
Semi-Supervised Extreme Learning Machine Channel Estimator and Equalizer for Vehicle to Vehicle Communications

 ,
,  , , and
, , and
Abstract
1. Introduction
- We propose a regularized ELM subject to SS learning as channel estimator and equalizer to enhance the performance of a representative IEEE 802.11p OFDM-based system in terms of Bit Error Rate (BER). To this end, we add a novel parameter denoted by in the Semi-supervised Extreme Learning Machine (SS-ELM) to address the time-domain fluctuations of the channel. Furthermore, a frequency-domain localized mapping is used to properly recover the OFDM signal, namely to address the frequency-selective channel;
- Taking the simulation framework of the evaluated system into account, we compute the sub-optimal SS-ELM hyper-parameters to diminish BER via extensive simulations. We also show that a supervised ELM does not improve the BER performance of a vehicular IEEE 802.11p system;
- We compare the proposed technique with current state-of-the-art machine-learning-based channel estimation schemes as well as traditional techniques in an urban environment for several values of Energy per Bit to Noise Power Spectral Density Ratios (). The addressed techniques are also contrasted in terms of the required processing time.
2. Background
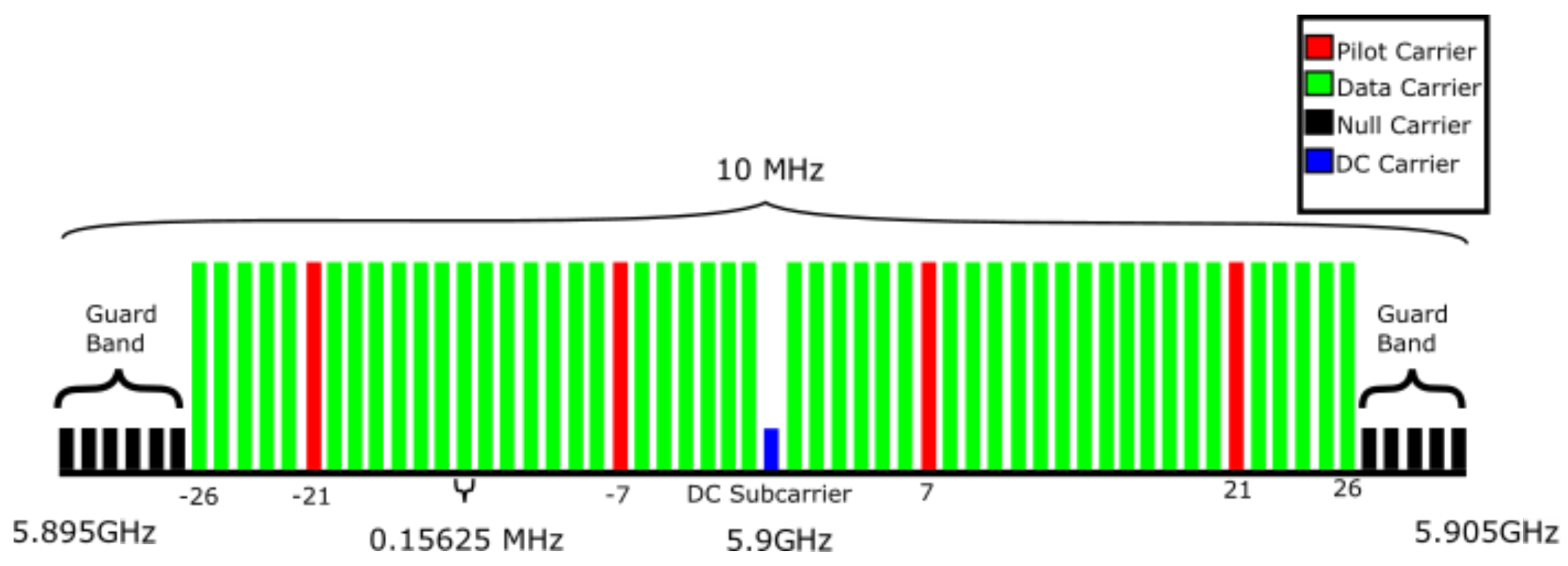
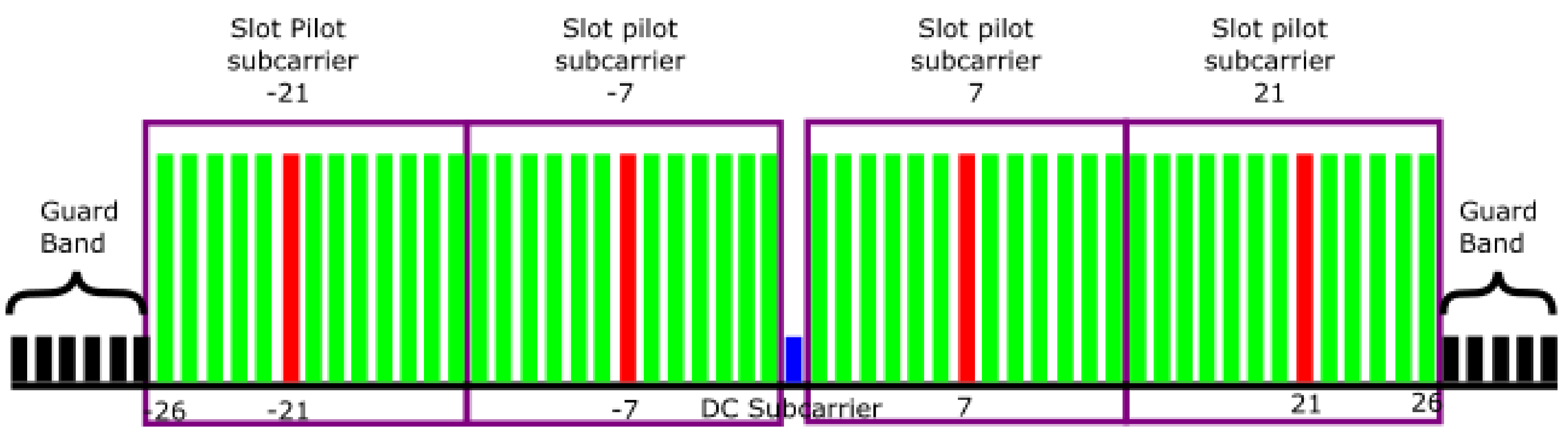
2.1. The IEEE 802.11p Standard
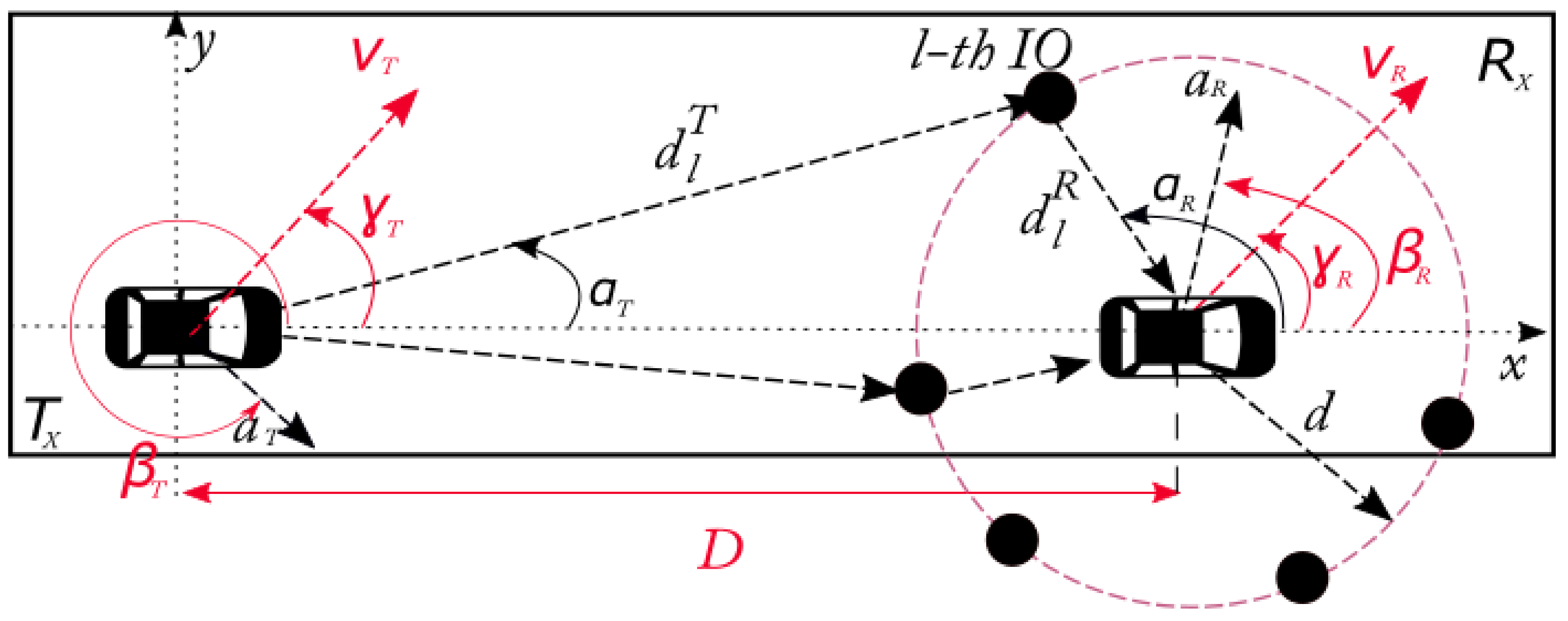
2.2. Single Ring Geometrical Scattering Channel Model
2.3. Extreme Learning Machine
| Algorithm 1: ELM algorithm. |
 |
2.4. Semi-Supervised Extreme Learning Machine
| Algorithm 2: SS-ELM algorithm. |
 |
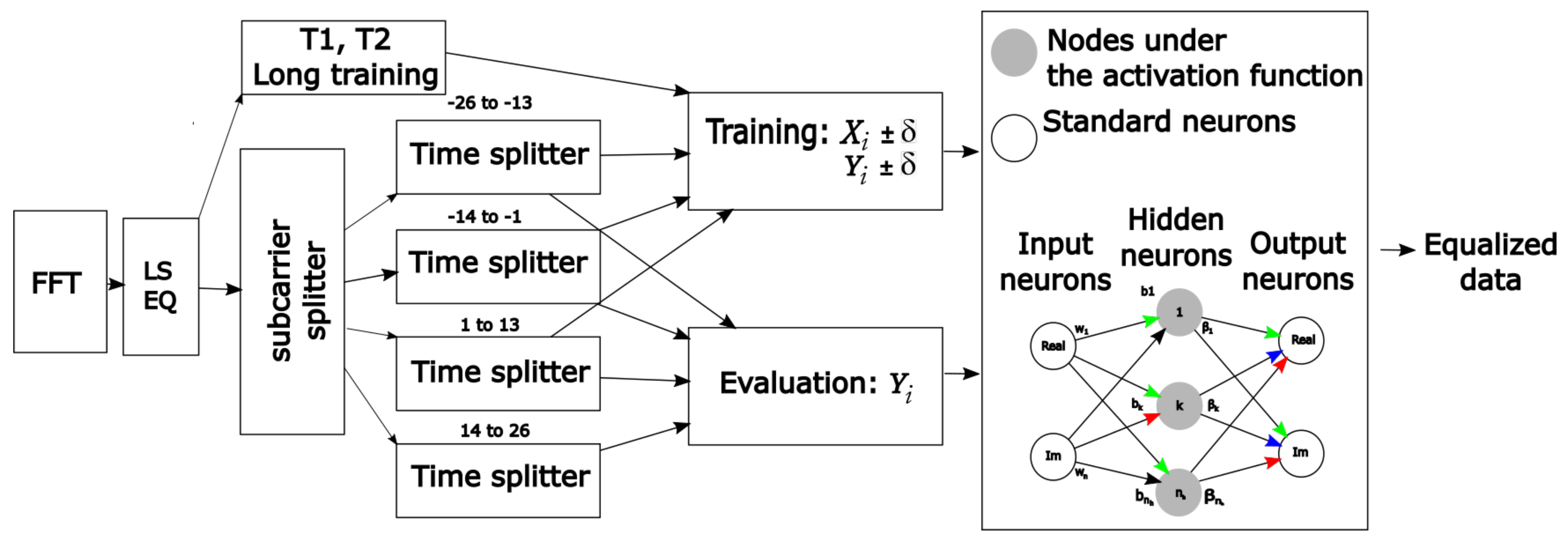
3. Proposed SS-ELM Equalizer
| Algorithm 3: SS-ELM training and equalization. |
 |
4. Simulation Results and Discussions
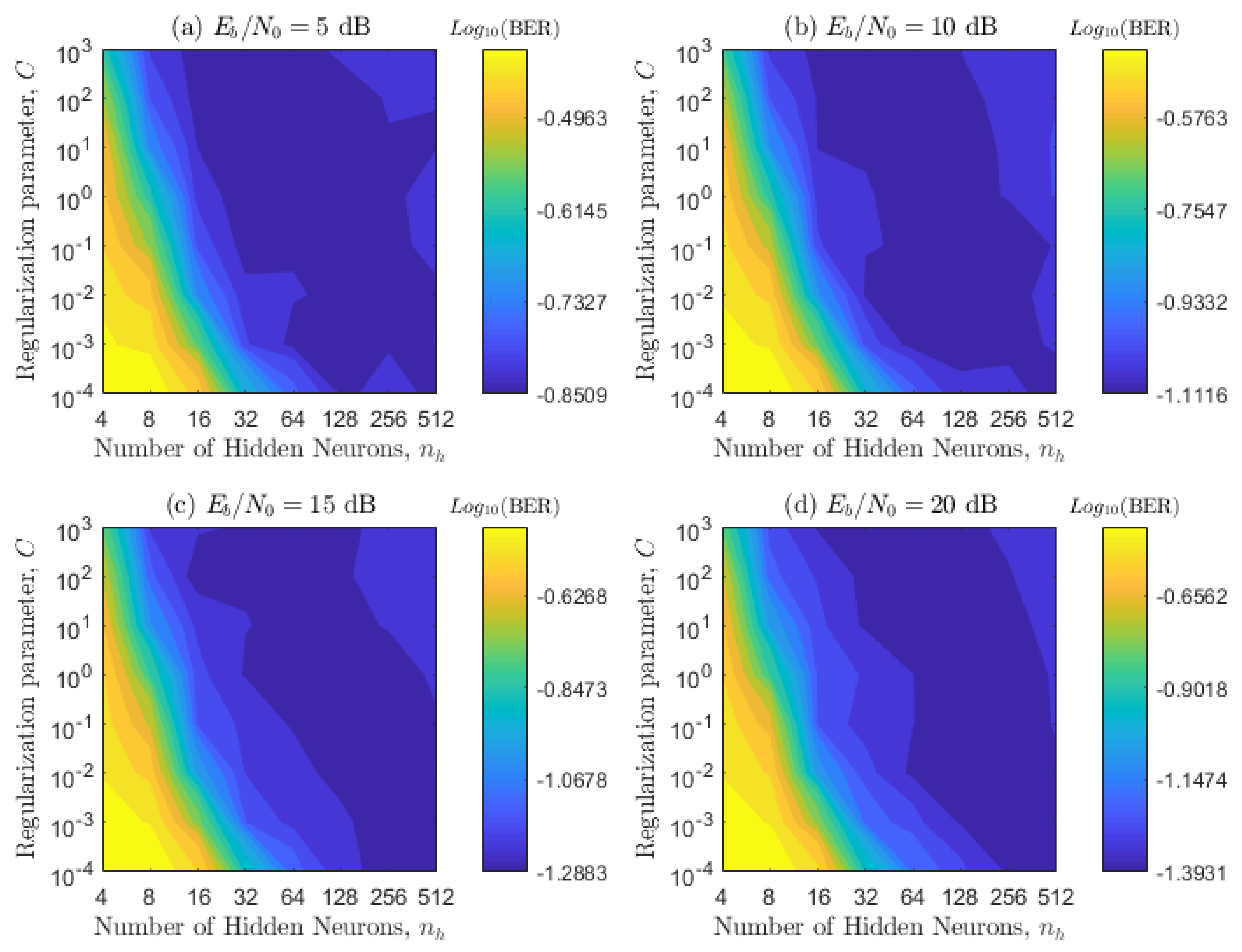
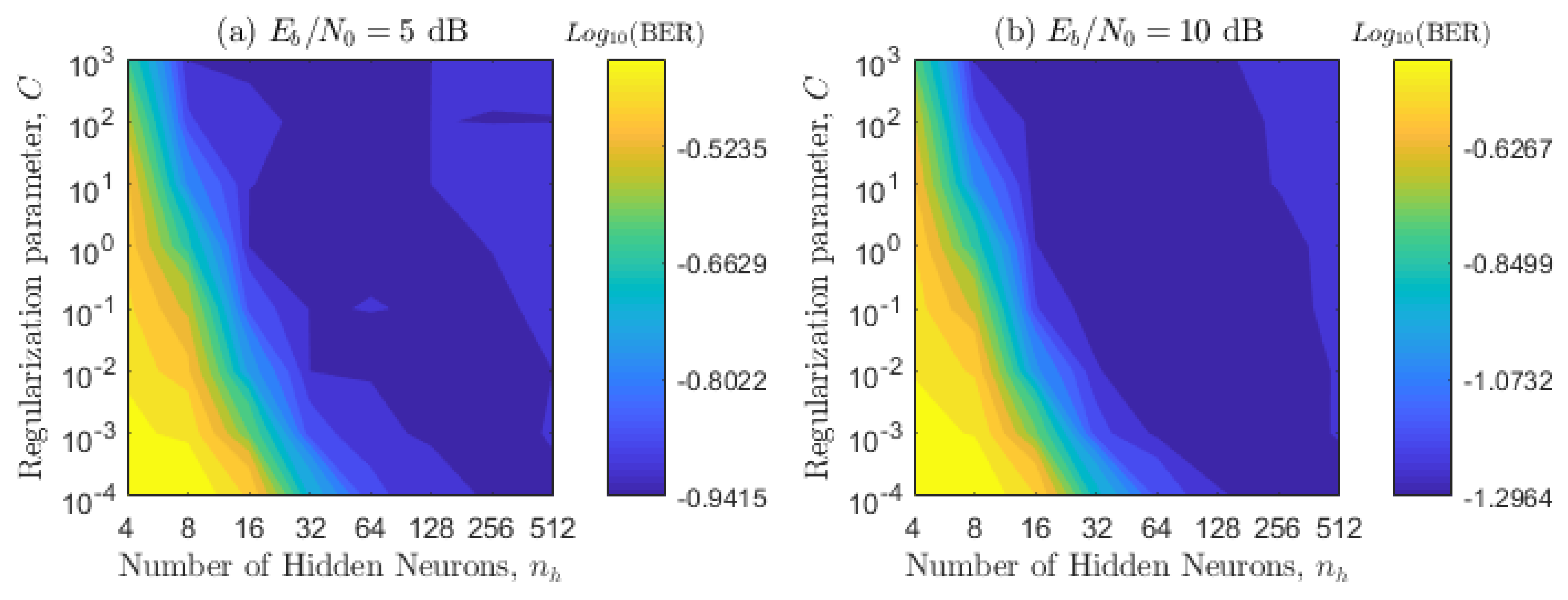
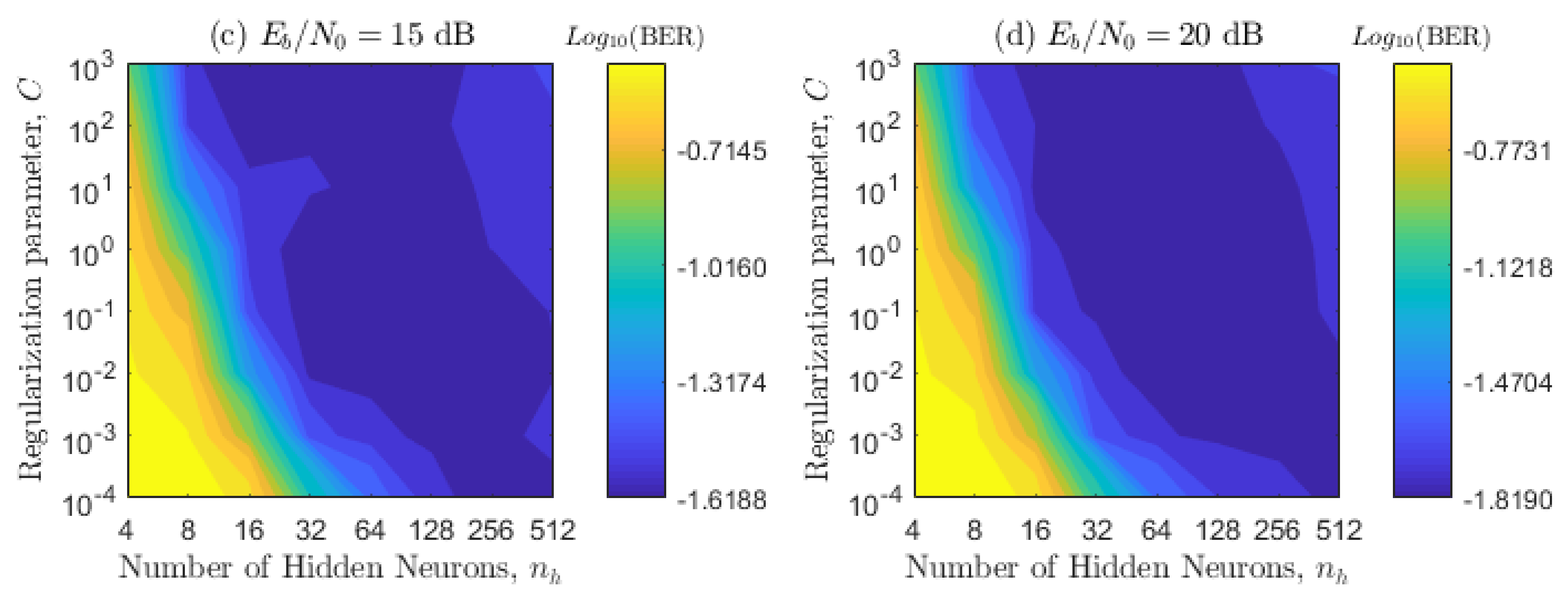
4.1. Numerical Optimization of the SS-ELM Hyper-Parameters
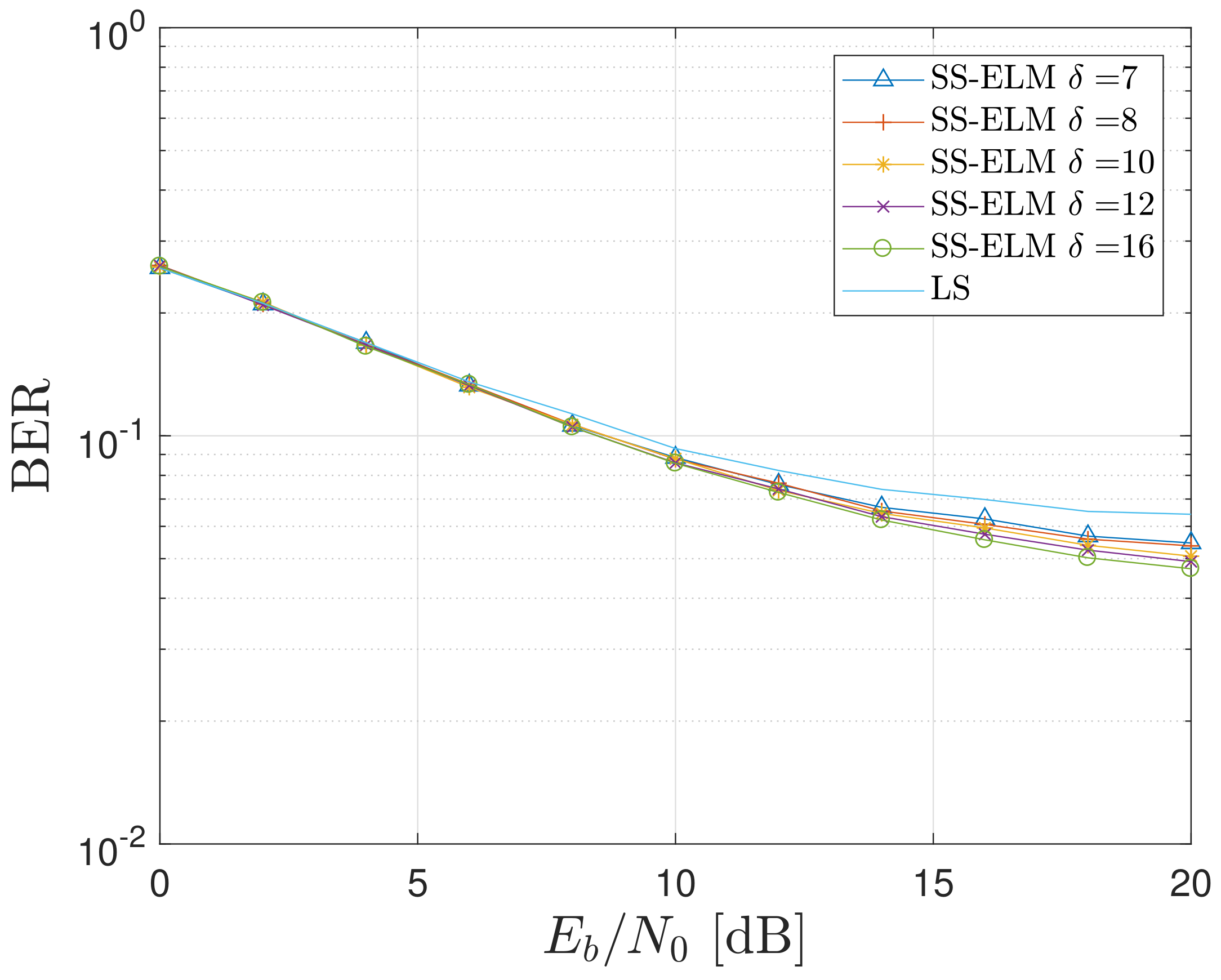
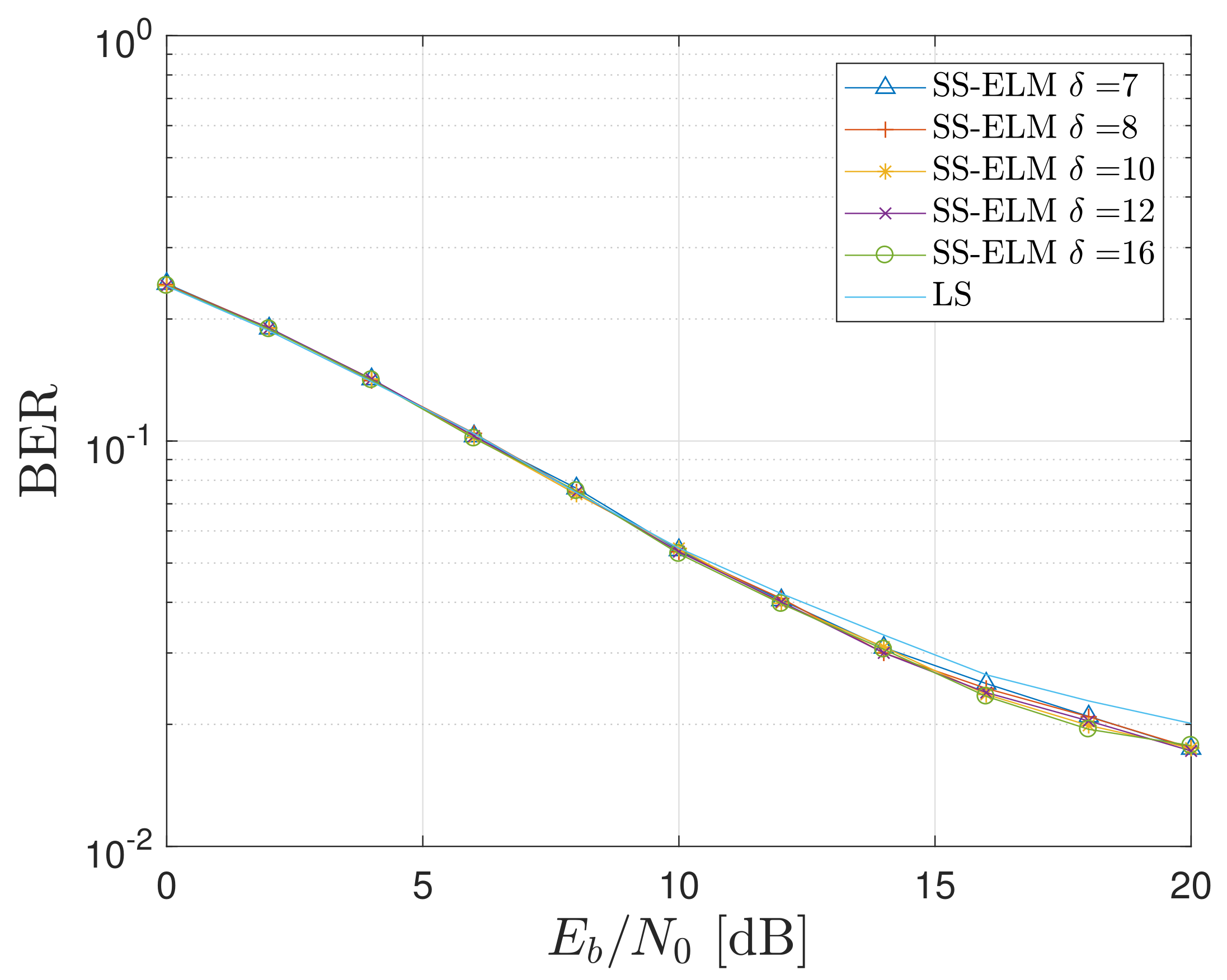
4.2. Impact of the Parameter on the BER Metric
4.3. Performance Comparison
4.4. Execution Time Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| AWGN | Additive White Gaussian Noise |
| BER | Bit Error Rate |
| BPSK | Binary Phase Shift Keying |
| CDP | Constructed Data Pilots |
| CFR | Channel Frequency Response |
| CP | Cyclic Prefix |
| CPU | Central Process Unit |
| C-ELM | Complex Extreme Learning Machine |
| C-V2X | Cellular Vehicular to Anything |
| DC | Direct Current |
| DL | Deep Learning |
| ELM | Extreme Learning Machine |
| ETSI | European Telecommunication Standards Institute |
| FFT | Fast Fourier Transform |
| FPGA | Field-Programmable Gate Array |
| GPU | Graphics Processing Unit |
| IFFT | Inverse Fast Fourier Transform |
| LS | Least Squares |
| ML | Machine Learning |
| MMSE | Minimum Mean-Square Error |
| OFDM | Orthogonal Frequency Division Multiplexing |
| PHY | Physical Layer |
| RAM | Random Access Memory |
| SS | Semi-Supervised |
| SS-ELM | Semi Supervised Extreme Learning Machine |
| STA | Spectral Temporal Averaging |
| SNR | Signal to Noise Ratio |
| VCS | Vehicular Communication Systems |
| V2V | Vehicle to Vehicle |
| V2I | Vehicle to Infrastructure |
| WiFi | Wireless Fidelity |
| WSSUS | Wide-Sense Stationary Uncorrelated Scattering |
| ZF | Zero Forcing |
References
- Ahmed, E.; Gharavi, H. Cooperative Vehicular Networking: A Survey. IEEE Trans. Intell. Transp. Syst. 2018, 19, 996–1014. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liu, J.; Kato, N. Networking and Communications in Autonomous Driving: A Survey. IEEE Commun. Surv. Tutor. I 2019, 21, 1243–1274. [Google Scholar] [CrossRef]
- ETSI TR 102 638 V1.1.1: Intelligent Transport Systems (ITS), Vehicular Communications, Basic Set of Applications, Definitions. Available online: https://www.etsi.org/deliver/etsi_tr/102600_102699/102638/01.01.01_60/tr_102638v010101p.pdf (accessed on 9 January 2015).
- ETSI. TS 101 539-2 V1.1.1: Intelligent Transport Systems (ITS), V2X Applications, Part 2: Intersection Collision Risk Warning (ICRW) Application Requirements Specification 1. Available online: https://www.etsi.org/deliver/etsi_ts/101500_101599/10153902/01.01.01_60/ts_10153902v010101p.pdf (accessed on 30 June 2018).
- ETSI. TS 101 539-3 V1.1.1: Intelligent Transport Systems (ITS), V2X Applications, Part 3: Longitudinal Collision Risk Warning (LCRW) Application Requirements Specification. Available online: https://www.etsi.org/deliver/etsi_ts/101500_101599/10153903/01.01.01_60/ts_10153903v010101p.pdf (accessed on 30 November 2013).
- Ortega, N.M.; Azurdia-Meza, C.A.; Gutierrez, C.A.; Maciel-Barboza, F.M. On the Influence of the non-WSSUS Condition in the Performance of IEEE 802.11-Based Channel Estimators for Vehicular Communications. In Proceedings of the IEEE 10th Latin-American Conference on Communications (LATINCOM), Guadalajara, Mexico, 14–16 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- 802.11-2016 - IEEE Standard for Information technology—Telecommunications and information exchange between systems Local and metropolitan area networks—Specific requirements - Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications; IEEE Std 802.11-2012 (Revision of IEEE Std 802.11-2007); IEEE: Miami, FL, USA, 2016; pp. 1–3534. [CrossRef]
- Zhao, Z.; Cheng, X.; Wen, M.; Jiao, B.; Wang, C. Channel Estimation Schemes for IEEE 802.11p Standard. IEEE Intell. Transp. Syst. 2009, 5, 38–49. [Google Scholar] [CrossRef]
- Fernandez, J.; Borries, K.; Cheng, L.; Kumar, B.V.K.V.; Stancil, D.D.; Bai, F. Performance of the 802.11p physical layer in vehicle-to-vehicle environments. IEEE Trans. Veh. Tech. 2018, 61, 3–14. [Google Scholar] [CrossRef]
- Ye, H.; Liang, L. Machine Learning for Vehicular Networks. arXiv 2018, arXiv:1712.07143. [Google Scholar]
- Ye, H.; Li, G.; Juang, B. Power of Deep Learning for Channel Estimation and Signal Detection in OFDM Systems. IEEE Wirel. Commun. Lett. 2018, 7, 114–117. [Google Scholar] [CrossRef]
- Sattiraju, R.; Weinand, A.; Schotten, H. Channel Estimation in C-V2X using Deep Learning. In Proceedings of the 2019 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Goa, India, 16–19 December 2019. [Google Scholar]
- Liu, J.; Mei, K.; Zhang, X.; Ma, D.; Wei, J. Online Extreme Learning Machine-Based Channel Estimation and Equalization for OFDM Systems. IEEE Commun. Lett. 2019, 23, 1276–1279. [Google Scholar] [CrossRef]
- Gutiérrez, C.; Pätzold, M.; Dahech, W.; Youssef, N. A Non-WSSUS Mobile-to-Mobile Channel Model Assuming Velocity Variations of the Mobile Stations. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017. [Google Scholar] [CrossRef]
- Gutierrez, C.; Gutierrez-Mena, J.; Luna-Rivera, J.; Campos-Delgado, D.; Velazquez, R.; Patzold, M. Geometry-Based Statistical Modeling of Non-WSSUS Mobile-To-Mobile Rayleigh Fading Channels. IEEE Trans. Veh. Technol. 2018, 1, 362–377. [Google Scholar] [CrossRef]
- Jaime-Rodríguez, J.J.; Gómez-Vega, C.A.; Gutiérrez, C.A.; Luna-Rivera, J.M.; Campos-Delgado, D.U.; Velázquez, R. A non-WSSUS channel simulator for V2X communication systems. Electronics 2020, 9, 1190. [Google Scholar] [CrossRef]
- Gutiérrez, C.A.; Pätzold, M.; Ortega, N.M.; Azurdia-Meza, C.; Maciel-Barboza, F.M. Doppler shift characterization of wideband mobile radio channels. IEEE Trans. Veh. Technol. 2019, 68, 12375–12380. [Google Scholar] [CrossRef]
- Huang, G.; Song, S.; Gupta, J. Semi-supervised and unsupervised extreme learning machines. IEEE Trans. Cybern. 2014, 12, 2405–2417. [Google Scholar] [CrossRef]
- Souza, P.V.d.C.; Torres, L.C.B.; Silva, G.R.L.; Braga, A.d.P.; Lughofer, E. An advanced pruning method in the architecture of extreme learning machines using l1-regularization and bootstrapping. Electronics 2020, 9, 811. [Google Scholar] [CrossRef]
- Li, S.; Song, S.; Wan, Y. Laplacian twin extreme learning machine for semi-supervised classification. Neurocomputing 2018, 321, 17–27. [Google Scholar] [CrossRef]
- Zabala-Blanco, D.; Mora, M.; Azurdia-Meza, C.A.; Dehghan Firoozabadi, A.; Palacios Játiva, P.; Soto, I. Relaxation of the Radio-Frequency Linewidth for Coherent-Optical Orthogonal Frequency-Division Multiplexing Schemes by Employing the Improved Extreme Learning Machine. Symmetry 2018, 8, 632. [Google Scholar] [CrossRef]
- Zabala-Blanco, D.; Mora, M.; Azurdia-Meza, C.A. Dehghan Firoozabadi, Extreme Learning Machines to Combat Phase Noise in RoF-OFDM Schemes. Electronics 2019, 12, 921. [Google Scholar] [CrossRef]
- Ijiga, O.E.; Ogundile, O.O.; Familua, A.D.; Versfeld, D.J. Review of channel estimation for candidate waveforms of next generation networks. Electronics 2019, 8, 956. [Google Scholar] [CrossRef]
- Liu, N.; Wang, H. Ensemble based extreme learning machine. IEEE Signal Process. Lett. 2010, 17, 754–757. [Google Scholar] [CrossRef]
- Carrera, D.F.; Zabala-Blanco, D.; Vargas-Rosales, C.; Azurdia-Meza, C.A. Extreme Learning Machine-Based458Receiver for Multi-User Massive MIMO Systems. IEEE Commun. Lett. 2021, 25, 484–488. [Google Scholar] [CrossRef]
- Yang, L.; Zhao, Q.; Jing, Y. Channel Equalization and Detection with ELM-Based Regressors for OFDM Systems. IEEE Commun. Lett. 2019, 24, 86–89. [Google Scholar] [CrossRef]
- Carrera, D.F.; Vargas-Rosales, C.; Yungaicela-Naula, N.M.; Azpilicueta, L. Comparative Study of Artificial Neural Network Based Channel Equalization Methods for MmWave Communications. IEEE Access 2021, 9, 41678–41687. [Google Scholar] [CrossRef]
- Shivaldova, V.; Winkelbauer, A.; Mecklenbrauker, C. Signal-to-noise ratio modeling for vehicle-to-infrastructure communications. In Proceedings of the 2014 IEEE 6th International Symposium on Wireless Vehicular Communications (WiVeC 2014), Vancouver, BC, Canada, 14–15 September 2014. [Google Scholar] [CrossRef]
- Ortega, N.M.; Azurdia-Meza, C.A.; Gutierrez, C.A.; Gómez-Vega, C.A. Second Order Statistics and BER Performance Analysis of a non-WSSUS V2X Channel Model that Considers Velocity Variations. In Proceedings of the 2019 IEEE Latin-American Conference on Communications (LATINCOM), Salvador, Brazil, 11–13 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- U.S. Department of Transportation. Vehicle Safety Communications Project V Final Report; Report DOT HS 810 591; National Highway Traffic Safety Administration: Washington, DC, USA, 2006.
- Feukeu, E.; Djouani, K.; Kurien, A. An MCS Adaptation Technique for Doppler Effect in IEEE 802.11p Vehicular Networks. Procedia Comput. Sci. 2013, 19, 570–577. [Google Scholar] [CrossRef][Green Version]
- Frances-Villora, J.V.; Rosado-Muñoz, A.; Bataller-Mompean, M.; Barrios-Aviles, J.; Guerrero-Martinez, J.F. Moving learning machine towards fast real-time applications: A high-speed FPGA-based implementation of the OS-ELM training algorithm. Electronics 2018, 7, 308. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of data subcarriers | 48 |
| Number of pilot subcarriers () | 4 |
| Number of subcarriers total () | 52 |
| Subcarrier frequency spacing () | 0.15625 MHz |
| IFFT/FFT periods () | 6.4 µs (1/) |
| PHY preamble duration () | 32 µs |
| Duration of the Signal BPSK-OFDM symbol () | 8 µs |
| Training symbol guard interval duration () | 3.2 µs |
| Symbol interval () | 8 µs |
| Short training sequence duration () | 16 µs |
| Long training sequence duration () | 16 µs |
| Parameter | Configuration 1 | Configuration 2 |
|---|---|---|
| Carrier Frequency () | 5.9 GHz | 5.9 GHz |
| Bandwidth (B) | 10 MHz | 10 MHz |
| Modulation | BPSK | BPSK |
| Number of OFDM symbols per package (L) | 128 | 128 |
| Transmitter velocity () | 40 km/h | 20 km/h |
| Receiver velocity () | 40 km/h | 20 km/h |
| Transmitter movement angle () | 105° | 10° |
| Receiver movement angle () | 70° | 70° |
| Transmitter acceleration angle () | 105° | 15° |
| Receiver acceleration angle () | 250° | 70° |
| Initial distance (D) | 300 m | 100 m |
| Radius of the ring (d) | 30 m | 30 m |
| Component | Model |
|---|---|
| Central Processing Unit (CPU) | Intel i5 10400F 2.9 GHz–4.1 GHz |
| Random Access Memory (RAM) | 16 GB 2133 MHz |
| Graphics Processing Unit (GPU) | GTX1060 6 GB |
| Algorithm | Time [ms] |
|---|---|
| LS | 0.0269 ± 0.0095 |
| STA | 13.5 ± 0.344 |
| CDP | 18.4 ± 0.471 |
| ELM | 40.5 ± 5.1 |
| C-ELM [13] | 127 ± 9.74 |
| SS-ELM | 658 ± 10.4 |
| Parallel SS-ELM | 167 ± 2.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salazar, E.; Azurdia-Meza, C.A.; Zabala-Blanco, D.; Bolufé, S.; Soto, I. Semi-Supervised Extreme Learning Machine Channel Estimator and Equalizer for Vehicle to Vehicle Communications. Electronics 2021, 10, 968. https://doi.org/10.3390/electronics10080968
Salazar E, Azurdia-Meza CA, Zabala-Blanco D, Bolufé S, Soto I. Semi-Supervised Extreme Learning Machine Channel Estimator and Equalizer for Vehicle to Vehicle Communications. Electronics. 2021; 10(8):968. https://doi.org/10.3390/electronics10080968
Chicago/Turabian StyleSalazar, Eduardo, Cesar A. Azurdia-Meza, David Zabala-Blanco, Sandy Bolufé, and Ismael Soto. 2021. "Semi-Supervised Extreme Learning Machine Channel Estimator and Equalizer for Vehicle to Vehicle Communications" Electronics 10, no. 8: 968. https://doi.org/10.3390/electronics10080968
APA StyleSalazar, E., Azurdia-Meza, C. A., Zabala-Blanco, D., Bolufé, S., & Soto, I. (2021). Semi-Supervised Extreme Learning Machine Channel Estimator and Equalizer for Vehicle to Vehicle Communications. Electronics, 10(8), 968. https://doi.org/10.3390/electronics10080968