2.1. Face Recognition
Face recognition has become a very active area of research since the 1970s [
1] due to its wide range of applications in many fields such as public security, human–computer interaction, computer vision, and verification [
2,
4]. Face recognition systems could be applied in many applications such as (a) security, (b) surveillance, (c) general identity verification, (d) criminal justice systems, (e) image database investigations, (f) “Smart Card” applications, (g) multi-media environments with adaptive human–computer interfaces, (h) video indexing, and (i) witness face reconstruction [
5]. However, there are major drawbacks or concerns for face recognition systems including privacy violation. Moreover, Wei et al. [
6] discussed some of the facial geometric features such as eye distance to the midline, horizontal eye-level deviation, eye–mouth angle, vertical midline deviation, ear–nose angle, mouth angle, eye–mouth diagonal, and the Laplacian coordinates of facial landmarks. The authors claimed that these features are comparable to those extracted from a set with much denser facial landmarks. Additionally, Gabryel and Damaševičius [
7] discussed the concept of keypoint features where they adopted a Bag-of-Words algorithm for image classification. The authors based their image classification on the keypoints retrieved by the Speeded-Up Robust Features (SURF) algorithm.
This is considered one of the most challenging zones in the computer vision field. The facial recognition system is a technology that can identify or verify an individual from an acquisition source, e.g., a digital image or a video frame. The first step for face recognition is face detection, which means localizing and extracting areas of a human’s face from the background. In this step, active contour models are used to detect edges and boundaries of the face. Recognition in computer vision takes the form of face detection, face localization, face tracking, face orientation extraction, facial features, and facial expressions. Face recognition needs to consider some technical issues, e.g., poses, occlusions, and illumination [
8].
There are many methods for facial recognition systems’ mechanism; generally, they compare selected or global features of a specified face image with a dataset containing many images of faces. These extracted features are selected based on examining patterns of individuals’ facial color, textures, or shape. The human face is not unique. Hence, several factors cause variations in facial appearance. The facial appearance variations develop two image categories, which are intrinsic and extrinsic factors [
5].
Emergent face recognition systems [
9] have achieved an identification rate of better than 90% for massive databases within optimal poses and lighting conditions. They have moved from computer-based applications to being used in various mobile platforms such as human–computer interaction with robotics, automatic indexing of images, surveillance, etc. They are also used in security systems for access control in comparison with other biometrics such as eye iris or fingerprint recognition systems. Although the accuracy of face recognition systems is less accurate than other biometrics recognition systems, they has been adopted extensively because of their non-invasive and contactless processes.
The face recognition process [
10,
11,
12] starts with a face detection process to isolate a human face within an input image that contains a human face. Then, the detected face is pre-processed to obtain a low-dimensional representation. This low-dimensional representation is vital for effective classification. Most of the issues in recognizing human faces arise because they are not a rigid object, and the image can be taken from different viewpoints. It is important for face recognition systems to be resilient to intrapersonal variations in an image, e.g., age, expressions, and style, but still able to distinguish between different people’s interpersonal image variations [
13].
According to Schwartz et al. [
14], the face recognition method consists of (a) detection: detecting a person face within an image; (b) identification: an unknown person’s image is matched to a gallery of known people; and (c) verification: acceptance or denial of an identity claimed by a person. Previous studies stated that applying face recognition in well-controlled acquisition conditions gives a high recognition rate even with the use of large image sets. However, the face recognition rate became low when applying it in uncontrolled conditions, leading to a more laborious recognition process [
14].
The following is the chronological summary of some of the relevant studies conducted in the area of face recognition.
In 2012, Rouhi et al. [
15] reviewed four techniques for face recognition in the feature extraction phase. The four techniques are 15-Gabor filter, 10-Gabor filter, Optimal- Elastic Base Graph Method (EBGM), and Local Binary Pattern (LBP). They concluded that the weighted LBP has the highest recognition rate, whereas the non-weighted LBP has the maximum performance in the feature extraction between the used techniques. However, the extracted recognition rates in the 10-Gabor and 15-Gabor filter techniques are higher than those in the EBGM and Optimal-EBGM methods, even though the vector length is long. In [
6], Schwartz et al. used a large and rich set of facial identification feature descriptors using partial squares for multichannel weighting. They then extend the method to a tree-based discriminative structure to reduce the time needed to evaluate samples. Their study shows that the proposed identification method outperforms current state-of-the-art results, particularly in identifying faces acquired across varying conditions.
Nanni et al. [
16] conducted a study to determine how best to describe a given texture using a Local Binary Pattern (LBP) approach. They performed several empirical experiments on some benchmark databases to decide on the best feature extraction method using LBP-based techniques. In 2014, Kumar et al. [
17] completed a comparative study to compare global and local feature descriptors. This study considered experimental and theoretical aspects to check those descriptors’ efficiency and effectiveness. In 2017, Soltanpour et al. [
18] conducted a survey illustrating a state-of-the-art for 3D face recognition using local features, with the primary focus on the process of feature extraction. Nanni et al. [
16] also presented a novel face recognition system to identify faces based on various descriptors using different preprocessing techniques. Two datasets demonstrate their approach: (a) the Facial Recognition Technology (FERET) dataset and (b) the Wild Faces (LFW) dataset. They use angle distance in FERET datasets, where identification was intended. In 2018, Khanday et al. [
19] reviewed various face recognition algorithms based on local feature extraction methods, hybrid methods, and dimensionality reduction approaches. They aimed to study the main methods/techniques used in recognition of faces. They provide a critical review of face recognition techniques with a description of major face recognition algorithms.
In 2019, VenkateswarLal et al. [
20] suggested that an ensemble-aided facial recognition framework performed well in wild environments using preprocessing approaches and an ensemble of feature descriptors. A combination of texture and color descriptors is extracted from preprocessed facial images and classified using the Support Vector Machines (SVM) algorithm. The framework is evaluated using two databases, the FERET dataset samples and Labeled Faces in the Wild dataset. The results show that the proposed approach achieved a good classification accuracy, and the combination of preprocessing techniques achieved an average classification accuracy for both datasets at 99% and 94%, respectively. Wang et al. [
21] proposed a multiple Gabor feature-based facial expression recognition algorithm. They evaluated the effectiveness of their proposed algorithm on the Japanese Female Facial Expression (JAFFE) database, where the algorithm performance primarily relies on the final combination strategy and the scale and orientation of the features selected. The results indicate that the fusion methods perform better than the original Gabor method. However, the neural network-based fusion method performs the best.
Latif et al. [
22] presented a comprehensive review of recent Content-Based Image Retrieval (CBIR) and image representation developments. They studied the main aspects of image retrieval and representation from low-level object extraction to modern semantic deep-learning approaches. Their object representation description is achieved utilizing low-level visual features such as color, texture, spatial structure, and form. Due to the diversity of image datasets, single-feature representation is not possible. There are some solutions to be used to increase CBIR and image representation performance, such as the utilization of low-level feature infusion. The conceptual difference could be minimized by using the fusion of different local features as they reflect the image in a patch shape. It is also possible to combine local and global features. Furthermore, traditional machine learning approaches for CBIR and image representation have shown good results in various domains. Recently, CBIR research and development have shifted towards utilizing deep neural networks that have presented significant results in many datasets and outperformed handcrafted features prior to fine-tuning of the deep neural network.
In 2020, Yang et al. [
23] developed a Local Multiple Pattern (LMP) feature descriptor based on Weber’s extraction and face recognition law. They modified Weber’s ratio to contain change direction to quantize multiple intervals and to generate multiple feature maps to describe different changes. Then LMP focuses on the histograms of the non-overlapping regions of the feature maps for image representation. Further, a multi-scale block LMP (MB-LMP) is presented to generate more discriminative and robust visual features because LMP could only capture small-scale structures. This combined MB-LMP approach could capture both the large-scale and small-scale structures. They claimed that the MB-LMP is computationally efficient using an integral image. Their LMP and MB-LMP are evaluated upon four public face recognition datasets. The results demonstrate that there is a promising future for the proposed LMP and MB-LMP descriptors with good efficiency.
2.2. Face recognition Acquisition and Processing Techniques
Research and development in the face recognition has significantly progressed over the last few years. The following paragraphs briefly summarize some of used face recognition techniques.
Traditional approach: This approach uses algorithms to identify facial features by extracting landmarks from an individual’s face image. The first type of algorithms would analyze the size and/or shape of the eyes’ relative position, nose, cheekbones, mouth, and jaw. The output is used to match the selected image with similar features within an image set. On the other hand, some algorithms adopt template matching techniques, and it is conducted via analyzing and compressing only face data that are important for the face recognition process and then compare it with a set of face images.
Dimensional recognition approach: This approach utilizes 3D sensors to capture information of an individual’s face shape [
13,
18]. These sensors work by projecting structured light on an individual’s face and work as a group with each other to capture different views of the face. The information is used to identify unique and distinctive facial features such as the eye socket contour, chin, and nose. This approach overcomes the traditional approach by identifying faces from different angles, and it is not affected by light changes.
Texture analysis Approach: The texture analysis approach, also known as Skin Texture Analysis [
4], utilizes the visual details of the skin of an individual’s face image. This transforms the distinctive lines, patterns, and spots in the skin of a person into numerical value. A skin patch of an image is called a skinprint. This patch is broken up into smaller blocks, and then the algorithms transform/convert them into measurable and mathematical values for the system to be able to identify the actual skin texture and any pores or lines. This allows identifying the contrast between identical pairs that could not possibly be carried out by traditional face recognition tools alone. The test result of this approach showed that it could increase the performance of face recognition by 20–25%.
Thermal camera approach: This approach requires a thermal camera as a technology for face image acquisition. It produces different forms of data for an individual’s face by detecting only the head shape and ignoring other accessories such as glasses or hats [
18]. Compared to traditional image acquisition, this approach can capture face image at night or even in a low-light condition without an external source of light, e.g., flash. One major limitation of this approach is that the dataset of such thermal images is limited for face recognition in comparison to other types of datasets.
Statistical approach: There are several statistical techniques for face recognition, e.g., Principal Component Analysis (PCA) [
13], Eigenfaces [
24], and Fisherfaces [
25]. The methods in this approach can be mainly categorized into:
- -
Principal Component Analysis (PCA): this analyzes data to identify patterns and find patterns reducing the dataset’s computational complexity with nominal loss of information.
- -
Discrete Cosine Transform (DCT): this is used for local and global features to identify the related face picture from a database [
26].
- -
Linear Discriminant Analysis (LDA): this is a dimensionality reduction technique that is used to maximize the class scattering matrix measure.
- -
Independent Component Analysis (ICA): this decreases the second-order and higher-order dependencies in the input and determines a set of statistically independent variables [
27].
Hybrid approach: Most of the current face recognition systems have combined different approaches from the list mentioned above [
15]. Those systems would have a higher accuracy rate when recognizing an individual’s face. This is because, in most cases, the disadvantages of one approach could be overcome by another approach. However, this cannot be generalized.
There are several software and tools used in image retrieval, and the most well-known ones are MATLAB [
28], OpenCV [
29], and LIRE [
30]. The LIRE Library is the tool we utilized in this paper. A Java tool is developed for the purpose of framework implementation.
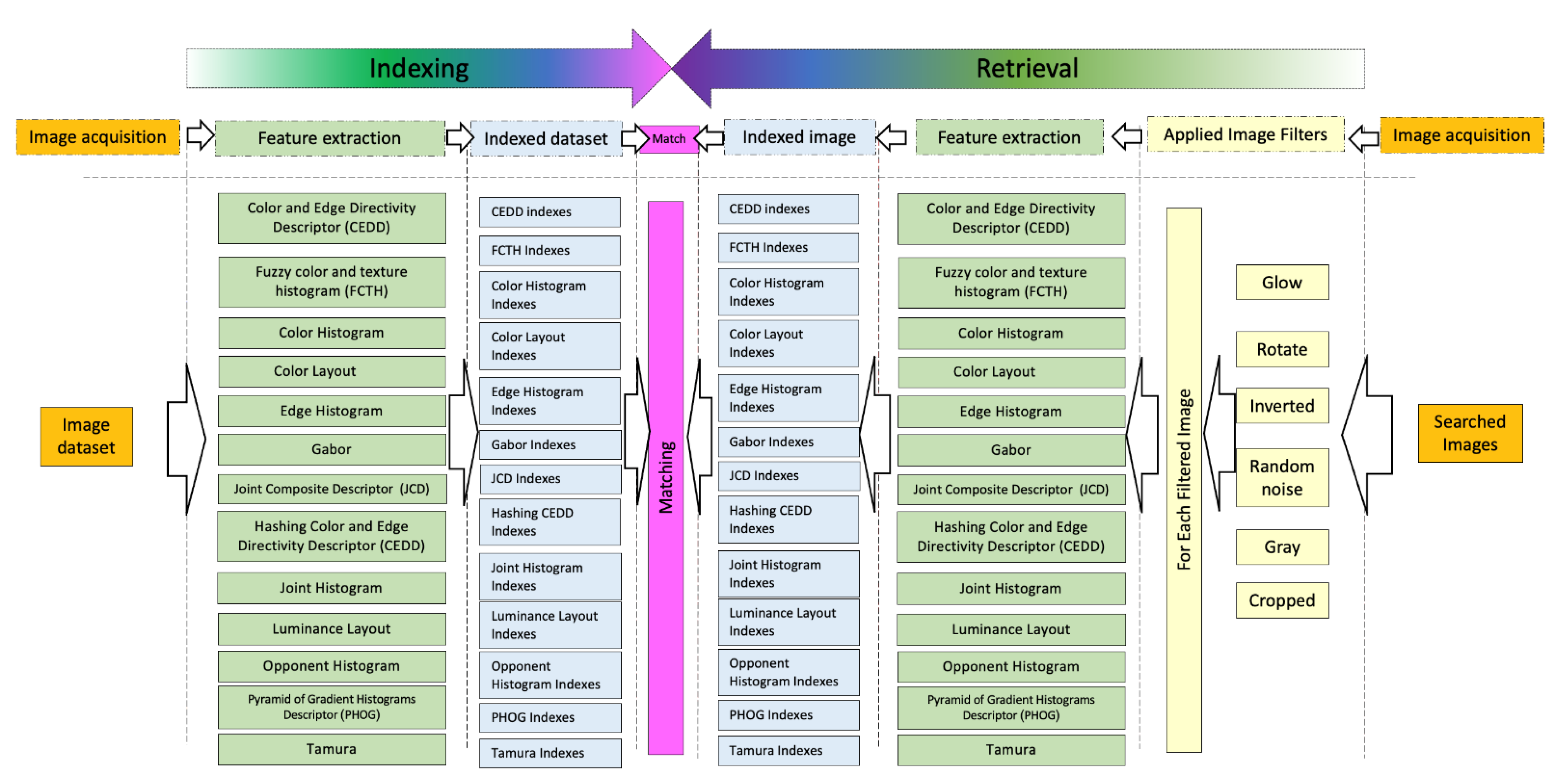
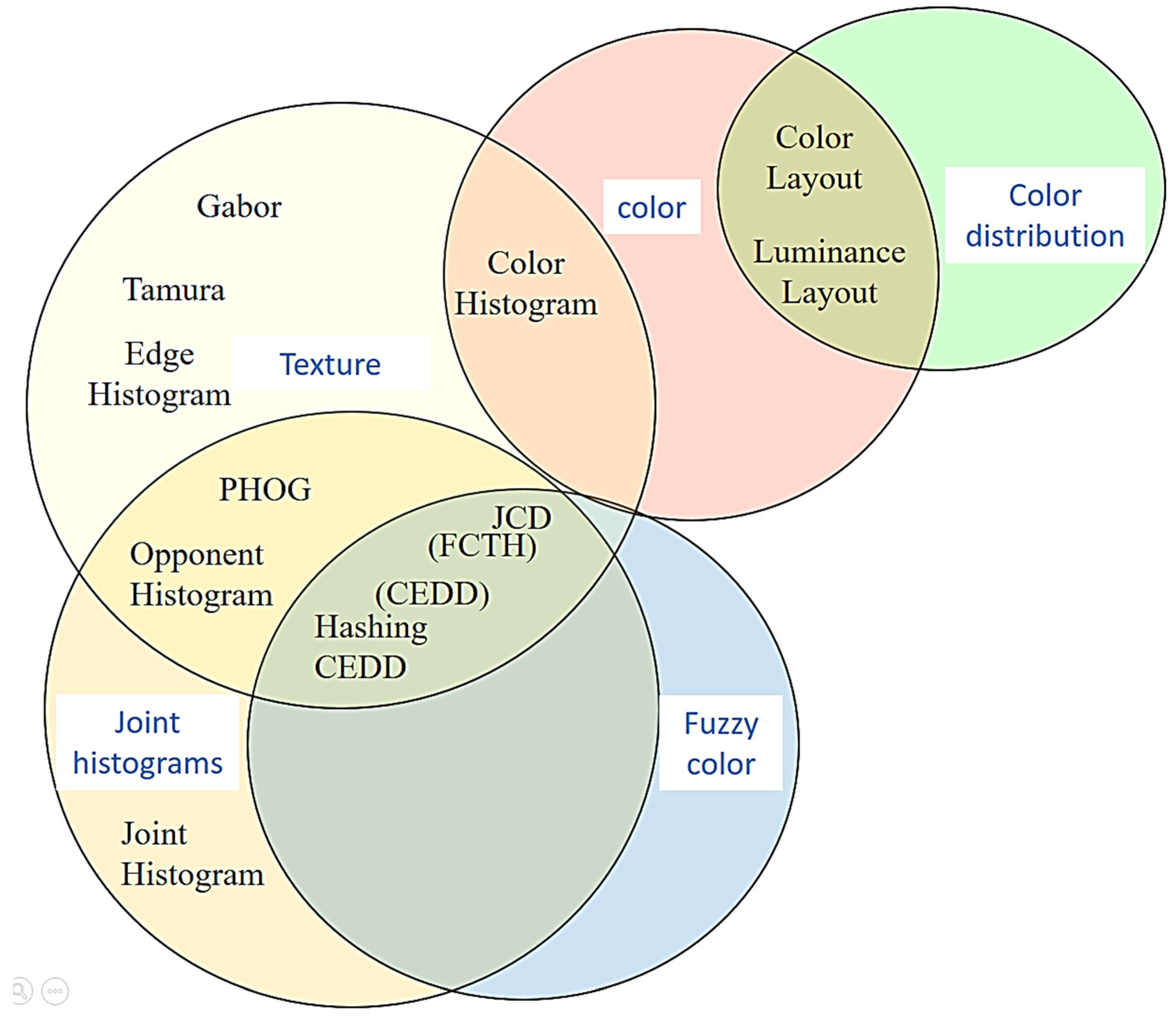
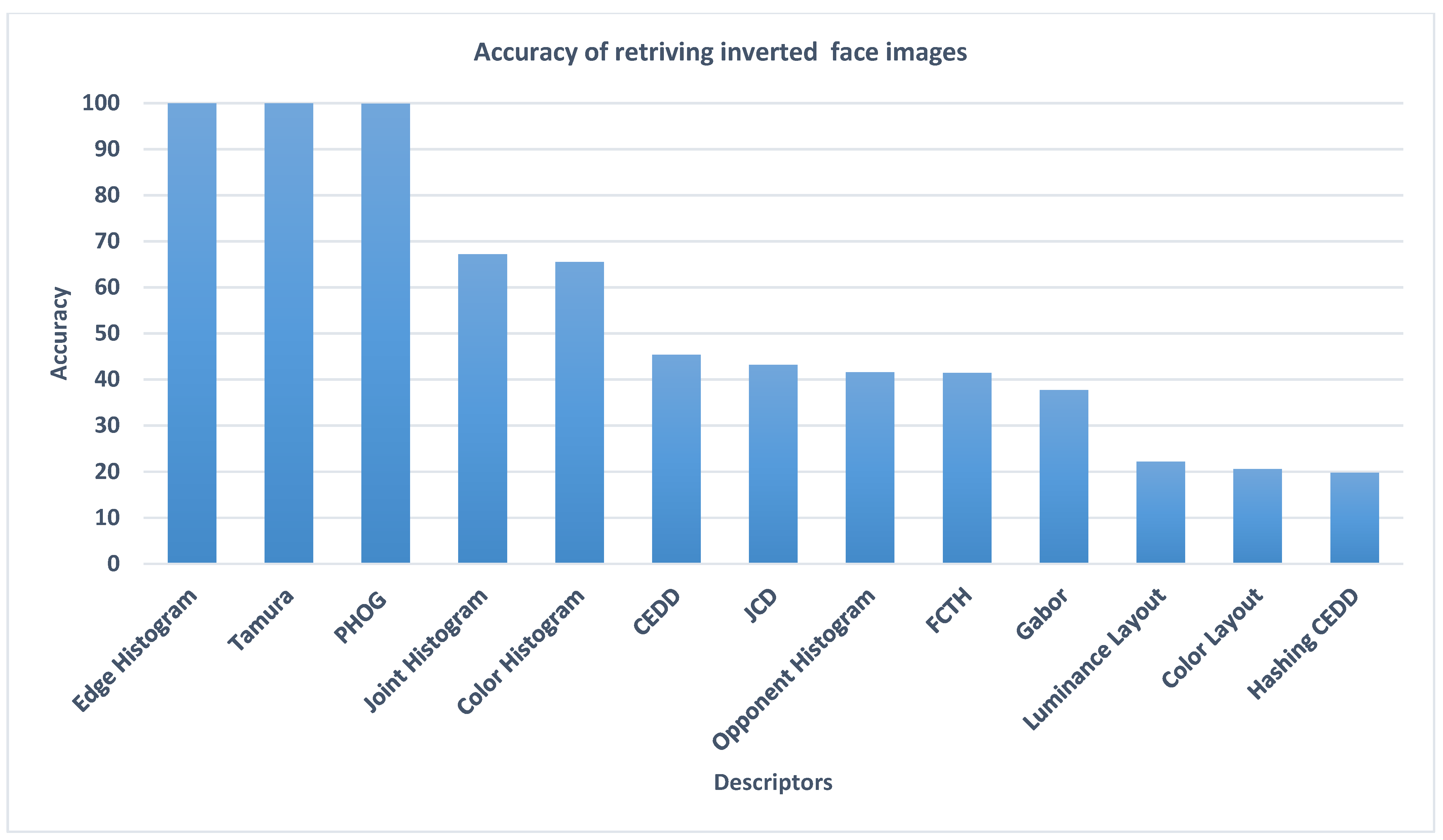
2.3. Image Descriptors Analysis
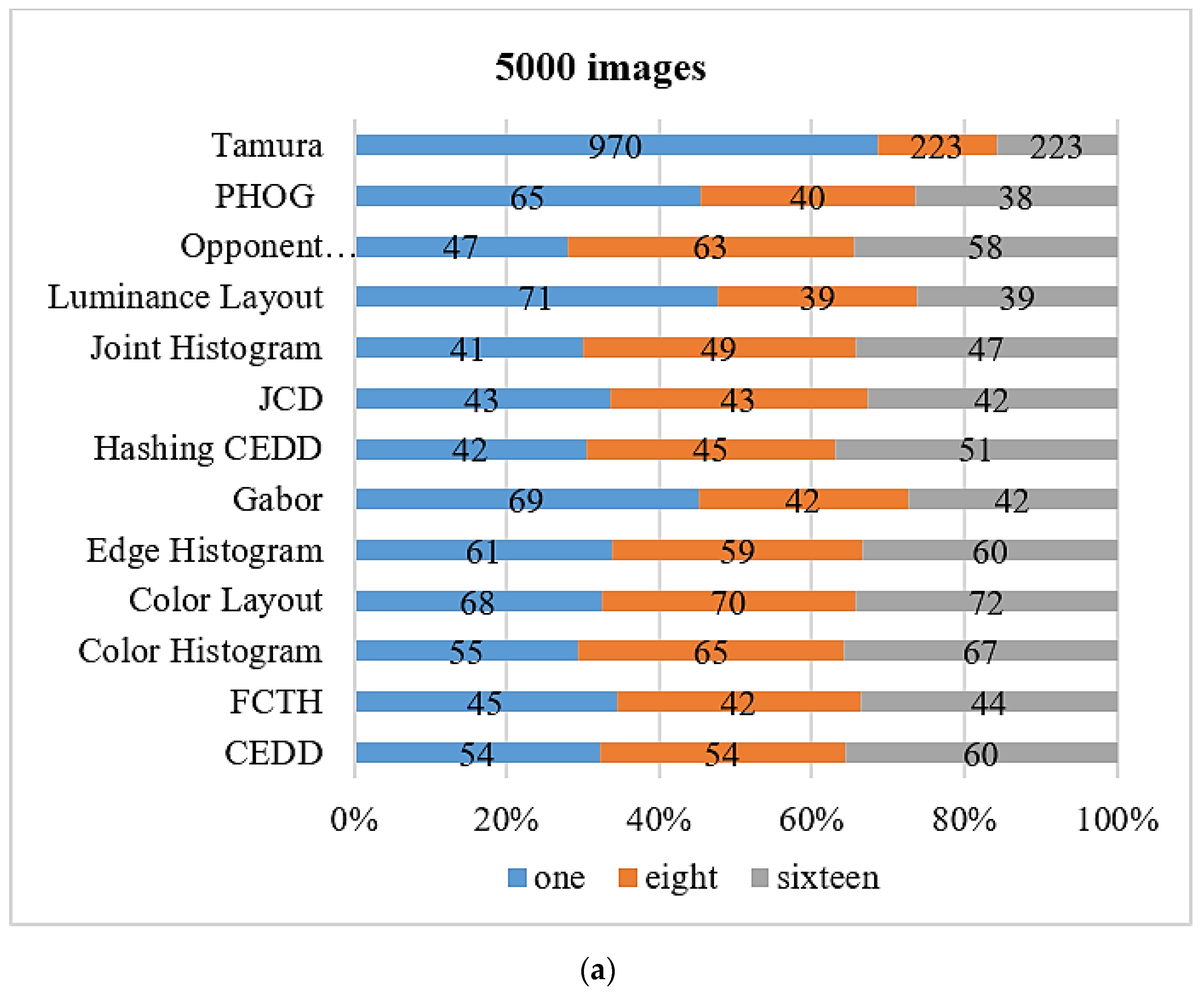
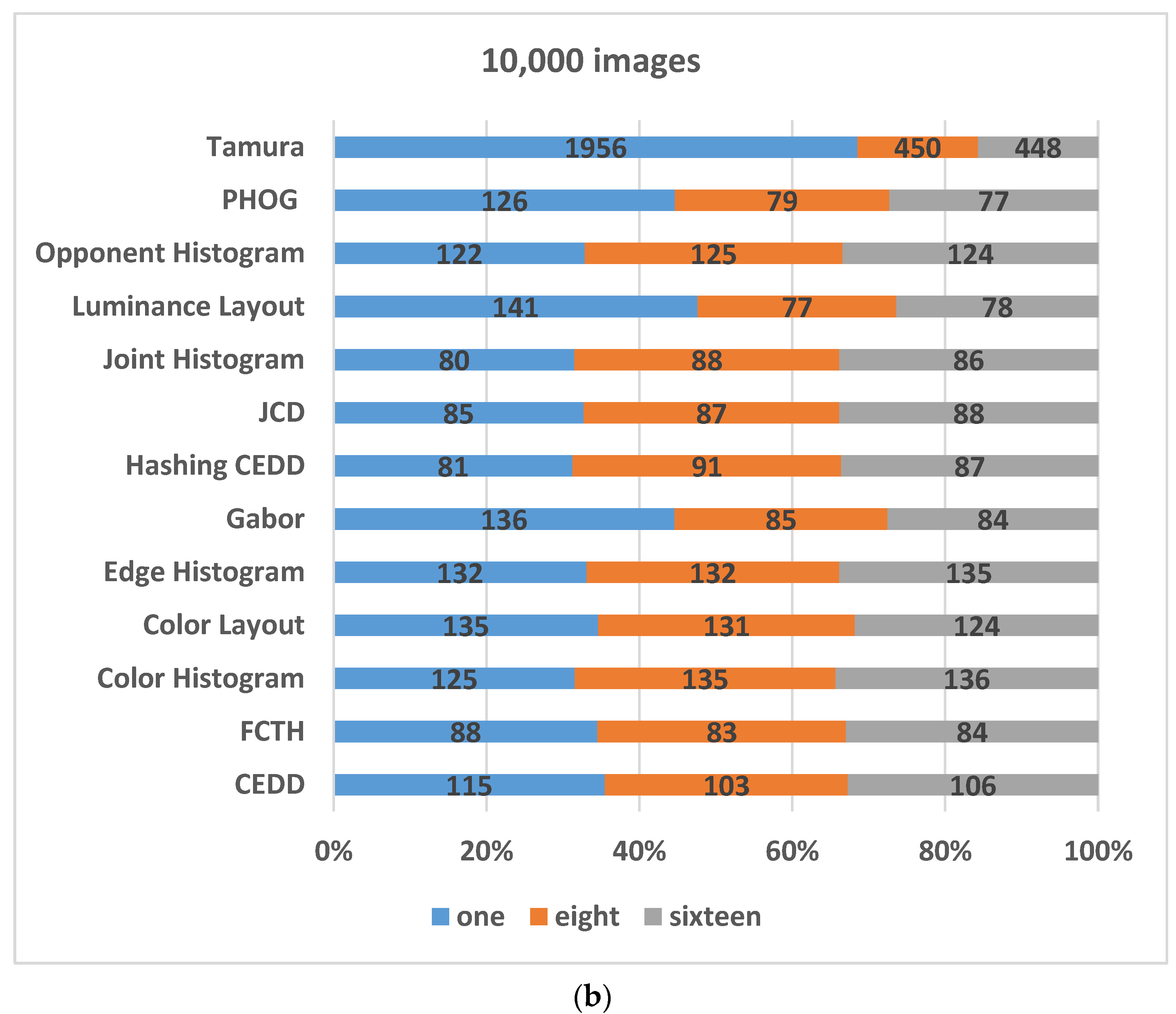
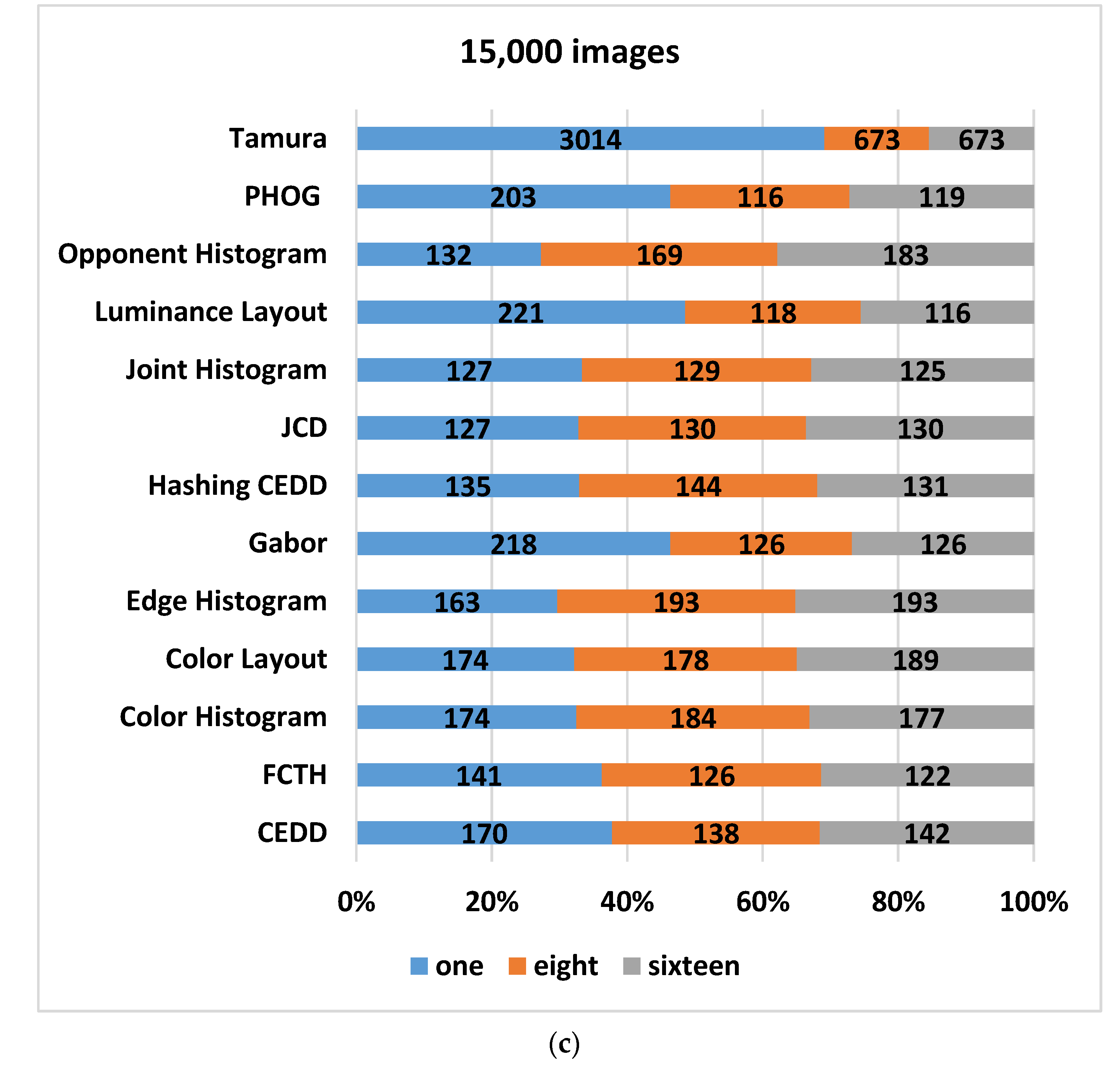
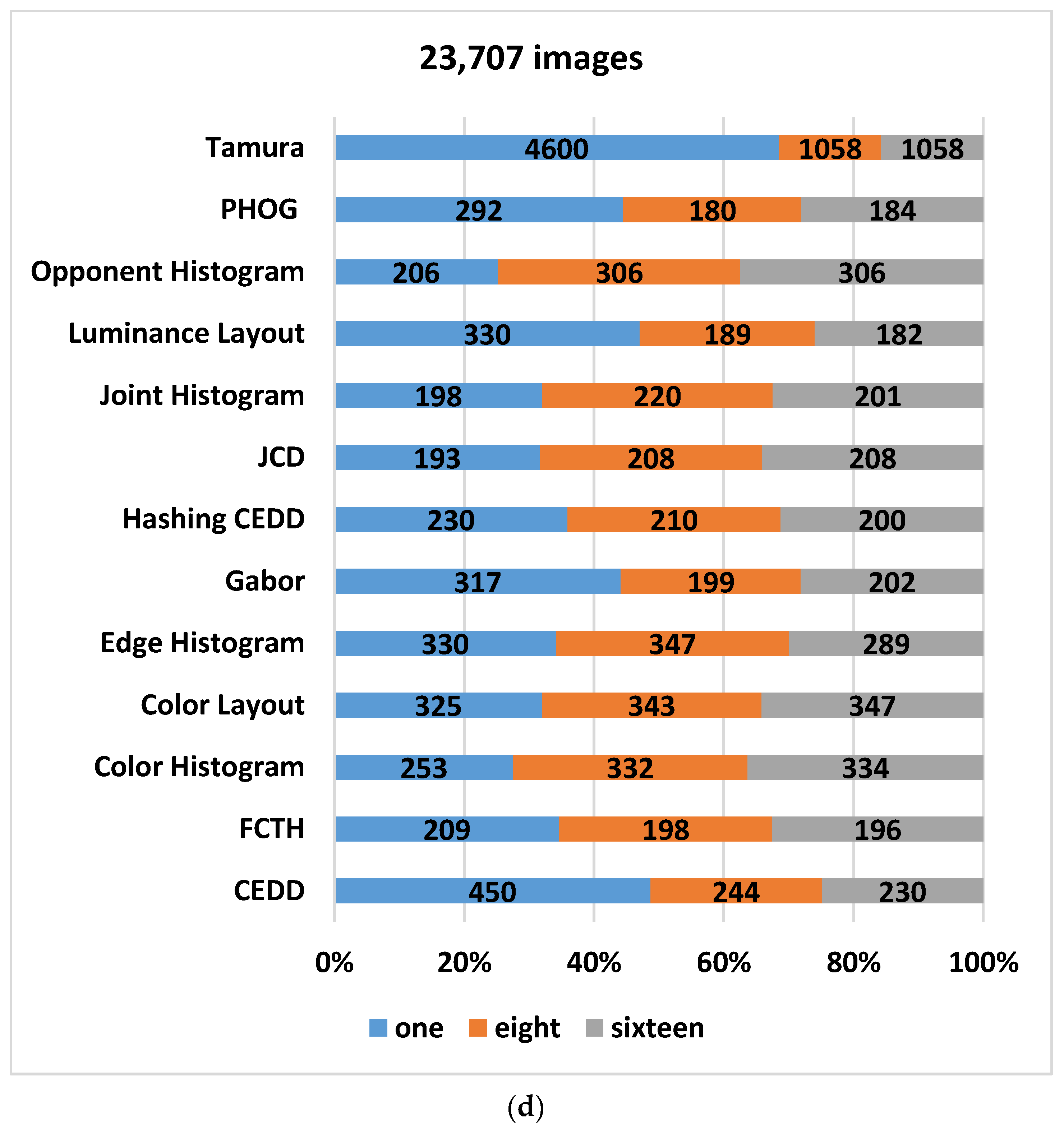
The following
Figure 1 shows most of the image descriptors stated in the literature [
17]. The inner-circle represents the type of descriptors, while the middle circle represents the different descriptors. Moreover, the outer circle represents the features used by each descriptor. However, this paper experiments with different features on a dataset of faces, and specific descriptors that cover most of the previously mentioned features are selected. The selected descriptors are briefly described in the following paragraphs:
Color and Edge Directivity Descriptor (CEDD): The CEDD incorporates fuzzy information about color and edge. This blends a black, brown, white, dark red, red, light red, medium orange, light orange, dark purple, yellow, light yellow, dark green, dark green, dark cyan, cyan, light cyan, dark blue, blue, light blue, dark magenta, magenta, and light magenta with six different colors. It is a low-level image extraction function that can be used for indexing and retrieval. This integrates details about color and texture in a histogram. The size of the CEDD is limited to 54 bytes per image, making it ideal for use in large image databases. One of the CEDD’s most important attributes is the low computing power needed to extract it, relative to most MPEG-7 descriptors’ specifications.
Fuzzy Color and Texture Histogram (FCTH) Descriptor [
31]: The FCTH descriptor uses the same fluffy color scheme used by CEDD, but it uses a more detailed edge definition with 8 bins, resulting in a 192-bin overall function.
Luminance Layout Descriptor [
32]: The luminance of light is a unit intensity value per light area of the movement in a given direction. The luminance of light may take the same light energy and absorb it at a time or disperse it across a wider area. Luminance is, in other words, a light calculation not over time (such as brightness) but over an area. The luminance can be displayed as L in Hue, Saturation, Lightness (HSL) in photo editing. The layer mask is based on a small dark or light spectrum in the picture. It helps one explicitly alter certain parts, such as making them lighter or darker or even changing their color or saturation.
Color Histogram Descriptor [
33]: This descriptor is one of the most intuitive and growing visual descriptors. Each bin in a color histogram reflects the relative pixel quantity of a certain color. One color bin is assigned to each pixel of an image, and the corresponding count increases. Intuitively, a 16M color image will result in a 16M bins histogram. Usually, the color data are quantized to limit the number of measurements; thus, identical colors are treated in the original color space as if they were the same, and their rate of occurrence is measured for the same bin. Color quantization is a crucial step in building a characteristic. The most straightforward approach to color quantization is to divide the color space of the Red, Green, Blue (RGB) into partitions of equal size, similar to stacked boxes in 3D space.
Color Layout Descriptor [
33]: A Color Layout Descriptor (CLD) is designed to capture a picture’s spatial color distribution. The function’s extraction process consists of two parts: grid-based representative color selection and the quantization of discrete cosine transform. Color is the visual content’s most basic value; thus, colors can be used to define and reflect an object. The Multimedia Content Description Interface (MPEG-7) specification is tested as the most effective way to describe the color and chose those that produced more satisfactory results. The norm suggests different methods of obtaining such descriptors, and one tool for describing the color is the CLD, which enables the color relationship to be represented.
Edge Histogram Descriptor [
34]: The Edge Histogram function is part of the standard MPEG-7, a multimedia meta-data specification that includes many visual information retrieval features. The function of the Edge Histogram captures the spatial distribution within an image of (undirected) edges. Next, the image is divided into 16 blocks of equal size, which are not overlapping. The data are then processed for each block edge and positioned in a 5-bin histogram counting edge in the following categories: vertical, horizontal, 35mm, 135 mm, and non-directional. This function is mostly robust against scaling.
Joint Composite Descriptor (JCD) Descriptor [
35]: The JCD is a mixture of the CEDD and FCTH. Compact Composite Descriptors (CCDs) are low-level features that can be used to describe different forms of multimedia data as global or local descriptors. SIMPLE Descriptors are the regional edition of the CCDs. JCD consists of seven areas of texture, each of which consists of 24 sub-regions corresponding to color areas. The surface areas are as follows: linear region, horizontal activation, 45-degree activation, vertical activation, 135-degree activation, horizontal and vertical activation, and non-directional activation.
Joint Histogram Descriptor [
35]: A color histogram is a vector where each entry records the number of pixels in the image. Before histogramming, all images are scaled to have the same number of pixels; then, the image colors are mapped into a separate color space with n colors. Usually, images are represented in the color space of the RGB using some of the most important bits per color channel to isolate the space. Color histograms do not relate spatial information to certain color pixels; they are primarily invariant in image reference rotation and translation. Therefore, color histograms are resistant to occlusion and lens perspective changes.
Opponent Histogram Descriptor [
36]: The opposing histogram is a mixture of three 1D histograms based on the opponent’s color space streams. The frequency is displayed in channel O3, Equation (1), and the color data are displayed in channels O1 and O2. The offsets will be cancelled if they are equal for all sources (e.g., a white light source) due to the subtraction in O1 and O2. Therefore, in terms of light intensity, these color models are shift invariant. There are no invariance properties in the frequency stream O3. The competing color space histogram intervals have ranges that are different from the RGB standard.
Pyramid of Gradient Histograms (PHOG) Descriptor [
37]: The PHOG descriptor is used to apply material identification. Support Vector Machines (SVM) can use the kernel trick to perform an effective non-linear classification, mapping their inputs into high-dimensional feature spaces. PHOG is an outstanding global image shape descriptor, consisting of a histogram of the gradients of orientation over each image’s sub-region at each resolution point. PHOG is an outstanding global image form descriptor, consisting of a histogram of the gradients of orientation at each resolution level over each object sub-region.
Tamura Descriptor [
38]: The features of Tamura represent texture on a global level; thus, they are limited in their utility for images with complex scenes involving different textures. The so-called Tamura features are the classic collection of basic features. Generally, six different surface characteristics are identified: (i) coarseness (coarse vs. fine), (ii) contrast (high contrast vs. low contrast), (iii) directionality (directional vs. non-directional), (iv) line-like vs. blob-like, (v) regularity (regular vs. irregular), and (vi) roughness (rough vs. smooth).
Gabor Descriptor [
39]: A Gabor Descriptor named after Dennis Gabor. It is a linear filter used for texture analysis, meaning that it essentially analyzes whether there is any particular frequency material in the image in specific directions around the point area of analysis in a localized field. A 2D Gabor filter is a Gaussian kernel function that is modulated by a sinusoidal plane wave in the spatial domain.
Hashing CEDD Descriptor [
40]: Hashed Color and Edge Directivity Descriptor (CEDD) is the main feature, and a hashing algorithm puts multiple hashes per image, which are to be translated into words. This makes it much faster in retrieval without losing too many images on the way, which means the method has an acceptable recall.
The following
Table 2 summarizes the related work stated in this section.



 ,
, 






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}