
Gender Neutralisation for Unbiased Speech Synthesising



Abstract
:1. Introduction
- We assembled and trained a network for SGR, with previously unseen accuracy and robustness towards a variety of sounds.
- We created a pipeline for eliminating gender parameters from the speech.
- We demonstrated that said method does not create unwanted artefacts in the sound, showing that speech-to-text performance and conveyed emotion stay the same.
2. Related Work
3. Methodology
3.1. Databases
3.1.1. RAVDESS
3.1.2. CREMA-D
3.1.3. EMO-DB
3.1.4. LibriSpeech
3.2. Speaker Gender Recognition
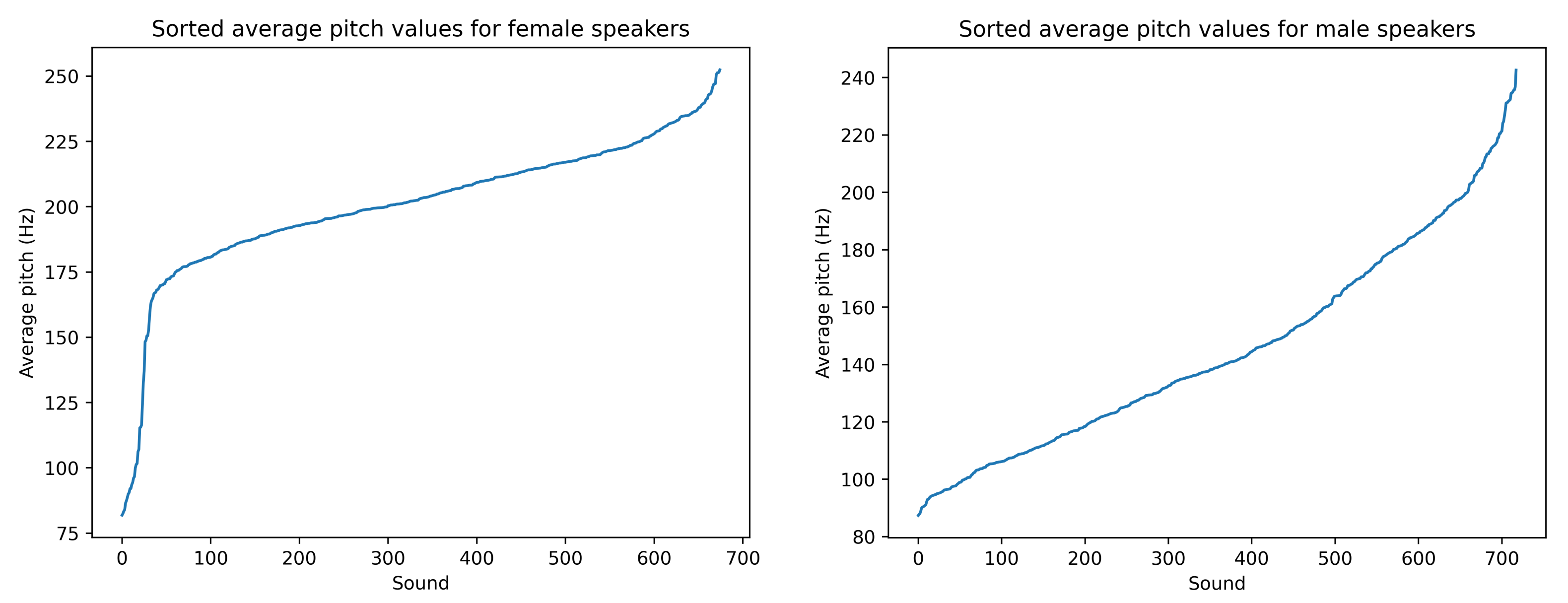
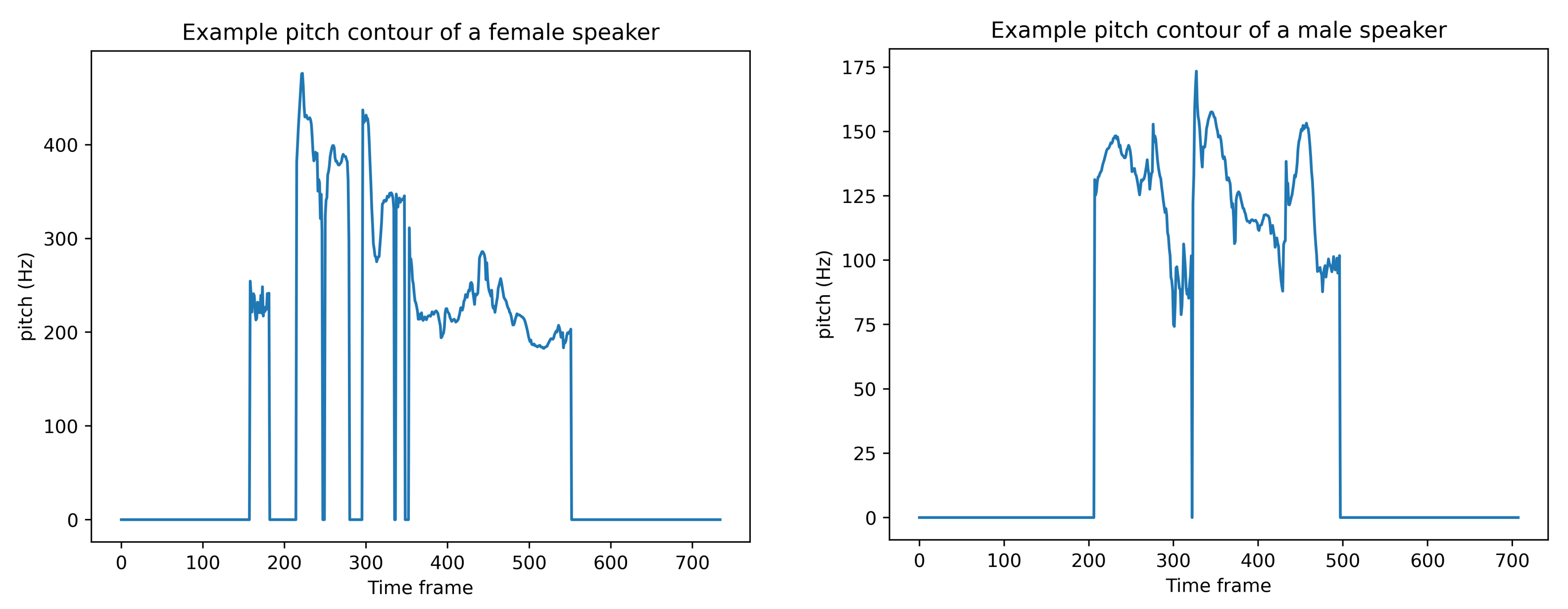
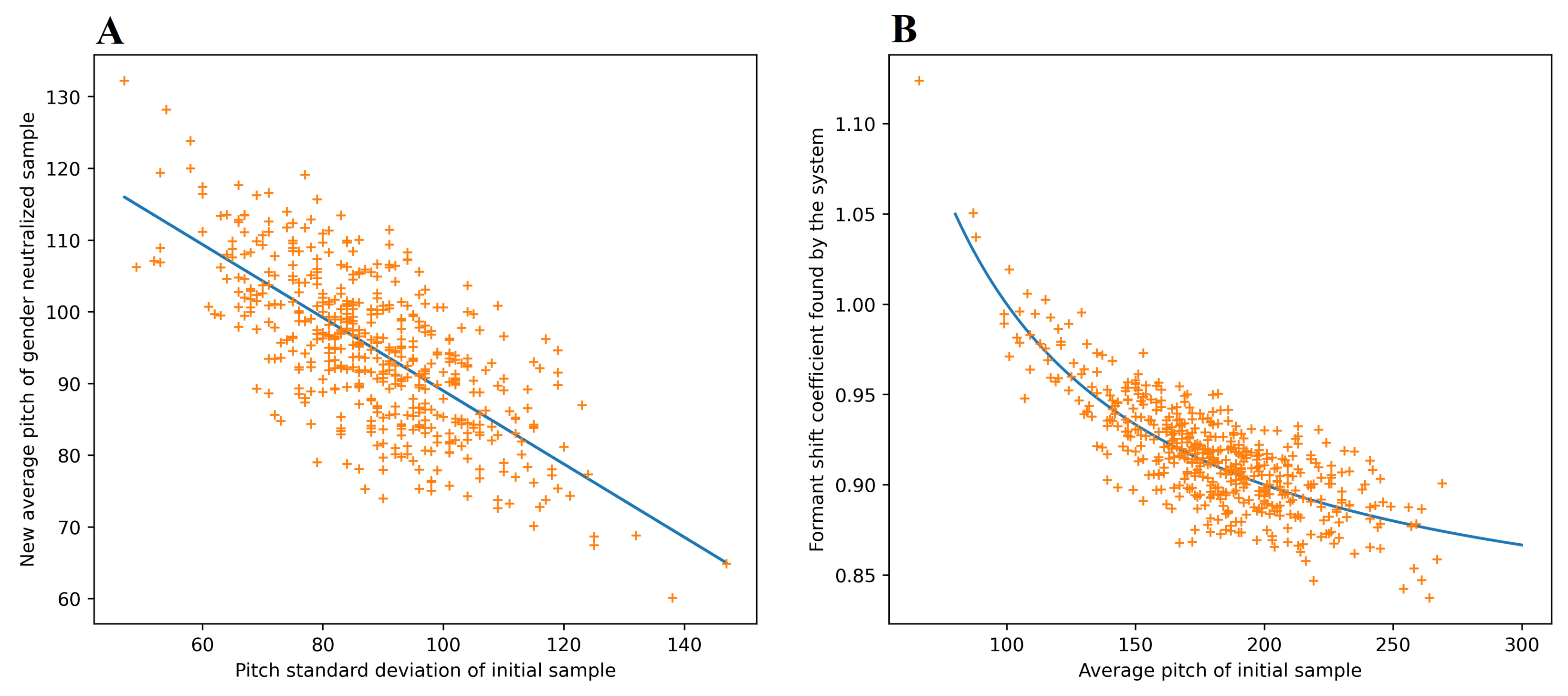
3.3. Neutralization Process
4. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mittelstadt, B.; Allo, P.; Taddeo, M.; Wachter, S.; Floridi, L. The Ethics of Algorithms: Mapping the Debate. Big Data Soc. 2016, 3, 2053951716679679. [Google Scholar] [CrossRef] [Green Version]
- Domnich, A.; Anbarjafari, G. Responsible AI: Gender bias assessment in emotion recognition. arXiv 2021, arXiv:2103.11436. [Google Scholar]
- Sham, A.H.; Aktas, K.; Rizhinashvili, D.; Kuklianov, D.; Alisinanoglu, F.; Ofodile, I.; Ozcinar, C.; Anbarjafari, G. Ethical AI in facial expression analysis: Racial bias. Signal Image Video Process. 2022, 1–8. [Google Scholar] [CrossRef]
- Rolf, E.; Simchowitz, M.; Dean, S.; Liu, L.T.; Bjorkegren, D.; Hardt, M.; Blumenstock, J. Balancing Competing Objectives with Noisy Data: Score-Based Classifiers for Welfare-Aware Machine Learning. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; Volume 119, pp. 8158–8168. [Google Scholar]
- Jiang, Y.; Murphy, P. Voice Source Analysis for Pitch-Scale Modification of Speech Signals. In Proceedings of the COST G-6 Conference on Digital Audio Effects (DAFX-01), Limerick, Ireland, 6–8 December 2001. [Google Scholar]
- Fischer, A.H.; Kret, M.E.; Broekens, J. Gender differences in emotion perception and self-reported emotional intelligence: A test of the emotion sensitivity hypothesis. PLoS ONE 2018, 13, e0190712. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vallor, S. Artificial Intelligence and Public Trust. Santa Clara Mag. 2017, 58, 42–45. [Google Scholar]
- Gorrostieta, C.; Lotfian, R.; Taylor, K.; Brutti, R.; Kane, J. Gender De-Biasing in Speech Emotion Recognition. In Proceedings of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, ISCA, Graz, Austria, 15–19 September 2019. [Google Scholar] [CrossRef]
- Kusner, M.J.; Loftus, J.; Russell, C.; Silva, R. Counterfactual fairness. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Feldman, T.; Peake, A. On the Basis of Sex: A Review of Gender Bias in Machine Learning Applications. arXiv 2021, arXiv:2104.02532v1. [Google Scholar]
- Pépiot, E. Male and female speech: A study of mean f0, f0 range, phonation type and speech rate in parisian French and American English speakers. In Proceedings of the International Conference on Speech Prosody, Dublin, Ireland, 20–23 May 2014; pp. 305–309. [Google Scholar]
- Sun, T.; Gaut, A.; Tang, S.; Huang, Y.; ElSherief, M.; Zhao, J.; Mirza, D.; Belding, E.; Chang, K.W.; Wang, W.Y. Mitigating gender bias in natural language processing: Literature review. arXiv 2019, arXiv:1906.08976. [Google Scholar]
- Wang, T.; Zhao, J.; Yatskar, M.; Chang, K.W.; Ordonez, V. Balanced Datasets Are Not Enough: Estimating and Mitigating Gender Bias in Deep Image Representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Cohen, L.; Lipton, Z.C.; Mansour, Y. Efficient candidate screening under multiple tests and implications for fairness. arXiv 2019, arXiv:1905.11361. [Google Scholar]
- Raghavan, M.; Barocas, S.; Kleinberg, J.; Levy, K. Mitigating bias in algorithmic hiring: Evaluating claims and practices. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 469–481. [Google Scholar]
- Gorbova, J.; Avots, E.; Lüsi, I.; Fishel, M.; Escalera, S.; Anbarjafari, G. Integrating vision and language for first-impression personality analysis. IEEE MultiMedia 2018, 25, 24–33. [Google Scholar] [CrossRef]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A Survey on Bias and Fairness in Machine Learning. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Dailey, M.N.; Joyce, C.; Lyons, M.J.; Kamachi, M.; Ishi, H.; Gyoba, J.; Cottrell, G.W. Evidence and a computational explanation of cultural differences in facial expression recognition. Emotion 2010, 10, 874–893. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Conley, M.I.; Dellarco, D.V.; Rubien-Thomas, E.; Cohen, A.O.; Cervera, A.; Tottenham, N.; Casey, B. The racially diverse affective expression (RADIATE) face stimulus set. Psychiatry Res. 2018, 270, 1059–1067. [Google Scholar] [CrossRef]
- Fischer, A.H.; Rodriguez Mosquera, P.M.; Van Vianen, A.E.; Manstead, A.S. Gender and culture differences in emotion. Emotion 2004, 4, 87–94. [Google Scholar] [CrossRef] [Green Version]
- Plant, E.A.; Hyde, J.S.; Keltner, D.; Devine, P.G. The Gender Stereotyping of Emotions. Psychol. Women Q. 2000, 24, 81–92. [Google Scholar] [CrossRef]
- Sedaaghi, M. A Comparative Study of Gender and Age Classification in Speech Signals. Iran. J. Electr. Electron. Eng. 2009, 5, 1–12. [Google Scholar]
- Alkhawaldeh, R.S. DGR: Gender Recognition of Human Speech Using One-Dimensional Conventional Neural Network. Sci. Program. 2019, 2019, 7213717. [Google Scholar] [CrossRef]
- Childers, D.G.; Wu, K. Gender recognition from speech. Part II: Fine analysis. J. Acoust. Soc. Am. 1991, 90, 1841–1856. [Google Scholar] [CrossRef] [PubMed]
- Abdulsatar, A.A.; Davydov, V.V.; Yushkova, V.V.; Glinushkin, A.P.; Rud, V.Y. Age and gender recognition from speech signals. J. Phys. Conf. Ser. 2019, 1410, 012073. [Google Scholar] [CrossRef]
- Levitan, S.; Mishra, T.; Bangalore, S. Automatic identification of gender from speech. In Proceedings of the Speech Prosody 2016, Boston, MA, USA, 31 May–3 June 2016; pp. 84–88. [Google Scholar] [CrossRef] [Green Version]
- Ali, M.; Islam, M.; Hossain, M.A. Gender recognition system using speech signal. Int. J. Comput. Sci. Eng. Inf. Technol. (IJCSEIT) 2012, 2, 1–9. [Google Scholar]
- Bajorek, J. Voice Recognition Still Has Significant Race and Gender Biases. 2019. Available online: https://hbr.org/2019/05/voice-recognition-still-has-significant-race-and-gender-biases (accessed on 10 January 2022).
- Savoldi, B.; Gaido, M.; Bentivogli, L.; Negri, M.; Turchi, M. Gender Bias in Machine Translation. Trans. Assoc. Comput. Linguist. 2021, 9, 845–874. [Google Scholar] [CrossRef]
- Du, Y.; Wu, Y.; Lan, M. Exploring Human Gender Stereotypes with Word Association Test. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 6133–6143. [Google Scholar] [CrossRef]
- Ghallab, M. Responsible AI: Requirements and challenges. AI Perspect. 2019, 1, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Benjamins, R.; Barbado, A.; Sierra, D. Responsible AI by design in practice. arXiv 2019, arXiv:1909.12838. [Google Scholar]
- Hardt, M.; Price, E.; Srebro, N. Equality of opportunity in supervised learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Bellamy, R.K.E.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Lohia, P.; Martino, J.; Mehta, S.; Mojsilović, A.; et al. AI Fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias. IBM J. Res. Dev. 2019, 63, 4:1–4:15. [Google Scholar] [CrossRef]
- Feldman, M.; Friedler, S.A.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 259–268. [Google Scholar]
- Celis, L.E.; Keswani, V.; Yildiz, O.; Vishnoi, N.K. Fair Distributions from Biased Samples: A Maximum Entropy Optimization Framework. arXiv 2019, arXiv:1906.02164. [Google Scholar]
- Wang, T.; Zhao, J.; Chang, K.W.; Yatskar, M.; Ordonez, V. Adversarial removal of gender from deep image representations. arXiv 2018, arXiv:1811.08489. [Google Scholar]
- Thong, W.; Snoek, C.G. Feature and Label Embedding Spaces Matter in Addressing Image Classifier Bias. arXiv 2021, arXiv:2110.14336. [Google Scholar]
- David, K.E.; Liu, Q.; Fong, R. Debiasing Convolutional Neural Networks via Meta Orthogonalization. arXiv 2020, arXiv:2011.07453. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised pre-training for speech recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Samples | Genders | Emotions | Language |
|---|---|---|---|---|
| CREMA-D | 7442 | Male + Female | 6 | English |
| DEMoS | 9365 | Male + Female | 6 | Italian |
| TESS | 2800 | only female | 7 | English |
| AudioMNIST | 30,000 | Male + Female | – | English |
| EMO-DB | 535 | Male + Female | 7 | German |
| LibriSpeech | 280,000 | Male + Female | – | English |
| RAVDESS | 1440 | Male + Female | 8 | English |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rizhinashvili, D.; Sham, A.H.; Anbarjafari, G. Gender Neutralisation for Unbiased Speech Synthesising. Electronics 2022, 11, 1594. https://doi.org/10.3390/electronics11101594
Rizhinashvili D, Sham AH, Anbarjafari G. Gender Neutralisation for Unbiased Speech Synthesising. Electronics. 2022; 11(10):1594. https://doi.org/10.3390/electronics11101594
Chicago/Turabian StyleRizhinashvili, Davit, Abdallah Hussein Sham, and Gholamreza Anbarjafari. 2022. "Gender Neutralisation for Unbiased Speech Synthesising" Electronics 11, no. 10: 1594. https://doi.org/10.3390/electronics11101594
APA StyleRizhinashvili, D., Sham, A. H., & Anbarjafari, G. (2022). Gender Neutralisation for Unbiased Speech Synthesising. Electronics, 11(10), 1594. https://doi.org/10.3390/electronics11101594