
Supporting SLA via Adaptive Mapping and Heterogeneous Storage Devices in Ceph †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
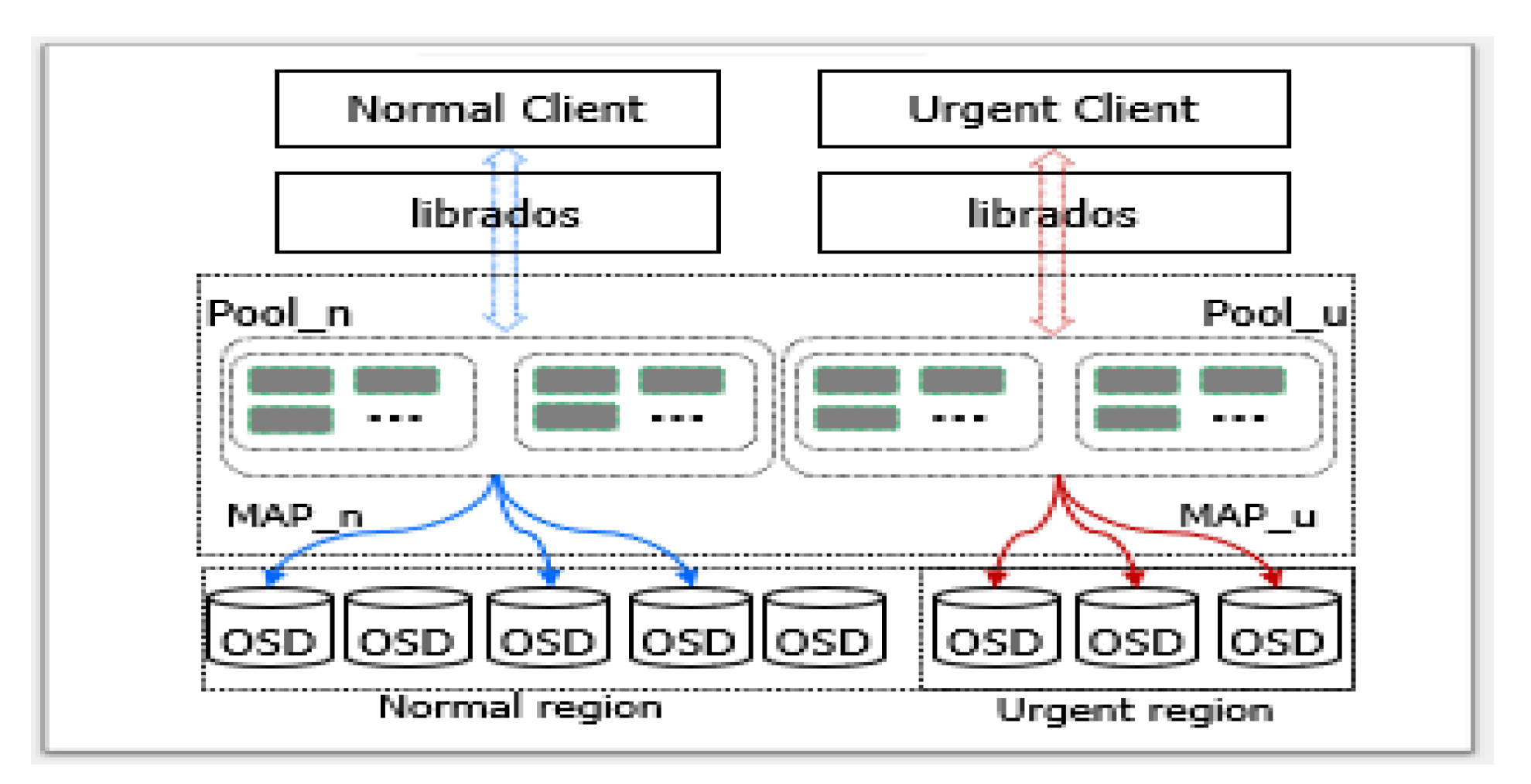
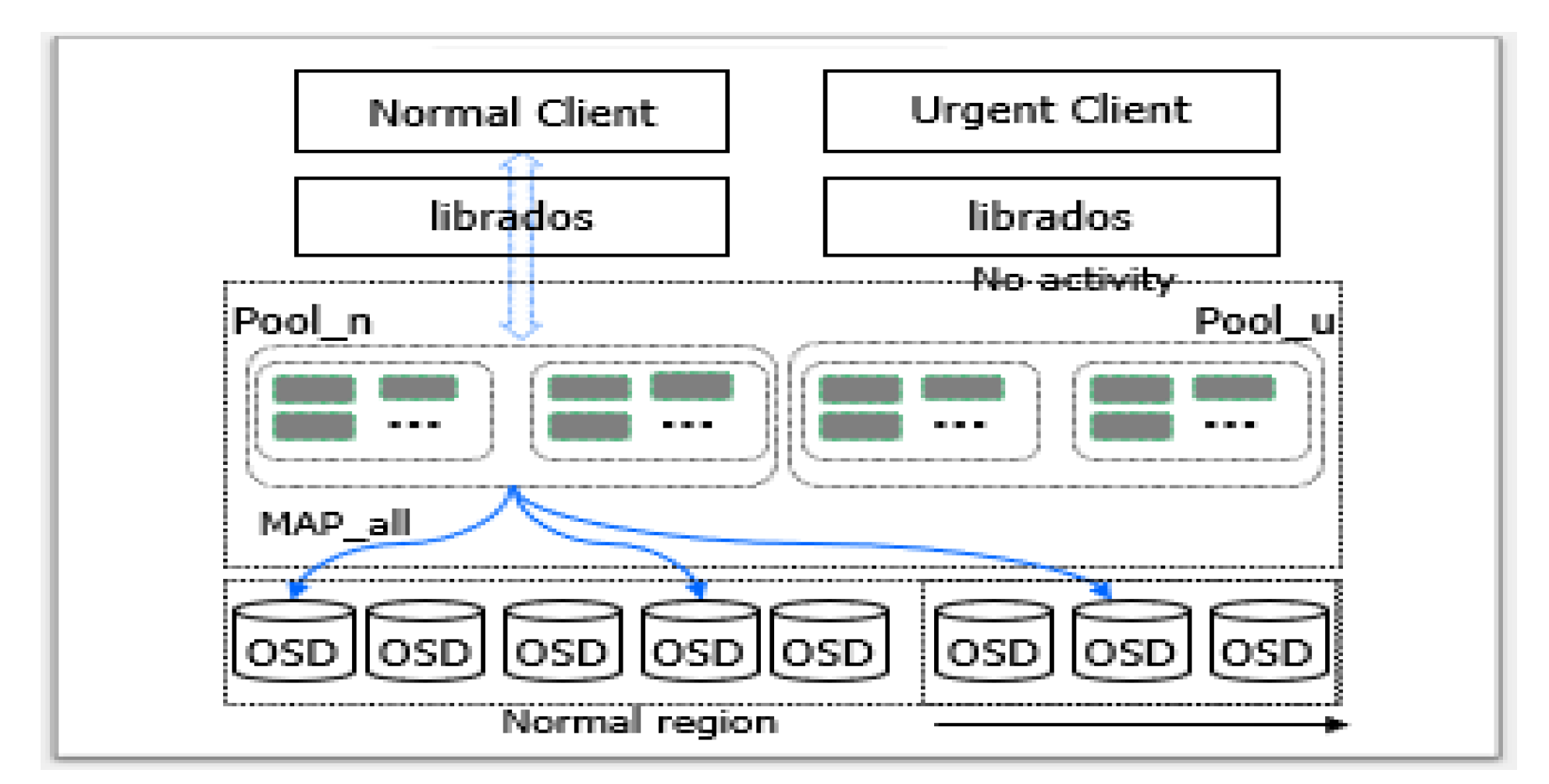
- It explores diverse design spaces to ensure SLA in a distributed storage system from three perspectives: mapping mechanism, client type, and storage heterogeneity.
- It proposes an adaptive mapping based on two new techniques, called logical cluster and normal inclusion, to provide different abstractions and to assure data accessibility, respectively.
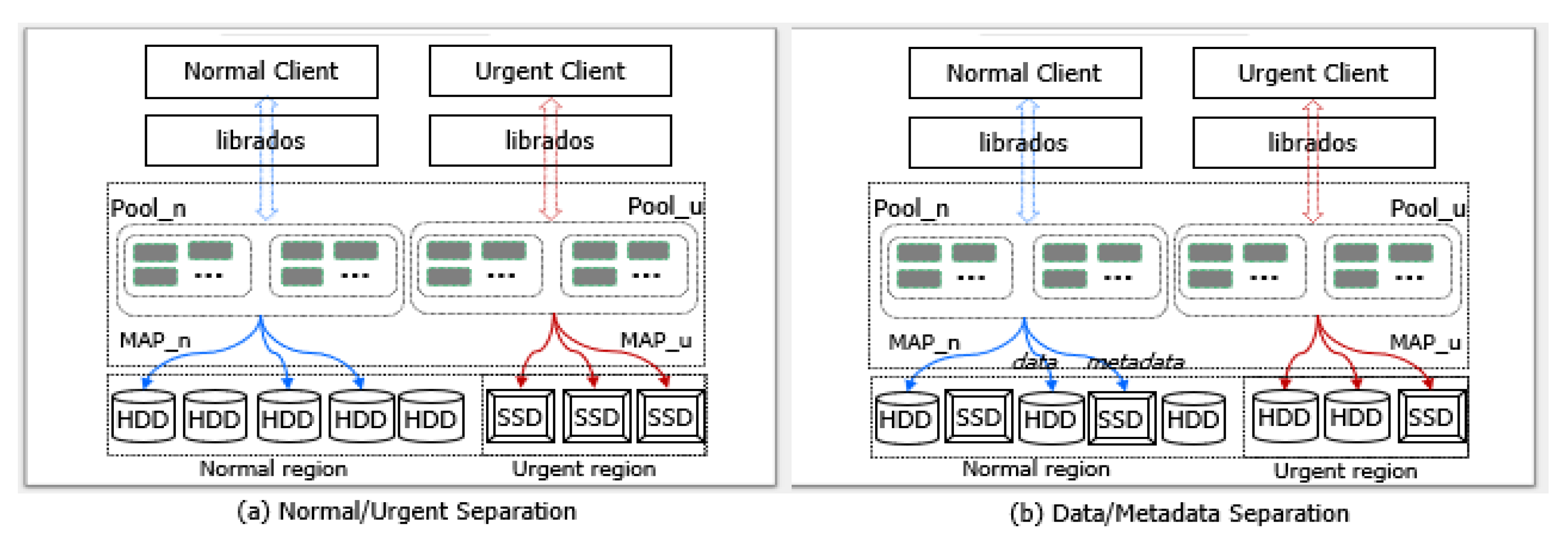
- It examines two use cases, called normal/urgent separation and data/metadata separation, for heterogeneous storage devices with the consideration of size and access pattern.
- It provides real-implementation-based experimental results in terms of QoS, performance, and cost.
2. Background
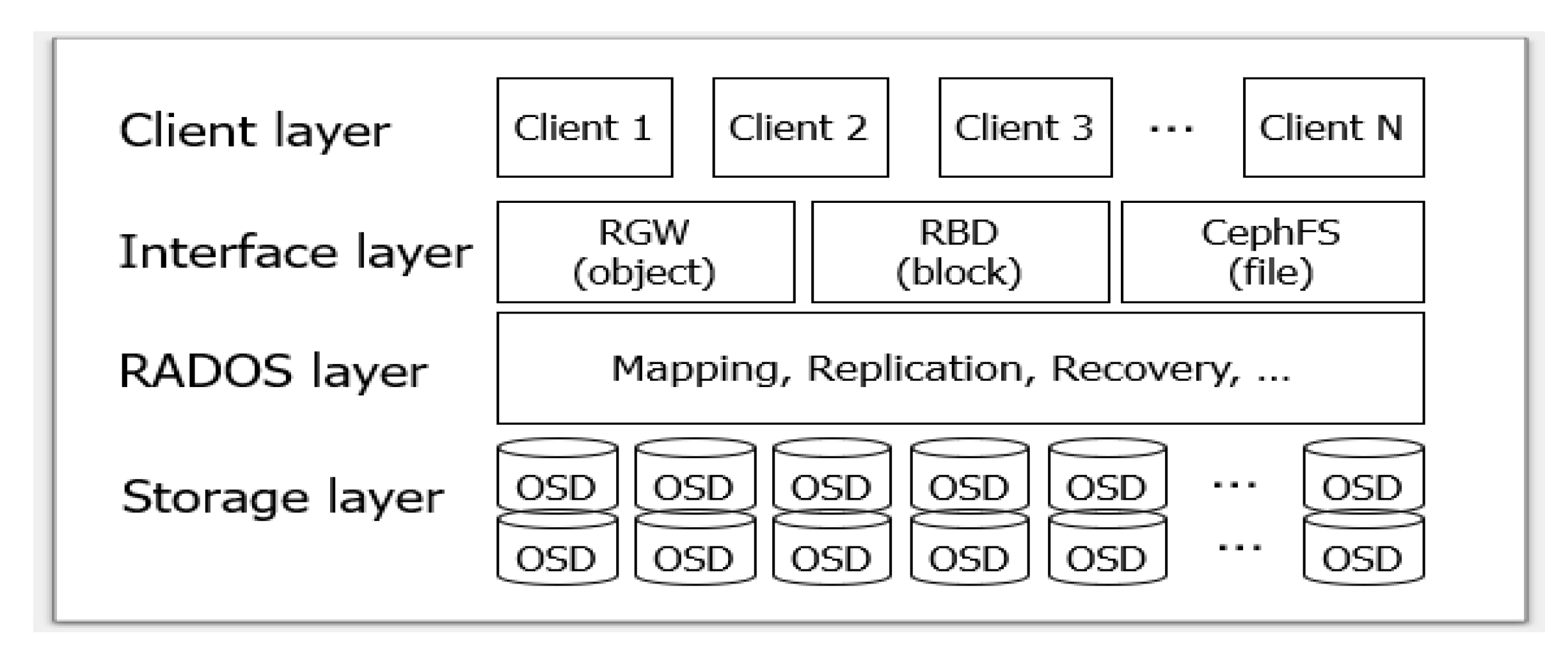
2.1. Ceph Architecture
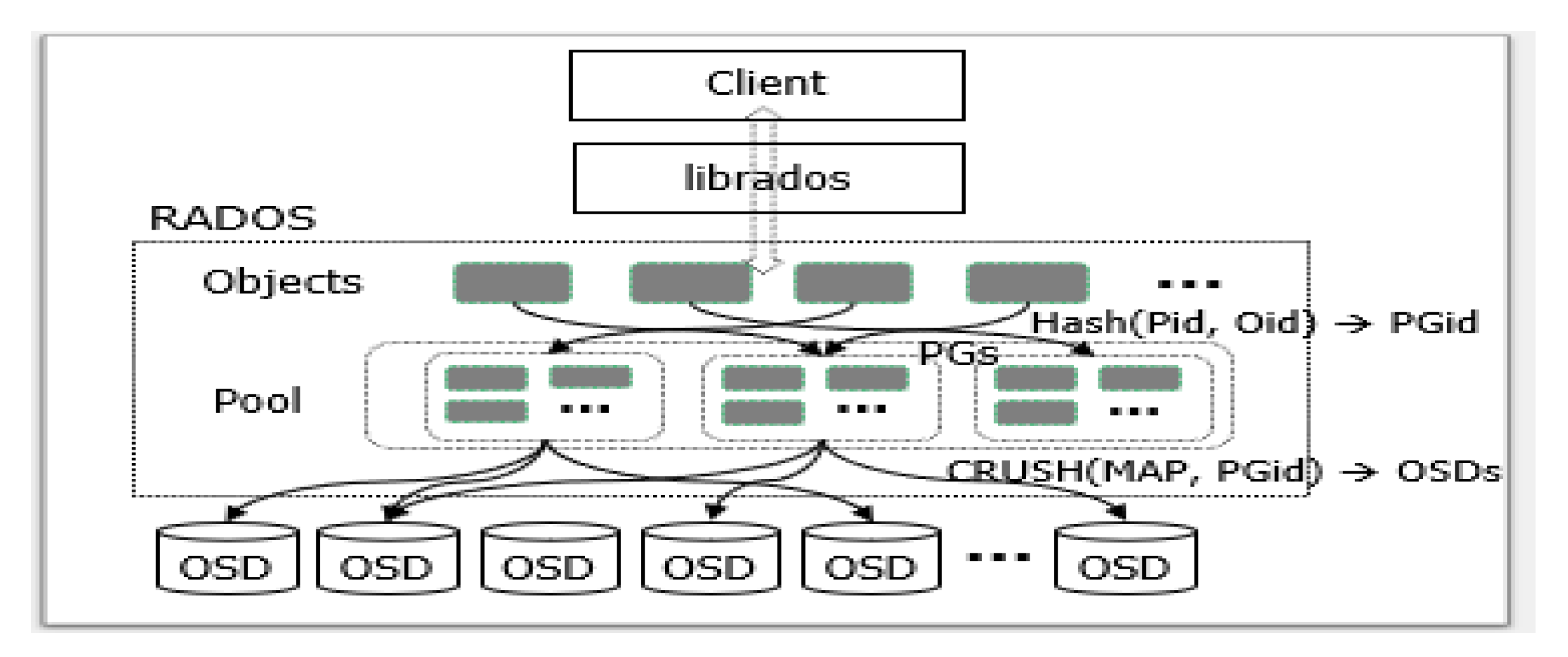
2.2. Mapping Mechanism
2.3. Motivation
3. Supporting SLA
3.1. Adaptive Mapping
3.2. Heterogeneous Storage Devices
4. Evaluation
4.1. Experimental Environment
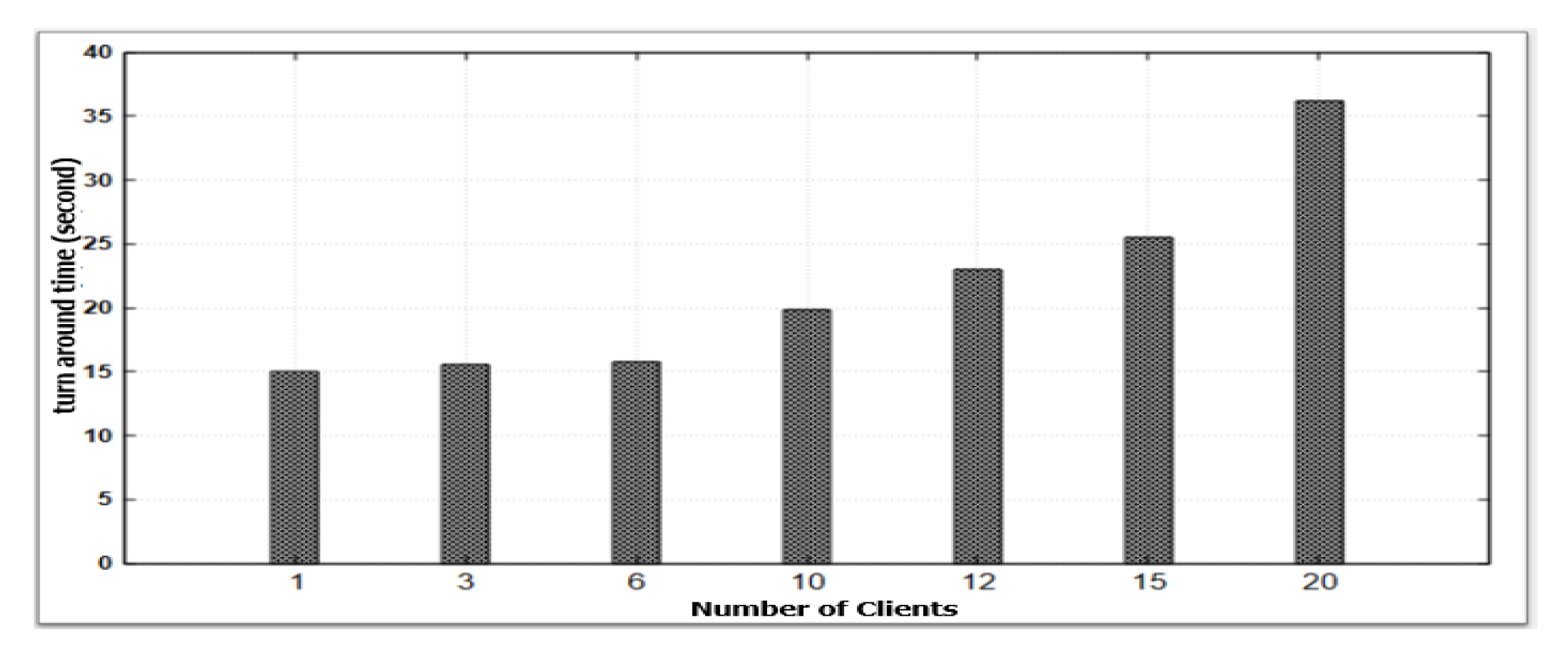
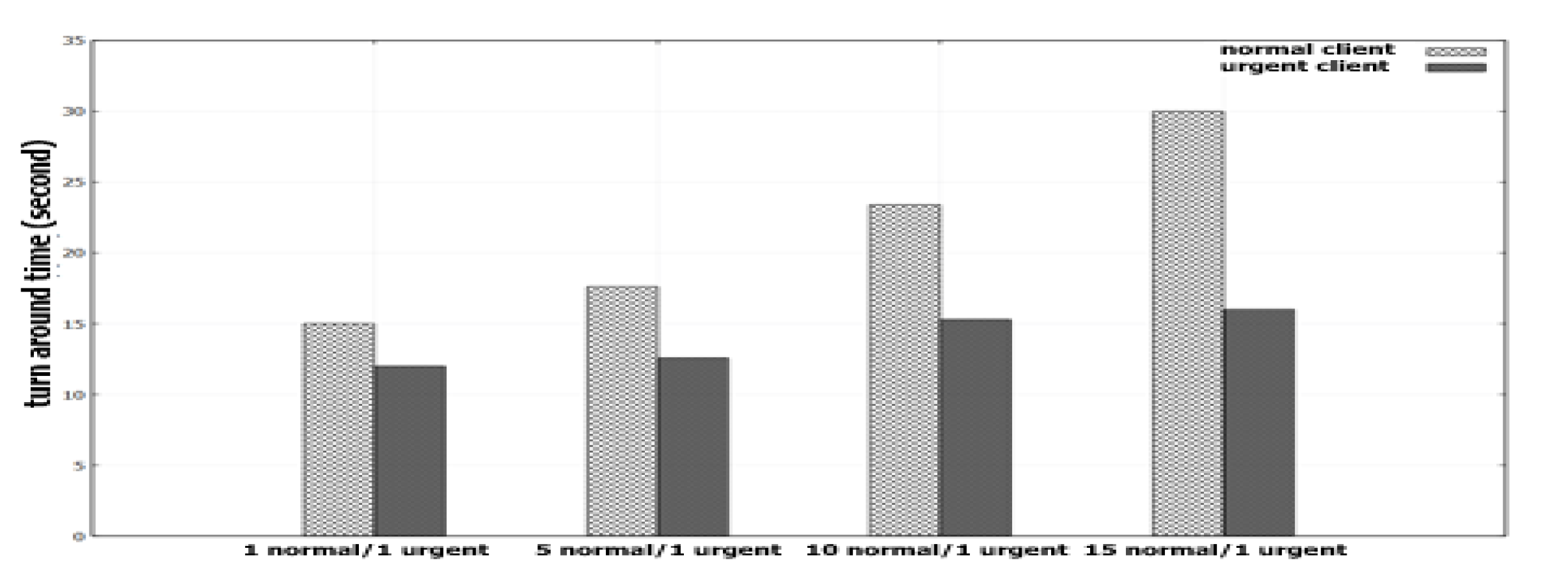
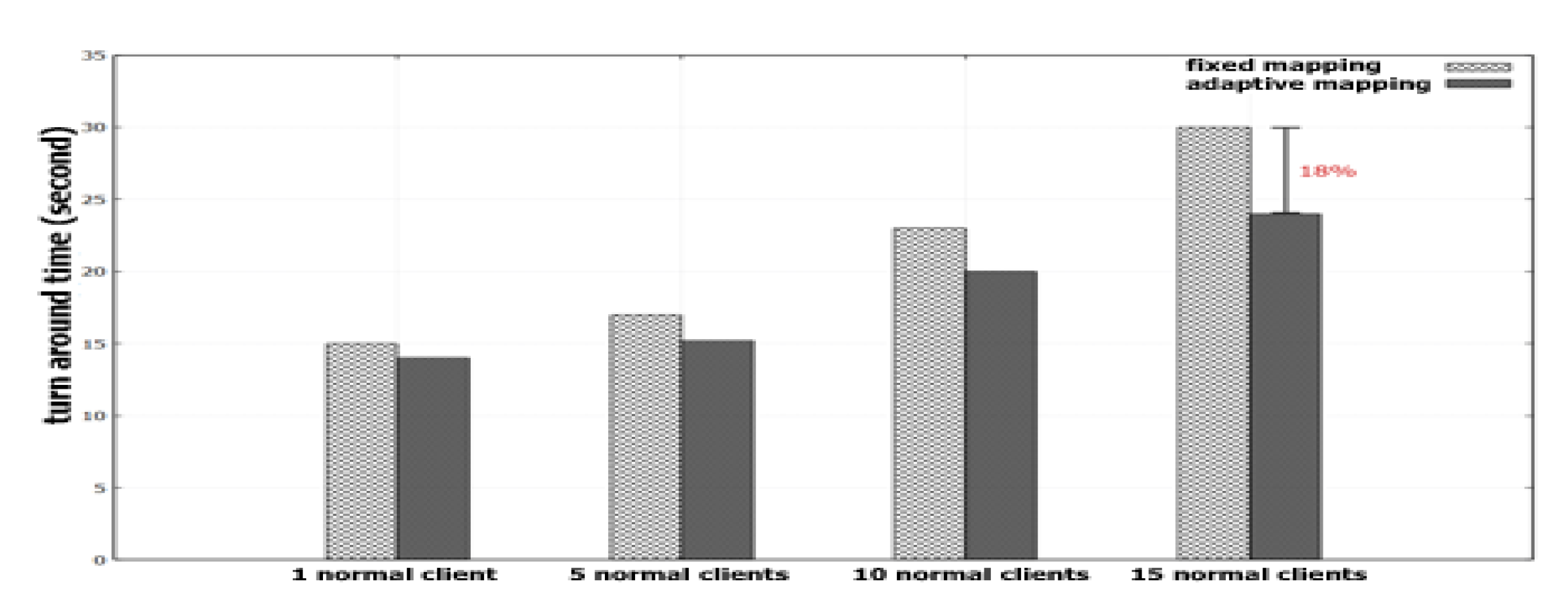
4.2. Effect of Adaptive Mapping
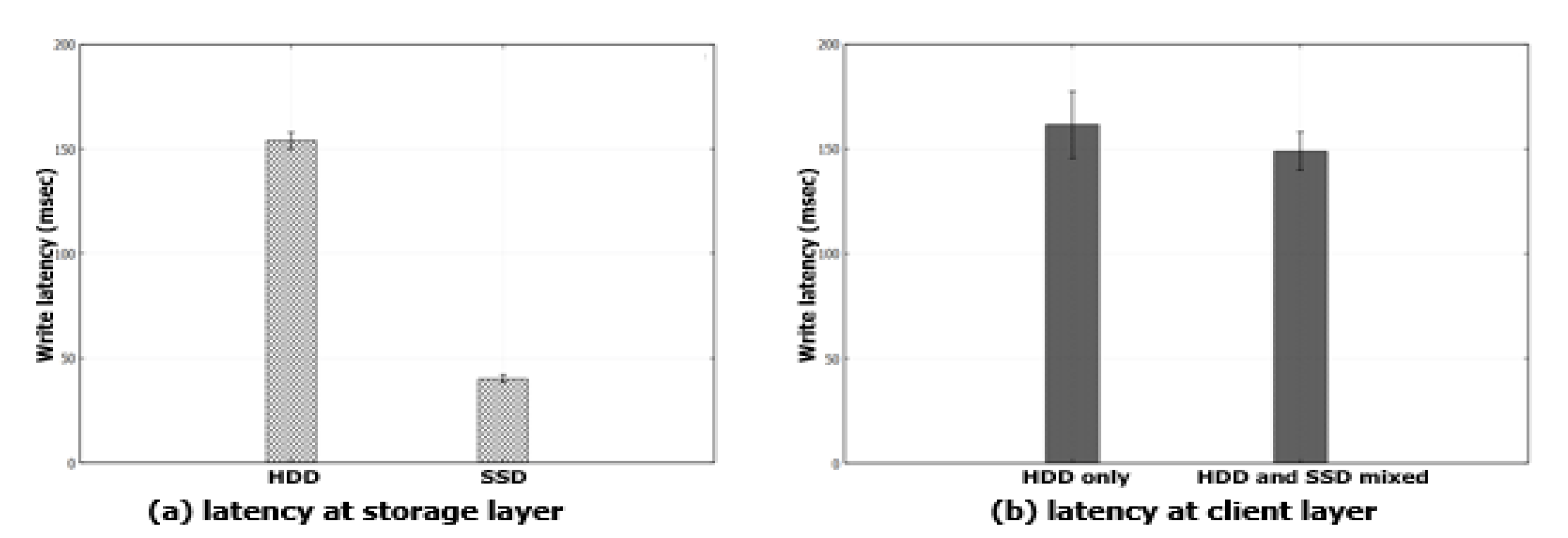
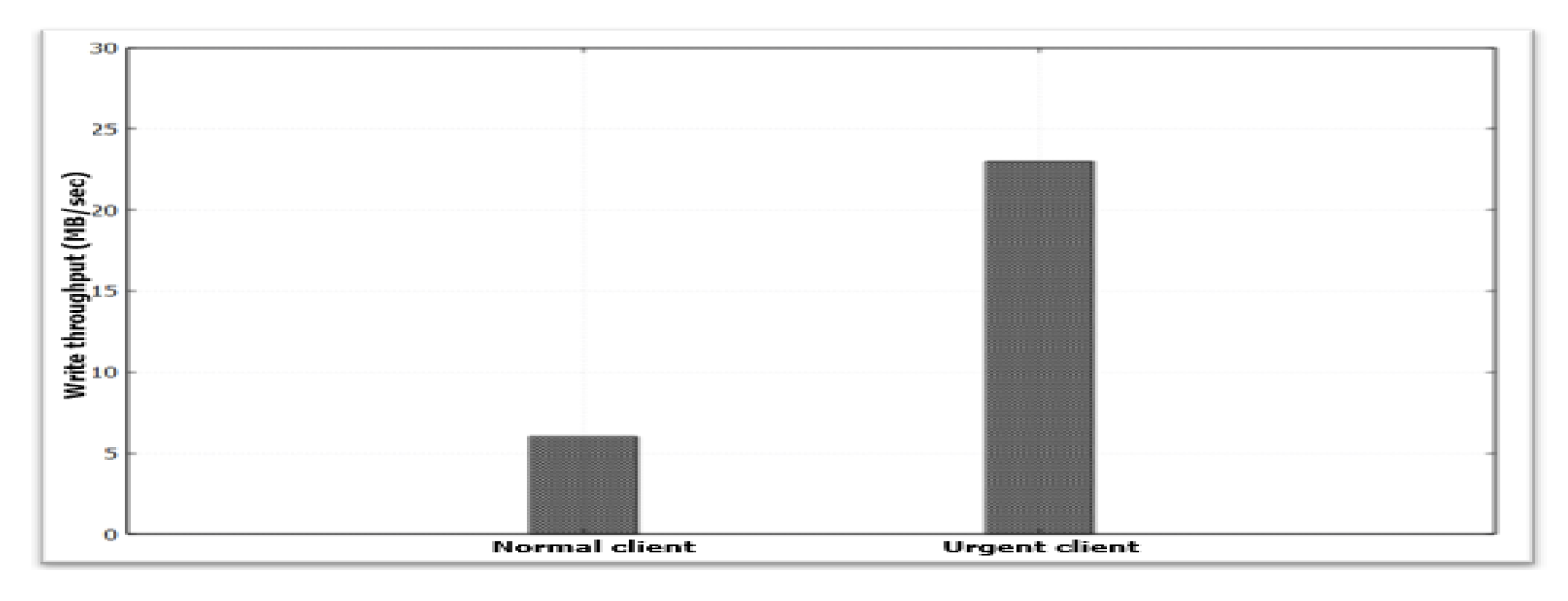
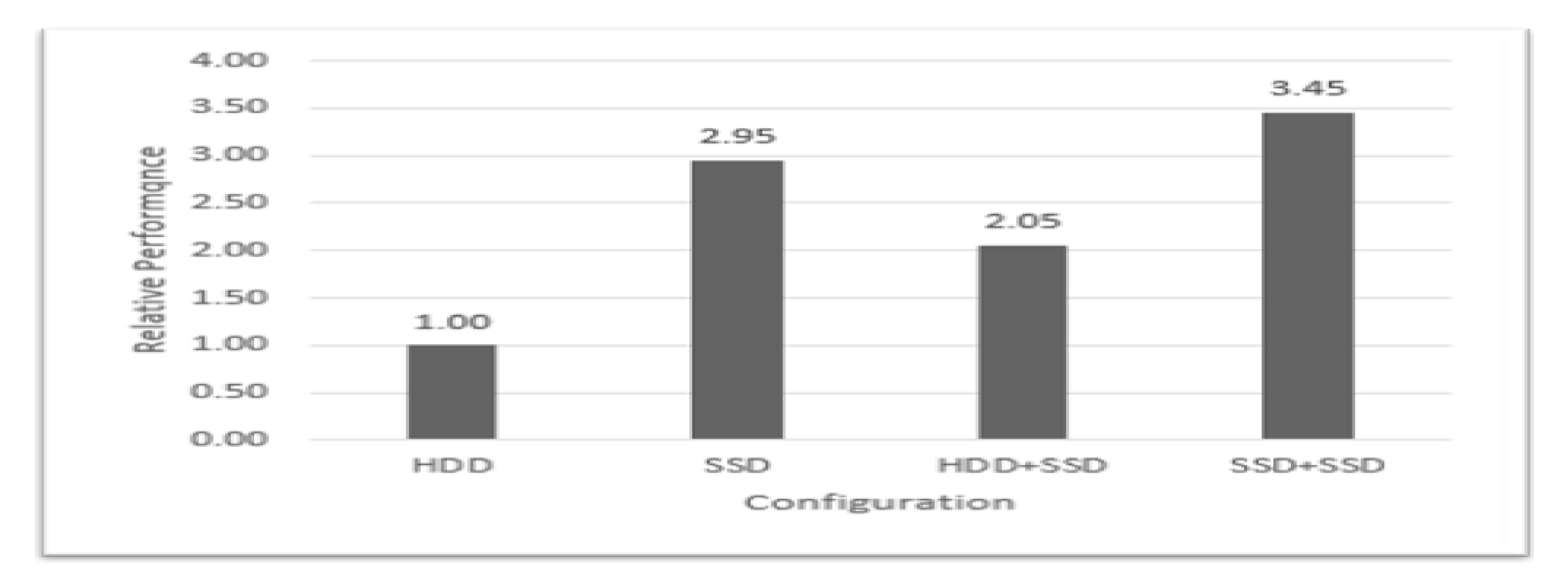
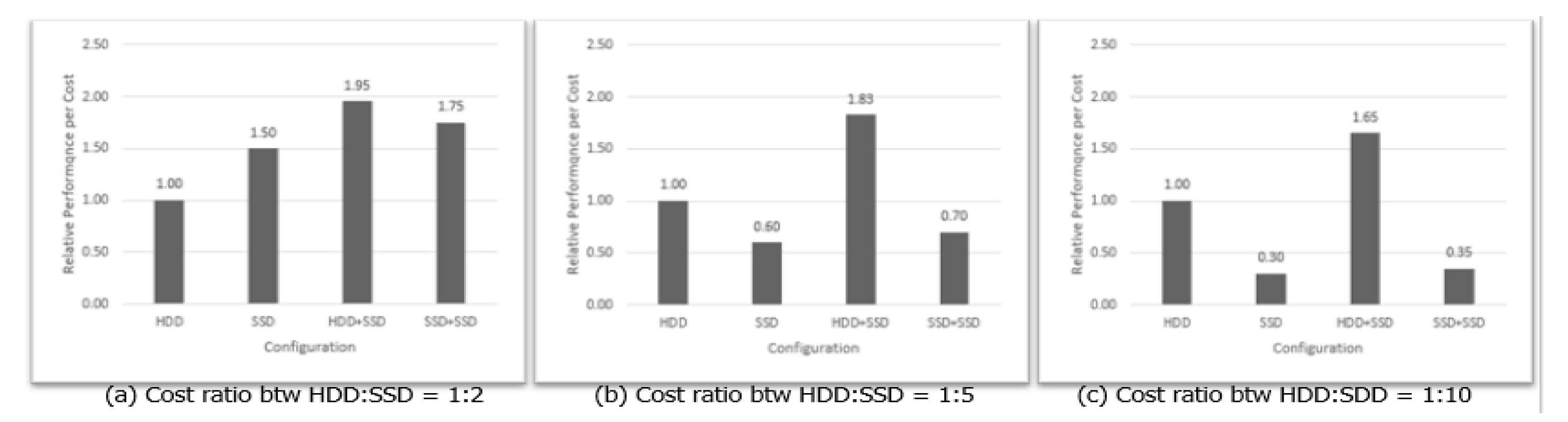
4.3. Effect of Heterogeneous Storage Devices
5. Related Work
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Akter, S.; Wamba, F. Big Data Analytics in E-commerce: A Systematic Review and Agenda for Future Research. Faculty of Business—Papers (Archive), 886. Available online: https://ro.uow.edu.au/buspapers/886 (accessed on 28 January 2021).
- Formica, A.; Pourabbas, E.; Taglino, F. Semantic Search Enhanced with Rating Scores. Future Internet 2020, 12, 67. [Google Scholar] [CrossRef]
- Blazquez, D.; Domenech, J. Big Data sources and methods for social and economic analyses. Technol. Forecast. Soc. Chang. 2018, 130, 99–113. [Google Scholar] [CrossRef]
- Najafabadi, M.N.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Serrano, W. Neural Networks in Big Data and Web Search. Data 2019, 4, 7. [Google Scholar] [CrossRef]
- Qi, G.; Luo, J. Small Data Challenges in Big Data Era: A Survey of Recent Progress on Unsupervised and Semi-Supervised Methods. Available online: https://arxiv.org/abs/1903.11260 (accessed on 28 January 2021).
- Amini, S.; Gerostathopoulos, I.; Prehofer, C. Big data analytics architecture for real-time traffic control. In Proceedings of the 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Naples, Italy, 26–28 June 2017. [Google Scholar]
- Xu, F.; Zheng, H.; Jiang, H.; Shao, W.; Liu, H.; Zhou, Z. Cost-Effective Cloud Server Provisioning for Predictable Performance of Big Data Analytics. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 1036–1051. [Google Scholar] [CrossRef]
- Trivedi, A.; Stuedi, P.; Pfefferle, J.; Schuepbach, A.; Metzler, B. Albis: High-Performance File Format for Big Data Systems. In Proceedings of the USENIX Annual Technical Conference (ATC), Boston, MA, USA, 11–13 July 2018. [Google Scholar]
- Orenga-Roglá, S.; Chalmeta, R. Framework for Implementing a Big Data Ecosystem in Organizations. Commun. ACM 2019, 62, 58–65. [Google Scholar] [CrossRef]
- Patrizio, A. IDC: Expect 175 Zettabytes of Data Worldwide by 2025. Available online: https://www.networkworld.com/article/3325397/idc-expect-175-zettabytes-of-data-worldwide-by-2025.html (accessed on 28 January 2021).
- Ghemawat, S.; Gobioff, H.; Leung, S.T. The Google File System. In Proceedings of the 19th ACM Symposium on Operating Systems Principles (SOSP), Bolton Landing (Lake George), New York, NY, USA, 19–22 October 2003. [Google Scholar]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop Distributed File System. In Proceedings of the 26th IEEE Symposium on Massive Storage Systems and Technologies (MSST), Lake Tahoe, NV, USA, 3–7 May 2010. [Google Scholar]
- Weil, S.A.; Brandt, S.A.; Miller, E.L.; Long, D.D.E.; Maltzahn, C. Ceph: A Scalable, High-Performance Distributed File System. In Proceedings of the 7th symposium on Operating Systems Design and Implementation (OSDI), Seattle, WA, USA, 6–8 November 2006. [Google Scholar]
- Huang, C.; Simitci, H.; Xu, Y.; Ogus, A.; Calder, B.; Gopalan, P.; Li, J.; Yekhanin, S. Erasure Coding in Windows Azure Storage. In Proceedings of the 10th USENIX Conference on File and Storage Technologies (FAST), San Jose, CA, USA, 14–17 February 2012. [Google Scholar]
- Palankar, M.; Iamnitchi, A.; Ripeanu, M.; Garfinkel, S. Amazon S3 for Science Grids: A Viable Solution? In Proceedings of the International Workshop on Data-Aware Distributed Computing (DADC), Boston, MA, USA, 24–27 June 2008. [Google Scholar]
- Kapadia, A.; Varma, S.; Rajana, K. Implementing Cloud Storage with OpenStack Swift, 1st ed.; Packt Publishing: Birmingham, UK, 2014. [Google Scholar]
- Beaver, D.; Kumar, S.; Li, H.C.; Sobel, J.; Vajgel, P. Finding a needle in Haystack: Facebook’s photo storage. In Proceedings of the USENIX Annual Technical Conference (ATC), Boston, MA, USA, 22–25 June 2006; 2006. [Google Scholar]
- Lustre Architecture. Available online: http://wiki.lustre.org/images/6/64/LustreArchitecture-v4.pdf (accessed on 28 January 2021).
- GlusterFS Architecture. Available online: https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/ (accessed on 28 January 2021).
- Zhou, W.; Wang, W.; Hua, X.; Zhang, Y. Real-Time Traffic Flow Forecasting via a Novel Method Combining Periodic-Trend Decomposition. Sustainability 2020, 12, 5891. [Google Scholar] [CrossRef]
- Chen, G.; Wiener, J.L.; Iyer, S.; Jaiswal, A.; Lei, R.; Simha, N.; Wang, W.; Wilfong, K.; Williamson, T.; Yilma, S. Realtime Data Processing at Facebook. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD), San Francisco, CA, USA, 26–30 June 2016. [Google Scholar]
- Divakaran, D.M.; Le, T.; Gurusamy, M. An Online Integrated Resource Allocator for Guaranteed Performance in Data Centers. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 6. [Google Scholar] [CrossRef]
- Chuang, J.C.; Sirbu, M. Distributed network storage service with quality-of-service guarantees. J. Netw. Comput. Appl. 2000, 23, 163–185. [Google Scholar] [CrossRef]
- Tanimura, Y.; Hidetaka, K.; Kudoh, T.; Kojima, I.; Tanaka, Y. A distributed storage system allowing application users to reserve I/O performance in advance for achieving SLA. In Proceedings of the 11th ACM/IEEE International Conference on Grid Computing (GRID), Brussels, Belgium, 25–28 October 2010. [Google Scholar]
- Terry, D.B.; Prabhakaran, V.; Kotla, R.; Balakrishnan, M.; Aguilera, M.K.; Abu-Libdeh, H. Consistency-Based Service Level Agreements for Cloud Storage. In Proceedings of the 24th ACM Symposium on Operating Systems Principles (SOSP), Farmington, PA, USA, 3–6 November 2013. [Google Scholar]
- Alhamad, M.; Dillon, T.; Chang, E. Conceptual SLA framework for cloud computing. In Proceedings of the 4th IEEE International Conference on Digital Ecosystems and Technologies, Dubai, United Arab Emirates, 14–16 April 2010. [Google Scholar]
- Chum, S.; Li, J.; Park, H.; Choi, J. SLA-Aware Adaptive Mapping Scheme in Bigdata Distributed Storage Systems. In Proceedings of the 9th International Conference on Smart Media and Applications (SMA), Jeju, Korea, 17–19 September 2020. [Google Scholar]
- Aghayev, A.; Weil, S.A.; Kuchnik, M.; Nelson, M.; Ganger, G.R.; Amvrosiadis, G. File Systems Unfit as Distributed Storage Backends: Lessons from 10 Years of Ceph Evolution. In Proceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP), Huntsville, ON, Canada, 27–30 September 2019. [Google Scholar]
- Weil, S.A.; Brandt, S.A.; Miller, E.L.; Maltzahn, C. CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data. In Proceedings of the 2006 ACM/IEEE conference on Supercomputing, Tampa, FL, USA, 11–17 November 2006. [Google Scholar]
- D’Atri, A.; Bhembre, V.; Singh, K. Learning Ceph: Unifed, Scalable, and Reliable Open Source Storage Solution, 2nd ed.; Packt Publishing: Birmingham, UK, 2017. [Google Scholar]
- Ceph Storage Datasheet. Available online: https://www.redhat.com/en/resources/ceph-storage-datasheet (accessed on 28 January 2021).
- Mellanox White Paper. Installing Hadoop over Ceph, Using High Performance Networking. Available online: https://www.mellanox.com/related-docs/whitepapers/wp_hadoop_on_cephfs.pdf (accessed on 28 January 2021).
- Chien, S.; Markidis, S.; Sishtla, C.P.; Santos, L.; Herman, P.; Narasimhamurthy, S.; Laure, E. Characterizing Deep-Learning I/O Workloads in TensorFlow. In Proceedings of the IEEE/ACM 3rd International Workshop on Parallel Data Storage and Data Intensive Scalable Computing Systems (PDSW-DISCS), Dallas, TX, USA, 12 November 2018. [Google Scholar]
- Yang, C.; Liu, J.; Kristiani, E.; Liu, M.; You, I.; Pau, G. NetFlow Monitoring and Cyberattack Detection Using Deep Learning with Ceph. IEEE Access 2020, 8, 7842–7850. [Google Scholar] [CrossRef]
- Weil, S.A.; Leung, A.W.; Brandt, S.A.; Maltzahn, C. RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters. In Proceedings of the 2nd Parallel Data Storage Workshop (PDSW), Reno, NV, USA, 11 November 2007. [Google Scholar]
- Lee, D.; Jeong, K.; Han, S.; Kim, J.; Hwang, J.; Cho, S. Understanding Write Behaviors of Storage Backends in Ceph Object Store. In Proceedings of the 33rd International Conference on Massive Storage Systems and Technology (MSST), Santa Clara, CA, USA, 15–19 May 2017. [Google Scholar]
- Introduction to Ceph. Available online: https://docs.ceph.com/en/latest/start/intro/ (accessed on 28 January 2021).
- De Candia, G.; Hastorun, D.; Jampani, M.; Kakulapati, G.; Lakshman, A.; Pilchin, A.; Sivasubramanian, S.; Vosshall, P.; Vogels, W. Dynamo: Amazon’s Highly Available Key-value Store. In Proceedings of the 21st ACM Symposium on Operating Systems Principles (SOSP), Stevenson, WA, USA, 14–17 October 2007. [Google Scholar]
- Wu, X.; Qiu, S.; Reddy, N.L. SCMFS: A File System for Storage Class Memory and its Extensions. ACM Trans. Storage 2013, 9, 1822–1833. [Google Scholar] [CrossRef]
- Ortiz, J.; Lee, B.; Balazinska, M.; Gehrke, J.; Hellerstein, J.L. SLAOrchestrator: Reducing the Cost of Performance SLAs for Cloud Data Analytics. In Proceedings of the USENIX Annual Technical Conference (ATC), Boston, MA, USA, 11–13 July 2018. [Google Scholar]
- Gulati, A.; Merchant, A.; Varman, P.J. mClock: Handling Throughput Variability for Hypervisor IO Scheduling. In Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Bancouver, BC, Canada, 4–6 October 2010. [Google Scholar]
- Shue, D.; Freedman, M.J.; Shaikh, A. Performance Isolation and Fairness for Multi-Tenant Cloud Storage. In Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Hollywood, CA, USA, 8–10 October 2012. [Google Scholar]
- Ardekani, M.S.; Terry, D.B. A Self-Configurable Geo-Replicated Cloud Storage System. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Bloomfield, CO, USA, 6–8 October 2014. [Google Scholar]
- Wang, F.; Nelson, M.; Oral, S.; Atchley, S.; Weil, S.A.; Settlemyer, B.W.; Caldwell, B.; Hill, J. Performance and Scalability Evaluation of the Ceph Parallel File System. In Proceedings of the 8th Parallel Data Storage Workshop (PDSW), Denver, CO, USA, 18 November 2013. [Google Scholar]
- Chagam, A.; Ferber, D.; Leone, D.J.; Moreno, O.; Wang, Y.; Zhang, Y.; Zhang, J.; Zou, Y.; Henderson, M.W. Intel Solutions for Ceph Deployments. Available online: https://builders.intel.com/docs/storagebuilders/Intel_solutions_for_ceph_deployments.pdf (accessed on 28 January 2021).
- Wang, L.; Chuxing, D.; Zhang, Y.; Xu, J.; Xue, G. MAPX: Controlled Data Migration in the Expansion of Decentralized Object-Based Storage Systems. In Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST), Santa Clara, CA, USA, 24–27 February 2020. [Google Scholar]
- Wu, J.C.; Brandt, S.A. Providing Quality of Service Support in Object-Based File System. In Proceedings of the 24th IEEE Conference on Mass Storage Systems and Technologies (MSST), San Diego, CA, USA, 24–27 September 2007. [Google Scholar]
- Wu, K.; Arpaci-Dusseau, A.; Arpaci-Dusseau, R. Towards an Unwritten Contract of Intel Optane SSD. In Proceedings of the 11th USENIX Workshop on Hot Topics in Storage and File Systems, Renton, WA, USA, 8–9 July 2019. [Google Scholar]
- Choi, G.; Oh, M.; Lee, K.; Choi, J.; Jin, J.; Oh, Y. A New LSM-style Garbage Collection Scheme for ZNS SSDs. In Proceedings of the 12th USENIX Workshop on Hot Topics in Storage and File Systems, Virtual event, 13–14 July 2020. [Google Scholar]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chum, S.; Park, H.; Choi, J. Supporting SLA via Adaptive Mapping and Heterogeneous Storage Devices in Ceph. Electronics 2021, 10, 847. https://doi.org/10.3390/electronics10070847
Chum S, Park H, Choi J. Supporting SLA via Adaptive Mapping and Heterogeneous Storage Devices in Ceph. Electronics. 2021; 10(7):847. https://doi.org/10.3390/electronics10070847
Chicago/Turabian StyleChum, Sopanhapich, Heekwon Park, and Jongmoo Choi. 2021. "Supporting SLA via Adaptive Mapping and Heterogeneous Storage Devices in Ceph" Electronics 10, no. 7: 847. https://doi.org/10.3390/electronics10070847
APA StyleChum, S., Park, H., & Choi, J. (2021). Supporting SLA via Adaptive Mapping and Heterogeneous Storage Devices in Ceph. Electronics, 10(7), 847. https://doi.org/10.3390/electronics10070847