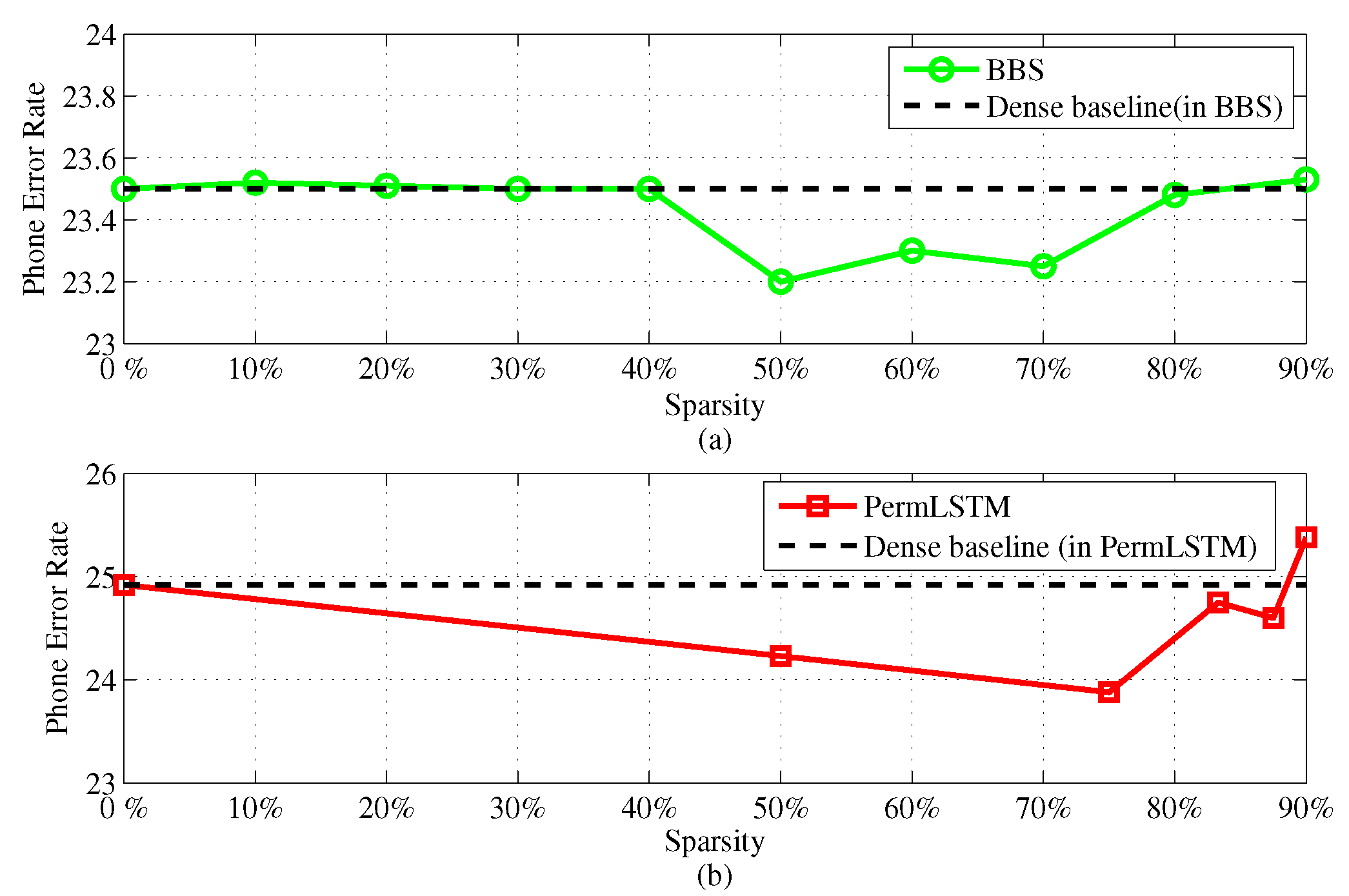
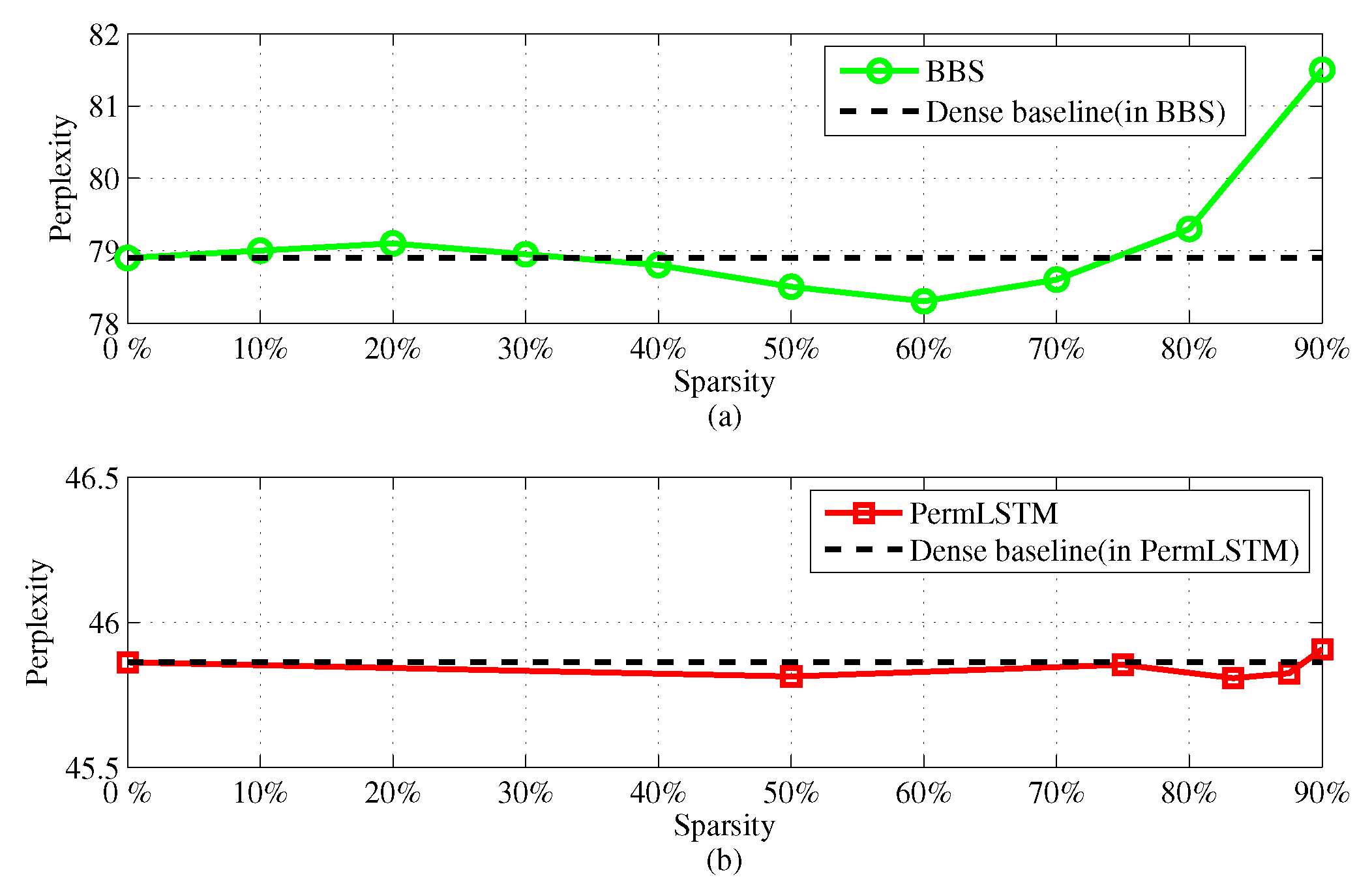
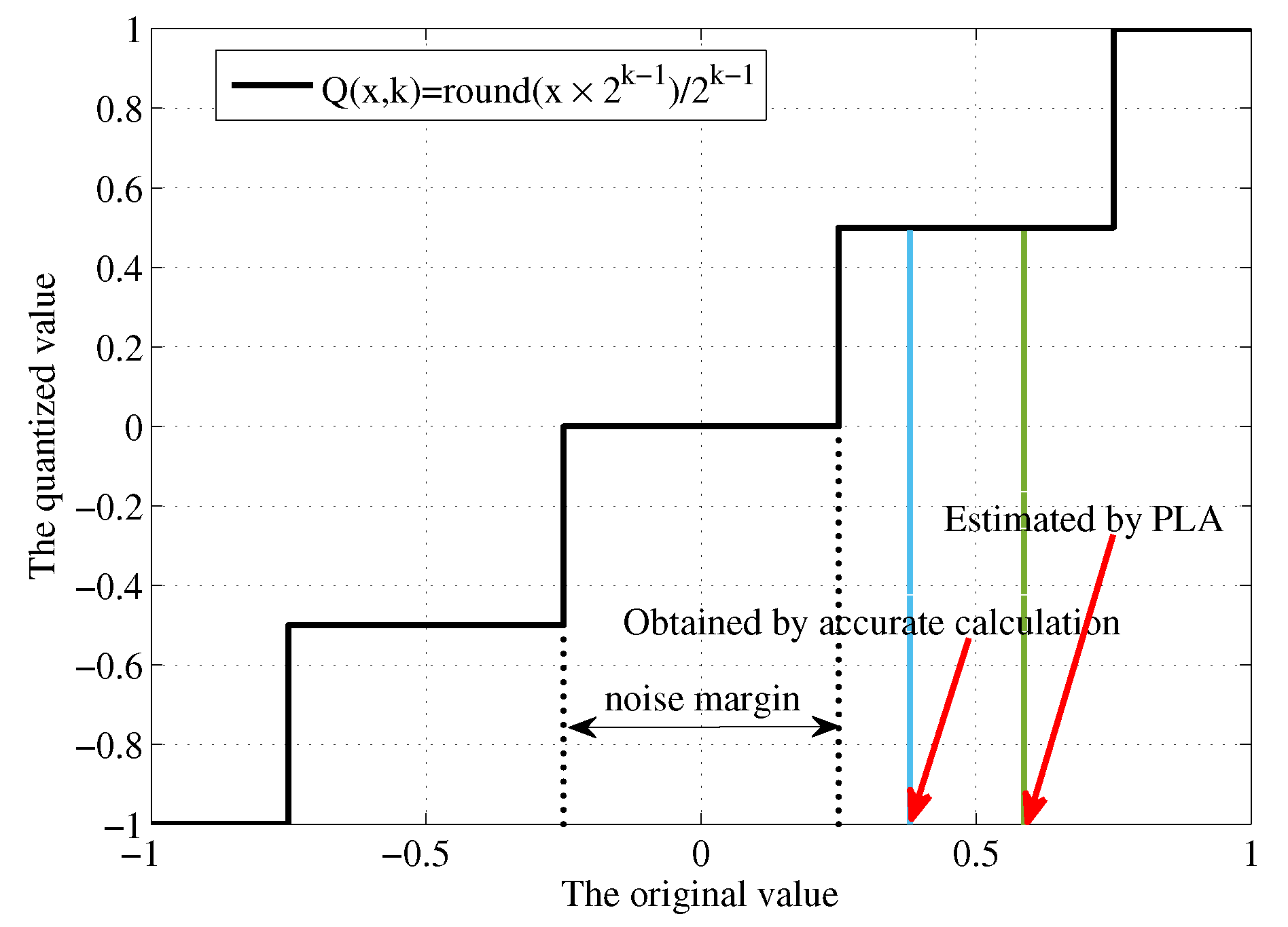
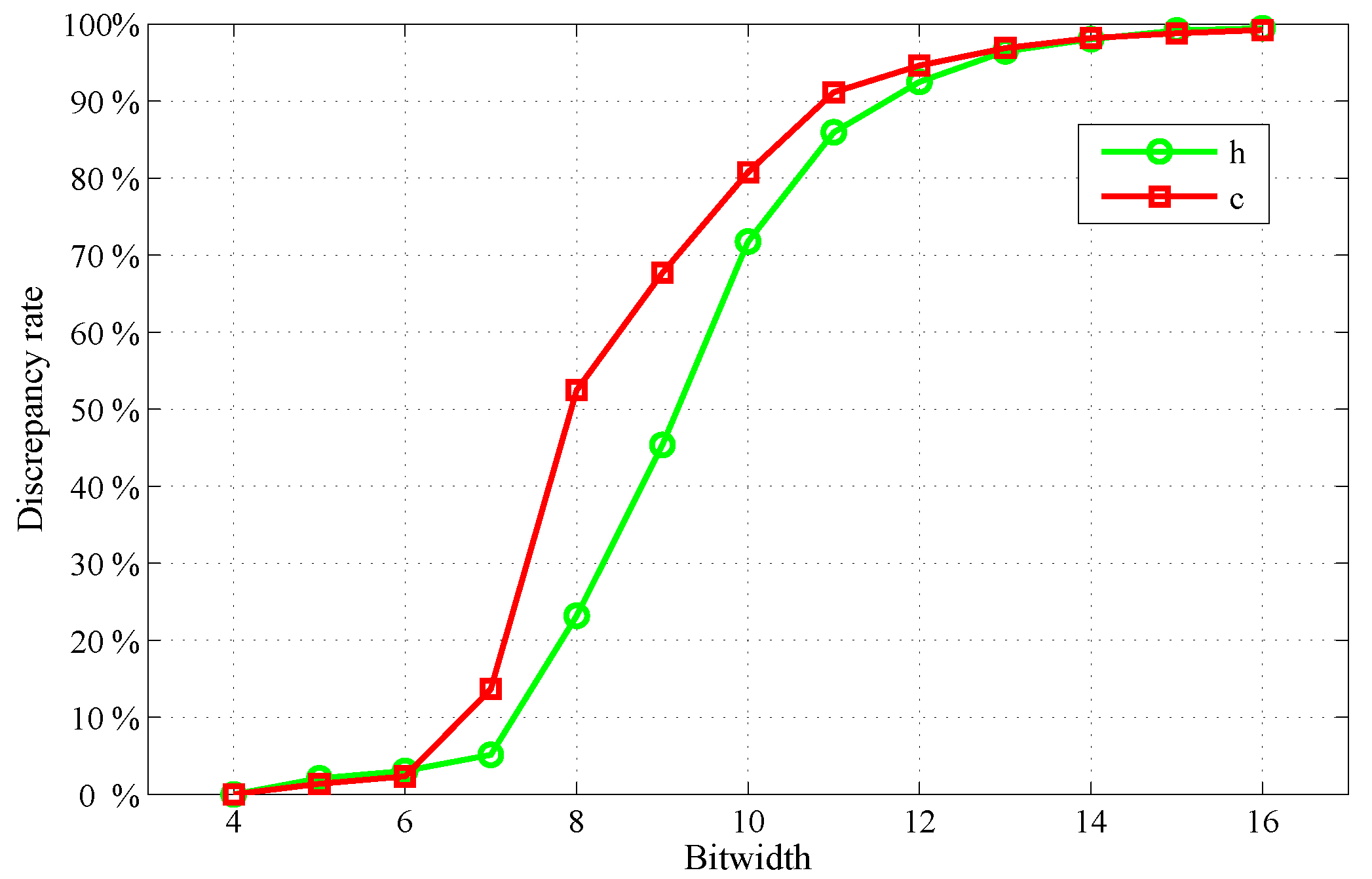
In this section, we will discuss the design of the hardware architecture for the proposed LSTM accelerator, by addressing some challenging issues regarding an optimization towards high operational efficiency in terms of energy and resources.
5.1. System Overview
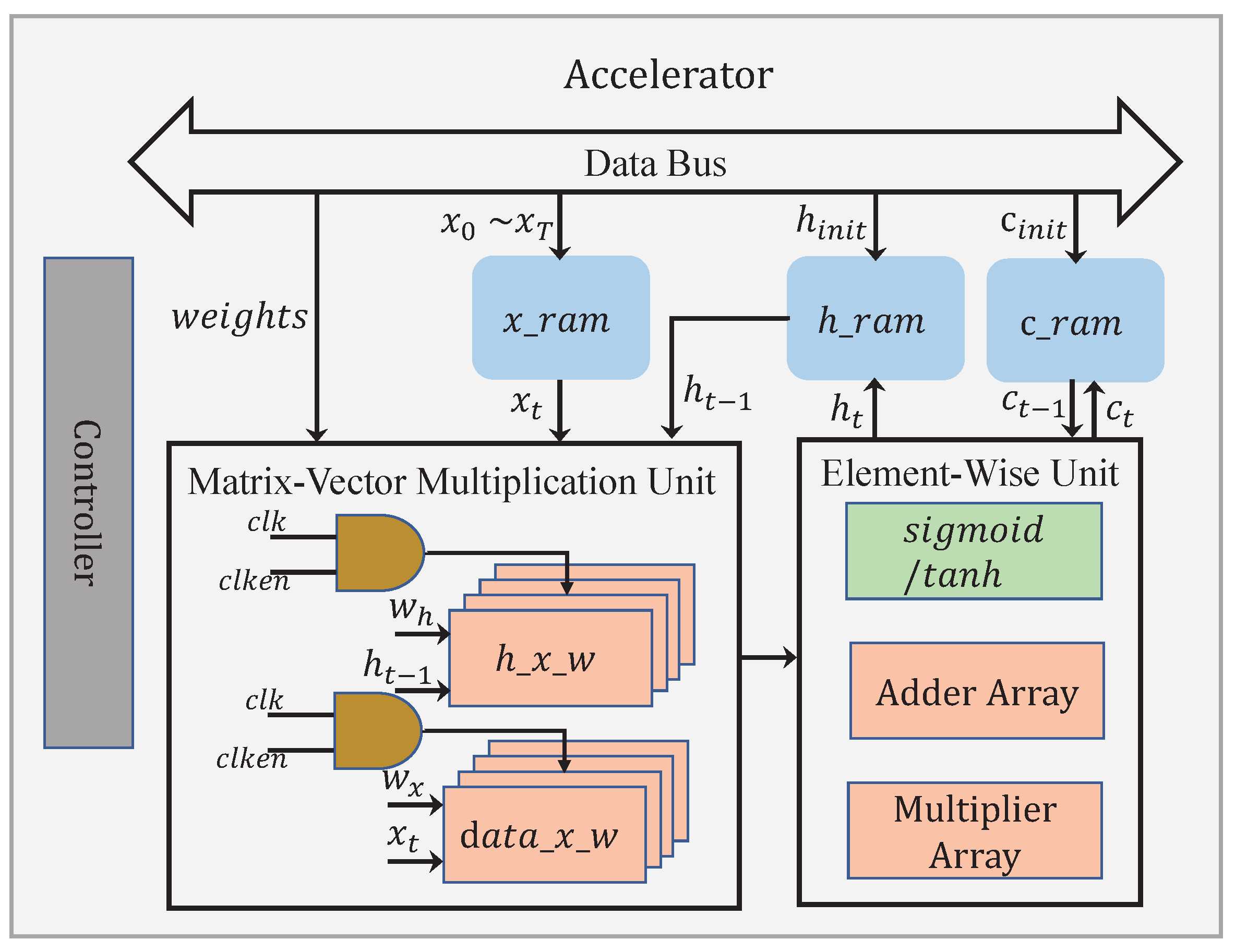
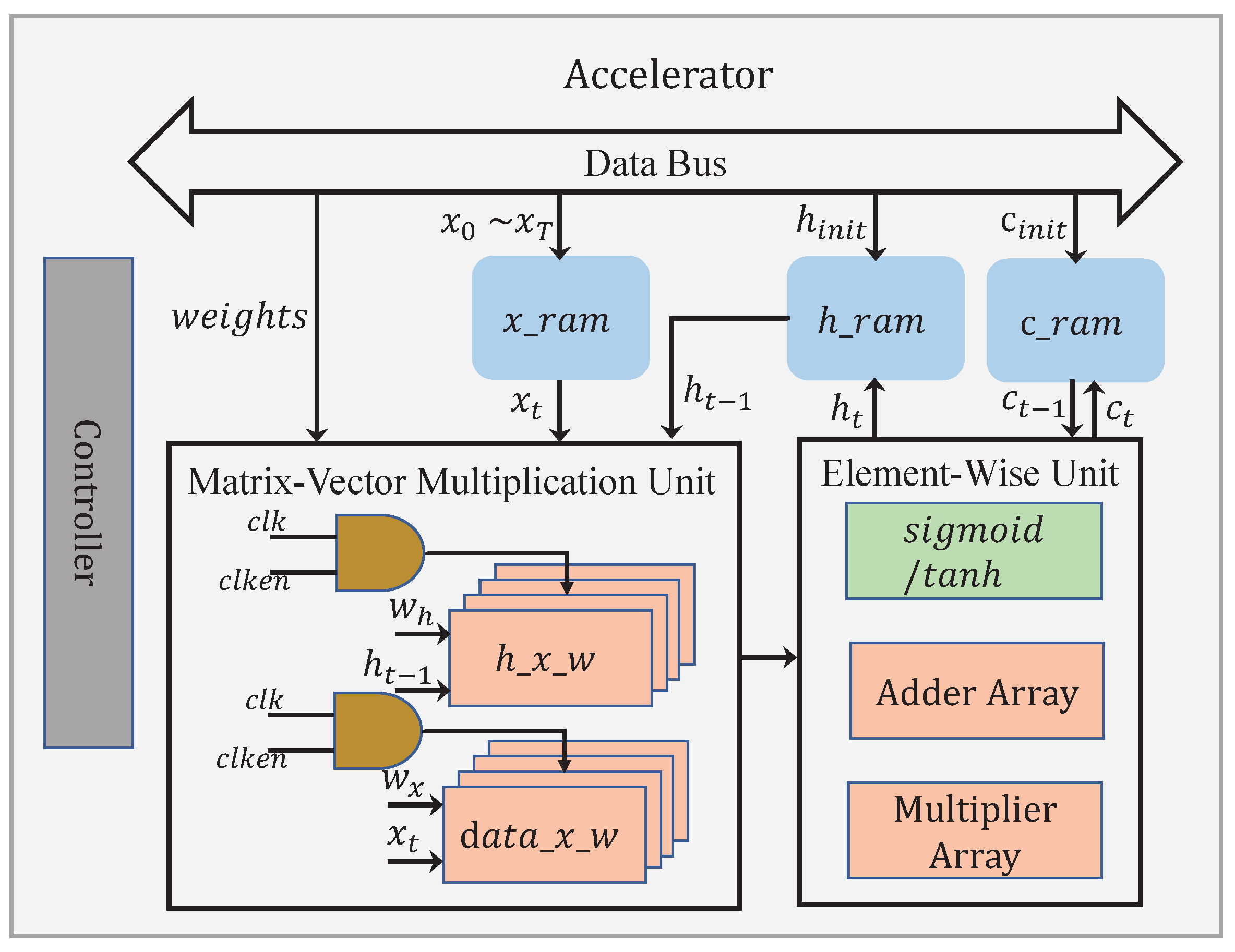
An architecture diagram for the proposed accelerator is shown in
Figure 10. The accelerator has two main functional blocks, namely the matrix–vector multiplication unit and the element-wise unit, containing all the basic operations required by the LSTM. The matrix–vector multiplication unit is primarily responsible for the computations regarding
and
defined in Equations (1)–(4), where
. As
and
are usually differing in dimension, the run times required to complete these two categories of multiplications are different. By exploiting the waiting intervals for the sake of energy saving, our architecture has two separate modules, i.e.,
and
, dedicated to accomplishing
and
, respectively. When
,
will be read from
at a later time, in a way to align the finishing time for both matrix–vector multiplications. During the time before the next
is read from
, the module
is idle, with its clock disabled. When
, it should be the other way around. This time, reading
from
is being delayed until a later time, in the meantime setting the module
at idle. By doing so, a big chunk of the total dynamic power consumption can be effectively cut off. For example, in a typical word sequence generation case, the difference between
m (e.g., 27) and
n (e.g., 256 or 512) could be quite large, benefiting the energy savings to a large extent. Note that the element-wise unit performs the element-wise addition, the element-wise multiplication, and the activation function.
5.2. Matrix–Vector Multiplication
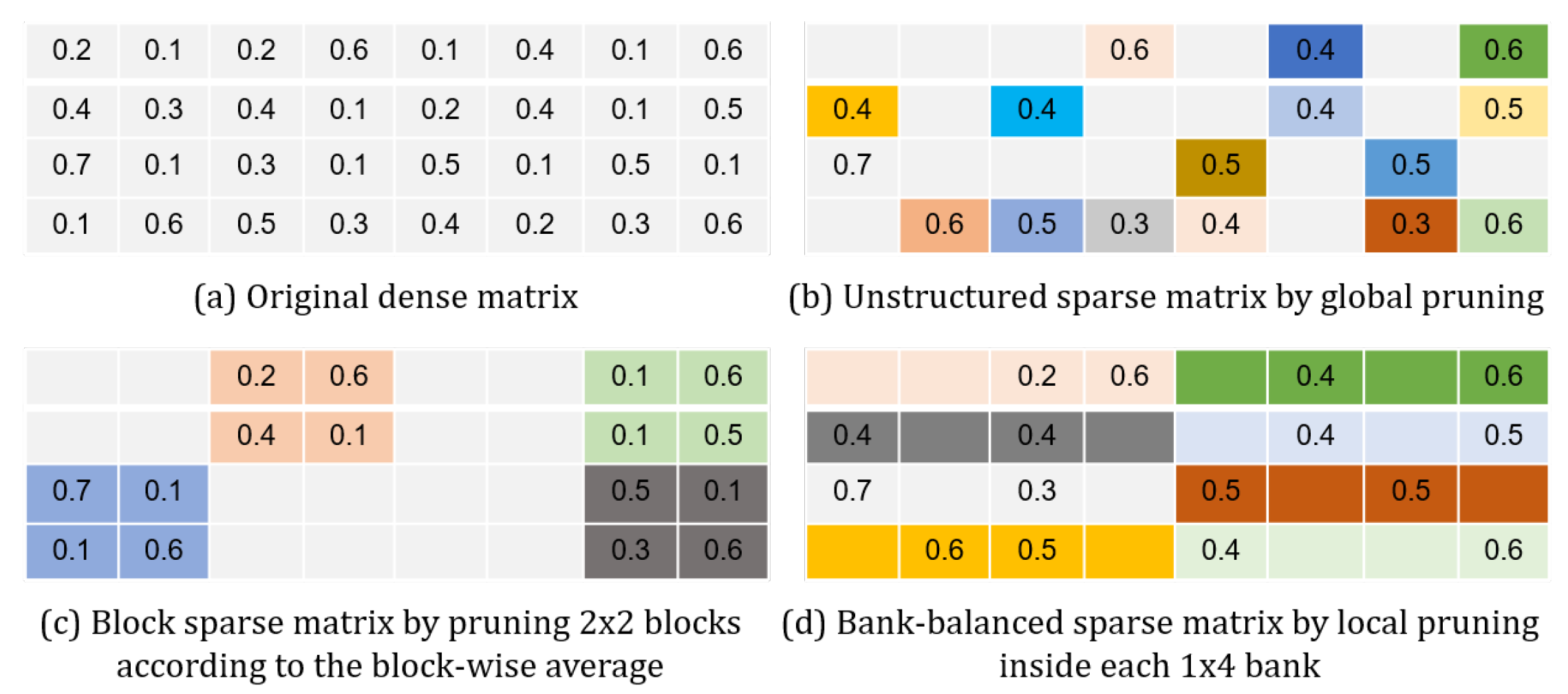
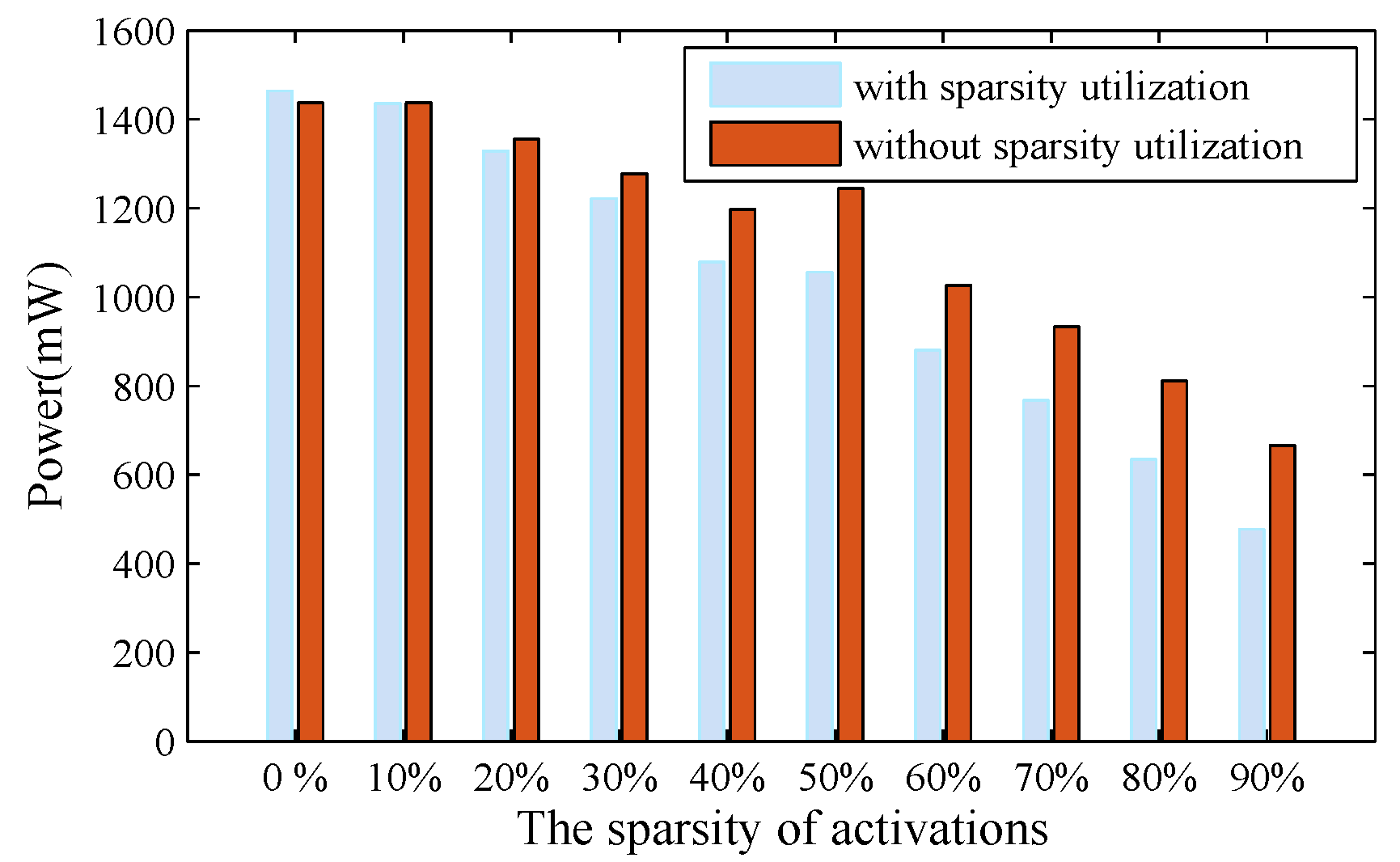
All the matrix–vector multiplications are regarded as the most computationally intensive during the LSTM inference. Therefore, an effort is directed towards possible reductions in such operations, by tapping into the enhanced sparsity in the weight, the activation, and the product after the compression. However, solutions to a complete treatment were seldom discussed in the prior works.
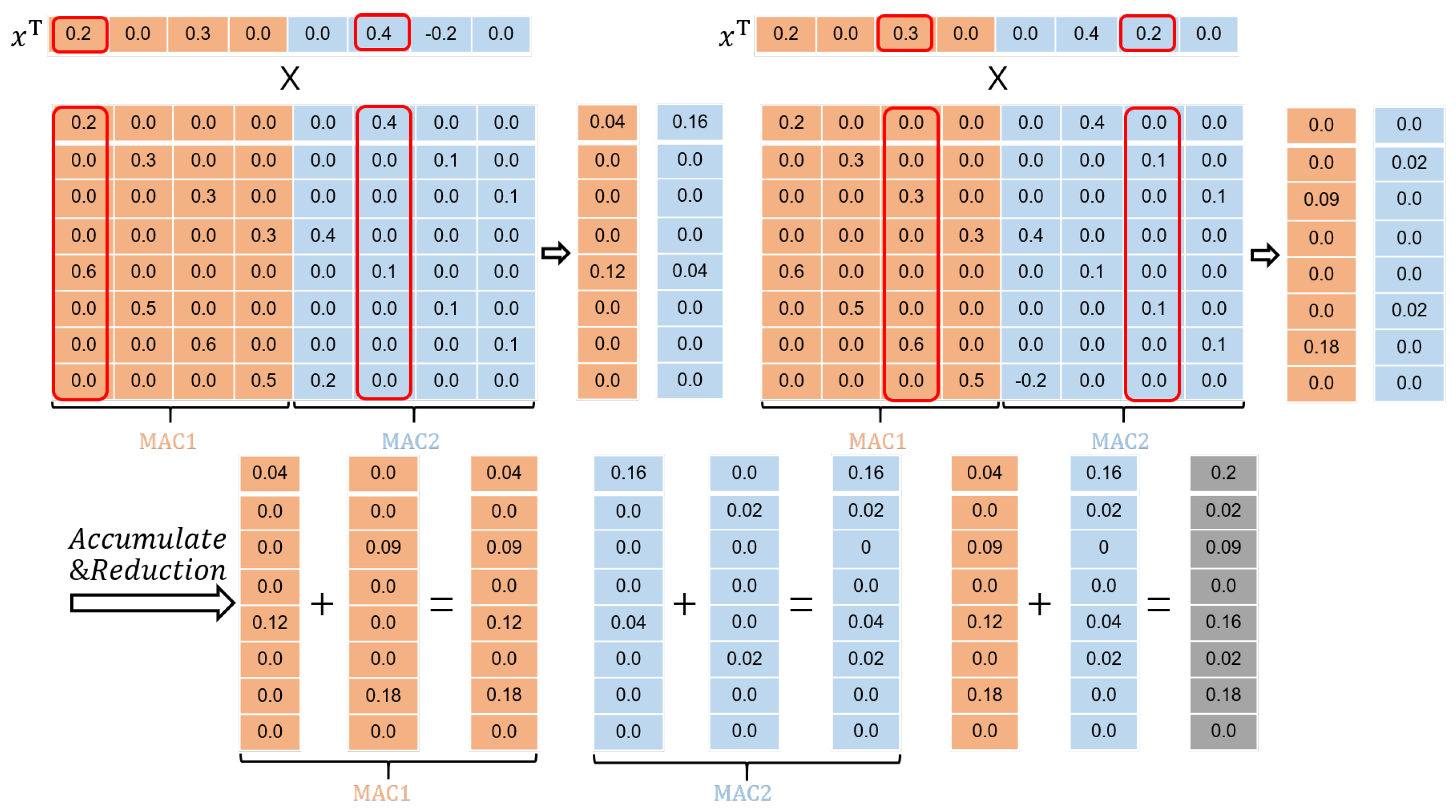
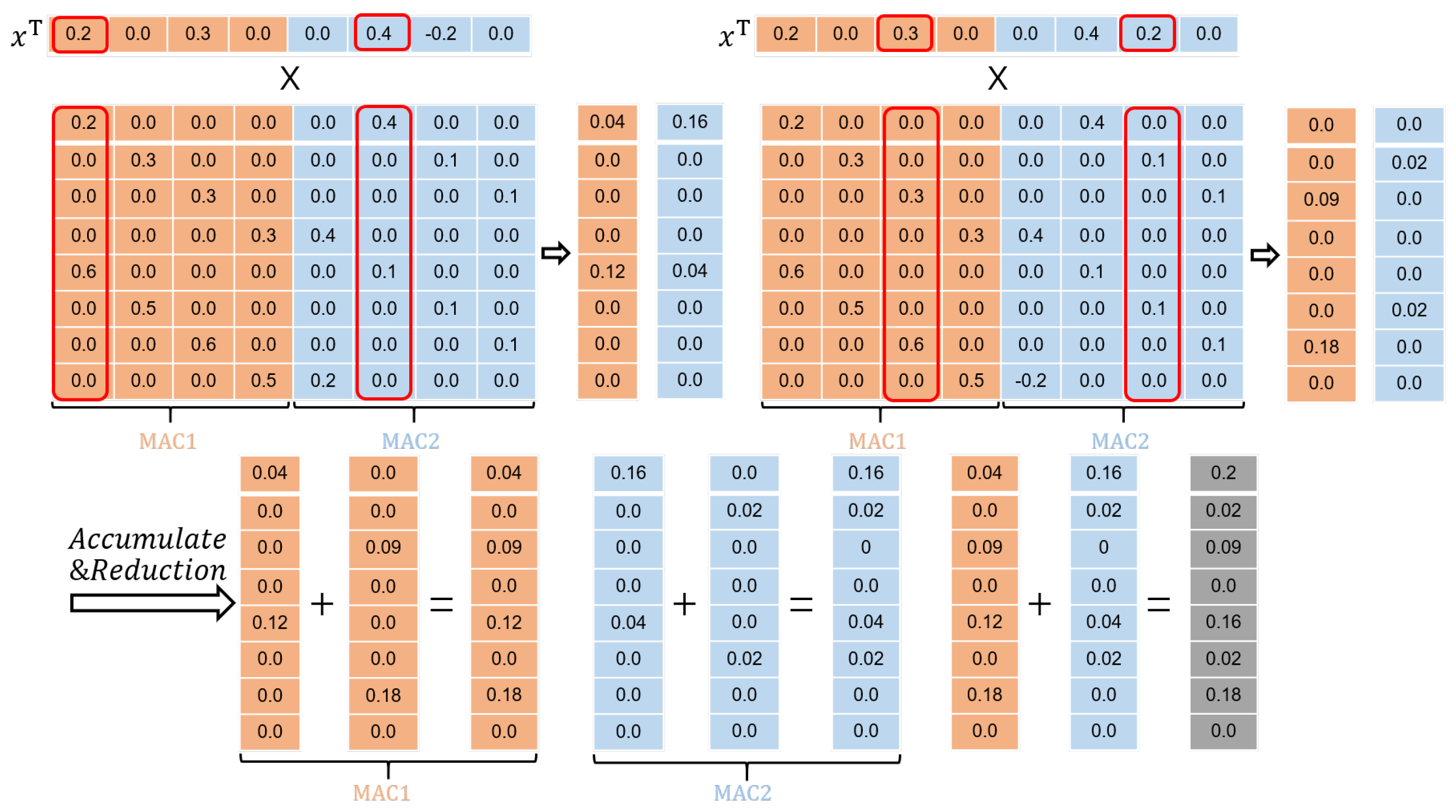
As for the activation, the accelerator has been designed to calculate the matrix–vector multiplications in a column-wise fashion, as depicted in
Figure 11. As long as an activation
is zero, the subsequent multiplications involving
and
will be bypassed. Here,
represents all the weights from a corresponding column.
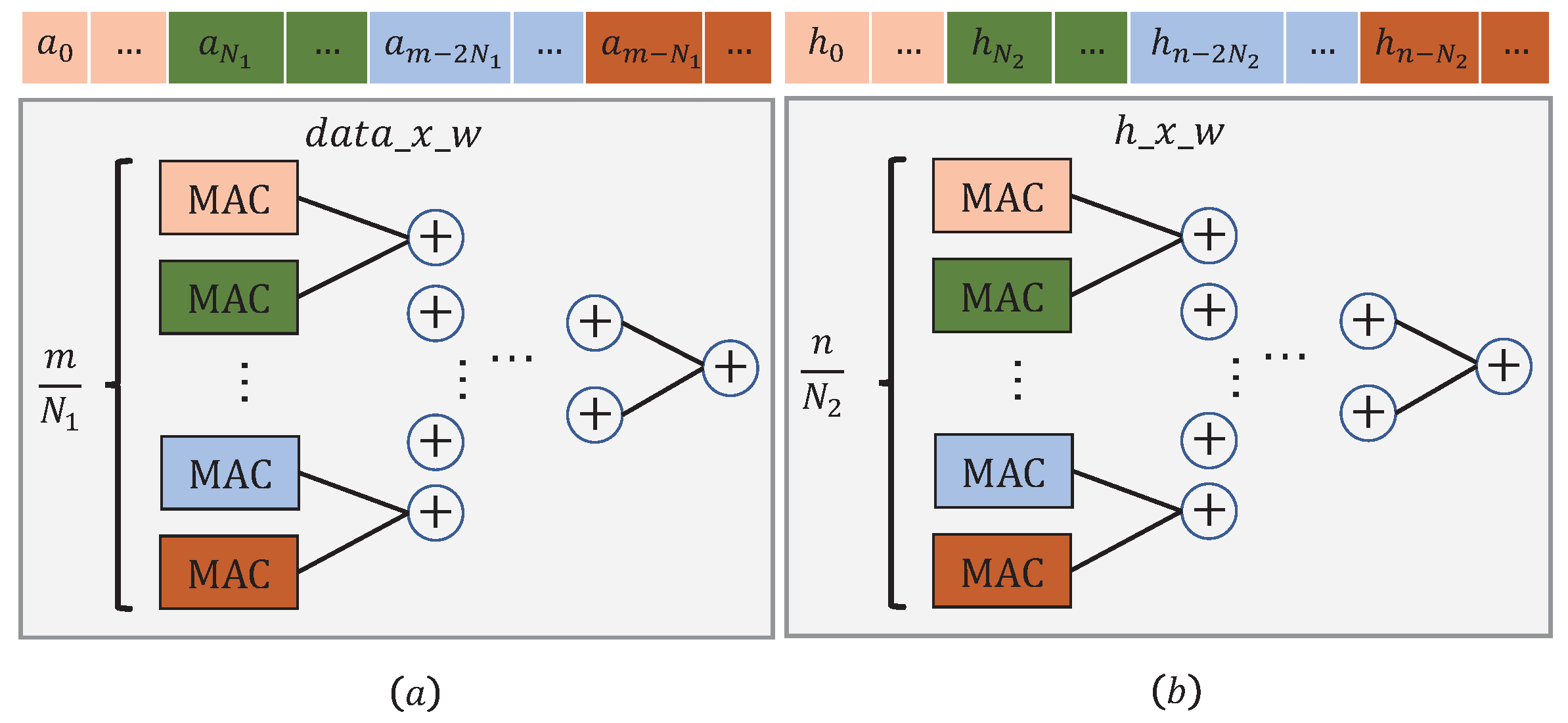
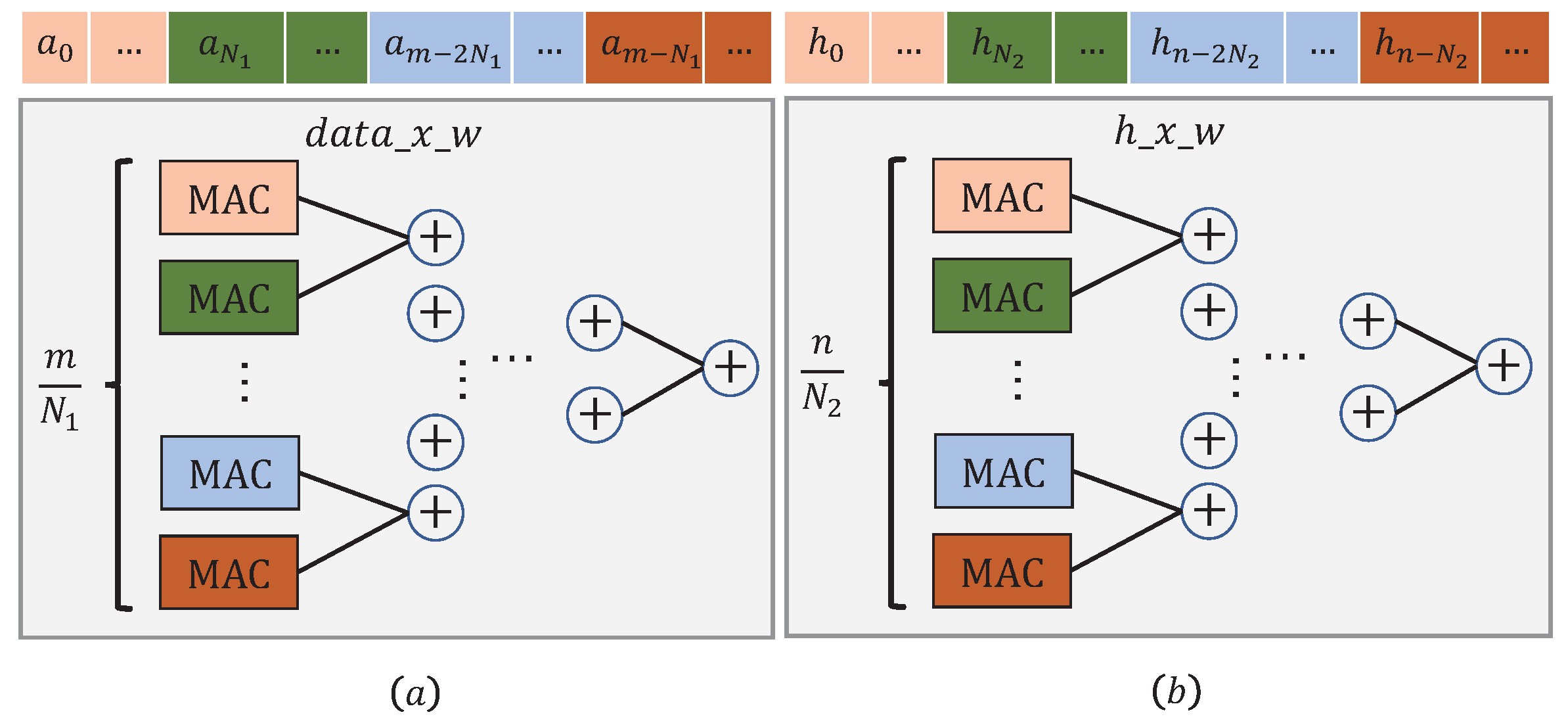
Figure 12 illustrates the processing flow executed in module
. Along the way,
m activations are being fed into
over
clock cycles.
Note that the MAC (Multiply and accumulate) unit marked in a color should coordinate those data slices marked with the same color. A similar procedure can also be applied to the module .
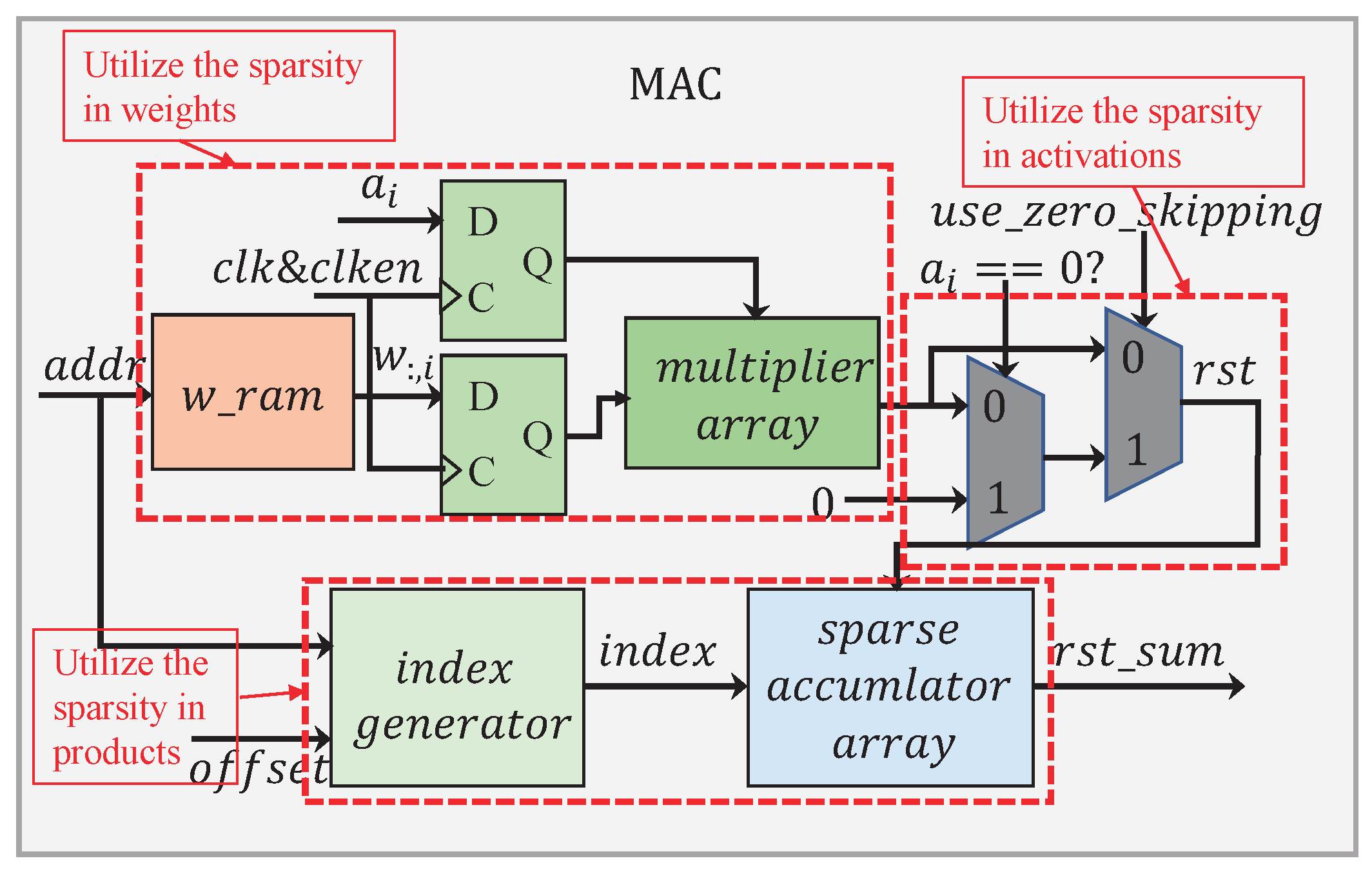
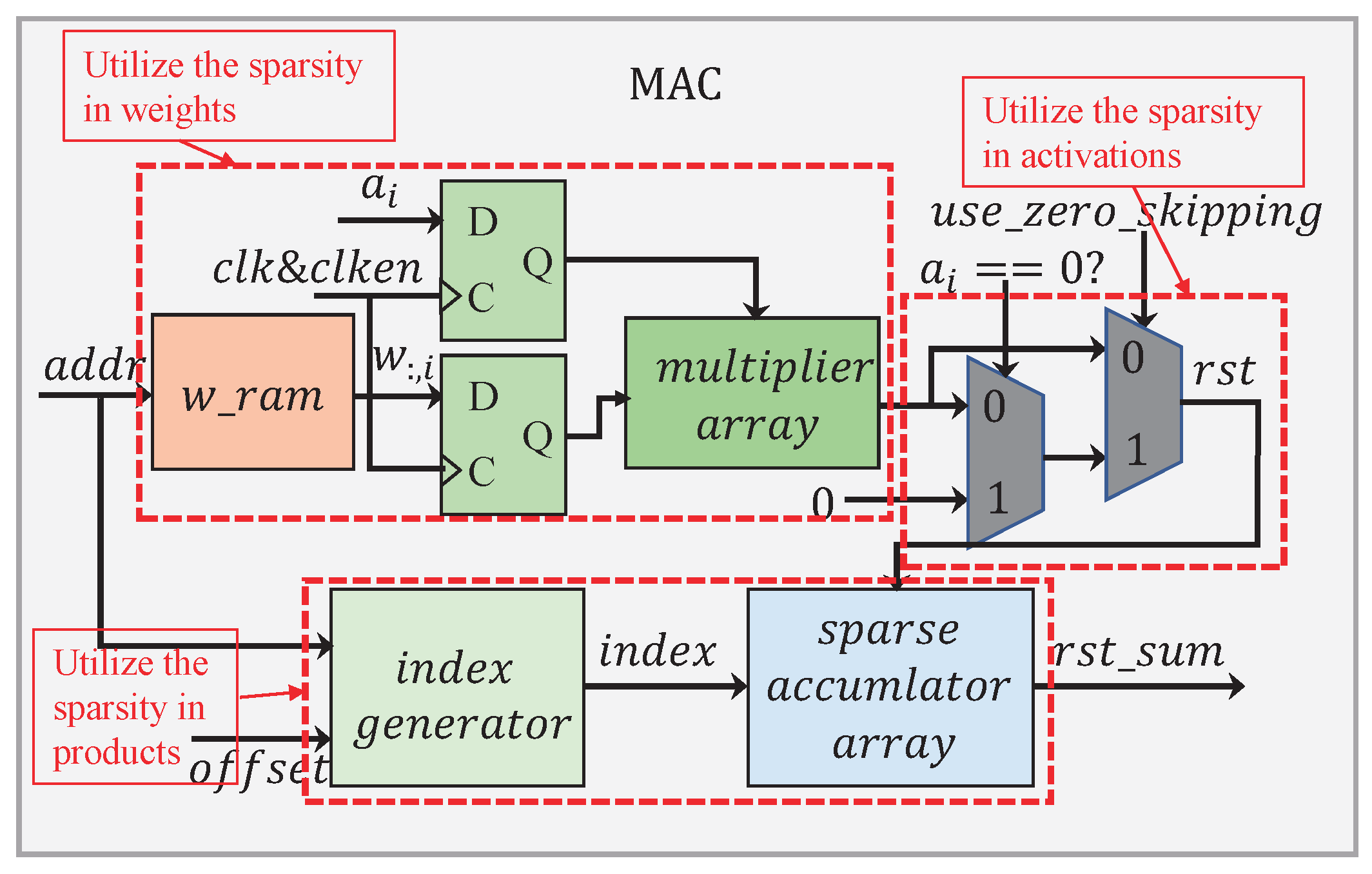
The MAC submodule has a processing flow as given in
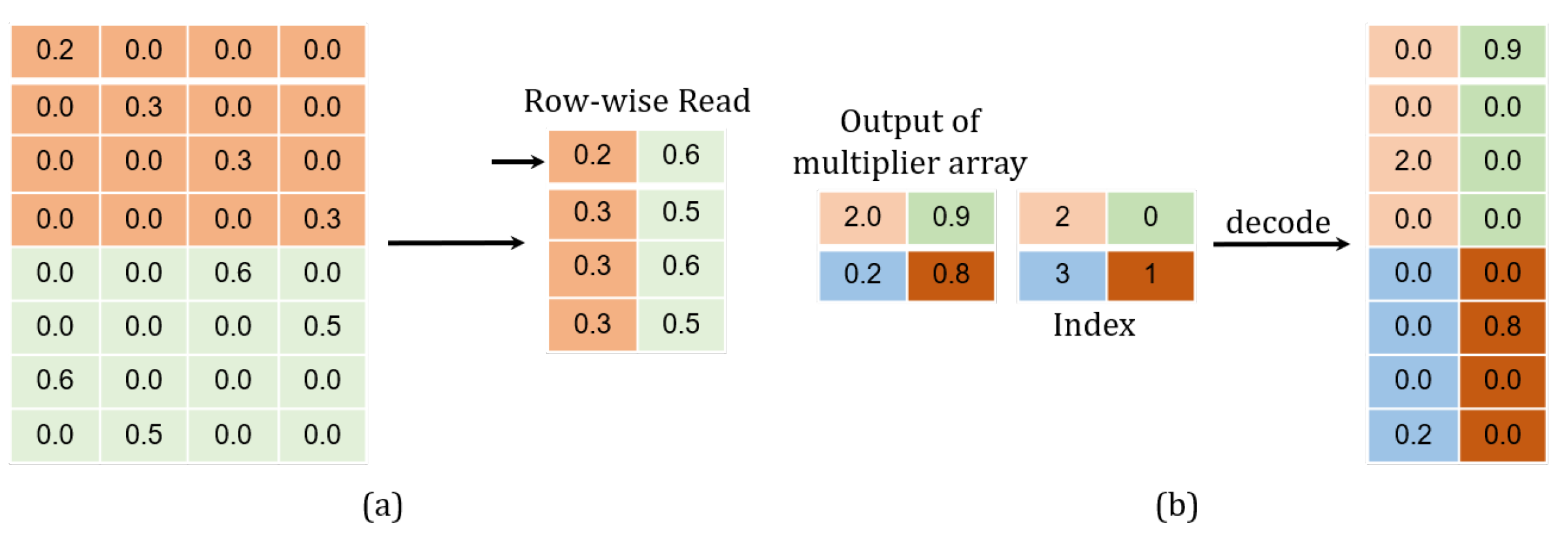
Figure 13. In order to reduce the memory footprint and lessen the multiplication operation, we developed a memory-accessing strategy by catering fully for the weight sparsity. As illustrated in
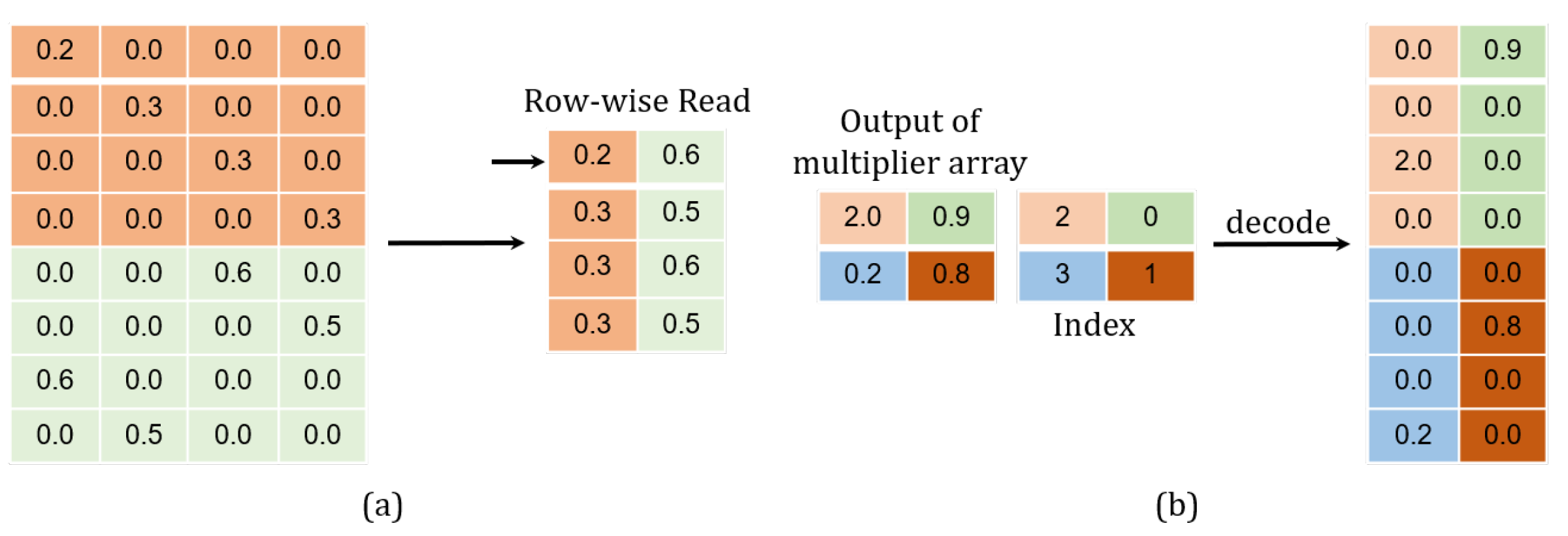
Figure 14a, only non-zero weights at the same column in the matrix are stored along a single row in the memory, facilitating for them to be read once a clock cycle.
In
Figure 13, there are two 2:1 multiplexers that have been employed to dynamically configure the circuit according to the sparsity in the activation. When
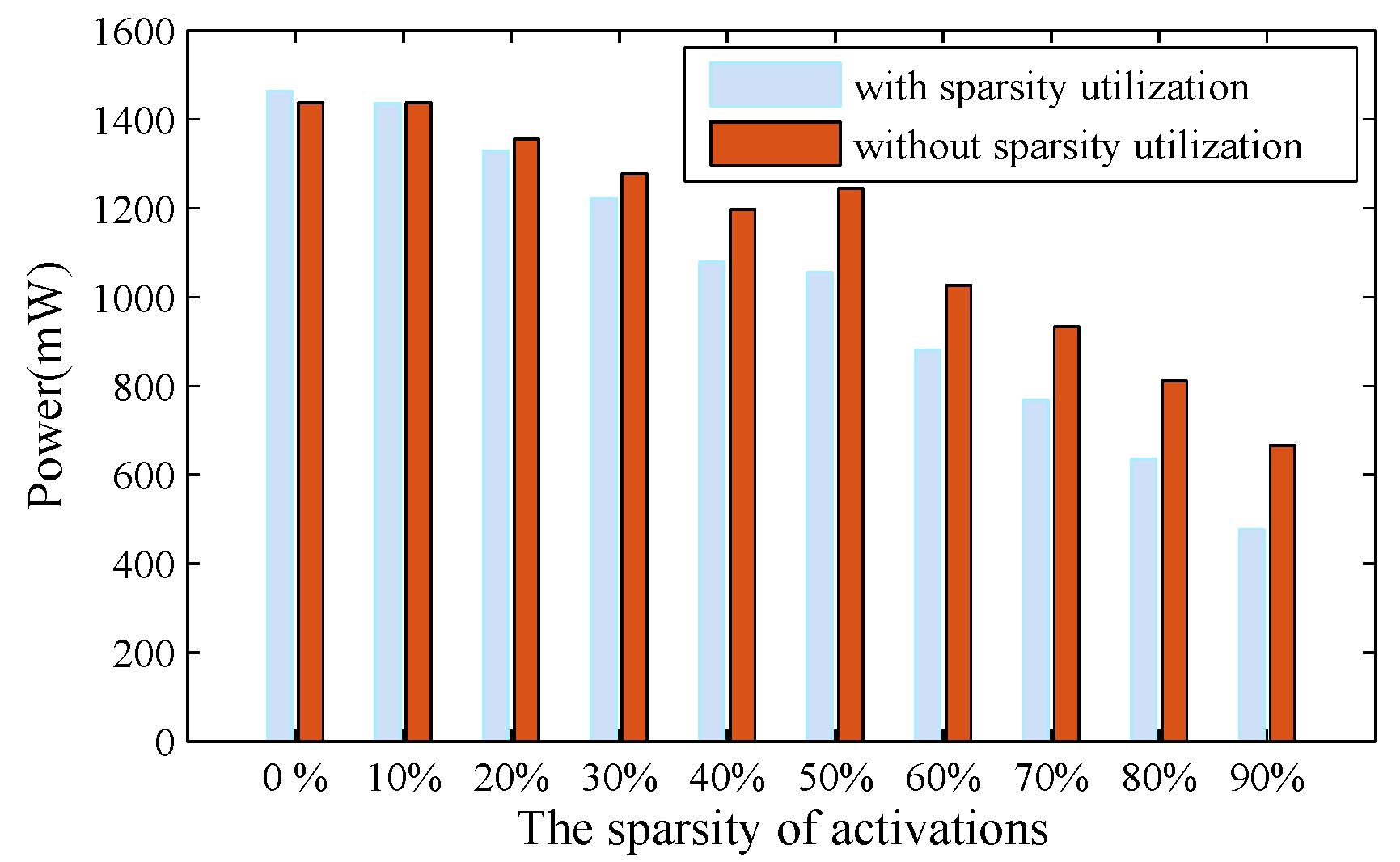
, the first multiplexer selects zero as its output. At the same time, the clocking to those weight and activation registers is disabled. As a result, all the operations have been shut down in the multiplier array. Apparently, this allows for a great deal of power-saving, considering the activation being highly sparse. When
, the result calculated from the multiplier array will pass straight through the first multiplexer. The second multiplexer is used to switch over between the zero-skipping and the non-zero-skipping modes, simply by controlling the signal
, in a way to further cutting down the power consumption.
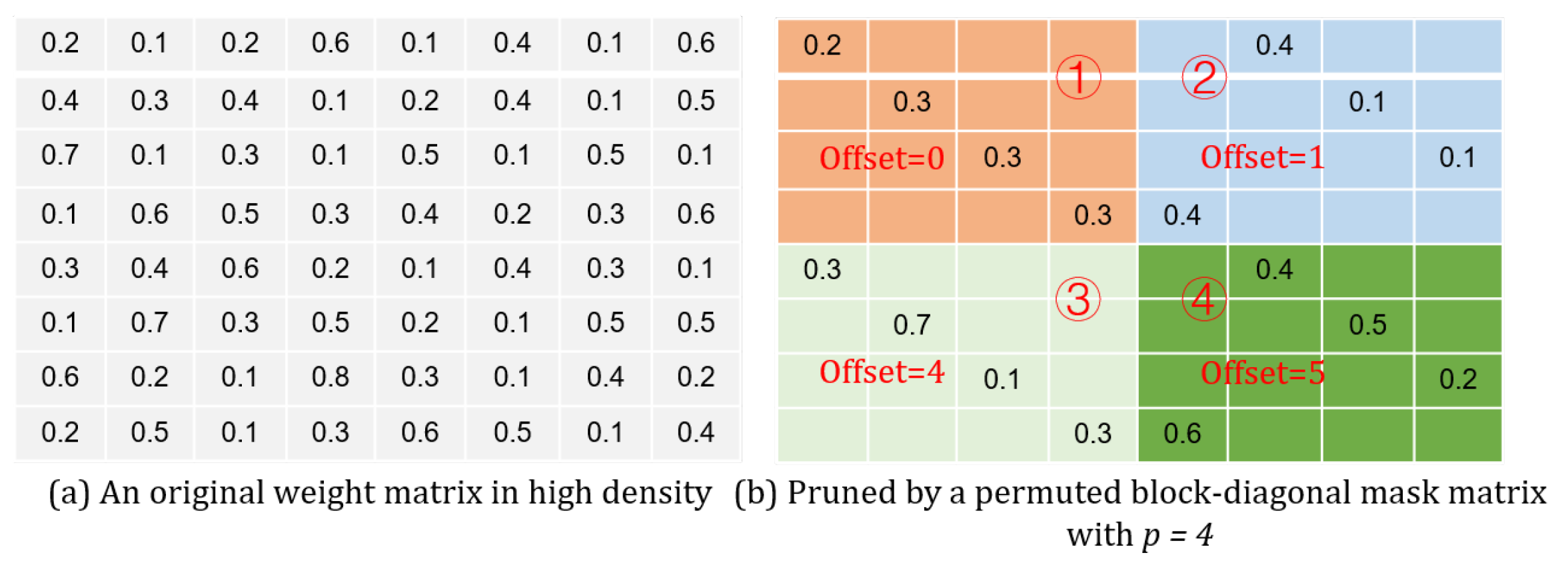
The sparsity in the product should also be taken into account. In order to have only the non-zero products sent for accumulation, their positions in the matrix need to be recorded. As long as either the multiplier or the multiplicand is zero, their product must be zero. In a way, the positions regarding these non-zero products are directly related to the corresponding non-zero weights. According to (
7), the coordinates for the non-zero values in a weight matrix should observe the following relations:
In (
17), the term
calculates the longitude coordinate for all the non-zero weights in a relevant sub-matrix. Since the non-zero values belonging to the same column in the weight matrix are stored along a specific row in the memory
,
j is then regarded as this row’s address (
). As for the offset, it can be decided just by a calculation of
, considering that
. The module
takes such a differentiation route to determine all the locations regarding the non-zero products, e.g.,
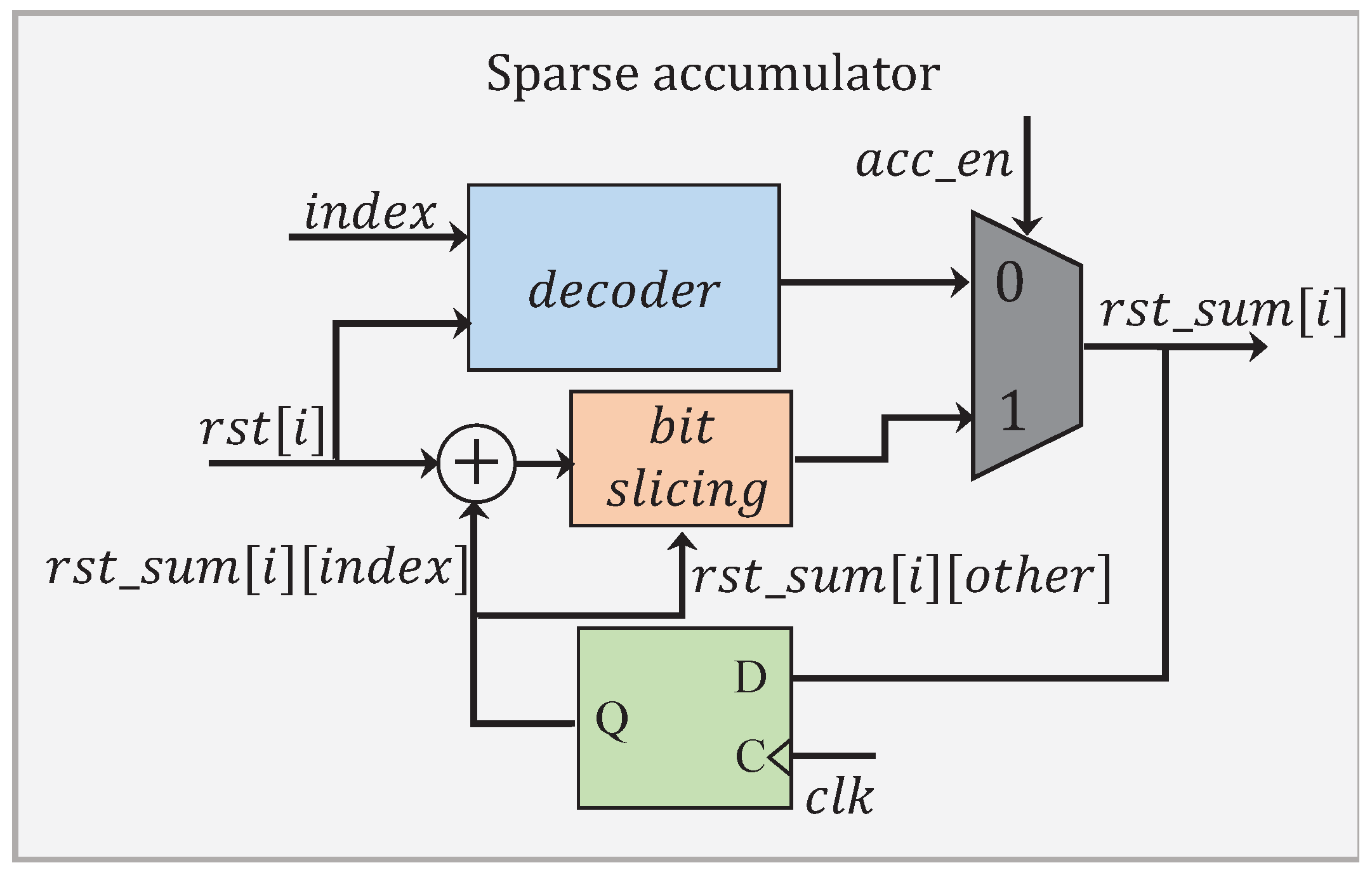
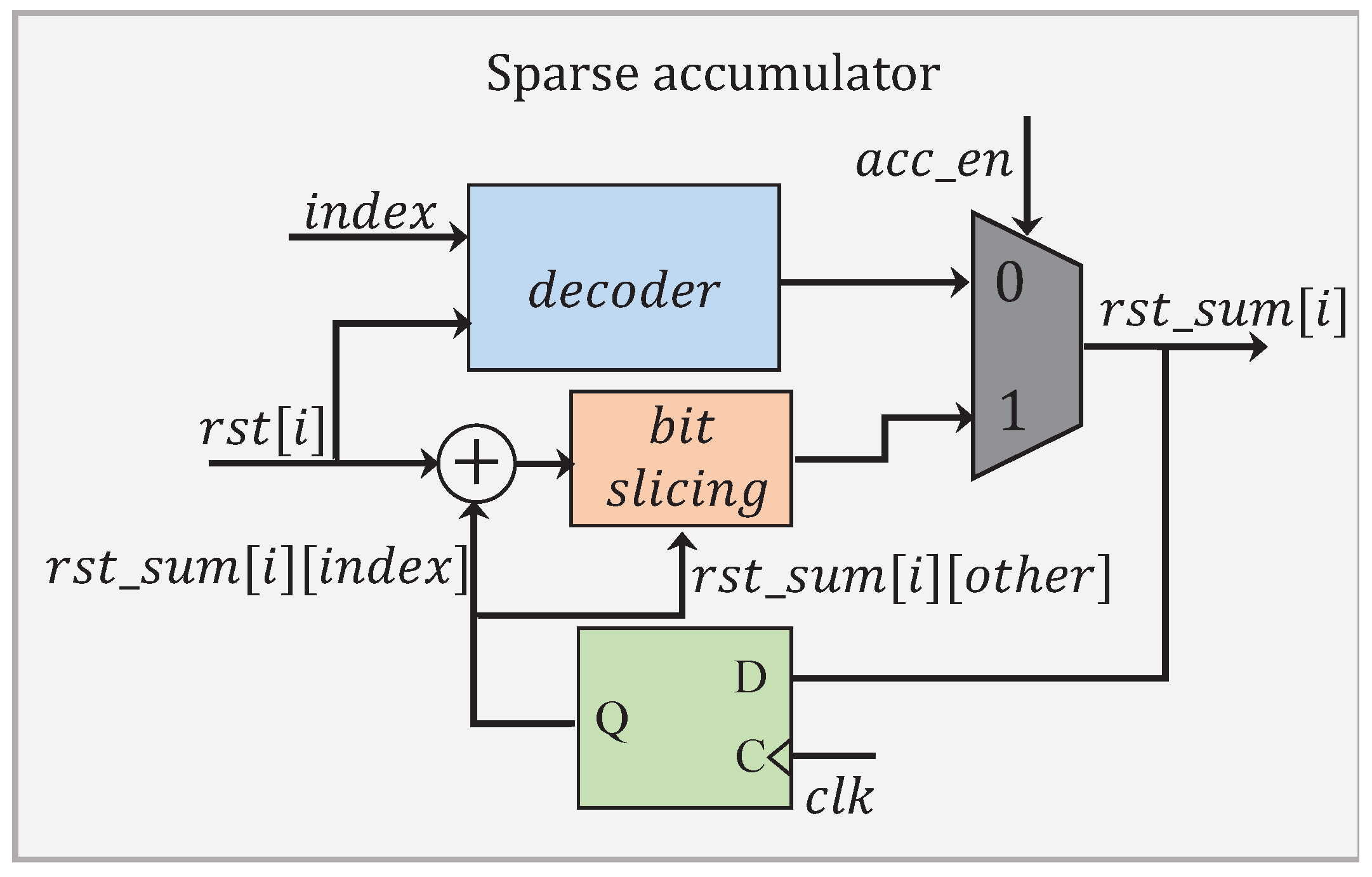
The module
has a processing flow as depicted in
Figure 15. When an accumulation is not required, the signal
is set to 0. This allows for performing only the decoding operation, which has been illustrated in
Figure 14b. The non-zero product
is decoded in a format of
. A total of
p accumulated results are individually concatenated into
bits in the representation. When the accumulation is required, the signal
is set to 1. Instead of performing all the
p additions, only those additions involving
and the corresponding contents in
are processed. The intermediate results obtained are later stitched up with the others in
to complete a full accumulation.
5.3. Operations Reduction Analysis
A theoretical analysis has been carried out on the reduced operation effect brought by our proposed design approach. For a weight matrix
, it is pruned individually by
mask matrices in
p-by-
p dimensions. Hence, the ratio in terms of the multiplication reduction by treating the weight sparsity can be estimated as follows:
Furthermore, suppose the non-zero activation ratio is
. In addition, all the weights take part in the multiplication have been pruned. Then, the multiplication reduction ratio due to attending the sparsity in the activation can also be estimated by:
In terms of the product, the sparsity-aware processing can just lead to reducing the number of additions—in the case where the model is being pruned through the permuted block diagonal mask matrices, and the matrix–vector multiplication is being executed in a column-wise way (see
Figure 11). In each column, there are
non-zero products. Thus, the number of the additions reduced, as a result from the product sparsity exploitation, can be calculated according to the following:







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}