics11111675
Bouya-Moko BE, Boahen EK, Wang C. Fuzzy Local Information and Bhattacharya-Based C-Means Clustering and Optimized Deep Learning in Spark Framework for Intrusion Detection. Electronics. 2022; 11(11):1675. https://doi.org/10.3390/electronics11111675
Chicago/Turabian StyleBouya-Moko, Brunel Elvire, Edward Kwadwo Boahen, and Changda Wang. 2022. "Fuzzy Local Information and Bhattacharya-Based C-Means Clustering and Optimized Deep Learning in Spark Framework for Intrusion Detection" Electronics 11, no. 11: 1675. https://doi.org/10.3390/electronics11111675
APA StyleBouya-Moko, B. E., Boahen, E. K., & Wang, C. (2022). Fuzzy Local Information and Bhattacharya-Based C-Means Clustering and Optimized Deep Learning in Spark Framework for Intrusion Detection. Electronics, 11(11), 1675. https://doi.org/10.3390/electronics11111675