
Object Detection Using Improved Bi-Directional Feature Pyramid Network



Abstract
1. Introduction
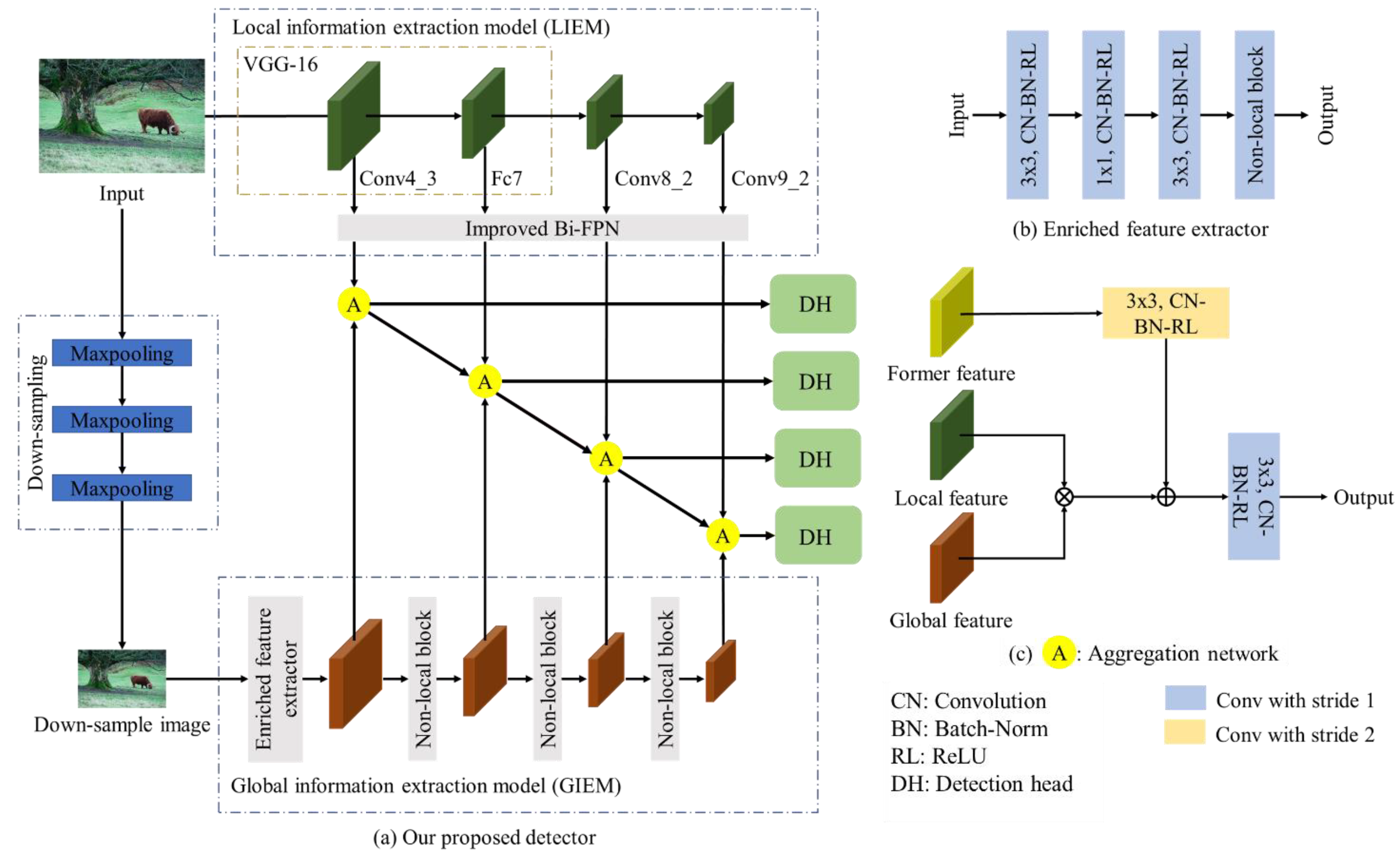
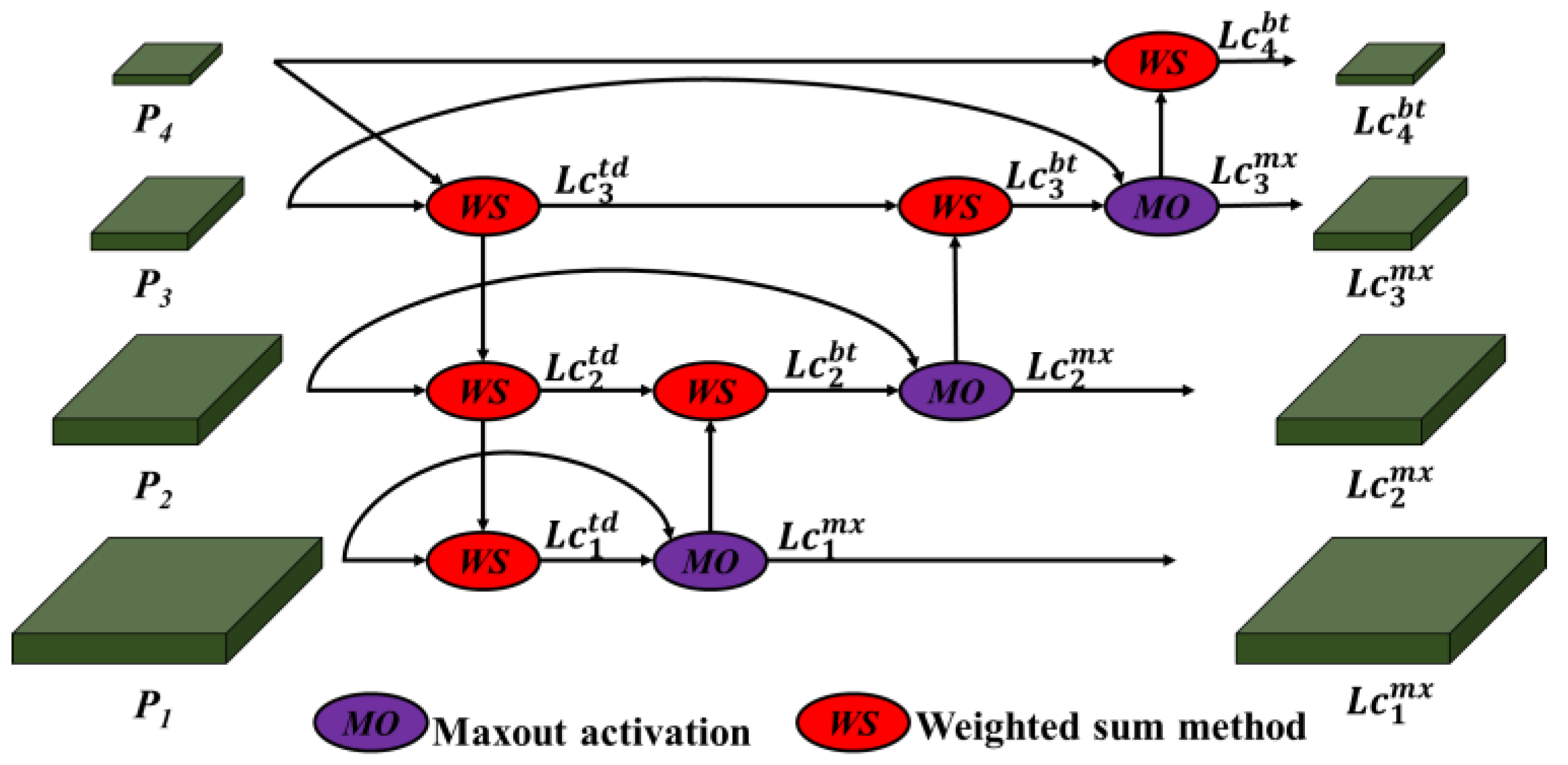
- This paper proposes an improved Bi-FPN that minimizes information loss by combining aggregation models of existing FPN-based single object detectors.
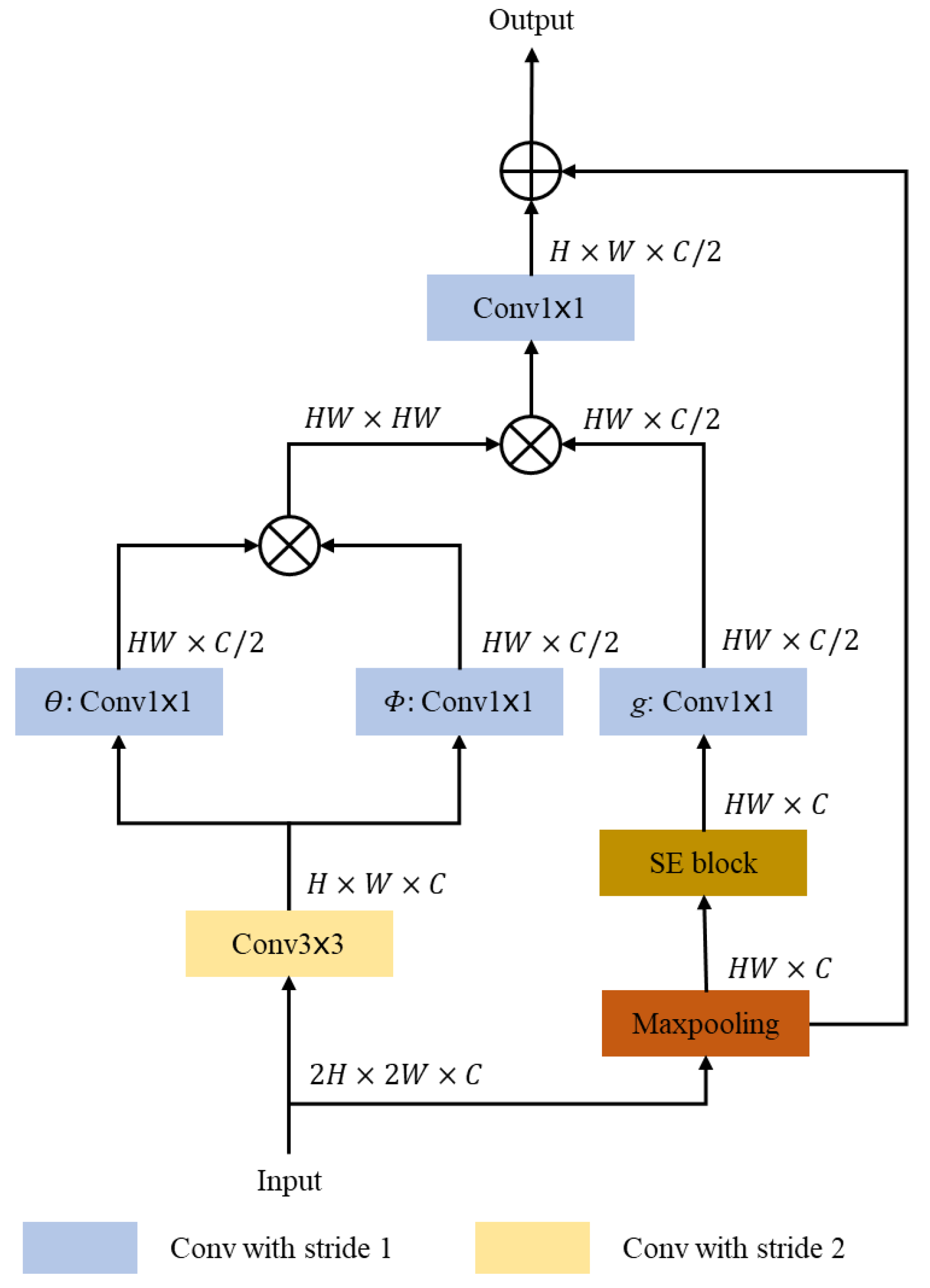
- GIEM introduces NLNN to understand the relation between the feature vector and the entire feature map, i.e., obtain global information.
2. Related Work
2.1. Multi-Scale Feature Representation
2.2. Global Information Extraction Network
3. Methods
3.1. Local Information Extraction Model (LIEM)
3.2. Global Information Extraction Model (GIEM)
3.3. Aggregation Network
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Results
4.4. Ablation Study and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation Inc.: San Diego, CA, USA, 2015; pp. 91–99. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Nie, J.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. Enriched feature guided refinement network for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9537–9546. [Google Scholar]
- Wang, T.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. Learning rich features at high-speed for single-shot object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1971–1980. [Google Scholar]
- Shen, Z.; Shi, H.; Yu, J.; Phan, H.; Feris, R.; Cao, L.; Liu, D.; Wang, X.; Huang, T.; Savvides, M. Improving object detection from scratch via gated feature reuse. arXiv 2017, arXiv:1712.00886. [Google Scholar]
- Pang, Y.; Wang, T.; Anwer, R.M.; Khan, F.S.; Shao, L. Efficient featurized image pyramid network for single shot detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Bench, CA, USA, 16–20 June 2019; pp. 7336–7344. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Bench, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Li, Y.; Pang, Y.; Shen, J.; Cao, J.; Shao, L. NETNet: Neighbor Erasing and Transferring Network for Better Single Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13349–13358. [Google Scholar]
- Jang, H.D.; Woo, S.; Benz, P.; Park, J.; Kweon, I.S. Propose-and-attend single shot detector. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 815–824. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Bench, CA, USA, 16–20 June 2019; pp. 7036–7045. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kong, T.; Sun, F.; Tan, C.; Liu, H.; Huang, W. Deep feature pyramid reconfiguration for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 169–185. [Google Scholar]
- Li, S.; Yang, L.; Huang, J.; Hua, X.S.; Zhang, L. Dynamic anchor feature selection for single-shot object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6609–6618. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation Inc.: San Diego, CA, USA, 2016; pp. 379–387. [Google Scholar]
- Xu, X.; Luo, X.; Ma, L. Context-Aware Hierarchical Feature Attention Network for Multi-Scale Object Detection. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2011–2015. [Google Scholar]
- Fan, B.; Chen, W.; Cong, Y.; Tian, J. Dual Refinement Underwater Object Detection Network. Constr. Side Channel Anal. Secur. Des. 2020, 275–291. [Google Scholar] [CrossRef]
- Antioquia, A.M.C.; Tan, D.S.; Azcarraga, A.; Hua, K.L. Single-Fusion Detector: Towards Faster Multi-Scale Object Detection. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 76–80. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zhang, Z.; Qiao, S.; Xie, C.; Shen, W.; Wang, B.; Yuille, A.L. Single-shot object detection with enriched semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5813–5821. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4203–4212. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. Ron: Reverse connection with objectness prior networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5936–5944. [Google Scholar]
- Li, W.; Liu, G. A Single-Shot Object Detector with Feature Aggregation and Enhancement. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3910–3914. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Input Size | mAP | FPS |
|---|---|---|---|---|
| Two-Stage Detectors: | ||||
| Faster RCNN [2] | ResNet101 | 1000 × 600 | 76.4 | - |
| R-FCN [22] | ResNet101 | 1000 × 600 | 80.5 | - |
| Single-Stage Detectors: | ||||
| CHFANet [23] | VGG16 | 300 × 300 | 79.9 | - |
| FERNet [24] | VGG16 | 300 × 300 | 80.2 | - |
| EFIPNet [10] | VGG16 | 300 × 300 | 80.4 | 111 |
| SFDet [25] | VGG16 | 300 × 300 | 78.8 | - |
| RFBNet [26] | VGG16 | 300 × 300 | 78.6 | - |
| DES [27] | VGG16 | 300 × 300 | 79.7 | 76.8 |
| DFPR [20] | VGG16 | 300 × 300 | 80 | - |
| GFR-DSOD [9] | DSOD | 300 × 300 | 78.9 | - |
| SSD [3] | VGG16 | 300 × 300 | 77.93 | 64.23 |
| IBi-FPN (Ours) | VGG16 | 300 × 300 | 79.92 | 45.68 |
| EFGRNet [7] | VGG16 | 320 × 320 | 81.37 | 44.4 |
| DAFS [21] | VGG16 | 320 × 320 | 80.6 | - |
| RefineDet [28] | VGG16 | 320 × 320 | 80 | 40.3 |
| DSSD [29] | ResNet101 | 321 × 321 | 78.6 | 9.5 |
| GFR-DSOD [9] | DSOD | 320 × 320 | 79.2 | - |
| RON [30] | VGG16 | 320 × 320 | 76.6 | - |
| SSD [3] | VGG16 | 320 × 320 | 78.35 | - |
| IBi-FPN (Ours) | VGG16 | 320 × 320 | 80.37 | 44 |
| Methods | Input Size | Backbone | FPS | AP (0.5:0.95) | AP (0.5) | AP (0.75) | APs (0.5:0.95) | APm (0.5:0.95) | APl (0.5:0.95) |
|---|---|---|---|---|---|---|---|---|---|
| FAENet [31] | 300 × 300 | VGG-16 | - | 28.3 | 47.9 | 29.7 | 10.5 | 30.9 | 41.9 |
| SSD [3] | 300 × 300 | VGG-16 | 50 | 25.1 | 43.1 | 25.8 | 6.6 | 25.9 | 47.6 |
| LSNet [8] | 300 × 300 | VGG-16 | 76.9 | 32 | 51.5 | 33.8 | 12.6 | 34.9 | 47 |
| EFIPNet [10] | 300 × 300 | VGG-16 | 71.4 | 30 | 48.8 | 31.7 | 10.9 | 32.8 | 46.3 |
| IBi-FPN (Ours) | 300 × 300 | VGG-16 | 45.43 | 31.6 | 50.3 | 33 | 10.7 | 36.9 | 47.7 |
| EFGRNet [7] | 320 × 320 | VGG-16 | 47.62 | 33.2 | 53.4 | 35.4 | 13.4 | 37.1 | 47.9 |
| DAFS [21] | 320 × 320 | VGG-16 | 46 | 31.2 | 50.8 | 33.4 | 10.8 | 34 | 47.1 |
| PASSD [13] | 320 × 320 | VGG-16 | 40 | 31.4 | 51.6 | 33.6 | 12.0 | 35.1 | 45.8 |
| M2Det [5] | 320 × 320 | VGG-16 | 33.4 | 33.5 | 52.4 | 35.6 | 14.4 | 37.6 | 47.6 |
| IBi-FPN (Ours) | 320 × 320 | VGG-16 | 42.01 | 32 | 50.9 | 33.7 | 12 | 37 | 47.1 |
| Methods | mAP | ||||
|---|---|---|---|---|---|
| Standard SSD | BiFPN | LIEM | GIEM | ||
| NLNN | Split Branch | ||||
| √ | - | - | - | - | 78.35 |
| - | √ | - | - | - | 79.53 |
| - | - | √ | - | - | 79.84 |
| - | - | √ | √ | - | 80.16 |
| - | - | √ | √ | √ | 80.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quang, T.N.; Lee, S.; Song, B.C. Object Detection Using Improved Bi-Directional Feature Pyramid Network. Electronics 2021, 10, 746. https://doi.org/10.3390/electronics10060746
Quang TN, Lee S, Song BC. Object Detection Using Improved Bi-Directional Feature Pyramid Network. Electronics. 2021; 10(6):746. https://doi.org/10.3390/electronics10060746
Chicago/Turabian StyleQuang, Tran Ngoc, Seunghyun Lee, and Byung Cheol Song. 2021. "Object Detection Using Improved Bi-Directional Feature Pyramid Network" Electronics 10, no. 6: 746. https://doi.org/10.3390/electronics10060746
APA StyleQuang, T. N., Lee, S., & Song, B. C. (2021). Object Detection Using Improved Bi-Directional Feature Pyramid Network. Electronics, 10(6), 746. https://doi.org/10.3390/electronics10060746