
Robust Pedestrian Detection Based on Multi-Spectral Image Fusion and Convolutional Neural Networks


Abstract
:1. Introduction
- (1)
- In light of the insufficient research on multi-spectral image fusion in the existing multi-spectral pedestrian detection methods, we further study the multi-spectral pedestrian detection methods by using pixel-level image fusion. In addition, a multi-spectral pedestrian detection method based on pixel-level image fusion and a convolutional neural network is proposed. This method makes full use of the different feature information of infrared images and visible images and combines YOLOv3 to achieve robust pedestrian detection.
- (2)
- Aiming at the information loss caused by mutual cancellation of opposite information when infrared and visible light images are fused, a multi-spectral image fusion method via TV minimization and local structure transfer is proposed. This method effectively preserves the intensity distribution of infrared images and the local structural features of visible images. In addition, an infrared detail enhancement method is introduced to increase the detail information of the thermal target area. The fusion image can highlight pedestrian targets and retain abundant appearance information, which is conducive to pedestrian detection.
- (3)
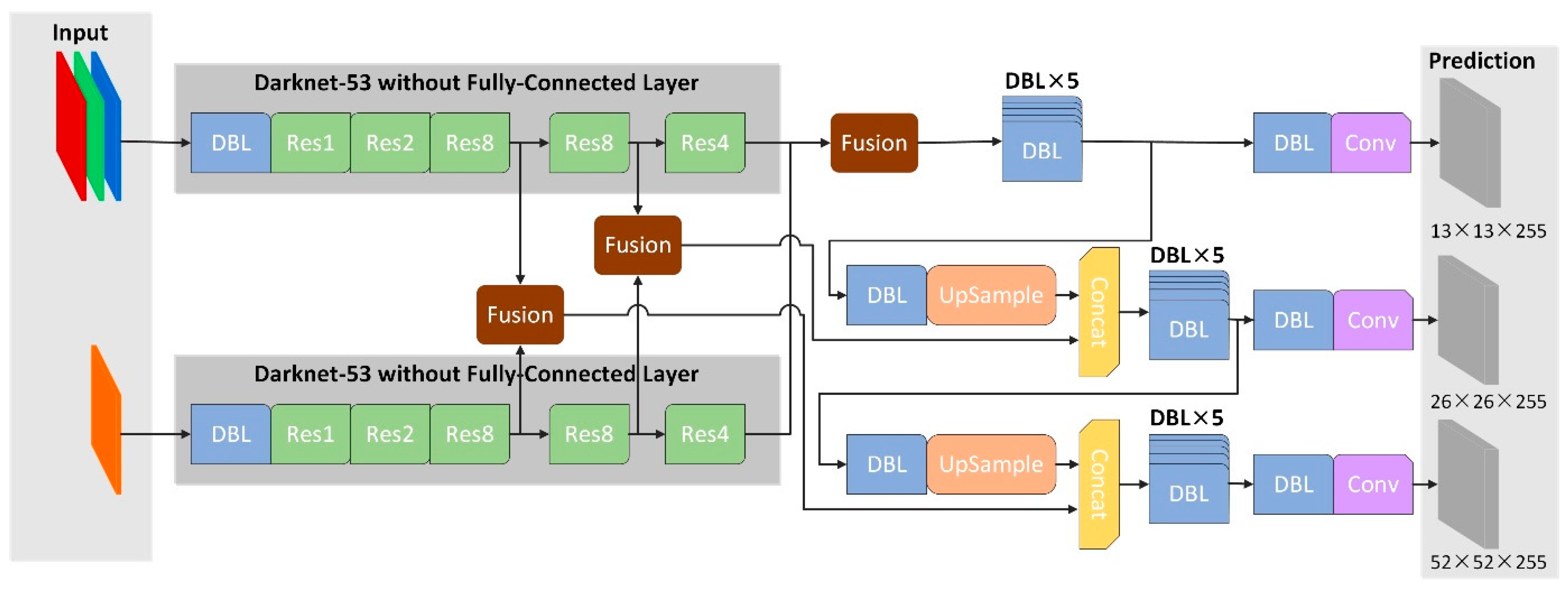
- Two fusion architectures based on YOLOv3 are designed and implemented for comparison, namely early fusion and late fusion. Multi-spectral pedestrian detection is realized by the fusion of features with different scales at different network depths in YOLOv3.
- (4)
- We qualitatively and quantitatively compare and evaluate the detection results of our proposed method with four pixel-level fusion methods and two fusion network architectures. The experimental results illustrate that our proposed method effectively improves the robustness and accuracy of pedestrian detection, especially under harsh visual conditions.
2. Proposed Method
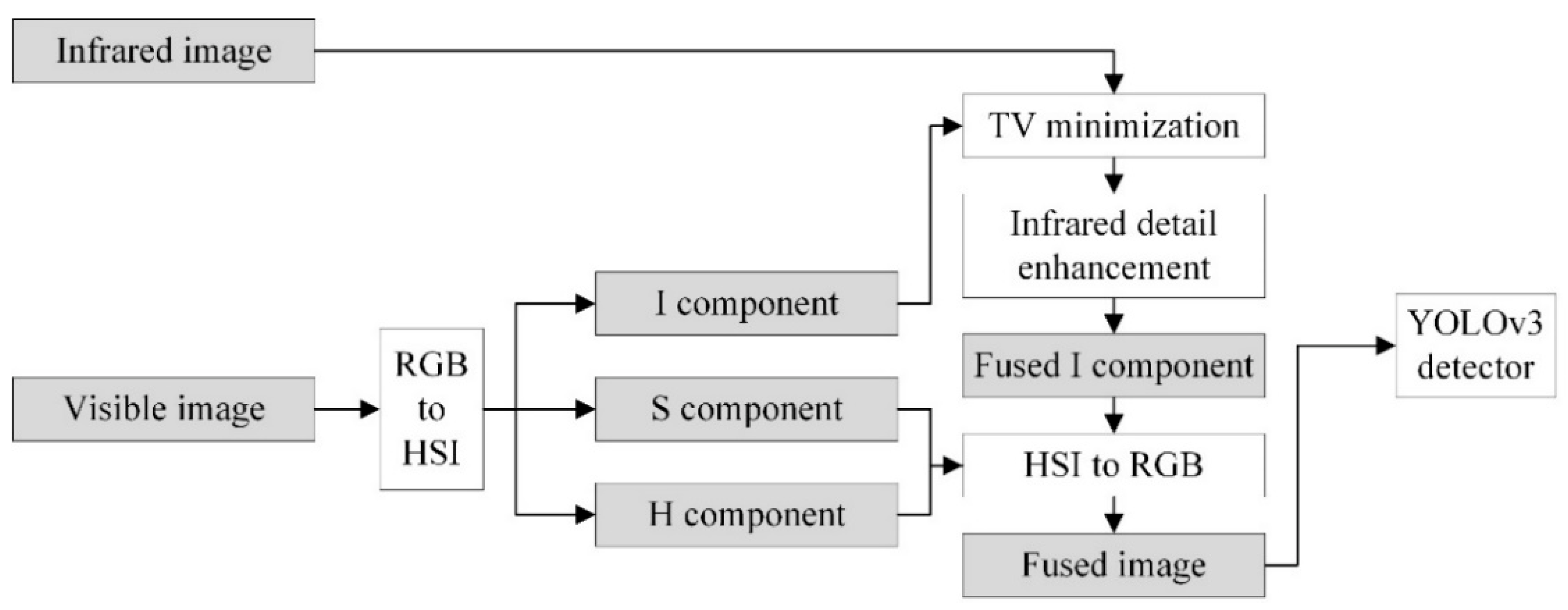
2.1. Pedestrian Detection Based on Pixel-Level Color Image Fusion
2.1.1. Color Space Transformation
2.1.2. Image Fusion Based on TV Minimization and Structure Transfer
2.1.3. Infrared Detail Enhancement
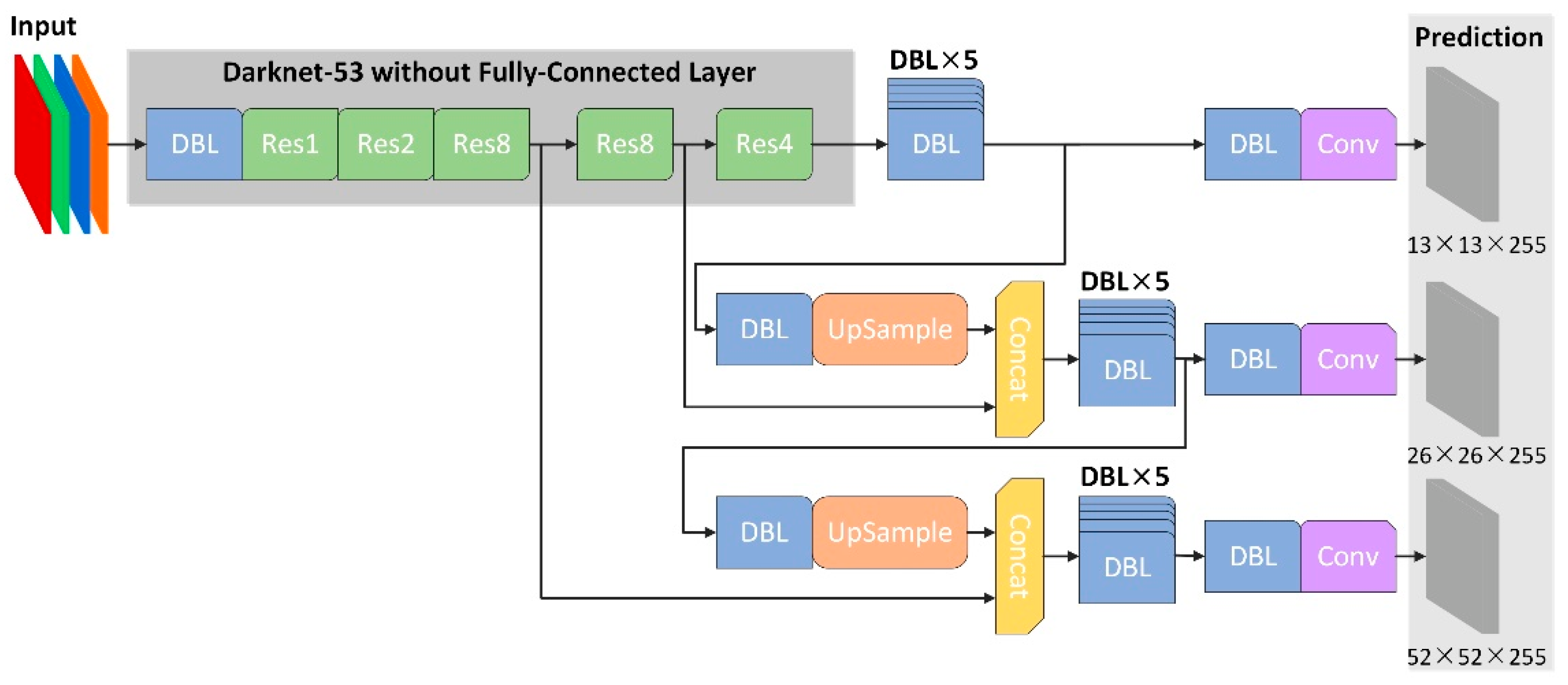
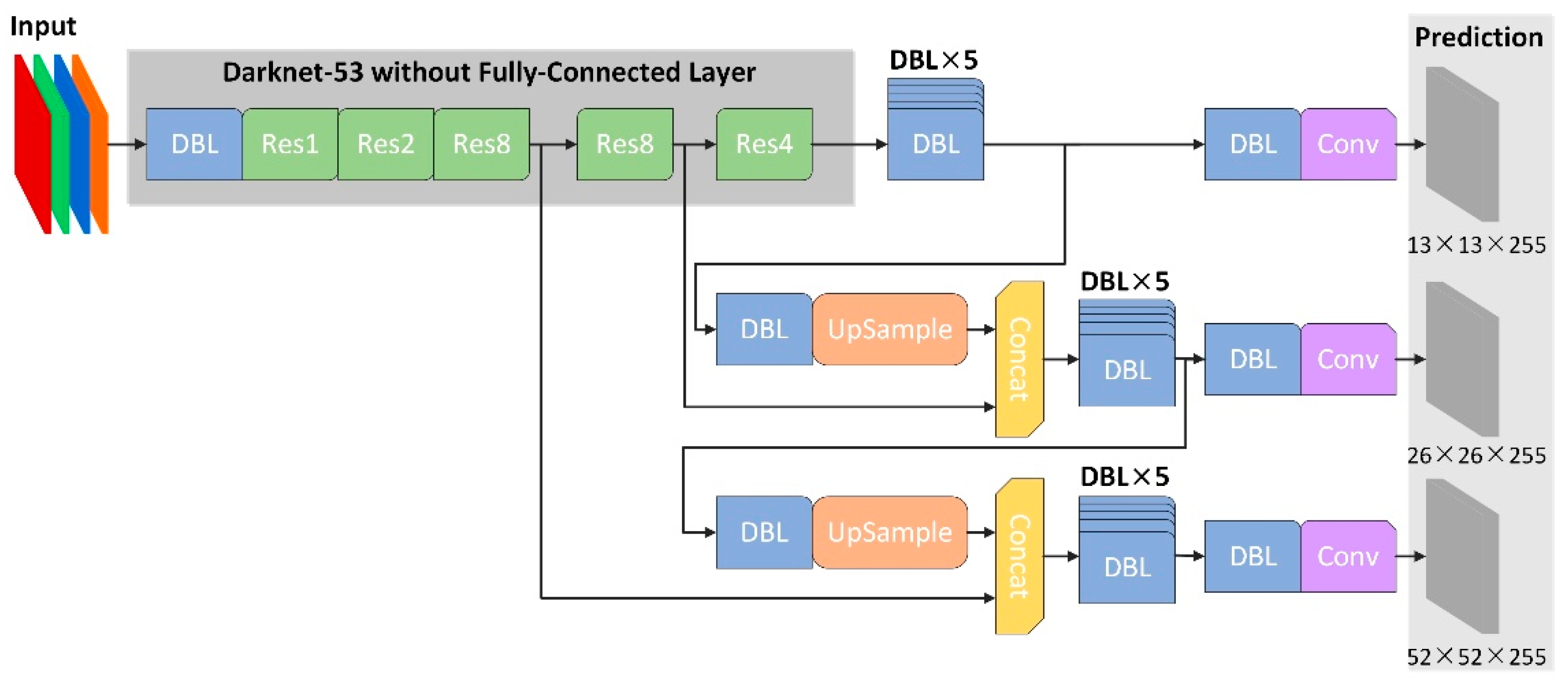
2.1.4. Pedestrian Detection Based on Multi-Spectral Fusion Results and YOLOv3
2.2. Pedestrian Detection Based on Fusion Architectures
3. Experiments and Analysis
3.1. Datasets and Settings
3.2. Comparison of the Fused Results via Different Fusion Methods
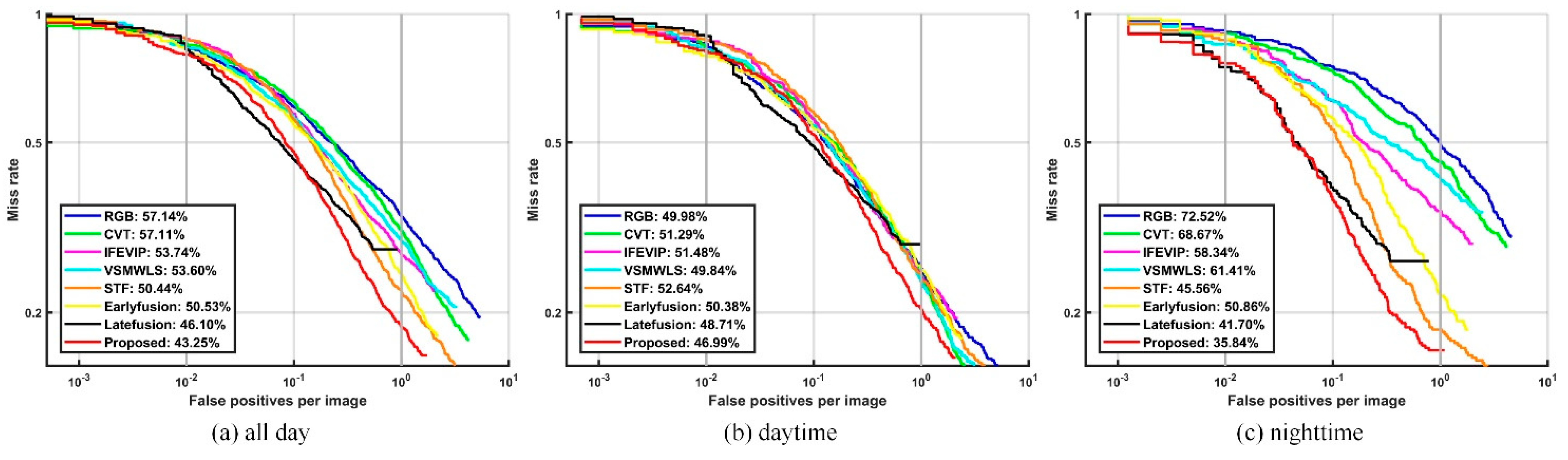
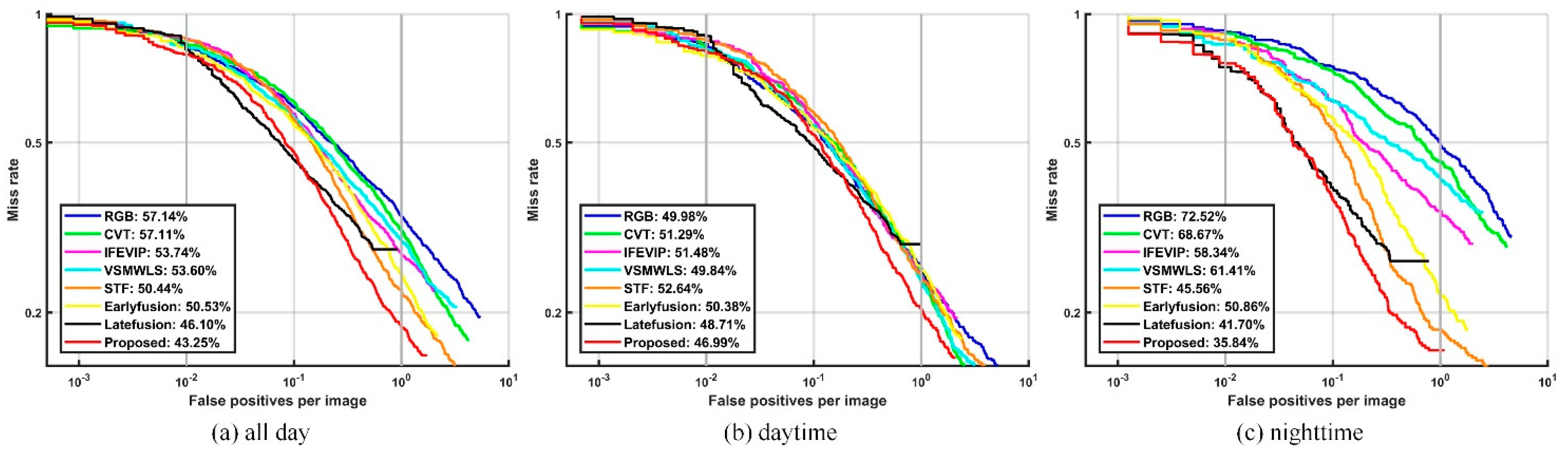
3.3. Comparison of the Detection Results via Different Fusion Methods
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- DNguyen, T.; Li, W.; Ogunbona, P.O. Human detection from images and videos: A survey. Pattern Recognit. 2016, 51, 148–175. [Google Scholar]
- Dai, J.; Zhang, P.; Lu, H.; Wang, H. Dynamic imposter based online instance matching for person search. Pattern Recognit. 2020, 100, 107120. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, X.; Liu, Y.; Xu, C. Asymmetric Multi-stage CNNs for Small-scale Pedestrian Detection. Neurocomputing 2020, 409, 12–26. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Jin, X.; Jiang, Q.; Yao, S.; Zhou, D.; Nie, R.; Hai, J.; He, K. A survey of infrared and visual image fusion methods. Infrared Phys. Technol. 2017, 85, 478–501. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, B.; Li, S.; Dong, M. Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with gaussian and bilateral filters. Inf. Fusion 2016, 30, 15–26. [Google Scholar] [CrossRef]
- Zhao, J.; Chen, Y.; Feng, H.; Xu, Z.; Li, Q. Infrared image enhancement through saliency feature analysis based on multi-scale decomposition. Infrared Phys. Technol. 2014, 62, 86–93. [Google Scholar] [CrossRef]
- Zhu, Y.; Lu, Y.; Gao, Q.; Sun, D. Infrared and visible image fusion based on convolutional sparse representation and guided filtering. J. Electron. Imaging 2021, 30, 043003. [Google Scholar] [CrossRef]
- Yang, B.; Li, S. Visual attention guided image fusion with sparse representation. Optik 2014, 125, 4881–4888. [Google Scholar] [CrossRef]
- Zhu, Y.; Peng, T.; Su, S.; Li, C. Multi-Modal Subspace Fusion via Cauchy Multi-Set Canonical Correlations. IEEE Access 2020, 8, 115228–115239. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Liu, G. Multi-sensor image fusion based on fourth order partial differential equations. In Proceedings of the 20th International Conference on Information Fusion, Xi’an, China, 10–13 July 2017; pp. 1–9. [Google Scholar]
- Wang, Q.; Gao, Z.; Xie, C.; Chen, G.; Luo, Q. Fractional-order total variation for improving image fusion based on saliency map. Signal Image Video Process 2020, 14, 991–999. [Google Scholar] [CrossRef]
- Ma, J.; Liang, P.; Yu, W.; Chen, C.; Guo, X.; Wu, J.; Jiang, J. Infrared and visible image fusion via detail preserving adversarial learning. Inf. Fusion 2020, 54, 85–98. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jing, J. Fusiongan: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unifified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Liu, Y.; Jin, J.; Wang, Q.; Shen, Y.; Dong, X. Region level based multi-focus image fusion using quaternion wavelet and normalized cut. Signal Process. 2014, 97, 9–30. [Google Scholar] [CrossRef]
- Choi, M.; Kim, R.Y.; Nam, M.-R.; Kim, H.O. Fusion of multispectral and panchromatic satellite images using the curvelet transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 136–140. [Google Scholar] [CrossRef]
- Ji, X.; Zhang, G. Image fusion method of SAR and infrared image based on Curvelet transform with adaptive weighting. Multimed. Tools Appl. 2017, 76, 17633–17649. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, Y.; Fan, F.; Zhang, Y.; Huang, J. Infrared and visible image fusion via saliency analysis and local edge-preserving multi-scale decomposition. J. Opt. Soc. Am. A 2017, 34, 1400–1410. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, M. Image fusion using multiscale edge-preserving decomposition based on weighted least squares filter. IET Image Process 2014, 8, 183–190. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, J.; Chen, C.; Fan, F.; Ma, J. Infrared and visible image fusion using total variation model. Neurocomputing 2016, 202, 12–19. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L.; Bai, X.; Zhang, L. Infrared and visual image fusion through infrared feature extraction and visual information preservation. Infrared Phys. Technol. 2017, 83, 227–237. [Google Scholar] [CrossRef]
- Kong, X.; Liu, L.; Qian, Y.; Wang, Y. Infrared and visible image fusion using structure-transferring fusion method. Infrared Phys. Technol. 2019, 98, 161–173. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Multispectral Pedestrian Detection via Simultaneous Detection and Segmentation. arXiv 2018, arXiv:1808.04818. Available online: https://arxiv.org/abs/1808.04818 (accessed on 14 August 2018).
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral Pedestrian Detection: Benchmark Dataset and Baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Yang, M.Y. Fusion of multispectral data through illumination-aware deep neural networks for pedestrian detection. Inf. Fusion 2019, 50, 148–157. [Google Scholar] [CrossRef] [Green Version]
- Tong, J.; Mao, L.; Sun, J. Multimodal Pedestrian Detection Algorithm Based on Fusion Feature Pyramids. Comput. Eng. Appl. 2019, 55, 214–222. [Google Scholar]
- Sciuto, G.L.; Napoli, C.; Capizzi, G.; Shikler, R. Organic solar cells defects detection by means of an elliptical basis neural network and a new feature extraction technique. Optik 2019, 194, 163038. [Google Scholar] [CrossRef]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral pedestrian detection using deep fusion convolutional neural networks. In Proceedings of the 24th European Symposium on Artificial Neural Networks, Bruges, Belgium, 27–29 April 2016; pp. 509–514. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral Deep Neural Networks for Pedestrian Detection. arXiv 2016, arXiv:1611.02644. Available online: https://arxiv.org/abs/1611.02644 (accessed on 8 November 2016).
- Cao, Y.; Guan, D.; Huang, W.; Yang, J.; Cao, Y.; Qiao, Y. Pedestrian detection with unsupervised multispectral feature learning using deep neural networks. Inf. Fusion 2019, 46, 206–217. [Google Scholar] [CrossRef]
- Chen, Y.; Shin, H. Multispectral image fusion based pedestrian detection using a multilayer fused deconvolutional single-shot detector. J. Opt. Soc. Am. A 2020, 37, 768–779. [Google Scholar] [CrossRef]
- Hou, Y.; Song, Y.; Hao, X.; Shen, Y.; Qian, M.; Chen, H. Multispectral pedestrian detection based on deep convolutional neural networks. Infrared Phys. Technol. 2018, 94, 69–77. [Google Scholar] [CrossRef]
- Nawaz, A.; Kanwal, I.; Idrees, S.; Imtiaz, R.; Jalil, A.; Ali, A.; Ahmed, J. Fusion of color and infrared images using gradient transfer and total variation minimization. In Proceedings of the International Conference on Computer and Communication Systems, Krakow, Poland, 11–14 July 2017; pp. 82–85. [Google Scholar]
- Qu, Z. Research on Color Fusion Algorithm and Application of Infrared and Low Light Level Images Based on Scene Recognition. Master’s Thesis, Shanghai Jiao Tong University, Shanghai, China, 2017. [Google Scholar]
- Wang, B.; Gong, W.; Wang, C. Infrared and color visible image fusion system based on luminance-contrast transfer technique. In Proceedings of the SPIE on Infrared, Millimeter-Wave, and Terahertz Technologies II, Beijing, China, 5–7 November 2012; Volume 8562, p. 85621Q. [Google Scholar]
- Li, C.; Deng, Y. Color Image Fusion Utilizing YCbCr Transform and SWT. Infrared Technol. 2018, 40, 654–659. [Google Scholar]
- Yao, C.; Pan, W.; Shen, L.; Li, X. Research of Multi-sensor Images Based on Color Fusion Methods. J. Netw. 2013, 8, 2635–2641. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Li, X.; Li, C.; Wang, D.; Cheng, L.; Zheng, C. Infrared and Visible Image Fusion Algorithm Based on Threshold Segmentation. Smart Innov. Syst. Technol. 2020, 179, 203–212. [Google Scholar]
- Yuan, Y.; Peng, J.; Shen, Y.; Chen, X. Fusion Algorithm for Near-Infrared and Color Visible Images Based on Tetrolet Transform. Infrared Technol. 2020, 42, 223–230. [Google Scholar]
- Song, M.; Liu, L.; Peng, Y.; Jiang, T.; Li, J. Infrared & visible images fusion based on redundant directional lifting-based wavelet and saliency detection. Infrared Phys. Technol. 2019, 101, 45–55. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Tisse, C.-L. Exploiting fusion architectures for multispectral pedestrian detection and segmentation. Appl. Opt. 2018, 57, D108–D116. [Google Scholar] [CrossRef] [PubMed]
- Roberts, J.W.; van Aardt, J.; Ahmed, F. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Yang, F. Research on Object Detection Based on Multi-Model Images. Master’s Thesis, Nanjing University, Nanjing, China, 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images | Metrics | CVT | IFEVIP | VSMWLS | STF | Proposed |
|---|---|---|---|---|---|---|
| IM1 | MCC | 1.1918 | 1.0927 | 1.1701 | 1.3349 | 1.3553 |
| SF | 7.8644 | 10.671 | 10.0784 | 9.9651 | 12.2615 | |
| EN | 6.8309 | 7.1229 | 7.1906 | 7.2936 | 7.36 | |
| AG | 2.4887 | 3.4168 | 3.4674 | 3.7597 | 4.1013 | |
| IM2 | MCC | 1.5983 | 1.5083 | 1.5617 | 1.6187 | 1.637 |
| SF | 9.0672 | 12.5468 | 11.9432 | 11.1744 | 14.2152 | |
| EN | 7.5442 | 7.5929 | 7.6619 | 7.4994 | 7.6885 | |
| AG | 3.4018 | 4.5238 | 4.6586 | 4.5967 | 5.353 | |
| IM3 | MCC | 1.4016 | 0.6532 | 1.4086 | 1.5853 | 1.6559 |
| SF | 7.4361 | 12.4645 | 9.6137 | 16.4532 | 14.9262 | |
| EN | 6.5595 | 7.1805 | 7.0967 | 6.6205 | 6.8944 | |
| AG | 2.1096 | 3.424 | 3.0389 | 4.4684 | 4.105 | |
| IM4 | MCC | 1.1097 | 1.0094 | 1.1994 | 1.0071 | 1.1443 |
| SF | 5.8053 | 8.1269 | 7.747 | 10.3357 | 8.2588 | |
| EN | 6.7783 | 7.0253 | 6.9894 | 6.9619 | 7.123 | |
| AG | 2.4294 | 3.4705 | 3.5266 | 4.3216 | 3.7777 | |
| IM5 | MCC | 0.9759 | 1.0465 | 1.0513 | 1.0216 | 1.0668 |
| SF | 6.6447 | 10.0782 | 9.4477 | 7.8325 | 10.6976 | |
| EN | 7.0949 | 7.3614 | 7.314 | 6.7392 | 6.8128 | |
| AG | 2.3316 | 3.4456 | 3.5094 | 3.3504 | 3.9016 | |
| IM6 | MCC | 1.4509 | 1.4192 | 1.4462 | 1.4294 | 1.4681 |
| SF | 7.5171 | 10.9581 | 10.658 | 8.6367 | 12.7359 | |
| EN | 7.3604 | 7.2918 | 7.5574 | 7.0863 | 7.1386 | |
| AG | 2.7683 | 3.8174 | 4.1147 | 3.314 | 4.6592 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Liu, L.; Tan, X. Robust Pedestrian Detection Based on Multi-Spectral Image Fusion and Convolutional Neural Networks. Electronics 2022, 11, 1. https://doi.org/10.3390/electronics11010001
Chen X, Liu L, Tan X. Robust Pedestrian Detection Based on Multi-Spectral Image Fusion and Convolutional Neural Networks. Electronics. 2022; 11(1):1. https://doi.org/10.3390/electronics11010001
Chicago/Turabian StyleChen, Xu, Lei Liu, and Xin Tan. 2022. "Robust Pedestrian Detection Based on Multi-Spectral Image Fusion and Convolutional Neural Networks" Electronics 11, no. 1: 1. https://doi.org/10.3390/electronics11010001
APA StyleChen, X., Liu, L., & Tan, X. (2022). Robust Pedestrian Detection Based on Multi-Spectral Image Fusion and Convolutional Neural Networks. Electronics, 11(1), 1. https://doi.org/10.3390/electronics11010001